Embed Size (px)
Citation preview
logoonly
Lecture 8: EITF20 Computer Architecture
Anders Ardö
EIT – Electrical and Information Technology, Lund University
December 2, 2014
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 1 / 44
logoonly
Outline
1 Reiteration
2 Virtual memory
3 Case study AMD Opteron
4 Crosscutting issues
5 Summary
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 2 / 44
logoonly
Cache Performance
Execution Time =
IC ∗ (CPIexecution +mem accesses
instruction∗miss rate ∗miss penalty) ∗ TC
Three(+) ways to increase performance:Reduce miss rateReduce miss penaltyReduce hit time... increase bandwidth
However, remember:Execution time is the only true measure!
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 3 / 44
logoonly
Cache optimizationsHit Band- Miss Miss HW
time width penalty rate complexitySimple + - 0Addr. transl. + 1Way-predict + 1Trace + 3Pipelined - + 1Banked + 1Non-blocking + + 3Early start + 2Merging write + 1Multilevel + 2Read priority + 1Prefetch + + 2-3Victim + + 2Compiler + 0Larger block - + 0Larger cache - + 1Associativity - + 1
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 4 / 44
logoonly
Memory hierarchy
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 5 / 44
logoonly
Questions!
QUESTIONS?
COMMENTS?
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 6 / 44
logoonly
Chip floor-plan
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 7 / 44
logoonly
Lecture 8 agenda
Appendix C.4 and Chapters 5.5-5.6 in "Computer Architecture"
1 Reiteration
2 Virtual memory
3 Case study AMD Opteron
4 Crosscutting issues
5 Summary
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 8 / 44
logoonly
Outline
1 Reiteration
2 Virtual memory
3 Case study AMD Opteron
4 Crosscutting issues
5 Summary
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 9 / 44
logoonly
Memory hierarchy tricks
Use two “magic” tricks
Make a small memory seem bigger virtual memory(Without making it much slower)Make a slow memory seem faster cache memory(Without making it smaller)
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 10 / 44
logoonly
Memory tricks (techniques)
Use a hierarchysuper-fast Registers
FAST Cachecache memory (HW)
Memory CHEAP Mainvirtual memory (SW)
BIG Disk
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 11 / 44
logoonly
Levels of the Memory Hierarchy
SRAM DRAM
(From Dubois, Annavaram, Stenström: “Parallel Computer Organization and Design”, ISBN 978-0-521-88675-8)
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 12 / 44
logoonly
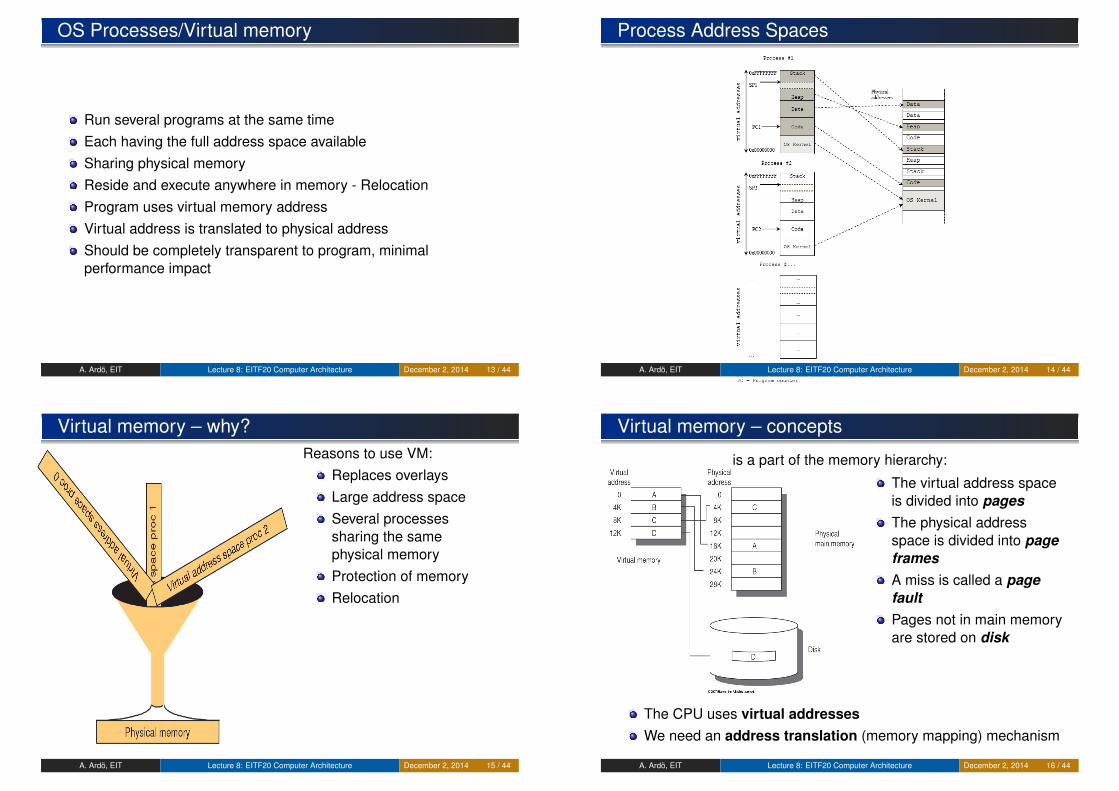
OS Processes/Virtual memory
Run several programs at the same timeEach having the full address space availableSharing physical memoryReside and execute anywhere in memory - RelocationProgram uses virtual memory addressVirtual address is translated to physical addressShould be completely transparent to program, minimalperformance impact
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 13 / 44
logoonly
Process Address Spaces
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 14 / 44
logoonly
Virtual memory – why?Reasons to use VM:
Replaces overlaysLarge address spaceSeveral processessharing the samephysical memoryProtection of memoryRelocation
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 15 / 44
logoonly
Virtual memory – concepts
is a part of the memory hierarchy:
The virtual address spaceis divided into pagesThe physical addressspace is divided into pageframesA miss is called a pagefaultPages not in main memoryare stored on disk
The CPU uses virtual addressesWe need an address translation (memory mapping) mechanism
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 16 / 44

logoonly
Virtual memory parameters
Regs L1 L2 Main memory DiskAccess (ns) 0.2 0.5 7 100 10 000 000Capacity (kB) 1 64 1 000 32 000 000 6 000 000 000Block size (B) 8 64 128 4 000 - 16 0000
Replacement in cache handled by HWReplacement in VM handled by SWSize of VM determined by no of address bitsThe backing store for VM (paging (swap) partition on disk) isshared with the file system
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 17 / 44
logoonly
More Virtual memory parameters
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 18 / 44
logoonly
4 questions for the Memory Hierarchy
Q1: Where can a block be placed in the upper level?(Block/Page placement)Q2: How is a block found if it is in the upper level?(Block/Page identification)Q3: Which block should be replaced on a miss?(Block/Page replacement)Q4: What happens on a write?(Write strategy)
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 19 / 44
logoonly
VM: Page placement
Where can a page be placed in main memory?
Cache access: ∼ nsMemory access: ∼ 100 nsDisk access: ∼ 10,000,000 ns
=⇒ HIGH miss penalty
The high miss penalty makes itnecessary to minimize miss ratepossible to use software solutions to implement afully associative address mapping
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 20 / 44
logoonly
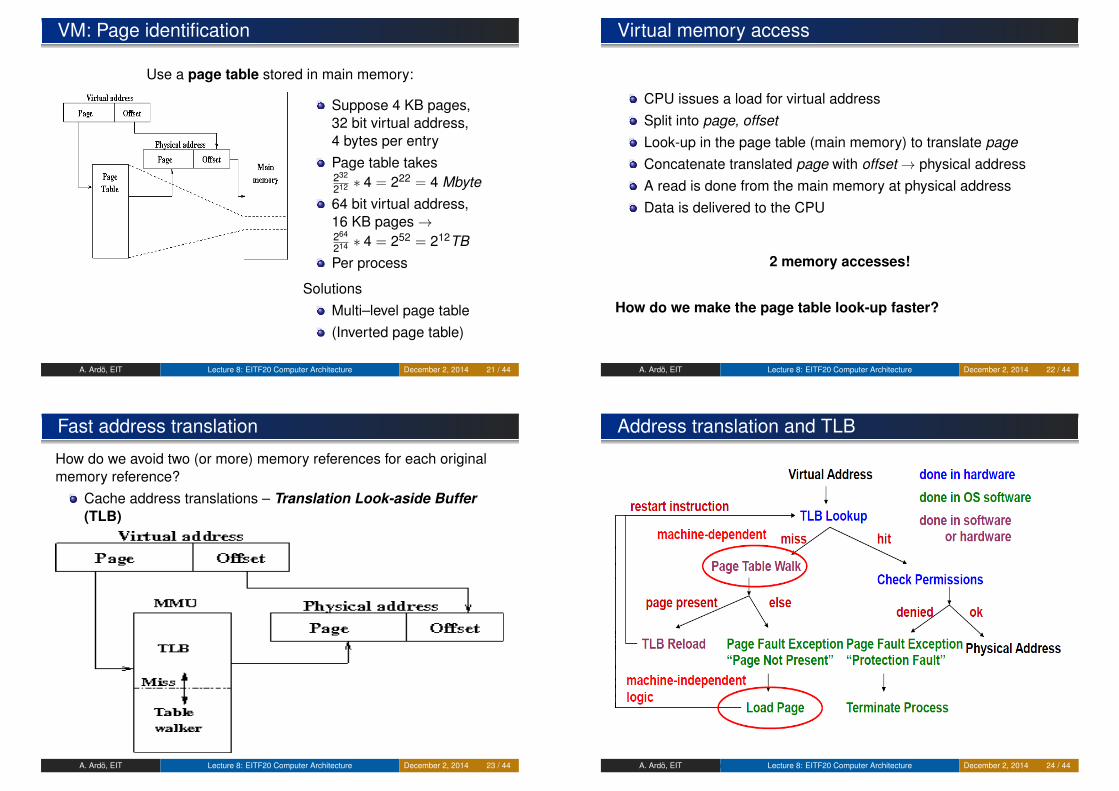
VM: Page identification
Use a page table stored in main memory:
Suppose 4 KB pages,32 bit virtual address,4 bytes per entryPage table takes232
212 ∗ 4 = 222 = 4 Mbyte64 bit virtual address,16 KB pages→264
214 ∗ 4 = 252 = 212TBPer process
SolutionsMulti–level page table(Inverted page table)
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 21 / 44
logoonly
Virtual memory access
CPU issues a load for virtual addressSplit into page, offsetLook-up in the page table (main memory) to translate pageConcatenate translated page with offset→ physical addressA read is done from the main memory at physical addressData is delivered to the CPU
2 memory accesses!
How do we make the page table look-up faster?
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 22 / 44
logoonly
Fast address translation
How do we avoid two (or more) memory references for each originalmemory reference?
Cache address translations – Translation Look-aside Buffer(TLB)
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 23 / 44
logoonly
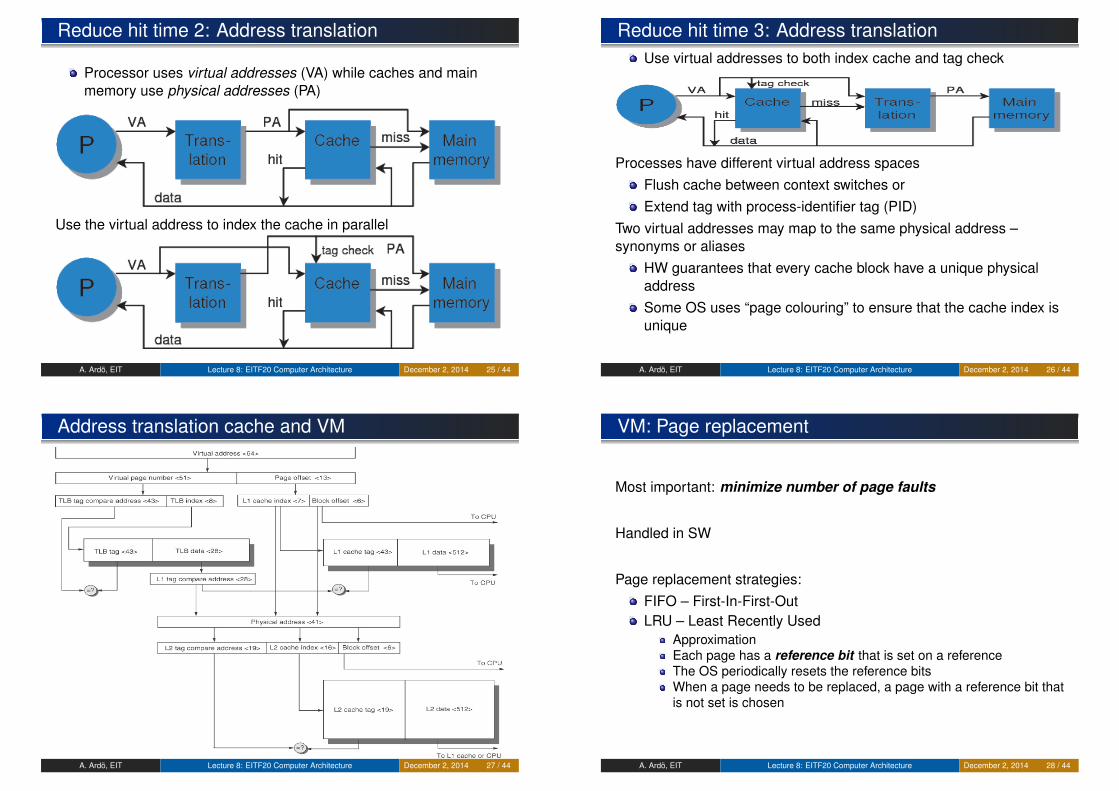
Address translation and TLB
(From Ali Butt, Operating Systems, Lecture 17A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 24 / 44
logoonly
Reduce hit time 2: Address translation
Processor uses virtual addresses (VA) while caches and mainmemory use physical addresses (PA)
Use the virtual address to index the cache in parallel
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 25 / 44
logoonly
Reduce hit time 3: Address translationUse virtual addresses to both index cache and tag check
Processes have different virtual address spacesFlush cache between context switches orExtend tag with process-identifier tag (PID)
Two virtual addresses may map to the same physical address –synonyms or aliases
HW guarantees that every cache block have a unique physicaladdressSome OS uses “page colouring” to ensure that the cache index isunique
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 26 / 44
logoonly
Address translation cache and VM
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 27 / 44
logoonly
VM: Page replacement
Most important: minimize number of page faults
Handled in SW
Page replacement strategies:FIFO – First-In-First-OutLRU – Least Recently Used
ApproximationEach page has a reference bit that is set on a referenceThe OS periodically resets the reference bitsWhen a page needs to be replaced, a page with a reference bit thatis not set is chosen
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 28 / 44
logoonly
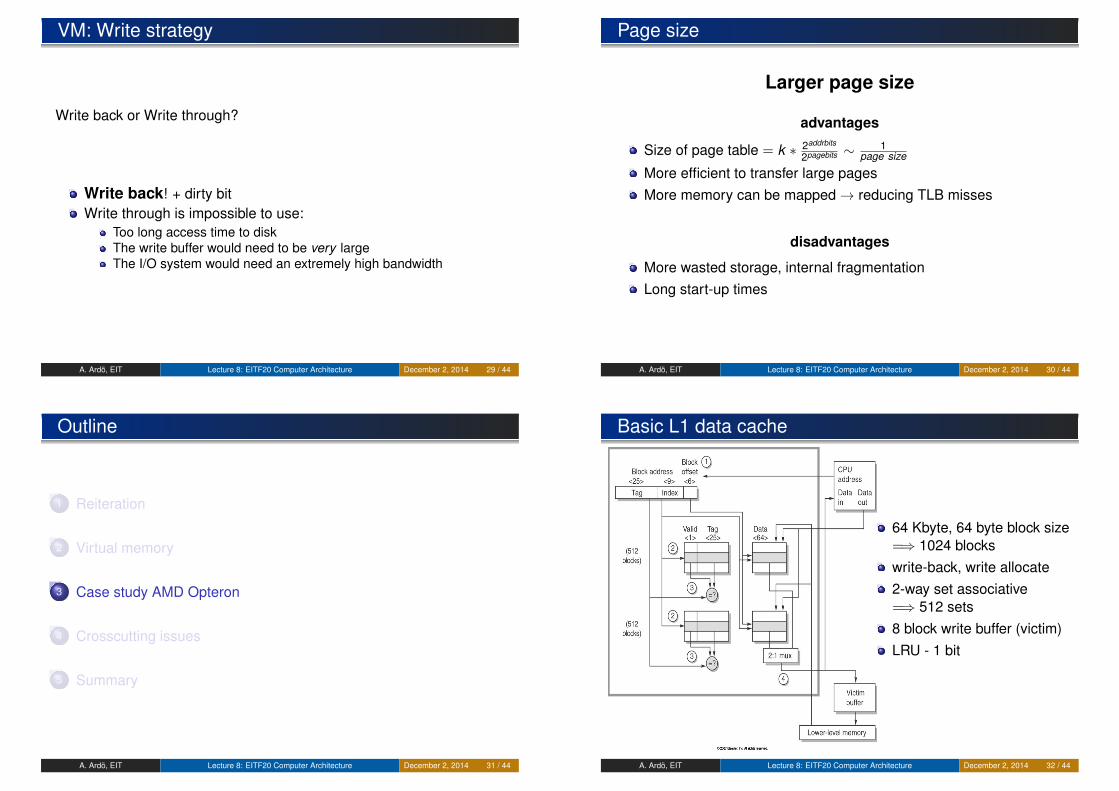
VM: Write strategy
Write back or Write through?
Write back! + dirty bitWrite through is impossible to use:
Too long access time to diskThe write buffer would need to be very largeThe I/O system would need an extremely high bandwidth
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 29 / 44
logoonly
Page size
Larger page size
advantages
Size of page table = k ∗ 2addrbits
2pagebits ∼ 1page size
More efficient to transfer large pagesMore memory can be mapped→ reducing TLB misses
disadvantages
More wasted storage, internal fragmentationLong start-up times
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 30 / 44
logoonly
Outline
1 Reiteration
2 Virtual memory
3 Case study AMD Opteron
4 Crosscutting issues
5 Summary
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 31 / 44
logoonly
Basic L1 data cache
64 Kbyte, 64 byte block size=⇒ 1024 blockswrite-back, write allocate2-way set associative=⇒ 512 sets8 block write buffer (victim)LRU - 1 bit
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 32 / 44
logoonly
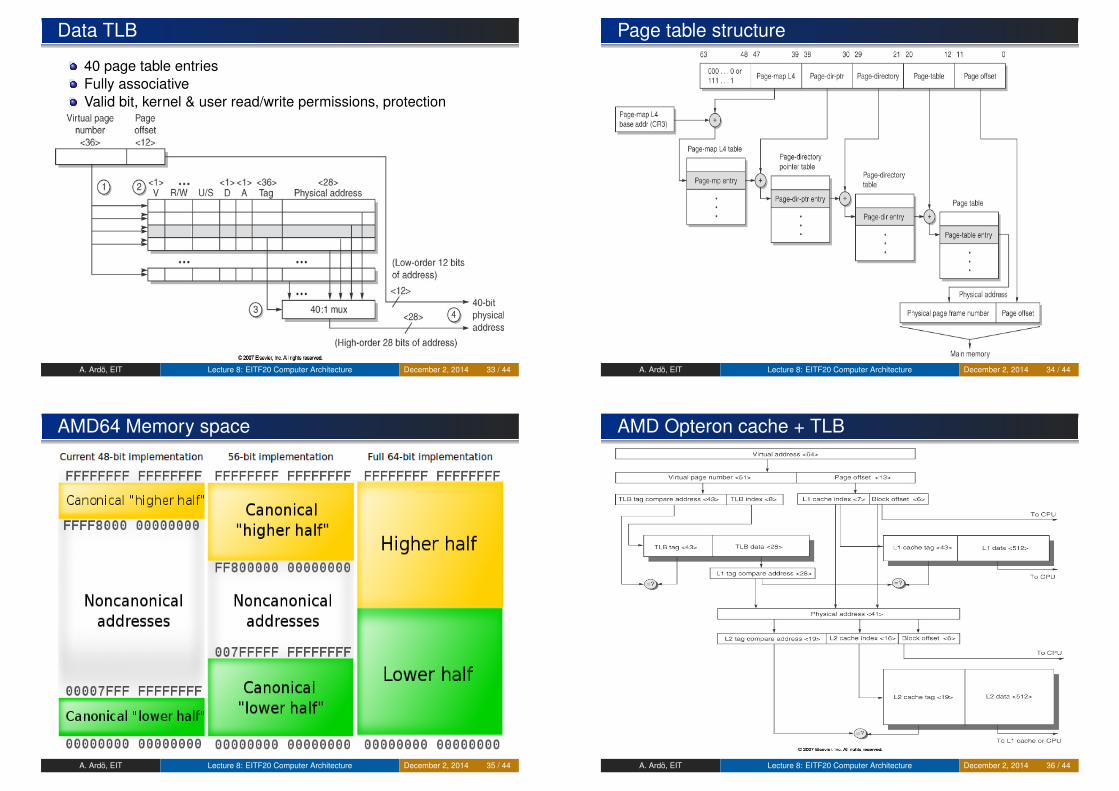
Data TLB
40 page table entriesFully associativeValid bit, kernel & user read/write permissions, protection
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 33 / 44
logoonly
Page table structure
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 34 / 44
logoonly
AMD64 Memory space
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 35 / 44
logoonly
AMD Opteron cache + TLB
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 36 / 44

logoonly
The memory hierarchy of AMD Opteron
Separate Instr & Data TLBand Caches2-level TLBsL1 TLBs fully associativeL2 TLBs 4 way set associativeWrite buffer (and Victim cache)Way predictionLine prediction - prefetchhit under 10 misses1 MB L2 cache, shared,16 way set associative,write back
(HP fig 5.19) (complex - no details)
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 37 / 44
logoonly
Performance
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 38 / 44
logoonly
Outline
1 Reiteration
2 Virtual memory
3 Case study AMD Opteron
4 Crosscutting issues
5 Summary
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 39 / 44
logoonly
Crosscutting issues
Protection needs support in the ISASpeculative execution =⇒
Non-blocking cachesSuppress exceptions
Embedded computers =⇒Real time performance predictabilityPower limitations
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 40 / 44

logoonly
Outline
1 Reiteration
2 Virtual memory
3 Case study AMD Opteron
4 Crosscutting issues
5 Summary
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 41 / 44
logoonly
Summary memory hierarchy
Hide CPU - memory performance gapMemory hierarchy with several levels
Principle of localityCache memories:
Fast, small - Close to CPUHardwareTLBCPU performance equationAverage memory accesstimeOptimizations
Virtual memory:Slow, big - Close to diskSoftwareTLBPage-tableVery high miss penalty =⇒miss rate must be lowAlso facilitates: relocation;memory protection; andmultiprogramming
Same 4 design questions - Different answers
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 42 / 44
logoonly
Program behavior vs cache organization
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 43 / 44
logoonly
Example organizations
A. Ardö, EIT Lecture 8: EITF20 Computer Architecture December 2, 2014 44 / 44




























