Embed Size (px)
Citation preview

1
Materiale di base per un percorso didattico sulla macchina fotografica digitale
L.M.Gratton, M. Rossi, S.Oss
Laboratorio di Comunicazione delle Scienze Fisiche
Dipartimento di fisica
Università degli Studi di Trento
In questo lavoro vengono proposte delle attività da svolgere con studenti di un liceo o dei primi anni di un
corso universitario sullo studio di alcune caratteristiche che le fotocamere digitali devono avere per essere
utilizzate come strumento di analisi quantitativa. Ci si sofferma su come verificare che il sensore, in genere
il CCD (Charge-Coupled Device), dia una risposta lineare in funzione dell’intensità del segnale e di quali
eventuali problemi possano sorgere a causa dei “colori”. Un docente interessato si renderà conto di quali
caratteristiche deve avere la fotocamera di quali accorgimenti servirsi perché i risultati siano significativi. In
appendice verranno poi fatti dei cenni all’utilizzo più convenzionale di tali apparecchi in relazione allo
studio del moto di oggetti materiali.
Introduzione
Strumenti per l’acquisizione di immagine digitale sono oggi comunissimi. Quasi ogni “cellulare”, ipod,
computer portatile,…, permettono di ottenere fotografie o filmati di qualità accettabile.
Come ricaduta l’uso di tali strumenti nella didattica di laboratorio di fisica è ormai diventato molto
frequente. Videocamere e fotocamere digitali permettono di acquisire immagini che sono rese subito
disponibili per l’analisi tramite appropriati programmi facilmente reperibili (anche a costo zero) e che
possono essere caricati su qualsiasi personal computer. Ciò è stato reso possibile dall’introduzione dei
sistemi di registrazione miniaturizzati: schede SSD (Solid State Disk) ecc.. Questo rapido progresso ha
permesso di superare la grande limitazione delle “obsolete” macchine fotografiche a rullino e delle
videocamere analogiche (od anche digitali ma con supporto di registrazione a nastro magnetico) cioè il
tempo necessario per avere disponibili le immagini e le difficoltà di fare copie delle stesse. Infatti i tempi
per lo sviluppo e la stampa delle foto che, a parte l’utilizzo di sistemi “polaroid” (peraltro ormai quasi
irreperibili), erano uno dei limiti non sono più un problema; inoltre l’analisi delle immagini che una volta
doveva essere fatta con righelli, microscopi, micrometri e, per misure di intensità, fotometri oggi possono
facilmente essere fatte dagli studenti con l’uso di appropriati software.
Linearità
In tutte le nostre misure faremo uso della fotocamera Nikon D80.
Prima di affrontare la parte più prettamente sperimentale conviene ricordare, almeno per sommi capi, il
principio di funzionamento di un CCD. In ultima analisi avviene che quando l’elemento sensibile è colpito da
un fotone con appropriata energia, viene prodotta una coppia elettrone buca, e se il dispositivo è
polarizzato si possono separare le cariche e infine misurare questa carica. La carica dipende ovviamente dal
numero di coppie prodotte. La sensibilità del dispositivo dipende da quale sia la probabilità che un fotone
produca una coppia, questa varia in funzione della lunghezza d’onda associata al fotone (sarebbe più
corretto parlare di energia o frequenza). Più che di probabilità si suole parlare di “efficienza quantica”(QE
che sta per Quantum Efficiency) che esprime la percentuale di fotoni che producono una coppia. La QE
dipende dalla lunghezza d’onda e varia tra il 30% e il 90% a seconda della zona spettrale (nota: le vecchie
“pellicole”che hanno un QE di circa il 10%). Oltre il 1.1 µm è 0 perche i fotoni non hanno energia sufficiente
a produrre una coppia. E’ da osservare che il sensore risponde anche in zone spettrali (UV e vicini IR) per le

2
quali l’occhio non è sensibile: si possono ottenere immagini dei led IR dei telecomandi quando sono
“accesi”. Di questo fatto bisognerà tenere conto quando si vogliano fare analisi quantitative.
La sensibilità del singolo sensore del CCD (il pixel) sarà legata alla minima carica che il circuito di lettura è in
grado di misurare o, se si vuole, al numero minimo di fotoni necessari per produrre questa carica. Il “range
dinamico” (il fondo scala) sarà determinato dalla massima carica accumulabile. All’interno del range
dinamico la risposta del sensore è lineare ed è proprio ciò che ci proponiamo di controllare.
Va osservato che il valore della carica del singolo sensore è un processo intrinsecamente probabilistico e
perciò è soggetto a fluttuazioni. Dire che si ha un’intensità di luce costante significa in realtà che si ha un
flusso di fotoni con fluttuazioni piccole rispetto al valore medio. Tradotto in “segnale” raccolto dal sensore
significa che se si fanno due misure della stessa durata temporale si otterranno con grande probabilità due
valori diversi ma vicini. Anche pixel affiancati soggetti allo stesso flusso di fotoni daranno valori diversi.
Questa differenza sarà percentualmente tanto più grande quanto più piccola sarà la carica (il numero di
fotoni coinvolti). Perciò, quando si fanno foto, conviene che siano coinvolti alti numeri di fotoni, questo può
essere ottenuto per esempio allungando i tempi di posa.
Infine va fatto un cenno al “rumore” di fondo di un CCD. Si chiama rumore perché si comporta come un
segnale indesiderato. Sono due i fattori principali che lo determinano: il rumore termico e quello
elettronico (dovuto al circuito). Il rumore termico è dovuto al fatto si possono avere elettroni prodotti
all’interno del CCD non per effetto dell’interazione con un fotone (si creano anche al buio! Da cui il termine
rumore di buio o dark noise in inglese). Questo rumore dipende dalla temperatura (perciò si chiama
termico), per ridurlo bisognerebbe raffreddare il CCD (cosa che fanno gli astronomi). Il rumore elettronico e
dovuto ai circuiti che permettono di leggere la carica e di convertirla (come vedremo tra poco) in numeri. Il
rumore si somma al segnale e perciò bisogna tenerne conto quando si prevede di allungare i tempi di posa
specialmente con poca luce (basso flusso di fotoni). Poiché il segnale (quello che si vuole studiare, per
esempio fotografando li cielo stellato di notte) dà sempre un contributo, con le sue fluttuazioni, mentre il
rumore può essere presente o meno nei singoli pixel, a volte è molto conveniente fare molte fotografie
nelle identiche condizioni dello stesso soggetto (il cielo stellato), sommarle tra di loro e poi fare una media
(comprenderemo meglio in seguito cosa si intenda) piuttosto che fare un'unica foto a tempo di posa lungo.
Infatti in quest’ultimo caso il rumore si somma (aumenta), mentre nel primo caso il rumore si media.
Il rumore dei CCD viene usualmente “misurato” in elettrone (fotoni) equivalenti.
La carica accumulata nei singoli pixel viene “letta” da un circuito elettronico e convertita in un numero da
un apposito circuito elettronico (convertitore analogico digitale DAC: Digital Analog Converter). Tale
numero dipende, oltre che dal valore della carica, dal tipo di convertitore. Quasi tutte le macchine
fotografiche usano convertitori a 12 bit. Poiché 212=4096 il range dinamico è 4096: carica 0 (niente segnale)
vale 1 (o 0) carica di saturazione vale 4096 (o 4095). Quando prima abbiamo scritto di fluttuazioni del
segnale si traduce in fluttuazioni di questo numero che è direttamente proporzionale alla carica. Le
fluttuazione attese sono la radice del valore in cui è stata convertita la carica: circa 1.5% per valori di carica
corrispondenti a 4000, ma del 10% per valori corrispondenti a 100. Con ciò si intende la discrepanza media
prevista tra pixel affiancati sottoposti allo stesso flusso di fotoni. Va osservato che se c’è saturazione le
fluttuazioni oltre il valore massimo (4096) sono nulle.
Tutte le macchine fotografiche permettono di cambiare la “sensibilità” ciò viene fatto utilizzando il così
detto numero ISO. In pratica cambiare il numero ISO corrisponde ad amplificare il segnale corrispondente
alla carica accumulata prima di convertirlo in digitale, in questo modo può essere amplificato anche un
segnale molto debole, la controparte è che si amplifica anche il rumore esattamente dello stesso valore!

3
Ogni macchina ha un così detto ISO Nativo che corrisponde alla “minima sensibilità”, o sarebbe meglio dire,
alla sensibilità nativa del CCD. Nel nostro caso ISO 100. Per evitare di introdurre rumore imposteremo in
tutte le misura ISO 100 nel nostro apparato.
Quando registriamo una fotografia e la salviamo sulla scheda SSD troviamo un file che può essere del tipo
xxxxxx.JPG e talvolta yyyyyy.RAW (NEF nel caso della Nikon D80). Osserviamo immediatamente che i file
con estensione JPG sono molto più compatti degli altri.
Il formato JPG è un formato universale mentre il formato RAW è un formato caratteristico di ogni casa
produttrice di apparati fotografici. Alcune fotocamere salvano solo in formato JPG*.
Per procedere alla verifica della linearità del CCD discuteremo due esperimenti quasi equivalenti
schematizzati in Figura 1a. Sul coperchio di una grande scatola (annerita all’interno) è stato praticato un
foro che viene delimitato da cartoncino bianco. Il foro costituisce pertanto un “corpo nero” da cui non esce
radiazione visibile. La superficie bianca attorno al foro, ed il foro stesso sono illuminate da una lampada
alogena connessa ad un alimentatore stabilizzato in modo che l’intensità della luce emessa sia controllabile
e stabile nel tempo. La fotocamera è posta in asse con il centro del foro e programmata in modalità
completamente manuale. Il bilanciamento del bianco è selezionato “automatico” e l’analisi seguente è fatta
trattando la foto come se fosse in bianco e nero† (sul bilanciamento del bianco, che è attivo solo per il
formato JPG e non può essere disabilitato, torneremo in seguito). La messa a fuoco è manuale. Per
effettuare gli esperimenti vengono eliminate tutte le sorgenti di luce tranne la lampada alogena.
a b
Figura 1 a: schema dell’assemblaggio dell’apparato. b: esempio di foto nella quale è evidenziata l’area analizzata.
In Figura 1b è riportato un esempio di foto ottenuta. Le foto sono salvate contemporaneamente nei formati
JPG e RAW. Servendosi del programma ImageJ ‡ si può fare l’analisi del profilo di intensità del segnale
dell’area rettangolare selezionata. Il programma considera la zona analizzata come costituita dalla matrice
righe per colonne di pixel contenuta in tale area e riporta in ascissa i pixel determinati dalla base dal
rettangolo analizzato e in ordinata le medie dei valori delle colonne corrispondenti. Tale valore è in
relazione all’intensità della luce che illumina il cartoncino, in ultima analisi rappresenta, attraverso un
valore numerico, la carica elettrica media della colonna di pixel che a sua volta è direttamente
proporzionale al numero di fotoni che incidono sul singolo pixel. Il numero che il programma legge
* JPG o JPEG: Joint Photographic Expert Group ; RAW: in inglese sta per “grezzo”; NEF è il formato RAW della Nikon.
† Ciò può essere fatto perché la foto contiene un unico “colore”: il bianco. Perciò la conversione in “livelli di grigio” non
inficia la misura. Questo punto verrà affrontato più in dettaglio nel seguito. ‡ ImageJ è un software freeware scaricabile al sito http://rsbweb.nih.gov/ij/. Il software è in grado di analizzare le
immagini sia in formato JPG cha RAW eventualmente con l’ausilio di opportuni plugin.
4
rappresenta in “unità numeriche arbitrarie (u.n.a.)” l’intensità della luce.
Se al posto di un area si scegliesse una sola riga le fluttuazioni sarebbero più elevate.
Le due modalità sperimentali di cui abbiamo scritto prima consistono: la prima nello studiare la linearità in
funzione del tempo di posa ad apertura fissa (diaframma fisso); la seconda a tempo di posa fisso in funzione
dell’apertura. Le foto e il tipo di analisi sono analoghe per le due modalità.
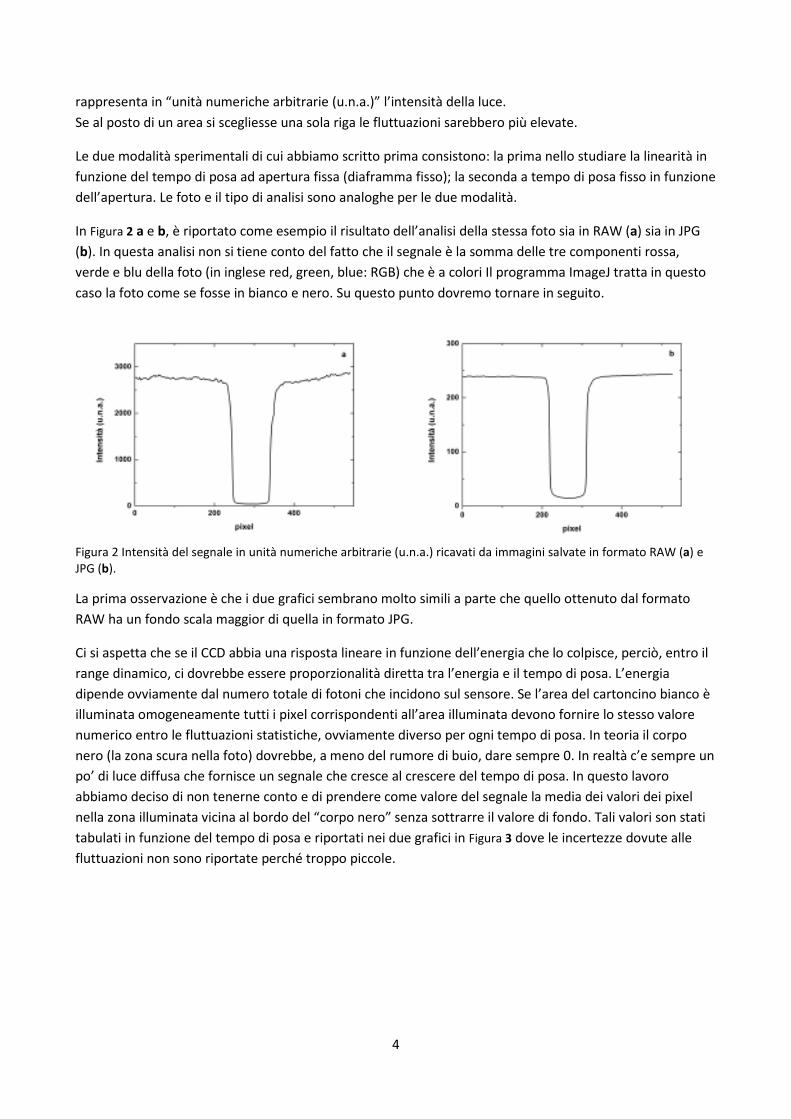
In Figura 2 a e b, è riportato come esempio il risultato dell’analisi della stessa foto sia in RAW (a) sia in JPG
(b). In questa analisi non si tiene conto del fatto che il segnale è la somma delle tre componenti rossa,
verde e blu della foto (in inglese red, green, blue: RGB) che è a colori Il programma ImageJ tratta in questo
caso la foto come se fosse in bianco e nero. Su questo punto dovremo tornare in seguito.
Figura 2 Intensità del segnale in unità numeriche arbitrarie (u.n.a.) ricavati da immagini salvate in formato RAW (a) e JPG (b).
La prima osservazione è che i due grafici sembrano molto simili a parte che quello ottenuto dal formato
RAW ha un fondo scala maggior di quella in formato JPG.
Ci si aspetta che se il CCD abbia una risposta lineare in funzione dell’energia che lo colpisce, perciò, entro il
range dinamico, ci dovrebbe essere proporzionalità diretta tra l’energia e il tempo di posa. L’energia
dipende ovviamente dal numero totale di fotoni che incidono sul sensore. Se l’area del cartoncino bianco è
illuminata omogeneamente tutti i pixel corrispondenti all’area illuminata devono fornire lo stesso valore
numerico entro le fluttuazioni statistiche, ovviamente diverso per ogni tempo di posa. In teoria il corpo
nero (la zona scura nella foto) dovrebbe, a meno del rumore di buio, dare sempre 0. In realtà c’e sempre un
po’ di luce diffusa che fornisce un segnale che cresce al crescere del tempo di posa. In questo lavoro
abbiamo deciso di non tenerne conto e di prendere come valore del segnale la media dei valori dei pixel
nella zona illuminata vicina al bordo del “corpo nero” senza sottrarre il valore di fondo. Tali valori son stati
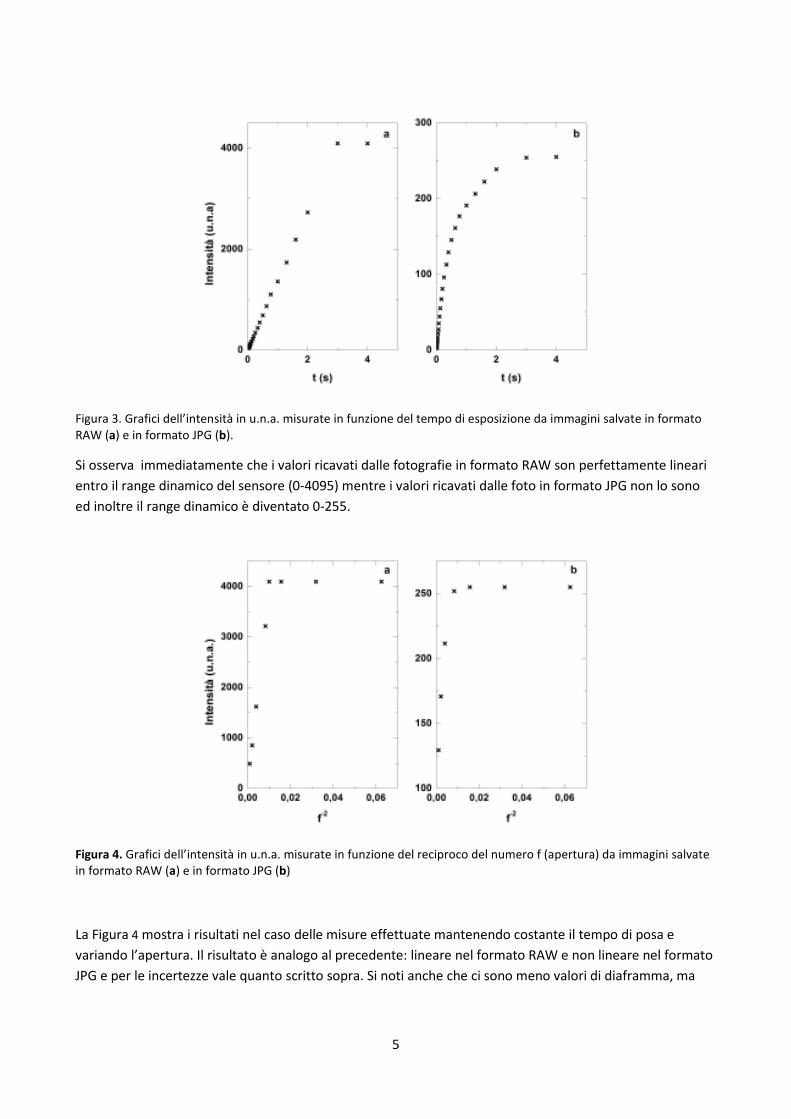
tabulati in funzione del tempo di posa e riportati nei due grafici in Figura 3 dove le incertezze dovute alle
fluttuazioni non sono riportate perché troppo piccole.
5
Figura 3. Grafici dell’intensità in u.n.a. misurate in funzione del tempo di esposizione da immagini salvate in formato RAW (a) e in formato JPG (b).
Si osserva immediatamente che i valori ricavati dalle fotografie in formato RAW son perfettamente lineari
entro il range dinamico del sensore (0-4095) mentre i valori ricavati dalle foto in formato JPG non lo sono
ed inoltre il range dinamico è diventato 0-255.
Figura 4. Grafici dell’intensità in u.n.a. misurate in funzione del reciproco del numero f (apertura) da immagini salvate in formato RAW (a) e in formato JPG (b)
La Figura 4 mostra i risultati nel caso delle misure effettuate mantenendo costante il tempo di posa e
variando l’apertura. Il risultato è analogo al precedente: lineare nel formato RAW e non lineare nel formato
JPG e per le incertezze vale quanto scritto sopra. Si noti anche che ci sono meno valori di diaframma, ma

6
soprattutto che, a causa di come viene variata l’apertura (un sistema meccanico a lamelle), la linearità
risulta meno ben definita rispetto a quella ottenuta variando i tempi di posa che sono molto accurati§.
I grafici mostrano che in ogni caso il formato JPG non può essere utilizzato per misure quantitative di
intensità di luce, mentre le immagini salvate in formato RAW vanno molto bene purché si stia attenti a non
superare il range dinamico del sensore.
In sostanza con il formato RAW vengono salvate le informazioni ricavate dal sensore senza alcuna modifica,
mentre il formato JPG comprime anche la scala delle intensità. La compressione consiste nel passare da
valori a 12 bit (0-4095) a valori a 8 bit (0-255) per risparmiare spazio nella memorizzazione e questa
“compressione” non è lineare ma bensì logaritmica. Questo viene fatto perché anche la risposta dell’occhio
umano alla intensità di luce è logaritmica. L’occhio umano distingue bene piccole variazioni di luminosità se
la luce è scarsa , ma non distingue altrettanto bene variazioni di luminosità se la luce è molto intensa.
L’amplificazione logaritmica riproduce bene questo comportamento. Se si osserva attentamente la Figura 2
b si nota che il fondo della zona “buia” da un segnale relativamente alto se confrontato con quello RAW.
Nella Figura 3 si osserva che solo per basse energie (tempi di posa molto brevi) il formato JPG può essere
considerato a risposta lineare. Il formato JPG esalta in le piccole variazioni di segnale e “schiaccia” le
variazioni quando il segnale è intenso riproducendo bene quanto fa l’occhio. Perciò tale formato va molto
bene per riprodurre immagini, ma è inutilizzabile per misure quantitative di intensità luminosa.
COLORE
Riprodurre in un’immagine il mondo reale in tutte le sue sfumature, compreso il “colore”, è una delle cose
che il progettista di un apparato fotografico si propone come obiettivo. Il colore è un concetto che non ha
molto significato in fisica. La luce non ha colore ma è il nostro cervello che interpreta le informazioni che ci
pervengono attraverso l’apparato visivo che ci da la sensazione che chiamiamo colore. Noi percepiamo un
oggetto come colorato se e solo se la luce che da esso proviene (per diffusione, riflessione o per emissione)
contiene delle determinate frequenze o combinazioni di frequenze in opportuni rapporti di intensità. Il
sensore della macchina fotografica deve essere perciò in grado di riprodurre nel miglior modo possibile ciò
che i nostri occhi “vedono” quando osservano il mondo circostante. Per comprendere e analizzare come sia
progettato il CCD per ottenere questo scopo, è necessario avere un’idea schematica di come funziona la
percezione visiva. In ultima analisi l’occhio è un sensore che si comporta in modo molto simile al CCD.
Sulla retina sono presenti due tipi di cellule sensibili alla luce: i coni e i bastoncelli. Solo i coni sono
responsabili della visione “a colori” (la cosiddetta “visione fotopica”). I bastoncelli (visione scotopica) hanno
una sensibilità estremamente elevata e sono i responsabili della visione notturna (al chiaro di luna non
§ Negli obiettivi delle macchine fotografiche si trovano delle sequenze numeriche del tipo f/1.4,f/ 2,f/2.8,.... Tali valori
si riferiscono all’apertura del diaframma ed indicano il rapporto F/D la focale F tra e il diametro D dell’obiettivo; più grande è il numero f più il diaframma è chiuso. Tali serie si trovano anche in ogni fotocamera digitale. Il diametro dell’obiettivo corrisponde in genere al diametro della lente di ingresso (o all’apertura massima del diaframma), la focale dell’obiettivo è fissa a meno che non si tratti di un obiettivo ”zoom”. Il “diametro utile” dell’obiettivo può essere ridotto mediante la chiusura del diaframma che ha un contorno circolare (diaframma a iride); ciò viene fatto per ridurre effetti dovuti ad aberrazione sferiche (le aberrazioni sono tanto minori quanto più i raggi sono parassiali, cioè formanti piccoli angoli rispetto all’asse ottico della lente obiettivo). La riduzione del diametro del diaframma comporta che l’energia che raggiunge il sensore viene ridotta in funzione dell’area del diaframma: l’energia totale che raggiunge l’obiettivo è ridotta proporzionalmente al diametro del diaframma elevato al quadrato. Si osserva
facilmente che la serie di numeri f è una progressione geometrica di ragione√2; ciò equivale a dire che l’area del diaframma f/2 è doppia dell’area del diaframma f/2.8 e così via. Pertanto per ottenere la stessa energia passando da un diaframma a quello successivo bisogna raddoppiare il tempo di posa. In sostanza il numero f è proporzionale al reciproco del diametro del diaframma. Perciò nel grafico è riportata l’intensità in funzione di 1/f
2.

7
percepiamo i colori); bastano pochi fotoni, meno di dieci, perché lo stimolo sia sufficiente a farci percepire
un lampo di luce. Di giorno i bastoncelli sono “in saturazione” e non partecipano alla visione si può dire che
il “range dinamico” dei bastoncelli non è sufficientemente ampio (in realtà è estremamente ampio: più di 7
ordini di grandezza!); perché divengano attivi si devono “scaricare”: è necessario del tempo. Se entriamo in
un ambiente buio ci vuole un po’ di attesa prima di adattarci alla luminosità dell’ambiente. I bastoncelli,
così come i coni e i “pixel” del CCD sono dei “contatori” di fotoni nel senso che è l’assorbimento di un
fotone che produce il segnale percepito. Si può quindi definire un QE anche per i bastoncelli e per i coni.
Oltre a ciò hanno una curva di sensibilità spettrale ben definita che va dal blu al rosso o, meglio, dai 400 nm
ai 650 nm circa con un massimo attorno ai 500 nm.
I coni sono molto meno sensibili dei bastoncelli nel senso che occorrono molti più fotoni per produrre uno
stimolo che il cervello riesca ad elaborare. Il loro “range dinamico” è molto ampio cioè dello stesso ordine
di quello dei bastoncelli. Per ottenere questo risultato “l’evoluzione naturale” ha prodotto un organo
sensoriale con una curva di risposta logaritmica. Per inciso tutti i nostri sensi hanno una risposta
logaritmica, ciò significa che raddoppiando l’intensità di uno stimolo non raddoppia la risposta allo stesso: è
più noto ciò che succede per l’udito o per il gusto (per esempio la sensazione che abbiamo quando
assaggiamo del peperoncino di diversa “piccantezza”). Ricordo che la compressione JPG si basa anche sullo
sfruttamento di questo comportamento del nostro sistema di percezione visiva.
Senza entrare troppo nei dettagli** possiamo dire che in un occhio sano esistono tre tipi di coni. Un tipo è
più sensibile alla luce nel zona spettrale blu, un altro tipo nel verde, e infine una nel rosso††. In Figura 5 sono
Figura 5 Sensibilità normalizzata dei tre tipi di coni in funzione della lunghezza d’onda.
riportate le sensibilità spettrali normalizzate per i tre tipi di coni. È importante osservare che la risposta dei
tre tipi di coni è tutt’altro che monocromatica. Ciò vuol dire che se la luce contiene anche fotoni
“perfettamente” monocromatici (per esempio la luce di un laser nella regione del visibile) vengono
stimolati tutti e tre i tipi di coni. Al cervello pervengono contemporaneamente tre stimoli (un così detto
“tri-stimolo”) ed è questa combinazione di tre stimoli che è, in ultima analisi, responsabile della percezione
di un colore. E’ sufficiente che la luce contenga le giuste frequenze (non importa quali, ma con le intensità
opportune) che producano il tri-stimolo che corrisponde ad una certa percezione perché un colore venga
“visto”. Si può dimostrare che sono necessarie e sufficienti tre frequenze (tre colori) opportunamente
**
Bisognerebbe aggiungere che il cervello a volte “completa” le informazioni che provengono dai sensi. Per esempio alla luce di una candela la neve ci appare bianca nonostante la radiazione emessa dalla fiamma non contenga le componenti necessarie per ottenere il bianco!. ††
Il numero totale dei coni varia tra i 6 e i 7 milioni: di cui circa il 64% più sensibili al rosso, circa il 32% al verde e circa il 2% al blu. I coni blu sono molto più sensibili di quelli verdi e rossi, ma anche molto meno numerosi ed inoltre sono situati fuori dalla zona centrale della fovea da ciò deriva la scarsa sensibilità al blu (da Hyperphysics).

scelte per poter riprodurre ogni colore. Le infinite terne di colori che possono essere scelte vengono talora
chiamate terne di colori primari‡‡. La più usuale
(Red, Green, Blue).
I tre tipi di coni non sono ugualmente sensibili, ma ciò che conta è che la sensibilità nella zona spettrale del
verde (540 nm circa) è molto maggiore cha ad altre frequenze (a
che a 540 nm), ciò è dovuto a ragioni evolutive: il massimo nello spettro di emissione del sole è proprio a
quelle frequenze
Torniamo ora al CCD. I singoli sensori, i pixel, sono sensibili
lunghezze d’onda tra i 300 nm 1100
Ovviamente non sono in grado di distinguere i colori. Per risolvere il problema della riproduzione dei colori
la via più semplice (ed economica) consiste nel filtrare la luce che raggiunge il sensore in maniera che
assomigli il più possibile a ciò che succede nell’occhio. E’ necessario selezionare tre colori (tre bande di
lunghezza d’onda) ciò viene fatto ponendo sopra i sensori de
Figura 6 Schema della disposizione dei filtri colorati sul CCD.
In Figura 6 è schematizzata la più usuale disposizione dei pixel con i rispettivi filtri; se si osserva con
attenzione si vede che la matrice di pixel e suddivisa in quadrati di quattro pixel adiacenti,
verde e due con filtro rispettivamente rosso e blu. Il fatto che i pixel verdi siano doppi rispetto a quelli rossi
o blu, serve proprio per riprodurre la molto maggiore sensibilità dell’occhio alle frequenze corrispondenti al
verde. Le bande passanti dei filtri dovrebbero assomigliare il più possibile alle curve di risposta dei tre tipi di
coni; tuttavia i filtri lasciano passare anche radiazione nella regione dell’infrarosso. A differenza di ciò che
avviene per l’occhio il CCD risulta sensib
Il principale problema che devono risolvere i progettisti di apparati fotografici basati sui CCD è quello di
bilanciare correttamente il segnale proveniente dai tre tipi di “pixel colorati” in modo da riprodurre
correttamente i colori. La luce che illumina il soggetto fotografato può avere origine diversa (può essere il
sole, una lampada a incandescenza, a fluorescenza …) ed avere di conseguenza uno spettro completamente
differente. Ovviamente non si possono cambiare i filtri al
problema viene risolto via software. Esiste in praticamente tutte le macchine fotografiche digitali una
funzione che si chiama “bilanciamento del bianco” che ha lo scopo di modificare il segnale provenient
tre tipi di pixel per tenere conto della diversa composizione spettrale della luce che si utilizza per
fotografare. Questo è molto utile per ottenere immagini a colori realistici ma è dannoso per l’utilizzo
‡‡
Perché una terna di colori possa essere definita primaria è necessario che i trepercezione visiva (il colore ) di uno qualunque dei tre non si ottenibile combinando in qualunque modo gli atri due.
8
scelte per poter riprodurre ogni colore. Le infinite terne di colori che possono essere scelte vengono talora
. La più usuale (quella adoperata negli schermi televisivi) è la terna RGB
pi di coni non sono ugualmente sensibili, ma ciò che conta è che la sensibilità nella zona spettrale del
nm circa) è molto maggiore cha ad altre frequenze (a 400 nm è circa 100 volte meno sensibile
nm), ciò è dovuto a ragioni evolutive: il massimo nello spettro di emissione del sole è proprio a
ensori, i pixel, sono sensibili nell’intervallo di frequen
nm 1100 nm. Il massimo della sensibilità (della QE) è attorno a 550
Ovviamente non sono in grado di distinguere i colori. Per risolvere il problema della riproduzione dei colori
e (ed economica) consiste nel filtrare la luce che raggiunge il sensore in maniera che
assomigli il più possibile a ciò che succede nell’occhio. E’ necessario selezionare tre colori (tre bande di
lunghezza d’onda) ciò viene fatto ponendo sopra i sensori dei filtri rispettivamente rosso verde è blu.
Schema della disposizione dei filtri colorati sul CCD.
è schematizzata la più usuale disposizione dei pixel con i rispettivi filtri; se si osserva con
attenzione si vede che la matrice di pixel e suddivisa in quadrati di quattro pixel adiacenti,
verde e due con filtro rispettivamente rosso e blu. Il fatto che i pixel verdi siano doppi rispetto a quelli rossi
o blu, serve proprio per riprodurre la molto maggiore sensibilità dell’occhio alle frequenze corrispondenti al
passanti dei filtri dovrebbero assomigliare il più possibile alle curve di risposta dei tre tipi di
coni; tuttavia i filtri lasciano passare anche radiazione nella regione dell’infrarosso. A differenza di ciò che
occhio il CCD risulta sensibile anche in questa regione.
Il principale problema che devono risolvere i progettisti di apparati fotografici basati sui CCD è quello di
bilanciare correttamente il segnale proveniente dai tre tipi di “pixel colorati” in modo da riprodurre
colori. La luce che illumina il soggetto fotografato può avere origine diversa (può essere il
sole, una lampada a incandescenza, a fluorescenza …) ed avere di conseguenza uno spettro completamente
differente. Ovviamente non si possono cambiare i filtri all’occorrenza, perciò nella macchina fotografica il
problema viene risolto via software. Esiste in praticamente tutte le macchine fotografiche digitali una
funzione che si chiama “bilanciamento del bianco” che ha lo scopo di modificare il segnale provenient
tre tipi di pixel per tenere conto della diversa composizione spettrale della luce che si utilizza per
fotografare. Questo è molto utile per ottenere immagini a colori realistici ma è dannoso per l’utilizzo
Perché una terna di colori possa essere definita primaria è necessario che i tre colori siano scelti in modo che la percezione visiva (il colore ) di uno qualunque dei tre non si ottenibile combinando in qualunque modo gli atri due.
scelte per poter riprodurre ogni colore. Le infinite terne di colori che possono essere scelte vengono talora
(quella adoperata negli schermi televisivi) è la terna RGB
pi di coni non sono ugualmente sensibili, ma ciò che conta è che la sensibilità nella zona spettrale del
nm è circa 100 volte meno sensibile
nm), ciò è dovuto a ragioni evolutive: il massimo nello spettro di emissione del sole è proprio a
nell’intervallo di frequenze corrispondenti a alle
nm. Il massimo della sensibilità (della QE) è attorno a 550-600 nm.
Ovviamente non sono in grado di distinguere i colori. Per risolvere il problema della riproduzione dei colori
e (ed economica) consiste nel filtrare la luce che raggiunge il sensore in maniera che
assomigli il più possibile a ciò che succede nell’occhio. E’ necessario selezionare tre colori (tre bande di
i filtri rispettivamente rosso verde è blu.
è schematizzata la più usuale disposizione dei pixel con i rispettivi filtri; se si osserva con
attenzione si vede che la matrice di pixel e suddivisa in quadrati di quattro pixel adiacenti, due con filtro
verde e due con filtro rispettivamente rosso e blu. Il fatto che i pixel verdi siano doppi rispetto a quelli rossi
o blu, serve proprio per riprodurre la molto maggiore sensibilità dell’occhio alle frequenze corrispondenti al
passanti dei filtri dovrebbero assomigliare il più possibile alle curve di risposta dei tre tipi di
coni; tuttavia i filtri lasciano passare anche radiazione nella regione dell’infrarosso. A differenza di ciò che
Il principale problema che devono risolvere i progettisti di apparati fotografici basati sui CCD è quello di
bilanciare correttamente il segnale proveniente dai tre tipi di “pixel colorati” in modo da riprodurre
colori. La luce che illumina il soggetto fotografato può avere origine diversa (può essere il
sole, una lampada a incandescenza, a fluorescenza …) ed avere di conseguenza uno spettro completamente
l’occorrenza, perciò nella macchina fotografica il
problema viene risolto via software. Esiste in praticamente tutte le macchine fotografiche digitali una
funzione che si chiama “bilanciamento del bianco” che ha lo scopo di modificare il segnale proveniente dai
tre tipi di pixel per tenere conto della diversa composizione spettrale della luce che si utilizza per
fotografare. Questo è molto utile per ottenere immagini a colori realistici ma è dannoso per l’utilizzo
colori siano scelti in modo che la percezione visiva (il colore ) di uno qualunque dei tre non si ottenibile combinando in qualunque modo gli atri due.

9
dell’apparecchio in un laboratorio di fisica. §§
Il formato JPEG introduce sempre un bilanciamento del bianco che può essere predeterminato da chi fa la
fotografia secondo del tipo di illuminazione. Il formato RAW invece esclude questa funzione.
La riproduzione del colore viene fatta combinando il segnale dei tre canali RGB così come vengono dal CCD,
nel caso del RAW, o moltiplicati per opportuni fattori (bilanciamento del bianco) nel caso del JPG. Poiché il
range dinamico nel JPG è 28 (256), i colori possibili (le combinazioni possibili dei tre canali) sono 2563
(16777216). Questi sono i colori ottenibili su uno schermo televisivo o sul monitor del computer. Il formato
RAW permette un intervallo molto maggiore.
Un breve discorso merita il modo con cui si riesce ad ottenere una foto in bianco e nero (toni di grigio).
Ci occupiamo solo del JPG ma per il formato RAW vale un discorso del tutto analogo. Il nero si ottiene
quando i tre canali sono a 0 (canale del rosso R=0, canale del verde R=0 e canale del blu B=0), il bianco se
R=255, V=255 e B=255) se i tre canali hanno un valore uguale compreso tra 0 e 255 si ottengono i toni di
grigio. I livelli di grigio ottenibili sono 256. Il CCD registra i tre canali e per ciascuno fornisce un certo valore
(per una dato punto della matrice di pixel). Si può pertanto ottenere una immagine a livelli di grigio per ogni
canale RGB, per esempio ponendo uguale al valore del canale R anche i canali G e B: in questo caso si avrà
un’immagine in toni di grigio relativa al canale rosso. Ciò che normalmente fanno le macchine fotografiche
(o i software dedicati) è quello di combinare i tre canali normalizzando il valore massimo a 255. Il modo più
semplice sarebbe quello di porre i canali RGB uguali a (R+G+B)/3 attribuendo lo stesso peso ai tre canali. In
realtà quasi sempre i canali vengono sommati moltiplicandoli per un fattore opportuno in modo da esaltare
il contrasto o la luminosità dell’immagine o per mettere in risalto qualche particolare. In ogni caso non è
facile sapere a priori quale metodo e quali fattori vengano utilizzati.
Anche il tono di grigio ottenuto dalle immagini in formato RAW vengono elaborati allo stesso modo.
Finché in laboratorio si effettuano esperimenti in luce bianca o in luce monocromatica, a parte quanto
sottolineato nel paragrafo precedente, non ci sono problemi. Infatti anche se la luce fosse monocromatica
(luce di un laser) i sensori rosso verde è blu risponderebbero ancora in maniera lineare (anche
singolarmente presi)
Il problema sorge quando si vuole analizzare la luce nei suoi componenti spettrali, per esempio analizzare
l’intensità delle righe spettrali di una lampada per confrontarle tra di loro, l’immagine dello spettro solare,
fare misure quantitative di assorbimento, ecc..
Effettuare misure di intensità di righe spettrali o di intensità di spettri continui, anche se solo in unità
arbitrarie è particolarmente complesso. Bisogna infatti tenere conto della risposta spettrale del sensore
(quella del CCD non è costante anche nella zona del visibile), della curva di risposta del sistema che viene
utilizzato per disperdere la luce (prisma o reticolo di diffrazione), inoltre c’è la necessità di calibrare in
lunghezza d’onda l’immagine ottenuta. Mentre di questa ultima parte ci occuperemo in un successivo
lavoro, qui ci soffermeremo soltanto nell’analizzare le caratteristiche che il CCD debba avere per
§§
In sintesi noi vediamo un figlio bianco perché esso diffonde in ugual modo tutti i colori che ovviamente devono essere presenti nella luce che lo illumina. La luce diffusa dal foglio produce il “tri-stimolo” giusto solo se le componenti rossa, verde è blu sono presenti al valore opportuno. Il bilanciamento del bianco opera in modo da regolare il segnale del canale rosso verde e blu dei pixel che riproducono un oggetto “bianco”, in modo che a noi appaia bianco nell’immagine, anche se la luce che abbiamo utilizzato per ottener la foto risultava sbilanciata nelle componenti. Per esempio la luce di una lampada a incandescenza è relativamente più ricca nella componente rossa rispetto alla luce del sole (che viene presa a riferimento), e di contro è povera della componente blu sempre rispetto a quella del sole. Il bilanciamento del bianco risolve il problema amplificando il segnale del canale blu e riducendo il segnale del canale rosso nelle foto fatte con lampade a incandescenza. Per chi fosse interessato si consiglia approfondire il concetto di “temperatura di colore”.

10
permettere misure di assorbimento o di trasmissione e di come possa essere calibrato in energia, almeno in
unità arbitrarie. In pratica si tratta verificare se la macchina fotografica possa essere utilizzata come sensore
di uno spettrofotometro.
Ci proponiamo di misurare l’assorbimento della luce dovuto ad un filtro colorato a diverse lunghezze. Con
dei filtri opportuni selezioniamo una banda 450 nm, una a 550 nm ed una a 600 nm*** e misuriamo con il
CCD il rapporto tra il segnale in presenza e in assenza di filtro .
All’interno di una scatola mettiamo una lampada alogena alimentata da un alimentatore stabilizzato in
modo da essere certi che l’illuminazione sia costante. Sul foro, dalla parte interna, è posto un foglio bianco
per diffondere la luce. La scatola è nera all’esterno, pertanto il segnale raccolto dal CCD risulta del tipo di
quello in Figura 2 ovviamente con segnale circa zero ai bordi e massimo al centro. Lo schema è in Figura 7.
Figura 7 Schema dell’apparato utilizzato per la misura della risposta del CCD alle varie lunghezze d’onda.
Un’analoga misura la effettuiamo sostituendo la macchina fotografica con un sensore di riferimento a
spettro di risposta piatto. Per questo scopo abbiamo utilizzato una termopila†††, che ha una finestra di FBa2
che ne limita il range da 300 nm a 10000 nm. Per evitare che del segnale infrarosso disturbi la misura
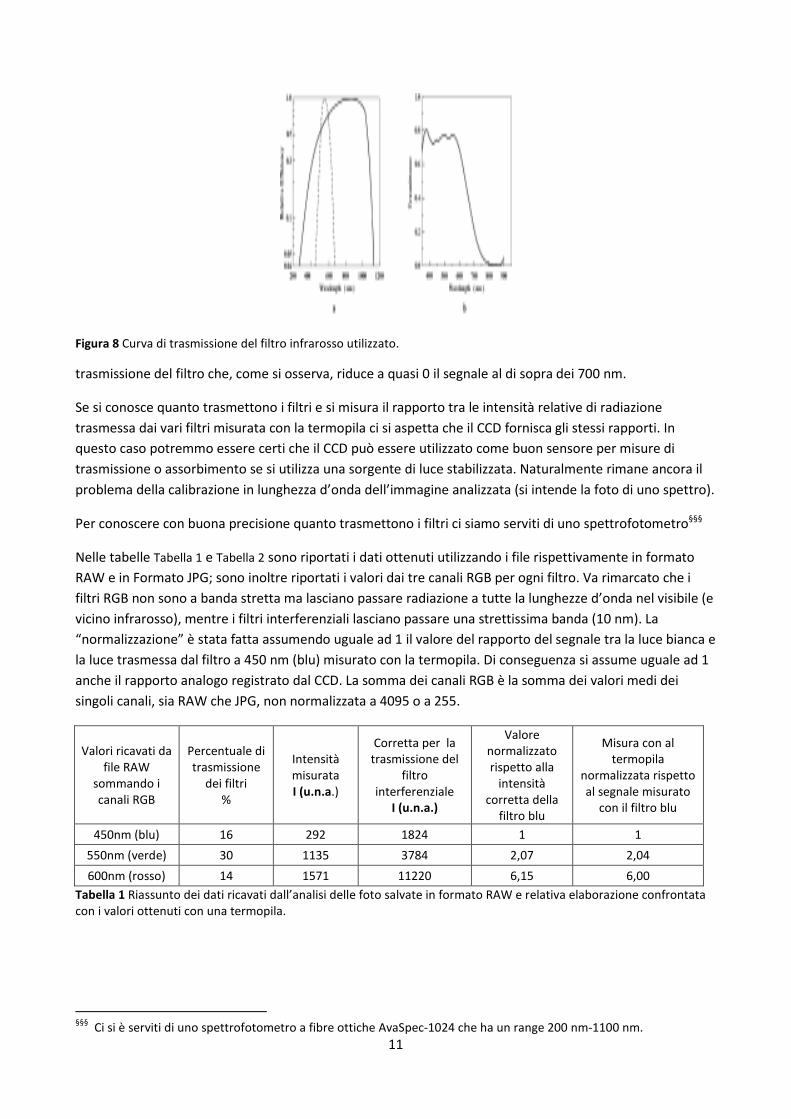
abbiamo posto sopra il foro un filtro‡‡‡ che elimina tale segnale. In Figura 8 è riportato lo spettro di
***
Sono stati utilizzati dei filtri interferenziali con una banda passante di 10 nm. †††
PASCO CI-6630 Light Broad Spectrum. ‡‡‡
Abbiamo utilizzato il filtro infrarosso prelevato da un proiettore da diapositive.
11
Figura 8 Curva di trasmissione del filtro infrarosso utilizzato.
trasmissione del filtro che, come si osserva, riduce a quasi 0 il segnale al di sopra dei 700 nm.
Se si conosce quanto trasmettono i filtri e si misura il rapporto tra le intensità relative di radiazione
trasmessa dai vari filtri misurata con la termopila ci si aspetta che il CCD fornisca gli stessi rapporti. In
questo caso potremmo essere certi che il CCD può essere utilizzato come buon sensore per misure di
trasmissione o assorbimento se si utilizza una sorgente di luce stabilizzata. Naturalmente rimane ancora il
problema della calibrazione in lunghezza d’onda dell’immagine analizzata (si intende la foto di uno spettro).
Per conoscere con buona precisione quanto trasmettono i filtri ci siamo serviti di uno spettrofotometro§§§
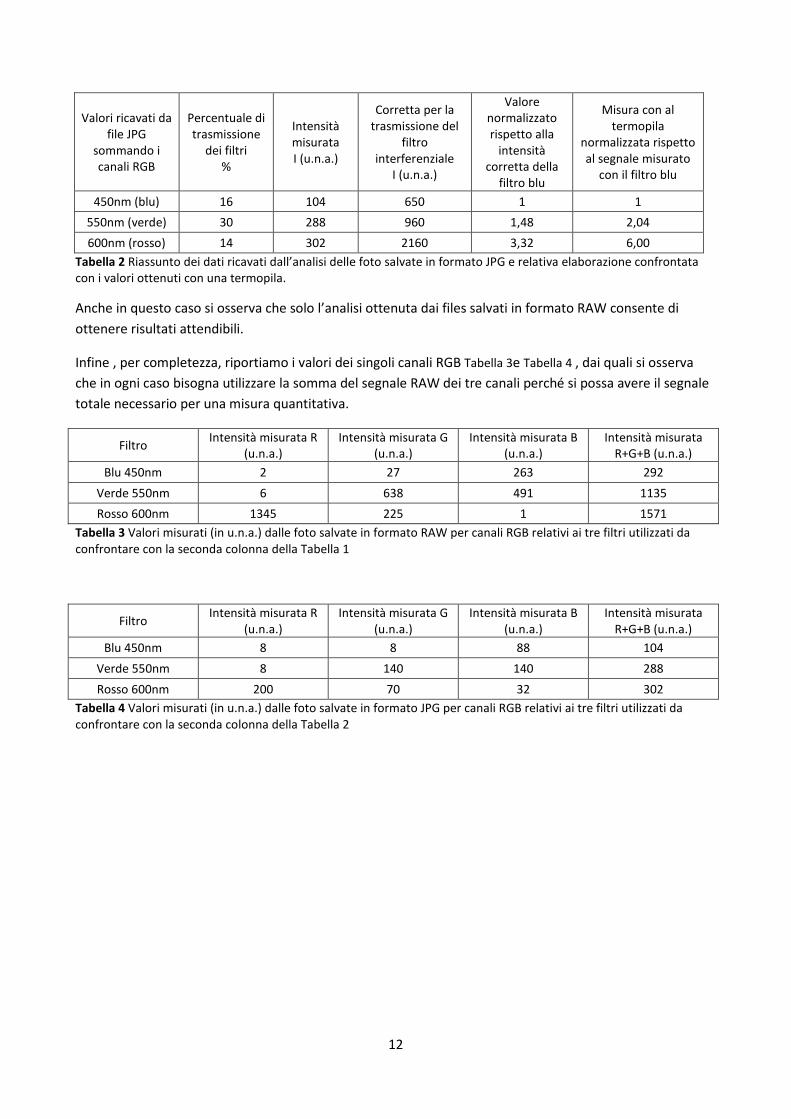
Nelle tabelle Tabella 1 e Tabella 2 sono riportati i dati ottenuti utilizzando i file rispettivamente in formato
RAW e in Formato JPG; sono inoltre riportati i valori dai tre canali RGB per ogni filtro. Va rimarcato che i
filtri RGB non sono a banda stretta ma lasciano passare radiazione a tutte la lunghezze d’onda nel visibile (e
vicino infrarosso), mentre i filtri interferenziali lasciano passare una strettissima banda (10 nm). La
“normalizzazione” è stata fatta assumendo uguale ad 1 il valore del rapporto del segnale tra la luce bianca e
la luce trasmessa dal filtro a 450 nm (blu) misurato con la termopila. Di conseguenza si assume uguale ad 1
anche il rapporto analogo registrato dal CCD. La somma dei canali RGB è la somma dei valori medi dei
singoli canali, sia RAW che JPG, non normalizzata a 4095 o a 255.
Valori ricavati da file RAW
sommando i canali RGB
Percentuale di trasmissione
dei filtri %
Intensità misurata I (u.n.a.)
Corretta per la trasmissione del
filtro interferenziale
I (u.n.a.)
Valore normalizzato rispetto alla
intensità corretta della
filtro blu
Misura con al termopila
normalizzata rispetto al segnale misurato
con il filtro blu
450nm (blu) 16 292 1824 1 1
550nm (verde) 30 1135 3784 2,07 2,04
600nm (rosso) 14 1571 11220 6,15 6,00
Tabella 1 Riassunto dei dati ricavati dall’analisi delle foto salvate in formato RAW e relativa elaborazione confrontata con i valori ottenuti con una termopila.
§§§
Ci si è serviti di uno spettrofotometro a fibre ottiche AvaSpec-1024 che ha un range 200 nm-1100 nm.
12
Valori ricavati da file JPG
sommando i canali RGB
Percentuale di trasmissione
dei filtri %
Intensità misurata I (u.n.a.)
Corretta per la trasmissione del
filtro interferenziale
I (u.n.a.)
Valore normalizzato rispetto alla
intensità corretta della
filtro blu
Misura con al termopila
normalizzata rispetto al segnale misurato
con il filtro blu
450nm (blu) 16 104 650 1 1
550nm (verde) 30 288 960 1,48 2,04
600nm (rosso) 14 302 2160 3,32 6,00
Tabella 2 Riassunto dei dati ricavati dall’analisi delle foto salvate in formato JPG e relativa elaborazione confrontata con i valori ottenuti con una termopila.
Anche in questo caso si osserva che solo l’analisi ottenuta dai files salvati in formato RAW consente di
ottenere risultati attendibili.
Infine , per completezza, riportiamo i valori dei singoli canali RGB Tabella 3e Tabella 4 , dai quali si osserva
che in ogni caso bisogna utilizzare la somma del segnale RAW dei tre canali perché si possa avere il segnale
totale necessario per una misura quantitativa.
Filtro Intensità misurata R
(u.n.a.) Intensità misurata G
(u.n.a.) Intensità misurata B
(u.n.a.) Intensità misurata
R+G+B (u.n.a.)
Blu 450nm 2 27 263 292
Verde 550nm 6 638 491 1135
Rosso 600nm 1345 225 1 1571
Tabella 3 Valori misurati (in u.n.a.) dalle foto salvate in formato RAW per canali RGB relativi ai tre filtri utilizzati da confrontare con la seconda colonna della Tabella 1
Filtro Intensità misurata R
(u.n.a.) Intensità misurata G
(u.n.a.) Intensità misurata B
(u.n.a.) Intensità misurata
R+G+B (u.n.a.)
Blu 450nm 8 8 88 104
Verde 550nm 8 140 140 288
Rosso 600nm 200 70 32 302
Tabella 4 Valori misurati (in u.n.a.) dalle foto salvate in formato JPG per canali RGB relativi ai tre filtri utilizzati da confrontare con la seconda colonna della Tabella 2

13
Esempi di utilizzo della macchina fotografica digitale in cui la linearità della risposta del CCD è
messa alla prova
Intensità della radiazione emessa da una sorgente “puntiforme “ in funzione della distanza
Questo è un esperimento classico per una scuola superiore. L’apparato sperimentale è schematizzato in
Figura 9 con il solito accorgimento di minimizzare ogni sorgente di luce spuria comprese le riflessioni sulla
guida e sulle, pareti, ecc.
Figura 9 Schema dell’apparato utilizzato per la misura dell’intensità della radiazione emessa da una “sorgente puntiforme” in funzione della distanza. Notare che la sorgente luminosa è all’interno del cilindro nero e la radiazione fuoriesce da un piccolo foro sul quale è stato posto come diffusore un foglio di carta bianca.
La sorgente luminosa è costruita come quella della schematizzata in Figura 7 senza il filtro infrarosso che in
questo caso non è necessario.
Per prima cosa abbiamo effettuato una misura utilizzando un fotodiodo**** da utilizzare come confronto.
A questo punto si potrebbe pensare di effettuare la misura dell’intensità in funzione della distanza
mantenendo la focale fissa , il tempo di posa fisso (0.001 s) ed il diaframma fisso e misurare come abbiamo
fatto fin’ora l’intensità media, con l’accorgimento che non si raggiunga la saturazione (a circa 1 m di
distanza). L’intensità della luce raccolta dovrebbe essere misurabile a partire dall’immagine della sorgente,
dopo aver messo a fuoco, utilizzando il metodo di cui ci siamo serviti fin qui. Il risultato riportato per il
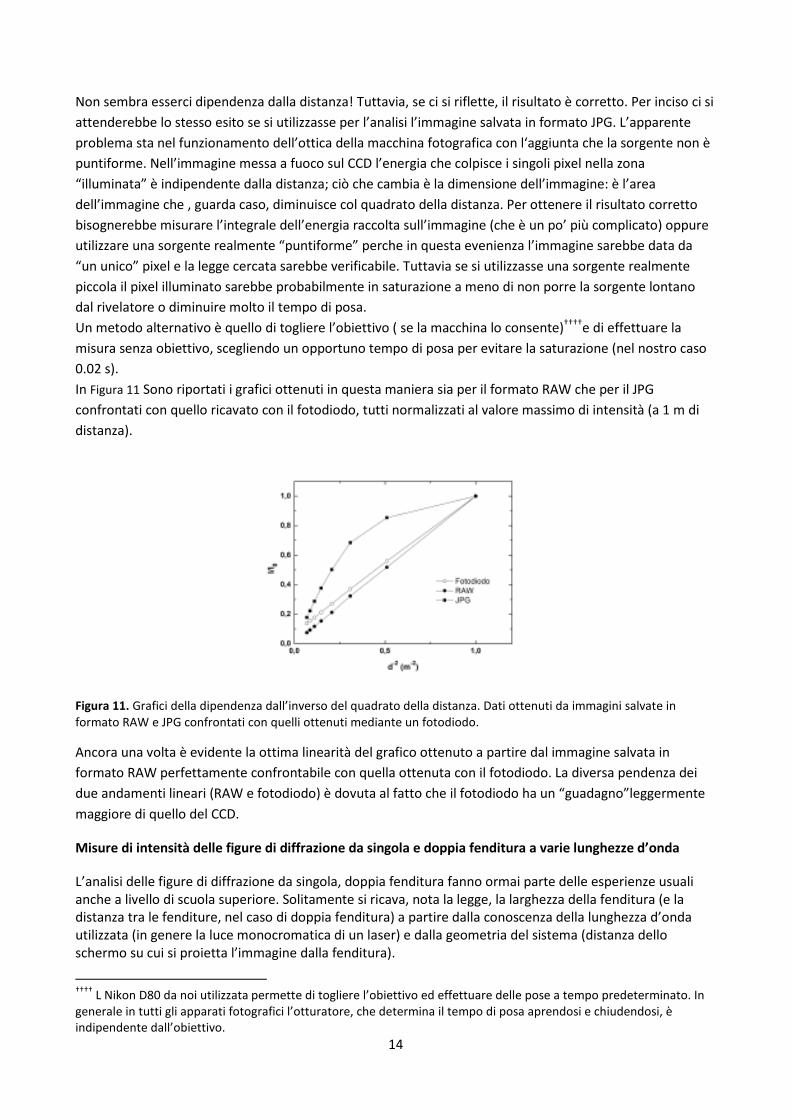
formato RAW (scala di grigi) in Figura 10 è apparentemente sorprendente.
Figura 10 Grafico del valore dell’intensità della radiazione in funzione di d-2
misurato senza togliere obiettivo e mettendo di volta in volta a fuoco l’immagine della sorgente.
****
E’ stato utilizzato il sensore Pasco CI-6604.
14
Non sembra esserci dipendenza dalla distanza! Tuttavia, se ci si riflette, il risultato è corretto. Per inciso ci si
attenderebbe lo stesso esito se si utilizzasse per l’analisi l’immagine salvata in formato JPG. L’apparente
problema sta nel funzionamento dell’ottica della macchina fotografica con l‘aggiunta che la sorgente non è
puntiforme. Nell’immagine messa a fuoco sul CCD l’energia che colpisce i singoli pixel nella zona
“illuminata” è indipendente dalla distanza; ciò che cambia è la dimensione dell’immagine: è l’area
dell’immagine che , guarda caso, diminuisce col quadrato della distanza. Per ottenere il risultato corretto
bisognerebbe misurare l’integrale dell’energia raccolta sull’immagine (che è un po’ più complicato) oppure
utilizzare una sorgente realmente “puntiforme” perche in questa evenienza l’immagine sarebbe data da
“un unico” pixel e la legge cercata sarebbe verificabile. Tuttavia se si utilizzasse una sorgente realmente
piccola il pixel illuminato sarebbe probabilmente in saturazione a meno di non porre la sorgente lontano
dal rivelatore o diminuire molto il tempo di posa.
Un metodo alternativo è quello di togliere l’obiettivo ( se la macchina lo consente)††††e di effettuare la
misura senza obiettivo, scegliendo un opportuno tempo di posa per evitare la saturazione (nel nostro caso
0.02 s).
In Figura 11 Sono riportati i grafici ottenuti in questa maniera sia per il formato RAW che per il JPG
confrontati con quello ricavato con il fotodiodo, tutti normalizzati al valore massimo di intensità (a 1 m di
distanza).
Figura 11. Grafici della dipendenza dall’inverso del quadrato della distanza. Dati ottenuti da immagini salvate in formato RAW e JPG confrontati con quelli ottenuti mediante un fotodiodo.
Ancora una volta è evidente la ottima linearità del grafico ottenuto a partire dal immagine salvata in
formato RAW perfettamente confrontabile con quella ottenuta con il fotodiodo. La diversa pendenza dei
due andamenti lineari (RAW e fotodiodo) è dovuta al fatto che il fotodiodo ha un “guadagno”leggermente
maggiore di quello del CCD.
Misure di intensità delle figure di diffrazione da singola e doppia fenditura a varie lunghezze d’onda
L’analisi delle figure di diffrazione da singola, doppia fenditura fanno ormai parte delle esperienze usuali anche a livello di scuola superiore. Solitamente si ricava, nota la legge, la larghezza della fenditura (e la distanza tra le fenditure, nel caso di doppia fenditura) a partire dalla conoscenza della lunghezza d’onda utilizzata (in genere la luce monocromatica di un laser) e dalla geometria del sistema (distanza dello schermo su cui si proietta l’immagine dalla fenditura).
††††
L Nikon D80 da noi utilizzata permette di togliere l’obiettivo ed effettuare delle pose a tempo predeterminato. In generale in tutti gli apparati fotografici l’otturatore, che determina il tempo di posa aprendosi e chiudendosi, è indipendente dall’obiettivo.

15
Una macchina fotografica usata in maniera “convenzionale” permette di registrare le immagini di diffrazione e di effettuare a posteriori i calcoli necessari a ricavare i valori cercati se si utilizzano gli opportuni fattori di scala (rapporto tra le dimensioni in pixel dell’immagine e i mm reali) e la distanza della fenditura dallo schermo. Ciò che ci proponiamo qui è di completare questa proposta sperimentale con la misura dell’intensità delle massimi di diffrazione. La misura, forse più adatte ad un livello universitario, viene di solito fatta con l’ausilio di un fotodiodo che viene fatto scorrere lungo l’immagine di diffrazione ad una distanza fissa dalla fenditura (Figura 12); la raccolta dei dati richiede un notevole tempo ed accuratezza perché l’intensità misurata riproduca accettabilmente quanto previsto dalla teoria.
Figura 12 Schema “classico” per la misura dell’intensità dell’immagine di diffrazione.
L’utilizzo corretto della macchina fotografica digitale permette non solo di ridurre i tempi di acquisizione, ma anche una notevole accuratezza, oltre al vantaggio che si può facilmente fare copie dell’immagine da analizzare, in modo da far lavorare contemporaneamente gruppi diversi di studenti.
Figura 13 Schema di montaggio dell’apparato per la ripresa fotografica delle figure di diffrazione.

In Figura 13 è schematizzato l’assemblaggio sperimentale da noi utilizzato. Ci siamo serviti i un fenditura singola di larghezza 0.04 mm e di una doppia fenditura della stessa larghezza con spaziatura di Come sorgenti monocromatiche abbiamo utilizzato un laser(543 nm, 5 mW) e un laser a diodo blu (405la fenditura in modo che l’immagine fotografata
distanza di (2.75±0.01) m dallo schermo. La fenditura è stata posta a sorgente laser e per singola e doppia fenditura, sono state fatte delle serie di foto a tein modo che nell’immagine a tempo pidella figura di diffrazione, mentre nella immagine a tempo più lungo risultassero visibili numerosi massimi secondari. Infine abbiamo deciso di analizzare soltanto l’immagine nella quale il massimappena al di sotto del valore di saturazione (al limite del range dinamico del CCD). Questo perché si sa a priori che l’intensità del massimo centrale è di gran lunga più intensa di quella dei massimi secondaririsultano appena visibili nelle foto (vedi
Figura 14 Immagine di diffrazione da singola e doppia
rispettivamente.
Aggiungiamo a commento, che le foto rappresentate in
sono state effettuate (lasciando in automatico il bilanciamento del bianco) in toni di grigio. Infatti in questo
caso non interessa la composizione spettrale ma solo che la ri
I risultati d
Figura 15 eFigura 16 confrontati con le rispettive curve calcolate teoricamente a partire dalle caratteristiche
delle fenditure e le lunghezze d’onda della radiazione utilizzata.
16
è schematizzato l’assemblaggio sperimentale da noi utilizzato. Ci siamo serviti i un fenditura mm e di una doppia fenditura della stessa larghezza con spaziatura di
Come sorgenti monocromatiche abbiamo utilizzato un laser HeNe (632.8 nm 30 mW) un laser HeNe a diodo blu (405 nm, 4.5 mW). La macchina fotografica è stata posta in asse con
la fenditura in modo che l’immagine fotografata delle figura di diffrazione risultasse simmetrica ad a
dallo schermo. La fenditura è stata posta a (3.60±0.01) m sorgente laser e per singola e doppia fenditura, sono state fatte delle serie di foto a tein modo che nell’immagine a tempo più breve risultasse appena visibile il massimo centrale più intenso della figura di diffrazione, mentre nella immagine a tempo più lungo risultassero visibili numerosi massimi secondari. Infine abbiamo deciso di analizzare soltanto l’immagine nella quale il massimappena al di sotto del valore di saturazione (al limite del range dinamico del CCD). Questo perché si sa a priori che l’intensità del massimo centrale è di gran lunga più intensa di quella dei massimi secondari
vedi Figura 14).
Immagine di diffrazione da singola e doppia fenditura per laser rosso (a e b), verde (
Aggiungiamo a commento, che le foto rappresentate in Figura 14 sono a colori e in formato JPG
sono state effettuate (lasciando in automatico il bilanciamento del bianco) in toni di grigio. Infatti in questo
caso non interessa la composizione spettrale ma solo che la risposta del sensore sia lineare.
I risultati delle analisi sono riportati nelle
confrontati con le rispettive curve calcolate teoricamente a partire dalle caratteristiche
delle fenditure e le lunghezze d’onda della radiazione utilizzata.
è schematizzato l’assemblaggio sperimentale da noi utilizzato. Ci siamo serviti i un fenditura mm e di una doppia fenditura della stessa larghezza con spaziatura di 0.25 mm.
mW) un laser HeNe . La macchina fotografica è stata posta in asse con
delle figura di diffrazione risultasse simmetrica ad alla
dallo schermo. Per ogni sorgente laser e per singola e doppia fenditura, sono state fatte delle serie di foto a tempi di posa crescenti
risultasse appena visibile il massimo centrale più intenso della figura di diffrazione, mentre nella immagine a tempo più lungo risultassero visibili numerosi massimi secondari. Infine abbiamo deciso di analizzare soltanto l’immagine nella quale il massimo centrale fosse appena al di sotto del valore di saturazione (al limite del range dinamico del CCD). Questo perché si sa a priori che l’intensità del massimo centrale è di gran lunga più intensa di quella dei massimi secondari che
a
b
c
d
e
f
), verde (c e d) e blu (e e f)
colori e in formato JPG. Le analisi
sono state effettuate (lasciando in automatico il bilanciamento del bianco) in toni di grigio. Infatti in questo
sposta del sensore sia lineare.
confrontati con le rispettive curve calcolate teoricamente a partire dalle caratteristiche
17
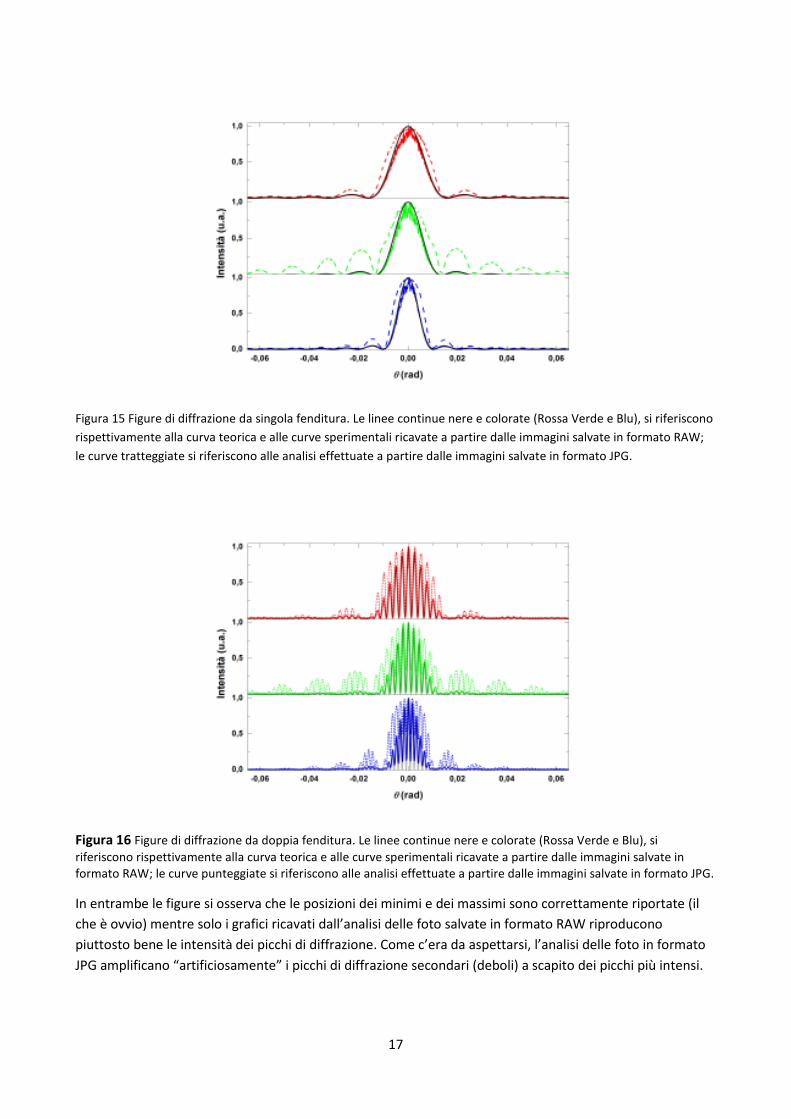
Figura 15 Figure di diffrazione da singola fenditura. Le linee continue nere e colorate (Rossa Verde e Blu), si riferiscono
rispettivamente alla curva teorica e alle curve sperimentali ricavate a partire dalle immagini salvate in formato RAW;
le curve tratteggiate si riferiscono alle analisi effettuate a partire dalle immagini salvate in formato JPG.
Figura 16 Figure di diffrazione da doppia fenditura. Le linee continue nere e colorate (Rossa Verde e Blu), si
riferiscono rispettivamente alla curva teorica e alle curve sperimentali ricavate a partire dalle immagini salvate in formato RAW; le curve punteggiate si riferiscono alle analisi effettuate a partire dalle immagini salvate in formato JPG.
In entrambe le figure si osserva che le posizioni dei minimi e dei massimi sono correttamente riportate (il
che è ovvio) mentre solo i grafici ricavati dall’analisi delle foto salvate in formato RAW riproducono
piuttosto bene le intensità dei picchi di diffrazione. Come c’era da aspettarsi, l’analisi delle foto in formato
JPG amplificano “artificiosamente” i picchi di diffrazione secondari (deboli) a scapito dei picchi più intensi.

18
Conclusioni
In queste pagine si è voluto mettere in risalto come una comune macchina fotografica (purché possa
salvare le immagini in formato RAW) possa proficuamente essere utilizzata come strumento per analisi
anche quantitative in un laboratorio di fisica scolastico.
Il vantaggio, oltreché economico (anche i software proposti sono gratuiti), sta anche nel tempo richiesto
per le misure che potrebbero essere fatte “dalla cattedra” e poi fornite immediatamente in copia agli
studenti per le analisi. Si presuppone che gli studenti abbiano a gruppi di due o tre, a disposizione un
computer con precaricati i programmi per le analisi delle foto (ImageJ) e un foglio elettronico per la
successiva elaborazione.
Appendice
Da tempo l’utilizzo di immagini e filmati viene proposto per lo studio del moto di oggetti reali. Non tutte le
fotocamere o videocamere (alogiche o digitali che si voglia) permettono di ottenere buoni risultati. Nello
studio del moto infatti è necessario che la posizione degli oggetti sia individuabile con la maggior precisione
possibile ed inoltre che i tempi intercorsi tra un immagine e la successiva siano determinabili con la
massima variabilità per poter seguire sia moti lenti che moti rapidi. Mentre un moto lento può necessitare
di poche immagini al secondo un moto rapido necessita di svariate immagini al secondo; in quest’ultimo
caso, affinché le immagini non risultino mosse, i tempi di esposizione devono essere molto brevi. Per dare
un’idea nel caso di un oggetto in caduta libera per evitare di avere immagini mosse (e quindi imprecisione
nelle localizzazione dell’oggetto) bisogna utilizzare tempi di posa da 0.002 s in giù. L’utilizzo di uno
stroboscopio in ambiente buio mantenendo aperto il diaframma risolve il problema. Se invece si utilizza la
macchia fotografica per riprendere filmati ci sono due inconvenienti: il primo è che il numero di immagini al
secondo è prefissato (in genere 25 fotogrammi la secondo) il secondo e che in quasi nessun modello si può
regolare il tempo di posa per le singole immagini; questo viene regolato automaticamente in base alla luce
intensità della luce ambiante. Questo rende indispensabile illuminare con dei fari gli oggetti di cui si vuole
studiare il moto per evitare immagini mosse. Lo stesso inconveniente c’è con la maggior parte dei sistemi di
acquisizione presenti nei cellulari o nei computer portatili.
Le videocamere generalmente permettono la regolazione manuale dei tempi di posa, ma comunque, per
tempi di esposizione molto brevi, è necessario servirsi di opportuni sistemi di illuminazione per evitare
problemi di immagini troppo scure (sottoesposte).
Infine con le videocamere (a meno di non utilizzare strumenti “speciale” Casio Exilim EX-FH20 per esempio)
c’è la limitazione al numero di fotogrammi la secondo che possono essere acquisiti. Nei sistemi europei si
tratta di 25Fps (fotogrammi la secondo) mentre in quelli americani 30 Fps. Conviene ricordare che i film
(quelli del cinematografo) sono a 24 Fps. In realtà bisogna dire che ogni fotogramma è costituito
dall’interlacciamento di due “mezze immagini” riprese a 50 Fps. Una di queste immagini e costituita dalle
righe disparii della matrice di pixel del sensore(righe 1,3,5,…), la seconda da quelle pari (righe 2,4,6,..).
Quando si analizzano i fotogrammi del filmato, gli oggetti in movimento vengono visti come “doppi” nel
fermo immagine. Il problema viene risolto via software (per esempio il software Tracker‡‡‡‡ lo fa
automaticamente) scegliendo di analizzare le “mezze immagini” costituite dalle solo righe pari o dispari ma
con meta risoluzione verticale. Per non avere l’immagine deformata il software raddoppia il numero di
righe (alcuni software più sofisticati fanno delle interpolazioni più complesse per rendere esteticamente più
belle le immagini. L’operazione si chiama “deinterlacciamento”. Con opportuni software è anche possibile
‡‡‡‡
Tracker video analysis and model tool è un software gratuito reperibile al link: http://www.cabrillo.edu/~dbrown/tracker/

19
ricostruire un filmato a 50 Fps che mette in sequenza le due mezze immagini che sono prese a 0.02 s di
intervallo e completando le righe mancanti. I filmati con le immagini “interlacciate” e le videocamere che li
producono sono i più comuni perché gli apparati per la riproduzione sono progettati proprio per questo
generare di registrazione. Tutto questo può sembrare strano ma le ragioni del tutto sono “storiche”:
compatibilità con i vecchi sistemi di registrazione analogica! Attualmente si stanno affermando sistemi di
acquisizione e di riproduzione in cui le singole mezze immagini non vengono più “interlacciate “ ma messe
in maniera sequenziale (righe 1,2,3,4…) si tratta quindi di due immagini complete! questo sistema si chiama
“progressivo”, si tratta, in sintesi, di un filmato con frame rate doppio. Gli apparati più recenti (TV digitali o
registratori digitali) sono in grado di produrre/riprodurre entrambi i formati (nelle caratteristiche tecniche
compare sempre una sigla de tipo 1024x768i oppure 1024x768p dove “i” sta per interlacciato e “p” per
progressivo; la coppia di numeri indicano la risoluzione in pixel (righe per colonne) del sistema di
registrazione (videocamera , videoregistratore) o del sistema di riproduzione digitale (TV o
videoproiettore).