Embed Size (px)
Citation preview

Modeling User Behavior and Interactions
Lecture 3: Improving Ranking with
Behavior DataBehavior Data
1Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Lecture 3 Plan�� �� � � � �� �� � � �� � � � ��� �� � � � � � � � �� � � � � � � � �� � � � � � � �–
�� �� �� � ! "# $ #% �& ! # $ � ' # $(–
)& " ! * & + ,# � � � "# (- � ! #.� /0 � � � 0 � � � � � � 12 3� � 0 / � � 4 � �–
5 # � $ & +6 � *7 ! � $ #–
5 # � $ & +6 � *8 � �� (- � "( #& # ( (9� : � � ; � � < � � ��–
�! � % # $ # � "& & +–
=�& > & + ,� "8 % # "( �?2Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Review: Learning to Rank
•
�� � �� �� � � � � �� � � �� �� � � � � �� � � � �� � � � ��–
�� �� � ��� �� �� ! " �� # �$ � %& ' & () & #* +� , � - . /0 � � 12� ' %� � , 3� # # � # " - 4 "5 46 # " , � - � "* -7 89 $ � : � %$ � 2� ;$–
<7 3� 8 � #= � %$ �$ >� & ;$ ) 9 ?) ; �@ $ & : :) A �$ %�–
' ? ? = B C ?–
D� 7 .� � �� 2 %) > ' ?$ ? = � BE @ $ : C) ?�F•
G HI JK LMN H K H K O H K P LN K Q J PR–
STUV WX YUV W Z[ \] ^_ `ab b c dX e _ `a b b cU d•
f JN M K N MN K g H K O hi K Q L Hj K–
[ STUV kX l TUV mU Z3Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Ordinal Regression Approaches
•
� �� �� �� �� � � � � � �� � �� ���� �� �� �� � � ��� � �� �� � ��� ! �" # �� $ �% $ ! $ �" & ' (� � � � )� � � *� �� � � + ��� ! �" #,-. /0 1 12 3-4 5� 6 7 ) )� � �8 �� � �� 9: ) )� � � ;� 8 �� � <� � �� � �= � >�� � � �� � ?@ � (A B•
� �� �� �� �� � �C � � � � D � �� �EFG HIJ K KG LG M N N LOJ MJ MP FG NFQ N LOJ MR S O F FJ KJ G LF TUV V TW X Y Z[ \]^ _`a b cd eV Q fg O M hJ MP iJ N j k [ S NJ l SG mn lG L l S O MG F V o Zpq p g rs s t]^ _`a b cd eV Q g O M hJ MP iJ N j k [ S NJ l SG mn lG L l S O MG F V Zpq p g rs s t•
u � � v � � �w � � � � D � � � � C �� �xd a yz b c{ | [ LP G F G N O SV Q }G O L MJ MP N~ g O M h EFJ MP q LO IJ G M N �G F R G M NQ p T k } s�
•
u � � v � �� � �� �� � �� � �� � � � �� ��J LG R N Sn ~ l NJ \J �G � M � � Tq �J O S ~ R O S O l l L~� J \ O NJ ~ M ~ K P LO IJ G M N�d � �� d xd a y� TV | [ LP G FQ G N O SV Q f }G O L MJ MP N~ g O M h iJ N j� ~ M� Z \ ~ ~ N j T ~ F N� [ MR NJ ~ MF V o� p� Z rs s�4Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Learning to Rank Summary
•
�� �� �� ��� � � � � � � � � �� � � � � �� � � � � � �� �� � �•
�� �� � � � � � � � � �� � � �� �� � � � � � �� � � � � � � �� � � �•
� ��� � � �! "� � # � # �$ �� "� % &� '� & (–
)*+ ,-. / 01 23 45 6 2 78 -9 :;< *= - 7> /? . 9 @–
*+ ,-. / 1 23 45 6 2 78 -9 :;< *=A - 7> /? . 9A B @–
C9 -. 9D E ? 89 ? F 29 -. G- 1 4H > ? .•
I�! " ' " � #! J � % "K � �L–
M- 4. 5 > 5 8 F? . 3 2 E 4 /> ? 5 45 79 - / 2 ,A /? NOP QR 45 7ST UE - 4. 5 > 5 8 /? . 45 V 4 E 8 ? . > /1 3 95Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Approaches to Use Behavior Data
•
� �� � � � � � � � � � � � � "� � # � # �$ � �� &� J �!–
� ? 4� 1 > 3 9A �� � �–
< 4 7 E> 5 9 V> � ? 4� 1 > 3 9A �� ��••
�� � � � � � � �� � �� �� � � � �� � � � � � � # " # �� J '� � " K� �!–
< > � 1 4. 79 ? 5 - / 4 E�A � � � �� ��–
�8 > � 1 /- > 5 - / 4 E�A ��� �< �� ��–
�> E - 5 V? 45 7 �1 > /-A � � � �� ��–
�1 2 45 7 � >9 1 5 -A �� ��6Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Recap: Available Behavior Data
7Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Training Examples from Click Data[ Joachims 2002 ]
8Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Loss Function[ Joachims 2002 ]
9Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Learned Retrieval Function[ Joachims 2002 ]
10Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Features[ Joachims 2002 ]
11Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Results[ Joachims 2002 ]
Summary:
Learned outperforms all base
methods in experiment
� Learning from clickthrough
data is possible
� Relative preferences are
useful training data.
12
useful training data.
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Extension: Query Chains[Radlinski & Joachims, KDD 2005]
13Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
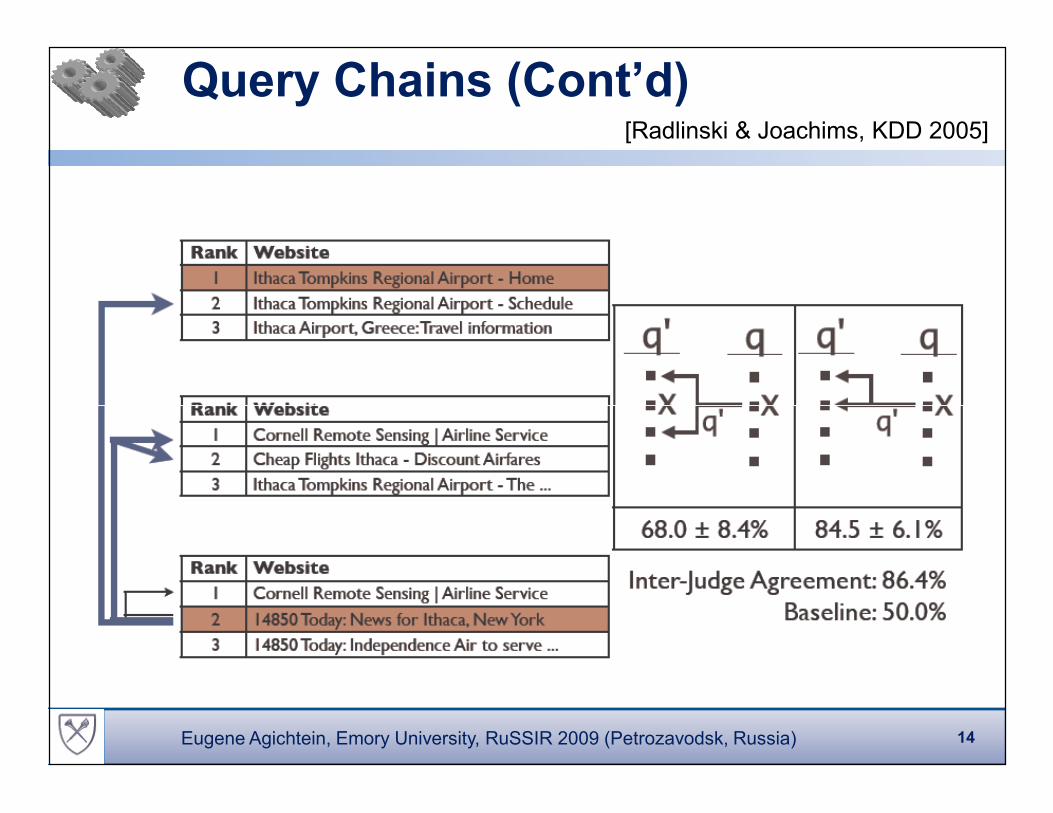
Query Chains (Cont’d) [Radlinski & Joachims, KDD 2005]
14Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Query Chains (Results)
•
�� � � � � � � � � � � � � � � �� � � � � � � � � � � � � � � � �[Radlinski & Joachims, KDD 2005]
15Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Lecture 3 Plan
�
�� � � � �� �� �� � �� � � �
�� � � � � � � �� � � � � � � � � � � �� � � � � ��
�[ N ~ \ O NJ R LG SG �O MR G S O �G SF�
� M LJ R jJ MP N jG LO M hJ MP KG O N[ LG F l O R G�� �� � � � � � � � � � � � �� � � � � � � � ! � �–
�G O SJ MP iJ N j ZR O SG–
�G O SJ MP iJ N j I O N O F l O LFG MG F F"� # � � $ �� � % � � � �–
�R NJ �G SG O L MJ MP–
g O M hJ MP K~ L IJ �G LFJ Nn–
� [ M O MI P O \G F16Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
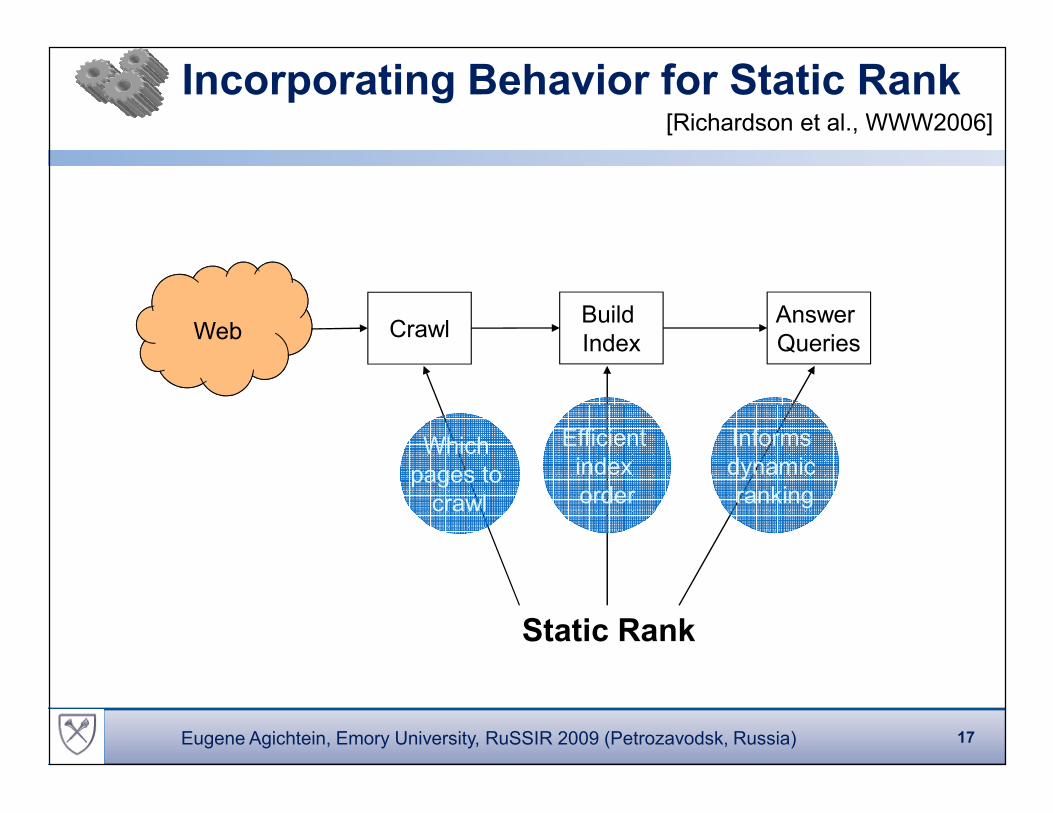
Incorporating Behavior for Static Rank
Web CrawlBuild
Index
Answer
Queries
[Richardson et al., WWW2006]
17
Static Rank
Which
pages to
crawl
Efficient
index
order
Informs
dynamic
ranking
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
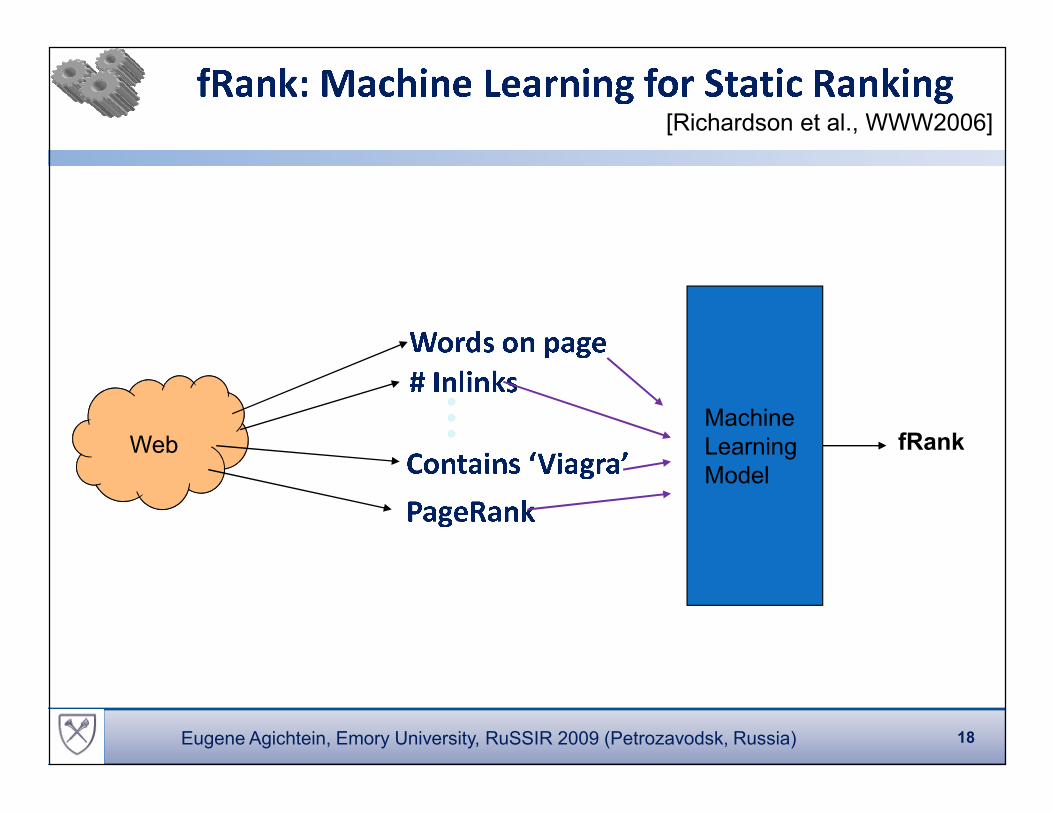
' I� � �L �� % � # �� �� � � � # �$ ' � � "� " # % I� � � # �$
��� �� �� � � �� ��� ��Machine
[Richardson et al., WWW2006]
18
Web �� � �� �� �� � �� � �� � � � � Machine
Learning
Model
fRank
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Features: Summary
•
� � K J� � # "�
•
�� � � � � � �� �� � � � � � �•
� � �
•
� � � � �
[Richardson et al., WWW2006]
19
•
•
� � � � �� �Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
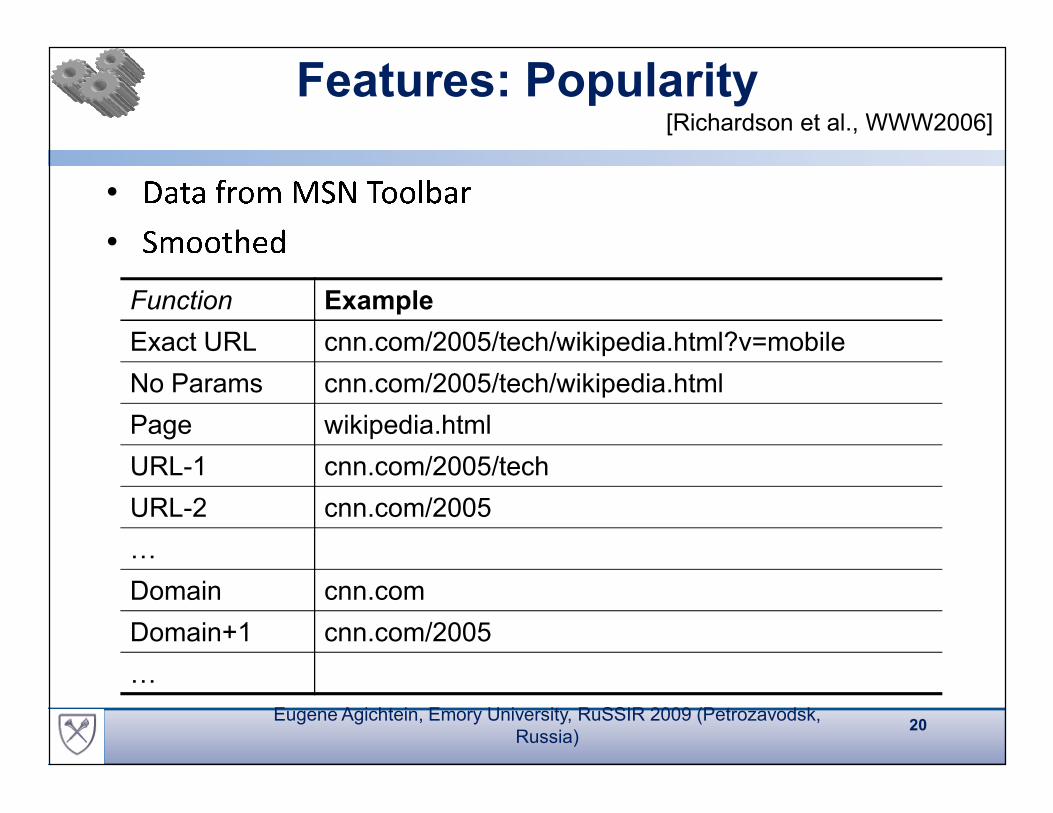
Features: Popularity
•
�� �� [ ] \ � �� c� \ \ �� � ]•
� � \ \ � e
Function Example
Exact URL cnn.com/2005/tech/wikipedia.html?v=mobile
No Params cnn.com/2005/tech/wikipedia.html
[Richardson et al., WWW2006]
20
Page wikipedia.html
URL-1 cnn.com/2005/tech
URL-2 cnn.com/2005
?
Domain cnn.com
Domain+1 cnn.com/2005
?
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk,
Russia)

Features: Anchor, Page, Domain
•
�� � � � � � �� �� � � � � � �–
; ? / 4 E 4 3 ? 25 / ? F 45 � 1 ? . /- + /A 25 >� 2 - 45 � 1 ? . /- + /�? . 79A 5 23 G-. ? F > 5 E > 5 V9A - /� �•
� � �
[Richardson et al., WWW2006]
21
–
� �- 4 / 2. -9 G 49 - 7 ? 5 , 4 8 - 4 E ? 5 -D �? . 79 > 5 G ? 7�AF. - � 2 - 5 � � ? F 3 ? 9 / � ? 3 3 ? 5 /-. 3A - /� �•
� � � � �–
�H -. 4 8 -9 > 5 7 ? 3 4 > 5D 4H -. 4 8 - �? 2 / E > 5 V9A - /� �
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Data
•
� � � �� �� � � � � � ��� < 45 7 ? 3 E � � 1 ? ? 9 - � 2 -. � F. ? 3 � �� 29 -. 9�� = 1 ? 9 - /? , C< M9 G� 9 - 4. � 1 - 5 8 > 5 -�� < 4 /- � 2 4 E > /� ? F C< M F? . /1 4 /� 2 -. �[Richardson et al., WWW2006]
22
•
�� � � � �� � � �� � �� � � �� � � � � � � � �•
� � � � � �� � � � �� � � � � � � � � � �–
< -9 2 E /9 4 , , E � /? > 5 7 - + ? . 7 -. > 5 8A . - E - H 45 � -–
= . 4 � E ? . 7 -. > 5 8 . - � 2>. -9 25 G> 49 - 79 4 3 , E -
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Becoming Query Independent
•
� �� � � �� � �� � � �� � �
→
� � �� � � �� � �•
� � �� � � � � � � � �� � �� � � � � � ��–
�� � � �P � U Q� O U � U� P R N � � O P N � UP T N � R U S U O •
�� � � � � �� � �� � � � �→
� �� � � �� � � � �� � � � � � � � � �[Richardson et al., WWW2006]
23
�� � � � �� � �� �� � � � � �Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Measure
•
� � � �� � � � �� �� � � �� � � � � � � � � � �� � � ���� � � � �� � � � � �� � �� �� � �� � � � � � � � �pp
H
SH ∩
=accuracy pairwise
[Richardson et al., WWW2006]
24
•
�� �� � � � � � � � � � � �� � �� � �� �� � � � � � � � � � �� � �� � � � � � �� � �� � � � �� � � � �� � � �� �� � � � � � � � � � � �� � � � � � � � ��pH
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
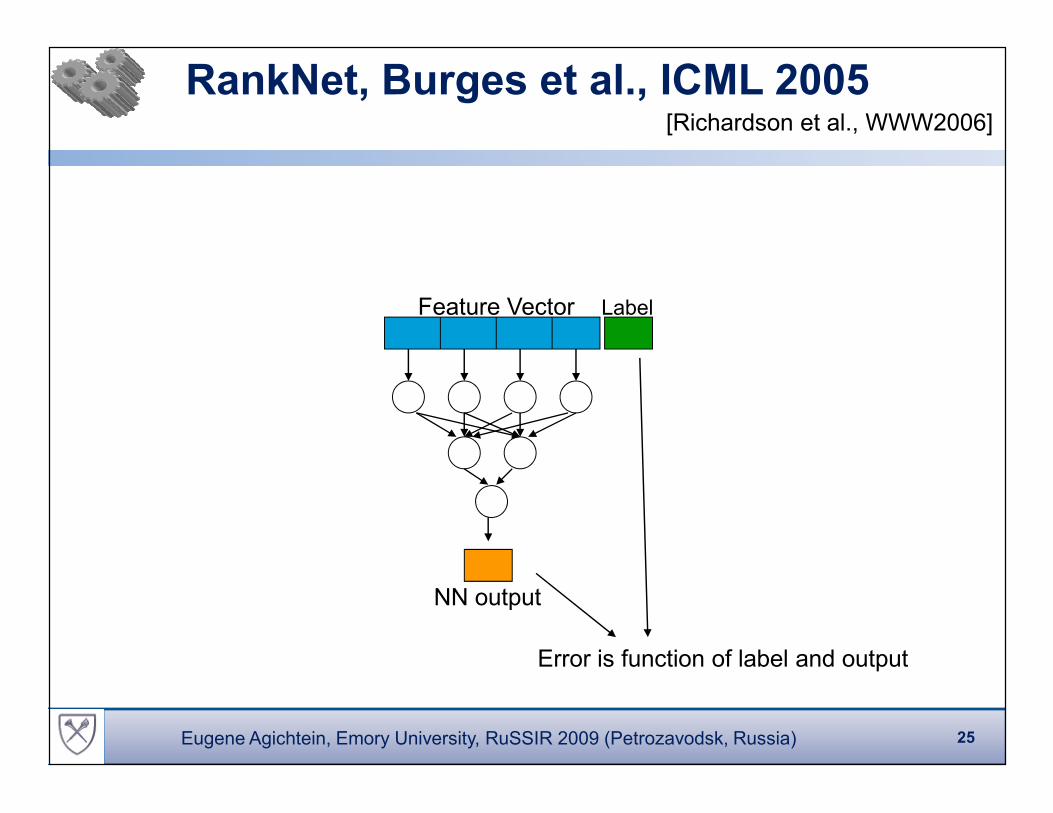
RankNet, Burges et al., ICML 2005
Feature Vector Label
[Richardson et al., WWW2006]
25
NN output
Error is function of label and output
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

RankNet [Burges et al. 2005]
Feature Vector1 Label1
•
�� � � � � � � � � �–
�� �� �� � � � � � �� � � � � � � � �� � �� �� � � �� �[Richardson et al., WWW2006]
26
NN output 1
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

RankNet [Burges et al. 2005]
Feature Vector2 Label2
•
�� � � � � � � � � �–
�� �� �� � � � � � �� � � � � � � � �� � �� �� � � �� �[Richardson et al., WWW2006]
27
NN output 1 NN output 2
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
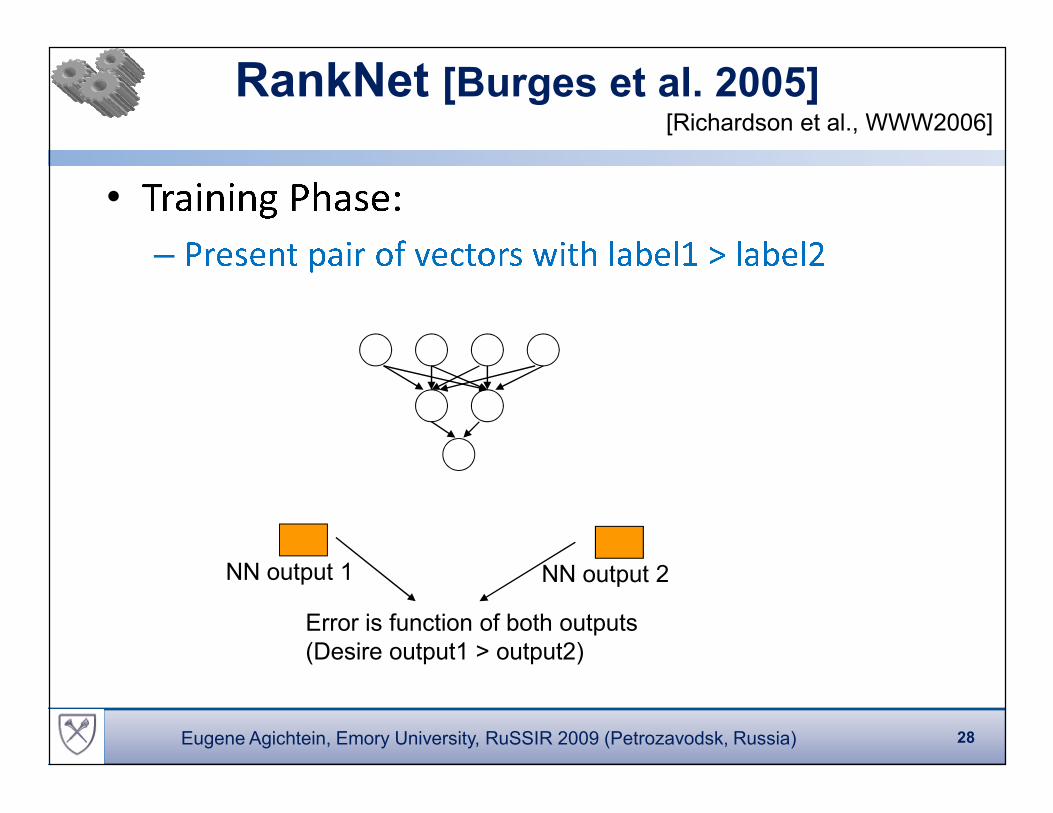
RankNet [Burges et al. 2005]
•
�� � � � � � � � � �–
�� �� �� � � � � � �� � � � � � � � �� � �� �� � � �� �[Richardson et al., WWW2006]
28
NN output 1 NN output 2
Error is function of both outputs
(Desire output1 > output2)
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
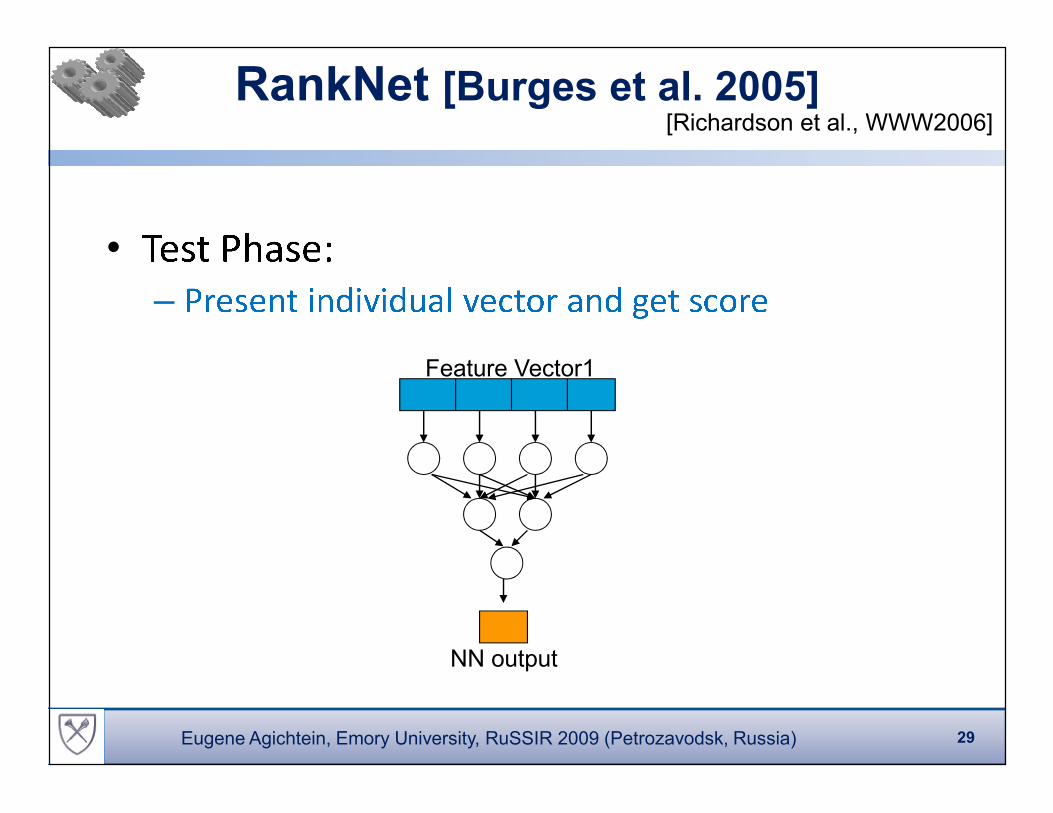
RankNet [Burges et al. 2005]
Feature Vector1
•
�� � � � � � �
–
�� �� �� � � � � �� � � � � � �� � �� � � � � � � � �� �[Richardson et al., WWW2006]
29
NN output
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Experimental Methodology
•
� � � � � � � � � �
–
�� � �� � � � � � � � �–
� � � � � � � � �� � � �–
� � � �� � � � ��
[Richardson et al., WWW2006]
30
�
�� � � � � � � � �� � � � � �� � �•
� � � � � � � � � � � � � � �� � � �•
�� � � � � � � � � � � � � � � � � � �� � � � �� �Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
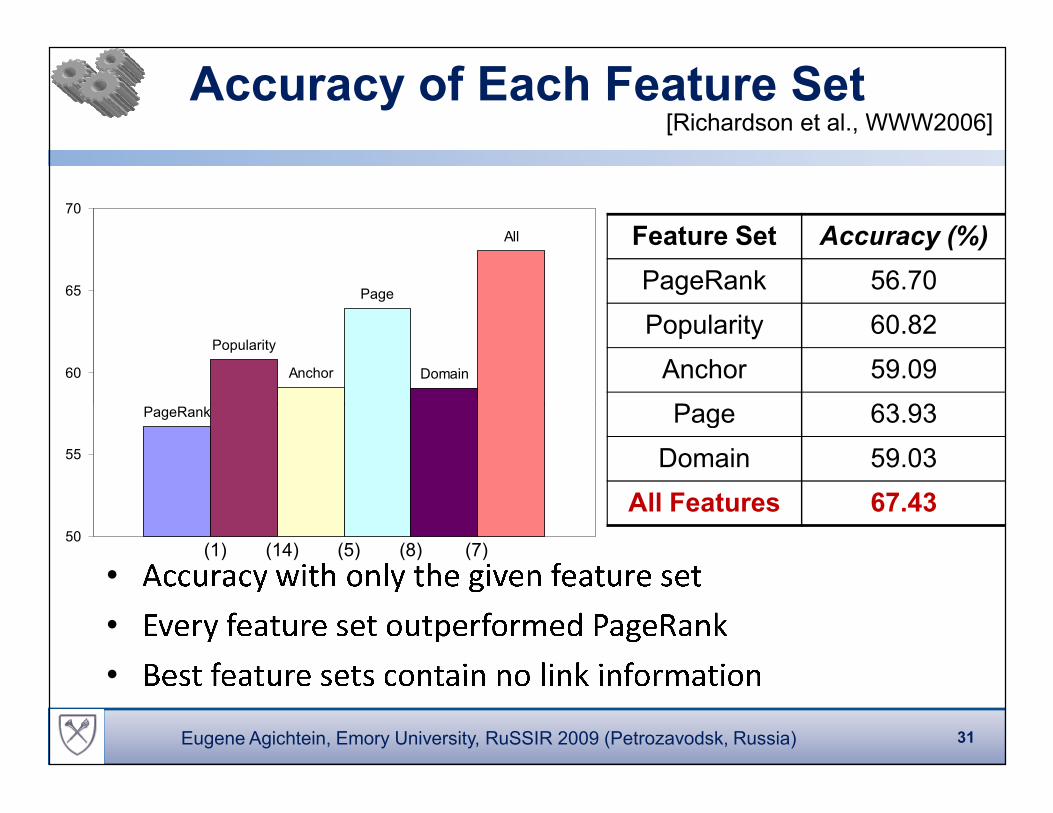
PageRank
Popularity
Anchor
Page
Domain
All
60
65
70
Accuracy of Each Feature Set
Feature Set Accuracy (%)
PageRank 56.70
Popularity 60.82
Anchor 59.09
Page 63.93
[Richardson et al., WWW2006]
31
PageRank
50
55
Page 63.93
Domain 59.03
All Features 67.43
•
�� � �� � � � � �� � � � � � �� � � �� �� � �•
�� � � � �� �� � � � � � � � � � �� � � � � � �•
� �� � �� �� � � � � �� � � � � � � � � � � � � � �� � �(1) (14) (5) (8) (7)
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
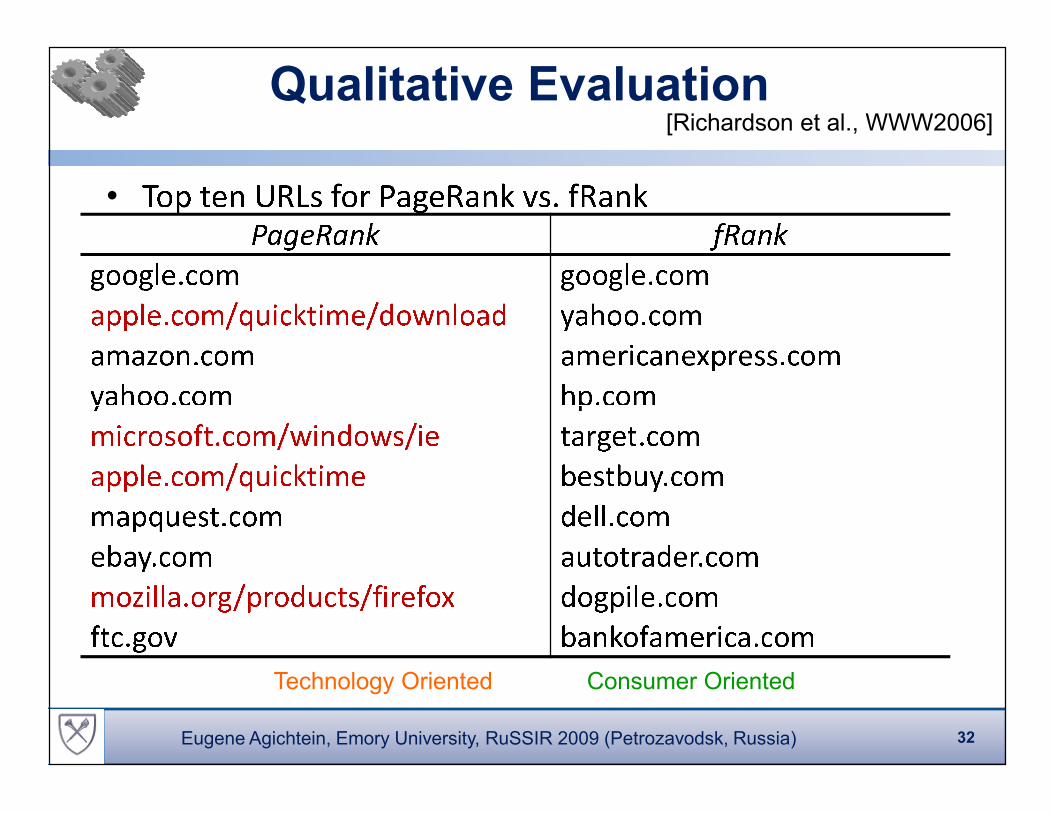
Qualitative Evaluation
•
� � � � � �� � � � � � � � � � � � �� � � � � ��� �� � � � � � � � �� � � � � � �� � � ��� � �� � � � �� � � � �� � �� �� �� � � � � � � � � �� � � � � � � � �� ! � � � � � "� !� # # � � �� � � � � � �� � � �[Richardson et al., WWW2006]
32
� � � � � � �� � � �� � � ! # $� � � � � � � � � � # � �� � � ! �� � � � ��� � �� � � � �� � � � �� � �� %� # � % � � � � �� �� � �� # � � � � � � � � � � �� % � � � � � � � � � ! � � � ! � � �� � � � � � ! � �� ! � � � � # � $ � !� $ " � �� � �� � � �$� � � � & % � � � $ � �� ! � � � � � �
Technology Oriented Consumer Oriented
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
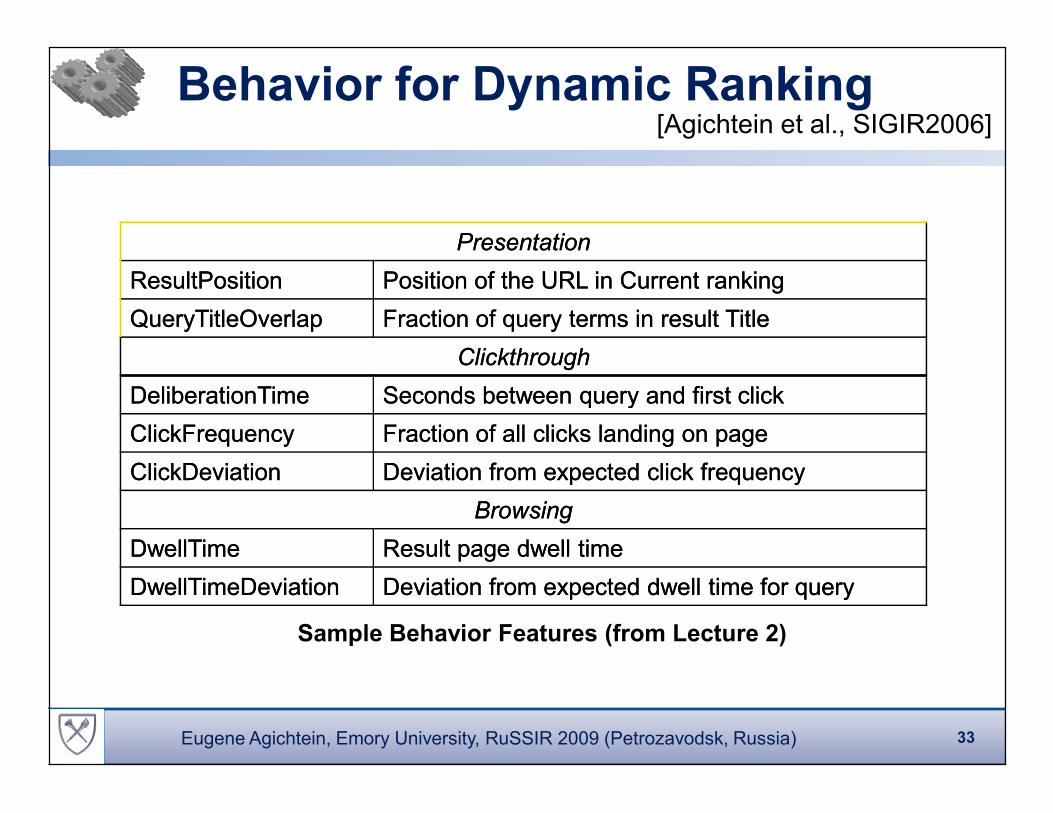
Behavior for Dynamic Ranking[Agichtein et al., SIGIR2006]
PresentationPresentation
ResultPositionResultPosition Position of the URL in Current rankingPosition of the URL in Current ranking
QueryTitleOverlapQueryTitleOverlap Fraction of query terms in result TitleFraction of query terms in result Title
Clickthrough Clickthrough
DeliberationTimeDeliberationTime Seconds between query and first clickSeconds between query and first click
33
DeliberationTimeDeliberationTime Seconds between query and first clickSeconds between query and first click
ClickFrequencyClickFrequency Fraction of all clicks landing on pageFraction of all clicks landing on page
ClickDeviationClickDeviation Deviation from expected click frequencyDeviation from expected click frequency
Browsing Browsing
DwellTimeDwellTime Result page dwell timeResult page dwell time
DwellTimeDeviationDwellTimeDeviation Deviation from expected dwell time for queryDeviation from expected dwell time for query
Sample Behavior Features (from Lecture 2)
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Feature Merging: Details
Result URL BM25 PageRank � Clicks DwellTime �sigir2007.org 2.4 0.5 � ? ? �Sigir2006.org 1.4 1.1 � 150 145.2 �acm.org/sigs/sigir/ 1.2 2 � 60 23.5 �Query: SIGIR, fake results w/ fake feature values
[Agichtein et al., SIGIR2006]
•
�� �� �� � � � � �–
�� � �� �� �� �� �� � �� �� �� �� � �� �� � � � � ��� �� �� � � !•
" � � � �� �� �� �–
� # �$ �� � �� � %� � � � �$ � � �& � ' % �� () � � � � � ) � � �� (� �� � # !
•
*+ � � �, - . � / �0 12 3 14 15 6 3 7 � + � 8 - � � -� + � 9� :� - � .; +< = � � .�acm.org/sigs/sigir/ 1.2 2 60 23.5
34Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
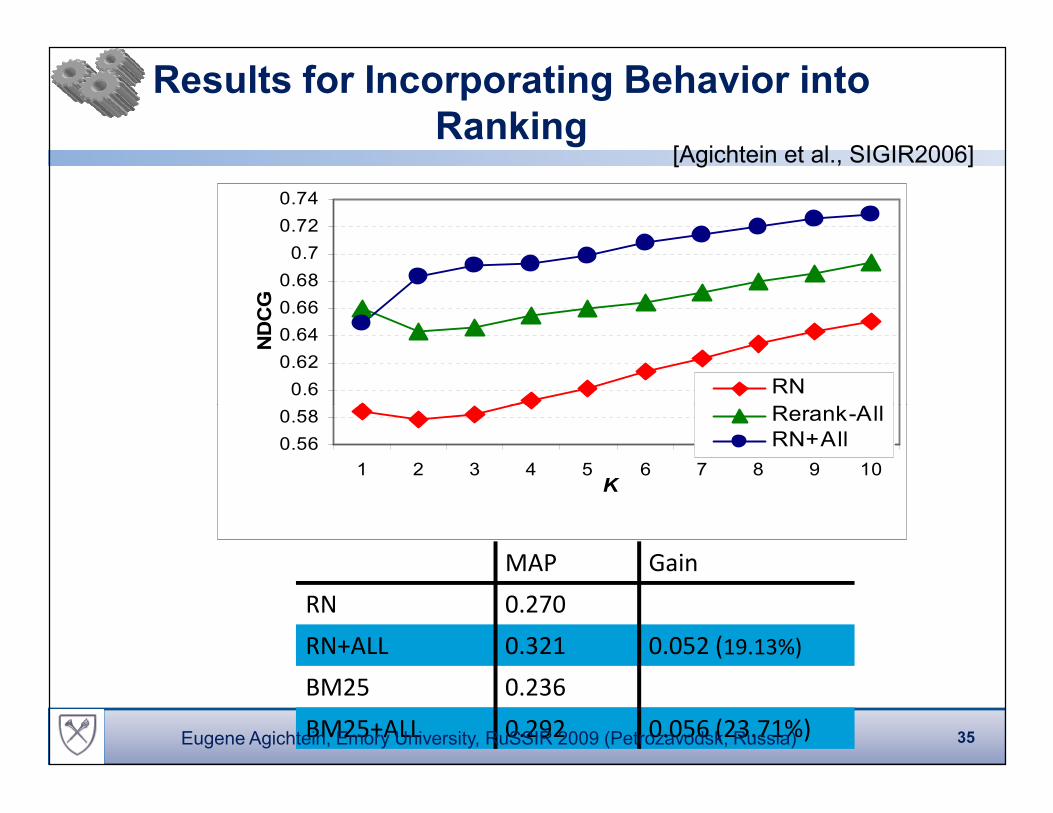
Results for Incorporating Behavior into
Ranking
0.6
0.62
0.64
0.66
0.68
0.7
0.72
0.74
NDCG
RN
Rerank-All
[Agichtein et al., SIGIR2006]
MAP Gain
RN 0.270
RN+ALL 0.321 0.052 (19.13%)
BM25 0.236
BM25+ALL 0.292 0.056 (23.71%)
0.56
0.58
1 2 3 4 5 6 7 8 9 10K
Rerank-All
RN+All
35Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
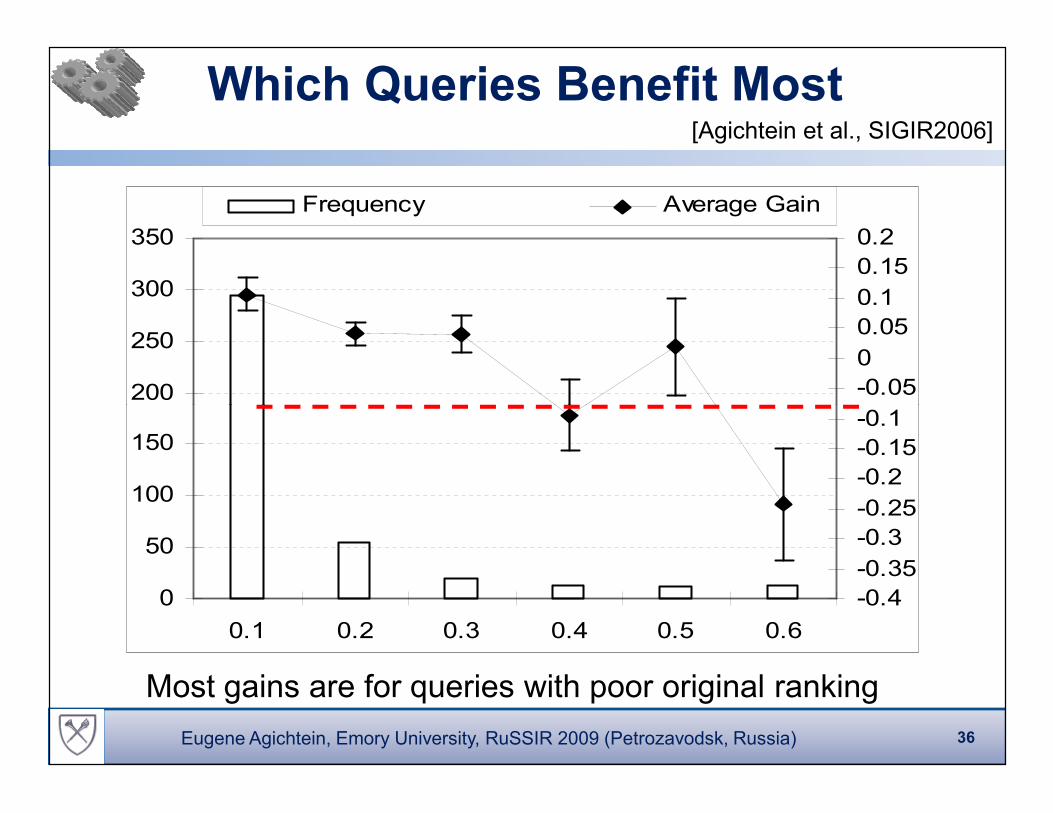
Which Queries Benefit Most
200
250
300
350
-0.05
0
0.05
0.1
0.15
0.2
Frequency Average Gain
[Agichtein et al., SIGIR2006]
0
50
100
150
0.1 0.2 0.3 0.4 0.5 0.6
-0.4
-0.35
-0.3
-0.25
-0.2
-0.15
-0.1
Most gains are for queries with poor original ranking
36Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Lecture 3 Plan
�
�� � � � �� �� �� � �� � � �
�� � � � � � � �� � � � � � � � � � � �� � � � � �� Automatic relevance labels
� Enriching feature space�� �� � � � � � � � � � � � �� �� � � � � � � � � �� Dealing with data sparseness
– Dealing with Scale�� � � ! �� � " � � � �– Active learning
– Ranking for diversity
– Fun and games
37Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Extension to Unseen
Queries/Documents: Search Trails
[Bilenko and White, WWW 2008]
38
• Trails start with a search engine query
• Continue until a terminating event
– Another search
– Visit to an unrelated site (social networks, webmail)
– Timeout, browser homepage, browser closing
Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Probabilistic Model
• IR via language modeling [Zhai-Lafferty, Lavrenko]
• Query-term distribution gives more mass to rare
terms:
[Bilenko and White, WWW 2008]
terms:
• Term-website weights �� � ��� � �� � � � �� � � �� ��
39Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
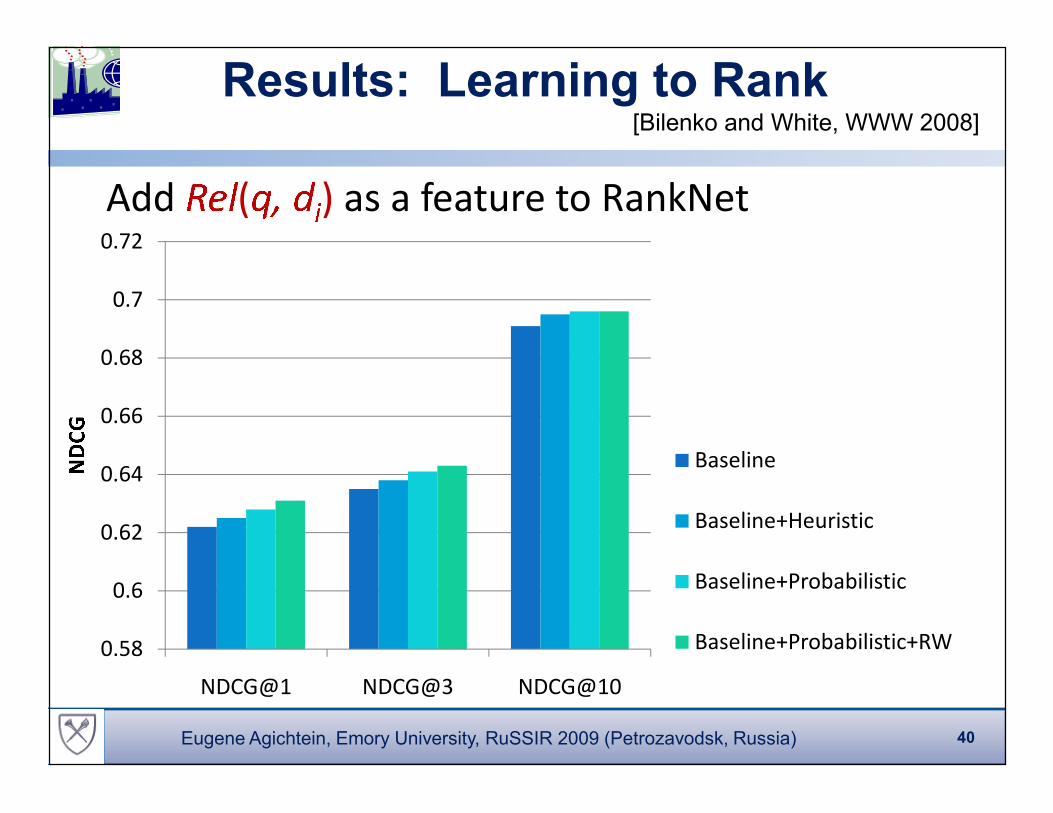
Results: Learning to Rank
Add
�� �
(
�� �� ) as a feature to RankNet
0.66
0.68
0.7
0.72
[Bilenko and White, WWW 2008]
0.58
0.6
0.62
0.64
0.66
NDCG@1 NDCG@3 NDCG@10
�� Baseline
Baseline+Heuristic
Baseline+Probabilistic
Baseline+Probabilistic+RW
40Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
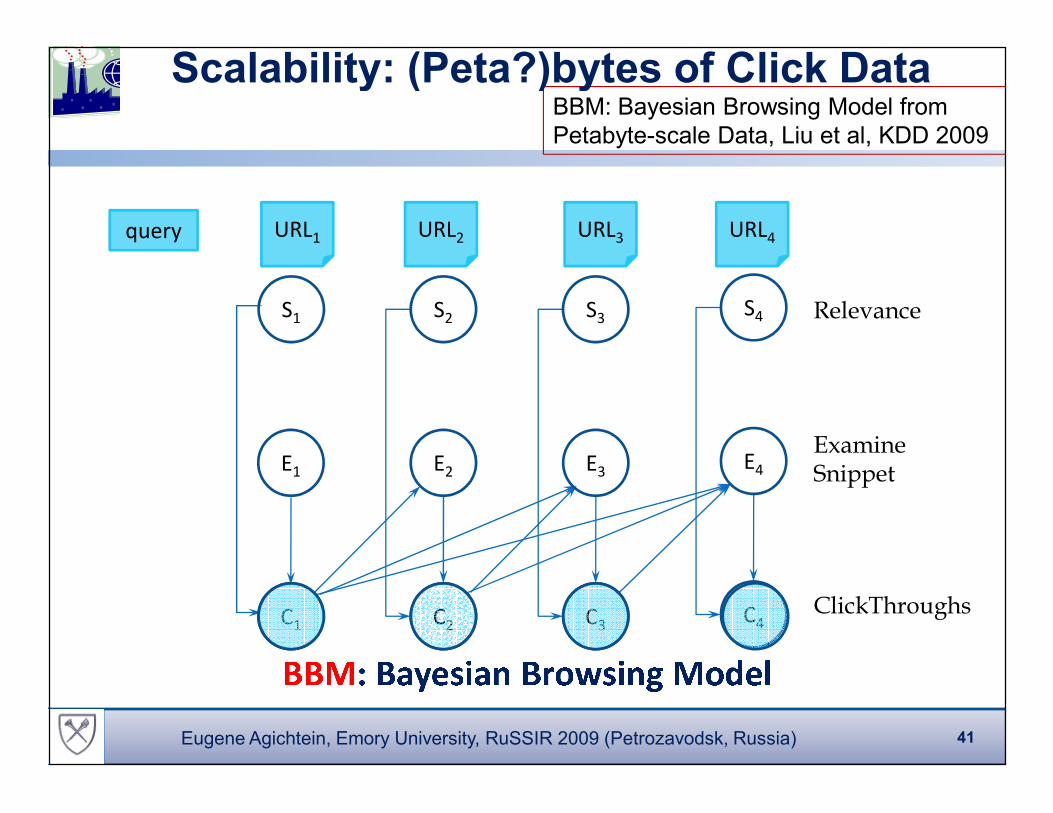
query URL1 URL2 URL3 URL4
S1 S2 S3S4 Relevance
BBM: Bayesian Browsing Model from
Petabyte-scale Data, Liu et al, KDD 2009
Scalability: (Peta?)bytes of Click Data
� � � � �� ��� � � � � �� � �� � � �C1 C2 C3C4
E1 E2 E3E4
Examine Snippet
ClickThroughs
41Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Training BBM: One-Pass CountingBBM: Bayesian Browsing Model from
Petabyte-scale Data, Liu et al, KDD 2009
Find Rj
42Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Training BBM on MapReduce
• Map: emit((q,u), idx)
• Reduce: construct the
count vector
BBM: Bayesian Browsing Model from
Petabyte-scale Data, Liu et al, KDD 2009
43Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
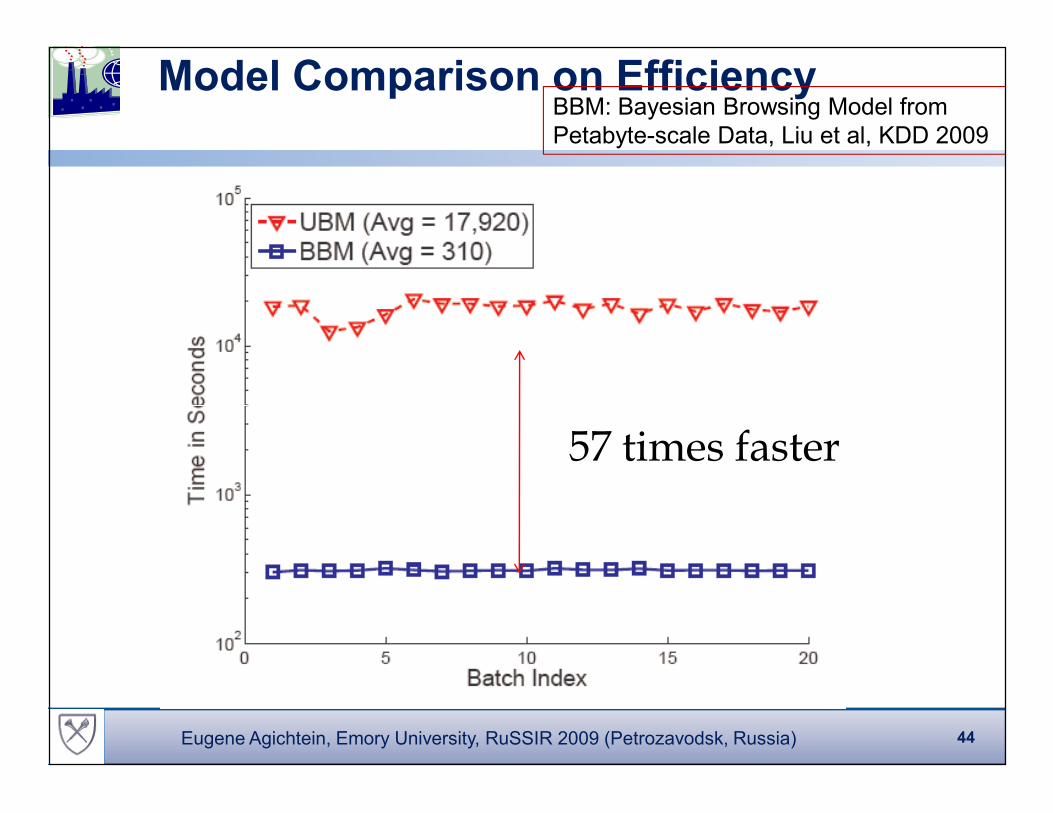
Model Comparison on EfficiencyBBM: Bayesian Browsing Model from
Petabyte-scale Data, Liu et al, KDD 2009
57 times faster
44Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
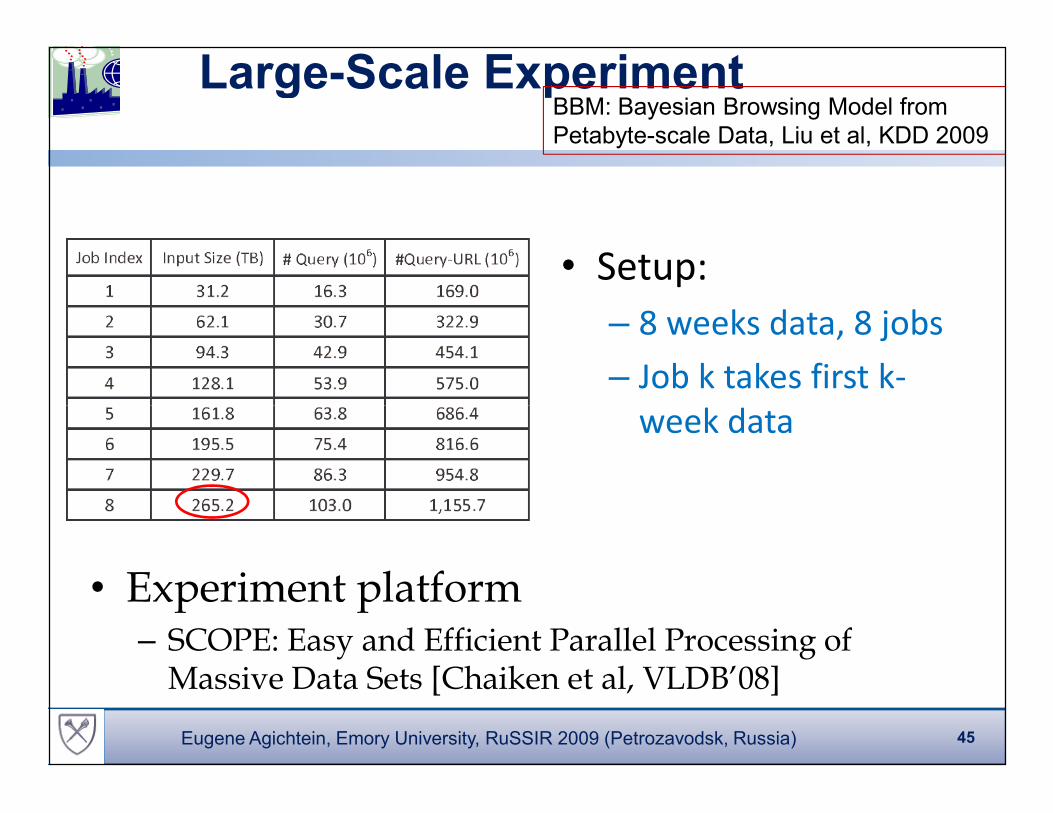
Large-Scale Experiment
• Setup:
– 8 weeks data, 8 jobs
– Job k takes first k-
week data
BBM: Bayesian Browsing Model from
Petabyte-scale Data, Liu et al, KDD 2009
week data
• Experiment platform– SCOPE: Easy and Efficient Parallel Processing of Massive Data Sets [Chaiken et al, VLDB’08]
45Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
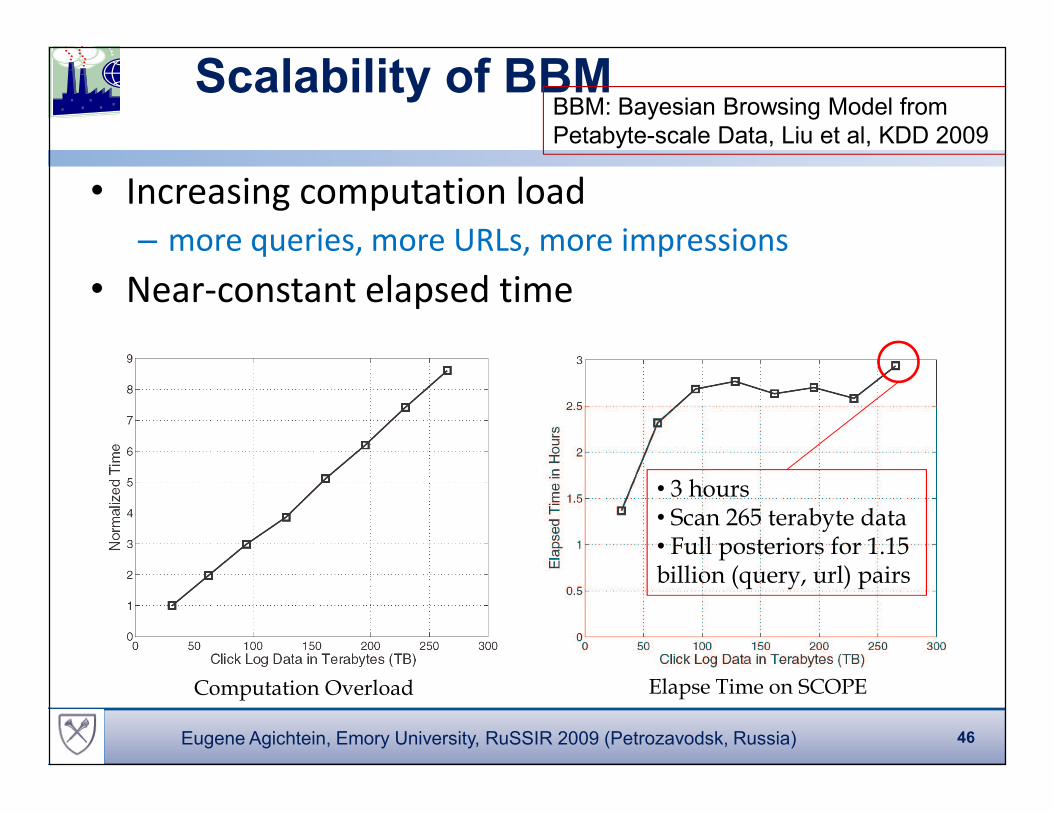
Scalability of BBM
• Increasing computation load
– more queries, more URLs, more impressions
• Near-constant elapsed time
BBM: Bayesian Browsing Model from
Petabyte-scale Data, Liu et al, KDD 2009
Computation Overload Elapse Time on SCOPE
• 3 hours• Scan 265 terabyte data• Full posteriors for 1.15 billion (query, url) pairs
46Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Lecture 3 Plan
�
�� � � � �� �� �� � �� � � �
�� � � � � � � �� � � � � � � � � � � �� � � � � �� Automatic relevance labels
� Enriching feature space
�
�� � � � � � � � � � � � �� �� �� � � � � � � �� Dealing with data sparseness
� Dealing with Scale
�
� � � � �� � � � � � �� Active learning
� Ranking for diversity
47Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

New Direction: Active Learning
• Goal: Learn the relevances with as little training
data as possible.
• Search involves a three step process:�� � �� � � � � � � � �� � �� � � � � � �� � � �� � � � � �� � �� � � � � �[Radlinski & Joachims, KDD 2007]
� � � �2. Given a ranking, users provide feedback: User clicks
provide pairwise relevance judgments.
3. Given feedback, update the relevance estimates.
48Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Overview of Approach
• Available information:1. Have an estimate of the relevance of each result.
2. Can obtain pairwise comparisons of the top few results.
3. Do
� � �
have absolute relevance information.
• Goal: Learn the document relevance quickly.
[Radlinski & Joachims, KDD 2007]
• Goal: Learn the document relevance quickly.
• Will address four questions:1. How to represent knowledge about doc relevance.
2. How to maintain this knowledge as we collect data.
3. Given our knowledge, what is the best ranking?
4. What rankings do we show users to get useful data?
49Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

1: Representing Document Relevance
• Given a query, q , let M = (µ 1, . . . , µ |C|) M be
the true relevance values of the documents.
• Model knowledge of M with a Bayesian:
P (M |D) = P (D|M ) P (M )/P (D)
[Radlinski & Joachims, KDD 2007]
• Assume P (M|D) is spherical multivariate normal:
P (M |D) = N (ν1, . . . , ν|C|; σ12, . . . , σ|C|
2)
Eugene Agichtein, Emory University, RuSSIR
2009 (Petrozavodsk, Russia) 50

• Given a fixed query, maintain knowledge about
relevance as clicks are observed.
– This tells us which documents we are sure about, and
which ones need more data.
1: Representing Document Relevance
[Radlinski & Joachims, KDD 2007]
Eugene Agichtein, Emory University, RuSSIR
2009 (Petrozavodsk, Russia) 51

Model noisy pairwise judgments w [Bradley-Terry’52]
Adding a Gaussian prior, apply off-the-shelf algorithm
2: Maintaining P(M|D)[Radlinski & Joachims, KDD 2007]
Adding a Gaussian prior, apply off-the-shelf algorithm
to maintain
� ��� �� �� �� �� �� �, commonly used
for chess [Glickman 1999]
Eugene Agichtein, Emory University, RuSSIR
2009 (Petrozavodsk, Russia) 52

• Want to assign relevances M = (µ1, . . . , µ|C|) such
that L(M, M ) is small, but M is unknown.
• Minimize
�� � �� � � �loss (pairwise):
3: Ranking (Inference)[Radlinski & Joachims, KDD 2007]
• Minimize
�� � �� � � �loss (pairwise):
Eugene Agichtein, Emory University, RuSSIR
2009 (Petrozavodsk, Russia) 53

•
�� � �� � �
: could present the ranking based on � � � � �� �
best estimate of relevance.
– Then the data we get would always be about the
documents already ranked highly.
4: Getting Useful Data[Radlinski & Joachims, KDD 2007]
• Instead,
� � � � � � �ranking shown users:
1. Pick top two docs to minimize
� � � � ��� �2. Append current best estimate ranking.
Eugene Agichtein, Emory University, RuSSIR
2009 (Petrozavodsk, Russia) 54

4: Exploration Strategies[Radlinski & Joachims, KDD 2007]
Eugene Agichtein, Emory University, RuSSIR
2009 (Petrozavodsk, Russia) 55

4: Loss Functions[Radlinski & Joachims, KDD 2007]
Eugene Agichtein, Emory University, RuSSIR
2009 (Petrozavodsk, Russia) 56
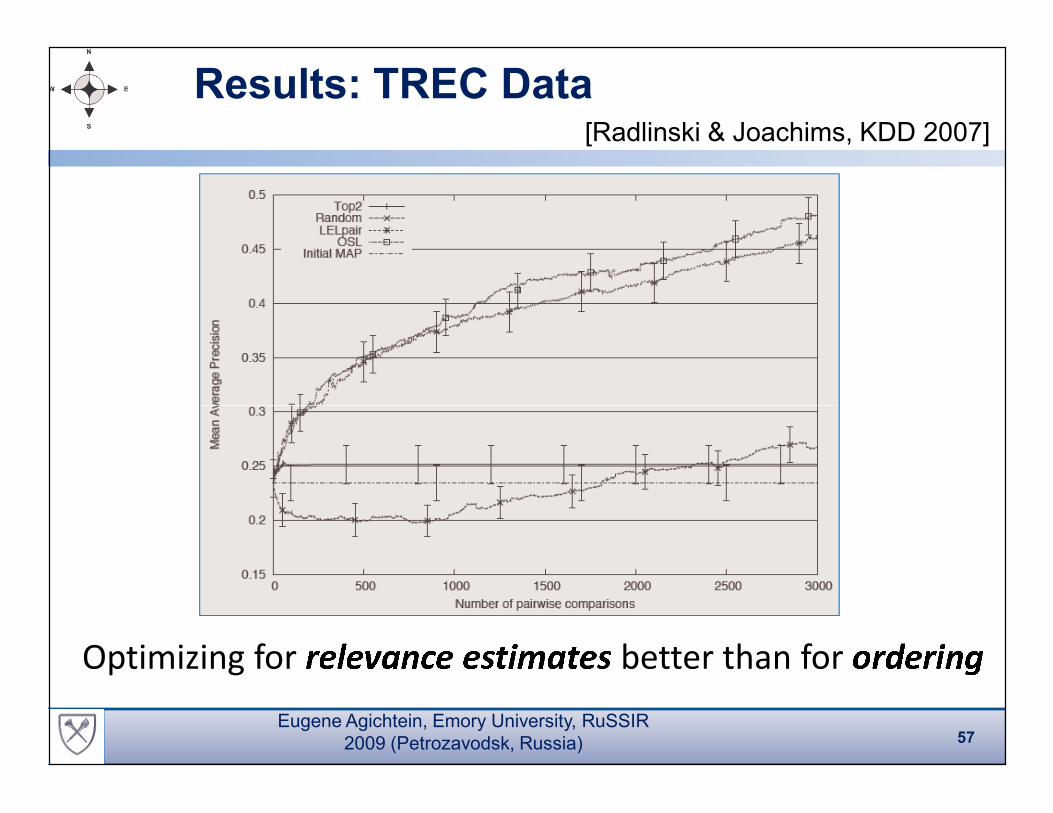
Results: TREC Data [Radlinski & Joachims, KDD 2007]
Eugene Agichtein, Emory University, RuSSIR
2009 (Petrozavodsk, Russia) 57
Optimizing for
�� �� �� �� � � � � � � � �better than for
� � �� � �

Need for Diversity (in IR)
• Ambiguous Queries
– Users with different information needs issuing the same textual
query (“Jaguar”)
• Informational (Exploratory) Queries:
– User interested in “a specific detail or entire breadth of
[Predicting Diverse Subsets Using Structural SVMs,
Y. Yue and Joachims, ICML 2008]
– User interested in “a specific detail or entire breadth of
knowledge available” [Swaminathan et al., 2008]
– Want results with high information diversity
58Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Optimizing for Diversity
• Long interest in IR community
• Requires
� � �� �� � �� � � � � � � � � � � � � � � �� Impossible given current learning to rank methods
• Problem: no consensus on how to measure diversity.� Formulate as predicting diverse subsets
[Predicting Diverse Subsets Using Structural SVMs,
Y. Yue and Joachims, ICML 2008]
� Formulate as predicting diverse subsets
• Experiment: – Use training data with explicitly labeled subtopics (TREC 6-8
Interactive Track)
– Use loss function to encode subtopic loss
– Train using structural SVMs [Tsochantaridis et al., 2005]
59Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Representing Diversity
• Existing datasets with manual subtopic labels
– E.g., “Use of robots in the world today”
• Nanorobots
• Space mission robots
• Underwater robots
[Predicting Diverse Subsets Using Structural SVMs,
Y. Yue and Joachims, ICML 2008]
• Underwater robots
– Manual partitioning of the total information regarding a
query
– Relatively reliable
60Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
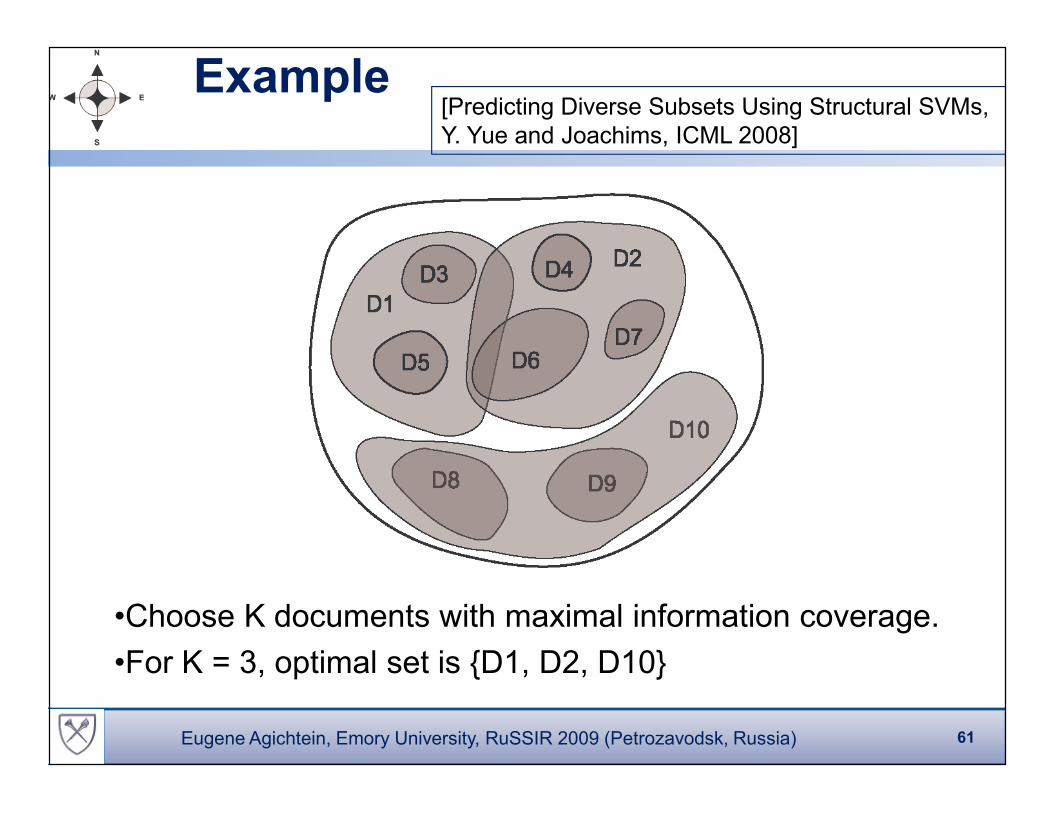
Example[Predicting Diverse Subsets Using Structural SVMs,
Y. Yue and Joachims, ICML 2008]
•Choose K documents with maximal information coverage.
•For K = 3, optimal set is {D1, D2, D10}
61Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Maximizing Subtopic Coverage
•
� �� ��
select K documents which collectively cover
as many subtopics as possible.
• Perfect selection takes n choose K time.
[Predicting Diverse Subsets Using Structural SVMs,
Y. Yue and Joachims, ICML 2008]
– Set cover problem.
• Greedy gives (1-1/e)-approximation bound.
– Special case of Max Coverage (Khuller et al, 1997)
62Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Weighted Word Coverage
• More distinct words = more information
– Weight word importance
– Does not depend on human labels
•
� �� ��
select K documents which collectively
[Predicting Diverse Subsets Using Structural SVMs,
Y. Yue and Joachims, ICML 2008]
• select K documents which collectively
cover as many distinct (weighted) words as
possible
– Greedy selection also yields (1-1/e) bound.
– Need to find good weighting function (learning
problem).
63Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
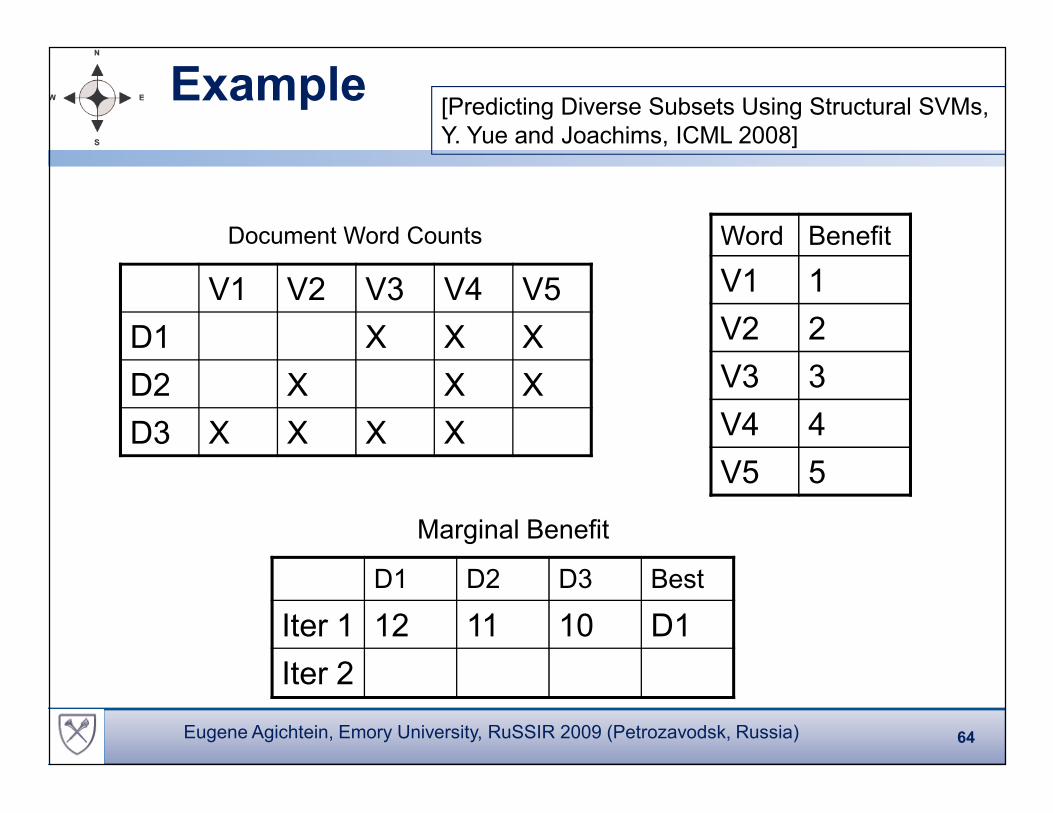
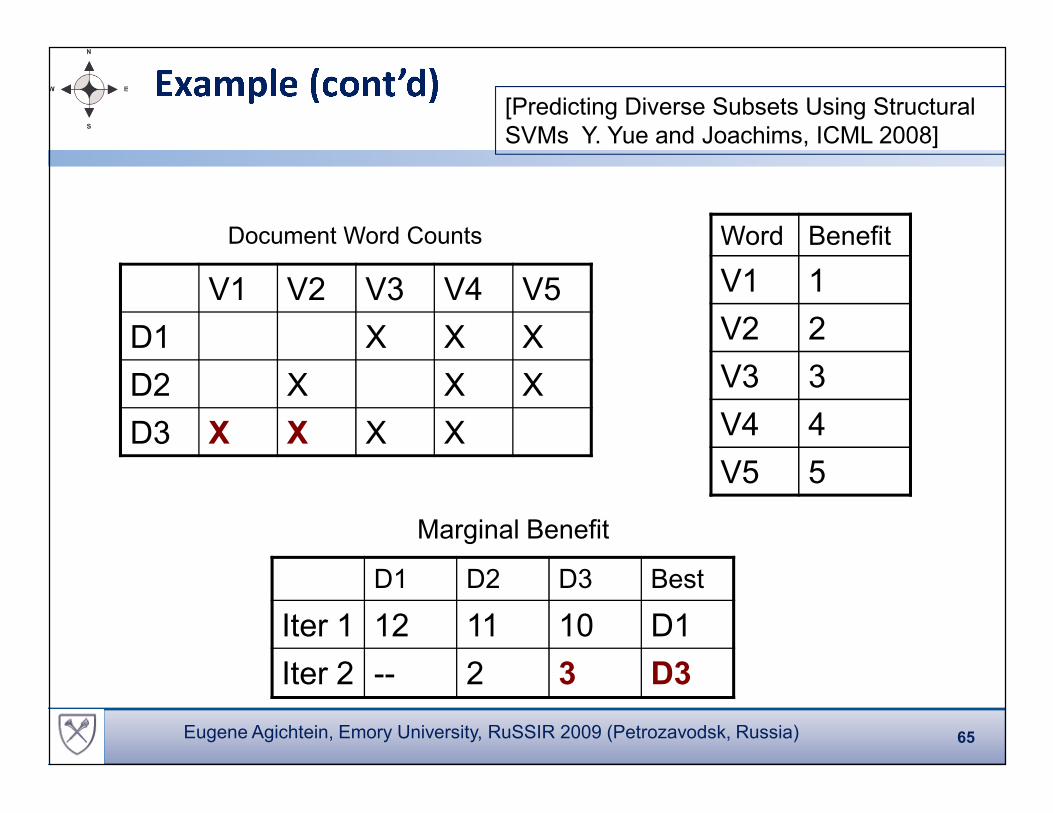
Example
V1 V2 V3 V4 V5
D1 X X X
D2 X X X
Word Benefit
V1 1
V2 2
V3 3
Document Word Counts
[Predicting Diverse Subsets Using Structural SVMs,
Y. Yue and Joachims, ICML 2008]
D1 D2 D3 Best
Iter 1 12 11 10 D1
Iter 2
Marginal Benefit
D3 X X X X V4 4
V5 5
64Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
V1 V2 V3 V4 V5
D1 X X X
D2 X X X
Word Benefit
V1 1
V2 2
V3 3
Document Word Counts
� �� �� �� �� � � �
[Predicting Diverse Subsets Using Structural
SVMs Y. Yue and Joachims, ICML 2008]
D1 D2 D3 Best
Iter 1 12 11 10 D1
Iter 2 -- 2 3 D3
Marginal Benefit
D3 X X X X V4 4
V5 5
65Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

�� �� �� �� � �� � � �• 12/4/1 train/valid/test split
– Approx 500 documents in training set
• Permuted until all 17 queries were tested once
• Set K=5 (some queries have very few documents)
[Predicting Diverse Subsets Using Structural
SVMs Y. Yue and Joachims, ICML 2008]
• SVM-div – uses term frequency thresholds to define importance
levels
• SVM-div2 – in addition uses TFIDF thresholds
66Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
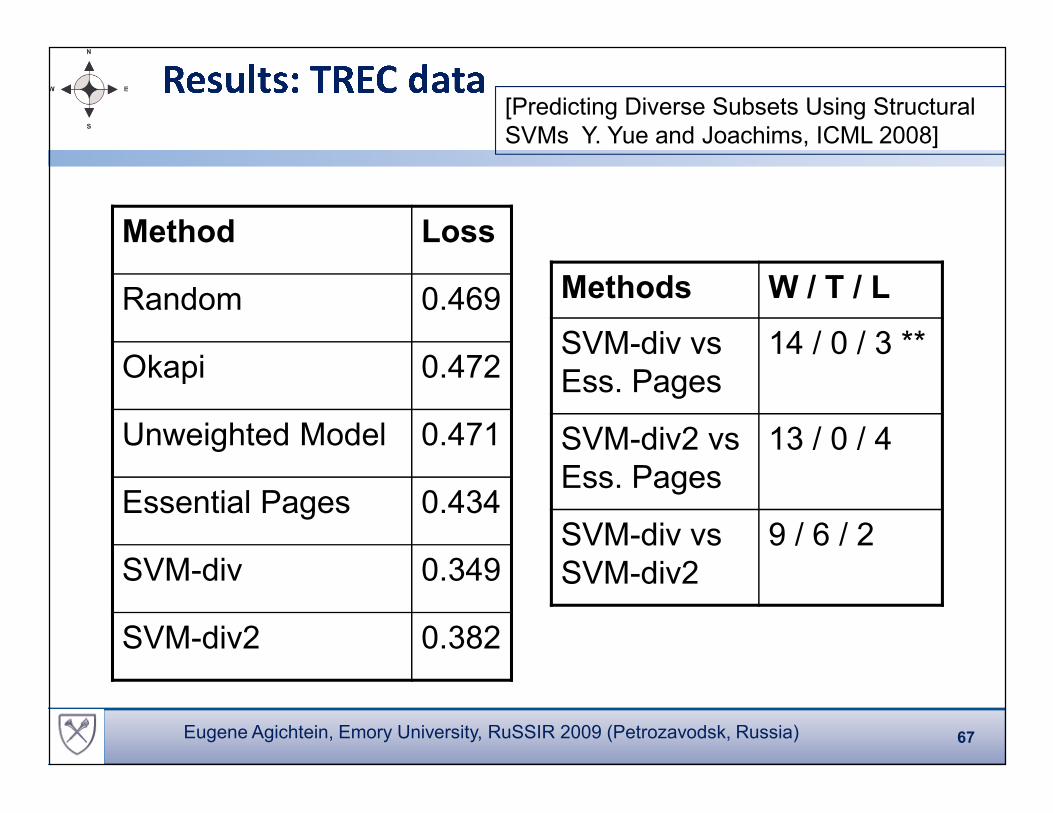
Method Loss
Random 0.469
Okapi 0.472
Methods W / T / L
SVM-div vs
Ess. Pages
14 / 0 / 3 **
�� �� �� �� � �� � � �
[Predicting Diverse Subsets Using Structural
SVMs Y. Yue and Joachims, ICML 2008]
Unweighted Model 0.471
Essential Pages 0.434
SVM-div 0.349
SVM-div2 0.382
SVM-div2 vs
Ess. Pages
13 / 0 / 4
SVM-div vs
SVM-div2
9 / 6 / 2
67Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)
�� �� �� �� � �� � � �
[Predicting Diverse Subsets Using Structural
SVMs Y. Yue and Joachims, ICML 2008]
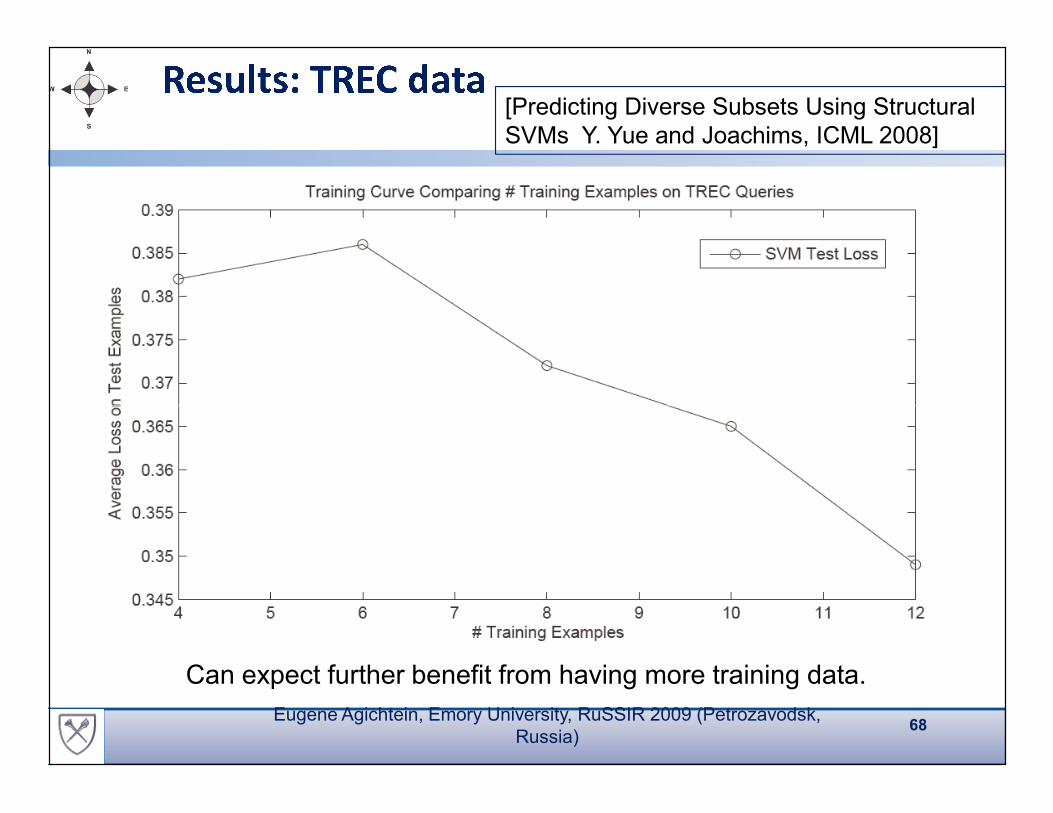
Can expect further benefit from having more training data.
68Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk,
Russia)

�� � �� ��
• Formulated diversified retrieval as predicting
diverse subsets
– Efficient training and prediction algorithms
• Used weighted word coverage as proxy to
information coverage.
Predicting Diverse Subsets Using Structural
SVMs Y. Yue and Joachims, ICML 2008
information coverage.
• Encode diversity criteria using loss function
– Weighted subtopic loss
http://projects.yisongyue.com/svmdiv/
69Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Lecture 3 Summary
�
�� � � � �� �� �� � �� � � �
�� � � � � � � �� � � � � � � � � � � �� � � � � �� Automatic relevance labels
� Enriching feature space
�
�� � � � � � � � � � � � �� �� �� � � � � � � �� Dealing with data sparseness
� Dealing with Scale
�
� � � � �� � � � � � �� Active learning
� Ranking for diversity
70Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)

Key References and Further Reading� �� � �� ��
, T. 2002.
� � � � �� �� �� �� � �� � �� �� �� �� � � �� � � � �� � � ��� �
, KDD 2002�� � � ��� ��
, E., Brill, E., Dumais, S.
� �� ! �� � " � #� �� �� � �� � � �� � #$�� � � � � �� �� � �� � � # � � � !� � � �� %� � � � � � �, SIGIR 2006&� '( �� � )�
, F. and Joachims, T.
* � � �$ � � � �� �+ � �� �� �� � � �� � � % � � �� � �� � � % � � � # � � �, KDD 2005
, F. and Joachims, T.
&� '( �� � )�
, F. and Joachims, T.
, � � ! � �- � � �� � � � %� � � �� �� �� ��� � � �� �� % �� � � �� � � � �� � � � �� �, KDD 2007.� (� � ) �
, M and White, R,
/ �� �� � � �� �� �� � �� � �� � %� � � %�� � � �� " �� +� � �� � %$ �� � � � � � !� � " � #� � �� % � � � �� � � � � � ! � $0 , WWW 200812 �, Y and Joachims,
3 � � �� � �� � 4 � ! � �� � 5 � #� � � 6� �� � 5 � � � � �� �57 /�, ICML 20088� 2
, C., Guo, F., and Faloutsos, C.
9 9 /+ 9 � $ �� � � � 9 �� "� �� � / � � � �% � � � 3 � � #$ �: 5 � � � � 4� �, KDD 2009
71Eugene Agichtein, Emory University, RuSSIR 2009 (Petrozavodsk, Russia)





























