Embed Size (px)
Citation preview

Learning to Predict the Departure Dynamics ofWikidata Editors
Guangyuan Piao1 and Weipeng Huang2
1 Department of Computer Science, Maynooth University, Maynooth, [email protected]
2 Insight Centre for Data Analytics, University College Dublin, Dublin, [email protected]
Abstract. Wikidata as one of the largest open collaborative knowledgebases has drawn much attention from researchers and practitioners sinceits launch in 2012. As it is collaboratively developed and maintained bya community of a great number of volunteer editors, understanding andpredicting the departure dynamics of those editors are crucial but havenot been studied extensively in previous works. In this paper, we inves-tigate the synergistic effect of two different types of features: statisticaland pattern-based ones with DeepFM as our classification model whichhas not been explored in a similar context and problem for predictingwhether a Wikidata editor will stay or leave the platform. Our exper-imental results show that using the two sets of features with DeepFMprovides the best performance regarding AUROC (0.9561) and F1 score(0.8843), and achieves substantial improvement compared to using eitherof the sets of features and over a wide range of baselines.
Keywords: Wikidata editors · Crowdsourcing dynamics · Classification.
1 Introduction
Wikidata [28] is a community-driven knowledge base with its initial primary goalto be a central knowledge base to serve all Wikimedia projects. Since its launchin late 2012, it has become one of the most active projects of the WikimediaFoundation in terms of contributors [13]. As one of the largest open, free, mul-tilingual knowledge bases, Wikidata has contributed significantly to the LinkedOpen Data Cloud34 and our research community along with DBpedia [11]. Wiki-data currently contains over 90M items and over 13B edits have been made sincethe project launch5, and has been widely used in various domains such as naturallanguage processing [10], recommender systems [23], and life sciences [29].
As a community effort, editors on open collaborative knowledge bases suchas Wikidata and Wikipedia add and edit information collaboratively and playa crucial role in the growth of those platforms. Therefore, in the context of
3 https://lod-cloud.net/4 https://bit.ly/2O1KZAV5 https://www.wikidata.org/wiki/Wikidata:Statistics/en

2 Guangyuan Piao et al.
Wikipedia, there have been many studies on predicting the editing dynamicsof users6 such as how many contributions an editor will make or whether theeditor will stay on or leave the platform [31,2]. Similar to Wikipedia, editors onWikidata platform are critical to its success and understanding editing dynamicssuch as whether an editor will leave the platform is important but little attentionhas been given in the context of Wikidata [24], which is our focus of this study.
We seek answers to questions such as (1) what types of features are use-ful for predicting the departure dynamics of Wikidata editors, (2) what typesof machine learning (ML) approaches perform well for the prediction, and (3)how well those approaches applied to Wikipedia can perform in the context ofWikidata. To this end, we investigate different types of features and investigatea wide range of ML approaches including best-performing ones adapted fromprevious studies in the context of Wikipedia, and investigate a new approachadopted from the recommender system domain which has not been explored inprevious studies for predicting whether an editor will stay on or leave Wikidata.In summary, our contributions are: (1) We investigate two sets of features –statistical and pattern-based ones – for predicting inactive editors on Wikidata(Section 3). We show the synergistic effect on using both sets of features in Sec-tion 6, which has not been used together in a similar context; (2) We adoptDeepFM model [9] as our classification approach, which is exploited for the pre-diction task in the context of Wikidata for the first time to our best knowledge,and show its effectiveness by comparing a wide range of classification modelsin Section 6 including those applied to Wikipedia; (3) Our source code and theprocessed Wikidata dataset can be found here7. The dataset includes more than5B edits by 371,068 users (Section 4), which can be a good resource for studyingdifferent problems such as recommending Wikidata items.
2 Related Work
In the context of Wikipedia, many studies have been conducted regarding thedeparture dynamics of Wikipedia editors in the literature. For example, Gandicaet al. [7] defined a function of edit probability and showed that the editing be-havior of Wikipedia editors is far from random and the number of previous editsis a good indicator of their future edits. Zhang et al. [31] proposed a ML ap-proach with a set of statistical features extracted from different periods of eachuser’s edit history for predicting the future edit volume of Wikipedia editorswhere they showed that GBT (Gradient Boosted Trees) and kNN (k-NearestNeighbors) provide the best performance. Instead of statistical features, Arelliet al. [1,2] proposed leveraging pattern-based features with respect to consecu-tive edited pages, and constructed Boolean features regarding a set of frequentpatterns for predicting whether a Wikipedia user might leave or stay on theplatform. In addition to predicting activeness or edit volume of users, other as-pects regarding edit behaviors such as quality, edit sessions on the platform, and
6 We use the words editors and users interchangeably in this rest of the paper.7 https://bit.ly/3yyJhZj

Learning to Predict the Departure Dynamics of Wikidata Editors 3
the difference between Wikipedians and non-Wikipedian editors have been stud-ied as well [4,8,16]. In contrast to the popularity of previous studies regardingdifferent aspects on Wikipedia, less studies have been explored in the contextof Wikidata, which is our focus in this study for classifying potential inactiveWikidata editors.
Recently, Mora-Cantallops et al. [14] conducted a literature review of researchon Wikidata and revealed the main research topics on Wikidata such as usersand their editing practices, knowledge organization, external references, and thelanguage of editors [19,21,10]. We focus on the first topic (users and their edit-ing practices), which is most relevant to our work. Piscopo et al. [20] studieddifferent types of editors such as bots, human editors, registered, anonymous ed-itors to understand how those editors influence the quality of items on Wikidata.In [15,3] the authors performed a cluster analysis of the editing activities of Wiki-data editors to compare them with typical roles found in peer-production andcollaborative ontology engineering projects, and studied the dynamic participa-tion patterns across those characterized roles of Wikidata editors. More recently,Sarasua et al. [24] conducted a large-scale longitudinal data analysis for Wikidataedit history over around four years until 2016 to study the evolution of differenttypes of Wikidata editors. Their study revealed many interesting findings suchas the number of new editors joining the Wikidata has been increasing over time,and the majority of contribution has been made by a few editors with a skeweddistribution of contributions. We observe that similar trends have continued inour Wikidata dataset with edit history until 2020 (Section 4). The authors [24]also investigated the edit volume and the lifespan (i.e., short or long) of editorsduring their active time on Wikidata where their focus is on gone editors.
Compared with those works, we focus on the problem of predicting the ac-tiveness of registered editors in the future on Wikidata in this work, investigatethe synergistic effect of considering both statistical and pattern-based features,and exploit DeepFM model for the first time for the problem.
3 Proposed Approach
This section provides a formal definition of the Wikidata user classification task,followed by the description of the proposed approach.
Problem formulation. Our goal is to learn a binary classifier f(xu)→ yuwhere xu denotes a set of features based on the edit history of a user u, and yuis the class label indicating activeness of u with 1 for inactive and 0 for active.
Overview of our approach. The approach for the classification task ofWikidata editors consists of (1) statistical and/or pattern-based features, and(2) a DeepFM classification model where those features are used as an input.
3.1 Statistical Features
Here we discuss the set of statistical features used in our model. These featuresutilize the edit history of Wikidata editors. All of these features try to captureusers’ editing behavior on Wikidata from different perspectives.

4 Guangyuan Piao et al.
1. Total # of edits (Ntotal·edit·ent) indicates the total number of edits have beenmade by an editor on Wikidata.
2. Distinct # of edited entities (Ndist·edit). The total # of edits does not dis-tinguish edited entities. This feature aims to capture the number of distinctentities have been edited by a user.
3. Diversity of edit actions (Divedit·act). To capture the diversity of differenttypes of edit actions (see Section 4), we use the Shannon-Entropy [25] ofdifferent edit actions in the same manner as in [24] as: H(T ) = −
∑ni=1 P (ti)·
logP (ti) where T indicates different types of edit actions, and |T | = n.4. Diversity of entities (Divent). We measure the diversity of edited entities
of a user using the Shannon-Entropy. The intuition is that the diversity ofedited entities of a user could also be different across active and inactiveeditors.
5. The # of days between first and last edits (Tedit) refers to the time differencebetween a user’s first and last edits during a certain period.
6. Diversity of day of week (Divday). This measures the diversity of day of theweek based on the edit history of each user using the Shannon-Entropy.
7. The # of days between first edit and prediction time (Lfirst·pred). This in-dicates the time difference between a user’s first edit on Wikidata and theprediction time to predict whether a user will become inactive or not.
8. The # of days between the last edit and prediction time (Llast·pred) indicatesthe time difference between a user’s last edit and the predicted time.
For the first six features, we extract those in the last p months from the predictiontime using 10 different time periods p ∈ P = { 1
16 ,18 ,
14 ,
12 , 1, 2, 4, 12, 36, 108} to
capture the editing behavior over different time periods, which has been inspiredby [31] in the context of Wikipedia for predicting the edit volume of users. Forinstance, we extract the set of features based on the edit history from the last12 months from the prediction time when p = 12. Here, 108 months in ourWikidata dataset (see Section 4) cover the whole edit history of each editor. Asa result, there are 6 × 10 + 2 = 62 statistical features in total. As one mightexpect, some of those features can be skewed and we apply a logarithmic scale,xafter = log(xbefore + 1), to them before feeding those into any ML approach.
3.2 Pattern-based Features
In contrast to statistical features such as the above-mentioned ones, pattern-based features have been explored in the context of Wikipedia for predicting thedeparture dynamics of editors [1]. To investigate which type of features performsbetter or the synergistic effect of combining those two sets of features for ourclassification task on Wikidata, we investigate those statistical and pattern-basedfeatures – separately and together – in our experiments in Section 5. In thefollowing paragraphs, we describe the set of pattern-based features used.
To start with, the edit history of each user is considered as a chronologicalsequence of each consecutive pair (i1, i2) of edited entities. For each pair (i1, i2),the following information is extracted for describing each pair:

Learning to Predict the Departure Dynamics of Wikidata Editors 5
– r/n: Whether i2 is an entity that has already been edited by the user before,i.e., r if i2 is a re-edit, and n otherwise.
– m/n: Whether i2 is a normal entity (n) or others such as properties (m). OnWikidata, each entity is identified by a unique entity ID, which is a numberprefixed by a letter (Q, L, P)8. Here we consider an entity which starts with“Q” as a normal entity.
– If i2 is a re-edit – c/n: Whether i1 is the same as i2, i.e., these are twoconsecutive edits (c) on the same entity or not (n).Otherwise (i2 is a new edit) – z/o/u: Common classes (via the propertyinstance of ) between entity i1 and i2: z for zero classes in common, o for atleast one class in common, and u for information is not available.
– v/f/s: Time difference between the two edits where v indicates very fastedit (less than three minutes), f refers to fast edit (less than 15 minutes),and s for slow edit (more than 15 minutes).
For example, rncv for a pair of entities (i1, i2) indicates that i2 is a re-edit (r)and is a normal entity (n) which is the same as i1 (c), and the time differencebetween the two consecutive edits is less than three minutes (v). Given thisrepresentation of edit history, pattern-based features can be extracted with thefollowing two main steps [1].
First, frequent patterns from the active and inactive user edit histories inthe training set are extracted separately using PrefixSpan [18] algorithm, whichis one of the fastest sequential pattern mining algorithm. Those pattern-basedfeatures are extracted using SPFM data mining library [6]. Each pattern containsa sequence of pairs of entities consecutively edited by an editor where each pair isdescribed using above-mentioned features (e.g., rncv). Afterwards, the frequencyof each pattern f is calculated for both the active and inactive classes.
Next, two sets of patterns are extracted where the first one contains topfrequent patterns that appear in both classes based on the absolute frequencydifference between the two classes, and the second set contains top frequentpatterns only appear for active class9. Finally, we select the set of top k patternsof length l that appear for both classes and for active editors only. We used thesame setting as in [1] where k = 13 and l ∈ {1, 2, 3}, which results in a totalof 78 Boolean features for any classifier as an input with 1 indicates a patternappears in the edit history of an editor, 0 otherwise.
3.3 DeepFM as the Classification Model
On top of above-mentioned features, we adopt a DeepFM-based classificationmodel which was proposed in [9] for recommender systems. To the best of ourknowledge, this is the first attempt of utilizing the DeepFM model for user clas-sification tasks on Wikidata. DeepFM was designed to automatically capture
8 https://www.wikidata.org/wiki/Wikidata:Identifiers: items are prefixed withQ, properties are prefixed by P, lexemes are prefixed by L.
9 Similar to the observation in [1], there is no pattern only appears for inactive editors.

6 Guangyuan Piao et al.
sparse
features… … …
field 1 field 2 field m
…
embeddings …
output units
FM layer …
hidden
layer
addition
inner product
sigmoid function
activation function
weight-1 connection
normal connectionembedding
…
Fig. 1: DeepFM architecture from [9], which consists of two main components:FM part on the left and DNN part on the right.
feature interactions by modeling low-order feature interactions through Factor-ization Machines (FM) and high-order feature interactions via Deep Neural Net-works (DNN). Intuitively, modeling different types of interactions via DeepFMplays a crucial role in capturing the temporal dynamics of editing behaviors.
The model consists of two main components: an FM component and DNNcomponent as illustrated in Figure 1. Moreover, the model has the ability ofmemorizing low- and high-order feature interactions and generalizing featurecombinations by jointly training the FM and DNN components for the combinedprediction model:
y = σ(yFM + yDNN ) (1)
where yFM indicates the output from the FM part, yDNN indicates the outputfrom the DNN part of DeepFM, and σ is the sigmoid function. In the following,we briefly introduce the FM component and Deep component separately.
The FM component of DeepFM is a factorization machine introduced by Ren-dle et al. [22] to learn feature interactions for recommender systems. It consistsof two parts with the first one considers linear interactions among features, andthe second one with pairwise feature interactions as inner product of respectivefeature latent vectors as follows.
yFM =⟨w,x
⟩+
d∑i=1
d∑j=i+1
⟨vi,vj
⟩xixj (2)
where w,x ∈ Rd, vi ∈ Rk, and d and k indicate the number of features and thedimension of a feature’s latent factor, respectively. And 〈·, ·〉 is the dot productof two vectors.
The DNN component is a feed-forward neural network which aims to learnhigh-order feature interactions. The first layer a(0) in Eq. 3 is an embed-ding layer which compresses the input field vectors to the embedding vectors:[e1, e2, . . . , em] for sparse/categorical features where for dense/numerical fea-tures the embedding layer will be ignored. DeepFM reuses the latent feature

Learning to Predict the Departure Dynamics of Wikidata Editors 7
vectors in the FM component as network weights which are learned and usedfor this compression, and the FM and DNN components share the same featureembeddings.
a(0) = [e1, e2, . . . , em], a(l+1) = σ(W(l)a(l) + b(l)) (3)
yDNN = W|H|+1a|H| + b|H|+1 (4)
where a(l), W(l), and b(l) refer to the output, weights, and bias of l -th layer,and |H| is the total number of hidden layers.
Training details We use the cross-entropy loss (or log loss) as our loss function,and the objective is to minimize the loss over all N training examples.
L = − 1
N
N∑i=1
[yi · log yi + (1− yi) · log (1− yi)] (5)
where yi and yi denote the ground truth and the predicted probability of class1 for i-th instance, respectively. To resolve the overfitting problem, we use 20%of the training data as our validation set to adopt an early stopping strategy.We run up to 1,000 epochs for training, but the early stopping strategy stopsthe training if there is no improvement of AUROC (Area Under the ReceiverOperating Characteristics) on the validation set.
4 Wikidata Dataset
In this section, we discuss the Wikidata dataset for our study and provide ex-ploratory analysis with respect to edit history of Wikidata users in Section 4.1.We use the Wikidata dump of 2020-12-0110 with respect to edit history for ourstudy. As we are interested in ordinary human editors who are registered onWikidata, we further excluded edits from anonymous users (who we only knowan IP address), bot accounts and administrators of Wikidata based on the openbot list11 and admin list12. After filtering, the dataset contains 371,068 userswith 519,121,793 edits in total for our analysis and experiments. The raw dataincludes crucial edit information for each edit such as:
– Username which indicates unique username who made an edit.– Time with respect to the edit.– Entity which refers to the unique entity ID such as Q13580495.– Edit action type which denotes an automatic comment such as
wbcreateredirect (Creates entity redirects) generated by the Wikidata’sbackend13. We choose top 50 edit action types which covers 99.9% of thewhole data and treat the rest as “others”.
We explore the filtered Wikidata dataset in detail in the following.
10 https://dumps.wikimedia.org/wikidatawiki/20201201/11 https://www.wikidata.org/wiki/Wikidata:Bots12 https://www.wikidata.org/wiki/Wikidata:Administrators13 Registered actions in Wikidata’s backend: https://bit.ly/39NsrMh
8 Guangyuan Piao et al.
0 5 10 15ln(# of edits)
0
25000
50000
75000
100000
125000#
of e
dito
rs
(a)
0.0 0.2 0.4 0.6 0.8 1.0users (%)
0.0
0.2
0.4
0.6
0.8
1.0
CD
F of
edi
ts (%
)
295 (0.08%) heavy users contributed 80% of edits
2,705 (0.73%) heavy users contributed 95% of edits
(b)
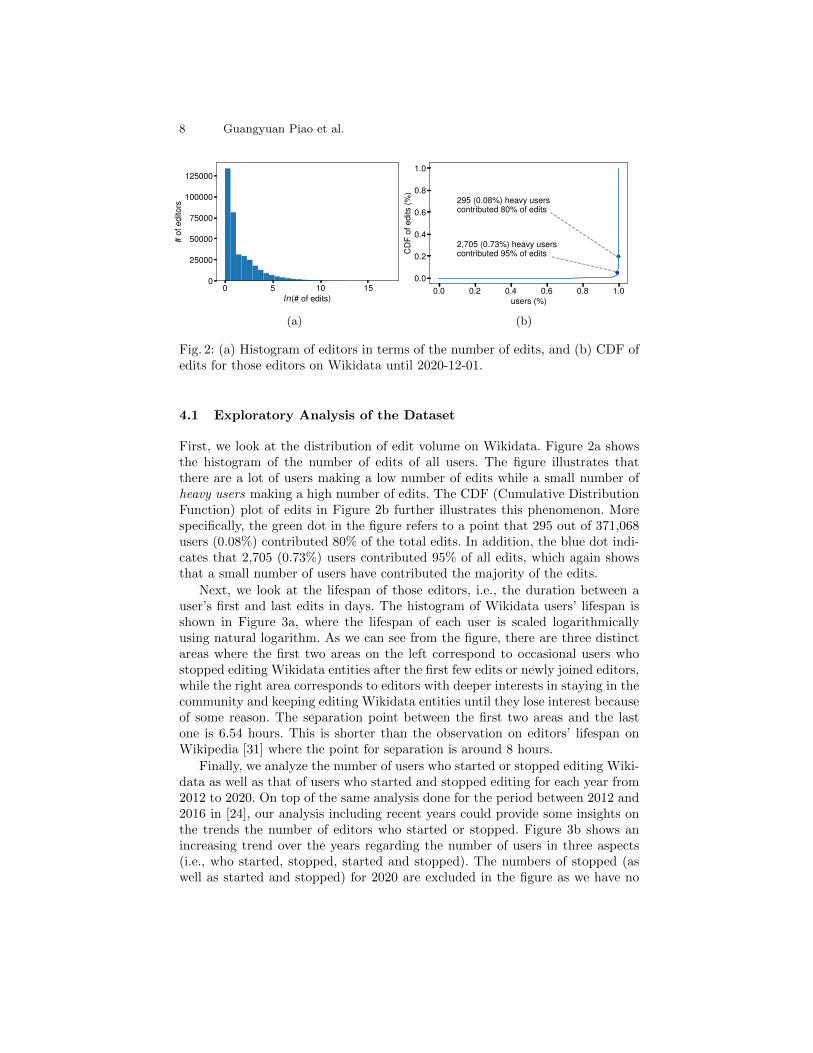
Fig. 2: (a) Histogram of editors in terms of the number of edits, and (b) CDF ofedits for those editors on Wikidata until 2020-12-01.
4.1 Exploratory Analysis of the Dataset
First, we look at the distribution of edit volume on Wikidata. Figure 2a showsthe histogram of the number of edits of all users. The figure illustrates thatthere are a lot of users making a low number of edits while a small number ofheavy users making a high number of edits. The CDF (Cumulative DistributionFunction) plot of edits in Figure 2b further illustrates this phenomenon. Morespecifically, the green dot in the figure refers to a point that 295 out of 371,068users (0.08%) contributed 80% of the total edits. In addition, the blue dot indi-cates that 2,705 (0.73%) users contributed 95% of all edits, which again showsthat a small number of users have contributed the majority of the edits.
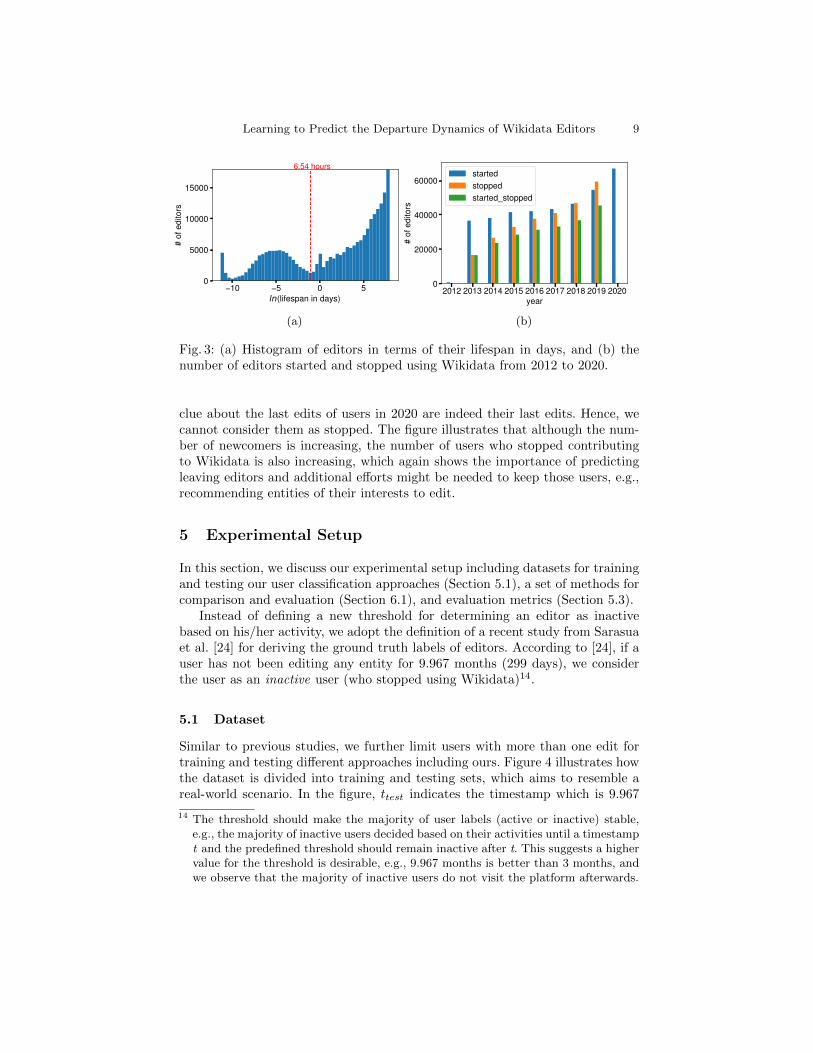
Next, we look at the lifespan of those editors, i.e., the duration between auser’s first and last edits in days. The histogram of Wikidata users’ lifespan isshown in Figure 3a, where the lifespan of each user is scaled logarithmicallyusing natural logarithm. As we can see from the figure, there are three distinctareas where the first two areas on the left correspond to occasional users whostopped editing Wikidata entities after the first few edits or newly joined editors,while the right area corresponds to editors with deeper interests in staying in thecommunity and keeping editing Wikidata entities until they lose interest becauseof some reason. The separation point between the first two areas and the lastone is 6.54 hours. This is shorter than the observation on editors’ lifespan onWikipedia [31] where the point for separation is around 8 hours.
Finally, we analyze the number of users who started or stopped editing Wiki-data as well as that of users who started and stopped editing for each year from2012 to 2020. On top of the same analysis done for the period between 2012 and2016 in [24], our analysis including recent years could provide some insights onthe trends the number of editors who started or stopped. Figure 3b shows anincreasing trend over the years regarding the number of users in three aspects(i.e., who started, stopped, started and stopped). The numbers of stopped (aswell as started and stopped) for 2020 are excluded in the figure as we have no
Learning to Predict the Departure Dynamics of Wikidata Editors 9
10 5 0 5ln(lifespan in days)
0
5000
10000
15000#
of e
dito
rs6.54 hours
(a)
2012 2013 2014 2015 2016 2017 2018 2019 2020year
0
20000
40000
60000
# of
edi
tors
startedstoppedstarted_stopped
(b)
Fig. 3: (a) Histogram of editors in terms of their lifespan in days, and (b) thenumber of editors started and stopped using Wikidata from 2012 to 2020.
clue about the last edits of users in 2020 are indeed their last edits. Hence, wecannot consider them as stopped. The figure illustrates that although the num-ber of newcomers is increasing, the number of users who stopped contributingto Wikidata is also increasing, which again shows the importance of predictingleaving editors and additional efforts might be needed to keep those users, e.g.,recommending entities of their interests to edit.
5 Experimental Setup
In this section, we discuss our experimental setup including datasets for trainingand testing our user classification approaches (Section 5.1), a set of methods forcomparison and evaluation (Section 6.1), and evaluation metrics (Section 5.3).
Instead of defining a new threshold for determining an editor as inactivebased on his/her activity, we adopt the definition of a recent study from Sarasuaet al. [24] for deriving the ground truth labels of editors. According to [24], if auser has not been editing any entity for 9.967 months (299 days), we considerthe user as an inactive user (who stopped using Wikidata)14.
5.1 Dataset
Similar to previous studies, we further limit users with more than one edit fortraining and testing different approaches including ours. Figure 4 illustrates howthe dataset is divided into training and testing sets, which aims to resemble areal-world scenario. In the figure, ttest indicates the timestamp which is 9.967
14 The threshold should make the majority of user labels (active or inactive) stable,e.g., the majority of inactive users decided based on their activities until a timestampt and the predefined threshold should remain inactive after t. This suggests a highervalue for the threshold is desirable, e.g., 9.967 months is better than 3 months, andwe observe that the majority of inactive users do not visit the platform afterwards.

10 Guangyuan Piao et al.
Fig. 4: Dataset split for training and testing and their statistics.
ttrain9.967
Training
Testing
9.967ttest
f
f
Training (# of users) Test (# of users)
Active Inactive Total Active Inactive Total29,509 31,283 60,792 32,068 33,500 65,568
months before the last edit time in our dataset, and ttrain refers to the times-tamp which is 9.967 months before ttest. We train a classification model f basedon the edit history of users before ttest and their ground truth labels (i.e., inac-tive if there is no edit in the 9.967 months between ttrain and ttest, and activeotherwise), and test with f for predicting whether a user will be active or in-active after ttest. For both training and testing, we limit users who are activebefore ttrain and ttest to predict whether those active users will remain activeor become inactive. Take testing as an example, we limit active users based ontheir activity between ttrain and ttest, i.e., those inactive users during the timebetween ttrain and ttest by our definition are already “gone” and therefore ex-cluded for testing. As summarized in Figure 4, there are 60,792 editors with29,509 active and 31,283 inactive ones in the training set, and 65,568 editors intotal with 32,068 active and 33,500 inactive ones in the test set for evaluation.
5.2 Compared Methods
Due to the difference between our task and the tasks of previous studies discussedin Section 2, and the difference between the Wikidata and Wikipedia datasets,those approaches from previous works could not apply to our problem directly.Nevertheless, we tried our best to adapt five previous approaches proposed in thecontext of Wikipedia or different tasks for our task in the context of Wikidata inaddition to using DeepFM to investigate the classification performance. We usea naming convention of [ML model]-[the first two characters of the main
author] in the following to distinguish those methods adapted for comparison,and provide their details.
GBT-Zh [31] uses Gradient Boosted Trees with three features such as thenumber of edits, the number of edited entities, and the length between the firstand the last edit extracted from each of the 10 periods in P for each user inthe same manner as ours. We tuned the max depth hyper-parameter with agrid search over {2, 4, 6, 8, 10} using a 3-fold cross validation. The drift featurewhich measures the average number of edits of all editors in [31] is the samefor all examples and is not important for our classification task although it isimportant for predicting the number of edits of users by capturing the overallchanges of edit volume over time. Therefore, this feature is excluded in thisadapted method.
kNN-Zh [31] leverages the same set of features as GBT-Zh but uses kNN asthe classification model. The number of neighbors k is drawn from 200 to 3,000in step of 200 using a 3-fold cross validation.

Learning to Predict the Departure Dynamics of Wikidata Editors 11
RF-Sa [24] is adapted to our context using Random Forest with a set offeatures such as the number of total edits, the average number of edits per item,the number of distinct items edited, and the diversity of types of edits extractedfrom each of the last 10 consecutive months introduced in [24]. Similar to GBT-Zh,we tuned the max depth hyper-parameter with a grid search over {2, 4, 6, 8, 10}using a 3-fold cross validation. The ML model used in [24] was designed toanalyze the edit volume of each user during his/her lifetime on Wikidata beforehe/she becomes inactive (or leaves the platform), and cannot be directly appliedin our context for several reasons. For example, it trains a RANSAC model [5]for each user with the aforementioned features, and uses the parameters of theRANSAC model for training a Random Forest model to classify high/low volumeor long/short lifespan editors with the focus on “gone” users. As one mightexpect, this results in not only training a great number of RANSAC models butalso requires a good number of edits for each user for fitting the correspondingRANSAC model. Therefore, we use the set of features with Random Forestdirectly here as our baseline.
LR-Sa [24] leverages the same set of features as RF-Sa but uses LogisticRegression for classification. We tuned the regularization strength with a gridsearch over {0.1, 1, 10, 100, 1000} using a 3-fold cross validation.
SVM-Ar is adapted from [1] which utilizes the set of pattern-based featuresintroduced in Section 3.2 with a Support Vector Machine (SVM) classifier forpredicting inactive editors. We tuned the regularization strength and the kernelparameter (γ) of a non-linear Radial Basis Function (RBF) kernel of SVM witha grid search over {0.1, 1, 10, 100, 1000} and {1, 0.1, 0.01, 0.001, 0.0001} using a3-fold cross validation.
DeepFM-Stat refers to the proposed approach using DeepFM with the set ofstatistical features introduced in Section 3.1. We implemented DeepFM-Stat withDeepCTR library [26]. After tuning parameters such as dropout, batch sizes, andthe number of hidden layers using 20% of the training set for validation, we optto use the default DeepFM architecture of DeepCTR, which uses two hiddenlayers both with 128 nodes for its DNN part, embedding size k = 4, withoutdropout [27] as there is no significant improvement compared to the defaultarchitecture.
DeepFM-Pattern uses the same architecture as DeepFM-Stat but uses the setof pattern-based features used for SVM-Ar and introduced in Section 3.2.
DeepFM-Stat+Pattern considers both the statistical features and pattern-based features, which has not been explored together before. We investigate thesynergistic effect of those two sets of features in the context of DeepFM.
We implemented GBT-Zh, kNN-Zh, RF-Sa, LR-Sa, and SVM-Ar with scikit-learn [17]. For DeepFM with different sets of features such as Stat, we runfive times and the results in Section 6 are based on the averages over the fiveruns. All experiments are run on a laptop with Intel(R) Core(TM) i5-3230M(@2.6GHZ) processor and 8GB RAM.

12 Guangyuan Piao et al.
5.3 Evaluation Metrics
We use AUROC /AUC (Area Under the Receiver Operating Characteristics),F1 (F1 score) to evaluate the classification performance of different methodsintroduced in Section 6.1. The F1 score: F1 = 2 · precision·recall
precision+recall is the harmonicmean of precision and recall, where the precision is the number of true positivepredictions divided by the number of total positive predictions, and the recallrefers to the number of true positive predictions divided by the number of allinstances should have been predicted as positive. Compared to F1 where clas-sification is based on a single threshold 0.5 (one if the predicted probability isequal or higher than the threshold, and zero otherwise), AUROC reflects theclassification performance at various threshold settings by measuring the areaunder the ROC curve, which shows a trade-off between the true positive rateand false positive rate. We analyze the F1 score of inactive class and AUROCas our focus here is predicting editors that would become inactive.
6 Results
In this section, we first investigate the classification performance of those meth-ods introduced in Section 6.1, and analyze the usefulness of our statistical fea-tures introduced in Section 3.1 in detail.
6.1 Comparison with the Set of Different Methods
Here we discuss the results with respect to two questions mentioned in Section 1such as what types of ML approaches perform well for the prediction, and howwell those approaches applied to Wikipedia can perform in the context of Wiki-data. Table 1 shows the overall classification results in terms of AUROC andF1 with the set of methods compared. As shown in the table, for approachesusing either statistical or pattern-based features, DeepFM-Stat achieves the bestperformance of AUROC (0.8928) and F1 (0.8247) followed by GBT-Zh. Despitethe fact that GBT-Zh is adapted from edit volume prediction on Wikipedia, wenotice that the approach provides a strong performance with an AUROC scoreof 0.8890 and an F1 score of 0.8205 for classifying inactive users on Wikidataas well. Similar to the observation for predicting edit volume on Wikipedia, theclassification performance of kNN-Zh is worse than GBT-Zh with the same set offeatures. RF-Sa and LR-Sa, which are adapted from the method for analyzing theedit volume of a Wikidata editor during his/her lifetime on the platform, performworse than other methods. Overall, DeepFM-Stat improves the AUROC score0.43%-16.75% and the F1 score 0.51%-6.15% compared to those non-DeepFMalternatives either using statistical features or pattern-based ones for classifyinginactive editors on Wikidata.
Next, we investigate what types of features (e.g., statistical, pattern-based, or both of them) are useful in the context of DeepFM. We observe

Learning to Predict the Departure Dynamics of Wikidata Editors 13
Table 1: Classification performance of the set of methods compared in terms ofAUROC and F1 with the best-performing ones in bold.
Method AUROC F1
GBT-Zh 0.8890 0.8205kNN-Zh 0.8731 0.7935RF-Sa 0.7647 0.7769LR-Sa 0.7656 0.7795SVM-Ar 0.8396 0.8029DeepFM-Pattern 0.8786±0.0002 0.7992±0.0028DeepFM-Stat 0.8928±0.0001 0.8247±0.0006DeepFM-Stat+Pattern 0.9561±0.0005 0.8843±0.0012
that DeepFM-Stat+Pattern, which considers both the statistical and pattern-based features together, further improves the performance significantly com-pared to using either statistical or pattern-based features alone. For example,DeepFM-Stat+Pattern achieves an AUROC score of 0.9561 and an F1 score of0.8843, which outperforms DeepFM-Stat (+7.09% of AUROC, +7.23% of F1 )and DeepFM-Pattern (+8.82% of AUROC, +10.65% of F1 ). This shows thatthe two types of features – statistical and pattern-based ones – can complementeach other and achieves the best classification performance on predicting inactiveeditors, which has not been explored in previous studies15.
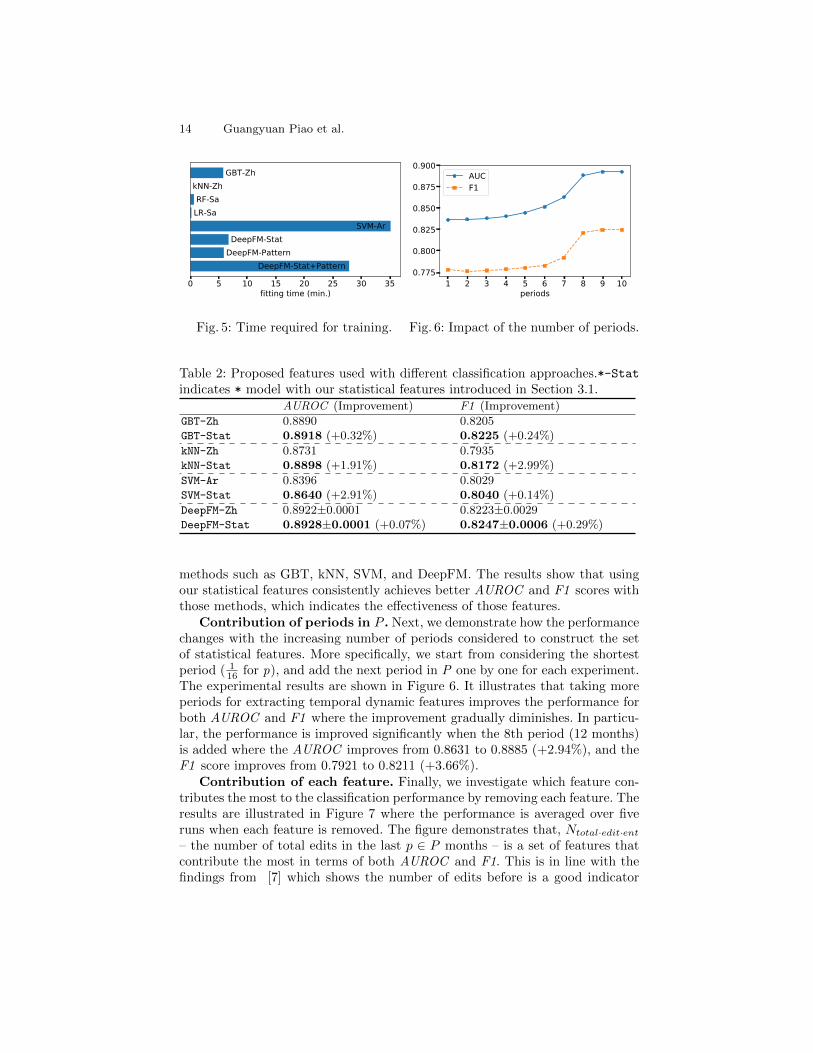
Finally, Figure 5 illustrates the time required for training each of thosemethods where we observe all except SVM-Ar can be trained within 30 min-utes. As one might expect, leveraging both statistical and pattern-based fea-tures (DeepFM-Stat+Pattern) results in increased training time compared toonly using either of the sets of features. The training/fitting time for all meth-ods is arguably reasonable, which can be updated periodically (e.g., every day orweek) easily, and the time can be further improved with a better infrastructure.
6.2 Analysis of Statistical Features
In this section, we analyze the set of statistical features introduced in Section 3.1to answer the following questions: (1) Are those features improving the classi-fication performance compared to the features adapted in previous studies whenthe same ML approach is applied? (2) How much improvement can we achieveby considering a greater number of periods in P? (3) Which statistical featurecontributes the most to the performance with DeepFM?
Contribution of proposed features. Here we investigate whether usingour features improves the classification performance compared to using the setof features that are adapted from previous studies when the same ML approachis applied. Table 2 illustrates the performance in the context of four different
15 Similar trends can be observed when we limit users with at least five edits insteadof one. For example, DeepFM-Stat+Pattern provides the best performance and im-proves AUROC 10.7% and 11.5% compared to using GBT-Zh and kNN-Zh.
14 Guangyuan Piao et al.
0 5 10 15 20 25 30 35fitting time (min.)
DeepFM-Stat+PatternDeepFM-PatternDeepFM-Stat
SVM-ArLR-SaRF-Sa
kNN-ZhGBT-Zh
Fig. 5: Time required for training.
1 2 3 4 5 6 7 8 9 10periods
0.775
0.800
0.825
0.850
0.875
0.900AUCF1
Fig. 6: Impact of the number of periods.
Table 2: Proposed features used with different classification approaches.*-Statindicates * model with our statistical features introduced in Section 3.1.
AUROC (Improvement) F1 (Improvement)
GBT-Zh 0.8890 0.8205GBT-Stat 0.8918 (+0.32%) 0.8225 (+0.24%)
kNN-Zh 0.8731 0.7935kNN-Stat 0.8898 (+1.91%) 0.8172 (+2.99%)
SVM-Ar 0.8396 0.8029SVM-Stat 0.8640 (+2.91%) 0.8040 (+0.14%)
DeepFM-Zh 0.8922±0.0001 0.8223±0.0029DeepFM-Stat 0.8928±0.0001 (+0.07%) 0.8247±0.0006 (+0.29%)
methods such as GBT, kNN, SVM, and DeepFM. The results show that usingour statistical features consistently achieves better AUROC and F1 scores withthose methods, which indicates the effectiveness of those features.
Contribution of periods in P . Next, we demonstrate how the performancechanges with the increasing number of periods considered to construct the setof statistical features. More specifically, we start from considering the shortestperiod ( 1
16 for p), and add the next period in P one by one for each experiment.The experimental results are shown in Figure 6. It illustrates that taking moreperiods for extracting temporal dynamic features improves the performance forboth AUROC and F1 where the improvement gradually diminishes. In particu-lar, the performance is improved significantly when the 8th period (12 months)is added where the AUROC improves from 0.8631 to 0.8885 (+2.94%), and theF1 score improves from 0.7921 to 0.8211 (+3.66%).
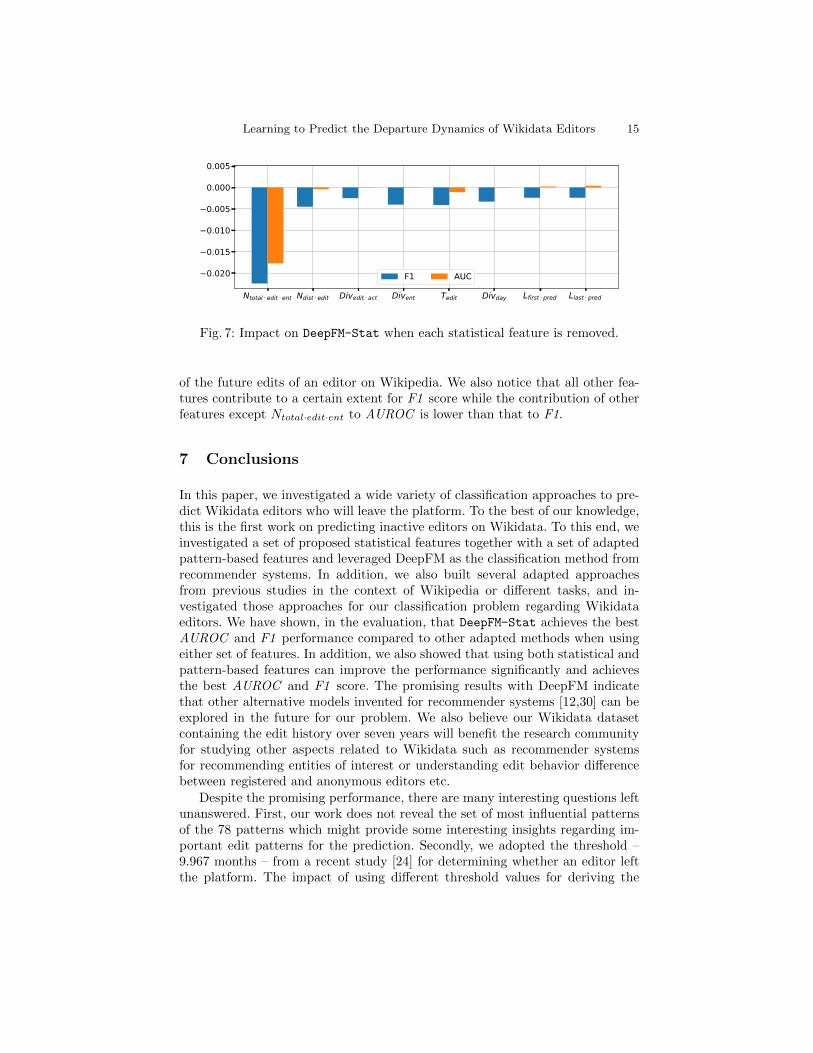
Contribution of each feature. Finally, we investigate which feature con-tributes the most to the classification performance by removing each feature. Theresults are illustrated in Figure 7 where the performance is averaged over fiveruns when each feature is removed. The figure demonstrates that, Ntotal·edit·ent– the number of total edits in the last p ∈ P months – is a set of features thatcontribute the most in terms of both AUROC and F1. This is in line with thefindings from [7] which shows the number of edits before is a good indicator
Learning to Predict the Departure Dynamics of Wikidata Editors 15
Ntotal edit ent Ndist edit Divedit act Divent Tedit Divday Lfirst pred Llast pred
0.020
0.015
0.010
0.005
0.000
0.005
F1 AUC
Fig. 7: Impact on DeepFM-Stat when each statistical feature is removed.
of the future edits of an editor on Wikipedia. We also notice that all other fea-tures contribute to a certain extent for F1 score while the contribution of otherfeatures except Ntotal·edit·ent to AUROC is lower than that to F1.
7 Conclusions
In this paper, we investigated a wide variety of classification approaches to pre-dict Wikidata editors who will leave the platform. To the best of our knowledge,this is the first work on predicting inactive editors on Wikidata. To this end, weinvestigated a set of proposed statistical features together with a set of adaptedpattern-based features and leveraged DeepFM as the classification method fromrecommender systems. In addition, we also built several adapted approachesfrom previous studies in the context of Wikipedia or different tasks, and in-vestigated those approaches for our classification problem regarding Wikidataeditors. We have shown, in the evaluation, that DeepFM-Stat achieves the bestAUROC and F1 performance compared to other adapted methods when usingeither set of features. In addition, we also showed that using both statistical andpattern-based features can improve the performance significantly and achievesthe best AUROC and F1 score. The promising results with DeepFM indicatethat other alternative models invented for recommender systems [12,30] can beexplored in the future for our problem. We also believe our Wikidata datasetcontaining the edit history over seven years will benefit the research communityfor studying other aspects related to Wikidata such as recommender systemsfor recommending entities of interest or understanding edit behavior differencebetween registered and anonymous editors etc.
Despite the promising performance, there are many interesting questions leftunanswered. First, our work does not reveal the set of most influential patternsof the 78 patterns which might provide some interesting insights regarding im-portant edit patterns for the prediction. Secondly, we adopted the threshold –9.967 months – from a recent study [24] for determining whether an editor leftthe platform. The impact of using different threshold values for deriving the

16 Guangyuan Piao et al.
ground truth labels of editors needs to be further investigated. Finally, currentapproaches require manual feature engineering. In the future, we plan to focuson end-to-end approaches and investigate whether an end-to-end classificationmodel without manual feature engineering is feasible.
Acknowledgements We thank the reviewers for the helpful feedback. WeipengHuang is supported by SFI under the grant SFI/12/RC/2289 P2.
References
1. Arelli, H., Spezzano, F.: Who will stop contributingƒ predicting inactive editors inwikipedia. In: 2017 IEEE/ACM International Conference on Advances in SocialNetworks Analysis and Mining (ASONAM). pp. 355–358. IEEE (2017)
2. Arelli, H., Spezzano, F., Shrestha, A.: Editing behavior analysis for predictingactive and inactive users in wikipedia. In: IEEE/ACM International Conference onAdvances in Social Networks Analysis and Mining. pp. 127–147. Springer (2018)
3. Cuong, T.T., Muller-Birn, C.: Applicability of sequence analysis methods in analyz-ing peer-production systems: a case study in wikidata. In: International Conferenceon Social Informatics. pp. 142–156. Springer (2016)
4. Druck, G., Miklau, G., McCallum, A.: Learning to predict the quality of contribu-tions to wikipedia. WikiAI 8, 7–12 (2008)
5. Fischler, M.A., Bolles, R.C.: Random sample consensus: a paradigm for modelfitting with applications to image analysis and automated cartography. Communi-cations of the ACM 24(6), 381–395 (1981)
6. Fournier-Viger, P., Lin, J.C.W., Gomariz, A., Gueniche, T., Soltani, A., Deng, Z.,Lam, H.T.: The spmf open-source data mining library version 2. In: ECML/PKDD.pp. 36–40. Springer (2016)
7. Gandica, Y., Carvalho, J., Dos Aidos, F.S.: Wikipedia editing dynamics. PhysicalReview E 91(1), 012824 (2015)
8. Geiger, R.S., Halfaker, A.: Using edit sessions to measure participation inwikipedia. In: CSCW. pp. 861–870 (2013)
9. Guo, H., Tang, R., Ye, Y., Li, Z., He, X.: Deepfm: A factorization-machine basedneural network for ctr prediction. In: IJCAI (2017)
10. Kaffee, L.A., Elsahar, H., Vougiouklis, P., Gravier, C., Laforest, F., Hare, J., Sim-perl, E.: Mind the (language) gap: Generation of multilingual wikipedia summariesfrom wikidata for articleplaceholders. In: ESWC. pp. 319–334. Springer (2018)
11. Lehmann, J., Isele, R., Jakob, M., Jentzsch, A., Kontokostas, D., Mendes, P.N.,Hellmann, S., Morsey, M., Van Kleef, P., Auer, S., et al.: Dbpedia–a large-scale,multilingual knowledge base extracted from wikipedia. Semantic Web 6(2), 167–195 (2015)
12. Lian, J., Zhou, X., Zhang, F., Chen, Z., Xie, X., Sun, G.: xdeepfm: Combiningexplicit and implicit feature interactions for recommender systems. In: Proceedingsof the 24th ACM SIGKDD International Conference on Knowledge Discovery &Data Mining. pp. 1754–1763 (2018)
13. Malyshev, S., Krotzsch, M., Gonzalez, L., Gonsior, J., Bielefeldt, A.: Getting themost out of wikidata: Semantic technology usage in wikipedia’s knowledge graph.In: International Semantic Web Conference. pp. 376–394. Springer (2018)

Learning to Predict the Departure Dynamics of Wikidata Editors 17
14. Mora-Cantallops, M., Sanchez-Alonso, S., Garcıa-Barriocanal, E.: A systematicliterature review on wikidata. Data Technologies and Applications (2019)
15. Muller-Birn, C., Karran, B., Lehmann, J., Luczak-Rosch, M.: Peer-production sys-tem or collaborative ontology engineering effort: What is wikidata? In: Proceedingsof the 11th International Symposium on Open Collaboration. pp. 1–10 (2015)
16. Panciera, K., Halfaker, A., Terveen, L.: Wikipedians are born, not made: a studyof power editors on wikipedia. In: CSCW. pp. 51–60 (2009)
17. Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O.,Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., et al.: Scikit-learn: Machinelearning in python. JMLR 12, 2825–2830 (2011)
18. Pei, J., Han, J., Mortazavi-Asl, B., Wang, J., Pinto, H., Chen, Q., Dayal, U., Hsu,M.C.: Mining sequential patterns by pattern-growth: The prefixspan approach.IEEE Transactions on Knowledge and Data Engineering 16(11), 1424–1440 (2004)
19. Pellissier Tanon, T., Kaffee, L.A.: Property label stability in wikidata: evolutionand convergence of schemas in collaborative knowledge bases. In: Companion Pro-ceedings of the The Web Conference 2018. pp. 1801–1803 (2018)
20. Piscopo, A., Phethean, C., Simperl, E.: What makes a good collaborative knowl-edge graph: group composition and quality in wikidata. In: International Confer-ence on Social Informatics. pp. 305–322. Springer (2017)
21. Piscopo, A., Vougiouklis, P., Kaffee, L.A., Phethean, C., Hare, J., Simperl, E.:What do wikidata and wikipedia have in common? an analysis of their use ofexternal references. In: Proceedings of the 13th International Symposium on OpenCollaboration. pp. 1–10 (2017)
22. Rendle, S.: Factorization machines. In: 2010 IEEE International Conference onData Mining. pp. 995–1000. IEEE (2010)
23. Ristoski, P., Paulheim, H.: Rdf2vec: Rdf graph embeddings for data mining. In:International Semantic Web Conference. pp. 498–514. Springer (2016)
24. Sarasua, C., Checco, A., Demartini, G., Difallah, D., Feldman, M., Pintscher, L.:The evolution of power and standard wikidata editors: comparing editing behaviorover time to predict lifespan and volume of edits. CSCW 28(5), 843–882 (2019)
25. Shannon, C.E.: A mathematical theory of communication. acm sigmobile mob.Comput. Commun. Rev 5(1), 3–55 (2001)
26. Shen, W.: Deepctr: Easy-to-use,modular and extendible package of deep-learningbased ctr models. https://github.com/shenweichen/deepctr (2017)
27. Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.:Dropout: a simple way to prevent neural networks from overfitting. The Journalof Machine Learning Research 15(1), 1929–1958 (2014)
28. Vrandecic, D., Krotzsch, M.: Wikidata: a free collaborative knowledgebase. Com-munications of the ACM 57(10), 78–85 (2014)
29. Waagmeester, A., Stupp, G., Burgstaller-Muehlbacher, S., Good, B.M., Griffith,M., Griffith, O.L., Hanspers, K., Hermjakob, H., Hudson, T.S., Hybiske, K., et al.:Science forum: Wikidata as a knowledge graph for the life sciences. Elife 9 (2020)
30. Yang, Y., Xu, B., Shen, S., Shen, F., Zhao, J.: Operation-aware neural networksfor user response prediction. Neural Networks 121, 161–168 (2020)
31. Zhang, D., Prior, K., Levene, M., Mao, R., van Liere, D.: Leave or stay: Thedeparture dynamics of wikipedia editors. In: International Conference on AdvancedData Mining and Applications. pp. 1–14. Springer (2012)
![Wikimania 2016 Maarten Dammers [[User:Multichill]]...Welcome to Wikidata, Spinster! Wikidata is a tree knowledge base that you can edit! It can be WIKIDATA Hi Spinster! I am Iñaki](https://img.pdfslide.net/doc/110x75/5f0b821d7e708231d430dd70/wikimania-2016-maarten-dammers-usermultichill-welcome-to-wikidata-spinster.jpg)



























