Embed Size (px)
Citation preview

© 2010 IBM Corporation2010/8/2
Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop 入門
Linux/OSS & Cloud Support CenterIBM Japan
Version 1.8

© 2010 IBM Corporation2 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
はじめに
この技術資料では、Apache Hadoop について紹介しています。
この技術資料は、お客様、販売店様、その他の関係者に、IBM Systems 製品を活用していただくことを目的として作成されました。利用条件の詳細につきましては、次の URL をご参照ください。
► http://www.ibm.com/legal/jp/ja/
当技術資料に含まれる、IBM 以外のベンダー製品に関する情報は、各ベンダーにより提供されたものであり、IBM はその正確性または完全性についてはいかなる責任も負いません。
当技術資料の個々の項目は、特定の状況における正確性について検証されていますが、お客様の環境において全く同一または同様な結果が得られる保証はありません。また、全ての場合において移行が可能なことを意味するものではありません。お客様の環境、その他の要因によって異なります。お客様自身の環境に、(オープンソースソフトウェアを含む)これらの技術を適用される場合は、お客様自身の責任において行なってください。

© 2010 IBM Corporation3 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
目次
Hadoop とは
Hadoop のアーキテクチャー
Hadoop の導入と構成
サンプルジョブによる動作確認
スクリプトによるジョブの作成
Pig の利用
HBase の導入と構成
参考資料

© 2010 IBM Corporation4 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop とはHadoop とは

© 2010 IBM Corporation5 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop が開発された背景
Google などのネットワークサービスを提供する企業では、Web サーバーのアクセスログ解析の様
に、レコード単位(行単位)の比較的単純なデータ解析処理を莫大な量のデータに対して実施する必要があります。
従来、このようなデータ解析は、処理対象のデータを複数に分割して、複数のサーバー上で個別に解析して、それぞれの結果を最後に一つにまとめる、という形で分散処理することにより、解析時間を短縮していました。
Google では、このような一連の作業を自動化するフレームワークを独自開発して利用していました。
► このフレームワークでは、各レコードに対する処理内容を記述した map 関数と、最終結果をまとめる処理を記述した reduce 関数を用意すると、上述のデータ分割と複数サーバーでの個別解析(各レコードに対するmap 関数の適用)、そして、最終結果のとりまとめ(各サーバーで実施された 結果に対する reduce 関数の適
用)が自動的に実施されます。
Google がこのフレームワークの概要を MapReduce という名称で紹介した後、同等の機能を提供する Hadoop が OSS として開発され、Google 以外のネットワークサービス企業でも広く利用され
るようになりました。► Google が開発したフレームワークのソースコードは公開されていません。

© 2010 IBM Corporation6 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop とは
Hadoop は、Google が提唱した分散データ処理を実装するために必要なコンポーネント(フレームワーク)を OSS として提供します。
► HDFS (Hadoop Distributed File System)– 複数のノードのローカルファイルシステムを論理的に結合して、1 つの共有ファイルシステムを作成します。
► MapReduce– MapReduce と呼ばれる分散コンピューティングモデルに基づくプログラムを Java で作成するためのフレームワークを提
供します。
前述のように、MapReduce は比較的単純なデータ処理を主な目的としたものですが、Google がMapReduce モデルによる分散コンピューティングで実際に大規模なデータ解析を実現し、このモ
デルの有用性を証明したことが、データ解析の研究における画期的な出来事だと言えます。► これにより、『複雑な理論で少数のデータを解析するよりも、単純な理論で莫大な量のデータを解析する方が
より有用な結果が得られる場合がある』という事実が実証されたと考えられています。
► 最近は、ネットワークサービス企業以外でも、クレジットカードの使用履歴の分析(金融機関)や証券取引履
歴の分析(証券会社)に利用されていると言われています。

© 2010 IBM Corporation7 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
MapReduce の考え方 (1)
広義の MapReduce とは、Google のエンジニアが提唱した、並列データ処理のための分散コン
ピューティングモデルです。► 考え方は非常に単純で、次の 2 つのステップでデータを処理するというだけのものです。
– 処理対象のデータをレコード毎に処理して、それぞれの結果をキーとバリューの組で表現する。⇒ Map 処理
– 同一のキーを持つ結果毎に処理結果を総合して、最終結果を取り出す。⇒ Reduce 処理
► 例: 1000 ページのドキュメントに含まれる IBM と Linux いう単語の出現回数を検索する。
– 1 レコードは、1 ページ分のテキストで、処理結果のキーとバリューは、単語(IBM、もしくは、Linux)とその出現回数とすると下記の MapReduce 処理で結果を得ることができます。
ページ毎に処理を行う(Map)
ページ 1 (IBM, 3 回)(Linux, 1 回) 単語毎に結果を合計する
(Reduce)
合計(IBM, 102 回)(Linux, 293 回)・
・・
ページ 2 (IBM, 0 回)(Linux, 2 回)
ページ 1000 (IBM, 0 回)(Linux, 0 回)

© 2010 IBM Corporation8 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
MapReduce の考え方 (2)
MapReduce はデータ処理の手続きを定めているだけであり、実際の Map 処理と Reduce 処理の
内容は、解くべき問題に応じて、個々に考えて実装する必要があります。► 全てのデータ解析が MapReduce モデルで実装できるわけではありません。解くべき問題が、レコード単位の独立した map 処理に分割できる必要があります。
– 複数の MapReduce 処理の組み合わせによる解析はもちろん可能です。
► 下の Google での例から分かる様に、静的データの解析(データマイニング)に向いています。
個々のレコードの map 処理は、独立したノード上で並列処理ができるので、大規模なデータを効率
的に処理することが可能になります。► reduce 処理についても、map 処理の結果に含まれるキーの値ごとに独立して集計を行いますので、reduce 処理を複数のノードで並列処理することも可能です。
Google では、次のようなデータ処理を MapReduce モデルで実装していると言っています。
► Web サイト内の文字列検索
► URL 毎のアクセスカウント(Web サーバーのアクセスログの解析)
► 特定の URL にリンクを貼っている Web サイトのリストの作成
► Web サイト毎の単語の出現回数のリストの作成
► 特定の単語が含まれる Web ページのリストの作成
► 大規模なソート処理

© 2010 IBM Corporation9 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop の MapReduce (1)
Hadoop の MapReduce は、Java で利用できる MapReduce 処理のフレームワークを提供します。
► map 処理と reduce 処理を複数のノードにディスパッチする機能があり、複数ノードによる並列データ処理を
容易に実装することができます。
► 各ノードの map 処理と reduce 処理の結果をトラッキングして、ノード障害などで結果を得られなかった場合
は、再度、他のノードにディスパッチを行います。
具体的には次のような動作を行います。► 全データを一定サイズのレコードの集合(split)に分割して、この集合(split)単位で、異なるノードに map 処理をディスパッチします。各ノードは、与えられた split に含まれるそれぞれのレコードに対して map 関数を適
用して、その結果を返します。– 処理対象のデータは、HDFS により各ノードのローカルディスクに分散して保存されますが、できるだけ、各ノードのローカ
ルディスク上のデータを処理対象とするように map 処理のディスパッチが行われます。
► 各ノードから返ってきた結果に対して、結果に含まれるキーの値ごとにデータをまとめた後、それぞれのキーに対応するデータの集合に対して、reduce 処理をディスパッチします。
先の単語検索の例では、次のような処理に例えることができます。► ドキュメントを 10 分割して、1-100 ページの処理、101-200 ページの処理、・・・、901-1000 ページの処理をそれぞれ、異なるサーバーで実施します。(map 処理のディスパッチ)
► 各サーバーの処理結果を元に、IBM という単語の総計と Linux という単語の総計をそれぞれ、異なるサーバーで実施します。(reduce 処理のディスパッチ)

© 2010 IBM Corporation10 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop の MapReduce (2)
Hadoop の MapReduce は、map 処理と reduce 処理を実装するための Java クラスのテンプレート(Interface)を提供しますので、実際のプログラムの作成には、Java プログラミングの技術が
必要になります。► Unix/Linux の標準入出力へのインターフェースを提供するアダプターが提供されているので、テキストデータの各行をレコードとして処理するような場合は、簡易的な方法として、スクリプト言語で map 処理/reduce 処理
の関数を作成することも可能です。
Google では、平均的に次のような規模の MapReduce 処理を実装していると言っています。
► 使用ノード数 2,000► map 処理の分割数 200,000► reduce 処理の分割数 5,000

© 2010 IBM Corporation11 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
(参考) MapReduce の処理形式
MapReduce は、関数型言語におけるリスト演算の map/reduce に相当すると考える事ができます。具体的には、次の 3 つの処理を実行する事に相当します。
1. Map 処理: 処理対象データの各レコードを要素とするリストに対して、map 演算で、map 処理関数を各要素に適用します。map 処理関数は、個々の要素に対して、(Key, Value) タプルを結果として返します。従って、map 演算の最終結果は、(Key, Value) タプルのリストになります。
– 一般には、map 処理関数が複数のタプルを返すことも可能で、この場合は、個々の map 処理関数の結果はタプルのリストになるので、最終結果は、(Key, Value) タプルのリストのリストになります。
2. Shuffle 処理: 1 の結果に含まれる Key の値ごとに、同一 Key に対する Value を集めたリストを作成します。
3. Reduce 処理: 2 で作成されたそれぞれのリストに対して、reduce 演算で、リストの各要素に対する演算を再
帰的に実行して、最終的な値を導きます。
先の単語検索の例では、次のような map 処理/reduce 処理の関数を用意することになります。
► map 処理関数: 1 ページ分のテキスト ⇒ [ ( IBM, 出現回数 ), ( Linux, 出現回数 ) ]– 従って、Map 処理全体の結果は、次のようなタプルのリストのリストになります。
[ [ ( IBM, 1 ページ目の出現回数), ( Linux, 1 ページ目の出現回数 ) ], [ ( IBM, 2 ページ目の出現回数), ( Linux, 2 ページ目の出現回数 ) ], ・・・, [ ( IBM, 1000 ページ目の出現回数), ( Linux, 1000 ページ目の出現回数 ) ]]
– これを Shuffle 処理すると、次のような 2 つのリストが得られます。(この Shuffle 処理は MapReduce フレームワークが
自動的に実施します。)
( IBM, [ 1 ページ目の出現回数, 2 ページ目の出現回数, ・・・, 1000 ページ目の出現回数 ] )( Linux, [ 1 ページ目の出現回数, 2 ページ目の出現回数, ・・・, 1000 ページ目の出現回数 ] )
► reduce 処理関数: ( 単語, [1 ページ目の出現回数, 2 ページ目の出現回数, ・・・) ⇒ 出現回数の合計

© 2010 IBM Corporation12 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
(参考) オンライントランザクションにおける MapReduce
Hadoop が提供する MapReduce は、ディスクに格納された静的データをバッチで処理するものですが、Web アプリケーションサーバーによるオンライントランザクションでのデータ処理にMapReduce を利用する商用製品もあります。
IBM WebSphere eXtreme Scale が提供する DataGrid Agent は、Web アプリケーションサー
バーに対して次のような機能を提供します。► 処理対象のデータを複数のノードのメモリー上に (Key, Value) 形式で分散保存します。
► Web アプリケーションサーバーのオンライントランザクション処理の中で MapReduce 処理を実行します。
– Map 処理は、処理対象のデータを保持するノード上の Agent によって実行されるため、ネットワーク経由でのデータ転送が発生せず、オンメモリーで Map 処理が実施されます。
– ディスク上のデータを使用する MapReduce 処理よりも高速に MapReduce 処理が実施できるため、バッチ処理だけではなく、オンライントランザクションの中でも利用することが可能になります。
► 詳細は、下記の資料を参照ください。
– IBM WebSphere eXtreme Scale で実現するデータ・アクセスのボトルネック解消
– http://www-06.ibm.com/software/jp/websphere/apptransaction/extremescale/pdf/wex_whitepaper.pdf

© 2010 IBM Corporation13 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop のアーキテクチャー
Hadoop のアーキテクチャー

© 2010 IBM Corporation14 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
HDFS のアーキテクチャー
HDFS には、ファイルシステムのメタデータを管理する Name ノード、および、Secondary Name ノードと、実際のデータを保存する Data ノードがあります。
Name ノードでは、メタデータ情報を維持する NameNode デーモンが稼働し、Secondary Name ノードでは、エディットログの管理をする SecondaryNameNode デーモンが稼働します。
► Name ノードが管理するメタデータ情報は、NameNode デーモンの起動時にディスクからメモリーに読み込
まれ、メタデータの変更が発生した場合は、メモリー上のデータを変更すると共に、変更内容のジャーナルをエディットログファイルに書き出します。(ディスク上のメタデータ情報は更新しません。)
► Secondary Name ノードはエディットログファイルの内容を元に、ファイルに保存されたメタデータ情報を定期
的に最新の状態に更新します。(これは、チェックポイント処理と呼ばれます。)
► メタデータ情報を保存するファイルとエディットログファイルは、冗長性のために、各ノードのローカルファイルシステムと NFS マウントしたリモートディスクの 2 箇所に保存します。
Data ノードでは、実データへのアクセスを行う DataNode デーモンが稼働します。
► Data ノードでは、ローカルディスク上で、HDFS として使用するディスク領域をディレクトリで指定します。(異なる物理ディスクに対応する)複数のディレクトリを指定することで I/O の分散を行うことも可能です。
► データの冗長性は、複数の Data ノード(デフォルトでは 3 ノード)に同一のデータブロックを書き込むことで実
現されます。

© 2010 IBM Corporation15 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
HDFS の Web インターフェース
Web ブラウザーから Name ノードに接続することで、HDFS を構成する Data ノード やディスクの使用状況などを確認することができます。HDFS 内のディレクトリーの閲覧も可能です。

© 2010 IBM Corporation16 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
MapReduce のアーキテクチャー
MapReduce には、Job の実行を管理する Job Tracker ノードと、Job に伴う実際のデータ解析を実行する Task Tracker ノードがあります。
► Job Tracker ノードに Job の投入を行うと、1 つの Job は複数の Map Task / Reduce Task に分割されて、Task Tracker ノードにディスパッチされます。
– Job の投入はクラスターに参加している任意のノードから実行することが可能です。
Job Tracker ノードでは、Job の実行管理と Task のディスパッチを行う JobTracker デーモンが稼
働します。► JobTracker デーモンは各 Task Tracker ノードでの Task の実行状況をトラッキングして、Task の実行に失敗した場合は、他の Task Tracker ノードに失敗した Task を再ディスパッチします。
Task Tracker ノードでは、ディスパッチされた Task のキューイングと実行処理を行う TaskTracker デーモンが稼働します。► TaskTracker デーモンは、ディスクパッチされた複数の Task をキューイングしながら、各 Task を順次実行
していきます。
► 実際の Task の実行は、TaskTracker デーモンから生成された Child プロセスが実行します。1 つの Task Tracker ノードで並列に実行する Task の数(Child プロセスの同時起動数)はデフォルトでは Map Task, Reduce Task それぞれで 2 個づつです。

© 2010 IBM Corporation17 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
MapReduce の Web インターフェース
Web ブラウザーから Job Tracker ノードに接続することで、Job の実行状況や Job に伴う Task の実行状況を確認することができます。
© 2010 IBM Corporation18 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
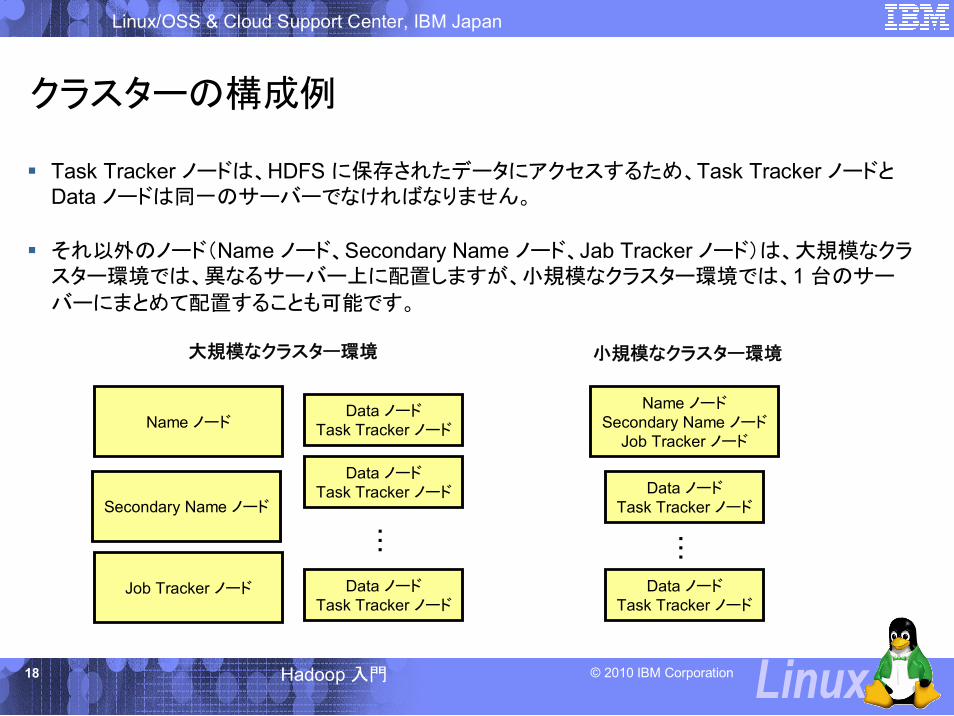
クラスターの構成例
Task Tracker ノードは、HDFS に保存されたデータにアクセスするため、Task Tracker ノードとData ノードは同一のサーバーでなければなりません。
それ以外のノード(Name ノード、Secondary Name ノード、Jab Tracker ノード)は、大規模なクラスター環境では、異なるサーバー上に配置しますが、小規模なクラスター環境では、1 台のサー
バーにまとめて配置することも可能です。
Name ノードSecondary Name ノード
Job Tracker ノード
Data ノードTask Tracker ノード
Data ノードTask Tracker ノード
・・・
Secondary Name ノード
Data ノードTask Tracker ノード
Data ノードTask Tracker ノード
・・・
Job Tracker ノード
Name ノード
小規模なクラスター環境大規模なクラスター環境
Data ノードTask Tracker ノード

© 2010 IBM Corporation19 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop の導入と構成Hadoop の導入と構成

© 2010 IBM Corporation20 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
導入環境 (1)
ここでは、例として、4 台のサーバーからなるクラスターを構成します。
► 1 台の管理サーバーに、Name ノード、Secondary Name ノード、Job Tracker ノードを配置します。
► 3 台の計算サーバーのそれぞれに Data ノード、および、Task Tracker ノードを配置します。
この手順で使用する HW / SW 構成は次の通りです。
► HW: IBM BladeCenter HS20– CPU: Xeon 3.2GHz, 1 core x 2 way (HyperThread)– Memory: 4GB – Disk: 36.4GB
► OS: RHEL5.4 (x86_64)► Java: SUN JDK 6 Update 17► Hadoop: 0.20.2
管理サーバーhdpmgmt01
計算サーバーhdpnode01
GbE ネットワーク
計算サーバーhdpnode02
計算サーバーhdpnode03
Name ノード
Secondary Name ノード
Job Tracker ノード
hdpmgmt01
Data ノード
Task Tracker ノード
hdpnode01hdpnode01hdpnode03
配置ノードホストネーム

© 2010 IBM Corporation21 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
導入環境 (2)
Hadoop の導入と実行は、ユーザー hadoop で行います。
各サーバーのディレクトリー構成は次の通りです。► /disk01 には HDFS に使用するためのディスク領域をマウントしているものとします。
► 各サーバーに配置するノードに応じて、必要なディレクトリーが作成されます。
/disk01/hdfs/dataHDFS データData ノード
/disk01/hdfs/name_secondary/nfs/hdfs/neme_secondary (NFS マウント領域)
HDFS メタデータSecondary Name ノード
/disk01/hdfs/name/nfs/hdfs/name (NFS マウント領域)
HDFS メタデータName ノード
/disk01/mapred/local/tmp/hadoop/mapred/system (HDFS 内の領域)
MapReduce 作業領域
/home/hadoop/logsHadoop ログ
/opt/hadoop-0.20.2(シンボリックリンク /home/hadoop/hadoop を作成)
Haddop 導入先
/home/hadoophadoop ユーザーホーム全ノード共通

© 2010 IBM Corporation22 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
導入環境 (3)
各ノードで起動するデーモンに割り当てる最大メモリーは次の通りとします。► これらの値は、使用するサーバーのメモリー容量に応じて、後述の設定パラメーターで変更してください。
/home/hadoop/conf/hadoop-env.shHADOOP_HEAPSIZE
2400MB合計
2800MB合計
/home/hadoop/conf/mapred-site.xmlmapred.child.java.optsmapred.tasktracker.map.tasks.maximummapred.tasktracker.reduce.tasks.maximum
/home/hadoop/conf/hadoop-env.shHADOOP_HEAPSIZE
設定パラメーター
200MB x (3 + 3)
Child
800MB
800MB
800MB
800MB
800MB
メモリー
TaskTrackerTask Tracker ノード
DataNode
JobTracker
SecondaryNameNode
NameNode
デーモン
Job Tracker ノード
Secondary Name ノード
Name ノードhdpmgmt01
Data ノードhdpnode01hdpnode01hdpnode03
配置ノードサーバー

© 2010 IBM Corporation23 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
OS と JDK の導入
この作業は各サーバーで共通に root ユーザーで実施します。
各サーバーに RHEL5.4 (x86_64) を導入して、IP アドレス、ホストネームの設定を行います。
► RHEL5.4 導入時は、開発環境用のパッケージを選択します。後から SUN JDK を導入するため、Java 関連
のパッケージはここでは選択しません。
► 各サーバーのホストネーム hdpmgmt01, hdpnode01, hdpnode02, hdpnode03 がお互いに名前解決できるように /etc/hosts に記載しておきます。
► NTP を使用して各サーバーの時刻を同期させておきます。
Sun Developer Network の Web サイトより JDK 6 Update 21 をダウンロードして、導入します。– http://java.sun.com/javase/downloads/index.jsp
► # chmod u+x jdk-6u21-linux-x64-rpm.bin
► # ./jdk-6u21-linux-x64-rpm.bin

© 2010 IBM Corporation24 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop の導入 (1)
この作業は各サーバーで共通に root ユーザーで実施します。
Hadoop の実行ユーザー・グループを作成して、パスワードを設定します。
► # groupadd hadoop
► # useradd hadoop -g hadoop
► # passwd hadoop
Apache のダウンロードサイトから Hadoop 0.20.2 をダウンロードして導入します。– http://www.apache.org/dyn/closer.cgi/hadoop/core/– ダウンロードしたファイルは /tmp/hadoop-0.20.2.tar.gz に置くものとします。
► # cd /opt
► # tar -xvzf /tmp/hadoop-0.20.2.tar.gz
► # chown -R hadoop.hadoop hadoop-0.20.2/
► # ln -s /opt/hadoop-0.20.2 /home/hadoop/hadoop
► # chown hadoop.hadoop /home/hadoop/hadoop

© 2010 IBM Corporation25 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop の導入 (2)
HDFS に使用するファイルシステムを用意します。
► /disk01 に HDFS に使用するファイルシステムをマウントしておきます。
► # chown hadoop.hadoop /disk01
管理サーバーで、HDFS メタデータのバックアップ用ディレクトリを用意します。– この作業は hdpmgmt01 のみで実施します。
► /nfs に NFS サーバーのリモートディレクトリをマウントしておきます。
► # mkdir /nfs/hdfs
► # chown hadoop.hadoop /nfs/hdfs

© 2010 IBM Corporation26 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop の構成 (1)
この作業は管理サーバー hdpmgmt01 上で hadoop ユーザーで実施します。
► # su - hadoop
管理サーバーの hadoop ユーザーから(管理サーバー自身を含む)各サーバーの hadoop ユーザーにパスワード入力なしの SSH 接続ができるように設定します。
► $ ssh-keygen -t rsa
► $ ssh hdpnode01 "mkdir ~/.ssh; chmod 700 ~/.ssh"
► $ ssh hdpnode02 "mkdir ~/.ssh; chmod 700 ~/.ssh"
► $ ssh hdpnode03 "mkdir ~/.ssh; chmod 700 ~/.ssh"
► $ scp ~/.ssh/id_rsa.pub hdpmgmt01:~/.ssh/authorized_keys
► $ scp ~/.ssh/id_rsa.pub hdpnode01:~/.ssh/authorized_keys
► $ scp ~/.ssh/id_rsa.pub hdpnode02:~/.ssh/authorized_keys
► $ scp ~/.ssh/id_rsa.pub hdpnode03:~/.ssh/authorized_keys

© 2010 IBM Corporation27 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop の構成 (2)
.bashrc に環境変数の設定を追加します。
► $ vi ~/.bashrc
– 右図の内容をファイルの最後に追加します。
► $ . ~/.bashrc
► $ scp ~/.bashrc hdpnode01:~/
► $ scp ~/.bashrc hdpnode02:~/
► $ scp ~/.bashrc hdpnode03:~/
Hadoop の構成ファイルを編集します。
► $ cd ~/hadoop/conf
► $ vi masters– 右図のように Secondary Name ノードを記載します。
► $ vi slaves– 右図のように TaskTracker ノードを記載します。
► $ vi hadoop-env.sh
– 既存の内容に、右図の各エントリーを追加します。
– HADOOP_HEAPSIZE は、各デーモンの最大使用メモリー (MB) を指定していますので、環境(サーバーのメモリー容量)に応じて変更してください。
export HADOOP_HOME=/home/hadoop/hadoopexport JAVA_HOME=/usr/java/defaultexport PATH=$PATH:$HADOOP_HOME/bin:$JAVA_HOME/binexport CLASSPATHfor f in $HADOOP_HOME/*.jar; do
CLASSPATH=${CLASSPATH}:$f;donefor f in $HADOOP_HOME/lib/*.jar; do
CLASSPATH=${CLASSPATH}:$f;done
.bashrc
export JAVA_HOME=/usr/java/defaultexport HADOOP_LOG_DIR=/home/hadoop/logsexport HADOOP_HEAPSIZE=800
hadoop-env.sh
hdpmgmt01
masters
hdpnode01hdpnode02hdpnode03
slaves

© 2010 IBM Corporation28 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop の構成 (3)
► $ vi core-site.xml– 既存の configuration タグ内に、右図の内
容を記載します。
► $ vi hdfs-site.xml– 既存の configuration タグ内に、右図の内
容を記載します。
– HDFS のデータを保存するディレクトリーを複数指定する場合は、dfs.data.dir プロパティに、コンマ (,) 区切りで複数のディレクトリーを指定します。(異なる物理ディスク上のディレクトリーを指定することで I/O の分散が行われます。)
<property><name>fs.default.name</name><value>hdfs://hdpmgmt01/</value><final>true</final>
</property>
core-site.xml
<property><name>dfs.name.dir</name><value>/disk01/hdfs/name,/nfs/hdfs/name</value><final>true</final>
</property>
<property><name>fs.checkpoint.dir</name> <value>/disk01/hdfs/name_secondary,/nfs/hdfs/name_secondary</value><final>true</final>
</property>
<property><name>dfs.data.dir</name><value>/disk01/hdfs/data</value><final>true</final>
</property>
hdfs-site.xml

© 2010 IBM Corporation29 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop の構成 (4)
► $ vi mapred-site.xml– 既存の configuration タグ内に、右図の内容を記
載します。
– MapReduce の作業用ディレクトリを複数指定する場合は、mapred.local.dir プロパティに、コンマ(,) 区切りで複数のディレクトリーを指定します。(異なる物理ディスク上のディレクトリーを指定することで I/O の分散が行われます。)
– 下記のプロパティは、環境(サーバー CPU コア数やメモリー容量)に応じて変更してください。
► mapred.tasktracker.map.tasks.maximum– TaskTracker ノードで並列に実行する Map Task
の数を指定します。
► mapred.tasktracker.reduce.tasks.maximum– TaskTracker ノードで並列に実行する Reduce
Task の数を指定します。
► mapred.child.java.opts– 1 つの Map Task、および、Reduce Task を実行
する Child プロセスの最大使用メモリー (MB) を指定します。
<property><name>mapred.job.tracker</name><value>hdpmgmt01:8021</value><final>true</final>
</property>
<property><name>mapred.local.dir</name><value>/disk01/mapred/local</value><final>true</final>
</property>
<property><name>mapred.system.dir</name><value>/tmp/hadoop/mapred/system</value><final>true</final>
</property>
<property><name>mapred.tasktracker.map.tasks.maximum</name><value>3</value><final>true</final>
</property><property><name>mapred.tasktracker.reduce.tasks.maximum</name><value>3</value><final>true</final>
</property><property><name>mapred.child.java.opts</name><value>-Xmx200m</value><final>true</final>
</property>
mapred-site.xml

© 2010 IBM Corporation30 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop の構成 (5)
構成ファイルを各ノードに配布します。
► $ rsync -av ~/hadoop/conf/ hdpnode01:~/hadoop/conf/
► $ rsync -av ~/hadoop/conf/ hdpnode02:~/hadoop/conf/
► $ rsync -av ~/hadoop/conf/ hdpnode03:~/hadoop/conf/
HDFS を新規にフォーマットして、 HDFS に関連するデーモンを起動します。(*)
► $ hadoop namenode -format
► $ start-dfs.sh
HDFS 内に Hadoop ユーザーのホームディレクトリーを作成します。
► $ hadoop fs -mkdir /user/hadoop
► $ hadoop fs -chown hadoop:hadoop /user/hadoop
► 右図のコマンドで、HDFS 内にディレクトリー
が作成されていることを確認します。
HDFS に関連するデーモンを一旦停止しておきます。
► $ stop-dfs.sh
(*) 各 DataNode デーモンが起動して、NameNode デーモンに登録されるまで 、しばらく時間かかる場合があります。
デーモン起動後は、3 分程度待ってから次の操作を実施してください。
$ hadoop fs -lsr /drwxr-xr-x - hadoop supergroup 0 2009-12-09 11:53 /userdrwxr-xr-x - hadoop hadoop 0 2009-12-09 11:53 /user/hadoop

© 2010 IBM Corporation31 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
サンプルジョブによる動作確認
サンプルジョブによる動作確認

© 2010 IBM Corporation32 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop の動作確認 (1)
Hadoop に標準で付属するサンプルのジョブを利用して動作確認を行います。この作業は管理サーバー hdpmgmt01 上で hadoop ユーザーで実施します。
► # su - hadoop
HDFS 関連のデーモンを起動します。
► $ start-dfs.sh
– 一般に、このコマンドは Name ノードを配置したサーバー上で実行します。
► 各サーバーの ~/logs/ 以下のログファイルから各デーモンが起動した事を確認します。
– NameNode デーモン : hadoop-hadoop-namenode-hdpmgmt01.log– SecondaryNameNode デーモン: hadoop-hadoop-secondarynamenode-hdpmgmt01.log– DataNode デーモン : hadoop-hadoop-datanode-hdpnode(01|02|03).log
MapReduce 関連のデーモンを起動します。(*)
► $ start-mapred.sh
– 一般に、このコマンドは JobTracker ノードを配置したサーバー上で実行します。
► 各サーバーの ~/logs/ 以下のログファイルから各デーモンが起動した事を確認します。
– JobTracker デーモン : hadoop-hadoop-jobtracker-hdpmgmt01.log– TaskTracker デーモン: hadoop-hadoop-tasktracker-hdpnode(01|02|03).log
(*) jps コマンドで各デーモンの起動が確認できます。ただし、各 TaskTracker デーモンが起動して、JobTracker デーモンに
登録されるまで 、しばらく時間かかる場合があります。デーモン起動後は、3 分程度待ってから次の操作を実施してください。

© 2010 IBM Corporation33 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop の動作確認 (2)
サンプルジョブを利用して、ランダムなデータを作成します。
► $ hadoop jar ~/hadoop/hadoop-0.20.2-examples.jar randomwriter -D test.randomwrite.bytes_per_map=100000000 -D test.randomwriter.maps_per_host=3 random-data
– これは、各 Task Tracker ノードで 100MB のデータを作成する Map Task を 3 個づつ実行します。この環境では、合計、900MB のデータが作成されます。
► 下図のコマンドで HDFS 内の /user/hadoop/random-data 以下に 900MB のデータが作成された事を確認
します。(*)
► Web ブラウザーから管理サーバーの下記の URL に接続することで、ジョブの完了状況が確認できます。
– http://hdpmgmt01:50030/
$ hadoop fs -lsr random-data(結果は省略)$ hadoop fs -dus random-datahdfs://hdpmgmt01/user/hadoop/random-data 903069153
(*) HDFS 内のディレクトリを指定する場合、/ から始まるパスは絶対パスとして解釈され、頭に/を付けないパスは、HDFS内のホームディレクトリ /user/hadoop に対する相対パスとして解釈されます。

© 2010 IBM Corporation34 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop の動作確認 (3)
► 同様に下記の URL に接続することで、HDFS の使用状況が確認できます。
– http://hdpmgmt01:50070/– 900MB のデータが(冗長性のために) 3 箇所に保存されているため、HDFS の総使用量は、2.7GB 程度になります。
サンプルジョブを利用して、作成したデータのソートを行います。
► $ hadoop jar ~/hadoop/hadoop-0.20.2-examples.jar sort random-data sorted-data
► 下図のコマンドで HDFS 内の /user/hadoop/sorted-data 以下にソート済みのデータが作成された事を確認
します。
サンプルジョブを利用して、ソートが正しく行われた事を確認します。
► $ hadoop jar ~/hadoop/hadoop-0.20.2-test.jar testmapredsort -sortInput random-data -sortOutput sorted-data
– ジョブの終了時に “SUCCESS! Validated the MapReduce framework‘s ’sort‘ successfully.” と表示されれば、ソートは正しく行われています。
$ hadoop fs -lsr sorted-data(結果は省略)$ hadoop fs -dus sorted-datahdfs://hdpmgmt01/user/hadoop/sorted-data 903103835

© 2010 IBM Corporation35 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop の動作確認 (4)
作成したテストデータを HDFS から削除しておきます。(*)
► $ hadoop fs -rmr random-data
► $ hadoop fs -rmr sorted-data
デーモンを停止する場合は、次のコマンドを使用します。
► $ stop-dfs.sh
► $ stop-mapred.sh
(*) これらの HDFS 内のディレクトリは、サンプルジョブを実行した際に、自動的に作成されますが、逆に、これらのディレクトリが存在する状態でサンプルジョブを実行するとエラーになります。そのような場合は、このコマンドでディレクトリを削除してからサンプルジョブを実行してください。この後のさまざまなジョブを実行する際も、再実行の際は、出力ディレクトリを事前に削除してください。

© 2010 IBM Corporation36 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
(参考) クラスターメンバーの登録について
Name ノードが管理対象として認識する Data ノードの登録は、DataNode デーモンが NameNode デーモンに対して、自ノードの存在を自発的に登録することで行われます。► Data ノードで DataNode デーモンが起動すると、自ノード上の core-site.xml の fs.default.name プロパティで指定された Name ノードに対して、自ノードの存在を登録します。
同様に、JobTracker ノードが管理対象として認識する TaskTracker ノードは、TaskTracker デー
モンが自ノードの存在を自発的に登録することで行われます。► TaskTracker ノードで TaskTracker デーモンが起動すると、自ノード上の mapred-site.xml の
mapred.job.tracker プロパティで指定された JobTrakcer ノードに対して、自ノードの存在を登録します。
デフォルトの設定では、Name ノード、および、JobTracker ノードは任意のサーバー上のDataNode デーモン、および、TaskTracker デーモンを管理対象ノードとして受け入れます。
► この状態は、セキュリティ上の問題ありますので、設定ファイルにより、管理対象ノードとして受け入れるサー
バーを指定することが可能です。
► 設定ファイル master および slave は、起動スクリプト start-dfs.sh, start-mapred.sh が SSH でデーモンを起動するサーバーを指定するためのものです。NameNode デーモン、JobTracker デーモンなどがこれらの
ファイルを参照することはありません。

© 2010 IBM Corporation37 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
スクリプトによるジョブの作成
スクリプトによるジョブの作成

© 2010 IBM Corporation38 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop Streaming について
Hadoop の MapReduce で使用する map および reduce 処理の内容は、本来は Java で記述する必要がありますが、Linux のパイプを通して map 処理および reduce 処理のデータを入出力する API である Hadoop Streaming が用意されており、これを利用すると、スクリプト言語で map 処理および reduce 処理を記述することができます。
► 入力データは複数のブロックに分割されて、それぞれ、独立した Map Task にディスパッチされ、各 Map Task は、与えられた範囲のデータを行単位で map 処理を行うスクリプトに渡します。
► map 処理を行うスクリプトは、標準入力から行単位でデータを読み込み、map 処理の結果(Key と Value の組)をタブ区切りのテキスト(行末は改行コード)として標準出力に出力します。
► 各 Map Task の処理が終わると、map 処理の結果全体が Key の値でソートされた後に、1 つの Reduce Task にディスパッチされます。Reduce Task は、与えられたデータを行単位で reduce 処理を行うスクリプト
に渡します。– オプション指定で複数の Reduce Task にデータを分割してディスパッチすることも可能です。この場合、各 Key について、
その値の Hash 計算でディスパッチ先の Reduce Task が決まります。また、各 Reduce Task は、(Hash 計算で決まった)受け取り対象のデータを Key の値でソートされた順で受け取ります。
► reduce 処理を行うスクリプトは、標準入力から行単位でデータ(タブ区切りの Key と Value の組)を読み込み、reduce 処理の結果(Key と Value の組)をタブ区切りのテキスト(行末は改行コード)として標準出力に出
力します。
ここでは例として、テキストファイルに含まれる各単語の出現回数を検索するジョブを Perl スクリプ
トで作成してみます。

© 2010 IBM Corporation39 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
検索対象文書の用意
最初に検索に使用するテキストファイルを用意します。► プロジェクト・グーテンベルクにより公開されているドストエフスキーの小説のテキストファイルをダウンロード
します。
– The Brothers Karamazov http://www.gutenberg.org/files/28054/28054.zip– The Gambler http://www.gutenberg.org/files/2197/2197.zip– Crime and Punishment http://www.gutenberg.org/files/2554/2554.zip– The Grand Inquisitor http://www.gutenberg.org/dirs/etext05/inqus10.zip– The Idiot http://www.gutenberg.org/files/2638/2638.zip– Notes from the Underground http://www.gutenberg.org/files/600/600.zip
► 各圧縮ファイルを展開して得られるテキストファイル (*.txt) を ~/work/ 以下に配置します。
► テキストファイルを HDFS の /user/hadoop/input/ 以下にコピーします。
– $ cd ~/work
– $ hadoop fs -mkdir input
– $ hadoop fs -copyFromLocal *.txt input
► 下図のコマンドでコピーされたファイルが確認できます。
$ hadoop fs -lsr input-rw-r--r-- 3 hadoop supergroup 357760 2009-12-09 18:13 /user/hadoop/input/2197.txt-rw-r--r-- 3 hadoop supergroup 1176831 2009-12-09 18:13 /user/hadoop/input/2554.txt-rw-r--r-- 3 hadoop supergroup 1395790 2009-12-09 18:13 /user/hadoop/input/2638.txt-rw-r--r-- 3 hadoop supergroup 1995783 2009-12-09 18:13 /user/hadoop/input/28054.txt-rw-r--r-- 3 hadoop supergroup 265613 2009-12-09 18:13 /user/hadoop/input/600.txt-rw-r--r-- 3 hadoop supergroup 70760 2009-12-09 18:13 /user/hadoop/input/inqus10.txt
© 2010 IBM Corporation40 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
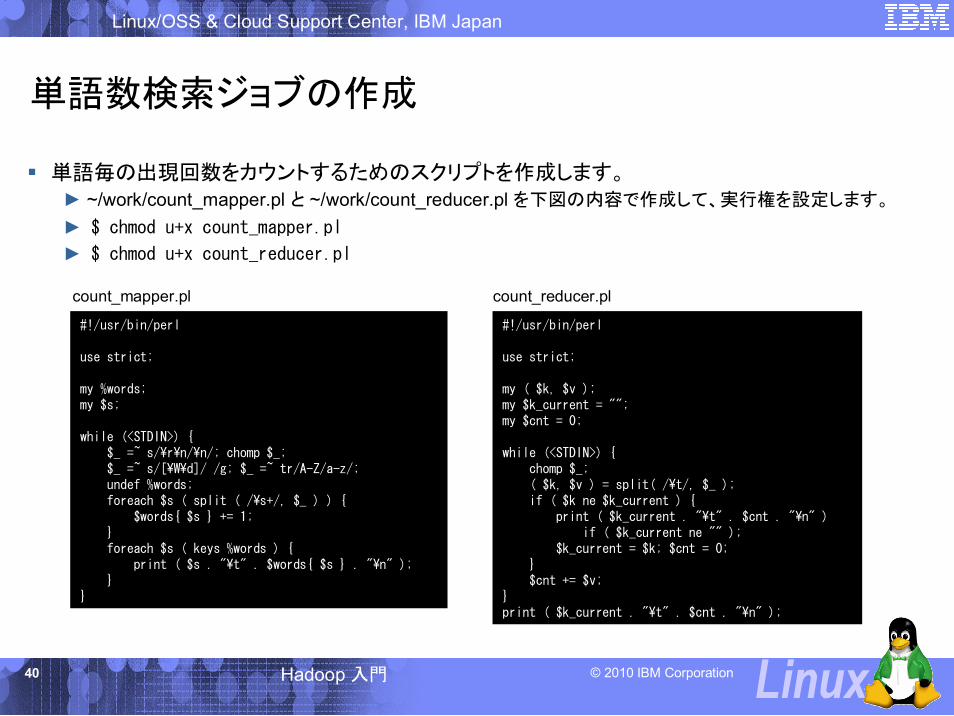
単語数検索ジョブの作成
単語毎の出現回数をカウントするためのスクリプトを作成します。► ~/work/count_mapper.pl と ~/work/count_reducer.pl を下図の内容で作成して、実行権を設定します。
► $ chmod u+x count_mapper.pl
► $ chmod u+x count_reducer.pl
#!/usr/bin/perl
use strict;
my %words;my $s;
while (<STDIN>) {$_ =~ s/¥r¥n/¥n/; chomp $_;$_ =~ s/[¥W¥d]/ /g; $_ =~ tr/A-Z/a-z/;undef %words;foreach $s ( split ( /¥s+/, $_ ) ) {
$words{ $s } += 1;}foreach $s ( keys %words ) {
print ( $s . "¥t" . $words{ $s } . "¥n" );}
}
#!/usr/bin/perl
use strict;
my ( $k, $v );my $k_current = "";my $cnt = 0;
while (<STDIN>) {chomp $_;( $k, $v ) = split( /¥t/, $_ );if ( $k ne $k_current ) {
print ( $k_current . "¥t" . $cnt . "¥n" )if ( $k_current ne "" );
$k_current = $k; $cnt = 0;}$cnt += $v;
}print ( $k_current . "¥t" . $cnt . "¥n" );
count_mapper.pl count_reducer.pl

© 2010 IBM Corporation41 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Hadoop is wonderful. I love Hadoop.Wonderful! You think Hadoop is wonderful, don't you?
検索対象の文書
hadoop 2is 1wonderful 1i 1love 1 wonderful 2
you 2think 1hadoop 2is 1don't 1
1 行目の Map 処理結果
2 行目の Map 処理結果
don't 1hadoop 2hadoop 2i 1is 1is 1love 1think 1you 2wonderful 1wonderful 2
Reduce 処理に渡されるデータ
don't 1hadoop 4i 1is 2love 1think 1you 2wonderful 3
Reduce 処理の結果
(参考) 単語数検索スクリプトの動作説明
これらのスクリプトは、次のような処理を行います。► count_mapper.pl は、標準入力からデータを 1 行受け取る毎に、その行に含まれる単語とその行での出現回数を標準出力に書き出します。そして、出力データ全体が、各行に出現した単語でソートされて、Reduce 処理に渡ります。つまり、下図のように、複数行に出現した同じ単語が、連続して Reduce 処理に渡ります。
► count_reducer.pl は、標準入力から 1 行づつデータを受け取りますが、同じ単語のデータが続く間、その値
(各行での出現回数)を足していき、単語が変わるタイミングで、単語とその合計数を標準出力に書き出します。

© 2010 IBM Corporation42 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
単語数検索ジョブの動作確認
Hadoop のジョブとして実行する前に、少量のデータに対して、通常のスクリプトとして実行して、動
作確認を行います。► count_mapper.pl は、各行に含まれる単語毎にその行内での出現回数を(単語, 出現回数)の形式で出力し
ます。
– map 処理関数は、1行のデータに対して、複数の結果を返しても構いません。
– 処理を簡略化するために、各行に含まれるアルファベット以外の記号を削除して、大文字は全て小文字に変換しています。
– 左下図のようにテキストの 1 行だけを処理させた結果が確認できます。
► count_reducer.pl は、入力データの同一の Key (単語)毎に、Value (出現回数)の値を合計して、(単語, 出現回数合計)の形式で結果を出力します。
– 右下図のように 1 冊分のテキストに対して、map 処理およびreduce 処理を実施した結果が確認できます。(ここでは、map 処理の結果を sort コマンドによって Key の値でソートして、reduce 処理に渡しています。)
$ cd ~/work$ head -1 600.txt | ./count_mapper.plthe 1gutenberg 1project 1s 1by 1underground 1dostoevsky 1notes 1from 1feodor 1
$ cat 600.txt | ./count_mapper.pl | sort | ./count_reducer.pl | heada 970abandon 4abashed 1abide 1abject 2abjectly 1abjectness 2able 13abnormal 1abolished 1

© 2010 IBM Corporation43 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
単語数検索ジョブの実行
動作確認のできたスクリプトを Hadoop のジョブとして実行します。ここでは、先に HDFS に保存した全てのテキスト(/user/hadoop/input/*.txt)を処理対象とします。
► $ hadoop jar ~/hadoop/contrib/streaming/hadoop-0.20.2-streaming.jar -input input -output output/count -mapper ./count_mapper.pl -reducer ./count_reducer.pl -file ./count_mapper.pl-file ./count_reducer.pl
► 上記のジョブ実行時のオプションの意味は次の通りです。
– -input: HDFS 上の入力データを指定します。ディレクトリーを指定した場合は、ディレクトリー内の全ファイルが処理対象になります。
– -output: ジョブの結果を出力する HDFS 上のディレクトリーを指定します。
– -mapper, -reducer: map 処理、および、reduce 処理を実行するスクリプトを指定します。
– -file: ジョブの実行に必要なファイルを指定します。ここで指定されたファイルが、Task Tracker ノードに転送されて実行されます。
► 下図の様に、実行結果の出力ファイルが /user/hadoop/output/count/part-00000 に作成されています。
– 各 Reduce Task は個別の出力ファイルを作成しますので、一般には、実行された Reduce Task の数だけファイルが作
成されます。
► 次のコマンドで出力ファイルの内容を表示することもできます。
– $ hadoop fs -cat output/count/part-00000
$ hadoop fs -lsr output/count/part-*-rw-r--r-- 3 hadoop supergroup 209002 2009-12-09 19:21 /user/hadoop/output/count/part-00000

© 2010 IBM Corporation44 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
検索結果のソート処理
さらに、先の検索結果を出現回数でソートする処理を行うスクリプトを作成してみます。► ~/work/sort_mapper.pl と ~/work/sort_reducer.pl を下図の内容で作成して、実行権を設定します。
► $ chmod u+x sort_mapper.pl
► $ chmod u+x sort_reducer.pl
► sort_mapper.pl は、各行の形式を(単語, 出現回数)から(出現回数, 単語)に変更します。
– このとき、出現回数は、 (頭の不足する桁を 0 で埋めた) 10 桁固定のフォーマットで出力します。これにより、Reduce Task にデータを渡す前のソート処理によって、出現回数でのソートが行われます。
► sort_reducer.pl は、ソート済みの結果が渡されますので、受け取ったデータをそのまま出力しています。
#!/usr/bin/perl
use strict;
my ( $w, $c );
while (<STDIN>) {chomp $_;( $w, $c ) = split( /¥t/, $_ );printf ( "%010d¥t%s¥n", $c, $w );
}
#!/usr/bin/perl
use strict;
while (<STDIN>) {print $_;
}
sort_mapper.pl sort_reducer.pl

© 2010 IBM Corporation45 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
検索結果のソート処理の実行
作成したスクリプトを Hadoop のジョブとして実行します。
► $ hadoop jar ~/hadoop/contrib/streaming/hadoop-0.20.2-streaming.jar -input output/count/part-00000 -output output/sort -mapper ./sort_mapper.pl -reducer ./sort_reducer.pl -file ./sort_mapper.pl -file ./sort_reducer.pl
► 下図の様に、実行結果の出力ファイルが /user/hadoop/output/sort/part-00000 に作成されています。
► 下図のコマンドで、出力結果の末尾を確認すると、the の出現回数が最も多く 39,288 回であることが分かり
ます。
$ hadoop fs -cat output/sort/part-00000 | tail0000014608 in0000015749 that0000017323 you0000018514 he0000019172 a0000020087 of0000022049 i0000025725 to0000029777 and0000039288 the
$ hadoop fs -ls output/sort/part-*Found 1 items-rw-r--r-- 3 hadoop supergroup 375539 2009-12-09 19:47 /user/hadoop/output/sort/part-00000

© 2010 IBM Corporation46 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Pig の利用Pig の利用

© 2010 IBM Corporation47 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Pig とは
Pig は、Pig Latin と呼ばれる簡易言語により MapReduce を利用する環境を提供します。
► MapReduce で行われる典型的なデータ処理を Pig Latin で記述することで、対応する MapReduce ジョブ
を自動的に組み立てて実行することが可能です。
► Pig は、Apache Hadoop のサブプロジェクトとして開発されています。
先に実行した単語数検索のジョブは、Pig を利用すると、下図のような Pig Latin スクリプトで実行
することができます。► 1 ~ 6 行目でデータ処理の内容を定義しており、7 行目の store コマンドを実行すると、一連の処理に対応する MapReduce ジョブが組み立てられて実行されます。
► Pig Latin の詳細については、参考資料を参照ください。
define word_counter `count_mapper.pl` ship ('/home/hadoop/work/count_mapper.pl');texts = load 'input/*.txt';words_raw = stream texts through word_counter as (word:chararray, count:int);words_grouped = group words_raw by word;words_sum = foreach words_grouped generate group as word, SUM(words_raw.count) as count;words_ordered = order words_sum by count desc;store words_ordered into 'pigout' using PigStorage(',');
word_count.pig

© 2010 IBM Corporation48 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Pig の導入
この作業は管理サーバー hdpmgmt01 上で実施します。
Apache のダウンロードサイトから Pig 0.5.0 をダウンロードして、root ユーザーで導入します。– http://www.apache.org/dyn/closer.cgi/hadoop/pig/– ダウンロードしたファイルは /tmp/pig-0.5.0.tar.gz に置くものとします。
► # cd /opt
► # tar -xvzf /tmp/pig-0.5.0.tar.gz
► # chown -R hadoop.hadoop pig-0.5.0/
► # ln -s /opt/pig-0.5.0 /home/hadoop/pig
► # chown hadoop.hadoop /home/hadoop/pig
ユーザー hadoop の .bashrc に環境変数の設定を追加します。
► # su - hadoop
► $ vi ~/.bashrc
– 右図の内容をファイルの最後に追加します。
– PIG_HADOOP_VERSION で利用する Hadoop のバージョンを指定しています。(Pig はバージョン毎に利用可能なHadoop のバージョンが決まっています。)
– PIG_CLASSPATH に Hadoop の設定ファイルディレクトリーを指定することで、Pig から対応する Hadoop のジョブの実行が可能になります。
► $ . ~/.bashrc
export PIG_HADOOP_VERSION=20export PIG_CLASSPATH=$HADOOP_HOME/conf/export PATH=$PATH:~/pig/bin
.bashrc

© 2010 IBM Corporation49 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
Pig Latin スクリプトの実行
単語数検索を行う Pig Latin スクリプトを用意して、実行します。
► ~/work/word_count.pig を『Pig とは』のページに記載の内容で作成します。
► $ pig ~/work/word_count.pig
► 下図の様に、実行結果の出力ファイルが /user/hadoop/pigout/part-00000 に作成されています。
► 下図のコマンドで、出力結果を確認すると、先と同じ結果が得られていることが分かります。
$ hadoop fs -cat pigout/part-00000 | headthe,39288and,29777to,25725i,22049of,20087a,19172he,18514you,17323that,15749in,14608
$ hadoop fs -ls pigout/part-*Found 1 items-rw-r--r-- 3 hadoop supergroup 209009 2009-12-15 12:28 /user/hadoop/pigout/part-00000

© 2010 IBM Corporation50 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
HBase の導入と構成HBase の導入と構成

© 2010 IBM Corporation51 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
HBase とは
HBase は、HDFS をバックエンド・ストレージとする Key-Value ストアです。
► Key-Value ストアとは、検索キー (Key) に対する値 (Value) を格納するデータベースで、プログラム言語の
連想配列に相当する機能を提供します。
► HBase では、1 行のデータが、1 つの連想配列変数に相当します。つまり、行と Key を指定することで、対応する Value を取り出すことができます。(*)
– RDB と異なり、複雑な検索処理はできませんので、保存したデータを HBase 自身の機能で解析することはできません。HBase に格納したデータを MapReduce で解析したり、MapReduce で解析した結果を HBase に格納するといった使い
方をします。
► HBase は、Apache Hadoop のサブプロジェクトとして開発が始まり、現在は、トップレベル・プロジェクトに移
行しました。
図は、複数テキストの単語の出現回数を解析した結果を保存する HBase のテーブルの例です。
10482
11030
17458
text:c
2572580097234to
29777100238724and
39288982712003the
total:text:btext:a
行の名前に単語名を使用
カラム► 行の名前として、単語名を使用しています。
► 各行のカラム(検索キー)として、テキスト名(text:a, text:b, text:c)、および、全テキストの合計(total:)を使用しています。
– HBase のテーブルのカラム名は、”カラムファミリー:ラベル” という形で指定します。カラムファミリ-は、テーブル(カラム)を定義する際に指定しますが、ラベルは、事前定義なしに自由に指定ができます。”total:” のように、ラベルを指定しない事も可能です。
(*) HBase のデータ形式の詳しい説明は参考資料「Key-Value Store (KVS) 入門」を参照してください。

© 2010 IBM Corporation52 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
RDB と HBase の違いについて (1)
RDB と HBase の違いを理解するために、簡単な例として、複数ユーザーが複数コミュニティに参加する SNS で、次のような情報を格納するテーブルを考えます。
► ユーザー情報 : ユーザー名、年齢
► 参加コミュニティ情報 : ユーザー名、参加コミュニティ、参加日
※ 実際に格納するデータは下記を用います。
– User A, 23 才, 参加コミュニティと参加日 : (Linux, 2009/12/01), (Windows, 2008/03/03), (AIX, 2010/04/01)– User B, 30 才, 参加コミュニティと参加日 : (Linux, 2008/11/10), (AIX, 2008/03/02)– User C, 18 才, 参加コミュニティと参加日 : (Windows, 2010/04/11)
2008/03/02AIXUser B
2010/04/01AIXUser A
2008/11/10LinuxUser B
2010/04/11WindowsUser C
2008/03/03WindowsUser A
2009/12/01LinuxUser A
join_datecommunityname
主キー
18User C
30User B
23User A
agename
主キー
ユーザ-テーブル(テーブル名 : user_info)
参加コミュニティ・テーブル(テーブル名 : community_info)
RDB の場合は、情報の種類ごとにテーブル
を作成して、各テーブルのカラムには、格納する情報の名前を指定します。► この例では、ユーザー情報のテーブルと参加コ
ミュニティ情報のテーブルが右図のように定義できます。
► 複数のテーブルにまたがる情報は、それぞれのテーブルに共通の情報を用いて、SQL で結合
して検索することができます。
– この例では、ユーザー名がテーブルを結合するための情報になります。

© 2010 IBM Corporation53 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
RDB と HBase の違いについて (2)
HBase の場合は、HBase 自身の機能では、テーブルの結合ができないため、あらかじめ結合済みの情報を 1 つのテーブルに格納する事が多くなります。
► この例では、ユーザー名で結合した情報をユーザー名ごとに格納します。また、1 人のユーザーが複数のコミュニティに参加するような 1:N の情報は、カラムファミリーを利用して格納することで対応します。結果、
下図のようなテーブルが定義されます。
– カラムファミリーに対するラベル部分は任意の値が指定できるので、ラベル自身を連想配列のキーと考えると、カラムフファミリーは、「連想配列の連想配列」というデータ構造を表すことが分かります。
次に、格納された情報から、各コミュニティの参加者の平均年齢を検索する場合を考えます。► RDB の場合は、次のような SQL で検索が可能です。オンライン・トランザクションの中でこのような検索を
行うこともよく行われます。
– select community, avg(age) from user_info, community_info where user_info.name=community_info.namegroup by community;
► HBase の場合は、各行を検索して、カラムファミリー community のラベル毎にユーザーの年齢の平均を計算するようなMapReduce ジョブを作成します。
– オンライン・トランザクションで平均年齢の情報が必要な場合は、事前にバッチで計算した結果を、別途、コミュニティ毎の平均年齢のテーブルに格納して、このテーブルのデータを参照します。
18
30
23
age
-
2008/03/02
2010/04/01
community:AIX
2010/04/11-User C
-2008/11/10User B
2008/03/032009/12/01User A
community:Windowscommunity:Linux
行の名前にユーザー名を使用
ユーザ- & 参加コミュニティ・テーブル(テーブル名 : UserCommunityInfo)
カラム

© 2010 IBM Corporation54 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
HBase の導入 (1)
この作業は各サーバーで共通に root ユーザーで実施します。
Apache のダウンロードサイトから HBase 0.20.3 をダウンロードして導入します。– http://hadoop.apache.org/hbase/releases.html– ダウンロードしたファイルは /tmp/hbase-0.20.3.tar.gz に置くものとします。
► # cd /opt
► # tar -xvzf /tmp/hbase-0.20.3.tar.gz
► # chown -R hadoop.hadoop hbase-0.20.3/
► # ln -s /opt/hbase-0.20.3 /home/hadoop/hbase
► # chown hadoop.hadoop /home/hadoop/hbase

© 2010 IBM Corporation55 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
HBase の構成 (1)
.bashrc に環境変数の設定を追加します。
► $ vi ~/.bashrc
– 右図の内容をファイルの最後に追加します。
► $ . ~/.bashrc
► $ scp ~/.bashrc hdpnode01:~/
► $ scp ~/.bashrc hdpnode02:~/
► $ scp ~/.bashrc hdpnode03:~/
HBase の構成ファイルを編集します。
► $ cd ~/hbase/conf
► $ vi regionservers– 右図のように Data ノードを記載します。
► $ vi hbase-env.sh
– 既存の内容に、右図の各エントリーを追加します。
– HBASE_HEAPSIZE は、HBase に関連する 2 個のデーモンの最大使用メモリー (MB) を指定していますので、環境(サーバーのメモリー容量)に応じて変更してください。
export HBASE_HOME=/home/hadoop/hbaseexport PATH=$PATH:~/hbase/bin
.bashrc
export JAVA_HOME=/usr/java/defaultexport HBASE_LOG_DIR=/home/hadoop/logsexport HBASE_HEAPSIZE=500export HBASE_MANAGES_ZK=true
hbase-env.sh
hdpnode01hdpnode02hdpnode03
regionservers
この作業は管理サーバー hdpmgmt01 上で hadoop ユーザーで実施します。
► # su - hadoop

© 2010 IBM Corporation56 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
HBase の構成 (2)
► $ vi hbase-site.xml– 既存の configuration タグ内に、右図の内容を記載し
ます。
hbase-site.xml
<property><name>hbase.rootdir</name><value>hdfs://hdpmgmt01/hbase</value><final>true</final>
</property>
<property><name>hbase.cluster.distributed</name><value>true</value><final>true</final>
</property>
<property><name>zookeeper.znode.rootserver</name><value>hdpmgmt01</value><final>true</final>
</property>
<property><name>hbase.zookeeper.quorum</name><value>hdpmgmt01,hdpnode01,hdpnode02,hdpnode03</value><final>true</final>
</property>構成ファイルを各ノードに配布します。
► $ rsync -av ~/hbase/conf/ hdpnode01:~/hbase/conf/
► $ rsync -av ~/hbase/conf/ hdpnode02:~/hbase/conf/
► $ rsync -av ~/hbase/conf/ hdpnode03:~/hbase/conf/

© 2010 IBM Corporation57 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
HBase の動作確認 (1)
HDFS が停止している場合は、事前に HDFS のデーモンを起動しておきます。
► $ start-dfs.sh
HBase のデーモンを起動します。
► $ start-hbase.sh
► 各サーバーの ~/logs/ 以下のログファイルから各デーモンが起動した事を確認します。
– HBase Master Server : hbase-hadoop-master-hdpmgmt01.log– HBase Region Server : hbase-hadoop-regionserver-hdpnode(01|02|03).log– ZooKeeper : hbase-hadoop-zookeeper-hdpmgmt01.log, hbase-hadoop-zookeeper-hdpnode(01|02|03).log
jps コマンドで各デーモンの稼働を確認することもできます。
HBase のデーモンを停止する際は次のコマンドを実行します。
► $ stop-hbase.sh

© 2010 IBM Corporation58 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
HBase の動作確認 (2)
ここでは、例として、HBase に付属のコマンドライン・ツールから、「RDB と HBase の違いについて(1)」のページに記載されたユーザーとコミュニティのテーブルを作成します。
► 次のコマンドでコマンドライン・ツールを起動します。
– $ hbase shell
► コマンドライン・ツールのプロンプトから、次のコマンドでテーブル UserCommunityInfo を作成して、データを格納します。行の名前(ユーザー名)とカラム名のペアーに対して、データ値(Value)を指定することが分かり
ます。
– > create 'UserCommunityInfo', 'age', 'community'
– > put 'UserCommunityInfo', 'User A', 'age', '23'
– > put 'UserCommunityInfo', 'User A', 'community:Linux', '2009/12/01'
– > put 'UserCommunityInfo', 'User A', 'community:Windows', '2008/03/03'
– > put 'UserCommunityInfo', 'User A', 'community:AIX', '2010/04/01'
– > put 'UserCommunityInfo', 'User B', 'age', '30'
– > put 'UserCommunityInfo', 'User B', 'community:Linux', '2008/11/10'
– > put 'UserCommunityInfo', 'User B', 'community:AIX', '2008/03/02'
– > put 'UserCommunityInfo', 'User C', 'age', '18'
– > put 'UserCommunityInfo', 'User C', 'community:Windows', '2010/04/11'

© 2010 IBM Corporation59 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
HBase の動作確認 (3)
► 作成したデータを検索します。
– scan コマンドは各行のデータをダンプアウトします。
– get コマンドは、行の名前(ユーザー名)とカラム名を指定して、対応するデータを取得します。(カラム名を指定しない場合は、該当する行の全てのカラムが出力されます。 )
hbase(main):044:0> scan 'UserCommunityInfo'ROW COLUMN+CELLUser A column=age:, timestamp=1274094692172, value=23User A column=community:AIX, timestamp=1274094733424, value=2010/04/01User A column=community:Linux, timestamp=1274094707816, value=2009/12/01User A column=community:Windows, timestamp=1274094723467, value=2008/03/03User B column=age:, timestamp=1274094746025, value=30User B column=community:AIX, timestamp=1274094780144, value=2008/03/02User B column=community:Linuc, timestamp=1274094763619, value=2008/11/10User B column=community:Linux, timestamp=1274094766913, value=2008/11/10User C column=age:, timestamp=1274094790339, value=18User C column=community:Windows, timestamp=1274094807015, value=2010/04/113 row(s) in 0.0150 secondshbase(main):045:0> get 'UserCommunityInfo', 'User A'COLUMN CELLage: timestamp=1274094692172, value=23community:AIX timestamp=1274094733424, value=2010/04/01community:Linux timestamp=1274094707816, value=2009/12/01community:Windows timestamp=1274094723467, value=2008/03/034 row(s) in 0.0060 secondshbase(main):046:0> get 'UserCommunityInfo', 'User A', {COLUMN => 'community:Linux'}COLUMN CELLcommunity:Linux timestamp=1274094707816, value=2009/12/011 row(s) in 0.0040 seconds

© 2010 IBM Corporation60 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
HBase の動作確認 (4)
► コマンドライン・ツールは、次のコマンドで終了します。
– > quit
HBase のテーブルの内容は、HDFS の /hbase 以下に保存されています。
テーブル UserCommunityInfo を削除する時は、次のコマンドを実行します。– $ hbase shell
– > disable 'UserCommunityInfo'
– > drop 'UserCommunityInfo'
– > quit
$ hadoop fs -ls /hbaseFound 5 itemsdrwxr-xr-x - hadoop supergroup 0 2010-04-24 16:15 /hbase/-ROOT-drwxr-xr-x - hadoop supergroup 0 2010-04-24 16:13 /hbase/.META.drwxr-xr-x - hadoop supergroup 0 2010-05-17 15:44 /hbase/.logsdrwxr-xr-x - hadoop supergroup 0 2010-05-17 20:10 /hbase/UserCommunityInfo-rw-r--r-- 3 hadoop supergroup 3 2010-04-24 13:30 /hbase/hbase.version

© 2010 IBM Corporation61 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
参考資料参考資料

© 2010 IBM Corporation62 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
参考資料
Hadoop 開発コミュニティのページ– http://hadoop.apache.org/
Hadoop: The Definitive Guide (O'Reilly)– http://oreilly.com/catalog/9780596521974/index.html
MapReduce: Simplified Data Processing on Large Clusters► Google のエンジニアによる Map/Reduce モデルを解説した論文です。
– http://labs.google.com/papers/mapreduce.html
Linux at IBM - Key-Value Store (KVS) 入門
► HBase の説明があります。
– http://www-06.ibm.com/jp/domino01/mkt/cnpages7.nsf/page/default-001B017C

© 2010 IBM Corporation63 Hadoop 入門
Linux/OSS & Cloud Support Center, IBM Japan
変更履歴
Version 1.0 2009/12/09 公開
Version 1.1 2009/12/13 Hadoop Streaming の説明を修正
Version 1.2 2009/12/15 『Pig の利用』を追加
Version 1.3 2010/04/24 誤植修正。『HBase の導入と構成』を追加
Version 1.4 2010/05/07 単語数検索スクリプトの動作説明を追加
Version 1.5 2010/05/17 『RDB と HBase の違いについて』を追加
Version 1.6 2010/05/20 誤字修正。参考資料を追加
Version 1.7 2010/07/08 export CLASSPATH 追加。hadoop-0.20.2 に変更。
Version 1.8 2010/08/02 デーモン起動後の待ち時間の注記を追加
IBM、IBM ロゴおよび ibm.com は、世界の多くの国で登録されたInternational Business Machines Corp. の商標です。他の製品名およびサービス名等は、それぞれIBMまたは各社の商標である場合があります。現時点での IBM の商標リストについては、http://www.ibm.com/legal/copytrade.shtml をご覧ください。Linux は、Linus Torvalds の米国およびその他の国における登録商標です。Microsoft および Windows は、Microsoft Corporation の米国およびその他の国における商標です。
《商標について》