Embed Size (px)
Citation preview

Memory Subsystem and Cache
Adapted from lectures notes of Dr. Patterson and Dr. Kubiatowicz of UC Berkeley

The Big Picture
Control
Datapath
Memory
Processor
Input
Output

Technology Trends
DRAM
Year Size Cycle Time
1980 64 Kb 250 ns
1983 256 Kb 220 ns
1986 1 Mb 190 ns
1989 4 Mb 165 ns
1992 16 Mb 145 ns
1995 64 Mb 120 ns
Capacity Speed (latency)
Logic: 2x in 3 years 2x in 3 years
DRAM: 4x in 3 years 2x in 10 years
Disk: 4x in 3 years 2x in 10 years
1000:1! 2:1!
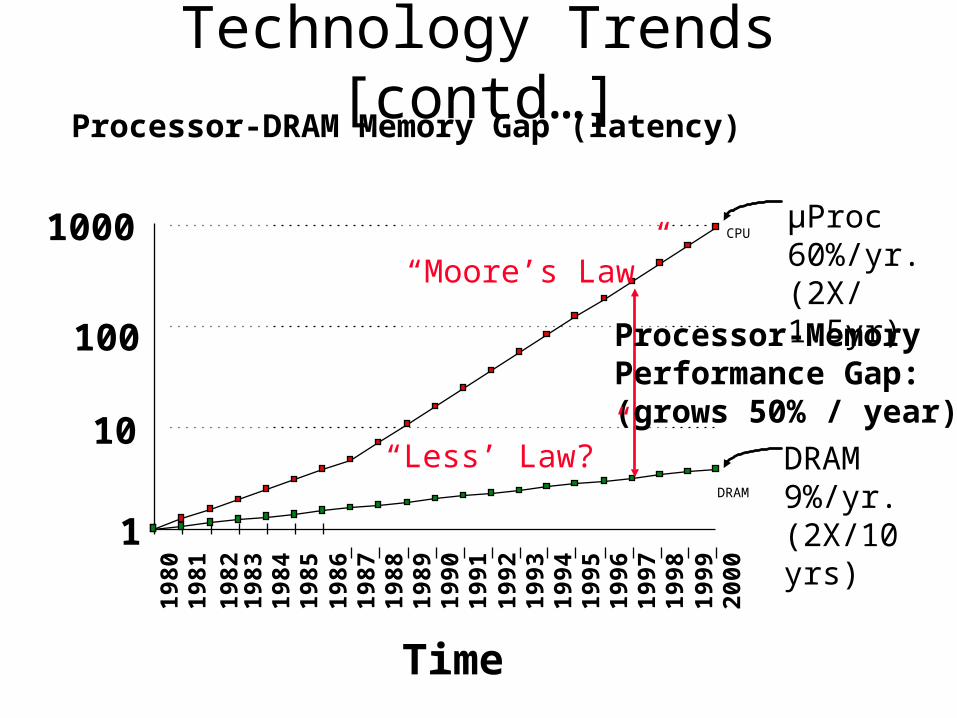
Technology Trends [contd…]
µProc60%/yr.(2X/1.5yr)
DRAM9%/yr.(2X/10 yrs)1
10
100
1000
198
0198
1 198
3198
4198
5 198
6198
7198
8198
9199
0199
1 199
2199
3199
4199
5199
6199
7199
8 199
9200
0
DRAM
CPU198
2
Processor-MemoryPerformance Gap:(grows 50% / year)
Time
“Moore’s Law”
Processor-DRAM Memory Gap (latency)
“Less’ Law?”

The Goal: Large, Fast, Cheap Memory !!!
• Fact– Large memories are slow– Fast memories are small
• How do we create a memory that is large, cheap and fast (most of the time) ?– Hierarchy– Parallelism

• By taking advantage of the principle of locality:
– Present the user with as much memory as is available in the cheapest technology.
– Provide access at the speed offered by the fastest technology.
Control
Datapath
SecondaryStorage(Disk)
Processor
Registers
MainMemory(DRAM)
SecondLevelCache
(SRAM)
On
-Ch
ipC
ache
1s 10,000,000ns
(10 ms)
Speed (ns): 10ns 100ns
100s GsSize (bytes): Ks Ms
TertiaryStorage(Tape)
10,000,000,000ns (10 sec)
Ts

Today’s Situation• Rely on caches to bridge gap
• Microprocessor-DRAM performance gap
– time of a full cache miss in instructions executed
1st Alpha (7000): 340 ns/5.0 ns = 68 clks x 2 or 136 instructions
2nd Alpha (8400): 266 ns/3.3 ns = 80 clks x 4 or 320 instructions

Memory Hierarchy (1/4)
• Processor– executes programs– runs on order of nanoseconds to picoseconds– needs to access code and data for programs:
where are these?
• Disk– HUGE capacity (virtually limitless)– VERY slow: runs on order of milliseconds– so how do we account for this gap?

Memory Hierarchy (2/4)• Memory (DRAM)
– smaller than disk (not limitless capacity)– contains subset of data on disk: basically portions
of programs that are currently being run– much faster than disk: memory accesses don’t
slow down processor quite as much– Problem: memory is still too slow
(hundreds of nanoseconds)– Solution: add more layers (caches)

Memory Hierarchy (3/4)
Processor
Size of memory at each level
Increasing Distance
from Proc.,Decreasing cost / MB
Level 1
Level 2
Level n
Level 3
. . .
Higher
Lower
Levels in memory
hierarchy

Memory Hierarchy (4/4)• If level is closer to Processor, it must be:
– smaller– faster– subset of all higher levels (contains most
recently used data)– contain at least all the data in all lower levels
• Lowest Level (usually disk) contains all available data

Analogy: Library
• You’re writing a term paper (Processor) at a table in Evans
• Evans Library is equivalent to disk– essentially limitless capacity– very slow to retrieve a book
• Table is memory– smaller capacity: means you must return book
when table fills up– easier and faster to find a book there once
you’ve already retrieved it

Analogy : Library [contd…]• Open books on table are cache
– smaller capacity: can have very few open books fit on table; again, when table fills up, you must close a book
– much, much faster to retrieve data
• Illusion created: whole library open on the tabletop – Keep as many recently used books open on table
as possible since likely to use again– Also keep as many books on table as possible,
since faster than going to library

Memory Hierarchy Basics• Disk contains everything.
• When Processor needs something, bring it into to all lower levels of memory.
• Cache contains copies of data in memory that are being used.
• Memory contains copies of data on disk that are being used.
• Entire idea is based on Temporal Locality: if we use it now, we’ll want to use it again soon (a Big Idea)

Caches : Why does it Work ?
• Temporal Locality (Locality in Time):
=> Keep most recently accessed data items closer to the processor
• Spatial Locality (Locality in Space):
=> Move blocks consists of contiguous words to the upper levels
Lower LevelMemoryUpper Level
MemoryTo Processor
From ProcessorBlk X
Blk Y
Address Space0 2^n - 1
Probabilityof reference

Cache Design Issues
• How do we organize cache?
• Where does each memory address map to? (Remember that cache is subset of memory, so multiple memory addresses map to the same cache location.)
• How do we know which elements are in cache?
• How do we quickly locate them?

Direct Mapped Cache• In a direct-mapped cache, each memory
address is associated with one possible block within the cache– Therefore, we only need to look in a single
location in the cache for the data if it exists in the cache
– Block is the unit of transfer between cache and memory

Direct Mapped Cache [contd…]
MemoryMemory Address
0123456789ABCDEF
4 Byte Direct Mapped Cache
Cache Index
0123
• Cache Location 0 can be occupied by data from:– Memory location 0, 4, 8, ... – In general: any memory location
that is multiple of 4

Issues with Direct Mapped Cache• Since multiple memory addresses map to
same cache index, how do we tell which one is in there?
• What if we have a block size > 1 byte?
• Result: divide memory address into three fieldsttttttttttttttttt iiiiiiiiii oooo
tag to check if you index to byte
have correct block select block offset

Example of a direct mapped cache• For a 2^N byte cache:
– The uppermost (32 - N) bits are always the Cache Tag
– The lowest M bits are the Byte Select (Block Size = 2^M)
Cache Index
0
1
2
3
:
Cache Data
Byte 0
0431
:
Cache Tag Example: 0x50
Ex: 0x01
0x50
Stored as partof the cache “state”
Valid Bit
:
31
Byte 1Byte 31 :
Byte 32Byte 33Byte 63 :Byte 992Byte 1023 :
Cache Tag
Byte Select
Ex: 0x00
9Block address

Terminology• All fields are read as unsigned integers.
• Index: specifies the cache index (which “row” of the cache we should look in)
• Offset: once we’ve found correct block, specifies which byte within the block we want
• Tag: the remaining bits after offset and index are determined; these are used to distinguish between all the memory addresses that map to the same location

Terminology [contd…]• Hit: data appears in some block in the upper level (example: Block X)
– Hit Rate: the fraction of memory access found in the upper level
– Hit Time: Time to access the upper level which consists of
RAM access time + Time to determine hit/miss
• Miss: data needs to be retrieve from a block in the lower level (Block Y)
– Miss Rate = 1 - (Hit Rate)
– Miss Penalty: Time to replace a block in the upper level +
Time to deliver the block the processor
• Hit Time << Miss Penalty
Lower LevelMemoryUpper Level
MemoryTo Processor
From ProcessorBlk X
Blk Y

How is the hierarchy managed ?
• Registers <-> Memory– by compiler (programmer?)
• cache <-> memory– by the hardware
• memory <-> disks– by the hardware and operating system (virtual
memory)– by the programmer (files)

Example• Suppose we have a 16KB of data in a direct-
mapped cache with 4 word blocks
• Determine the size of the tag, index and offset fields if we’re using a 32-bit architecture
• Offset– need to specify correct byte within a block– block contains 4 words
16 bytes24 bytes
– need 4 bits to specify correct byte

Example [contd…]• Index: (~index into an “array of blocks”)
– need to specify correct row in cache– cache contains 16 KB = 214 bytes– block contains 24 bytes (4 words)– # rows/cache = # blocks/cache (since
there’s one block/row) = bytes/cache
bytes/row = 214 bytes/cache
24 bytes/row
= 210 rows/cache– need 10 bits to specify this many rows

Example [contd…]• Tag: use remaining bits as tag
– tag length = mem addr length - offset- index
= 32 - 4 - 10 bits = 18 bits
– so tag is leftmost 18 bits of memory address

Accessing data in cache
• Ex.: 16KB of data, direct-mapped, 4 word blocks
• Read 4 addresses
–0x00000014, 0x0000001C, 0x00000034, 0x00008014
• Memory values on right:
–only cache/memory level of hierarchy
Address (hex)Value of WordMemory
0000001000000014000000180000001C
abcd
... ...
0000003000000034000000380000003C
efgh
0000801000008014000080180000801C
ijkl
... ...
... ...
... ...

Accessing data in cache [contd…]• 4 Addresses:
–0x00000014, 0x0000001C, 0x00000034, 0x00008014
• 4 Addresses divided (for convenience) into Tag, Index, Byte Offset fields
000000000000000000 0000000001 0100
000000000000000000 0000000001 1100
000000000000000000 0000000011 0100
000000000000000010 0000000001 0100
Tag Index Offset

Example Block
16 KB Direct Mapped Cache, 16B blocks• Valid bit: determines whether anything is stored in that row
(when computer initially turned on, all entries are invalid)
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
Index00000000
00

Read 0x00000014 = 0…00 0..001 0100• 000000000000000000 0000000001 0100
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
Index
Tag field Index field Offset
00000000
00
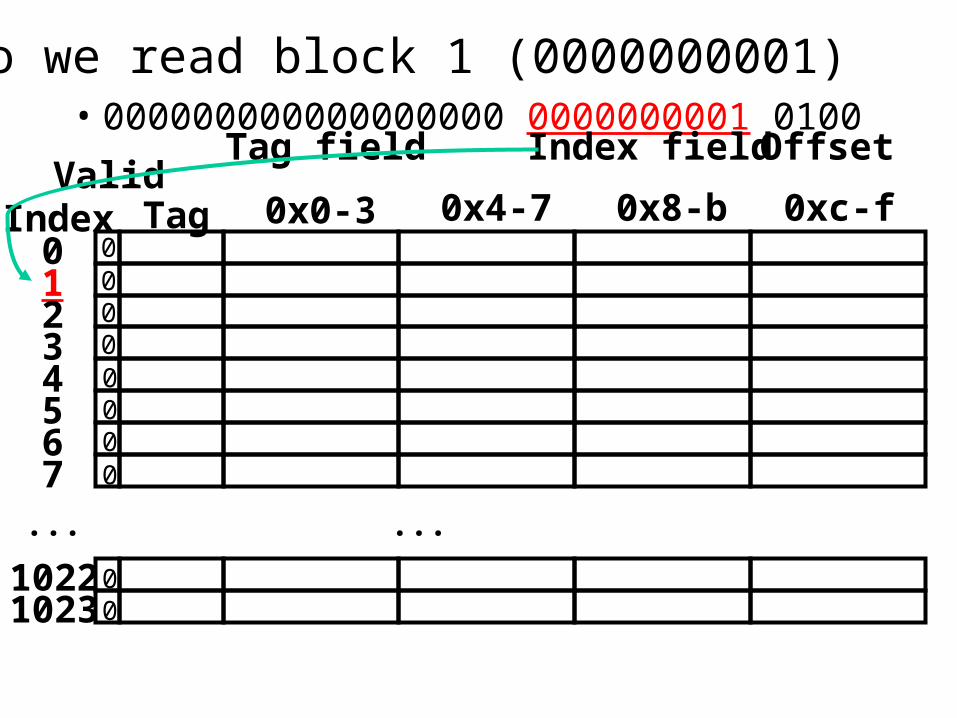
So we read block 1 (0000000001)
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
• 000000000000000000 0000000001 0100
Index
Tag field Index field Offset
00000000
00

No valid data
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
• 000000000000000000 0000000001 0100
Index
Tag field Index field Offset
00000000
00
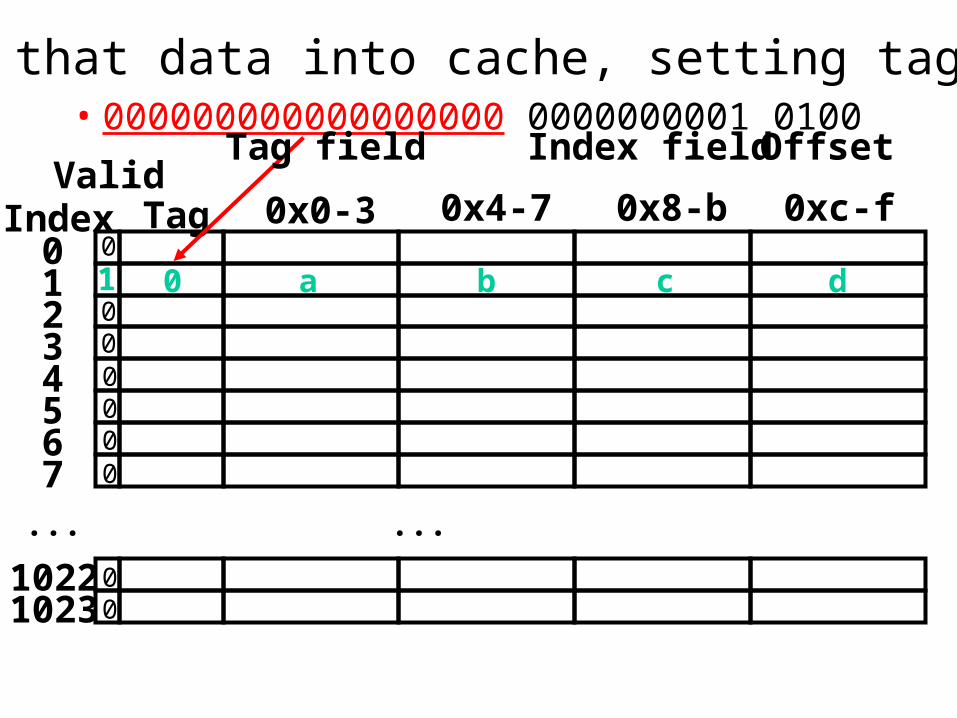
So load that data into cache, setting tag, valid
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000001 0100
Index
Tag field Index field Offset
0
000000
00

Read from cache at offset, return word b• 000000000000000000 0000000001 0100
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
Index
Tag field Index field Offset
0
000000
00

Read 0x0000001C = 0…00 0..001 1100
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000001 1100
Index
Tag field Index field Offset
0
000000
00

Data valid, tag OK, so read offset return word d
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000001 1100
Index0
000000
00

Read 0x00000034 = 0…00 0..011 0100
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000011 0100
Index
Tag field Index field Offset
0
000000
00

So read block 3
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000011 0100
Index
Tag field Index field Offset
0
000000
00

No valid data
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000011 0100
Index
Tag field Index field Offset
0
000000
00
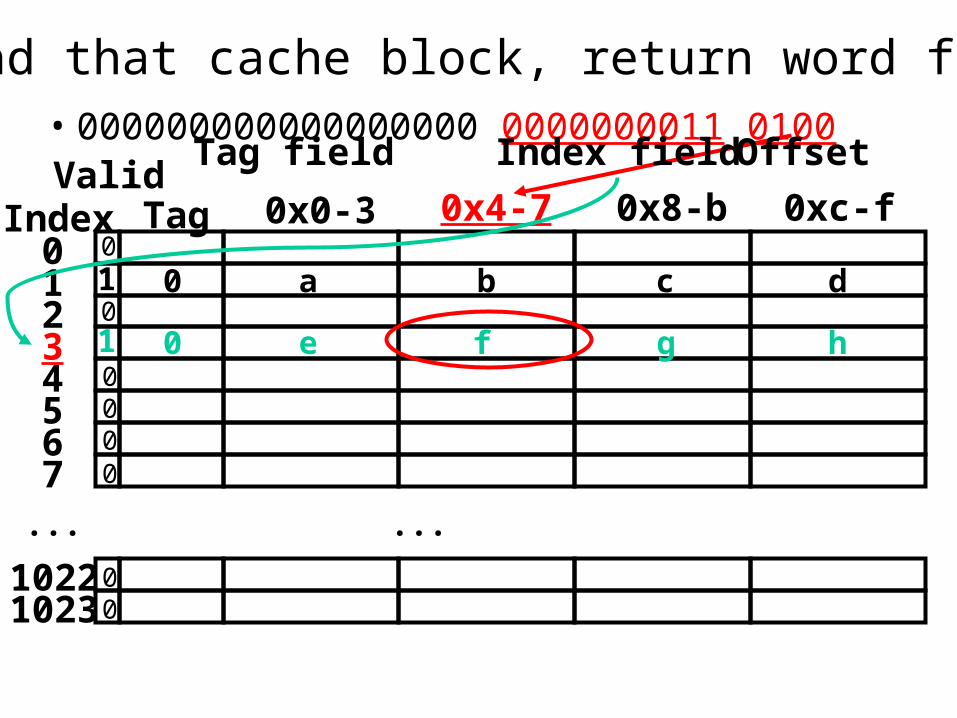
Load that cache block, return word f
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000011 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

Read 0x00008014 = 0…10 0..001 0100
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00
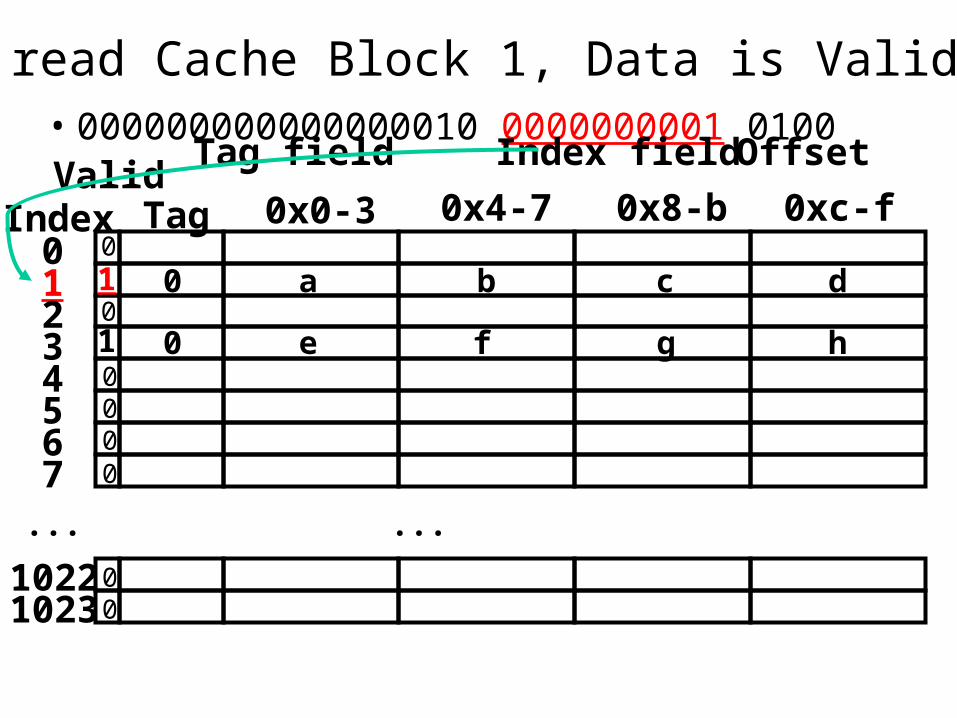
So read Cache Block 1, Data is Valid
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

Cache Block 1 Tag does not match (0 != 2)
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

Miss, so replace block 1 with new data & tag
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 2 i j k l
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

And return word j
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 2 i j k l
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

Things to Remember
• We would like to have the capacity of disk at the speed of the processor: unfortunately this is not feasible.
• So we create a memory hierarchy:– each successively lower level contains “most
used” data from next higher level
• Exploit temporal and spatial locality





























