Embed Size (px)
Citation preview

Mining Tree-Query Associations in a Graph
Bart GoethalsUniversity of Antwerp,
Belgium
Eveline Hoekx Jan Van den Bussche
Hasselt University, Belgium

2
Graph Data
A (directed) graph over a set of nodes N is a set G of edges: ordered pairs ij with ij N.
Snapshot of a graph representing the complete metabolic pathway of a human.

3
Graph Mining
Transactional category– dataset: set of many small graphs (transactions)
– frequency: transactions in which the pattern occurs (at least once)
– ILP: Warmr
[AGM, FSG, TreeMiner, gSpan, FFSM]
Single graph category– dataset: single large graph
– frequency: copies of the pattern in the large graph
[Subdue, Vanetik-Gudes-Shimony, SEuS, SiGraM, Jeh-Widom]
Focus on pattern mining, few work on association rule mining!

4
Our work
• Single graph category• Pattern + association rule mining • Patterns with:
– Existential nodes– Parameters
• Occurrence of the pattern in G is any homomorphism from the pattern in G.
• So far only considered in the ILP (transactional) setting

5
Example of a pattern
5
8 x
frequency x z 5z G z8 G zx G

6
Patterns are conjunctive queries.
frequency x z 5z G z8 G zx G
select distinct G3.to as xfrom G G1, G G2, G G3where G1.from=5 and G1.to=G2.from
and G1.to=G3.from and G2.to=8
5
8 x
( )x
7
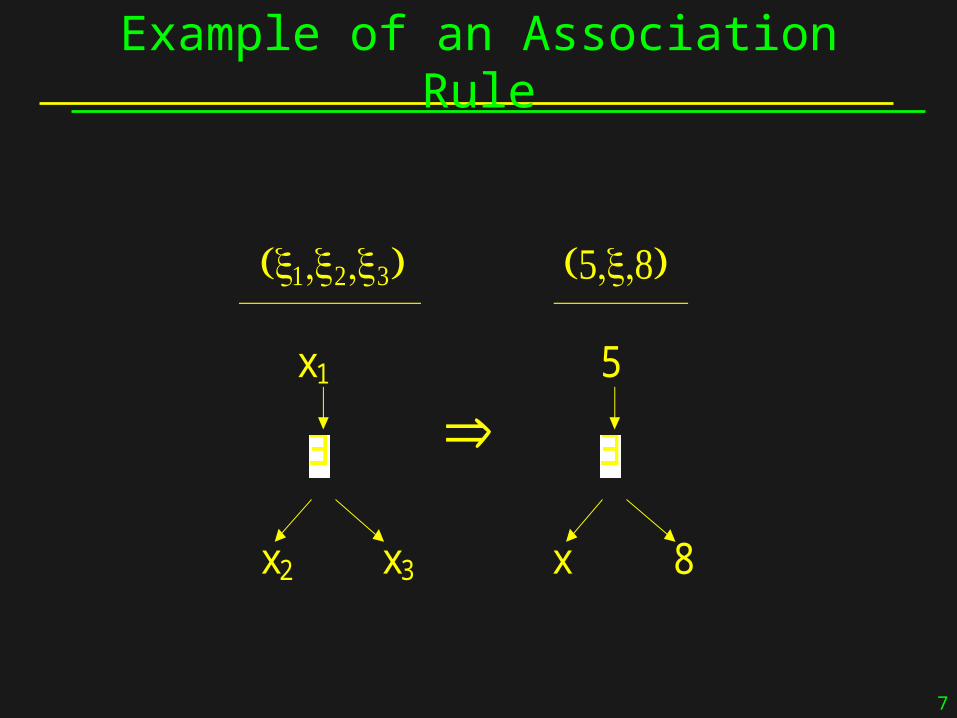
Example of an Association Rule
5
8 x
x1
x3 x2
⇒
(x1,x2,x3) (5, ,8)x

8
Features of the presented algorithms
• Pattern mining phase + association mining phase
• Restriction to trees => efficient algorithms
• Equivalence checking• Apply theory of conjunctive database queries
• Database oriented implementation
9
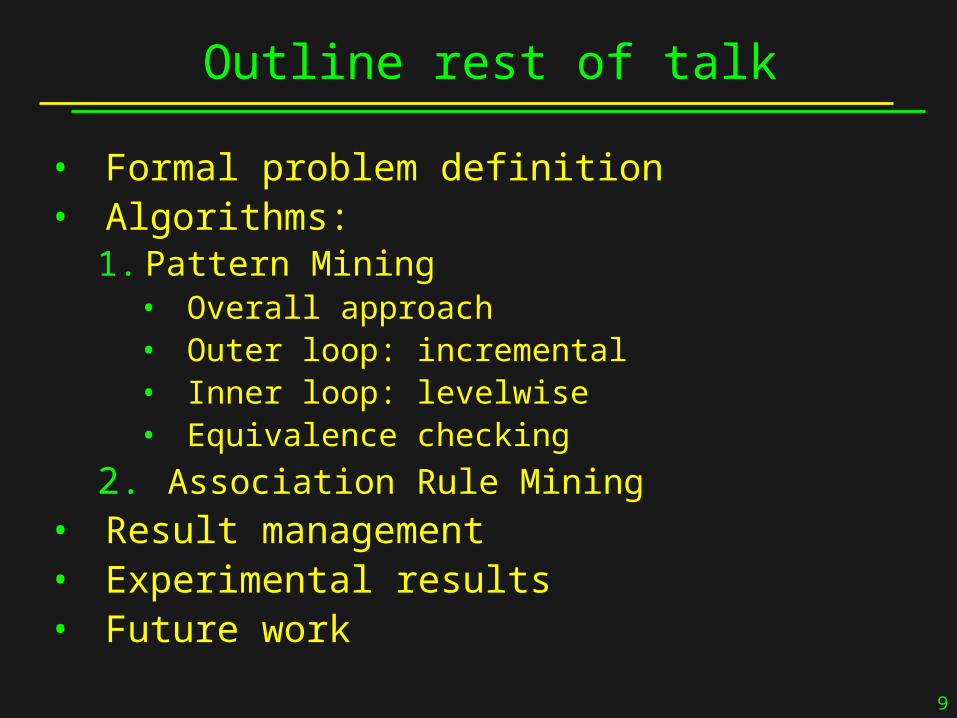
Outline rest of talk
• Formal problem definition• Algorithms:
1. Pattern Mining • Overall approach• Outer loop: incremental• Inner loop: levelwise• Equivalence checking
2. Association Rule Mining• Result management • Experimental results• Future work

10
Formal definition of a tree pattern.
A tree pattern is a tree P whose nodes are called variables, and:
• some variables marked as existential • some variables are parameters (labeled with a
constant)• remaining variables are called distinguished

11
Formal definition of a tree query.
A tree query Q is a pair (H,P) where:1. P is a tree pattern, the body of Q2. H is a tuple of distinguished variables and
parameters of P. All distinguished variables of P must appear at least once in H, the head of Q

12
Formal definition of a matching
A matching of a pattern P in a graph G is a homomorphism h: P G, with hz a, for parameters labeled a.

13
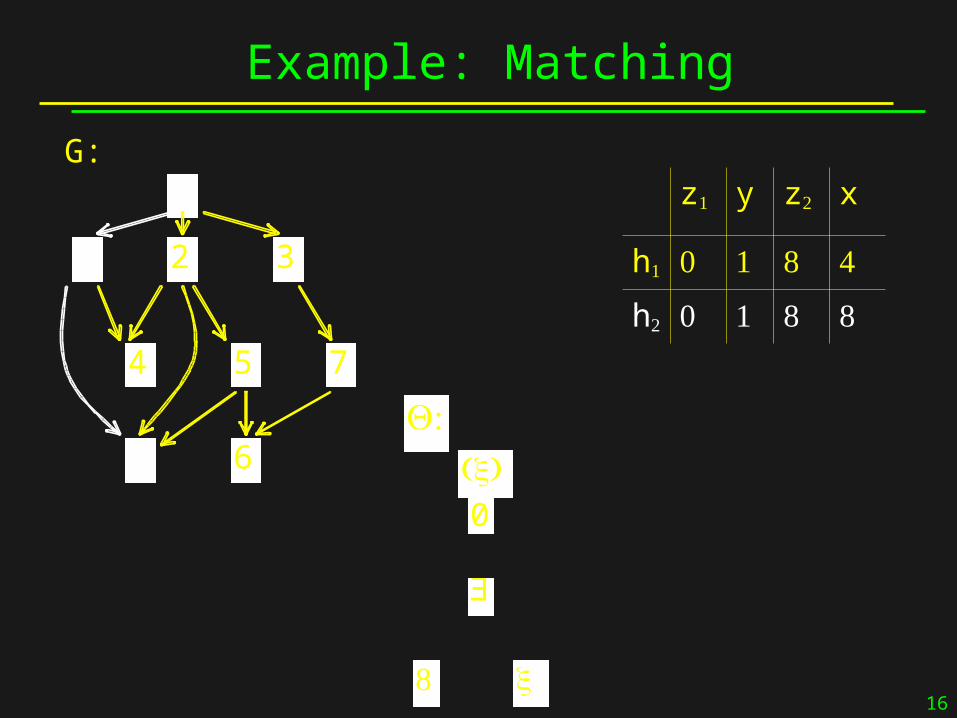
Example: Matching
0
1
5 4
2 3
7
6 8
G: z1 y z2 x
0
8 x
:Q ( )x

14
Example: Matching
0
1
5 4
2 3
7
6 8
G: z1 y z2 x
0
8 x
:Q ( )x

15
Example: Matching
0
1
5 4
2 3
7
6 8
G: z1 y z2 x
h1 1 8
0
8 x
:Q ( )x
16
Example: Matching
0
1
5 4
2 3
7
6 8
G: z1 y z2 x
h1 1 8
h2 1 8 8
0
8 x
:Q ( )x

17
Example: Matching
0
1
5 4
2 3
7
6 8
G: z1 y z2 x
h1 1 8
h2 1 8 8
h3 2 8
0
8 x
:Q ( )x

18
Example: Matching
0
1
5 4
2 3
7
6 8
G: z1 y z2 x
h1 1 8
h2 1 8 8
h3 2 8
h 2 8 5
0
8 x
:Q ( )x

19
Example: Matching
0
8 x
:Q ( )x
0
1
5 4
2 3
7
6 8
G: z1 y z2 x
h1 1 8
h2 1 8 8
h3 2 8
h 2 8 5
h5 2 8 8

20
Formal definition of frequency
The frequency of Q in G is #answers in the answer set.
We define the answer set of Q in G as follows: QG f(H)|f is a matching of P in G

21
Example: Matching
0
1
5 4
2 3
7
6 8
G: z1 y z2 x
h1 1 8
h2 1 8 8
h3 2 8
h 2 8 5
h5 2 8 8
frequency 3
0
8 x
:Q ( )x

22
Problem statement 1: Tree query mining
Given a graph G and a threshold k, find all tree queries that
have frequency at least k in G, those queries are calledfrequent.

23
Formal definition of an association rule
An association rule (AR) is of the form Q1 Q2 with Q1 and Q2
tree queries. The AR is legal if Q2 Q1. The confidence of the
AR in a graph G is defined as the frequency of Q2 divided by the
frequency of Q1.

24
Problem statement 2: Association rule mining
• Input: a graph G, minsup, a tree query Qleft frequent in G, minconf
• Output: all tree queries Q such that Qleft Q is a legal and confident association rule in G.

25
Outline rest of talk
• Formal problem definition• Algorithms:
1. Pattern Mining • Overall approach• Outer loop: incremental• Inner loop: levelwise• Equivalence checking
2. Association Rule Mining• Result management • Experimental results• Future work

26
Pattern Mining Algorithm
Outer loop: Generate, incrementally, all possible trees of increasing sizes. Avoid generation of isomorphic trees.
Inner loop: For each newly generated tree, generate all queries based on that tree, and test their frequency.
...
x1
x4x3
x2
x2x1
5
x2x1
x1
25

27
Outer loop
• It is well known how to efficiently generate all trees uniquely up to isomorphism
• Based on canonical form of trees.
• [Scions, Li-Ruskey, Zaki, Chi-Young-Muntz]

28
Inner loop: Levelwise approach
• A query Q is characterized by Q set of existential nodes Q set of parameters– Labeling Q of the parameters by constants.
• Q11 1 1 specializes Q22 2 2 if 1 2, 1 2 and 1 agrees with 2 on 2.
• If Q1 specializes Q2 then freqQ1 freqQ2
• Most general query: T = (, , )

29
Inner loop: Candidate generation
• CanTab is a candidate queryFreqTab is a frequent query
• Q’=’ ’ is a parent of Q= if either:– ’ and has precisely one more node than
’, or– ’ and has precisely one more node than
’
• Join Lemma: Each candidacy table can be computed by taking the natural join of its parent frequency tables.

30
Inner loop: Frequency counting
• Each candidacy table can be computed by a single SQL query. (ref. Join lemma).
• Suppose: Gfrom to table in the database, then each frequency table can be computed with a single SQL query.
» formulate in SQL and count
» formulate in SQL E» natural join of E with CanTab
» group by » count each group

31
Inner loop: Example
0
8 x
:Q
x1
x2
x3 x4
T: x2
x1 x3
x1 x38

32
Inner loop: Example
0
8 x
:Q
x1
x2
x3 x4
T: x2
x1 x3
x1 x38
• Join expression:
CanTab{x2}{x1,x3} = FreqTabx2x1 ⋈ FreqTabx2x3 ⋈ FreqTabx1x3

33
Inner loop: Example
0
8 x
:Q
x1
x2
x3 x4
T: x2
x1 x3
x1 x38
• SQL expression E for x2
select distinct G1.from as x1, G2.to as x3, G3.to as x4
from G G1, G G2, G G3where G1.to = G2.from and G3.from = G2.from

34
Inner loop: Example
0
8 x
:Q
x1
x2
x3 x4
T: x2
x1 x3
x1 x38
• SQL expression for filling the frequency table:
select distinct E.x1, E.x3, count(E.x4)from E, CanTab{x2}{x1,x3} as CT
where E.x1 = CT.x1 and E.x3 = CT.x3group by E.x1, E.x3having count(E.x4) >= k
35
Equivalent queries
Queries Q1 and Q2 are equivalent if same answer sets on all
graphs G (up to renaming of the distinguished variables)
• 2 cases of equivalent queries:1. Q1 has fewer nodes than Q2
2. Q1 and Q2 have the same number of nodes

36
Equivalence theorem
A containment mapping from Q1 to Q2 is a h: Q1 Q2 that
maps distinguished variables of Q1 one-to-one to distinguished
variables of Q2, and maps parameters of Q1 to parameters of Q2,
preserving labels
Two queries are equivalent if and only if there are containment mappings between them in both directions.

37
Q2 x1
x3
x2
Case 1: Q1 fewer nodes than Q2
Redundancy lemma: Let Q be a tree query without selected nodes. Then Q has aredundancy if and only if it contains a subtree C in the form of
alinear chain of nodes (possibly just a single node), such that
the parent of C has another subtree that is at least as deep as C.
Q1 x1
x3
x2
Redundantsubtree

38
Case 2: Q1 and Q2 same number of nodes
• Q1 and Q2 must be isomorphic.
• Canonical form of queries: refine the canonical ordering of the underlying unlabeled tree, taking into account node labels.

39
Association Mining Algorithm
• Input: a graph G, minsup, a tree query Qleft frequent in G, minconf
• Output: all tree queries Q such that Qleft Q is a legal and confident association rule in G.

40
Containment mappings
x
2
1
1
x1
x2
• For each tree query, generate all containment mappings from Qleft to Q, ignoring parameter assignments.

41
Instantiations
x
5
3
5
x1
x2
(x1, x3) (x1, 3)
⇒
• For each containment mapping, generate all parameter assignments such that Qleft Q is frequent and confident.

42
Equivalent Association rules
• Equivalence checking of association rules is as hard as general graph isomorphism testing.

43
Outline rest of talk
• Result management• Experimental results• Future work

44
Result management
• Output: frequency tables stored in a relational database.
• Browser

45

46
Experimental results: Real-life datasets
• Food web nodes15 edges3
x1
2
x2
2
frequency = 176

47
Experimental results: Real-life datasets
• Food web nodes15 edges3
⇒ x1
x5 101
x2
x4 x5 x3
x2
x4
(x1,x2,x4,x2,x5) (x1,x2,x3,x4,x5)
x1
confidence = 11%
48
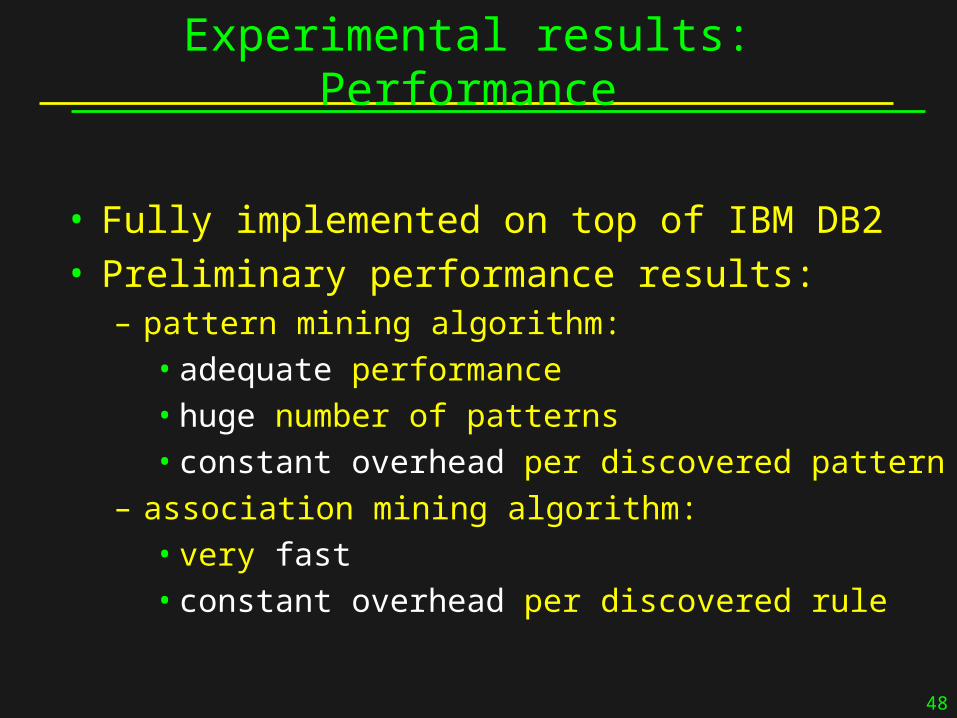
Experimental results: Performance
• Fully implemented on top of IBM DB2• Preliminary performance results:
– pattern mining algorithm:•adequate performance•huge number of patterns•constant overhead per discovered pattern
– association mining algorithm:•very fast•constant overhead per discovered rule

49
Future work
• Applications: scientific data mining• Loosen restriction to trees

50
References
• Bart Goethals, Eveline Hoekx and Jan Van den Bussche, Mining Tree Queries in a Graph, in Proceedings of the eleventh ACM SIGKDD International conference on Knowledge Discovery and Data Mining, p 61-69, ACM Press 2005
• Eveline Hoekx and Jan Van den Bussche, Mining for Tree-Query Associations in a Graph, to appear in Proceedings of the 2006 IEEE International Conference on Data Mining (ICDM 2006)





























