Embed Size (px)
Citation preview

LEARNING SITUATION-SPECIFIC CONTROL IN MULTI-AGENT SYSTEMS
A Dissertation Presented
by
MARAM V. NAGENDRAPRASAD
Submitted to the Graduate School of theUniversity of Massachusetts Amherst in partialfulfillment of the requirements for the degree of
DOCTOR OF PHILOSOPHY
May 1997
Department of Computer Science

c Copyright by Maram V. Nagendraprasad 1997
All Rights Reserved

LEARNING SITUATION-SPECIFIC CONTROL IN MULTI-AGENT SYSTEMS
A Dissertation Presented
by
MARAM V. NAGENDRAPRASAD
Approved as to style and content by:
Victor R. Lesser, Chair
Paul Utgoff, Member
Shlomo Zilberstein, Member
George Zinsmeister, Member
Sandip Sen, Member
David W. Stemple, Department ChairComputer Science

To my mother D. Vimala and my father V. Lakshmana Reddy

ACKNOWLEDGMENTS
When I came to UMass, I never heard about Distributed AI. I am deeply indebted to
my guru, Victor Lesser for molding a Distributed AI researcher out of clay. The intellectual
excitement during my collaboration with him is a ‘high’ that will last me a life time. I use the
word “guru” in its truest sense when I address Victor. He was there, like a sign post in a desert,
when I was lost exploring new frontiers. He has an uncanny sense of the right direction and
a never say die attitude when faced with hard problems. He was there, like a friend, when I
had personal problems. I consider myself to be truly fortunate to be a member of the “Victor’s
academic family”.
Many thanks go to my committee members: Sandip Sen, Paul Utgoff, Shlomo Zilberstein,
and George Zinsmeister. Sandip Sen guided me in my research, and served as a role model
and a friend. Sandip provided deep and insightful comments at various stages of this research.
Our late night discussions, at conferences and workshops, on the state of the field and where it
should be going served to spur me on in many interesting directions. I would like to express my
deep sense of gratitude to him for all this and more. Also, thanks go to him for putting learning
in multi-agent systems on the research map of Multi-agent Systems and Artificial Intelligence
communities. Paul Utgoff asked me the right questions and made sure that I noticed the
appropriate connections to the rest of the research community in the area of learning. He read
my documents carefully and provided keen feedback. He nailed home the point that I should
write to make others understand rather than to dazzle them with an array of Distributed AI
jargon. Thanks Paul, for being such an influence on how I present my ideas. I am indebted
to Shlomo Zilberstein for being extremely supportive and providing insights into the relevance
of my thesis along facets that I never thought of. He nudged me to make my ideas more crisp
and avoid ad-hocness in my writing style. I am thankful to Prof Z (George Zinsmeister) for
v

bringing an outside perspective and contributing towards a more balanced treatment of the
topics.
A very special thanks goes to Susan Lander for a very productive collaboration and friendly
advise at various stages of this work. Sue provided me the TEAM system on which I performed
the work in two of my thesis chapters. She gave me technical assistance even when she was
busy with finishing her thesis, patiently listened to me through my excited ramblings when I
had ideas and provided the much needed encouragement and guidance. Many of the follow
on ideas from my thesis owe their origin, either directly or indirectly, to my collaboration with
her. Thanks Sue, for being the best collaborator I ever had. Later part of my work relied on
Keith Decker’s GPGP system , Alan Garvey’s Design-to-time scheduler. Keith never said no
when I asked for help. It was no easy task going through tens of thousands of lines of LISP
code written by someone else had it not been for his readiness to help. Keith was the crutch
we (all of us in the lab) leaned on when we could not walk. From Latex to Babylon5, or
from coordination to beer-making, we had it all for the asking. Thanks Keith for being such
a scholar and a role model. Alan (Bart) Garvey’s help with the scheduler was essential to the
success of my experiments on learning coordination. When I needed to change something or
needed his help, he would always do it and do it without much ado. During the later part
of my stay, he became a source of trusted advise about lab affairs and technical matters. I am
grateful to Bart for his companionship.
I would like to thank other current and former members of the DAI group at the University
of Massachusetts: Malini Bhandaru, Norm Carver, Mike Chia, Frank Klassner, Quin Long,
Dorothy Mammen, Dan Neiman, Tuomas Sandholm, Toshi Sugawara, Thomas Wagner, and
Bob Whitehair, for making our group such lively and exciting place to be. Special thanks go
to Dan for suffering through my innumerable drafts and providing incisive criticisms and to
Frank for sharing his expertise in “getting a thesis done”. I would also like to thank Michele
Roberts for her efficient secretarial assistance despite almost always being inundated with work.
I am indebted to Kishore Swaminathan of Andersen Consulting for his frank criticism of
vi

my presentation style and for driving home the importance of clarity of presentation in talking
about ideas. Even though our association so far has been brief, he, along with Paul, has had a
tremendous influence on my style of writing in this thesis and in general.
Few people outside seem to realize how good the Department of Computer Science at
University of Massachusetts really is. I had exposure to some of the finest minds in Multi-agent
Systems, Machine Learning, Case-based Reasoning, NLP, Information Retrieval, Planning,
Robotics and Vision - all under one roof!!! One of the best decisions in my life is my decision
to move here from MIT (in case your jaw has dropped, I really mean it). Thanks go to some of
peers with whom I have had especially close association in my department: Tim Oates (I would
love to collaborate with you again), Arvind Nithrakashyap and Jayavel Shanmugasundaram (it
is great fun collaborating with you guys), Kumaresh Ramanathan, Sharad Singhai and Mohan
Kamath (true, there are other areas as interesting as AI).
My family and friends across USA helped me maintain my sanity through this long process
by giving me a chance to do something other than academics. Thanks to my sisters Sailaja and
Neeraja , my brothers-in-law Srinivas Reddy and Giridhar Reddy and friends YVSN Murthy,
BK Jayaram and G. Bhanu Prasad.
Big thanks to my parents for believing in me and providing the much needed emotional
support, especially when I “gave up”. I owe it all to them. Last but in no way the least, my
wife Pallavi provided invaluable support for me in this process. She prepared me for my talks,
provided comments on the draft versions of my papers, and nudged me along when I slacked
off, but importantly helped build many shared tender moments that sustain one through the
tougher times. To her, I am extremely grateful.
vii

ABSTRACT
LEARNING SITUATION-SPECIFIC CONTROL IN MULTI-AGENT SYSTEMS
May 1997
MARAM V. NAGENDRAPRASAD
B.Tech., INDIAN INSTITUTE OF TECHNOLOGY, MADRAS
M.S., INDIAN INSTITUTE OF TECHNOLOGY, MADRAS
M.S., MASSACHUSETTS INSTITUTE OF TECHNOLOGY, CAMBRIDGE
Ph.D., UNIVERSITY OF MASSACHUSETTS AMHERST
Directed by: Professor Victor R. Lesser
The work presented in this thesis deals with techniques to improve problem solving
control skills of cooperative agents through machine learning. In a multi-agent system, the
local problem solving control of an agent can interact in complex and intricate ways with the
problem solving control of other agents. In such systems, an agent cannot make effective
control decisions based purely on its local problem solving state. Effective cooperation requires
that the global problem-solving state influence the local control decisions made by an agent.
We call such an influence cooperative control. An agent with a purely local view of the problem
solving situation cannot learn effective cooperative control decisions that may have global
implications, due to the uncertainty about the overall state of the system. This gives rise to
the need for learning more globally situated control knowledge. An agent needs to associate
appropriate views of the global situation with the knowledge learned about effective control
decisions. We call this form of knowledge situation-specific control. This thesis investigates
learning such situation-specific cooperative control knowledge.
Despite the agreement among researchers in multi-agent systems about the importance
of the ability for agents to learn and improve their performance, this work represents one of
viii

the few attempts at demonstrating the utility and viability of machine learning techniques for
learning control in complex heterogeneous multi-agent systems. More specifically, this thesis
empirically demonstrates the effectiveness of learning situation-specific control for three aspects
of cooperative control:� Organizational Roles
Organizational Roles are policies for assigning responsibilities for various tasks to be
performed by each of the agents in the context of global problem solving. This thesis
studies learning organizational roles in a multi-agent parametric design system called
L-TEAM.� Negotiated Search
One way the agents can overcome the partial local perspective problem is by engaging
in a failure-driven exchange of non-local requirements to develop the closest possible
approximation to the actual composite search space. This thesis uses a case-based
learning method to endow the agents with the capability to approximate non-local
search requirements in a given situation, thus avoiding the need for communication.� Coordination Strategies
Coordination mechanisms provide an agent with the ability to behave more coherently
in a particular problem solving situation. The work presented in this thesis deals with
incorporating learning capabilities into agents to enable them to choose a suitable subset
of the coordination mechanisms based on the present problem solving situation to derive
appropriate coordination strategies.
ix

TABLE OF CONTENTS
Page
ACKNOWLEDGMENTS : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : v
ABSTRACT : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : viii
LIST OF TABLES : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : xiii
LIST OF FIGURES : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : xiv
Chapter
1. LEARNING IN MULTI-AGENT SYSTEMS : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 1
1.1 Agent-based Systems : : : : : : : : : : : : : : : : : : : : : : : : : : : : 21.2 Multi-agent Systems : : : : : : : : : : : : : : : : : : : : : : : : : : : : 31.3 Why Multi-agent Systems? : : : : : : : : : : : : : : : : : : : : : : : : 91.4 Why Learning? : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 101.5 Learning in Multi-agent Systems : : : : : : : : : : : : : : : : : : : : : : 16
1.5.1 Learning Organizational Roles in a Heterogeneous Multi-agent System 211.5.2 Cooperative Learning over Composite Search Spaces : : : : : : : : 221.5.3 Learning Situation-Specific Coordination : : : : : : : : : : : : : 231.5.4 Contributions of the Thesis : : : : : : : : : : : : : : : : : : : : 24
1.6 Guide to the Dissertation : : : : : : : : : : : : : : : : : : : : : : : : : 27
2. REVIEW OF RELATED WORK : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 28
2.1 Multi-agent Reinforcement Learning and Classifier Systems : : : : : : : : 282.2 Multi-agent CBL, EBL and Knowledge Refinement Systems : : : : : : : : 342.3 Robotic Soccer : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 412.4 Mutually Supervised Learning : : : : : : : : : : : : : : : : : : : : : : : 422.5 Learning in Game-theoretic Systems : : : : : : : : : : : : : : : : : : : : 432.6 Emergent Behaviors : : : : : : : : : : : : : : : : : : : : : : : : : : : : 442.7 Hybrid Learners : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 462.8 Summary : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 49
3. LEARNING ORGANIZATIONAL ROLES IN A HETEROGENEOUS MULTI-AGENT SYSTEM 52
3.1 Introduction : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 523.2 TEAM: A Heterogeneous Multi-agent Design System : : : : : : : : : : : 533.3 Organizational Roles in Distributed Search : : : : : : : : : : : : : : : : 623.4 Learning Role Assignments : : : : : : : : : : : : : : : : : : : : : : : : 643.5 Experimental Results : : : : : : : : : : : : : : : : : : : : : : : : : : : 693.6 Summary : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 78
x

4. COOPERATIVE LEARNING OVER COMPOSITE SEARCH SPACES : : : : : : : : : : : : : : : 80
4.1 Introduction : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 804.2 Distributed Search Spaces : : : : : : : : : : : : : : : : : : : : : : : : : 814.3 TEAM: A Multi-agent Design System : : : : : : : : : : : : : : : : : : : 854.4 Learning Efficient Search : : : : : : : : : : : : : : : : : : : : : : : : : 88
4.4.1 Conflict Driven Learning (CDL) : : : : : : : : : : : : : : : : : 884.4.2 Case-Based Learning (CBL) : : : : : : : : : : : : : : : : : : : : 90
4.5 Experimental Results : : : : : : : : : : : : : : : : : : : : : : : : : : : 934.6 Related Work : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 98
4.6.1 Distributed Search : : : : : : : : : : : : : : : : : : : : : : : : 984.6.2 Conflict Management : : : : : : : : : : : : : : : : : : : : : : : 99
4.7 Conclusion : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 100
5. LEARNING SITUATION-SPECIFIC COORDINATION IN GENERALIZED PARTIAL GLOBAL
PLANNING : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 102
5.1 Introduction : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 1025.2 TÆMS: Task Analysis, Environment Modeling, and Simulation : : : : : : 104
5.2.1 TÆMS models : : : : : : : : : : : : : : : : : : : : : : : : : : 1055.2.2 Grammar-based Task Structure Generation : : : : : : : : : : : : 109
5.2.2.1 Graph Grammars : : : : : : : : : : : : : : : : : : : : 1105.2.2.2 ASGGs and Distributed Data Processing : : : : : : : : 112
5.3 Instantiating Environment-specific Coordination Mechanisms : : : : : : : 114
5.3.1 Clustering : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 1215.3.2 Using Domain Knowledge : : : : : : : : : : : : : : : : : : : : 124
5.4 Empirical Explorations of Effects of Deadline and Crisis Tasks : : : : : : : 125
5.4.1 Effect of Crisis Tasks : : : : : : : : : : : : : : : : : : : : : : : 1265.4.2 Effect of Deadlines : : : : : : : : : : : : : : : : : : : : : : : : 1275.4.3 Discussion : : : : : : : : : : : : : : : : : : : : : : : : : : : : 128
5.5 COLLAGE: Learning Coordination : : : : : : : : : : : : : : : : : : : : 129
5.5.1 Overview : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 1295.5.2 Learning Coordination : : : : : : : : : : : : : : : : : : : : : : 130
5.5.2.1 Forming a Local Situation Vector : : : : : : : : : : : : 1325.5.2.2 Forming a Global Situation Vector : : : : : : : : : : : 135
5.5.3 Choosing a Coordination Strategy : : : : : : : : : : : : : : : : : 136
5.6 Experiments in Learning Situation-Specific Coordination : : : : : : : : : 137
5.6.1 Experiments with Synthetic Grammars : : : : : : : : : : : : : : 138
5.6.1.1 Grammar G1 : : : : : : : : : : : : : : : : : : : : : : 1395.6.1.2 Grammar 2 : : : : : : : : : : : : : : : : : : : : : : : 140
xi

5.6.1.3 Grammar 3 : : : : : : : : : : : : : : : : : : : : : : : 143
5.6.2 Experiments in the DDP domain : : : : : : : : : : : : : : : : : 148
5.6.2.1 Experiment 1 : : : : : : : : : : : : : : : : : : : : : : 1485.6.2.2 Experiment 2 : : : : : : : : : : : : : : : : : : : : : : 151
5.6.3 Discussion : : : : : : : : : : : : : : : : : : : : : : : : : : : : 153
5.7 Summary : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 153
6. CONCLUSIONS AND FUTURE WORK : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 157
6.1 Learning Organizational roles : : : : : : : : : : : : : : : : : : : : : : : 1586.2 Learning Non-local Requirements in a Cooperative Search Process : : : : : 1596.3 Learning Coordination in a Complex System : : : : : : : : : : : : : : : 1606.4 Future Work : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 161
APPENDICES
A. LEARNING RULES FOR UTILITY, PROBABILITY, AND POTENTIAL : : : : : : : : : : : : : 167
B. ROUGH COORDINATION : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 171
B.1 Implementing Rough Coordination : : : : : : : : : : : : : : : : : : : : 171B.2 Developing Rough Commitments : : : : : : : : : : : : : : : : : : : : : 171
C. DOMAIN GRAMMARS : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 173
C.1 Grammar G1 : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 174C.2 Grammar G2 : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 177C.3 Grammar G3 : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 180C.4 Routine Tasks Grammar : : : : : : : : : : : : : : : : : : : : : : : : : : 183C.5 Crisis Tasks Grammar : : : : : : : : : : : : : : : : : : : : : : : : : : : 185C.6 Low Priority Tasks Grammar : : : : : : : : : : : : : : : : : : : : : : : 186
REFERENCES : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 188
xii

LIST OF TABLES
PageTable
3.1 Average Cost of a Design : : : : : : : : : : : : : : : : : : : : : : : : : : 72
3.2 Average Cycles per Design : : : : : : : : : : : : : : : : : : : : : : : : : 73
3.3 Organizational roles for TEAM : : : : : : : : : : : : : : : : : : : : : : : 73
3.4 Organizational roles learned by situation-specific L-TEAM for Range 1 : : : 74
3.5 Organizational roles learned by situation-specific L-TEAM for Range 2 : : : 74
3.6 Organizational roles for non-situation-specific L-TEAM after learning : : : : 75
3.7 Results for ss-L-TEAM without potential : : : : : : : : : : : : : : : : : 76
3.8 Organizational roles in Range 1 for situation specific L-TEAM with no potential 77
3.9 Organizational roles in Range 2 for situation specific L-TEAM with no potential 77
4.1 Average Cost of a Design : : : : : : : : : : : : : : : : : : : : : : : : : : 96
4.2 Average number of cycles per design : : : : : : : : : : : : : : : : : : : : : 96
4.3 Average number of conflict resolution messages : : : : : : : : : : : : : : : 96
5.1 Average Quality for deadline 140 : : : : : : : : : : : : : : : : : : : : : : 127
5.2 Average Quality for different deadlines : : : : : : : : : : : : : : : : : : : 128
5.3 Average Quality for Grammar G3 : : : : : : : : : : : : : : : : : : : : : : 146
xiii

LIST OF FIGURES
PageFigure
1.1 A goal tree: ‘G’s represent goals and d’s represent data. Double headed arrowsbetween goals indicate that the goals are interdependent. Arrows between dataand goals indicate that the data are required for that goal’s solution. : : : : : 5
1.2 Goal tree for Updating an Environmental Database : : : : : : : : : : : : : 6
1.3 A distributed goal tree: The goal tree of the previous figure is distributedwith partial replication between two agents. The dotted arrows indicateinterdependencies among goals and data in different agents. : : : : : : : : 7
1.4 Conceptual view of a learning agent : : : : : : : : : : : : : : : : : : : : : 20
3.1 Steam Condenser : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 56
3.2 Negotiated Search : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 61
3.3 Local and Composite Search Spaces : : : : : : : : : : : : : : : : : : : : : 63
3.4 Distributed Search Over the Space of Possible Role Assignments : : : : : : : 67
4.1 Local Search Space for Pump Agent : : : : : : : : : : : : : : : : : : : : : 84
4.2 Composite Search Space for Pump and Motor Agents : : : : : : : : : : : : 86
4.3 State-based view of the Evolution of a Composite Solution : : : : : : : : : 87
4.4 Local and Composite Search Spaces : : : : : : : : : : : : : : : : : : : : : 91
4.5 Agent Control : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 94
5.1 Example of a Task Structure : : : : : : : : : : : : : : : : : : : : : : : : : 107
5.2 Example of a Graph Grammar Rewriting : : : : : : : : : : : : : : : : : : 111
5.3 Example of a Data Processing problem and its TÆMS representation : : : : 114
5.4 Example of a Graph Grammar Rewriting : : : : : : : : : : : : : : : : : : 115
5.5 Data Processing Problems : : : : : : : : : : : : : : : : : : : : : : : : : : 116
5.6 An Overview of Generalized Partial Global Planning : : : : : : : : : : : : 118
xiv

5.7 Coordination Strategies obtained from Clustering : : : : : : : : : : : : : : 123
5.8 Coordination Strategies for Distributed Data Processing : : : : : : : : : : : 126
5.9 Average Quality versus Size of Instance Base : : : : : : : : : : : : : : : : : 139
5.10 Average Quality versus Communication Cost for Grammar G1 : : : : : : : 141
5.11 Coordination Strategies chosen by Mode 1 COLLAGE for G1 : : : : : : : 141
5.12 Coordination Strategies chosen by Mode 2 COLLAGE for G1 : : : : : : : 142
5.13 Average Quality versus Communication Cost for Grammar G2 : : : : : : : 144
5.14 Coordination Strategies chosen by Mode 1 COLLAGE for G2 : : : : : : : 144
5.15 Coordination Strategies chosen by Mode 2 COLLAGE for G2 : : : : : : : 145
5.16 Average Quality versus Communication Cost for Grammar G3 : : : : : : : 146
5.17 Coordination Strategies chosen by Mode 1 COLLAGE for G3 : : : : : : : 147
5.18 Coordination Strategies chosen by Mode 2 COLLAGE for G3 : : : : : : : 147
5.19 Average Quality versus Communication Cost for Crisis TG Probability 0.25 149
5.20 Strategies chosen by Mode 1 COLLAGE for Crisis TG Probability 0.25 : : : 150
5.21 Strategies chosen by Mode 2 COLLAGE for Crisis TG Probability 0.25 : : : 150
5.22 Average Quality versus Communication Cost for Crisis TG Probability 1.0 : 151
5.23 Strategies chosen by Mode 1 COLLAGE for Crisis TG Probability 1.0 : : : 152
5.24 Strategies chosen by Mode 2 COLLAGE for Crisis TG Probability 1.0 : : : 152
6.1 Situation Representation versus Quality of Learning : : : : : : : : : : : : : 163
xv

C H A P T E R 1
LEARNING IN MULTI-AGENT SYSTEMS
Two roads diverged in a wood, and I–I took the one less traveled by,And that has made all the difference.
Robert Frost, The Road Not Taken
Beware of all enterprises that require new clothes.Henry David Thoreau, Walden(1854),I,Economy
This thesis deals with learning in multi-agent systems. Can systems of cooperative,heterogeneous, and reusable agents learn to interact coherently with each other and learnto manage their interdependencies so as to improve their performance? We can push thisquestion further and ask “How effectively can we introduce learning mechanisms into complex,realistic multi-agent systems, where the agents themselves are sophisticated problem solvers andinteract with each other in subtle and complicated ways?” Already existing machine learningtechniques can serve to leverage the implementation of more responsive agents that can adaptto act coherently and organize their local computations to take into account interdependenciesamong their activities. However, integrating learning techniques into sophisticated problemsolving agents is not a straightforward task. The required information and capabilities may bedistributed across the entire set of agents and no one agent may have a complete view of thestate of the system. This thesis is concerned with the utility and viability of learning in complex,heterogeneous multi-agent systems. Before we can elucidate these issues further, we need todefine and explain a number of terms and discuss some of the themes relevant to multi-agentsystems.
Below, we begin with a definition of the term “agent” and then introduce multi-agentproblem solving using a distributed version of the AND-OR goal tree representation. This isfollowed by a brief look at the significance of multi-agent systems and the impact learning canhave on a number of basic issues in this area. We then introduce the major theme of this thesis,which is situation-specific learning in multi-agent systems. We conclude with a list of majorcontributions of the dissertation.
1.1 Agent-based Systems
There has been an explosion of literature on agent-based systems in recent times and theyoccupy a prominent place in the popular press. So, what is an agent? As evidenced by the ragingdebates on the Internet news groups and special interest mailing lists on agent-based systems,this is a tricky question that has not yet been resolved to everyone’s satisfaction. However,there seems to be some sort of a tacit consensus in the “intelligent agents” community thatsome of the characteristics an intelligent program must exhibit for it to be called an agent
include[Russell and Norvig, 1995, Woolridge and Jennings, 1995]:

2� Autonomy: An agent is autonomous to the extent that its behavior is determined by itsown internal state and experience rather than through direct intervention by humans orothers. It has some control over its actions.� Situatedness: The process of deliberation and the resultant actions of an agent are tiedto its perception of its environment. An agent might have to perceive its physicalenvironment (ex: a robot) or its computational environments (ex: World Wide Web) oreven other agents and act accordingly.� Social ability: Agents may interact with humans (as in user agents) or other computationalagents (as in multi-agent systems) or both (as in mixed initiative systems).� Proactiveness: Agents exhibit goal-directed behavior, wherein they take initiative and actto achieve certain goals on behalf of a user or to make changes to the environment.� Mentalistic notions: A section of the community attributes stronger mentalistic notionslike beliefs, desires and intentions to agents. However, there is a sizable body of interestingagent-related research that goes on without the need to resort these stronger notions ofagent characteristics.
Note however, that the very terms used to define an agent, like autonomy, situatedness,and proactiveness are vaguely defined. Some researchers (including me) subscribe to the notionthat the right question to ask is not “Is a program an agent?”. One should instead ask “Howagent-like is a program?” Thus “agentness” is a spectrum defined by the above characteristics
and some programs are more agent-like than others[Hall, 1996]. In this thesis, we will bedealing with programs that are very strongly agent-like.
1.2 Multi-agent Systems
Research in Multi-agent Systems (MAS) is concerned with studying and manipulating thebehaviors of groups of agents embedded in an environment. Each of these agents is performingcertain goal-directed activities that affect and are affected by the activities of other agents andthe environment. In general, an agent in a multi-agent system has only a partial and possiblyout-dated view of the global problem solving process whereas any of its actions can have
non-local implications. Thus, at the heart of Distributed Artificial Intelligence (DAI) or MAS1concerns is the problem of each agent performing actions meaningful to the wider context ofthe problem solving process given its limited view. These actions include which local tasks toexecute next, what information about the local state to communicate and to whom, what andhow to model intentions and beliefs of other agents and also the state of the global problemsolving process, and what strategies to use to deal with disparate representations and conflicts.
We can view the distributed problem solving process as a search problem[Lesser, 1991].Consider a classical AND-OR goal tree as a representation of the search space of a problem-solving system. We can think of a goal/task node in such a tree as representing required1Some of the early literature[Bond and (Eds), 1988] distinguishes Multi-agent Systems from DistributedProblem Solving Systems and puts them both together under the rubric of Distributed AI (DAI). We believe that
this distinction is blurring within the DAI community and in this thesis MAS and DAI are used inter-changingly.

3
goal specification parameters and their characteristics, optional goal specification parametersand their characteristics, solution output parameters and their characteristics, and the levelof effort (resources and available time) to be invested in producing solutions that meet therequirements. Goals can be related to one another through goal-subgoal relationships andto data and resources via constraining interrelationships. Figure 1.1, originally from [Lesser,
1991], shows an example of such a goal tree. Solutions to high-level sibling goals like Gk�1and Gk or more distant goals like G1;1 and Gk;2 can have constraints between them. Theseinterrelationships can be independent of the specific solution(s) to a goal or highly dependenton the exact character of the solution(s). Constraints for goals at a particular level can haveimplications for achieving goals at both lower and higher levels. Goals may be related througha complex chain of interdependencies. For example, G1 and Gk�1 are interdependent throughGk . It is important to note here that the entire goal structure need not have been elaboratedbefore problem solving begins. The structure can be dynamic and can evolve with the agents’emerging composite view of the problem solving process. The goals and tasks are generated bythe problem solving components of the individual agents. The elaboration can be top-down,based on the higher-level goals of the agents, or bottom-up, driven by the data, or a combinationof both. Further, there are no restrictions on the consistency of the goal structure.
G1 G2 Gk-1 Gk Gn. . . . . . . . . . . .
G1,1 G1,2 G1,3Gk,1 Gk,2
Gk,1,1 Gk,1,4Gk,2,2
Gk,2,1
d1 dj dj+1 dz. . . . . . . . . . . . . . .. . . . . . .
and
or
and
or
and
resourcesdata
G
Figure 1.1. A goal tree: ‘G’s represent goals and d’s represent data. Double headed arrowsbetween goals indicate that the goals are interdependent. Arrows between data and goalsindicate that the data are required for that goal’s solution.
We now further ground this discussion by introducing an example from the Cooperative
Information Gathering domain[Oates et al., 1994]. Figure 1.2 shows the goal tree forupdating an environmental database by gathering information from relevant on-line sources.The database maintains current information about companies and universities involved in

4
environment related work, job information in related areas and any environment-related newsbriefs. Acquiring company and university information involves locating relevant informationand then retrieving and indexing the information appropriately. At the lowest level, this processinvolves gathering data from information repositories like “Environmental Route Net” and“Amazing Environmental Organization Webdirectory”. In case of unstructured information,there is a need for generating descriptors that map the content of the retrieved material intothe semantics of the domain. Constraining relationships such as facilitates, enables,and overlaps exist between various subgoals (these interrelationships are discussed in moredetail in the paragraph below).
Get info onCompanies &Universities
Involved
Get info on Jobsin EnvironmentRelated Areas
GetNews Briefs
LocateEnvironment related
company & universityDatabases & Sites
Retrieve &index
relevantdata
LocateDatabases &Sites relevantto Env Jobs
Update LocalEnvironmental
Database
Retrieve &index
relevantdata
Retrieve &index
relevantdata
Locate News Databases
EnvironmentalRoute Net
AmazingEnvironmentalOrganizationWebdirectory
NewsFeeds
NewsArchives
InternetNewsgroupsCosair
Job LeadReports
EnvironmentalEducation
Gopher Server
enablesenables enables
facili
tates
overlaps
facilitates
GI
G1I
G2I G3
I
G11I G12
I G21I G22
I G31I G32
I
Figure 1.2. Goal tree for Updating an Environmental Database
It is easy to see that there are numerous complications involved in performing “efficient”problem solving even in a single agent scenario. How does the agent detect interrelationshipsbetween sibling goals at various levels of the tree so that, for example, solving one goal beforeanother goal can facilitate the latter goal’s solution quality. The goal interrelationships can be ofvarious types such as facilitates, enables, overlaps, and hinders[Decker andLesser, 1992, Decker and Lesser, 1993a, Decker, 1994]. A facilitates interrelationshipimplies that the values of a solution output parameter of the facilitating goal can, in someway, determine an optional goal specification parameter of the facilitated goal. The facilitatedgoal could have been pursued without these optional parameters, but having them availablewill contribute to an improved search during the goal achievement process. The solution or

5
partial result from the facilitating goal provides constraints on the solution of the facilitated goaland consequently makes it possible to achieve this goal with fewer resources or higher quality.Similarly, an enables interrelationship implies that the enabling goal produces a solutionoutput parameter value that determines a required goal specification parameter of the enabledgoal. An overlaps interrelationship exists between two goals that share determinants ofsome of their solution output parameters. A favors interrelationship implies that a plan forachieving a goal can be used to achieve another favored goal through minor modifications (e.g.changing a query slightly so that the reformed query can produce results that not only satisfyone goal but also another subgoal). The detection and the use of such goal interrelationships for
efficient coordination is a hard problem in complex AI systems[Whitehair and Lesser, 1993].Figure 1.2 showsfacilitates,enables, andoverlaps between various subgoals.
There is afacilitates interrelationship fromGI1 toGI32 because information on the namesof companies and universities involved in environment-related activities can provide “key words”for a more refined retrieval from a large news-wire text-database. An overlaps exists betweenGI1 and GI3 because some of the news briefs provide information on companies and some ofthe companies maintain an on-line list of all news briefs related to their organization. Anoverlaps interrelationship says that the two goals involved may be doing similar work and
can hence benefit by sharing their partial results. Enables betweenGI11 to GI12 indicates thatan agent must locate databases related to environmental companies and universities before itcan extract appropriate information and update the local environmental database.
Now consider the case in which a goal tree is distributed across multiple agents, none ofwhich may have a complete global view of the goal tree. Each of the agents can model only apart of the global goal structure based on its role in the overall problem solving process. Thisleads to added complexity in an already complex situation as discussed above. Figure 1.3 (from[Lesser, 1991]) illustrates an example where the goal tree from Figure 1.1 is distributed acrosstwo agents. Detection of coordination relationships by the agents now becomes more difficultdue to their partial view of the goal tree.
Continuing with our example in Figure 1.2, let us distribute the goal tree across three
agents such that Agent 1 needs to achieve GI1, Agent 2 needs to achieve GI2 and Agent 3
is in charge of GI3. The resultant concurrency leads to a speed up that makes distributionattractive, especially when the amount of information to be accessed is large and time is alimited resource. However, distribution also gives rise to the need for effective managementof interrelationships between activities distributed across agents, so as to maximize the benefitsfrom inherent traits such as “parallelism”, “robustness” and “separation of concerns”, that areusually associated with multi-agent architectures. For example, how long should Agent 3 waitfor information from Agent 1 to be able to exploit the facilitates interrelationship for
achievingGI32? What kind of protocols are needed to detect the existence of interrelationships?How are inconsistencies between redundant data of Agent 1 and Agent 3 (with overlapsinterrelationship between their goals) resolved?
An agent in a MAS faces the need to act under uncertainty arising out of the lack of completeknowledge to determine how a particular action can affect the global problem solving process.Depending on the character of uncertainty, different organizations of varying complexity andsophistication are needed for efficient distributed problem solving. Large amounts of domainspecific knowledge are often used in these systems and they are typically parameterized alongmany dimensions, such as the types and amount of information communicated to other agents,

6
G1 G2Gk-1 Gk
. . . .
G1,1 G1,2Gk,1
Gk,1,1Gk,1,2
and
or
and
1 1 1 1
1 1 1
1 1
G1,3 Gk,1 Gk,2
Gk,1,3 Gk,1,4Gk,2,2
Gk,2,1
and
or
and
G1 Gk Gn. . . . .
and
2 2 2
2 2 2
22
2
2
d1 dj dj+1 dz. . . . . . . . . . . . . . .. . . . . . .
resourcesdata
Agent 1 Agent 2
G1 G
2
Figure 1.3. A distributed goal tree: The goal tree of the previous figure is distributed withpartial replication between two agents. The dotted arrows indicate interdependencies amonggoals and data in different agents.
the amount of time spent on local computations versus cooperative activities, and tradeoffsinvolved in local optimality versus global optimality. It is practically impossible for the systemdesigner to anticipate and code the huge number of possibilities in structuring the problemsolving process so as to achieve acceptable tradeoffs and system performance in all the potentialoperating environments. Acquiring, representing and tuning the domain specific knowledgecould be error-prone, cumbersome and time consuming. In view of these difficulties (andmore), learning various aspects of structuring the problem solving process and domain specificknowledge can be important for a MAS.
In the sections below, we discuss in more detail, why learning is important for DAI systemsand then go on to identify areas where we see incorporating learning as beneficial. We assumethe following working definition for learning:
Learning denotes changes in the system that are adaptive in the sense that theyenable the system to do the same tasks drawn from the same population moreefficiently and more effectively the next time. [Simon, 1986]
1.3 Why Multi-agent Systems?
Why does one need computational multi-agent systems? Can we not do with centralizedprocessing whatever we can with multi-agent systems? In theory yes, a Turing machine cansimulate any known computational system. However, more pragmatic considerations point toa genuine need for multi-agent systems:� The nature of the real world and the structure of the problem forces upon us the need for
a multi-agent approach. For example, Neiman and Lesser[Neiman et al., 1994] discuss

7
a distributed scheduling system for airport resource management. There are a numberservices like gate assignment, baggage handling, refueling, and catering. Different agentsare responsible for each of them. The agents are requiredto meet the arrival and departuredeadlines of all the incoming and outgoing aircraft. Resources are owned and managedby discrete agents that have proprietary knowledge about them and private privilegesand responsibilities. Forcing centralized solutions requires that these agents give up theirprivileges, responsibilities and proprietary knowledge. Such requirements may radicallyalter the social norms of the people working along with the system and it may requireenormous effort to make them accept such a system.� Simon[Simon, 1968] talks about “nearly decomposable systems” and their prominence insocial systems. Many problem domains exist where the interactions among subsystems areweak but not negligible. The inherent parallelism among these subsystems makes multi-agent solutions very attractive, especially in resource-bounded and time constrained
scenarios. A good example of this is information gathering on the Internet[Oates etal., 1994]. The amount of information is seemingly boundless and many resourcescharge money for access. Thus a user wanting some information must impose timeand resource (in this case, money) limitations on the information gathering programs.Oates, Nagendra Prasad and Lesser[Oates et al., 1994] present a framework for multi-agent information gathering where multiple agents are simultaneously spawned to accessinformation resources in parallel, while interacting on an “as-needed” basis, to meetcertain cost and deadline requirements.� Agent-based architectures offer modularity, robustness, separation of concerns, and otheradvantages of a distributed system. Agents can be constructed and maintained separately.An agent can build upon other agents to provide an abstraction of these informationsources.� At a more fundamental level, even a modularized, centralized intelligent system maycontain components exhibiting “agent-ness”. When a particular component X hasinteractions with another component Y but X has an associated uncertainty about thebehavior of Y, then the component X might benefit by using techniques from multi-agentsystems (such as modeling the behavior of Component Y at a certain level of abstraction).� In addition to the engineering issues, there are also purely intellectual justifications forstudying multi-agent systems. The ubiquitous nature of distributed intelligent systemsand multi-agent systems is apparent in nature. The problem solving capabilities of anarmy of ants are far beyond the scope of any individual ant. The human brain is a resultof wiring together a large number of neurons, each of which by itself is quite “dumb”.How does intelligence arise from such a system? How do the constituent elements ina multi-agent system act in concert? The multi-agent community has been seekinganswers to such questions for many decades now[Franks, 1989, Seeley, 1989].
1.4 Why Learning?
As they stand, most of the DAI systems to date have capabilities to cope adaptively withuncertainty in the problem solving knowledge but do not exhibit abilities to handle emergent

8
contexts and changing problem-solving roles for participant agents[Bond and (Eds), 1988].For example, consider a robot colony where, each of the robots is an autonomous intelligentagent that has to cooperate with others to avoid interfering with them in a destructive way.Over time, the agents may have to cope with emergent dynamic problem solving contexts.The wear and tear in the mechanical components could change the behavior of the robots. Itbecomes essential to observe, detect, and use these changes for the survival of the colony. Whilesome of these possibilities can be modeled as uncertainty in the problem solving knowledge,such a system more importantly needs to be equipped with adaptive capabilities that becomeinstantiated based on the changing problem solving roles of the agents. Some initial work on
adaptive systems has been presented in Corkill[Corkill, 1983], Ishida, Yokoo and Gasser[Ishidaet al., 1990], and So and Durfee[So and Durfee, 1993]. These systems are concerned withperformance activated change in the organizational structuring involving agents monitoringtheir performance in the environment and initiating changes, either individually or as a group,in response to observed measures of such performance. Organizational structure representsrelatively long term commitments about how agents organize their local computations, howthey handle interrelationships between their tasks, and what they communicate with oneanother. In order that a system be amenable to reorganization there is a need for constantmonitoring of the system based on performance measures. When these measures cross a certainthreshold, reorganization is initiated to select a new organization for the present context. This
process has also been called Organizational Self-Design (OSD)[Corkill, 1983]. The existingsystems perform OSD based one of the following major approaches:� Global Top-down approach [Corkill and Lesser, 1983, Durfee and Montgomery, 1991,
So and Durfee, 1993], where one or more of the agents monitor the global performanceof the system and restructure its organization when needed.� Bottom-up approach[Ishida et al., 1990], where agents, based on local estimates of theperformance of the organization, initiate local restructuring within their neighborhood.� Contract-net formalism[Davis and Smith, 1983], where a negotiation process consistingof an announce-bid-reward cycle is used by an agent to distribute subtasks decomposedfrom a task to various agents based on the outcome of the negotiations with them.This organization is statically determined at the start of the problem solving and is arelatively rigid structuring compared to the above two approaches. In the cases where afailure of a sub-contractor is detected, an exception handling mechanism is invoked andreorganization may take place.
Adaptive systems entail handling known uncertainties using flexible but pre-programmedstrategies. They do not incorporate previously unknown knowledge or change representationsor cache away beneficial experience from past problem solving episodes for later reuse; theseactivities fall under the regime of learning. Based on their experience, a set of agents can learn toreorganize themselves efficiently when they encounter problem solving situations structurallysimilar to some subset of the past problem instances. Moreover, as will be discussed below, thescope of learning encompasses activities beyond OSD.
Bond and Gasser [Bond and (Eds), 1988] identify six basic problems that DAI researchershave begun to address. We will now discuss these six problems [Gasser, 1991] and indicatehow learning can be of help in each of these six areas:

9� How to formulate, describe, decompose, and allocate problems and synthesizeresults among a group of intelligent agents.
Problem decomposition is the process of dividing up a problem into subproblems andallocating them to the appropriate agents or a subset of them. Once the agents solve thesubproblems there is also the issue of synthesizing results of the subproblems to producean overall solution to the problem.
Little work has been done in problem formulation and decomposition though Contract
Net and DVMT address the issues of problem allocation[Davis and Smith, 1983, Durfeeand Lesser, 1989]. Learning can be of help in all the three areas. For example, a systemcan learn problem decomposition by acquiring instances from a human operator andinductively generalizing on them. This is an instance of learning by being told. The humanteacher tells the system only about the decomposition of specific problem instances andthe system has to learn some generalized decomposition strategies based on these probleminstances and its knowledge of the task ontologies.� How to enable agents to communicate and interact: What communication
languages or protocols to use, and what and when to communicate.
Any set of intelligent agents needs a common language or a set of common conventionsto be able to work together as a system. Lack of common conventions or a view ofthe requirements of other agents leads to conflicts between agent activities. Multi-agentsystems may need to negotiate with one another to resolve the conflicts. Negotiation isthe process of trying to resolve conflicts either through communication or by reasoningabout other agents’ intentions and goals. It may involve trade-offs or coercion orrelaxation of requirements in order to avoid harmful interactions and create cooperativesituations[Sycara, 1989]. An agent endowed with learning abilities can, on the otherhand, use its past experience to “guess” and hence reduce the need for negotiation or at
least make it more directed. For example, in PERSUADER[Sycara, 1989], an arbitratoragent solves labor mediation disputes between the management and the union. Anarbitrator equipped with learning capabilities can converge to a compromise solutionmuch more quickly. One could imagine even a simple “tally” mechanism where sheclassifies the goals of each of the disputing parties into a set of predefined generalcategories and develops a measure of willingness of the parties to compromise on them.For example, the labor unions may be more willing to compromise on perks such aschild-care or health club memberships than on working conditions such as the numberof hours of work per day, even though the former benefits are financially alluring.� How to ensure that agents act coherently in making decisions or taking action,
accommodate the nonlocal effects of local decisions and avoid harmful interactions.
Just as an agent can learn goals, intentions and beliefs of another agent, it can also learnthe characterization of the task environment. An agent’s task environment includes thetasks that it needs to execute locally, and their effects on the tasks that other agentshave to execute and the overall utility of the system as a whole. Knowing the taskenvironment better has a direct impact on an agent’s ability to realize the implicationsof its decisions and their non-local effects. Later in the thesis, we discuss in more detail

10
how, in the GPGP context[Decker and Lesser, 1992, Decker and Lesser, 1995], learningtask environment characteristics can be achieved.� How to enable individual agents to represent and reason about actions, plans and
knowledge of other agents in order to coordinate with them.
The ability to model another agent’s goals and beliefs has a direct impact on an agent’sability to reason about other agents and consequently make it a better team player.
Methods like RMM[Gmytrasiewicz et al., 1991] have been proposed where each agentmodels the other agents at multiple levels of recursive reasoning involving, for example,knowledge of the other agent about the present agent and so on. These methods highlightthe need for an agent to model other agents for better coordination. However, the systemsin literature to date either deal with simple game-theoretic models or incorporate relativelysimple forms of modeling. In order to handle more complex issues in dealing withmodeling other agents, learning can play a prominent role. For example, initially, theagents negotiate to reach an agreement over a certain dispute. The learning componentis a passive observer mapping the discourse to the goals and utilities of the agent. Basedon these observations, it develops general strategies and starts playing a greater role innegotiation, gradually assisting the negotiation component in making it more directedand adept.� How to recognize and reconcile disparate viewpoints and conflicting intentions
among a collection of agents trying to coordinate their actions.
Agents in a multi-agent system may possess different viewpoints on the same situationsor related situations. The ability to model and reason about the task environment andthe other agents and about the conflicting intentions both within and between agents
can be of help in reconciling disparate viewpoints. Systems like DRESUN[Carver etal., 1993] quite aptly demonstrate the benefits of performing this kind of reasoning.However, we can view learning as a logical extension of the capabilities of these types ofsystems. The agents, through learning, can better relate their local problem solving to theglobal context (more on this later). For example, recognizing that resolving certain kindsof uncertainties before others in a DRESUN-like system could lead to better solutionsin lesser time.� How to engineer and construct practical DAI systems; how to design technology
platforms and the development methodologies for DAI.
An agent with learning abilities can do more with a DAI system while not movingout of the realm of credibility for many real world applications. DAI systems work inuncertain and dynamic environments. Agents that can change their behavior based on apredetermined strategy are considered adaptive [Ishida et al., 1990]. However, to encodeall possible strategies in a complex system is neither practical nor appealing in the longrun. Parameterization of a complex system may be difficult and may be changing overthe lifetime of the system. Some parameters may not be obtainable due to privacy reasonsor maybe even due to the lack of common language to communicate these. Generalmechanisms for learning these parameters can avoid the cumbersome engineering ofstrategies to tackle all possible situations. While mathematical techniques can analyze

11
simplified systems, many of the real life systems may be intractable to formal analysisand heuristic estimates of the parameters may even be the only way out.
Such being the case, it is important to look at what and how learning can be incorporatedinto multi-agent systems.
1.5 Learning in Multi-agent Systems
The work presented here deals with techniques to improve problem solving control skillsof cooperative agents. Problem solving control is the process by which an agent organizes itscomputation. An agent in a MAS faces control uncertainties due to its partial local view of theproblem solving states of the other agents in the system. Uncertainties about progress of problemsolving in other agents, characteristics of non-local interacting sub-problems, expectations ofnon-local problem-solving activity, and generated partial results can lead to global incoherenceand degradation in system performance if they are not managed effectively through cooperation.Effective cooperation in such systems requires that the global problem-solving state influencethe local control decisions made by an agent. We call such an influence cooperative control[Lesser,
1991]. For example, we will be discussing a multi-agent design system called TEAM wherea number of agents together design steam condensers. Each agent is an expert at designingone component of the overall steam condenser. At the start of the problem solving, given theuser requirements and local constraints on the components they produce, the agents may haveconflicting requirements on the steam condenser design. For example, one agent may havethe requirement that the power of the motor component should be more than 15 HP, whereas another agent may require it to be less than 10 HP. The components produced by thesetwo agents will be incompatible and the agent that detects this conflict negotiates with theother agent on what the compromise motor power should be. This process of negotiation isan aspect of cooperative control and it influences the future problem-solving searches of eachof the agents involved.
Cooperation among agents can be explicit or implicit. In explicitly cooperative systems, the
agents interact and exchange information or perform actions so as to benefit other agents2.On the other hand, implicitly cooperative agents perform actions that are a part of their own
goal-seeking process but these actions affect the other agents in beneficial ways[Mataric, 1993,Mataric, 1994b]. An example of implicit cooperation is presented in Sen, Sekaran and Hale[Senet al., 1994]. Two agents learn to push a box cooperatively to a pre-designated location. Eachagent is unaware of the other agent and both of them receive a large reinforcement if the boxis moved to the right location. Each agent tries to maximize its own reinforcement. In theprocess, cooperation emerges due to the fact that it leads to maximization of the reinforcementfor each of the agents.
A common form of exchange of information between agents is through communication.An agent in a MAS needs to communicate with other agents to acquire a view of the non-localproblem solving so as to make local decisions that are influenced by more global considerations.The agents perform direct communication or indirect communication as a part of their processof interaction with other agents. Direct communication involves intentionality entailinga sender and one or more receivers. The communication is purposeful and is aimed at2We will be dealing with these systems throughout the thesis, and later chapters will provide the examples.

12
particular members of the agent set. Much of the explicitly cooperative activities involvesdirect communication. In contrast, indirect communication is achieved through observation
of the behavior of the other agents and their effects on the environment[Mataric, 1993,Mataric, 1994b]. Indirect communication involves cues that are “simply by-products ofbehaviors performed for reasons other than communication”[Seeley, 1989]. An example ofindirect communication arises in honey bee colonies[Seeley, 1989]. In a honey bee colony, itis important that the forager bees stay informed about the colony’s nutritional status. Thishas implications for the kinds of flower patches chosen for foraging and also recruiting othernestmates for foraging. A forager derives this information from the delay she experiences beforea food storer bee can unload nectar from her. If the hive is full, it takes longer for a food storerto find a place to store the incoming nectar. The increased wait times indicate that the hivealready has much nectar or there are already a lot of foragers coming in to unload nectar.
The work presented in this thesis deals with explicitly cooperative directly communicatingsystems. In such systems, the local problem solving control of an agent can interact in complexand intricate ways with the problem solving control of other agents. In these systems, anagent cannot make effective control decisions based on purely local problem solving state. Agiven local problem solving state can map to a multitude of global problem solving states. Anagent with a purely local view of the problem solving situation cannot learn effective controldecisions that may have global implications, due the uncertainty about the overall state of thesystem. This gives rise to the need for learning more globally situated control knowledge. Onthe other hand, an agent cannot utilize the entire global problem solving state even if otheragents are willing to communicate all the necessary information because of the limitations onits computational resources, representational heterogeneity and phenomena such as distraction.If an agent A provides another agent B with an enormous amount of problem solving stateinformation, then agent B has to divert its computational resources away from local problemsolving towards the task of assimilating this information. This can have drastic consequencesin time constrained or resource bounded domains. Moreover, the phenomenon of distractioncan become a serious problem. The incorrect or irrelevant information provided by anotheragent with weakly constrained knowledge could lead the receiving agent’s computations along
unproductive directions[Lesser and Erman, 1980]. Representational heterogeneity impliesthat the agents represent their domain and control knowledge in different representations,eliminating the possibility of intimate understanding by an agent, the problem solving state ofanother agent. For example, a rule-based agent cannot understand the workings of a case-basedagent even if that agent provided all the details about its internal state (such as similarity metricused, most similar case retrieved and adapted).
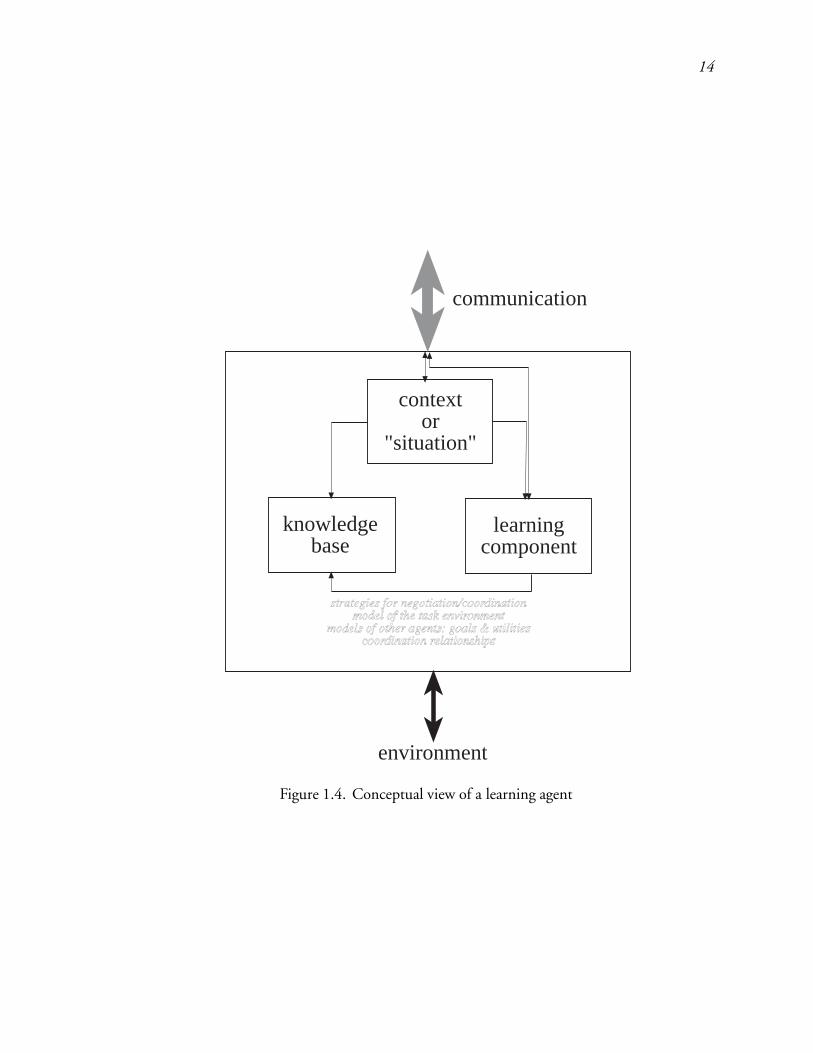
This brings us to the importance of communicating only relevant information at suitableabstractions to other agents. We call such information a situation. An agent needs to associateappropriate views of the global situation with the knowledge learned about effective controldecisions. We call this form of knowledge situation-specific control. In complex multi-agentsystems, the knowledge engineering involved in providing the agents with effective controlstrategies is a formidable and perhaps even impossible task due to the dynamic natureof the interactions among agents and between the environment and agents. Thus, weappeal to machine learning techniques to learn situation specific problem solving controlin such systems. A conceptual view of our model of a learning agent is presented inFigure 1.4. Learning can involve acquiring strategies for negotiation or coordination, detecting

13
coordination relationships, incrementally constructing models of other agents and the taskenvironment.
More specifically, in this thesis, we will be dealing with three aspects of cooperative control:� Organizational RolesOrganizational Roles are a form of organizational knowledge representing policies forassigning responsibilities for various tasks to be performed by each of the agents in thecontext of the global problem solving process. An organizational role played by anagent is intimately tied to the way the problem solving process is distributed across theagents and the extent of knowledge available to an agent about other agents’ state ofproblem-solving. This thesis studies organizational roles in a multi-agent parametricdesign system called L-TEAM.� Negotiated SearchA purely local view of the composite search space in a distributed search system is unlikelyto lead to solutions that are mutually acceptable to all agents. This leads to the needfor the agents to communicate relevant information to augment their local views of thesearch space with a more global view of the requirements of the composite solutionspace. One way the agents can achieve this is by engaging in a failure-driven exchangeof feedback on non-local requirements to develop the closest possible approximation tothe actual composite search space[Lander, 1994, Lander and Lesser, 1994]. This typeof search is called negotiated search. This thesis presents a case-based learning methodthat endows agents with the capability to approximate non-local search requirements ina given situation, thus minimizing or avoiding the need for a negotiated search while notsacrificing solution quality and time.� Coordination StrategiesCoordination is the act of managing interdependencies among activities[Malone and
Crowston, 1991]. Coordination strategies provide an agent with the ability to behavemore coherently in a particular problem solving situation. This includes avoidingneedless and redundant activities, providing helpful information as needed at the rightlevel of abstraction, meeting deadlines, and balancing workload among agents. Thework presented in this thesis studies learning such coordination strategies and empiricallyproves its utility.
1.5.1 Learning Organizational Roles in a Heterogeneous Multi-agent System
L-TEAM is an extension of the TEAM framework[Lander, 1994] that was developed tosupport the integration of heterogeneous reusable agents in cooperative distributed searchdomains. A reusable-agent system is defined as an integrated set of software agents, selectedfrom a catalogue of pre-existing agents, that are anchored into an infrastructure that providesthe communication and control backbone to enable effective cooperation.
Multi-agent parametric design is a form of cooperative search in which variable values areassigned to parameters of a design configuration that is pre-specified. Designs are initiatedby agents that can create an initial partial assignment of variable values from a problem
14
contextor
"situation"
knowledgebase
learningcomponent
environment
communication
Figure 1.4. Conceptual view of a learning agent

15
specification. Other agents then either extend or critique the initial design until it is completeand mutually acceptable to all participating agents.
Each agent in L-TEAM plays some organizational role in a distributed search episode. Arole defines a task or a set of tasks to be performed in the context of a solution. In L-TEAM, thepossible roles an agent can perform include initiating a new design, extending an existing partialdesign and criticizing an existing design. A particular assignment of roles to agents is definedfor each solution under development. These role assignments can affect the efficiency of thesearch process and the quality of final solutions produced. The underlying reasons for thesedifferences can be traced in part to the ability of particular agents to provide and use feedbackinformation from other agents in the set. Although it is the characteristics of individual agentsthat determine what interaction takes place, it is the way information flows through the agentset that determines the optimality of a particular role assignment. This thesis demonstrates thatlearning techniques can be applied to the task of organizing agent sets by using role assignmentsthat best utilize the abilities of the available agents.
1.5.2 Cooperative Learning over Composite Search Spaces
The search space in a multi-agent system such as TEAM can be viewed as consisting of twocomponents: the local search space of each individual agent and the composite search space of thesystem. A local search space is private to an agent whereas the composite search space is shared
by all agents3. The local search space is defined by the parameters the agent uses to constrainits local search. An agent defines a local solution space by assigning values to the parameters inits local solutions.
Problem solving in TEAM starts with agents possessing only local views of the searchand solution spaces. This is highly unlikely to lead to mutually acceptable solutions lying inthe composite search space. If the other agents can analyze the nature of the conflicts andprovide feedback to the agents involved, they can begin to build a global perspective. Thisglobal perspective is typically not complete because not all conflicts can be readily described.However, any global information that can be readily shared will be useful in making localdecisions.
We implemented a case-based learning algorithm that enables agents in TEAM to build apartial global perspective of constraints that exist in the agent set by accumulating conflict-drivenfeedback over a series of design episodes. This learned information can be used in several waysto improve solution quality and performance. It can be applied during an episode to control thesearch process intelligently. It can also be used across multiple episodes to augment or replaceruntime communication of conflict feedback. Our empirical studies have shown that this formof learning can lead to higher quality solutions in general and can reduce communication costsacross design episodes without a decline in solution quality.
1.5.3 Learning Situation-Specific Coordination
Coordination represents patterns of interaction between agents in the act of managing
interdependencies among their activities[Malone and Crowston, 1991]. Effective coordination3Composite search space is implicitly defined by the intersection of individual search spaces of the agents.
More details can be found in Chapter 4.

16
is important for achieving cooperation among agents. However, this is a difficult problem,again due the local view of an agent’s control decisions that may have global implications. Thismay lead to inappropriate decisions about which activity it should do next, what results itshould transmit to other agents and what results it should ask other agents to produce[Deckerand Lesser, 1992, Decker and Lesser, 1993a, Durfee and Lesser, 1987]. If an agent has a viewof the patterns of activities (at appropriate detail) of other agents, it can make more informedchoices. Algorithms for achieving this are called coordination strategies.
Clearly, no single coordination strategy is appropriate for all problems. The third partof our thesis presents learning algorithms for choosing appropriate coordination algorithmsbased on the problem-solving situation on hand. It relies on an approach to distributed
coordination called Generalized Partial Global Planning (GPGP)[Decker, 1995, Decker and
Lesser, 1995] that consists of an extensible set of modular coordination mechanisms. Anysubset of mechanisms can be selected in reaction to the characteristics of the observed taskenvironment. Experimental results have verified that for certain environments, a subset ofthe mechanisms is more effective than using the entire set of mechanisms[Decker, 1995,Decker and Lesser, 1995]. Our current work involves developing learning algorithms thatendow agents with capabilities to choose a suitable subset of the coordination mechanismsbased on the present problem solving situation.
We developed a tool for representing complex coordination problems and instantiatingenvironment-specific coordination mechanisms for facilitating empirical studies of effectivenessof different coordination mechanisms in different environments. This relies on a graph-grammar-based stochastic task structure description language and generation tool for modelingtask structures arising in a domain. User-defined stochastic graph grammars are used tocapture the morphological regularities in a domain. Grammars are augmented with attributesto capture additional aspects of domain semantics. Using such grammar-based generators, wemodeled functionally-structured agent organizations with interrelationships between functionsin the domain of distributed data processing and empirically study the effectiveness of variouscoordination mechanisms for different environments in this domain. This modeling effortfacilitated our subsequent study of the power of situation-specific learning for task environment-based choice of a coordination protocol. The learning algorithm, called COLLAGE, was testedon five different graph grammars representing domain theories and the empirical results stronglyindicate the superiority of situation-specific learning over any static choice of a coordinationalgorithm. Two of these grammars are based on abstract models for a distributed data processingtask.
1.5.4 Contributions of the Thesis
This thesis empirically demonstrates the potential of machine learning techniques foraddressing a number of issues in multi-agent systems. It exploits existing machine learningtechniques and studies how they can be modified and integrated into multi-agent systems.However, it is not concerned with the comparative performance of various types of learningalgorithms for learning a given aspect of a MAS. The contributions of this thesis include:� Studies learning in explicitly cooperative directly communicating systems.
Much of the learning work in multi-agent systems is concerned with implicitly cooper-ative or non-communicating or self-interested agents. Our work represents the earliest

17
known results demonstrating the effetiveness of learning in cooperative heterogeneousmulti-agent systems that exchange complex information (see the section on related workfor a more detailed coverage of this aspect).� Recognizing the need for situation-specificity in learning cooperative control in explicitlycooperative directly communicating systems.The thesis shows that learning situation-specific control is viable and useful in terms ofproducing good problem solving strategies. However, it does not deal with the problemof generating the best possible abstraction in terms of situations. We show that thestrategies evolved with a particular situation-vector produce better quality or lower costsolutions than hand-coded strategies for three aspects of problem solving control.� This thesis empirically demonstrates how learning can be achieved in the context of thefollowing aspects of problem solving control in multi-agent systems:
1. Organizational roles in a multi-agent design system.
2. Non-local requirements in a cooperative search process.
3. Coordination in a complex parametric coordination system.� A novel, Attributed Stochastic Graph Grammar-based framework for abstract modeling oforganizations and task environmentsWe introduce an attributed stochastic graph grammar-based framework for modelingmorphological regularities in the task structures in a domain while simultaneouslycapturing aspects of uncertainties arising from a number of different characteristicsin the domain being modeled. We demonstrate its power by modeling a distributeddata processing domain and empirically studying organizational designs for this domain.In the process, we discovered certain important limitations to a coordination protocolthat was designed to be “sophisticated” enough to detect just the right interactions andexchange just the right amount of information.� Shows the utility and viability of learning in complex, heterogeneous multi-agent systems.We used already existing, complex multi-agent systems and endowed them with learningcapabilities. Learning organizational roles and non-local requirements was done in aheterogeneous multi-agent parametric design system, where the non-learning version was
already developed as the TEAM system by Lander[Lander, 1994]. Learning coordinationstrategies was done on the generalized partial global planning system constructed forstudying coordination among heterogeneous agents in complex domains like distributed
sensor monitoring[Decker and Lesser, 1995, Nagendra Prasad et al., 1996a]. Theagents in these systems are of large granularity and are essentially sophisticated reasoners.Moreover, learning organizational roles and non-local requirements was done in thecontext of reusable design agents. Much of the literature in learning deals with systemsthat are stripped down to the bare essentials of the learning problem with little or nostate information and few inference steps. Some of the works assume homogeneousagents (see the section on related work for a more detailed coverage of this aspect.).Homogeneity can implicitly provide an agent with the ability to predict the non-localcontrol of other agents. While the author does not deny the importance of such studies

18
to a nascent field like learning in multi-agent systems, learning in complex systems canprovide many challenges and interesting insights that may not be forthcoming in simpletoy domains or homogeneous agent systems.� The concept of potential that measures the relation between an action and the progress of theoverall problem-solving process, introduced in the context of role learning.In a complex system, the effect of an action could be related in intricate ways to theend result that receives reinforcement. Assigning credit to an action purely based onsuch reinforcement may not only be difficult but almost impossible due to myriadconfounding intermediate influences that occur between the action and the end result.When using reinforcement learning algorithms for learning in such complex systems,taking into consideration meta-information about relationships between an action andits effect on the progress of the overall problem-solving can help a system achieve bettercredit assignment policies (Chapter 3).� Instance-based Learning (IBL) for decision-theoretic tasksMuch of the past work using IBL algorithms concentrated on classification or function
approximation tasks[Aha et al., 1991, Stanfill and Waltz, 1986, Atkeson, 1990]. Inour studies on learning coordination, COLLAGE extends IBL algorithms to a non-classification task involving decision-theoretic selection of good coordination algorithms.We use cumulative measures of past performances to select a coordination strategy froma pre-defined set.
1.6 Guide to the Dissertation
This chapter discussed the broad goals and themes of this dissertation. The rest of thethesis is organized as follows:
Chapter 2 Surveys the related work on multi-agent learning and places our work in the context ofthis existing work. In addition, the related works specific to the particulars dealt with ineach of the chapters are discussed in those chapters.
Chapter 3 Deals with learning organizational roles in a multi-agent parametric design system calledL-TEAM.
Chapter 4 Formalizes and also empirically studies the distributed search process in TEAM and theprocess of learning non-local requirements in negotiated search.
Chapter 5 Deals with learning coordination strategies in a complex parametric coordination system.
Chapter 6 Summarizes the research results and discusses interesting future work possibilities anddirections that this research will take.

C H A P T E R 2
REVIEW OF RELATED WORK
Do you know what I learned from you? I learned what is possible, and now I musthold out for what I thought we had. I want to be very close to someone I respect andadmire and have somebody who feels the same way about me. That or nothing. Irealized that what I’m looking for is not what you’re looking for. You don’t wantwhat I want.
Leslie Parrish, The Bridge Across Forever (Richard Bach)
If I have seen farther than others, it is because I was standing on the shoulders ofgiants.
Isaac Newton
Despite the agreement among researchers in multi-agent systems about the importanceof the ability for agents to learn and improve their performance, this aspect has been ignoredfor a long time. Fortunately, the past few years have begun to see an increasing attention toaspects of learning in multi-agent systems. However, the body of work related to learningin multi-agent systems is still limited, especially given the potential of learning to address anumber of longstanding issues in the field. This chapter reviews some of the work on learningin multi-agent systems. This review is meant to be representative rather than exhaustive.
2.1 Multi-agent Reinforcement Learning and Classifier Systems
Much of the literature in multi-agent learning relies on reinforcement learning[Barto etal., 1990, Sutton, 1988] and classifier systems[Holland, 1985] as learning algorithms. Someof the earliest attempts at multi-agent learning used these methods because they are simple toimplement and have elegant theoretical formalisms. More importantly, these algorithms relyon weak reinforcement learning signals provided as feedback by the environment. These signalsimpose few, if any, demands in terms of their content. In most cases they are just numericalmeasures of “goodness” of the performance of the system as a whole.
Tan[Tan, 1993] presents a predator-prey domain where a set of predators learn to surroundand capture a prey trying to escape from them in a grid world (a 10 � 10 grid). Predators andthe prey can either stay in the same location or move a step to North, South, East or West duringeach time step. Predators are reinforcement learning agents while the prey is not learning. Theagents are limited in their perception. Tan studies cases where the agents share their perceptiveinformation to overcome the limitations of their sensor ranges. In addition, he also studiessharing policies derived from reinforcement learning and exchange of episodes among peerpredators. His results indicate that agents cooperating to share learned knowledge and episodic
information did better than independent agents. Sandholm and Nagendra Prasad[Sandholm

20
and NagendraPrasad, 1993] performed studies in learning-by-observation in the same domainof predators trying to capture a prey. A novice agent learns by observing an expert. The typeof cooperation in these domains is simple, in part because of the simplicity of the domains.Explicit cooperation helps learning but is not an essential part of the prey capture itself. Inaddition, the agents are homogeneous. The systems presented in this thesis are characterizedby much higher sophistication and heterogeneity. In addition, both their problem-solving andlearning are characterized by direct communication for explicit cooperation.
Sen, Sekaran and Hale[Sen et al., 1994] present a reinforcement learning system[Barto etal., 1990, Sutton, 1988] where two agents learn to push a box cooperatively to a pre-designatedlocation. The agents learn complimentary policies to move a box from a start location to a goallocation without any knowledge about each other. They study interesting learning issues liketransfer of knowledge and complementary learning. However, as with the previously discussedsystems, they are implicitly cooperating and homogeneous. Agents in this system are simplewith no knowledge of the physics of the domain or any planning capabilities. Their knowledgeis encoded in the learned policy matrix.
Mataric[Mataric, 1993, Mataric, 1994a] studies learning in robot colonies. Based on theanimal behavior metaphor, she uses reinforcement learning to let a set of robots learn socialbehaviors like herding, convoying, foraging and gathering through simple local interactions.Interactions are based on observable external behavior and its interpretation. The role ofcommunication is minimal and is primarily used to overcome the perceptual limitation ofsimple sensors for the robots. The communication involves broadcast of position information,and other external state information such as “holding food”, and “finding home”. Thus, thecooperation is primarily implicit.
The agents are homogeneous: their capabilities are the same, and they embody similargoal structures. Each agent has a collection of basic group behaviors like collision avoidance,following, dispersion, aggregation, homing and flocking. Spatial and temporal combinationsof these basic behaviors form compound behaviors such as herding (flocking + homing), andconvoying (avoidance + following). Homogeneity of agents has important implications. Muchof the control knowledge of other agents can be inferred by an agent based on the external state
information. In addition, as Mataric[Mataric, 1994a] points out, in such homogeneous groups,the group behavior is not seriously affected by the irregular behavior of any individual. On theother hand, this thesis deals with systems in which all the agents are needed to accomplish a goaland no one of them can do it by itself. Irregular behavior of an agent has global ramificationsfor the entire agent set.
Mataric[Mataric, 1994b] also introduced the concept of progress estimators akin to the
idea of potential (in Chapter 3), independently developed by us[Nagendra Prasad et al., 1995a,Nagendra Prasad et al., 1996b]. In addition to the reinforcement upon reaching a goal, partialinternal critics called progress estimators, when active, provide a metric of improvement in thecontext of specific goals. For example, a progress estimator associated with homing behaviorgives a positive reinforcement if the distance to home is decreased upon picking up a puck.Movement away from home generates a negative reinforcement. Potential differs from progressestimators in that the latter was primarily used as a method of speeding up reinforcementlearning whereas the former plays a more complex role. In our work on learning organizationalroles, a role may receive some “potential” even when it leads to unacceptable designs if it causesexplicit exchange of information about conflicts. In explicitly cooperative multi-agent systems,

21
the concept of potential may lead to better quality results and it is not just a speedup device.As can be seen from the results in Chapter 3, role organizations resulting from learning withpotential are qualitatively different from those without potential.
Sandholm and Crites[Sandholm and Crites, 1995] use reinforcement learning to studyimplicit cooperation in Iterated Prisoner’s Dilemma. Prisoner’s Dilemma (PD) is an intenselystudied game-theoretic problem where an agent is faced with two choices: either act coopera-tively and do what is best for the entire society or defect and act selfishly. This paper studiesgames with two agents. Regardless of the opponent’s choice, each agent is better-off defecting.However, the sum of the agent’s payoff ’s is maximized if both choose to cooperate. IteratedPrisoner’s Dilemma is a supergame of the PD, where the agents interact repeatedly. In thesesupergames, a policy or strategy maps an agent’s history of interactions with the other agentto an action. The agents are selfish agents, but in an IPD game, it may be beneficial evenfor selfish agents to cooperate in a manner that evokes similar cooperative response from theopponent. Each agent tries to maximize its discounted future return at iteration n:P1i=n iri
Sandholm and Crites use both lookup tables and recurrent nets to learn policies andpresent a series of experiments where a learning agent plays against an agent that follows afixed strategy such as Tit-for-Tat. A single learning agent in a multi-agent system learns tocooperate successfully. However, when both the agents were learning, they faced difficultiesevolving cooperating strategies. They study a variety of issues regarding exploration schedules,and windows of history that an agent needs to examine, for making a decision. While thesestudies are interesting, it is not obvious how the insights in this domain can be used to engineercomplex multi-agent systems. More over, unlike the systems in this thesis they study implicitlycooperating, homogeneous agents.
Shaw and Whinston[Shaw and Whinston, 1989] discuss a classifier system based multi-agent learning system. Each agent contains a set of condition-action rules and a messagelist. The rules that can be triggered in the present cycle in an agent can bid, based on their
strengths(a variant of Holland’s Bucket Brigade algorithm[Holland, 1985]). The rule with thehighest bid is chosen and executed to output a message as an action, perhaps to other agents. Itsstrength is reduced by the amount it bid and is redistributed to the rules that were responsiblefor the messages that triggered it. These rules could be distributed among many agents. Anagent choosing to perform an action on the environment receives an external reinforcement. Aclassifier system has the effect of reinforcing chains of effective action sequences.
The system is tested on a flexible manufacturing domain. It functions in a contract-netframework where inter-agent bidding is used as a feedback mechanism that drives inter-agentlearning. An agent announces a task with a series of operations to be performed on it. Otheragents in the system bid for performing this task based on their past usefulness in performingsimilar jobs, the capability for the announced job and their readiness for the job. The winningagent increases its strength by an amount proportional to the bid and the agent announcing thetask decreases its strength by the same amount. This represents a kind of market mechanismwhere the announcing agent pays the winning agents for its services by the amount bid. In
addition, the agents themselves can use genetic operators like cross-over and mutation[Holland,1975] to improve and reorganize their own capabilities for performing various jobs. This typeof learning is purely local and does not involve any cooperative control component. In the

22
flexible manufacturing domain, the genetic learning capability can be mapped on to the needfor reconfiguration to avoid unbalanced utilization of high-performance cells.
While this system is explicitly cooperative and directly communicating, the kinds ofinteractions between agents are still not as complex as in the systems dealt with in this thesis.The contract-net mechanism effectively insulates the agents’ control mechanisms by confiningtheir interactions to occur through the bidding process. The actual problem solving (in this case,performing the operations on a task) is not a cooperative one. The contract-net mechanismis for dynamic task allocation and once a task is allocated, the agent works independentlyfrom the announcing agent. The classifier learning here is concerned with good task allocationstrategies. In addition, classifier systems require specific representational requirements. All theagents need to be constructed in a homogeneous condition-action rule-based representation.It is not realistic, especially in reusable agent-based systems to satisfy this requirement always.In contrast, the reinforcement-learning scheme in Chapter 3 and the case-based learningschemes in Chapter 4 do not need any special representational requirements from the agentsthemselves. In Chapter 5, the IBL learning method exploits the representational requirementson coordination problem instances that GPGP needs. It does not impose any additionalrequirements by itself.
A related piece of work using classifier systems for learning suitable multi-agent hierarchical
organizational structuring relationships is presented in Weiss[Weiss, 1994]. The agents learnto form and dissolve hierarchical groups as needed. A group consists of several compatibleagents or groups and a group leader. The agents use a variant of Holland’s[Holland, 1985]
bucket brigade algorithm to learn such hierarchical organizations. The algorithm consists oftwo components:� Each group announces its highest bid to perform an operator in a given situation based
on certain strength measures of the possible operators. The winning group reduces thestrength of its best operator by an amount proportional to the bid and the group that wonin the previous state is payed this amount, just as in the classifier mechanism discussed in
the work of Shaw and Winston[Shaw and Whinston, 1989]. If the goal state is reached,an external reward is provided to the last group that worked on this process. This has theeffect of stabilizing the sequence of winning units and disintegrating any unpromisingsequences.� Simultaneously, the agents also form and dissolve groups. If a sliding window ofpre-specified number of time units indicates stagnation in the strength of an agentgroup, then it is ready for forming a super group with other agents or groups. Each suchgroup announces a “cooperation offer” and other compatible groups deciding to acceptthe offer send out “cooperation response” leading to a merger of the groups involved.Similarly, group dissolution takes place when the leader of a group notices that thestrength of the group has fallen below a threshold.
The learning described in this work is similar to that in Shaw and Winston[Shaw and
Whinston, 1989]. Learning assembles good action sequences. As discussed previously, thekind of communication between agents is simple and primarily consists of bids and cooperationoffers and responses. Communication does not affect the internal control of an agent. Inaddition, the ideas were tested on a simple blocks world domain where the system learns

23
by repeatedly solving the same blocks world problem. However, we believe that this workrepresents a very interesting step in the direction of organizational learning. We hypothesizethat in order to generalize this work to hold beyond single instance problems even in a blocksworld domain, situation-specific measures for the strengths of various operators are in order.The situations here represent abstractions of the global state of the blocks world. A combinationof such measures with the framework developed in Chapter 3 can serve as a basis for moregeneral organizational learning.
Dowell and Stephens[Dowell and Stephens, 1993] present some early results in thisdirection. Their extension to Weiss’s work[Weiss, 1993] involves each agent developing modelsof other agent’s possible bids in a given situation. However, their view of a situation is verylimited in the sense that they index these models under local situations that can potentiallymap on to many global situations. There is no communication among agents to improve theirglobal views. In addition, they do not deal with group formation and dissolution aspects of the
algorithm in Weiss[Weiss, 1994]. The work is still in preliminary stages but holds out promiseas discussed above.
2.2 Multi-agent CBL, EBL and Knowledge Refinement Systems
Much of the work in multi-agent Case-based Learning (CBL) and Explanation-basedLearning (EBL) is in its early stages but holds out promise for learning various situation-specificaspects of cooperative control. Little by the way of statistical verification of the schemes hasbeen done except in the case of Nagendra Prasad, Lesser and Lander[Nagendra Prasad et al.,1996c], Grecu and Brown[Grecu and Brown, 1996] and Haynes and Sen[Haynes and Sen,1996].
Nagendra Prasad, Lesser and Lander[Nagendra Prasad et al., 1995b, Nagendra Prasad et al.,1996c, Nagendra Prasad and Lesser, 1996a] represents one of the earliest attempts at multi-agentcase-based reasoning. Each of the agents contributed a subcase to an overall composite case.Assembling the subcase is treated as a distributed constraint optimization problem where theconflicts between subcases are resolved through search rather than avoided through elaborateindexing using goals and subgoals representing the context of the subcases. Each agent retrieveslocal subcases using local knowledge and then the agents cooperatively search through thespace of partial cases to assemble a composite case that is mutually acceptable to all of them.Some of the more recent work in progress[Nagendra Prasad and Lesser, 1996a] provides anefficient search method that guarantees optimality of the composite case. However, the notionof globally situating local cases is not a part of this work. In addition, though some of the ideashave been tested empirically, the test domains are of much lesser complexity than the kind ofdomains dealt with in this thesis.
Sugawara[Sugawara, 1995] presents a hierarchical planner that can use past plans tominimize messages at planning time. It is based on Corkill’s[Corkill, 1979] approach to
distributing the hierarchical NOAH[Sacerdoti, 1977] planning system over multiple agents.Coordinating consists of avoiding undoing each other’s work using simple “wait and signal”synchronization messages in a blocks world domain. When an agent finds that action B ofanother agent can potentially prevent it from executing action A, it communicates a “wait”synchronization message to the other agent and inserts a local “signal” message after action A.The other agent inserts a “wait” message before action B preventing the execution of the action
until the corresponding “signal” message is received. Sugawara[Sugawara, 1995] extends this

24
mechanism to let an agent store its plan along with the synchronization sequence for a givenproblem solving run. The plan is indexed using the initial and goal states of the probleminstance. When a “similar” problem instance occurs later, the past plan is reused and the needfor synchronization message exchange is reduced at the plan time. All the synchronizationsneeded are sent out by an agent to another agent as a single message, reducing the need formultiple synchronization messages for plan generation. The paper presents some anecdotalevidence that this reduces the total planning time but the test cases were very specialized. Thesimilarity metric dealt with limited test cases that were almost identical to the past cases. Muchof the framework needs further elaboration and for the most part it is unclear how the learningcan perform reasonable generalizations over new instances except for some very specializedcases. More over, the agents are homogeneous and each agent is required to be a NOAHplanner with modifications for synchronization.
Garland and Alterman[Garland and Alterman, 1995] present a multi-agent system thatdevelops a collective memory to coordinate better. They present a more sophisticated approachto learning coordination using “wait-signal” primitives in Sugawara[Sugawara, 1995]. Theydeal with domains where the agents have very limited knowledge of each other and thereis no mandated cooperation or coordination strategy. The agents plan independently andcommunicate at execution time when they find that a need for cooperation arises dynamically.At the end of a run, each agent reflects on its history of problem solving and interaction andextracts the relevant information to store it for reuse in the future.
More specifically, Garland and Alterman[Garland and Alterman, 1995] deal with theMOVERS-WORLD domain. It contains agents with differing abilities to move variousobjects to a truck from a house. The need for coordination arises when an object is too heavyfor a single agent to move. It requests help from other agents who selectively reorder theiractivities to accommodate the request. Coordination consists of an agent sending a signal forhelp or receiving a message for wait or signal for agreement to help. Each agent summarizesits execution trace to remove redundant data, improve it to avoid inefficiencies and breaks itup into useful pieces of information. The trace retains cooperative conversations and actionsthat help cooperation. The reuse of this knowledge lets an agent anticipate coordination ratherthan dynamically communicate to establish it.
Given the sparse literature and early stages of this work, it is difficult to compare thissystem with our work. It is an explicitly cooperating directly communicating system. It learnscoordination in a relatively knowledge-poor environment, as far as coordination strategies areconcerned. However, many questions remain unanswered. What is the exact nature of indexingand retrieval of past cases? We suspect that using a more global-view of the problem-solvingsituation to index local cases can lead to more sophisticated forms of cooperation. For example,the agents could use load situations at the other agents to selectively send cooperation requestsonly to those agents that are not already heavily loaded with tasks and pending requests forhelp. However, at the present stage of development, this view of cooperative control does notseem to be explicit in their system. One of the important questions that remains unansweredis how they deal with the incoherence in subcases that each of the agents retrieve separately.Can execution time adaptation counterbalance this? Or is the system pushing the need forcoordination to something else (in this case incoherent subcases instead of incoherent actions)?Besides, there are questions about how well the techniques presented in their system scale-up.As the agents scale-up, in domains where there are a large number of multi-way interactions,

25
can execution time coordination lead to incoherence? In addition, the work is not supported bysufficient empirical evaluation and the evidence is anecdotal. However, it is a relatively youngproject, even for a subarea like learning in multi-agent systems, and holds out good promise.
Grecu and Brown[Grecu and Brown, 1996] study learning among Single Function Agents(SiFAs) that are highly specialized and very competent in making design decisions about aparticular aspect of parametric design. Each agent has a particular function like select,critic, praise, estimate or evaluate and deals with a single parameter from agiven point of view like “reliability” or “durability”. Agents use an interaction board, wherethey post their proposals, decisions and partially developed designs. The nature of these agentsrequires a large number of interactions in order to arrive at a mutually acceptable design.Grecu and Brown investigate the use of learning to reduce interactions among agents. Theirdomain deals with the parametric design of helical springs and their system consists of elevenagents: two selectors, five critics and four praisers. This system has a number of similaritiesto TEAM and the learning they propose bears a number of resemblances to our earlier workon case-based learning in Chapter 4[Nagendra Prasad et al., 1995a]. In order to reduce thenumber of interactions, an agent A can learn about the requirements of another agent B anduse it to predict non-local requirements in a new problem situation. Agent A creates a casefrom its interaction with agent B and indexes it using the design requirements of agent B.Their results indicate a steep reduction in the number of interactions, needed with learning,for arriving at a design agreeable to all agents. The view of problem solving situation taken inboth Chapter 4 and Grecu and Brown[Grecu and Brown, 1996] is relatively simple - designproblem specifications visible to the agents. This in fact may suffice for the particular aspectof multi-agent design that these two works are studying. However, Chapter 3 and Chapter 5take a more sophisticated view of the global situation, whereby each agent communicates anabstraction of its local situation to other agents so that they can develop a partial view of theglobal problem solving state.
Haynes and Sen[Haynes and Sen, 1996] present studies in learning cases to resolve conflictsin a multi-agent system. Their domain is a predator-prey domain similar to that used by
Tan[Tan, 1993]. A set of predators try to surround a prey and capture it on a grid world.The main idea behind this work is to use negative cases that represent conflict situations fromthe past problem instances. When an agent encounters conflicts, the situation in terms of theboard position of the immediate neighborhood of an agent is used to index the set of movesof the agents that led to the conflict. When the agent encounters a similar situation again, itcan avoid the default moves if it encounters a case for that situation indicating a conflict ordeadlock due to its move and the moves of the other agents. A conflict arises when two agentstry to move to the same location. The number of captures improves significantly using thismethod. The agents in this work do not explicitly cooperate and implicit cooperation is theoutcome of the agents modeling the group behavior using cases. The kinds of interactionsbetween agents in the predator-prey domain are relatively simple, in part because of thesimplicity of the domain. In addition, the agents are homogeneous. The work by Haynes and
Sen[Haynes and Sen, 1996] represents one of the few attempts at empirically demonstratingthe power of case-based learning for multi-agent cooperative control. As mentioned previously,this thesis deals with agents characterized by much higher sophistication and heterogeneity.In addition, the problem-solving and learning among agents are characterized by explicitcooperation through direct communication.

26
Sugawara and Lesser[Sugawara and Lesser, 1993] discuss a self-diagnosing Local AreaNetworking(LAN) system where each node or a network segment has an intelligent agent calledLODES that monitors traffic on the LAN. Initially the agents rely on coarse control strategiesfor this purpose. Upon detecting problems with these control rules, the agents exchangedetailed traces of execution, and perform comparative analysis to pinpoint the problems in thenetwork. For example, if the problem arose due to the saturation of a low bandwidth linkduring a packet storm involving redundant activities, a comparative analysis of the executiontraces of the LODES agents at either end of the low bandwidth link reveals the cause. Thecorresponding agents modify their control rules to check for a low-bandwidth line, and if so,choose a control strategy whereby one of the agents diagnoses a local problem and the otherswait for the result, thus avoiding redundant checks for the problem. In other words, the agentsrefine their control rules to be more situation-specific.
This work represents one of the earliest attempts at situation-specific learning of coordi-nation rules, though they do have the notion that situations are abstractions of global problemsolving states. They are concerned with learning to make the situations more discriminatingto avoid using an inappropriate coordination strategy. Their learning mechanisms rely ondeep domain knowledge and agent homogeneity assumptions. Comparative analysis involvesa lot of domain knowledge whereas the methods presented in this thesis involve minimumamount of domain knowledge engineering (developing the situation vectors). Comparativeanalysis involves elaborate domain knowledge about what it means for a pair of parameters tobe similar, indistinguishable, and different in a network diagnosis domain. In addition, oncethe differences for all the parameters are teased out of the traces, there need to be ways tomap these differences to causes in order to refine the control rules. It is a difficult problemto map a difference to its cause when there is more than one such difference. Moreover, theability of an agent to analyze the execution traces of another agent would imply homogeneityof representations. In addition, all the agents should be doing the same type of tasks(like diagnosing a particular type of network fault). MASs often deal with agents that aredifferentiated in their abilities and also task assignments. Unlike the studies in our thesis, theevidence in this work is anecdotal.
Byrne and Edwards[Byrne and Edwards, 1995] discuss knowledge refinement in agentgroups. A set of predators with differentiated capabilities are hunting a set of prey. Capturingcertain types of prey needs the cooperation of more than one predator. A predator detectingthe need for cooperation from other predators to hunt a prey requests and enlists their support.However, some attacks may fail due to a number of reasons like lack of proper timing orbecause some predators back out at the last minute as they wrongly believe they cannot attackcertain types of prey. Detection of failure leads to a refinement process where a fault involvingmisclassification of positive examples of failure-generating action leads to generalization and afault involving misclassification of negative examples leads to specialization. A positive exampleof an action is one that was successful and a negative example is the execution of an actionin inappropriate circumstances. Crucial to the refinement process is a refinement facilitatorthat coordinates the interactions between the agents during this process. It is a centralizedmediator that solicits refinement proposals, handles refinement request from agents, prioritizesrefinement alternatives and maintains consistency by making agents aware of the relevantchanges to the knowledge of other agents. The use of refinement facilitator circumvents someof the interesting issues of partial local knowledge of agents performing distributed learning.

27
In addition, much of this work is in rudimentary stages (circa 1996) and many of the ideasand proposals are hypothetical and need to be tested more throughly, especially in a realisticdomain, to be validated.
2.3 Robotic Soccer
In the recent times, Robotic Soccer[Kitano et al., 1995] has emerged as a domain that hasbeen generating a lot of activity in the multi-agent learning community. A reasonably realisticversion of the soccer game is played by agents in a simulated world. In this game, there are twoteams and the objective of each team is to take the football into the goal posts of the opponentteam. The opponent team players of course try to prevent this from happening by snatchingthe ball away from the other team. Robotic soccer is an interesting domain for a number ofreasons. The number of agents is sizable (up to twenty two agents) and the required behaviorsrange from purely reactive actions to strategic planning. There are both benevolent agents(same team players) and adversarial agents (opposite team players).
We discuss two representative works on Robotic Soccer here. Nadella and Sen[Nadellaand Sen, 1996] use simple learning methods to correlate internal parameters such as “shootingefficiency”, “tackling efficiency” and “throw-in efficiency” with the external performance suchas effective passing or estimating opponent skill levels. For example, effective passing notonly depends on a person’s passing efficiency but also on the environmental uncertainty (likethe nature of the surface of the football field), the length of the pass, and the opponentplayers guarding the receiver. The agents in [Nadella and Sen, 1996] use simple learningtechniques such as linear regression over the coordinates representing the distance of the passand the amount of error observed, to develop external performance models. Stone,Veloso,andAchim[Stone et al., 1996] describe a memory-based learning mechanism for letting an agentlearn low-level behaviors like ball interception. These low-level individual behaviors arethen incorporated into higher-level behaviors (such as passing). These higher-level behaviorsthemselves may involve learning to choose the appropriate low-level behaviors based on whatan agent sees on the field at a given time. This type of agent building is called layered learning
approach[Stone et al., 1996].Much of the work in this domain does not involve communication or involves very simple
forms of communication like a player announcing his position when he moves. However, someauthors do acknowledge the importance of negotiation or other forms of communication-based
complex cooperation[Nadella and Sen, 1996], and in time to come, Robotic Soccer holds outpromise as an interesting domain that can spur research advances in multi-agent learning. Thiswill especially be true when the more complex forms of strategic planning (such as executinga multi-step, multi-player plan with contingencies when a failure is encountered) start gettingincreasing attention. We suspect that situation-specific learning will play an important role inthis process.
2.4 Mutually Supervised Learning
Goldman and Rosenschien[Goldman and Rosenschein, 1995] present mutually supervisedlearning in multi-agent systems. They deal with an explicitly cooperative and directlycommunicating system where each agent can supervise the learning of other agents that aretrying to model its domain. The domain used in this study is the control of traffic signals at

28
an intersection. An agent is in charge of the signals for the road running North-South and theanother is in charge of the signals for the East-West road. The agents need to coordinate so thatboth the signals are not red at a time (waste of time) or green at a time (leading to collisions).Non-learning agents have to communicate to achieve this coordination. Alternatively, an agentcan learn models of traffic distribution of the other agent. Each agent is trained by the otheragent who acts as its teacher. An agent Ai sends its list of waiting time sample values to Ajthat annotates these sample values with the action that it would like Ai to take. Agent Aiuses this list to generalize the waiting times when the action is required to be red or greenand performs that action. This work has some similarities to our work in Chapter 4 in thatit models interaction between cooperative agents. However, the type of agents and the natureof interactions are far more complex in our work. The complexity of the agents needed us tosituate the knowledge in abstracted global situations (the problem specification in this case).On the other hand, in the work presented above, due to the simple nature of the domain, eachagent is able to model the entire sensing environment of the other agent.
2.5 Learning in Game-theoretic Systems
Game-theoretic studies relevant to learning are concerned with selfish agents seeking tomaximize their long term payoffs. These studies are characterized by the simple nature of theinteractions among agents and implicit cooperation. In addition, the agents themselves arestripped down to the bare essentials of the learning problem. Interactions are two-way andthe agents rely on certain assumptions of common knowledge about the way the environmentresponds to their activities or in some cases, the agents may not even explicitly be aware ofthe existence of other agents. We all ready discussed one such system by Sandholm andCrites[Sandholm and Crites, 1995], that used reinforcement learning to study evolution ofcooperation in Iterated Prisoner’s Dilemma. We present other relevant work here.
Carmel and Markovitch[Carmel and Markovitch, 1995] discuss learning models of op-ponent behavior by a pair of selfish agents, each trying to maximize its own sum rewardduring a repeated 2-player game. Each agent simultaneously performs an action in a givenencounter. Agents learn a strategy from the history of actions of the system. Learning is basedon induction of finite state automata from observed history of opponent’s and its own behavior.An opponent’s strategy is modeled as a Finite State Automaton and any discrepancy betweenobserved opponent action and the action predicted by an agent’s model of that opponent’sstrategy triggers an incremental update of the model for that agent.
Barto[Barto, 1985, Barto, 1986] proposes the AR�P reinforcement learning algorithmfor learning cooperation among networks of self-interested agents. All the agents have toproduce collectively a behavior based on the reinforcement that the environment gives inresponse to the global behavior of the system. Each agent has to learn to perform its rolein the collective behavior based on such reinforcement values evaluating the behavior of thesystem as a whole. In these systems, an agent is not even explicitly aware of the existenceof other agents. As far as an agent is concerned, the other agents are a part of its noisy
environment. Inspite of the simple nature of the agents, the work by Barto[Barto, 1985,
Barto, 1986] represents one of the pioneering attempts in learning among multiple agents.More recently, Crites and Barto[Crites and Barto, 1996, Crites, 1996] use similar techniquesto improve elevator dispatching performance.

29
2.6 Emergent Behaviors
Recent excitement in Artificial Life[Langton(Ed.), 1989, Langton et al., 1992] has led toa sizable body of work on emergent behaviors. A large number of extremely simple elements(“dumb” agents) engaging in local interactions of a simple nature give rise to complex behaviorsas a whole. This type of work is only distantly related to the kinds of systems that are ofprimary concern in this thesis: large grained, sophisticated agents with possibly large amountsof knowledge. However, we do present two representative pieces of work that give a flavorof the issues commonly investigated in this area. This survey by no means claims to give areasonable coverage of all the issues in the field of A-life.
Shoham and Tennenholtz[Shoham and Tennenholtz, 1992a] discusses co-learning and theemergence of conventions in multi-agent systems. Agents interact in pairs and every interactiveactivity leads to local adaptation of certain parameters that determine an agent’s future behavior.After a large number of interactions, common conventions emerge among the agents. In theexperiments presented, a convention for an agent is represented by a single bit that can be either0 or 1. Initially a society of a large number of agents starts with each agent taking a randomvalue for the convention bit. After a number of repeated interactions, a success in emergenceof a convention occurs if the majority of the agents (> 80 %) have the same value for theconvention bit. Different update functions like cumulative best response based on the numberof previous good and bad interactions between agents (meeting agents with same or differentconvention bits respectively) are investigated. All agents use the same update functions. Theauthors design and empirically demonstrate the effectiveness of a number of update rules thatpermit emergence of common conventions.
MacLennan and Burghardt[MacLennan and Burghardt, 1993] present experiments inevolution of communication in a cooperative society of simple simulated organism calledsimorgs. A simorg consists of local state represented by a single variable that can take an integervalue from 1 to L. Local state of a simorg represents that part of the environment that it alonecan sense. The global state is represented by a single variable that can take integer values from1 to G. Global state represents that part of the environment that is visible to all the agents.Each organism is modeled by an automaton with transition rules of the form(�; ; �) ! (�0; R)where � represents the internal state value, is the global state value, and � is a local statevalue. �0 is a new internal state and R is the response that can be either emission of signal ora cooperation act. An emission emit( 0) changes the global environment variable to 0. Anaction act(�0) represents an attempt to cooperate with a simorg in situation �0. A cooperationact succeeds if the local environment state of the last emitter is�0. A successful cooperation leadsto an increase in the fitness of both the simorgs involved. When cooperation is unsuccessfulbecause the local environment of the last emitter �00 6= �0, the acting simorg changes itstransition rules: (�; ; �) ! (�0; act(�00))
In addition, there is a genetic learning component that leads to breeding a new generationevery few environmental cycles. Based on the fitness of the simorgs, some of them (those with

30
low fitness) are selectively replaced by offspring obtained as a result of a crossover operationfrom parents of high fitness.
MacLennan and Burghardt[MacLennan and Burghardt, 1993] conduct a number ofexperiments to show the advantages of communication and evolution of simple forms ofcommunication among the simorgs. Communication suppression, achieved by randomizingthe global environment variable after every simorg responds, leads to poor cooperation.Communication and learning lead to good fitness measures of the society of simorgs as awhole. The simple form of learning of transition rules and the genetic operators together leadto evolution of cooperative communication strategies that globally increase the fitness of thesociety of agents.
2.7 Hybrid Learners
Certain multi-agent learning systems in the literature deal with a task different from thetask of learning problem solving control. Systems like ILS[Silver et al., 1990], MALE[Sian,
1991] and ANIMALS[Edwards and Davies, 1993] use multi-agent techniques to build hybridlearners from multiple learning agents. Most of these systems are characterized by distributionof the domain data over multiple agents, each with its own learning algorithm - either same ordifferent from others. Learning in these systems is concerned with acquiring knowledge aboutthe domain and takes place independently in each of these agents. They then collaborate toimprove or refine these hypotheses or improve consistency among multiple related hypotheses.Few, if any, cooperative control issues are involved in the functioning of the agents.
ILS[Silver et al., 1990], developed at GTE, integrates learning agents with different kindsof algorithms for inductive, search-based and knowledge-based learning of telephone trafficcontrol in a telecommunication network. The system consists of five learning agents: aknowledge-intensive learning agent called NETMAN using EBL techniques, an inductivelearning agent called FBI, search-based learners called MACLEARN and ZENITH, and areactive planner called DYNA. There is a central controller called The Learning Coordinator(TLC) that manages control flow and communication among the learning agents. Problem-solving starts with an ADVISE message issued by TLC to the agents to propose control actionsfor the domain. The agents respond by proposing hypotheses, rating them on a scale from 1to 5. TLC then asks other agents to CRITIQUE an agent’s hypothesis by rating it again on ascale from 1 to 5. Each hypothesis’s rating is the average of all the ratings. A best hypothesisis then selected by TLC. When the performance data for the control action is available, TLCnotifies the agents along with the actions performed. Based on the feedback from the domainand the set of actions performed, each of the agents learns locally. Secondary cooperation inthe form of intra-agent communication can occur between the FBI agent and the NETMANagent. The FBI agent can perform heuristic predictions and classifications for some of thedata that NETMAN uses for learning. This type of hybrid learner, involving adaptation byagents to improve their skills over the domain, was found to give encouraging results in termsof reducing the number of lost calls in a circuit-switched telephone network.
Sian[Sian, 1991] presents a multi-agent learning system called MALE, where each agentlearns locally and posts good hypotheses on a central interaction board. Each agent organizesits learned knowledge as a hierarchical experience store. This hierarchy contains instances atthe lowest level, and successive levels form increasingly higher level generalizations of theseinstances. The learning algorithm makes changes to this hierarchy. Each node in the hierarchy

31
has two values: in-conf (number of instances the generalization correctly covers) and out-conf(number of instances the generalization incorrectly covers) associated with it. The learningalgorithm tries to create maximum net value — (in-conf � out-conf) — at each node. Anynew instance that does not agree with the current knowledge is inserted into the hierarchy atthe most specific generalization that classifies it correctly. If a generalization missclassifies it,then the node is specialized so as to cover as many of the original instances and exclude thenew instance. If this cannot be done, then the out-conf of the node is increased. In addition,interaction with other agents also leads to changes in the hierarchy. An agent can PROPOSE ahypothesis with a certain level of confidence by placing it on the interaction board. It can alsoCONFIRM hypothesis that are totally consistent with its data, DISAGREE with a hypothesisthat is totally inconsistent, MODIFY a partially consistent data or have NOOPINION abouta hypothesis for which it has no relevant data. In addition, a hypothesis can be ASSERTEDor WITHDRAWN. Each agent evaluates a proposal on the interaction board and places itsevaluation of that proposal back on the board. These evaluations are combined using a specialintegration function and if the hypothesis with the highest confidence value is AGREED upon,it is removed from the interaction board and assimilated into the proposing agent. A modifiedhypothesis is subjected to further iterative evaluations. Thus the hypothesis hierarchy of anagent can be refined through interaction with other agents to exploit their knowledge structuresby subjecting selective nodes to collective evaluation and refinement schemes.
Brazdil and Muggleton[Brazdil and Muggleton, 1990] deal with integrating knowledgelearned independently by multiple agents. Agents learn independently and then pool theirknowledge in a single agent (or multiple agents). However, the rules learned by one agent mayuse vocabulary that is not a part of the repertoire of another agent and hence the micro-worldof the agent that receives a rule from another agent may not be able to exploit that rule. Hence,they develop approaches to learning the vocabulary of one agent using the vocabulary of anotheras primitives. This lets the latter agent use rules communicated by the former. The agents usean inductive learning method called GOLEM based on Relative Least General Generalization.Both the agents are subjected to the same problem. The agents sense the environment in termsof their available vocabulary. The agents then exchange their sensations and each agent triesto relate its local sensations to the sensations of the other agent and generalize to learn thevocabulary of the other agent in terms of its local vocabulary.
ANIMALS[Edwards and Davies, 1993] is another hybrid learning system where agentswith different learning algorithms and no centralized controller can learn to complement eachother’s knowledge gaps. This system employs two agents: an Explanation-based Generalization
(EBG) agent with Lazy Partial Evaluation[Clark and Holte, 1992] and an inductive learning
agent with ID3[Quinlan, 1986]. The domain is learning concepts about animals from theirfeatures (for example, rules like order(mammal,X) :- body-covering(hair,X)).
Given a target concept, the agents have to learn covering rules using already knownexamples and domain knowledge. If an agent fails to explain or classify the target concept, itcan send messages to other agents to enlist their help in the process. For example, if the EBGagent tries to explain a target concept and cannot complete the proof because some lower levelconcept cannot be explained, then it sends that lower level concept to the other agent - theinductive agent in this case. Inductive learning agent tries to use the facts it presently knowsand constructs a decision tree to classify the new goal. Any missing attribute knowledge in theexamples used to build the decision tree in turn leads to messages to the other agent asking it

32
to provide the relevant attribute information if it can. The evidence for the effectiveness ofthis framework is purely anecdotal and issues such as loops in the agent communication dueto missing knowledge, are not discussed in this paper. However, some of the more recent work
by the authors[Davies and Edwards, 1995] seems to be a step in this direction.
2.8 Summary
Much of the work in machine learning community concentrates on stand-alone systems,where a learning algorithm is supplied with abstractly represented data, either in the form offeatures or sequences, and it discovers regularities that can be generalized to new and previouslyunseen data. However, learning in multi-agent systems, by the very nature of its goals, needs toembed the learning algorithms into problem solving architectures to coexist with other aspectslike local domain problem solving and coordination or conflict avoidance for coherent groupactivities. Moreover, the incompleteness of an agent’s view of the overall problem solving stateleads to the need for learning in the presence of uncertainty. In addition, the situatedness oflearning systems sometimes leads to non-stationary environments when the learning is on-line.In such environments, as the agents learn, the environment changes in a way that mightobviate some of the already learned knowledge and require the agents to re-learn given thenew behaviors of the learning agents. Learned knowledge leads to behavior changes that mayin turn lead to further and possibly different learned knowledge and so on. Each one ofthese factors, in itself, can make learning in multi-agent systems an interesting and challengingproblem. When more than one of them co-occur, the intellectual challenges may require asubstantial and concerted effort to resolve. While the essence of the learning techniques maybe derived from the existing machine learning approaches, knotty problems like embeddingthem in multi-agent problem solving architectures and extracting useful behavior from thesealgorithms in the presence of uncertainty and non-stationarity pose problems that could offerdeep insights for both the MAS community and the machine learning community. In ourwork, we deal with learning embedded in problem solving and the agents have to deal withincomplete views while learning. Our systems do not deal with non-stationary environments.
Even though much of the work is still in its infancy, some of the insights that are beginningto emerge in the MAS community may be applicable to the more general machine learningcommunity. Progress estimators for more efficient reinforcement learning have emerged
from the work in this thesis and that of Mataric[Mataric, 1994b]. Chapter 5 presents anadaptation of instance-based learning algorithms for a decision-theoretic task. In addition, theneed for situating learned knowledge in an abstracted problem solving context could also bemore generally applicable for any learning system working in uncertain environments. Workon hybrid learners has developed insights that are more generally applicable to knowledgerefinement[Sian, 1991] and multi-strategy learning[Edwards and Davies, 1993]. Haynes and
Sen[Haynes and Sen, 1996] discuss a novel use of “negative” cases as a mechanism for avoidingharmful interactions.
Work on learning in multi-agent systems can be categorized into two major themes:� Hybrid learners that structure learning as a multi-agent problem:Hybrid learning systems can borrow more faithfully from the existing machine learningapproaches because their goals are closer to those of this community. Each agent is pri-marily engaged in improving its skills over the domain and the multi-agent aspects like co-ordination of activities are relatively simple. The knowledge learned independently by the

33
agents may be inconsistent and hence they need to “talk” with each other to reach a con-sensus iteratively without having to exchange all the local data. The learning subsystem
is usually not embedded in any problem solving system[Brazdil and Muggleton, 1990,Edwards and Davies, 1993, Sian, 1991] and interactions are mainly for augmentinglocal learning processes. However, these systems still encounter interesting and difficultproblems such as what is the right level of abstraction of learned knowledge that isexchanged, when is exchange of data preferred over generalized rules, how does an agentgeneralize given limited data that may be inconsistent with the data in other agents, howdo the differences in representation vocabulary of different agents affect the knowledgeexchange and refinement process.� Learning problem solving control in multi-agent systems:Problem solving control in multi-agent systems includes a number of aspects such ascoordination or negotiation strategies, organizational knowledge, and conflict avoidanceor resolution to derive coherence in a team of agents. A growing body of research hasbegun to address issues of learning cooperation among implicitly cooperating multi-agentsystems (albeit in toy domain or homogeneous agents) using reinforcement learning
techniques[Tan, 1993, Sen et al., 1994, Mataric, 1993, Mataric, 1994b, Sandholm andCrites, 1995], classifier systems[Shaw and Whinston, 1989, Weiss, 1994, Dowell andStephens, 1993] and case-based learning[Haynes and Sen, 1996]. On the other hand,some of the literature on multi-agent case-based learning[Nagendra Prasad et al., 1995b,Nagendra Prasad et al., 1996c, Nagendra Prasad and Lesser, 1996a, Sugawara, 1995,
Garland and Alterman, 1995], knowledge refinement[Byrne and Edwards, 1995] andmutually supervised learning[Goldman and Rosenschein, 1995] has started to addressthe issues in cooperation among explicitly cooperating systems. Much of this literaturedeals with systems with little or no state and few inference steps. The work in this thesisis distinguished from the existing literature in that it deals with explicitly cooperating,directly communicating heterogeneous agent systems working in complex domains suchas parametric design, and distributed data processing. The agents rely on sophisticatedplanning or search capabilities and complex state information.

C H A P T E R 3
LEARNING ORGANIZATIONAL ROLES IN A HETEROGENEOUS
MULTI-AGENT SYSTEM
“I was saying,” continued the Rocket, “I was saying - What was I saying?” “Youwere talking about yourself,” replied the Roman Candle. “Of course; I knew I wasdiscussing some interesting subject when I was so rudely interrupted.”
Oscar Wilde, The Remarkable Rocket
You can’t try to do things; you simply must do them.Ray Bradbury
3.1 Introduction
Requirements like reusability of legacy systems and heterogeneity of agent representationslead to a number of challenging issues in Multi-agent Systems (MAS). Lander and Lesser[Lander and Lesser, 1994] developed the TEAM framework to examine some of these issues inheterogeneous reusable agents in the context of parametric design. TEAM is an open systemassembled through minimally customized integration of a dynamically selected subset of acatalogue of existing agents. Each agent works on a specific part of the overall problem.The agents work towards achieving a set of local solutions to different parts of the problemthat are mutually consistent and that satisfy, as far as possible, the global considerationsrelated to the overall problem. Reusable agents may be involved in system configurations andsituations that may not have been explicitly anticipated at the time of their design. Adding alearning component to these agents so that they can modify their behavior based on the systemconfiguration can lead to enhanced performance. In this chapter, we present an extension ofTEAM called L-TEAM that learns to organize itself to let the agents play the most suitableroles in such a multi-agent search process for constructing an overall solution.
3.2 TEAM: A Heterogeneous Multi-agent Design System
The fundamental question driving the researchagenda in the TEAM project is “Can systemsof cooperative, heterogeneous and reusable agents interact coherently to solve search problemswhen the required information and capabilities are distributed among the agents?”[Lander,
1994] This implies that the system designer has to anticipate and engineer the agents to avoidpotential harmful interactions or conflicts among them, at the development time. However,a more practical strategy, especially in reusable agent systems, is to consider conflicts as aninherent part of the multi-agent problem solving process and equip the agents with conflictresolution mechanisms. TEAM is a general framework that studies issues concerning suchconflict resolution mechanisms. The key conflict management mechanism in TEAM is thenegotiated search, which uses conflicts to drive interaction among agents and guide local searchat the agents.
Conflicts in a multi-agent system (human or computational) can arise due to a number ofreasons:

35� Inconsistent, incomplete or possibly out-dated knowledge among agents.� Lack of common language or mutually understood problem solving techniques.� Differing criteria, goals, intentions and priorities.
For example, disputes between the labor and the management of companies usually arisedue to the differing priorities, goals and to some extent, due to the inconsistent and incompleteknowledge of the parties involved.
Negotiation is the process of iterative application of conflict-management techniques[Lan-der, 1994]. Negotiated search involves multiple agents searching for a mutually acceptable
solution through negotiation. Lander[Lander, 1994] gives an intuitive description of thisprocess as follows:
One agent generates a proposal and other agents review it. If some other agentdoesn’t like the proposal, it rejects it and provides some feedback about whatit doesn’t like. Some agents may generate a counter proposal. If so, the otheragents (including the agent that generated the first proposal) then review thecounter-proposal and the process repeats. As information is exchanged, conflictsbecome apparent among agents. Agents may respond to conflicts by incrementallyrelaxing individual preferences until some mutually acceptable ground is reached.
However, what is not apparent in the above description is the fact that each agent may beworking on its own subtask and the proposal that an agent makes may only be a component ofa solution composed of multiple interacting component proposals. This is in fact the case inthe parametric design domain used in TEAM. In such domains, agents may need the capabilityto criticize a component proposal, even though it may not actually have the expertise to designthat component.
In TEAM, an agent contributes a component proposal that is a part of the solution. Anoverall solution is a composition of the component proposals from all the agents in the system.
Negotiated search is a “multi-path incremental-extension algorithm”[Lander, 1994]. A solutionis initiated by an agent by proposing a “seed” component of the solution in some system cycle.Other agents extend this proposal or evaluate it in the subsequent system cycles. An agentcould be simultaneously developing multiple solutions.
In this thesis, we will be dealing with an instantiation of the TEAM frame work in thedomain of parametric design of steam condensers. In a parametric design problem, theconfiguration of the design is known a priori. The system has to choose values for the variousparameters associated with the configuration. This choice process is often not routine, andinvolves considerable domain knowledge of different types and reasoning techniques based on
arguments “for” or “against” a choice from various points of view[Grecu and Brown, 1996].Agents in TEAM do a heuristic constraint optimization search to arrive at a low cost
design. An agent’s local requirements on a design, the information derived from feedback byother agents, and the user requirements on the design are all expressed as constraints. Theconstraints may be implicit and procedural constraints or explicit, declarative constraints (aformal treatment of search in TEAM is given in the following chapter). Explicit constraintsin TEAM are organized as hard and soft constraints. In a constraint optimization search, notall constraints must be satisfied in a solution. All hard constraints are satisfied and the soft

36
constraints are satisfied to the extent possible. Those soft constraints that cannot be satisfiedare said to be relaxed. In TEAM, the soft constraints have three levels of flexibility (this choiceis arbitrary and it could as well have been another number). Relaxing a set of constraints leadsto a solution space that is a superset of the solution space defined by the unrelaxed constraints.
A steam condenser consists of a motor that powers a pump that in turn circulates waterthrough a heat-exchanger chamber. High temperature steam injected into this chamberis output as condensed steam (see Figure 3.1). A steam condenser consists of six majorcomponents: motor, pump, heat-exchanger, platform, vbelt, and shaft. Each component isdesigned by an agent and the agents cooperate to evolve a mutually acceptable design. Aset of agents interact through interface parameters. The interactions between agents arisein the process of assigning consistent values for these interface parameters. For example,both the heat-exchanger-agent and the pump-agent must agree on the values fortheir interface parameters water-flow-rate and minimum-head. Each agent takesthe responsibility either to design a component of a steam condenser for which it possessesexpertise or critique an evolving partial design. The agents must assign a consistent set of valuesfor the parameters in the design and also attempt to minimize the cost of the overall design.TEAM is a globally cooperative system, which implies that any local performance measures maybe sacrificed in the pursuit of better global performance. Thus, an agent is willing to producea component that is poorly rated locally (in terms of cost) but may participate in a design ofhigh overall quality. In TEAM, there are six agents that design the components described aboveand a seventh agent called frequency critic. This agent evaluates the natural frequency of theoverall steam condenser design to see if excessive vibrations will occur during its operation.f pump-agent, heat-exchanger-agent, motor-agent,
platform-agent, vbelt-agent, shaft-agent,system-frequency-criticg
motor pumpheat exchanger
water exhaust
steam input
pumpoutput
pumpshaft
simply supportedelastic platform
vbeltdrive
condensedsteam output
from watersource
Figure 3.1. Steam Condenser
The search in TEAM is performed over a space of partial designs. It is initiated by placinga problem specification in a centralized shared memory that also acts as a repository for the

37
emerging composite solutions (i.e. partial solutions) and is visible to all the agents. Theproblem specification is simply an assignment to a subset of the condenser attributes. Forexample, a problem specification looks as follows:
Problem Specification:Required Capacity 1200Maximum Platform Deflection 0.04Platform Side Length 120
The agents in TEAM perform a distributed constraint-optimization search to obtain a gooddesign. The agents search together to obtain the lowest cost design mutually acceptable tothem. Each of the agents has its own local state information, a local database with static anddynamic constraints on its design components and a local agenda of potential actions. Someof the agents initiate base proposals based on the requirements in the problem specificationand their own internal constraints and local state. These base proposals are partial designs thatserve as anchors for the evolution of the rest of the design. Any design component producedby an agent is placed in the centralized repository. Other agents in turn extend or critique theseproposals in future processing cycles to form complete designs. Extending a partial design onthe blackboard by an agent consists of adding a component to that design by the agent.
An agent may detect conflicts during the process of critiquing or extension. If the detectedconflict is due to violation of hard constraints, that solution is considered “infeasible” and thesolution path is pruned. If the conflicts are due to soft constraints that may be relaxable, thesolution is saved, as it may be recognized by the system as a compromise solution at a laterstage in the search process. Such a solution is considered “unacceptable” and may become“acceptable” later due to the relaxation of soft constraints. Another attribute of solutions istheir completeness: a solution is “complete” only if all the agents have had an opportunity toinitiate, extend, or critique that solution. Otherwise it is “incomplete”. The aim of TEAM isto produce complete acceptable solutions.
For an evolving composite design solution, an agent can play one of a set of organizationalroles. An organizational role represents a set of tasks an agent can perform on a compositesolution. An agent can be working on several composite solutions concurrently. In TEAM,there are three possible roles:� Initiate Solution Based on the problem specification, local requirements and known
external requirements, an agent produces a base proposal when it plays the role of asolution initiator in a particular design. These initiated proposals serve as “seeds” forfurther search through the process of extension by other agents. If the earlier proposalshave been rejected due to conflicts, the initiating agent may have received feedback thatmay constrain its generation of new base proposals to produce qualitatively differentones.
Multiple agents initiating base proposals lead to a better coverage of the compositesolution space. On the other hand, this could also lead to a distracting effect, wherebyan agent with weak constraints initiates a poor base proposal that could lead the restof the agents along this direction instead of working on more promising ones. Such a
trade-off has been observed in other distributed systems too[Lesser and Erman, 1980].

38
When an agents finds that, given the problem specification and its initial solutionrequirements, it cannot produce a base proposal, it relaxes some of its requirements toexpand the search space. If there are external soft requirements that are communicatedto the agent, then it can ignore one or more of these in its search. If there are norelaxable external requirements, the agent may relax some of its own local requirements.A constraint with the highest flexibility is chosen to be relaxed. In case of a tie, anexternal constraint (communicated by another agent) is chosen. If there is a further tie,a constraint on the least important parameter is chosen. The agents have an order ofimportance for their local parameters.� Extend Solution. An agent playing this role in a partial solution extends the evolvingsolution and evaluates it. This partial solution was initiated by some agent and perhapsextended by some others. An agent extending a solution searches for a compatiblesolution constrained by its known solution requirements and the requirements imposedby the already assigned shared parameter values of that solution. The result of this processis a proposal, an evaluation and conflict information, if any. A compatible proposal musthave the same values as the partial solution on the interface parameters, else a conflictarises.
Certain types of conflicts (details below) can generate feedback in the form of meta-information about the local search requirements. For example, upon detecting a conflictduring the extension of a motor component, the pump-agent may send the motor-agent feedback such as “No good; Try required-power � 1.5 horse power”.Certain other types of conflicts do not facilitate expression of the reasons for conflictin a way that the other agents understand. The agent simply says “No Good”. Anagent receiving feedback from another agent assimilates this information into its localrequirements. To the extent that the assimilated feedback increases an agent’s view ofthe non-local requirements, that agent tries to reorder its further search in that probleminstance to avoid similar conflicts.� Critique Solution. This role is similar to extend-solution except that the result is anevaluation and conflict information, if any. An evaluation of a proposal is “acceptable”,“unacceptable” or “infeasible”.
The constraints can be explicitly represented as in, for example, (run-speed� 3600) orthey may be implicit as in procedural representation. An example of a procedurally embeddedconstraint may look as follows:
if (run-speed <= 3600) thenwater-flow-rate = max (50 water-flow-rate)
end if
In this constraint, the run-speed parameter implicitly constrains the water-flow-rate. In complex systems like TEAM, it may often be the case that such implicit constraintsare not easily discernible and may be even more difficult to express explicitly to enable an agentto share it with other agents to let them know of its requirements.
The violated constraints could be either explicit or implicit. Explicit constraints could beshared and an agent detecting violations of explicit constraints generates feedback to the agents

39
that proposed the partial design involved in the conflict. In TEAM, explicit constraints arelimited to simple boundary constraints of the form (x < n), (x � n), (x > n), or (x � n)that specify the maximum or minimum values for a parameter. If x is a shared parameter, thenan explicit constraint on x can be shared with the other agents that share this parameter. Theagents abandon the design that led to the conflict and pursue other designs.
Problem solving terminates when the agents agree upon a design, i.e. they reach amutually acceptable design where each agent has either initiated, extended or critiqued thesolution. However, during the process of problem solving, the agents may relax some of theirrequirements either because these are too over-constrained or because they need to move thesearch into qualitatively different regions of the solution space. Problem-state relaxation isa form of relaxation that occurs in reaction to the lack of problem solving progress or as aresult of agents’ decision to move the search to different regions of the search space. In thecurrent TEAM framework, this type of relaxation occurs at specific processing-cycle intervals:for example, all agents may relax a solution requirement after five processing cycles. Otherstrategies are possible for problem-state relaxation. A user could specify the situations in whichthis should occur. There could be heuristic ways of detecting lack of problem solving progressthat could trigger the relaxation process. Problem-state relaxation guarantees that “if a proposalthat can result in a feasible solution is generated, then either that solution will be eventuallyaccepted or some other solution will become acceptable to all the agents and no deadlock willoccur”[Lander and Lesser, 1993].
The evolution of a composite solution in TEAM can be viewed as a series of state transitionsas shown in Figure 3.2 (from [Lander, 1994]). For example, let a set of four agents A1, A2,A3 and A4 apply negotiated search to produce a design. Moreover, let A1 initiate a solution,A2 and A4 extend a solution and A3 critique a solution. In a typical search, A1 initiates asolution (arc 1), A2 extends the solution (arc 3) and A3 critiques it and detects a conflict ona soft constraint (arc 10). This solution is stored away as a possible compromise in the futurewhen constraints have been relaxed. In the meanwhile, the agents work on other solutionsand let us assume that these lead to infeasible or unacceptable states and A3 relaxes constraintswhose violation made the initial solution unacceptable. The solution now becomes a partiallyacceptable solution (arc 13) and A4 extends the solution to complete it (arc 11).
In any given cycle, an agent is faced with the problem of choosing a role from the set ofallowed roles that it can play next. This decision is complicated by the fact that an agent has to
achieve this choice within its local view of the problem-solving situation[Lander, 1994]. Theobjective of this chapter is to investigate the utility of machine learning techniques as an aid tosuch a decision process in situations where the set of agents involved in problem solving are notnecessarily known to the designer of any single agent. The results in this chapter demonstratethe effectiveness of learning techniques for such a task and then go on to provide empiricalsupport to two important observations regarding learning in multi-agent systems:
1. A credit assignment scheme can lead to enhanced learning if it considers the relationsbetween an action and the progress of the overall problem-solving process, in additionto the end result of the action. This may be especially true of systems with complexinteractions involving transmission of meta-level information.
2. Treating problem solving control as situation-specific can be beneficial (discussed indetail in Section 3.4). In our case, situation-specific organizational roles led to betterperformance, especially in “harder” problems.
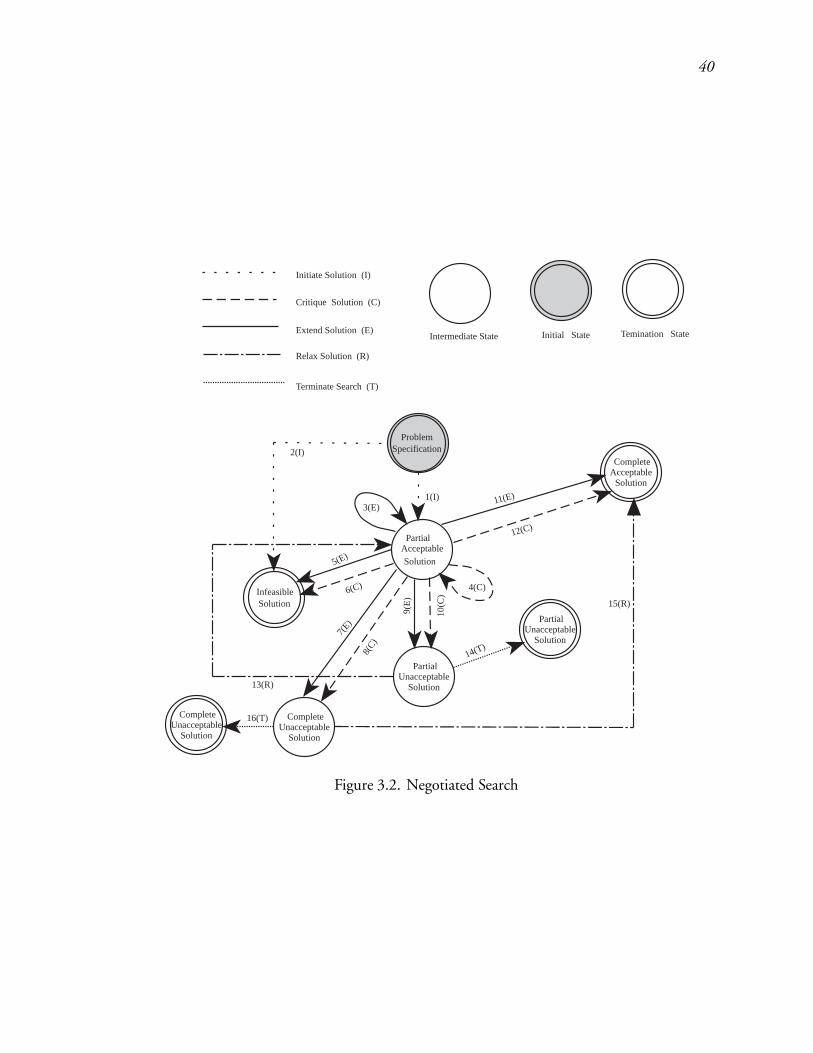
40
ProblemSpecification
PartialAcceptableSolution
CompleteAcceptableSolution
PartialUnacceptable
Solution
PartialUnacceptable
Solution
CompleteUnacceptable
Solution
CompleteUnacceptable
Solution
InfeasibleSolution
Initiate Solution (I)
Critique Solution (C)
Extend Solution (E)
Relax Solution (R)
Terminate Search (T)
Intermediate State Initial State Temination State
2(I)
1(I)3(E)
4(C)
5(E)
6(C)
7(E)
8(C
)
9(E
)
10(C
)
14(T)
11(E)
12(C)
15(R)
13(R)
16(T)
Figure 3.2. Negotiated Search

41
The rest of the chapter is organized as follows. Section 3.3 discusses the characteristics of adistributed search space and Section 3.4 presents our use of the UPC formalism[Whitehair andLesser, 1993] as a basis for learning organizational knowledge. The following section discussesan implementation of a learning version of TEAM, called L-TEAM based on this algorithmand presents the results of our empirical explorations. We conclude by discussing some of theimplications of this work and pointing out its limitations.
3.3 Organizational Roles in Distributed Search
Problem domains like those inL-TEAM can be viewed as comprising a set of interdependentsubproblems. The overall solution to a problem is constructed by the aggregation of solutionsto each of the subproblems. In these domains, partial search paths over a composite searchspace are interrelated in such a way that the extension of a path in the search space of onesubproblem may affect the results of extending another path, perhaps in another subproblem.In such complex search spaces, there is a need for organizing the search to choose those actionsthat lead to the generation of helpful constraints for subsequent searches for solving relatedsubproblems within the same problem instance. In multi-agent systems like L-TEAM, thesituation is further complicated by the fact that the search space is distributed across manyagents.
Organizational knowledge can be described as a specification of the way the overall searchshould be organized in terms of which agents play what roles in the search process andcommunicate what information, when and to whom. It provides the agents a way to effectivelyand reliably handle cooperative tasks. Organizational roles represent a form of organizationalknowledge that lets each agent inL-TEAM take part in the formation of a composite solution ina certain capacity. An organizational role is a task or a set of tasks to be performed in the contextof a single solution. A role may encompass one or more operators, e.g., the role extend-solutionincludes operators for generating design proposals, evaluating them and generating feedbackin case of conflicts. A pattern of activation of roles in an agent set is a role assignment. Allagents need not play all organizational roles; which in turn implies that agents can differ in thekinds of roles they are allotted. Organizational roles played by the agents are important for theefficiency of a search process and the quality of final solutions produced.
To illustrate the above issue, we will use a simple, generic two-agent example. Figure 3.3shows their search and solution spaces. The agents have just two parameters X, and Y definingtheir local search spaces and both these parameters are common to the two agents. Thedarkened portions in the local search spaces of the agents A and B are the local solution spacesand their intersection represents the global solution space. It is clear that if agent A initiatesand agent B extends, there is a greater chance of finding a mutually acceptable solution. AgentA trying to extend a solution initiated by Agent B is likely to lead to a failure more often thannot due to the small intersection space versus the large local solution space in Agent B. Notehowever, that the relative solution distribution of the search spaces is not known a priori to thedesigner to hand code good organizational roles at the design time.
During each cycle in L-TEAM, each agent decides on the role it can play next based onthe available partial designs. An agent can choose to be an initiator of a new design or anextender of an already existing partial design or a critic of an existing design. The agent needsto decide on the best role to assume next and accordingly construct a design component.This chapter investigates the effectiveness of learning situation-specific organizational role

42
Solution Spaces of Agents A and B over X and Y
x
Y
*
*
*
*
*
*
*
Composite Solution Space of A and B
x
Y
Agent Bx
Y
*
*
*
*
*
*
*
Agent A
Figure 3.3. Local and Composite Search Spaces
assignments. No single organizational role assignment may be good for all situations. Theagents adapt themselves to take on roles that are better suited for them in the current problemsolving situation, so as to be effective in the search process (we discuss situations in more detailin the following section).
3.4 Learning Role Assignments
Learning involves exploring the space of role assignments and developing rating measuresfor roles in various situations. The formal basis for learning role assignments is derived from
the UPC formalism for search control (see Whitehair and Lesser[Whitehair and Lesser, 1993])that relies on the calculation and the use of the Utility, Probability and Cost (UPC) valuesassociated with each hstate;R; final statei tuple. Utility represents an agent’s estimate ofthe final state’s expected value or utility if it takes on role R in the present state. Probabilityrepresents the expected uncertainty associated with the ability to reach the final state from thepresent state, given that the agent plays role R. Cost represents the expected computational costof reaching the final state. These values comprise an explicit representation of the position of asearch state with respect to the potential final states in a search space. Additionally, in complexsearch spaces, for which the UPC formalism was developed, playing a role in a state does morethan expand it. The role may result in an increase in the problem solver’s understanding ofthe interrelationships among states. In these situations, a role that looks like a poor choicefrom the perspective of a local control policy may actually be a good choice from a more globalperspective due to some increased information it makes available to the problem solver. Thisproperty of a role is referred to as its potential and it needs to be taken into account while ratingthe role. An evaluation function defines the objective strategy of the problem solving systembased on the UPC components of a role and its potential. For example, a system may want toreach any final state as quickly as possible with high quality solutions or it may want maximumutility per unit cost. An agent applies the evaluation function to all the roles applicable at thepresent state of the on-going search and a role that maximizes the ratings of all the applicableroles is selected.
Starting from this core of the UPC formalism, we modified it to suit our purpose of learningorganizational roles in negotiated search in multi-agent systems. Our first modification involvesclassification of all the possible states of a search into pre-enumerated finite classes of situations.These classes of situations represent abstractions of the state of a search. Thus, for each agent,

43
there is a UPC vector per situation per role. A situation in L-TEAM is represented by a featurevector whose values determine the class of a state of the search. Note that in order to get thevalues of a situation vector, an agent might have to communicate with other agents to obtainthe relevant information regarding the features that relate to their internal state. In L-TEAM,an agent choosing a role indexes into a database of UPC values using the situation vector toobtain the relevant UPC values for the roles applicable in the current state. Depending on theobjective function to be maximized, these UPC vectors are used to choose a role to be playednext. During learning, an organizational role is chosen probabilistically in the ratio of itsrating to the sum of the ratings of all the possible organizational roles for an agent in the givensituation. This permits the system to explore the contributions of all the roles probabilistically.Once the learning is done, an agent chooses the role with the maximum rating in a givensituation. This implies that after the learning phase, each agent organizes itself to play a fixed
role in a given situation1.We use the supervised-learning approach to prediction learning (see [Sutton, 1988]) to learn
estimates for the UPC vectors for each of the situations. The agents collectively explore the spaceof possible role assignments to identify good role assignments in each of the situations. The roleassignment at a particular agent is affected by the state of the problem solving at the other agentsand also the nature of the non-local search spaces. At each agent, the corresponding situationvector of the features representing the relevant problem-solving activities at that time and anagent’s choice of the role it plays are stored by that agent. The performance measures arising outof this decision will not be known at that time and become available only at the completion ofthe search. After a sequence of such steps leading to completion, the performance measures forthe entire problem solving process are available. The agents then back trace through these stepsassigning credit for the performance to the roles involved (the exact process will be described
below)2. At each agent, the values of the UPC vector for the role corresponding to the situationat that agent are adjusted. In our use of the UPC framework, we assume that there is a singlefinal state — the generation of a complete design mutually acceptable to all the agents.
LetnSkj o, 1� j�Mk , be the set of possible situation vectors for Agent k where each situa-
tion vector is a permutation of the possible values for the situation-vector features and letRki , 1�i�Nk, be the set of roles an Agent k can play in a composite solution. Agent k hasMk �Nk vec-
tors of UPC and Potential (abbreviated asPot) values:nRki ; Skj ; Agent k; Ukij; P kij; Ckij; P otkijo.
Given a situation Skb , objective function f(U;P;C; Pot) is used to select a role Rka such that1Even though we describe L-TEAM as an off-line learning system, we could make it on-line by letting thesystem heuristically identify a point at which it could stop learning and switch to choosing roles to maximize their
evaluations rather than choosing them probabilistically in proportion to their ratings.2Note that the supervised learning approach to prediction learning is different from reinforcement learning
which assigns credit by means of the differences between temporally successive predictions[Sutton, 1988]. Inthis thesis, we are primarily concerned with showing the benefits and characteristics of learning in multi-agentsystems rather than with the merits of a particular learning method over others. Appendix A gives some of thecharacteristics that these accumulation functions should exhibit. Our learning rules were derived to satisfy these
characteristics.

44Prob(Rka) = f(Ukab;P kab;Ckab;P otkab)Pi f(Ukib;P kib;Ckib;P otkib) During learningRka = kf�1R maxi f(Ukib; P kib; Ckib; P otkib) After learningwhere 1 � i � N, and kf�1R (rating) represents the role whose UPC values are such thatf(U;P;C; Pot) = rating.
Let T be the distributed search tree where each node is annotated with the triplenRki ; Skj ; Ako representing the role Rki played by Agent k in situation Skj (see Figure 3.4).
LetF(T ) be the set of states on the path to the terminal state T . A terminal state is a state thatis not expanded further due to the detection of a success or a failure. A final state is a terminalstate where the search ends successfully with a mutually acceptable design. For example, let thefollowing sequence of roles played by the agent set lead to a terminal state - say a success.[fR1; S1; A1g ; fR2; S2; A2g ; : : : ; fRm; Sm; Amg]
When the search enters a terminal state, the performance measures are propagated backto the relevant agents. In this case, the agents A1; A2; : : : ; Am adjust the UPC values fortheir respective situation-role pairs. Schemes for doing adjustments to various performancemeasures are discussed below.
Node 1:{1SF
1, 1SF
2, . . . .,
1 SF
n}
Node 2:{2SF
1, 2SF
2, . . . .,
2 SF
n}
Node m:{m
SF1, m
SF2, . . . .,
m SF
n}
Node 3:{3SF
1, 3SF
2, . . . .,
3 SF
n}
.
.
.
Agent A1
Agent Am
Agent A3
Agent A2
.
.
.
Seach Path Attributes:End Result : SuccessUtility of Solution: U
Seach Path Attributes:End Result : IncompleteUtility of Solution:
Seach Path Attributes:End Result : FailureUtility of Solution: U
[situation vector]
R1
R2
R3
Rm
Figure 3.4. Distributed Search Over the Space of Possible Role Assignments

45
There are various ways of doing the actual changes to the UPC and Potential values of each
situation vector and we discuss some simple schemes here. Let (p)Ukij represent the predicted
utility of the final solution achieved by Agent k playing roleRi in a state n that can be classifiedas situation j, accumulated after p problem solving instances. Let F(T ) be the set of states onthe path to a final state F . UF represents the utility of the solution and 0 � � � 1 is the stepsize. Then:(p+1)Ukij = (p)Ukij + � (UF � (p)Ukij); n 2 F(T ); state n 2 situation jThus, Agent k that played role Ri, modifies the Utility for its Ri in situation j.
Let (p)P kij represent Agent k’s estimated probability that playing role Ri in a state n, that
can be classified as situation j, will lead to a final state, accumulated after p problem solvinginstances. Let F(T ) be the set of states on the path to a terminal state T . OT 2 f0; 1g is theoutput of the terminal state T with 1 representing success and 0 a failure. 0 � � � 1 is thestep size. Then:(p+1)P kij = (1 � �)(p)P kij + �OT ; n 2 F(T ); state n 2 situation j
We will not dwell on the details of the Cost component update rule because the evaluationfunctions used in this work do not involve cost. In a design problem solving system, thecomputational costs are not a primary consideration. Successfully completing a good designtakes precedence over computational costs involved as long as the costs are not widely disparate.
Obtaining measures of potential is a more involved process and requires a certain un-derstanding of the system - at least to the extent of knowing which are the activities thatcan potentially make positive or negative contribution to the progress of the problem solvingprocess. For example, in L-TEAM, earlier on in a problem solving episode, the agents takeon roles that lead to infeasible solutions due to conflicts in their requirements. However, thisprocess of running into a conflict leads to certain important consequences like the exchangeof constraints that are violated. The constraints an agent receives from other agents aid thatagent’s subsequent search in that episode by letting it relate its local solution requirementsto more global requirements. Hence, the roles leading to conflicts followed by informationexchange are rewarded by “potential”. Learning algorithms similar to that for utility can be
used for learning the potential of a role. Let (p)Potkij represent the estimated potential of roleRi played by Agent k in a state n that can be classified as situation j, accumulated after pproblem solving instances. Let F(T ) be the set of states on the path to the terminal state T ,PotT 2 f0; 1g be the potential arising from the state T , where PotT = 1 if there is a conflictfollowed by information exchange else PotT = 0. Let 0 � � � 1 be the step size. Then:(p+1)Potkij = (p)Potkij + � (PotT � (p)Potkij); n 2 F(T ); state n 2 situation j
In the L-TEAM system, each role is tagged with the result of its execution - either anadded component to a partial design, or a conflict on certain local requirements along withthe communicated violated local constraints, that can be used to determine the potential of asequence of roles ending in a conflict.

46
3.5 Experimental Results
To demonstrate the effectiveness of the mechanisms in L-TEAM and compare themto those in TEAM, we used the same domain as in Lander[Lander, 1994] — parametricdesign of steam condensers. As discussed earlier, the multi-agent system for this domain, builtwithin the TEAM framework, consists of seven agents: pump-agent, heat-exchanger-agent, motor-agent, vbelt-agent, shaft-agent, platform-agent, andfrequency-critic. The problem solving process starts by placing a problem specificationon a central blackboard (BB). Problem specification consists of three parameters —required-capacity, platform-side-length, and platform-deflection. Duringeach cycle, each of the agents in L-TEAM can decide either to initiate a design based on theproblem specification or extend a partial design on the BB or to critique a partial design onthe BB. During the process of extending or critiquing a design, an agent can detect conflictsand communicate the cause of the conflict to other agents if it can articulate it. At present,an agent can communicate only single-clause numeric boundary constraints that are violated.If the receiving agent can understand the feedback (i.e. the parameter of the communicatedconstraint is in its vocabulary), it assimilates the information and uses it to constrain futuresearches. In addition, in order to avoid stagnation in the progress of the local problem solvingprocess, the agents relax the local soft constraints at a particular level after a certain numberof cycles (five in the following experiments). The system terminates upon the formation of amutually acceptable design.
Each agent has a single organizational role in any design. As mentioned before, L-TEAMidentifies three organizational roles — initiate-design, extend-design, and critique-design.Learning the appropriate application of all these roles can be achieved, but in this workwe confine ourselves to two roles in each agent - initiate-design and extend-design. Fourof the seven agents — pump-agent, heat-exchanger-agent, motor-agent, andvbelt-agent— are learning either to initiate a design or to extend an existing partial designin each situation. The other three agents have fixed organizational roles — shaft-agent,and platform-agent always extend and frequency-critic always critiques. Forthese three agents, their roles are relatively clear and hence we chose not to include them in thelearning process.
In the experiments reported below, the situation vector for each agent had three compo-nents. The first component represented changes in the non-local views of any of the agents inthe system. If any of the agents receives any new external constraints from other agents in thepast m time units (m was 4 in the experiments), this component is ‘1’ for all agents. Otherwiseit is ‘0’. If any of the agents has relaxed its local quality requirements in the past n time units(n = 2) then the second component is ‘1’ for all agents. Otherwise it is ‘0’. Receiving a newexternal constraint or relaxing local quality requirements changes the nature of the local searchspace of an agent. This could prompt it to initiate designs to seed the blackboard with partialdesigns that take these constraints into consideration. Typically, a problem solving episode inL-TEAM starts with an initial phase of generating seed designs, followed by a phase of exchangeof all the communicable information involved in conflicts and then a phase where the searchis more informed and all the information that leads to conflicts and can be communicatedhas already been exchanged. During the initial phase, the third component is ‘1’. During theintermediate phase of conflict detection and exchange of information, the third component is‘2’. In the final phase, it is ‘3’. During the initial phase, some agents may often play the role

47
of initiators of designs so as to lead to the discovery of conflicting requirements that can beexchanged during the intermediate phase to enhance each of the agents’ view of the non-localrequirements on its local search. It is important to note that these features are based on thenegotiated search mechanisms rather than the underlying steam condenser domain. They are
generic to the domain of parametric design that L-TEAM addresses3.In design problem solving, the probability of successfully completing a design and obtaining
a high utility design are of primary consideration. In addition, in a complex open environmentlike that in the L-TEAM system, some form of guidance to the problem solver regarding theintermediate stages of search that may have an indirect bearing on the final solution is helpful.So we used the following rating function:f(U;P;C; potential) = U � P + potential
Learning rates were heuristically set to a small value of 0.1 for the Utility and Probabilitycomponents and 0.01 for the Potential component.
We first trained L-TEAM on 150 randomly generated design requirements and then testedboth L-TEAM and TEAM on the same independent set of 100 randomly generated designrequirements. TEAM was setup so that the heat-exchanger-agent and the pump-agent could either initiate a design or extend a design whereas the vbelt-agent, theshaft-agent and the platform-agent could only extend a design. In TEAM, an agentinitiates a design only if there are no partial designs on the blackboard that it can extend. Welooked at two parameters of system performance. The primary parameter was the cost of thebest design produced (lowest cost). The other parameter was the number of cycles the systemwent through to produce the best cost design. In TEAM (and L-TEAM) each agent in turn getsa chance to play a role in an evolving composite solution during a cycle. The number of cyclesrepresents a good approximation of the amount of search performed by the entire system. It isimportant to note that design cost is different from search cost. Design cost is a representationof the solution quality while the search cost is a representation of the computational cost of thedesign process. Even though the computational cost is not a consideration in the credibilityfunction for choosing a role in design problem solving, it is informative to observe thesemeasures, as they are representative of the search efficiency of the underlying problem-solvingprocess.
We ran L-TEAM and TEAM in two ranges of the input parameters. Range 1 consisted ofrequired-capacity 50 - 1500, platform-side-length 25 - 225, platform-deflection 0.02 - 0.1. Range 2 consisted of required-capacity 1750 - 2000,platform-side-length 175 - 225, platform-deflection 0.06 - 0.1. Lowervalues of required-capacity in Range 1 represented easier problems. We chose the tworanges to represent “easy” and “tough” problems. One can see from Table 3.4 and Table 3.5 thatthe two learned organizations for Range 1 and Range 2 are different. In order to understand thecontribution of situation-specificity we also set up L-TEAM to learn organizational roles in asituation independent manner. Non-situation-specific L-TEAM learns the same organization,3While an understanding of the negotiated search is needed to get these features, we believe that it involvesmuch less effort than identifying the exact nature of interactions in a steam condenser domain, that a humanexpert needs to know before she can assign good roles. For example, in TEAM, the human needs to know thenature of the constraints in the pump-agent, the motor-agent, and the heat-exchanger-agentbefore she could assign roles to the agents.
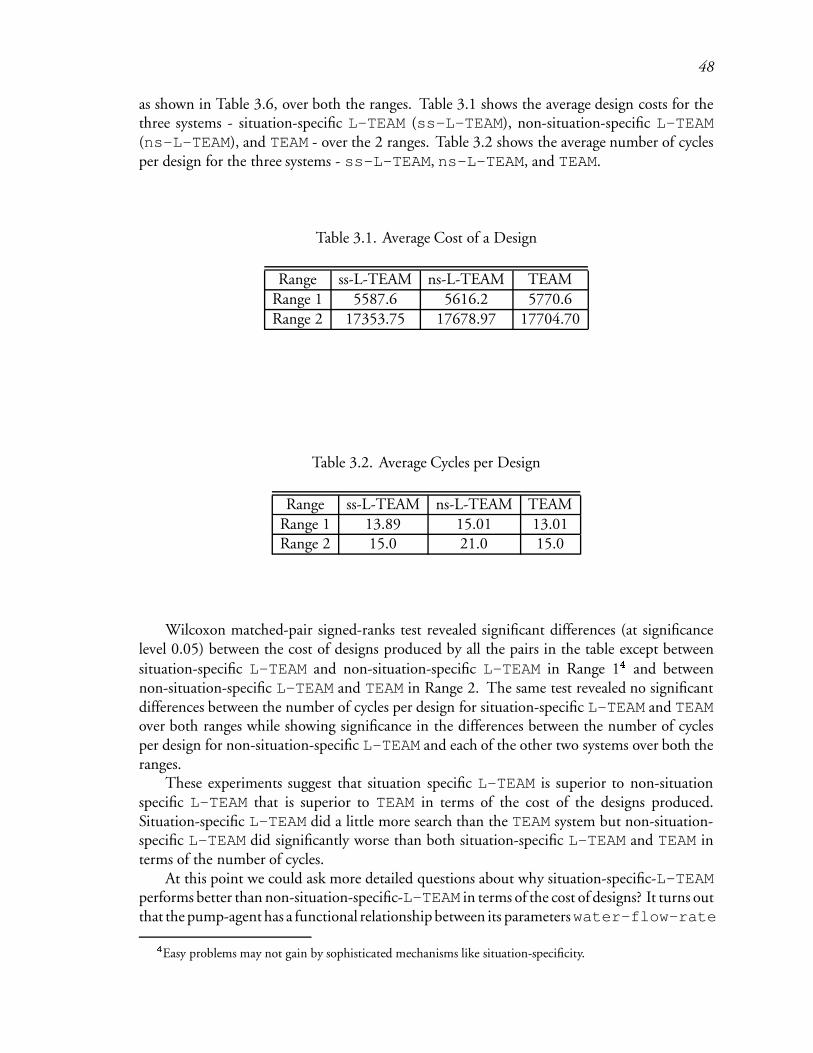
48
as shown in Table 3.6, over both the ranges. Table 3.1 shows the average design costs for thethree systems - situation-specific L-TEAM (ss-L-TEAM), non-situation-specific L-TEAM(ns-L-TEAM), and TEAM - over the 2 ranges. Table 3.2 shows the average number of cyclesper design for the three systems - ss-L-TEAM, ns-L-TEAM, and TEAM.
Table 3.1. Average Cost of a Design
Range ss-L-TEAM ns-L-TEAM TEAM
Range 1 5587.6 5616.2 5770.6
Range 2 17353.75 17678.97 17704.70
Table 3.2. Average Cycles per Design
Range ss-L-TEAM ns-L-TEAM TEAM
Range 1 13.89 15.01 13.01Range 2 15.0 21.0 15.0
Wilcoxon matched-pair signed-ranks test revealed significant differences (at significancelevel 0.05) between the cost of designs produced by all the pairs in the table except between
situation-specific L-TEAM and non-situation-specific L-TEAM in Range 14 and betweennon-situation-specific L-TEAM and TEAM in Range 2. The same test revealed no significantdifferences between the number of cycles per design for situation-specific L-TEAM and TEAMover both ranges while showing significance in the differences between the number of cyclesper design for non-situation-specific L-TEAM and each of the other two systems over both theranges.
These experiments suggest that situation specific L-TEAM is superior to non-situationspecific L-TEAM that is superior to TEAM in terms of the cost of the designs produced.Situation-specific L-TEAM did a little more search than the TEAM system but non-situation-specific L-TEAM did significantly worse than both situation-specific L-TEAM and TEAM interms of the number of cycles.
At this point we could ask more detailed questions about why situation-specific-L-TEAMperforms better than non-situation-specific-L-TEAM in terms of the cost of designs? It turns outthat the pump-agent has a functional relationship between its parameterswater-flow-rate4Easy problems may not gain by sophisticated mechanisms like situation-specificity.
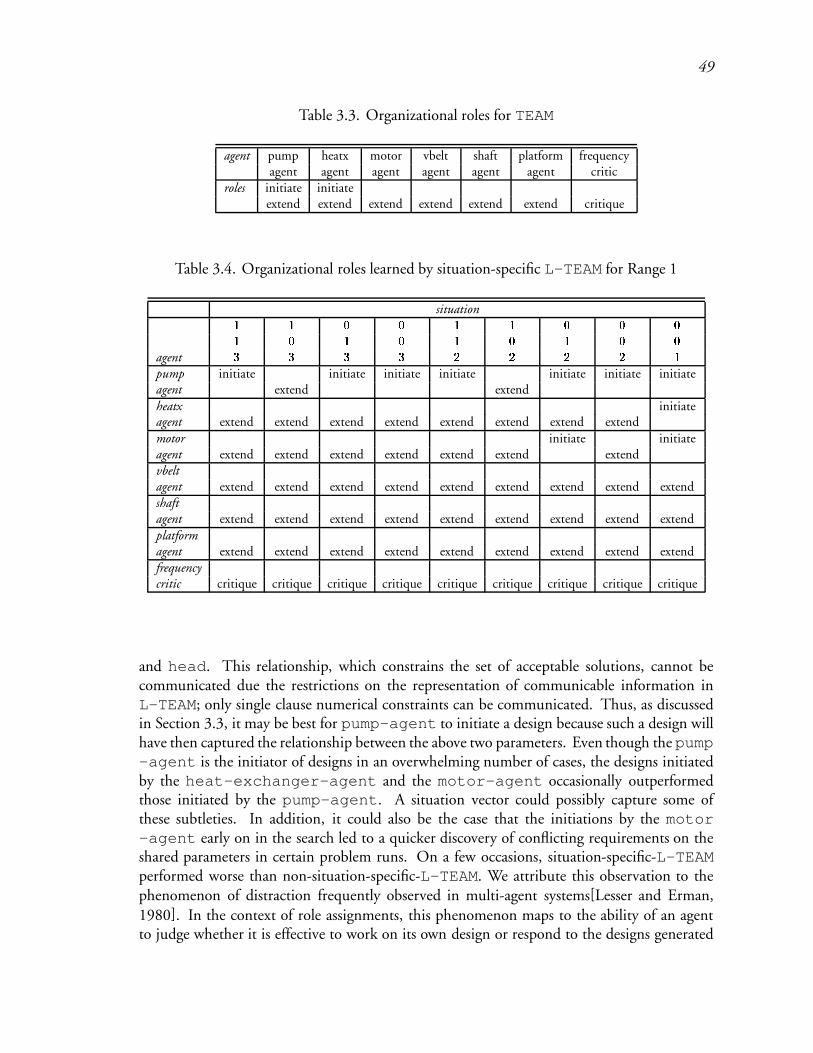
49
Table 3.3. Organizational roles for TEAM
agent pump heatx motor vbelt shaft platform frequencyagent agent agent agent agent agent critic
roles initiate initiateextend extend extend extend extend extend critique
Table 3.4. Organizational roles learned by situation-specific L-TEAM for Range 1
situation1 1 0 0 1 1 0 0 01 0 1 0 1 0 1 0 0agent 3 3 3 3 2 2 2 2 1pump initiate initiate initiate initiate initiate initiate initiateagent extend extend
heatx initiateagent extend extend extend extend extend extend extend extend
motor initiate initiateagent extend extend extend extend extend extend extendvbeltagent extend extend extend extend extend extend extend extend extendshaftagent extend extend extend extend extend extend extend extend extend
platformagent extend extend extend extend extend extend extend extend extendfrequencycritic critique critique critique critique critique critique critique critique critique
and head. This relationship, which constrains the set of acceptable solutions, cannot becommunicated due the restrictions on the representation of communicable information inL-TEAM; only single clause numerical constraints can be communicated. Thus, as discussedin Section 3.3, it may be best for pump-agent to initiate a design because such a design willhave then captured the relationship between the above two parameters. Even though the pump-agent is the initiator of designs in an overwhelming number of cases, the designs initiatedby the heat-exchanger-agent and the motor-agent occasionally outperformedthose initiated by the pump-agent. A situation vector could possibly capture some ofthese subtleties. In addition, it could also be the case that the initiations by the motor-agent early on in the search led to a quicker discovery of conflicting requirements on theshared parameters in certain problem runs. On a few occasions, situation-specific-L-TEAMperformed worse than non-situation-specific-L-TEAM. We attribute this observation to thephenomenon of distraction frequently observed in multi-agent systems[Lesser and Erman,
1980]. In the context of role assignments, this phenomenon maps to the ability of an agentto judge whether it is effective to work on its own design or respond to the designs generated
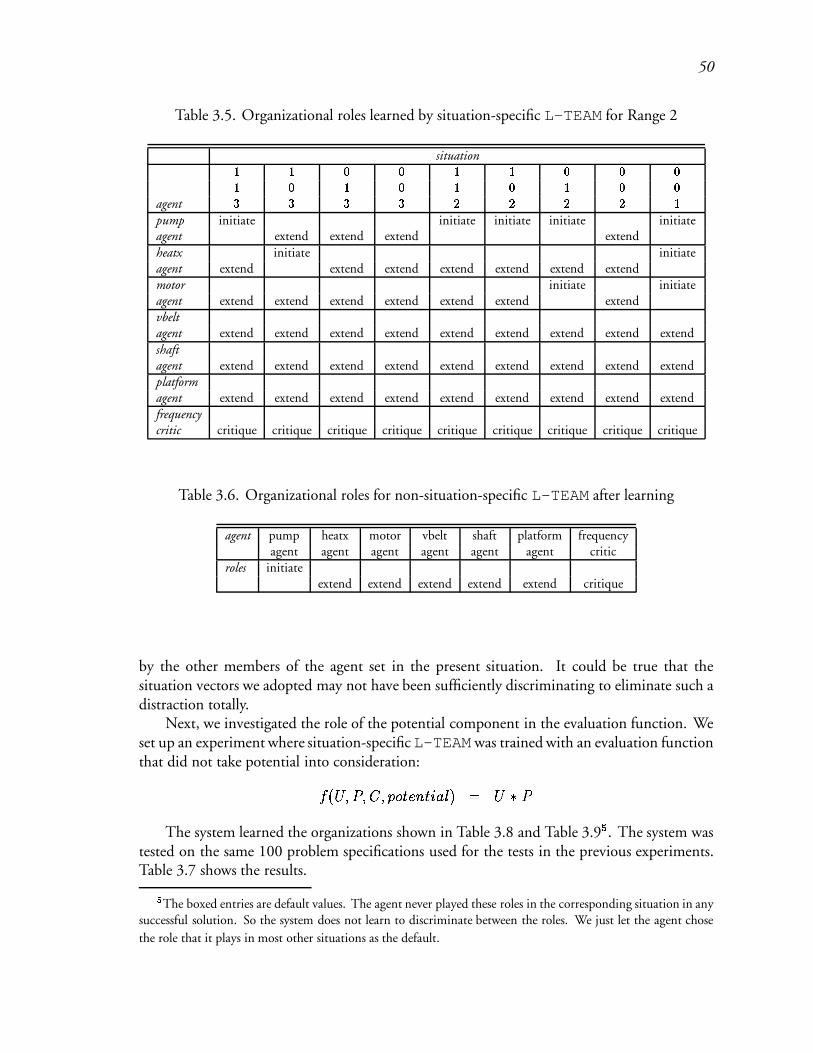
50
Table 3.5. Organizational roles learned by situation-specific L-TEAM for Range 2
situation1 1 0 0 1 1 0 0 01 0 1 0 1 0 1 0 0agent 3 3 3 3 2 2 2 2 1pump initiate initiate initiate initiate initiateagent extend extend extend extend
heatx initiate initiateagent extend extend extend extend extend extend extendmotor initiate initiateagent extend extend extend extend extend extend extendvbeltagent extend extend extend extend extend extend extend extend extend
shaftagent extend extend extend extend extend extend extend extend extendplatformagent extend extend extend extend extend extend extend extend extendfrequencycritic critique critique critique critique critique critique critique critique critique
Table 3.6. Organizational roles for non-situation-specific L-TEAM after learning
agent pump heatx motor vbelt shaft platform frequencyagent agent agent agent agent agent critic
roles initiateextend extend extend extend extend critique
by the other members of the agent set in the present situation. It could be true that thesituation vectors we adopted may not have been sufficiently discriminating to eliminate such adistraction totally.
Next, we investigated the role of the potential component in the evaluation function. Weset up an experiment where situation-specificL-TEAM was trained with an evaluation functionthat did not take potential into consideration:f(U;P;C; potential) = U � P
The system learned the organizations shown in Table 3.8 and Table 3.95. The system wastested on the same 100 problem specifications used for the tests in the previous experiments.Table 3.7 shows the results.5The boxed entries are default values. The agent never played these roles in the corresponding situation in anysuccessful solution. So the system does not learn to discriminate between the roles. We just let the agent chose
the role that it plays in most other situations as the default.
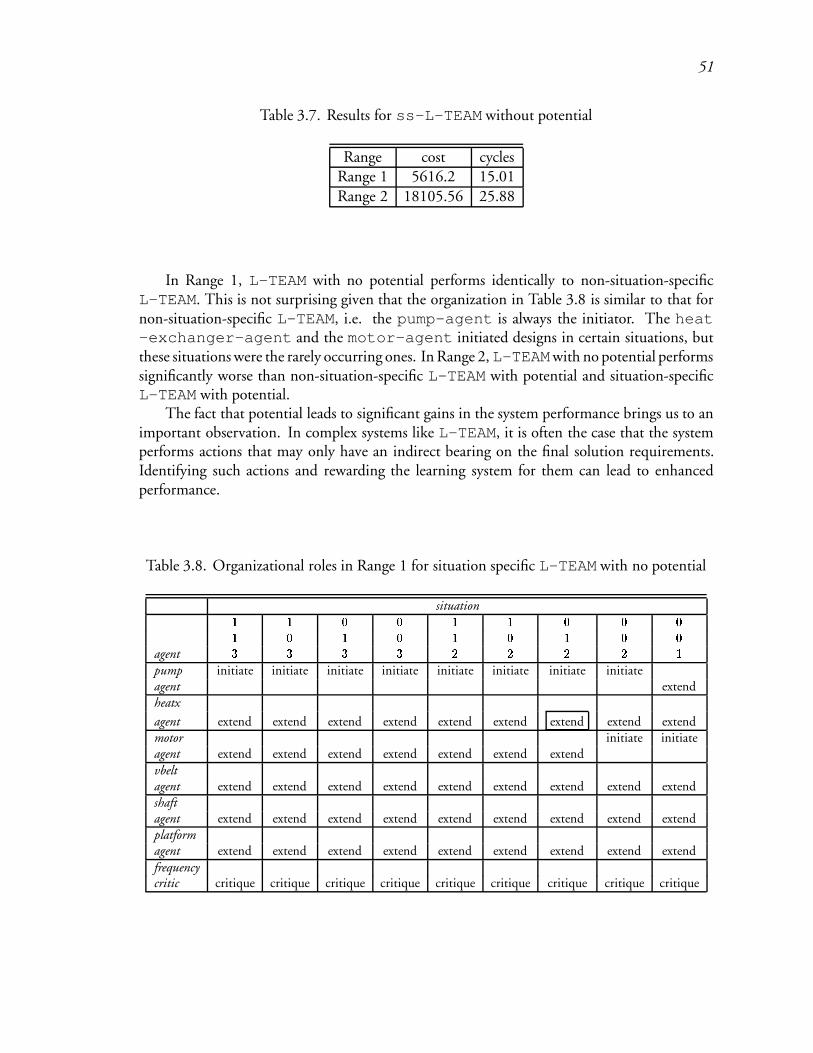
51
Table 3.7. Results for ss-L-TEAM without potential
Range cost cyclesRange 1 5616.2 15.01
Range 2 18105.56 25.88
In Range 1, L-TEAM with no potential performs identically to non-situation-specificL-TEAM. This is not surprising given that the organization in Table 3.8 is similar to that fornon-situation-specific L-TEAM, i.e. the pump-agent is always the initiator. The heat-exchanger-agent and the motor-agent initiated designs in certain situations, butthese situations were the rarely occurring ones. In Range 2, L-TEAMwith no potential performssignificantly worse than non-situation-specific L-TEAM with potential and situation-specificL-TEAM with potential.
The fact that potential leads to significant gains in the system performance brings us to animportant observation. In complex systems like L-TEAM, it is often the case that the systemperforms actions that may only have an indirect bearing on the final solution requirements.Identifying such actions and rewarding the learning system for them can lead to enhancedperformance.
Table 3.8. Organizational roles in Range 1 for situation specific L-TEAM with no potential
situation1 1 0 0 1 1 0 0 01 0 1 0 1 0 1 0 0agent 3 3 3 3 2 2 2 2 1pump initiate initiate initiate initiate initiate initiate initiate initiateagent extendheatx
agent extend extend extend extend extend extend extend extend extendmotor initiate initiateagent extend extend extend extend extend extend extend
vbeltagent extend extend extend extend extend extend extend extend extendshaftagent extend extend extend extend extend extend extend extend extendplatformagent extend extend extend extend extend extend extend extend extend
frequencycritic critique critique critique critique critique critique critique critique critique
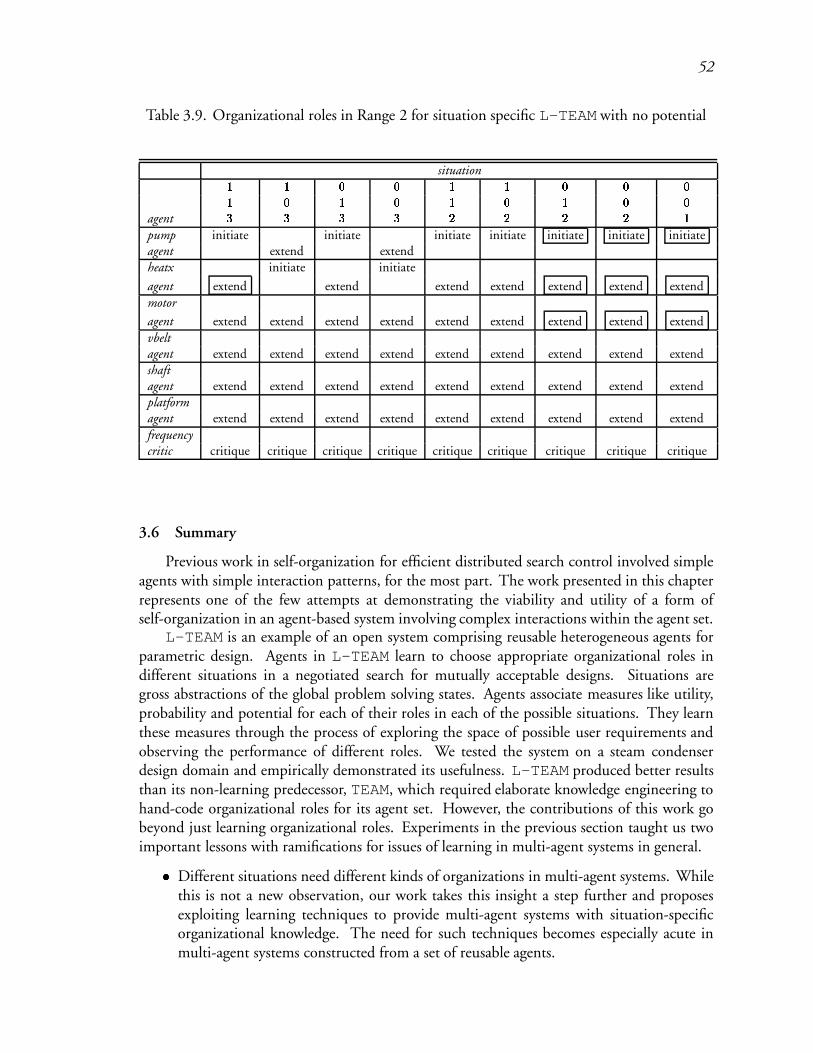
52
Table 3.9. Organizational roles in Range 2 for situation specific L-TEAM with no potential
situation1 1 0 0 1 1 0 0 01 0 1 0 1 0 1 0 0agent 3 3 3 3 2 2 2 2 1pump initiate initiate initiate initiate initiate initiate initiateagent extend extendheatx initiate initiate
agent extend extend extend extend extend extend extend
motor
agent extend extend extend extend extend extend extend extend extend
vbeltagent extend extend extend extend extend extend extend extend extendshaftagent extend extend extend extend extend extend extend extend extendplatformagent extend extend extend extend extend extend extend extend extend
frequencycritic critique critique critique critique critique critique critique critique critique
3.6 Summary
Previous work in self-organization for efficient distributed search control involved simpleagents with simple interaction patterns, for the most part. The work presented in this chapterrepresents one of the few attempts at demonstrating the viability and utility of a form ofself-organization in an agent-based system involving complex interactions within the agent set.
L-TEAM is an example of an open system comprising reusable heterogeneous agents forparametric design. Agents in L-TEAM learn to choose appropriate organizational roles indifferent situations in a negotiated search for mutually acceptable designs. Situations aregross abstractions of the global problem solving states. Agents associate measures like utility,probability and potential for each of their roles in each of the possible situations. They learnthese measures through the process of exploring the space of possible user requirements andobserving the performance of different roles. We tested the system on a steam condenserdesign domain and empirically demonstrated its usefulness. L-TEAM produced better resultsthan its non-learning predecessor, TEAM, which required elaborate knowledge engineering tohand-code organizational roles for its agent set. However, the contributions of this work gobeyond just learning organizational roles. Experiments in the previous section taught us twoimportant lessons with ramifications for issues of learning in multi-agent systems in general.� Different situations need different kinds of organizations in multi-agent systems. While
this is not a new observation, our work takes this insight a step further and proposesexploiting learning techniques to provide multi-agent systems with situation-specificorganizational knowledge. The need for such techniques becomes especially acute inmulti-agent systems constructed from a set of reusable agents.

53� It was noted that the performance was significantly better when an evaluation functiontook into consideration the potential of a role to make indirect contributions to the finalsolutions. In complex systems, the recognition and exploitation of actions with potentialcan result in a better learning process. This observation encourages the system designersto go beyond looking at the end result of a series of actions for credit-assignment schemes.They may also need to consider the role of meta-level information such as relationshipsbetween actions and the progress of the overall problem-solving process.
Our work on organizational roles served as the earliest indicator of the power of learningsituation-specific control. However, organizational roles are just one limited form of organiza-tional knowledge. In a system of complex agents, as the number of agents grows large, thereis a need to organize the system so as to control the combinatorial explosion of peer-to-peerinteractions. Organizational structuring reduces the available options for the agents and henceavoids the combinatorial nature of the interactions. Hierarchical organizations in humansystems is one such classic example. One of the important directions that this work left begging
is the need to study learning of more complex forms of organizational structuring. Weiss[Weiss,1994] (discussed in Chapter 2) takes some initial steps in that direction. However, the agentshave no notion of situation specificity. They learn to form hierarchical groups while tryingto solve the same problem repeatedly through the use of group formation and dissolutionheuristics. Introducing the notions of situation specificity will let the agents form heterarchies- agents could be a part of one hierarchy in one situation and another one in another situation.More importantly, they could generalize the learned organizational knowledge across probleminstances by categorizing different instances into different classes of situations.
There are other issues, pertinent to learning in multi-agent systems that are discussed inthe final chapter, in our future work section, that are also relevant in the context of L-TEAM.

C H A P T E R 4
COOPERATIVE LEARNING OVER COMPOSITE SEARCH SPACES
The farther back you can look, the farther forward you are likely to see.Winston Churchill
4.1 Introduction
In this chapter, we study machine-learning techniques that can be applied within multi-agent systems (MAS) to let an agent learn non-local requirements on local, search-based problemsolving. As discussed in Chapter 1, a ubiquitous problem with multi-agent systems that usecooperative search techniques is the “local perspective” problem. Constraining informationis distributed across the agent set but each individual agent perceives a search space boundedonly by its local constraints rather than by the constraints of all the agents in the system. Thisproblem could be easily addressed if all expertise could be represented in the form of explicitconstraints: the constraints could be collected and processed by a centralized constraint-satisfaction algorithm. However, the most compelling reasons for building multi-agent systemsmake it unlikely that the agents are that simple. More commonly, agents are complex systemsin their own right and their expertise is represented by a combination of declarative andprocedural knowledge that cannot be captured as a set of explicit constraints. Therefore, eachagent must operate independently to solve some subproblem associated with an overall task andthe individual solutions must be integrated into a globally consistent solution. An agent withonly a local view of the search space cannot avoid producing subproblem solutions that conflictwith other agents’ solutions and cannot always make intelligent decisions about managingconflicts that do occur.
In this chapter, we formalize the conflict-driven negotiation in TEAM as a learning processand compare its performance to a more long term learning method used for addressing thelocal perspective problem. The former technique allows an agent to accumulate and applyconstraining information about the global problem solving, gathered as a result of agentcommunication, to further problem solving within the same problem instance. The lattertechnique is used to classify problem instances and appropriately index and retrieve constraininginformation to apply to new problem instances. These techniques will be presented within thecontext of TEAM. We use the configuration that was presented in the previous chapter.
The remainder of this chapter is organized as follows: Section 4.2 formalizes our view ofdistributed search spaces for multi-agent systems; Section 4.3 briefly reviews the TEAM systemthat has been discussed in more detail in the previous chapter[Lander, 1994]; Section 4.4introduces two learning mechanisms used to enhance search efficiency; Section 4.5 presentsour experiments and results. We end with a discussion of the related work in Section 4.6 andthe conclusion.

55
4.2 Distributed Search Spaces
Search has been one of the fundamental concerns of Artificial Intelligence. When theentire search space is confined to a single logical entity, the search is centralized. On the otherhand, distributed search involves a state space, along with its associated search operators and
control regime, partitioned across multiple agents. Lesser[Lesser, 1990, Lesser, 1991] recognizesdistributed search as a framework for understanding a variety of issues in multi-agent systems.
In distributed search, multiple agents are required to search synergistically for a solutionthat is mutually acceptable to all of them and satisfies the constraints on global solutions.However, the constraining information is distributed across the agent set and each individualagent perceives a search space bounded only by its local constraints rather than by the constraintsof all the agents in the system. Thus we need to distinguish between a local search space and thecomposite search space. A local search space is private to an agent and is defined by the domainvalues of the parameters used to constrain the local search. A set of local constraints along withthe problem specification, define the local solution space as a subset of the local search space.More formally, for each agent Ai the following can be defined:� Parameters pij , 1 � j � xi with their respective domains Dij , 1 � j � xi from which
they take their values. Di1 � Di2 � : : :� Dixi defines the local search space for agentAi. A domain can be a set of discrete values, real values, labels or intervals. Pi = f pij ,1 � j � xi g.
A parameter is a shared parameter if it belongs to the parameter sets of more than oneagent. More formally, let AS(p) represent the set of agents that have parameter p as apart of their parameter set. AS(p) = fAi j p 2 PigParameter p is a shared parameter iff j AS(p) j > 1.� Hard constraints HC ti = fHCtij , 1 � j � yig that represent the solution requirements
that have to be satisfied for any local solution that agent Ai produces at time t.� Soft constraints SC ti = fSCtij , 1 � j � zig that represent the solution preferences of
agent Ai at time t. Soft constraints can be violated or modified without affecting theability of the agents to produce globally acceptable designs.
The set of hard and soft constraints, Cti =HC ti [ SC ti, defines a local solution space Sti �Di1 �Di2 � : : :�Dixi . Sti = Space(Cti )In constraint-optimization problems, not all constraints need to be satisfied. Hard
constraints are necessarily satisfied and soft constraints are satisfied to the extent possible.Soft constraints may have a varying degree of flexibility with some being softer than the others.Some of them may be relaxed when an agent is not able to satisfy all of them together. WhenSti = � the problem is over-constrained with respect to Ai. In this situation, domain-specific
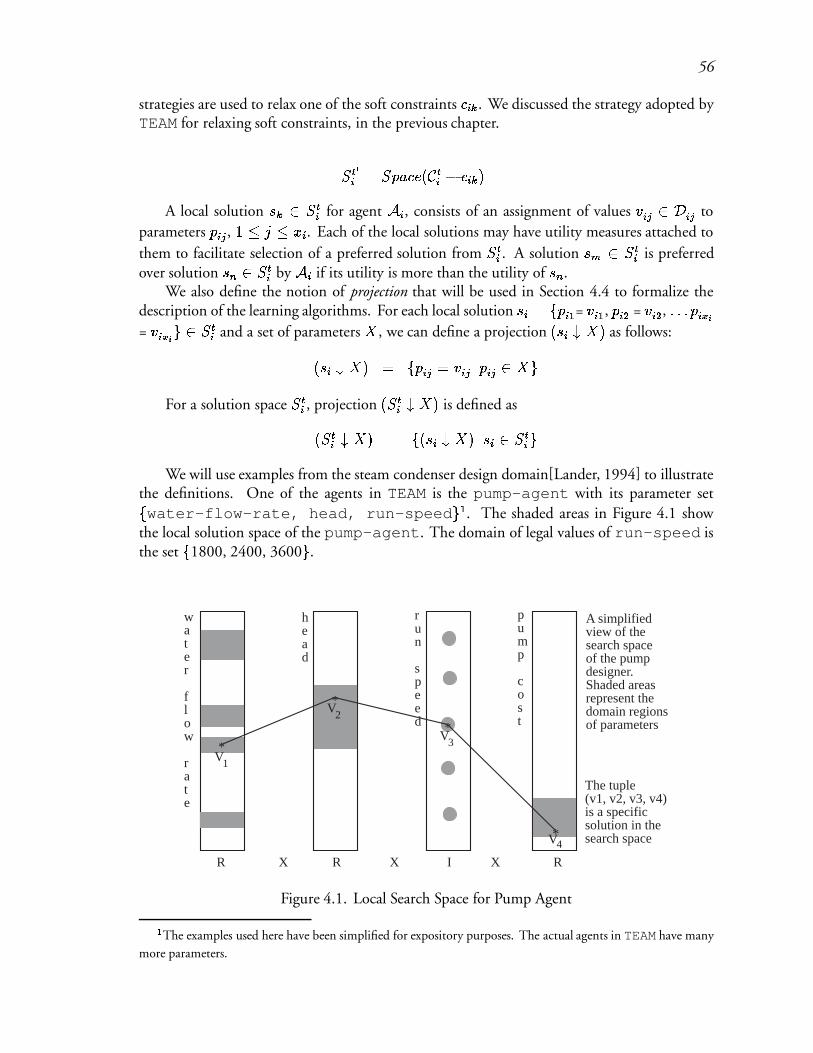
56
strategies are used to relax one of the soft constraints cik . We discussed the strategy adopted byTEAM for relaxing soft constraints, in the previous chapter.St0i = Space(Cti � cik)
A local solution sk 2 Sti for agent Ai, consists of an assignment of values vij 2 Dij to
parameters pij , 1 � j � xi. Each of the local solutions may have utility measures attached to
them to facilitate selection of a preferred solution from Sti . A solution sm 2 Sti is preferredover solution sn 2 Sti by Ai if its utility is more than the utility of sn.
We also define the notion of projection that will be used in Section 4.4 to formalize thedescription of the learning algorithms. For each local solution si = fpi1= vi1, pi2 = vi2, : : : pixi= vixig 2 Sti and a set of parameters X , we can define a projection (si # X) as follows:(si # X) = fpij = vijj pij 2 Xg
For a solution space Sti , projection (Sti # X) is defined as(Sti # X) = f(si # X)j si 2 StigWe will use examples from the steam condenser design domain[Lander, 1994] to illustrate
the definitions. One of the agents in TEAM is the pump-agent with its parameter setfwater-flow-rate, head, run-speedg1. The shaded areas in Figure 4.1 showthe local solution space of the pump-agent. The domain of legal values of run-speed isthe set f1800, 2400, 3600g.
*
*
*
*
water
flow
rate
head
run
speed
pump
cost
R X R X I X R
A simplifiedview of thesearch spaceof the pumpdesigner.Shaded areasrepresent thedomain regionsof parameters
V1
V3
V2
V4
The tuple(v1, v2, v3, v4)is a specificsolution in thesearch space
Figure 4.1. Local Search Space for Pump Agent1The examples used here have been simplified for expository purposes. The actual agents in TEAM have many
more parameters.

57
The constraints can be explicit and declarative or may be implicit and procedural. Explicitconstraints are limited to single clause numerical boundaries (for example, (run-speed� 3600)). Implicit constraints may involve multiple parameters and may be procedurallyembedded. For example:
if (run-speed <= 3600) thenwater-flow-rate = max (50 water-flow-rate)
end if
The soft constraints in TEAM are associated with three levels of flexibility – 2 to 4 – withconstraints at level 4 representing the highest preference (level 1 represents hard constraints). Anagent tries to satisfy as many of the constraints at higher levels as possible. Solutions satisfyingmore constraints at a higher level are preferred. If there are multiple design componentssatisfying the same number of constraints at the highest level, a component with the least costis chosen.
The composite search space CS is a shared search space derived from the composition ofthe local search spaces of the agents. The desired solution space for the multi-agent system is asubset of the composite search space. Parameters of the composite search space consist of:fpGk; 1 � k � gg � i=n[i=1 j=xi[j=1 pijDGk; 1 � k � g = \Dij j Ai 2 AS(pGk) ^ pij = pGk
The parameter set for the composite space represents the features of the overall design thatare constrained by the composite search space. The domain for a parameter in this set is derivedas the intersection of all the domains of the corresponding parameters in the agents that havethis parameter as a shared parameter.
Figure 4.2 shows a two agent example from TEAM system. The two agents involved arethe pump-agent and the heat-exchanger-agent. The parameter set of the pump-agent isfwater-flow-rate, head, run-speedg and theheat-exchanger-agent is fwater-flow-rate, head, required-capacityg. The parameterswater-flow-rate andhead are shared parameters while the rest are unique to the individ-ual agents. The composite search space CS contains the parameterswater-flow-rate andhead from both the pump-agent and the heat-exchanger-agent, and required-capacity from the heat-exchanger-agent. The solutions in the composite spaceare mutually acceptable to heat-exchanger-agent and the pump-agent only if bothof them agree on the values for their shared parameters water-flow-rate and head.
4.3 TEAM: A Multi-agent Design System
This section briefly summarizes the description of TEAM from Chapter 3 for the sakeof continuity here. TEAM is a parametric design system that produces steam condensers. Itconsists of the following agents for designing the components of such steam condensers andevaluating them.f pump-agent, heat-exchanger-agent, motor-agent,
platform-agent, vbelt-agent, shaft-agent,system-frequency-criticg
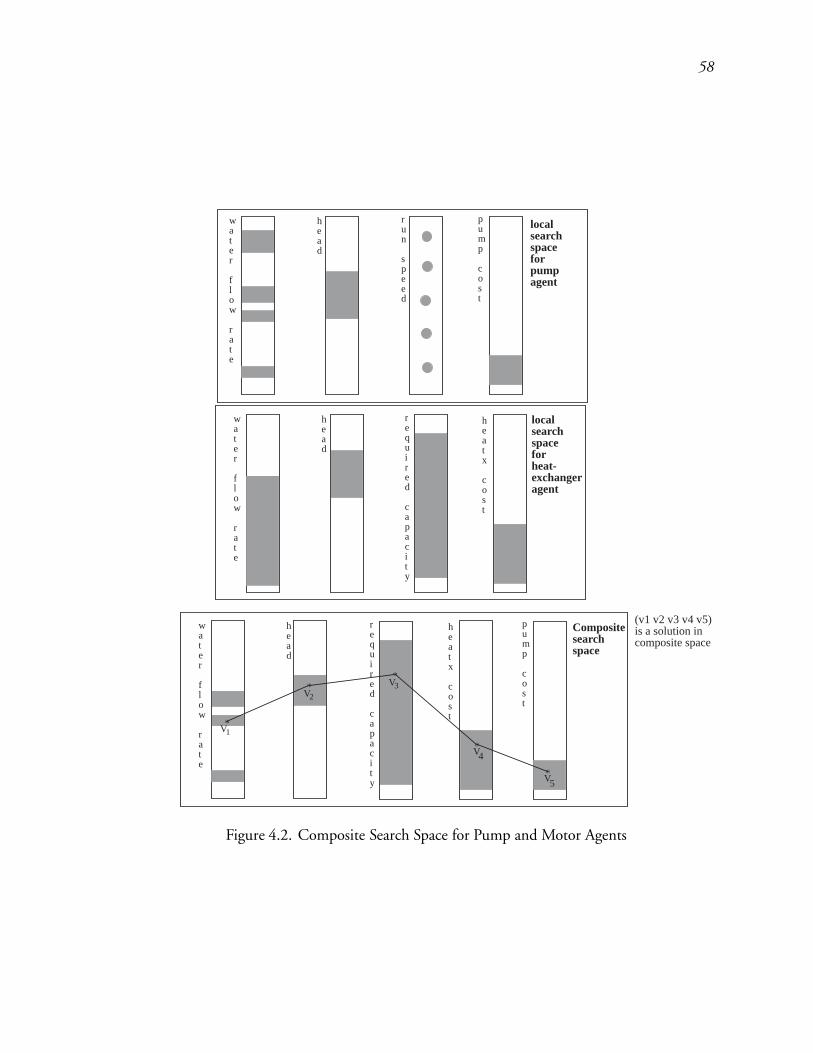
58
water
flow
rate
head
run
speed
pump
cost
water
flow
rate
head
required
capacity
heatx
cost
localsearchspaceforpumpagent
localsearchspaceforheat-exchangeragent
water
flow
rate
head
required
capacity
Compositesearchspace
*
**
V1
V2
V3
(v1 v2 v3 v4 v5)is a solution incomposite space
heatx
cost
pump
cost
4*V
*V5
Figure 4.2. Composite Search Space for Pump and Motor Agents

59
TEAM is a distributed search system. Each agent takes the responsibility either to designa component of a steam condenser for which it possesses expertise or critique an evolvingpartial design. Each agent constrains its local search based on the local parameters to producea component. It has its own local state information, a local database with static and dynamicconstraints on its design components and a local agenda of potential actions. The search inTEAM is performed over a space of partial designs. A partial design represents a partial solutionin the composite search space. It is initiated by placing a problem specification in a centralizedshared memory that also acts as a repository for the emerging composite solutions (i.e. partialsolutions) and is visible to all the agents. Any design component produced by an agent is placedin the centralized repository. Some of the agents initiate base proposals based on the problemspecifications and their own internal constraints and local state. Other agents in turn extendand critique these proposals to form complete designs. The evolution of a composite solution
in TEAM can be viewed as a series of state transitions as shown in Figure 4.3[Lander, 1994].For a composite solution in a given state, an agent can apply a set of operators representedby the set of arcs leaving that state. An agent can be working on several composite solutionsconcurrently.
4.4 Learning Efficient Search
Problem solving in TEAM starts with agents possessing only local views of the search andsolution spaces. Given such a limited perspective of the search space, an agent cannot avoidproducing components that conflict with other agents’ components. This section introducestwo machine learning techniques to exploit the situations that lead to conflicts so as to avoidsimilar conflicts in future.
4.4.1 Conflict Driven Learning (CDL)
CDL has been presented as negotiated search in Lander[Lander, 1994]. We reinterpret thisprocess as a form of learning and provide a formal basis for the learning mechanisms next. Asdiscussed previously, purely local views of the agents are unlikely to lead to composite solutionsthat are mutually acceptable to all of them. When an agent attempts to extend or critique apartial design, it may detect that the design violates some of its local constraints. Let the set ofparameters shared by agents Ai and Aj be Xij . Then agent Aj trying to extend or critique a
solution smi 2 Sti detects a conflict iff(smi # Xij) =2 (Stj # Xij)Explicit constraints that are violated could be shared with other agents. An agent detecting
such violations generates feedback to the agents that proposed the partial design involved in theconflict. Such a conflict-driven exchange of feedback on non-local requirements allows eachagent to develop an approximation of the composite (global) search space that includes both itslocal perspective and the explicit constraining information that it assimilates from other agents.This type of “negotiated search” can be viewed as learning by being told and is short-term innature—the exchanged information is applied only to further search in the current probleminstance. The following lemma shows that an exchange in CDL improves an agent’s view ofthe composite search space.
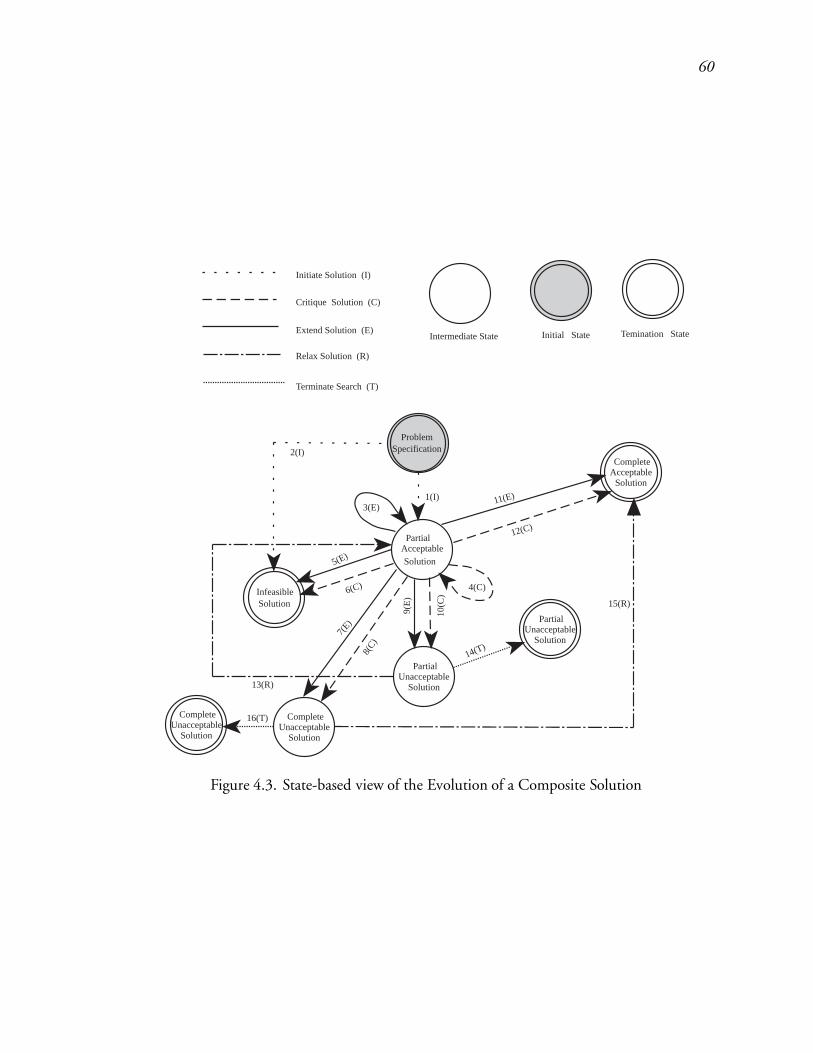
60
ProblemSpecification
PartialAcceptableSolution
CompleteAcceptableSolution
PartialUnacceptable
Solution
PartialUnacceptable
Solution
CompleteUnacceptable
Solution
CompleteUnacceptable
Solution
InfeasibleSolution
Initiate Solution (I)
Critique Solution (C)
Extend Solution (E)
Relax Solution (R)
Terminate Search (T)
Intermediate State Initial State Temination State
2(I)
1(I)3(E)
4(C)
5(E)
6(C)
7(E)
8(C
)
9(E
)
10(C
)
14(T)
11(E)
12(C)
15(R)
13(R)
16(T)
Figure 4.3. State-based view of the Evolution of a Composite Solution

61
Let the set of constraints communicated as feedback by agentAj to Ai at the time t upondetecting a conflict be FCj .Lemma: (CS # Pi) � (St0i = Space(Cti [ FCj)) � Sti
The lemma says that Ai’s view of the composite search space with the new conflictinformation assimilated is a refinement over the previous one with respect to the relevantportion of the actual composite search space.
Proof: The proof of this lemma is based on the following simple observations.
Observation 1Space(C [ D) = Space(C) \ Space(D)Space(C [ D) � Space(C)Space(C [ D) � Space(D)
where C and D are sets of constraints.Observation 2Let X(C) be the set of variables over which the constraints in C are defined.(CS # X(C)) � Space(C)
Observation 2 holds because the composite search is a result of the constraining effect ofall the constraints in all the agents.
Based on Observation 1, it is easy to see that St0i � Sti . We need to prove that it is a properinclusion. Let us assume that for some set of feedback constraints FCk, Space(Cti [ FCk) =Space(Cti ).Space(Cti [ FCk) = Space(Cti ) (1)) Space(Cti ) \ Space(FCk) = Space(Cti ) (2)) Space(Cti ) � Space(FCk) (3)
This however implies that the agent that communicated FCk does not detect a conflict
with respect to these constraints for a partial solution proposed by Ai from Space(Cti ). Thisis a contradiction to the way CDL works. Only those constraints involved in a conflict arecommunicated to the agents proposing the partial design.
Now we will prove that (CS # Pi) � (St0i = Space(Cti [ FCj)). It is true that(CS # Pi) � Space(Cti ) (4)(CS # X(FCj)) � Space(FCj ) (based on Observation 2) (5)) (CS # Pi) � Space(FCj) since X(FCj) � Pi (6)
4 & 6 ) (CS # Pi) � Space(Cti ) \ Space(FCj) (7)) (CS # Pi) � Space(Cti [ FCj) (8)The design leading to a conflict is abandoned and the agents pursue other designs but with
an enhanced knowledge of the composite solution requirements from there on2. Figure 4.4shows a simple two agent, two shared parameter system. After all the explicit constraints areexchanged through an iterative process of conflict detection and explicit constraint feedback,each agent’s approximation of the other agent’s solution space on the shared parameters isshown in the lower part of Figure 4.4.2Another alternative not explored at present in TEAM involves intelligently backtracking to an earlier stage in
the evolution of the offending design - i.e. dependency-directed backtracking.
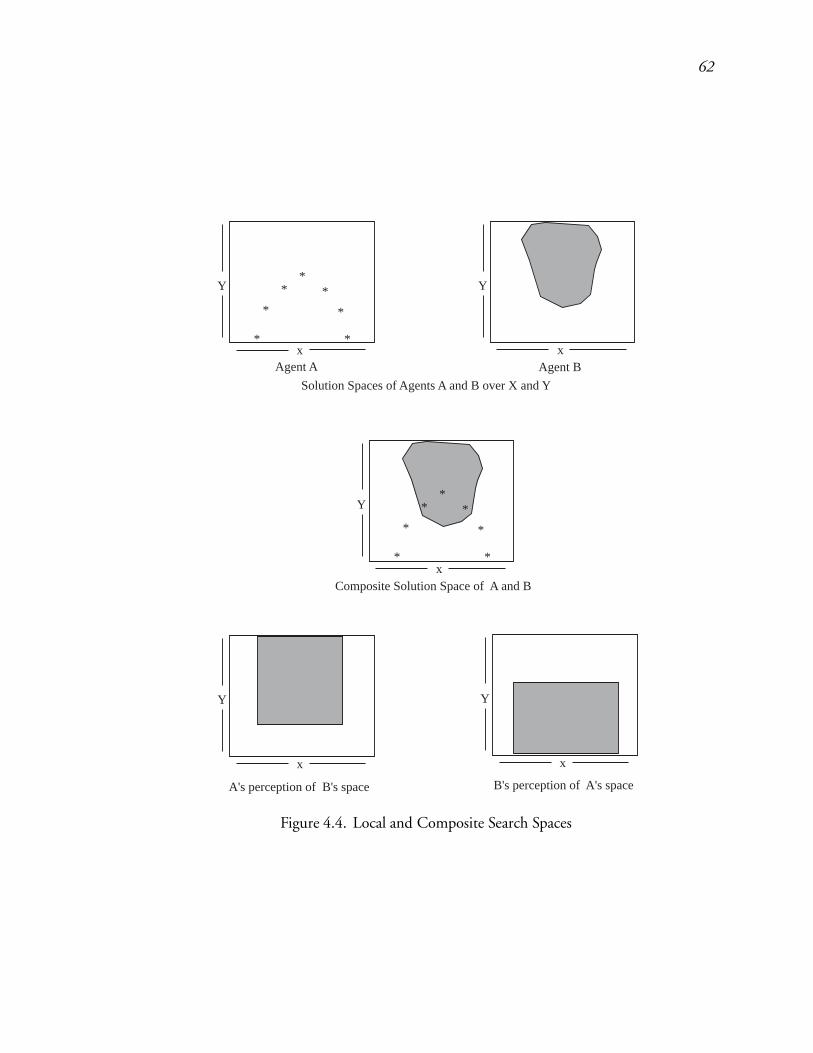
62
x
Y
*
*
*
*
*
*
*
x
Y
x
Y
*
*
*
*
*
*
*
Solution Spaces of Agents A and B over X and Y
Agent A Agent B
Composite Solution Space of A and B
x
Y
x
Y
A's perception of B's space B's perception of A's space
Figure 4.4. Local and Composite Search Spaces

63
The exchange of explicit constraints does not guarantee that the agents will find a mutuallyacceptable solution because of the presence of implicit constraints that cannot be shared. Thus,even if all the explicit constraints that lead to conflicts are exchanged by time tf , the resultingview of agent Ai of the composite search space is still an approximation of the true compositesearch space: (CS # Pi) � Stfi
However, to the extent that an agent’s local view approaches the global view, an agent islikely to be more effective at proposing conflict-free proposals.
4.4.2 Case-Based Learning (CBL)
Agents can also learn to predict composite solution requirements based on their pastproblem-solving experience. We endow the agents with capabilities for Case-based learning(CBL) to accumulate local views of the composite search space requirements across manydesign runs. This can be viewed as long-term learning—the learned information is availablefor retrieval with future problem instances.
During the learning phase, the agents perform their search with conflict-driven learning asdiscussed above. However, at the end of each search, an agent stores the problem specificationand the non-local constraints it received as feedback from the other agents as an approximationof the non-local requirements on the composite solution space for that problem specification.After the agents learn over a sufficiently large training set, they can replace the process ofassimilating feedback with learned knowledge. When a new problem instance is presented tothe agent set, it retrieves the set of non-local constraints that are stored under a past problemspecification that is similar to the present problem specification and adds them to the set oflocal requirements at the start of the search. Thus, agents can avoid communication to achieveapproximations of the composite search space. This work, unlike that in Chapters 3 & 5, takesa very limited and weak view of situation vectors, which are just the global user requirements.(CS # Pi) � St=0iwhere St=0i is defined by the local domain constraints and the constraints of the similar pastcase from the case base St=0i = Space(C0i + PC1NN)PC1NN is the set of constraints from a past similar problem instance, identified using 1-nearest-neighbor similarity metric.
For example, if TEAM gets the problem specification f required-capacity= 600,platform-side-length = 35.25, maximum-platform-deflection = 0.85 g,
the pump-agent uses the normalized problem specification3 to retrieve frequired-capacity= 576,platform-side-length= 38.0,maximum-platform-deflection3Normalization is performed using the maximum and minimum ranges of the parameters: 0- 1500 for required-capacity, 0 - 235 for platform-side-length, 0 - 1.0 formaximum-platform-deflection.

64
= 0.80 g from the case base of past problem instances and adds the constraints stored underthis instance as additional constraints on the local solutions (see the following example case).
Problem Specification:Required-capacity: 576Platform-side-length: 38.0Maximum-platform-deflection: 0.80
Water Flow Rate Constraints:(water-flow-rate :MIN 150.5 2 :heat-exchanger-agent)(water-flow-rate :MIN 100.5 1 :heat-exchanger-agent)
Minimum Head Constraints:(minimum-head :MIN 197.1590 2 :heat-exchanger-agent)(minimum-head :MIN 21.8156 1 :heat-exchanger-agent)
Available Head Constraints:(available-head :MIN 200.1 2 :heat-exchanger-agent)(available-head :MIN 50.1 1 :heat-exchanger-agent)
Require Power Constraints:(required-power :MAX 4.0 3 :motor-agent)
where a constraint is of the form (C1; C2; C3; C4; C5)C1 = parameter nameC2 = :MIN or :MAX representing lower or upper bounds on parameter valuesC3 = boundary value of the parameterC4 = flexibility level of the constraintC5 = agent which communicated this constraint during learning
4.5 Experimental Results
In this section, we will empirically demonstrate the merits of learning composite search-space requirements, both short-term and long-term. Before we present the experiments, wedescribe three different search strategies and relate them to Figure 4.5 that shows the controllogic of an agent in TEAM. ‘Initiate solution’, ‘extend solution’ and ‘critique solution’ representthe initiate-solution, extend-solution and critique-solution rolesplayed by an agent. ‘External-initiate’ represents an initiate-solution role by anotheragent. This presents an opportunity for the current agent to extend the design initiated byanother agent. ‘Assimilate-info’ represents assimilation of constraints (involved in conflict)communicated by other agents in the previous cycle.
In order to demonstrate the merits of our learning methods, we experimented with threesearch strategies as described below:� Blind Search (BS): No learning is applied. When an agent detects a conflict in a
particular design, it chooses another design to pursue. Agents do not communicateany information. Figure 4.5 can be modified to get the agent control for this strategy.The state corresponding toinitialize-with-learned-knowledge is absent.In addition, the link communicate-explicit-constraints leading out ofconflict-detected state is also absent.

65
Noextensiblesolutions
extensiblesolutions
exist
TerminateSearch
TerminationTest Satisfied
externalinitiate
initiatesolution
extendsolution
ConflictDetected
StartCycle
communicateexplicit constraints
in conflict
assimilateinfo
assimilateinfo
PartialAcceptableSolutions
extendsolution
critiquesolution
critiquesolution
assimilateinfo
Initializewith learnedknowledge
(IBL)
(CDL)
Figure 4.5. Agent Control� Conflict-Driven Learning (CDL): An agent that detects a conflict generates feedback thatis assimilated by the recipient agents. The recipients use the conflict information to con-strain future searches within a single design run: for example, when proposing or extend-ing alternative designs. If the state corresponding toinitialize-with-learned-knowledge is absent in Figure 4.5, we get a representation of the agent control forthis strategy.� Case-Based Learning (CBL): The agents use previously accumulated cases to start theirproblem-solving with an awareness of the non-local constraints. Agents do not com-municate during problem-solving. When agents detect conflicts in a particular de-sign, they choose another design to pursue. Each agent uses a 1-NN algorithmto find the case most similar to the present problem solving instance and initializesits non-local requirements with the constraints in the case. A minor modificationof removing the link communicate-explicit-constraints leading out ofconflict-detected state in Figure 4.5 gives the agent control representation forthis strategy. We ran the algorithm at different case base sizes: 50, 100 150, 200.
As described previously, the TEAM system used in these experiments had seven agents.Three of them — pump-agent, heat-exchanger-agent, and motor-agent —can either initiate a design or extend an existing partial design. vbelt-agent,platform-agent

66
and shaft-agent can only extend a design and frequency-critic always critiquesa partial design. Each agent in turn, gets a chance to perform an operation during a cycle. Thenumber of cycles represents a good approximation to the amount of search performed by the en-tire system. Problem specification consisted of three parameters — required-capacity,platform-side-length, and maximum-platform-deflection. Problem solv-ing terminates when the agents produce a mutually acceptable design. We trained the CBLsystem with randomly chosen instances and then tested all the three search strategies on thesame set of 100 instances different from the training instances.
Table 4.1 shows the average cost of designs produced by each of the algorithms. Table 4.2shows the average number of cycles per design. Table 4.3 shows the average number of feedbackmessages required for the agents to arrive at mutually acceptable designs.
Table 4.1. Average Cost of a Design
Blind CDL CBL-50 CBL-100 CBL-150 CBL-2007227.2 6598.0 6572.96 6571.54 6526.03 6514.76
Table 4.2. Average number of cycles per design
Blind CDL CBL-50 CBL-100 CBL-150 CBL-200
15.54 12.98 13.26 13.36 13.03 12.94
Table 4.3. Average number of conflict resolution messages
Blind CDL CBL-50 CBL-100 CBL-150 CBL-200
0 8.09 0 0 0 0
Wilcoxon matched-pair signed-ranks test revealed that the costs of designs produced byTEAM with CBL and CDL were lower than those produced by TEAM with blind search at

67
significance level 0.05. The same test however, revealed no significant difference between thecosts of designs produced by TEAM with CDL and those produced by TEAM with CBL.
CBL was able to produce slightly better designs than CDL because CDL performs blindsearch initially until it runs into conflicts and gains a better view of the composite searchspace through the exchange of feedback on these conflicts. CBL on the other hand, startsthe problem solving with a good approximation of the global solution space requirements andhence manages to do better than CDL.
Our results conclusively demonstrate that conflict-driven learning (CDL) and case-basedlearning (CBL) improve both solution quality and the processing time compared to blind search.In addition, once the learning is completed, CBL requires no run-time communication. Notehowever that CDL is required during the learning phase.
One of the questions that may have already occurred to the readers is “How do thetwo learning methods interact? If both the mechanisms - conflict-driven learning andcase-based learning - are turned on simultaneously, what is the behavior of the system?”.In case-based learning, the search starts out with a more informed view from the verybeginning. On the other hand, the non-local requirements obtained through conflict-drivenlearning are more accurate and specific to the problem whereas the case-based learningsystem relies on approximate knowledge of the non-local requirements (based on similarpast problem instances). Ideally, turning on these two mechanisms should compensate eachother’s shortcomings. However, in order to let these two mechanisms function simultaneously,L-TEAM needs strategies for handling conflicting requirements. What if the CBL knowledgesays0.53hp � required power � 0.60 and the CDL knowledge says0.61hp �required power � 0.65. We experimented with one simple strategy where the CDLknowledge was always favored over the CBL knowledge independent of the level of flexibilityof the conflicting constraints. This did not yield results that were significantly different fromusing either of the mechanisms alone. Some of the runs with both mechanisms turned on didbetter than either of the mechanisms alone and some runs did worse. One of the reasons forperforming worse could be attributed to the distracting effect of the “not so good” approximate
knowledge of the CBL before the more accurate CDL learning could take effect4. However, ourexperiments in this direction are not sufficient to make any broad claims and we do recognizethe need for experimenting with more sophisticated strategies for resolving conflicts betweenthe learned knowledge involving the flexibility of the constraints, importance of the parametersin the constraints and the stage of search at which these conflicts are detected.
4.6 Related Work
Chapter 2 summarizes the related work on learning. In this section, we relate the workspecific to this chapter to literature on Distributed Search and Conflict Management.
4.6.1 Distributed Search
Distributed Search has been the explicit focus of research amongst a small group of DAI
researchers for the past few years. Lesser[Lesser, 1991] introduced the FA/C approach, withdistributed search as a unifying framework for a variety of issues in distributed problem solving.4When to rely on CDL versus CBL could itself be formulated as a learning problem.

68
A problem is decomposed into subproblems to be solved by different agents in a multi-agentsystem. Overall solution to a problem is obtained by the aggregation of solutions to thesubproblems. The subproblems may be interdependent and the local search spaces of agentsmay be interrelated in such a way that the organization of search activity by an agent inits local search space may have non-local affects on the search activities by the other agents.
Yokoo, Durfee and Ishida[Yokoo et al., 1992], Conry et al.[Conry et al., 1991], Sycara etal.[Sycara et al., 1991], and Neiman et al.[Neiman et al., 1994] have investigated various issuesin Distributed Search. However, implicit in all of these pieces of work are the assumptionsthat the agents have homogeneous local knowledge and representations and tightly integratedsystem-wide problem-solving strategies across all agents.
Yokoo, Durfee and Ishida[Yokoo et al., 1992] attempt to develop formal descriptions fordistributed search algorithms for various problems: asynchronous backtracking and preprocess-ing procedures like distributed consistency algorithms for distributed constraint satisfaction,modified iterative asynchronous backtracking algorithm for distributed constraint optimization,abstract hierarchical search for distributed constraint optimization with local state space searchand heuristic best-first search for distributed constraint optimization with local and/or graphsearch.
Conry et al.[Conry et al., 1991] present a multi-stage negotiation protocol for distributedconstraint satisfaction problems. Agents progressively gain an understanding of the non-localeffects of their local decisions through negotiation and non-local information assimilation andconsequently produce a solution that is mutually acceptable to all the agents, if one exists.Each agent initially makes tentative commitments to a set of alternatives and announces itsintentions to its neighbors, who in turn confirm these commitments by making their ownlocally compatible commitments. If all agents arrive at a global alternative during this processthen a solution is found. Otherwise, some of the agents revise their local tentative commitmentsand the process is repeated.
Sycara et al.[Sycara et al., 1991] describe a system for decentralized constraint heuristicsearch in the job-shop scheduling domain. Agents communicate local demand profiles for re-sources to develop heuristic texture measures for variable ordering and variable tightness. Thesetexture are used to focus the local searches in agents. A type of dependency directed backtrackingcalled distributed asynchronous backjumping is used to perform efficient backtracking.
Neiman et al.[Neiman et al., 1994] show how the analysis of abstracted resource re-quirements (texture measures) of other agents can help an agent reduce its uncertainty about
local search and scheduling activities. Mammen and Lesser[Mammen and Lesser, 1992]
develop a new texture measure called Imbalance-in-Variable-Tightness for increased efficiencyin focusing the search in distributed systems. It measures the unevenness in the distributionof local measures of variable tightness among the agents. Some of the more recent work by
Mammen[Mammen, 1995] builds on the previous work and attempts to develop a theory ofsubproblem interactions that can be exploited in the design of efficient distributed problemsolvers.
4.6.2 Conflict Management
Conflict management approaches are very similar to the Conflict Driven Learning mecha-nism presented here. We discuss the work of Klein[Klein, 1991], and Khedro and Genesereth[Khe-dro and Genesereth, 1993] in conflict management in some detail below.

69
Klein[Klein, 1991] develops a theory of computational model of resolution of conflictsamong groups of expert agents. This model, based on studies in human cooperative design, restson two key insights: general conflict resolution expertise exists separately from the domain-levelexpertise and this expertise can be instantiated into specific conflict resolution advice in thecontext of particular conflicts. Associated with each conflict is an advice for resolving theconflict. A conflict class is activated if its preconditions are satisfied. A strategy based onthe set of conflict resolution advice of the active conflict classes is used to deal with theencountered conflict. We believe that Klein’s work provides a general foundation for handlingconflicts in design application systems. However, it falls short of embedding such conflictresolution mechanisms into the larger problem solving context that can involve studying issueslike solution evaluation, information exchange and learning.
Khedro and Genesereth[Khedro and Genesereth, 1993] present a strategy called ProgressiveNegotiation for resolving conflicts among multi-agent systems. Using this strategy, the agentscan provably converge to a mutually acceptable solution if one exists. However, the guaranteeof convergence relies crucially on explicit declarative representation and the exchange of allconstraining information. More commonly, TEAM-like systems are aggregations of complexagents whose expertise is represented by a combination of declarative and procedural knowledgethat cannot be captured as a set of explicit constraints. The presence of implicit constraintsleads to a break down of the kind of guarantees that Progressive Negotiation offers.
4.7 Conclusion
Our work investigates the role of learning in improving the efficiency of cooperative,distributed search among a set of heterogeneous agents for parametric design. Our experimentssuggest that conflict-driven short-term learning can drastically improve the search results.However, even more interestingly, these experiments also show that the agents can rely on theirpast problem solving experience across many problem instances to be able to predict the kindsof conflicts that can be encountered and thus avoid the need for communicating feedback onconflicts as in the case of short-term learning.
TEAM can also be viewed as an interim vehicle for investigating some of the importantissues in Concurrent Engineering (CE) and Distributed Design. CDL mechanisms in TEAMcan be adapted to allow downstream constraints in a product’s design cycle to be brought in,to bear on the assessment of early alternatives. CDL mechanisms are particularly well suitedfor those CE systems that capture the impact of a decision made concerning one phase of aproduct life cycle on other phases, as sets of declarative constraints[Bowen and Bahler, 1993].CBL mechanisms in TEAM can be viewed as a very rudimentary form of automated captureof design rationale. Rationale capture includes the identification and documentation of design
decisions, conflicts, their causes and potential resolutions[Klein, 1993]. In particular, CBLmechanisms in TEAM rely on exploiting the violated constraints leading to conflicts in pastsimilar problem requirements to avoid disagreements in the current design process. One ofour future areas of investigation is the use of case-based reasoning methods to perform a moresophisticated rationale capture in the design processes.

C H A P T E R 5
LEARNING SITUATION-SPECIFIC COORDINATION IN
GENERALIZED PARTIAL GLOBAL PLANNING
Get a good idea and stay with it. Dog it, and work at it until it’s done right.Walt Disney
It takes 20 years to make an overnight success.Eddie Cantor
5.1 Introduction
Coordination is the process of effectively managing interdependencies between activities
distributed across agents so as to derive maximum benefit from them[Malone and Crowston,1991, Decker and Lesser, 1995]. Based on the structure and uncertainty in their environment,agents have to choose and temporally order their activities to mitigate the effects of harmfulinterdependencies and exploit the beneficial interdependencies among them. Researchers inboth human and computational organizational theories have pointed out that there is nosingle organization or coordination protocol that is the best for all environments. In humanorganizations, environmental factors such as dynamism and task uncertainty have a strong effecton what coordinated actions are and how organizationally acceptable outcomes arise[Lawrence
and Lorsch, 1967, Galbraith, 1977, Stinchcombe, 1990]. These effects have been observed inpurely computational organizations as well[Fox, 1981, Durfee and Lesser, 1988, Decker andLesser, 1995, Nagendra Prasad et al., 1996a, Nagendra Prasad et al., 1996b].
Achieving effective coordination in a multi-agent system (MAS) is a difficult problem fora number of reasons. An agent’s local control decisions about what activity to do next orwhat information to communicate and to whom or what information to ask others may beinappropriate or suboptimal due to its limited view of the interactions between its own activitiesand those of the other agents. In order to make more informed control decisions, the agents haveto acquire a view of the task structures of other agents. To the extent that this resolves agents’uncertainty about the non-local problem solving activities, they can act coherently. However,an agent has to expend computational resources in acquiring and exploiting such non-localviews of other agents’ activities. This involves communication delays and the computationalcost of providing this information and assimilating the information from other agents. Giventhe inherent uncertainty in agents’ activities and the cost of meta-level processing, relyingon sophisticated coordination strategies to acquire non-local views of task structures maynot be worthwhile for all problem-solving situations. In certain situations, coordinationprotocols that permit some level of non-coherent activity and avoid the additional overhead forcoordination may lead to better performance[Durfee and Lesser, 1988, Decker and Lesser,1995,Nagendra Prasad et al., 1996a, Sugawara and Lesser, 1993]. For example, when the agents are

71
under severe time pressure and the load of the activities at the agents is high, sophisticated agentcoordination strategies do not generally payoff. Agents may not have the flexibility in theirown problem solving, given the time constraints, to benefit from the increased awareness theyderive through coordination in such situations. In this chapter, we deal with how agents canlearn to choose dynamically, the appropriate coordination strategy for different coordinationproblem instances. We empirically demonstrate that even for a narrow class of agent activities,learning to choose the appropriate coordination strategy based on meta-level characterizationof the global problem solving state outperforms using any single coordination strategy acrossall problem instances.
In order to accomplish learning, we break the coordination problem into two phases. Inthe first phase, the agents exchange meta-level information not directly used for coordination.This information is used by the agents to derive a prediction of the effectiveness of variouscoordination mechanisms in the present problem solving episode. These mechanisms differ inthe amount of non-local information they acquire and use, and in the complexity of analysisof interactions between activities at the agents. Agents choose an appropriate subset of thecoordination mechanisms (or a coordination strategy) based on the meta-level information andenter Phase II. In this phase, the coordination strategy selected in Phase I decides the typesof detailed information to be exchanged and the kind of reasoning about local and non-localactivities the agents need to perform to achieve coherent behavior. The meta-level informationis an abstraction of the global view of the problem instance and hence we call it a situation.The two phase process is called situation-specific coordination. Learning situation-specificcoordination involves associating appropriate views of the global situation with the knowledgelearned about the effectiveness of the coordination mechanisms. The agents in a cooperativemulti-agent system can learn to coordinate by proactively resolving some of their uncertaintyabout the global problem solving state and situating their learning in more global views.
The rest of the chapter is organized as follows. We review the TÆMS task structurerepresentation for complex multi-agent coordination problems and describe a graph-grammar-based stochastic task structure description language. As an illustration of the power of this tool,we show how it can be used to model a distributed data processing problem. Next, we introduceGeneralized Partial Global Planning as a flexible and powerful way of achieving coordinationby exploiting the domain-independent TÆMS representation of problem instances. We thenintroduce our learning algorithm that learns to choose the best candidate from a parameterizedfamily of coordination strategies and empirically demonstrate its effectiveness in a number ofdifferent domains and environments.
5.2 TÆMS: Task Analysis, Environment Modeling, and Simulation
The TÆMS framework (Task Analysis, Environment Modeling, and Simulation) [Decker,
1995, Decker and Lesser, 1993b] represents coordination problems in a formal, domain-independent way. Details of the domain are abstracted out and only the essence of the basiccoordination problem of choice and temporal ordering of possible actions is captured. It is basedon abstracted representation of the important decisions, available alternatives, and trade-offsabout tasks in a domain. TÆMS represents trade-offs between multiple ways of accomplishinga goal, progress towards achievement of goals, various interactions between the activities in theproblem instance and the effect of these activities on the performance of the system as a whole.TÆMS can model aspects of coordination in complex worth-oriented domains[Rosenschein and

72
Zlotkin, 1994] where the states are associated with functions that rate their acceptability (notnecessarily a binary rating). There are deadlines associated with the tasks and some of thesubtasks may be interdependent, that is, cannot be solved independently in isolation. Theremay be multiple ways to accomplish a task and these tradeoff quality of a result produced forthe time to produce that result. Quality is used to refer to all acceptability characteristics other
than the temporal characteristics[Decker, 1995, Decker and Lesser, 1993b].In a multi-agent system, the tasks may be distributed across multiple agents. There may
be interdependencies among subproblems at different agents. The incomplete or possiblyoutdated view of the tasks at other agents and their interactions with local tasks at an agentlead it to seek satisficing solutions, whereby an agent does the best it can given the missinginformation and the associated uncertainty[Decker and Lesser, ]. Agents may simultaneouslycontribute to multiple goals and the contributions from multiple agents may be needed toachieve a goal. We summarize the TÆMS framework below, and in the next section we discusshow agents can use different coordination mechanisms that rely on the TÆMS representationof the problem instance to achieve different types of coordination.
5.2.1 TÆMS models
A coordination problem instance is represented in TÆMS as a set of task groups T s1 Eachtask group, representing a set of computationally related actions, has an arrival time Ar(T ),and a deadline D(T ). The structure of a task group is a tree-like elaboration of the problem’stask structure. The nodes of a task structure graph are called tasks T . The root task is denotedby T . Tasks that have no children are called executable methods, or just methods M for short.Subtasks are those tasks that have children and are not the root task. Figure 5.1 shows asimple example task structure. A task structure is tree-like, though in actuality the existenceof arbitrary interrelationships makes it a general graph. For reasons of convenience, we usegraphical notation for describing tree-structures in the context of task groups but the reader isurged to keep its more general structure in mind.
TÆMS focuses on two kinds of performance criteria based on the temporal intervals oftask executions and the quality of results of such executions. Quality is an “intentionallyvaguely-defined term that must be instantiated for a particular environment and set of
performance criteria”[Decker, 1995]. Quality is assumed to be a scalar quantity that candefine the completeness of a result, usefulness or cost of a result, precision or any otherdesirable aspects of the result of a task execution. In a multi-agent system, the execution of atask can lead to a number of interactions with other tasks affecting their qualities, executiontimes, start times or deadlines.
Task or task group quality at a given time (Q(T; t)) can be recursively constructed fromthe qualities of its subtasks at time t and its quality accrual function. Domain semantics dictatethe form of the quality function Q (e.g., minimum, maximum, summation, or the arithmetic
mean). In this work, we will be specifically dealing with two quality accrual functions21The description here follows closely the exposition in Decker[Decker, 1995]. Interested readers will find
many more details and examples in Decker[Decker, 1995].2Decker[Decker, 1995] discusses other functions like Sum and Average.
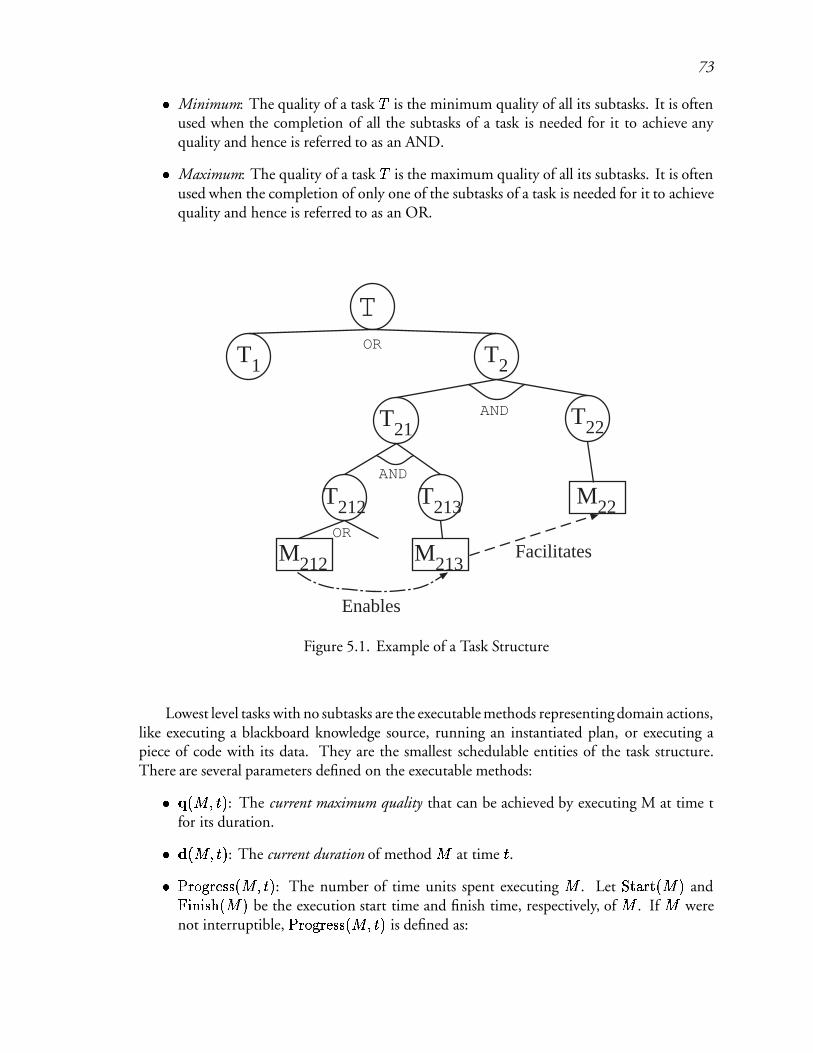
73� Minimum: The quality of a task T is the minimum quality of all its subtasks. It is oftenused when the completion of all the subtasks of a task is needed for it to achieve anyquality and hence is referred to as an AND.� Maximum: The quality of a task T is the maximum quality of all its subtasks. It is oftenused when the completion of only one of the subtasks of a task is needed for it to achievequality and hence is referred to as an OR.
T
T1 T2
T21T22
T212 T213
M212 M213
M22
Enables
Facilitates
AND
AND
OR
OR
Figure 5.1. Example of a Task Structure
Lowest level tasks with no subtasks are the executable methods representing domain actions,like executing a blackboard knowledge source, running an instantiated plan, or executing apiece of code with its data. They are the smallest schedulable entities of the task structure.There are several parameters defined on the executable methods:� q(M; t): The current maximum quality that can be achieved by executing M at time t
for its duration.� d(M; t): The current duration of method M at time t.� Progress(M; t): The number of time units spent executing M . Let Start(M) andFinish(M) be the execution start time and finish time, respectively, of M . If M werenot interruptible, Progress(M; t) is defined as:

74Progress(M; t) = 8><>: 0 t � Start(M)t � Start(M) Start(M) < t < Finish(M)Finish(M)� Start(M) t � Finish(M)� Q(M; t): The quality at M at time t. A method’s quality accumulation can potentiallybe any monotonically increasing function. Two of the more popular approaches are: theanytime models[Boddy, 1991] whereQ(M; t) has a monotonically decreasing gain, and
the design-to-time models[Decker et al., 1990, Garvey and Lesser, 1993a, Garvey and
Lesser, 1993b], where the results are not available until the task is complete. This workdeals with design-to-time models though the modeling framework does not impose suchrestrictions. More formally, in design-to-time models, Q(M; t) is defined as:QDTT(M; t) = ( 0 Progress(M; t) < d(M; t)q(M; t) Progress(M; t) � d(M; t)
There can potentially be non-local effects between a task T at an agent and a method Mat another agent. Each method has an initial maximum quality q0(M) and duration d0(M)at time 0. If a method contained in a task T starts executing before method M finishes then,T can potentially affect the execution of M . These effects have two possible outcomes:
quality effects: where q(M; t) is changed.duration effects: where d(M; t) is changed.In this work, we deal with two of the more common classes of non-local effects that
have been extensively studied by Decker[Decker, 1995]. Non-local effects that occur betweenmethods associated with different agents are called coordination relationships.Enables. If a task T enables a method M , then the execution task T produces a result thatis a required input parameter for the method M . M ’s maximum quality q(M; t) = 0, untilT is completed and the result of its execution is communicated to the agent associated withM . The maximum quality then changes to q(M; t) = q0(M). A scheduler will not execute amethod that is not enabled.enables(T;M; t; d; q; �) = ( [1; 0] t < �(T; �)[d0(M);q0(M)] t � �(T; theta) (5.1)
where �(T; �) = min(t) s.t. Q(T; t) > �. �(T; �) returns the earliest time when the qualitycrosses the threshold.Facilitates. A task T facilitates a method M if the execution of task T produces a result thataffects an optional parameter of method M . Method M could have been executed withoutthe result from task T , but the availability of the result provides constraints on the execution ofM , leading to improved quality and reduced time requirements. The facilitates effect has twoparameters called the power parameters: 0 � �d � 1 and 0 � �q � 1, that indicate the effecton duration and quality, respectively.

75R(Ta; s) = Qavail(Ta; s)q(Ta; s)facilitates(Ta;M; t; d; q; �d; �q) = [d(1� �dR(Ta; Start(M)));q(1 + �qR(Ta; Start(M)))] (5.2)
A design-to-time scheduling[Garvey and Lesser, 1993b] algorithm heuristically enumeratesa promising subset of quality and time trade-offs to produce schedules that maximize qualitygiven the deadlines. In a cooperative multi-agent system, the goal of the agents is to worktogether to produce the highest possible quality for as many task groups as possible. Each agentchooses an action, based on its current beliefs and knowledge, to maximize the expected globalperformance measure even at the expense of local performance degradation.
Each of the agents has only a partial and incomplete view of the actual task structures. Thesesubjective views constitute the beliefs of agents about the current problem solving instance andtheir problem solving control relies on these views to choose the actions to be executed.
5.2.2 Grammar-based Task Structure Generation
Decker and Lesser[Decker, 1995, Decker and Lesser, 1995] illustrate the importanceof extensive empirical studies in determining the role of different coordination strategiesin different task environments. However, these studies relied on a weak task environmentgenerator where the experimenter was limited to setting certain numerical parameters likemean of the task structure depth or mean and variance of the number of interrelationships intask structures. This often gives rise to a wide range of task structures and a huge variance inthe types of capabilities needed by the system to handle them effectively. More importantly, itis unlikely that most real applications involve an infinite variety of task structures. The domainsemantics dictate and limit the morphology of the task structures. While there is bound tobe some randomness in these structures, it is highly unlikely that the only regularity that canbe modeled in the task structure representations of a coordination problem instance are a fewparameters like its mean depth or branching factor. Below we introduce a graph grammarbased task structure specification language that is powerful enough to model the topologicalrelationships occurring in task structures representing many real life applications. We firstbriefly introduce graph grammars (GGs) and our extensions to traditional graph grammarsto capture the domain semantics beyond the topological relationships. We then show how adata-flow model of data processing can be captured by task structures and their grammaticalspecifications.
5.2.2.1 Graph Grammars
Graph grammars are a powerful tool used in a number of domains[Mullins and Rinderle,1991, Nagl, 1979] to capture and characterize the underlying structural regularities. They offera structured way of describing topological relationships between entities in a domain. Graph
grammars are fundamentally similar to string grammars[Chomsky, 1966, Nagl, 1979] with thedifference lying in the productions. A graph production is a triple p = (gl,gr,E) where gl is thesubgraph to be replaced (left hand side) and gr is the subgraph to be inserted in its place in

76
the host graph. E is the embedding transformation. A number of schemes for graph grammarshave been proposed and the primary differences between them arise from the differences in theembedding schemes. Much of the traditional literature in graph grammars does not deal withattribute valued nodes and edges and stochastic productions. We need attributes to capturea number of aspects of the domain semantics in addition to the topological relationshipsbetween entities. Stochasticity in the productions adds more power to the modeling potentialof these grammars by capturing aspects of uncertainty in the domain. Accordingly, we call ourgrammars Attribute Stochastic Graph Grammars (ASGGs).
Let a graph G = (V;E), where V is the set of vertices (also referred to as nodes) and E isthe set of edges. Nodes and edges can have labels. An Attribute Stochastic Graph Grammaris defined as a 8-tuple h�n; An;�t; At;�; A�; S; P i where the nonterminal node alphabet(�n), the terminal node alphabet (�t), and the edge-label alphabet(�) are finite, non-empty,mutually disjoint sets, An, At, and A� are the respective sets of attributes, S 2 �n is thestart label (can be a node or a graph) and P is a finite nonempty set of graph production
rules[Sanfeliu and Fu, 1983]. A graph production is a 4-tuple pi = hgil ; gir; E i; P r(pi)i wherePPr(pj) = 1 j (pj 2 P and gjl are isomorphic)Let G0 be a graph derived from S using P. Rewriting this graph involves what is called a
LEARRE method[Mullins and Rinderle, 1991]: Locate a subgraph g0 that is isomorphic to the
left-hand side, gil of production pi 2 P , establish the Embedding Area in G0, Remove g0 along
with all the edges incident on it, Replace g0 with gir and Embed it into the host graph G0 � g0.Figure 5.2 shows a simple example.
Embedding:Connect node(C) to neighbors(A)Connect node(C) to neighbors(B)Connect node(D) to neighbors(B)
:=
A
B
C
D
A
B
e
f
e
f
C
D
Production
Rewrite
Figure 5.2. Example of a Graph Grammar Rewriting

77
The rewriting stops when every node label is in the terminal alphabet set �t and theresultant graph is considered a member of the family of graphs generated by the ASGG. For thesake of expository clarity the example does not deal with attributes. Distributed data processingexamples in the next section show instances of attributes.
Another extension to our definition of graph grammars involves partial edges. A productionembedding can specify a link between a local label and non-local label (in the host graph) thatmay be non-existent at the time of the application of the production. This “hanging” edge getslinked if and when a node with the corresponding label arises at a later time due to rewritingin the host graph. If the termination graph is reached without a node with the correspondinglabel, this hanging edge is removed at that point.
5.2.2.2 ASGGs and Distributed Data Processing
Our example of a functional agent organization is derived from the domain of distributeddata processing (DDP) that involves a number of geographically dispersed data processingcenters (agents). Each center is responsible for conducting certain types of analysis tasks onstreams of satellite data arriving at its site: “routine analysis” that needs to be performed on thedata coming in at regular intervals during the day, “crisis analysis” that needs to be performed
on the incoming data but with a certain probability3 and “low priority analysis” that arises atthe beginning of the day with a certain probability. Low priority analysis involves performingspecialized analysis on specific archival data. Different types of analysis tasks have differentpriorities. A center should first attend to the “crisis analysis tasks” and then perform “routinetasks” on the data. Time permitting, it can handle the low-priority tasks. The processingcenters have limited resources to conduct their analysis on the incoming data and they haveto do this within certain deadlines. The results of processing data at a center may need to becommunicated to other centers due the interrelationships between the tasks at these centers.For example, in order begin analyzing a stream of satellite data, a center may need the resultsof a related analysis from another center. The question that we considered for this domainwas, whether appropriate coordination among centers could be provided by (1) a fairly simpledata-flow driven coordination algorithm, by (2) pre-computed standard operating plans, orwhether (3) a more complex but time-consuming algorithm using non-local commitments wasnecessary.
We used the Generalized Partial Global Planning (GPGP)[Decker and Lesser, 1995,
Decker, 1995] approach to model these three different coordination strategies of varyingsophistication. We first discuss how a data processing problem can be represented as a TÆMS
task structure and how ASGGs can be used to represent the domain semantics of a dataprocessing problem. In the following discussion, “data processing center” and “agent” are usedinterchangeably.
Figure 5.3a shows the data flow representation of an example DDP problem. It consists ofthree tasks: T1, T2, and T3. T1 facilitates T2, and T2 enables T3. As discussed in the previoussection, “facilitates” is a soft interrelationship that says that if the results of processing task T1are available at T2 when it starts processing, then the duration of the method for achieving T23Crisis analysis need not always be performed. The need for such an analysis arises depending on the external
situation.

78
is reduced and its quality is increased. “Enables” is a hard interrelationship that implies thatthe results of processing T2 must be available at T3 before it can start processing.
A TÆMS representation of the same problem can be seen in Figure 5.3b. The leaves ofthe task structure show available methods for the tasks. Figure 5.4 shows a graph grammarfor this task structure. To avoid cluttering, not all attributes are shown in the figure. Thereare a number of attributes such as the quality accrual function, termination time, earliest starttime for tasks, and type, duration, quality, deadline, and termination time for methods. Thequality and duration attributes of a method are specified as distributions representing certainaspects of uncertainty in the underlying domains. This feature of the grammar leads to a largevariety of semantically different task structures but their structural variety is limited by thegraph productions.
T3T2T1F E
TG
and
or oror
M11 M33M32M31M22M21M13M12
T3
T2
T1
A3
A2
A1F
E
a: Data flow b: TAEMS Task Structure
Figure 5.3. Example of a Data Processing problem and its TÆMS representation
We modeled the DDP domain using three graph grammars, each one generating taskstructures representing the type of operations that need to be performed on the incomingdata. A grammar is activated at regular intervals (representing arrival times for data) with aprobability corresponding to its type. For example, the low priority task structure grammaris activated with probability “low priority tasks probability” at time 0 (beginning of the day).Achieving all crisis tasks gets higher final quality than routine tasks and achieving routine tasksgets higher quality than low priority tasks. The task deadlines are basically determined by thepolicies at a center and they represent the amount of processing time available to a center toprocess the data it sees. Figure 5.5 shows the interrelationships of the three types of processingtasks we investigated in the following experiments. The tasks are distributed across agents asshown by the rectangles demarcating the agents. The TÆMS framework and the graph grammarbased generator allow us to represent easily and explore these tasks or others that may arise inthis domain.
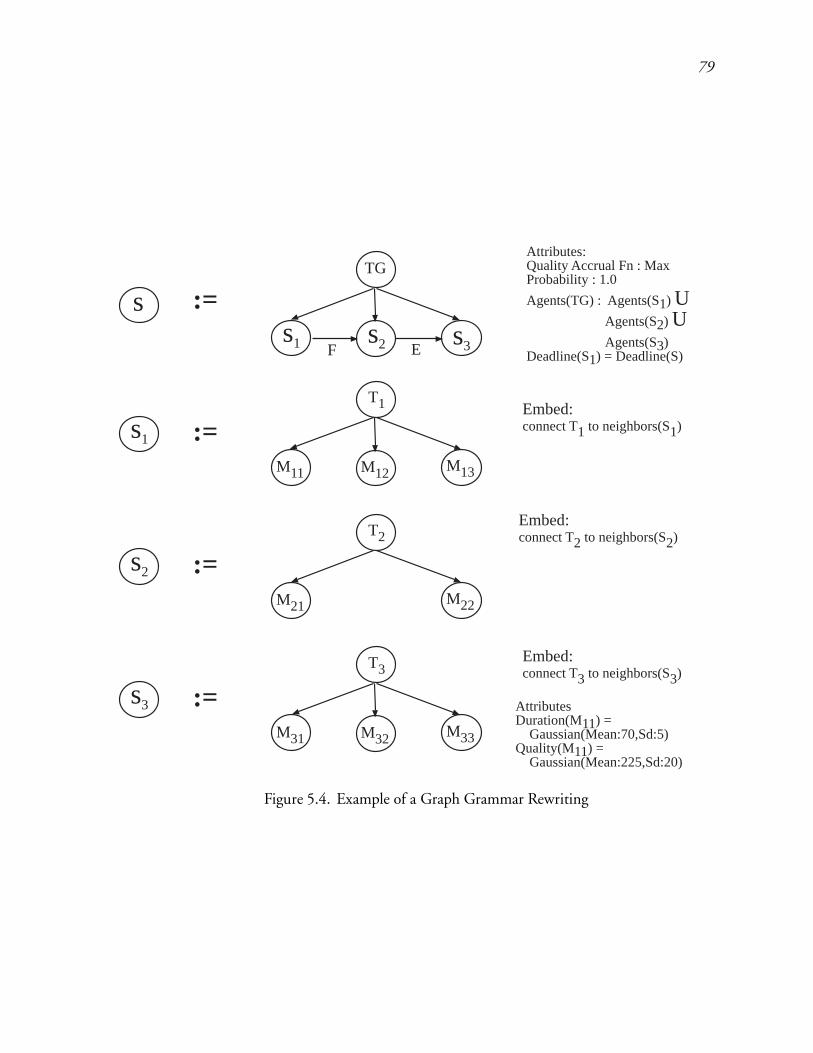
79
:=
:=Embed:connect T1 to neighbors(S1)
:=
Embed:connect T2 to neighbors(S2)
:=
Embed:connect T3 to neighbors(S3)
Attributes:Quality Accrual Fn : MaxProbability : 1.0
Agents(TG) : Agents(S1) U Agents(S2) U Agents(S3)Deadline(S1) = Deadline(S)
AttributesDuration(M11) = Gaussian(Mean:70,Sd:5)Quality(M11) = Gaussian(Mean:225,Sd:20)
s1
TG
s2 s3F E
s
M11 M12 M13
T1
s1
M21 M22
T2
s2
M31 M32 M33
T3
s3
Figure 5.4. Example of a Graph Grammar Rewriting

80
T1
T3
T4
T5
T2
A1
A3
A2
F
EE
F T3
T2T1
A3
A2A1
T3
T2
T1
A3
A2
A1F
E
a: Routine DFD b: Crisis DFD c: Low Priority DFD
Figure 5.5. Data Processing Problems
5.3 Instantiating Environment-specific Coordination Mechanisms
In this chapter, we show the effectiveness of learning situation-specific coordination byextending a domain-independent coordination framework called Generalized Partial Global
Planning (GPGP)[Decker and Lesser, 1995, Decker, 1995]. GPGP is a flexible and modularmethod that recognizes the need for creating tailored coordination strategies in response to thecharacteristics of a particular task environment. It is structured as an extensible set of modularcoordination mechanisms so that any subset of the mechanisms can be used. Each mechanismcan be invoked in response to the detection of certain features of the environment andinterdependencies between problem solving activities of agents. The coordination mechanismscan be configured (or parameterized) in different ways to derive different coordination strategies.In GPGP (without the learning extensions), once a set of mechanisms are configured (by ahuman expert) to derive a coordination strategy, that strategy is used across all problem instancesin the environment. We demonstrate experimentally that for some environments a subset of themechanisms is more effective than using the entire set of mechanisms [Nagendra Prasad et al.,1996a]. Later in this chapter, we present a learning extension, called COLLAGE, that endowsthe agents with the capability to choose a suitable subset of the coordination mechanisms basedon the present problem solving situation, instead of having a fixed subset across all the probleminstances in an environment.
In GPGP, each agent can be viewed as having three components: a local scheduler, acoordination module and a belief database. The belief database of an agent represents itssubjective view of the present coordination problem instance and it comprises the agent’sknowledge about the task structures in the environment, and their tasks with their inter-
relationships. Following Decker and Lesser[Decker and Lesser, 1993a], we useBtA(x) to meanthat agent A believesx at time t (or simplyB(x)when it is clear). HenceB(facilitates(Ta;Mb))represents agent’s belief that there is a facilitates interrelationship between Ta and

81Mb. The coordination module modulates the local scheduler rather than supplant it byimposing commitments that serve to constrain the set of feasible schedules. A commitmentrepresents a contract to achieve a particular quality by a specified deadline. The coordinationmodule notices the task structures in the belief database and does a number of activities likegathering information about new task structures in the environment, communicate informationabout local beliefs to other agents or receive information from them, and make or retract
commitments. In this work we use a design-to-time scheduler[Garvey and Lesser, 1993b] thatcan take into account the commitments provided by the coordination module, and provideschedules that maximize the global utility measure.
The coordination module has a number of mechanisms that notice certain features ofthe task structures in the belief database and react in certain ways. Below we describe thesemechanisms that are parameterized independently so that each combination of the parametersettings leads to a coordination strategy. Different mechanisms require different types ofinformation to operate. Thus, by choosing different sets of coordination mechanisms, theamount of communication and other overheads associated with coordination can be varied.The interface between the coordination mechanism and the local scheduler is bidirectional andnegotiation-based, permitting the coordination module to ask “what-if” questions[Garvey etal., 1994]. This is a crucial ability whose utility becomes obvious later, when we describe ourlearning algorithm in more detail.
Before we describe the details of GPGP, we would like to give a feel for the overallapproach through a simple example adopted from Decker[Decker, 1995]. Figure 5.6 (from
Decker[Decker, 1995]) shows two agents. Initially, the agents’ partial subjective views of thetask structure contains the tasks structures in their belief database except the shaded tasks andmethods - Methods D and E and Tasks 2 and 5. Moreover, an agent knows about the existenceof a coordination relationship only if it sees the tasks/methods at both its ends. Initially, agentX and agent Y do not know about the existence of the facilitates relationship betweenT2 and T5 and Agent Y does not know about the enables relationship between T4 andT5. One of the coordination mechanisms called “update-local-views” can detect the existenceof such non-local interrelationships leading to the exchange of relevant portions of the localtask structures between agents. In our example, it leads to the state shown in Figure 5.6. Atthis point, mechanisms for exploiting hard and soft coordination relationships are invoked.Agent Y sees that its local task, Task 2, facilitates Task 5 of agent X and makes a local deadlinecommitment to complete it by time 7 with minimum quality 45. This commitment iscommunicated to agent X, which can potentially exploit it for building better local schedules.For agent X, the expected time for receiving the results of execution of Task 2 is a unit later (attime 8) to account for the communication delays.
As described above, the coordination mechanisms in GPGP respond to the detectionof certain features in the environment, leading to either an exchange of information amongthe agents or posting constraints to the scheduler to modulate its control to produce betterschedules. There are five such mechanisms in GPGP and we describe them in some detailbelow.� Mechanism 1: Updating Non-local Viewpoints
Each agent’s subjective view of the current episode is only partial. This mechanismenables agents to determine what local information to communicate and when so as to

82
Agent Y
CoordinationModule
LocalScheduler
LocalScheduler
CoordinationModule
Agent XBeliefDatabase
BeliefDatabase
T
max
T1min
T4max
T2max
T3min
T5max
B7
45
C535
E540
A820
T
max
T1min
T4max
T2max
T3min
T5max
D540
F830
T
max
T1min
T4max
T2max
T3min
T5max
B7
45
C535
D5
40
E540
F8
30
A8
20 Q-effect: 0.5, D-effect: 0.5
Deadline: 25
B745
E540
A8
20
Finish = 8Quality = 20Violations = Cmt 1, no alternative
Finish = 12Quality = 45Violations = none
Commitment 1: Deadline 7, Quality 45
Non-Local Commitment 2: Deadline 6, Quality 40
Finish = 7Quality = 45Violations = none
B745
SchedulingConstraints
Schedules andalternatives
Non-Local Commitment 1: Deadline 8, Quality 45
Commitment 2: Deadline 5, Quality 40
Results,Non-local views,Commitments
ObjectiveTask Group
SubjectiveTask Group
Objective task or methodin the environment
Subjective representation ofanother agent's task(non-local view)
Tmin
local task withquality accrual function min
subtask relationship
enables relationship
local method (an executable task)
facilitates relationship
namedurationquality
Y
Y Y
YX X
D540
F830
Finish = 16Quality = 45Violations = none
Idle 3
Schedules andalternativesScheduling
Constraints
E540
D540
Figure 5.6. An Overview of Generalized Partial Global Planning
enable them to update their partial views with relevant non-local information. It has threeoptions: ‘none’ policy i.e. no non-local view, or ‘all of it’ i.e. global view for each agentor ‘some’ policy i.e. partial view. The latter policy needs some explanation. The agentsneed not know all the information about another agent to perform effective coordination.The ‘some’ policy enables an agent to communicate coordination relationships, privatetasks and their context only to the extent that the other agents can detect non-localinterrelationships with that agent.
Let P be the set of tasks and methods privately believed only by agent A at the task grouparrival time. Then private coordination relationships, PCR = fr j T1 2 P ^ T2 62P ^ [r(T1; T2) _ r(T2; T1)]g between private and non-local tasks. The task T2 maynot be known to agent A. It just knows that a coordination relationship exists betweenits local task T1 and some unknown task T2. The ‘some’ setting of the non-local viewsmechanisms communicates the private coordination relationships, the private tasks andtheir context.� Mechanism 2: Communicating Results
The availability of the results of execution of a method at an agent may have non-localeffects on another agent’s method execution. The result communication coordinationmechanism has three options: ‘minimum’ policy that communicates only the resultsnecessary to satisfy non-local commitments to relevant agents, ‘TG’ policy that commu-

83
nicates the information in minimum policy and also the final results of a task group, and‘all’ policy that communicates all the results.� Mechanism 3: Handling Simple Redundancy
For every set of redundant methods available to the agents, one agent is randomlychosen to execute it and send the results to other interested agents. One of the agentsis committed to executing the redundant method, and the other agents refrain fromexecuting it. This mechanism can be ‘active’ or ‘inactive’. In its present implementation,GPGP uses a simple method for choosing the agent to execute a redundant method.Each of the redundant methods is given a unique identifier and the method with thelexically smallest identifier is chosen for execution.� Mechanism 4: Handling Hard Coordination Relationships
Hard coordination involves the enables(M1,M2) relationship that implies that M1 mustbe executed before M2, so that M2 can obtain non-zero quality. Hard coordinationmechanism examines the current schedule for those methods that are predecessors ina hard coordination relationship and commits, both locally and socially (i.e. to agentsother than itself), to their execution by a certain deadline. The agent with the method atthe successor end of such a hard coordination relationship can post this commitment asa constraint on the earliest starting time of this method. This mechanism can be ‘active’or ‘inactive’.[Qest(T;D(T ); S) > 0] ^[enables(T;M) 2 HPCR] ) [C(DL(T;Qest(T;D(T ); S); tearly)) 2 C] ^[comm(C;Others(M); t) 2 I]whereHPCR is the set of hard predecessor coordination relationships andC(DL(T; q; tdl))is a ‘deadline’ commitment to do T by time tdl and is satisfied at the time t when[Q(T; t) � q] ^ [t � tdl]. At present, GPGP creates commitments only on thepredecessor side of coordination relationships. The time tearly is the min t such thatQest(T;D(T ); S) > 0� Mechanism 5: Handling Soft Coordination Relationships
Soft coordination involves the facilitates(M1;M2; �d; �q) relationship that implies thatexecuting M1 before M2 decreases the duration of M2 by a certain ‘power’ factor �dand increases the quality by a certain ‘power’ factor �q. This mechanism functions in amanner similar to the previous one. It can be ‘active’ or ‘inactive’. As with the previousmechanism, commitments are created only on the predecessor side of the coordinationrelationships.
Given that these mechanisms can be parameterized independently (3 possible settings foreach of the first two and 2 possible settings for each of the last three), there are 72 possiblecoordination strategies. Trying to learn to choose the best strategy from amongst this large aset can be quite cumbersome. We suggest two ways to prune this search space, leading to amore manageable set of distinct coordination strategies:

84� Cluster the entire set of possible strategies on the performance space and choose aprototypical instance from each cluster. The agent performance can be characterizedalong a number of dimensions like total quality, number of methods executed, numberof communications, and termination time.� Use domain knowledge to prune down the set of possible coordination strategies to asmall number of interesting distinct strategies.
5.3.1 Clustering
The idea here is to exploit the broad characteristics of the family of strategies to reducethe search for a particular set of mechanisms when using the machine learning algorithm. The72 possible coordination strategies obtained as combinations of parameter settings for the fivemechanisms discussed previously can be grouped into a fewer set of distinct classes based ontheir performances on a wide range of task structures.
Decker and Lesser[Decker and Lesser, 1995] explore the family performance space ofthese coordination strategies based on performance measures. They generated 63 randomtask structures from as many random environments and ran each of the 72 coordinationstrategies on them. They collected four performance measures: total quality, number ofmethods executed, number of communications, and termination time. Each performancemeasure for a task structure was represented in Standard Normal form as the number ofstandard deviations from the mean value in that environment. The statistics for eachcoordination strategy were then summarized into 72 summary cases of four performancemeasures each. A hierarchical clustering algorithm (SYSTAT JOIN with complete linkage)produced 5 prototypical coordination strategies (see Figure 5.7 for a summary):� balanced with all the mechanisms for detecting soft and hard coordination interre-
lationships and communication of relevant results turned on. Only the relevant partialviews are exchanged between agents for detecting these interrelationships and the resultsthat satisfy commitments are exchanged.� simple with no hard or soft coordination mechanisms or exchange of relevant partialnon-local views. All results obtained due to task executions are broadcast to all agents.� myopic with all commitment mechanisms on but no non-local view.� tough with no soft coordination but otherwise the same as balanced� mute with no hard or soft coordination mechanisms and no non-local-views and nocommunication whatsoever.
5.3.2 Using Domain Knowledge
Domain-specific knowledge can be used to identify appropriate settings for the coordina-tions mechanisms resulting in distinct coordination strategies suitable for the specific domain.In this work, we will be dealing with the distributed data processing domain as an example. Inthis domain, we have three strategies of interest: data flow and rough coordination strategies
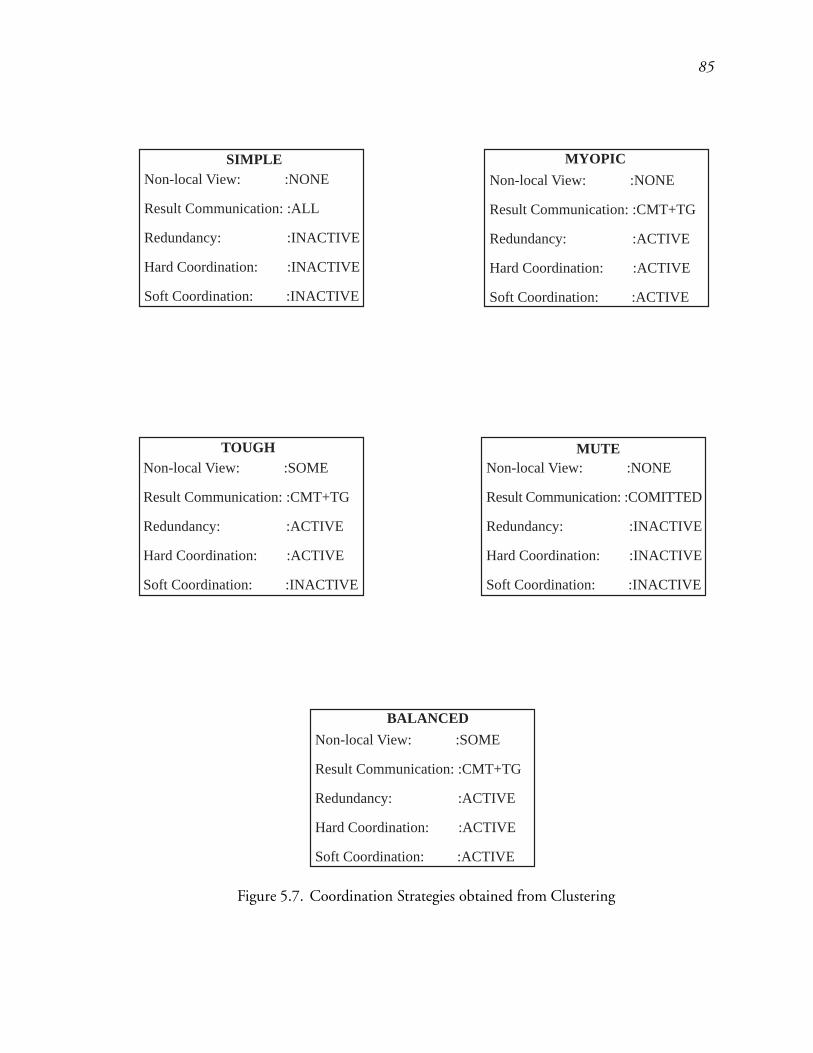
85
Non-local View: :NONE
Result Communication: :ALL
Redundancy: :INACTIVE
Hard Coordination: :INACTIVE
Soft Coordination: :INACTIVE
SIMPLENon-local View: :NONE
Result Communication: :CMT+TG
Redundancy: :ACTIVE
Hard Coordination: :ACTIVE
Soft Coordination: :ACTIVE
MYOPIC
Non-local View: :SOME
Result Communication: :CMT+TG
Redundancy: :ACTIVE
Hard Coordination: :ACTIVE
Soft Coordination: :INACTIVE
TOUGHNon-local View: :NONE
Result Communication: :COMITTED
Redundancy: :INACTIVE
Hard Coordination: :INACTIVE
Soft Coordination: :INACTIVE
MUTE
Non-local View: :SOME
Result Communication: :CMT+TG
Redundancy: :ACTIVE
Hard Coordination: :ACTIVE
Soft Coordination: :ACTIVE
BALANCED
Figure 5.7. Coordination Strategies obtained from Clustering

86
that are routinely used by domain experts in the real systems, and the balanced coordinationstrategy that was designed by Decker and Lesser[Decker and Lesser, 1995] as a sophisticatedcoordination strategy that exchanges minimal information to exploit coordination relationshipsbetween agent task structures. These strategies vary in their levels of sophistication regardingexploiting commitments as a means to achieve coordination: data flow uses no commitments,rough coordination exploits tacit a priori commitments and balanced coordination relies ondynamically generated commitments. Below we discuss these strategies in more detail(seeFigure 5.8 for a summary).
1. Balanced (or dynamic-scheduling): It is the same as previously described. Agentscoordinate their actions by dynamically forming commitments. Relevant results aregenerated by specific times and communicated to the agents to whom the correspondingcommitments are made. Agents schedule their local tasks trying to maximize the accrualof quality based on the commitments made to it by the other agents, while ensuring thatcommitments to other agents are satisfied. The agents have the relevant non-local viewof the coordination problem, detect coordination relationships, form commitments andcommunicate the committed results.
2. Data Flow Strategy: An agent communicates the result of performing a task to allthe agents and the other agents can exploit these results if they still can. Thereare no commitments from any agent to any other agent. In the case of facilitatesinterrelationships, the results need to arrive before the start of the facilitated task.If a recipient agent has a task that is enabled by the result, it can start executing itonly after receiving that result. In the GPGP approach, these characteristics can beobtained by turning off all coordination relationship exploitation mechanisms, turningon mechanisms for non-local view detection and communication of all results.
3. Rough4: This coordination is similar to balanced but commitments do not arise outof communication between agents. Each agent has an approximate idea of when theother agents complete their tasks and communicate results based on its past experience.“Rough commitments” are a form of tacit social contract between agents about thecompletion times of their tasks. However, it is unrealistic to expect the commitmentson low probability crisis tasks and low priority tasks to follow such tacit a priori roughcommitments. So this coordination type uses rough commitments for routine tasksbut behaves just like data flow for the non-routine crisis and low priority tasks. Theagents have the relevant non-local view of the coordination problem, detect coordinationrelationships, but use rough commitments for routine tasks and communicate thecommitted results. It might be possible to view rough commitments as pre-compiledsocial laws [Shoham and Tennenholtz, 1992b].
5.4 Empirical Explorations of Effects of Deadline and Crisis Tasks
In this section, we present a few experiments whose purpose is two fold: Firstly, weintend to demonstrate the effectiveness of our grammar-based modeling tool. We ran a set of4See Appendix for details on how rough coordination was implemented.
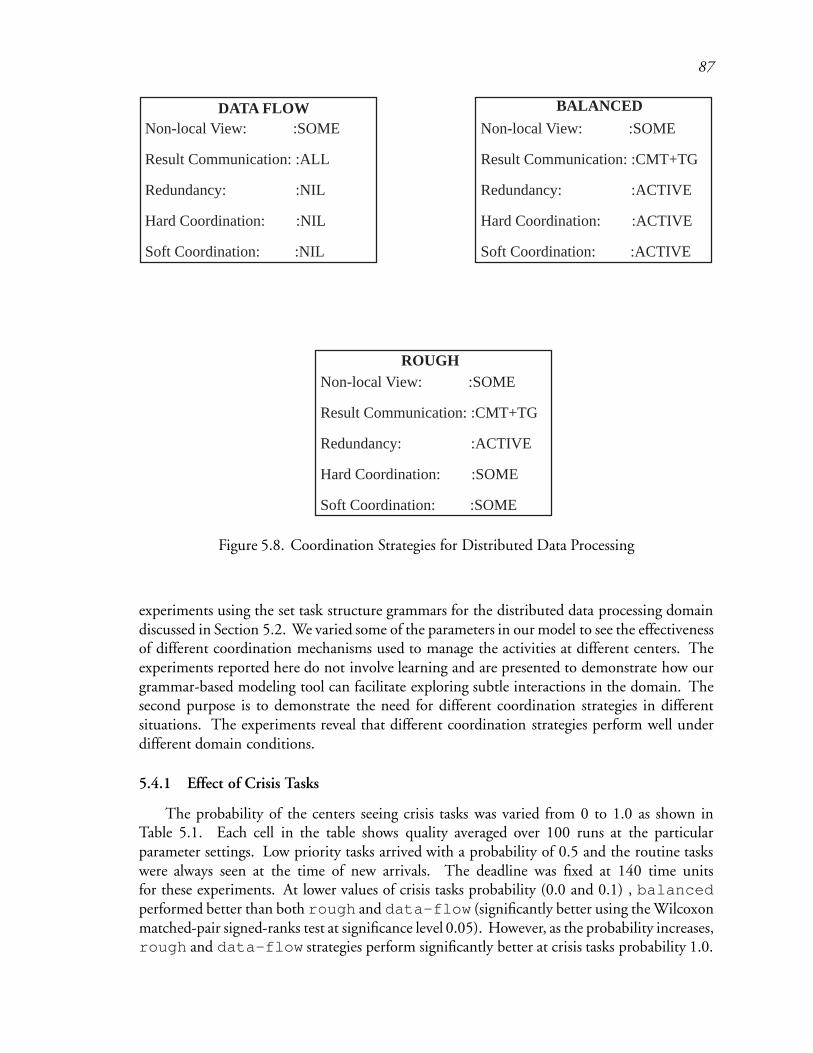
87
Non-local View: :SOME
Result Communication: :CMT+TG
Redundancy: :ACTIVE
Hard Coordination: :ACTIVE
Soft Coordination: :ACTIVE
BALANCED
Non-local View: :SOME
Result Communication: :ALL
Redundancy: :NIL
Hard Coordination: :NIL
Soft Coordination: :NIL
DATA FLOW
Non-local View: :SOME
Result Communication: :CMT+TG
Redundancy: :ACTIVE
Hard Coordination: :SOME
Soft Coordination: :SOME
ROUGH
Figure 5.8. Coordination Strategies for Distributed Data Processing
experiments using the set task structure grammars for the distributed data processing domaindiscussed in Section 5.2. We varied some of the parameters in our model to see the effectivenessof different coordination mechanisms used to manage the activities at different centers. Theexperiments reported here do not involve learning and are presented to demonstrate how ourgrammar-based modeling tool can facilitate exploring subtle interactions in the domain. Thesecond purpose is to demonstrate the need for different coordination strategies in differentsituations. The experiments reveal that different coordination strategies perform well underdifferent domain conditions.
5.4.1 Effect of Crisis Tasks
The probability of the centers seeing crisis tasks was varied from 0 to 1.0 as shown inTable 5.1. Each cell in the table shows quality averaged over 100 runs at the particularparameter settings. Low priority tasks arrived with a probability of 0.5 and the routine taskswere always seen at the time of new arrivals. The deadline was fixed at 140 time unitsfor these experiments. At lower values of crisis tasks probability (0.0 and 0.1) , balancedperformed better than both rough and data-flow (significantly better using the Wilcoxonmatched-pair signed-ranks test at significance level 0.05). However, as the probability increases,rough and data-flow strategies perform significantly better at crisis tasks probability 1.0.

88
This initially looked counterintuitive to us but a closer examination of the runs revealed thereasons. The commitment mechanisms implemented as of now in GPGP are “one-way”.There are commitments from the predecessor end of the interrelations to the agents at thesuccessor end but not the other way. For example, agent A1 commits to doing T1 of the crisistask structure (see Figure 5.5) by a certain time and agent A2 tries to take this commitmentinto consideration while scheduling for its crisis tasks. However, there are no commitmentsfrom agent A3 about the latest time it needs the results of execution of task T2 so that it canschedule its methods. This results in Agent A2 trying to take advantage of the commitmentsfrom A1 and in the process sometimes delaying execution of its methods until it is too latefor agent A3 to execute its methods enabled by the results from A2. These experimentslead us to an important general observation that just being sophisticated may not guaranteebetter performance of a coordination strategy. It has to be sufficiently and appropriatelysophisticated—in this case, commitments need to flow in both directions between predecessorsand successors. Otherwise, the coordination strategy may not only be wasteful in computationand communication resources but it may also lead to inappropriate behavior.
Table 5.1. Average Quality for deadline 140
Crisis TG Data Flow Balanced RoughProbability
0.0 0 147.6 91.5
0.1 64.2 184.5 149.9
0.5 243.1 282.5 295.2
1.0 437.4 406.1 439.77
5.4.2 Effect of Deadlines
We ran another set of experiments with ‘deadline’ being varied. The crisis tasks probabilitywas set to 0.1 and low priority tasks probability was set to 0.5. New routine tasks werealways seen at the time of new data arrival. The results of these experiments are shown inTable 5.2 where each cell in the table shows quality averaged over 100 runs at the particularparameter settings. Balanced performed significantly better than the other two coordinationmechanisms at higher deadlines (140, 200, 300, 500). However, much to our initial surprise,increasing the deadline from 140 time units to 200 led to a decrease in the average qualityfor both balanced and rough. This arises due to certain subtle interactions between thecoordination mechanism and the design-to-time scheduler. When the deadline is 140 timeunits, agent A2 chooses lower quality methods that have lower durations for performing itstasks. However, when the deadline increases to 200 time units, it chooses higher qualitymethods for its schedule of activities. However, since the agents are coordinated using onlypredecessor commitments, A2 now delays its higher duration methods long enough to affect
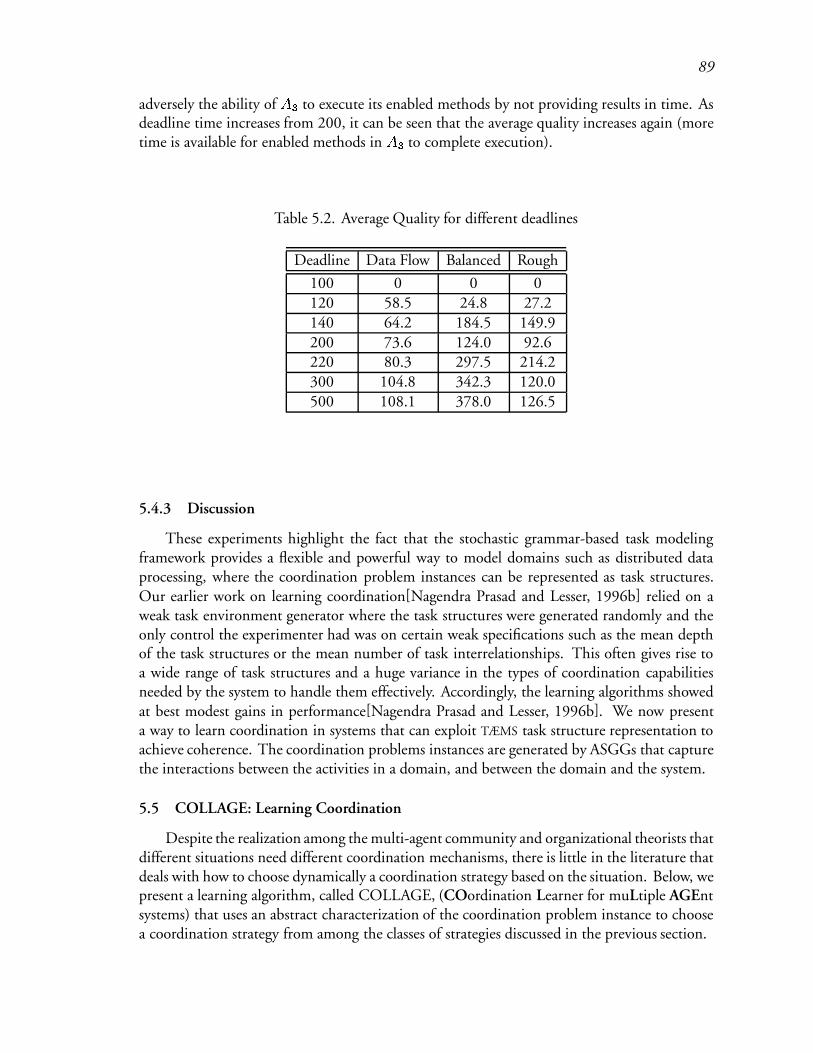
89
adversely the ability of A3 to execute its enabled methods by not providing results in time. Asdeadline time increases from 200, it can be seen that the average quality increases again (moretime is available for enabled methods in A3 to complete execution).
Table 5.2. Average Quality for different deadlines
Deadline Data Flow Balanced Rough
100 0 0 0
120 58.5 24.8 27.2
140 64.2 184.5 149.9
200 73.6 124.0 92.6220 80.3 297.5 214.2
300 104.8 342.3 120.0
500 108.1 378.0 126.5
5.4.3 Discussion
These experiments highlight the fact that the stochastic grammar-based task modelingframework provides a flexible and powerful way to model domains such as distributed dataprocessing, where the coordination problem instances can be represented as task structures.Our earlier work on learning coordination[Nagendra Prasad and Lesser, 1996b] relied on aweak task environment generator where the task structures were generated randomly and theonly control the experimenter had was on certain weak specifications such as the mean depthof the task structures or the mean number of task interrelationships. This often gives rise toa wide range of task structures and a huge variance in the types of coordination capabilitiesneeded by the system to handle them effectively. Accordingly, the learning algorithms showedat best modest gains in performance[Nagendra Prasad and Lesser, 1996b]. We now presenta way to learn coordination in systems that can exploit TÆMS task structure representation toachieve coherence. The coordination problems instances are generated by ASGGs that capturethe interactions between the activities in a domain, and between the domain and the system.
5.5 COLLAGE: Learning Coordination
Despite the realization among the multi-agent community and organizational theorists thatdifferent situations need different coordination mechanisms, there is little in the literature thatdeals with how to choose dynamically a coordination strategy based on the situation. Below, wepresent a learning algorithm, called COLLAGE, (COordination Learner for muLtiple AGEntsystems) that uses an abstract characterization of the coordination problem instance to choosea coordination strategy from among the classes of strategies discussed in the previous section.

90
5.5.1 Overview
Our learning algorithm falls into the category of Instance-Based Learning algorithms[Ahaet al., 1991]. It involves subjecting the multi-agent system to a series of runs to obtain a set ofsituation vectors and the corresponding system performances for each of the available set of coor-dination strategies. During training, the coordination strategies are run against a set of probleminstances to facilitate exploring the relative performance of the strategies for various system con-figurations. The training phase builds a set of fsituation,coordination,performanceg-tripletsfor each of the agents. Upon completion of learning, the agents use these past instances tochoose the best coordination strategy for any new coordination problem instance they see inthe future. The global performance of the agent system in the past similar instances aids thechoice of the coordination strategy.
5.5.2 Learning Coordination
Learning in COLLAGE involves running the multi-agent system on a large number oftraining coordination problem instances and observing the performance of different coordina-tion strategies on these instances. When a new task structure arises in the environment, each ofthe agents has a subjective view of the task structure. Based on its subjective view, each agentforms a local situation vector. A local situation represents an agent’s assessment of the utilityof reacting to various characteristics of the environment. Such an assessment can potentiallyindicate how to parameterize the GPGP mechanisms and consequently has a direct bearingon the type of coordination strategy that is the best for the given coordination episode. Theagents then exchange their local situation vectors and each of the agents composes all the localsituation vectors into a global situation vector. All agents agree on a choice of the coordinationstrategy and the choice depends on the kind of learning mode of the agents:� Mode 1. In this mode, the agents run all the available coordination strategies and
note their relative performances for each of the coordination problem instances. Thus,for example, an agent runs each of Simple, Myopic, Balanced, Tough and Mute for acoordination episode and stores their performances.� Mode 2. In this mode, the agents will randomly choose one of the coordination strategiesfor a given coordination episode, and observe and store the performance only for thatcoordination strategy. Of course, all agents agree on choosing the same coordinationstrategy and in addition, in our implementations, they choose the coordination that isrepresented the least number of times in the neighborhood of a small radius around thepresent global situation. An agent looks at the instance-base that it has learned so far andretrieves the set of situations that are within a small radius of the present global situation.It then tabulates the number of times each of the coordination strategies is representedin this set and chooses the one with the lowest representation. This is done to obtaina balanced representation for all the coordination strategies across the space of possibleglobal situations.
The Mode 1 algorithm develops less noisy knowledge because it runs all the availablecoordination strategies over each of the problem instances. On the other hand, Mode 2 getsto sample a large number of points in the feature space because no two runs are on the sameproblem instance.

91
Mode 2 is a quasi-online algorithm. In the initial stages it just explores and in the laterstages it just exploits the learned information. Studying COLLAGE in a setup that is moretypical of online learning algorithms, where exploration and exploitation are interleaved, ishigh on our agenda of future work.
At the end of each run of the coordination episode with a selected coordination strategy,the performance of the system is registered. This is represented as a vector of performancemeasures such as total quality, number of communications, and termination time. In thework presented here, the cost of scheduling is ignored and the time for scheduling is considerednegligible compared to the execution time of the methods. Our work could easily be generalizedto take into account these other forms of coordination overhead like the number of calls tothe scheduler and the total number of methods executed. We view this as one of our futuredirections of research.
Learning involves simply adding the new instance formed by the performance of thecoordination strategy along with the associated problem solving situation to the “instance-base”.Thus, the training phase builds a set of fsituation, coordination-strategy, performanceg tripletsfor each of the agents. Here the global situation vector is the abstraction of the global problemsolving state associated with the choice of a coordination-strategy. Note that at the beginningof a problem solving episode, all agents communicate their local problem solving situationsto other agents. Thus, each agent aggregates the local problem solving situations to form acommon global situation. All agents form identical instance-bases because they build the sameglobal situation vectors through communication. Our learning algorithm is very similar tothe Instance-Based Learning algorithms[Aha et al., 1991] proposed for supervised classificationlearning. We, however, use the IBL-paradigm for unsupervised learning of decision-theoreticchoice (details of this choice process are presented towards the end of this section).
5.5.2.1 Forming a Local Situation Vector
The situation vector is an abstraction of the coordination problem and the effects ofthe coordination mechanisms discussed previously. It is composed of six components. Inderiving the values for these components, it will become apparent that the availability ofnegotiation-based, bidirectional interface with the scheduler permitting “what-if” questions iscrucial. We now discuss in some detail, how each of the components of the situation vector isobtained:� The first component represents an approximation of the effect of detecting soft coor-
dination relationships on the quality component of the overall performance. An agentcreates a virtual task structure from the locally available task structure by letting eachof the facilitates coordination relationships potentially affecting a local task totake effect actually. In order to achieve this, the agent detects all the facilitatesinterrelationships that affect its tasks (i.e. local tasks at the end of a facilitatesrelationship arrow rather than at the beginning). An agent can be expected to knowthe interrelationships affecting its tasks though it may not know the exact tasks in otheragents that affect it without communicating with them. For example, in Figure 5.6,Agent X knows that its local task T5 is facilitated by some other task in another agenteven before non-local views are communicated. If the results of executing a task Tafacilitating a method Mb arrives at Mb before it starts executing, then the duration d of

92
the method is reduced to d(1��d) and the maximum quality q is increased to q(1+�q).In the virtual task structure, the duration and quality of a facilitated method is replacedwith d(1 � �d) and q(1 + �q). A call to the design-to-time real-time scheduler givesback a schedule for this virtual task structure. The agent then produces another virtualtask structure, but this time with the assumption that the facilitates relationships are notdetected and hence the tasks that can potentially be affected by them are not affectedin this task structure. The scheduler is again called with this task structure. The firstcomponent, representing the effect of detecting facilitates is now obtained as the ratioof the quality produced by the schedule without facilitates relationships and thequality produced by the schedule with facilitates relationships.Fac Quality Effect = Qno facilitates(T ;D(T ); S)Qfacilitates(T ;D(T ); S)Note however that this ratio is only an approximation of the actual effects of thefacilitates interrelationships. In actual problem solving process, it is highlyunlikely that all the facilitates interrelationships with be exploited with their fullstrength.� The second component represents an approximation of the effect of detecting softcoordination relationships on the duration component of the overall performance. It isformed using methods similar to that discussed above for quality, but using the durationof the schedules formed with the virtual task structures.Fac Duration Effect = Dfacilitates(T ;D(T ); S)Dno facilitates(T ;D(T ); S)� The third component represents an approximation of the effect of detecting hard coordi-nation inter-relationships on the quality of the local task structures at an agent. They areobtained in a manner similar to that described for facilitates interrelationship.An agent creates a virtual task structure from the locally available task structure by lettingeach of the enables coordination relationships potentially affecting a local task totake effect actually. This implies that the methods with enables interrelationship cominginto them are enabled in the virtual task structure and passed on to the scheduler. Theagent then produces and schedules another virtual task structure, but this time with theassumption that the enables relationships are not detected, leading to the quality of themethods affected by them being 0 and their durations 1 (a large number).Enables Quality Effect = Qnot enabled(T ;D(T ); S)Qenabled(T ;D(T ); S)� The fourth component represents an approximation of the effect of detecting hardcoordination relationships on the duration component of the overall performance. It is

93
formed using methods similar to that discussed above for quality, but using the durationof the schedules formed with the virtual task structures.Enables Duration Effect = Denabled(T ;D(T ); S)Dnot enabled(T ;D(T ); S)� The fifth component represents the time pressure on the agent. In a design-to-timescheduler, increased time pressure on an agent will lead to schedules that will still adhereto the deadline requirements as far as possible but with a sacrifice in quality. When thereis a choice, higher quality, higher duration methods are preferred over lower quality,lower duration methods for achieving a particular task. In order to get an estimate ofthe time pressure, we generate virtual task structures from the local task structures atan agent by setting the deadlines of the task groups, tasks and methods to 1 (a largenumber) and schedule these virtual task structures. The agents schedule again with thelocal task structures set to the actual deadline. Time pressure is obtained as the ratioof the schedule quality with the actual deadlines and the schedule quality with largedeadlines. T ime Pressure = Qactual DL(T ;D(T ); S)Q1(T ;D(T ); S)� The sixth component represents the load. It is formed by using methods similar tothat discussed above for time pressure but using the duration of the schedules formedwith the virtual task structures. The time taken by the schedule when it has no timepressure (deadline is1) represents the amount of work the agent would have done underideal conditions. However, time pressure makes the agent work almost right up to thedeadline. It may not work all the way to the deadline as it may not find a method thatcan be fitted into the last available chunk of time. Thus, load is obtained as:Load = Dactual DL(T ;D(T ); S)D1(T ;D(T ); S)
5.5.2.2 Forming a Global Situation Vector
Each agent communicates its local situation vector to all the other agents. An agentcomposes all the local situation vectors: its own and those it received from the others to form aglobal situation vector. A number of composition functions are possible. The one we used inthe experiments reported here is simple: component-wise average of the local situation vectors.Thus, the global situation vector has six components where each component is the average ofthe corresponding components of the local situation vectors.
An example global situation vector is: (0.82 0.77 0.66 0.89 1.0 0.87).Here the low value of the third component represents large quality gains by detecting and

94
coordinating on hard interrelationships. Thus two of the more sophisticated coordinationstrategies called balanced and tough[Decker and Lesser, 1995] are found to be betterperformers in this situation. On the other hand, in a global situation vector such as(0.80 0.90 0.88 0.80 0.61 0.69) the low values of fifth and sixth componentsindicate high time pressure and load in the present problem solving episode. Even if the agentsuse sophisticated strategies to coordinate, they may not have the time to benefit from it. Hence,relatively simple coordination strategies like simple or mute[Decker and Lesser, 1995] dobetter in this scenario.
Note, however, that in most situation vectors, these trade-offs are subtle and not as obviousas the above examples. It is difficult for a human to look at the situations and easily predictwhich strategy is the best performer. The trade-offs may be very specific to the kinds of taskstructures that occur in the domain. Hence, hand-coding the strategies by a designer is not apractical alternative.
Once the entire instance-base is formed, each of the features for each instance is normalizedby the range of the maximum and the minimum for that feature within the entire instance-base.This is done in order to avoid biasing the similarity metric in favor of any particular feature.
5.5.3 Choosing a Coordination Strategy
COLLAGE chooses a coordination strategy based on how the set of available strategies per-
formed in similar past cases. We shall adopt the notation from Gilboa and Schmeidler[Gilboa
and Schmeidler, 1995]5. Each case c is triplethp; a; ri 2 Ciwherep 2 P and P is the set of situations representing abstract characterization of coordinationproblems,a 2 A and A is the set of coordination choices available,r 2 R and R is the set of results from running a coordination strategy.Ci � P �A�R
Decisions about coordination strategy choice are made based on similar past cases. Out-comes decide the desirability of the strategies. We define a similarity function and a utilityfunctions as follows: s : P 2 ! [0; 1]u : R ! <
In the experiments presented later, we use the Euclidean metric for similarity.5Gilboa and Schmeidler[Gilboa and Schmeidler, 1995] describe case-based decision theory as a normativetheory of human behavior during decision making. Even though, we adopt their notation, there are crucialdifferences in the motivations and structure of the two works. Gilboa and Schmeidler are primary concerned witha descriptive theory of human decision making while our work, developed independently, is concerned primarily
with building computational systems based on case-based decision theory.

95
The desirability of a coordination strategy is determined by a similarity-weighted sumof the utility it yielded in the similar past cases in a small neighborhood around the presentsituation vector. We observed that such an averaging process in a neighborhood around thepresent situation vector was more robust than taking the nearest neighbor, possibly because theaveraging process was less sensitive to noise. Let M be the set of past similar cases to problempnew 2 P (greater than a threshold similarity).m 2M , s(pnew ;m) � sthreshold
For a 2 A, let Ma � fm = hp; �; rij� = ag The utility of a is defined asU(pnew; a) = 1jMaj Xhq;a;ri2Ma s(pnew ; q)u(r)5.6 Experiments in Learning Situation-Specific Coordination
In complex systems like TÆMS, or GPGP or its learning layer COLLAGE, there area number of degrees of freedom, and one can potentially vary a large number of parameterscreating a huge exploration space for experiment design. Our long term goals include exploringa sizable portion of this space but in the work presented here, we will primarily be interested inshowing that situation-specific learning is feasible and beneficial. In the future work section,we will be touching upon a number of issues we intend to investigate in this system.
In the environments described here, the agents are executing sequences of interrelatedmethods. Execution of a method has a certain utility associated with it. The agents are tryingto maximize the system-wide total utility. Each of the agents has only a partial view of theglobal problem solving situation and the execution of a method can positively or negativelyaffect the execution of methods at other agents. Agents have to communicate with each otherto augment their partial views so as to detect such interrelationships between their methods andschedule their local methods either to avoid or exploit them. Different coordination protocolsexchange different amounts of information at varying levels of details.
As noted previously, different problem solving situations need different coordinationstrategies. The experiments here demonstrate that learning globally situated control knowledgecan lead to an effective choice of a coordination strategy from a class of alternatives. For theseexperiments, utility is the primary performance parameter against which various strategies areevaluated. Each message an agent communicates to another agent penalizes the overall utilityby a small amount denoted by comm cost. However, achieving a better non-local view canpotentially lead to higher quality that adds to the system-wide utility.Utility = Quality� (total communication� comm cost)
In the following experiments the size of the case-base for Mode 1 learning was determinedby plotting the performance of the learner, averaged over 500 instances randomly generated bya grammar, for various sizes of the instance-base, and at communication cost of 0. Figure 5.9shows a second order fit to the data on performance versus the instance-base size for grammar
G1 (to be discussed in more detail below) at communication cost of 0. R2 value of 0.913 shows
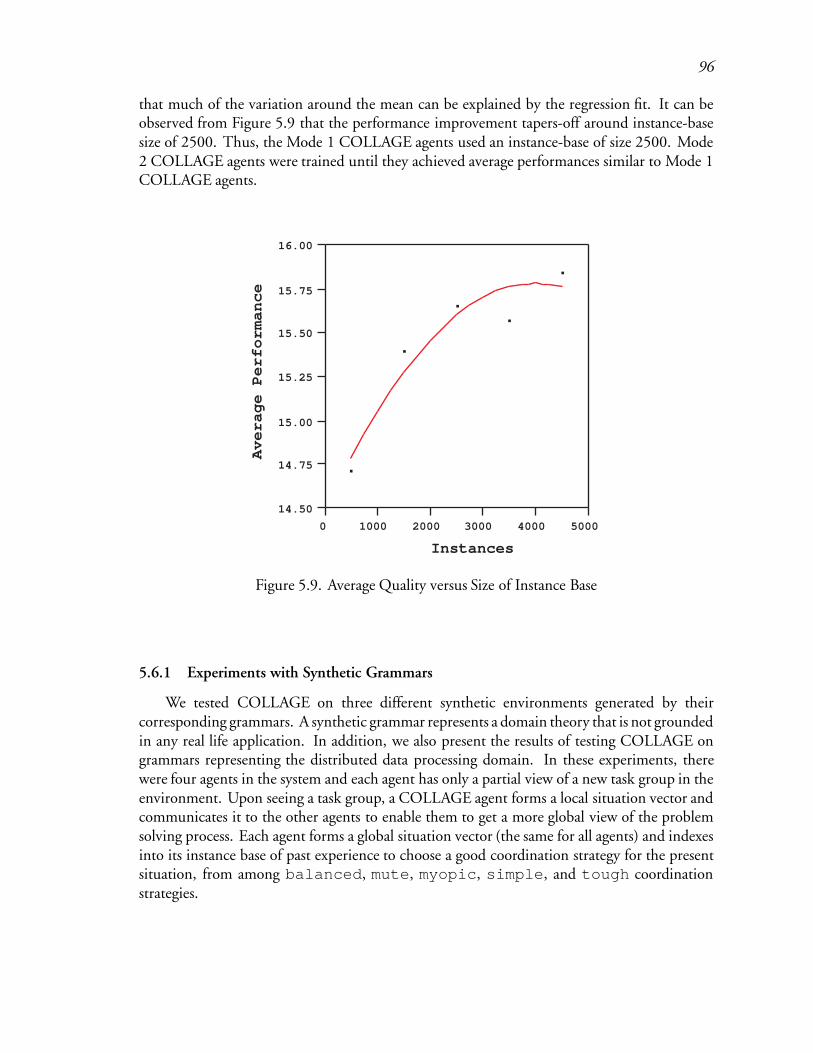
96
that much of the variation around the mean can be explained by the regression fit. It can beobserved from Figure 5.9 that the performance improvement tapers-off around instance-basesize of 2500. Thus, the Mode 1 COLLAGE agents used an instance-base of size 2500. Mode2 COLLAGE agents were trained until they achieved average performances similar to Mode 1COLLAGE agents.
Average Performance
14.50
14.75
15.00
15.25
15.50
15.75
16.00
0 1000 2000 3000 4000 5000
Instances
Figure 5.9. Average Quality versus Size of Instance Base
5.6.1 Experiments with Synthetic Grammars
We tested COLLAGE on three different synthetic environments generated by theircorresponding grammars. A synthetic grammar represents a domain theory that is not groundedin any real life application. In addition, we also present the results of testing COLLAGE ongrammars representing the distributed data processing domain. In these experiments, therewere four agents in the system and each agent has only a partial view of a new task group in theenvironment. Upon seeing a task group, a COLLAGE agent forms a local situation vector andcommunicates it to the other agents to enable them to get a more global view of the problemsolving process. Each agent forms a global situation vector (the same for all agents) and indexesinto its instance base of past experience to choose a good coordination strategy for the presentsituation, from among balanced, mute, myopic, simple, and tough coordinationstrategies.

97
5.6.1.1 Grammar G1
Mode 1 learning in COLLAGE involved training it on 2500 instances. Mode 2 learninginvolved training it on 18000 instances. Figure 5.10 shows the average quality over the same100 runs for different coordination strategies at various communication costs. The curves forboth Mode 1 and Mode 2 learning algorithms lie above those for all the other coordinationstrategies. We performed a Wilcoxon matched-pair signed ranks analysis to test for significantdifferences (at significance level 0.05) between the average performances of the strategies acrosscommunications costs upto 0.075 (as opposed to pairwise tests at each communication cost).This test revealed significant differences between the learning strategies (both Mode 1 and Mode2) and the other five coordination strategies, indicating that we can assert with a high degree ofconfidence that the performance of the learning algorithms across various communication costs
is better than statically using any one of the family of coordination strategies6. Note howeverthat as the communication costs go up, the mean performance of the learning algorithms goesdown. At some high value of communication cost, the performance of the learning algorithmfalls below that of mute because the learning agents use at least four units of communicationto publish their local situation vectors. The cost of communicating these local situation vectorscan overwhelm the benefits derived from a better choice of the coordination strategy. Whenthe communication cost was as high as 0.25, the performance of Mode 1 and Mode 2 learnerswere 12.88 and 12.495 respectively. On the other hand mute coordination gave a meanperformance of 13.55.
Figures 5.11 and 5.12 give the number of coordination strategies of each type chosen inthe 100 test runs. As communication costs increase, mute becomes the overwhelming favoritebut even at as high communication costs as 0.08, there are still problems where mute is notthe best choice.
5.6.1.2 Grammar 2
Grammar 2 is similar to Grammar 1 in structure but the distribution of quality andduration of the leaf methods is different from those in Grammar 1. Mode 1 learning inCOLLAGE again involved training it on 2500 instances. Mode 2 learning involved training iton 18000 instances. Figure 5.13 shows the average quality over the same 100 runs for differentcoordination strategies at various communication costs. The curves for both Mode 1 and Mode2 learning algorithms lie above those for all the other coordination strategies for the most part.As in Grammar 1, Wilcoxon matched-pair signed ranks analysis on the average performances ofthe strategies across communication costs upto 0.075, revealed significant differences betweenthe learning algorithms (both Mode 1 and Mode 2) and the other five coordination strategies.We can thus assert with a high degree of confidence that the performance of the learningalgorithms across various communication costs is better than statically using any one of thefamily of coordination strategies. Again, as in grammar G1, as the communication costs goup, the mean performance of the learning algorithms goes down. At some high value ofcommunication cost, the performance of the learning algorithm falls below that of mute.For the Mode 2 learning algorithm, the average performance in fact falls below that of mute6Testing across communication costs is justified because in reality, the cost may vary during the course of the
day.
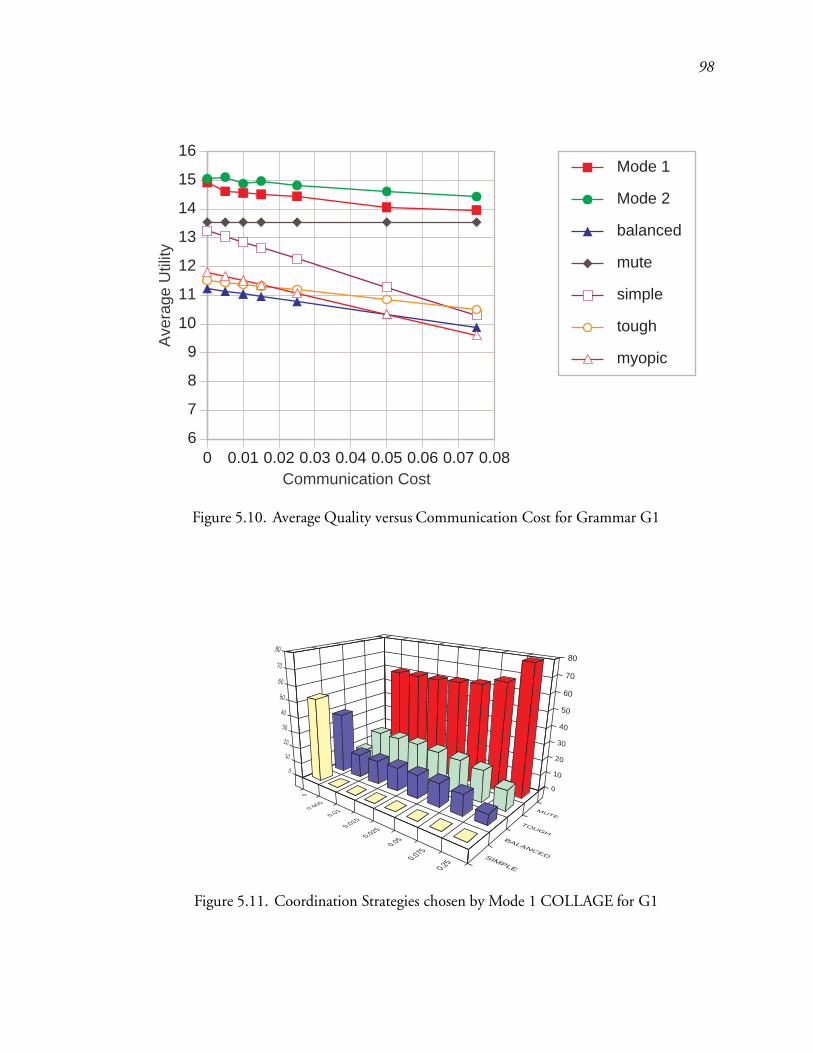
98
6
7
8
9
10
11
12
13
14
15
16
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08
Ave
rage
Util
ity
Communication Cost
Mode 1
Mode 2
balanced
mute
simple
tough
myopic
Figure 5.10. Average Quality versus Communication Cost for Grammar G1
80
70
60
50
40
30
20
10
0
0
10
20
30
40
50
60
70
80
MUTE
TOUGH
BALANCEDSIMPLE
0
0.005
0.01
0.015
0.025
0.05
0.075
0.25
Figure 5.11. Coordination Strategies chosen by Mode 1 COLLAGE for G1
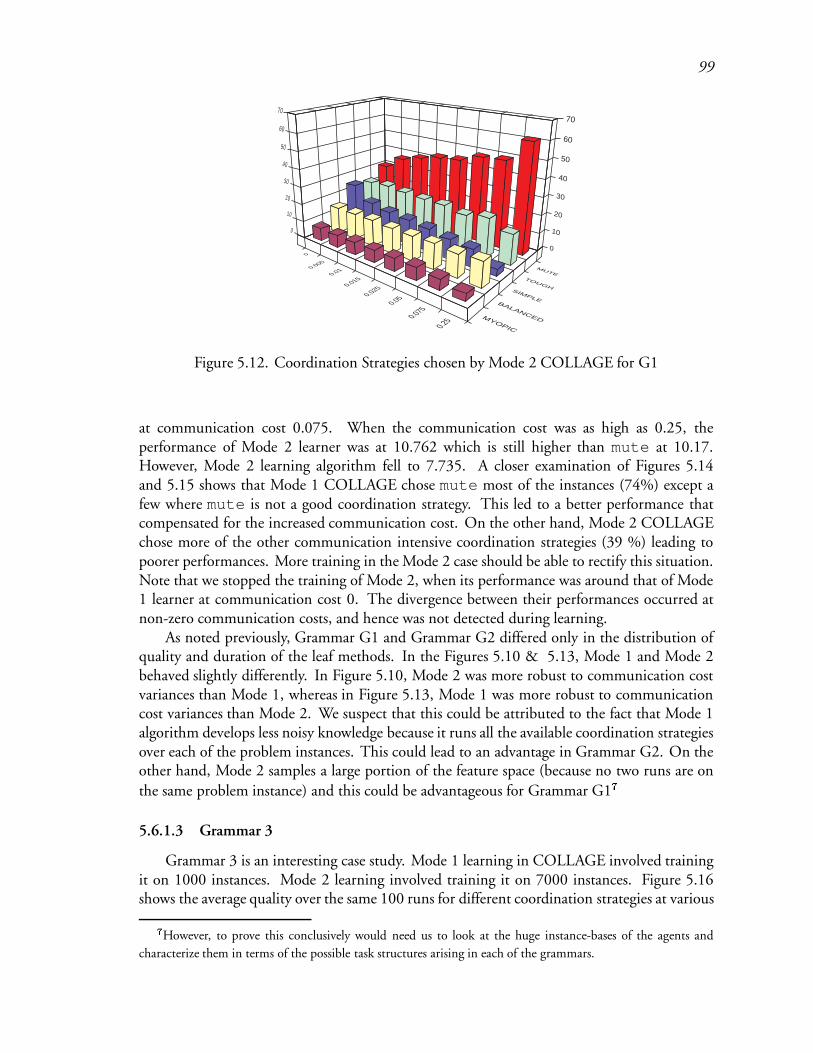
99
70
60
50
40
30
20
10
0
0
10
20
30
40
50
60
70
MUTETOUGH
SIMPLEBALANCEDMYOPIC
0
0.005
0.01
0.015
0.025
0.05
0.075
0.25
Figure 5.12. Coordination Strategies chosen by Mode 2 COLLAGE for G1
at communication cost 0.075. When the communication cost was as high as 0.25, theperformance of Mode 2 learner was at 10.762 which is still higher than mute at 10.17.However, Mode 2 learning algorithm fell to 7.735. A closer examination of Figures 5.14and 5.15 shows that Mode 1 COLLAGE chose mute most of the instances (74%) except afew where mute is not a good coordination strategy. This led to a better performance thatcompensated for the increased communication cost. On the other hand, Mode 2 COLLAGEchose more of the other communication intensive coordination strategies (39 %) leading topoorer performances. More training in the Mode 2 case should be able to rectify this situation.Note that we stopped the training of Mode 2, when its performance was around that of Mode1 learner at communication cost 0. The divergence between their performances occurred atnon-zero communication costs, and hence was not detected during learning.
As noted previously, Grammar G1 and Grammar G2 differed only in the distribution ofquality and duration of the leaf methods. In the Figures 5.10 & 5.13, Mode 1 and Mode 2behaved slightly differently. In Figure 5.10, Mode 2 was more robust to communication costvariances than Mode 1, whereas in Figure 5.13, Mode 1 was more robust to communicationcost variances than Mode 2. We suspect that this could be attributed to the fact that Mode 1algorithm develops less noisy knowledge because it runs all the available coordination strategiesover each of the problem instances. This could lead to an advantage in Grammar G2. On theother hand, Mode 2 samples a large portion of the feature space (because no two runs are on
the same problem instance) and this could be advantageous for Grammar G175.6.1.3 Grammar 3
Grammar 3 is an interesting case study. Mode 1 learning in COLLAGE involved trainingit on 1000 instances. Mode 2 learning involved training it on 7000 instances. Figure 5.16shows the average quality over the same 100 runs for different coordination strategies at various7However, to prove this conclusively would need us to look at the huge instance-bases of the agents and
characterize them in terms of the possible task structures arising in each of the grammars.
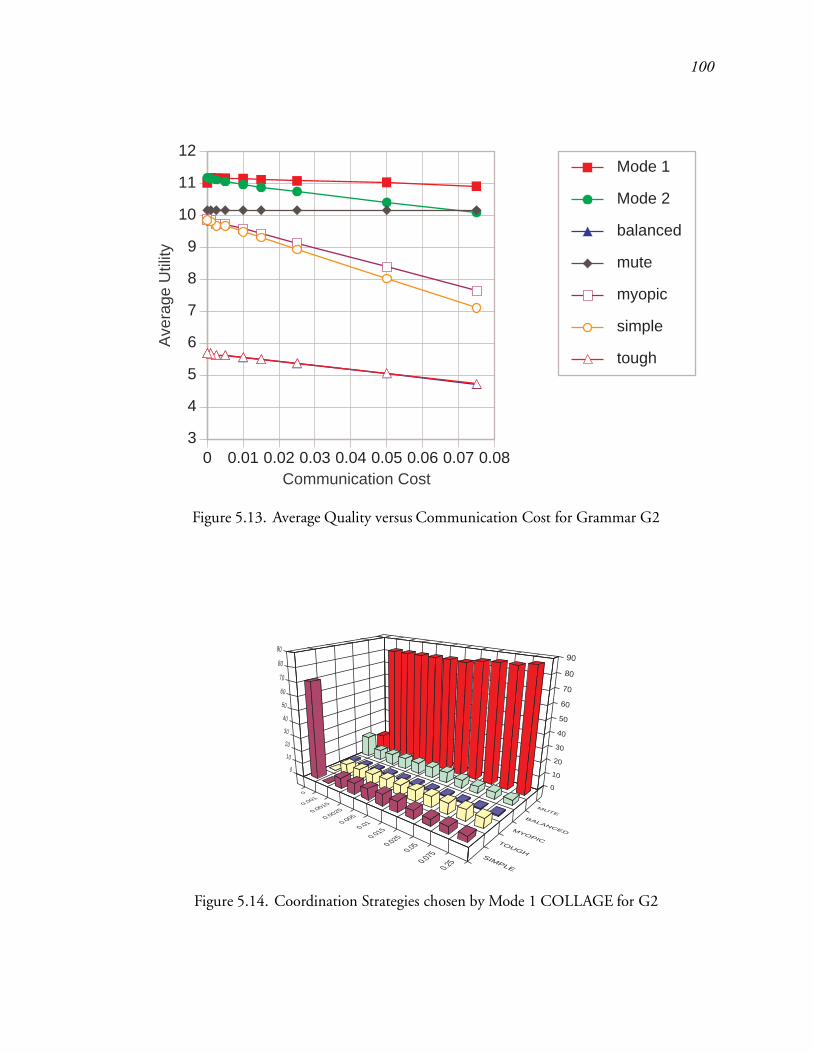
100
3
4
5
6
7
8
9
10
11
12
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08
Ave
rage
Util
ity
Communication Cost
Mode 1
Mode 2
balanced
mute
myopic
simple
tough
Figure 5.13. Average Quality versus Communication Cost for Grammar G2
90
80
70
60
50
40
30
20
10
0
0
10
20
30
40
50
60
70
80
90
MUTEBALANCEDMYOPICTOUGH
SIMPLE
0
0.001
0.0015
0.0025
0.005
0.01
0.015
0.025
0.05
0.075
0.25
Figure 5.14. Coordination Strategies chosen by Mode 1 COLLAGE for G2
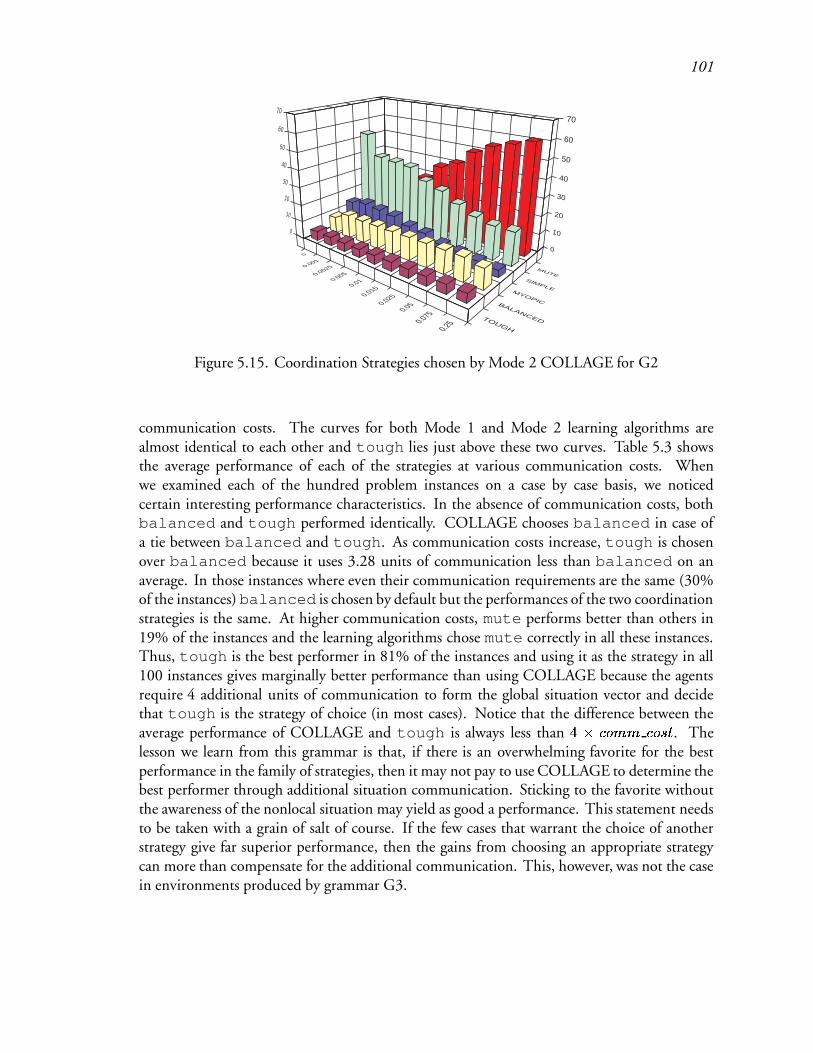
101
70
60
50
40
30
20
10
0
0
10
20
30
40
50
60
70
MUTESIMPLE
MYOPICBALANCEDTOUGH
0
0.001
0.0025
0.005
0.01
0.015
0.025
0.05
0.075
0.25
Figure 5.15. Coordination Strategies chosen by Mode 2 COLLAGE for G2
communication costs. The curves for both Mode 1 and Mode 2 learning algorithms arealmost identical to each other and tough lies just above these two curves. Table 5.3 showsthe average performance of each of the strategies at various communication costs. Whenwe examined each of the hundred problem instances on a case by case basis, we noticedcertain interesting performance characteristics. In the absence of communication costs, bothbalanced and tough performed identically. COLLAGE chooses balanced in case ofa tie between balanced and tough. As communication costs increase, tough is chosenover balanced because it uses 3.28 units of communication less than balanced on anaverage. In those instances where even their communication requirements are the same (30%of the instances)balanced is chosen by default but the performances of the two coordinationstrategies is the same. At higher communication costs, mute performs better than others in19% of the instances and the learning algorithms chose mute correctly in all these instances.Thus, tough is the best performer in 81% of the instances and using it as the strategy in all100 instances gives marginally better performance than using COLLAGE because the agentsrequire 4 additional units of communication to form the global situation vector and decidethat tough is the strategy of choice (in most cases). Notice that the difference between theaverage performance of COLLAGE and tough is always less than 4 � comm cost. Thelesson we learn from this grammar is that, if there is an overwhelming favorite for the bestperformance in the family of strategies, then it may not pay to use COLLAGE to determine thebest performer through additional situation communication. Sticking to the favorite withoutthe awareness of the nonlocal situation may yield as good a performance. This statement needsto be taken with a grain of salt of course. If the few cases that warrant the choice of anotherstrategy give far superior performance, then the gains from choosing an appropriate strategycan more than compensate for the additional communication. This, however, was not the casein environments produced by grammar G3.
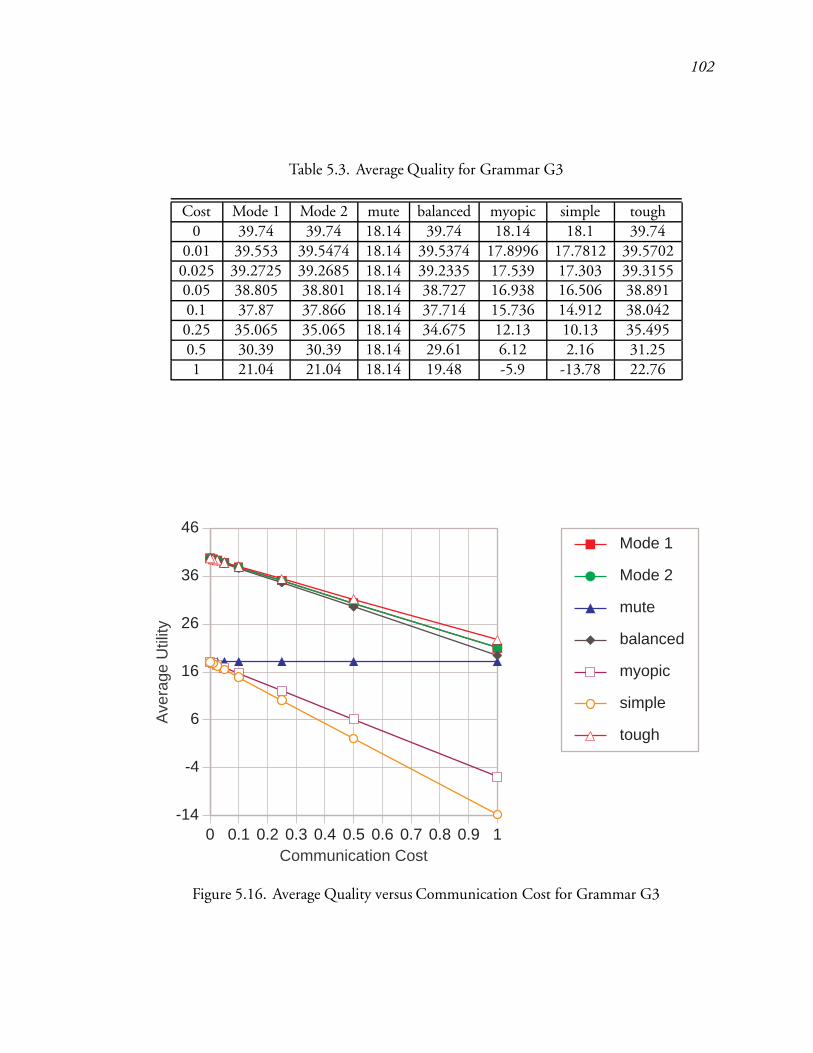
102
Table 5.3. Average Quality for Grammar G3
Cost Mode 1 Mode 2 mute balanced myopic simple tough
0 39.74 39.74 18.14 39.74 18.14 18.1 39.74
0.01 39.553 39.5474 18.14 39.5374 17.8996 17.7812 39.5702
0.025 39.2725 39.2685 18.14 39.2335 17.539 17.303 39.31550.05 38.805 38.801 18.14 38.727 16.938 16.506 38.891
0.1 37.87 37.866 18.14 37.714 15.736 14.912 38.042
0.25 35.065 35.065 18.14 34.675 12.13 10.13 35.495
0.5 30.39 30.39 18.14 29.61 6.12 2.16 31.25
1 21.04 21.04 18.14 19.48 -5.9 -13.78 22.76
-14
-4
6
16
26
36
46
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Ave
rage
Util
ity
Communication Cost
Mode 1
Mode 2
mute
balanced
myopic
simple
tough
Figure 5.16. Average Quality versus Communication Cost for Grammar G3
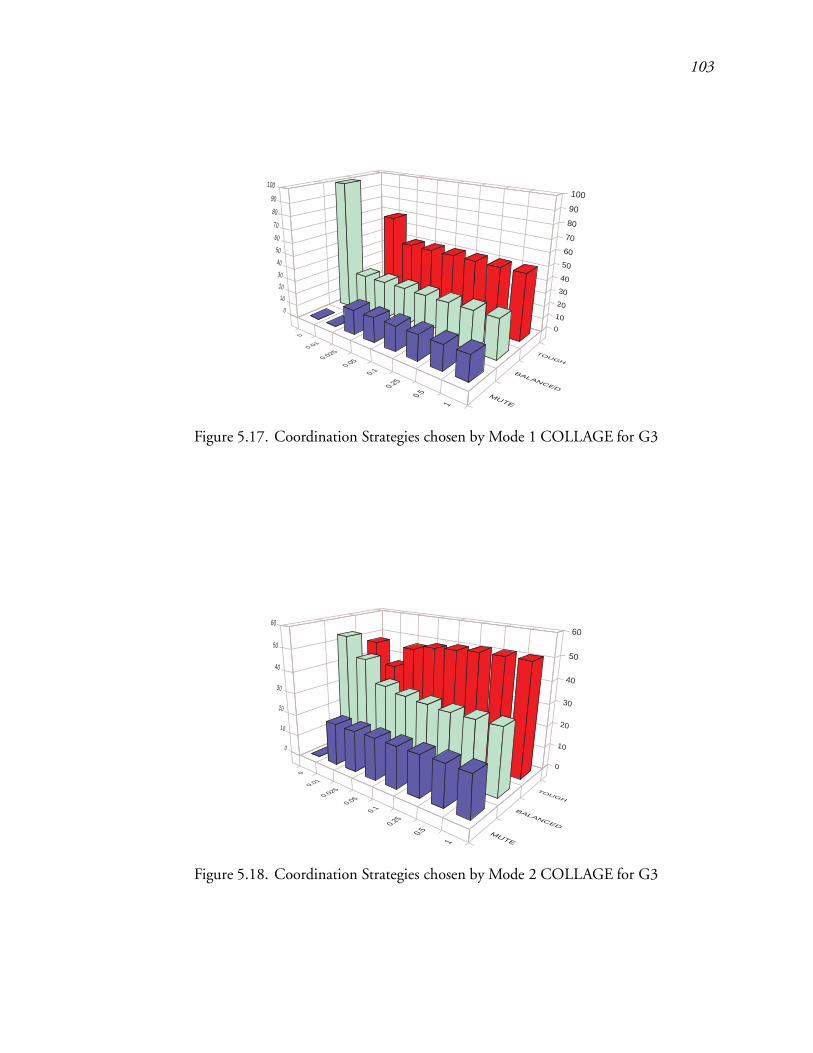
103
100
90
80
70
60
50
40
30
20
10
0
0
10
20
30
40
50
60
70
80
90
100
TOUGH
BALANCED
MUTE
0
0.01
0.025
0.05
0.1
0.25
0.5
1
Figure 5.17. Coordination Strategies chosen by Mode 1 COLLAGE for G3
60
50
40
30
20
10
0
0
10
20
30
40
50
60
TOUGH
BALANCED
MUTE
0
0.01
0.025
0.05
0.1
0.25
0.5
1
Figure 5.18. Coordination Strategies chosen by Mode 2 COLLAGE for G3

104
5.6.2 Experiments in the DDP domain
Section 5.4 discussed the results of our empirical explorations of the effects of varyingdeadlines and crisis task group arrival probability. Based on the experiments, we noted the needfor different coordination strategies in different situations to achieve good performance. In thissection, we intend to demonstrate the power of COLLAGE in choosing the most appropriatecoordination strategy in a given situation. We performed two sets of experiments varying theprobability of the centers seeing crisis tasks. In the first set of experiments, the crisis task grouparrival probability was 0.25 and in the second set it was 1.0. For both sets of experiments, lowpriority tasks arrived with a probability of 0.5 and the routine tasks were always seen at the timeof new arrivals. A day consisted of just one time slice of 140 time units and hence the deadlinewas fixed at 140 time units for these experiments. The system consisted of three agents (ordata processing centers), and they had to learn to choose the best coordination strategy fromamong balanced, rough, and data-flow.
5.6.2.1 Experiment 1
Mode 1 learning involved training COLLAGE on 4500 instances. Mode 2 learninginvolved training it on 10000 instances. Figure 5.19 shows the average quality over the same100 runs for different coordination strategies at various communication costs. The curves forboth Mode 1 and Mode 2 learning algorithms lie above those for all the other coordinationstrategies for the most part. We performed a Wilcoxon matched-pair signed ranks analysis totest for significant differences (at significance level 0.05) between the average performances ofthe strategies across communications costs upto 1.0. This test revealed significant differencesbetween the learning algorithms (both Mode 1 and Mode 2) and the other three coordinationstrategies, indicating that we can assert with a high degree of confidence that the performanceof the learning algorithms across various communication costs is better than statically usingany one of the family of coordination strategies. As in case of synthetic grammars, as thecommunication costs go up, the mean performance of the learning algorithms goes down.However, the slope of performance of the rough coordination strategy is smaller because itavoids communication for forming commitments.
Figures 5.20 and 5.21 give the number of coordination strategies of each type chosen in the100 test runs. As communication costs increase,balanced performs better than the learning
algorithms at high costs8 because, learning algorithms use three units of communication toform the global situation vectors. At communication cost of 1.0, Mode 1 learner and Mode 2learner average at 77.72 and 79.98 respectively, whereas, choosingbalanced always producesan average performance of 80.48.
5.6.2.2 Experiment 2
Mode 1 learning involved training COLLAGE on 2500 instances. Mode 2 learninginvolved training it on 12500 instances. Figure 5.22 shows the average quality over thesame 100 runs for different coordination strategies at various communication costs upto 1.0.However, the best performer among the three coordination strategies is data-flow unlike8These environments are entirely different from those for the previous experiments. What is a “high”
communication cost obviously depends on the environments.
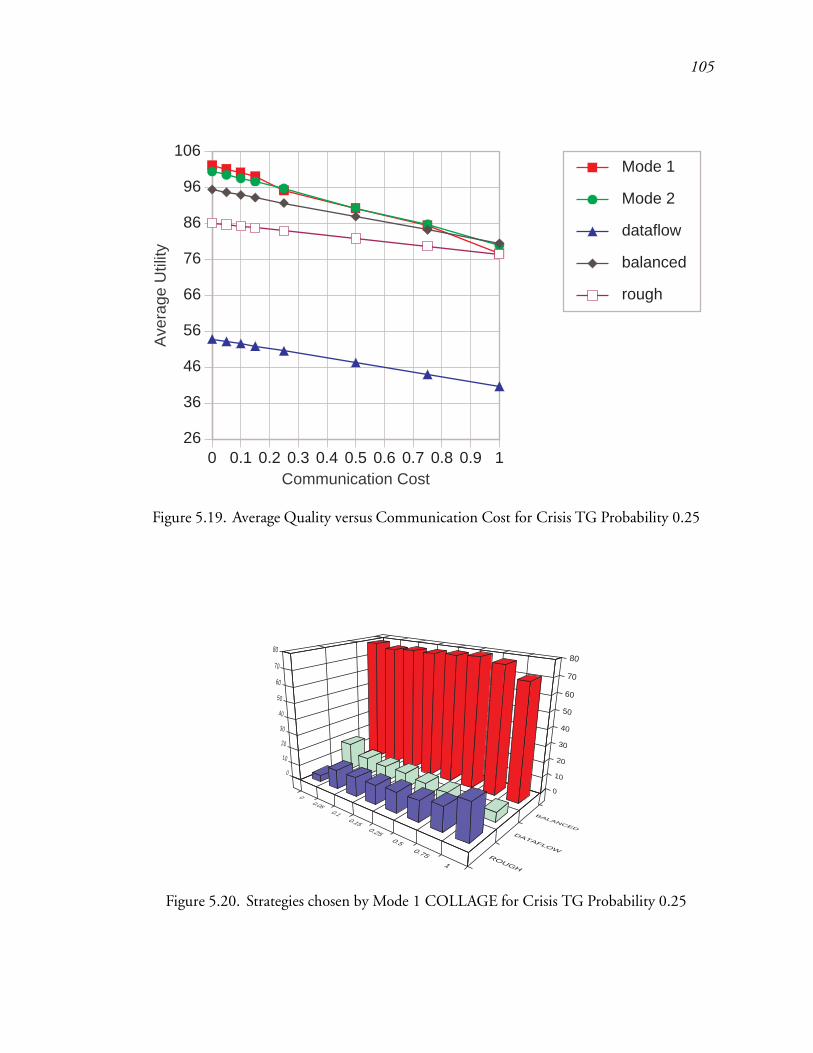
105
26
36
46
56
66
76
86
96
106
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Ave
rage
Util
ity
Communication Cost
Mode 1
Mode 2
dataflow
balanced
rough
Figure 5.19. Average Quality versus Communication Cost for Crisis TG Probability 0.25
80
70
60
50
40
30
20
10
0
0
10
20
30
40
50
60
70
80
BALANCED
DATAFLOW
ROUGH
00.05
0.10.15
0.250.5
0.751
Figure 5.20. Strategies chosen by Mode 1 COLLAGE for Crisis TG Probability 0.25

106
70
60
50
40
30
20
10
0
0
10
20
30
40
50
60
70
BALANCED
ROUGH
DATAFLOW
00.05
0.10.15
0.250.5
0.751
Figure 5.21. Strategies chosen by Mode 2 COLLAGE for Crisis TG Probability 0.25
in experiment 1 where the best performer was balanced. COLLAGE agents exploitinglearning of course do better than statically using any one of the coordination strategies as longas the communication costs are not “too high”. Wilcoxon matched-pair signed ranks analysisrevealed significant differences (at significance level 0.05) between the learning algorithms (bothMode 1 and Mode 2) and the other three coordination strategies. When the communicationcosts go as high as 2.0, the performance of Mode 2 learner was 183.87 and that of the Mode 1learner was 184.55 whereas rough coordination gave an average performance of 189.39.
5.6.3 Discussion
These experiments provide strong empirical evidence of the benefits of learning situation-specific coordination. This is true not only for task structures generated by different domains(in our case domain theories represented by ASGGs) but also for task structures generatedwithin a domain.
COLLAGE chooses a good coordination strategy by projecting decisions from past similarexperience into the newly perceived situation. COLLAGE agents performed better than usingany single coordination strategy across all the 100 instances in all grammars except G3. Inthese grammars, the cost incurred by additional communication for detecting global situationis offset by the benefits of choosing a coordination strategy based on globally grounded learnedknowledge. Grammar G3, however, is distinguished by the fact that there is little variance inthe choice the best coordination strategy that was almost always tough. In those cases wheremute performed better, the performance of tough was close. This highlights the fact thatlearning is especially beneficial in the more dynamic environments.
5.7 Summary
Many researchers have shown that no single coordination mechanism is good for allsituations. However, there is little in the literature that deals with how to choose dynamically acoordination strategy based on the problem solving situation. In this chapter, we presented the
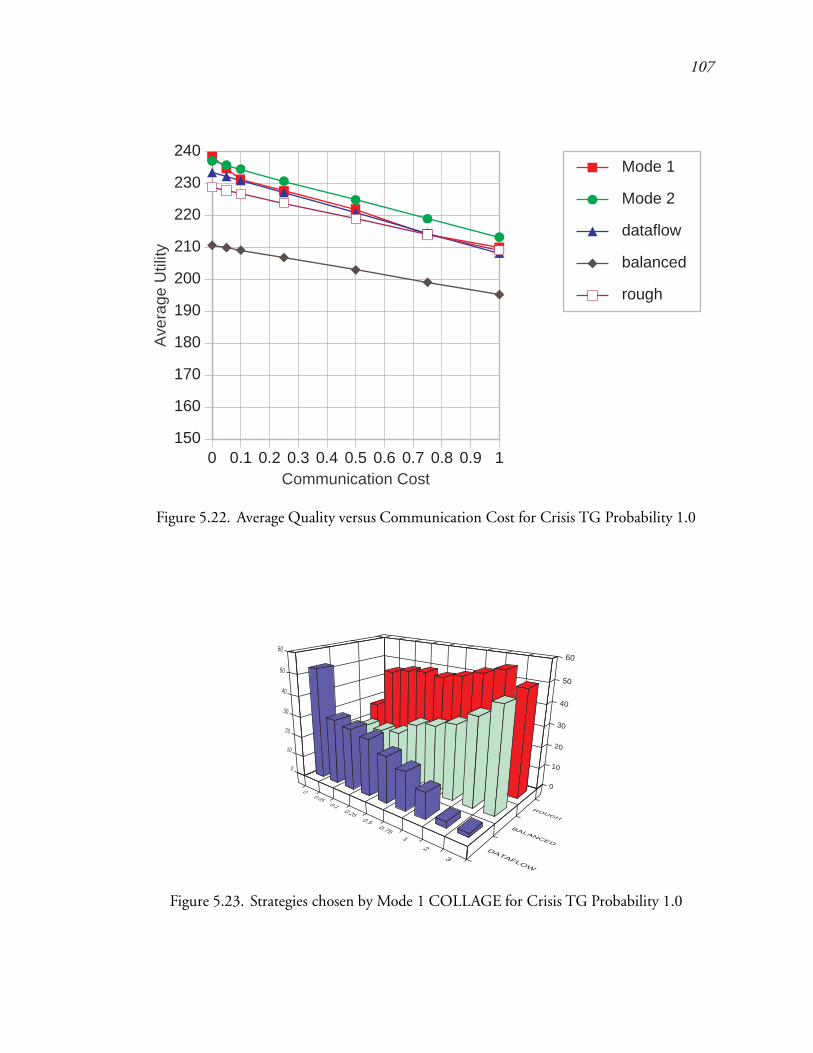
107
150
160
170
180
190
200
210
220
230
240
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Ave
rage
Util
ity
Communication Cost
Mode 1
Mode 2
dataflow
balanced
rough
Figure 5.22. Average Quality versus Communication Cost for Crisis TG Probability 1.0
60
50
40
30
20
10
0
0
10
20
30
40
50
60
ROUGH
BALANCED
DATAFLOW
00.05
0.10.25
0.50.75
1
2
3
Figure 5.23. Strategies chosen by Mode 1 COLLAGE for Crisis TG Probability 1.0
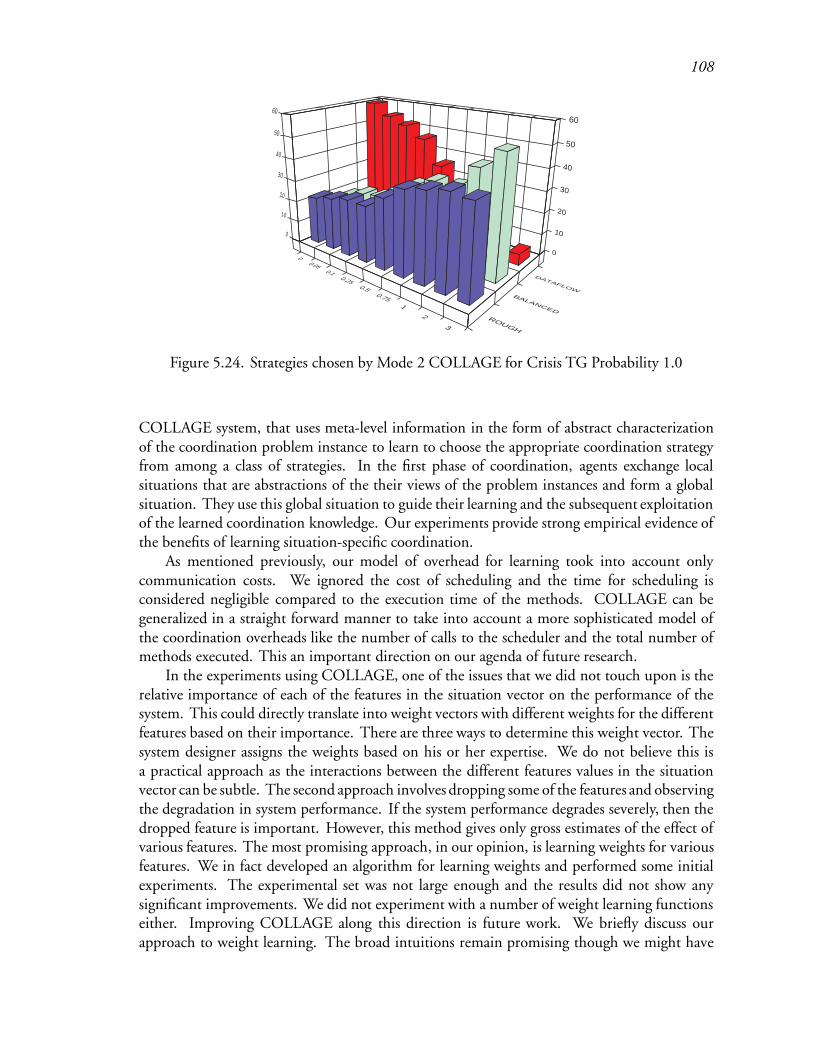
108
60
50
40
30
20
10
0
0
10
20
30
40
50
60
DATAFLOW
BALANCED
ROUGH
00.05
0.10.25
0.50.75
1
2
3
Figure 5.24. Strategies chosen by Mode 2 COLLAGE for Crisis TG Probability 1.0
COLLAGE system, that uses meta-level information in the form of abstract characterizationof the coordination problem instance to learn to choose the appropriate coordination strategyfrom among a class of strategies. In the first phase of coordination, agents exchange localsituations that are abstractions of the their views of the problem instances and form a globalsituation. They use this global situation to guide their learning and the subsequent exploitationof the learned coordination knowledge. Our experiments provide strong empirical evidence ofthe benefits of learning situation-specific coordination.
As mentioned previously, our model of overhead for learning took into account onlycommunication costs. We ignored the cost of scheduling and the time for scheduling isconsidered negligible compared to the execution time of the methods. COLLAGE can begeneralized in a straight forward manner to take into account a more sophisticated model ofthe coordination overheads like the number of calls to the scheduler and the total number ofmethods executed. This an important direction on our agenda of future research.
In the experiments using COLLAGE, one of the issues that we did not touch upon is therelative importance of each of the features in the situation vector on the performance of thesystem. This could directly translate into weight vectors with different weights for the differentfeatures based on their importance. There are three ways to determine this weight vector. Thesystem designer assigns the weights based on his or her expertise. We do not believe this isa practical approach as the interactions between the different features values in the situationvector can be subtle. The second approach involves dropping some of the features and observingthe degradation in system performance. If the system performance degrades severely, then thedropped feature is important. However, this method gives only gross estimates of the effect ofvarious features. The most promising approach, in our opinion, is learning weights for variousfeatures. We in fact developed an algorithm for learning weights and performed some initialexperiments. The experimental set was not large enough and the results did not show anysignificant improvements. We did not experiment with a number of weight learning functionseither. Improving COLLAGE along this direction is future work. We briefly discuss ourapproach to weight learning. The broad intuitions remain promising though we might have

109
to investigate a variety of functions for the specifics of weight modification. Let us look atCOLLAGE in MODE 1. During learning, the instance-based is formed as usual. The weightfunction has no effect as we do not use any similarity matching during learning in Mode 1.Once the learning terminates, the weight learning module makes a pass over the entire instancebase selecting each instance as a target instance (TI) and retrieving its neighborhood vectors.Each of the neighborhood instance (NI) and the TI have the performances for each of thepossible coordination strategies. If the maximum performing coordination strategies for NIand TI are the same, then the corresponding feature similarity has to move nearer in the ratioof the similarity of the feature values. So, the weight of a feature decreases (smaller value meansbetter similarity) more if it is more similar.�wti = �� utility� e��jNIfeaturei�TIfeatureijwhere � and � are small positive constants.
By the same intuition, if the maximum performing coordination strategies for NI and TIare different, then the corresponding feature similarity has to move farther. A similar weightingfunction as above is used to make weight changes in this case.
The work here is exciting to us as much for the kinds of questions and challenges it uncoversas it is for the results obtained so far. Some of the important questions that it raises are “Whatis a suitable level of abstraction for a situation and how can one determine it?” (more on thisin the last chapter), “How specific is the instance base to a particular domain and how muchof it can be transfered across domains?”
One important concern about COLLAGE is its scalability. As the number of coordinationalternatives becomes large, the learning phase could become computationally very intensive andthe instance-base size could increase enormously with respect to Mode 2. We are looking at howto integrate methods for progressively refining situation vector representations such as thosein [Sugawara and Lesser, 1993] (details in Chapter 2). Their learning relies on deep domainknowledge and agent homogeneity assumptions to learn to refine situations progressively,based on failure-driven explanation and comparative analysis of problem solving traces. Ourinitial ideas involve mapping the problem into a domain independent representation such asTÆMS for coordination problems and developing more general techniques to reason with theserepresentations to avoid the need for significant knowledge engineering as we generalize tomore instances. We also believe that there is a need for developing more sophisticated andformal theories of comparative analysis and explanation-based learning techniques.
Another way to tackle the scalability problem is to organize the instance-base to access anddetect regions where there is insufficient learning and do more directed experimentation duringlearning rather than randomly sampling the problem space. Some advances in the scalabilityproblems are needed to make a more faithful online version (than Mode 2) of COLLAGEbecause of the number of training instances involved. If both exploration and exploitationare interleaved and the exploration probability is 0.1, we will need approximately an order ofmagnitude more runs before the system learns “enough”.
In COLLAGE, all the agents form identical instance-bases. We could as well have donewith one designated agent forming the instance-base and choosing the coordination strategy.However, our configuration was set up with a more general scheme in mind. Instead of allagents choosing the same coordination strategy, they can choose in a pairwise or a group-wise

110
manner so that a subset of the agents coordinate to choose the same strategy. This will lead todifferent case-bases at different agents and an agent may have more than one case-base if it is apart of more than one group. This leads us to another scalability issue: the number of agents. Ifthere are a large number of agents, then common situation vectors may lose “too many” detailsabout the situations. Pairwise or group-wise coordination may be a better option. However, wehave to deal with issues such as inconsistent and conflicting knowledge among the case-bases,formation of appropriate groups, and different amounts of learning for different groups.
Even if you’re on the right track, you’ll get run over if you just sit there.Arthur Godfrey

C H A P T E R 6
CONCLUSIONS AND FUTURE WORK
To travel hopefully is a better thing than to arrive, and the true success is to labour.Robert L. Stevenson
When you have completed 95% of your journey you are halfway there.Japanese Proverb
Recent interest in the subarea of learning in multi-agent systems has led to work on twodifferent aspects: 1) learning structured as a multi-agent problem where the agents learn overa domain and 2) learning problem solving control in multi-agent systems. This thesis isconcerned with the latter aspect. We deal with multi-agent systems that cooperate explicitlythrough direct communication. In a multi-agent system, the local activities of an agenthave global implications about which the agent may only be partially informed. In orderto achieve coherent activity among such a group of agents, each agent resorts to certaincooperative control activities exploiting organizational knowledge or negotiation strategies orcoordination mechanisms. In this chapter, we briefly recapitulate the contributions of thisdissertation in learning such cooperative control knowledge and summarize what has alreadybeen accomplished and what needs to be done.
The gist of the contributions of this thesis is the recognition of the need for globallysituating the learned local cooperative control activities with non-local implications. Globalsituations are abstractions of the global problem solving states derived from the local problemsolving states of all the agents and the observed environment. We support this observationempirically, using three different studies, indicative of the generality of the need for groundingcontrol knowledge in situations, especially in explicitly cooperative directly communicatingMAS. Moreover, in our studies, learning capabilities were incorporated into already existing,complex, and realistic multi-agent search and coordination systems.6.1 Learning Organizational roles
Organizational roles represent an assignment of particular sets of tasks to be performedby each of the agents in the context of a solution. The kinds of organizational roles assignedto the agents have a crucial effect on the search efficiency and the solution quality of amulti-agent system. However, when a system integrator is using a resuable set of agents toassemble a multi-agent system, it is not feasible to expect him/her to know enough about theagents and their various interactions, to assign appropriate roles. In Chapter 3, we empiricallydemonstrated the effectiveness of learning situation-specific organizational roles in a systemcalled L-TEAM, that is a system comprising heterogeneous reusable agents. The agents inL-TEAM perform an asynchronous distributed constraint-optimization search to obtain agood overall design. Each of the agents in L-TEAM has its own local state information, a local

112
database with static and dynamic constraints on its design components and a local agenda ofpotential actions. Each agent is responsible for one component in the overall design and thegoal of the agents is to produce a mutually acceptable design. The search is performed over aspace of partial designs. It starts with the problem specification placed on a blackboard that isvisible to all the agents. Some of the agents may initiate seed proposals based on the problemspecification and locally known requirements on the design and place them on the blackboard.Other agents may extend or critique these proposals and in the process may detect conflicts.Conflict detection leads to feedback to the relevant agents; consequently affecting their furthersearch by either pruning or reordering the expansion of certain paths.
Learning organizational roles in L-TEAM involved evolving a credibility function based onutility, probability and potential measures for the possible alternative roles for each of the agents.The roles had situations associated with them and different roles were instantiated in differentsituations based on the utility, probability and potential measures. Reinforcement learningtechniques were used to accumulate these measures. We tested the system in a steam condenserdesign domain, where four agents - pump-agent, motor-agent, heat-exchanger-agent, and vbelt-agent- learned situation-specific choice between two organizationalroles - design-initiator or design-extender. Our experimental results demonstrated that theorganizational knowledge grounded in global situations leads to better designs (significantlybetter for harder problems) than non-situation specific organizations and also hand-codedorganizational role assignments. In addition, we introduced the concept of potential that playsan important role in reflecting the meta-level considerations in determining the suitability of arole for an agent in a particular situation. We empirically demonstrated that organizations thattake potential into consideration produce better designs than those that do not.
6.2 Learning Non-local Requirements in a Cooperative Search Process
Chapter 4 deals with learning to cooperatively search in a multi-agent parametric designsystem. We formalized the search process in TEAM as a distributed constraint optimizationsearch. We defined the notion of projection as a view of a search space with respect to a set ofvariables and used projections on shared variables between agents to derive an agent’s view ofanother agent’s local search space. A view that is incompatible with an agent’s local search spaceleads to conflicts and the consequent feedback process. Composite search space in which afeasible solution lies can be derived as the intersection of the projections of agents’ local searchspaces with respect to the variables in the overall design. An agent needs to learn about otheragents’ constraints on the composite search space with respect to shared variables to performlocal search effectively and contribute acceptable components to the final designs.
We used this framework to formalize and study two types of learning in such a cooperativesearch process: Negotiated search is formalized as a short term learning method and case-basedlearning is formalized as a long term learning method that bypasses the need for negotiatedsearch by caching away past problem-solving experience in terms of the kinds of conflictsencountered and the resultant feedback from other agents. As shown in Chapter 4, both thelearning methods performed significantly better than not having any learning at all. Moreover,case-based learning method achieves this performance without recourse to communication. Itrelies on past conflict knowledge associated with similar overall design requirements. Empiricalresults have again demonstrated to us, the power of situation-specific learning in acquiringanother aspect of cooperative control. Weak notions of situation-specificity as the overall

113
design requirements sufficed in these studies. However, our notion of situations is moresophisticated, as evidenced by the studies in Chapter 3, and Chapter 5.
6.3 Learning Coordination in a Complex System
Chapter 5 deals with learning yet another important aspect of cooperative control:coordination strategies. The studies in this chapter are based on Generalized Partial GlobalPlanning algorithms that were laid out as a set of domain independent coordination mechanismsfor achieving effective management of interdependent activities in a multi-agent system. Ourwork in this area empirically showed the effectiveness of learning situation-specific coordination.The learning methods enabled the agents to exploit the meta-level information about the globalproblem solving state to allow them to choose a coordination strategy from among a fixed classof strategies. Each agent forms a local situation vector that predicts the effectiveness of detectingcoordination interrelationships, the load and the time pressure at an agent. Agents exchangethese situations to form a global situation vector representing an abstraction of the globalproblem solving state. Agents use the situation vectors to form an instance base that storesthe relative performance of various coordination strategies in these situations. Agents can usesimilar instances in the past to approximate the relative performance of various coordinationstrategies in a given problem instance. Our experiments revealed that the learning agentsperformed better than using any one coordination strategy over all the problem instances.We studied two learning modes: off-line learning and quasi-online learning in five domains,two of which belonged to the distributed data processing task and three were synthetic. Infour of these domains, the learning algorithms performed better than using any one of thecoordination strategies on all the problem instances. In one grammar, the lack of variance inthe best coordination algorithm made it not worthwhile to incur the additional expense ofcommunicating situations to exploit the learned knowledge.
In the process of testing our insights on learning coordination, we created an attributestochastic graph-grammar-based task structure description language and generation tool forabstract modeling of the coordination activities arising in a domain. This framework capturesthe morphological regularities in the domain task structures while simultaneously modelingdomain semantics through a number of attributes associated with the rewrite rules. We usedthis tool to model the NASA distributed data processing domain and experimentally studiedissues concerning functional organization and learning coordination. We also created a numberof synthetic domains to test our insights on learning coordination, and concluded that learningis especially effective in dynamic domains where the variance in the effectiveness of differentcoordination strategies is large.
In addition, we used the IBL methods in a novel task of decision theoretic choice ofcoordination strategies. The use of IBL methods in the past has been primarily confined tosupervised classification tasks and function approximation tasks.
6.4 Future Work
It’s tough to make predictions, especially about the future.Yogi Berra
The work in this thesis leads to many interesting questions. In fact, we view this work asonly a first pass at a more unified theory of learning in multi-agent systems - especially complex

114
cooperative multi-agent systems. We discussed some of the issues pertinent to each of thespecific pieces of work in Chapter 3, Chapter 4 and Chapter 5. In Chapter 3, we discussed theneed for learning for complex forms of organizational knowledge, beyond the roles of the agents.As evidenced from the diversity and sophistication of human organizations, there is much thatcan be studied in this direction. Towards the end of Chapter 4, we discussed our initial foraysinto how conflict-driven learning and case-based learning may be used to complement eachother. We pointed out the need to study a variety of conflict resolution mechanisms that let theagents choose among the different types of options for resolving inconsistencies between thedifferent types of learned knowledge. We also pointed out the possibility of extending theselearning mechanisms to serve as a basis for capturing more complex forms of design rationale.The end of Chapter 5 raises issues that need much more attention than we have so far provided.Learning weights for the features in a situation vector could enhance the performance of thesystem. Issues of scalability of COLLAGE along the dimensions of the size of the instance-baseand the number of agents also need much more attention. As the number of coordinationstrategies grows, there may be a need for a better way to explore the space of situation vectorsto derive a more manageable and yet sufficiently discriminating instance-base. This may beachieved through a structured organization of the instance-base and focused experimentation.As the number of agents increases, we may need to have better mechanisms for forming globalsituations, and perhaps different coordination mechanisms and their corresponding case-basesfor different subsets of agents.
In the more general context of multi-agent learning, three important questions may havealready risen in the minds of the readers:� How does an agent designer or an agent choose a representation for situations? As
mentioned previously, in Chapter 1, more detailed and discriminating situations leadto a better and more informed learning on the part of the agents. However, there isa cost to be payed because more detailed situations would imply more control costs interms of packaging and communicating, and assimilating this information on the partof the agents. One of the important future directions of our work is to investigatehow situation representations can be designed in principled way. We can appeal toautomated methods for abstraction as in Knoblock et al.[Knoblock et al., 1991] orlearning methods as in Sugawara and Lesser[Sugawara and Lesser, 1993]. Knoblock et
al.[Knoblock et al., 1991] discuss a system called ALPINE that automatically generatesabstractions by systematically dropping literals from the original problem definition. It isnot immediately obvious how this work can be extended to systems such as L-TEAM orCOLLAGE, where the problem definition and the problem solving control are notnecessarily expressed declaratively. However, the methods in ALPINE and relatedsystems are expected to provide inspiration in our search for ways to automaticallygenerate situation abstractions. The work done by Sugawara and Lesser[Sugawara and
Lesser, 1993] is interesting in that the agents start out with a weak or no notion ofsituation-specificity for coordination and gradually learn to evolve better representationsfor situations based on failure driven learning. However, their learning methods appealto knowledge intensive explanation-based learning and comparative traces. Thesemethods have strong assumptions about deep domain knowledge and homogeneityof problem solving processes (in order to facilitate comparison of traces). In spite of
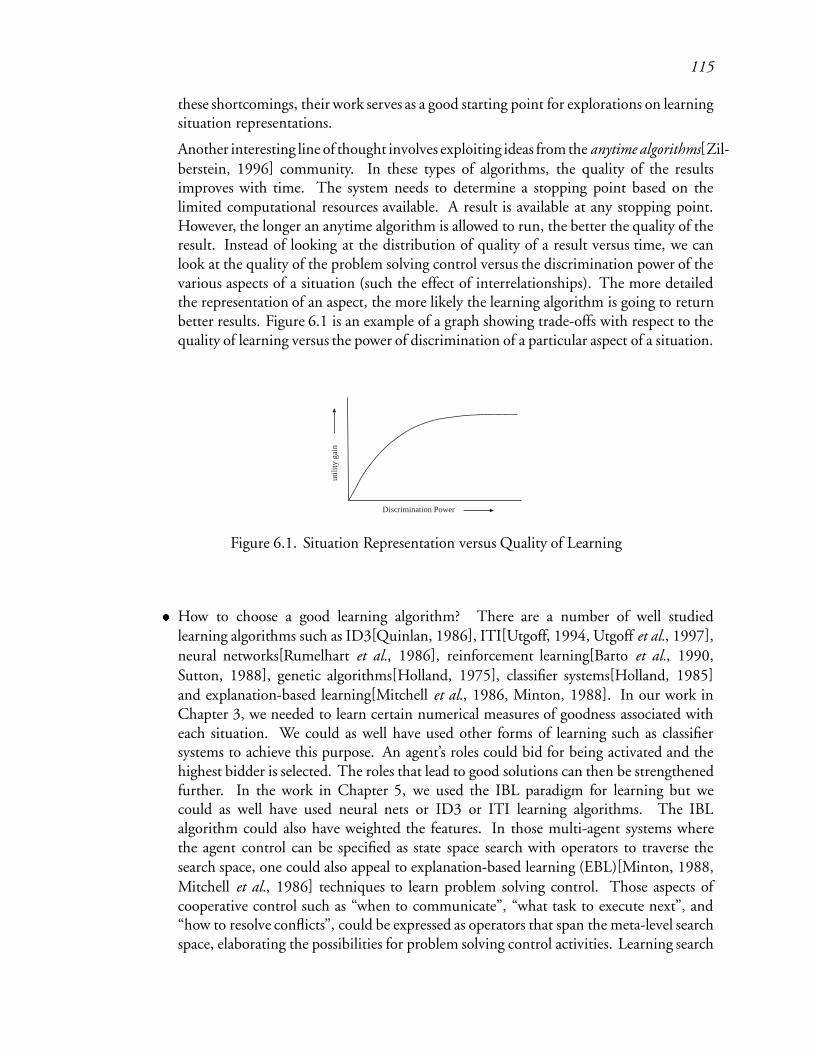
115
these shortcomings, their work serves as a good starting point for explorations on learningsituation representations.
Another interesting line of thought involves exploiting ideas from the anytime algorithms[Zil-
berstein, 1996] community. In these types of algorithms, the quality of the resultsimproves with time. The system needs to determine a stopping point based on thelimited computational resources available. A result is available at any stopping point.However, the longer an anytime algorithm is allowed to run, the better the quality of theresult. Instead of looking at the distribution of quality of a result versus time, we canlook at the quality of the problem solving control versus the discrimination power of thevarious aspects of a situation (such the effect of interrelationships). The more detailedthe representation of an aspect, the more likely the learning algorithm is going to returnbetter results. Figure 6.1 is an example of a graph showing trade-offs with respect to thequality of learning versus the power of discrimination of a particular aspect of a situation.
Discrimination Power
utili
ty g
ain
Figure 6.1. Situation Representation versus Quality of Learning� How to choose a good learning algorithm? There are a number of well studiedlearning algorithms such as ID3[Quinlan, 1986], ITI[Utgoff, 1994, Utgoff et al., 1997],
neural networks[Rumelhart et al., 1986], reinforcement learning[Barto et al., 1990,
Sutton, 1988], genetic algorithms[Holland, 1975], classifier systems[Holland, 1985]
and explanation-based learning[Mitchell et al., 1986, Minton, 1988]. In our work inChapter 3, we needed to learn certain numerical measures of goodness associated witheach situation. We could as well have used other forms of learning such as classifiersystems to achieve this purpose. An agent’s roles could bid for being activated and thehighest bidder is selected. The roles that lead to good solutions can then be strengthenedfurther. In the work in Chapter 5, we used the IBL paradigm for learning but wecould as well have used neural nets or ID3 or ITI learning algorithms. The IBLalgorithm could also have weighted the features. In those multi-agent systems wherethe agent control can be specified as state space search with operators to traverse thesearch space, one could also appeal to explanation-based learning (EBL)[Minton, 1988,
Mitchell et al., 1986] techniques to learn problem solving control. Those aspects ofcooperative control such as “when to communicate”, “what task to execute next”, and“how to resolve conflicts”, could be expressed as operators that span the meta-level searchspace, elaborating the possibilities for problem solving control activities. Learning search

116
control in such a system can lead to a more efficient problem solving control. Forexample, iterative conflict resolution through a sequential and reactive application of theconflict resolution operators can be replaced by “macros” learned through EBL. These“macros” obviate the need for a sequential application of the operators and create theeffect of application of these operators through a single application of such a “macro”.
The main intention of our work was not comparative performances of different algo-rithms. However, this does not take away from the fact that there is a need to characterizethe features of the environment and the learning tasks that may indicate the suitabilityof different learning algorithms for different needs.� Can these methods hold for selfish agents? At first it might look implausible. Whyshould a selfish agent give all the information that another agent needs about its localsituation? What is the guarantee that an agent is not lying about its local situations?However, a closer examination reveals some possible directions for extending this workto selfish agents. An agent asking another agent may not get all the information it wants.The other agent may reveal some of it - to the extent that it works to its benefit in future.An agent may coerce, threaten, cheat or entice other agents to obtain the situations.Schemes can be devised to let selfish agents negotiate among themselves to exchange
situations[Rosenschein and Zlotkin, 1994] or form coalitions to benefit from situationexchanges[Sandholm and Lesser, 1995]. Learning situation-specific control in a systemof selfish agents remains a relatively unexplored and yet, a very interesting direction ofresearch.
Some of our recent work on learning explores a radically different end of the spectrumof situation specific learning. In Nagendra Prasad, Lesser and Lander[Nagendra Prasad et al.,1995b, Nagendra Prasad et al., 1996c, Nagendra Prasad and Lesser, 1996a], we deal with multi-agent case-based reasoning. Each of the agents contributes a subcase to an overall compositecase and assembling such a composite case is achieved through distributed search. In theprocess of assembling the subcases, conflicts between subcases are resolved through cooperativesearch rather than avoided through elaborate indexing using goals and subgoals representingthe context of the subcases. Herein lies the major difference between the learning in the systemspresented in this thesis and the work by Nagendra Prasad, Lesser and Lander[Nagendra Prasad
et al., 1995b, Nagendra Prasad et al., 1996c]. In order to overcome uncertainty, the agentsneed to augment their process of exploiting past knowledge with lazy search (lazy in the senseof searching on an “as needed” basis), rather than avoid uncertainty by a priori grounding
in global situations. Some of the more recent work in progress[Nagendra Prasad and Lesser,1996a] is tackling the interplay between the two ends of this spectrum and what lies in the
middle. Preliminary results have been very illuminating[Nagendra Prasad and Lesser, 1996a].We strongly believe that understanding such an interplay will play a profound role in evolvinga general theory of multi-agent learning and could possibly shed light on complex systems withinteracting components.
It is better to know some of the questions than all the answersJames Thurber

A P P E N D I X A
LEARNING RULES FOR UTILITY, PROBABILITY, AND
POTENTIAL
The learning rules we used in Chapter 3 for Utility, Probability, and Potential measuresare based on certain intuitive properties. Below, we present these properties and prove that thelearning rules satisfy these properties.
Let us assume that k passes of learning have already been achieved and the system now islearning from the search resulting from (k+1) th problem solving instance.
For updating the Utility of each participant node at the (k+1) th learning pass, we need anupdate rule which satisfies the following intuitive requirements:
1. The predicted utility of a state should remain within [-m, n] where m and n are realnumbers. In some systems, these bounds may be artificial but it is advantageous to letthe solution utilities not grow unbounded.
2. If the system, at k+1 th search performs better (ends in a higher utility final state) thanwhat was predicted by accumulated measures from k passes for the same situation foran operator, then the utility of that operator in the situation should be increased for thesubsequent passes.
3. If the system, at k+1 th search performs worse (ends in a lower utility final state) thanwhat was predicted by accumulated measures from k passes for the same situation for anoperator, then the utility of that operator for the situation should be decreased for thesubsequent passes.
Let (k)U ji represent the predicted utility of the final solution achieved by using an operator i
in a state n which can be classified as situation j, accumulated after k problem solving instances1and let T be the search tree, F (T ) be the set of states on the path to a final state F , UF be theutility of the solution and let 0 � � � 1 be the learning rate. Then:(k+1)U ji = (k)U ji + � (UF � (k)U ji ); n 2 F (T ) and n 2 situation j (A.1)
Thus the agent that applied opi, modifies the Utility for its opi in situation j.It is easy to see that the above equation satisfies previously discussed properties we wanted
a utility update scheme to exhibit.1In the discussion below we just use (k)U for a utility value after k iteration in order not to clutter the
presentation.

118
1. At any given iteration k, Umin � (k)U � Umax where Umin and Umax are respectivelythe minimum and maximum possible solution utilities.
The proof is by induction. Assume that at zeroth iteration we start with a (0)U such thatUmin � 0U � Umax.
Let it be true after m iterations of the learner. Then we haveUmin � (m)U � UmaxAt (m+1) th iteration,If UF � (m)U , then it is apparent thatUmin � (m)U + �(UF � (m)U)= (m+1)Usince Umin � (m)U and �(UF � (m)U ) � 0.
If UF < (m)U Umin = (m)U + Umin � (m)U� (m)U + �(Umin � (m)U ) since 0 � � � 1� (m)U + �(UF � (m)U) since UF � Umin= (k+1)U:The proof for (m+1)U � Umax follows similar lines and is omitted here.
2 & 3. If the utility of the solution at iteration (k+1), UF , is � kU , then(k+1)U = (k)U + �(UF � (k)U)� (k)USimilarly , if the utility of the solution at iteration (k+1), UF , is � (k)U , then(k+1)U = (k)U + �(UF � (k)U)� (k)U
The derivation for the learning rules for potetial follows along similar lines. For updatingthe estimates of probabilities, we would like the learning rule to have the following desirableproperties:
1. The probability values should be contained in [0,1].
2. Each agent that, in a given situation applies an operator while participating in a successfulsolution path should have the probability value for that operator, given that situationincremented for the subsequent iterations.

119
3. Each agent that, in a given situation applies an operator while participating in anunsuccessful solution path should have the probability value for that operator, given thatsituation decremented for the subsequent iterations.
Let (k)P ji represent the probability that using an operator i in a state n which can be
classified as situation j will lead to a final state, acc umulated after k problem solving instances2.Let T be the search tree, F (T ) be the set of states on the path to a terminal state F , letOF 2 f0; 1g be the output of the terminal state F with 1 representing success and 0 a failureand let 0 � � � 1 be the learning rate. Then:(k+1)P ji = (1� �)(k)P ji + �OF ; n 2 F (T ) and n 2 situation j (A.2)
The above equation satisfies previously discussed properties we wanted a probability updatescheme to exhibit. The proofs are very similar to those discussed for utility update scheme andare hence omitted here.
2In the discussion below we just use (k)P for a probability value after k iterations.

A P P E N D I X B
ROUGH COORDINATION
B.1 Implementing Rough Coordination
In order to implement rough coordination, we had to extend the existing set of mechanismsin GPGP for hard and soft coordination relationships. These mechanisms were modified totake three options: active, inactive or rough. Rough commitments in an agent’s belief databasearise out of it’s past experience or organizational knowledge handed to it either by the agentdesigner or through certain system parameters. An agent with rough coordination option addsthe rough commitments in its belief database to the set of active commitments. Note howeverthat Agent X on the predecessor side of the commitment need not communicate it to thesuccessor side, as Agent Y corresponding to the successor side derives a non-local commitmentfrom Agent X from its rough commitments and adds it to its set of active commitments. Moreformally, both Agent X and Agent Y add commitments as follows:[Crough(DL(T;Qrough(T;D(T )); trough)) 2 RC] ^ [enables(T;M) 2 HPCR]) [C(DL(T;Qrough(T;D(T )); tearly)) 2 C]Rough commitments on soft coordination relationships are treated similarly.
B.2 Developing Rough Commitments
There are a number ways an agent could develop rough commitments. Agents could beenendowed with rough commitments by a domain expert. Alternately, agents could learn themfrom past experience. In our experiments on rough coordination, agents rely on the latterapproach to develop their rough commitments. Agents use a coordination strategy that formscommitments dynamically (in our case balanced) and use the time and quality of thesecommitments to develop average time and quality of each commitment and their variancesover a number of runs (we used 100 runs in our experiments). The quality of a result for a roughcommitment is derived as average quality � standard deviation in quality. Similarly,the time is derived as average time+ standard deviation in time.

A P P E N D I X C
DOMAIN GRAMMARS
This appendix specifies the grammars we used in our experiments for learning coordination.The syntax for specifying these grammars is relatively self-explanatory. Note that eventhoughthe grammar specification looks like a string grammar specification, it is actually a graph gram-mar. A rewrite rule like S --> (S1 S2 S4) is implies that node S in the graph is replacedby a subgraph that has a task S and subtasks S1, S2, S3 and the interrelationships fieldspecifies additional types of edges that exist between the tasks. Other attributes include q-fnfor the quality accumulation function, method-q-fn for the method quality accumulationfunction, agents for the agents that see that method at the time of the generation of the taskstructure, duration-distributions for the parameters of the distributions (Gaussianwas used in our experiments) from which the initial maximum duration of the method isderived, and quality-distributions from which the initial maximum quality of themethod was derived.

122
C.1 Grammar G1
(:start-symbol S)
(:terminals (A111 A112 A121 A122 A131 A132 A211 A212 A221 A222A231 A232 A311 A312 A321 A322 A411 A412 A421 A422A431 A432))
(:non-terminals (S S1 S2 S3 S4 S11 S12 S13 S21 S22 S23 S31 S32S41 S42 S43 S111 S112 S121 S122 S131 S132 S211S212 S221 S222 S231 S232 S311 S312 S321 S322S411 S412 S421 S422 S431 S432))
S --> (S1 S2 S4) :probability 0.5:attributes (:q-fn q-max)
S --> (S1 S2 S3) :probability 0.3:attributes (:q-fn q-max)
S --> (S1 S2) :probability 0.2:attributes (:q-fn q-max)
S1 --> (S11 S12 S13) :probability 0.5:attributes ((:q-fn q-min):interrelationships (enables S11 S12)
S1 --> (S11 S12) :probability 0.5:attributes (:q-fn q-min):interrelationships (facilitates S11 S12 0.5 0.5)
S2 --> (S21 S22) :probability 0.5:attributes (:q-fn q-min):interrelationships (enables S21 S22)
S2 --> (S21 S23) :probability 0.5:attributes (:q-fn q-min):interrelationships (facilitates S21 S23 0.5 0.5)
S3 --> (S31 S32) :probability 1.0:attributes (:q-fn q-min):interrelationships (facilitates S31 S32 0.5 0.5)
S4 --> (S41 S42) :probability 0.2:attributes (:q-fn q-min):interrelationships (enables S41 S42)
S4 --> (S41 S43) :probability 0.8:attributes ((:q-fn q-min):interrelationships (enables S41 S43)
S11 --> (S111 S112) :probability 1.0:attributes (:q-fn q-min):interrelationships (facilitates S111 S112 0.5 0.5)
S12 --> (S121 S122) :probability 1.0:attributes (:q-fn q-min)
S13 --> (S131 S132) :probability 1.0:attributes (:q-fn q-min):interrelationships (facilitates S131 S132 0.5 0.5)
S21 --> (S211 S212) :probability 1.0:attributes (:q-fn q-min)
S22 --> (S221 S222) :probability 1.0:attributes (:q-fn q-min)
S23 --> (S231 S232) :probability 1.0:attributes (:q-fn q-min)
S31 --> (S311 S312) :probability 1.0:attributes (:q-fn q-min)
S32 --> (S321 S322) :probability 1.0:attributes (:q-fn q-min)
S41 --> (S411 S412) :probability 1.0:attributes (:q-fn q-min)
S42 --> (S421 S422) :probability 1.0:attributes (:q-fn q-min)
S43 --> (S431 S432) :probability 1.0:attributes (:q-fn q-min)
S111 --> (A111) :probability 1.0

123
:attributes (:q-fn q-max)(:method-q-fns (A111 q-dtt-dead))
:agents (A111 (1)):duration-distributions (A111 (5 1.5):quality-distributions (A111 (15 3)
S112 --> (A112) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A112 q-dtt-dead)):agents (A112 (2)):duration-distributions (A112 (5 1.5)):quality-distributions (A112 (15 3))
S121 --> (A121) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A121 q-dtt-dead)):agents (A121 (1)):duration-distributions (A121 (5 1.5)):quality-distributions (A121 (15 3))
S122 --> (A122) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A122 q-dtt-dead)):agents (A122 (2)):duration-distributions (A122 (5 1.5)):quality-distributions (A122 (15 3))
S131 --> (A131) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A131 q-dtt-dead)):agents (A131 (4)):duration-distributions (A131 (5 1.5)):quality-distributions (A131 (15 3))
S132 --> (A132) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A132 q-dtt-dead)):agents (A132 (3)):duration-distributions (A132 (5 1.5)):quality-distributions (A132 (15 3))
S211 --> (A211) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A211 q-dtt-dead)):agents (A211 (4)):duration-distributions (A211 (5 1.5)):quality-distributions (A211 (15 3))
S212 --> (A212) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A212 q-dtt-dead)):agents (A212 (4)):duration-distributions (A212 (5 1.5)):quality-distributions (A212 (15 3))
S221 --> (A221) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A221 q-dtt-dead)):agents (A221 (3)):duration-distributions (A221 (5 1.5)):quality-distributions (A221 (15 3))
S222 --> (A222) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A222 q-dtt-dead)):agents (A222 (3)):duration-distributions (A222 (5 1.5)):quality-distributions (A222 (15 3))
S231 --> (A231) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A231 q-dtt-dead)):agents (A231 (3)):duration-distributions (A231 (5 1.5)):quality-distributions (A231 (15 3))
S232 --> (A232) :probability 1.0:attributes (:q-fn q-max)

124
(:method-q-fns (A232 q-dtt-dead)):agents (A232 (4)):duration-distributions (A232 (5 1.5)):quality-distributions (A232 (15 3))
S311 --> (A311) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A311 q-dtt-dead)):agents (A311 (3)):duration-distributions (A311 (5 1.5)):quality-distributions (A311 (15 3))
S312 --> (A312) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A312 q-dtt-dead)):agents (A312 (3)):duration-distributions (A312 (5 1.5)):quality-distributions (A312 (15 3))
S321 --> (A321) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A321 q-dtt-dead)):agents (A321 (3)):duration-distributions (A321 (5 1.5)):quality-distributions (A321 (15 3))
S322 --> (A322) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A322 q-dtt-dead)):agents (A322 (3)):duration-distributions (A322 (5 1.5)):quality-distributions (A322 (15 3))
S411 --> (A411) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A411 q-dtt-dead)):agents (A411 (1)):duration-distributions (A411 (5 1.5)):quality-distributions (A411 (15 3))
S412 --> (A412) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A412 q-dtt-dead)):agents (A412 (1)):duration-distributions (A412 (5 1.5)):quality-distributions (A412 (15 3))
S421 --> (A421) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A421 q-dtt-dead)):agents (A421 (1)):duration-distributions (A421 (5 1.5)):quality-distributions (A421 (15 3))
S422 --> (A422) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A422 q-dtt-dead)):agents (A422 (1)):duration-distributions (A422 (5 1.5)):quality-distributions (A422 (15 3))
S431 --> (A431) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A431 q-dtt-dead)):agents (A431 (1)):duration-distributions (A431 (5 1.5)):quality-distributions (A431 (15 3))
S432 --> (A432) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A432 q-dtt-dead)):agents (A432 (1)):duration-distributions (A432 (5 1.5)):quality-distributions (A432 (15 3))
(:deadline (0.75 6))

125
C.2 Grammar G2
(:start-symbol S)
(:terminals (A111 A112 A121 A122 A131 A132 A211 A212 A221 A222A231 A232 A311 A312 A321 A322 A411 A412 A421 A422A431 A432))
(:non-terminals (S S1 S2 S3 S4 S11 S12 S13 S21 S22 S23 S31 S32S41 S42 S43 S111 S112 S121 S122 S131 S132 S211S212 S221 S222 S231 S232 S311 S312 S321 S322S411 S412 S421 S422 S431 S432))
S --> (S1 S2 S4) :probability 0.5:attributes (:q-fn q-max)
S --> (S1 S2 S3) :probability 0.3:attributes (:q-fn q-max)
S --> (S1 S2) :probability 0.2:attributes (:q-fn q-max)
S1 --> (S11 S12 S13) :probability 0.5:attributes ((:q-fn q-min):interrelationships (enables S11 S12)
S1 --> (S11 S12) :probability 0.5:attributes (:q-fn q-min):interrelationships (facilitates S11 S12 0.5 0.5)
S2 --> (S21 S22) :probability 0.5:attributes (:q-fn q-min):interrelationships (enables S21 S22)
S2 --> (S21 S23) :probability 0.5:attributes (:q-fn q-min):interrelationships (facilitates S21 S23 0.5 0.5)
S3 --> (S31 S32) :probability 1.0:attributes (:q-fn q-min):interrelationships (facilitates S31 S32 0.5 0.5)
S4 --> (S41 S42) :probability 0.2:attributes (:q-fn q-min):interrelationships (enables S41 S42)
S4 --> (S41 S43) :probability 0.8:attributes ((:q-fn q-min):interrelationships (enables S41 S43)
S11 --> (S111 S112) :probability 1.0:attributes (:q-fn q-min):interrelationships (facilitates S111 S112 0.5 0.5)
S12 --> (S121 S122) :probability 1.0:attributes (:q-fn q-min)
S13 --> (S131 S132) :probability 1.0:attributes (:q-fn q-min):interrelationships (facilitates S131 S132 0.5 0.5)
S21 --> (S211 S212) :probability 1.0:attributes (:q-fn q-min)
S22 --> (S221 S222) :probability 1.0:attributes (:q-fn q-min)
S23 --> (S231 S232) :probability 1.0:attributes (:q-fn q-min)
S31 --> (S311 S312) :probability 1.0:attributes (:q-fn q-min)
S32 --> (S321 S322) :probability 1.0:attributes (:q-fn q-min)
S41 --> (S411 S412) :probability 1.0:attributes (:q-fn q-min)
S42 --> (S421 S422) :probability 1.0:attributes (:q-fn q-min)
S43 --> (S431 S432) :probability 1.0:attributes (:q-fn q-min)
S111 --> (A111) :probability 1.0

126
:attributes (:q-fn q-max)(:method-q-fns (A111 q-dtt-dead))
:agents (A111 (1)):duration-distributions (A111 (5 2)):quality-distributions (A111 (15 3))
S112 --> (A112) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A112 q-dtt-dead)):agents (A112 (2)):duration-distributions (A112 (13 2))(:quality-distributions((A112 (25 3))
S121 --> (A121) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A121 q-dtt-dead)):agents (A121 (1)):duration-distributions (A121 (4 1)):quality-distributions (A121 (15 3))
S122 --> (A122) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A122 q-dtt-dead)):agents (A122 (2)):duration-distributions (A122 (11 2))(:quality-distributions((A122 (23 2))
S131 --> (A131) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A131 q-dtt-dead)):agents (A131 (4)):duration-distributions (A131 (5 2)):quality-distributions (A131 (10 3))
S132 --> (A132) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A132 q-dtt-dead)):agents (A132 (3)):duration-distributions (A132 (15 3))(:quality-distributions((A132 (20 3))
S211 --> (A211) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A211 q-dtt-dead)):agents (A211 (4)):duration-distributions (A211 (6 2)):quality-distributions (A211 (15 3))
S212 --> (A212) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A212 q-dtt-dead)):agents (A212 (4)):duration-distributions (A212 (16 3))(:quality-distributions((A212 (25 3))
S221 --> (A221) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A221 q-dtt-dead)):agents (A221 (3)):duration-distributions (A221 (5 1)):quality-distributions (A221 (12 3))
S222 --> (A222) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A222 q-dtt-dead)):agents (A222 (3)):duration-distributions (A222 (11 2))(:quality-distributions((A222 (22 3))
S231 --> (A231) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A231 q-dtt-dead)):agents (A231 (3)):duration-distributions (A231 (10 2))(:quality-distributions((A231 (15 3))
S232 --> (A232) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A232 q-dtt-dead))

127
:agents (A232 (4)):duration-distributions (A232 (20 2))(:quality-distributions((A232 (25 2))
S311 --> (A311) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A311 q-dtt-dead)):agents (A311 (3)):duration-distributions (A311 (8 3)):quality-distributions (A311 (15 2))
S312 --> (A312) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A312 q-dtt-dead)):agents (A312 (3)):duration-distributions (A312 (20 3))(:quality-distributions((A312 (25 3))
S321 --> (A321) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A321 q-dtt-dead)):agents (A321 (3)):duration-distributions (A321 (4 1)):quality-distributions (A321 (10 3))
S322 --> (A322) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A322 q-dtt-dead)):agents (A322 (3)):duration-distributions (A322 (15 4))(:quality-distributions((A322 (20 3))
S411 --> (A411) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A411 q-dtt-dead)):agents (A411 (1)):duration-distributions (A411 (5 1)):quality-distributions (A411 (15 3))
S412 --> (A412) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A412 q-dtt-dead)):agents (A412 (1)):duration-distributions (A412 (10 2))(:quality-distributions((A412 (25 3))
S421 --> (A421) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A421 q-dtt-dead)):agents (A421 (1)):duration-distributions (A421 (5 1.5)):QUALITY-DISTRIBUTION (A421 (15 3))
S422 --> (A422) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A422 q-dtt-dead)):agents (A422 (1)):duration-distributions (A422 (10 1.5)):quality-distributions (A422 (25 3))
S431 --> (A431) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A431 q-dtt-dead)):agents (A431 (1)):duration-distributions (A431 (5 1.5)):QUALITY-DISTRIBUTION (A431 (15 3))
S432 --> (A432) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A432 q-dtt-dead)):agents (A432 (1)):duration-distributions (A432 (10 1.5)):quality-distributions (A432 (25 3))
(:deadline (0.75 6))

128
C.3 Grammar G3
(:start-symbol S)(:terminals (A11 A12 A13 A21 A22 A31 A32 A33 A41 A42 A51
A52 A61 A62 A63 A71 A72 A81 A82 A83))(:non-terminals (S S1 S2 S3 S4 S5 S6 S7 S8 S11 S12 S13 S21 S22
S31 S32 S33 S41 S42 S51 S52 S61 S62 S63 S71S72 S81 S82 S83))
S --> (S1 S2 S3 S4) :probability 0.5:attributes (:q-fn q-min):INTER-RELATIONSHIPS (facilitates S1 S2 0.5 0.5)
(facilitates S3 S4 0.5 0.5)S --> (S5 S6 S7 S8) :probability 0.5
:attributes (:q-fn q-min):INTER-RELATIONSHIPS (enables S5 S6)
(enables S7 S8)
S1 --> (S11 S12 S13) :probability 1.0:attributes (:q-fn q-max)
S2 --> (S21 S22) :probability 1.0:attributes (:q-fn q-max)
S3 --> (S31 S32 S33) :probability 1.0:attributes (:q-fn q-max)
S4 --> (S41 S42) :probability 1.0:attributes (:q-fn q-max)
S5 --> (S51 S52) :probability 1.0:attributes (:q-fn q-max)
S6 --> (S61 S62 S63) :probability 1.0:attributes (:q-fn q-max)
S7 --> (S71 S72) :probability 1.0:attributes (:q-fn q-max)
S8 --> (S81 S82 S83) :probability 1.0:attributes (:q-fn q-max)
S11 --> (A11) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A11 q-dtt-dead)):agents (A11 (1)):duration-distributions (A11 (6 2)):quality-distributions (A11 (15 3))
S12 --> (A12) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A12 q-dtt-dead)):agents (A12 (1)):duration-distributions (A12 (15 3)):quality-distributions (A12 (27 3))
S13 --> (A13) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A13 q-dtt-dead)):agents (A13 (1)):duration-distributions (A13 (24 2)):quality-distributions (A13 (40 3))
S21 --> (A21) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A21 q-dtt-dead)):agents (A21 (2)):duration-distributions (A21 (8 2)):quality-distributions (A21 (10 3))
S22 --> (A22) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A22 q-dtt-dead)):agents (A22 (2)):duration-distributions (A22 (18 2)):quality-distributions (A22 (22 3))
S31 --> (A31) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A31 q-dtt-dead))

129
:agents (A31 (3)):duration-distributions (A31 (5 2)):quality-distributions (A31 (10 3))
S32 --> (A32) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A32 q-dtt-dead)):agents (A32 (3)):duration-distributions (A32 (13 2)):quality-distributions (A32 (25 3))
S33 --> (A33) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A33 q-dtt-dead)):agents (A33 (3)):duration-distributions (A33 (20 2)):quality-distributions (A33 (40 3))
S41 --> (A41) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A41 q-dtt-dead)):agents (A41 (4)):duration-distributions (A41 (8 2)):quality-distributions (A41 (10 2))
S42 --> (A42) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A42 q-dtt-dead)):agents (A42 (4)):duration-distributions (A42 (15 2)):quality-distributions (A42 (20 2))
S51 --> (A51) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A51 q-dtt-dead)):agents (A51 (1)):duration-distributions (A51 (5 1)):quality-distributions (A51 (12 3))
S52 --> (A52) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A52 q-dtt-dead)):agents (A52 (1)):duration-distributions (A52 (8 1)):quality-distributions (A52 (23 3))
S61 --> (A61) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A61 q-dtt-dead)):agents (A61 (2)):duration-distributions (A61 (5 2))quality-distributions (A61 (10 3))
S62 --> (A62) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A62 q-dtt-dead)):agents (A62 (2)):duration-distributions (A62 (13 2)):quality-distributions (A62 (25 3))
S63 --> (A63) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A63 q-dtt-dead)):agents (A63 (2)):duration-distributions (A63 (20 2)):quality-distributions (A63 (35 2))
S71 --> (A71) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A71 q-dtt-dead)):agents (A71 (3)):duration-distributions (A71 (6 1))quality-distributions (A71 (10 3))
S72 --> (A72) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A72 q-dtt-dead)):agents (A72 (3)):duration-distributions (A72 (10 1))

130
:quality-distributions (A72 (25 3))S81 --> (A81) :probability 1.0
:attributes (:q-fn q-max)(:method-q-fns (A81 q-dtt-dead))
:agents (A81 (4)):duration-distributions (A81 (6 2))quality-distributions (A81 (25 3))
S82 --> (A82) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A82 q-dtt-dead)):agents (A82 (4)):duration-distributions (A82 (13 2)):quality-distributions (A82 (25 3))
S83 --> (A83) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A83 q-dtt-dead)):agents (A83 (4)):duration-distributions (A83 (21 2)):quality-distributions (A83 (35 3))
(:deadline (0.85 6))

131
C.4 Routine Tasks Grammar
(:start-symbol S)(:terminals (A11 A12 A13 A21 A22 A23 A31
A32 A33 A41 A42 A51 A52))(:non-terminals (S S1 S2 S3 S4 S5 S11 S12 S13 S21 S22
S23 S31 S32 S33 S41 S42 S51 S52))
S --> (S1 S2 S3 S4 S5) :probability 1.0:attributes (:q-fn q-min)
S1 --> (S11 S12 S13) :probability 1.0:attributes (:q-fn q-max)
S2 --> (S21 S22 S23) :probability 1.0:attributes (:q-fn q-max)
S3 --> (S31 S32 S33) :probability 1.0:attributes (:q-fn q-max)
S4 --> (S41 S42) :probability 1.0:attributes (:q-fn q-max)
S5 --> (S51 S52) :probability 1.0:attributes (:q-fn q-max)
S11 --> (A11) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A11 q-dtt-dead)):agents (A11 (1)):duration-distributions (a11 (40 5)):quality-distributions (A11 (100 10))
S12 --> (A12) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A12 q-dtt-dead)):agents (A12 (1)):duration-distributions (A12 (55 5)):quality-distributions (A12 (150 10))
S13 --> (A13) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A13 q-dtt-dead)):agents (A13 (1)):duration-distributions (A13 (70 5)):quality-distributions (A13 (180 10))
S21 --> (A21) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A21 q-dtt-dead)):agents (A21 (2)):duration-distributions (A21 (45 5)):quality-distributions (A21 (120 5))
S22 --> (A22) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A22 q-dtt-dead)):agents (A22 (2)):duration-distributions (A22 (60 5)):quality-distributions (A22 (150 5))
S23 --> (A23) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A23 q-dtt-dead)):agents (A23 (2)):duration-distributions (A23 (80 5)):quality-distributions (A23 (175 5))
S31 --> (A31) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A31 q-dtt-dead)):agents (A31 (2)):duration-distributions (A31 (40 5)):quality-distributions (A31 (100 10))
S32 --> (A32) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A32 q-dtt-dead)):agents (A32 (2)):duration-distributions (A32 (60 5))

132
:quality-distributions (A32 (135 5))S33 --> (A33) :probability 1.0
:attributes (:q-fn q-max)(:method-q-fns (A33 q-dtt-dead))
:agents (A33 (2)):duration-distributions (A33 (75 5)):quality-distributions (A33 (160 10))
S41 --> (A41) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A41 q-dtt-dead)):agents (A41 (3)):duration-distributions (A41 (42 5)):quality-distributions (A41 (100 5))
S42 --> (A42) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A42 q-dtt-dead)):agents (A42 (3)):duration-distributions (A42 (54 5)):quality-distributions (A42 (140 10))
S51 --> (A51) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A51 q-dtt-dead)):agents (A51 (3)):duration-distributions (A51 (45 5)):quality-distributions (A51 (115 10))
S52 --> (A52) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A52 q-dtt-dead)):agents (A52 (3)):duration-distributions (A52 (65 5)):quality-distributions (A52 (150 5))
(:interrelationship (facilitates S1 S2 0.5 0.5))(:interrelationship (enables S2 S4))(:interrelationship (enables S3 S4))(:interrelationship (facilitates S4 S5 0.5 0.5))
(:deadline 140)
(:prior-commitment (S3 2 S3 1 94.0 97.8))(:prior-commitment (S1 1 S1 3 78.0 178.8))(:prior-commitment (S2 2 S2 1 94.1 118.4))(:prior-commitment (S2 2 S2 3 94.1 118.4))(:prior-commitment (S1 1 S1 2 78.0 178.8))(:prior-commitment (S3 2 S3 3 94.1 97.8))

133
C.5 Crisis Tasks Grammar
(:start-symbol S)(:terminals (A11 A12 A13 A21 A22 A31 A32 A33))(:non-terminals (S S1 S2 S3 S11 S12 S13 S21 S22 S23 S31 S32 S33))S --> (S1 S2 S3) :probability 1.0
:attributes (:q-fn q-min):interrelationships (facilitates S1 S2 0.5 0.5))
S1 --> (S11 S12 S13) :probability 1.0:attributes (:q-fn q-max))
S2 --> (S21 S22) :probability 1.0:attributes (:q-fn q-max))
S3 --> (S31 S32 S33) :probability 1.0:attributes (:q-fn q-max))
S11 --> (A11) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A11 q-dtt-dead)):agents (A11 (1)):duration-distributions (A11 (40 5)):quality-distributions (A11 (225 5))
S12 --> (A12) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A12 q-dtt-dead)):agents (A12 (1)):duration-distributions (A12 (55 5)):quality-distributions (A12 (250 5))
S13 --> (A13) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A13 q-dtt-dead)):agents (A13 (1)):duration-distributions (A13 (70 5)):quality-distributions (A13 (275 5))
S21 --> (A21) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A21 q-dtt-dead)):agents (A21 (2)):duration-distributions (A21 (45 10))(:quality-distributions((A21 (250 10))
S22 --> (A22) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A22 q-dtt-dead)):agents (A22 (2)):duration-distributions (A22 (65 10))(:quality-distributions((A22 (275 5))
S31 --> (A31) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A31 q-dtt-dead)):agents (A31 (3)):duration-distributions (A31 (42 5)):quality-distributions (A31 (225 5))
S32 --> (A32) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A32 q-dtt-dead)):agents (A32 (3)):duration-distributions (A32 (55 5)):quality-distributions (A32 (240 5))
S33 --> (A33) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A33 q-dtt-dead)):agents (A33 (3)):duration-distributions (A33 (70 5)):quality-distributions (A33 (275 10))
(:interrelationship ((enables S2 S3)))(:deadline 140)

134
C.6 Low Priority Tasks Grammar
(:start-symbol S)(:terminals (A11 A12 A13 A21 A22 A23 A31 A32 A33))(:non-terminals (S S1 S2 S3 S11 S12 S13 S21 S22 S23 S31 S32 S33))
S --> (S1 S2 S3) :probability 1.0:attributes (:q-fn q-min))
S1 --> (S11 S12 S13) :probability 1.0:attributes (:q-fn q-max))
S2 --> (S21 S22 S23) :probability 1.0:attributes (:q-fn q-max))
S3 --> (S31 S32 S33) :probability 1.0:attributes (:q-fn q-max))
S11 --> (A11) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A11 q-dtt-dead)):agents (A11 (1)):duration-distributions (A11 (45 5)):quality-distributions (A11 (30 5))
S12 --> (A12) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A12 q-dtt-dead)):agents (A12 (1)):duration-distributions (A12 (60 5)):quality-distributions (A12 (45 5))
S13 --> (A13) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A13 q-dtt-dead)):agents (A13 (1)):duration-distributions (A13 (75 5)):quality-distributions (A13 (65 5))
S21 --> (A21) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A21 q-dtt-dead)):agents (A21 (2)):duration-distributions (A21 (40 5)):quality-distributions (A21 (35 5))
S22 --> (A22) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A22 q-dtt-dead)):agents (A22 (2)):duration-distributions (A22 (55 3)):quality-distributions (A22 (50 5))
S23 --> (A23) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A23 q-dtt-dead)):agents (A23 (2)):duration-distributions (A23 (63 3)):quality-distributions (A23 (65 5))
S31 --> (A31) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A31 q-dtt-dead)):agents (A31 (3)):duration-distributions (A31 (30 3)):quality-distributions (A31 (40 3))
S32 --> (A32) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A32 q-dtt-dead)):agents (A32 (3)):duration-distributions (A32 (45 5)):quality-distributions (A32 (52 3))
S33 --> (A33) :probability 1.0:attributes (:q-fn q-max)
(:method-q-fns (A33 q-dtt-dead)):agents (A33 (3)):duration-distributions (A33 (68 3))

135
:quality-distributions (A33 (65 5))
(:interrelationship ((enables S2 S3)))(:interrelationship ((facilitates S1 S3 0.5 0.5)))
(:deadline 140)

REFERENCES
[Aha et al., 1991] Aha, D. W.; Kibler, D.; and Albert, M. K. Instance-based LearningAlgorithms. Machine Learning, 6:37–66, 1991.
[Atkeson, 1990] Atkeson, C. G. Using Local Models to Control Movement. In Advances inNeural Information Processing Systems 2, pages 316–323, 1990.
[Barto et al., 1990] Barto, A.; Sutton, R.; and Watkins, C. Learning and sequential decisionmaking. In Gariel, M. and Moore, J. W., editors, Learning and Computational Neuroscience,Cambridge, MA, 1990. MIT Press.
[Barto, 1985] Barto, A. G. Learning by Statistical Cooperation of Self-interested Neuron-likeComputing Elements. Human Neurobilogy, 4:229–256, 1985.
[Barto, 1986] Barto, A. G. Game-theoretic cooperativity in networks of self-interested units.In Neural Networks for Computing (ed. J. S. Denker), pages 41–46, Snowbird, UT., 1986.
[Boddy, 1991] Boddy, M. Solving time-dependent problems: A decision-theoretic approachto planning in dynamic environments. Ph.D. Dissertation CS-91-06, Department ofComputer Science, Brown University, Providence, RI, 1991.
[Bond and (Eds), 1988] Bond, A. and (Eds), L. G. Readings in Distributed Artificial Intelli-gence. Morgan Kaufmann Publishers, San Mateo, CA, 1988.
[Bowen and Bahler, 1993] Bowen, J. and Bahler, D. Constraint-based software for concurrentengineering. IEEE Computer, 26(1):66–68, 1993.
[Brazdil and Muggleton, 1990] Brazdil, P. and Muggleton, S. Learning to relate terms in amultiple agent environment. In Kodratroff, Y., editor, Current Trends in Artificial Intelligence.IOS Press, Amsterdam, 1990.
[Byrne and Edwards, 1995] Byrne, C. and Edwards, P. Refinement in a multi-agent world.In Proceedings of the IJCAI-95 Workshop on Adaptation and Learning in Multi-Agent Systems,Montreal, CA., August 1995.
[Carmel and Markovitch, 1995] Carmel, D. and Markovitch, S. Opponent modeling in amulti-agent system. In Proceedings of the IJCAI-95 Workshop on Adaptation and Learning inMulti-Agent Systems, Montreal, CA., August 1995.
[Carver et al., 1993] Carver, N.; Lesser, V.; and Long, Q. Resolving global inconsistencyin distributed sensor interpretation: Modeling agent interpretations in DRESUN. InProceedings of the Twelfth International Workshop on Distributed AI, Hidden Valley, Pa, May1993.
[Chomsky, 1966] Chomsky, N. Syntactic Structures. Mouton and Co., 1966.

137
[Clark and Holte, 1992] Clark, P. and Holte, R. Lazy partial evaluation: An integrationof explanation-based generalization and partial evaluation. In Proceedings of the NinthInternational Machine Learning Conference, pages 82–91, 1992.
[Conry et al., 1991] Conry, S. E.; Kuwabara, K.; Lesser, V. R.; and Meyer, R. A. Multistagenegotiation for distributed constraint satisfaction. IEEE Transactions on Systems, Man, andCybernetics, 21(6), November 1991.
[Corkill and Lesser, 1983] Corkill, D. D. and Lesser, V. R. The use of meta-level controlfor coordination in a distributed problem solving network. In Proceedings of the EighthInternational Joint Conference on Artificial Intelligence, pages 748–755, Karlsruhe, Germany,August 1983.
[Corkill, 1979] Corkill, D. D. Hierarchical palnning in a distributed environment. InProceedings of the Sixth International Joint Conference on Artificial Intelligence, pages 168–175,Tokya, Japan, August 1979.
[Corkill, 1983] Corkill, D. D. A Framework for Organizational Self-design in DistributedProblem-solving Networks. PhD thesis, Dept. of Computer Sceince, University of Mas-sachusetts, Amherst, 1983.
[Crites and Barto, 1996] Crites, R. H. and Barto, A. G. Improving elevator performanceusing reinforcement learning. In Advances in Neural Information Processing Systems 8, MITPress, Cambridge, MA, 1996.
[Crites, 1996] Crites, R. H. Large-Scale Dynamic Optimization Using Teams Of ReinforcementLearning Agents. PhD thesis, Dept. of Computer Sceince, University of Massachusetts,Amherst, 1996.
[Davies and Edwards, 1995] Davies, W. H. E. and Edwards, P. Distributed learning: Anagent-based approach to data-mining. In Proceedings of ML95 Workshop on Agents thatLearn from Other Agents, Tahoe City, California, July 1995.
[Davis and Smith, 1983] Davis, R. and Smith, R. G. Negotiation as a metaphor for distributedproblem solving. Artificial Intelligence, 20(1):63–109, January 1983.
[Decker and Lesser, ] Decker, K. S. and Lesser, V. R. A formal environment-centeredframework for agent coordination. Forthcoming Technical Report.
[Decker and Lesser, 1992] Decker, K. S. and Lesser, V. R. Generalizing the partial globalplanning algorithm. International Journal of Intelligent and Cooperative Information Systems,1(2):319–346, June 1992.
[Decker and Lesser, 1993a] Decker, K. S. and Lesser, V. R. Quantitative modeling ofcomplex environments. International Journal of Intelligent Systems in Accounting, Finance,and Management, 2(4):215–234, December 1993. Special issue on “Mathematical andComputational Models of Organizations: Models and Characteristics of Agent Behavior”.

138
[Decker and Lesser, 1993b] Decker, K. S. and Lesser, V. R. Quantitative modeling of complexcomputational task environments. In Proceedings of the Eleventh National Conference onArtificial Intelligence, pages 217–224, Washington, July 1993.
[Decker and Lesser, 1995] Decker, K. S. and Lesser, V. R. Designing a family of coordinationalgorithms. In Proceedings of the First International Conference on Multi-Agent Systems, pages73–80, San Francisco, CA, June 1995. AAAI Press.
[Decker et al., 1990] Decker, K. S.; Lesser, V. R.; and Whitehair, R. C. Extending a blackboardarchitecture for approximate processing. The Journal of Real-Time Systems, 2(1/2):47–79,1990.
[Decker, 1994] Decker, K. S. Environment Centered Analysis and Design of CoordinationMechanisms. PhD thesis, Dept. of Computer Sceince, University of Massachusetts, Amherst,1994.
[Decker, 1995] Decker, K. S. Environment Centered Analysis and Design ofCoordination Mechanisms. PhD thesis, University of Massachusetts, 1995.http://dis.cs.umass.edu/˜decker/thesis.html.
[Dowell and Stephens, 1993] Dowell, M. and Stephens, L. M. Mage: Additions to the agealgorithm for learning in multi-agent systems. In Proceedings of the Cooperative Knowledge-Based Systems Conference, June 1993.
[Durfee and Lesser, 1987] Durfee, E. H. and Lesser, V. R. Using partial global plans tocoordinate distributed problem solvers. In Proceedings of the Tenth International JointConference on Artificial Intelligence, August 1987.
[Durfee and Lesser, 1988] Durfee, E. and Lesser, V. Predictability vs. responsiveness: Co-ordinating problem solvers in dynamic domains. In Proceedings of the Seventh NationalConference on Artificial Intelligence, pages 66–71, St. Paul, Minnesota, August 1988.
[Durfee and Lesser, 1989] Durfee, E. H. and Lesser, V. R. Negotiating task decompositionand allocation using partial global planning. In Gasser, L. and Huhns, M. N., editors,Distributed Artificial Intelligence, Vol. II. Pitman Publishing Ltd., 1989.
[Durfee and Montgomery, 1991] Durfee, E. H. and Montgomery, T. A. Coordination asdistributed search in a hierarchical behavior space. IEEE Transactions on Systems, Man, andCybernetics, 21(6):1363–1378, November 1991.
[Edwards and Davies, 1993] Edwards, P. and Davies, W. H. E. A heterogeneous multi-agentmachine learning system. In Proceedings of the Special Interest Group on CooperatingKnowledge-Based Systems, 1993.
[Fox, 1981] Fox, M. S. An organizational view of distributed systems. IEEE Transactions onSystems, Man, and Cybernetics, 11(1):70–80, January 1981.
[Franks, 1989] Franks, N. R. Army ants: A collective intelligence. American Scientist, 1989.
[Galbraith, 1977] Galbraith, J. Organizational Design. Addison-Wesley, Reading, MA, 1977.

139
[Garland and Alterman, 1995] Garland, A. and Alterman, R. Preparation of multi-agentknowledge for reuse. In Proceedings of the 1995 AAAI Fall Symposium, pages 26–33,Cambridge, MA, 1995.
[Garvey and Lesser, 1993a] Garvey, A. and Lesser, V. Design-to-time real-time scheduling.IEEE Transactions on Systems, Man, and Cybernetics, 23(6):1491–1502, 1993.
[Garvey and Lesser, 1993b] Garvey, A. and Lesser, V. Design-to-time real-time scheduling.IEEE Transactions on Systems, Man and Cybernetics, 23(6):1491–1502, 1993.
[Garvey et al., 1994] Garvey, A.; Decker, K.; and Lesser, V. A negotiation-based interfacebetween a real-time scheduler and a decision-maker. CS Technical Report 94–08, Universityof Massachusetts, 1994.
[Gasser, 1991] Gasser, L. Social conceptions of knowledge and action. Artificial Intelligence,47(1):107–138, 1991.
[Gilboa and Schmeidler, 1995] Gilboa, I. and Schmeidler, D. Case-based Decision Theory.The Quaterly Journal of Economics, pages 605–639, August 1995.
[Gmytrasiewicz et al., 1991] Gmytrasiewicz, P. J.; Durfee, E. H.; and Wehe, D. K. A decision-theoretic approach to coordinating multiagent interactions. In Proceedings of the TwelfthInternational Joint Conference on Artificial Intelligence, pages 62–68, Sydney, Australia, August1991.
[Goldman and Rosenschein, 1995] Goldman, C. and Rosenschein, J. Mutually supervisedlearning in multi-agent systems. In Proceedings of the IJCAI-95 Workshop on Adaptation andLearning in Multi-Agent Systems, Montreal, CA., August 1995.
[Grecu and Brown, 1996] Grecu, D. and Brown, D. Learning to design together. Acceptedfor presentation at the 1996 AAAI Spring Symposium on Adaptation, Co-evolution andLearning in Multiagent Systems, Stanford, CA, 1996.
[Hall, 1996] Hall, R. J. Personal communication, July 1996.
[Haynes and Sen, 1996] Haynes, T. and Sen, S. Learning cases to resolve conflicts and improvegroup behavior. Submitted, 1996.
[Holland, 1975] Holland, J. H. Adaptation in Natural and Artificial Systems. University ofMichigan Press, Ann Arbor, Michigan, 1975.
[Holland, 1985] Holland, J. H. Properties of bucket brigade algorithm. In First InternationalConference on Genetic Algorithms and their Applications, pages 1–7, Pittsburgh, PA, 1985.
[Ishida et al., 1990] Ishida, T.; Yokoo, M.; and Gasser, L. An organizational approach toadaptive production systems. In Proceedings of the Eighth National Conference on ArtificialIntelligence, 1990.

140
[Khedro and Genesereth, 1993] Khedro, T. and Genesereth, M. Progressive negotiation: Astrategy for resolving conflicts in cooperative distributed multi-disciplinary design. InProceedings of the Conflict Resolution Workshop, IJCAI-93, Chambery, France, September1993.
[Kitano et al., 1995] Kitano, H.; Asada, M.; Kuniyoshi, Y.; Noda, I.; and Osawa, E. Robocup:The robot world cup initiative. In IJCAI-95 Workshop on Entertainment snd AI/Alife, pages19–24, Montreal, Canada, August 1995.
[Klein, 1991] Klein, M. Supporting conflict resolution in cooperative design systems. IEEETransactions on Systems, Man, and Cybernetics, 21(6):1379–1390, 1991.
[Klein, 1993] Klein, M. Capturing design rationale in concurrent engineering teams. IEEEComputer, 26(1):39–47, 1993.
[Knoblock et al., 1991] Knoblock, C. A.; Tenenberg, J. D.; and Yang, Q. CharacterizingAbstraction Hierarchies for Planning. In Proceedings of the Ninth National Conference onArtificial Intelligence, Anaheim, CA, 1991.
[Lander and Lesser, 1993] Lander, S. E. and Lesser, V. R. Understanding the role of nego-tiation in distributed search among heterogeneous agents. In Proceedings of the ThirteenthInternational Joint Conference on Artificial Intelligence, pages 438–444, Chambery, France,August 1993. IJCAI.
[Lander and Lesser, 1994] Lander, S. E. and Lesser, V. R. Sharing meta-information to guidecooperative search among heterogeneous reusable agents. Computer Science TechnicalReport 94–48, University of Massachusetts, 1994. To appear in IEEE Transactions onKnowledge and Data Engineering, 1996.
[Lander, 1994] Lander, S. E. Distributed Search in Heterogeneous and Reusable Multi-AgentSystems. PhD thesis, Dept. of Computer Sceince, University of Massachusetts, Amherst,1994.
[Langton et al., 1992] Langton, C. G.; Taylor, C.; Farmer, J. D.; and Rasmussen(Eds.), S.Artificial Life. Addison-Wesley, Redwood City, CA, 1992.
[Langton(Ed.), 1989] Langton(Ed.), C. G. Artificial Life. Addison-Wesley, Redwood City,CA, 1989.
[Lawrence and Lorsch, 1967] Lawrence, P. and Lorsch, J. Organization and Environment.Harvard University Press, Cambridge, MA, 1967.
[Lesser and Erman, 1980] Lesser, V. R. and Erman, L. D. Distributed interpretation: A modeland an experiment. IEEE Transactions on Computers, C-29(12):1144–1163, December1980.
[Lesser, 1990] Lesser, V. R. An Overview of DAI: Distributed AI as Distributed Search.Journal of the Japanese Society for Artificial Intelligence, 5(4):392–400, 1990.

141
[Lesser, 1991] Lesser, V. R. A retrospective view of FA/C distributed problem solving. IEEETransactions on Systems, Man, and Cybernetics, 21(6):1347–1362, 1991.
[MacLennan and Burghardt, 1993] MacLennan, B. and Burghardt, G. M. Synthetic ethologyand the evolution of cooperative communication. Adaptive Behavior, 2(2):161–188, 1993.
[Malone and Crowston, 1991] Malone, T. and Crowston, K. Toward an interdisciplinarytheory of coordination. Center for Coordination Science Technical Report 120, MIT SloanSchool of Management, 1991.
[Mammen and Lesser, 1992] Mammen, D. L. and Lesser, V. R. Using textures to controldistributed problem solving. In Working Notes from the AAAI Workshop on CooperationAmong Hetegeneous Intelligent Systems, San Jose, CA, 1992. AAAI-92.
[Mammen, 1995] Mammen, D. L. Sharing and interpreting partial results in distributedproblem solving systems. Ph. D. Proposal, June 1995.
[Mataric, 1993] Mataric, M. J. Kin recognition, similarity, and group behavior. In Proceedingsof the Fifteenth Annual Cognitive Science Society Conference, pages 705–710, Boulder,Colorado, 1993.
[Mataric, 1994a] Mataric, M. J. Learning to behave socially. In Proceedings of the ThirdInternational Conference on Simulation of Adaptive Behavior (SAB-94), 1994.
[Mataric, 1994b] Mataric, M. J. Reward functions for accelerated learning. In Proceedings ofthe Eleventh International Conference on Machine Learning, San Francisco, CA, 1994.
[Minton, 1988] Minton, S. Learning Search Control Knowledge: An Explanation-BasedApproach. Kluwer Academic Publishers, Boston, 1988.
[Mitchell et al., 1986] Mitchell, T.; Keller, R.; and Kedar-Cabelli, S. Explanation-basedgeneralization: A unified view. Machine Learning, 1, 1986.
[Mullins and Rinderle, 1991] Mullins, S. and Rinderle, J. R. Grammatical approaches toengineering design, part i. Research in Engineering Design, 2:121–135, 1991.
[Nadella and Sen, 1996] Nadella, R. and Sen, S. Correlating Internal Parameters and ExternalPerformance: Learning Soccer Agents. In ICMAS96 Workshop on Learning, Interaction andOrganizations in Multiagent Environments, Kyoto, Japan, December 1996.
[Nagendra Prasad and Lesser, 1996a] Nagendra Prasad, M. V. and Lesser, V. R. Distributedcase based learning. Forthcoming Technical Report, 1996.
[Nagendra Prasad and Lesser, 1996b] Nagendra Prasad, M. V. and Lesser, V. R. LearningSituation-Specific Coordination in Generalized Partial Global Planning. In 1996 AAAISpring Symposium on Adaptation, Co-evolution and Learning in Multi-agent Systems, Stanford,CA, 1996. AAAI Press.

142
[Nagendra Prasad et al., 1995a] Nagendra Prasad, M. V.; Lesser, V. R.; and Lander, S. E.Learning Experiments in a Heterogeneous Multi-agent System. In Proceedings of the IJCAI-95 Workshop on Adaptation and Learning in Multi-Agent Systems, Montreal, CA., August1995.
[Nagendra Prasad et al., 1995b] Nagendra Prasad, M. V.; Lesser, V. R.; and Lander, S. E. Onretrieval and reasoning in distributed case bases. In 1995 IEEE International Conference onSystems Man and Cybernetics, Vancouver, Canada., October 1995.
[Nagendra Prasad et al., 1996a] Nagendra Prasad, M. V.; Decker, K. S.; Garvey, A.; and Lesser,V. R. Exploring Organizational Designs with TAEMS: A Case Study of Distributed DataProcessing. In Proceedings of the Second International Conference on Multi-Agent Systems,Kyoto, Japan, December 1996. AAAI Press.
[Nagendra Prasad et al., 1996b] Nagendra Prasad, M. V.; Lesser, V. R.; and Lander, S. E.Learning organizational roles in a heterogeneous multi-agent system. In Proceedings of theSecond International Conference on Multi-Agent Systems, Kyoto, Japan, December 1996.AAAI Press.
[Nagendra Prasad et al., 1996c] Nagendra Prasad, M. V.; Lesser, V. R.; and Lander, S. E.Retrieval and Reasoning in Distributed Case Bases. Journal of Visual Communication andImage Representation, Special Issue on Digital Libraries, 7(1):74–87, March 1996.
[Nagl, 1979] Nagl, M. A Tutorial and Bibliographic Survey on Graph Grammars. In Claus,V.; Ehrig, H.; and Rozenberg, G., editors, Graph Grammars and their Application to ComputerScience and Biology, LNCS 73, pages 70–126. Springer-Verlag, Berlin, 1979.
[Neiman et al., 1994] Neiman, D.; Hildum, D.; Lesser, V.; and Sandholm, T. Exploitingmeta-level information in a distributed scheduling system. In Proceedings of the 12th NationalConference on Artificial Intelligence, Seattle WA, July 1994.
[Oates et al., 1994] Oates, T.; Nagendra Prasad, M. V.; and Lesser, V. R. CooperativeInformation Gathering: A Distributed Problem Solving Approach. Computer ScienceTechnical Report 94–66, University of Massachusetts, 1994. To appear in Journal ofSoftware Engineering, Special Issue on Developing Agent Based Systems, 1997.
[Quinlan, 1986] Quinlan, J. R. Induction of decision trees. Machine Learning, 1(1):81–106,1986.
[Rosenschein and Zlotkin, 1994] Rosenschein, J. S. and Zlotkin, G. Designing conventionsfor automated negotition. AI Magazine, pages 29–46, Fall 1994.
[Rumelhart et al., 1986] Rumelhart, D.; Hinton, G.; and Williams, R. J. Learning IinternalRepresentations by Error Propogation. In D. Rumelhart, J. L. M. and the PDP Re-search Group, editors, Parallel Distributed Processing, pages 318–362. MIT Press, Cambridge,MA, 1986.
[Russell and Norvig, 1995] Russell, S. and Norvig, P. Artificial Intelligence: A ModernApproach. Printice Hall, Englewood Cliffs, New Jersey, 1995.

143
[Sacerdoti, 1977] Sacerdoti, E. D. A Structure for Plans and Behavior. American Elsevier, NewYork, 1977.
[Sandholm and Crites, 1995] Sandholm, T. and Crites, R. Multi-agent reinforcement learningin the repeated prisoner’s dilemma. to appear in Biosystems, 1995.
[Sandholm and Lesser, 1995] Sandholm, T. and Lesser, V. Coalition formation amongbounded rational agents. In Proceeding of the 14th International Joint Conference on ArtificialIntelligence, pages 662–669, Montreal, Canada, 1995.
[Sandholm and NagendraPrasad, 1993] Sandholm, T. and NagendraPrasad, M. V. Muscle:Multi-agent system for coordinated learning experiments. Unpublished working paper,1993.
[Sanfeliu and Fu, 1983] Sanfeliu, A. and Fu, K. S. Tree-graph Grammars for PatternRecognition. In Ehrig, H.; Nagl, M.; and Rozenberg, G., editors, Graph Grammars andtheir Application to Computer Science, LNCS 153, pages 349–368. Springer-Verlag, Berlin,1983.
[Seeley, 1989] Seeley, T. D. The Honey Bee Colony as a Superorganism. American Scientist,77:546–553, November–December 1989.
[Sen et al., 1994] Sen, S.; Sekaran, M.; and Hale, J. Learning to coordinate without sharinginformation. In Proceedings of the Twelfth National Conference on Artificial Intelligence, pages426–431, Seattle, WA, July 1994. AAAI.
[Shaw and Whinston, 1989] Shaw, M. J. and Whinston, A. B. Learning and adaptation in daisystems. In Gasser, L. and Huhns, M., editors, Distributed Artificial Intelligence, volume 2,pages 413–429. Pittman Publishing/Morgan Kauffmann Pub., 1989.
[Shoham and Tennenholtz, 1992a] Shoham, Y. and Tennenholtz, M. Emergent conventionsin multi-agent systems: initial experimental results and observations. In Proccedings ofKR-92, 1992.
[Shoham and Tennenholtz, 1992b] Shoham, Y. and Tennenholtz, M. On the synthesis ofuseful social laws for artificial agent societies (preliminary report). In Proceedings of the TenthNational Conference on Artificial Intelligence, pages 276–281, San Jose, July 1992.
[Sian, 1991] Sian, S. S. Extending learning to multiple agents: issues and a model formulti-agent machine learning. In Proceedings of Machine Learning - EWSL 91, pages440–456, Springer-Verlag, 1991.
[Silver et al., 1990] Silver, B.; Frawely, W.; Iba, G.; Vittal, J.; and Bradford, K. A frameworkfor multi-paradigmatic learning. In Proceedings of the Seventh International Conference onMachine Learning, pages 348–358, 1990.
[Simon, 1968] Simon, H. A. The Sciences of the Artificial. MIT Press, Cambridge, MA, 1968.
[Simon, 1986] Simon, H. A. Why should machines learn? In Michalski, R. S.; Carbonell,J. G.; and Mitchell, T. M., editors, Machine Learning: An Artificial Intelligence Approach,pages pp 25–37. Morgan Kaufmann, 1986.

144
[So and Durfee, 1993] So, Y. and Durfee, E. H. An organizational self-design model fororganizational change. In AAAI-93 Workshop on AI and Theories of Groups and Organizations:Conceptual and Empirical Research, pages 8–15, Washington, D.C., July 1993.
[Stanfill and Waltz, 1986] Stanfill, C. and Waltz, D. Towards memory-based reasoning.Communications of the ACM, 29(12):1213–1228, 1986.
[Stinchcombe, 1990] Stinchcombe, A. L. Information and Organizations. University ofCalifornia Press, Berkeley, CA, 1990.
[Stone et al., 1996] Stone, P.; Veloso, M.; and Achim, S. Collaboration and Learning inRobotic Soccer. In Proceedings of the Micro-robot World Cup Soccer Tournament, Taejon,Korea, November 1996.
[Sugawara and Lesser, 1993] Sugawara, T. and Lesser, V. R. On-line learning of coordinationplans. In Proceedings of the Twelfth International Workshop on Distributed AI, Hidden Valley,Pa, May 1993.
[Sugawara, 1995] Sugawara, T. Reusing past plans in distributed planning. In Proceedings ofthe First International Conference on Multi-Agent Systems, pages 360–367, San Francisco, CA,June 1995. AAAI Press.
[Sutton, 1988] Sutton, R. Learning to predict by the methods of temporal differences.Machine Learning, 3:9–44, 1988.
[Sycara et al., 1991] Sycara, K.; Roth, S.; Sadeh, N.; and Fox, M. Distributed constrainedheuristic search. IEEE Transactions on Systems, Man, and Cybernetics, 21(6):1446–1461,November/December 1991.
[Sycara, 1989] Sycara, K. P. Multi-agent compromise via negotiation. In Gasser, L. andHuhns, M. N., editors, Distributed Artificial Intelligence, Vol. II, pages 119–137. PitmanPublishing Ltd., 1989.
[Tan, 1993] Tan, M. Multi-agent reinforcement learning: Independent vs. cooperative agents.In Proceedings of the Tenth International Conference on Machine Learning, pages 330–337,1993.
[Utgoff et al., 1997] Utgoff, P. E.; Berkman, N.; and Clouse, J. Decision tree induction basedon efficient tree restructuring. To appear in the Machine Learning Journal, 1997.
[Utgoff, 1994] Utgoff, P. E. An improved algorithm for incremental induction of decisiontrees. In Proceedings of the Eleventh International Conference on Machine Learning, pages318–325, 1994.
[Weiss, 1993] Weiss, G. Learning to coordinate actions in multi-agent systems. In Proceedingsof the Thirteenth International Joint Conference on Artificial Intelligence, pages 311–316, aug1993.
[Weiss, 1994] Weiss, G. Some studies in distributed machine learning and organizationaldesign. Technical Report FKI-189-94, Institut f�ur Informatik, TU M�unchen, 1994.

145
[Whitehair and Lesser, 1993] Whitehair, R. and Lesser, V. R. A framework for the analysis ofsophisticated control in interpretation systems. Computer Science Technical Report 93–53,University of Massachusetts, 1993.
[Woolridge and Jennings, 1995] Woolridge, M. and Jennings, N. Intelligent Agents: Theoryand Practice. Knowledge Engineering Review, 10(2), 1995.
[Yokoo et al., 1992] Yokoo, M.; Durfee, E. H.; and Ishida, T. Distributed cosntraintsatisfaction for formalizing distributed problem solving. In Proceedings of the TwelfthConference on Distributed Computing Systems, Yokohama, Japan, June 1992.
[Zilberstein, 1996] Zilberstein, S. Using anytime algorithms in intelligent systems. AIMagazine, 17(3):73–83, 1996.