Embed Size (px)
Citation preview

Meetup Machine Learning Spain XIV
Competiciones de Machine Learning
Madrid, 05-Oct-2016

2
Javier Tejedor AguileraIngeniero en Telecomunicación. Data Scientist. Kaggle Competitions Master. Responsable de campañas y sistemas de detección de fraude en Endesa
https://linkedin.com/in/javier-tejedor-aguilera
Virilo Tejedor AguileraIngeniero Informático. Data Scientist. Kaggle Competitions Master.Responsable Servicios y Proyectos de Business Intelligence Colegio de Registradores
https://www.linkedin.com/in/virilo-tejedor-aguilera-7aa19753
Fernando Constantino AguileraCientífico de Datos con MBA. Kaggle Competitions Master.Cofundador de CleverPPC y CleverML
https://linkedin.com/in/fernandoconstantino
Team Datacousins

3
The Home of Data Science
www.kaggle.com

4
EmpresasInstituciones públicasCentros investigación
RetoDatosDinero
Código que resuelve su problemaPosibilidad fichar DataScientists
ConocimientoCódigo
AprendizajeEmpleoDinero
ComunidadData Scientists

5
Algunas empresas que han propuesto retos

6
Comunidad data scientists

7
s

8
Premiadas, de investigación, de iniciación y de juego
Problemas de Machine Learning Supervisado

9
Problema supervisado de clasificación multiclase. Datos: imágenes fondo de ojos
Problema supervisado de clasificación binaria. Datos: coordenadas x, y del cada viaje

10
Problema supervisado de clasificación binaria. Datos anonimizados cuentas y prods bancarios clientes
Problema supervisado de regresión. Datos: histórico de ventas de 1k tiendas, festivos, promos, etc.

11
¿Cómo funciona una competición?

12
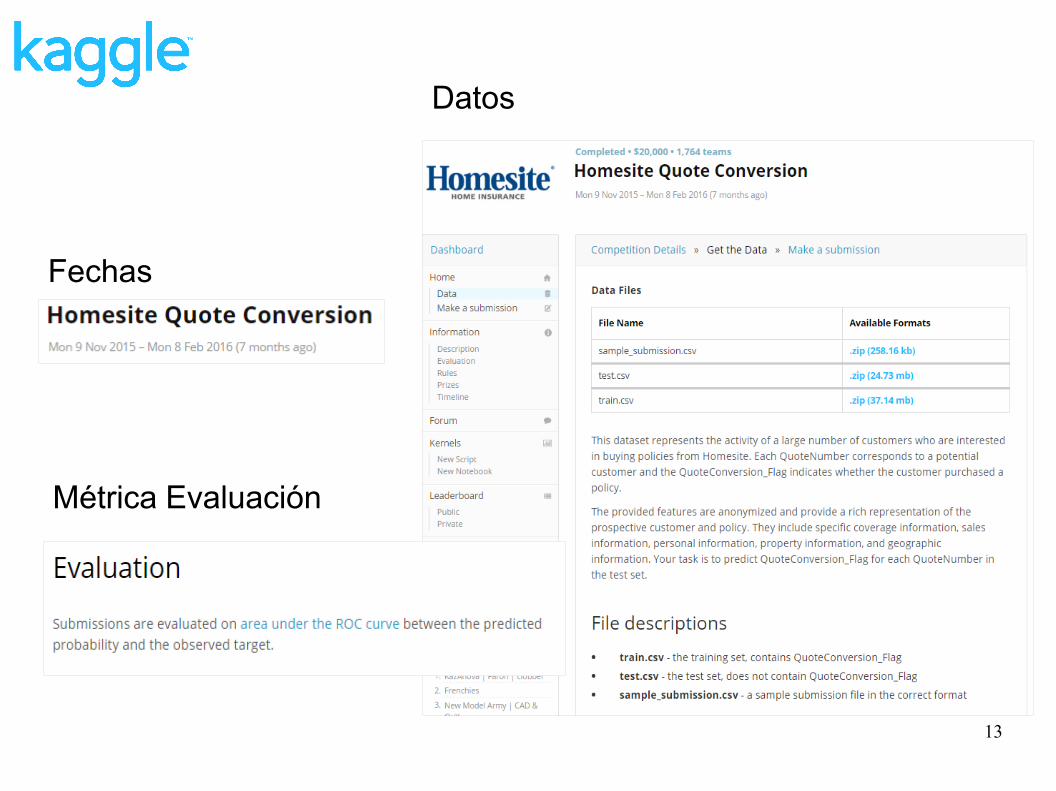
¿Cómo funciona una competición?
Fechas de la competición09-Nov-15 a 09-Feb-15
DatosTrain.csv (target)Test.csv (hay que predecir target)
ForoPreguntas y respuestas
KernelsCódigo compartido
Métrica de evaluaciónROC-AUC
LeaderboardLB Público y LB Privado
13
Datos
Métrica Evaluación
Fechas

14
Métricas Evaluación

15
Foro

16
Kernels

17
Leaderboard

18
Participar y competir en equipo!
Cuanto más diverso, mejor.
Surgen más ideas que de forma individual
Se aprende mucho más
También … se discute mucho más
“Si quieres ir rápido, ve solo. Si quieres llegar lejos, ve acompañado”
Tip 4Kaggle

19
¿Cuáles lenguajes son los más usados?

20
R y Python

21
… o Python y R

22
¿Qué paquetes / librerías?

23
pandasnumpyscikit-learnmatplotlibseabornnltkkerastheanoh2otensorflowxgboost
http://scikit-learn.org/
caret: Classif. and Regres.Trainingmice: missing valuesnnetgmb (Gradient Boosting)e1071 (SVM)randomForestglmnet: (Ridge, Lasso and Elastic-Net reg. glm)Matrix: Sparse and Dense Matrixdplyrdata.tableForeachdoMCggplot2h2otensorflowxgboost

24
XGBoost
(Tianqi Chen / Carlos Guestrin)
https://arxiv.org/pdf/1603.02754v3.pdf
https://www.youtube.com/watch?v=Vly8xGnNiWs
Tip 4Kaggle

25
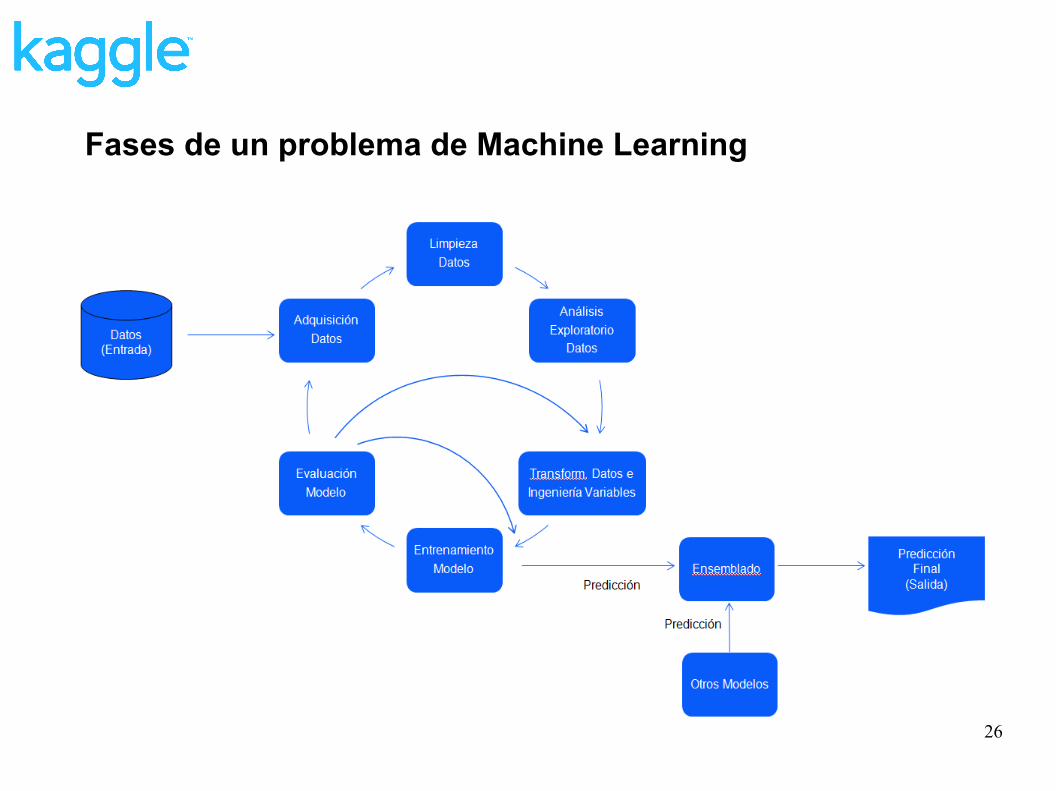
Fases de un proyecto de ML y de una competición de Kaggle
26
Fases de un problema de Machine Learning

27
Transformar features
Combinar features
Generar nuevas features
Reducir el número de features
Seleccionar features
Enriquecer con features externas y de libre acceso:datos temperatura, demográficos, geográficos, ...
Ingeniería de Variables Tip 4Kaggle

28
Crossvalidación Tip 4Kaggle

29
Ensembles Tip 4Kaggle
Votación por mayoría
Votación ponderada por mayoría
Media
Promedio de rankings
...
Avanzados
Stacked generalization
Blending

Competición KaggleNoviembre 2015 – Febrero 2016
Homesite: Proveedor de Seguros para el Hogar
Equipo: Datacousins (posteriormente ‘A few with no Clue’)

Variable a Predecir:
¿Cual es la probabilidad de que un cliente potencial contrate una poliza de seguro que se le ha ofrecido?

BBDD Anonimizada
Features:– Información del Cliente Potencial
– Tipo de Cobertura
– Información de la Propiedad
– Información Geográfica

Train: 200 MB (260K filas, 300 cols)
Test: 150 MB
Evaluation Metric: Area under the ROC curve
(true positive vs. false positive )

Preprocessing

'DATE_ENCODE' :
Año Mes Año_Mes Dia de la Semana ...
LAGGED VARIABLES:
Ventas Ayer Ventas Última Semana Ventas Último Mes ...
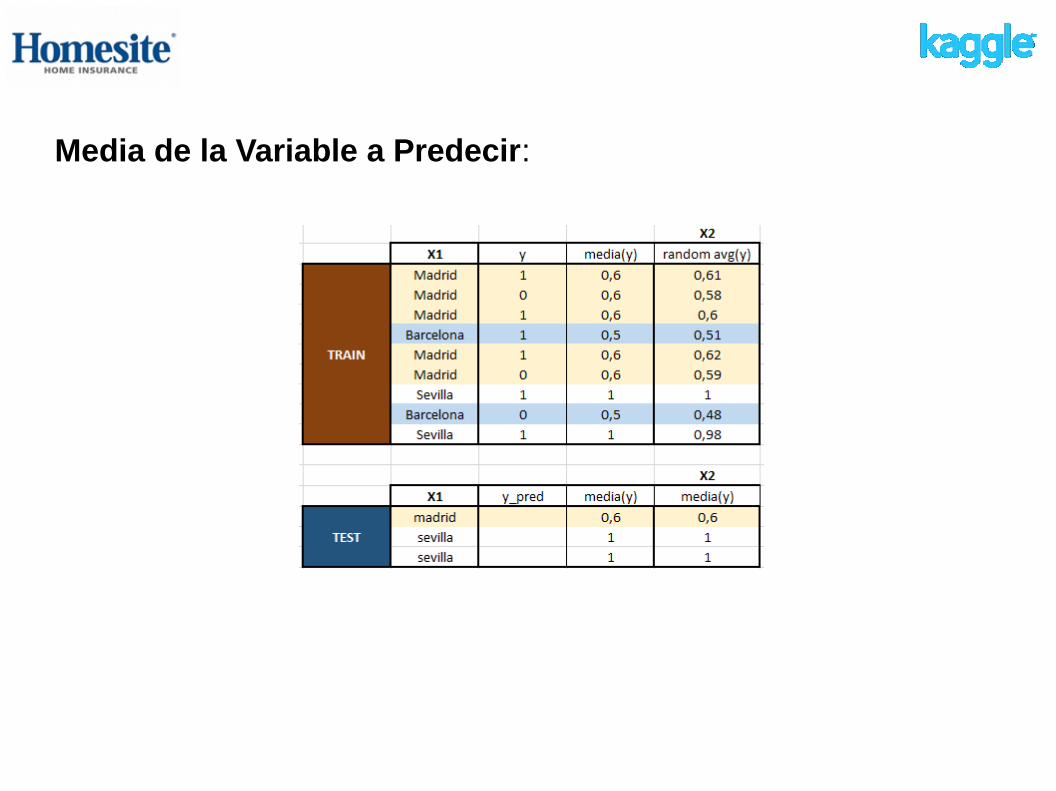
Media de la Variable a Predecir:

Monotonic Transformation:

Dummy Variables (One Hot Encode):
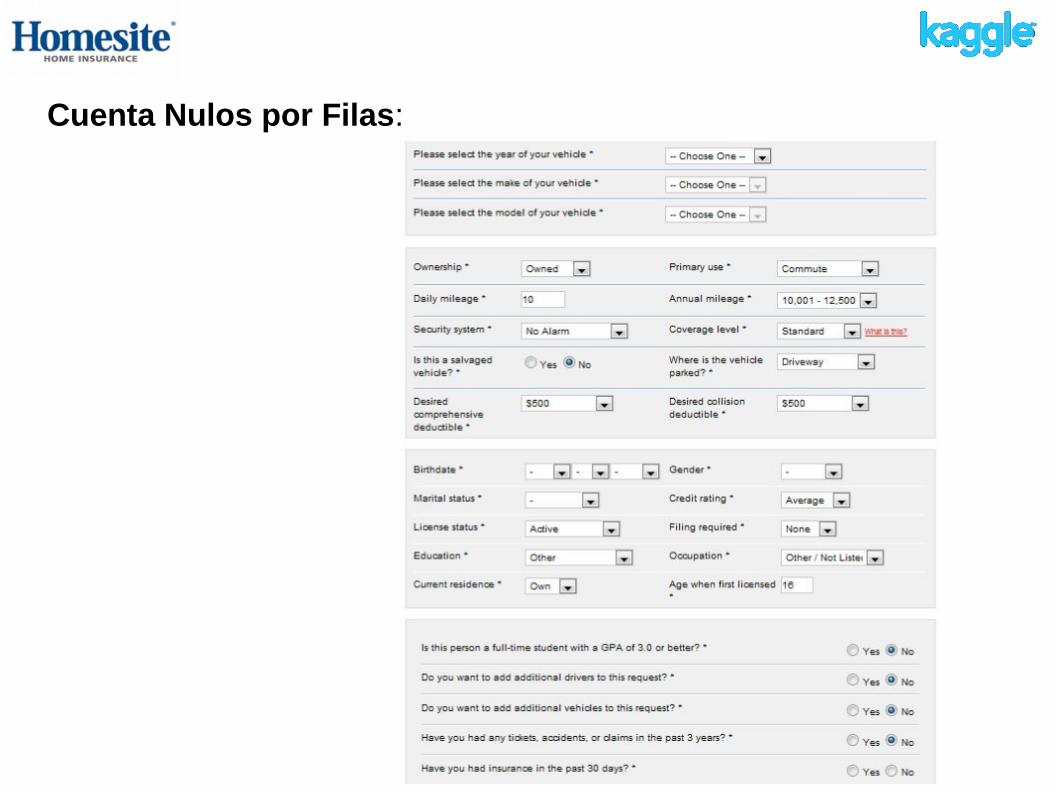
Cuenta Nulos por Filas:

Ejemplo:
y_str_LMen20_Top10_orig
Top10: Las 10 principales por Feature ImportanceBot5: Las 5 peores por Feature Importance
LMas10: Features con más de 10 levelsLMen20: Features con menos de 20 levels
CorrTop30: Las 30 features más correladas a YCorrBot15: Las 15 features menos correladas a Y
Orig: Sólo seleccionamos features originales del dataset (Ninguna engineered)
Scope del Preprocessing:

'COLS_JOIN'
'COLS_MULTIPLY' : [(['y_num_Top5'], 'Many_3')]
Más Feat. Engineering:

Otros Preprocessing
'FLOAT_QUANTILE'
'NA_BINARIZE' 'NA_FILL'
'NORMALIZE_NUMERIC'
'RARE_STRINGS_REPLACE'
'WINSORING' ...
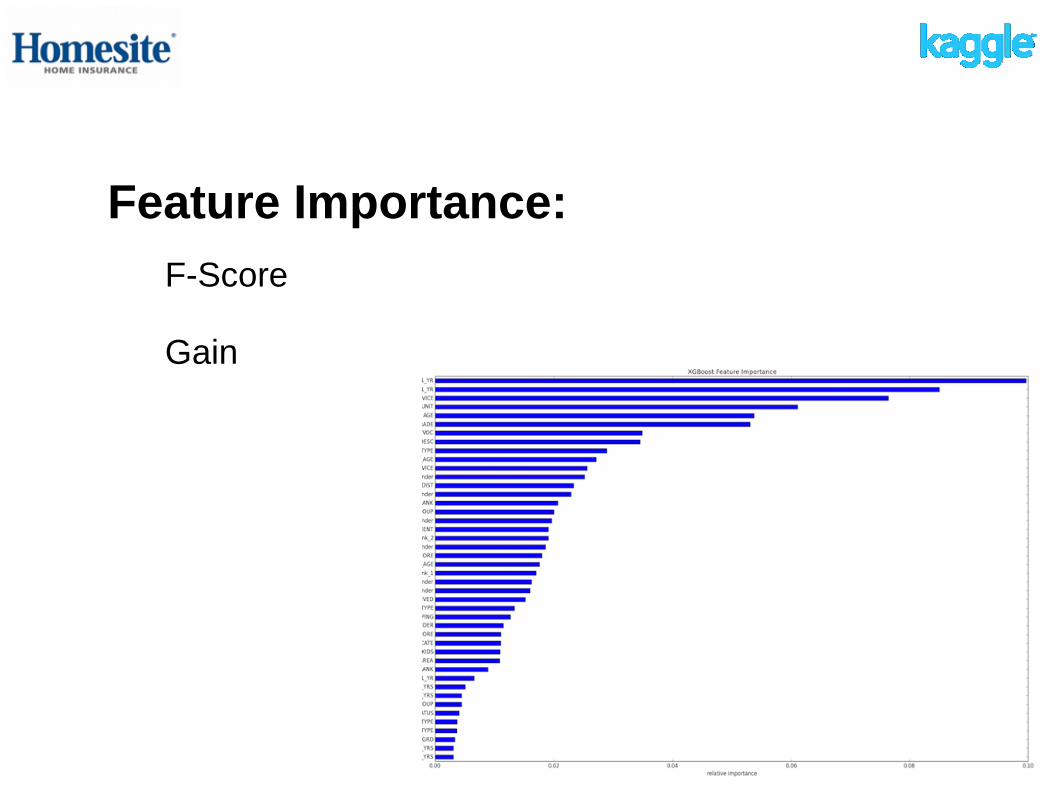
Feature Importance:
F-Score
Gain

Trabajo en Equipo









level 2 & ensembles Tip 4Kaggle

blog.kaggle.com
Regularized Greedy Forest vs XGBoost
A tener en cuenta:
- score- correlación
level 2 & ensembles


level 2
out of fold predictions | Y
train set test set
Tip 4Kaggle

ensembles
Ensemble Selection from Libraries of Modelshttp://www.cs.cornell.edu/~caruana/ctp/ct.papers/caruana.icml04.icdm06long.pdf
Feature-Weighted Linear Stackinghttp://arxiv.org/pdf/0911.0460.pdf
Combining Predictions for Accurate Recommender Systemshttp://elf-project.sourceforge.net/CombiningPredictionsForAccurateRecommenderSystems.pdf
The BigChaos Solution to the Netflix Prizehttp://www.netflixprize.com/assets/GrandPrize2009_BPC_BigChaos.pdf
Kaggle Ensembling Guidehttp://mlwave.com/kaggle-ensembling-guide/
Buscaremos pesos que dar a cada predicción, usando un conjunto de validación,y en ocasiones meta-features
? ? ? ? Final ensemble: 0.54 · XGB1 + 0.21 · XGB2 + 0.17 · GMLNET + 0.08 · NN
¿de donde han salido estos pesos?
Tip 4Kaggle

boosterama
Ciclo completo ML: importación, preprocesado, entrenamiento y predicción, submission.csv (Kaggle)
Distintos tipos de problemas: clasificación binaria, clasificación múltiple, regresión
Declarativo
Optimización y búsqueda de hiperparámetros
Biblioteca de ejecuciones: csv, pickle, hdf5 y sqlite
Caché
Feature importance, feature selection y feature engineering
Gráficas: matriz de confusión, histograma y diagrama de bigotes
Repetibilidad de los experimentos
git clone https://bitbucket.org/boosterama/boosterama.git
https://boosterama.io

boosterama - dashboards
Ejemplo dashboard
'LEVEL' : '1_ML','SPLIT_CV_TYPE': 'Stratified','SPLIT_CV_KFOLDS' : 5, 'COMP_NAME' : "homesite", 'COMP_PROBLEM_TYPE': 'Class_B', 'COMP_COLUMN_ID' : "QuoteNumber", 'COMP_COLUMN_CLASS' : "QuoteConversion_Flag",'COMP_TRAIN_FILES' : ['train.csv'],'COMP_TEST_FILES' : ['test.csv'],'COMP_EVALUATION_METRIC' : "ROC_AUC",'COMP_EVALUATION_METRIC_GREATER_IS_BETTER' : 1, # True
'PRP_DROP_NEAR_ZERO_VARIANCE' : 'No','PRP_WINSORING': (),

boosterama - dashboards
Ejemplo dashboard + exploration
'LEVEL' : '1_ML','SPLIT_CV_TYPE': 'Stratified','SPLIT_CV_KFOLDS' : 5, 'COMP_NAME' : "homesite", 'COMP_PROBLEM_TYPE': 'Class_B', 'COMP_COLUMN_ID' : "QuoteNumber", 'COMP_COLUMN_CLASS' : "QuoteConversion_Flag",'COMP_TRAIN_FILES' : ['train.csv'],'COMP_TEST_FILES' : ['test.csv'],'COMP_EVALUATION_METRIC' : "ROC_AUC",'COMP_EVALUATION_METRIC_GREATER_IS_BETTER' : 1, # True
'ITERATOR' : 'fastloop',
'PRP_DROP_NEAR_ZERO_VARIANCE*' : ['No', 0.05, 0.1], # drops features with variance LOWER than 0.1. Works better when normalized/standarized features.'PRP_WINSORING*': [(), (['y_float_int'],0.03,0.97), (['y_float_int'],0.05,0.95)]
} Tip 4Kaggle

boosterama - dashboards
Configuración por defectoVer dsh_DEFAULT.py (+150 var. configuración)
contiene descripción, valores admitidos y valores por defectopara cada parámetro configurable del dashboard
cada vez que sacamos versión con una nueva funcionalidad,establecemos en la configuración por defecto nuevos parámetros
con la nueva funcionalidad desactivada(compatibilidad hacia atrás)

boosterama
https://boosterama.io

boosterama-ensembles
Ensemble Selection from Libraries of Models
'LEVEL' : '2_CARUANA',
'L2_QUERY_WHERE' : "DO_MODEL_LEVEL ='1_ML' AND SPLIT_CV_KFOLDS=5"
'CARUANA_MAX_ROUNDS' : 200, 'CARUANA_MAX_ROUNDS_WITHOUT_IMPROVEMENTS' : 10, 'CARUANA_SORT' : 'score',
'CARUANA_NUM_PREDICTIONS' : 0, # 0 = use all, otherwise = ensemble the first N predictions
Tip 4Kaggle

Kaggle
- Formación
- Seguir a los número 1
- Leer los foros de Kaggle.
- Reutilizar cada idea que pongas en práctica entre competiciones (framework)
- Busca una buen set de validación cross validación
- Deja los ensembles para el final
- Si llegas al top 50 en una competición de 2000… es que puedes llegar al top 10
- Si estás comenzando, no intentes hacerlo todo a la vez
- Trabaja en equipo
“Si quieres llegar rápido, camina solo.
Si quieres llegar lejos, camina acompañado”
Proverbio Africano
- “La potencia sin control no sirve de nada”
Neumáticos Pirelli
Tip 4Kaggle

¡Esto es todo amigos!
¡Esperamos veros en Kaggle en próximas competiciones!
Preguntas, dudas...

Selection Ensemble example Validation Score
1 Model + 1 Model 2 + 0 Model 3 + 0 Model 4 + 0 Model 5 0.90 Round 1: ____________________________________________________________
2 2 Model + 2 Model 2 + 0 Model 3 + 0 Model 4 + 0 Model 5 0.91 Round 2: ____________________________________________________________
4
3 Model + 3 Model 2 + 0 Model 3 + 1 Model 4 + 0 Model 5 0.92 Round 1: ____________________________________________________________
7

Hardware para Kaggle
CPU
- Cuanta más mejor: más CPUs, más experimentos - Suele ser el cuello de botella - No garantiza el éxito
GPU
- Para competiciones de Deep Learning
Memoria
- No suele ser limitante en Kaggle





























