Embed Size (px)
Citation preview

Liang Jin* UC Irvine
Nick Koudas University of Toronto
Chen Li* UC Irvine
Anthony K.H. Tung National University of Singapore
VLDB’2005
* Liang Jin and Chen Li: supported by NSF CAREER Award IIS-0238586
Indexing Mixed Types for Approximate Retrieval

2
Queries with Mixed-Type Predicates
Star Title Year GenreKeanu Reeves The Matrix 1999 Sci-Fi
Samuel Jackson Star Wars: Episode III - Revenge of the Sith
2005 Sci-Fi
Schwarzenegger The Terminator 1984 Sci-Fi
Samuel Jackson Goodfellas 1990 Drama
… … … …
SELECT *
FROM Movies
WHERE star SIMILARTO ’Schwarrzenger’
AND |year – 1980| <= 5;• SIMLARTO:
– a domain-specific function – returns a similarity value between two strings
• Example: edit distance ed(Tom Hanks, Ton Hank) = 2

3
Why fuzzy predicates?
• Errors in queries– User doesn’t remember a string exactly– User types a wrong string
Samuel Jackson
…
Schwarzenegger
Samuel Jackson
Keanu ReevesStar
…
Samuel L. Jackson
Schwarzenegger
Samuel L. Jackson
Keanu ReevesStar
Relation R Relation S
• Errors in databases:– Data is not clean– Especially true in data integration and cleansing

4
Problem Formulation
SELECT *
FROM Movies
WHERE star SIMILARTO ’Schwarrzenger’
AND |year – 1980| <= 5;
Given: A query with fuzzy predicates on strings and
range predicates on numeric attributes
on a single relation
Goal: Answer the query efficiently

5
Rest of the talk
• Motivation: supporting queries with mixed-type predicates
• Our approach: MAT tree• Construction and maintenance of MAT tree• Experiments

6
Assumptions
SELECT *
FROM Movies
WHERE star SIMILARTO ’Schwarrzenger’
AND |year – 1980| <= 5;
• One fuzzy string predicate (edit distance)
• One numeric predicate
(’Schwarrzenger’, 2, 1980, 5)
(Qs, δs, Qn, δn)Query:

7
Intuition of MAT (Mixed-attribute-type) Tree
• “2 > 1 + 1”– One integrated indexing structure is better than– two independent indexing structures on two attributes
• Indexing numeric attributes: B-tree or R-tree• Indexing strings as a tree to support fuzzy predicates?
Spielberg1946
Hanks1956
Gibson1956
Hanks1957
Crowe1964
Robert1968
DiCaprio1974
Roberrts1977
<1946,1956> <1956,1957>
<1946,1957> <1964,1977>
MBR
Root
Leaf nodes
*
<1964,1968>
*
<1974,1977>
*
* *
......
...
......
*
...
MAT tree

8
Answering a query (Qs, δs, Qn, δn)
• Top-down traverse the MAT-tree• At each node, do pruning by checking:
– If [Qn – δn, Qn + δn] overlap with the numeric range.
– If minEditDistance(Qs, Tn) <= δs.
Spielberg1946
Hanks1956
Gibson1956
Hanks1957
Crowe1964
Robert1968
DiCaprio1974
Roberrts1977
<1946,1956> <1956,1957>
<1946,1957> <1964,1977>
MBR
Root
Leaf nodes
*
<1964,1968>
*
<1974,1977>
*
* *
......
...
......
*
...

9
Spielberg1946
Hanks1956
Gibson1956
Hanks1957
Crowe1964
Robert1968
DiCaprio1974
Roberrts1977
<1946,1956> <1956,1957>
<1946,1957> <1964,1977>
MBR
Root
Leaf nodes
*
<1964,1968>
*
<1974,1977>
*
* *
......
...
......
*
...
Challenge
• How to represent strings to fit into a limited space• and support fuzzy-predicate pruning
Limited space (disk based)

10
Existing Approaches to Indexing Strings as Trees
• M-tree: – Edit distance: metric space
• Q-tree– Utilize the q-gram property of strings. – See our paper for details

11
Representing strings as a trie
n1
n2 n3 n4
n5 n6 n7 n8
n14
n9
n10 n11 n12 n13
n15
a b c
a b
c
d
e a b
dd h
Strings:aad, abcde, abdfg, beh, ca, cb
n16 n17e
f
g

12
Compressing a trie
• Select k representative nodes (centers).
• Each center is in the format of <alphabet,height>.
• A compressed trie represents more strings
n1
n2 n4
n5 n6
n7
n11
n13
n15
<{b},2>
<{e},1>
<{h},1>
<{a,b,c},2><{a},1>
<{a,d},2>
<{b,d},2>
<{f,g},2><{c,d,e},3>
Strings:aad, abcde, abdfg, beh, ca, cb
n1
n2 n3 n4
n5 n6 n7 n8
n14
n9
n10 n11 n12 n13
n15
a b c
a b
c
d
e a b
dd h
Strings:aad, abcde, abdfg, beh, ca, cb
n16 n17e
f
g
compression

13
minEditDistace (Qs, Tn)?– Convert a trie to an automaton.– Compute the min distance between a string and an automaton [Myers and
Miller, 1989]– Early termination possible
Minimum edit distance between a string a trie
a
b
d
a
b
d
a
b
d
[a,*]
[a,*]
[a,*]
[a,*]
[c,*][c,*]
[c,*]
[c,*]
[*,b]
[*,d]
[*,*]
[*,*]
[*,*]
[*,d]
[*,d]
[*,a]
[*,a]
[*,a]
[*,b]
[*,b]
[a,b]
[a,a] [a,d]
[c,b][c,a] [c,d]
a
b
d
Automaton
Query String
“ac”
Edit Graph

14
Compressed trie Automaton
• Each node is a state.• Each edge becomes a transition between two states.• For compressed node <Σ, L>, expand it to L levels.
At each level, all characters in Σ become single states and are connected to a common tail ε.
Convert a compressed node <{a,b,c},2> into automaton nodes.
c
a
b
c
a
b

15
Outline
• Motivation: supporting queries with mixed-type predicates
• Our approach: MAT tree• Construction and maintenance of MAT tree• Experiments

16
Constructing MAT-tree
• Option 1: insert records one by one. • Option 2:
– bulk-load records– construct the MAT-tree bottom-up

17
Compressing a trie
• Important:– Accurately represent strings in a limited space.– Minimize “information loss”.– Maintain the pruning power during a traversal.
• Three methods:– (1) Reducing # of accepted strings– (2) Keeping accepted strings “clustered”– (3) Combining of (1) and (2)

18
Method (1): Reducing # of accepted strings
• Intuition: – reducing this # makes the compressed trie more
accurate
• Goodness function: # of accepted strings• Algorithm: “Randomized”
– Randomly select k initial centers– Randomly select one of the centers– Randomly select an unselected node– Swap them if it can improve the goodness function– Do certain # of iterations

19
Method (2): Keeping accepted strings clustered
• Intuition: – keeping the accepted strings similar to the original ones by
letting them share common prefix. – Place k centers as close to the root as possible.
• Algorithm: “BreadthFirst”
n1
n2 n3 n4
n5 n6 n7 n8 n9
a b c
<{a,d},2>
<{b,c,d,e,f,g},4> <{e,h},2>
<{a},1>
<{b},1>
Strings:aad, abcde, abdfg, beh, ca, cb

20
Method (3): Combining (1) and (2)
• Intuition: – minimize the number of accepted strings, and in
the same time maintain their similarity to the originals.
• Algorithm: “Bottomup”– Keep shrinking the trie bottom up until we have k
nodes– Compress a node that minimizes # of additional
strings

21
Dynamic maintenance
Insertion (s, n)• Search the index for (s, n). If it’s not in the
index, identify the correct leaf node.• If no overflow:
– update the “MBR” of the leaf node and its precedents recursively if necessary.
• If overflow:– Split the leaf node and – Construct two compressed tries– Cascade the split to the precedents if necessary.
Deletion and Update are handled similarly

22
Outline
• Motivation: supporting queries with mixed-type predicates
• Our approach: MAT tree• Construction and maintenance of MAT tree• Experiments

23
Setting
• Data– IMDB: 100K movie star records (Name and YOB).– Customers: 50K records (Name and YOB)
• Test bed– PC: 2.4G P4, 1.2GB Memory, Windows XP– Visual C++ compiler
• Similar results. Report result for IMDB.

24
Implemented approaches
• B-tree• Q-tree• B-tree & Q-tree• BQ-tree• BM-tree• Sequential scan
“BBQ-tree”?

25
“2 > 1 + 1”
An integrated indexing structure is better than two separate indexing structures
δs=3, δn=4

26
Scalability

27
Effect of numeric threshold δn

28
Effect of string threshold δs

29
Dynamic Maintenance: time

30
Dynamic maintenance: MAT quality
31
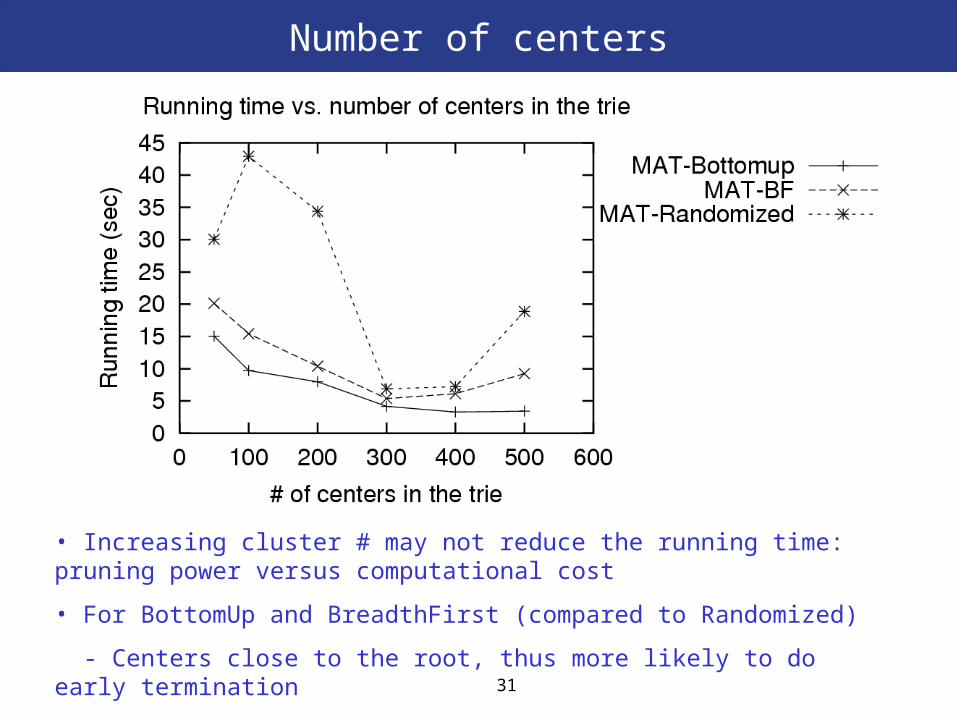
Number of centers
• Increasing cluster # may not reduce the running time: pruning power versus computational cost
• For BottomUp and BreadthFirst (compared to Randomized)
- Centers close to the root, thus more likely to do early termination

32
Conclusion
• MAT-tree: an efficient indexing structure for queries with mixed-type predicates
• Can be efficiently constructed and maintained
• Future work: develop a uniform framework to support different kinds of similarity functions
Q&A?
The Flamingo Project : http://www.ics.uci.edu/~flamingo/





























