Embed Size (px)
Citation preview

An Introduction to Locally Linear Embedding
LawrenceK. SaulAT&T Labs– Research
180ParkAve,FlorhamPark,[email protected]
SamT. RoweisGatsbyComputationalNeuroscienceUnit, UCL
17QueenSquare,LondonWC1N3AR, [email protected]
Abstract
Many problemsin informationprocessinginvolvesomeform of dimension-ality reduction.Herewe describelocally linearembedding(LLE), anunsu-pervisedlearningalgorithmthat computeslow dimensional,neighborhoodpreservingembeddingsof high dimensionaldata.LLE attemptsto discovernonlinearstructurein high dimensionaldataby exploiting thelocal symme-tries of linear reconstructions.Notably, LLE mapsits inputs into a singleglobal coordinatesystemof lower dimensionality, and its optimizations—thoughcapableof generatinghighly nonlinearembeddings—donot involvelocalminima.We illustratethemethodon imagesof lips usedin audiovisualspeechsynthesis.
1 Introduction
Many problemsin statisticalpatternrecognitionbegin with the preprocessingofmultidimensionalsignals, such as imagesof facesor spectrogramsof speech.Often, thegoalof preprocessingis someform of dimensionalityreduction:to com-pressthesignalsin sizeandto discovercompactrepresentationsof theirvariability.
Two popularformsof dimensionalityreductionarethemethodsof principalcom-ponentanalysis(PCA)[1] andmultidimensionalscaling(MDS) [2]. BothPCAandMDS areeigenvectormethodsdesignedto modellinearvariabilitiesin highdimen-sionaldata.In PCA,onecomputesthelinearprojectionsof greatestvariancefrom
1

the top eigenvectorsof thedatacovariancematrix. In classical(or metric)MDS,one computesthe low dimensionalembeddingthat bestpreserves pairwisedis-tancesbetweendatapoints. If thesedistancescorrespondto Euclideandistances,the resultsof metric MDS are equivalent to PCA. Both methodsare simple toimplement,andtheir optimizationsdo not involve localminima.Thesevirtuesac-countfor thewidespreaduseof PCA andMDS, despitetheir inherentlimitationsaslinearmethods.
Recently, we introducedaneigenvectormethod—calledlocally linearembedding(LLE)—for the problemof nonlineardimensionalityreduction[4]. This problemis illustratedby the nonlinearmanifold in Figure1. In this example,the dimen-sionalityreductionby LLE succeedsin identifying theunderlyingstructureof themanifold,while projectionsof thedataby PCA or metricMDS mapfaraway datapointsto nearbypointsin the plane. Like PCA andMDS, our algorithmis sim-ple to implement,andits optimizationsdo not involve local minima. At thesametime, however, it is capableof generatinghighly nonlinearembeddings.Notethatmixturemodelsfor localdimensionalityreduction[5, 6], whichclusterthedataandperformPCA within eachcluster, do not addressthe problemconsideredhere—namely, how to maphigh dimensionaldatainto a singleglobalcoordinatesystemof lowerdimensionality.
In this paper, we review theLLE algorithmin its mostbasicform andillustrateapotentialapplicationto audiovisualspeechsynthesis[3].
-1 0 1 0
5-1
0
1
2
3
(A)
-1 0 1 0
5-1
0
1
2
3
(B)
-2 -1 0 1 2-2
-1
0
1
2
(C)
Figure 1: The problemof nonlineardimensionalityreduction,as illustratedforthreedimensionaldata(B) sampledfrom a two dimensionalmanifold(A). An un-supervisedlearningalgorithmmustdiscover theglobal internalcoordinatesof themanifold without signalsthat explicitly indicatehow the datashouldbe embed-dedin two dimensions.Theshadingin (C) illustratestheneighborhood-preservingmappingdiscoveredby LLE.
2

2 Algorithm
TheLLE algorithm,summarizedin Fig. 2, is basedonsimplegeometricintuitions.Supposethedataconsistof
�real-valuedvectors
����, eachof dimensionality� ,
sampledfrom somesmoothunderlyingmanifold. Providedthereis sufficient data(suchthatthemanifoldis well-sampled),we expecteachdatapoint andits neigh-borsto lie onor closeto a locally linearpatchof themanifold.
We cancharacterizethelocal geometryof thesepatchesby linearcoefficientsthatreconstructeachdatapoint from its neighbors.In thesimplestformulationof LLE,oneidentifies � nearestneighborsperdatapoint, asmeasuredby Euclideandis-tance. (Alternatively, onecanidentify neighborsby choosingall pointswithin aball of fixedradius,or by usingmoresophisticatedrulesbasedon local metrics.)Reconstructionerrorsarethenmeasuredby thecostfunction:��� ����� � ���� �� ��� ���� � � �� � ���� ��� (1)
which addsup the squareddistancesbetweenall thedatapointsandtheir recon-structions. The weights
� �summarizethe contribution of the � th datapoint to
the � th reconstruction.To computethe weights � �
, we minimize the costfunc-tion subjectto two constraints:first, thateachdatapoint
�� �is reconstructedonly
from its neighbors,enforcing � � ���
if�� �
doesnot belongto this set;second,that the rows of the weight matrix sumto one: � � � � � . The reasonfor thesum-to-oneconstraintwill becomeclearshortly. Theoptimalweights
� �subject
to theseconstraintsarefoundby solvinga leastsquaresproblem,asdiscussedinAppendixA.
Notethattheconstrainedweightsthatminimizethesereconstructionerrorsobey animportantsymmetry:for any particulardatapoint, they areinvariantto rotations,rescalings,andtranslationsof thatdatapoint andits neighbors.Theinvariancetorotationsandrescalingsfollows immediatelyfrom theform of eq.(1); the invari-anceto translationsis enforcedby the sum-to-oneconstrainton the rows of theweightmatrix. A consequenceof this symmetryis that thereconstructionweightscharacterizeintrinsic geometricpropertiesof eachneighborhood,as opposedtopropertiesthatdependon aparticularframeof reference.
Supposethe datalie on or neara smoothnonlinearmanifold of dimensionality!#" � . To a goodapproximation,then,thereexistsa linearmapping—consistingof a translation,rotation,andrescaling—thatmapsthe high dimensionalcoordi-natesof eachneighborhoodto global internal coordinateson the manifold. Bydesign,thereconstructionweights
� �reflectintrinsicgeometricpropertiesof the
3

datathat areinvariant to exactly suchtransformations.We thereforeexpecttheircharacterizationof localgeometryin theoriginaldataspaceto beequallyvalid forlocal patcheson themanifold. In particular, thesameweights
� �thatreconstruct
the � th datapoint in � dimensionsshouldalsoreconstructits embeddedmanifoldcoordinatesin
!dimensions.
(Informally, imaginetaking a pair of scissors,cutting out locally linear patchesof the underlyingmanifold,andplacingthemin the low dimensionalembeddingspace.Assumefurtherthatthisoperationis donein awaythatpreservestheanglesformedby eachdatapoint to its nearestneighbors.In thiscase,thetransplantationof eachpatchinvolves no more than a translation,rotation, and rescalingof itsdata,exactly the operationsto which the weightsare invariant. Thus,when thepatcharrives at its low dimensionaldestination,we expect the sameweightstoreconstructeachdatapoint from its neighbors.)
LLE constructsaneighborhoodpreservingmappingbasedontheaboveidea.In thefinal stepof thealgorithm,eachhigh dimensionalobservation
����is mappedto a
low dimensionalvector�$ �
representingglobalinternalcoordinatesonthemanifold.This is doneby choosing
!-dimensionalcoordinates
�$ �to minimizetheembedding
costfunction: % � $ �&��� � ���� �$ �'� � � � � �$ � ���� �)( (2)
Thiscostfunction—like thepreviousone—isbasedonlocally linearreconstructionerrors,but herewe fix theweights
� �while optimizing thecoordinates
�$ �. The
embeddingcost in Eq. (2) definesa quadraticform in the vectors�$ �
. Subjecttoconstraintsthat make the problemwell-posed,it canbe minimizedby solving asparse
�+*,�eigenvectorproblem,whosebottom
!non-zeroeigenvectorsprovide
an orderedset of orthogonalcoordinatescenteredon the origin. Detailsof thiseigenvectorproblemarediscussedin AppendixB.
Notethatwhile thereconstructionweightsfor eachdatapoint arecomputedfromits localneighborhood—independent of theweightsfor otherdatapoints—theem-beddingcoordinatesarecomputedby an
�-*.�eigensolver, aglobaloperationthat
couplesall datapointsin connectedcomponentsof thegraphdefinedby theweightmatrix. Thedifferentdimensionsin theembeddingspacecanbecomputedsucces-sively; this is donesimply by computingthebottomeigenvectorsfrom eq.(2) oneat a time. But thecomputationis alwayscoupledacrossdatapoints. This is howthealgorithmleveragesoverlappinglocal informationto discover globalstructure.
Implementationof thealgorithmis fairly straightforward,asthealgorithmhasonlyonefree parameter:the numberof neighborsperdatapoint, � . Onceneighbors
4

LLE ALGORITHM
1. Computetheneighborsof eachdatapoint,�� �
.
2. Computetheweights � �
thatbestreconstructeachdatapoint�� �
fromits neighbors,minimizing thecostin eq.(1) by constrainedlinearfits.
3. Computethevectors�$/�
bestreconstructedby theweights � �
, minimizingthequadraticform in eq.(2) by its bottomnonzeroeigenvectors.
Figure2: Summaryof theLLE algorithm,mappinghigh dimensionaldatapoints,����, to low dimensionalembeddingvectors,
�$0�.
arechosen,theoptimalweights � �
andcoordinates$ �
arecomputedby standardmethodsin linearalgebra.Thealgorithminvolvesa singlepassthroughthethreestepsin Fig. 2 andfindsglobalminimaof thereconstructionandembeddingcostsin Eqs.(1) and(2). As discussedin AppendixA, in the unusualcasewheretheneighborsoutnumbertheinputdimensionality
� �213� � , theleastsquaresproblemfor findingtheweightsdoesnothaveauniquesolution,andaregularizationterm—for example,onethatpenalizesthesquaredmagnitudesof the weights—mustbeaddedto thereconstructioncost.
Thealgorithm,asdescribedin Fig. 2, takesasinput the�
high dimensionalvec-tors,
�� �. In many settings,however, theusermay not have accessto dataof this
form, but only to measurementsof dissimilarityor pairwisedistancebetweendif-ferentdatapoints. A simplevariationof LLE, describedin AppendixC, canbeappliedto input of this form. In this way, matricesof pairwisedistancescanbeanalyzedby LLE just aseasilyasMDS[2]; in factonly a smallfractionof all pos-sible pairwisedistances(representingdistancesbetweenneighboringpoints andtheir respective neighbors)arerequiredfor runningLLE.
3 Examples
The embeddingsdiscoveredby LLE areeasiestto visualizefor intrinsically twodimensionalmanifolds.In Fig.1, for example,theinputtoLLE consisted
� �546�7�datapointssampledoff the S-shapedmanifold. The resultingembeddingshowshow thealgorithm,using � �8 :9
neighborsperdatapoint,successfullyunraveledtheunderlyingtwo dimensionalstructure.
5

Fig. 3 shows anothertwo dimensionalmanifold, this oneliving in a muchhigherdimensionalspace.Here,we generatedexamples—shown in themiddlepanelofthe figure—bytranslatingthe imageof a single faceacrossa larger backgroundof randomnoise.Thenoisewasuncorrelatedfrom oneexampleto thenext. Theonly consistentstructurein theresultingimagesthusdescribeda two-dimensionalmanifoldparameterizedby theface’s centerof mass.The input to LLE consistedof� �<;74=
grayscaleimages,with eachimagecontaininga97> * 96�
facesu-perimposedon a ? ; * ? backgroundof noise. Note that while simple to visu-alize, themanifoldof translatedfacesis highly nonlinearin thehigh dimensional( � ��@6�7�A;
) vectorspaceof pixel coordinates.Thebottomportionof Fig. 3 showsthefirst two componentsdiscoveredby LLE, with � �CB
neighborsperdatapoint.By contrast,thetopportionshows thefirst two componentsdiscoveredby PCA.Itis clearthatthemanifoldstructurein thisexampleis muchbettermodeledby LLE.
Finally, in additionto theseexamples,for which the true manifold structurewasknown, we alsoappliedLLE to imagesof lips usedin the animationof talkingheads[3]. Our databasecontained
� �D> ? >7> color (RGB) imagesof lips at E�A> *>FB
resolution.Dimensionalityreductionof theseimages( � �59AG69= :4) is usefulfor
fasterandmoreefficient animation.Thetop andbottompanelsof Fig. 4 show thefirst two componentsdiscovered,respectively, by PCA andLLE (with � �H :4
).If the lip imagesdescribeda nearly linear manifold, thesetwo methodswouldyield similar results;thus,the significantdifferencesin theseembeddingsrevealthepresenceof nonlinearstructure.Note thatwhile the linearprojectionby PCAhasa somewhatuniform distribution aboutits mean,thelocally linearembeddinghasadistinctlyspiny structure,with thetipsof thespinescorrespondingtoextremalconfigurationsof thelips.
4 Discussion
It is worth notingthatmany popularlearningalgorithmsfor nonlineardimension-ality reductiondonotsharethefavorablepropertiesof LLE. Iterativehill-climbingmethodsfor autoencoderneuralnetworks[7, 8], self-organizingmaps[9], andlatentvariablemodels[10] do not have thesameguaranteesof globaloptimality or con-vergence;they alsotendto involve many morefree parameters,suchaslearningrates,convergencecriteria,andarchitecturalspecifications.
Thedifferentstepsof LLE have thefollowing complexities. In Step1, computingnearestneighborsscales(in the worst case)as I � � � � � , or linearly in the inputdimensionality, � , andquadraticallyin the numberof datapoints,
�. For many
6
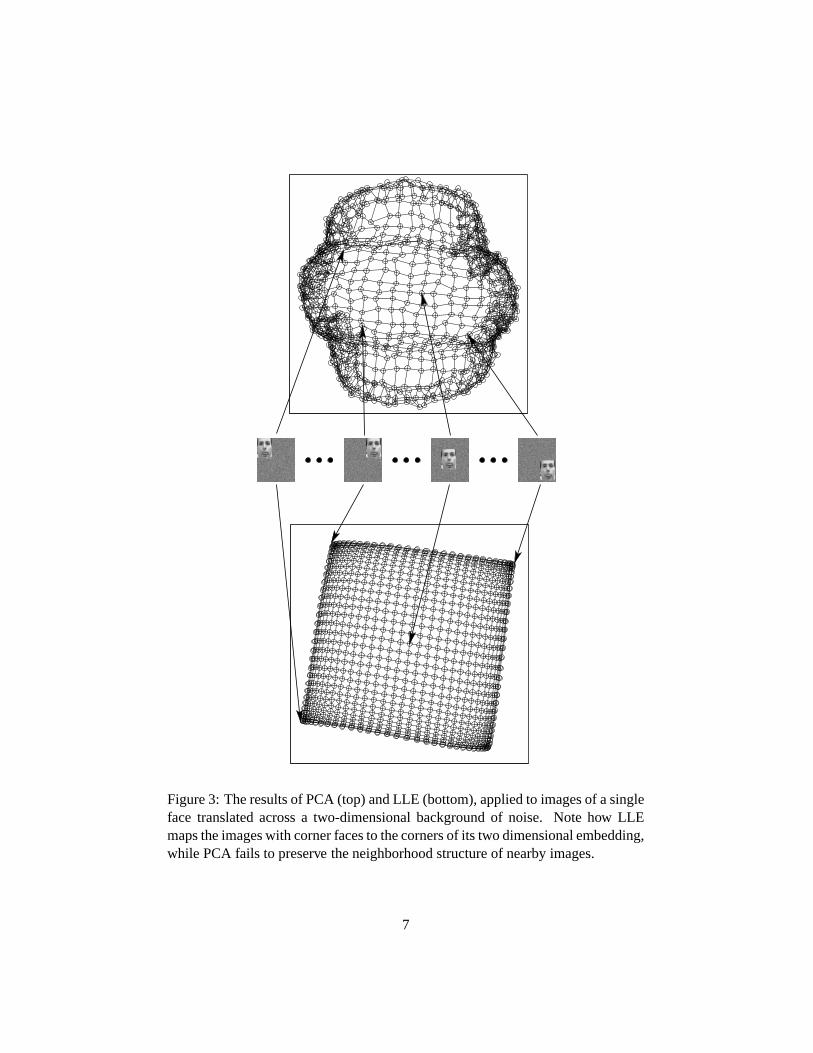
Figure3: Theresultsof PCA(top)andLLE (bottom),appliedto imagesof asingleface translatedacrossa two-dimensionalbackgroundof noise. Note how LLEmapstheimageswith cornerfacesto thecornersof its twodimensionalembedding,while PCA fails to preserve theneighborhoodstructureof nearbyimages.
7
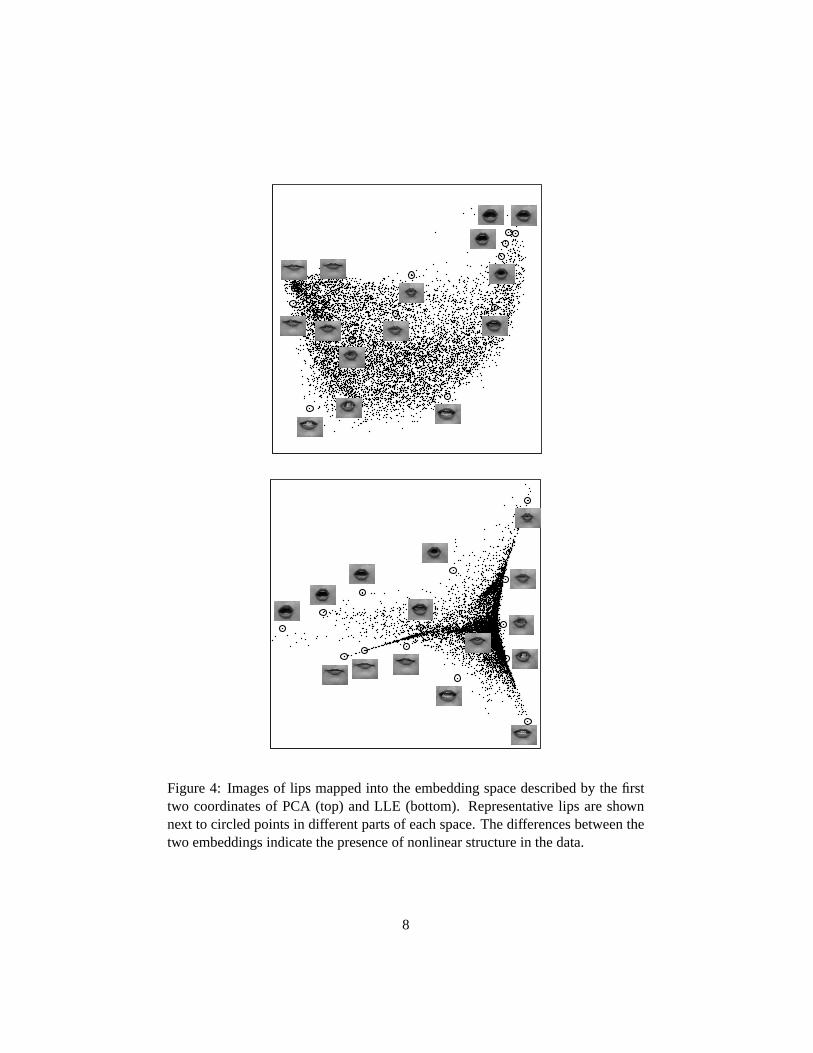
Figure4: Imagesof lips mappedinto theembeddingspacedescribedby thefirsttwo coordinatesof PCA (top) andLLE (bottom). Representative lips areshownnext to circledpointsin differentpartsof eachspace.Thedifferencesbetweenthetwo embeddingsindicatethepresenceof nonlinearstructurein thedata.
8

datadistributions,however – andespeciallyfor datadistributedon a thin subman-ifold of the observation space– constructionssuchasK-D treescanbe usedtocomputetheneighborsin I � �8JLK7M� � time[13]. In Step2, computingthe recon-structionweightsscalesas I � � � �ON � ; this is thenumberof operationsrequiredto solve a � * � setof linearequationsfor eachdatapoint. In Step3, computingthe bottomeigenvectorsscalesas I � ! � � � , linearly in the numberof embeddingdimensions,
!, andquadraticallyin the numberof datapoints,
�. Methodsfor
sparseeigenproblems[14], however, canbeusedto reducethecomplexity to sub-quadraticin
�. Notethatasmoredimensionsareaddedto theembeddingspace,
theexistingonesdo not change,sothatLLE doesnothave to bererunto computehigherdimensionalembeddings.Thestoragerequirementsof LLE arelimited bytheweightmatrixwhich is sizeN by K.
LLE illustratesageneralprincipleof manifoldlearning,elucidatedby Tenenbaumet al[11], that overlappinglocal neighborhoods—collectively analyzed—canpro-vide informationaboutglobal geometry. Many virtuesof LLE aresharedby theIsomapalgorithm[11], which hasbeensuccessfullyappliedto similar problemsin nonlineardimensionalityreduction. Isomapis an extensionof MDS in whichembeddingsareoptimizedto preserve “geodesic”distancesbetweenpairsof datapoints; thesedistancesare estimatedby computingshortestpathsthroughlargesublatticesof data. A virtue of LLE is that it avoids the needto solve large dy-namicprogrammingproblems.LLE alsotendsto accumulateverysparsematrices,whosestructurecanbeexploitedfor savingsin timeandspace.
LLE is likely to be even moreuseful in combinationwith othermethodsin dataanalysisandstatisticallearning. An interestingandimportantquestionis how tolearnaparametricmappingbetweentheobservationandembeddingspaces,giventhe resultsof LLE. Onepossibleapproachis to use P �� � � �$ �RQ pairsaslabeledex-amplesfor statisticalmodelsof supervisedlearning.Theability to learnsuchmap-pingsshouldmake LLE broadlyusefulin many areasof informationprocessing.
A Constrained Least Squares Problem
The constrainedweightsthat bestreconstructeachdatapoint from its neighborscanbecomputedin closedform. Consideraparticulardatapoint
�S with � nearestneighbors
�T � and reconstructionweights U � that sumto one. We canwrite thereconstructionerroras:V � ��� �S � � � U � �T � ��� � � ���W� � U � � �S � �T � � ��� � � � �YX U � U X7Z)�YX � (3)
9

wherein thefirst identity, we have exploitedthefact that theweightssumto one,andin thesecondidentity, we have introducedthelocal covariancematrix,Z)�YX �+� �S � �T � ��[\� �S � �T X � ( (4)
Thiserrorcanbeminimizedin closedform, usingaLagrangemultiplier to enforcetheconstraintthat � � U � �] . In termsof theinverselocal covariancematrix, theoptimalweightsaregivenby: U � � � X Z#^`_�aX�cbed Z ^`_bfd ( (5)
The solution,aswritten in eq. (5), appearsto requirean explicit inversionof thelocal covariancematrix. In practice,a moreefficient way to minimizetheerror issimply to solve thelinearsystemof equations,� � Z)�aX U X � , andthento rescaletheweightssothatthey sumto one(whichyieldsthesameresult).By construction,the local covariancematrix in eq. (4) is symmetricandsemipositive definite. Ifthecovariancematrix is singularor nearlysingular—asarises,for example,whentherearemoreneighborsthaninput dimensions( �21g� ), or whenthedatapointsarenot in generalposition—it canbeconditioned(beforesolving thesystem)byaddinga smallmultiple of theidentity matrix,Z)�aX,hiZ)�aXkjml)n ��porq �YX � (6)
where n � is small comparedto the traceofZ
. This amountsto penalizinglargeweightsthat exploit correlationsbeyond somelevel of precisionin the datasam-pling process.
B Eigenvector Problem
Theembeddingvectors�$0�
arefoundby minimizing thecostfunction,eq.(2), forfixedweights
� �: sutwvx % � $ �y� � � ���� �$ �/� �2�F � � �$ � ���� �)( (7)
Notethatthecostdefinesaquadraticform,% � $ ��� � � �{z � � � �$ � [ �$ � � �10

involving innerproductsof theembeddingvectorsandthe��*|�
matrix z :z � � � q � � � � � � � � j � X X � X}� � (8)
where q � � is 1 if � � � and0 otherwise.
This optimizationis performedsubjectto constraintsthatmake theproblemwellposed.It is clearthat thecoordinates
�$ �canbe translatedby a constantdisplace-
ment without affecting the cost,
% � $ �. We remove this degreeof freedomby
requiringthecoordinatesto becenteredon theorigin:� � �$ � � �� ((9)
Also, to avoid degeneratesolutions,we constrainthe embeddingvectorsto haveunit covariance,with outerproductsthatsatisfy � � � �$ � �$#~� ��� �
(10)
where�
is the! * !
identity matrix. Note that thereis no loss in generalityinconstrainingthecovarianceof
�$to bediagonalandof orderunity, sincethecost
functionin eq.(2) is invariantto rotationsandhomogeneousrescalings.Thefurtherconstraintthat thecovarianceis equalto theidentity matrix expressesanassump-tion that reconstructionerrorsfor different coordinatesin the embeddingspaceshouldbemeasuredon thesamescale.
Theoptimalembedding—upto aglobalrotationof theembeddingspace—isfoundby computingthebottom
! j eigenvectorsof thematrix, z ; this is a versionof
the Rayleitz-Ritztheorem[12]. The bottomeigenvectorof this matrix, which wediscard,is theunit vectorwith all equalcomponents;it representsafreetranslationmodeof eigenvaluezero. Discardingthis eigenvectorenforcestheconstraintthattheembeddingshave zeromean,sincethecomponentsof othereigenvectorsmustsumto zero,by virtue of orthogonality. The remaining
!eigenvectorsform the!
embeddingcoordinatesfoundby LLE.
Notethatthebottom! j
eigenvectorsof thematrix z (thatis, thosecorrespond-ing to its smallest
! j eigenvalues)canbefoundwithoutperformingafull matrix
diagonalization[14]. Moreover, thematrix z canbestoredandmanipulatedasthesparsesymmetricmatrix z �+��� � 8������ � � �
(11)
11

giving substantialcomputationalsavings for large valuesof�
. In particular, leftmultiplicationby z (thesubroutinerequiredby mostsparseeigensolvers)canbeperformedas z-� ��� � � � � � ~ � � � � � � (12)
requiring just one multiplication by
and one multiplication by ~
, both ofwhich areextremelysparse.Thus,thematrix z never needsto beexplicitly cre-atedor stored;it is sufficient to storeandmultiply thematrix
.
C LLE from Pairwise Distances
LLE canbe appliedto userinput in the form of pairwisedistances.In this case,nearestneighborsareidentifiedby thesmallestnon-zeroelementsof eachrow inthedistancematrix. To derive the reconstructionweightsfor eachdatapoint, weneedto computethe local covariancematrix
Z)�aXbetweenits nearestneighbors,
as definedby eq. (4) in appendixA. This can be doneby exploiting the usualrelationbetweenpairwisedistancesanddotproductsthatformsthebasisof metricMDS[2]. Thus,for aparticulardatapoint,we set:Z)�aX � 9 � � � j � X � � �aX � ��� � � (13)
where � �aX denotesthe squareddistancebetweenthe � th and � th neighbors,��� � ���`��� � and � � � � �aX � �aX . In termsof this local covariancematrix, thereconstructionweightsfor eachdatapoint aregiven by eq. (5). The restof thealgorithmproceedsasusual.
Note that this variantof LLE requiressignificantly lessuserinput thanthe com-plete matrix of pairwisedistances. Instead,for eachdatapoint, the userneedsonly to specifyits nearestneighborsandthe submatrixof pairwisedistancesbe-tweenthoseneighbors.Is it possibleto recover manifoldstructurefrom even lessuserinput—say, just thepairwisedistancesbetweeneachdatapoint andits near-estneighbors?A simplecounterexampleshows that this is not possible.Considerthesquarelatticeof threedimensionaldatapointswhoseintegercoordinatessumtozero.Imaginethatpointswith even S -coordinatesarecoloredblack,andthatpointswith odd S -coordinatesarecoloredred. The“two point” embeddingthatmapsallblackpointsto theorigin andall redpointsto oneunit awaypreservesthedistancebetweeneachpoint andits four nearestneighbors.Nevertheless,this embeddingcompletelyfails to preserve theunderlyingstructureof theoriginalmanifold.
12

Acknowledgements
TheauthorsthankE. Cosatto,H.P. Graf, andY. LeCun(AT&T Labs)andB. Frey(U. Toronto)for providing datafor theseexperiments.S. Roweis acknowledgesthesupportof theGatsbyCharitableFoundation,theNationalScienceFoundation,andtheNationalSciencesandEngineeringResearchCouncilof Canada.
References
[1] I.T. Jolliffe, Principal Component Analysis (Springer-Verlag,New York, 1989).
[2] T. CoxandM. Cox.Multidimensional Scaling (Chapman& Hall, London,1994).
[3] E. CosattoandH.P. Graf.Sample-BasedSynthesisof Photo-RealisticTalking-Heads.Proceedings of Computer Animation, 103–110.IEEEComputerSociety(1998).
[4] S. T. Roweis andL. K. Saul.Nonlineardimensionalityreductionby locally linearembedding.Science 290, 2323-2326(2000).
[5] K. FukunagaandD. R. Olsen,An algorithmfor finding intrinsic dimensionalityofdata.IEEE Transactions on Computers 20(2),176-193(1971).
[6] N. KambhatlaandT. K. Leen.Dimensionreductionby local principal componentanalysis.Neural Computation 9, 1493–1516(1997).
[7] D. DeMersandG.W. Cottrell. Nonlineardimensionalityreduction.In Advances inNeural Information Processing Systems 5, D. Hanson,J.Cowan,L. Giles,Eds.(Mor-ganKaufmann,SanMateo,CA, 1993),pp.580–587.
[8] M. Kramer. Nonlinearprincipalcomponentanalysisusingautoassociativeneuralnet-works.AIChE Journal 37, 233–243(1991).
[9] T. Kohonen.Self-organization and Associative Memory (Springer-Verlag, Berlin,1988).
[10] C.Bishop,M. Svensen,andC.Williams.GTM: Thegenerativetopographicmapping.Neural Computation 10, 215–234(1998).
[11] J.B. Tenenbaum,V. deSilva,andJ.C. Langford.A globalgeometricframework fornonlineardimensionalityreduction.Science 290, 2319-2323(2000).
[12] R. A. Horn andC. R. Johnson.Matrix Analysis (CambridgeUniversityPress,Cam-bridge,1990).
[13] J.H. Friedman,J.L. Bentley andR. A. Finkel.An algorithmfor findingbestmatchesin logarithmic expectedtime. ACM Transactions on Mathematical Software, 3(3),290-226(1977).
[14] Z. Bai, J. Demmel,J. Dongarra,A. Ruhe,andH. van der Vorst. Templates for theSolution of Algebraic Eigenvalue Problems: A Practical Guide (Societyfor IndustrialandAppliedMathematics,Philadelphia,2000).
13





























