Embed Size (px)
Citation preview

Making Sequential Consistency Practical in TitaniumPractical in Titanium
Amir Kamil, Jimmy Su, and Katherine Yelick, y ,Titanium Group
http://titanium.cs.berkeley.edu
U.C. BerkeleyNovember 15 2005November 15, 2005
1SC|05: Practical Sequential Consistency Amir Kamil
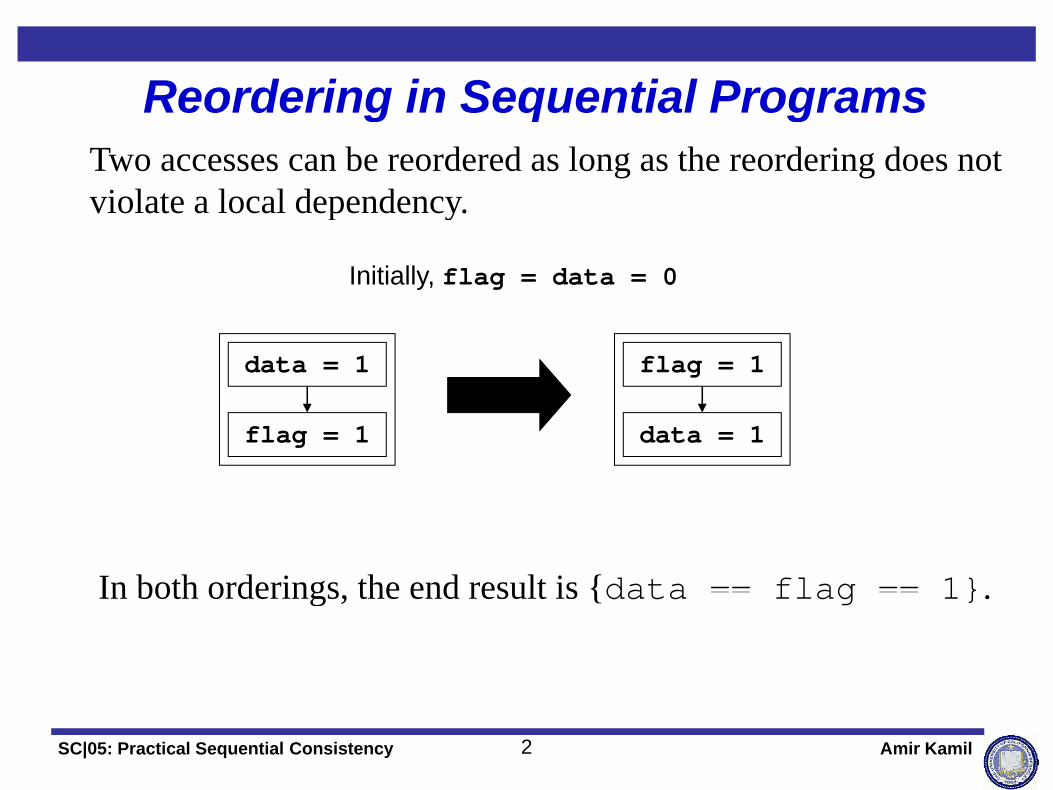
Reordering in Sequential ProgramsTwo accesses can be reordered as long as the reordering does not violate a local dependency
Reordering in Sequential Programs
violate a local dependency.
Initially, flag = data = 0
data = 1 flag = 1
flag = 1 data = 1
In both orderings the end result is {data == flag == 1}In both orderings, the end result is {data flag 1}.
2 Amir KamilSC|05: Practical Sequential Consistency

Reordering in Parallel ProgramsIn parallel programs, a reordering can change the semantics even if no local dependencies exist
Reordering in Parallel Programs
if no local dependencies exist.
Initially, flag = data = 0
data = 1 flag = 1
T1 T1
T2 T2g
f = flag
T2
f = flag
T2
flag = 1 data = 1
d = data d = data
g
{f == 1, d == 0} is a possible result in the reordered code, b i h i i l d
3 Amir KamilSC|05: Practical Sequential Consistency
but not in the original code.

Memory Models• In relaxed consistency, reordering is
allowed if no local dependencies or
Memory Models
allowed if no local dependencies or synchronization operations are violated
• In sequential consistency a reordering is• In sequential consistency, a reordering is illegal if it can be observed by another threadthread
• Titanium, Java, UPC, and many other languages do not provide sequentiallanguages do not provide sequential consistency due to the (perceived) cost of enforcing itg
4 Amir KamilSC|05: Practical Sequential Consistency

Software and Hardware Reordering• Compiler can reorder accesses as part of
an optimization
Software and Hardware Reordering
an optimization• Example: copy propagation• Logical fences inserted where reordering is illegal• Logical fences inserted where reordering is illegal
– optimizations respect these fences• Hardware can reorder accessesHardware can reorder accesses
• Examples: out of order execution, remote accesses
• Fence instructions inserted into generated code –waits until all prior memory operations have completedcompleted
• Can cost a complete round trip time due to remote accesses
5 Amir KamilSC|05: Practical Sequential Consistency
accesses

Conflicts• Reordering of an access is observable
only if it conflicts with some other access:
Conflicts
only if it conflicts with some other access:• The accesses can be to the same memory location• At least one access is a write• At least one access is a write• The accesses can run concurrently
T1 T2
data = 1
T1
f = flag
T2
flag = 1 d = data
• Fences only need to be inserted around h fli
Conflicts
6 Amir KamilSC|05: Practical Sequential Consistency
accesses that conflict

Sequential Consistency in TitaniumSequential Consistency in Titanium• Minimize number of fences – allow same
ti i ti l d d loptimizations as relaxed model• Concurrency analysis identifies
tconcurrent accesses• Relies on Titanium’s textual barriers and single-
l d ivalued expressions• Alias analysis identifies accesses to the
l tisame location• Relies on SPMD nature of Titanium
7 Amir KamilSC|05: Practical Sequential Consistency

Barrier Alignment• Many parallel languages make no attempt
Barrier Alignment
to ensure that barriers line up• Example code that is legal but will deadlock:if (Ti.thisProc() % 2 == 0)
Ti.barrier(); // even ID threadselse
; // odd ID threads
8 Amir KamilSC|05: Practical Sequential Consistency

Structural Correctness• Aiken and Gay introduced structural
Structural Correctness
correctness (POPL’98)• Ensures that every thread executes the same
b f b inumber of barriers• Example of structurally correct code:if (Ti thi P () % 2 0)if (Ti.thisProc() % 2 == 0)
Ti.barrier(); // even ID threadslelseTi.barrier(); // odd ID threads
9 Amir KamilSC|05: Practical Sequential Consistency

Textual Barrier Alignment• Titanium has textual barriers: all threads
Textual Barrier Alignment
must execute the same textual sequence of barriers• Stronger guarantee than structural correctness –
this example is illegal:if (Ti thi P () % 2 0)if (Ti.thisProc() % 2 == 0)
Ti.barrier(); // even ID threadselseelse
Ti.barrier(); // odd ID threads
Si l l d i d t f• Single-valued expressions used to enforce textual barriers
10 Amir KamilSC|05: Practical Sequential Consistency

Single-Valued Expressions• A single-valued expression has the same
l ll th d h l t d
Single-Valued Expressions
value on all threads when evaluated• Example: Ti.numProcs() > 1
• All threads guaranteed to take the same branch of a conditional guarded by a i l l d isingle-valued expression• Only single-valued conditionals may have barriers
E l f l l b i• Example of legal barrier use:if (Ti.numProcs() > 1)
Ti b i () // lti l th dTi.barrier(); // multiple threadselse
// l th d t t l11 Amir KamilSC|05: Practical Sequential Consistency
; // only one thread total

Concurrency Analysis (I)Concurrency Analysis (I)• Graph generated from program as follows:
Node added for each code segment between• Node added for each code segment between barriers and single-valued conditionals
• Edges added to represent control flow betweenEdges added to represent control flow between segments
// code segment 11
if ([single])
// code segment 2 2 3else
// code segment 3 4// code segment 4
Ti.barrier()
// code segment 5 5
barrier
12 Amir KamilSC|05: Practical Sequential Consistency
// code segment 5 5

Concurrency Analysis (II)Concurrency Analysis (II)• Two accesses can run concurrently if:
They are in the same node or• They are in the same node, or• One access’s node is reachable from the other
access’s node without hitting a barrieraccess s node without hitting a barrier• Algorithm: remove barrier edges, do DFS
11
2 3
Concurrent Segments1 2 3 4 52 3
4
1 X X X X2 X X X
5
barrier3 X X X4 X X X X5 X
13 Amir KamilSC|05: Practical Sequential Consistency
5 5 X

Alias AnalysisAlias Analysis• Allocation sites correspond to abstract
locations (a locs)locations (a-locs)• All explicit and implict program variables
have points to setshave points-to sets• A-locs are typed and have points-to sets
for each field of the corresponding typefor each field of the corresponding type• Arrays have a single points-to set for all indices
• Analysis is flow context insensitive• Analysis is flow,context-insensitive• Experimental call-site sensitive version – doesn’t
seem to help muchseem to help much
14 Amir KamilSC|05: Practical Sequential Consistency

Thread-Aware Alias AnalysisThread-Aware Alias Analysis• Two types of abstract locations: local and
remoteremote• Local locations reside in local thread’s memory• Remote locations reside on another thread• Remote locations reside on another thread
• Exploits SPMD property• Results are a summary over all threads• Results are a summary over all threads• Independent of the number of threads at runtime
15 Amir KamilSC|05: Practical Sequential Consistency

Alias Analysis: AllocationAlias Analysis: Allocation• Creates new local abstract location
R lt f ll ti t id i l l• Result of allocation must reside in local memory
class Foo {Obj t
A-locs 1, 2Object z;
} Points-to Setsastatic void bar() {
L1: Foo a = new Foo();Foo b = broadcast a from 0;
abc
Foo c = a;L2: a.z = new Object();}
c
16 Amir KamilSC|05: Practical Sequential Consistency
}

Alias Analysis: AssignmentAlias Analysis: Assignment• Copies source abstract locations into
points to set of targetpoints-to set of target
class Foo {Obj t
A-locs 1, 2Object z;
} Points-to Setsa 1static void bar() {
L1: Foo a = new Foo();Foo b = broadcast a from 0;
a 1bc 1Foo c = a;
L2: a.z = new Object();}
c 11.z 2
17 Amir KamilSC|05: Practical Sequential Consistency
}

Alias Analysis: BroadcastAlias Analysis: Broadcast• Produces both local and remote versions
of source abstract locationof source abstract location• Remote a-loc points to remote analog of what
local a-loc points tolocal a loc points to
class Foo {Obj t
A-locs 1, 2, 1rObject z;} Points-to Sets
a 1
r
static void bar() {L1: Foo a = new Foo();
Foo b = broadcast a from 0;
a 1b 1, 1rc 1Foo c = a;
L2: a.z = new Object();}
c 11.z 21 z 2
18 Amir KamilSC|05: Practical Sequential Consistency
} 1r.z 2r

Aliasing ResultsAliasing Results• Two variables A and B may
li ifalias if:∃ x∈pointsTo(A).
Points-to Setsa 1
x∈pointsTo(B)• Two variables A and B may
b 1, 1rc 1y
alias across threads if:∃ x∈pointsTo(A). Alias [Across
Threads]:p ( )R(x)∈pointsTo(B),
(where R(x) is the remote
Threads]: a b, c [b]b a c [a c](where R(x) is the remote
counterpart of x)b a, c [a, c]c a, b [b]
19 Amir KamilSC|05: Practical Sequential Consistency

BenchmarksBenchmarksBenchmark Lines1 Descriptionpi 56 Monte Carlo integrationdemv 122 Dense matrix-vector multiplysample-sort 321 Parallel sortlu-fact 420 Dense linear algebra3d ff 614 F i t f3d-fft 614 Fourier transformgsrb 1090 Computational fluid dynamics kernelgsrb* 1099 Slightly modified version of bgsrb* 1099 Slightly modified version of gsrbspmv 1493 Sparse matrix-vector multiplygas 8841 Hyperbolic solver for gas dynamicsgas 8841 Hyperbolic solver for gas dynamics
1 Line counts do not include the reachable portion of the 1 37 000 li Ti i /J 1 0 lib i
20 Amir KamilSC|05: Practical Sequential Consistency
1 37,000 line Titanium/Java 1.0 libraries

Analysis Levels• We tested analyses of varying levels of
i i
Analysis Levels
precisionAnalysis Description
naïve All heap accesses
sharing All shared accessessharing All shared accesses
concur Concurrency analysis + type-based AA
concur/saa Concurrency analysis + sequential AA
concur/taa Concurrency analysis + thread-aware AA/ Concurrency analysis thread aware AA
concur/taa/cycle Concurrency analysis + thread-aware AA + cycle detection
21 Amir KamilSC|05: Practical Sequential Consistency
cycle detection

Static (Logical) FencesStatic Fence Removal
Static (Logical) Fences
80100120
ge
20406080
Perc
enta
g
0
naïve
shar
ing
conc
uron
cur/s
aa
conc
ur/ta
ar/t
aa/cy
cle
GOODco co
conc
ur/
pi demv sample sort
GOOD
lu fact 3d fft gsrbgsrb* spmv gas
Percentages are for number of static fences reduced over naive22 Amir KamilSC|05: Practical Sequential Consistency
Percentages are for number of static fences reduced over naive

Dynamic (Executed) FencesDynamic Fence Removal
Dynamic (Executed) Fences
80100120
age
20406080
Perc
enta
g
0
naïve
shar
ing
conc
urco
ncur
/saa
conc
ur/ta
ar/t
aa/cy
cle
GOODco co
conc
ur/
pi demv sample sort
GOOD
Percentages are for number of dynamic fences reduced over naive
p plu fact 3d fft gsrbgsrb* spmv gas
23 Amir KamilSC|05: Practical Sequential Consistency
Percentages are for number of dynamic fences reduced over naive

Dynamic Fences: gsrbDynamic Fences: gsrb• gsrb relies on dynamic locality checks
li ht difi ti t h k ( )• slight modification to remove checks (gsrb*) greatly increases precision of analysis
gsrb Dynamic Fence Removal
100
120
40
60
80
erce
ntag
e
GOOD0
20
40Pe
naïve
shari
ng
conc
urco
ncur/
saa
conc
ur/taa
ncur/
taa/cy
cle
24 Amir KamilSC|05: Practical Sequential Consistency
concgsrb gsrb*

Two Example Optimizations• Consider two optimizations for GAS
Two Example Optimizations
languages1.Overlap bulk memory copies2.Communication aggregation for irregular array
accesses (i.e. a[b[i]])B th ti i ti d• Both optimizations reorder accesses, so sequential consistency can inhibit them
• Both are addressing network performance, so potential payoff is high
25 Amir KamilSC|05: Practical Sequential Consistency

Array Copies in TitaniumArray Copies in Titanium• Array copy operations are commonly used
dst.copy(src);
• Content in the domain intersection of the two arrays is copied from dst to src
srcdst
• Communication (possibly with packing) required if arrays reside on different threadsq y
• Processor blocks until the operation is complete.
26 Amir KamilSC|05: Practical Sequential Consistency
complete.

Non Blocking Array Copy OptimizationNon-Blocking Array Copy Optimization• Automatically convert blocking array copies y g y p
into non-blocking array copies• Push sync as far down the instruction stream as
possible to allow overlap with computation• Interprocedural: syncs can be moved
across method boundaries• Optimization reorders memory accesses –p y
may be illegal under sequential consistency
27 Amir KamilSC|05: Practical Sequential Consistency

Communication Aggregation on IrregularCommunication Aggregation on Irregular Array Accesses (Inspector/Executor)
• A loop containing indirect array accesses is• A loop containing indirect array accesses is split into phases• Inspector examines loop and computes referenceInspector examines loop and computes reference
targets• Required remote data gathered in a bulk operation• Executor uses data to perform actual computation
for ( ) {schd = inspect(remote, b);
for (...) {a[i] = remote[b[i]];// other accesses
}
tmp = get(remote, schd);for (...) {a[i] = tmp[i];
Can be illegal under sequential consistency
} // other accesses}
28 Amir KamilSC|05: Practical Sequential Consistency
• Can be illegal under sequential consistency

Relaxed + SC with 3 AnalysesRelaxed + SC with 3 Analyses• We tested performance using analyses of
Name Description
varying levels of precisionp
relaxed Uses Titanium’s relaxed memory model
naïve Uses sequential consistency, puts fences around every heap accessfences around every heap access
sharing Uses sequential consistency, puts fences around every shared heap access
concur/taa/cycle Uses sequential consistency, uses our most aggressive analysis
29 Amir KamilSC|05: Practical Sequential Consistency
gg y

Dense Matrix Vector MultiplyDense Matrix Vector MultiplyDense Matrix Vector Multiply
1.5
2
p
0.5
1
spee
du
0
0.5
1 2 4 8 16# of processors
relaxed naive sharing concur/taa/cycle
• Non-blocking array copy optimization applied• Strongest analysis is necessary: other SC
30 Amir KamilSC|05: Practical Sequential Consistency
implementations suffer relative to relaxed
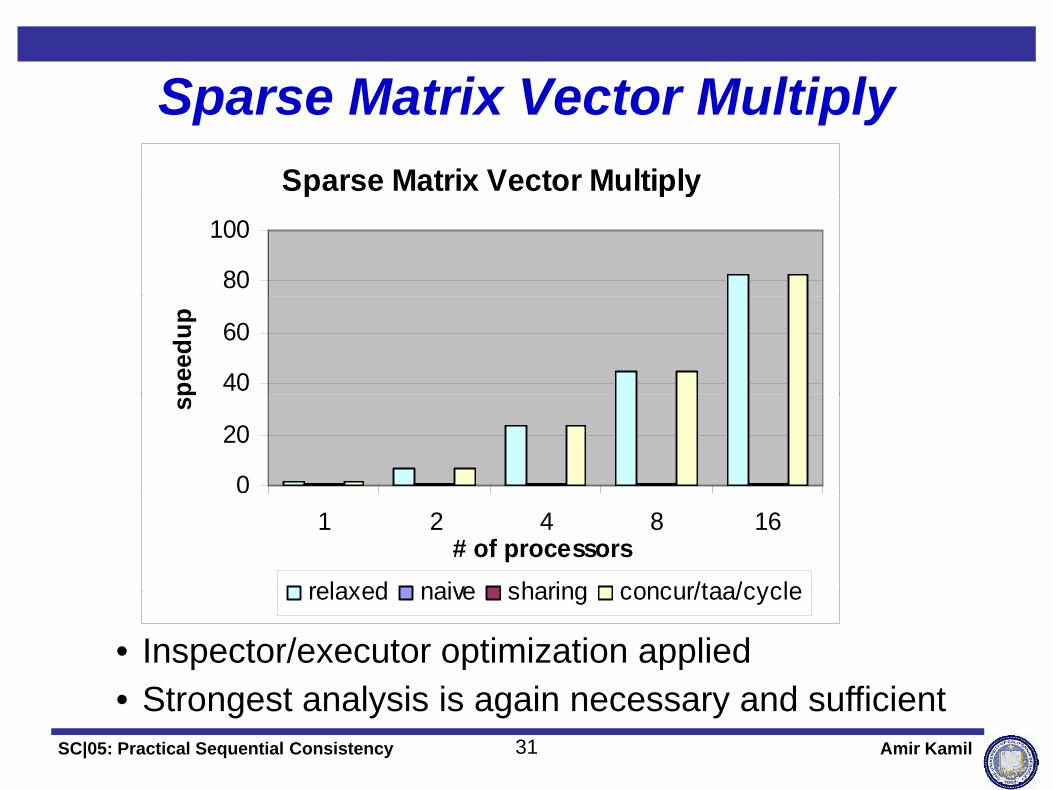
Sparse Matrix Vector MultiplySparse Matrix Vector MultiplySparse Matrix Vector Multiply
80
100
40
60
peed
up
0
20
sp
1 2 4 8 16# of processors
relaxed naive sharing concur/taa/cyclerelaxed naive sharing concur/taa/cycle
• Inspector/executor optimization appliedSt t l i i i d ffi i t
31 Amir KamilSC|05: Practical Sequential Consistency
• Strongest analysis is again necessary and sufficient

ConclusionConclusion• Titanium’s textual barriers and single-
l d i ll f i l b tvalued expressions allow for simple but precise concurrency analysisS ti l i t li i t• Sequential consistency can eliminate nearly all fences for the benchmarks t t dtested
• On two linear algebra kernels, sequential i t b id d ith littlconsistency can be provided with little or
no performance cost with our analysisA l i ll h i i i b• Analysis allows the same optimizations to be performed as in the relaxed memory model
32 Amir KamilSC|05: Practical Sequential Consistency





















![Problem M4.3: Sequential Consistency [? Hours]](https://img.pdfslide.net/doc/110x75/61a88377f5d8864d6d02c636/problem-m43-sequential-consistency-hours.jpg)







