Embed Size (px)
Citation preview

Lecture 4:FILE SYSTEM

INTERNAL REPRESENTATIONOF FILES
• Every file on a UNIX system has a unique inode (contains information necessary for a process to access a file)
• Inodes exist in a static form on disk and the kernel reads them into an in-core inode to manipulate them

Lower Level File System Algorithms
• The algorithm iget returns a previously identified inode, possible reading it from disk via the buffer cache and the algorithm iput releases this inode. The algorithm bmap sets kernel parameter for accessing a file. The algorithm namei converts a user-level path name to an inode, using the algorithms iget, iput, and bmap. Algorithms alloc and free allocate and free disk blocks for files and algorithms ialloc and ifree assign and free inodes for files.

InodesConsist of:• File owner identifier (individual owner & group owner)• File type (regular, directory, character or block
special, or FIFO – pipes)• File access permissions (owner, group, other: read,
write, execute)• File access time• Number of links to the file• Table of contents for the disk addresses of data in a
file• File size
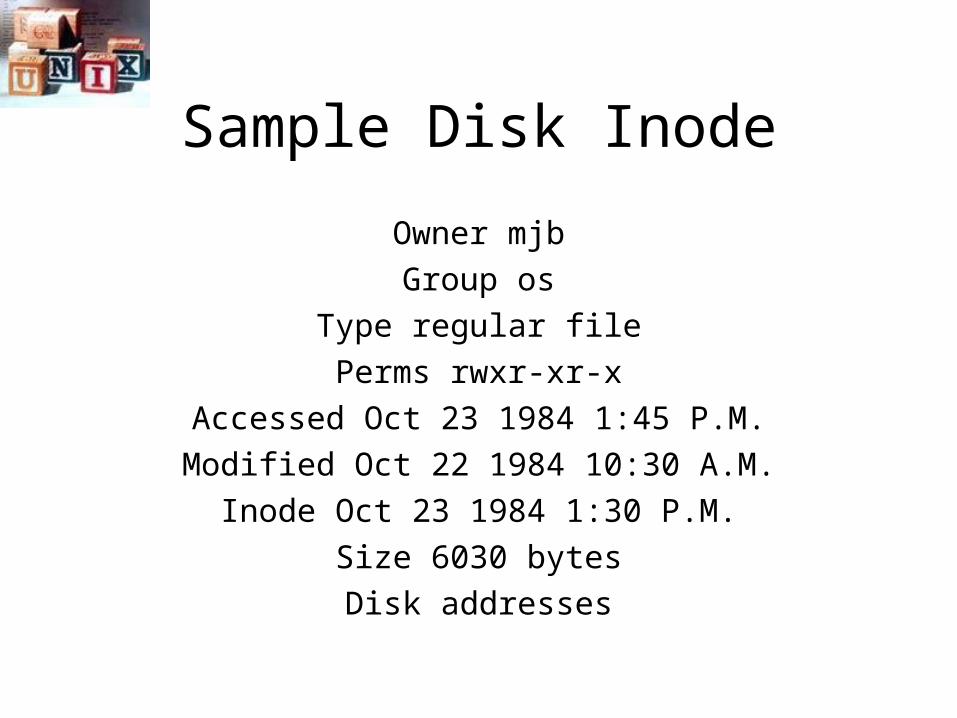
Sample Disk Inode
Owner mjb
Group os
Type regular file
Perms rwxr-xr-x
Accessed Oct 23 1984 1:45 P.M.
Modified Oct 22 1984 10:30 A.M.
Inode Oct 23 1984 1:30 P.M.
Size 6030 bytes
Disk addresses

Algorithm for allocation of in-core inodesalgorithm igetinput: file system inode numberoutput: locked inode{
while (not done){
if (inode in inode cache){
if (inode locked){
sleep (event inode becomes unlocked);continue; /*loop back to while */
}/*special processing for mount points */if (inode on inode free list)
remove from free list;increment inode reference count;return (inode);
}/*inode not in inode cache */if (no inodes on free list)
return (error);remove new inode from free list;reset inode number and fiel system;remove inode from old hash queue, place on new one;read inode from disk (algorithm bread);initialise inode (e.g. reference count to 1);return (inode);
}

Accessing inodes• The kernel identifies particular inodes by their file system and inode number and
allocates in-core inodes at the request of higher level algorithms. The algorithm iget allocates an in-core copy of an inode. The kernel maps the device number and inode number into a hash queue and searches the queue for the inode. If it cannot find the inode, it allocates one from the free list and locks it. The kernel then prepares to read the disk copy of the newly accessed inode into the in-core copy. It already knows the inode number and the logical device and computes the logical disk block that contains the inode according to how many disk inodes fit into a disk block. The computation follows the formula:
Block number = ((inode number –1)/ number of inodes per block) + start block of inode list
Example:
Assuming that block 2 is the beginning of theinode list and thatthere are 8 inodes per block, then inode number 8 is in disk block 2 and inode number 9 is in disk block 3!
• To compute the byte offset of the inode in the block:
((inode number –1) modulo (number of inodes per block))*size of disk inode
Example:
If each disk inode occupies 64 bytes and there are 8 inodes per disk block, then inode number 8 starts at byte offset 448 in the disk block!

Releasing Inodes
• When the kernel releases an inode (algorithm iput), it decrements its in-core reference count. If the count drops to 0, the kernel writes the inode to disk if the in-core copy differs from the disk copy. They differ if the file data has changed, if the file access time has changed or if the file owner or access permissions have changed. The kernel places the inode on the free list of inodes, effectively caching the inode in case it is needed again soon. The kernel may release all data blocks associated with the file and free the inode if the number of links to the file is 0.

Structure of a regular file The inode contains the table of contents to locate a file’s
data on disk. Since each block on a disk is addressable by number, the table of contents consists of a set of disk block numbers. If the data in a file were stored in a contiguous section of the disk (that is, the file occupued a linear sequence of disk blocks), then storing the start block address and the file size in the inode would suffice to access all the data in the file. However, such an allocation strategy would not allow for simple expansion and contraction of files in the file system without running the risk of fragmenting free storage area on the disk. EXAMPLE

Structure of a regular file
File B
File A File CFile B…….. ……..Block address
40 50 60 70
File A File CFree…….. ……..Block address
40 50 60 70 85
Allocation of Contiguous Files and Fragmentation of Free Space
The kernel could minimise fragmentation of storage space by periodically running garbage collection procedures to compact available storage, but that would place an added drain on processing power!!

For greater flexibility, the kernel allocates file space one block at a time and allows the data in a file to be spread throughout the file system! But this allocation scheme complicates the task of locating the data.
To keep the inode structure small yet still allow large files, the table of contents of disk blocks conforms to that shown next

Direct and Indirect Blocks in Inode
Direct 0
Direct 1
Direct 2
Direct 3
Direct 4
Direct 5
Direct 6
Direct 7
Direct 8
Direct 9
Single direct
Double direct
Triple direct
inode
.
.
.
.

Byte Capacity of a File – 1K Bytes Per Block
• 10 direct blocks with 1K bytes each = 10K bytes
• 1 indirect block with 256 direct blocks = 256K bytes
• 1 double indirect block with 256 indirect blocks = 64M bytes
• 1 triple indirect block with 256 double indirect blocks = 16G bytes

bmap
• Processes access data in a file by byte offset. They work in terms of byte counts and view a file as a stream of bytes starting at byte address 0 and going up to the size of file. The kernel converts the user view of bytes into a view of blocks. The file starts at logical block 0 and continues to a logical block number corresponding to the file size. The kernel access the inode and converts the logical file block into the appropriate disk block. The algorithm bmap converts a file byte offset into a physical disk block

Directories
• Give the file system its hierarchical structure• Important role in conversion of a file name to
an inode number• Initial access: open, chdir, link system calls• Algorithm namei uses intermediate inodes
as it parses a path name

Algorithm for conversion of path name to an inode
algorithm namei /* convert path name to inode */input: path nameoutput: locked inode{
if (path name starts from root)working inode = root inode (algorithm iget);
elseworking inode = current directory inode (algorithm iget);
while (there is more path name){
read next path name component from input;verify that working inode is of directory, access permissions OK;if (working inode is of root and component is “..”)
continue; /*loop back to while */read directory (working inode) by repeated use of algorithms
bmap, bread and brelse;if (component matches an entry in directory (working inode)){
get inode number for matched component;release working inode (algorithm iput);working inode = inode of matched component (algorithm iget);
}else /*component not in directory */
return (no inode);}return (working node);
}

Example:
• Suppose a process wants to open the file “/etc/passwd”. When the kernel starts parsing the file name, it encounters “/” and gets the system root inode. Making root its current working inode, the kernel gathers in the string “etc”. After checking that the current inode is that of a directory (“/”) and that the process has the necessary permissions to search it, the kernel searches root for a fiel whose name is “etc”: It accesses the data in the root directory block by block and searches each block one entry at a time until it locates an entry ofr “etc”. On finding the entry, the kernel releases the inode for root (algorithm iput) and allocates the inode for “etc” (algorithm iget) according to the inode number of the entry just found. After ascertaining the “etc” is a directory and that it has the requisite search permissions, the kernel searches “etc” block by block for the file “passwd”. On finding it, releases the inode for “etc” and allocate sthe inode for “passwd” and… returns that inode

Super block
Consists of:• The size of the file system• The number of free blocks in the file system• A list of free blocks available on the file system• The index of the next free block in the free block list• The size of the inode list• The number of free inodes in the file system• A list of free inodes in the file system• The index of the next free inode in the free inode list• Lock fields for the free block and free inode lists• A flag indicating that the super block has been modified

ialloc - ifree• Algorithm ialloc assigns a disk inode to a newly
created file• The file system contains a linear list of inodes. An
inode is free if its type field is zero. When a process needs a new inode, the kernel could theoretically search the inode list for a free inode
• Such a search would be expensive, requiring at least one read operation for every inode! To improve performance, the file system super block contains an array to cache the numbers of free inodes in the file system
• ifree: freeing an inode

Algorithm for assigning new inodes
algorithm ialloc /* allocate inode */input: file systemoutput: locked inode{ while (not done)
{ if (super blocked locked){ sleep (event super block becomes free);
continue; /*loop back to while */}if (inode list in super block is empty){ lock super block;
get remembered inode for free inode search;search disk for free inodes until super block full, or no more
free inodes (algorithms bread and brelse);unlock super block;wake up (event super block becomes free);if (no free inodes found on disk)
return (no inode);set remembered inode for next free inode search;
}/*there are inodes in super block inode list */get inode number form super block inode list;get inode (algorithm iget);if (inode not free after all){ write inode to disk;
release inode (algorithm iput);continue;
}/*inode is free */initialise inode;write inode to disk;decrement file system free inode count;return (inode);}
}

Assigning Free Inode from Middle of List
Free inodes
Super Block Free Inode List
83 48empty
18 19 20
index
Free inodes
Super Block Free Inode List
83empty
18 19 20
index
array 1
array 2

Assigning Free Inode – Super Block List Empty
470
Super Block Free Inode List
empty
index
array 10
535
Super Block Free Inode List
free inodes
index
array 2
0
476 475 471
504948
Remembered inode

Allocation of disk blocks• When a process writes data to a file, the kernel
must allocate disk blocks from the file system for direct data blocks and sometimes for indirect blocks.
• The file system super block contains an array that is used to cache the numbers of free disk blocks in the file system

Other file types: Pipes
• A pipe, sometimes called FIFO, difers from a regular file in that its data is transient: Once data is read from a pipe, it cannot be read again. Also the data is read in order that it was written to the pipe and the system allows no deviation from that order. The kernel stores data in a pipe the same way it stores data in an ordinary file, except that it uses only the direct blocks, not the indirect blocks!

Other file types: special files
• Including block device special files and character device special files. Both types specify devices and therefore the file inodes do not reference any data. Instead, the inode contains two numbers known as the major and minor device numbers: The major number indicates a device type such as terminal or disk, and the minor number indicates the unit number of the device

The File System
The best way to learn about files is to play with them. Creating a small file:
$ ed
a
Now is the time
For all good people
.
w junk
36
q
$ ls –l junk
-rw-r--r– 1 you 36 Sept 27 06:11 junk
$
$ cat junk
Now is the time
For all good people
$

Basics
• Cat shows what the file looks like. The command od (octal dump) prints a visible representation of all the bytes of a file. Try:
$ od –c junk
-c means “interpret bytes as characters”. Turning on the –b option will show the bytes as octal (base 8) numbers as well.
$ od -cb junk
• Try something different: type some characters and then a ctr-d, rather than a return. This will immediately send the characters you have typed to the program that is reading from the terminal. (Ctr-d logs you out, as the shell sees no more input). What happens when you type ctl-d to ed?

What is in a file?
• The file command makes an educated guess:$ file /bin /bin/ed /usr/src/cmd/ed.c /usr/man/man1/ed.1
/bin: directory
/bin/ed: pure executable
/usr/src/cmd/ed.c: c program text
/usr/man/man1/ed.1 roff, nroff, or eqn input text
$ sort /bin/ed
• Directories and filenames:$ ls
$ pwd
$ mkdir recipes
$ file *
$ ls recipes

Permissions
• Every file has a set of permissions associated with it, which determine who can do what with the file.
• The file /etc/passwd is the password file; it contains all the login information about each user. You can discover you uid and groupid, as does the system, by looking up your name in /etc/passwd
$ grep you /etc/passwd
you:gkmbCTrJ04COM:604:1:Y.O.A.People:/usr/you:• The –l option of ls command prints the permissions information, among other
things:
$ ls –l /etc/passwd
-rw-r- - r - - 1 root 5115 Aug 30 10:40 /etc/passwd• The chmod command changes permissions on files:
$ chmod permissions filenames….
$ chmod +x command
$ chmod –w command

Inodes
• A file has several components: a name, contents and administrative information such as permissions and modification times. The administrative information is stored in the inode along with essential system data such as how long it is, where on the disc the contents of the file are stored and so on
• There are three times in the inode: the time that the contents of the file were last modified (written); the time that the file was last used (read or executed); and the time that the inode itself was last changed, for example to set the permissions

Interesting directories/ Root of the file system
/bin Essential programs in executable form (“binaries”)
/dev Device files
/etc System miscellany
/etc/motd Login message of the day
/etc/passwd Password file
/lib Essenhtial libraries
/tmp Temporary files; cleaned when system is restarted
/unix Executable form of the operating system
/usr User file system
/usr/adm System administration: accounting info
/usr/bin User binaries
/usr/dict Dictionary and support for spell()
/usr/games Game programs
/usr/include Header files for C programs

Interesting directories/usr/include/sys System header files for C programs
/usr/lib Libraries for C, etc
/usr/man On-line manual
/usr/man/man1 Manual pages for section 1 of manual
/usr/mdec Hardware diagnostics, bootstrap programs
/usr/news Community service messages
/usr/pub Public oddments
/usr/src Source code for utilities and libraries
/usr/src/cmd Source for commands
/usr/src/lib Source code for subroutine libraries
/usr/spool Working directories for communication programs
/usr/spool/lpd Line printer temporary directory
/usr/spool/mail Mail in-boxes
/usr/spool/uucp Working directory for the uucp programs
/usr/sys Source for the operating system kernel
/usr/tmp Arternate temporary directory
/usr/you Your login directory
/usr/you/bin Your personal programs

Lecture 5:

Just a reminder of what we have seen so far…

UNIX System Structure
Center: operating system interacts directly with the hardware, providing common services to programs. System kernel: operating system; isolated from user programs. Programs such as shell and editors (ed, vi) interact with kernel with a set of system calls commands!
SCCS: Source Code Control System

Major Components of UNIX:
• Kernel: The master control program of the computer. It resides in the computer’s main memory and it manages the computer’s resources. It is the kernel that handles the switching necessary to provide multitasking
• File System: UNIX organises data into collections calles files. Files may be grouped together into collection called directory files or directories
• Shell: The part of UNIX that interprets user commands and passes them on to the kernel is called the shell. A typical shell provides a command-line interface, where the user can type commands.
• Utilities: A utility is a useful software tool that is included as a standard part of the UNIX operating system. Utilities are often called commands

Block Diagram of Kernel
Hardware
Hardware controlKernel Level Hardware Level
libraries
System call interface
File subsystem
Buffer cache
Character | block
Device drivers
process
control
subsystem
Inter-process communication
scheduler
Memory management
User programs
User Level
Kernel Level

Lecture 5:More on Inodes(as requested)

File System Implementation
Boot block
Superblock I nodes Data blocks

File System Implementation• Block 0
– Used by Unix to boot the computer
• Block 1 or super-block– Contains critical information about the layout of the file
system (number of i-nodes, of disk blocks, etc.)
• I-nodes– Is 64 bytes and describes exactly one file– Contains counting information (owner, protections, etc.)
• Data blocks – All files and directories are stored here

Inodes
• Remember: All types of UNIX files are administrated by the operating system by means of inodes
• An inode (index node) is a control structure that contains the key information needed by the operating system for a particular file.
• Several file names may be associated with exactly one file, and each file is controlled by exactly one inode!
• The attributes of the file as well as its permissions and other control information are stored in the inode. The next table lists its contents:

Table: Information in a UNIX Disk-Resident Inode
File Mode 16-bit flag that stores access and execution permissions associated with the file:12-14 File type (regular, directory, character or block special, FIFO pipe)
9-11 Execution flags
8 Owner Read permission
7 Owner Write permission
6 Owner Execute permission
5 Group Read permission
4 Group Write permission
3 Group Execute permission
2 Other Read permission
1 Other Write permission
0 Other Execute permission
Link Count Number of directory references to this inode
Owner ID Individual owner of file
Group ID Group owner associated with this file
File Size Number of bytes in file
File Addresses 39 bytes of address information
Last Accessed Time of last file access
Last Modified Time of last file modification
Inode Modified Time of last inode modification

Schematic structure of an Inode
Figure shows the inode structure of a typical file. In addition to descriptive information, the inode contains pointers to the first few data blocks of the file. If the file is large, the indirect pointer contains a pointer to a block of pointers to the file fragments.

Directory Layout for /etc
Byte Offset in Directory
Inode Number (2 bytes)
File Names
0
16
32
48
64
80
96
112
128
144
160
176
192
208
224
240
256
83
2
1798
1276
85
1268
1799
88
2114
1717
1851
92
84
1432
0
95
188
.
..
init
fsck
clri
motd
mount
mknod
passwd
umount
ckecklist
fsdb1b
config
getty
crash
mkfs
inittab
Every directory contains the file names dot and dot-dot whose inode numbers are those of the directory and its parent directory, respectively. The number of “.” in /etc is allocated at offset 0, and its value is 83. Directory entries may be empty, indicated by an inode number 0. For instance, the entry at address 224 in /etc is empty, although it once contained an entry for a file named “crash”.

Assigning Free Inode from Middle of List
Free inodes
Super Block Free Inode List
83 48empty
18 19 20
index
Free inodes
Super Block Free Inode List
83empty
18 19 20
index
array 1
array 2
If the list of free inodes in the super block is like the first one above, when the kernel assigns an inode, it decrements the index fro the next valid inode number to 18 and takes inode number 48.

Remembered inodes:
• If the super block list of free inodes is empty, the kernel searches the disk and places as many free inode numbers as possible into the super block. The kernel reads the inode list on disk, block by block, and fills the super block list of inode numbers to capacity, remembering the highest-numbered inode that it finds. Call that inode the “remembered”inode; it is the last one saved in the super block. The next time the kernel searches the disk for free inodes, it uses the remembered inode as its starting point, thereby assuring that it wastes no time reading disk blocks where no free inodes should exist.

Assigning Free Inode – Super Block List Empty
470
Super Block Free Inode List
empty
index
array 10
535
Super Block Free Inode List
free inodes
index
array 2
0
476 475 471
504948
Remembered inode
If the list of free inodes in the super block is like the first one above, it will notice that the array is empty and search the disk for free inodes, starting from inode number 470, the remembered inode. When the kernel fills the super block free list to capacity, it remembers the last inode as the start point for the next search of the disk. The kernel assigns an inode it just took from the disk and continues whatever it was doing.

File Allocation(more details about direct-
indirect blocks)• Files are allocated on a block basis. Allocation is dynamic
as needed. Hence, the blocks of a file on disk are not necessarily contiguous.
• An indexed method is used to keep track of each file, with part of the index stored in the inode for the file.
• The inode includes 39 bytes of address information organised as 13 3-byte addresses, or pointers. The first 10 addresses point to the first 10 data blocks of file. If the file is longer than 10 blocks, then one or more levels of information are used as follows:

Levels of indirection:
• The eleventh address in the inode points to a block on disk that contains the next portion of the index. This block is referred to as the single indirect block. This block contains the pointers to succeeding blocks in the file.
• If the file contains more blocks, the twelfth address in the inode points to a double indirect block. This block contains a list of addresses of additional single indirect blocks. Each of the single indirect blocks in turn contains pointers to file blocks
• If the file contains still more blocks, the thirteenth address in the inode points to a triple indirect block that is a third level of indexing. This block points to additional double indirect blocks.
• Have a look again at the diagram of Slide no 12 for the UNIX block addressing scheme

An example:
4096
228
45423
0
0
11111
0
101
367
0
428
9156
824
367
331
Data block
331
331
3333
Data block9156 Double indirect
33330
75
331 Single indirect
Assume that a disk block contains 1024 bytes. If a process wants to access byte offset 9000, the kernel calculates that the byte is in direct block 8 in the file. If it wants the 350000 in the file?

Advantages of this scheme:
• The inode is of fixed size and relatively small and hence may be kept in main memory for long periods
• Smaller files may be accessed with little or no indirection, reducing processing and disk access time
• The theoretical maximum size of a file is large enough to satisfy virtually all applications!

WHAT HAPPENS WITHIN LINUX?
Linux retains UNIX’s standard file-system model. Files can be anything capable of handling the input or output of a stream of data. The Linux kernel handles all these types of file by hiding the implementation details of any single file type behind a layer of software, the virtual file system (VFS)

The LINUX VFS
• The LINUX VFS is designed around object-oriented principles:– inode-object: inode– file-object: represent individual files– file-system-object: represents an entire file
system

VFS• For each of these three types of object the VFS
defines a set of operations that must be implemented by that structure. Every object contains a pointer to a function table
• The function table lists the addresses of the actual functions that implement those operations for that particular object
• Thus, the VFS software layer can perform an operation on one of these objects by calling the appropriate function from that object’s function table.
• The VFS does not know, whether an inode represents a networked file, a disk file, a network socket or a directory file!

The file-system object• The file-system object represents a
connected set of files that forms a self-contained directory hierarchy
• The operating system kernel maintains a single file-system object for each disk device. Its main responsibility is to give access to inodes.
• Inode-object represents a file as a whole, while a file-object represents a point of access to the data in the file.

What happens with directory files
• Directory files are dealt with slightly differently from other files. The UNIX programming interface defines a number of operations on directories, such as creating, deleting and renaming a file in a directory. Unlike reading and writing data, for which a file must be opened, the system calls (we will discuss this the following week) for these directory operations do not require that the user open the files concerned. The VFS therefore defines these directory operations in the inode-object, rather than in the file object!

The LINUX ext2fs File System• The standard on-disk file system is called: Second
extended file system (ext2fs)• Locating the data blocks belonging to a specific file,
storing data-block pointers in indirect blocks throughout the file system with up to three levels of indirection. Directory files are stored on disk just like normal files, although their contents are interpreted differently. Each block in a directory file consists of a linked list of entries, where each entry contains the length of the entry, the name of a file and the inode number of the inode to which that entry refers
• Ext2fs does not use fragments, but performs all its allocations in smaller units. The default block size on ext2fs is 1KB, although 2KB and 4KB blocks are also supported.

Allocation policies:• 1KB I/O request size is too small to
maintain good performance, so ext2fs uses allocation policies designed to place logically adjacent blocks of a file into physically adjacent blocks on disk, so that it can submit an I/O request for several disk blocks as a single operation
• An ext2fs is partitioned into multiple block groups

Choosing data blocks• When allocating a file, ext2fs must first select the
block group for that file. For data blocks, it attempts to choose the same block group that in which the file’s inode has been allocated. For inode allocations, it selects the same block group as the file’s parent directory, for non-directory files. Directory files are not kept together, but rather are dispensed throughout the available block groups. These policies are designed to keep related information within the same block group, but also to spread out the disk load among the disk’s block groups to reduce the fragmentation of any one area of the disk

How the fragmentation is reduced?
• It maintains a bitmap of all free blocks in a block group. When allocating the first blocks for a new file, it starts searching for a free block from the beginning of the block group; when extending a file, it continuous the search from the block most recently allocated to the file. The search is performed in two stages:– It searches for an entire free byte in the bitmap; if it fails to find
one, it looks for any free bit. The search for free bytes aims to allocate disk space in chunks of at least eight blocks where possible
– Once a free block has been identified, the search is extended backward until an allocated block is encountered (this prevents from leaving a hole between the most recently allocated block in the previous non zero byte and the zero byte found. After that it pre-allocates these extra blocks.

Block-allocation policies
.
Allocating scattered free blocks
.
Allocating continuous free blocks

Tutorials are compulsory!
Just before the 3 week break in March, there will be a marked assignment which will count
10% of the overall mark and it will take place at the lab

Hints for the tutorials
• Other Operations on Files• The UNIX operating system contains a
large number of commands for examining, manipulating, and modifying files. As you gain more familiarity with UNIX, you will find dozens of useful utilities. Some of the more useful operations are comparing, searching, compressing, and archiving.

• Comparing - diff• The diff command can be used to look for
differences between two files. It takes two filenames as arguments. When differences are found between the two, the differing lines are printed to the screen. The lines from the first file are preceded with a less than symbol < lines from the second file are preceded with a greater than symbol >

• Searching - grep• UNIX has a very powerful utility called grep
(for Get Regular ExPression). grep takes two arguments: a pattern and a file. Both of the arguments may contain wild-card characters. grep returns a list of occurrences of the pattern preceded by the name of the file each occurs in and a colon. For instance:
$ grep foobar *.{c,cc,pl} Finds all occurrences of the string foobar in
files that end with .c, .cc, or .pl

• Compressed Files - gzip/gunzip• Files may be compressed with the gzip command to
reduce their size. $ gzip filename Files compressed with this utility will
have the extension .gz appended to the filenames. • To uncompress a file with a .gz suffix, use the
command gunzip: $ gunzip filename There are variations of the common
UNIX file utilities that can be used on gzip compressed files. They behave like the original commands do, but they work on compressed files. Some of these commands are gzgrep, gzmore, gzcat, and gzdiff.

Recovering Deleted Files
• When a file is deleted in UNIX it is gone. There is no practical way of recovering it. However, the system administrators do nightly backups of the file system. If you have some version of the file that existed prior to the last backup, it is likely that it can be restored. If you lose or delete such files, send email or inform your demonstrators and give the path for each of the files that were deleted and when. If possible, also tell demonstrators when the latest version was known to exist. Time permitting, the staff will try to recover the most recently backed-up version if one exists. Turn-around time on file discovery and recovery is measured in hours, so do not get dependent on this service. Save copies of important files your are working on.









![Parallel File I/O Profiling Using Darshan · Linux inode data; •Data nodes actually store the file data. There are more data nodes ... •Darshan [1] is able to profile all four](https://img.pdfslide.net/doc/110x75/5f8f8f6079f34b3b81013459/parallel-file-io-profiling-using-darshan-linux-inode-data-adata-nodes-actually.jpg)