Embed Size (px)
Citation preview

MapReduce Design Patterns
CMSC 491Hadoop-Based Distributed Computing
Spring 2015Adam Shook

Agenda
• Summarization Patterns• Filtering Patterns• Data Organization Patterns• Joins Patterns• Metapatterns• I/O Patterns• Bloom Filters

SUMMARIZATION PATTERNSNumerical Summarizations, Inverted Index, Counting with Counters

Overview
• Top-down summarization of large data sets• Most straightforward patterns• Calculate aggregates over entire data set or
groups• Build indexes

Numerical Summarizations
• Group records together by a field or set of fields and calculate a numerical aggregate per group
• Build histograms or calculate statistics from numerical values

Known Uses
• Word Count• Record Count• Min/Max/Count• Average/Median/Standard Deviation
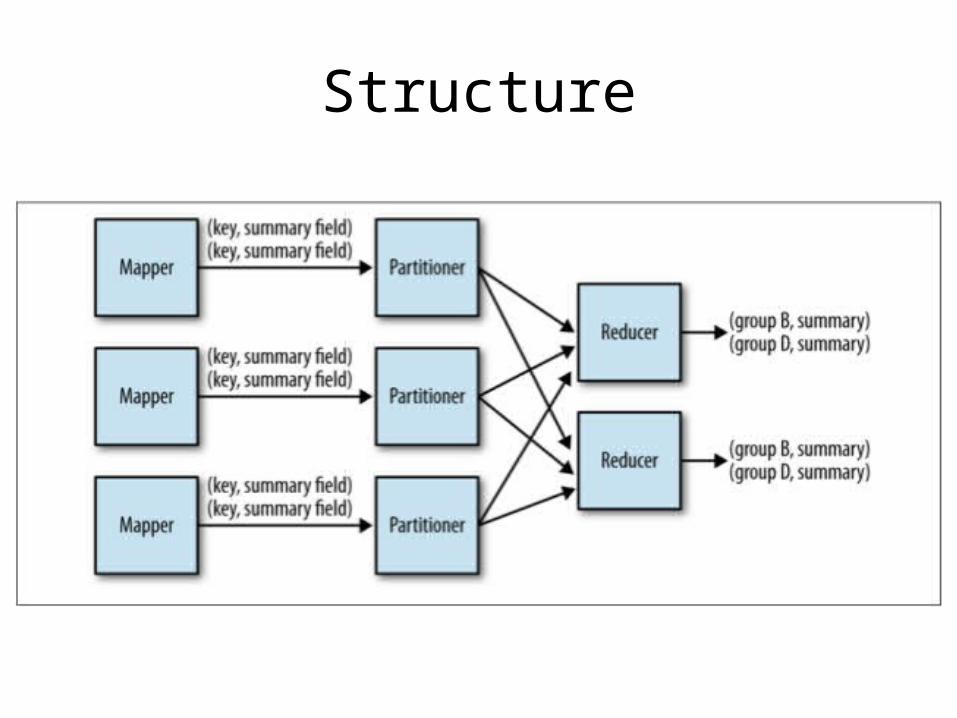
Structure

Performance
• Perform well, especially when combiner is used
• Need to be concerned about data skew with from the key

Example
• Discover the first time a StackOverflow user posted, the last time a user posted, and the number of posts in between
• User ID, Min Date, Max Date, Count
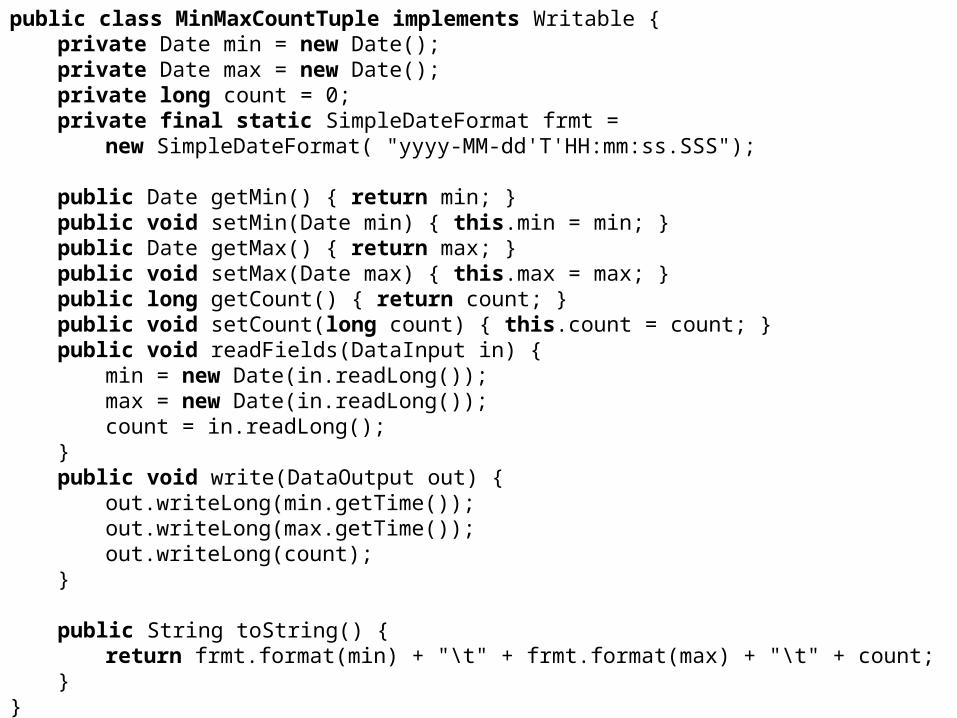
public class MinMaxCountTuple implements Writable {private Date min = new Date();private Date max = new Date();private long count = 0; private final static SimpleDateFormat frmt =
new SimpleDateFormat( "yyyy-MM-dd'T'HH:mm:ss.SSS");
public Date getMin() { return min; } public void setMin(Date min) { this.min = min; } public Date getMax() { return max; } public void setMax(Date max) { this.max = max; } public long getCount() { return count; } public void setCount(long count) { this.count = count; }public void readFields(DataInput in) {
min = new Date(in.readLong()); max = new Date(in.readLong()); count = in.readLong();
}public void write(DataOutput out) {
out.writeLong(min.getTime());out.writeLong(max.getTime());out.writeLong(count);
}
public String toString() {return frmt.format(min) + "\t" + frmt.format(max) + "\t" +
count; }
}

public static class MinMaxCountMapper extends Mapper<Object, Text, Text,
MinMaxCountTuple> {
private Text outUserId = new Text();private MinMaxCountTuple outTuple =
new MinMaxCountTuple();
private final static SimpleDateFormat frmt = new SimpleDateFormat("yyyy-MM-
dd'T'HH:mm:ss.SSS");
public void map(Object key, Text value, Context context) {
Map<String, String> parsed = xmlToMap(value.toString());
String strDate = parsed.get("CreationDate"); String userId = parsed.get("UserId");
Date creationDate = frmt.parse(strDate); outTuple.setMin(creationDate); outTuple.setMax(creationDate)outTuple.setCount(1);outUserId.set(userId);context.write(outUserId, outTuple);
}}

public static class MinMaxCountReducer extends Reducer<Text, MinMaxCountTuple, Text, MinMaxCountTuple>
{
private MinMaxCountTuple result = new MinMaxCountTuple();
public void reduce(Text key, Iterable<MinMaxCountTuple> values,
Context context) {
result.setMin(null); result.setMax(null); result.setCount(0);
int sum=0;for (MinMaxCountTuple val : values) {
if (result.getMin() == null ||
val.getMin().compareTo(result.getMin()) < 0) { result.setMin(val.getMin());
}if (result.getMax() == null ||
val.getMax().compareTo(result.getMax()) > 0) {result.setMax(val.getMax());
} sum += val.getCount();
}result.setCount(sum); context.write(key, result);
}}
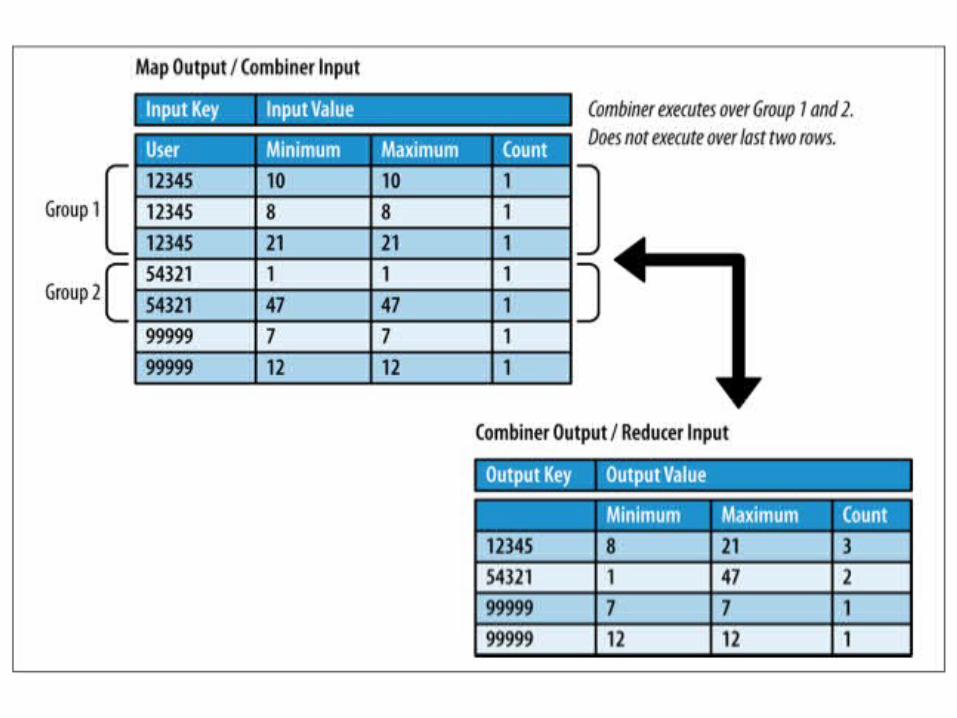

public static void main(String[] args) {
Configuration conf = new Configuration();String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {System.err.println("Usage: MinMaxCountDriver <in>
<out>");System.exit(2);
}
Job job = new Job(conf, "Comment Date Min Max Count");job.setJarByClass(MinMaxCountDriver.class);
job.setMapperClass(MinMaxCountMapper.class);job.setCombinerClass(MinMaxCountReducer.class);job.setReducerClass(MinMaxCountReducer.class);
job.setOutputKeyClass(Text.class);job.setOutputValueClass(MinMaxCountTuple.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);}

Inverted Index
• Generate an index from a data set to enable fast searches or data enrichment
• Building an index takes time, but can greatly reduce the amount of time to search for something
• Output can be ingested into key/value store
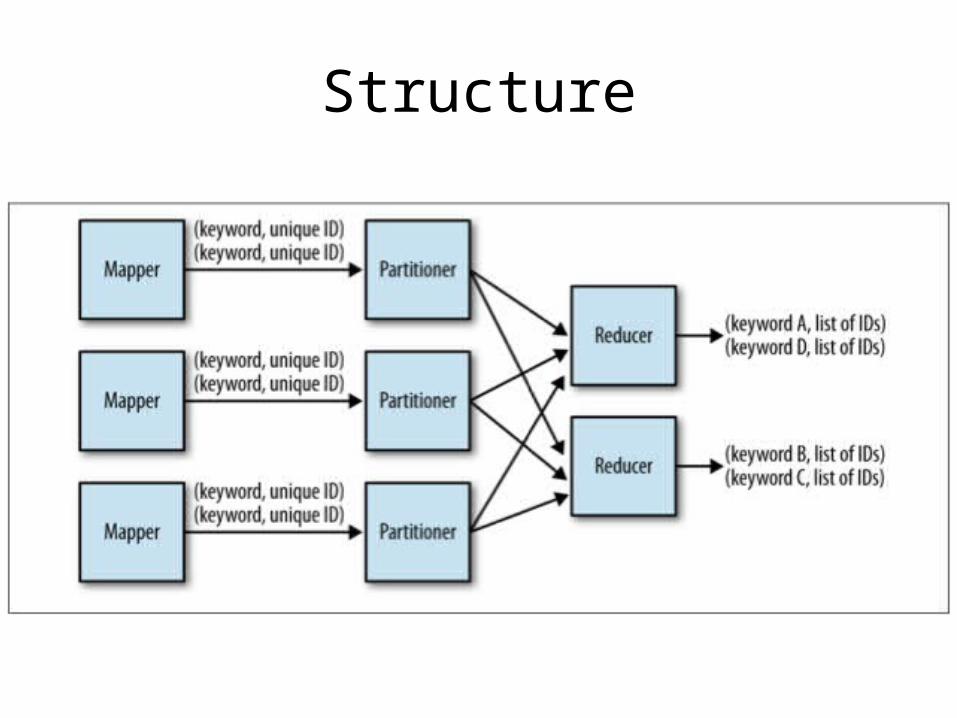
Structure

Counting with Counters
• Use MapReduce framework’s counter utility to calculate global sum entirely on the map side, producing no output
• Small number of counters only!!

Known Uses
• Count number of records• Count a small number of unique field
instances• Sum fields of data together
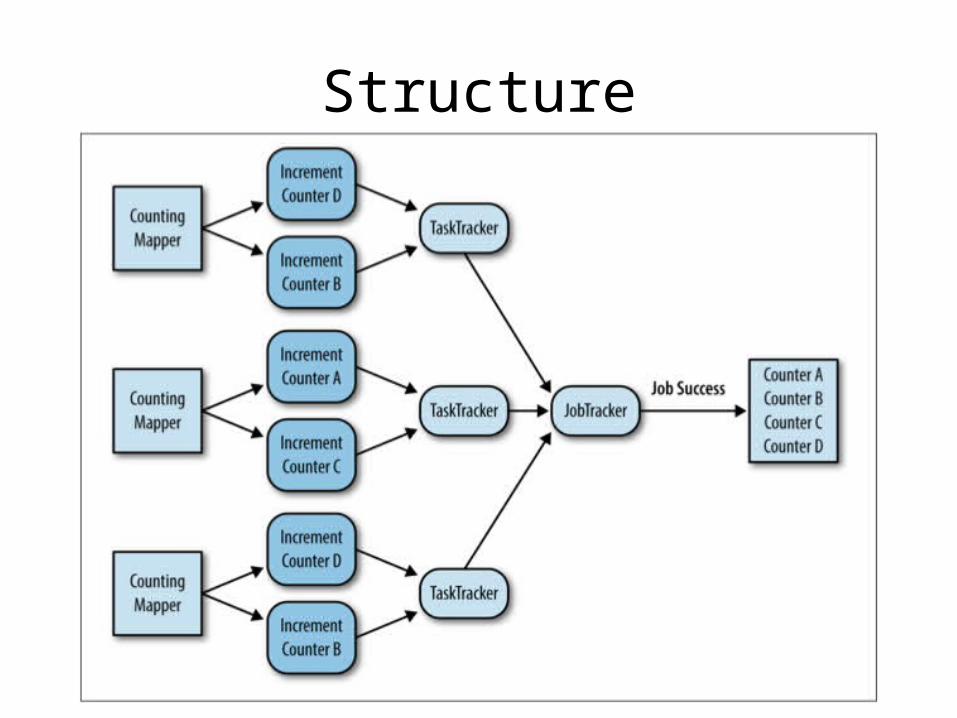
Structure

FILTERING PATTERNSFiltering, Bloom Filtering, Top Ten, Distinct

Filtering
• Discard records that are not of interest
• Create subsets of your big data sets that you want to further analyze

Known Uses
• Closer view of the data• Tracking a thread of events• Distributed grep• Data cleansing• Simple random sampling
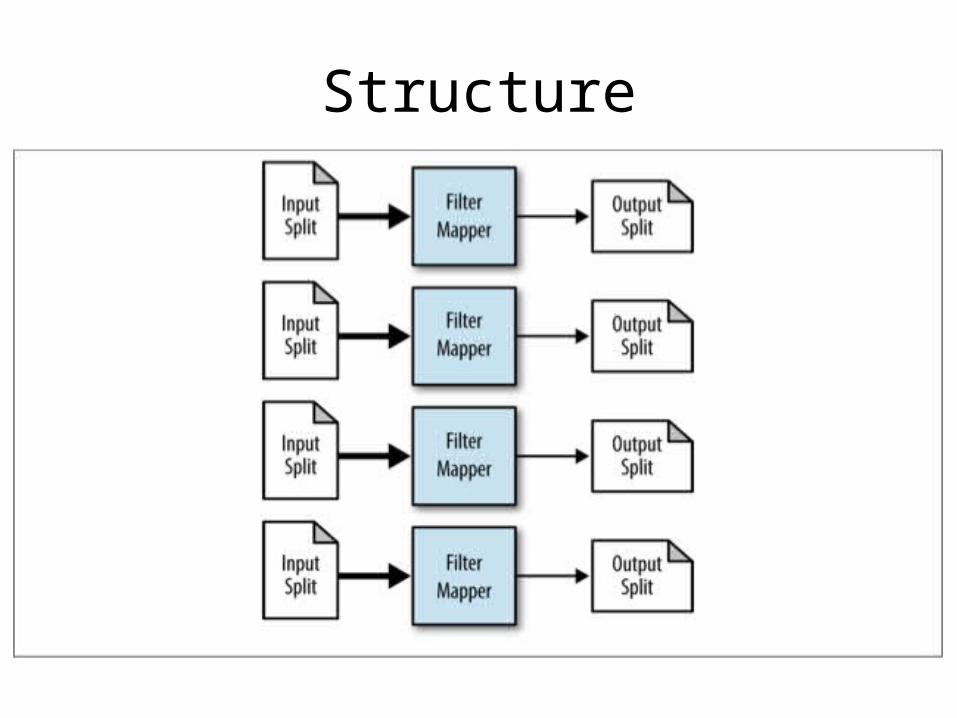
Structure

Bloom Filtering
• Keep records that are a member of a large predefined set of values
• Inherent possibility of false positives

Known Uses
• Removing most of the non-watched values• Pre-filtering a data set prior to expensive
membership test
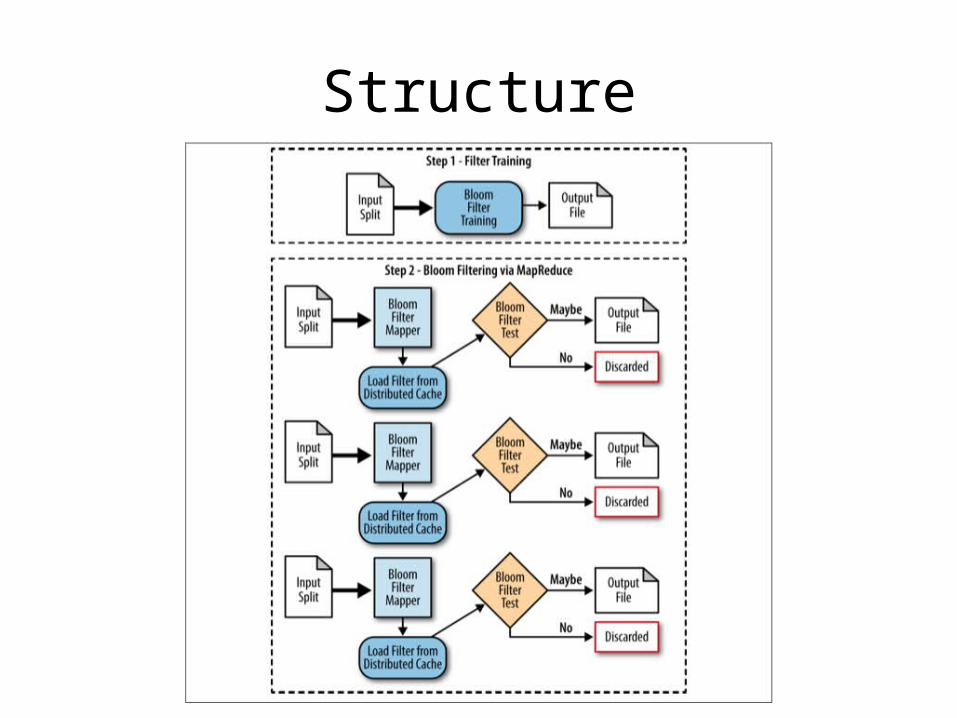
Structure

Top Ten
• Retrieve a relatively small number of top K records based on a ranking scheme
• Find the outliers or most interesting records

Known Uses
• Outlier analysis• Selecting interesting data• Catchy dashboards
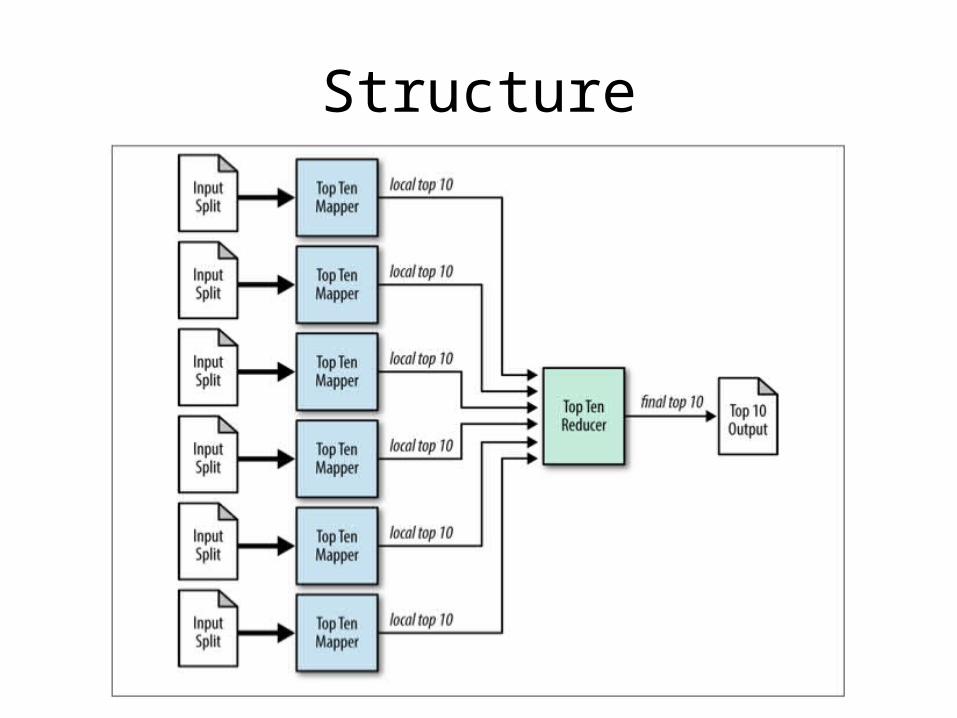
Structure

Distinct
• Remove duplicate entries of your data, either full records or a subset of fields
• That fourth V nobody talks about that much

Known Uses
• Deduplicate data• Get distinct values• Protect from inner join explosion
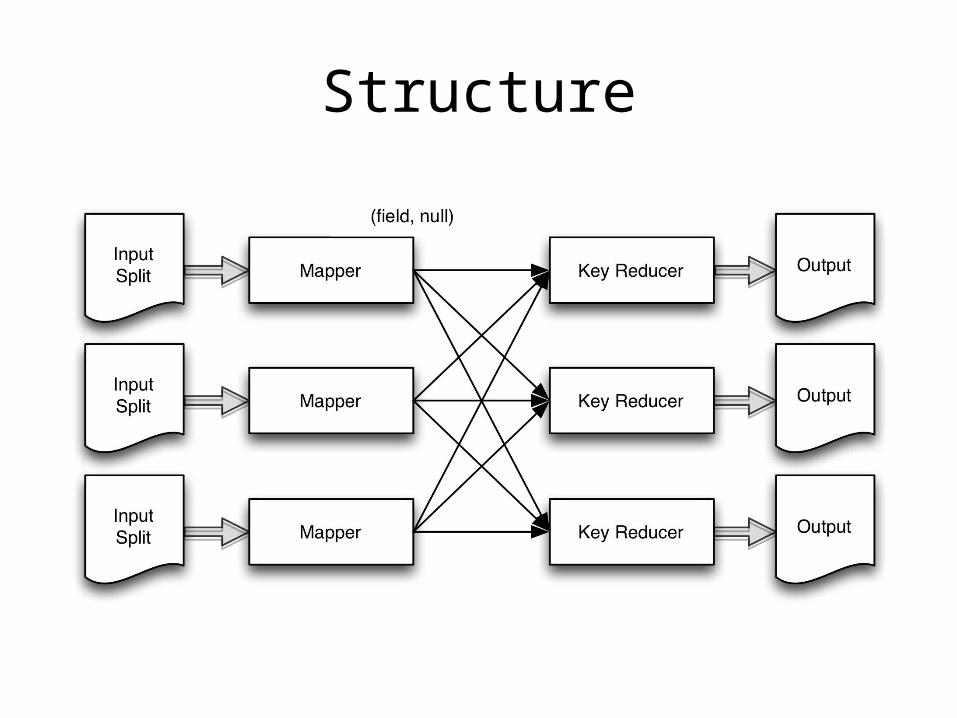
Structure

DATA ORGANIZATION PATTERNS
Structured to Hierarchical, Partitioning, Binning,Total Order Sorting, Shuffling

Structured to Hierarchical
• Transformed row-based data to a hierarchical format
• Reformatting RDBMS data to a more conducive structure

Known Uses
• Pre-joining data• Prepare data for HBase or MongoDB
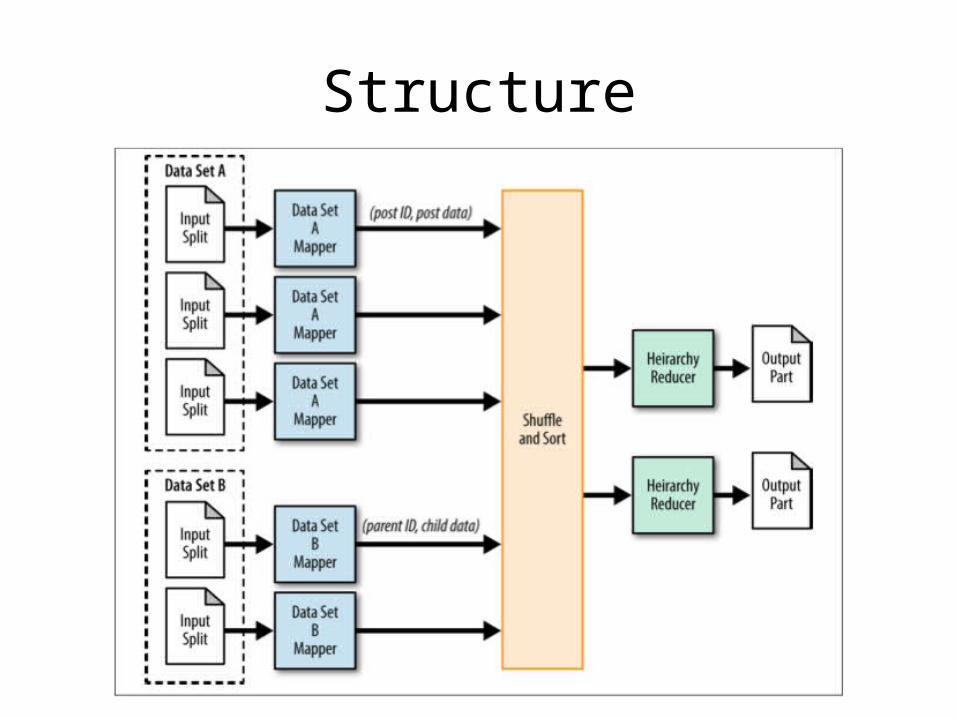
Structure

Partitioning
• Partition records into smaller data sets
• Enables faster future query times due to partition pruning

Known Uses
• Partition pruning by continuous value• Partition pruning by category• Sharding
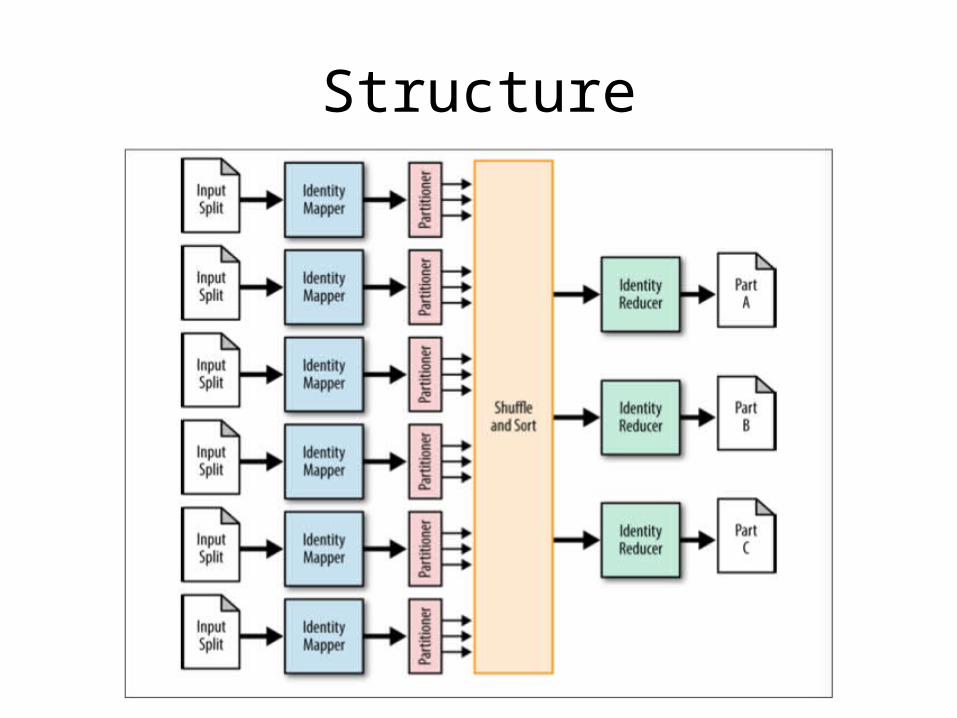
Structure

Binning
• File records into one or more categories– Similar to partitioning, but the implementation is
different
• Can be used to solve similar problems to Partitioning

Known Uses
• Pruning for follow-on analytics• Categorizing data
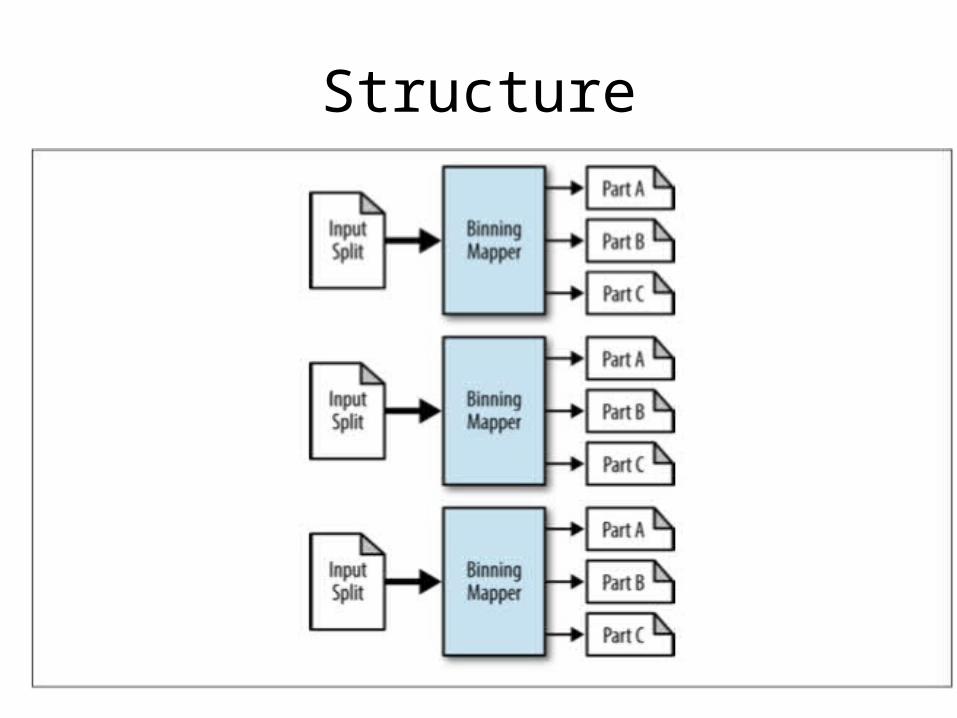
Structure

Total Order Sorting
• Sort your data set in parallel
• Difficult to apply “divide and conquer” technique of MapReduce

Known Uses
• Sorting
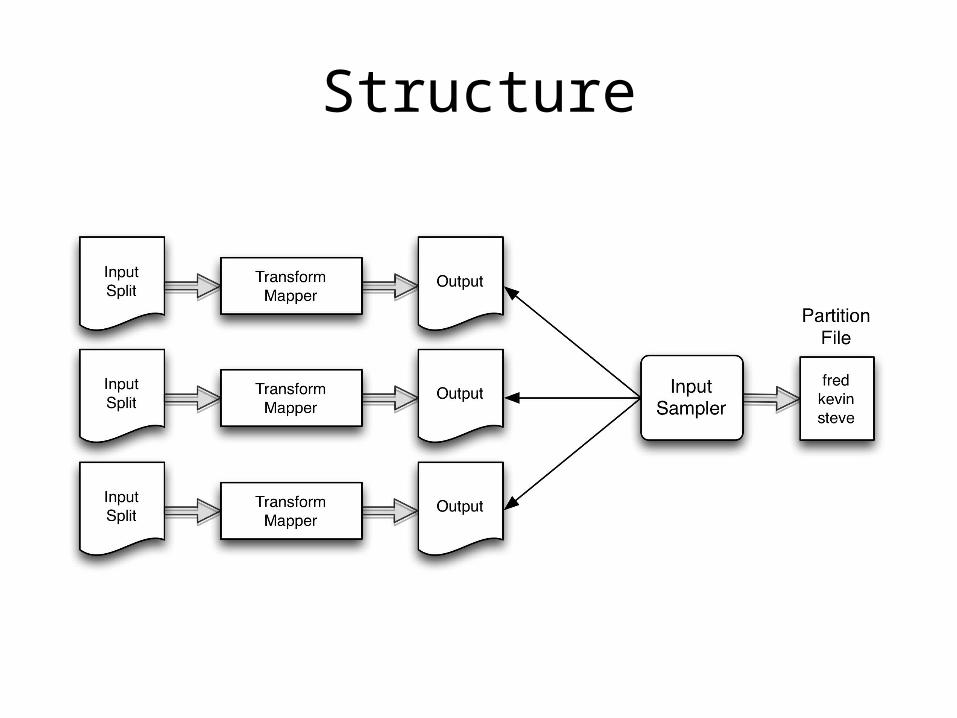
Structure
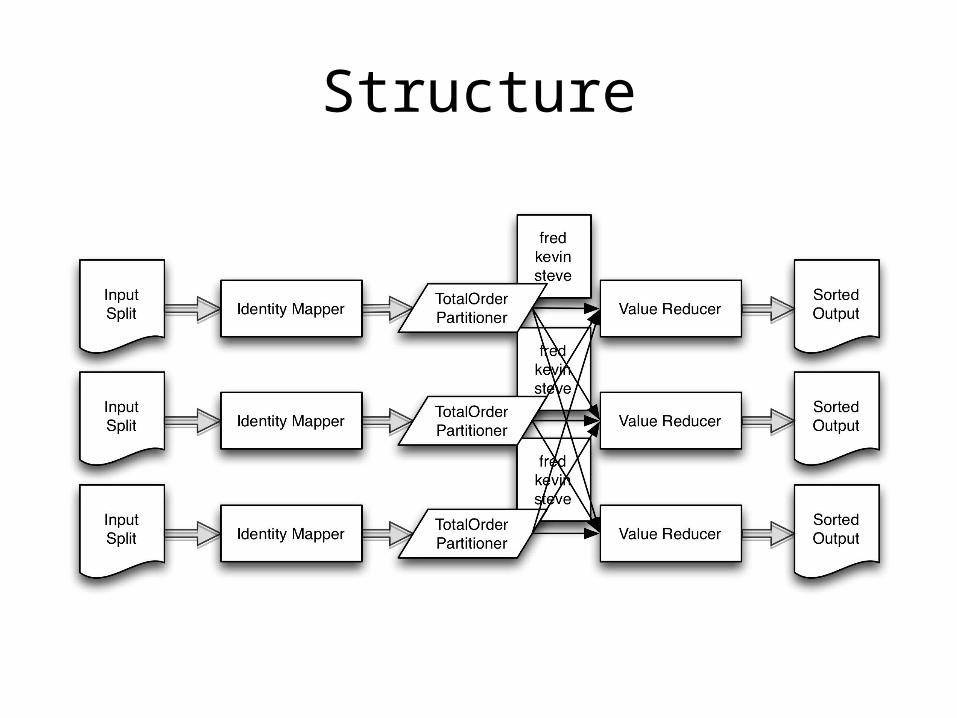
Structure

Shuffling
• Set of records that you want to completely randomize
• Instill some anonymity or create some repeatable random sampling

Known Uses
• Anonymize the order of the data set• Repeatable random sampling after shuffled
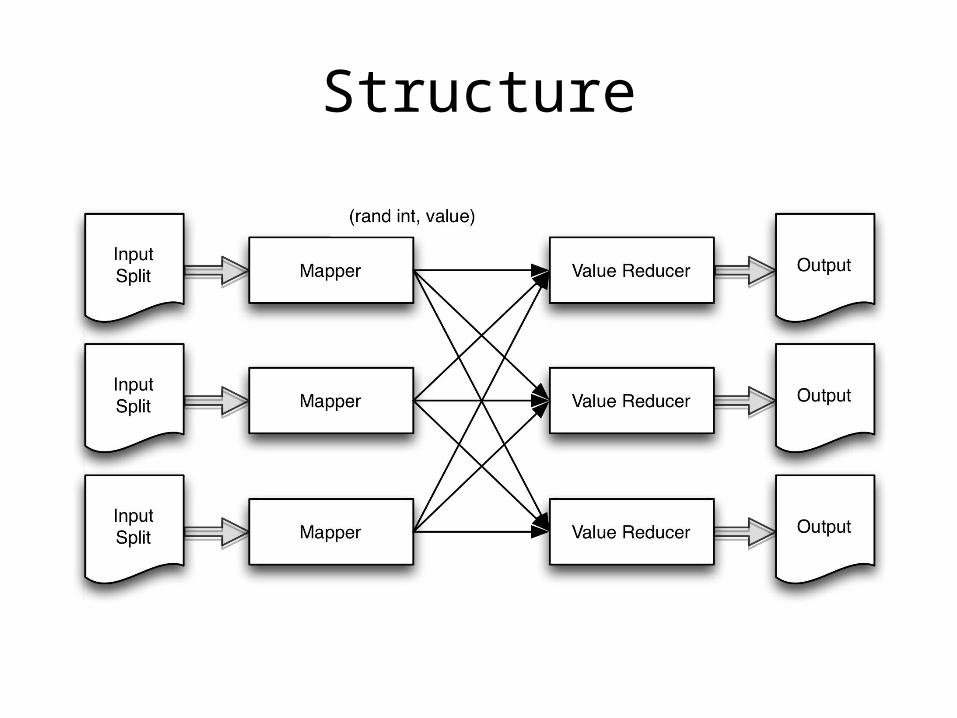
Structure

JOIN PATTERNS
Join Refresher, Reduce-Side Join w/ and w/o Bloom Filter,Replicated Join, Composite Join, Cartesian Product

Join Refresher
• A join is an operation that combines records from two or more data sets based on a field or set of fields, known as a foreign key
• Let’s go over the different types of joins before talking about how to do it in MapReduce
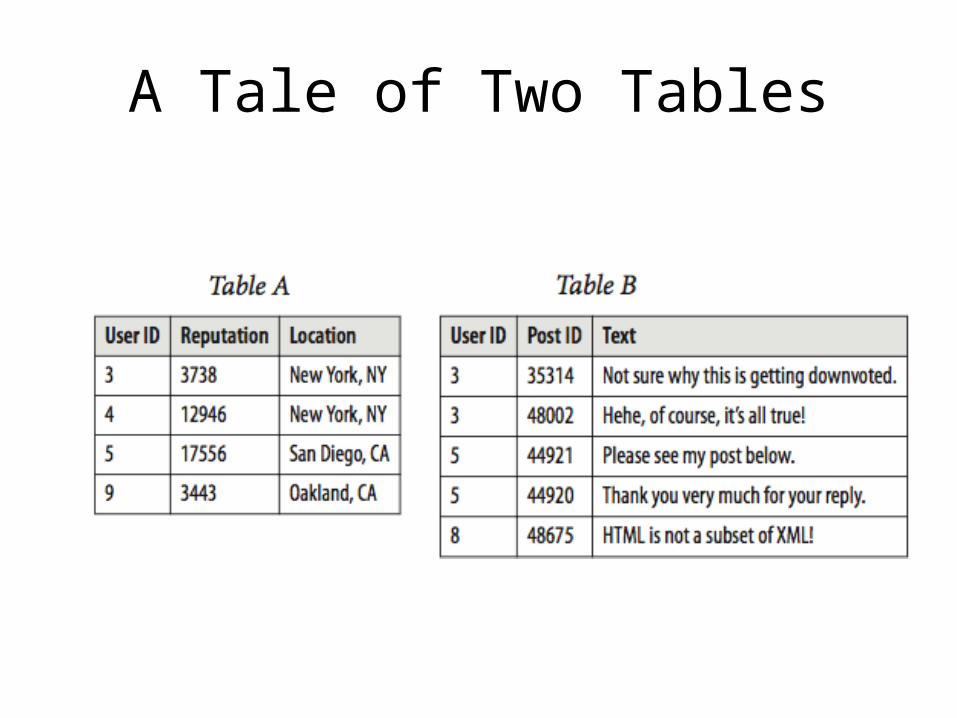
A Tale of Two Tables
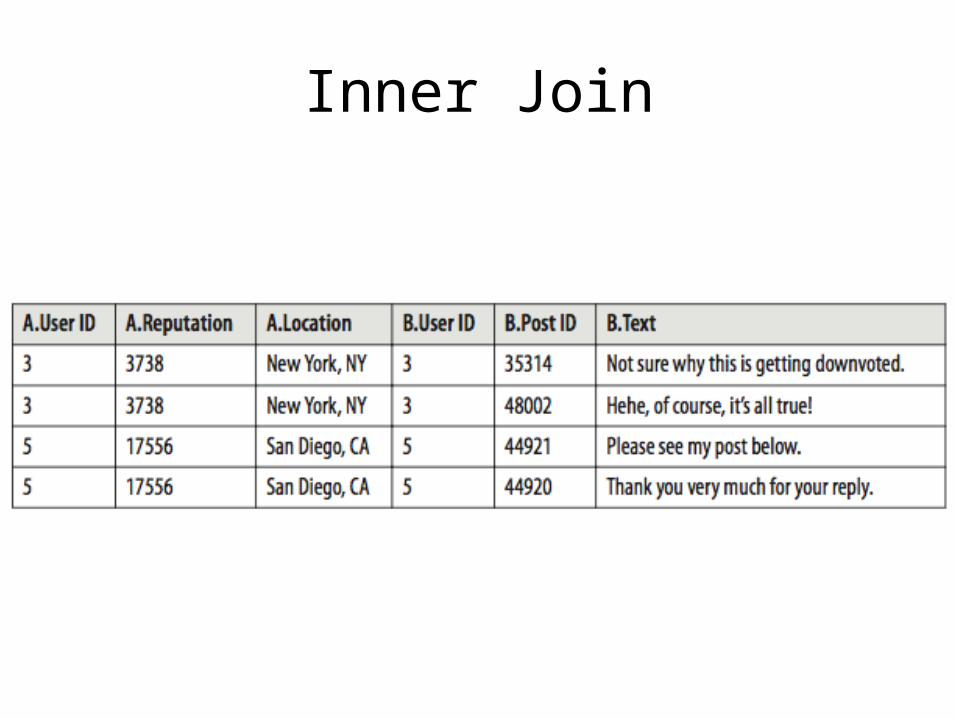
Inner Join
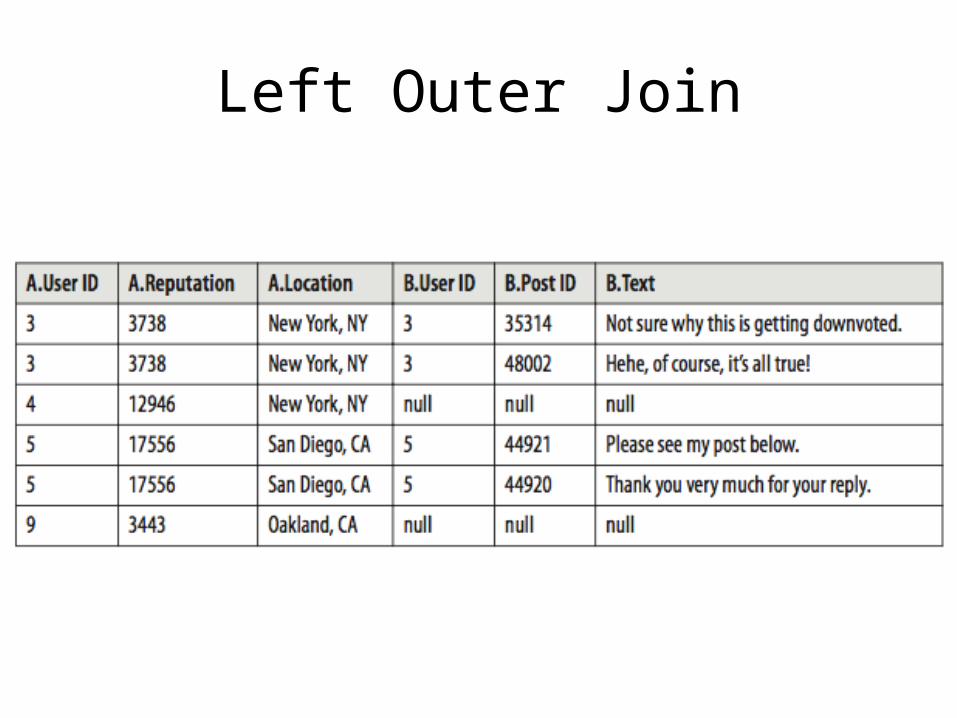
Left Outer Join
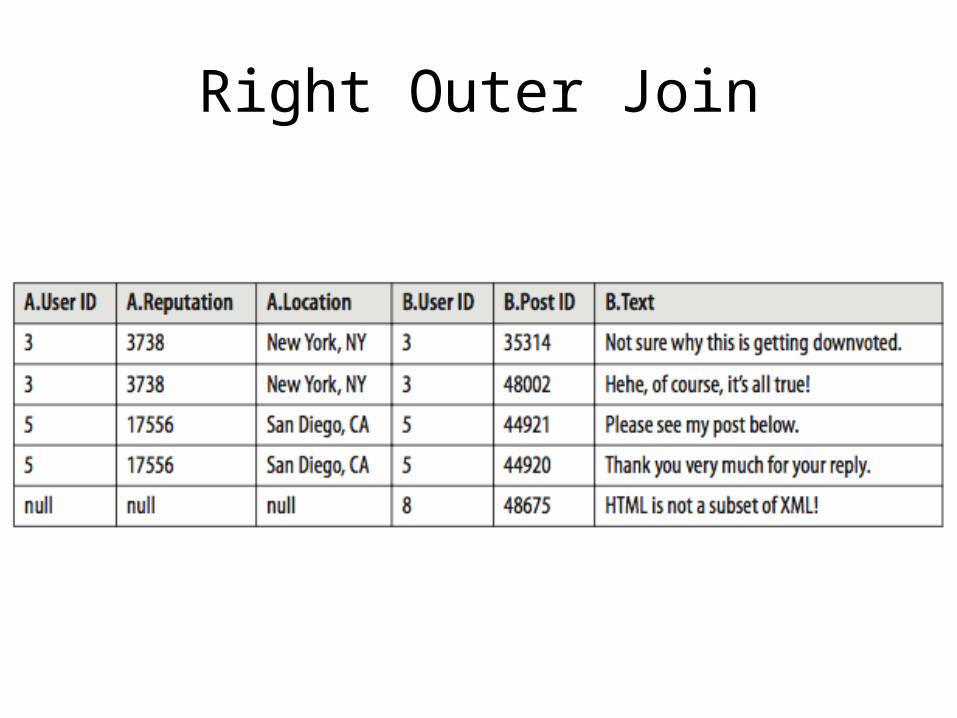
Right Outer Join
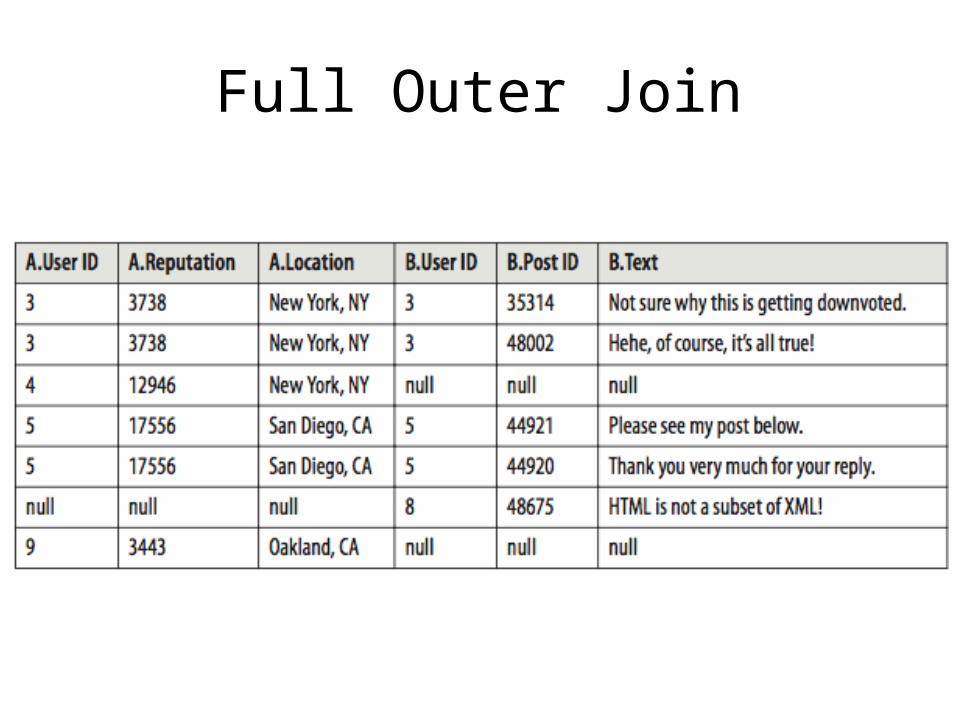
Full Outer Join
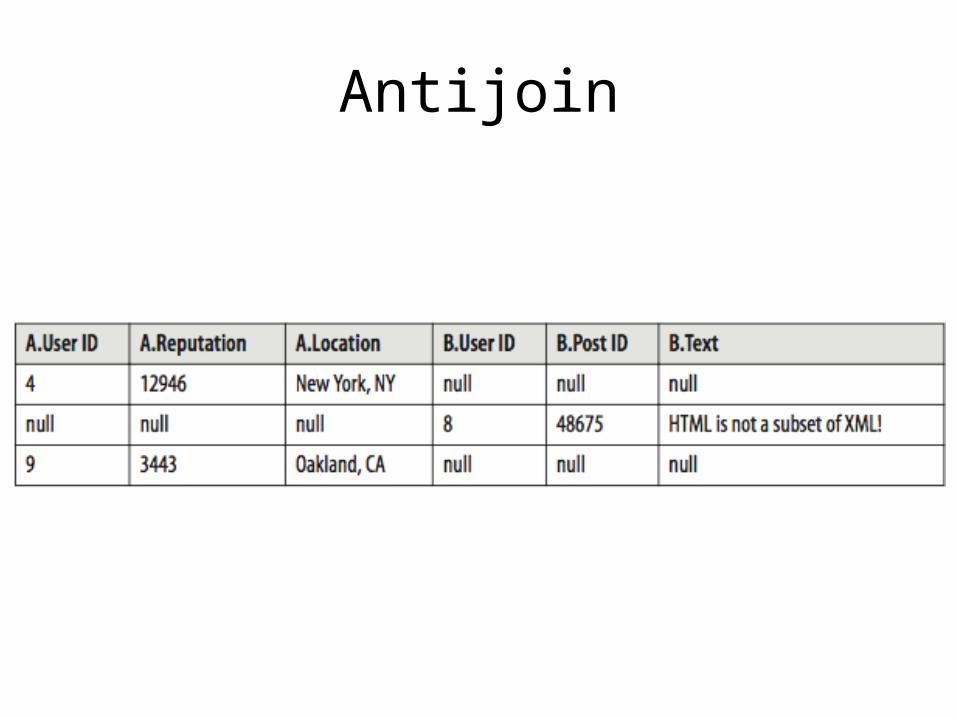
Antijoin
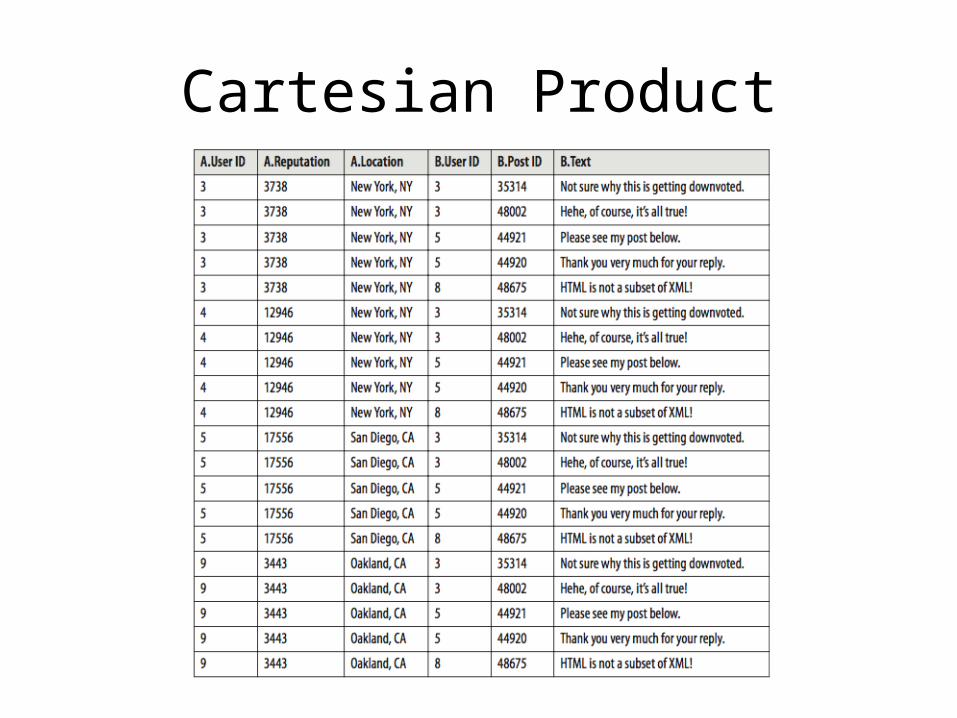
Cartesian Product

How to implement?
• Reduce-Side Join w/ and w/o Bloom Filter• Replicated Join• Composite Join
• Cartesian Product stands alone

Reduce Side Join
• Two or more data sets are joined in the reduce phase
• Covers all join types we have discussed– Exception: Mr. Cartesian
• All data is sent over the network– If applicable, filter using Bloom filter
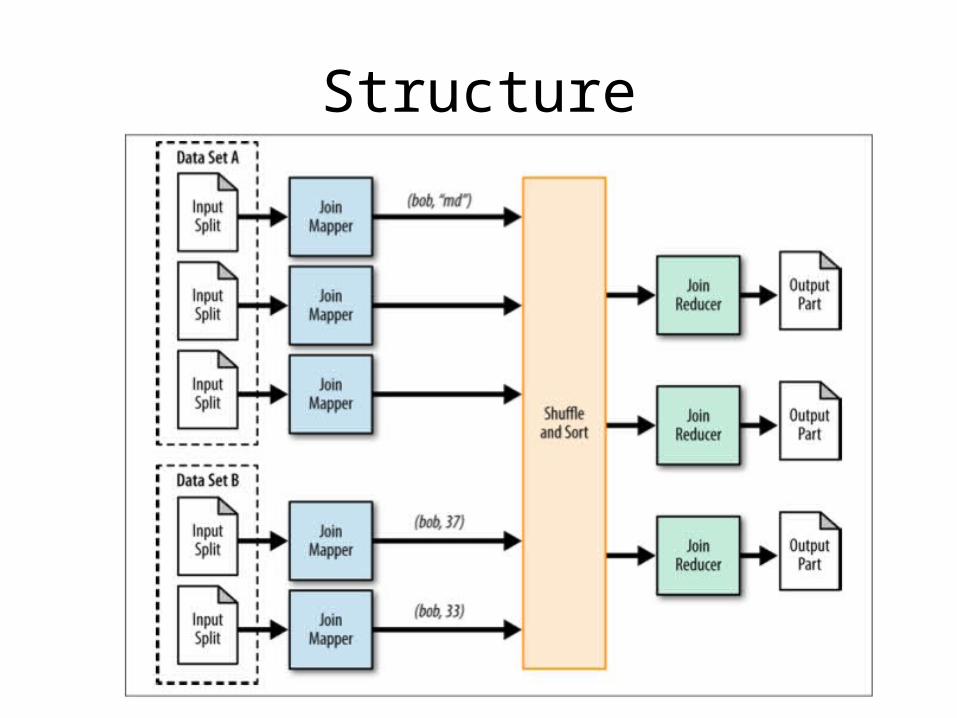
Structure

Performance
• Need to be concerned about data skew• 2 PB joined on 2 PB means 4 PB of network
traffic

Replicated Join
• Inner and Left Outer Joins• Removes need to shuffle any data to the
reduce phase
• Very useful, but requires one large data set and the remaining data sets to be able to fit into memory of each map task
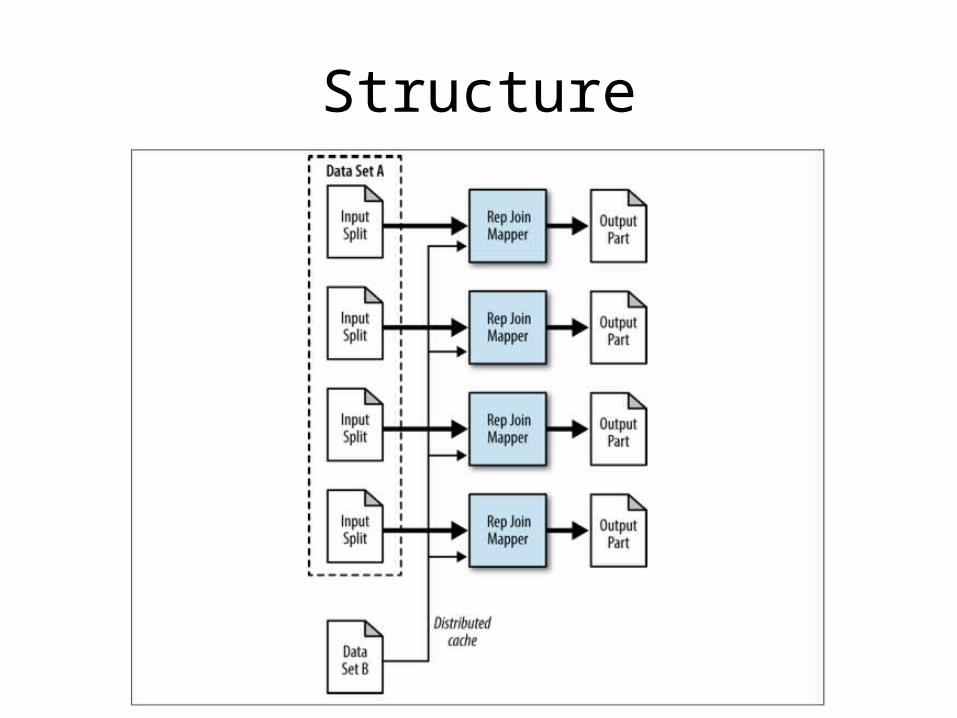
Structure

Performance
• Fastest type of join• Map-only
• Limited based on how much data you can safely store inside JVM
• Need to be concerned about growing data sets
• Could optionally use a Bloom filter

Composite Join
• Leverages built-in Hadoop utilities to join the data
• Requires the data to be already organized and prepared in a specific way
• Really only useful if you have one large data set that you are using a lot
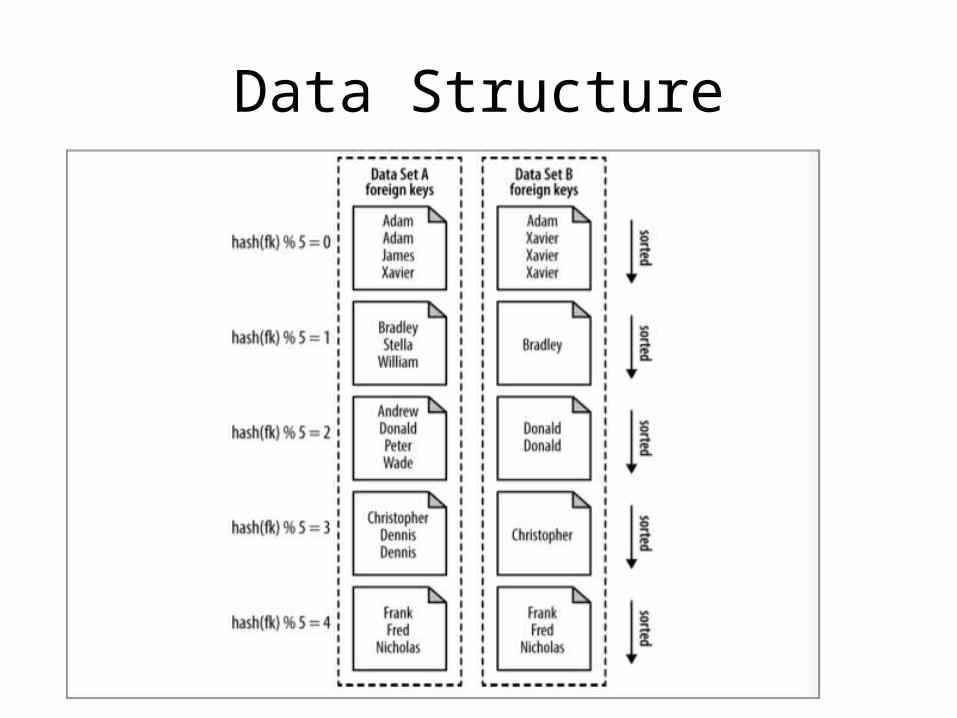
Data Structure
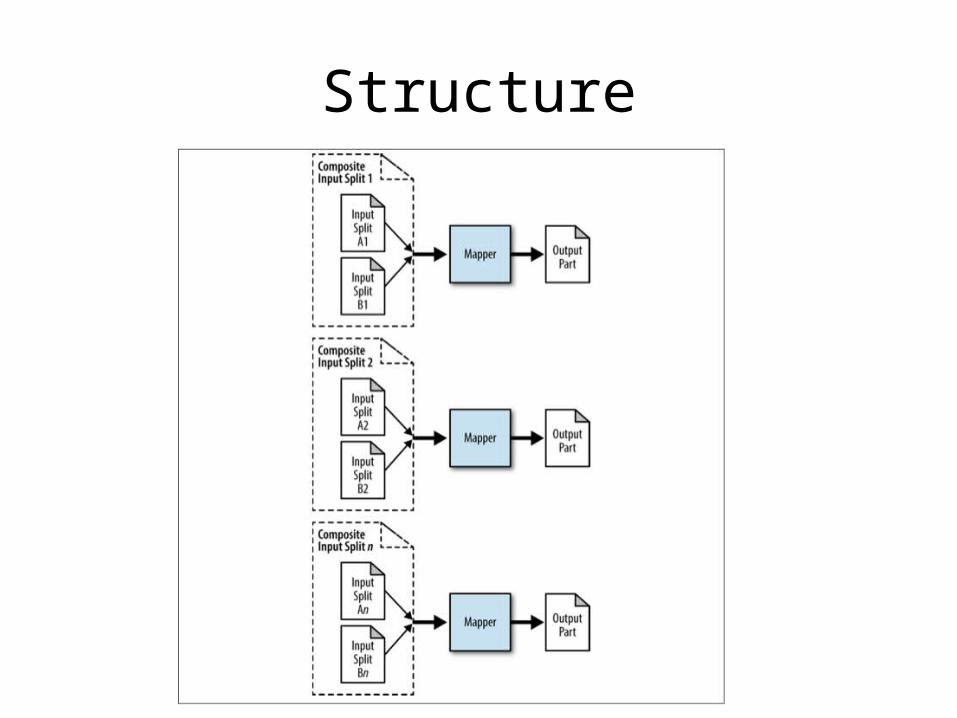
Structure

Performance
• Good performance, join operation is done on the map side
• Requires the data to have the same number of partitions, partitioned in the same way, and each partition must be sorted

Cartesian Product
• Pair up and compare every single record with every other record in a data set
• Allows relationships between many different data sets to be uncovered at a fine-grain level

Known Uses
• Document or image comparisons• Math stuff or something
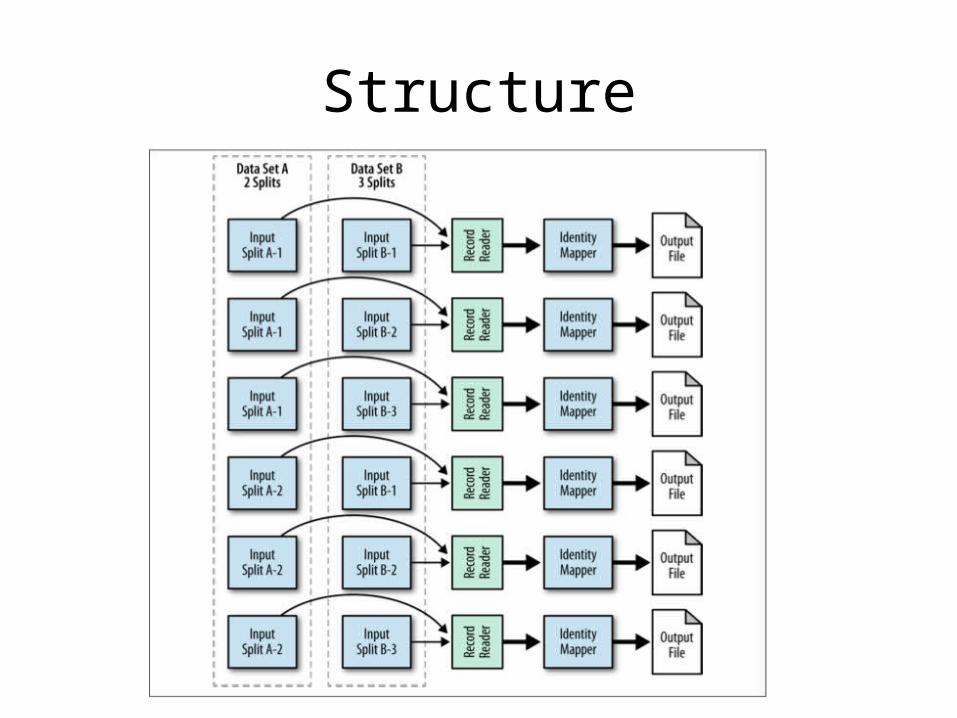
Structure

Performance
• Massive data explosion!• Can use many map slots for a long time
• Effectively creates a data set size O(n2)– Need to make sure your cluster can fit what you
are doing

METAPATTERNSJob Chaining, Chain Folding, Job Merging

Job Chaining
• One job is often not enough• Need a combination of patterns discussed to
do your workflow
• Sequential vs Parallel

Methodologies
• In the Driver• In a Bash run script• With the JobControl utility

Chain Folding
• Each record can be submitted to multiple mappers, then a reducer, then a mapper
• Reduces amount of data movement in the pipeline
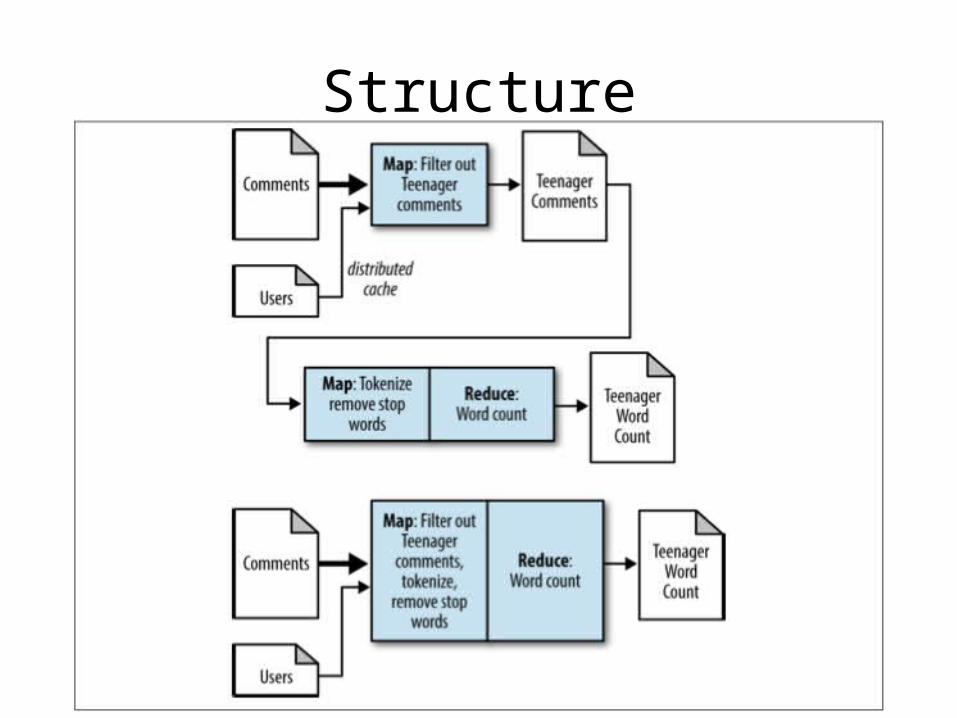
Structure
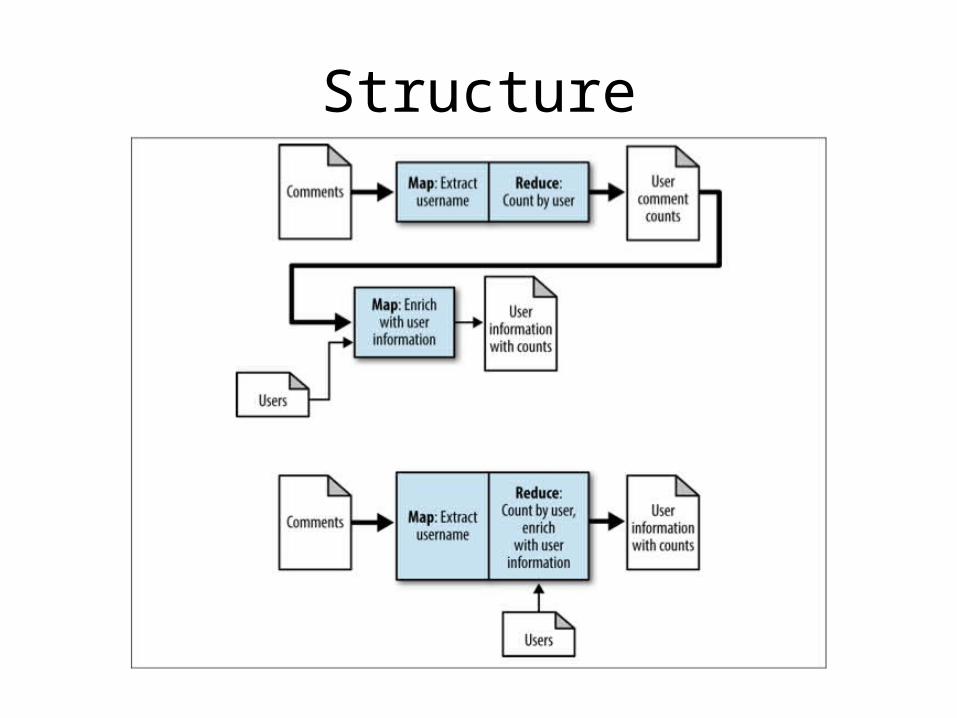
Structure

Methodologies
• Just do it• ChainMapper/ChainReducer

Job Merging
• Merge unrelated jobs together into the same pipeline
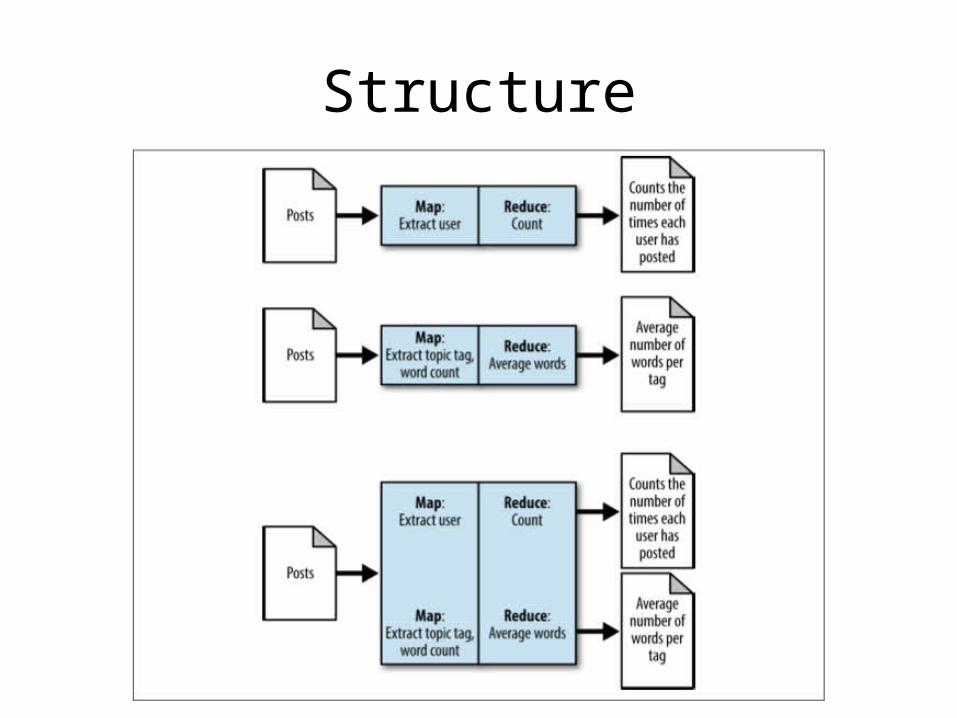
Structure

Methodologies
• Tag map output records• Use MultipleOutputs

I/O PATTERNS
Generating Data, External Source Output,External Source Input, Partition Pruning

Customizing I/O
• Unstructured and semi-structured data often calls for a custom input format to be developed

Generating Data
• Generate lots of data in parallel from nothing
• Random or representative big data sets for you to test your analytics with

Known Uses
• Benchmarking your new cluster• Making more data to represent a sample you
were given
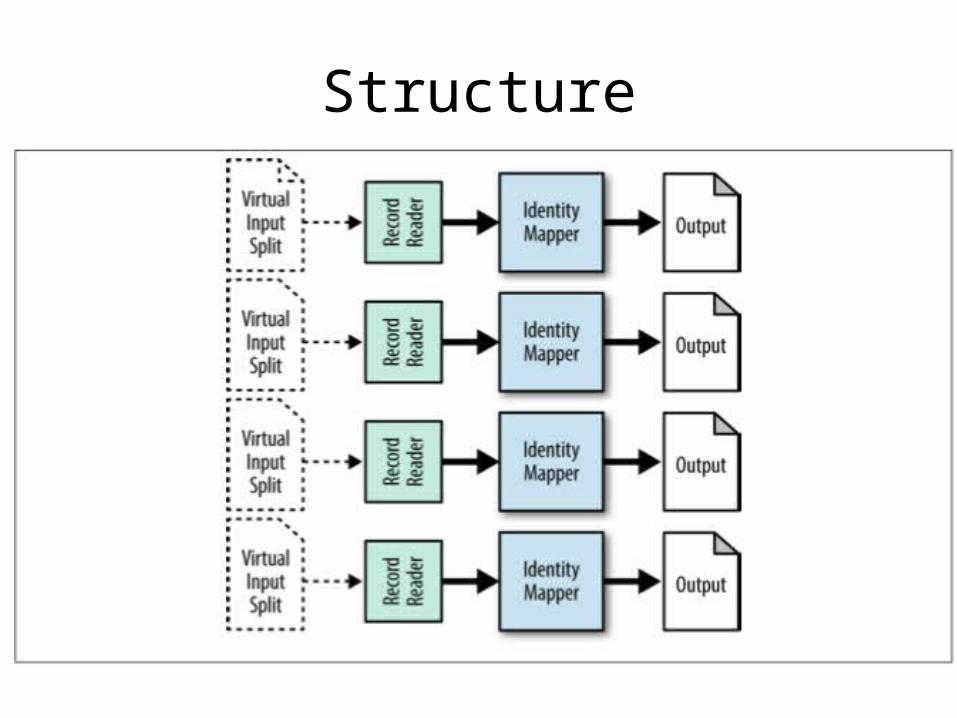
Structure

External Source Output
• You want to write MapReduce output to some non-native location
• Direct loading into a system instead of using HDFS as a staging area

Known Uses
• Write directly out to some non-HDFS solution– Key/Value Store– RDBMS– In-Memory Store
• Many of these are already written
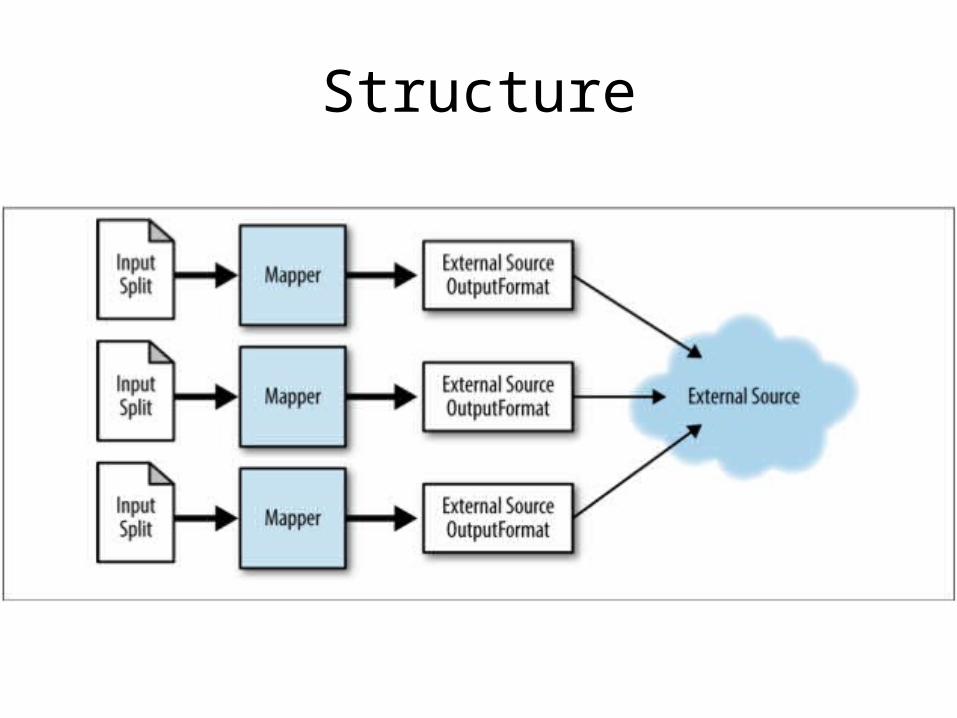
Structure

External Source Input
• You want to load data in parallel from some other source
• Hook other systems into the MapReduce framework

Known Uses
• Skip the staging area and load directly into MapReduce
• Key/Value store• RDBMS• In-Memory store
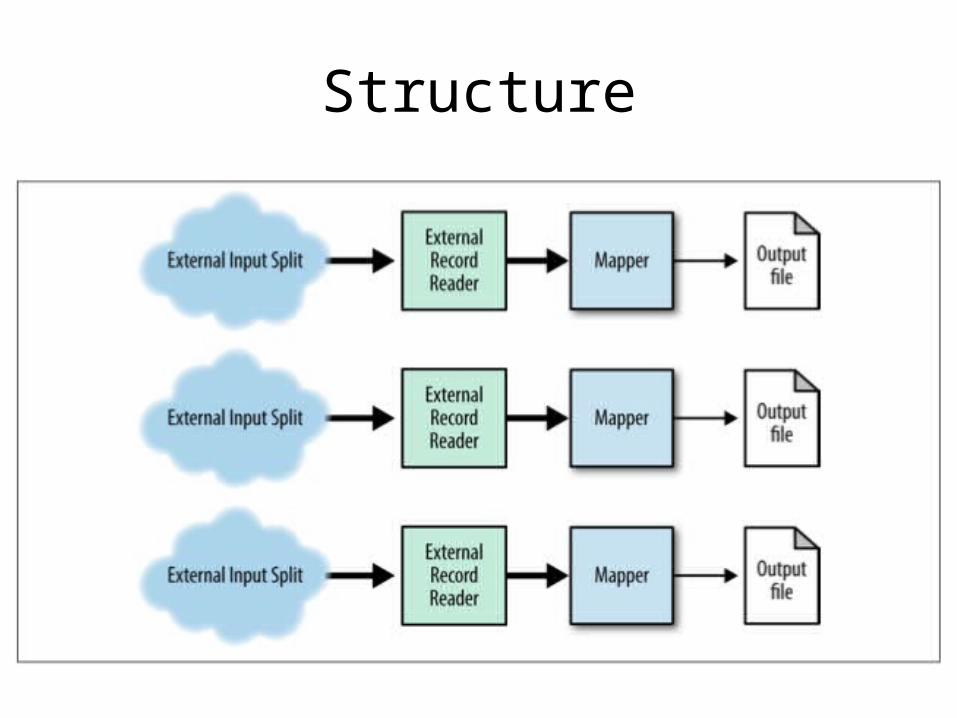
Structure

Partition Pruning
• Abstract away how the data is stored to load what data is needed based on the query

Known Uses
• Discard unneeded files based on the query• Abstract data storage from query, allowing for
powerful middleware to be built
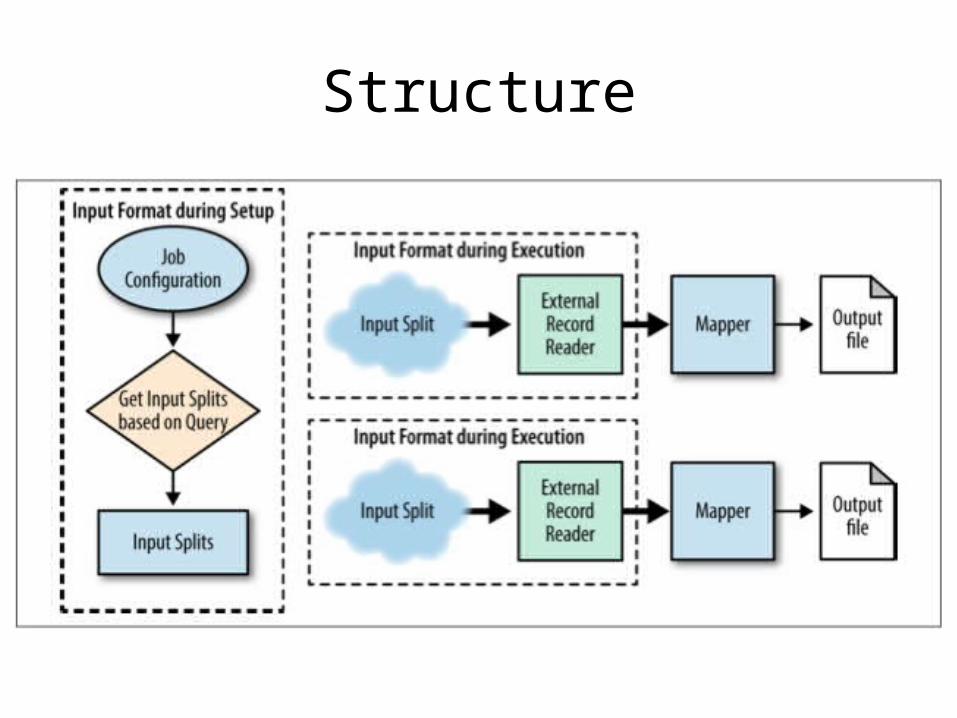
Structure

References
• “MapReduce Design Patterns” – O’Reilly 2012
• www.github.com/adamjshook/mapreducepatterns
• http://en.wikipedia.org/wiki/Bloom_filter





























