Embed Size (px)
DESCRIPTION
lecture10.pdf
Citation preview

Database Systems
Mohamed Zahran (aka Z)
http://www.mzahran.com
CSCI-GA.2433-001
Lecture 10: More on Indexing

Tuples/Records
Relations
Sectors
Files
Blocks
Pages
Query Optimization
and Execution
Relational Operators
Files and Access Methods
Buffer Management
Disk Space Management
DB

Data Records Index
Organized by
Search key
Contains data entry pointing to data record

Two main Wishes for Indexes
• Efficient support for range searches
• Efficient insertion and deletion
• ISAM • B+ Tree
• Hash-based

ISAM
• Indexed Sequential Access Method
• Static index structure
• Effective when the file is not frequently updated

ISAM
Non-leaf
Pages
Pages
Overflow page
Primary pages
Leaf
• Leaf pages contain data entries and allocated sequentially •Primary leaf pages are static • The data entry can be the data itself or pointer to the data

ISAM
• File creation: data pages allocated sequentially, sorted by search key; then index pages allocated, then space for overflow pages.
• Index entries: <search key value, page id>; they direct search for data entries.
• Search: Start at root; use key comparisons to go to leaf.
• Insert: Find leaf data entry belongs to, and put it there.
• Delete: Find and remove from leaf; if empty overflow page, de-allocate.

ISAM
10* 15* 20* 27* 33* 37* 40* 46* 51* 55* 63* 97*
20 33 51 63
40
Root Example:
• Find record with key value 27 • Insert entry 23 (assume a page can have two records only).

ISAM
Example:
After Inserting 23*, 48*, 41*, 42* ...
10* 15* 20* 27* 33* 37* 40* 46* 51* 55* 63* 97*
20 33 51 63
40
Root
23* 48* 41*
42*
Overflow
Pages
Leaf
Index
Pages
Pages
Primary
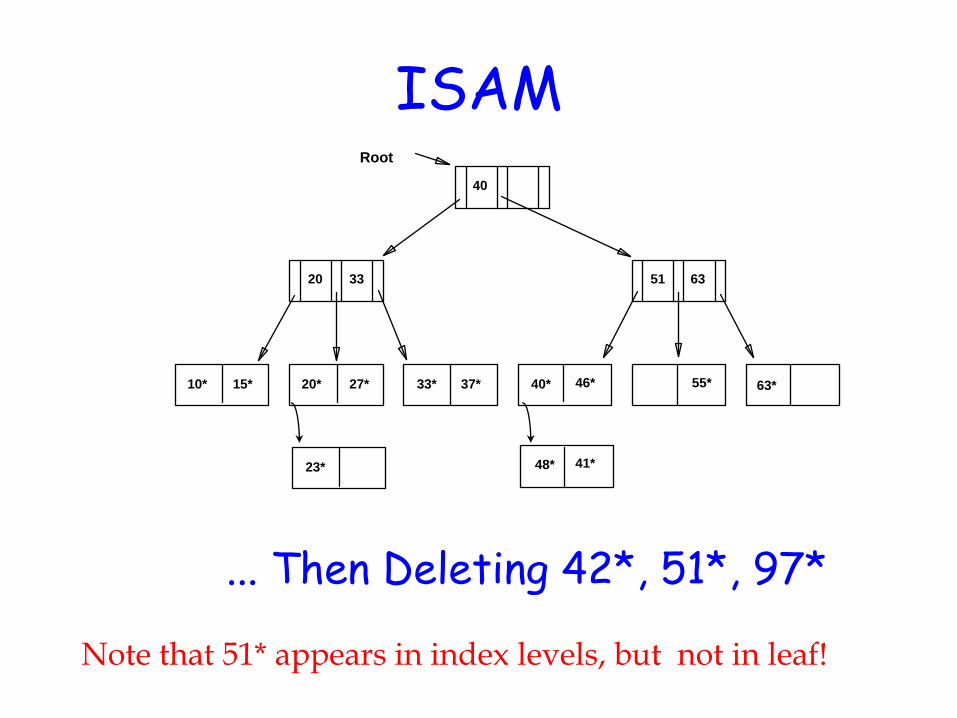
ISAM
... Then Deleting 42*, 51*, 97*
Note that 51* appears in index levels, but not in leaf!
10* 15* 20* 27* 33* 37* 40* 46* 55* 63*
20 33 51 63
40
Root
23* 48* 41*

Main Problem of ISAM
Long overflow chain can develop poor performance
What can we do?

B+ Tree
• Dynamic structure
• Balanced tree
• Adjusts to changes in the file gracefully
• Internal nodes direct the search
• Leaf nodes contain the date entry
Index Entries
Data Entries
("Sequence set")
(Direct search)

Characteristics of B+ Trees
• Addition and insertion operations keep the tree balanced
• Every node contains m entries
• d <= m <= 2d (d is a parameter of the B+ tree called the degree of the tree)
• Only the root node is the exception where 1 <= m <= 2d

B+ Tree: Insertion
• Find correct leaf L. • Put data entry onto L.
– If L has enough space, done! – Else, must split L (into L and a new node L2)
• Redistribute entries evenly, copy up middle key. • Insert index entry pointing to L2 into parent of L.
• This can happen recursively – To split index node, redistribute entries evenly,
but push up middle key. (Contrast with leaf splits.)
• Splits “grow” tree; root split increases height. – Tree growth: gets wider or one level taller at top.

B+ Tree: Insertion Root
17 24 30
2* 3* 5* 7* 14* 16* 19* 20* 22* 24* 27* 29* 33* 34* 38* 39*
13
Inserting 8*: 2* 3* 5* 7* 8*
5 (Note that 5 is continues to appear in the leaf.)
s copied up and
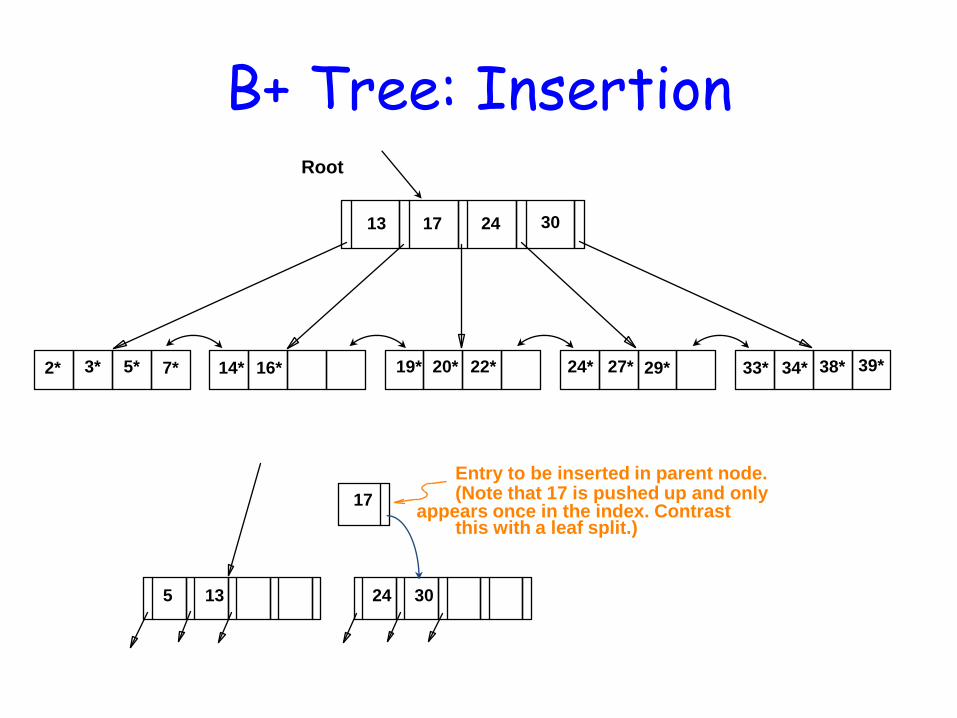
B+ Tree: Insertion Root
17 24 30
2* 3* 5* 7* 14* 16* 19* 20* 22* 24* 27* 29* 33* 34* 38* 39*
13
appears once in the index. Contrast
5 24 30
17
13
Entry to be inserted in parent node. (Note that 17 is pushed up and only
this with a leaf split.)

B+ Tree: Insertion
Notice that root was split, leading to increase in height.
2* 3*
Root
17
24 30
14* 16* 19* 20* 22* 24* 27* 29* 33* 34* 38* 39*
13 5
7* 5* 8*

B+ Tree: Deletion
• Start at root, find leaf L where entry belongs • Delete the entry
– If L is at least half-full, done! – If L has only d-1 entries,
• Try to re-distribute, borrowing from sibling (adjacent node with same parent as L).
• If re-distribution fails, merge L and sibling.
• If merge occurred, must delete entry (pointing to L or sibling) from parent of L.
• Merge could propagate to root, decreasing height.

B+ Tree: Deletion
2* 3*
Root
17
24 30
14* 16* 19* 20* 22* 24* 27* 29* 33* 34* 38* 39*
13 5
7* 5* 8*
We want to delete 19* and 20*

B+ Tree: Deletion
2* 3*
Root
17
30
14* 16* 33* 34* 38* 39*
13 5
7* 5* 8* 22* 24*
27
27* 29*
• Deleting 19* is easy.
• Deleting 20* is done with re-distribution. Notice how middle key is copied up.
How about if we want to delete 24* ?

B+ Tree: Deletion
• Must merge. • Observe toss of
index entry (on right), and pull down of index entry (below).
30
22* 27* 29* 33* 34* 38* 39*
2* 3* 7* 14* 16* 22* 27* 29* 33* 34* 38* 39* 5* 8*
Root
30 13 5 17

Some Insights on B+ Tree
• Is it important to increase fan-out? why?
• What are the factors controlling the height of a B+ tree?
• What to do is we already have large number of records and we want to build a B+ tree indexing for it them?

Static Hashing
• # primary pages fixed, allocated sequentially, never de-allocated; overflow pages if needed.
• h(k) mod M = bucket to which data entry with key k belongs. (M = # of buckets) h(key) mod N
h key
Primary bucket pages Overflow pages
2
0
N-1

Static Hashing
• Buckets contain data entries. • Hash function works on search key field of
record r. • Must distribute values over range 0 ... M-1.
– h(key) = (a * key + b) usually works well. – a and b are constants; lots known about how to
tune h.
• Long overflow chains can develop and degrade performance.

Static Hashing
• To speed the search of a bucket, we can maintain data entries in sorted order by search key value.
• To insert a data entry: – use the hash function to identify the correct
bucket – put the data entry there – If there is no space for this data entry, we
allocate a new overflow page, put the data entry on this page, and add the page to the overflow chain of the bucket.

Static Hashing
• To delete an entry: – we use the hashing function to identify the
correct bucket,
– locate the data entry by searching the bucket, and then remove it.
– If this data entry is the last in an overflow page, the overflow page is removed from the overflow chain of the bucket and added to a list of free pages.

Static Hashing
• Good for equality not range
• As file grows, overflow chain grows performance deterioration
• The number of buckets is fixed if the file shrinks, space is wasted
Can we do better than that?

Extendible Hashing
• If overflow chain becomes long, can’t we just double the number of buckets?
very expensive • Idea:
– Use directory of pointers to buckets, double # of buckets by doubling the directory, splitting just the bucket that overflowed!
– Directory much smaller than file, so doubling it is much cheaper. Only one page of data entries is split. No overflow page!
– Trick lies in how hash function is adjusted!

Extendible Hashing: Example
13* 00
01
10
11
2
2
2
2
2
LOCAL DEPTH
GLOBAL DEPTH
DIRECTORY
Bucket A
Bucket B
Bucket C
Bucket D
DATA PAGES
10*
1* 21*
4* 12* 32* 16*
15* 7* 19*
5*
• h(r) = least significant
d digits of the key
• Bucket has up to 4
entries

Insert h(r)=20 (Causes Doubling)
20*
00
01
10
11
2 2
2
2
LOCAL DEPTH 2
2
DIRECTORY
GLOBAL DEPTH Bucket A
Bucket B
Bucket C
Bucket D
Bucket A2 (`split image' of Bucket A)
1* 5* 21* 13*
32* 16*
10*
15* 7* 19*
4* 12*
19*
2
2
2
000
001
010
011
100
101
110
111
3
3
3
DIRECTORY
Bucket A
Bucket B
Bucket C
Bucket D
Bucket A2
(`split image' of Bucket A)
32*
1* 5* 21* 13*
16*
10*
15* 7*
4* 20* 12*
LOCAL DEPTH
GLOBAL DEPTH

Extendible Hashing: Insights
• When to split? When the following conditions are true – global depth = local depth
– bucket is full before when insert the new entry
• Can we use most significant bits instead?
• Can we “half the directory”?

Linear Hashing
• Also a dynamic hashing
• Does not require a directory
• Deals naturally with collisions
• Offers a lot of flexibility with respect to the timing of bucket splits

Linear Hashing
• Idea: Use a family of hash functions h0, h1, h2, ... – hi(key) = h(key) mod(2iN); N = initial #
buckets – h is some hash function – If N = 2d0, for some d0, hi consists of
applying h and looking at the last di bits, where di = d0 + i.
– hi+1 doubles the range of hi (similar to directory doubling) hi+1 = hi mod(2i N)

Linear Hashing
• using overflow pages • choosing bucket to split round-robin.
– Splitting proceeds in rounds. – Round ends when all NR initial (for round R) buckets
are split. – Buckets 0 to Next-1 have been split; Next to NR
yet to be split. – Current round number is Level.
• Search: To find bucket for data entry r, find hLevel(r):
• If hLevel(r) in range `Next to NR’ , r belongs here. • Else, r could belong to bucket hLevel(r) or bucket hLevel(r) +
NR; must apply hLevel+1(r) to find out.
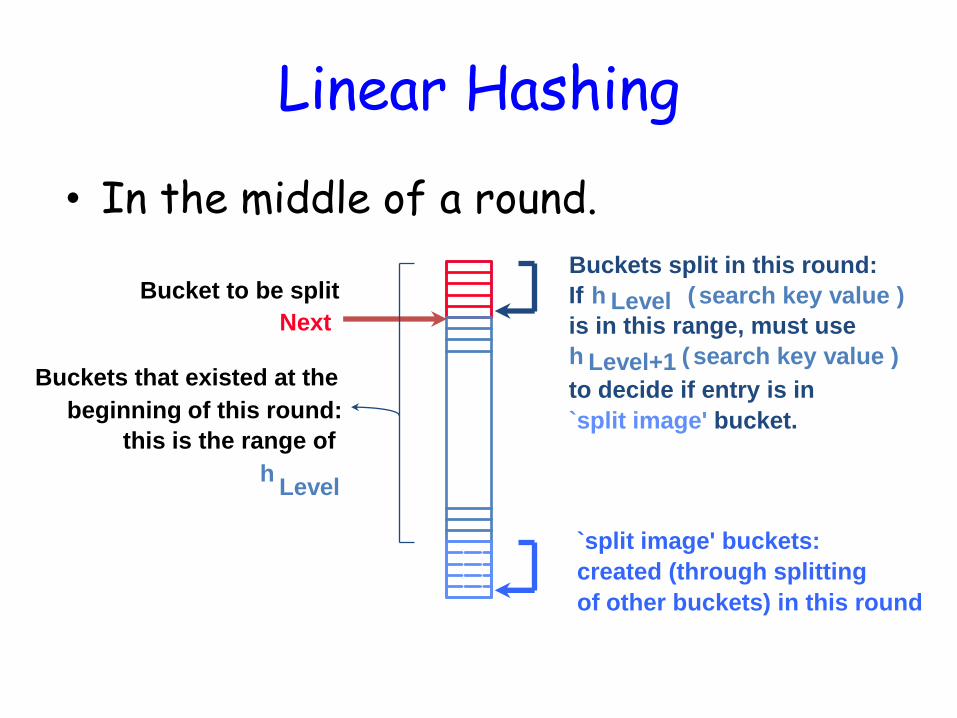
Linear Hashing
• In the middle of a round.
Level h
Buckets that existed at the
beginning of this round:
this is the range of
Next
Bucket to be split
of other buckets) in this round
Level h search key value ) (
search key value ) (
Buckets split in this round:
If
is in this range, must use
h Level+1
`split image' bucket.
to decide if entry is in
created (through splitting
`split image' buckets:

Linear Hashing
• Insert: Find bucket by applying hLevel and, if needed,hLevel+1: – If bucket to insert into is full:
• Add overflow page and insert data entry. • (Maybe) Split Next bucket and increment Next.
• Can choose any criterion to `trigger’ split.
• Since buckets are split round-robin, long overflow chains don’t develop!
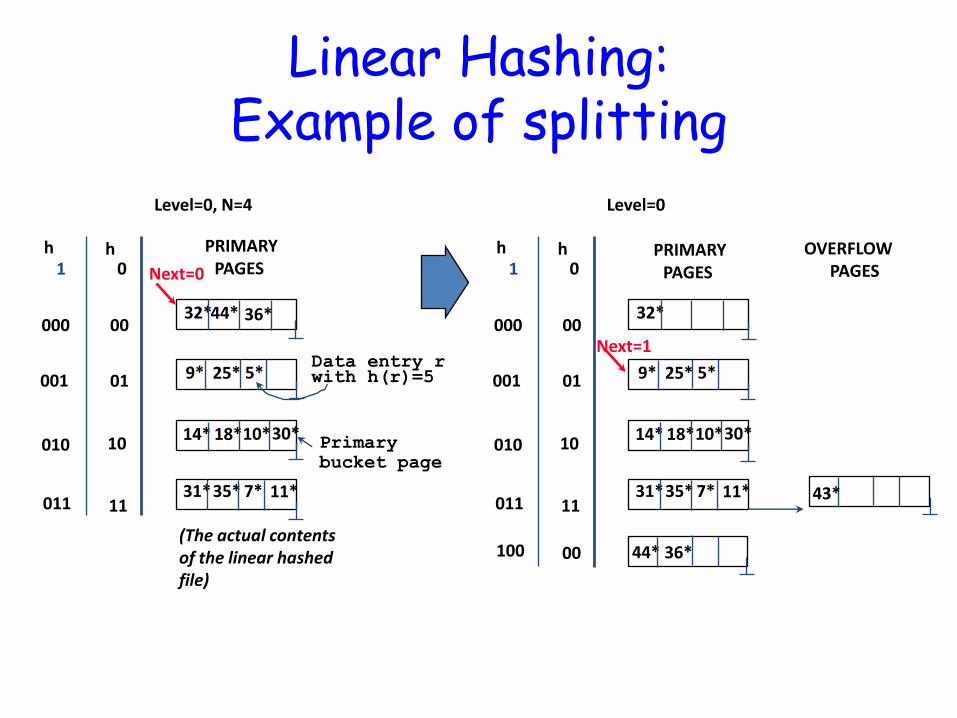
Linear Hashing: Example of splitting
0 h h
1
Level=0, N=4
00
01
10
11
000
001
010
011
(The actual contents of the linear hashed file)
Next=0
PRIMARY PAGES
Data entry r with h(r)=5
Primary
bucket page
44* 36* 32*
25* 9* 5*
14* 18* 10* 30*
31* 35* 11* 7*
0 h h
1
Level=0
00
01
10
11
000
001
010
011
Next=1
PRIMARY PAGES
44* 36*
32*
25* 9* 5*
14* 18* 10* 30*
31* 35* 11* 7*
OVERFLOW PAGES
43*
00 100

Conclusions
• Tree-structured indexes are ideal for range-searches, also good for equality searches.
• ISAM is used when files do not get updated frequently. Otherwise B+ tree is preferable.
• Hash-based indexes: best for equality searches, cannot support range searches.





























