Embed Size (px)
Citation preview

Metric Learning for Large Scale Image Classification:
Generalizing to New Classes at Near-Zero Cost
Thomas Mensink, Jakob Verbeek, Florent Perronnin, and Gabriela Csurka
Presented by Karen Simonyan (VGG)

Objectives
• Large-scale classification for growing number of classes and images
• Learn (and update) classifiers at low cost
– (re-)training SVMs might be slow
• Learn classifiers from a few (or zero) images
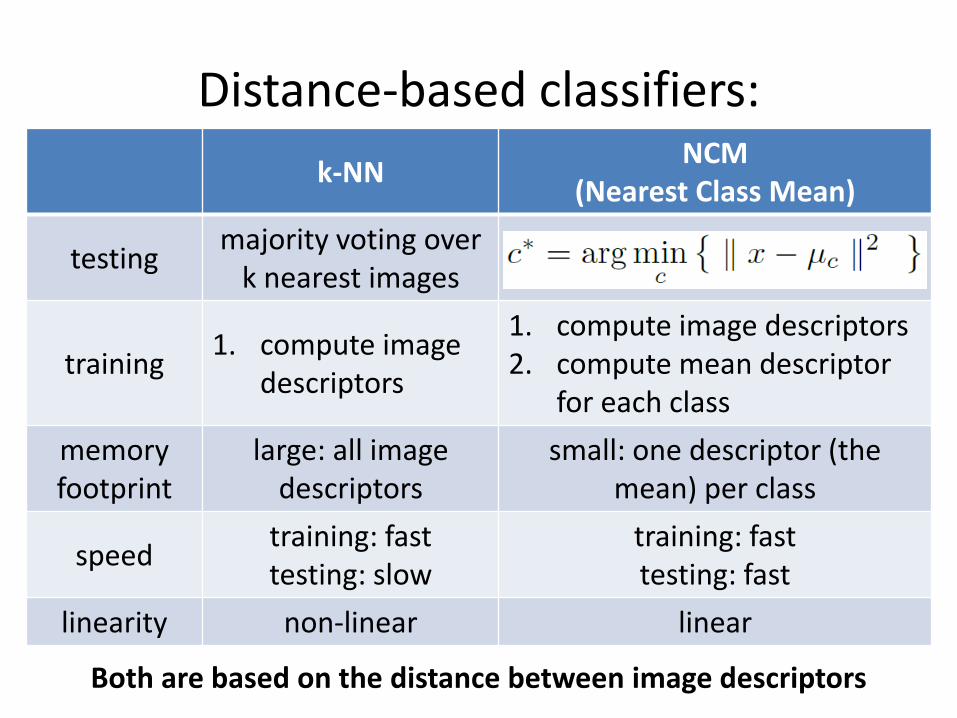
Distance-based classifiers:
k-NN NCM
(Nearest Class Mean)
testing majority voting over
k nearest images
training 1. compute image
descriptors
1. compute image descriptors 2. compute mean descriptor
for each class
memory footprint
large: all image descriptors
small: one descriptor (the mean) per class
speed training: fast testing: slow
training: fast testing: fast
linearity non-linear linear
Both are based on the distance between image descriptors

(Generalised) Mahalanobis distance
d2(x,x')=
• M≥0: positive semi-definite to ensure non-negativity
• M=I → Euclidean distance
• originally, M was inverse covariance matrix
• M can also be learnt s.t. P.S.D. constraint
• equivalent to the Euclidean distance in the W-projected space, :

Large-margin metric learning for k-NN
• Based on Large Margin Nearest Neighbour (LMNN) [1]
• Learning constraints:
– for each image q, distance to images p of the same class is smaller than distance to images n of other classes
• Hinge loss:
• Pq & Nq – sets of same-class & other-class images
[1] Weinberger, Saul: "Distance metric learning for large margin nearest neighbor classification", JMLR 2009

Large-margin metric learning for k-NN
• Loss:
• Choice of Pq (target selection) is important
– LMNN: fix to k nearest neighbours w.r.t. Euclidean metric • introduces an unnecessary bias towards Euclidean metric
– set to all images of the same class
– dynamically set to k nearest neighbours w.r.t. current metric
• Non-convex objective, SGD optimisation:

Large-margin metric learning for NCM
• Could use similar constraints, but defined on the means
• Instead:
– multi-class logistic regression:
– objective: min negative log-likelihood:
• minimise distance to the class mean
• maximise distance to other class means
• gradient:

Relationship between NCM and other methods
WSABIE [2]
• simultaneously learn projection W and weight vectors vc
• scoring function:
• projection is shared, weight vectors are class-specific
NCM is a special case:
• enforces
• can add new classes without learning models vc
bias weight vector
[2] Weston, et al.: “WSABIE: Scaling up to large vocabulary image annotation”, IJCAI 2011
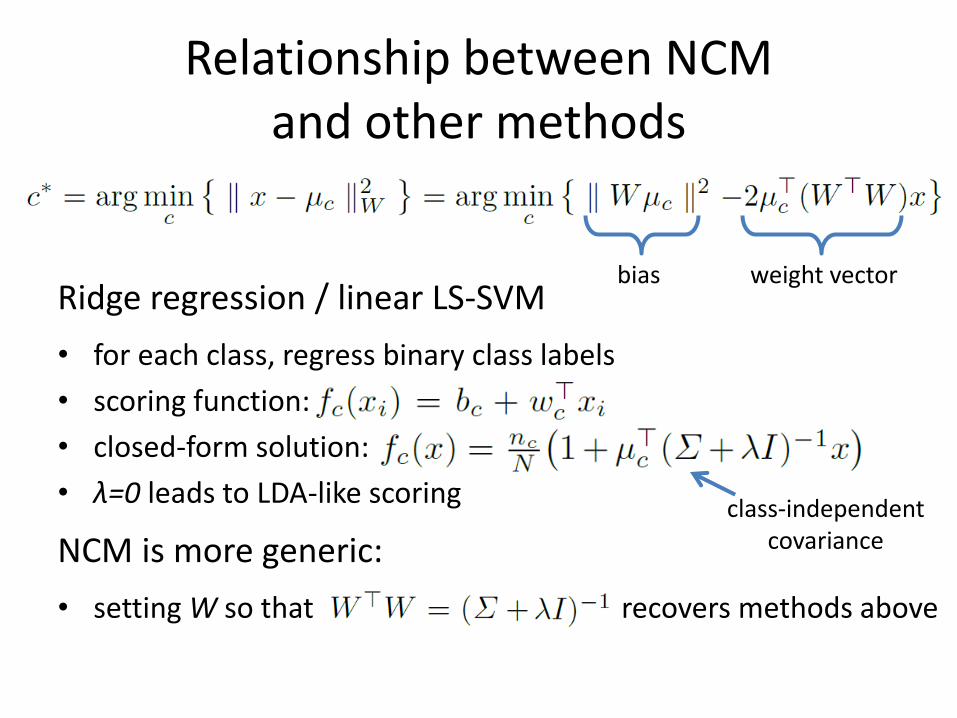
Relationship between NCM and other methods
Ridge regression / linear LS-SVM
• for each class, regress binary class labels
• scoring function:
• closed-form solution:
• λ=0 leads to LDA-like scoring
NCM is more generic:
• setting W so that recovers methods above
bias weight vector
class-independent covariance

Evaluation framework
• Dataset: ImageNet challenge 2010
– 1000 classes, 1.2M train set, 50K val set, 150K test set
• Image features
– Fisher vectors over dense SIFT & colour
– 16 Gaussians → 4K features; 256 Gaussians → 64K features
– compression using product quantisation
• Measures: top-1 & top-5 error rates
• Baseline: 1000 one-vs-rest linear SVMs
– top-5 error: 28.0%
– state-of-the-art (with 1M features) : 25.7%

k-NN evaluation
• 4K image features
– "Full" – no dimensionality reduction,
– otherwise, projection to 128-D
• Conclusions
– learnt metric is better than Euclidean or PCA
– dynamic target selection is better than static or using all same-class images
three target selection methods
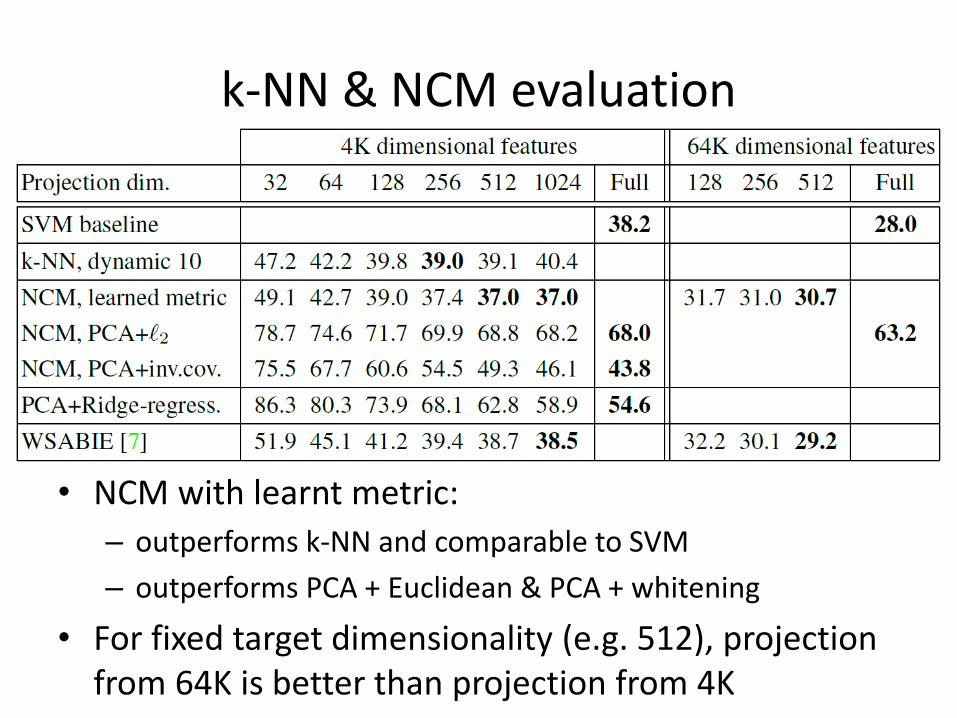
k-NN & NCM evaluation
• NCM with learnt metric:
– outperforms k-NN and comparable to SVM
– outperforms PCA + Euclidean & PCA + whitening
• For fixed target dimensionality (e.g. 512), projection from 64K is better than projection from 4K

NCM with learnt metric vs L2
• 3 "queries": average descriptors of 3 reference classes
• probabilities of the ref. class and 5 nearest classes are shown
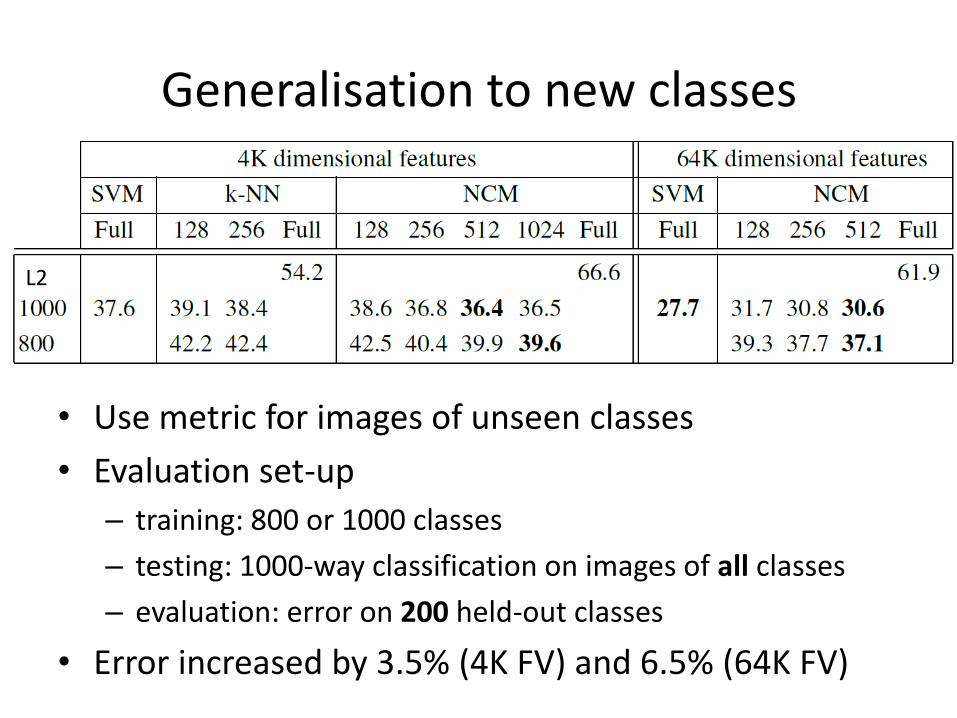
Generalisation to new classes
• Use metric for images of unseen classes
• Evaluation set-up
– training: 800 or 1000 classes
– testing: 1000-way classification on images of all classes
– evaluation: error on 200 held-out classes
• Error increased by 3.5% (4K FV) and 6.5% (64K FV)
L2
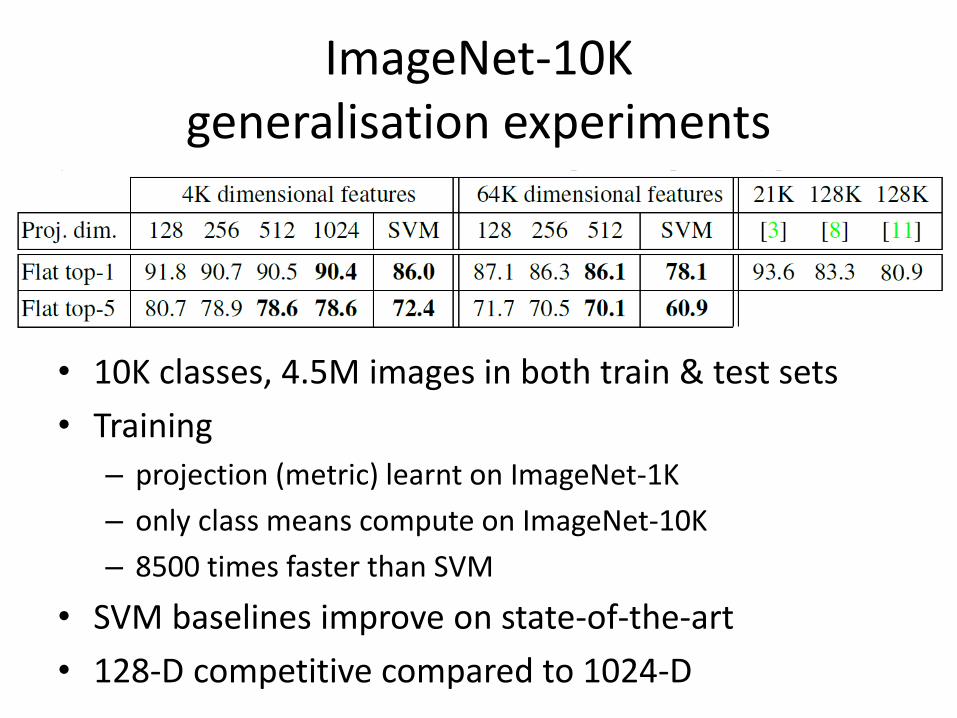
ImageNet-10K generalisation experiments
• 10K classes, 4.5M images in both train & test sets
• Training
– projection (metric) learnt on ImageNet-1K
– only class means compute on ImageNet-10K
– 8500 times faster than SVM
• SVM baselines improve on state-of-the-art
• 128-D competitive compared to 1024-D

Zero-shot learning
• How many images do we need to compute the class mean?
• Zero-shot learning:
– no images of the class are used
– class mean – average of means of WordNet ancestors (for leaf nodes) or descendants (for internal nodes)
• Middle ground
– combine zero-shot "prior" μz with the mean μs of available images:
– linear combination weights determined on the validation set
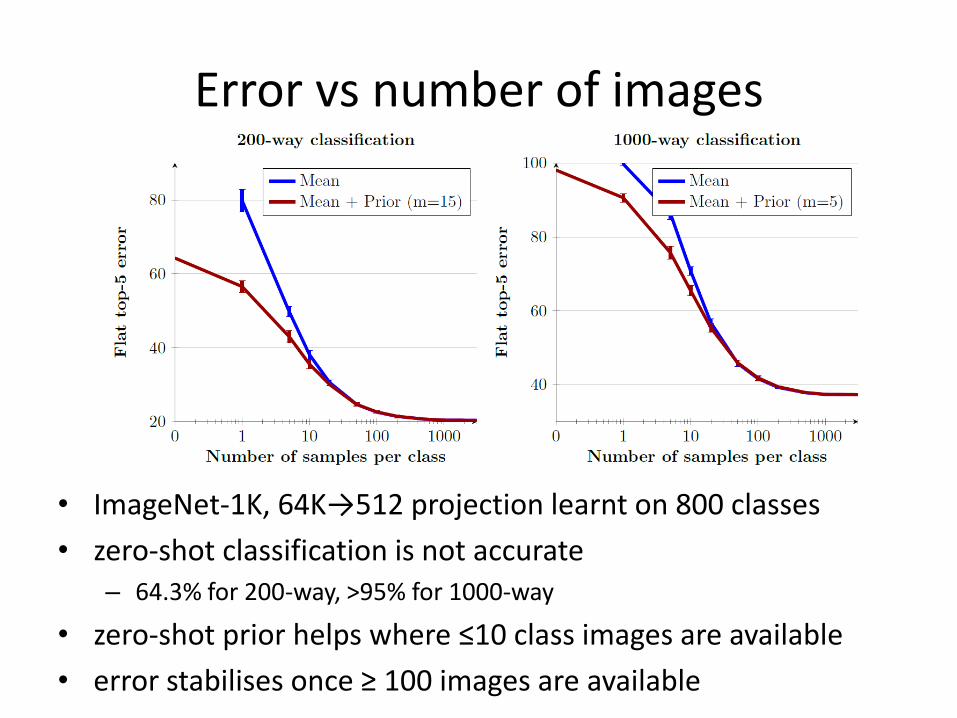
Error vs number of images
• ImageNet-1K, 64K→512 projection learnt on 800 classes
• zero-shot classification is not accurate – 64.3% for 200-way, >95% for 1000-way
• zero-shot prior helps where ≤10 class images are available
• error stabilises once ≥ 100 images are available

Summary
• NCM with a learnt metric
– outperforms k-NN
– comparable to SVM
• Projection to 256-D or 512-D space suffices
• Zero-shot prior is helpful if only a few class images are given








![arXiv:1505.00607v3 [math.MG] 13 Jul 2016Keywords. the visual angle metric, the hyperbolic metric, Lipschitz map, quasiregular map 2010 Mathematics Subject Classification. 30C65 (30F45)](https://img.pdfslide.net/doc/110x75/5f70247c39abd500766391dc/arxiv150500607v3-mathmg-13-jul-2016-keywords-the-visual-angle-metric-the.jpg)




















