Embed Size (px)
Citation preview

Hedefler
Bu üniteyi çalıştıktan sonra;
- Basit Doğrusal regresyon öğrenecek- Regresyon Modeli kurma öğrenilecek- Çoklu regresyon modeli öğrenilecek
Anahtar Kavramlar
Beta katsayısıHata terimiScatter plotNormallik testiR2Durbin Watson İstatistiğiVIF DeğeriOtokorelasyon
İçindekiler
1. Basit Doğrusal Regresyon2. Basit Doğrusal Regresyon Modeli3. Çoklu Doğrusal Regresyon Modeli
1. Basit Doğrusal Regresyon
Regresyon analizi bir bağımlı değişken ile bir bağımsız (basit regresyon) veya birden fazla bağımsız (çoklu regresyon) değişken arasındaki ilişkilerin matematiksel eşitlik ile açılanması sürecidir. Regresyon analizinde değişkenler arasındaki ilişki doğrusal ise doğrusal regresyon, değil ise doğrusal olmayan regresyon olarak adlandırılır.
Onbirinci Bölüm
Regresyon Analizi

2 Sakarya Üniversitesi Bilimsel Araştırma ve Bilimsel Araştırma Süreci
2. Basit Doğrusal Regresyon Modeli
Y = β0 + β1x + e
β0 = Doğrunun y eksenini kestiği nokta
β1 = Doğrunun eğimi
e = şansa bağlı hata terimi
Burada β0 ve β1 hesaplanan ana kütlenin parametreleridir. Ancak yine de dikkate alınmayan bağımsız değişkenler olabileceğinden, verilen tesadüfi değişimleri gösteren ana kütle hata terimi de modele eklenmiştir.
Pratikte β0 ve β1 değerleri bilinmiyorsa, ana kütleden bir örnek alınarak ana kütle parametreleri hakkında istenilen bilgiler üretilir. Bu noktada tahmini değerler olarak b0 ve b1 kullanılır.
y = b0 + b1x
y = y’nin tahmini değeri
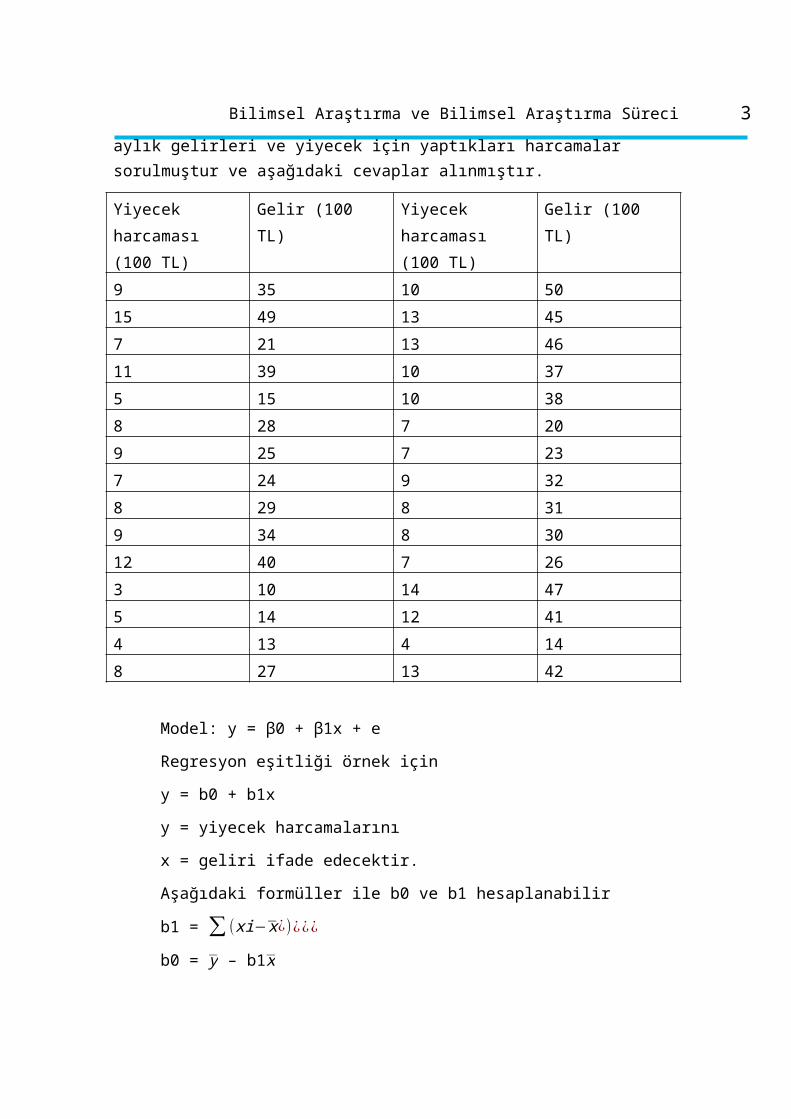
Örnek: Kişilerin aylık yiyecek harcamaları ile aylık gelirleri arasındaki ilişkiyi bulabilmek için 30 kişiye aylık gelirleri ve yiyecek için yaptıkları harcamalar sorulmuştur ve aşağıdaki cevaplar alınmıştır.
Yiyecek harcaması
(100 TL)
Gelir (100 TL) Yiyecek harcaması
(100 TL)
Gelir (100 TL)
9 35 10 50
15 49 13 45
7 21 13 46
11 39 10 37
5 15 10 38
8 28 7 20
9 25 7 23
7 24 9 32
8 29 8 31
3Bilimsel Araştırma ve Bilimsel Araştırma Süreci
9 34 8 30
12 40 7 26
3 10 14 47
5 14 12 41
4 13 4 14
8 27 13 42
Model: y = β0 + β1x + e
Regresyon eşitliği örnek için
y = b0 + b1x
y = yiyecek harcamalarını
x = geliri ifade edecektir.
Aşağıdaki formüller ile b0 ve b1 hesaplanabilir
b1 = ∑ (xi−x¿)¿¿¿
b0 = y – b1x
Yukarıdaki formüller kullanılarak b0 = 0,314 ve b1 = 0,283 ve doğrusal
regresyon modeli de
y= 0,314 + 0,283x olarak bulunur.
Regresyon parametreleri b0 ve b1 şu şekilde yorumlanabilir.
b0, x = 0 olduğunda bağımlı değişkenin tahmini değeridir. Yukarıdaki
problemde b0 = 0,314 olması şu anlama gelir. Bir insanın hiç geliri olmasa bile aylık en
az 31,4 TL tutarında bir yiyecek masrafı vardır.
b1 değeri regresyon katsayısıdır ve x’deki bir birimlik artışa karşılık y’deki
değişim miktarını gösterir. b1’in pozitif olması, bağımsız değişken x’in arttığında y’nin
artacağı anlamına gelir. Bu pozitif doğrusal ilişkidir. Aynı şekilde b1’in negatif olması,

4 Sakarya Üniversitesi Bilimsel Araştırma ve Bilimsel Araştırma Süreci
bağımsız değişken x’in arttığında y’nin azalacağını gösterir (negatif doğrusal ilişki).
Buna göre gelirimiz 1 TL arttığında yiyecek harcamalarımız 28,3 kuruş artmaktadır.
Regresyon denklemi kullanılarak, verilen bir x değeri için y’nin tahmini değeri
bulunabilir. Örneğimizde gelir düzeyi yaklaşık 3500 TL olan bir kişinin tahmini yiyecek
harcamasını hesaplarsak,
y = 0,314 + 0,283x = 0,314 + 0,283 * (3500) = 990,814 TL tahmini yiyecek
masrafı olacaktır.
Basit regresyon analizine geçmeden önce değişkenler arasındaki normal dağılım
ve doğrusal ilişki varsayımlarının test edilmesi gerekir. Değişkenler arasındaki ilişkinin
doğrusal olup, olmadığı serpilme grafiği Scatter Plot ile test edilebilir. Graphs
menüsünden legacy dialogs ve Scatter Plot seçilir. Y axis kısmına bağımlı değişken, X
axis kısmına bağımsız değişken yerleştirilir ve Ok tuşuna basılır ve doğrusal ilişkinin
varlığı veya yokluğu gözlemlenir. Normal dağılım için Analyze menüsünde
Descriptives ve Explore seçenekleri seçilir. Burada Normality Tests with Plots seçeneği
seçilir ve Normallik testleri Komolgov Smirnov veya Shapiro Wilkes’e bakılır.
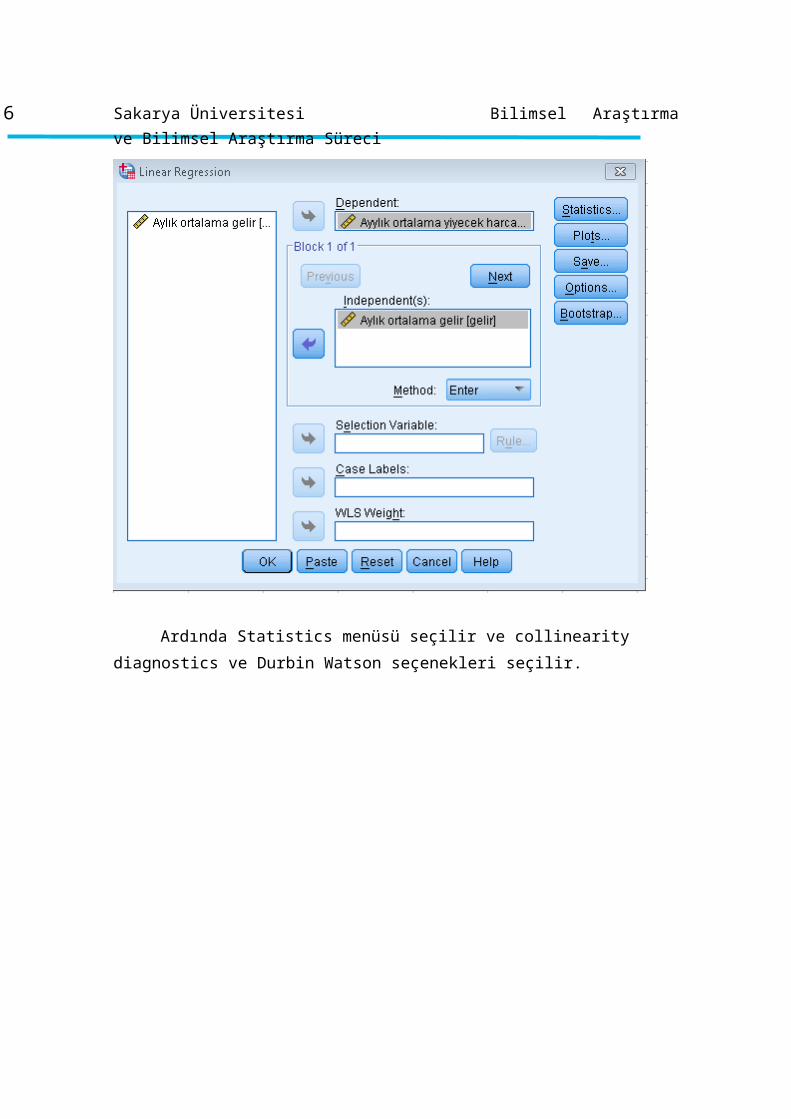
Basit doğrusal regresyon analizini SPSS’te yapmak için Analyze > regression >
Linear şeçenekleri seçilir. Bağımlı ve bağımsız değişken serileri tanımlandıktan sonra
istenilen regresyon metotu seçilir ve Ok tuşuna basılarak sonuçlar elde edilir.

5Bilimsel Araştırma ve Bilimsel Araştırma Süreci
Ardında Statistics menüsü seçilir ve collinearity diagnostics ve Durbin Watson
seçenekleri seçilir.
6 Sakarya Üniversitesi Bilimsel Araştırma ve Bilimsel Araştırma Süreci
Continue ve Ok tuşlarına basılır ve doğrusal basit regresyon sonuçları elde edilir.
Variables Entered/Removedb
Model
Variables
Entered
Variables
Removed Method
1 Aylık ortalama
gelir
. Enter
a. All requested variables entered.
b. Dependent Variable: Ayylık ortalama yiyecek
harcaması
İlk Tabloda enter metodu kullanıldığını ve aylık ortalama gelir değişkeninin
regresyon modeline girdiği belirtilmiştir.
Model Summaryb
Model R R Square
Adjusted R
Square
Std. Error of the
Estimate Durbin-Watson
1 ,946a ,895 ,891 1,01654 2,237
a. Predictors: (Constant), Aylık ortalama gelir
b. Dependent Variable: Ayylık ortalama yiyecek harcaması
Yukarıdaki Tabloda R2 değeri verilmektedir. Bulunan R2 değeri 0,895’tir.
Bunun anlamı bağımlı değişkendeki (Yemek harcaması) değişimin %89,5’i modele
giren bağımsız değişken (gelir) tarafından açıklanmaktadır. Yemek harcamalarındaki
değişimin %89,5’luk kısmı gelirdeki değişmeler tarafından açıklanabilmektedir. Burada
önemli bir istatistikte Durbin Watson istatistiğidir. Regresyonun önemli
varsayımlarından bir bağımsız ve bağımlı değişkenler arasında korelasyon olmamasıdır.
Ayrıca hata terimleri arasında da korelasyon olmamasıdır. SPSS korelasyon problemleri
için basit bir ölçüt geliştirmiştir. Durbin Watson istatistiği hata terimleri arasında
korelasyon olup, olmadığına bakmaktadır. Bu istatistik 0 ile 4 arasında yer alır. Eğer
istatistik değeri 2 civarında ise, korelasyon olmadığı şeklinde yorumlanır. 0’a yakın
değerler yüksek pozitif korelasyonu, 4’e yakın değerler yüksek negatif korelasyonu
belirtir. Bizim örneğimizde Durbin Watson istatistik değeri 2,237’dir. Yani 2

7Bilimsel Araştırma ve Bilimsel Araştırma Süreci
civarındadır ve hata terimleri arasında korelasyon olmadığı şeklinde yorumlanmalıdır.
Bu olumlu bir şeydir.
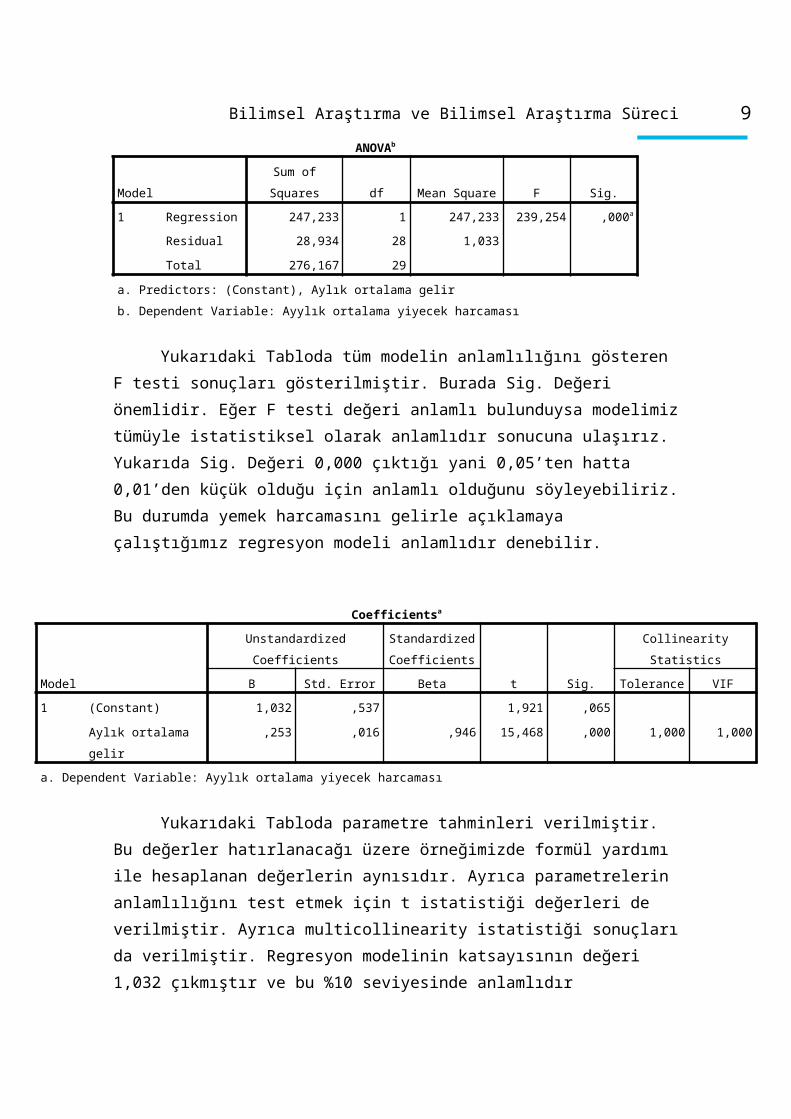
ANOVAb
Model Sum of Squares df Mean Square F Sig.
1 Regression 247,233 1 247,233 239,254 ,000a
Residual 28,934 28 1,033
Total 276,167 29
a. Predictors: (Constant), Aylık ortalama gelir
b. Dependent Variable: Ayylık ortalama yiyecek harcaması
Yukarıdaki Tabloda tüm modelin anlamlılığını gösteren F testi sonuçları
gösterilmiştir. Burada Sig. Değeri önemlidir. Eğer F testi değeri anlamlı bulunduysa
modelimiz tümüyle istatistiksel olarak anlamlıdır sonucuna ulaşırız. Yukarıda Sig.
Değeri 0,000 çıktığı yani 0,05’ten hatta 0,01’den küçük olduğu için anlamlı olduğunu
söyleyebiliriz. Bu durumda yemek harcamasını gelirle açıklamaya çalıştığımız
regresyon modeli anlamlıdır denebilir.
Coefficientsa
Model
Unstandardized Coefficients
Standardized
Coefficients
t Sig.
Collinearity Statistics
B Std. Error Beta Tolerance VIF
1 (Constant) 1,032 ,537 1,921 ,065
Aylık ortalama gelir ,253 ,016 ,946 15,468 ,000 1,000 1,000
a. Dependent Variable: Ayylık ortalama yiyecek harcaması
Yukarıdaki Tabloda parametre tahminleri verilmiştir. Bu değerler hatırlanacağı
üzere örneğimizde formül yardımı ile hesaplanan değerlerin aynısıdır. Ayrıca
parametrelerin anlamlılığını test etmek için t istatistiği değerleri de verilmiştir. Ayrıca
multicollinearity istatistiği sonuçları da verilmiştir. Regresyon modelinin katsayısının
değeri 1,032 çıkmıştır ve bu %10 seviyesinde anlamlıdır (significance değeri 0,065
olarak hesaplanmıştır). Gelirdeki 1 birimlik artış aylık yemek harcamalarını 0,253 birim
arttıracaktır. Bu katsayıya ilişkin t istatistiği değeri ve bunun significance değeri 0,000
çıkmıştır. Yani %1 anlamlılık seviyesinde bile bu katsayı anlamlıdır. Regresyon

8 Sakarya Üniversitesi Bilimsel Araştırma ve Bilimsel Araştırma Süreci
modelindeki bir diğer önemli kural ise bağımlı ve bağımsız değişkenler arasında yüksek
korelasyon olmamasıdır. VIF değeri bu sorunun varlığını saptamamıza yarar. VIF
değeri 5 ve yukarısı söz konusu değişkenin diğer regresyon modeli değişkenleri ile
yüksek korelasyona sahip olduğunu ve modelden çıkarılması gerektiğini bildirir. Burada
VIF değeri aylık ortalama gelir için 1,00’dır. Yani bağımlı değişkenler ile yüksek
korelasyona sahip değildir. Eğer burada birden fazla bağımsız değişken olsaydı VIF
değerinin yorumu daha anlamlı olabilecekti.
3. Çoklu Doğrusal Regresyon Modeli
Basit doğrusal regresyon modeli birçok durum için elverişli olabilir ancak
gerçek hayatta birçok modelin açıklanması için iki veya daha fazla açıklayıcı (bağımsız)
değişkene ihtiyaç duyulacaktır. Birden fazla açıklayıcı değişkene sahip regresyon
modellerine çoklu regresyon modelleri adı verilmektedir.
y = β0 + β1x + e Basit doğrusal regresyon modeli
y = β0 + β1x1 + ….. + βnxn + e Çoklu doğrusal regresyon modeli
y = Bağımlı değişken
xi = Bağımsız değişkenler
βi = Tahmin edilecek parametreler
e = Hata terimi
Çoklu regresyon modelinin varsayımları aşağıdadır
1. Normallik dağılımı
2. Doğrusallık
3. Hata terimlerinin ortalması 0’dır
4. Sabit varyans
5. Otokorelayon olmaması
6. Bağımsız değişkenler arasında çoklu bağlantının olmaması
Çoklu regresyon modelinde H0 hipotezi tüm regresyon katsayılarının sıfıra eşit
olduğunu (H0 = β1 = β2 = β3 = …. = βn) şeklinde kurulurken Ha hipotezi en az bir
9Bilimsel Araştırma ve Bilimsel Araştırma Süreci
βi’nin sıfırdan farklı olduğu şeklinde kurulur. Parametrelerin tek tek istatistiksel olarak
anlamlılığı için t testi sonuçlarına ve modelin bir bütün olarak anlamlılığı için F testi
sonuçlarına bakılır.
Belirlilik katsayısı (R2) bağımlı değişkenin yüzde kaçının modele dahil edilen
bağımsız değişkenler tarafından açıklandığını gösterir. Çoklu regresyonda modeler dahil
edilen değişken sayısı arttıkça otomatik olarak R2 artar. Dolayısıyla çoklu regresyonda
adjusted R2 değerini kullanmamız daha doğru olur.
Ölçüm yapılan bağımsız değişkenler, bağımlı değişken arasındaki ilişki,
değişken sayısı arttıkça daha iyi izah edilir duruma gelir. Ancak değişken sayısının
artması ek ölçümleri gerektirdiğinden zahmetli ve pahalı bir iştir. Bu nedenler toplam
değişimi en az değişkenle açıklamak amaç olmalıdır.
Değişken seçiminde en fazla kullanılan metot enter metodudur. Enter metotunda
araştırmacı modeli oluşturan bağımsız değişkenleri belirtir. Ardından bu modelin
bağımlı değişkenleri tahmin etme başarısı değerlendirilir. Eğer bir bağımsız değişkenin
diğerinden daha önemli olduğu düşünülüyorsa bu model kullanılır. Her bir değişken
modele eklendiği gibi, her birinin modele katkısı da değerlendirilir. Eğer eklenen
değişkenin modeli tahmin etme gücü artmıyorsa değişkenin modelden çıkarılmasında
bir sakınca yoktur.
Değişken ekleme metodunda (Forward Selection), SPSS değişkenleri bağımlı
değişkenler olan korelasyonlarının güçlerine göre modele sırayla sokar. Modele giren
her bir değişkenin etkisi ölçülür ve modeli önemli derecede etkilemeyen değişkenler
modelden çıkarılır.
Değişken eleme işlemi (Backward Selection), SPSS tüm değişkenleri modele
dahil eder. En güçsüz bağımsız değişken modelden çıkarılır ve regresyon tekrar
hesaplanır. Eğer bu durumda model önemli derecede güçsüzleniyorsa, bağımsız
değişken tekrar modele eklenir, eğer güçsüzleşme önemli derecede değilse bağımsız
değişken modelden çıkarılır. Bu süreç sadece yararlı bağımsız değişkenler modelde
kalıncaya kadar devam eder.

10 Sakarya Üniversitesi Bilimsel Araştırma ve Bilimsel Araştırma Süreci
Değişken ekleme ve eleme metodu (Stepwise Selection) ise her değişken modele
sırayla eklenir ve model değerlendirilir. Eğer eklenen değişken modele katkı sağlıyorsa
modelde bu değişken kalır. Ancak modeldeki diğer değişkenlerin tümü, modele katkı
yapıp yapmadıklarını değerlendirmek için yeniden test edilir. Eğer önemli derecede
katkı sağlanmıyorsa modelden çıkarılır. Böylece en az sayıda değişken yardımı ile
model açıklanmış olur.
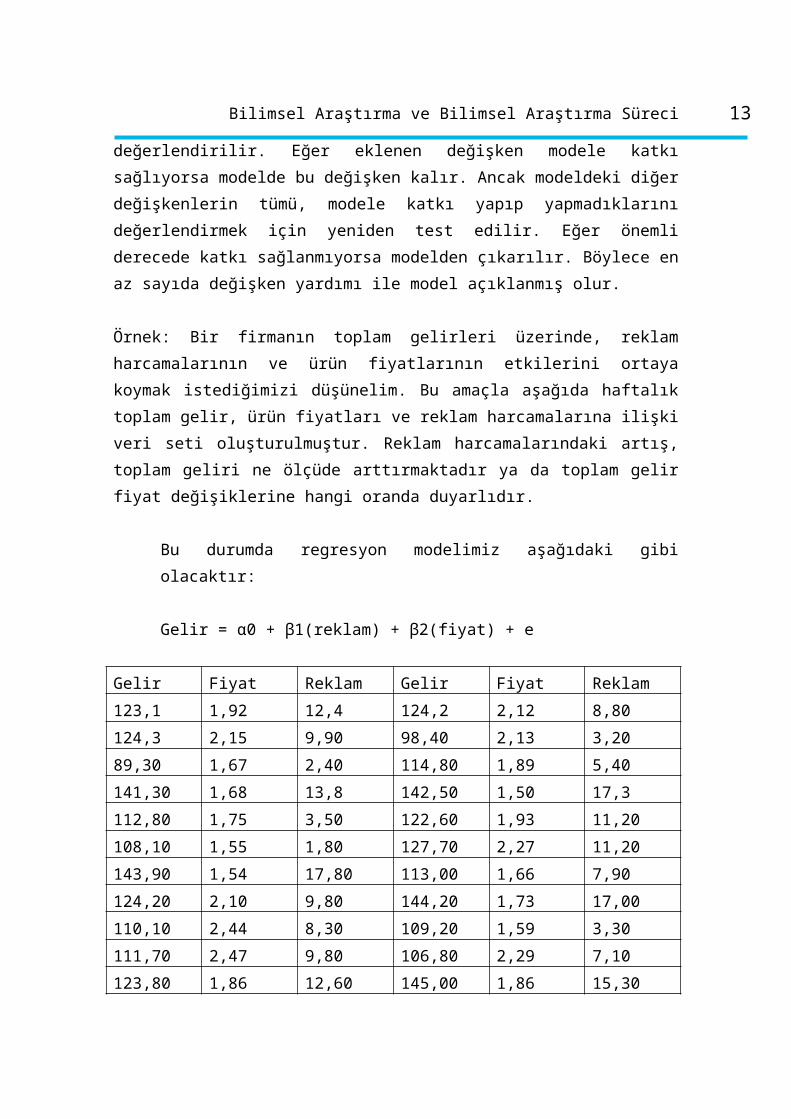
Örnek: Bir firmanın toplam gelirleri üzerinde, reklam harcamalarının ve ürün
fiyatlarının etkilerini ortaya koymak istediğimizi düşünelim. Bu amaçla aşağıda haftalık
toplam gelir, ürün fiyatları ve reklam harcamalarına ilişki veri seti oluşturulmuştur.
Reklam harcamalarındaki artış, toplam geliri ne ölçüde arttırmaktadır ya da toplam gelir
fiyat değişiklerine hangi oranda duyarlıdır.
Bu durumda regresyon modelimiz aşağıdaki gibi olacaktır:
Gelir = α0 + β1(reklam) + β2(fiyat) + e
Gelir Fiyat Reklam Gelir Fiyat Reklam
123,1 1,92 12,4 124,2 2,12 8,80
124,3 2,15 9,90 98,40 2,13 3,20
89,30 1,67 2,40 114,80 1,89 5,40
141,30 1,68 13,8 142,50 1,50 17,3
112,80 1,75 3,50 122,60 1,93 11,20
108,10 1,55 1,80 127,70 2,27 11,20
143,90 1,54 17,80 113,00 1,66 7,90
124,20 2,10 9,80 144,20 1,73 17,00
110,10 2,44 8,30 109,20 1,59 3,30
111,70 2,47 9,80 106,80 2,29 7,10
123,80 1,86 12,60 145,00 1,86 15,30
123,50 1,93 11,50 124,00 1,91 12,70
110,20 2,47 7,40 106,70 2,34 6,10

11Bilimsel Araştırma ve Bilimsel Araştırma Süreci
100,90 2,11 6,10 153,20 2,13 19,60
123,30 2,10 9,50 120,10 2,05 6,30
115,70 1,73 8,80 119,30 1,89 9,00
116,60 1,86 4,90 150,60 2,12 18,70
153,50 2,19 18,80 92,20 1,87 2,20
149,20 1,90 18,90 130,50 2,09 16,00
89,00 1,67 2,30 112,50 1,76 4,50
132,60 2,43 14,10 111,80 1,77 4,30
97,50 2,13 2,90 120,10 1,94 9,30
106,10 2,33 5,90 107,40 2,37 8,30
115,30 1,75 7,60 128,60 2,10 15,40
98,50 2,05 5,30 124,60 2,29 9,20
135,10 2,35 16,80 127,20 2,36 10,20
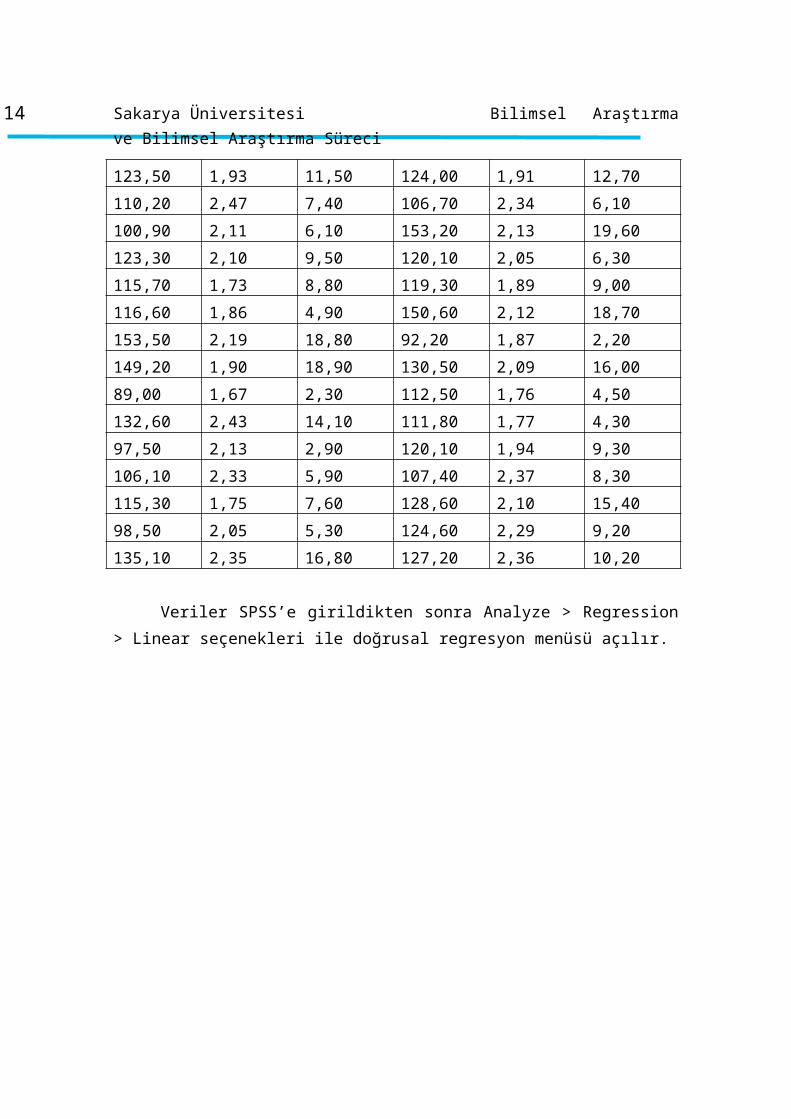
Veriler SPSS’e girildikten sonra Analyze > Regression > Linear seçenekleri ile
doğrusal regresyon menüsü açılır.
Az sayıda bağımsız değişken olduğu için enter metodu daha uygun olacaktır.
Haftalık ortalama gelir değişkeni dependent kutucuğuna bağımlı değişken olarak taşınır.
Haftalık ortalama ürün fiyatı ve haftalık ortalama reklam harcamaları independent

12 Sakarya Üniversitesi Bilimsel Araştırma ve Bilimsel Araştırma Süreci
kutucuğuna bağımsız değişkenler olarak aktarılır. Ardından sağ tarafta bulunan
Statistics kutucuğu tıklanır.
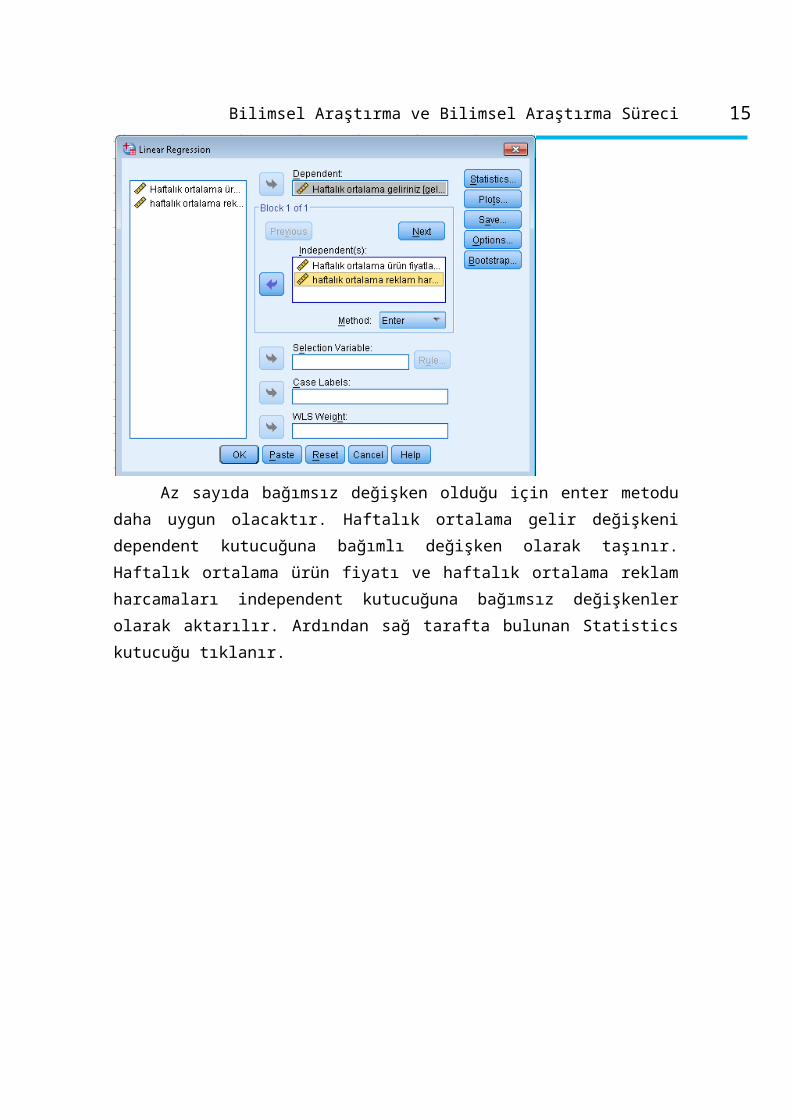
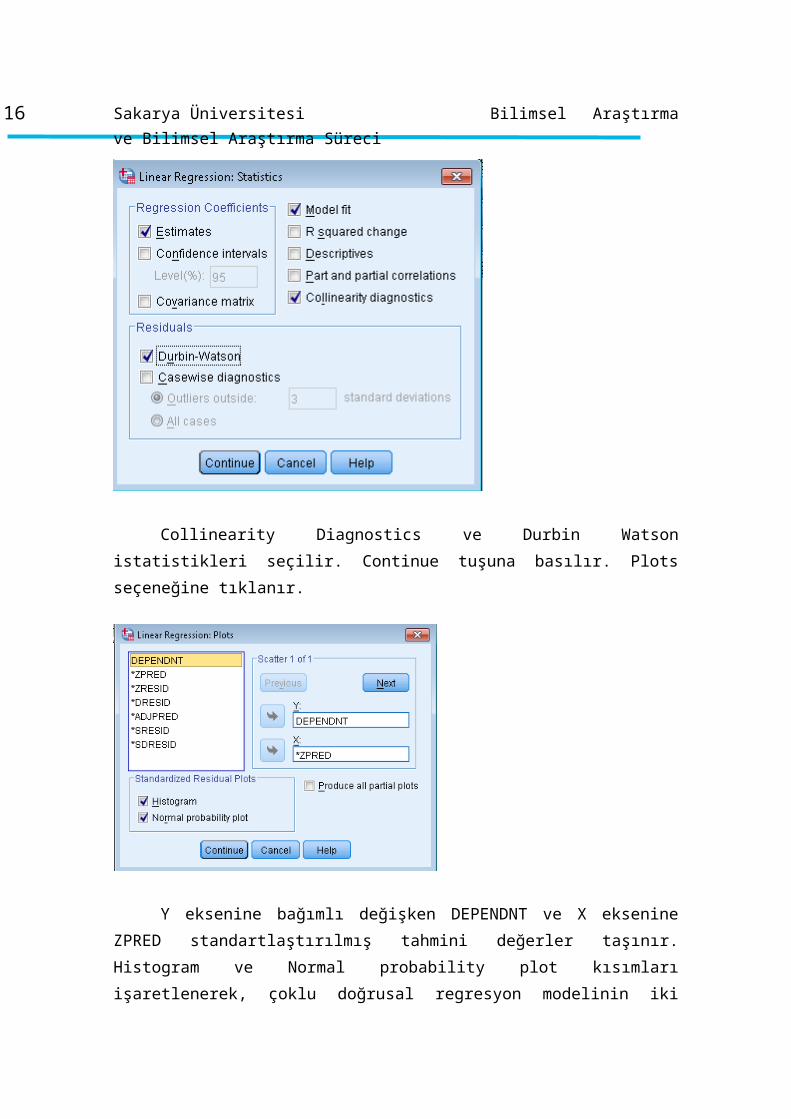
Collinearity Diagnostics ve Durbin Watson istatistikleri seçilir. Continue tuşuna
basılır. Plots seçeneğine tıklanır.
Y eksenine bağımlı değişken DEPENDNT ve X eksenine ZPRED
standartlaştırılmış tahmini değerler taşınır. Histogram ve Normal probability plot
kısımları işaretlenerek, çoklu doğrusal regresyon modelinin iki varsayımının (çoklu
13Bilimsel Araştırma ve Bilimsel Araştırma Süreci
normal dağılım ve doğrusallık varsayımlarının) testi yapılır. Continue tuşuna ve
ardından OK tuşuna basılır ve aşağıda yer alan SPSS analiz çıktıları elde edilir ve
yorumlanır.
Variables Entered/Removedb
Model
Variables
Entered
Variables
Removed Method
1 haftalık ortalama
reklam
harcamaları,
Haftalık
ortalama ürün
fiyatları
. Enter
a. All requested variables entered.
b. Dependent Variable: Haftalık ortalama geliriniz
Haftalık ortalama reklam harcamaları ve haftalık ortalama ürün fiyatları
değişkenleri regresyon modeline ente metodu ile dahil edilmiştir.
Model Summaryb
Model R R Square
Adjusted R
Square
Std. Error of the
Estimate Durbin-Watson
1 ,931a ,867 ,862 6,06961 2,041
a. Predictors: (Constant), haftalık ortalama reklam harcamaları, Haftalık ortalama ürün
fiyatları
b. Dependent Variable: Haftalık ortalama geliriniz
R2 değeri 0,931 çıkmıştır ancak çoklu regresyon olduğu için Adjusted R2 değeri
değeri dikkate alınmalıdır. Bu değer 0,862 olarak hesaplanmıştır. Yani iki bağımsız
değişken (reklam harcamaları ve ürün fiyatı), bağımlı değişkendeki (gelir) değişimin
%86,2’sini açıklayabilmektedirler. Bu değer oldukça yüksektir ve sosyal bilimler
araştırmalarında tatmin edicidir. Bu arada Durbin Watson istatistiği 2,041 olarak
hesaplanmıştır. 2 civarında çıktığı için otokorelasyon olmadığının bir göstergesidir.
14 Sakarya Üniversitesi Bilimsel Araştırma ve Bilimsel Araştırma Süreci
ANOVAb
Model Sum of Squares df Mean Square F Sig.
1 Regression 11776,184 2 5888,092 159,828 ,000a
Residual 1805,168 49 36,840
Total 13581,352 51
a. Predictors: (Constant), haftalık ortalama reklam harcamaları, Haftalık ortalama ürün fiyatları
b. Dependent Variable: Haftalık ortalama geliriniz
ANOVA testi anlamlı çıkmıştır. P değeri 0,000’dır. Yani regresyon modeli bir
bütün olarak anlamlıdır.
Coefficientsa
Model
Unstandardized Coefficients
Standardized
Coefficients
t Sig.
Collinearity Statistics
B Std. Error Beta Tolerance VIF
1 (Constant) 104,786 6,483 16,164 ,000
Haftalık ortalama ürün
fiyatları
-6,642 3,191 -,109 -2,081 ,043 ,990 1,010
haftalık ortalama reklam
harcamaları
2,984 ,167 ,936 17,877 ,000 ,990 1,010
a. Dependent Variable: Haftalık ortalama geliriniz
Regresyon modelinin katsayıları ve anlamlılık değeri yukarıdaki tabloda
verilmiştir. Sabit terimin katsayısı 104,786 olarak hesaplanmış ve p değeri 0,000 olarak
belirtilmiştir. Bu durumda sabit terim anlamlıdır. Ürün fiyatlarının regresyon modeli
katsayısı -6,642 olarak hesaplanmıştır. T testi sonucunda anlamlılık derecesi 0,043
olarak hesaplanmıştır. 0,05’ten küçük olduğu için %5 anlamlılık derecesinde anlamlıdır.
Ancak görüldüğü gibi gelirler ürün fiyatı ters orantılı bir şekilde ilişkilidir. Çünkü
regresyon modeli katsayısı negatif çıkmıştır. Reklam harcamalarının regresyon modeli
katsayısı 2,984 olarak hesaplanmış ve p değeri 0,000 çıkmıştır yani modelin sabit terimi
gibi reklam harcamaları da yüksek derecede anlamlıdır. Collinearity istatistikleri 1,010
civarında çıkmıştır. 5 ve daha yüksek çıkmadığı için bağımsız değişkenler arasında
korelasyon olmadığı ve her iki değişkenin de modelde kalmasının uygun olacağı
şeklinde yorumlanabilir.
15Bilimsel Araştırma ve Bilimsel Araştırma Süreci
Aylık ortalama gelir histogramdan görüldüğü gibi yaklaşık normal olarak
dağılmaktadır. Normallik varsayımı sağlanmıştır.
Haftalık ortalama gelir ile tahmin edilen değerler arasındaki dağılım grafiği de
doğrusal pozitif bir ilişki olduğu yönündedir. Regresyon modelinin doğrusallık
varsayımı da sağlanmıştır.
16 Sakarya Üniversitesi Bilimsel Araştırma ve Bilimsel Araştırma Süreci
Değerlendirme Soruları
1. Basit doğrusal regresyon modelini açıklayınız..2. Beta katsayısı, hata terimi regresyon modelinde ne ifade eder?3. Multicollinearity ve Durbin Watson İstatistiğini açıklayınız.4. Çoklu regresyon modelinin özellikleri nelerdir.
Kaynakça
Spiers, N., Manktelow, B. Ve Hewitt, M. J.(2009), Practical Statistics Using SPSS, National Institude for Health Research NHS, England.
Field, A. (2005), Discovering Statistics using SPSS, SAGE, London.
Kalaycı, Ş. (2006), SPSS Uygulamalaı Çok değişkenli İstatistik Teknikleri, Asil Yayın Dağıtım






















