Embed Size (px)
Citation preview

The 4th Workshop on South and Southeast Asian NLP (WSSANLP), International Joint Conference on Natural Language Processing, pages 9–16,Nagoya, Japan, 14-18 October 2013.
LexToPlus: A Thai Lexeme Tokenization and Normalization Tool
Choochart Haruechaiyasak and Alisa KongthonSpeech and Audio Technology Laboratory (SPT)
National Electronics and Computer Technology Center (NECTEC)Thailand Science Park, Klong Luang, Pathumthani 12120, Thailand
{choochart.har, alisa.kon}@nectec.or.th
Abstract
The increasing popularity of social me-dia has a large impact on the evolution oflanguage usage. The evolution includesthe transformation of some existing termsto enhance the expression of the writer’semotion and feeling. Text processing taskson social media texts have become muchmore challenging. In this paper, we pro-pose LexToPlus, a Thai lexeme tokenizerwith term normalization process. Lex-ToPlus is designed to handle the inten-tional errors caused by the repeated char-acters at the end of words. LexToPlus is adictionary-based parser which detects ex-isting terms in a dictionary. Unknown to-kens with repeated characters are mergedand removed. We performed statisticalanalysis and evaluated the performance ofthe proposed approach by using a Twit-ter corpus. The experimental results showthat the proposed algorithm yields an ac-curacy of 96.3% on a test data set. Theerrors are mostly caused by the out-of-vocabulary problem which can be solvedby adding newly found terms into the dic-tionary.
1 Introduction
Thailand is among the top countries having a largepopulation on social networking websites such asFacebook and Twitter. The recent statistics showthat the number of social media users in Thai-land has reached 18 millions (approximately 25%of the total population) as of the first quarter of20131. In addition to the enormous amount oftexts being created daily, another challenging is-sue is the language usage on social media is much
1Zocial Inc. blog, http://blog.zocialinc.com/thailand-zocial-award-2013-summary/
different from the traditional and formal language.Social media texts include chat message, SMS,comments and posts. These texts are usually shortand noisy, i.e., contain some ill-formed, out-of-vocabulary, abbreviated, transliterated and homo-phonic transformed terms. These special charac-teristics are due to many reasons including incon-venience in typing on virtual keyboards of smart-phones and intentional transformation of existingterms to better express the emotion and feelingof the writers. As a result, performing basic textprocessing tasks such as term tokenization has be-come much more challenging.
Tokenizing Thai written texts is more difficultthan languages in which word boundary mark-ers are placed between words. Thai language isconsidered as an unsegmented language in whichwords are written continuously without the use ofword delimiters. Word segmentation is considereda basic yet very important NLP task in many un-segmented languages. The main goal of word seg-mentation task is to assign correct word bound-aries on given text strings. Previous approachesapplied to Thai word segmentation can be broadlyclassified as dictionary-based and machine learn-ing. The dictionary-based approach relies on a setof terms from a dictionary for parsing and seg-menting input texts into word tokens. During theparsing process, series of characters are looked upon the dictionary for matching terms. The perfor-mance of the dictionary-based approach dependson the quality and size of the word set in the dic-tionary. Recent works in Thai word segmenta-tion have adopted machine learning algorithms.The machine learning approach relies on a modeltrained from a corpus by using sequential labelingalgorithms. Using the annotated corpus in whichword boundaries are explicitly marked with a spe-cial character, the algorithm could be applied totrain a model based on the features (e.g., charactertypes) surrounding these boundaries.
9

The errors caused during the tokenization pro-cess can be categorized into two classes, uninten-tional and intentional. The unintentional errors arethe typographical errors caused by careless typing(Peterson, 1980; Brill and Moore., 2000). Thistype of errors has been rigorously studied in thearea of word editing and optical character recogni-tion (OCR). There are three cases of typographicalerrors: insertion, deletion and transposition. In-sertion error is caused by additional characters ina word. Deletion error is caused by missing char-acters in a word. Transposition error are caused byswapping of characters in the adjacent positions.Table 1 shows some examples of Thai word errorsfor all cases. The correct spellings are shown inparentheses with translations.
Table 1: Unintentional spelling error types and ex-amples
The scope of this paper does not include theunintentional errors which have been well stud-ied. Instead we focus on intentional errors, i.e.,words in which users intentionally create andtype. Based on our preliminary study, the in-tentional errors can be classified into four cate-gories: insertion, transformation, transliterationand onomatopoeia. The intentional insertion er-ror is caused by typing repeated characters at theend of a word to emphasize the emotion or feeling.The transformation error is caused by alterationof existing terms and can be categorized into twosubtypes: homophonic and syllable trimming. Thehomophonic terms refer to terms with the same orsimilar pronunciation to existing terms. The sylla-ble trimming is a transformed term by deleting oneor more syllables from an existing term for the pur-pose of reducing the keystrokes. The transliteratedterms are created by using the Thai character set tocreate new terms from other languages. The lastintentional error is the onomatopoeia terms whichare created to phonetically imitate various sounds.
In this paper, we propose a solution for tokeniz-ing and normalizing texts with the intentional in-sertion errors, i.e., users insert repeated charac-
ters at the end of words. The statistics on a 2-million Twitter corpus show that this type of er-rors accounts for approximately 4.8% of corpussize. Our proposed method is a longest matchingdictionary-based approach with a rule-based nor-malization process. From our initial evaluation,the dictionary-based approach can handle the caseof repeated characters better than the machine-learning based. More analysis and discussion willbe given in the paper.
The remainder of this paper is organized as fol-lows. In next section, we review some relatedworks in word segmentation, text tokenization andterm normalization for both segmented and unseg-mented languages. In Section 3, we first give a for-mal definition of the tokenization task. Then wepresent the proposed algorithm for implementingLexToPlus. In Section 4, we give the performanceevaluation by using a data set collected from Twit-ter. Some examples of errors are presented withsome discussion. Section 5 concludes the paperwith the future work.
2 Related work
Many techniques for word segmentation and mor-phological analysis have been reported for un-segmented languages. Peng et al. applied thelinear-chain CRFs model for Chinese word seg-mentation (Peng et al., 2004). Their proposedmodel included a probabilistic new word detectionmethod to further improve the performance. ForThai word segmentation, many previous worksalso applied machine learning algorithms to trainthe models. Meknavin et al. combined the modelof word segmentation with the POS tagging (Mek-navin et al., 1997). Their proposed model solvedthe ambiguity problem by using a feature-basedmodel. Kruengkrai and Isahara applied the CRFsto train a word segmentation model for Thai lan-guage (Kruengkrai and Isahara, 2006). Two pathselection schemes based on confidence estimationand Viterbi were proposed to solve the ambiguityproblem. Haruechaiyasak et al. compared the per-formance among the dictionary-based approachand many machine learning techniques such asCRFs and the Support Vector Machines (SVMs)(Haruechaiyasak et al., 2008). The CRFs modelwas reported to outperform the dictionary-basedapproach and other machine learning algorithms.
While the majority of previous works focusedon formal written texts, some works in text to-
10

Figure 1: Thai Unicode Characters
kenization have expanded the scope into real-world texts which often contains many out-of-vocabulary terms. Tokenization for short andnoisy texts requires an additional process of textnormalization. Early works for text normalizationwere focused on news text, newsgroups posts andclassified ads. Sprout et al. performed a studyon non-standard words (NSWs), including num-bers, abbreviations, dates, currency amounts andacronyms (Sprout et al., 2001). They applied sev-eral techniques including n-gram language mod-els, decision trees and weighted finite-state trans-ducers and showed that the machine learning ap-proaches yielded better performance than the rule-based approach.
More recent works in text normalization fo-cused on real world texts which contain informallanguage, such as SMS, chat and social media.Aw et al. proposed an approach for normaliz-ing SMS texts for machine translation task (Awet al., 2006). The normalization task is viewedas a translation problem from the SMS languageto the English language. The results showed thatnormalizing SMS texts before performing transla-tion significantly improved the performance basedon the BLEU score. Costa-Jussa and Banchs pro-posed an approach for normalizing short texts, i.e.,SMS (Costa-Jussa and Banchs, 2013). The pro-posed approach adopted the idea from statisticalmachine translation (SMT) by combining statisti-cal and rule-based techniques.
Han et al. proposed a classification-based ap-proach to detect ill-formed words, and generatescorrection candidates based on morphophonemicsimilarity (Han and Baldwin, 2011; Han et al.,2013). The proposed approach was evaluated onboth SMS and Twitter corpus. The best perfor-mance was achieved with the combination of dic-tionary lookup, word similarity and context sup-port modelling. Hirst and Budanitsky proposed
a method for detecting and correcting spelling er-rors (Hirst and Budanitsky, 2005). The proposedmethod is based on the identification of tokensthat are semantically unrelated to their context.The method also detects tokens which are spellingvariations of words that would be related to thecontext. Liu et al. identified and distinguishednonstandard tokens found in social media textsas intentionally and unintentionally (Liu et al.,2012). A normalization system was proposed byintegrating different techniques including the en-hanced letter transformation, visual priming, andstring/phonetic similarity. The proposed systemwas evaluated on SMS and Twitter data sets. Theresults showed that the proposed system achievedover 90% word-coverage across all data sets.
Another related research is the study of ono-matopoeia in which terms are created to pho-netically imitate different sounds. Research inonomatopoeia has recently gained much atten-tion for Japanese language. Asaga et al. pre-sented an online onomatopoeia example-baseddictionary called ONOMATOPEDIA (Asaga etal., 2008). The proposed approach includes theextraction and clustering of sentences containingonomatopoeias as learning examples. Uchida etal. studied some Japanese onomatopoeias whichcontain various emotions (Uchida et al., 2001).Users are asked to rate emotion in each ono-matopoeia. Correct identification of emotion fromonomatopoeia could be used in advanced seman-tic analysis. Kato et al. proposed an approachto extract onomatopoeia found in food reviews(Kato et al., 2012). The extracted onomatopoeiaterms can help users search for food or restaurants.In Thai language, many onomatopoeia terms arefound in chat and social media texts. We classifyonomatopoeia as another type of intentional errorswhile performing tokenization. Details are givenand discussed in later section of the paper.
11

Table 2: Intentional spelling error types and examples
3 Tokenization and normalization forThai texts
Thai language has its own set of characters or al-phabets. It has 44 consonants, 15 vowel symbolsand four tone marks. Consonants are written hor-izontally from left to right, with vowels placedin four positions: above, below, left and right ofthe corresponding consonant. Tone marks can beplaced in the position above of consonants andsome vowels. There are 87 valid characters in Uni-code system (shown in Figure 1).
3.1 Problem definition
The problem of tokenization for unsegmented lan-guages can be defined as follows. Given a string ofN words, w0w1 . . . wN−1, each word wi consistsof a series of characters, ci
0ci1 . . . ci
|wi|−1, where|wi| is the number of characters in wi. The to-kenization task is to assign a word boundary be-tween two words, e.g., wi|wj , where | represents aword boundary character.
From our preliminary study, the errors from tok-enizing Thai texts from social media texts are dueto four cases: insertion, transformation, translit-eration and onomatopoeia. These error types areconsidered as intentional errors as opposed to theunintentional errors previously mentioned. Inten-tional errors are caused by users intentionally cre-ate, alter and transform existing words on differentpurposes. Table 2 lists all error types with some
examples. The original terms or brief descriptionsare shown in parentheses with translations. Eacherror type is fully explained as follows.
1. Insertion: This type of error is causedby repeated characters at the end of aword. Using the above problem defini-tion, the error can be described as fol-lows, ci
0ci1 . . . ci
|wi|−1ci|wi|−1c
i|wi|−1c
i|wi|−1, in
which the last character ci|wi|−1 is repeated
more than once. This error type also ap-pears in English, e.g., whatttt, sleepyyy andloveeee.
2. Transformation: This error type is causedby transformation of existing terms and canbe categorized into two following types.
Homophonic: The homophonic termsrefer to terms with the same or similar pro-nunciation. A homophonic term is normallycreated by replacing an original vowel with anew vowel which has similar sound. Someexamples in English are luv (love), kinda(kind of) and gal (girl).
Syllable trimming: The syllable trim-ming is a transformed term by deleting oneor more syllables from an existing term forthe purpose of reducing the keystrokes.
3. Transliteration: Thai Transliterated termsare newly created terms converted from other
12

language scripts. Transliterated terms arecommonly found in modern Thai writtentexts, e.g., chat and social media. Most of theterms are transliterated from English termsincluding named entities such as companyand product names.
4. Onomatopoeia: Thai onomatopoeia termsare created by using the Thai character setto form new terms to imitate different soundsin nature and environment including humansand animals. Onomatopoeia terms are typ-ically used in chat and social media textsto make the communications between usersmore vivid. For example, to make the kissingaction sound more realistic, the word joob inThai (or smooch in English) which imitatesthe kissing sound is normally used.
3.2 The proposed solution
To select an appropriate approach for tokeniz-ing and normalizing social media texts, we firstperform a comparison between two approaches,dictionary-based (DCB) and machine learningbased (MLB) (Haruechaiyasak et al., 2008). Formachine learning based approach, we adopt theconditional random fields (CRFs) algorithm totrain the tokenization model. The dictionary-based approach is a lexicon-based parser whichsolves the ambiguity with a longest matchingheuristic. Table 3 shows tokenized results fromdifferent approaches. The input text consists ofthree words. Each word contains the insertion ofsome repeated characters at the end. The correctterms are bolded and underlined. The MLB ap-proach cannot correctly assign the word bound-aries between words. The first problem is due tothe repeated characters at the end of each word.All repeated characters are recognized as part ofthe word. The second problem is due to the out-of-vocabulary which results in a word is incorrectlytokenized as two separating words.
The DCB approach can correctly tokenize allthe terms which are included in the dictionary.The repeated word-ending characters are mergedinto a chunk. To further normalize the out-put words, we propose an algorithm DCB-Norm,which is a dictionary-based tokenization with aterm normalization process. The DCB-Norm al-gorithm is shown in Figure 2. The algorithm per-forms text parsing with longest matching strat-egy (LM PARSE). The strategy is used to solve
Table 3: An example of tokenized results
the ambiguity problem in which there are morethan one possible path to select in the parsing tree.The longest matching uses the heuristic such thatlonger terms contain better semantic than shorterterms. Figure 3 illustrates the dictionary-based to-kenization with longest matching. From the ex-ample, there are four possible path to select. Thelongest matching strategy select the path (shownwith a thick solid line) which contains a term withthe largest length.
Figure 2: DCB-Norm algorithm
Figure 3: An example of tokenizing parse tree.
13
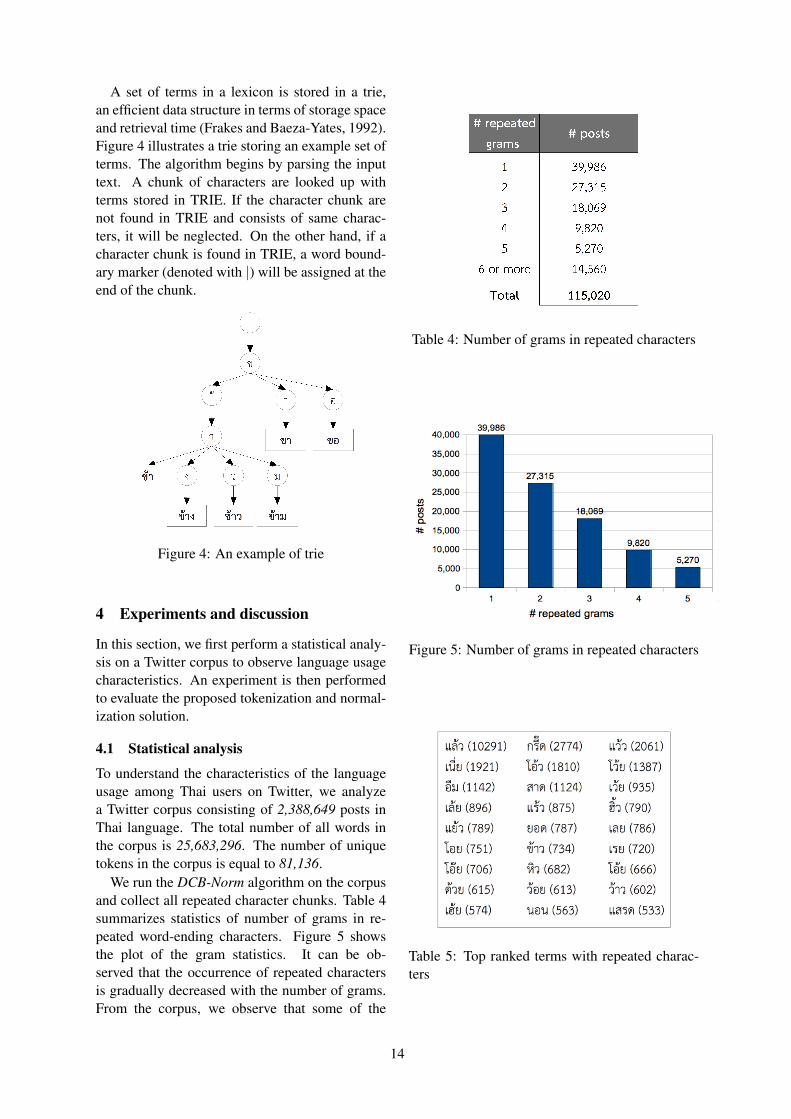
A set of terms in a lexicon is stored in a trie,an efficient data structure in terms of storage spaceand retrieval time (Frakes and Baeza-Yates, 1992).Figure 4 illustrates a trie storing an example set ofterms. The algorithm begins by parsing the inputtext. A chunk of characters are looked up withterms stored in TRIE. If the character chunk arenot found in TRIE and consists of same charac-ters, it will be neglected. On the other hand, if acharacter chunk is found in TRIE, a word bound-ary marker (denoted with |) will be assigned at theend of the chunk.
Figure 4: An example of trie
4 Experiments and discussion
In this section, we first perform a statistical analy-sis on a Twitter corpus to observe language usagecharacteristics. An experiment is then performedto evaluate the proposed tokenization and normal-ization solution.
4.1 Statistical analysis
To understand the characteristics of the languageusage among Thai users on Twitter, we analyzea Twitter corpus consisting of 2,388,649 posts inThai language. The total number of all words inthe corpus is 25,683,296. The number of uniquetokens in the corpus is equal to 81,136.
We run the DCB-Norm algorithm on the corpusand collect all repeated character chunks. Table 4summarizes statistics of number of grams in re-peated word-ending characters. Figure 5 showsthe plot of the gram statistics. It can be ob-served that the occurrence of repeated charactersis gradually decreased with the number of grams.From the corpus, we observe that some of the
Table 4: Number of grams in repeated characters
Figure 5: Number of grams in repeated characters
Table 5: Top ranked terms with repeated charac-ters
14

Figure 6: Top ranked terms with repeated charac-ters
posts containing more than 10 repeated charactergrams. Another observation is the repeated char-acters mostly occur at the end of the words as weexpected.
Next, we analyze the high frequent terms whichcontains the repeated characters. Table 5 showstop ranked terms with repeated characters. The to-tal number of posts which contain some repeatedcharacters is 115,020 which is equal to 4.8% ofcorpus size. Figure 6 shows the plot of top rankedterms. From the figure, we observe the Zipf (orlong-tail) distribution over the terms with repeatedcharacters. Most of the top terms are very informaland often used in conversational language. Someof the terms are used to express the feeling andemotion of the users.
4.2 Experiments and discussion
To evaluate the performance of the proposed ap-proach, we perform an experiment by using a setof 1,000 randomly selected Twitter posts writtenin Thai language. Each post contains some re-peated characters and is manually assigned withcorrect word boundary markers. For the pro-posed DCB-Norm algorithm, we use a lexiconfrom LEXiTRON2 which contains 35,328 generalterms. We also include another lexicon consist-ing of 1,341 terms frequently found in Twitter cor-pus. Words obtained from Twitter lexicon includechat, slangs and transliterated words from otherlanguages.
The performance evaluation is carried out on anotebook with a 2 GHz Intel Core 2 Duo CPU, 4GB RAM running under Mac OS X. We evaluatethe algorithm in terms of accuracy, i.e., the number
2LEXiTRON, http://lexitron.nectec.or.th
of correctly tokenized texts over the total numberof test texts. We also evaluate the running timeefficiency. The results are summarized in Table 6.The overall accuracy is equal to 96.3%. To analyzethe errors, we manually look at the incorrectly to-kenized results. We observe that in the case of allwords in the text are in the dictionary, the wordsare recognized and the repeated characters are cor-rectly removed. However, the problem is mostlydue to out-of-vocabulary (OOV) which causes theincorrect assignment of word boundary markers.As a result, the words with repeated characters atthe end could be not normalized correctly. Two er-ror types associated with OOV problem is homo-phonic transformation and transliteration. Table 7shows some examples from the error analysis. Thesimplest solution to the OOV problem is to manu-ally collect newly created terms from the corpus.
Table 6: Evaluation results
Table 7: Examples of tokenized errors
5 Conclusion and future work
We proposed a tool called LexToPlus for tokeniz-ing and normalizing Thai written texts. LexTo-Plus is designed to handle the intentional worderrors commonly found in social media texts. Inthis paper, we focus on solving the tokenizationerrors caused by repeated characters at the end ofwords. The proposed algorithm DCB-Norm is adictionary-based parser with a rule-based exten-sion to merge and remove repeated characters. We
15

performed some statistical analysis on a Twittercorpus consisting of over 2 million posts written inThai language. One interesting result is the rank-ing distribution of top terms with repeated charac-ters follows the Zipf or long-tail distribution. Weevaluated the proposed algorithm by using a cor-pus of 1,000 manually tokenized texts. The accu-racy is equal to 96.3% with the average throughputof 435,596 words/second.
From the error analysis, we found that themajor problem is the out-of-vocabulary (OOV)which comes from homophonic transformationand transliteration. Although the OOV problemcan be partially solved by adding new terms intothe dictionary. However, it is labor intensive andineffective in long terms. For future work, we planto improve the performance of the proposed algo-rithm by constructing a machine learning model toautomatically detect new terms based on the con-textual information.
ReferencesChisato Asaga, Yusuf Mukarramah and Chiemi Watan-
abe. 2008. ONOMATOPEDIA: onomatopoeia on-line example dictionary system extracted from dataon the web. Proc. of the 10th Asia-Pacific web conf.on Progress in WWW research and development ,601-612.
AiTi Aw, Min Zhang, Juan Xiao, and Jian Su. 2006. Aphrase-based statistical model for SMS text normal-ization. Proc. of the COLING/ACL on Main confer-ence poster sessions, 33–40.
Eric Brill and Robert C. Moore. 2000. An improvederror model for noisy channel spelling correction.Proc. of the 38th Annual Meeting on Association forComputational Linguistics, 286–293.
Marta R. Costa-Jussa and Rafael E. Banchs. 2013. Au-tomatic normalization of short texts by combiningstatistical and rule-based techniques. Language Re-sources and Evaluation , 47(1):179–193.
William B. Frakes and Ricardo Baeza-Yates (Eds.).1992. Information Retrieval: Data Structures andAlgorithms , Prentice-Hall, Englewood Cliffs, NJ.
Bo Han and Timothy Baldwin. 2011. Lexical normal-isation of short text messages: makn sens a #twitter.Proc. of the 49th Annual Meeting of the Associationfor Computational Linguistics, 368–378.
Bo Han, Paul Cook, and Timothy Baldwin. 2013.Lexical normalization for social media text. ACMTransactions on Intelligent Systems and Technology,4(1): 1–27.
Choochart Haruechaiyasak, Sarawoot Kongyoung andMatthew Dailey. 2008. A comparative study onThai word segmentation approaches. Proc. of theECTI-CON 2008, 1:125-128.
Graeme Hirst and Alexander Budanitsky. 2005. Cor-recting real-word spelling errors by restoring lexicalcohesion. Natural Language Engineering, 11:87–111.
Ayumi Kato, Yusuke Fukazawa, Tomomasa Sato andTaketoshi Mori. 2012. Extraction of onomatopoeiaused for foods from food reviews and its applicationto restaurant search. Proc. of the 21st int. conf. com-panion on World Wide Web , 719-728.
Canasai Kruengkrai and Hitoshi Isahara. 2006. A con-ditional random field framework for thai morpholog-ical analysis. Proc. of the Fifth Int. Conf. on Lan-guage Resources and Evaluation (LREC-2006).
Fei Liu, Fuliang Weng, and Xiao Jiang. 2012. Abroad-coverage normalization system for social me-dia language. Proc. of the 50th Annual Meetingof the Association for Computational Linguistics,1035-1044.
Surapant Meknavin, Paisarn Charoenpornsawat, andBoonserm Kijsirikul. 1997. Feature-Based ThaiWord Segmentation. Proc. of the Natural LanguageProcessing Pacific Rim Symposium, 289–296.
Fuchun Peng, Fangfang Feng, and Andrew McCallum.2004. Chinese Segmentation and New Word Detec-tion Using Conditional Random Fields. Proc. of the20th COLING, 562–568.
James L. Peterson. 1980. Computer programs for de-tecting and correcting spelling errors. Communica-tions of ACM, 23:676–687.
Richard Sproat, Alan W. Black, Stanley Chen, ShankarKumar, Mari Ostendorf, and Christopher Richards.2001. Normalization of non-standard words. Com-puter Speech and Language, 15(3):287 333.
Yuzu Uchida, Kenji Araki, and Jun Yoneyama. 2012.Classification of Emotional Onomatopoeias Basedon Questionnaire Surveys. Proc. of the 2012 Inter-national Conference on Asian Language Processing,1–4.
16