Embed Size (px)
Citation preview

MachineLearning Overview
Jeff Kirk, Server CTO Office
Dell EMC HPC Community Meeting3/29/17

A breakthrough in machine learning would be worth ten Microsofts.
- Bill Gates

IntelligencefromProcessing
LEARNING– condensingdataintoahigh-dimensionalprobabilitymodeltobeusedfor:
§ JUDGEMENT – summarizingthecontentoftheprobabilitymodel
§ PREDICTION – usingthemodeltodeduceprobableoutputsgivensomeinputs
§ INFERENCE – usingthemodeltodeduceprobableinputsgivensomeoutputs
§ CLASSIFICATION – usingthemodeltolabelortagthedata
3

Andnowforsomethingcompletelynew…
4
From1930’suntil2010’s:
CPU(andGPU)+
programming

Andnowforsomethingcompletelynew…
5
From1930’suntil2010’s:
CPU(andGPU)+
programming
Recently:
NeuralNetworks
+Learning

BigPicture- Algorithms
Subject Area Algorithms
Regression GradientDescent,Coordinate Descent
Classification StochasticGradientDescent, Boosting
Clusteringand Retrieval KD-trees, LSH,K-means,EM
MatrixFactorizationandDimensionality Reduction CoordinateDescent, Eigendecomposition,SVD
DeepLearning Neural Networks(non-linear)
LSH=Locality-SensitiveHashingEM=Expectation-MaximizationSVD=SingularValueDecomposition
seeWikipediaforgoodoverview ofneuralnetworks6
LargeNeuralnetworksaretheonlyalgorithmthatrequiresmassivecomputepower

DeepLearning(http://abstrusegoose.com/496) !
7

Learning Process(independent of algorithm)

TheLearningProcess
MLAlgorithm
Scoring
ClassificationEngine
trainedparametersorweights(Ŵ)
trainingdata
usefulintelligence
iterateuntilsatisfied
realworddata
TrainingPhase UsePhase9
TheclassificationengineimplementstheMLmodel

MatrixformofRSS*(minimizetheerror)
y=truevalueHxw=predictedɛ =error
10
+=
W=parametersorcoefficients
*residualsumofsquares
H=trainingdata
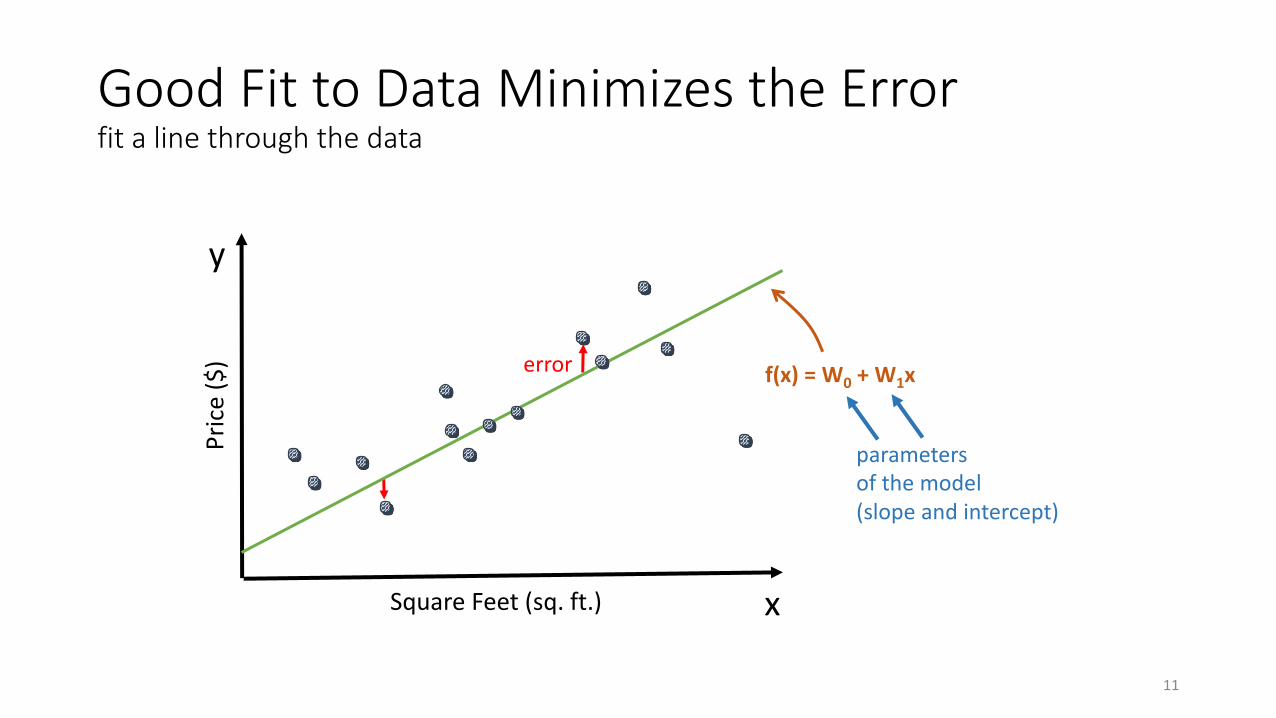
GoodFittoDataMinimizestheErrorfitalinethroughthedata
11
error f(x)=W0 +W1x
parametersofthemodel(slopeandintercept)
y
x
Price($)
SquareFeet(sq.ft.)

BetterFit?
fw(x)=w0 +w1x+w2x2
Maybeastraightlineisnotthebestchoice
Addanewfeaturetominimizeerrorsacrossthedataset
12
y
Price($)
xSquareFeet(sq.ft.)
error

OverFit WecanminimizeRSSwithmorefeatures
but…
Resultsinover-fittingandnotusefulforprediction
Fix:use“testdata”splittocheckforovertraining
13
y
Price($)
xSquareFeet(sq.ft.)
fw(x)=w0 +w1x+w2x2 …w15x15
Verysmallerrors
Badprediction

Hyper-parameters:affectingthetrainingprocess
• Inthecontextofmachinelearning,hyper-parameteroptimizationormodelselectionistheproblemofchoosingasetofhyper-parametersforalearningalgorithm,usuallywiththegoalofoptimizingameasureofthealgorithm'sperformance onanindependentdataset.
• Ineffect,learningalgorithmslearnparametersthatmodel/reconstructtheirinputswell(ŵ),whilehyper-parameteroptimizationcontrolsthetrainingprocessornetworkarchitectureitselftoeitherspeeduptheprocessorpreventoverfitting.
• Forexample,aratio(percentage)oftheweight'sgradientinfluencesthespeedandqualityoflearning;itiscalledthe learningrate
14

Dell - Restricted - Confidential
Background:MathPerformanceisKey
• MostoftherecentperformancegainsbyGPUs(andKNM)isduetoprecisionoptimizations:
• Butthereisonemoreoptimizationstep:specializedsilicon• Special16bitprecisionenhancements• Betterinternalnetwork,i.e.graphsupportandmoreconnectivity• Betteruseofmemory
• DellEMCneedstosupportthisnewsilicon
15
64-bitDP 16-bitHP32-bitSP Some8bit
PrecisionEvolution:

Special Case (Deep Learning):Neural Networks

NeuralNetworks
§ Layersandlayersoflinearmodelsandnon-lineartransformations
§ Aroundforabout50years• Felloutoffavorinthe90’s
§ Inthelastfewyearsabigresurgenceofinterest
• Impressiveaccuracyonseveralbenchmarkproblems
• Poweredbyhugedatasets,fastercompute,andalgorithmimprovements
17

BackPropagationtrainingbigneuralnetworks
• Howdowetrainthehiddenlayersofabig(deep)network?• Answer:BackPropagation.Errorvaluesarepropagatedbackwards,startingfromtheoutput,untileachneuronhasanassociatederrorvaluewhichroughlyrepresentsitscontributiontotheoriginaloutput
• Thegoalofbackpropagationistocomputethepartialderivative,orgradient,withrespecttoanyweightwinthenetwork
• Foreachweight,thefollowingstepsmustbefollowed:1. Theweight'soutputdeltaandinputactivationaremultipliedtofindthe
gradientoftheweight.2. Aratio(percentage)oftheweight'sgradientissubtractedfromtheweight.
18

TypesofNeurons
• LinearNeuron• BinaryThreshold• RectifiedLinearNeuron• SigmoidNeurons<-- mostcommon(logisticfunction,smoothderivatives)
• StochasticBinaryNeurons• LSTM<-- usedinRNN
• Alsousesthelogisticfunction• Turing-complete
19

Hyper-tuning– selectingamodel
20

DeepLearningScoreCard
Pro:• Enableslearningoffeaturesratherthanhandtuning
• Impressiveperformancegains- Computervision
- Speechrecognition- Sometextanalysis
• Potentialformoreimpact
Con:• Requiresalotofdataforhighaccuracy
• Computationallyreallyexpensive
• Extremelyhardtotune- Choiceofarchitecture- Parametertypes- Hyperparameters- Learningalgorithm…
21
computationalcost+somanychoices=
incrediably hardtotune
Plus,
notanalytic,i.e.oftenlittleinsighttotheweights

Frameworks

23 of YRestricted - Confidential
Background: Most AI Frameworks Are Open Source
Key points:
• Some of the frameworks supported by major players:• TensorFlow: Google• Mxnet: Amazon• CNTK: Microsoft• Apple: Turi

Summing Up

So,whatisimportanttoDellEMCinML?
• CUSTOMERSUCCESS – tobeabroad-basedsupplierweneedALLDellcustomerstobesuccessful.Therefore:
• Easeofuse• Accuracy• Hyper-tuning
• ThebigguysuselotsofPhDstoovercomethelimitations,itisunlikelyDellEMCcustomerswilldoso,therefore,DellEMCneedstoprovidemorethanhardware.
• AllPOC’sneedtoreportasmuchofthisinformationaspossible
Thisiswhatweneedto“benchmark”
25

Thank-you
26








![Chapter 1: Overview of TensorFlow and Machine LearningChapter 1: Overview of TensorFlow and Machine Learning. Graphics [ 2 ] Chapter 2: Using Machine Learning to Detect Exoplanets](https://img.pdfslide.net/doc/110x75/5ec46c95ad4c9658a01463b7/chapter-1-overview-of-tensorflow-and-machine-learning-chapter-1-overview-of-tensorflow.jpg)



















![Machine Learning, STOR 565 [.1in] Clustering: Overview and](https://img.pdfslide.net/doc/110x75/61ccffb6941ab3559f21359a/machine-learning-stor-565-1in-clustering-overview-and-.jpg)
