Embed Size (px)
Citation preview

MODUL 8
AnalisisData
Analisis data merupakan langkah penting dalam menyelesaikan sebuah proyek penelitian. Beberapa tahapan dalam analisis data yang perlu dilakukan adalah :
Mempersiapkan data untuk analisis yang terdiri dari kegiatan editing data, menangani respon yang kosong, pengkodean data, kategorisasi data, dan pembuatan file data dan pemograman (kalau menggunakan perhitungan khusus)
Analisis data awal melalui analisis statistika deskriptif yaitu menaksir karakteristik sampel seperti rata-rata, simpangan baku, koefisien variasi, analisis korelasi, serta penyajian data baik dalam bentuk distribusi frekuensi atau secara visual (grafik, diagram dan lain sebagainya).
Uji kelaikan data melalui uji reliabilitas dan validitas (lihat bab 5). Uji kenormalan data apabila menggunakan analisis statistika yang mengharuskan
dipenuhinya asumsi normalitas. Uji hipotesis melalui analisis statistika yang sesuai.
Dalam buku ini akan dibahas beberapa analisis statistika yang umum digunakan dalam sebuah penelitian sederhana. Mulai dari statistika deskriptif hingga inferensial. Meski sekarang ini telah banyak perangkat lunak khusus untuk mengolah data seperti SPSS, Minitab, Systat, Statistica, Lisrel dan lain sebagainya, namun rumus-rumus perhitungan tetap diberikan agar peneliti tetap dapat melakukan analisis secara manual. Dalam buku ini secara khusus akan menyajikan petunjuk penggunaan perangkat lunak SPSS.
1. STATISTIKA DESKRIPTIFStatistika deskriptif berisikan perhitungan-perhitungan untuk melihat bagaimana pola atau karakteristik data serta mendeteksi ketidakwajaran respon dalam menjawab kuesioner. Selain perhitungan disarankan pula untuk meringkas hasil-hasil dalam bentuk tabel atau secara visual untuk membantu pemakai memahami apa yang telah dihasilkan dari penelitian.
Contoh 1. Penyajian frekuensi
Usia Responden
Usia Frekuensi Persentase % kumulatif19 – 23 10 8,0 8,024 – 28 21 16,8 24,829 – 33 28 22,4 47,234 – 38 30 24,0 71,239 – 43 15 12,0 83,244 – 48 10 8,0 91,249 – 53 8 6,4 97,6
> 53 3 2,4 100Total 125 100,0 100,0
Untuk memberikan gambaran secara visual, data dari tabel di atas sebaiknya juga disajikan dalam bentuk diagram seperti berikut ini.

ANALISIS DATA
Selain itu perlu disajikan statistik sampling seperti :
Rata-rata :
Varians :
Simpangan baku :
Kesalahan baku :
Koefisien variasi :
Interval taksiran untuk rata-rata populasi :
atau
Berikut ini diberikan contoh kongkrit bagaimana mengolah data dari sebuah penelitian kepuasan konsumen.
Contoh 2. : Survei kepuasan konsumen atas pelayanan sebuah perusahaan (Hayes, 1998)
2

ANALISIS DATA
Kuesioner :Kuesioner berikut dirancang untuk mengukur beberapa kebutuhan konsumen dan kepuasan konsumen secara menyeluruh. Ada tiga dimensi untuk mengukur kualitas layanan ini
Dimensi 1 : ketersediaan layanan : butir pernyataan 1 sampai 3Dimensi 2 : ketanggapan (responsiveness) : butir 4 sampai 6 Dimensi 3 : kepuasan konsumen secara menyeluruh : butir 7 sampai 9.
Kuesioner diberikan kepada 20 konsumen.
Untuk mempermudah analisis, sebaiknya data disajikan dalam bentuk sebuah tabel seperti berikut ini.
Tabel 1. Contoh data dari tanggapan 20 konsumen
3
Berikanlah tanggapan anda apakah setuju atau tidak terhadap pernyataan berikut menyangkut pelayanan yang anda rasakan. Lingkari jawaban untuk setiap pernyataan yang diberikan dengan menggunakan skala berikut :
1. Saya Sangat Tidak Setuju dengan pernyataan ini (STS)2. Saya Tidak Setuju dengan pernyataan ini (TS)3. Saya Tidak Tahu (TT)4. Saya Setuju dengan pernyataan ini (S)5. Saya Sangat Setuju dengan pernyataan ini (SS)
Apa pendapat anda atas pernyataan berikut
STS TS TT S SS
1. Saya dapat membuat janji dengan pengusaha kapan saja 1 2 3 4 5
2. Pengusaha selalu siap untuk membuat jadual pertemuan sesuai waktu yang saya inginkan
1 2 3 4 5
3. Janji pertemuan pada waktu yang sesuai dengan keinginan saya 1 2 3 4 5
4. Pengusaha cepat melayani ketika saya datang untuk memenuhi janji
1 2 3 4 5
5. Pengusaha langsung membantu ketika saya memasuki tempatnya 1 2 3 4 5
6. Janji pertemuan dimulai sesuai dengan jadual yang ditetapkan 1 2 3 4 5
7. Kualitas layanan pengusaha melayani saya tinggi 1 2 3 4 5
8. Cara pengusaha melayani saya sesuai dengan harapan saya 1 2 3 4 5

ANALISIS DATA
Konsumen Butir pernyataan1 2 3 4 5 6 7 8 9
4

ANALISIS DATA
1 5 4 5 3 4 4 3 4 32 3 2 3 5 4 5 4 4 43 4 5 5 3 2 2 3 3 44 3 2 3 4 3 4 4 5 45 3 3 3 4 4 4 3 3 36 4 4 5 4 5 4 4 5 47 3 4 2 4 3 3 3 2 38 5 4 5 4 4 4 5 4 59 3 2 3 4 3 4 4 4 310 3 4 3 4 4 4 3 4 311 5 5 5 5 5 5 5 5 512 4 4 4 3 3 4 4 4 413 4 4 5 5 5 4 4 4 514 2 2 3 4 4 5 3 3 215 4 5 5 4 4 3 4 3 316 5 4 5 5 5 5 4 4 417 3 4 3 5 4 4 4 4 418 3 2 4 3 3 4 2 2 219 5 4 3 4 5 4 3 3 420 3 3 3 4 3 3 4 4 4
3,70 3,55 3,83 4,05 3,85 3,95 3,65 3,70 3,65S 0,92 1,05 1,04 0,69 0,88 0,76 0,75 0,87 0,88
Ringkasan untuk ketiga dimensi
Dimensi 1 Dimensi 2 Dimensi 3Reliabilitas 0,85 0,81 0,88
3,70 3,95 3,67S 0,88 0,66 0,74
Contoh di atas memperlihatkan bagaimana menyajikan data yang dapat digunakan sebagai bahan analisis bagi manajemen tingkat menengah maupun atas. Selain staistik untuk setiap butir, sebaiknya juga menyajikan statistik untuk setiap dimensi sehingga dapat terlihat keadaan umum dari tingkat pelayanan.
Petunjuk penggunaan SPSS :
Dari menu, pilih :Analyze Descriptive Statistics Statistics… (pilih variabel yang akan dianalisis)
Options… (pilih statistik yang diinginkan)
2. UJI KENORMALAN DATAUji kenormalan data diperlukan apabila kita berhadapan dengan analisis statistika parametrik seperti uji perbedaan dua atau lebih rata-rata, uji korelasi antara dua atau lebih variabel dan
5

ANALISIS DATA
lain sebagainya. Ada beberapa uji yang tersedia untuk mengetahui kenormalan dari sekelompok data seperti uji Kolmogorov-Smirnov atau Lilliefors.Bentuk umum hipotesis uji kenormalan Liliefors (dengan asumsi bahwa sampel adalah sampel acak) adalah :
H0 : Sampel acak berdistribusi normalH1 : Fungsi distribusi Xi tidak normal
Karena penjelasannya yang terlalu matematis, maka uji kenormalan data tidak diberikan secara manual akan tetapi pembaca dapat langsung mempraktekkannya melalui perangkat lunak SPSS sebagai berikut :
Dari menu, pilih :Analyze
Descriptive Statistics Explore … (pilih variabel yang akan dianalisis) Output dari SPSS akan berbentuk seperti berikut :
Tests of NormalityKolmogorov-Smirnova
Statistic df Sig. DAYA .104 60 .168
a Lilliefors Significance Correction
Penjelasan dari tabel di atas adalah sebagai berikut. DAYA adalah nama variabel yang diuji, df adalah derajat bebas (dalam hal ini jumlah data) dan Sig. adalah singkatan dari significance yang dalam statistika dikenal sebagai nilai peluang (untuk selanjutnya akan digunakan istilah p untuk nilai Sig. ini). Semua output SPSS menggunakan istilah Sig ini untuk melihat apakah hipotesis diterima atau tidak. Apabila nilai p lebih kecil dari tingkat signifikansi () yang telah kita tetapkan, maka dikatakan bahwa data menyebar secara tidak normal. Sebaliknya data menyebar secara normal. Secara notasi dua keadaan ini dapat dituliskan sebagai berikut :
p : data menyebar secara tidak normalp > : data menyebar secara normal
Untuk contoh di atas, tampak bahwa nilai p adalah 0,168. Jika uji mengambil tingkat signifikansi 5% (0,05) ternyata p > 0,05 atau terima H0. Berarti data menyebar secara normal.
3. UJI HIPOTESIS STATISTIKMeski uji hipotesis telah dikemukan dalam bab sebelumnya, tidak ada salahnya menjelaskan kembali dengan penjelasan yang rinci dalam bab ini khususnya yang menyangkut uji hipotesis
6

ANALISIS DATA
statistik. Seperti telah dikemukakan sebelumnya bahwa hipotesis terdiri dari hipotesis penelitian, hipotesis nol, dan hipotesis statistik. Hipotesis statistik adalah pernyataan yang berkaitan dengan populasi (lebih spesifik lagi mengenai karakteristik populasi) dimana kita ingin menentukan apakah menerima atau menolak hipotesis ini berdasarkan data pengamatan. Uji hipotesis statistik terdiri dari beberapa tahapan sebagai berikut :
1. Rumuskan hipotesis yang akan diuji2. Hitung statistik uji3. Tentukan taraf siginikansi atau daerah kritis 4. Tarik kesimpulan
3.1. Merumuskan hipotesisRumusan hipotesis statistik dinyatakan dalam bentuk simbolik dan numerik dan tergantung dari karakteristik populasi atau parameter yang akan diuji. Beberapa contoh parameter populasi adalah :
Parameter Notasi Rata-rata Selisih dua rata-rata 1 – 2
Simpangan baku Koefisien korelasi Koefisien regresi
Rumusan hipotesis terdiri dari tiga bentuk uji yaitu :
1. Uji dua pihak dengan bentuk :
H0 : 1 = 2 H1 : 1 2
2. Uji pihak kiri
H0 : 1 2 H1 : 1 < 2
3. Uji pihak kanan
H0 : 1 2 H1 : 1 > 2
di mana adalah parameter yang akan diuji.
Contoh 3. Hipotesis menguji dua rata-rata
Sebuah perusahaan elektronik menggunakan tenaga pria dan wanita dalam merakit produk elektronik tertentu. Diduga bahwa pekerja wanita biasanya bekerja lebih teliti daripada pria sehingga rata-rata jumlah kesalahan yang dibuat pekerja wanita lebih sedikit dari pria. Untuk
7

ANALISIS DATA
membuktikannya dilakukan penelitian dengan mengamati jumlah kesalahan yang dibuat kedua kelompok ini dalam kurun waktu tertentu. Untuk menguji hipotesis ini maka rumusan hipotesis statistiknya adalah :
H0 : 1 2
H1 : 1 > 2
di mana 1 adalah rata-rata kesalahan yang dibuat pekerja pria, 2 rata-rata kesalahan yang dibuat pekerjaan wanita.
Perhatikan, H1 dalam hipotesis statistik sebenarnya adalah hipotesis penelitian.
Contoh 8.4. Menguji hubungan antar dua variabel
Hipotesis penelitiannya adalah ada hubungan antara variabel X dan Y.Untuk menguji hipotesis ini digunakan hipotesis statistik :
H0 : = 0H1 : 0
di mana adalah koefisien korelasi populasi.
3.2. Statistik ujiStatistik uji yang akan digunakan untuk menguji hipotesis tergantung dari masalah yang akan diteliti. Beberapa statistik uji yang umum digunakan untuk penelitian diantaranya adalah :
Statistik t atau Z Statistik 2
Statistik F Statistik B (Bartlett) dan berbagai statistik lainnya
Contoh 5. Statistik uji untuk menguji perbedaan dua rata-rata
Untuk menguji hipotesis seperti yang diberikan dalam contoh 8.3. maka statistik uji yang sesuai :
dengan asumsi varians populasi sama. (akan dijelaskan selanjutnya)
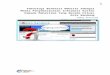
3.3. Menentukan daerah kritisApapun statistik uji yang diambil, menentukan daerah kritis pada prinsipnya sama saja yaitu terdiri dari tiga alternatif [1] uji dua pihak, [2] uji pihak kiri, dan [3] uji pihak kanan. Daerah kritis untuk ketiga uji ini diilustrasikan dalam gambar berikut ini. Kita ambil contoh statistik uji-nya adalah Z.
8

ANALISIS DATA
1. Uji dua pihak dengan taraf signifikansi .
Penjelasan : Daerah kritis adalah daerah penolakan H0. Besarnya daerah ini tergantung
kepada taraf signifikansi yang ditetapkan biasanya diambil 1% dan 5%. Karena ujinya dua pihak maka luas daerah ini adalah /2.
Nilai –z1 dan z2 diambil dari tabel Normal (Lihat Tabel 2 lampiran). Nilai ini tergantung pada taraf . Sebagai contoh nilai z untuk = 0,05 adalah 1,96, untuk = 0.01 adalah 2,58 (lihat tabel normal). Karena distribusi z simetris maka nilainya sama untuk –z1 dan z2.
Kriteria pengujian, tolak H0 apabila nilai statistik uji terletak di dalam daerah ini.
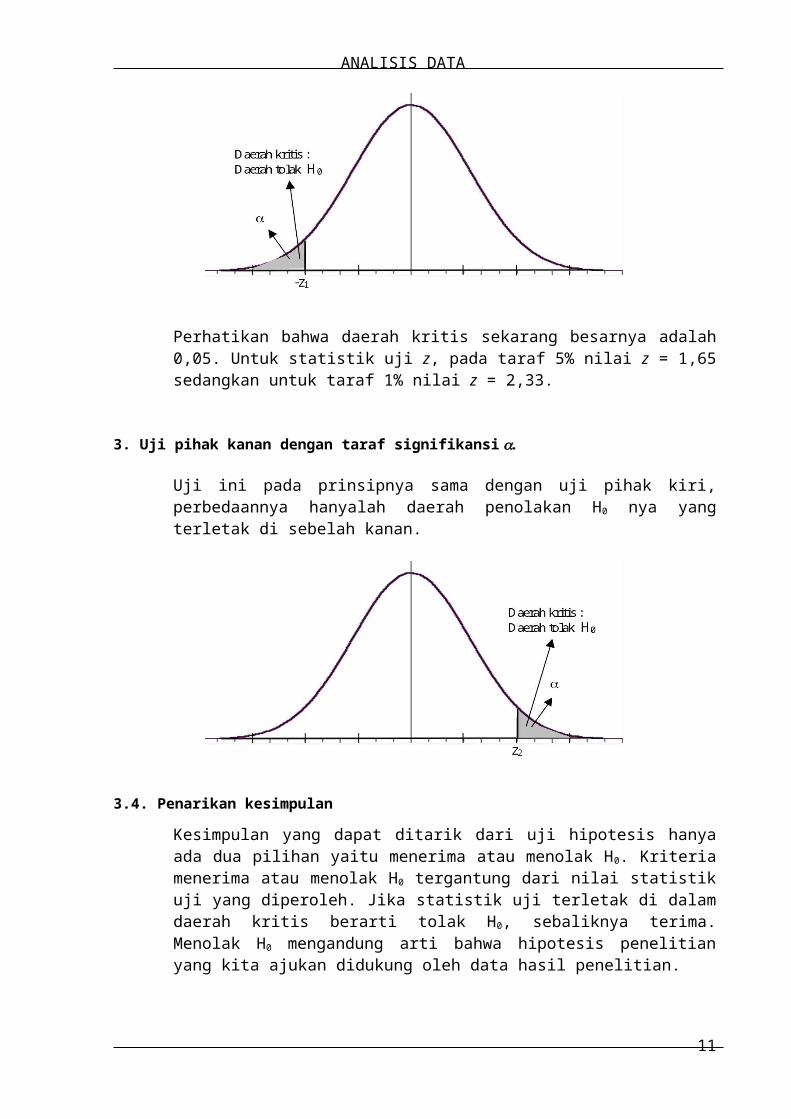
2. Uji pihak kiri dengan taraf signifikansi .
Perhatikan bahwa daerah kritis sekarang besarnya adalah 0,05. Untuk statistik uji z, pada taraf 5% nilai z = 1,65 sedangkan untuk taraf 1% nilai z = 2,33.
3. Uji pihak kanan dengan taraf signifikansi .
Uji ini pada prinsipnya sama dengan uji pihak kiri, perbedaannya hanyalah daerah penolakan H0 nya yang terletak di sebelah kanan.
9

ANALISIS DATA
3.4. Penarikan kesimpulanKesimpulan yang dapat ditarik dari uji hipotesis hanya ada dua pilihan yaitu menerima atau menolak H0. Kriteria menerima atau menolak H0 tergantung dari nilai statistik uji yang diperoleh. Jika statistik uji terletak di dalam daerah kritis berarti tolak H0, sebaliknya terima. Menolak H0 mengandung arti bahwa hipotesis penelitian yang kita ajukan didukung oleh data hasil penelitian.
4. ANALISIS STATISTIKStatistika Parametrik versus non-parametrikBerbagai tehnik analisis statistik telah tersedia untuk mengolah data hasil sebuah penelitian. Berhasil atau tidaknya sebuah penelitian akan sangat tergantung pada analisis data yang sesuai dengan hipotesis yang diajukan.
Analisis statistik sendiri dapat dibagi ke dalam dua kategori besar yaitu analisis statistika parametrik dan statistika non-parametrik. Statistika parametrik digunakan apabila kita mengetahui bagaimana distribusi dari populasi yang dihadapi serta jenis data yang digunakan. Analisis statistika parametrik sangat menekankan pada pemenuhan asumsi-asumsi penyebaran data khususnya asumsi kenormalan data. Apabila kenormalan data tidak dipenuhi maka perlu dilakukan transformasi terhadap data asli ke dalam fungsi-fungsi tertentu sehingga asumsi kenormalan ini dipenuhi. Beberapa jenis transformasi yang umum digunakan di antaranya adalah :
Logaritma basis 10 : Logaritma basis e : Log-log : Akar :
dimana yi adalah nilai-nilai hasil transformasi, sedangkan Xi adalah data hasil pengamatan.Untuk mengetahui apakah data harus ditransformasi atau tidak maka perlu dilakukan uji
kenormalan seperti yang telah dikemukan di atas. Apabila data tidak normal lakukan transformasi tersebut, kemudian diuji lagi. Setelah dipenuhi asumsi kenormalan maka baru dilakukan analisis yang sesuai. Statistika parametrik mensyaratkan bahwa data yang akan dianalisis paling sedikit harus berskala interval.
10
ANALISIS DATA
Statistika non-parametrik digunakan apabila kita tidak begitu perduli dengan bentuk distribusi data. Data yang berskala nominal dan ordinal harus dilakukan melalui statistika parametrik ini. Meski demikian, dalam beberapa kasus tertentu data berskala ordinal dapat ditransformasikan menjadi skala interval dengan melakukan transformasi dengan cara method of successive interval.
Dalam buku ini akan diberikan beberapa analisis statistika yang umum digunakan dalam sebuah penelitian.
5. ANALISIS UNTUK KAJIAN KOMPARATIF
Persoalan yang sering dijumpai dijumpai dalam sebuh penelitian adalah bagaimana membandingkan dua atau lebih keadaan baik secara spasial (ruang) maupun temporal (waktu).
Beberapa analisis yang tersedia
5.1. UJI DUA RATA-RATA SECARA PARAMETRIK (minimal skala interval)
Statistik uji :
… (8.1)
di mana
varians dari sampel 1
varians dari sampel 2
Uji untuk perbedaan dua rata-rata populasi (varians tidak diketahui, )
Uji ini merupakan suatu pendekatan dan itu pun apabila populasi berdistribusi normal atau ukuran samplenya cukup besar (n > 30). Selain itu uji ini sebaiknya digunakan khusus untuk hipotesis 1 = 2 (uji dua pihak). Syarat lain kedua sampel independen.
Statistik uji :
11

ANALISIS DATA
… (8.2)
di mana :
dan
Statistik uji di atas dibandingkan dengan t tabel dengan derajat bebas
Uji untuk dua rata-rata populasi (metode observasi berpasangan)
Metode ini cukup banyak dipakai. Contohnya adalah apabila kita ingin membandingkan dua keadaan akan tetapi sampelnya sama (kajian longitudinal) atau sekelompok subjek yang diberikan dua perlakuan yang berbeda.
Batasan :1. Pengamatan harus diambil dari dua sampel yang berpasangan. Setiap pasang pengataman
harus diambil dari kondisi yang sama atau hampir sama2. Uji akan lebih akurat apabila populasi menyebar secara normal. Jika tidak normal maka
uji dapat dianggap sebagai sebuah pendekatan.3. Tidak ada asumsi mengenai varians populasi
Hipotesis :H0 : tidak ada perbedaan rata-rata kedua populasi H1 : ada perbedaan kedua rata-rata populasi
Metode :Hitung selisih setiap pasangan atau dinotasikan dengan d. Jika ada n pasangan maka kita bisa menghitung varians selisih ini dengan :
Statistik uji :
12

ANALISIS DATA
Daerah kritis :Bandingkan dengan tabel t dengan derajat bebas = n-1. Jika t > t tabel, tolak H0, sebaliknya terima H0.Uji ini bisa untuk uji dua pihak atau satu pihak.
6. ANALISIS UNTUK KAJIAN ASOSIATIFAsosiasi adalah suatu bentuk fenomena yang menunjukkan adanya hubungan antara dua atau lebih variabel. Namun demikian adanya hubungan atau asosiasi antara dua variabel bukan berarti bahwa adanya hubungan sebab akibat di dalamnya. Adanya asosiasi tidaklah cukup sebagai pertimbangan untuk menyatakann bahwa satu variabel menyebabkan terjadinya variabel lain. Meski demikian, pada dasarnya kita harus mengamati asosiasi antar variabel adalah untuk mengarah kepada pengungkapan hubungan sebab akibat tersebut. Untuk itulah sebuah penelitian ilmiah dilakukan.
Pernyataan sampai seberapa besar derajat sehingga fluktuasi antara satu variabel dapat memprediksi variabel lainnya dikatakan sebagai koefisien asosiasi. Prosedur untuk menghasilkan koefisien ini dikatakan sebagai pengukuran asosiasi. Adanya asosiasi yang kuat antar dua variabel dapat dicirikan oleh sampai seberapa besar kita mencapai angka + 1,00 (asosiasi positif sempurna) atau –1,00 (asosiasi negatif sempurna). Untuk menetapkan apakah swebuah koefisien asosiasi signifikan secara statistik dapat digunakan berbagai uji signifikansi atau dari berbagai tabel yang telah disediakan. Akan tetapi sebagai perkiraan kasar, Champion (1981) memberikan kriteria keeratan asosiasi sebagai berikut :
Koefisien Korelasi Keterangan 0,00 – 0,25 Tidak ada hubungan atau hubungan yang sangat lemah 0,26 – 0,50 Hubungan cukup lemah 0,51 – 0,75 Hubungan yang cukup kuat 0,76 – 1.00 Hubungan sangat kuat
Namun yang perlu diperhatikan bahwa kriteria tersebut di atas hanyalah sebagai petunjuk awal atau kasar bagi seorang peneliti. Kriteria ini bisa digunakan apabila analisis tidak tersedia uji signifikansi. Sedangkan untuk uji melalui statistika parametrik uji signifikansi tetap harus dilakukan.
1. Rho Spearman, rs Rho Spearman merupakan salah satu ukuran asosiasi dua variabel berskala ordinal yang benar-benar sangat terbatas pemakaiannya. Ukuran ini juga merupakan ukuran berbasis rangking seperti tau Kendal. Sayangnya banyak peneliti yang salah kaprah dalam menggunakan ukuran ini karena skala variabel yang digunakan adalah interval, meski pada awalnya rho Spearman memang mensyaratkan bahwa kedua variabel paling rendah berskala ordinal (Siegel, 1956). Di samping itu rho Spearman sebenarnya memiliki kepekaan apabila
13

ANALISIS DATA
pengamatan mengandung data yang sama. Meski demikian Siegel (1956) memberikan cara perhitungan khusus untuk rho Spearman untuk menangani masalah ini. Champion (1981) memasukkan rho Spearman ini ke dalam analisis data interval.
Untuk menghitung rho Spearman, masing-masing variabel harus dirangking terlebih dahulu dari terkecil hingga terbesar. Bentuk umum Rho Spearman adalah :
; -1.00 rs +1.00
di = selisih ranking kedua variabelN = ukuran sampel
Hipotesis : H0 : s = 0H1 : s 0
AsumsiSampel diambil secara acak
KelebihanKoefisien Rho Spearman merupakan salah satu ukuran yang cukup baik dan efisiensinya dibandingkan dengan korelasi terbaik Pearson r sekitar 91%, dalam artian bahwa semua asumsi seperti pada korelasi Pearson dipenuhi.
KelemahanKoefisien ini tidak sesuai jika terdapat data yang sama (tie). Bisa ditangani oleh Tau Kendal meski tau kendal juga tidak cocok, akan tetapi lebih baik dari Spearman. Jika jumlah data yang sama mencapai 25% maka sebaiknya menggunakan Gamma. Siegel (1956) memberikan pemecahan melalui koreksi terhadap data yang sama ini.
SignifikansiSignifikansi rs dapat diuji menggunakan pendekatan uji-t untuk N 10 yaitu :
yang berdistribusi t dengan derajat bebas db = N - 2.Sedangkan untuk N mulai dari 4 hingga 30, nilai-nilai kritis untuk rs telah tersedia (lihat Tabel 7 lampiran )
14

ANALISIS DATA
2. UKURAN ASOSIASI UNTUK VARIABEL INTERVALJika seorang peneliti mempunyai dua variabel yang keduanya berskala interval, maka dapat digunakan korelasi Pearson r. Ukuran ini secara komputasi mudah dan telah tersedia di berbagai perangkat lunak untuk menghitungnya. Namun karena kemudahan ini, banyak peneliti yang menggunakannya secara keliru karena tidak memahami atau bahkan tidak memenuhi asumsi-asumsi yang ditetapkan.
Koefisien r PearsonKorelasi Pearson merupakan ukuran korelasi terbaik dalam statistika parametrik. Kelebihan dari ukuran ini hanya bisa diperoleh apabila asumsi-asumsi tentang variabelnya dapat dipenuhi secara tepat dan utuh. Apabila dalam statistika nonparametrik (data berskala nominal atau ordinal) pengertian asosiasi kerapkali dapat menyesatkan si peneliti karena ada ukuran yang memberikan nilai mendekati nol atau bahkan nol sekalipun, akan tetapi pada kenyataannya kedua variabel mempunyai hubungan. Tidak demikian halnya dengan korelasi Pearson. Koefisien korelasi Pearson dapat mengindikasikan bahwa dua buah variabel yang tidak mempunyai hubungan, pasti akan menghasilkan koefisien nol selama asumsi tentang variabelnya dipenuhi (Gibbons, 1971). Asumsi yang dimaksud dan harus dipenuhi adalah :
Asumsi Sampel diambil secara acak Variabel diukur minimal dalam skala interval Hubungan harus linier X dan Y adalah berdistribusi normal bivariat Titik-titik pertemuan antara X dan Y hendaknya berbentuk elips disekitar garis
slope atau dikenal pula sebagai asumsi homoskedastisitas (homoscedasticity).
Bentuk umum koefisien korelasi Pearson adalah :
; -1.00 r 1.00
KelebihanMerupakan ukuran terbaik dari ukuran asosiasi yang ada, asalkan semua asumsi dipenuhi. Nilai r2 dapat digunakan sebagai alat untuk menjelaskan seberapa besar variabel dependen dapat dijelaskan oleh variabel independen
KelemahanSulit untuk memenuhi semua asumsi yang ditetapkan
Signifikansi
bandingkan dengan tabel t dengan derajat bebas = (n-2). Atau dapat juga menggunakan nilai-nilai kritis untuk r (Tabel 5 dalam lampiran)
15

ANALISIS DATA
Untuk n > 50, gunakan :
; distribusi normal
bandingkan dengan tabel z.
Contoh perhitungan lihat dalam bab uji reliabilitas dan validitas.
Penggunaan SPSS untuk uji dua rata-rata
Perlu diperhatikan bahwa untuk uji dua rata-rata, pemasukan data ke dalam format SPSS adalah dalam bentuk 2 kolom. Kolom pertama untuk variabel pembentuk kelompok dan variabel kedua sebagai datanya. Contoh ada dua sampel dengan data sebagai berikut
Sampel 1 Sampel 212 1514 2018 1815 2318 24
Untuk menguji dua rata-rata dari sampel di atas baik parametrik maupun nonparamterik, maka dalam format SPSS harus berbentuk seperti berikut :
var0001 var0002
Group 1(Sampel 1)
1 151 201 181 231 24
Group 2(Sampel 2)
2 122 142 182 152 18
Var0001 merupakan variabel pembentuk kelompok, sedangkan var0002 adalah variabel yang akan diuji. Jadi SPSS akan membedakan kedua sampel berdasarkan var0001.
16

ANALISIS DATA
Uji dua rata-rata : 1 = 2
Dari menu, pilih :Analyze Compare Means (akan muncul tampilan berikut)
(Pilih Test Variables) Grouping Variables (Pilih variabel pembentuk kelompok) Klik Define Groups (akan muncul tampilan)
(masukkan angka 1 untuk sampel 1 dan 2 untuk sampel 2) Options (akan muncul tampilan berikut) (pilih taraf keyakinan yang diinginkan)
Klik Continue
Uji dua rata-rata berpasangan : d = 017

ANALISIS DATA
Untuk uji berpasangan, format datanya adalah :
var0001 var0002 Var0003 Var0004
Group 1(Sampel 1)
1 15 15 121 20 20 141 18 18 181 23 23 151 24 24 18
Group 2(Sampel 2)
2 122 142 182 152 18
(var0003 dan var0004 dalam tabel di atas diambil dari kolom 1 dan 2)
Prosesnya sama dengan di atas:
Dari menu, pilih :Analyze Compare Means Paired Samples T-Test (akan muncul tampiulan berikut)
(Pilih dua variabel yang akan diuji)
Options (Pilih taraf keyakinan)
7. ANALISIS REGRESI18

ANALISIS DATA
Selain analisis asosiasi, adakalanya seorang peneliti ingin mengetahui bagaimana hubungan fungsional antara dua atau lebih variabel. Analisis yang umum dikenal untuk melakukan analisis ini adalah analisis regresi. Biasanya analisis regresi digunakan untuk meramalkan variabel dependen berdasarkan variabel independen.
Analisis regresi bisa berbentuk liner atau non-linier. Demikian pula dari sisi variabel independen dapat berbentuk linier sederhana (dua variabel) atau multivariabel (lebih dari satu variabel independen). Yang akan dibahas dalam buku ini adalah analisis regresi linier.
Model umum dari regresi untuk populasi adalah :
di mana Y adalah variabel dependen (terikat) dan X1, X2, …, Xp adalah variabel independen, sedangkan 0, 1, 2 , . . ., p adalah koefisien yang akan ditaksir dari data sampel, p banyaknya variabel independen dan ei adalah kekeliruan acak.Dalam analisis regresi, suatu hal yang perlu diperhatikan oleh peneliti adalah mana varibel yang dependen maupun independen.
Analisis regresi linier sederhana
Persamaan garis model regresi sederhana dapat dituliskan sebagai :
dimana x adalah variabel independen, adalah notasi untuk taksiran nilai-nilai variabel y berdasarkan persamaan garis regresi, dan b1 adalah taksiran koefisien regresi populasi.
Asumsi1. Untuk setiap variabel bebas X yang diberikan, variabel takbebas Yi secara
statistik adalah independen dan berdistribusi normal di sepanjang garis regresi. Sebagai contoh jika nilai Y1 besar belum tentu menyebabkan Y2 besar, artinya Y2
tidak dipengaruhi oleh Y1.2. Tidak ada asumsi yang ketat tentang bentuk distribusi variabel X. Variabel X bisa
berbentuk tetap (misalkan X = 10, 20, 30, 40 . . .) atau bersifat variabel.3. Kekeliruan prediksi ei adalah variable acak takbebas yang berdistribusi normal
dengan rata-rata = 0 dan varians = .
Taksiran koefisien regresi.Untuk menghitung b0 dan b1 sebagai penaksir koefisien regresi populasi 0 dan 1
digunakan metode kuadrat terkecil dengan rumus :
19

ANALISIS DATA
Koefisien determinasiDalam analisis regresi kita perlu mengetahui sampai seberapa besar persamaan garis yang dibuat cocok atau sesuai dengan data sampel. Atau dengan perkataan lain “berapa besar proporsi variasi total yang dapat dijelaskan oleh persamaan garis tersebut?”. Ukuran untuk mengetahui hal ini dikenal dengan nama koefisien determinasi atau dinotasikan dengan R2
(baca R kuadrat) yang diperoleh dari koefisien korelasi antara x dan y. Perlu diingat bahwa R2
semata-mata adalah sebuah ukuran untuk melihat kecocokan garis regresi bukan untuk melihat kualitas prediktif dari persamaan regresi (Dielman, 1991).
Cara lain untuk melihat sampai seberapa baik garis regresi cocok dengan data adalah dengan menguji apakah koefisien = 0 atau tidak. Untuk ini perlu dilakukan uji hipotesis :
H0 : = 0H1 : 0
Dengan statistik uji :
Bandingkan dengan tabel t untuk taraf signifikansi yang ditetapkan dan derajat bebas = n – 2. Jika t > t tabel tolak H0.Dari statistik uji di atas terdapat notasi yang merupakan simpangan baku koefisien regresi dan dihitung dengan rumus :
di mana :
20

ANALISIS DATA
Penggunaan SPSS untuk analisis korelasi
Format data dalam analisis korelasi dan regresi berbentu dua kolom atau lebih tergantung jumlah variabel yang diteliti. Contoh :
Variabel penelitian
var0001 var0002100 15115 20112 18120 23125 24109 12
Dari menu, pilih :Analyze Correlate Bivariate
(Pilih variabel yang diinginkan, bisa untuk banyak variabel) (Pilih koefisien korelasi yang diinginkan, Pearson, Spearman dan Kendall)
Tampilan dari proses di atas tampak seperti berikut ini :
21

ANALISIS DATA
22