Embed Size (px)
Citation preview

Level 3 Award in Mathematics for numeracy
Teaching:
Session 5: Handling data
Gail Lydon & Jo Byrne

Log into the online page for data handling
• https://ccpathways.co.uk/level-3-maths-online/
• You'll need the password L3Maths16
• Click on the Data Handling button
• Have you had a chance to look at HO1 Data Handling?
If not have a look now and note on your ILP anything you
need to look at after the session.

Session aim
• To review & extend participants’
personal mathematics relating to
statistics and probability
• To apply concepts of statistics and
probability to solve problems

What do you need to know about statistics?

What do you need to know about statistics?
• Mean, median and mode
• Sampling techniques
• Data transformation (measures of
dispersion, curve fitting, spread, upper and
lower quartiles, interquartile range,
standard deviation)
• Statistical diagrams
• Regression
• Correlations
• Probability

Flipped activity review
• HO1

Frequency distributions
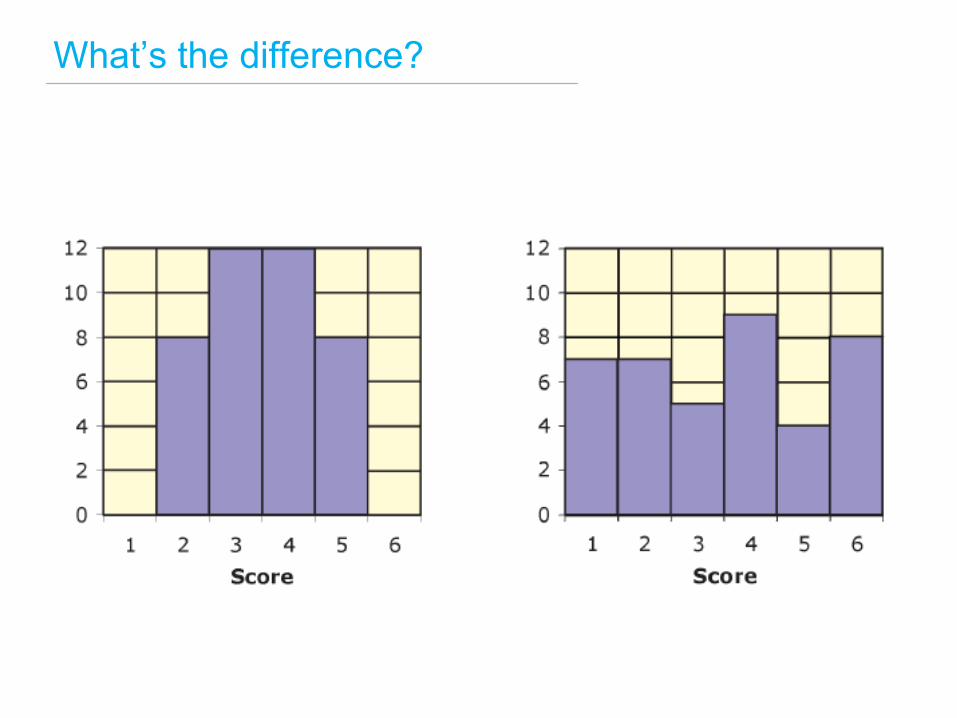
What’s the difference?

Measures of dispersion
• Range
• Interquartile range
• Variance
• Standard deviation
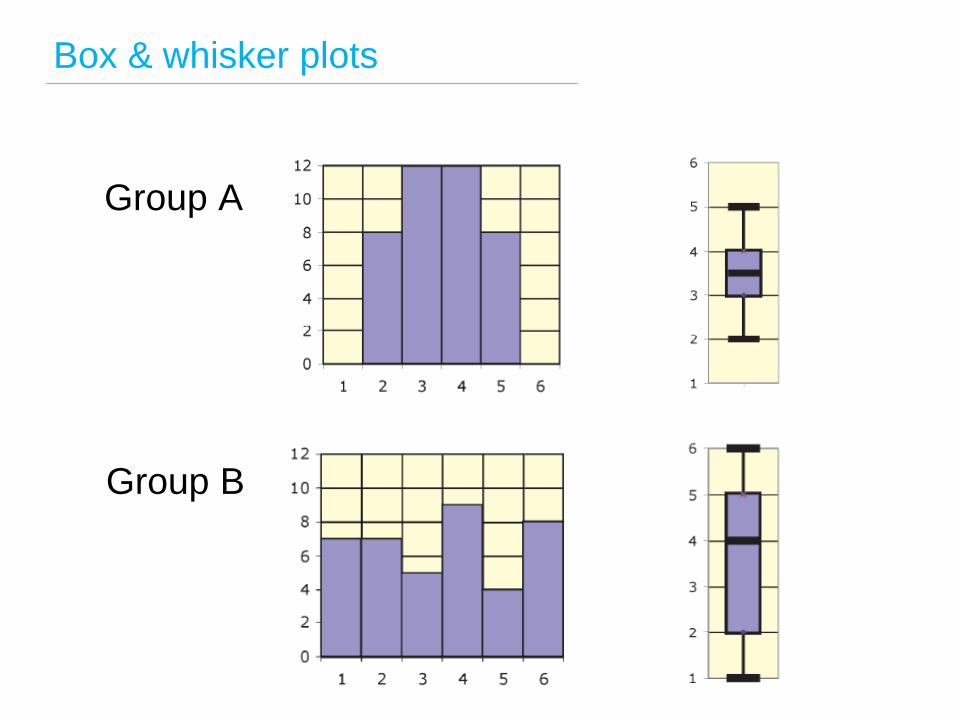
Box & whisker plots
Group A
Group B

Variance and standard deviation
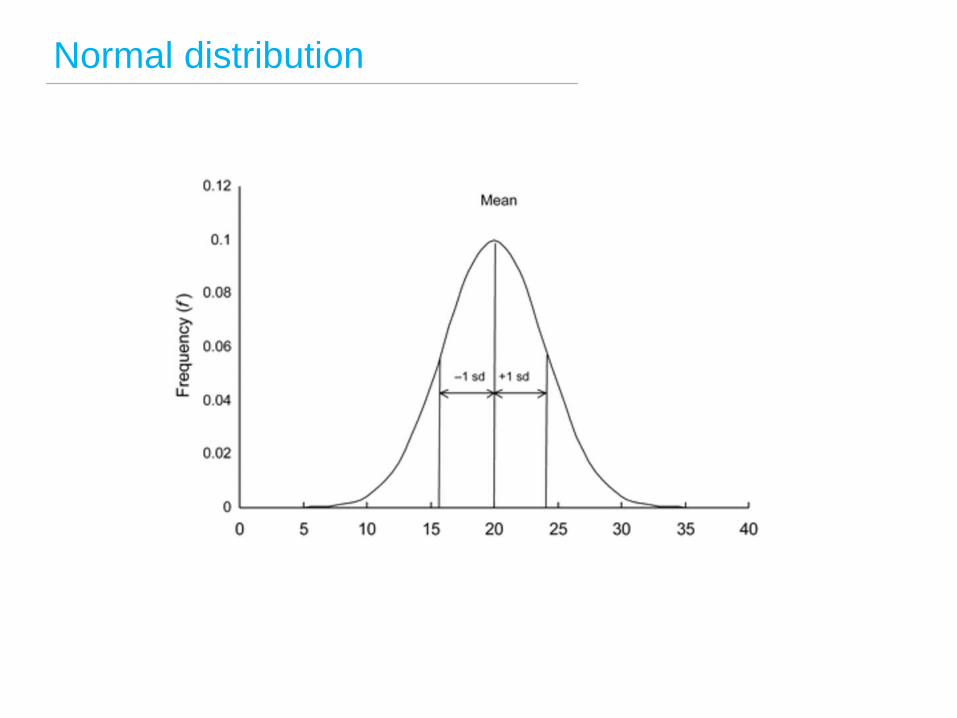
Normal distribution

Standard deviation
Standard deviation is used to assess if a data point is
OR
Standard and
expected (ie within expected variation)
Unexpected
and unusual (significantly above or
below the average)

Standard deviation is represented by lower case
sigma
𝝈
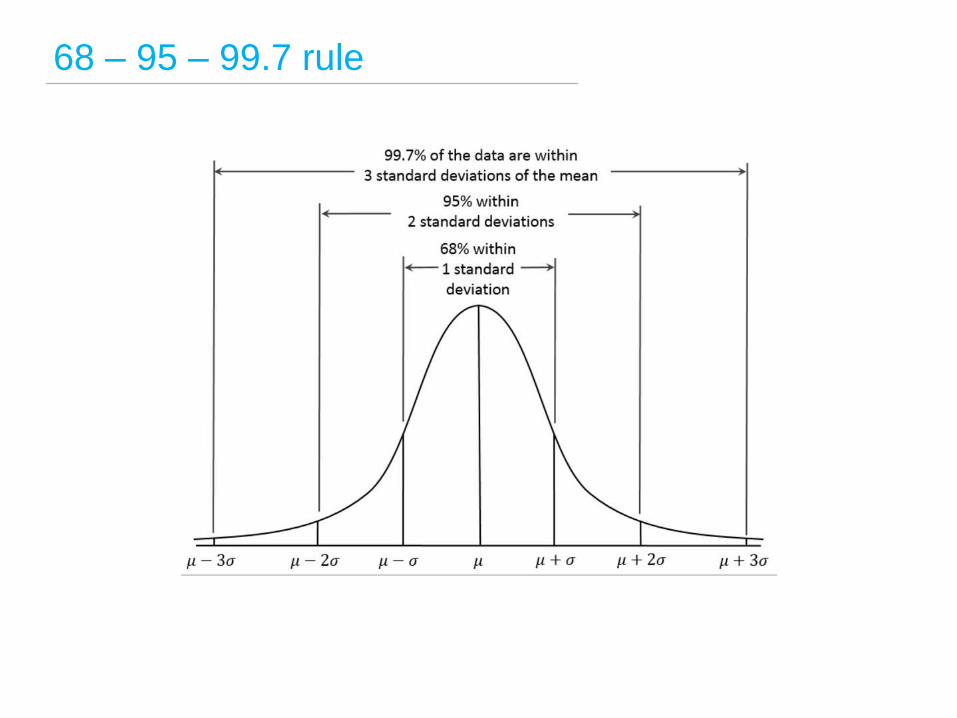
68 – 95 – 99.7 rule

Σ
Upper case sigma

• What does Σ mean?
• It is the summation operator (so have a go at
calculating the following)
Upper case sigma

Standard deviation
Use the population
standard deviation (σ)
when data is relates to
the entire population:
The standard deviation
of a sample of the
population (s) can be
estimated using:
Note:
• xi represents the individual values of x;
• is the mean of all the values of x
(sometimes μ is used)
• N is the number of values

Let’s have a go at a standard
deviation problem
• Have a look at HO2 (under R5)

Grouped and cumulative
frequency distributions
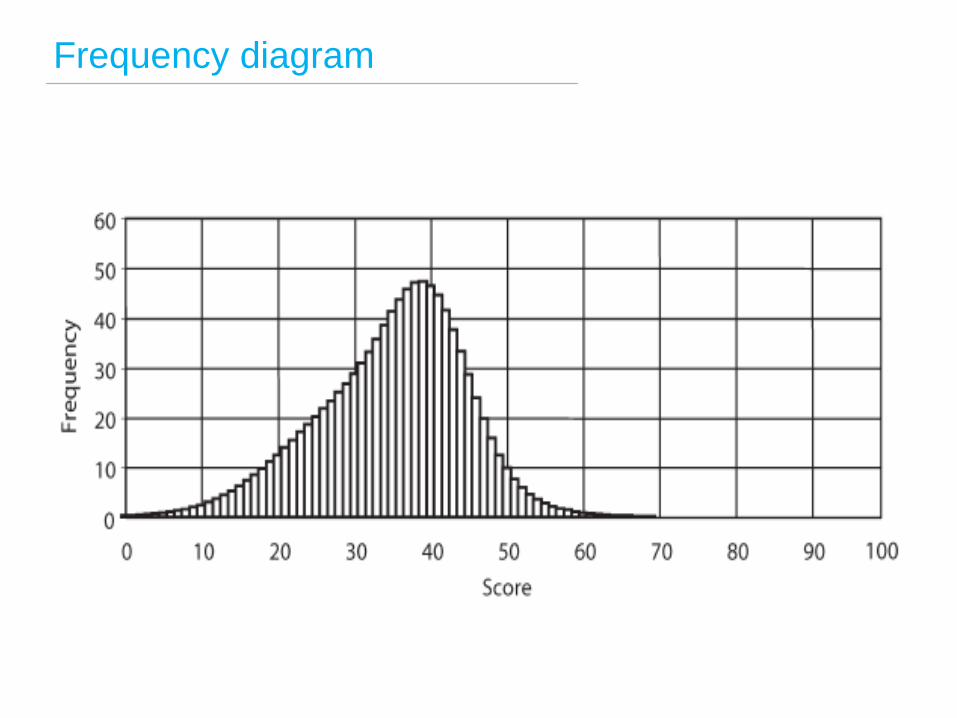
Frequency diagram
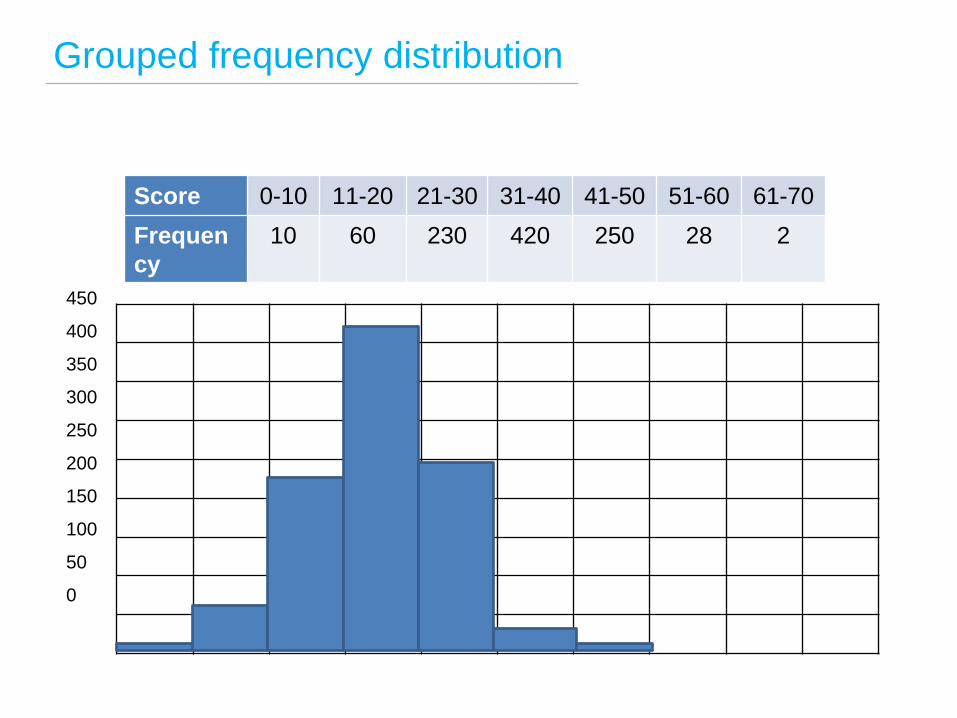
Grouped frequency distribution
450
400
350
300
250
200
150
100
50
0
Score 0-10 11-20 21-30 31-40 41-50 51-60 61-70
Frequen
cy
10 60 230 420 250 28 2
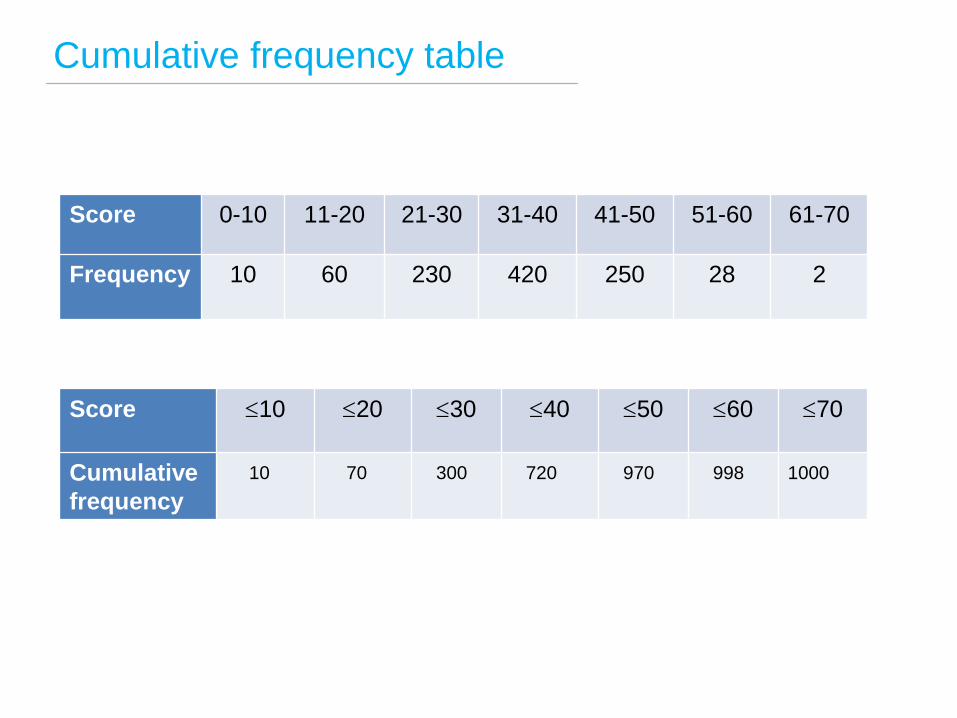
Cumulative frequency table
Score 0-10 11-20 21-30 31-40 41-50 51-60 61-70
Frequency 10 60 230 420 250 28 2
Score 10 20 30 40 50 60 70
Cumulative
frequency
10 70 300 720 1000 998 970
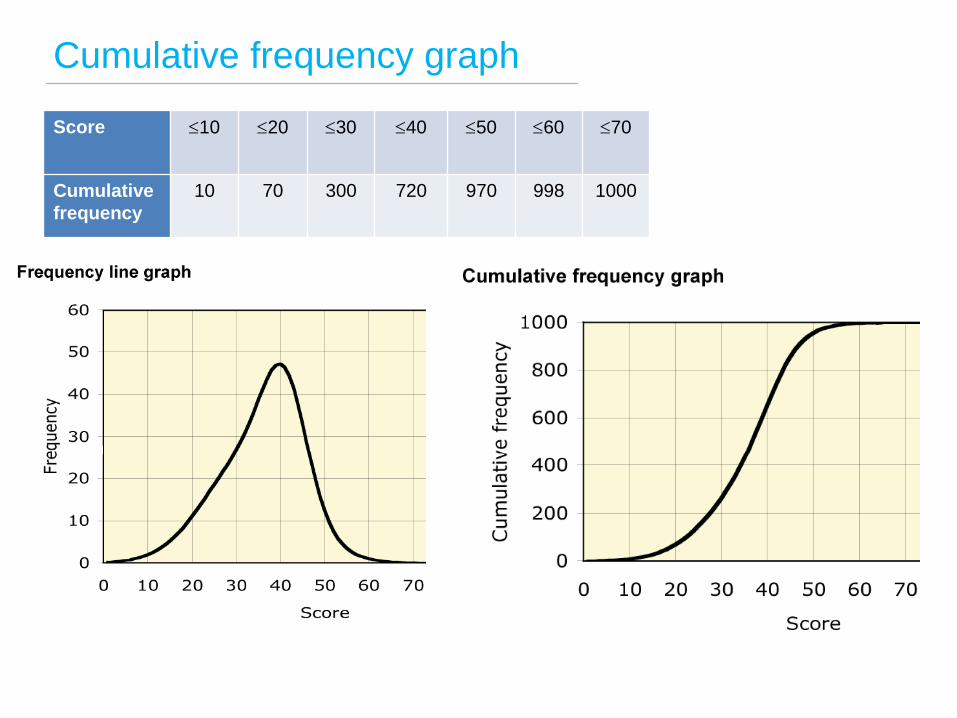
Cumulative frequency graph
Score 10 20 30 40 50 60 70
Cumulative
frequency
10 70 300 720 970 998 1000
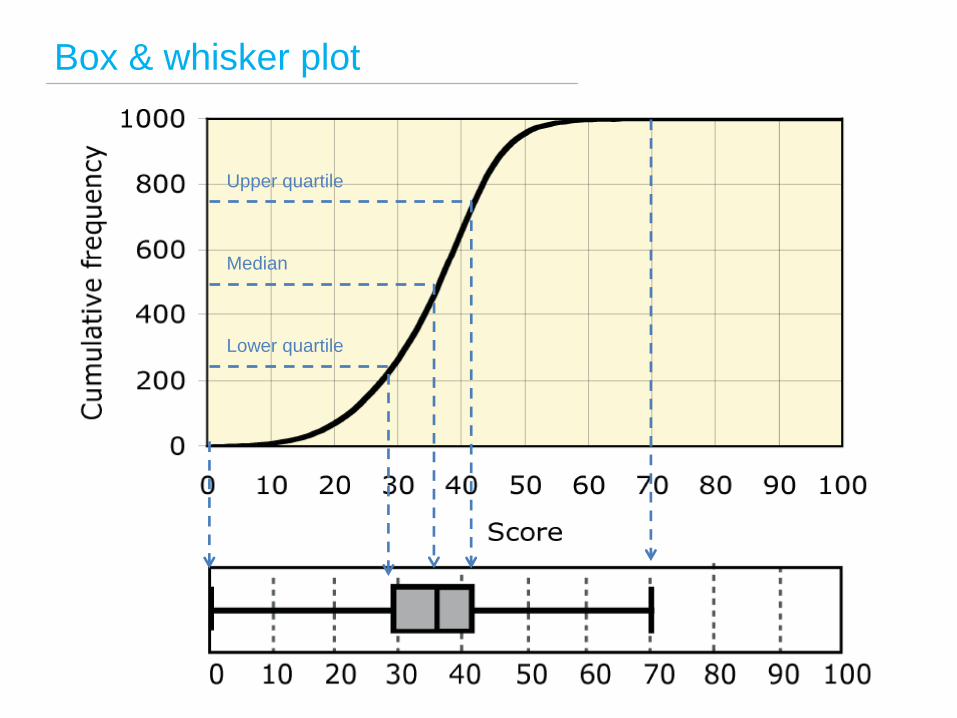
Box & whisker plot
Lower quartile
Upper quartile
Median
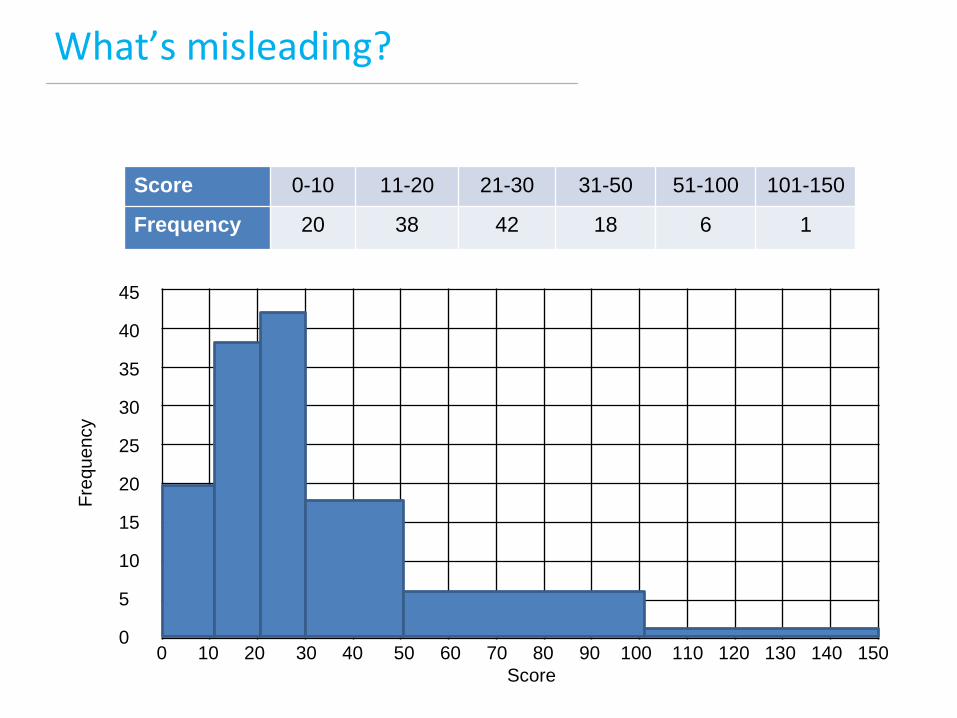
What’s misleading?
45
40
35
30
25
20
15
10
5
0 0 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150
Score
Fre
qu
en
cy
Score 0-10 11-20 21-30 31-50 51-100 101-150
Frequency 20 38 42 18 6 1
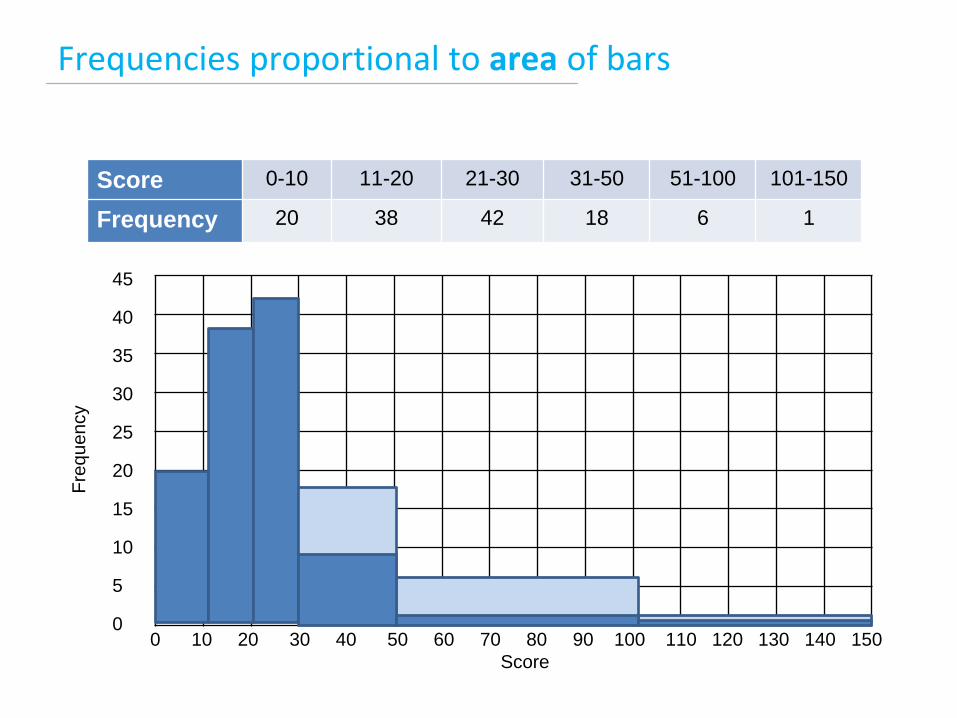
Frequencies proportional to area of bars
45
40
35
30
25
20
15
10
5
0 0 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150
Score
Fre
qu
en
cy
Score 0-10 11-20 21-30 31-50 51-100 101-150
Frequency 20 38 42 18 6 1

Bivariate analysis
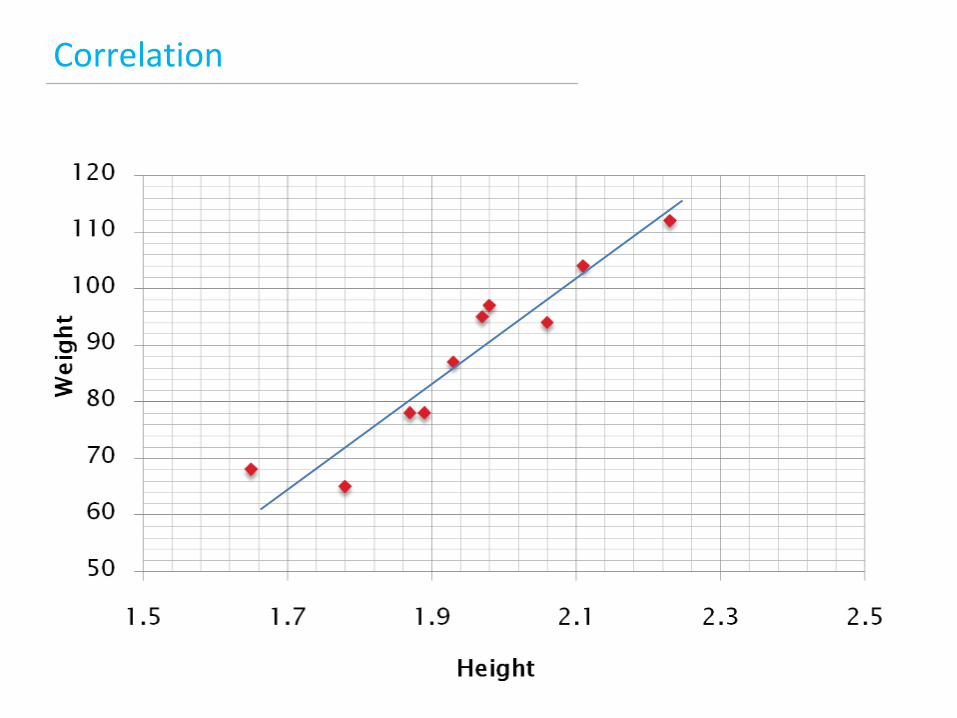
Correlation
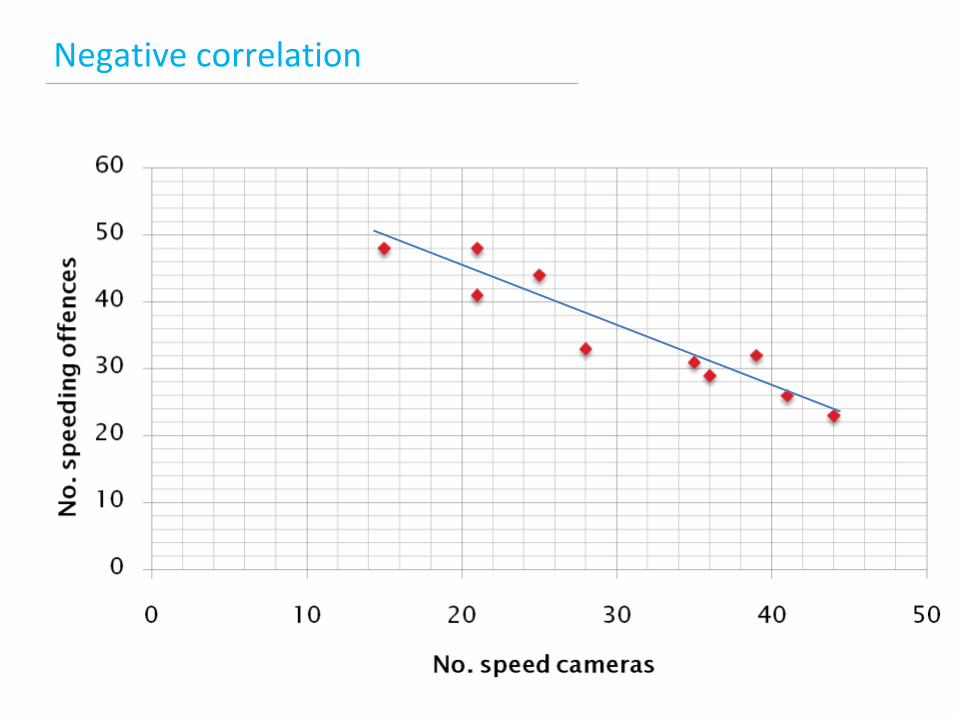
Negative correlation

Probability

Probability
P(a) = No. successful outcomes
Total possible outcomes

Combined probabilities
When two coins are tossed there are
three possible outcomes:
• Two heads
• One head
• No heads
The probability of two heads is
therefore ⅓
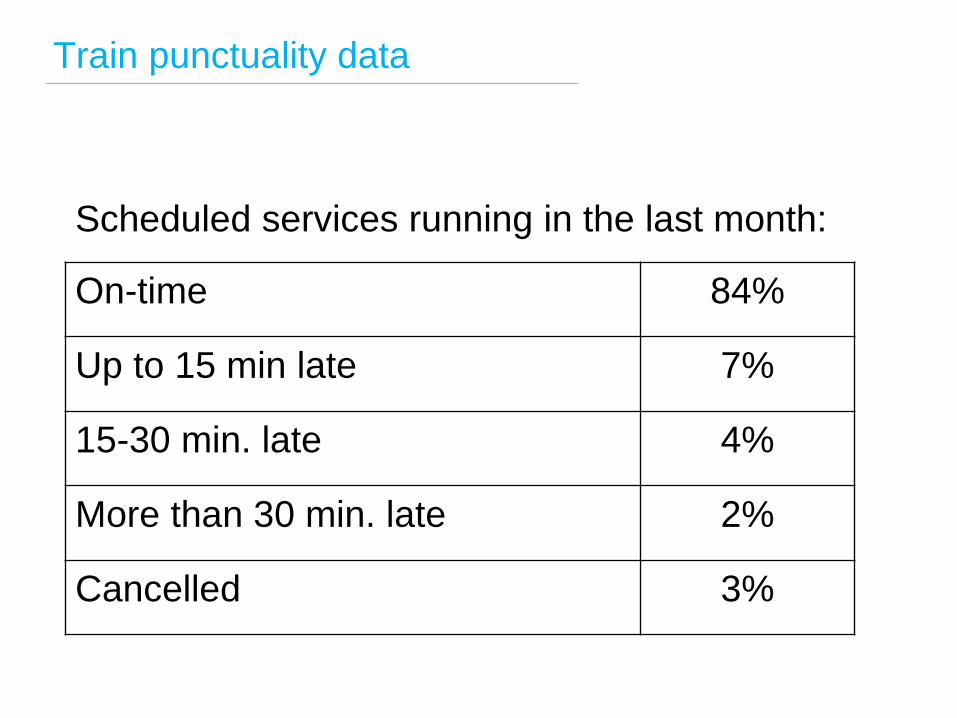
Train punctuality data
On-time 84%
Up to 15 min late 7%
15-30 min. late 4%
More than 30 min. late 2%
Cancelled 3%
Scheduled services running in the last month:
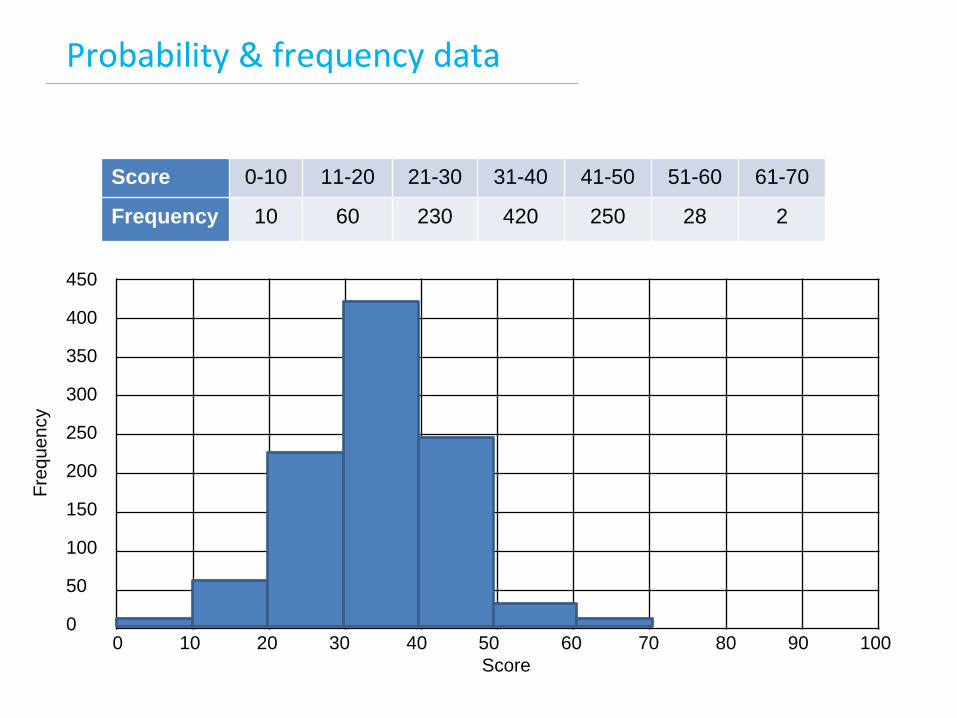
Probability & frequency data
450
400
350
300
250
200
150
100
50
0 0 10 20 30 40 50 60 70 80 90 100
Score
Fre
qu
en
cy
Score 0-10 11-20 21-30 31-40 41-50 51-60 61-70
Frequency 10 60 230 420 250 28 2

Pearson’s correlation coefficient

The Pearson product-moment correlation
coefficient (or Pearson correlation coefficient, for
short)
is a measure of the strength of a linear association (the
relationship) between two variables and is denoted by r.
Basically, a Pearson product-moment correlation
attempts to draw a line of best fit through the data of two
variables, and the Pearson correlation coefficient, r,
indicates how far away all these data points are to this
line of best fit (i.e., how well the data points fit this new
model/line of best fit).

Pearson correlation coefficient – working it out
There are a number of variations of Pearson’s.

Pearson correlation coefficient cont
Pearson’s r is always between -1 and 1

Pearson correlation coefficient cont
Example 1 – a perfect positive relationship between x and
y.
As x increases y increases exactly the same.
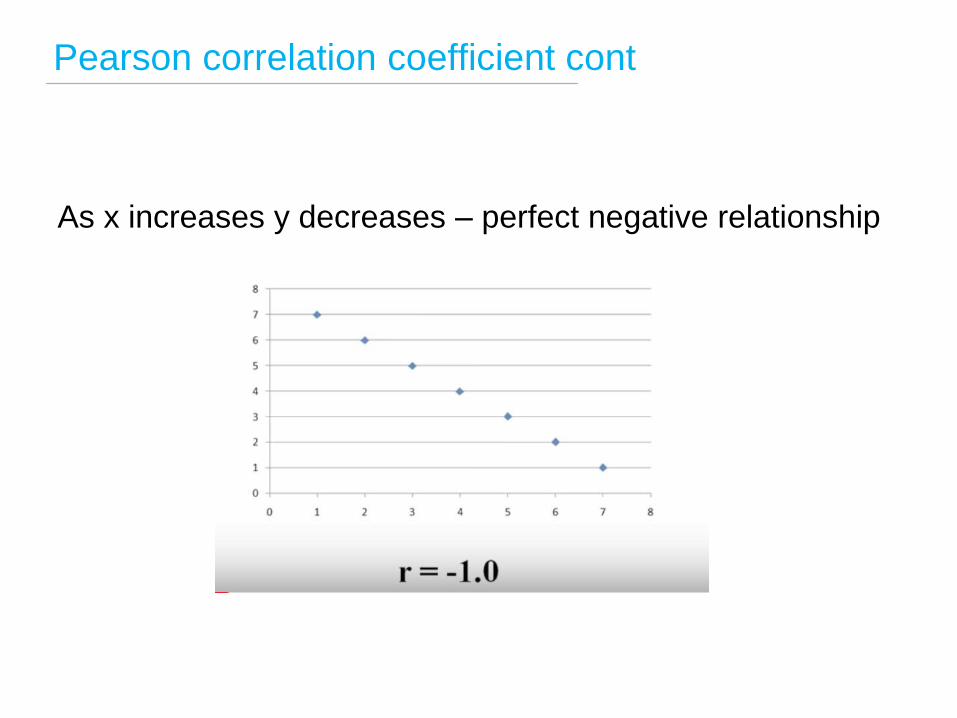
Pearson correlation coefficient cont
As x increases y decreases – perfect negative relationship
Pearson correlation coefficient cont
So what r=0 look like?
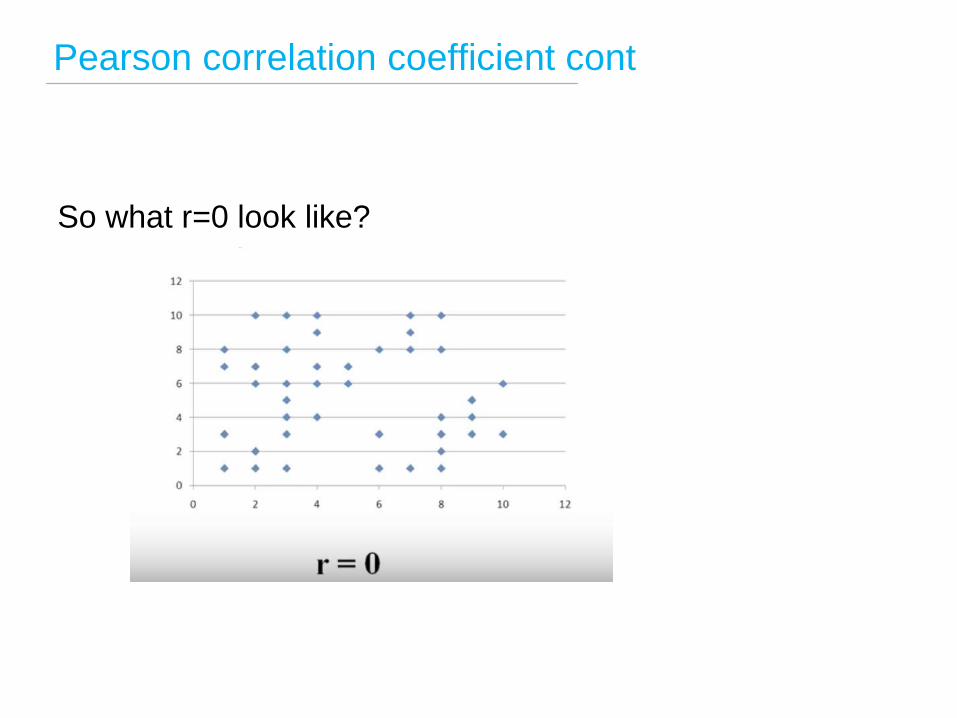
Pearson correlation coefficient cont
So what r=0 look like?

• Let’s look back at the equation we saw earlier
• What does Σ mean? Remember?
• It is the summation operator and you calculated
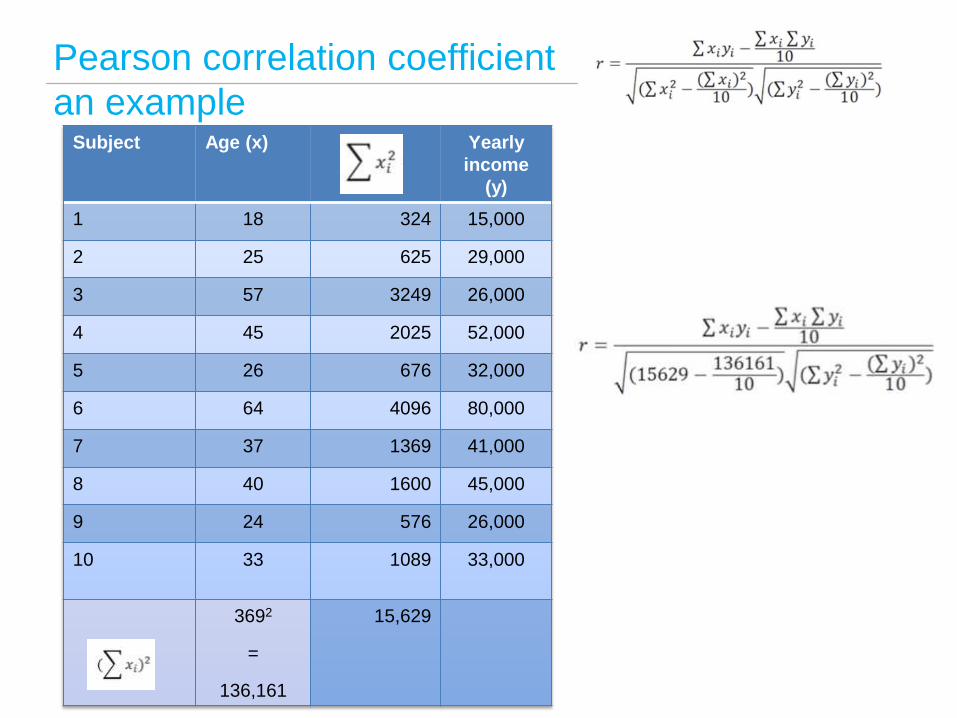
Pearson correlation coefficient an example

• What does √ mean?
• So this isn’t a complicated equation – its just a long
winded one – so you need to write down all of your
steps.
Pearson correlation coefficient an example

Pearson correlation coefficient an example
Subject Age (x) Yearly income
(y)
1 18 15,000
2 25 29,000
3 57 26,000
4 45 52,000
5 26 32,000
6 64 80,000
7 37 41,000
8 40 45,000
9 24 26,000
10 33 33,000
In this case what does
n=?
n=10 so
Pearson correlation coefficient
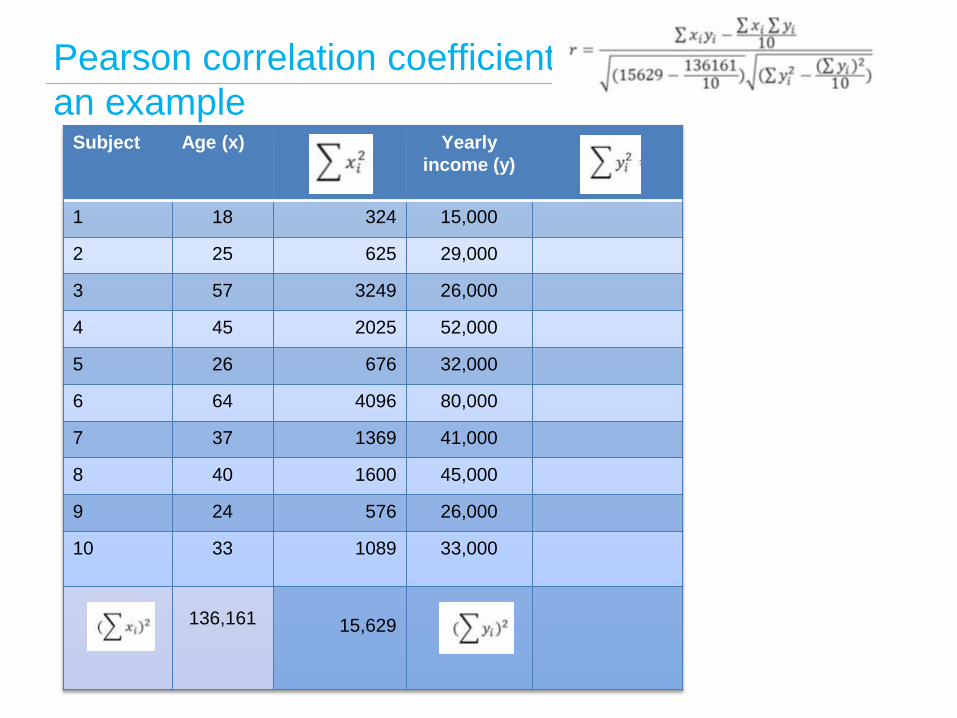
an example
Subject Age (x) Yearly
income
(y)
1 18 324 15,000
2 25 625 29,000
3 57 3249 26,000
4 45 2025 52,000
5 26 676 32,000
6 64 4096 80,000
7 37 1369 41,000
8 40 1600 45,000
9 24 576 26,000
10 33 1089 33,000
3692
=
136,161
15,629
Pearson correlation coefficient
an example
Subject Age (x) Yearly
income (y)
1 18 324 15,000
2 25 625 29,000
3 57 3249 26,000
4 45 2025 52,000
5 26 676 32,000
6 64 4096 80,000
7 37 1369 41,000
8 40 1600 45,000
9 24 576 26,000
10 33 1089 33,000
136,161
15,629
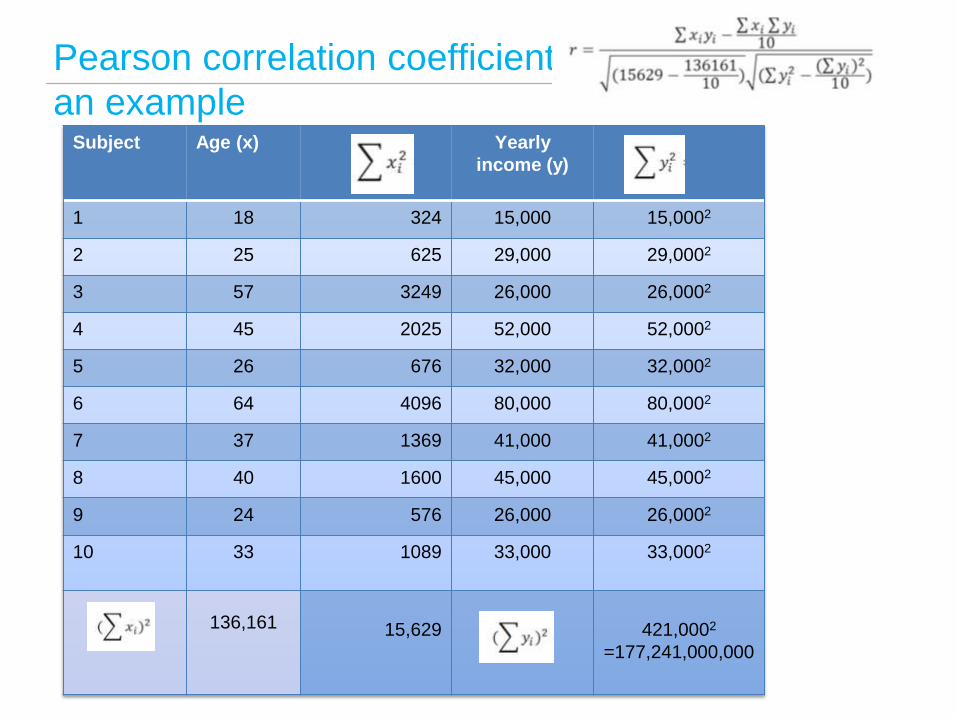
Pearson correlation coefficient
an example
Subject Age (x) Yearly
income (y)
1 18 324 15,000 15,0002
2 25 625 29,000 29,0002
3 57 3249 26,000 26,0002
4 45 2025 52,000 52,0002
5 26 676 32,000 32,0002
6 64 4096 80,000 80,0002
7 37 1369 41,000 41,0002
8 40 1600 45,000 45,0002
9 24 576 26,000 26,0002
10 33 1089 33,000 33,0002
136,161
15,629
421,0002
=177,241,000,000

Pearson correlation coefficient
an example
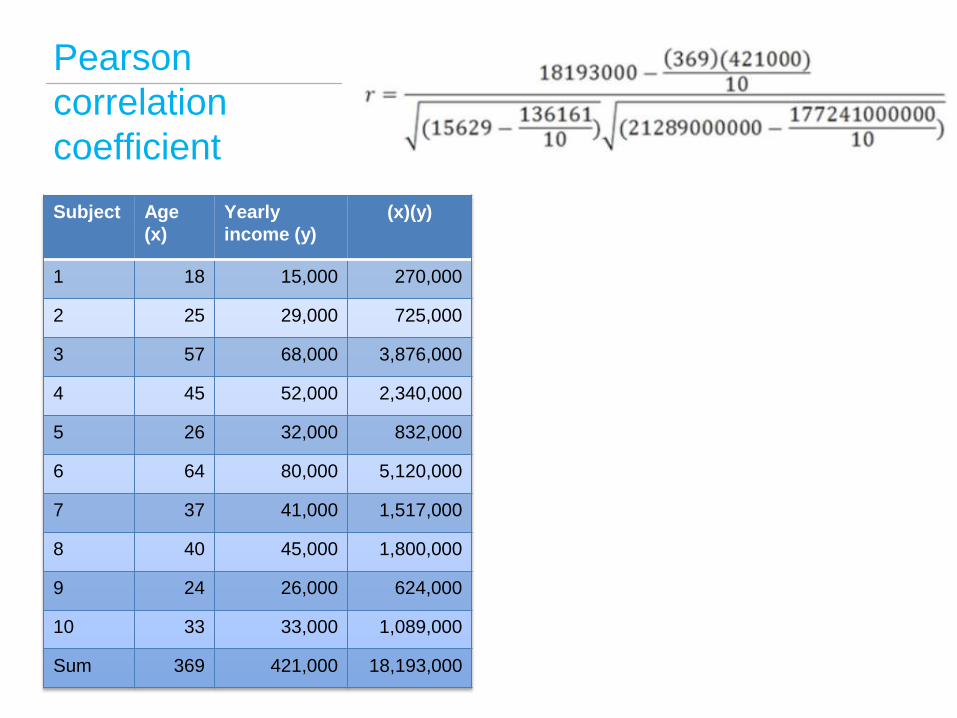
Pearson
correlation
coefficient
Subject Age
(x)
Yearly
income (y)
(x)(y)
1 18 15,000 270,000
2 25 29,000 725,000
3 57 68,000 3,876,000
4 45 52,000 2,340,000
5 26 32,000 832,000
6 64 80,000 5,120,000
7 37 41,000 1,517,000
8 40 45,000 1,800,000
9 24 26,000 624,000
10 33 33,000 1,089,000
Sum 369 421,000 18,193,000

Pearson correlation coefficient
So what is the 0.99 indicating?
That x (age) and y (yearly income) have a
strong positive relationship.

Pearson correlation coefficient cont
Pearson’s r is always between -1 and 1
https://statistics.laerd.com/statistical-guides/pearson-
correlation-coefficient-statistical-guide.php
http://study.com/academy/lesson/pearson-correlation-
coefficient-formula-example-significance.html
• https://www.youtube.com/watch?v=BXXtkYOqAfM
• https://www.youtube.com/watch?v=SC1kvvoH10Y
• https://www.youtube.com/watch?v=2SCg8Kuh0tE -
this is my favourite
• Estimating from a scatterplot
• https://www.youtube.com/watch?v=372iaWfH-Dg
• https://www.youtube.com/watch?v=2B_UW-RweSE
• This example is age and yearly income but can just
as easily be used to consider whether there is a
correlation between maths and music
Pearson Product Moment Correlation
Coefficient

Questions for you to work on:
• Probability
• Statistics
• Statistical distributions
• Correlation and regression

Probability:
Matthew is an A-level student studying English, History and
French.
He plans to go to University and has received a conditional
offer from the University of Central Lancashire of ‘B C C’
in any combination of subjects
a) What are the chances that Matthew exactly meets the
offer from the University of Central Lancashire?
b) What are the chances that Matthew meets or exceeds
the University of Central Lancashire’s offer?
c) How would it affect your conclusions if your assumptions
are wrong?
Matthew’s homework grades English B C C C D C D B
History B C C B C D C B
French C D C B C B C C

Statistics
In April 2011 a survey of customer transaction values was carried out by a
retail business. The following data was collected
a) i) Plot the histogram and the Cumulative Frequency Curve for this data
ii) Estimate the median transaction value and its Inter-quartile range from
the graphs.
b) For the above data calculate
i) The mean transaction value (stating clearly any assumptions made)
ii) The standard deviation
c) A similar survey was carried out in October 2010. The resulting data gave a
mean value of £27.90 and a standard deviation of £14.30.
Comment on how the spending pattern of customers has changed between the
two months.
Transaction value (£’s) No. of customers Below 10.00 137 10.00 to 19.99 259 20.00 to 29.99 297 30.00 to 39.99 378 40.00 to 49.99 193 50.00 to 59.99 84 60.00 to 69.99 52

Statistical distributions
Applicants for a certain job are given an aptitude test. Past-
experience shows that the scores from the test are
normally distributed with a mean of 60 and standard
deviation of 12 marks.
What percentage of applicants would be expected to pass
the test if the minimum score required was 75?
What would the pass mark need to be if the company
wanted only 4% of applicants to pass?
What would be the percentage failing if the standard
deviation were 20 points?
What practical use could the company make of this
information?

Correlation and regression
The number of customers in different regions and the corresponding
monthly sales of a product are:
1. Plot a scatter diagram of ‘Sales Volume’ against ‘Number of customers’
2. Calculate the regression line and the coefficient of determination r2
3. Check your answers to b) in ONE way by using Excel functions or its Regression
facility
4. Plot the regression line on the same graph as the scatter diagram
What information does the coefficient of determination give you about
the regression line?
Comment on the match between the data-points and the regression
line. Is this consistent with the r2 value? 5. Use the regression line to predict ‘Sales Volume’ for Regions having 1000, 4000 and
7000 customers. In each case comment critically on the reliability of these predictions
Sales Region 1 2 3 4 5 6 7 8 9 10
Number of customers (00’s) 26 22 50 43 48 32 30 34 40 50
Sales volume ((£000s) 146 149 325 252 312 188 195 196 260 298





























