Embed Size (px)
DESCRIPTION
Loop Tiling for Iterative Stencil Computations. Marta Jiménez. What is an Iterative Stencil Computation?. Matrix A. DO K = 1, NITER /* time-step loop */ do J = ... do I = ... {A(I,J), A(I+1,J),…} enddo enddo { wrapped-around computations } ENDDO. - PowerPoint PPT Presentation
Citation preview

Loop Tiling for Iterative Stencil Computations
Marta Jiménez

What is an Iterative Stencil Computation?
• ISC often performed for PDE, GM, IP– swim, tomcatv, mgrid (from SPEC95 benchmark)
– Jacobi
DO K = 1, NITER /* time-step loop */ do J = ... do I = ... {A(I,J), A(I+1,J),…} enddo enddo {wrapped-around computations}ENDDO
Matrix A

Loop Tiling• Loop Tiling
– divides IS into regular tiles to make the working set fit in the memory level being exploited
– can be applied hierarchically (Multilevel Tiling)
• Current algorithms for Loop Tiling are limited to loops that:– are “perfectly” nested
– are fully permutable
– define a rectangular IS
• However, in iterative stencil computations, loops are:– NOT perfectly nested
– NOT fully permutable

• Show how Loop Tiling can be applied to iterative stencil computations– based on Song & Li’s paper [PLDI99]
• define a Program Model• 1 Level of 1D-Tiling (cache)
– program example: SWIM• 2 levels of Tiling
– 2D-Tiling at the cache level
– 1D-Tiling at the register level (based on Jiménez et al. [ICS98][HPCA98])
• Performance Results– Loop Tiling on EV5 & EV6
Today’s talk

Steps
1- Apply a set of transformations to the original program to achieve the desired program model defined by Song & Li
2- Perform 2D-Tiling for the Cache Level
3- Perform 1D-Tiling for the Register Level

1st Step: achieve desired program model
DO K = 1, NITER /* time-step loop */ do J1 = LJ1, UJ1
do I1 = LI1, UI1
{A(I,J), A(I+1,J),…} enddo enddo . . . do Jm = LJm, UJm
do Im = LIm, UIm
{A(I,J), A(I+1,J),…} enddo enddo
ENDDO
Program Model:
Usually, programs are NOT directly written in this form – We must apply a set of transformations to achieve this program model

SWIM original code
initializations90 NCYCLE = NCYCLE +1
CALL CALC1
CALL CALC2
IF (NCYCLE >= ITMAX) STOP
IF (NCYCLE <= 1) THEN
CALL CALC3Z
ELSE
CALL CALC3
ENDIF
GO TO 90
Transformations–Inline subroutines
–Convert GO TO into DO-loop
–Peel iterations of the time-step loop to eliminate IF-statements guarded by NCYCLE
SUBROUTINE CALCX do J = 1,N do I = 1,M ... enddo enddoc wrapped-around computations do J = 1, N ... enddo do I = 1, M ... enddo
...
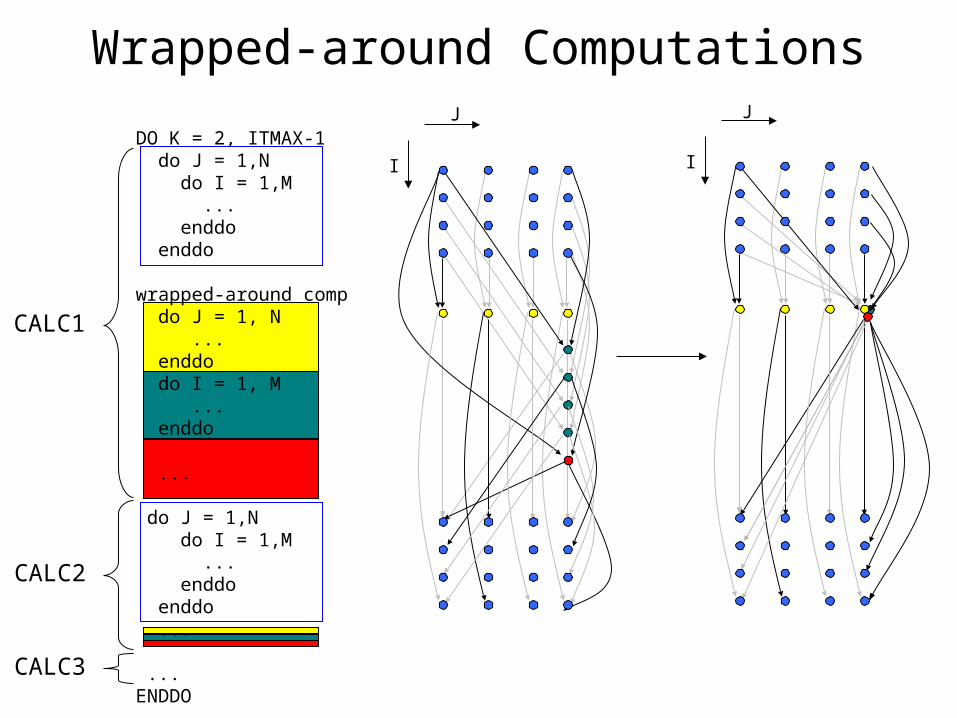
Wrapped-around Computations
DO K = 2, ITMAX-1 do J = 1,N do I = 1,M ... enddo enddo
wrapped-around comp do J = 1, N ... enddo do I = 1, M ... enddo ... do J = 1,N do I = 1,M ... enddo enddo ...
...ENDDO
J
I I
J
CALC1
CALC2
CALC3
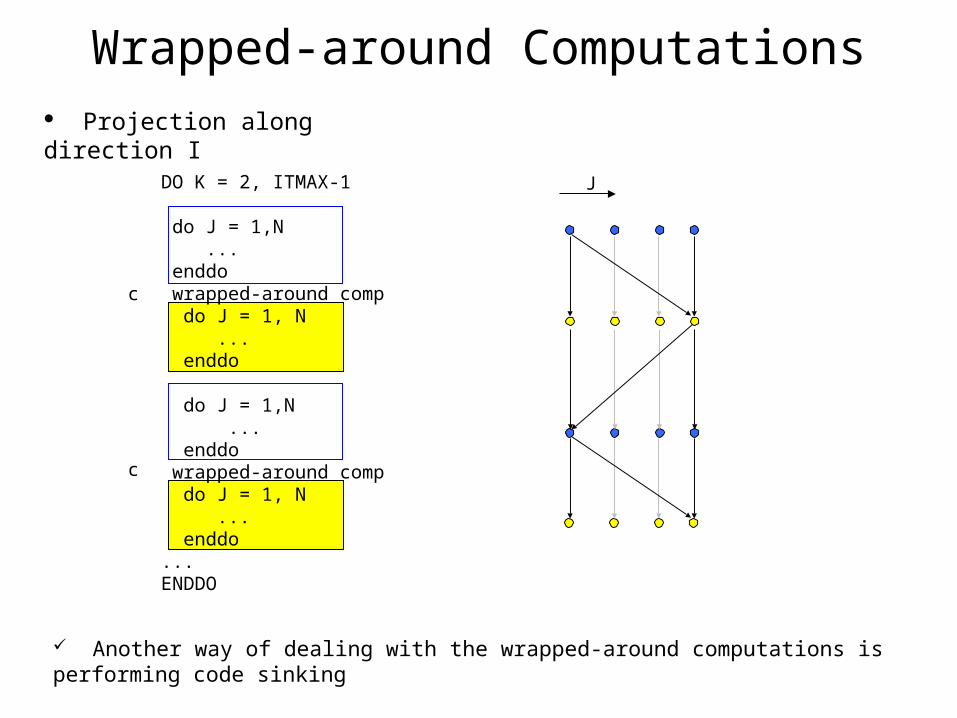
Projection along direction I
DO K = 2, ITMAX-1 do J = 1,N ... enddo wrapped-around comp do J = 1, N ... enddo do J = 1,N ... enddo wrapped-around comp do J = 1, N ... enddo...ENDDO
c
J
Wrapped-around Computations
c
Another way of dealing with the wrapped-around computations is performing code sinking
DO K = 2, ITMAX-1 do J = 1,N ... enddo wrapped-around do J = 1,N ... enddo wrapped-around
do J = 1,N ... enddo
wrapped-around
ENDDO
J
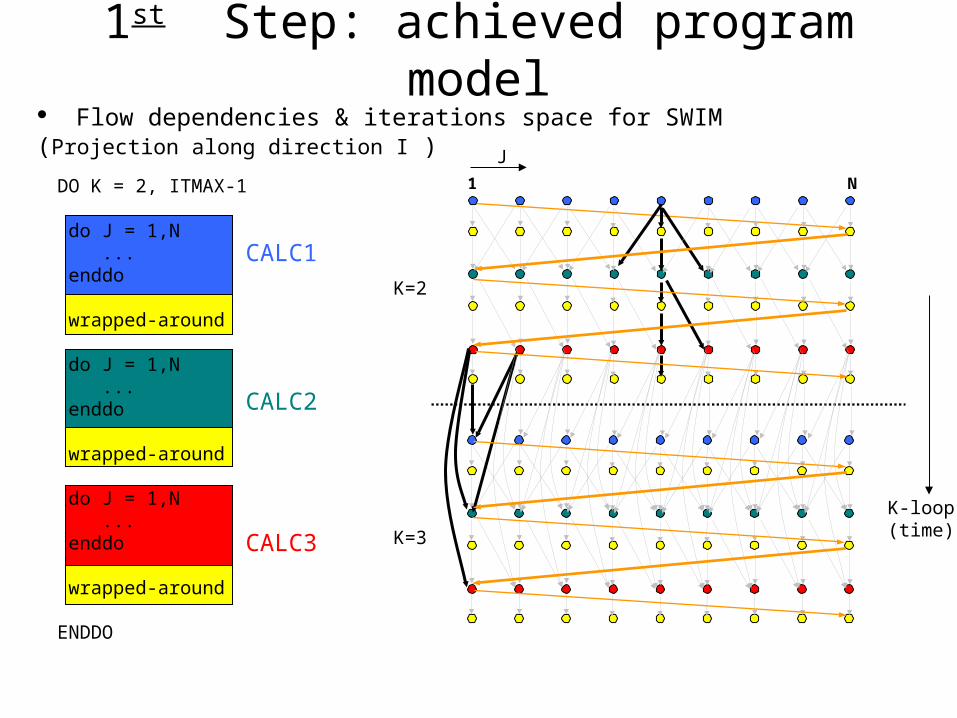
1st Step: achieved program model Flow dependencies & iterations space for SWIM (Projection along direction I )
CALC1
CALC2
CALC3
K-loop(time)
K=2
K=3
1 N

Steps
1- Apply a set of transformations to the original program to achieve the program model defined by Song & Li
2- Perform 2D-Tiling for the Cache Level
3- Perform 1D-Tiling for the Register Level
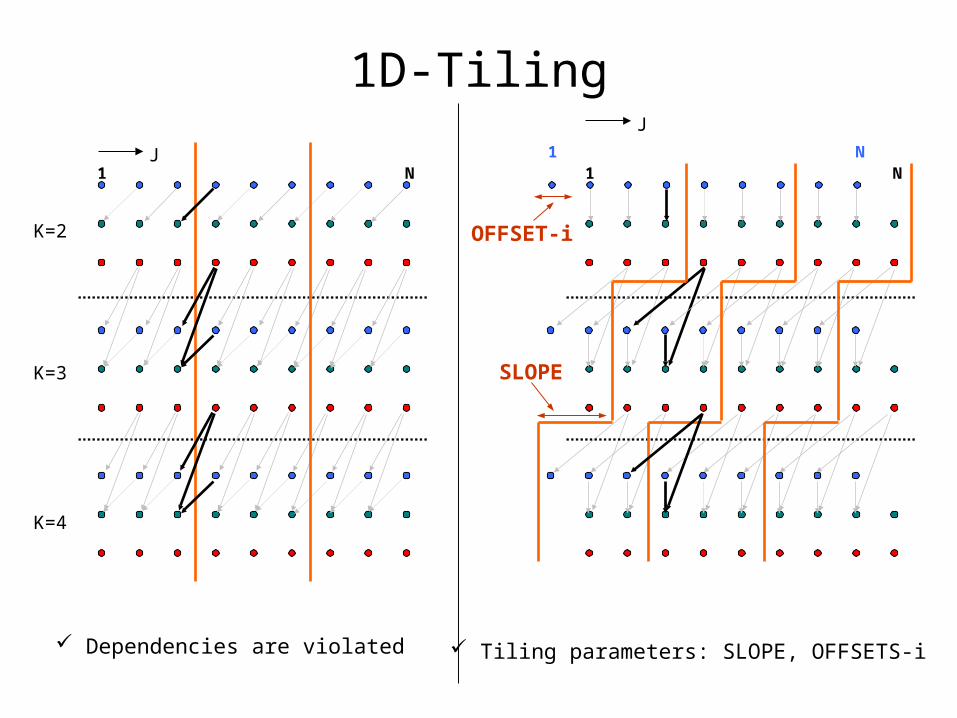
1D-Tiling
K=2
K=3
K=4
J1 N
Dependencies are violated Tiling parameters: SLOPE, OFFSETS-i
SLOPE
OFFSET-i
J
1 N1 N
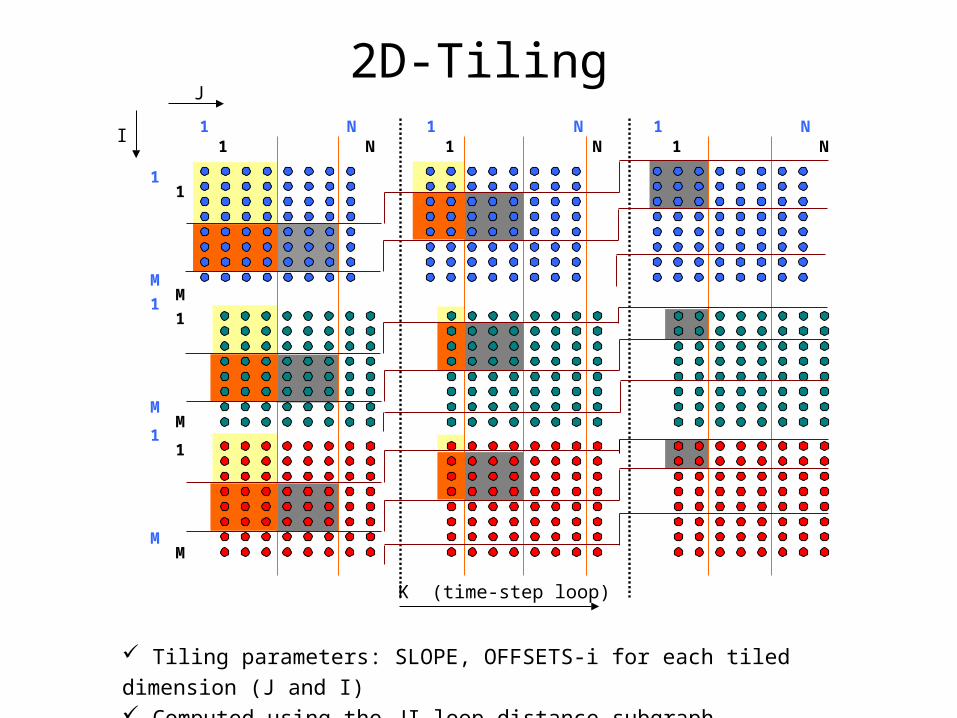
2D-Tiling
K (time-step loop)
J
I
1
M
N1
1
M
1
M
N1 N1
Tiling parameters: SLOPE, OFFSETS-i for each tiled dimension (J and I) Computed using the JI-loop distance subgraph
N1 N1 N1
1
M
1
M
1
M
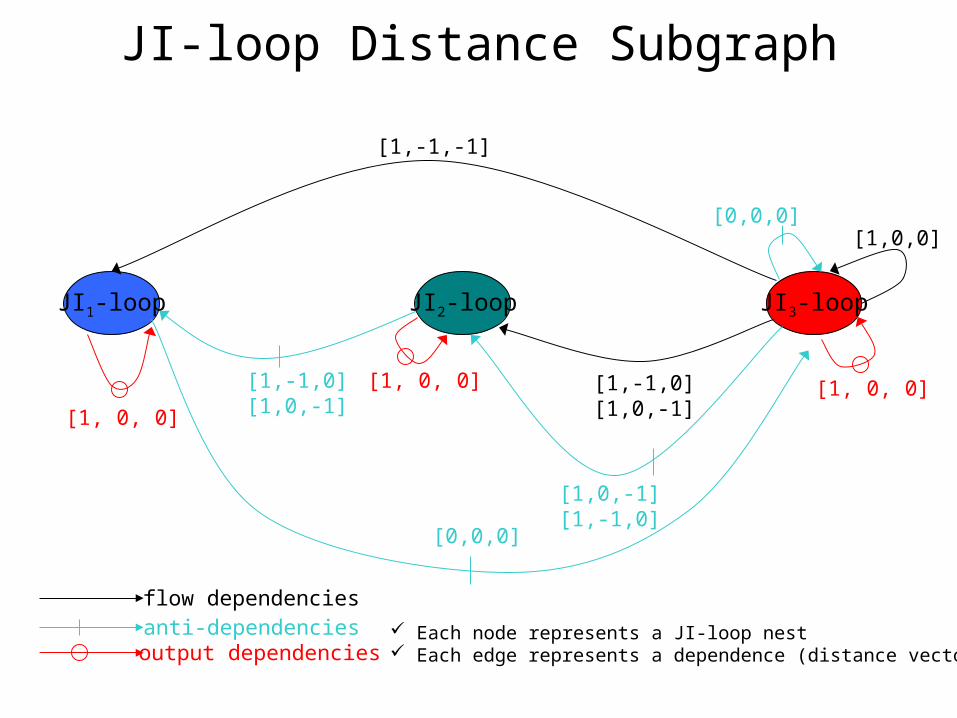
flow dependenciesanti-dependenciesoutput dependencies
JI3-loopJI2-loopJI1-loop
[1,-1,0][1,0,-1]
[1,-1,-1]
[1,0,0]
[1, 0, 0][1, 0, 0][1, 0, 0]
[0,0,0]
[1,-1,0][1,0,-1]
[1,0,-1][1,-1,0]
[0,0,0]
JI-loop Distance Subgraph
Each node represents a JI-loop nest Each edge represents a dependence (distance vector)
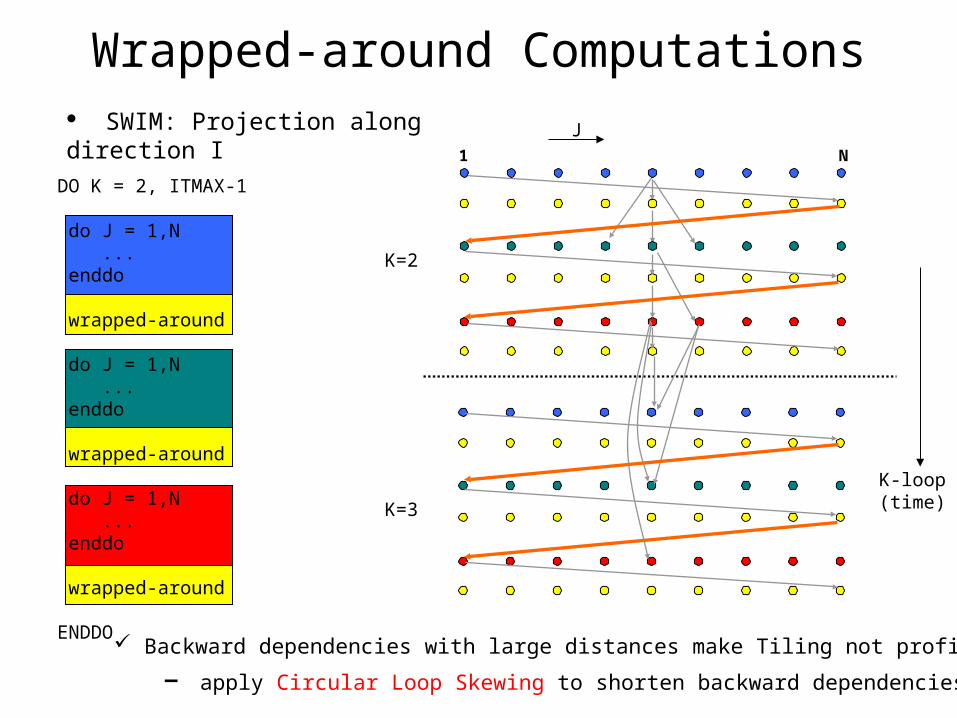
SWIM: Projection along direction I
Wrapped-around Computations
Backward dependencies with large distances make Tiling not profitable
– apply Circular Loop Skewing to shorten backward dependencies
DO K = 2, ITMAX-1 do J = 1,N ... enddo wrapped-around do J = 1,N ... enddo wrapped-around
do J = 1,N ... enddo
wrapped-around
ENDDO
K-loop(time)
K=2
K=3
1 N
J
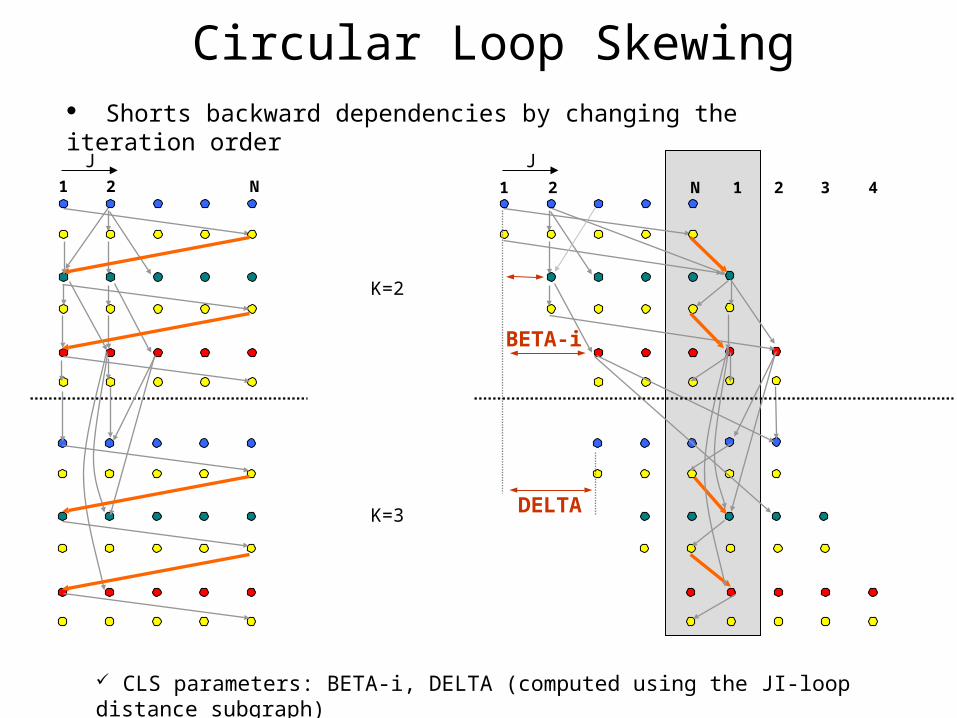
Shorts backward dependencies by changing the iteration order
Circular Loop Skewing
1 N
J
CLS parameters: BETA-i, DELTA (computed using the JI-loop distance subgraph)
K=2
K=3
1 N
J1 42 3
BETA-i
DELTA
22
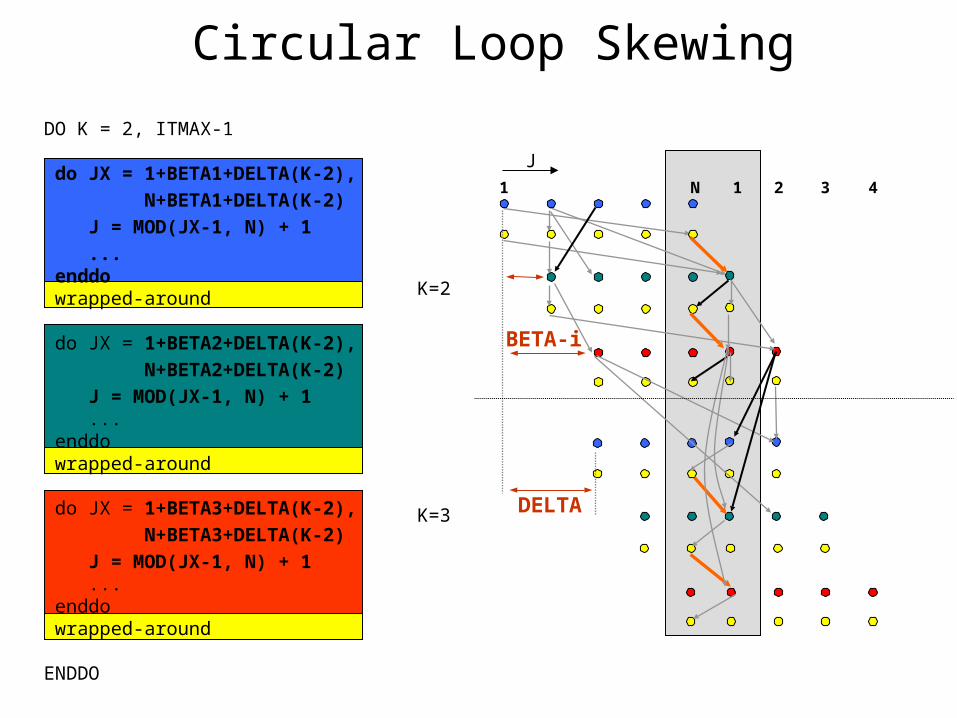
Circular Loop Skewing
DO K = 2, ITMAX-1 do JX = 1+BETA1+DELTA(K-2),
N+BETA1+DELTA(K-2)
J = MOD(JX-1, N) + 1
... enddo wrapped-around do JX = 1+BETA2+DELTA(K-2),
N+BETA2+DELTA(K-2)
J = MOD(JX-1, N) + 1 ... enddo wrapped-around
do JX = 1+BETA3+DELTA(K-2),
N+BETA3+DELTA(K-2)
J = MOD(JX-1, N) + 1 ... enddo wrapped-around
ENDDO
K=2
K=3
1 N
J1 42 3
BETA-i
DELTA
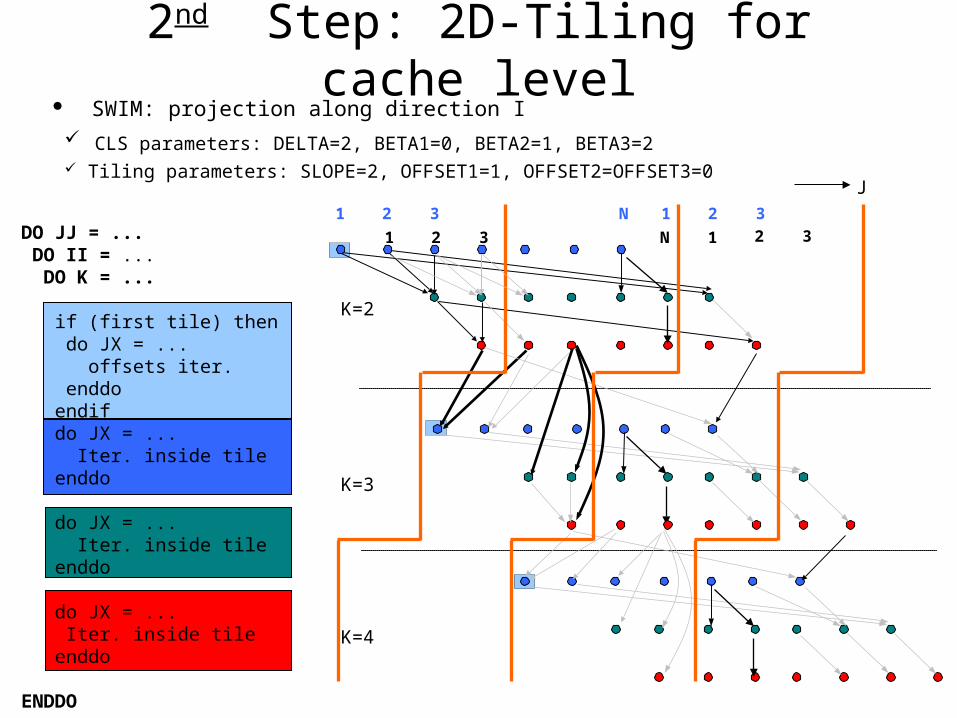
DO JJ = ... DO II = ... DO K = ... if (first tile) then do JX = ... offsets iter. enddo endif do JX = ... Iter. inside tile enddo do JX = ... Iter. inside tile enddo do JX = ... Iter. inside tile enddo
ENDDO
SWIM: projection along direction I CLS parameters: DELTA=2, BETA1=0, BETA2=1, BETA3=2 Tiling parameters: SLOPE=2, OFFSET1=1, OFFSET2=OFFSET3=0
2nd Step: 2D-Tiling for cache level
J
31 2 N 31 2
K=2
K=3
K=4
31 2 N 31 2

Steps
1- Apply a set of transformations to the original program to achieve the program model defined by Song & Li
2- Perform 2D-Tiling for the Cache Level
3- Perform 1D-Tiling for the Register Level

3rd Step: 1D-Tiling for register level
DO JJ = ... DO II = ... DO K = ... ...
do JX = LJ, UJ
J = MOD (JX-1, N)+1
do IX = LI, UI
I = MOD (IX-1, M)+1
[loop body: {I,J}]
enddo
enddo
...ENDDO
The MOD operation introduced by CLS prevents us to fully unroll the loop
Apply first Index Set Splitting to loop J
J
I
1
M
M-1
2
M-2
N 1N-1 2N-2
unrolled
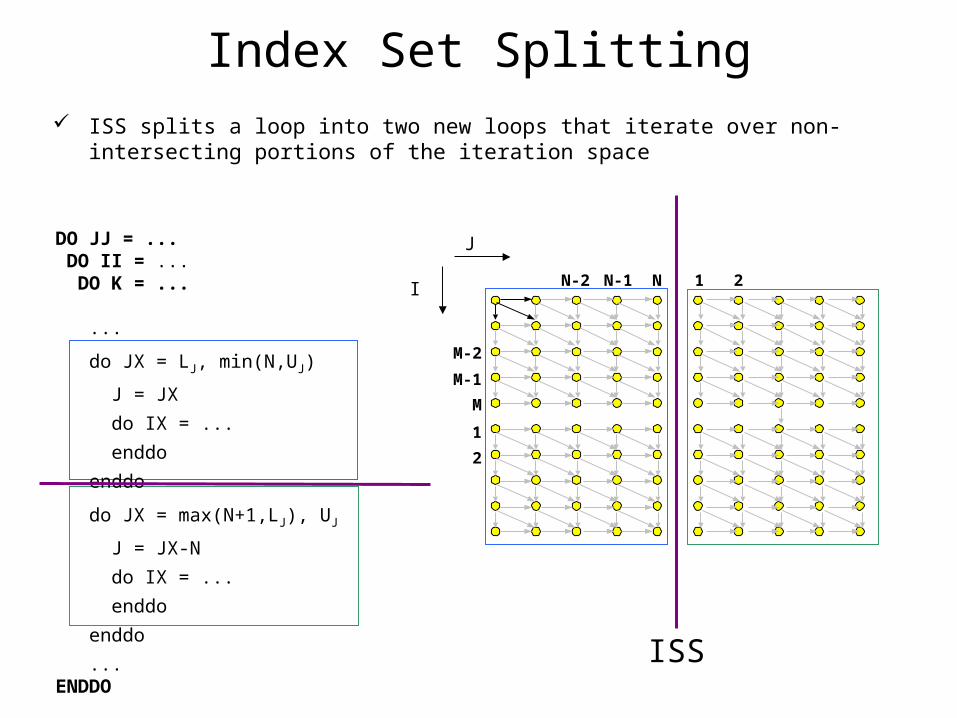
Index Set Splitting ISS splits a loop into two new loops that iterate over non-intersecting portions of
the iteration space
DO JJ = ... DO II = ... DO K = ... ...
do JX = LJ, min(N,UJ)
J = JX
do IX = ...
enddo
enddo
do JX = max(N+1,LJ), UJ
J = JX-N
do IX = ...
enddo
enddo
...ENDDO
J
I
1
M
M-1
2
M-2
N 1N-1 2N-2
ISS
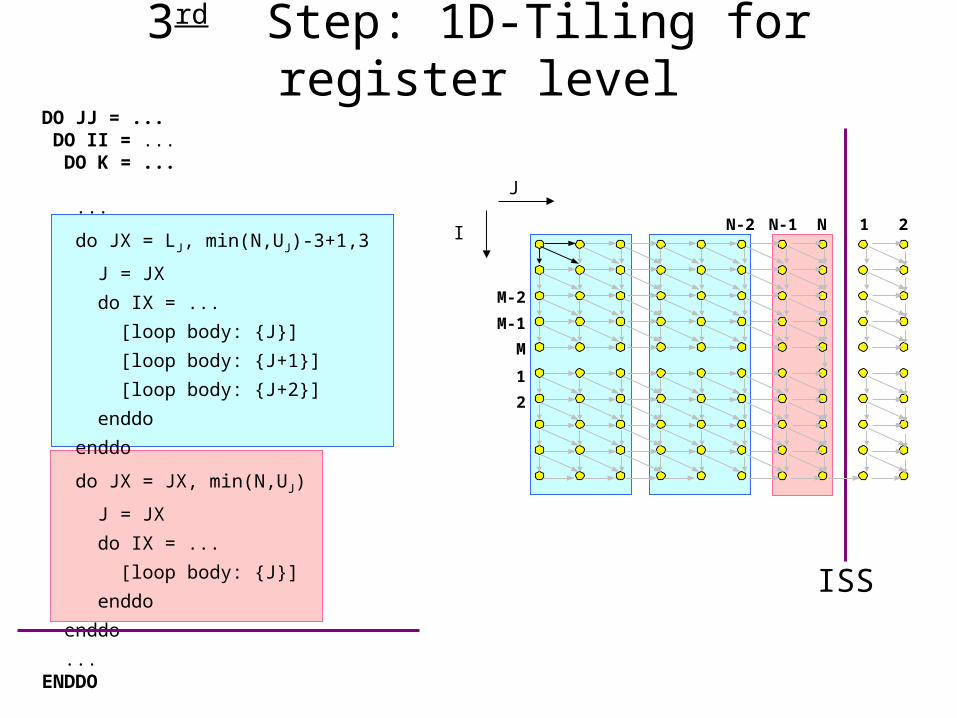
DO JJ = ... DO II = ... DO K = ... ...
do JX = LJ, min(N,UJ)-3+1,3
J = JX
do IX = ...
[loop body: {J}]
[loop body: {J+1}]
[loop body: {J+2}]
enddo
enddo
do JX = JX, min(N,UJ)
J = JX
do IX = ...
[loop body: {J}]
enddo
enddo
...ENDDO
J
I
1
M
M-1
2
M-2
N 1N-1 2N-2
ISS
3rd Step: 1D-Tiling for register level

Code Transformations Summary
1- Apply a set of transformations to the original program to achieve
the program model defined by Song & Li– Inline subroutines
– Convert GOTO into DO-loop
– Peel iterations of the time-step loop to eliminate IF-statements
2- Perform 2D-Tiling for the Cache Level– Construct JI-loop distance subgraph
– Compute DELTA and BETAs and apply CLS to shorten backwards dep.
– Update JI-loop distance subgraph
– Compute OFSSETs and SLOPE and tile the IS
3- Perform 1D-Tiling for the Register Level– Index Set Splitting
– Tiling in a straightforward manner
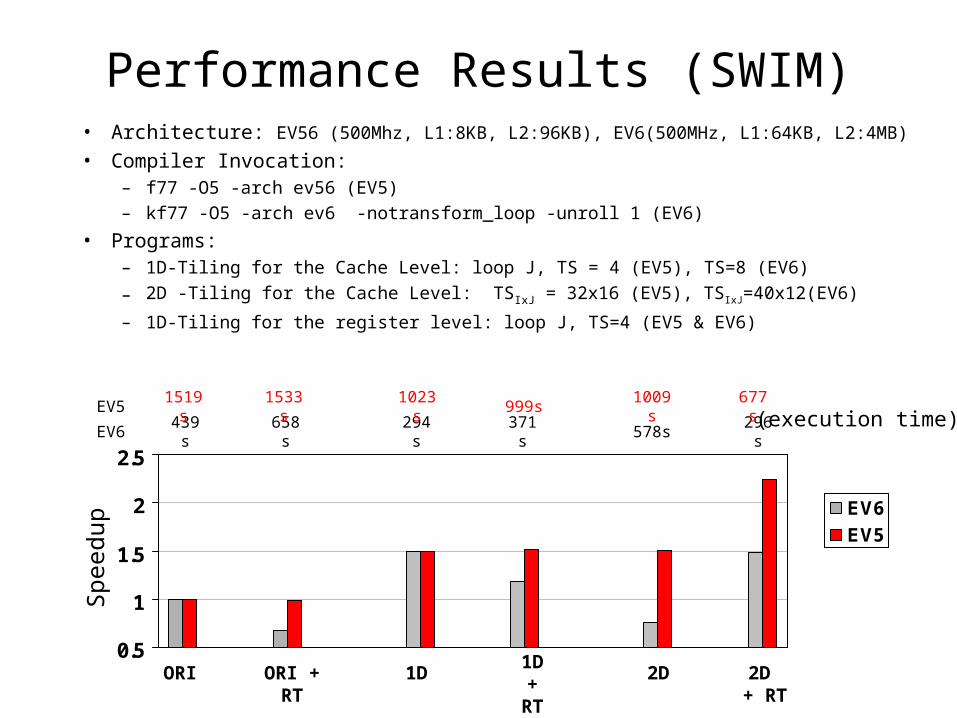
• Architecture: EV56 (500Mhz, L1:8KB, L2:96KB), EV6(500MHz, L1:64KB, L2:4MB) • Compiler Invocation:
– f77 -O5 -arch ev56 (EV5) – kf77 -O5 -arch ev6 -notransform_loop -unroll 1 (EV6)
• Programs:– 1D-Tiling for the Cache Level: loop J, TS = 4 (EV5), TS=8 (EV6)
– 2D -Tiling for the Cache Level: TSIxJ = 32x16 (EV5), TSIxJ=40x12(EV6)
– 1D-Tiling for the register level: loop J, TS=4 (EV5 & EV6)
Performance Results (SWIM)
0.5
1
1.5
2
2.5
EV6
EV5
Spe
edup
ORI ORI + RT
1D 1D + RT
2D 2D + RT
439s 658s 294s 371s 578s 296s(execution time)
1519s 1533s 1023s 999s 1009s 677sEV5
EV6
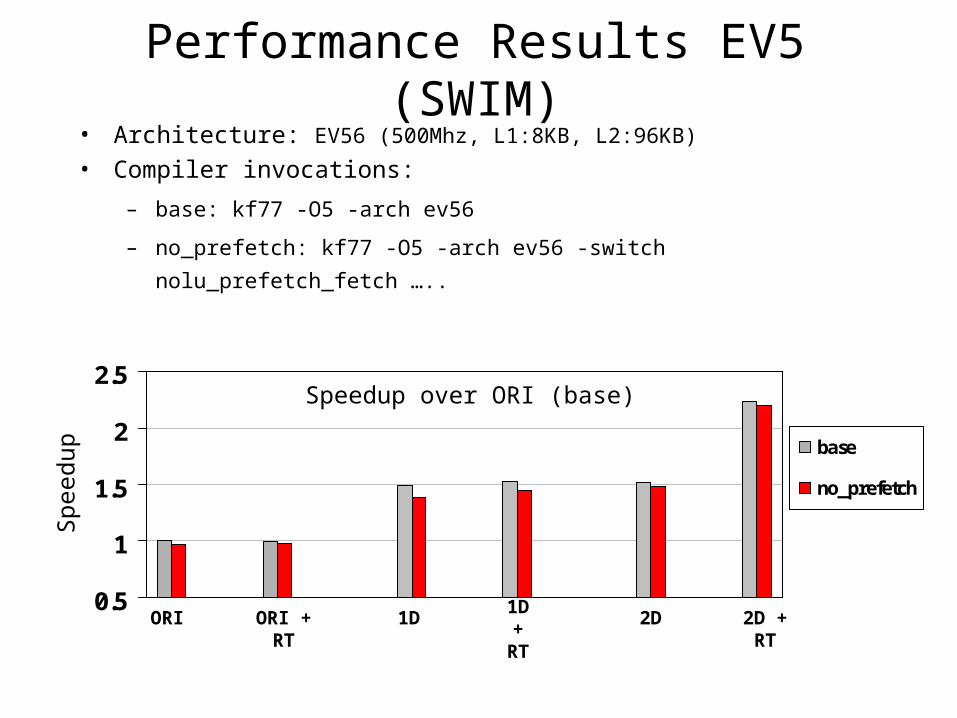
• Architecture: EV56 (500Mhz, L1:8KB, L2:96KB)
• Compiler invocations:
– base: kf77 -O5 -arch ev56
– no_prefetch: kf77 -O5 -arch ev56 -switch nolu_prefetch_fetch …..
Performance Results EV5 (SWIM)
0.5
1
1.5
2
2.5
base
no_prefetch
Speedup over ORI (base)
ORI ORI + RT
1D 1D + RT
2D 2D + RT
Spe
edup
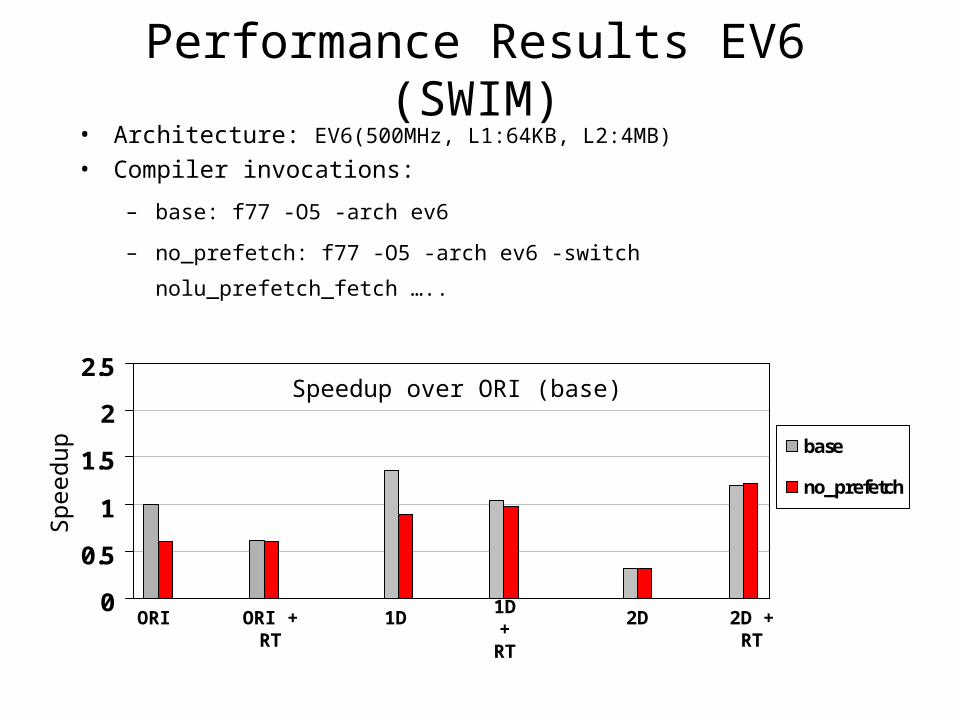
• Architecture: EV6(500MHz, L1:64KB, L2:4MB)
• Compiler invocations:
– base: f77 -O5 -arch ev6
– no_prefetch: f77 -O5 -arch ev6 -switch nolu_prefetch_fetch …..
Performance Results EV6 (SWIM)
0
0.5
1
1.5
2
2.5
base
no_prefetch
Speedup over ORI (base)
Spe
edup
ORI ORI + RT
1D 1D + RT
2D 2D + RT

J
Code for Result Verification
DO K = 2, ITMAX-1 ... do J = 1,N ... enddo
result verification
IF (MOD(K,MPRINT).eq.0) THEN do I = do J = UCHECK = UCHECK + {UNEW(I,J)} enddo UNEW (I,I) = . . . enddo PRINTS
ENDIF do J = 1,N ... enddoENDDO
c
Apply strip-mining to loop K (only useful if MPRINT is large)
NEW in SPEC2000!!





























