Embed Size (px)
Citation preview

Measuring Monolinguality
Chris BiemannNLP Department, University of Leipzig
LREC-06 Workshop on Quality Assurance and Quality Measurement for Language and Speech
Resources, Genova
27 May 2006

2
Why Monolinguality ?
Alien language noise disturbs statistics for corpus-based methods:
• Language Models, e.g. n-gram
• Lexical Acquisition
• Semantic Indexing
• Co-occurrence Statistics

3
What is Monolinguality?
• Foreign language sentences should be removed
• Sentences containing few foreign language words or phrases, such as movie titles, terminology etc. should remain.

4
Korean Example
• A:Yes. The traffic cop said I had one too many and made me take the sobriety test, but I passed it. B:Lucky you !
• 무인도 표류 소년 25명 통해 인간의 야만성 그려 영국 소설가 윌리엄 골딩의 83 년 노벨문학상 수상작을 영화화한 ` 파리대왕 '(Lord of the flies) 은 결코 편안하게 감상할 수 있는 영화는 아니다 .
5
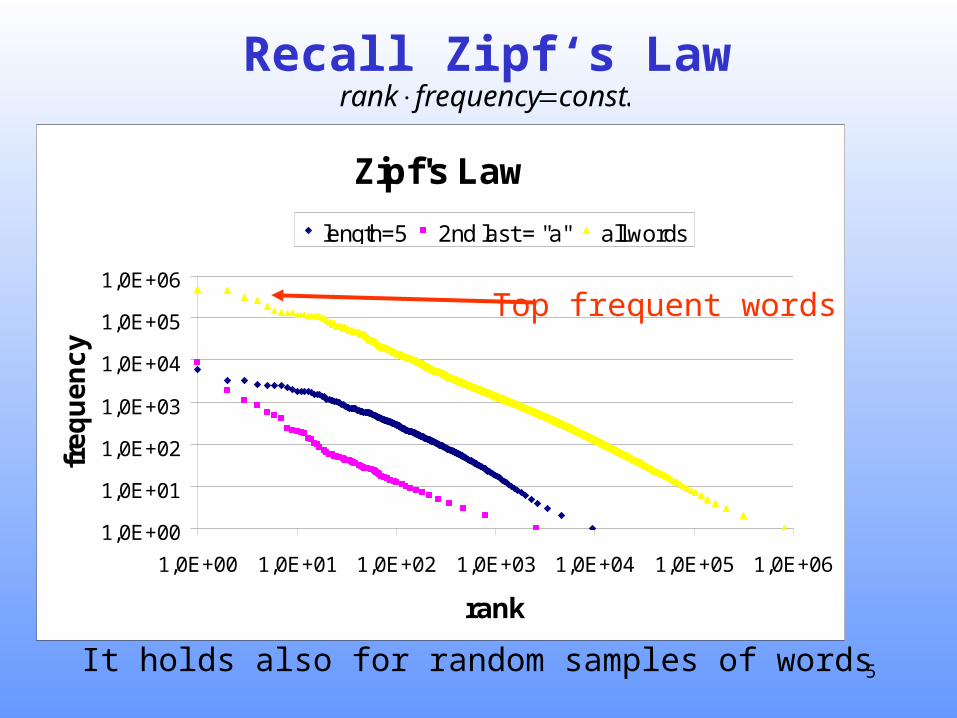
Recall Zipf‘s Law.constfrequencyrank
Zipf's Law
1,0E+00
1,0E+01
1,0E+02
1,0E+03
1,0E+04
1,0E+05
1,0E+06
1,0E+00 1,0E+01 1,0E+02 1,0E+03 1,0E+04 1,0E+05 1,0E+06
rank
fre
qu
en
cy
length=5 2nd last = "a" all words
It holds also for random samples of words
Top frequent words

6
Measuring Monolinguality Given a corpus of language A with x%
noise of language B, the amount of noise is measured:
• For top frequency words of B, divide the relative frequency in the corpus by the relative frequency of a clean B corpus
• The amount of noise is the predominant ratio: many ratios will be close to x%.

7
The top frequency words of B w.r.t. A
• Words that do not occur in language A. Their frequency ratio will be around x%.
• Words that are also amongst the highest frequency words of language A and moreover have the same function. Their frequency ratio will be around 1.
• Words that occur in language A, but at different frequency bands. They are a random sample of words of L and distributed in a Zipf way
• Words of B that are often used in named entities and titles (such as capitalized stop words). They appear in the corpus of language A more frequently then the expected x% of noise.
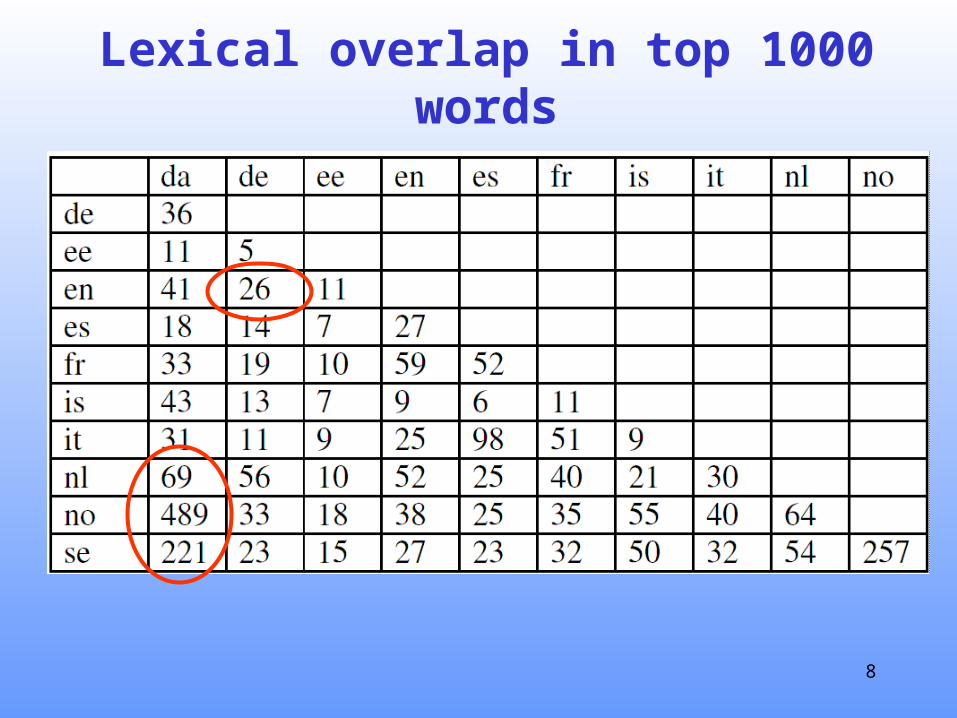
The second group of words is only present in languages that are very similar to each other.
8
Lexical overlap in top 1000 words

9
Experiment 1
Artificial noise mixtures: Injecting alien language material in monolingual corpora
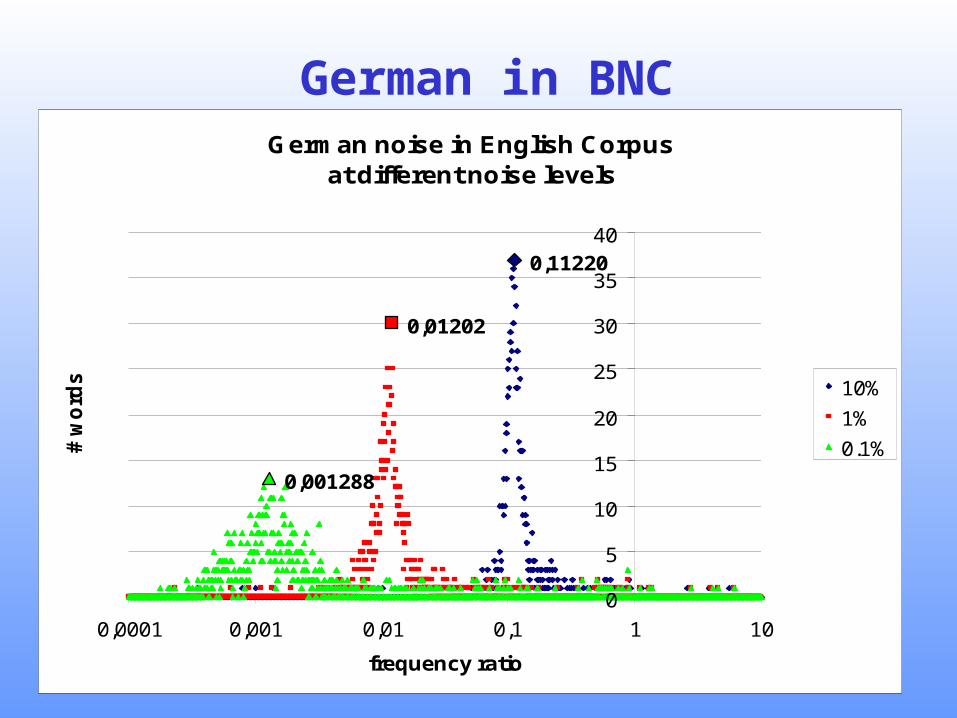
• Experiment 1a: Injecting different amounts of German Noise in a chunk of the British National Corpus (~ 20 Million words)
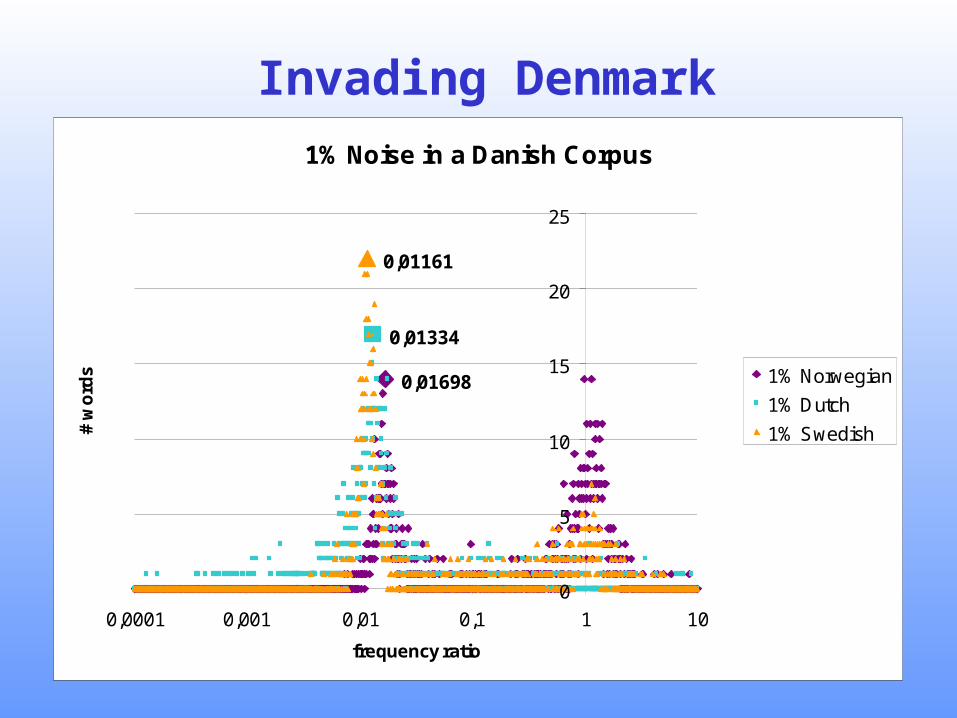
• Experiment 1b: Injecting 1% noise of Norwegian, Swedish and Dutch into a Danish corpus (~17 Million words)
For measuring, we used the top 1000 words
10
German in BNCGerman noise in English Corpus
at different noise levels
0,11220
0,01202
0,001288
0
5
10
15
20
25
30
35
40
0,0001 0,001 0,01 0,1 1 10
frequency ratio
# w
ord
s 10%
1%
0.1%
11
Invading Denmark1% Noise in a Danish Corpus
0,01698
0,01334
0,01161
0
5
10
15
20
25
0,0001 0,001 0,01 0,1 1 10
frequency ratio
# w
ord
s 1% Norwegian
1% Dutch
1% Swedish

12
Experiment 2For a collection of web documents (~700 Million
words from .de domains, we measure the effect of a corpus cleaning method that strips alien language material
Before cleaning After cleaning
Number of top-1000-words found
Approx. Frequency ratio
Number of top-1000-words found
Frequency ratio
German 1000 0.708 1000 0.946
English 995 0.126 987 0.0010
French 924 0.0398 906 0.00002
Dutch 995 0.000891 775 0.000006
Turkish 642 0.0000631 562 0.000006
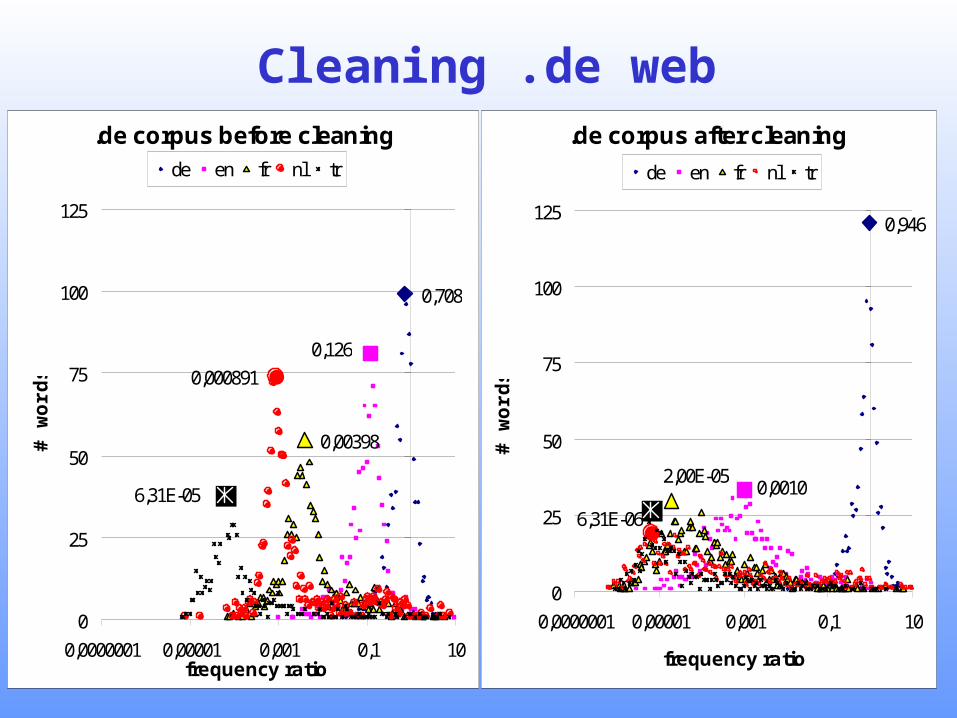
13
Cleaning .de web.de corpus before cleaning
0,708
0,126
0,00398
0,000891
6,31E-05
0
25
50
75
100
125
0,0000001 0,00001 0,001 0,1 10frequency ratio
# w
ord
s
de en fr nl tr
.de corpus after cleaning
0,946
0,00102,00E-05
6,31E-06
0
25
50
75
100
125
0,0000001 0,00001 0,001 0,1 10
frequency ratio
# w
ord
s
de en fr nl tr

14
Conclusion
• Measure captures well the amount of noise
• Noise measured down to a ratio of 10-5
• Effective: involves 1000 frequency counts per language

15
Application: Monolingual Corpora
• Screenshot corpora
http://corpora.uni-leipzig.de

16
Workflow
Text Text TextText
Language detection, Cleaning
lang. 1...
lang. 2 lang. n
POS Tagging
Classified Objects
Texts: Web / Newspapers
Crawling
Standard Size Corpora
URLs
Language Statistics
SmallWorlds
Co-occurrencesetc.
Clustering Classification
• Neologisms• Trend Mining• Topic Tracking
Language +TimeTools
Dictionaries (Dornseiff, WordNets, Wikipedia, ...)
WebStatistics
SmallWorlds
SmallWorlds Words
Dictionaries
Resources
Techniques
Results
•Similar objects (words, sentences, documents, URLs)•Classification (se-mantic properties, subject areas, ...)•Combined objects (NE-Recognition, terminology, ...): determine patterns,extract multi-words
•Decomposition
•Morphology
•Inflection
•Translation pairs

17
Corpus
Browser
Per word:• Frequency• Example
sentences• Co-occurrences:
left and right neighbours, sentence-based
• Co-occurrence graph

18
Only a few copies left!
DVD:
• 15 languages
• Corpus Browser
• Corpora in plain text and database format

19
Questions??
THANK YOU!

20
Factor distribution for different monolinguality values
0,00001
0,0001
0,001
0,01
0,1
1
10
100
0 200 400 600 800 1000fac
tor
10 %
1 %
0.1%





























