Embed Size (px)
Citation preview

Modernization of European Official Statistics ESS Rome, 31 March & 1 April 2014
v v erbi is

SUMMARY OF SESSIONS
Session 1A + 1B : Methodology, quality issues and accreditation of Big Data sets Session 2A + 2B : Learning & Development Session 3A + 3B : Strategy, programming and planning for Big Data in Statistical Programmes Session 4A + 4B : IT & Security

High Medium Low
• Representativeness and selectivity • Exploring new techniques • Use cases and Roles of Big Data
Source • Data processing • Timeliness • Privacy and volatility in access to Big
Data sources • Quality framework and certification
• Integration with traditional data sources
Methodology, quality issues and accreditation of Big Data sets. Session 1A: ISSUES

Methodology, quality issues and accreditation of Big Data sets. Session 1A: ACTIONS
• Representativeness and selectivity : Use other sources (survey-based and admin)
• Exploring new techniques : adapting existing ones establish standard practices in Big Data inference.
• Use cases and Roles of Big Data Source: mixed approach, Common Use cases • Integration with traditional data sources: Linking with privacy constraints
country dependant • Big Data Quality Framework: source –specific dimensions, subject-specific
dimension, look at admin data experience • Timeliness : IT infrastructure (computational time, but also real time
processing • Data Access: privacy can «block» the usage of some sources , beyond
regulation privacy by-design

High Medium Low
• Identify which scientific areas can contribute to methodological and quality issues on Big Data
• How to involve Academia • How to set up joint research and
application projects with Academia
• How to set stable relationships with Academia
Relationships with Academia Session 1B: ISSUES

Relationships with Academia Session 1 B: SOLUTIONS
• Identify which scientific areas can contribute to methodological and quality issues on Big Data: • Contact groups from several fields that are doing research projects on Big data
• How to involve Academia • We can provide also other kinds of data (survey-based, admin) and simplify
procedures for acamic access, Training, Public competitions involving them directly, Work on Real cases
• How to set stable relationships Relationships with Academia • Joint labs, Temporary recruitment of people (e.g., post-docs) supervised by
universities, NSOs sponsored Ph.Ds, Regular lectures by both sides, Research protocols and facilities to access NSOs’ data, Steering Committee on the Big Data topic
• how to set up joint research and application projects with Academia • Government to asks partnerships btw NSOs and Univ for funded research
programmes (both national and international), Eurostat funded projects (like ESSnets): jointly univ and NSOs

Sh
ort
te
rm
Lon
g t
erm
• No Big Data-related IT skills in NSIs • Lack of soft skills necessary for team work: communication and Data Science team
mgt • Lack of statistical skills/legal barriers for data linking/matching • Need for concretely identifying the skills needed • Rapid technology evolution makes it difficult to plan for stable curricula • Lack of innovative/creative culture in NSIs, few change management skills • No turnover in some Nsis: no generational renovation
• Better salaries in the industry for data scientists • Legal barriers to use of Big Data may hamper creativity/innovative uses • Training not always alligned to business plan • Difficulty to connect with the “traditional academic mathematical statistician” and
machine learning experts • Low/no recognition of self-training and online training in NSIs • Demographics of NSI staff (ageing)
Learning & development Session 2A/B: ISSUES

Session 2A/B: SOLUTIONS
Sh
ort
te
rm
Lon
g t
erm
• Proposals for Horizon 2020 (Marie Sklodowska-Curie)
• Adapt ESTP courses’ format to allow for blended (face-to-face + distance e.g. e-summer school) learning (next ESTP call?)
• Study the possibility of including Big Data in the “Statistical week” of Eurostat
• Identify staff who can start with selected online, free course on Big Data
• Develop statistical courses based on Big Data
• Give time to explore and get trained during work schedule
• Study the replication of ESTP2014 BIG DATA course at national levels
• Study to opening up of ESTP2014 BIG DATA course sessions by videoconferences/webinars
• Introductory (not detailed) courses on specific software (what can the software offer: R, Hadoop, etc.) and how to get the data (cf. UNECE’s sandbox/lab)
• ESS WG on Learning and Devt. to identify NSIs’ Big Data training needs
• Organize/attend Big Data meet-ups at the national level
• Obligation of participants to courses on Big Data to share knowledge (if possible, replicate) at NSS level
• Establish joint working groups of academics and NSIs on Big Data
• Identifying/mapping opportunities in Official Statistics and outside (by EMOS)
• Use ERASMUS PLUS to develop EMOS-labelled Master with Big Data profile
• Establish a Centre of Competence on Big Data
• Expert career tracks in NSIs
• Design instruments for the exchange of Big Data experts within NSS
• Offer traineeships in NSIs to graduate students on a variety of subjects (stats, math, IT but also marketing, art & design)
• Offer low-budget research positions in NSIs
Learning & development
Difficult Medium Easy

Sh
ort
te
rm
Lon
g t
erm
• Share experiences within Europe and abroad also beyond NSIs - distill best practices
• Define a number of concrete areas to collaborate at EU level
• Communication strategy for BD towards society at large
• Within NSI define the strategical importance of BD
• Structured common
approach for the way of using BD for statistical production
• Establishment of Private Public Partnership for BD from private sector.
• Costs or free of charge? • Few providers of BD-
strong companies
Strategy, programming and planning for BD in Statistical Programmes
Session 3A/B: ISSUES
• Put pressure at EU political level for funding BD usage for OS explaining the value added of BD
• Combine BD with other sources (surveys)
• Risk assesment of the
use of BD (HR- stability of sources,...) • How can NSIs can be
useful for private providers

Session 3A/B: ACTIONS
Sh
ort
te
rm
Lon
g t
erm
• Preparation of a Handbook on experiences and best practices
• Set up in each NSI of an
interdisciplinary “Big Data Structure”
• Proactively use cross-portal and other platforms
• Collaboration with academia and stakeholders
• Set up of a frame:
Guidelines, Rules, Principles, Glossary (for the different topics)
• Global collaboration (HLG)
• ESS collaboration for a common practical approach
• National collaboration for domestical issues
• Intentional Agreement at International level. Specific National agreements.
• Legal obligation to provide for free as BD are of public utility
• Communicate to society at large how BD can be useful for them (real-
time data) • Dialoque with private
data providers on the potenciality of the statistics based on their BD
Strategy, programming and planning for BD in Statistical Programmes

High Medium Low
Sh
ort
te
rm
Lon
g t
erm
• How to overcome legal issues with ‘sandboxes’ for Big Data experimentation (in some jurisdictions)?
• Not all parties are free to share data with NSOs (e.g. telcos) in some jurisdictions
• How to manage access rights to (combining) unstructured Big Data sets?
• How to deal with commercially sensitive information from private parties?
• How to solve copyright/IPR issues regarding Big Data sets/analyses?
• Who has ownership over which combinations of Big Data sets?
• How to prevent misuse of Big Data sets?
• How to incentivize third parties to share data with NSO?
Data protection & security Session 4A: ISSUES
• What kind of infrastructure should we build?
• How to deal with auditing requirements in Big Data context?
• How to anonymize Big Data sets?
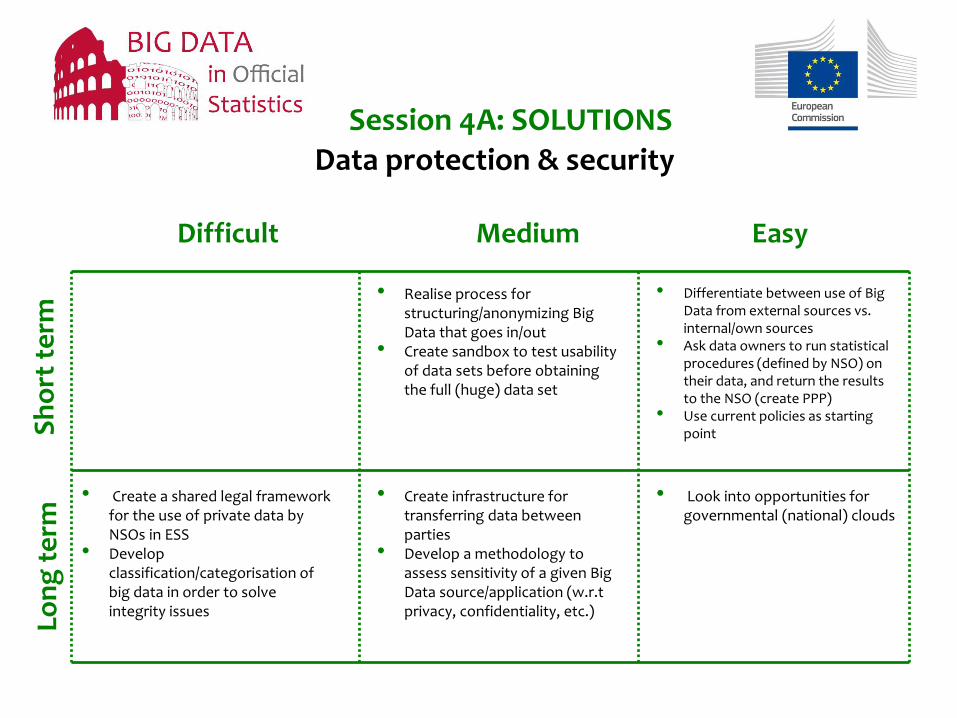
Session 4A: SOLUTIONS
Sh
ort
te
rm
Lon
g t
erm
• Realise process for structuring/anonymizing Big Data that goes in/out
• Create sandbox to test usability of data sets before obtaining the full (huge) data set
• Differentiate between use of Big Data from external sources vs. internal/own sources
• Ask data owners to run statistical procedures (defined by NSO) on their data, and return the results to the NSO (create PPP)
• Use current policies as starting point
• Create a shared legal framework for the use of private data by NSOs in ESS
• Develop classification/categorisation of big data in order to solve integrity issues
• Create infrastructure for transferring data between parties
• Develop a methodology to assess sensitivity of a given Big Data source/application (w.r.t privacy, confidentiality, etc.)
• Look into opportunities for governmental (national) clouds
Difficult Medium Easy
Data protection & security

High Medium Low
Sh
ort
te
rm
Lon
g t
erm
IT Session 4B: ISSUES
• Need info on quality and availability of Big Data sets/repositories
• Privacy/security features not an integral part of currently available tools
• How to securely distribute / collaborate on Big Data sets?
• How to encrypt exabytes of data (quickly)?
• What is the place of Big Data analysis tools in the NSI data lifecycle?
• Issues with usage of a private-sector cloud
• How to share tools and best practices? • Improving mid-size data set analysis
performance w/ Big Data processing • How to find existing sources of Big
Data inside NSI? (‘dark data’)
• Lack of user-friendly tools for analysis of Big Data
• Personnel is scarce • Integration of Big Data
architecture with existing architecture
• Need architecture, not (just) tools
• Validity of Big Data
• Statistical burden needs to be reduced
• Quality of statistics needs to be improved: trade-off between new methods and continuity/auditability
• Training/knowledge building • Sourcing of staff
• Changes to Hadoop for other purposes might influence usage by NSIs
• Too much focus on NoSQL databases while many Big Data sets are highly structured
• Too much focus on Facebook etc., should be on internet of things-type sources.
• Real-time data analysis • Scenario planning

Session 4B: SOLUTIONS
Sh
ort
te
rm
Lon
g t
erm
Difficult Medium Easy
IT
• Develop methodologies for Big Data analysis, then determine software needs (not vice versa)?
• Invent an incentive for third parties to register potentially interesting Big Data sets
• Create multi-disciplinary teams that create Big Data proof-of-concepts: learn by doing
• Agree on a tool set with the NSIs to facilitate collaboration (<> existing software sharing policy!)
• Determine position of Big Data analysis in the statistical process (when do we use it?)
• Create architecture for metadata on Big Data
• Share knowledge of existing user-friendly tools for analysis
• Stick to traditional security methods whenever possible
• Explore tools. Give NoSQL databases a ‘test run’, may be suitable for particular kinds of data sets
• Generate ideas on possible analyses assuming unlimited access to data
• Use small sets of Big Data to test processes
• Define architecture for handling Big Data: don’t choose single tools, but focus on process / integration issues
• Offer traineeships to master students • More shared, new kinds of training
programmes (specifically on Big Data skills) e.g. on NoSQL
• Experiment with unconventional tools (e.g. Splunk)
• Participate in practical, international activities like the HLG sandbox

Some Statistics… 107 Participants
27 Countries
21 EU Member States + 1 Candidate country (Turkey) 5 Other countries (USA, México, Switzerland, Australia,
Canada)
Other
ECB, UNSD, UNECE, OECD, The World Bank Univ. Berkeley, Sapienza, Napoli, Pisa, Durham, London,
GENES

Grazie mille!!
v v erbi is






























