Embed Size (px)
DESCRIPTION
MEVAL : A Practically Efficient System for Secure Multi-party Statistical Analysis. Koki Hamada NTT Secure Platform Laboratories. Overview. Introduction of our MPC system MEVAL ( M ulti-party EVAL uator ) Main features of MEVAL : - PowerPoint PPT Presentation
Citation preview

1
MEVAL: A Practically Efficient System forSecure Multi-party Statistical Analysis
Koki Hamada
NTT Secure Platform Laboratories

2
Overview• Introduction of our MPC system MEVAL (Multi-party EVALuator)
• Main features of MEVAL:
– 8.7 MIPS (million instructions per second) 61-bit multiplication
– 6.9 seconds for Sorting 1 million 20-bit items

3
Outline• Overview of MEVAL
• Performance
• Techniques
• Demonstration

4
OVERVIEW OF MEVAL

5
MEVAL (Multi-party EVALuator)
Design concept of MEVAL:general purpose high-performance secure computation system
• MPC system based on secret sharing– Built on Shamir’s secret sharing scheme
– The number of parties is 3
– Corruption tolerance is 1
• Secure against passive adversaries
• Values are 61-bit word– Mersenne prime field with is used for efficiency
(mechanism is discussed later)

6
Intended applicationSecure outsourcing of data storage and analysis
1. Data holders outsource data storage to MEVAL servers
2. Servers conduct analysis on request and return the result
Requirement: MEVAL servers never see the stored data
MEVAL servers
⋯
1.
2.

7
Implemented operations• Basic MPC protocols
– Dealing, revealing
– Addition, multiplication
– Bet-decomposition, comparison, equality test
– Shuffling
– Sorting
• Statistical functions– Count, sum, min, max, median, sum of squares
– Mean, variance, Student’s t-test
Fully realizedas MPC protocols
Computed fromrevealed count, sum,and sum of squares

8
Practical accomplishments of MEVAL• Joint experiment with a medical study group, 2011 – 2013
– Analyses conducted in clinical research were replicated on MEVAL• Mean, variance, min, max, median, survival analysis, tests, etc.
– real clinical data of adult leukemia patients were used
• Joint research with a university hospital, 2012 –– Performance evaluation of MEVAL
• Intended application: analysis on real medical receipt
– dummy insurance claim data were used
• Joint research with Japanese statistics bureau, 2012 –– Performance evaluation of MEVAL
• Intended application: advanced use of official statistics
– official statistic data were used
Data holders’ requirements: better security without performance loss

9
PERFORMANCE OF MEVAL

10
Experimental outline• Run on 3 desktop machines
– CPU: Intel Core i7 3930K 3.2 GHz
– RAM: 20 GB
– SSD: 128 GB
– OS: Linux (Ubuntu 12.04)
– Networks:• 1-Gbps LAN, 10-Gbps LAN, 200-Mbps WAN
• Performance of basic MPC protocols were measured– Addition, multiplication, shuffling (with 61-bit input values)
– Equality test, comparison, sorting (with 20-bit input values)• Size of field is , but secret values are known to be less than

11
Performance on 1-Gbps LAN• Running-time on 1-Gbps LAN in seconds
– Input values were randomly chosen
# items Addition 0.001 0.001 0.012 0.138 = 724.63 MIPSMultiplication 0.017 0.135 1.191 11.449 = 8.73 MIPSShuffling 0.031 0.234 2.603 29.073 = 3,439,617 items/sEquality test (20-bit) 0.839 0.668 0.880 9.024 = 11.08 MIPSComparison (20-bit) 0.413 0.287 0.592 13.680 = 7.30 MIPSSorting (20-bit) 0.738 6.875 73.382 - = 136,273 items/s

12
Performance on 10-Gbps LAN• Running-time on 10-Gbps LAN in seconds
– Input values were randomly chosen
# items Addition 0.001 0.001 0.012 0.139 = 719.42 MIPSMultiplication 0.017 0.050 0.469 4.752 = 21.04 MIPSShuffling 0.020 0.118 1.315 15.073 = 6,634,379 items/sEquality test (20-bit) 0.710 0.664 0.674 2.689 = 37.18 MIPSComparison (20-bit) 0.322 0.263 0.287 1.699 = 58.85 MIPSSorting (20-bit) 0.253 2.211 30.207 - = 331,049 items/s

13
Performance on WAN• Running-time on WAN in seconds
– 200-Mbps best-effort delivery network was used
– Network delay between machines were 24.6 , 36.1 and, 46.7 ms
– Input values were real medical data
# items 1 100 1,547 10,829 108,290Addition - 0.001 0.001 0.001 0.002 = 54.009 MIPSMultiplication - 0.091 0.063 0.074 0.233 = 0.464 MIPSShuffling - 0.059 0.062 0.125 0.671 = 161,385 items/sEquality test (20-bit) 0.970 0.930 1.030 1.591 5.468 = 0.019 MIPSComparison (20-bit) 0.634 0.771 0.961 1.647 6.174 = 0.017 MIPSSorting (20-bit) 1.075 1.032 0.772 1.595 12.723 = 8,511 items/s

14
TECHNIQUES USED IN MEVAL

15
Techniques used in MEVAL• Implementation techniques
• Efficient high-level protocols

16
Implementation techniques• Careful implementation was done for real-world performance
• Main points of our efficient implementation are:1. Asynchronous processing
2. Pseudorandom secret sharing technique implemented with AES-NI
3. Optimized field operations on Mersenne prime field

17
Without asynchronous processing• In our settings, times consumed by data transfer and local
computation are comparable
• So, naïve implementation leaves many resources unused– Example: cascade conductions of MPC protocols
ComputeReceive Send
1st conduction
ComputeReceive Send
2nd conduction
Receive ⋯
Networkusage
CPUusage

18
Implementation techniques• Careful implementation was done for real-world performance
• Main points of our efficient implementation are:1. Asynchronous processing
2. Pseudorandom secret sharing technique implemented with AES-NI
3. Optimized field operations on Mersenne prime field
Time consumed by sending/receiving
Time consumed by local computation
Running time
Running time details (before applying our ideas):

19
Asynchronous processing• Asynchronous implementation enables better resource usage
ComputeReceive Send
ComputeReceive Send
Receive
Receive Compute
Compute
Send
Receive
Thread 1
Thread 2
Thread 3
⋯
Compute
Send
Networkusage
CPUusage

20
Implementation techniques• Careful implementation was done for real-world performance
• Main points of our efficient implementation are:1. Asynchronous processing
2. Pseudorandom secret sharing technique implemented with AES-NI
3. Optimized field operations on Mersenne prime field
Time consumed by sending/receiving
Time consumed by local computation
Running time
Running time details:

21
Balancing resource usage• If implementation is asynchronous, maximum of resource
usages determines total running time
• Balancing resource usage is important for reducing running time on asynchronous implementation
Sending/receiving
Computation
Running time
30 s
8 s
30 s
30 s
8 s
30 s
18 s
20 s
20 s
Case #2Case #1 Case #3

22
Pseudorandom secret sharing• Pseudorandom secret sharing technique [CDI05] is used to
convert network communication to local computation– Almost half of communications can be converted to local computation
– AES-NI is used to obtain 30-Gbps pseudorandom generation
Typical communication on 3-party MPC: mask and send
𝑃1
𝑃2 𝑃3
(1) Generate random
(2) Send (2) Send
𝑃1
𝑃2 𝑃3
(1) Generate pseudorandom
(2) Send
(0) and share a seed for pseudorandom
(1) Generatepseudorandom

23
Implementation techniques• Careful implementation was done for real-world performance
• Main points of our efficient implementation are:1. Asynchronous processing
2. Pseudorandom secret sharing technique implemented with AES-NI
3. Optimized field operations on Mersenne prime field
Time consumed by sending/receiving
Time consumed by local computation
Running time
Running time details:

24
Mersenne prime field operation• Local computations mainly consist of the following operations:
Example:Multiplication (computing ) on Mersenne prime field :1. 2. (higher bits of )
(lower bits of )3. 4. if then 5. Return
Throughputs overprime field ()
- Pseudorandom number generation 30-Gbps
- Field addition 12-Gbps
- Field multiplication 0.5-Gbps
Throughputs overprime field ()
Throughputs overMersenne prime field ()
- Pseudorandom number generation 30-Gbps 30-Gbps
- Field addition 12-Gbps 70-Gbps
- Field multiplication 0.5-Gbps 30-Gbps

25
Implementation techniques• Careful implementation was done for real-world performance
• Main points of our efficient implementation are:1. Asynchronous processing
2. Pseudorandom secret sharing technique implemented with AES-NI
3. Optimized field operations on Mersenne prime field
Time consumed by sending/receiving
Time consumed by local computation
Running time
Running time details:

26
Our efficient protocols• Efficient high-level protocols were also investigated:
– Bit-decomposition for small number of parties
– Radix sort protocol
27
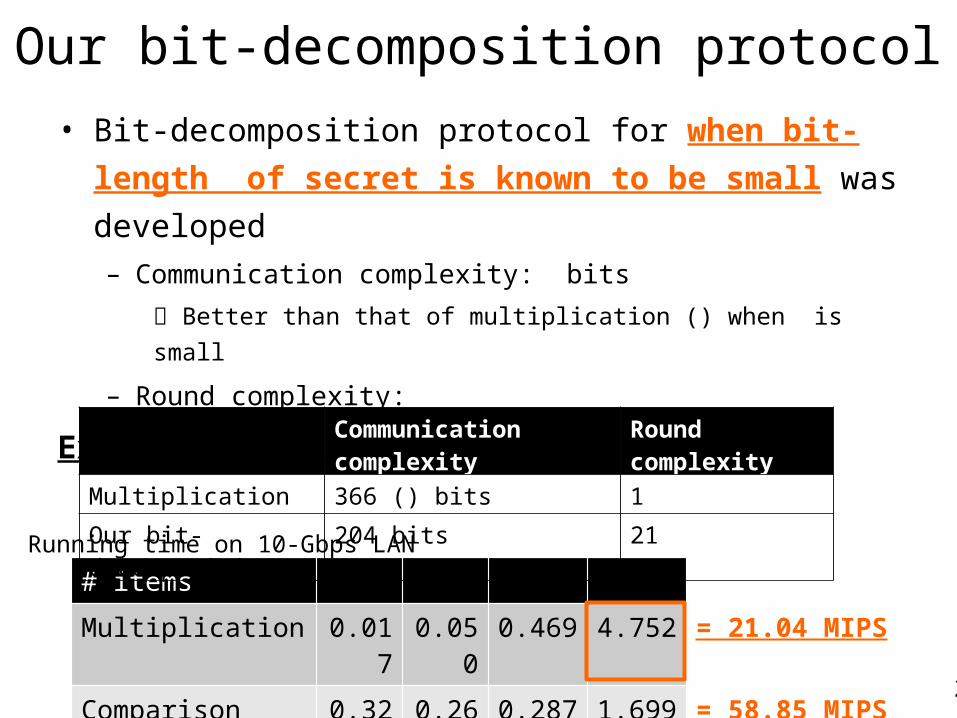
Our bit-decomposition protocol• Bit-decomposition protocol for when bit-length of secret is
known to be small was developed– Communication complexity: bits
Better than that of multiplication () when is small
– Round complexity:
Example: and
# items Multiplication 0.017 0.050 0.469 4.752 = 21.04 MIPSComparison (20-bit) 0.322 0.263 0.287 1.699 = 58.85 MIPS
Running time on 10-Gbps LAN
Communication complexity Round complexity
Multiplication 366 () bits 1
Our bit-decomposition 204 bits 21

28
Our bit-decomposition protocol (contd.)Our bit-decomposition protocol is based on two ideas:
1. Replicated secret sharing over is used for shared bits– Using smaller field saves communication complexity of protocols on bits
– We can compute XOR on shared bits for free
2. Efficient over flow detection when we know – When and ,
iff
– We can remove full-bit addition circuit computation with this technique

29
Our sorting protocol• Sorting protocol with communication in rounds was developed
– is # input items
– # parties and field size are assumed to be constant
• Our sorting protocol is based on radix sort algorithm
Bit-decomposition and bitwise stable sort protocols are sufficient to construct MPC radix sort protocol
1 1 01 0 11 0 10 1 11 0 0
1 1 01 0 01 0 11 0 10 1 1
1 0 01 0 11 0 11 1 00 1 1
0 1 11 0 01 0 11 0 11 1 0
Radix sort algorithm:

30
Our sorting protocol (contd.)• Our technique: “Shuffle and reveal”
• In addition, “Shuffle and reveal” technique is again used to improve efficiency of resultant MPC radix sort protocol
10010
41253
00110
43215
00011
12345
Computingdestinations
Shuffling Revealing
MPC bitwise stable sort:

31
DEMONSTRATION
32
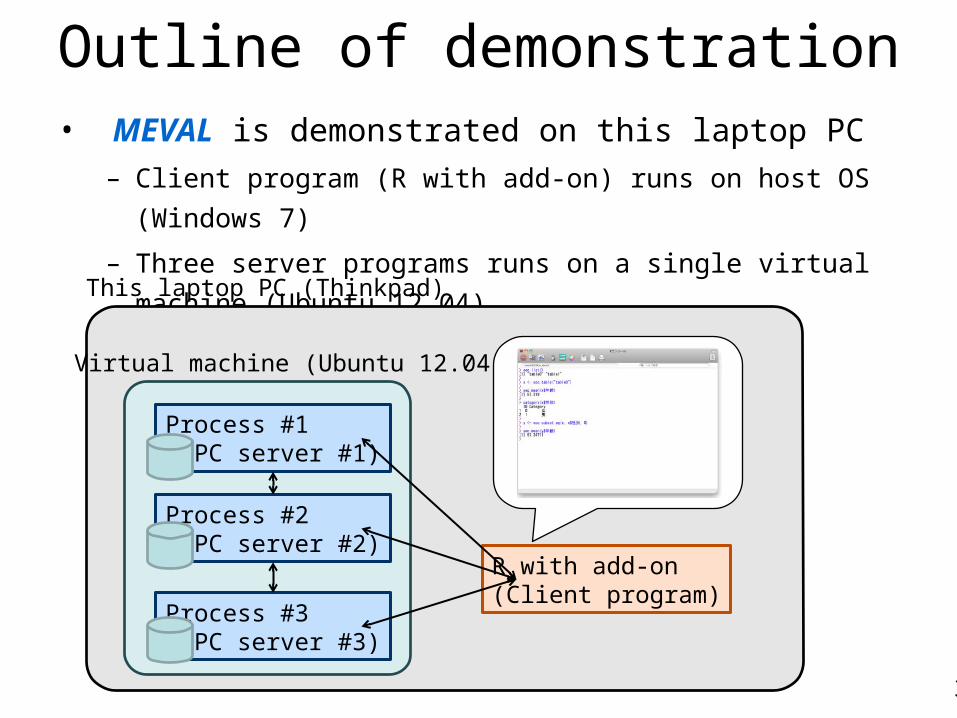
Outline of demonstration• MEVAL is demonstrated on this laptop PC
– Client program (R with add-on) runs on host OS (Windows 7)
– Three server programs runs on a single virtual machine (Ubuntu 12.04)This laptop PC (Thinkpad)
Virtual machine (Ubuntu 12.04)
Process #1(MPC server #1)
Process #2(MPC server #2)
Process #3(MPC server #3)
R with add-on(Client program)





























