Embed Size (px)
Citation preview

Multidimensional Access MethodsVOLKER GAEDE
IC-Parc, Imperial College, London
AND
OLIVER GUNTHER
Humboldt-Universitat, Berlin
Search operations in databases require special support at the physical level. This istrue for conventional databases as well as spatial databases, where typical searchoperations include the point query (find all objects that contain a given searchpoint) and the region query (find all objects that overlap a given search region).More than ten years of spatial database research have resulted in a great varietyof multidimensional access methods to support such operations. We give anoverview of that work. After a brief survey of spatial data management in general,we first present the class of point access methods, which are used to search sets ofpoints in two or more dimensions. The second part of the paper is devoted tospatial access methods to handle extended objects, such as rectangles or polyhedra.We conclude with a discussion of theoretical and experimental results concerningthe relative performance of various approaches.
Categories and Subject Descriptors: H.2.2 [Database Management]: PhysicalDesign—access methods; H.2.4 [Database Management]: Systems; H.2.8[Database Management]: Database Applications—spatial databases and GIS;H.3.3 [Information Storage and Retrieval]: Information Search and Retrieval—search process, selection process
General Terms: Design, Experimentation, Performance
Additional Key Words and Phrases: Data structures, multidimensional accessmethods
1. INTRODUCTION
With an increasing number of computerapplications that rely heavily on multi-dimensional data, the database commu-nity has recently devoted considerableattention to spatial data management.Although the main motivation origi-
nated in the geosciences and mechani-cal CAD, the range of possible applica-tions has expanded to areas such asrobotics, visual perception, autonomousnavigation, environmental protection,and medical imaging [Gunther andBuchmann 1990].
The range of interpretation given to
This work was partially supported by the German Research Society (DFG/SFB 373) and by the ESPRITWorking Group CONTESSA (8666).Authors’ address: Institut fur Wirtschaftsinformatik, Humboldt-Universitat zu Berlin, Spandauer Str.1, 10178 Berlin, Germany; email: ^{gaede,guenther}@wiwi.hu-berlin.de&.Permission to make digital / hard copy of part or all of this work for personal or classroom use is grantedwithout fee provided that the copies are not made or distributed for profit or commercial advantage, thecopyright notice, the title of the publication, and its date appear, and notice is given that copying is bypermission of the ACM, Inc. To copy otherwise, to republish, to post on servers, or to redistribute tolists, requires prior specific permission and / or a fee.© 1998 ACM 0360-0300/98/0600–0170 $05.00
ACM Computing Surveys, Vol. 30, No. 2, June 1998

the term spatial data management isjust as broad as the range of applica-tions. In VLSI CAD and cartography,this term refers to applications that relymostly on two-dimensional or layeredtwo-dimensional data. VLSI data areusually represented by rectilinear poly-lines or polygons whose edges are iso-oriented, that is, parallel to the coordi-nate axes. Typical operations includeintersection and geometric routing[Shekhar and Liu 1995]. Cartographicdata are also two-dimensional withpoints, lines, and regions as basic prim-itives. In contrast to VLSI CAD, how-ever, the shapes are often characterizedby extreme irregularities. Common op-erations include spatial searches andmap overlay, as well as distance-relatedoperations. In mechanical CAD, on theother hand, data objects are usuallythree-dimensional solids. They may berepresented in a variety of data formats,including cell decomposition schemes,constructive solid geometry (CSG), andboundary representations [Kemper andWallrath 1987]. Yet other applicationsemphasize the processing of unanalyzedimages, such as X-rays and satellite im-agery, from which features are ex-tracted. In those areas, the terms spa-
tial database and image database aresometimes even used interchangeably.
Strictly speaking, however, spatialdatabases contain multidimensionaldata with explicit knowledge about ob-jects, their extent, and their position inspace. The objects are usually repre-sented in some vector-based format, andtheir relative positions may be explicitor implicit (i.e., derivable from the in-ternal representation of their absolutepositions). Image databases often placeless emphasis on data analysis. Theyprovide storage and retrieval for unana-lyzed pictorial data, which are typicallyrepresented in some raster format.Techniques developed for the storageand manipulation of image data can beapplied to other media as well, such asinfrared sensor signals or sound.
In this survey we assume that thegoal is to manipulate analyzed multidi-mensional data and that unanalyzedimages are handled only as the sourcefrom which spatial data can be derived.The challenge for the developers of aspatial database system lies not somuch in providing yet another collectionof special-purpose data structures.Rather, one has to find abstractions andarchitectures to implement generic sys-tems, that is, to build systems with ge-neric spatial data-management capabil-ities that can be tailored to therequirements of a particular applicationdomain. Important issues in this con-text include the handling of spatial rep-resentations and data models, multidi-mensional access methods, and pictorialor spatial query languages and theiroptimization.
This article is a survey of multidimen-sional access methods to support searchoperations in spatial databases. Figure1, which was inspired by a similargraph by Lu and Ooi [1993], gives a firstoverview of the diversity of existingmultidimensional access methods. Thegoal is not to describe all of these struc-tures, but to discuss the most prominentones, to present possible taxonomies,and to establish references to other lit-erature.
CONTENTS
1. INTRODUCTION2. ORGANIZATION OF SPATIAL DATA
2.1 What Is Special About Spatial?2.2 Definitions and Queries
3. BASIC DATA STRUCTURES3.1 One-Dimensional Access Methods3.2 Main Memory Structures
4. POINT ACCESS METHODS4.1 Multidimensional Hashing4.2 Hierarchical Access Methods4.3 Space-Filling Curves for Point Data
5. SPATIAL ACCESS METHODS5.1 Transformation5.2 Overlapping Regions5.3 Clipping5.4 Multiple Layers
6. COMPARATIVE STUDIES7. CONCLUSIONS
Multidimensional Access Methods • 171
ACM Computing Surveys, Vol. 30, No. 2, June 1998

Several shorter surveys have beenpublished previously in various Ph.D.theses such as Ooi [1990], Kolovson[1990], Oosterom [1990], and Schiwietz[1993]. Widmayer [1991] gives an over-view of work published before 1991.Like the thesis by Schiwietz, however,his survey is available only in German.Samet’s books [1989, 1990] present thestate of the art until 1989. However,they primarily cover quadtrees and re-lated data structures. Lomet [1991] dis-cusses the field from a systems-orientedpoint of view.
The remainder of the article is orga-nized as follows. Section 2 discussessome basic properties of spatial dataand their implications for the designand implementation of spatial data-bases. Section 3 gives an overview ofsome traditional data structures that
had an impact on the design of multidi-mensional access methods. Sections 4and 5 form the core of this survey, pre-senting a variety of point access meth-ods (PAMs) and spatial access methods(SAMs), respectively. Some remarksabout theoretical and experimentalanalyses are contained in Section 6, andSection 7 concludes the article.
2. ORGANIZATION OF SPATIAL DATA
2.1 What Is Special About Spatial?
To obtain a better understanding of therequirements in spatial database sys-tems, we first discuss some basic prop-erties of spatial data. First, spatial datahave a complex structure. A spatialdata object may be composed of a singlepoint or several thousands of polygons,
Figure 1. History of multidimensional access methods.
172 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

arbitrarily distributed across space. Itis usually not possible to store collec-tions of such objects in a single rela-tional table with a fixed tuple size. Sec-ond, spatial data are often dynamic.Insertions and deletions are interleavedwith updates, and data structures usedin this context have to support this dy-namic behavior without deterioratingover time. Third, spatial databases tendto be large. Geographic maps, for exam-ple, typically occupy several gigabytesof storage. The integration of secondaryand tertiary memory is therefore essen-tial for efficient processing [Chen et al.1995]. Fourth, there is no standard al-gebra defined on spatial data, althoughseveral proposals have been made in thepast [Egenhofer 1989; Guting 1989;Scholl and Voisard 1989; Guting andSchneider 1993]. This means in particu-lar that there is no standardized set ofbase operators. The set of operators de-pends heavily on the given applicationdomain, although some operators (suchas intersection) are more common thanothers. Fifth, many spatial operatorsare not closed. The intersection of twopolygons, for example, may return anynumber of single points, dangling edges,or disjoint polygons. This is particularlyrelevant when operators are appliedconsecutively. Sixth, although the com-putational costs vary among spatial da-tabase operators, they are generallymore expensive than standard rela-tional operators.
An important class of geometric oper-ators that needs special support at thephysical level is the class of spatialsearch operators. Retrieval and updateof spatial data are usually based notonly on the value of certain alphanu-meric attributes but also on the spatiallocation of a data object. A retrievalquery on a spatial database often re-quires the fast execution of a geometricsearch operation such as a point or re-gion query. Both operations require fastaccess to those data objects in the data-base that occupy a given location inspace.
To support such search operations,
one needs special multidimensional ac-cess methods. The main problem in thedesign of such methods, however, isthat there exists no total orderingamong spatial objects that preservesspatial proximity. In other words, thereis no mapping from two- or higher-di-mensional space into one-dimensionalspace such that any two objects that arespatially close in the higher-dimen-sional space are also close to each otherin the one-dimensional sorted sequence.
This makes the design of efficient ac-cess methods in the spatial domainmuch more difficult than in traditionaldatabases, where a broad range of effi-cient and well-understood access meth-ods is available. Examples for such one-dimensional access methods (also calledsingle key structures, although thatterm is somewhat misleading) includethe B-tree [Bayer and McCreight 1972]and extendible hashing [Fagin et al.1979]; see Section 3.1 for a brief discus-sion. A popular approach to handlingmultidimensional search queries con-sists of the consecutive application ofsuch single key structures, one per di-mension. Unfortunately, this approachcan be very inefficient [Kriegel 1984].Since each index is traversed indepen-dently of the others, we cannot exploitthe possibly high selectivity in one di-mension to narrow down the search inthe remaining dimensions. In general,there is no easy and obvious way toextend single key structures in order tohandle multidimensional data.
There is a variety of requirementsthat multidimensional access methodsshould meet, based on the properties ofspatial data and their applications[Robinson 1981; Lomet and Salzberg1989; Nievergelt 1989]:
(1) Dynamics. As data objects are in-serted and deleted from the data-base in any given order, accessmethods should continuously keeptrack of the changes.
(2) Secondary/tertiary storage man-agement. Despite growing mainmemories, it is often not possible to
Multidimensional Access Methods • 173
ACM Computing Surveys, Vol. 30, No. 2, June 1998

hold the complete database in mainmemory. Therefore, access methodsneed to integrate secondary and ter-tiary storage in a seamless manner.
(3) Broad range of supported opera-tions. Access methods should notsupport just one particular type ofoperation (such as retrieval) at theexpense of other tasks (such as de-letion).
(4) Independence of the input data andinsertion sequence. Access methodsshould maintain their efficiencyeven when input data are highlyskewed or the insertion sequence ischanged. This point is especiallyimportant for data that are distrib-uted differently along the variousdimensions.
(5) Simplicity. Intricate access meth-ods with many special cases areoften error-prone to implement andthus not sufficiently robust forlarge-scale applications.
(6) Scalability. Access methods shouldadapt well to database growth.
(7) Time efficiency. Spatial searchesshould be fast. A major design goalis to meet the performance charac-teristics of one-dimensional B-trees:first, access methods should guar-antee a logarithmic worst-casesearch performance for all possibleinput data distributions regardlessof the insertion sequence and sec-ond, this worst-case performanceshould hold for any combination ofthe d attributes.
(8) Space efficiency. An index shouldbe small in size compared to thedata to be addressed and thereforeguarantee a certain storage utiliza-tion.
(9) Concurrency and recovery. In mod-ern databases where multiple us-ers concurrently update, retrieve,and insert data, access methodsshould provide robust techniquesfor transaction management with-out significant performance penal-ties.
(10) Minimum impact. The integrationof an access method into a data-base system should have minimumimpact on existing parts of the sys-tem.
2.2 Definitions and Queries
We have already introduced the termmultidimensional access methods to de-note the large class of access methodsthat support searches in spatial data-bases and are the subject of this survey.Within this class, we distinguish be-tween point access methods (PAMs) andspatial access methods (SAMs). Pointaccess methods have primarily been de-signed to perform spatial searches onpoint databases (i.e., databases thatstore only points). The points may beembedded in two or more dimensions,but they do not have a spatial exten-sion. Spatial access methods, however,can manage extended objects, such aslines, polygons, or even higher-dimen-sional polyhedra. In the literature, oneoften finds the term spatial accessmethod referring to what we call multi-dimensional access method. Other termsused for this purpose include spatialindex or spatial index structure.
We generally assume that the givenobjects are embedded in d-dimensionalEuclidean space Ed or a suitable sub-space thereof. In this article, this spaceis also referred to as the universe ororiginal space. Any point object storedin a spatial database has a unique loca-tion in the universe, defined by its dcoordinates. Unless the distinction isessential, we use the term point both forlocations in space and for point objectsstored in the database. Note, however,that any point in space can be occupiedby several point objects stored in thedatabase.
A (convex) d-dimensional polytope Pin Ed is defined to be the intersection ofsome finite number of closed halfspacesin Ed, such that the dimension of thesmallest affine subspace containing P isd. If a [ Ed 2 {0} and c [ E1 then the(d 2 1)-dimensional set H(a, c) 5 {x [
174 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

Ed : x z a 5 c} defines a hyperplane inEd. A hyperplane H(a, c) defines twoclosed halfspaces: the positive halfspace1 z H(a, c) 5 {x [ Ed : x z a $ c}, andthe negative halfspace 21 z H(a, c) 5{x [ Ed : x z a # c}. A hyperplaneH(a, c) supports a polytope P if H(a, c)ù P Þ À and P # 1 z H(a, c), that is, ifH(a, c) embeds parts of P’s boundary. IfH(a, c) is any hyperplane supporting Pthen P ù H(a, c) is a face of P. Thefaces of dimension 1 are called edges;those of dimension 0 vertices.
By forming the union of some finitenumber of polytopes Q1, . . . , Qn, weobtain a (d-dimensional) polyhedron Qin Ed that is not necessarily convex.Following the intuitive understandingof polyhedra, we require that the Qi(i 51, . . . , n) be connected. Note that thisstill allows for polyhedra with holes.Each face of Q is either the face of someQi, or a fraction thereof, or the result ofthe intersection of two or more Qi. Eachpolyhedron P divides the points in spaceinto three subsets that are mutuallydisjoint: its interior, its boundary, andits exterior.
Following usual conventions, we usethe terms line and polyline to denote aone-dimensional polyhedron and theterms polygon and region to denote atwo-dimensional polyhedron. We fur-ther assume that for each k(0 # k # d),
the set of k-dimensional polyhedraforms a data type, which leads us to thecommon collection of spatial data types{Point, Line, Region, . . .}. Combinedtypes sometimes also occur. An object oin a spatial database is usually definedby several nonspatial attributes and oneattribute of some spatial data type. Thisspatial attribute describes the object’sspatial extent o.G. In the spatial data-base literature, the terms geometry,shape, and spatial extension are oftenused instead of spatial extent. For thedescription of o.G one finds the termsshape descriptor, shape description,shape information, and geometric de-scription, among others.
Indices often perform more efficientlywhen handling simple entries of thesame size. One therefore often abstractsfrom the actual shape of a spatial objectbefore inserting it into an index. Thiscan be achieved by approximating theoriginal data object with a simplershape, such as a bounding box or asphere. Given a minimum bounding in-terval Ii(o) 5 [li, ui] (li, ui [ E1) de-scribing the extent of the spatial objecto along dimension i, the d-dimensionalminimum bounding box (MBB) is de-fined by Id(o) 5 I1(o) 3 I2(o) 3 . . . 3Id(o).
An index may administer only theMBB of each object, together with a
Figure 2. Multistep spatial query processing [Brinkhoff et al. 1994].
Multidimensional Access Methods • 175
ACM Computing Surveys, Vol. 30, No. 2, June 1998

pointer to the object’s database entry(object ID or object reference). With thisdesign, the index produces only a set ofcandidate solutions (Figure 2). For eachcandidate obtained during this filterstep, we have to decide whether theMBB is sufficient to guarantee that theobject itself satisfies the search predi-cate. In those cases, the object can beadded directly to the query result(dashed line). However, there are oftencases where the MBB does not provesufficient. In a refinement step we thenmust retrieve the exact shape informa-tion from secondary memory and test itagainst the predicate. If the predicateevaluates to true, the object is added tothe query result; otherwise we have afalse drop.
Another way of obtaining simple in-dex entries is to represent the shape ofeach data object as the geometric unionof simpler shapes (e.g., convex polygonswith a bounded number of vertices).This approach is called decomposition.
We have mentioned the term effi-ciency several times so far without giv-ing a formal definition. In the case ofspace efficiency, this can easily be done:the goal is to minimize the number ofbytes occupied by the index. For timeefficiency the situation is not so clear.Elapsed time is obviously what the usercares about, but one should keep inmind that the corresponding measure-ments greatly depend on implementa-tion details, hardware utilization, andother external factors. In the literature,one therefore often finds a seeminglymore objective performance measure:the number of disk accesses performedduring a search. This approach, whichhas become popular with the B-tree, isbased on the assumption that mostsearches are I/O-bound rather thanCPU-bound—an assumption that is notalways true in spatial data manage-ment, however. In applications whereobjects have complex shapes, the refine-ment step can incur major CPU costsand change the balance with I/O [Gaede1995b; Hoel and Samet 1995]. Ofcourse, one should keep the minimiza-
tion of the number of disk accesses inmind as one design goal. Practical eval-uations, however, should always givesome information on elapsed times andthe conditions under which they wereachieved.
As noted previously, in contrast torelational databases, there exists nei-ther a standard spatial algebra nor astandard spatial query language. Theset of operators strongly depends on thegiven application domain, althoughsome operators (such as intersection)are generally more common than oth-ers. Queries are often expressed bysome extension of SQL that allows ab-stract data types to represent spatialobjects and their associated operators[Roussopoulos and Leifker 1984; Egen-hofer 1994]. The result of a query isusually a set of spatial data objects. Inthe remainder of this section, we give aformal definition of several of the morecommon spatial database operators.Figures 3 through 8 give some concreteexamples.
Query 1 (Exact Match Query EMQ,Object Query). Given an object o9 withspatial extent o9.G # Ed, find all objectso with the same spatial extent as o9:
EMQ~o9! 5 $ouo9.G 5 o.G%.
Query 2 (Point Query PQ). Given apoint p [ Ed, find all objects o overlap-
Figure 3. Point query.
176 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

ping p:
PQ~ p! 5 $oup ù o.G 5 p%.
The point query can be regarded as aspecial case of several of the followingqueries, such as the intersection query,the window query, or the enclosurequery.
Query 3 (Window Query WQ, RangeQuery). Given a d-dimensional intervalId 5 [l1, u1] 3 [l2, u2] 3 . . . 3 [ld, ud],find all objects o having at least onepoint in common with Id:
WQ~Id! 5 $ouId ù o.G Þ À%.
The query implies that the window isiso-oriented; that is, its faces are paral-lel to the coordinate axes. A more gen-eral variant is the region query thatpermits search regions to have arbitraryorientations and shapes.
Query 4 (Intersection Query IQ, Re-gion Query, Overlap Query). Given anobject o9 with spatial extent o9.G # Ed,find all objects o having at least onepoint in common with o9:
IQ~o9! 5 $ouo9.G ù o.G Þ À%.
Query 5 (Enclosure Query EQ). Givenan object o9 with spatial extent o9.G #
Figure 4. Window query.
Figure 5. Intersection query.
Figure 6. Enclosure query.
Figure 7. Containment query.
Multidimensional Access Methods • 177
ACM Computing Surveys, Vol. 30, No. 2, June 1998

Ed, find all objects o enclosing o9:
EQ~o9! 5 $ou~o9.G ù o.G! 5 o9.G%.
Query 6 (Containment Query CQ).Given an object o9 with spatial extento9.G # Ed, find all objects o enclosed byo9:
CQ~o9! 5 $ou~o9.G ù o.G! 5 o.G%.
The enclosure and the containmentquery are duals of each other. They areboth more restrictive formulations ofthe intersection query by specifying theresult of the intersection to be one of thetwo inputs.
Query 7 (Adjacency Query AQ). Givenan object o9 with spatial extent o9.G #Ed, find all objects o adjacent to o9:
AQ~o9! 5 $ouo.G ù o9.G Þ À
` o9.G° ù o.G° 5 À}.
Here o9.G° and o.G° denote the interi-ors of the spatial extents o9.G and o.G,respectively.
Query 8 (Nearest-Neighbor QueryNNQ). Given an object o9 with spatialextent o9.G # Ed, find all objects o
having a minimum distance from o9:
NNQ~o9! 5 $ou@o0 : dist~o9.G, o.G!
# dist~o9.G, o0.G!}.
The distance between extended spatialdata objects is usually defined as thedistance between their closest points.Common distance functions for pointsinclude the Euclidean and the Manhat-tan distance.
Besides spatial selections, as exempli-fied by Queries 1 through 8, the spatialjoin is one of the most important spatialoperations and can be defined as follows[Gunther 1993]:
Query 9 (Spatial Join). Given two col-lections R and S of spatial objects and aspatial predicate u, find all pairs of ob-jects (o, o9) [ R 3 S where u(o.G, o9.G)evaluates to true:
R ”“u S 5 $~o, o9!uo [ R ` o9
[ S ` u ~o.G, o9.G!}.
As for the spatial predicate u, a briefsurvey of the literature1 yields a widevariety of possibilities, including
intersects[contains[is_enclosed_by[distance[Qq, with Q [ {5, #, ,, $, .}
and q [ E1
northwest[adjacent[.
A closer inspection of these spatial pred-icates shows that the intersection joinR ”“intersects S plays a crucial role forthe computation in virtually all thesecases [Gaede and Riekert 1994]. Forpredicates such as contains, encloses, oradjacent, for example, the intersectionjoin is an efficient filter that yields a setof candidate solutions typically much
1 See Orenstein [1986], Becker [1992], Rotem[1991], Gunther [1993], Brinkhoff et al. [1993a],Gaede and Riekert [1994], Brinkhoff [1994], Loand Ravishankar [1994], Aref and Samet [1994],Papadias et al. [1995] and Gunther et al. [1998].
Figure 8. Adjacency query.
178 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

smaller than the Cartesian productR 3 S.
3. BASIC DATA STRUCTURES
3.1 One-Dimensional Access Methods
Classical one-dimensional access meth-ods are an important foundation for al-most all multidimensional access meth-ods. Although the related surveys byKnott [1975] and Comer [1979] aresomewhat dated, they represent goodcoverage of the different approaches. Inpractice, the most common one-dimen-sional structures include linear hashing[Litwin 1980; Larson 1980], extendiblehashing [Fagin et al. 1979], and theB-tree [Bayer and McCreight 1972]. Hi-erarchical access methods such as theB-tree are scalable and behave well inthe case of skewed input; they arenearly independent of the distributionof the input data. This is not necessarilytrue for hashing techniques, whose per-formance may degenerate depending onthe given input data and hash function.This problem is aggravated by the useof order-preserving hash functions[Orenstein 1983; Garg and Gotlieb1986] that try to preserve neighborhoodrelationships between data items in or-der to support range queries. As a re-sult, highly skewed data keep accumu-lating at a few selected locations inimage space.
3.1.1 Linear Hashing [Larson 1980;Litwin 1980]. Linear hashing dividesthe universe [A, B) of possible hash val-ues into binary intervals of size (B 2A)/2k or (B 2 A)/2k11 for some k $ 0.Each interval corresponds to a bucket,that is, a collection of records stored ona disk page. t [ [A, B) is a pointer thatseparates the smaller intervals from thelarger ones: all intervals of size (B 2A)/2k are to the left of t and all intervalsof size (B 2 A)/2k11 are to the right of t.If a bucket reaches its capacity due toan insertion, the interval [t, t 1 (B 2A)/2k) is split into two subintervals ofequal size, and t is advanced to the next
large interval remaining. Note that thesplit interval need not be the same in-terval as the one that caused the split;consequently, there is no guarantee thatthe split relieves the bucket in questionfrom its overload. If an interval containsmore objects than bucket capacity per-mits, the overload is stored on an over-flow page, which is linked to the origi-nal page. When t 5 B, the file hasdoubled and all intervals have the samelength (B 2 A)/2k11. In this case wereset the pointer t to A and resume thesplit procedure for the smaller inter-vals.
3.1.2 Extendible Hashing [Fagin etal. 1979]. As does linear hashing, ex-tendible hashing organizes the data inbinary intervals, here called cells. Over-flow pages are avoided in extendiblehashing by using a central directory.Each cell has an index entry in thatdirectory; it initially corresponds to onebucket. If during an insertion a bucketat maximal depth exceeds its maximumcapacity, all cells are split into two. Newindex entries are created and the direc-tory doubles in size. Since each bucketwas not at full capacity before the split,it may now be possible to fit more thanone cell in the same bucket. In thatcase, adjacent cells are regrouped indata regions and stored on the samedisk page. In the case of skewed datathis may lead to a situation where nu-merous directory entries exist for thesame data region (and therefore thesame disk page). Even in the case ofuniformly distributed data, the averagedirectory size is Q(n111/b) and thereforesuperlinear [Flajolet 1983]. Here b de-notes the bucket size and n is the num-ber of index entries. Exact matchsearches take no more than two pageaccesses: one for the directory and onefor the bucket with the data. This ismore than the best-case performance oflinear hashing, but better than theworst case.
Besides the potentially poor space uti-lization of the index, extendible hashingalso suffers from a nonincremental
Multidimensional Access Methods • 179
ACM Computing Surveys, Vol. 30, No. 2, June 1998

growth of the index due to the doublingsteps. To address these problems,Lomet [1983] proposed a techniquecalled bounded-index extendible hash-ing. In this proposal, the index grows asin extendible hashing until its sizereaches a predetermined maximum;that is, the index size is bounded. Oncethis limit is reached while inserting newitems, bounded-index extendible hash-ing starts doubling the data bucket sizerather than the index size.
3.1.3 The B-Tree [Bayer and Mc-Creight 1972]. Other than hashingschemes, the B-tree and its variants[Comer 1979] organize the data in ahierarchical manner. B-trees are bal-anced trees that correspond to a nestingof intervals. Each node n corresponds toa disk page D(n) and an interval I(n). Ifn is an interior node then the intervalsI(ni) corresponding to the immediate de-scendants of n are mutually disjointsubsets of I(n). Leaf nodes containpointers to data items; depending on thetype of B-tree, interior nodes may do soas well. B-trees have an upper andlower bound for the number of descen-dants of a node. The lower bound pre-vents the degeneration of trees andleads to an efficient storage utilization.Nodes whose number of descendantsdrops below the lower bound are deletedand their contents distributed amongthe adjacent nodes at the same treelevel. The upper bound follows from thefact that each tree node corresponds toexactly one disk page. If during an in-sertion a node reaches its capacity, it issplit in two. Splits may propagate upthe tree. As the size of the intervalsdepends on the given data (and the in-sertion sequence), the B-tree is an adap-tive data structure. For uniformly dis-tributed data, however, extendible aswell as linear hashing outperform theB-tree on the average for exact matchqueries, insertions, and deletions.
3.2 Main Memory Structures
Early multidimensional access methodsdid not take into account paged second-
ary memory and are therefore lesssuited for large spatial databases. Inthis section, we review several of thesefundamental data structures, which areadapted and incorporated in numerousmultidimensional access methods. To il-lustrate the methods, we introduce asmall scenario that we use as a runningexample throughout this survey. Thescenario, depicted in Figure 9, contains10 points pi and 10 polygons ri, ran-domly distributed in a finite two-dimen-sional universe. To represent polygons,we often use their centroids ci (not pic-tured) or their minimum boundingboxes (MBBs) mi. Note that the qualityof the MBB approximation varies con-siderably. The MBB m8, for example,provides a fairly tight fit, whereas r5 isonly about half as large as its MBB m5.
3.2.1 The k-d-Tree [Bentley 1975,1979]. One of the most prominent d-dimensional data structures is the k-d-tree. The k-d-tree is a binary search treethat represents a recursive subdivisionof the universe into subspaces by meansof (d 2 1)-dimensional hyperplanes.The hyperplanes are iso-oriented, andtheir direction alternates among the dpossibilities. For d 5 3, for example,splitting hyperplanes are alternatelyperpendicular to the x-, y-, and z-axes.Each splitting hyperplane has to con-tain at least one data point, which isused for its representation in the tree.Interior nodes have one or two descen-dants each and function as discrimina-tors to guide the search. Searching andinsertion of new points are straightfor-ward operations. Deletion is somewhatmore complicated and may cause a reor-ganization of the subtree below the datapoint to be deleted.
Figure 10 shows a k-d-tree for therunning example. Because the tree canonly handle points, we represent thepolygons by their centroids ci. The firstsplitting line is the vertical line crossingc3. We therefore store c3 in the root ofthe corresponding k-d-tree. The nextsplits occur along horizontal lines cross-
180 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

ing p10 (for the left subtree) and c7 (forthe right subtree), and so on.
One disadvantage of the k-d-tree isthat the structure is sensitive to theorder in which the points are inserted.Another one is that data points are scat-tered all over the tree. The adaptivek-d-tree [Bentley and Friedman 1979]mitigates these problems by choosing asplit such that one finds about the samenumber of elements on both sides. Al-though the splitting hyperplanes arestill parallel to the axes, they need notcontain a data point and their directions
need not be strictly alternating any-more. As a result, the split points arenot part of the input data; all datapoints are stored in the leaves. Interiornodes contain the dimension (e.g., x ory) and the coordinate of the correspond-ing split. Splitting is continued recur-sively until each subspace contains onlya certain number of points. The adap-tive k-d-tree is a rather static structure;it is obviously difficult to keep the treebalanced in the presence of frequentinsertions and deletions. The structureworks best if all the data are known a
Figure 9. Running example.
Figure 10. k-d-tree.
Multidimensional Access Methods • 181
ACM Computing Surveys, Vol. 30, No. 2, June 1998

priori and if updates are rare. Figure 11shows an adaptive k-d-tree for the run-ning example. Note that the tree stilldepends on the order of insertion.
Another variant of the k-d-tree is thebintree [Tamminen 1984]. This struc-ture partitions the universe recursivelyinto d-dimensional boxes of equal sizeuntil each one contains only a certainnumber of points. Even though thiskind of partitioning is less adaptive, ithas several advantages, such as the im-plicit knowledge of the partitioning hy-perplanes. In the remainder of this arti-cle, we encounter several otherstructures based on this kind of parti-tioning.
A disadvantage common to all k-d-trees is that for certain distributions nohyperplane can be found that splits thedata points evenly [Lomet and Salzberg1989]. By introducing a more flexiblepartitioning scheme, the following BSP-tree avoids this problem completely.
3.2.2 The BSP-Tree [Fuchs et al.1980, 1983]. Splitting the universe onlyalong iso-oriented hyperplanes is a se-vere restriction in the schemes pre-sented so far. Allowing arbitrary orien-tations gives more flexibility to find ahyperplane that is well suited for thesplit. A well-known example for such amethod is the binary space partitioning(BSP)-tree. Like k-d-trees, BSP-treesare binary trees that represent a recur-sive subdivision of the universe into
subspaces by means of (d 2 1)-dimen-sional hyperplanes. Each subspace issubdivided independently of its historyand of the other subspaces. The choiceof the partitioning hyperplanes dependson the distribution of the data objects ina given subspace. The decompositionusually continues until the number ofobjects in each subspace is below agiven threshold.
The resulting partition of the uni-verse can be represented by a BSP-treein which each hyperplane correspondsto an interior node of the tree and eachsubspace corresponds to a leaf. Eachleaf stores references to those objectsthat are contained in the correspondingsubspace. Figure 12 shows a BSP-treefor the running example with no morethan two objects per subspace.
In order to perform a point query, weinsert the search point into the root ofthe tree and determine on which side ofthe corresponding hyperplane it is lo-cated. Next, we insert the point into thecorresponding subtree and proceed re-cursively until we reach a leaf of thetree. Finally, we examine the data ob-jects in the corresponding subspace tosee whether they contain the searchpoint. The range search algorithm is astraightforward generalization.
BSP-trees can adapt well to differentdata distributions. However, they aretypically not balanced and may havevery deep subtrees, which has a nega-
Figure 11. Adaptive k-d-tree.
182 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

tive impact on the tree performance.BSP-trees also have higher space re-quirements, since storing an arbitraryhyperplane per split occupies more stor-age space than a simple discriminator,which is typically just a real number.
3.2.3 The BD-Tree [Ohsawa andSakauchi 1983]. The BD-tree is a bi-nary tree representing a subdivision ofthe data space into interval-shaped re-gions. Each of those regions is encodedin a bit string and associated with oneof the BD-tree nodes. Here, these bitstrings are called DZ-expressions; theyare also known as Peano codes, ST_Mor-tonNumber, or z-values (cf. Section5.1.2).
Given a region R, one computes thecorresponding DZ-expression as follows.For simplicity we restrict this presenta-tion to the two-dimensional case; wealso assume that the first subdividinghyperplane is a vertical line. If R lies tothe left of that line, the first bit of thecorresponding DZ-expression is 0; other-wise it is 1. In the next step, we subdi-vide the subspace containing R by ahorizontal line. If R lies below that line,the second bit of the DZ-expression is 0,otherwise it is 1. As this decompositionprogresses, we obtain one bit per split-ting line. Bits at odd positions refer tovertical lines and bits at even positionsto horizontal lines, which explains whythis scheme is often referred to as bitinterleaving.
To avoid the storage utilization prob-lems that are often associated with astrictly regular partitioning, the BD-tree employs a more flexible splittingpolicy. Here one can split a node bymaking an interval-shaped excisionfrom the corresponding region. The twochild nodes of the node to be split willthen have different interpretations: onerepresents the excision; the other onerepresents the remainder of the originalregion. Note that the remaining regionis no longer interval-shaped. With thispolicy, the BD-tree can guarantee that,after node splitting, each of the databuckets contains at least one third ofthe original entries.
Figure 13 shows a BD-tree for therunning example. An excision is alwaysrepresented by the left child of the nodethat was split.
For an exact match we first computethe full bit-interleaved prefix of thesearch record. Starting from the root,we recursively compare this prefix withthe stored DZ-expressions of each inter-nal node. If it matches, we follow thecorresponding link; otherwise we followthe other link until we reach the leaflevel of the BD-tree. More sophisticatedalgorithms were proposed later by Dan-damudi and Sorenson [1986, 1991].
3.2.4 The Quadtree. The quadtreewith its many variants is closely relatedto the k-d-tree. For an extensive discus-sion of this structure, see Samet [1984,
Figure 12. BSP-tree.
Multidimensional Access Methods • 183
ACM Computing Surveys, Vol. 30, No. 2, June 1998

1990a,b]. Although the term quadtreeusually refers to the two-dimensionalvariant, the basic idea applies to anarbitrary d. Like the k-d-tree, thequadtree decomposes the universe bymeans of iso-oriented hyperplanes. Animportant difference, however, is thefact that quadtrees are not binary treesanymore. In d dimensions, the interiornodes of a quadtree have 2d descen-dants, each corresponding to an inter-val-shaped partition of the given sub-space. These partitions do not have tobe of equal size, although that is oftenthe case. For d 5 2, for example, eachinterior node has four descendants, eachcorresponding to a rectangle. Theserectangles are typically referred to asthe NW, NE, SW, and SE (northwest,etc.) quadrants. The decomposition intosubspaces is usually continued until thenumber of objects in each partition isbelow a given threshold. Quadtrees aretherefore not necessarily balanced; sub-trees corresponding to densely popu-lated regions may be deeper than oth-ers.
Searching in a quadtree is similar tosearching in an ordinary binary searchtree. At each level, one has to decidewhich of the four subtrees need be in-cluded in the future search. In the caseof a point query, typically only one sub-tree qualifies, whereas for range queriesthere are often several. We repeat thissearch step recursively until we reachthe leaves of the tree.
Finkel and Bentley [1974] proposed
one of the first quadtree variants: thepoint quadtree, essentially a multidi-mensional binary search tree. The pointquadtree is constructed consecutively byinserting the data points one by one.For each point, we first perform a pointsearch. If we do not find the point in thetree, we insert it into the leaf nodewhere the search has terminated. Thecorresponding partition is divided into2d subspaces with the new point at thecenter. The deletion of a point requiresthe restructuring of the subtree belowthe corresponding quadtree node. Asimple way to achieve this is to reinsertall points into the subtree. Figure 14shows a two-dimensional point quadtreefor the running example.
Another popular variant is the regionquadtree [Samet 1984]. Region quadtreesare based on a regular decomposition ofthe universe; that is, the 2d subspacesresulting from a partition are always ofequal size. This greatly facilitatessearches. For the running example, Fig-ure 15 shows how region quadtrees canbe used to represent sets of points. Herethe threshold for the number of pointsin any given subspace was set to one. Inmore complex versions of the regionquadtree, such as the PM quadtree[Samet and Webber 1985], it is alsopossible to store polygonal data directly.PM quadtrees divide the quadtree re-gions (and the data objects in them)until they contain only a small numberof polygon edges or vertices. Theseedges or vertices (which together form
Figure 13. BD-tree.
184 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

an exact description of the data objects)are then attached to the leaves of thetree. Another class of quadtree struc-tures has been designed for the manage-ment of collections of rectangles; seeSamet [1988] for a survey.
4. POINT ACCESS METHODS
The multidimensional data structurespresented in the previous section do nottake secondary storage managementinto account explicitly. They were origi-nally designed for main memory appli-cations where all the data are availablewithout accessing the disk. Despitegrowing main memories, this is ofcourse not always the case. In manyspatial database applications, such asgeography, the amount of data to bemanaged is notoriously large. One can
certainly use main memory structuresfor data that reside on disk, but theirperformance is often considerably belowthe optimum because there is no controlover how the operating system performsthe disk accesses. The access methodspresented in this and the following sec-tion have been designed with secondarystorage management in mind. Their op-erations are closely coordinated withthe operating system to ensure thatoverall performance is optimized.
As mentioned before, we first presenta selection of point access methods.Usually, the points in the database areorganized in a number of buckets, eachof which corresponds to a disk page andto some subspace of the universe. Thesubspaces (often called data regions,bucket regions, or simply regions, even
Figure 14. Point quadtree.
Figure 15. Region quadtree.
Multidimensional Access Methods • 185
ACM Computing Surveys, Vol. 30, No. 2, June 1998

though their dimension may be greaterthan two) need not be rectilinear, al-though they often are. The buckets areaccessed by means of a search tree orsome d-dimensional hash function.
The grid file [Nievergelt et al. 1984],for example, uses a directory and a grid-like partition of the universe to answeran exact match query with exactly twodisk accesses. Furthermore, there aremultidimensional hashing schemes[Tamminen 1982; Kriegel and Seeger1986, 1988], multilevel grid files[Whang and Krishnamurthy 1985; Hut-flesz et al. 1988b], and hash trees [Ouk-sel 1985; Otoo 1985], which organize thedirectory as a tree structure. Tree-basedaccess methods are usually a generali-zation of the B-tree to higher dimen-sions, such as the k-d-B-tree [Robinson1981] or the hB-tree [Lomet and Salz-berg 1989].
In the remainder of this section, wefirst discuss the approaches based onhashing, followed by hierarchical (tree-based) methods, and space-fillingcurves. This classification is hardly un-ambiguous, especially in the presence ofan increasing number of hybrid ap-proaches that attempt to combine theadvantages of several different tech-niques. Our approach resembles theclassification of Samet [1990], who dis-
tinguishes between hierarchical meth-ods (point/region quadtrees, k-d-trees,range trees) and bucket methods (gridfile, EXCELL). His discussion of theformer is primarily in the context ofmain memory applications. Our presen-tation focuses throughout on structuresthat take secondary storage manage-ment into account.
Another interesting taxonomy hasbeen proposed by Seeger and Kriegel[1990], who classify point access meth-ods by the properties of the bucket re-gions (Table 1). First, they may be pair-wise disjoint or they may have mutualoverlaps. Second, they may have theshape of an interval (box) or be of somearbitrary polyhedral shape. Third, theymay cover the complete universe or justthose parts that contain some data ob-jects. This taxonomy results in eightclasses, four of which are populated byexisting access methods.
4.1 Multidimensional Hashing
Although there is no total order for ob-jects in two- and higher-dimensionalspace that completely preserves spatialproximity, there have been numerousattempts to construct hashing functionsthat preserve proximity at least to someextent. The goal of all these heuristics is
Table 1. Classification of PAMs Following Seeger and Kriegel [1990]
186 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

that objects located close to each otherin original space should be likely to bestored close together on the disk. Thiscould contribute substantially to mini-mizing the number of disk accesses perrange query. We begin our presentationwith several structures based on ex-tendible hashing. Structures based onlinear hashing are discussed in Section4.1.5. The discussion of two hybridmethods, the BANG file and the buddytree, is postponed until Section 4.2.
4.1.1 The Grid File (Nievergelt et al.1981]. As a typical representative of anaccess method based on hashing, wefirst discuss the grid file and some of itsvariants.2 The grid file superimposes a
d-dimensional orthogonal grid on theuniverse. Because the grid is not neces-sarily regular, the resulting cells maybe of different shapes and sizes. A griddirectory associates one or more of thesecells with data buckets, which arestored on one disk page each. Each cellis associated with one bucket, but abucket may contain several adjacentcells. Since the directory may growlarge, it is usually kept on secondarystorage. To guarantee that data itemsare always found with no more than twodisk accesses for exact match queries,the grid itself is kept in main memory,represented by d one-dimensional ar-rays called scales.
Figure 16 shows a grid file for therunning example. We assume bucket ca-pacity to be four data points. The centerof the figure shows the directory with
2 See Hinrichs [1985], Ouksel [1985], Whang andKrishnamurthy [1985], Six and Widmayer [1988],and Blanken et al. [1990].
Figure 16. Grid file.
Multidimensional Access Methods • 187
ACM Computing Surveys, Vol. 30, No. 2, June 1998

scales on the x- and y-axes. The datapoints are displayed in the directory fordemonstration purposes only; they arenot, of course, stored there. In the lowerleft part, four cells are combined into asingle bucket, represented by fourpointers to a single page. There are thusfour directory entries for the same page,which illustrates a well-known problemof the grid file: it suffers from a super-linear growth of the directory even fordata that are uniformly distributed[Regnier 1985; Widmayer 1991]. Thebucket region containing the point c5could have been merged with one of theneighboring buckets for better storageutilization. We present various mergingstrategies later, when we discuss thedeletion of data points.
To answer an exact match query, onefirst uses the scales to locate the cellcontaining the search point. If the ap-propriate grid cell is not in main mem-ory, one disk access is necessary. Theloaded cell contains a reference to thepage where possibly matching data canbe found. Retrieving this page may re-quire another disk access. Altogether,no more than two page accesses arenecessary to answer this query. For arange query, one must examine all cellsthat overlap the search region. Aftereliminating duplicates, one fetches thecorresponding data pages into memoryfor more detailed inspection.
To insert a point, one first performsan exact match query to locate the celland the data page ni where the entryshould be inserted. If there is sufficientspace left on ni, the new entry is in-serted. If not, we have to distinguishtwo cases, depending on the number ofgrid cells that point to the data pagewhere the new data item is to be in-serted. If there are several, one checkswhether an existing hyperplane storedin the scales can be used for splittingthe data page successfully. If so, a newdata page is allocated and the datapoints are distributed accordinglyamong the data pages. If none of theexisting hyperplanes is suitable, or ifonly one grid cell points to the data
page in question, a splitting hyperplaneH is introduced and a new data page njis allocated. The new entry and the en-tries of the original page ni are redis-tributed among ni and nj, depending ontheir location relative to H. H is in-serted into the corresponding scale; allcells that intersect H are split accord-ingly. Splitting is therefore not a localoperation and can lead to superlineardirectory growth even for uniformly dis-tributed data [Regnier 1985; Freeston1987; Widmayer 1991].
Deletion is not a local operation ei-ther. With the deletion of an entry, thestorage utilization of the correspondingdata page may drop below the giventhreshold. Depending on the currentpartitioning of space, it may then bepossible to merge this page with aneighbor page and to drop the partition-ing hyperplane from the correspondingscale. Depending on the implementationof the grid directory, merging may re-quire a complete directory scan [Hin-richs 1985]. Hinrichs discusses severalmethods for finding candidates withwhich a given data bucket can merge,including the neighbor system and themultidimensional buddy system. Theneighbor system allows merging two ad-jacent regions if the result is a rectan-gular region again. In the buddy sys-tem, two adjacent regions can bemerged provided that the joined regioncan be obtained by a regular binarysubdivision of the universe. Both sys-tems are not able to eliminate com-pletely the possibility of a deadlock, inwhich case no merging is feasible be-cause the resulting bucket region wouldnot be box-shaped [Hinrichs 1985; See-ger and Kriegel 1990].
For a theoretical analysis of the gridfile and some of its variants, see Reg-nier [1985] and Becker [1992]. Regniershows in particular that the grid file’saverage directory size for uniformly dis-tributed data is Q(n11(d21)/(db11)),where b is bucket size. He also provesthat the average space occupancy of thedata buckets is about 69% (ln 2).
188 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

4.1.2 EXCELL [Tamminen 1982].Closely related to the grid file is theEXCELL method (Extendible CELL)proposed by Tamminen [1982]. In con-trast to the grid file, where the parti-tioning hyperplanes may be spaced ar-bitrarily, the EXCELL methoddecomposes the universe regularly: allgrid cells are of equal size. In order tomaintain this property in the presenceof insertions, each new split results inthe halving of all cells and therefore inthe doubling of the directory size. Toalleviate this problem, Tamminen[1983] later suggested a hierarchicalmethod, similar to the multilevel gridfile of Whang and Krishnamurthy[1985]. Overflow pages are introducedto limit the depth of the hierarchy.
4.1.3 The Two-Level Grid File [Hin-richs 1985]. The basic idea of the two-level grid file is to use a second grid fileto manage the grid directory. The firstof the two levels is called the root direc-
tory, which is a coarsened version of thesecond level, the actual grid directory.Entries of the root directory containpointers to the directory pages of thelower level, which in turn contain point-ers to the data pages. By having a sec-ond level, splits are often confined tothe subdirectory regions without affect-ing too much of their surroundings.Even though this modification leads to aslower directory growth, it does notsolve the problem of superlinear direc-tory size. Furthermore, Hinrichs implic-itly assumes that the second level canbe kept in main memory, so that thetwo-disk access principle still holds.Figure 17 shows a two-level grid file forthe running example. Each cell in theroot directory has a pointer to the corre-sponding entries in the subdirectory,which have their own scales in turn.
4.1.4 The Twin Grid File [Hutflesz etal. 1988b]. The twin grid file tries toincrease space utilization compared to
Figure 17. Two-level grid file.
Multidimensional Access Methods • 189
ACM Computing Surveys, Vol. 30, No. 2, June 1998

the original grid file by introducing asecond grid file. As indicated by thename “twin,” the relationship betweenthese two grid files is not hierarchical,as in the case of the two-level grid file,but somewhat more balanced. Both gridfiles span the whole universe. The dis-tribution of the data among the two filesis performed dynamically. Hutflesz etal. [1988b] report an average occupancyof 90% for the twin grid file (comparedto 69% for the original grid file) withoutsubstantial performance penalties.
To illustrate the underlying tech-nique, consider the running example de-picted in Figure 18. Let us assume thateach bucket can accommodate fourpoints. If the number of points in abucket exceeds that limit, one possibil-ity is to create a new bucket and redis-tribute the points among the two newbuckets. Before doing this, however, thetwin grid file tries to redistribute thepoints between the two grid files. Atransfer of points from the primary fileP to the secondary file S may lead to abucket overflow in S. It may, however,also imply a bucket underflow in P,which may in turn lead to a bucketmerge and therefore to a reduction ofbuckets in P. The overall objective ofthe reshuffling is to minimize the totalnumber of buckets in the two grid filesP and S. Therefore we shift points fromP to S if and only if the resulting de-crease in the number of buckets in Poutweighs the increase in the number ofbuckets in S. This strategy also favorspoints to be placed in the primary file inorder to form large and empty buckets
in the secondary file. Consequently, allpoints in S can be associated with anempty or a full bucket region of P. Notethat there usually exists no unique opti-mum for the distribution of data pointsbetween the two files.
The fact that data points may befound in either of the two grid filesrequires search operations to visit thetwo files, which causes some overhead.Nevertheless, the performance resultsreported by Hutflesz et al. [1988b] indi-cate that the search efficiency of thetwin grid file is competitive with theoriginal grid file. Although the twin gridfile is somewhat inferior to the originalgrid file for smaller query ranges, thischanges for larger search spaces.
4.1.5 Multidimensional Linear Hash-ing. Unlike multidimensional extend-ible hashing, multidimensional linearhashing uses no or only a very smalldirectory. It therefore occupies rela-tively little storage compared to extend-ible hashing, and it is usually possibleto keep all relevant information in mainmemory.
Several different strategies have beenproposed to perform the required ad-dress computation. Early proposals[Ouksel and Scheuermann 1983] failedto support range queries; however, Krie-gel and Seeger [1986] later proposed avariant of linear hashing called multidi-mensional order-preserving linear hash-ing with partial expansions (MOLHPE).This structure is based on the idea ofpartially extending the buckets withoutexpanding the file size at the same
Figure 18. Twin grid file.
190 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

time. To this end, they use a d-dimen-sional expansion pointer referring to thegroup of pages to be expanded next.With this strategy, Kriegel and Seegercan guarantee a modest file growth, atleast in the case of well-behaved data.According to their experimental results,MOLHPE outperforms its competitorsfor uniformly distributed data. It fails,however, for nonuniform distributions,mostly because the hashing functiondoes not adapt gracefully to the givendistribution.
To solve this problem, the same au-thors later applied a stochastic tech-nique [Burkhard 1984] to determine thesplit points. Because of the name of thattechnique (a-quantiles), the accessmethod was called quantile hashing[Kriegel and Seeger 1987, 1989]. Thecritical property of the division in quan-tile hashing is that the original data,which may have a nonuniform distribu-tion, are transformed into uniformlydistributed values for a. These valuesare then used as input to the MOLHPEalgorithms for retrieval and update.Since the region boundaries are not nec-essarily simple binary intervals, a smalldirectory is needed. In exchange,skewed input data can be maintained asefficiently as uniformly distributeddata. Piecewise linear order-preserving(PLOP) hashing was proposed by thesame authors a year later [Kriegel andSeeger 1988]. Because this structurecan also be used as an access method forextended objects, we delay its discus-sion until Section 5.2.7.
Another variant with better order-preserving properties than MOLHPEhas been reported by Hutflesz et al.[1988a]. Their dynamic z-hashing uses aspace-filling technique called z-ordering[Orenstein and Merrett 1984] to guar-antee that points located close to eachother are also stored close together onthe disk. Z-ordering is described in de-tail in Section 5.1.2. One disadvantageof z-hashing is that a number of uselessdata blocks will be generated, as in theinterpolation-based grid file [Ouksel1985]. On the other hand, z-hashing lets
three to four buckets be read in a row onthe average before a seek is required,whereas MOLHPE manages to readonly one [Hutflesz et al. 1988a]. Wid-mayer [1991] later noted, however, thatboth z-hashing and MOLHPE are oflimited use in practice, due to their in-ability to adapt to different data distri-butions.
4.2 Hierarchical Access Methods
In this section we discuss several PAMsthat are based on a binary or multiwaytree structure. Except for the BANG fileand the buddy tree, which are hybridstructures, they perform no addresscomputation. Like hashing-based meth-ods, however, they organize the datapoints in a number of buckets. Eachbucket usually corresponds to a leafnode of the tree (also called data node)and a disk page, which contains thosepoints located in the correspondingbucket region. The interior nodes of thetree (also called index nodes) are used toguide the search; each of them typicallycorresponds to a larger subspace of theuniverse that contains all bucket re-gions in the subtree below. A searchoperation is then performed by a top-down tree traversal.
At this point, individual tree struc-tures still dominate the field, althoughmore generic concepts are gradually at-tracting more attention. The general-ized search (GIST) tree by Hellerstein etal. [1995], for example, attempts to sub-sume many of these common featuresunder a generic architecture.
Differences among individual struc-tures are mainly based on the charac-teristics of the regions. Table 1 showsthat in most PAMs the regions at thesame tree level form a partitioning ofthe universe; that is, they are mutuallydisjoint, with their union being the com-plete space. For SAMs this is not neces-sarily true; as we show in Section 5,overlapping regions and partial cover-age are important techniques to im-prove the search performance of SAMs.
Multidimensional Access Methods • 191
ACM Computing Surveys, Vol. 30, No. 2, June 1998

4.2.1 The k-d-B-Tree [Robinson 1981].The k-d-B-tree combines some of theproperties of the adaptive k-d-tree[Bentley and Friedman 1979] and theB-tree [Comer 1979] to handle multidi-mensional points. It partitions the uni-verse in the manner of an adaptive k-d-tree and associates the resultingsubspaces with tree nodes. Each inte-rior node corresponds to an interval-shaped region. Regions corresponding tonodes at the same tree level are mutu-ally disjoint; their union is the completeuniverse. The leaf nodes store the datapoints that are located in the corre-sponding partition. Like the B-tree, thek-d-B-tree is a perfectly balanced treethat adapts well to the distribution ofthe data. Other than for B-trees, how-ever, no minimum space utilization canbe guaranteed. A k-d-B-tree for the run-ning example is sketched in Figure 19.
Search queries are answered in astraightforward manner, analogously tothe k-d-tree algorithms. For the inser-tion of a new data point, one first per-forms a point search to locate the rightbucket. If it is not full, the entry isinserted. Otherwise, it is split and
about half the entries are shifted to thenew data node. Various heuristics areavailable to find an optimal split [Rob-inson 1981]. If the parent index nodedoes not have enough space left to ac-commodate the new entries, a new pageis allocated and the index node is splitby a hyperplane. The entries are dis-tributed among the two pages depend-ing on their position relative to thesplitting hyperplane, and the split ispropagated up the tree. The split of theindex node may also affect regions atlower levels of the tree, which must besplit by this hyperplane as well. Be-cause of this forced split effect, it is notpossible to guarantee a minimum stor-age utilization.
Deletion is straightforward. After per-forming an exact match query, the entryis removed. If the number of entriesdrops below a given threshold, the datanode may be merged with a sibling datanode as long as the union remains ad-dimensional interval. The procedureto find a suitable sibling node to mergewith may involve several nodes. Theunion of data pages results in the dele-tion of at least one hyperplane in the
Figure 19. k-d-B-tree.
192 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

parent index node. If an underflow oc-curs, the deletion has to be propagatedup the tree.
4.2.2 The LSD-Tree [Henrich et al.1989]. We list the LSD (Local Split De-cision) tree as a point access methodalthough its inventors emphasize thatthe structure can also be used for man-aging extended objects. This claim isbased on the fact that the LSD-treeadapts well to data that are nonuni-formly distributed and that it is there-fore well-suited for use in connectionwith the transformation technique; amore detailed discussion of this ap-proach appears in Section 5.1.1.
The directory of the LSD-tree is orga-nized as an adaptive k-d-tree, partition-ing the universe into disjoint cells ofvarious sizes. This results in a betteradaption to the data distribution thanthe fixed binary partitioning. Althoughthe k-d-tree may be arbitrarily unbal-anced, the LSD-tree preserves the ex-ternal balancing property; that is, theheights of its external subtrees differ atmost by one. This property is main-tained by a special paging algorithm. Ifthe structure becomes too large to fit inmain memory, this algorithm identifiessubtrees that can be paged out suchthat the external balancing property ispreserved. Although efficient, this spe-cial paging strategy is obviously a majorimpediment for the integration of theLSD-tree into a general-purpose data-base system. Figure 20 shows an LSD-
tree for the running example with oneexternal directory page.
As indicated previously, the splitstrategy of the LSD-tree does not as-sume the data to be uniformly distrib-uted. On the contrary, it tries to accom-modate skewed data by combining twosplit strategies:
—data-dependent (SP1): The choice ofthe split depends on the data andtries to achieve a most balancedstructure; that is, there should be anequal number of objects on both sidesof the split. As the name of the struc-ture suggests, this split decision ismade locally.
—distribution-dependent (SP2): Thesplit is done at a fixed dimension andposition. The given data are not takeninto account because an underlying(known) distribution is assumed.
To determine the split position SP, onecomputes the linear combination of thesplit locations that would result fromapplying just one of those strategies:
SP 5 aSP1 1 ~1 2 a!SP2 .
The factor a is determined empiricallybased on the given data; it can vary asobjects are inserted and deleted fromthe tree.
Henrich [1995] presented two algo-rithms to improve the storage utiliza-tion of the LSD-tree by redistributingdata entries among buckets. Since these
Figure 20. LSD-tree.
Multidimensional Access Methods • 193
ACM Computing Surveys, Vol. 30, No. 2, June 1998

strategies make the LSD-tree sensitiveto the insertion sequence, the splittingstrategy must be adapted accordingly.In order to improve the search perfor-mance for nonpoint data and range que-ries, Henrich and Moller [1995] suggeststoring auxiliary information on the ex-isting data regions along with the indexentries of the LSD-tree.
4.2.3 The Buddy Tree [Seeger andKriegel 1990]. The buddy tree is a dy-namic hashing scheme with a tree-structured directory. The tree is con-structed by consecutive insertion,cutting the universe recursively intotwo parts of equal size with iso-orientedhyperplanes. Each interior node n corre-sponds to a d-dimensional partitionPd(n) and to an interval Id(n) # Pd(n).Id(n) is the MBB of the points or inter-vals below n. Partitions Pd (and there-fore intervals Id) that correspond tonodes on the same tree level are mutu-ally disjoint. As in all tree-based struc-tures, the leaves of the directory pointto the data pages. Other importantproperties of the buddy tree include:
(1) each directory node contains at leasttwo entries;
(2) whenever a node n is split, theMBBs Id(ni) and Id(nj) of the tworesulting subnodes ni and nj are re-computed to reflect the current situ-ation; and
(3) except for the root of the directory,there is exactly one pointer refer-ring to each directory page.
Due to property 1, the buddy tree maynot be balanced; that is, the leaves ofthe directory may be on different levels.Property 2 tries to achieve a high selec-tivity at the directory level. Properties 1and 3 make sure that the growth of thedirectory remains linear. To avoid thedeadlock problem of the grid file, thebuddy tree uses k-d-trees [Orenstein1982] to partition the universe. Only arestricted number of buddies are admit-ted, namely, those that could have beenobtained by some recursive halving ofthe universe. However, as shown by
Seeger and Kriegel [1990], the numberof possible buddies is larger than in thegrid file and other structures, whichmakes the buddy tree more flexible inthe case of updates. Experiments byKriegel et al. [1990] indicate that thebuddy tree is superior to several otherPAMs, including the hB-tree, the BANGfile, and the two-level grid file. A buddytree for the running example is shownin Figure 21.
Two older structures, the interpola-tion-based grid file by Ouksel [1985]and the balanced multidimensional ex-tendible hash tree by Otoo [1986], areboth special cases of the buddy tree thatcan be obtained by restricting the prop-erties of the regions. Interpolation-based grid files avoid the excessivegrowth of the grid file directory by rep-resenting blocks explicitly, which guar-antees that there is only one directoryentry for each data bucket. The disad-vantage of this approach is that emptyregions have to be introduced in thecase of skewed data input. Seeger[1991] later showed that the buddy treecan easily be modified to handle spa-tially extended objects by using one ofthe techniques presented in Section 5.
4.2.4 The BANG File [Freeston1987]. To obtain a better adaption tothe given data points, Freeston [1987]proposed a new structure, which hecalled the BANG (Balanced And NestedGrid) file—even though it differs fromthe grid file in many aspects. Similar tothe grid file, it partitions the universeinto intervals (boxes). What is different,however, is that in the BANG filebucket regions may intersect, which isnot possible in the regular grid file. Inparticular, one can form nonrectangularbucket regions by taking the geometricdifference of two or more intervals(nesting). To increase storage utiliza-tion, it is possible during insertion toredistribute points between differentbuckets. To manage the directory, theBANG file uses a balanced search treestructure. In combination with thehash-based partitioning of the universe,
194 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

the BANG file can therefore be viewedas a hybrid structure.
Figure 22 shows the BANG file for therunning example. Three rectangles havebeen cut out of the universe R1: R2, R5,and R6. In turn, the rectangles R3 andR4 are nested into R2 and R5, respec-tively. If one represents the resultingspace partitioning as a tree using bitinterleaving, one obtains the structureshown on the right-hand side of Figure22. Here the asterisk represents theempty string, that is, the universe. Acomparison with Figure 13 shows thatthe BANG file can in fact be regarded asa paginated version of the BD-tree dis-cussed in Section 3.2.3.
In order to achieve a high storageutilization, the BANG file performsspanning splits that may lead to thedisplacement of parts of the tree. As aresult, a point search may in the worstcase require the traversal of the entiredirectory in a depth-first manner. Toaddress this problem, Freeston [1989a]later proposed different splitting strate-gies, including forced splits as used bythe k-d-B-tree. These strategies avoid
the spanning problem at the possibleexpense of lower storage utilization. Ku-mar [1994a] made a similar proposalbased on the BD-tree and called theresulting structure a G-tree (grid tree).The structure differs from the BD-treein the way the partitions are mappedinto buckets. To obtain a simpler map-ping, the G-tree sacrifices the minimumstorage utilization that holds for theBD-tree.
Although the data partitioning givenin Figure 22 is feasible for the BD-treeand the original BANG file, it cannot beachieved with the BANG file usingforced splits [Freeston 1989a]. For thisvariant, we would have to split the rootand move, for example, entry c5 to thebucket containing the entries p7 and c6.
Freeston [1989b] also proposed an ex-tension to the BANG file to handle ex-tended objects. As often found in PAMextensions, the centroid is used to deter-mine the bucket in which to place agiven object. To account for the object’sspatial extension, the bucket regionsare extended where necessary [Seegerand Kriegel 1988; Ooi 1990].
Figure 21. Buddy tree.
Multidimensional Access Methods • 195
ACM Computing Surveys, Vol. 30, No. 2, June 1998

Ouksel and Mayer [1992] proposed anaccess method called a nested interpola-tion-based grid file that is closely re-lated to the BANG file. The major dif-ference concerns the way the directoryis organized. In essence, the directoryconsists of a list of one-dimensional ac-cess methods (e.g., B-trees) storing thez-order encoding of the different dataregions, along with pointers to the re-spective data buckets. By doing so, Ouk-sel and Mayer improved the worst-casebounds from O(n) (as in the case of theBANG file) to O(logb n), where b isbucket size.
4.2.5 The hB-Tree [Lomet and Salz-berg 1989, 1990]. The hB-tree (holeybrick tree) is related to the k-d-B-tree inthat it utilizes k-d-trees to organize thespace represented by its interior nodes.One of the most noteworthy differencesis that node splitting is based on multi-ple attributes. As a result, nodes nolonger correspond to d-dimensional in-tervals but to intervals from whichsmaller intervals have been excised.Similar to the BANG file, the result is asomewhat fractal structure (a holeybrick) with an external enclosing regionand several cavities called extracted re-gions. As we show later, this techniqueavoids the cascading of splits that istypical for many other structures.
In order to minimize redundancy, thek-d-tree corresponding to an interiornode can have several leaves pointing tothe same child node. Strictly speaking,the hB-tree is therefore no longer a tree
but a directed acyclic graph. With re-gard to the geometry, this correspondsto the union of the corresponding re-gions. Once again, the resulting regionis typically no longer box-shaped. Thispeculiarity is illustrated in Figure 23,which shows an hB-tree for the runningexample. Here the root node containstwo pointers to its left descendant node.Its corresponding region u is the unionof two rectangles: the one to the left ofx1 and the one above y1. The remainingspace (the right lower quadrant) is ex-cluded from u, which is made explicit bythe entry ext in the corresponding k-d-tree. A similar observation applies toregion G, which is again L-shaped: itcorresponds to the NW, the SE, and theNE quadrants of the rectangle above y1.
Searching is similar to the k-d-B-tree;each internal k-d-tree is traversed asusual. Insertions are also carried outanalogously to the k-d-B-tree until aleaf node reaches its capacity and a splitis required. Instead of using just onesingle hyperplane to split the node, thehB-tree split is based on more than oneattribute and on the internal k-d-tree ofthe data node to be split. Lomet andSalzberg [1989] show that this policyguarantees a worst-case data distribu-tion between the two resulting twonodes of 1
3 : 23. This observation is not
restricted to the hB-tree but generalizesto other access methods such as theBD-tree and the BANG file.
The split of the leaf node causes theintroduction of an additional k-d-tree
Figure 22. BANG file.
196 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

node to describe the resulting subspace.This may in turn lead to the split of theancestor node and its k-d-tree. Sincek-d-trees are not height-balanced, split-ting the tree at its root may lead to anunbalanced distribution of the nodes.The tree is therefore usually split at alower level, which corresponds to theexcision of a convex region from thespace corresponding to the node to besplit. The entries belonging to that sub-space are extracted and moved to a newhB-tree node. To reflect the absence ofthe excised region, the hB-tree node isassigned an external marker, which in-dicates that the region is no longer asimple interval. With this technique theproblem of forced splits is avoided.Splits are local and do not have to bepropagated downwards.
In summary, the leaf nodes of theinternal k-d-trees are used to
—reference a collection of data records;—reference other hB-tree nodes;—indicate that a part of this tree has
been extracted.
In a later Ph.D. thesis [Evangelidis1994], the hB-tree is extended to allowfor concurrency and recovery by modify-ing it in such a way that it becomes aspecial case of the P-tree [Lomet andSalzberg 1992]. Consequently, the newstructure is called the hBP-tree [Evan-gelidis et al. 1995]. As a result of thesemodifications, the new structure canimmediately take advantage of the
P-tree node consolidation algorithm.The lack of such an algorithm has beenone of the major weaknesses of the hB-tree. Furthermore, the hBP-tree cor-rects a flaw in the splitting/posting al-gorithm of the hB-tree that may occurfor more than three index levels. Theessential idea of the correction is toimpose restrictions on the splitting/posting algorithms, which in turn af-fects the space occupancy.
One minor problem remains: as men-tioned, the hB-tree may store severalreferences to the same child node. Thenumber of nodes may in principle ex-pose a growth behavior that is superlin-ear in the number of regions; however,this observation seems of mainly theo-retical interest. According to the au-thors of the hBP-tree [Evangelidis et al.1995], it is quite rare that more thanone leaf of the underlying k-d tree refersto any given child. In their experiments,more than 95% of the index nodes andall of the data nodes had only one suchreference.
4.2.6 The BV-Tree [Freeston 1995].The BV-tree represents an attempt tosolve the d-dimensional B-tree problem,that is, to find a generic generalizationof the B-tree to higher dimensions. TheBV-tree is not meant to be a concreteaccess method, but rather a conceptualframework that can be applied to a va-riety of existing access methods, includ-ing the BANG file or the hB-tree.
Freeston’s proposal is based on the
Figure 23. hB-tree.
Multidimensional Access Methods • 197
ACM Computing Surveys, Vol. 30, No. 2, June 1998

conjecture that one can maintain themajor strengths of the B-tree in higherdimensions, provided one relaxes thestrict requirements concerning treebalance and storage utilization. The BV-tree is not completely balanced. Fur-thermore, although the B-tree guaran-tees a worst-case storage utilization of50%, Freeston argues that such a com-paratively high storage utilization can-not be ensured for higher dimensionsfor topological reasons. However, theBV-tree manages to achieve the 33%lower bound suggested by Lomet andSalzberg [1989].
To achieve a guaranteed worst-casesearch performance, the BV-tree com-bines the excision concept [Freeston1987] with a technique called promo-tion. Here, intervals from lower levels ofthe tree are moved up the tree, that is,closer to the root. To keep track of theresulting changes, with each promotedregion we store a level number (called aguard) that denotes the region’s originallevel.
The search algorithms are based on anotional backtracking technique. Whiledescending the tree, we store possiblealternatives (relevant guards of the dif-ferent index levels) in a guard set. Theentries of this set act as backtrackingpoints and represent a single path fromthe root to the level currently inspected;for point queries, they can be main-tained as a stack. To answer a pointquery, we start at the root and inspectall node entries to see whether the cor-
responding regions overlap the searchpoint. Among those entries inspected,we choose the best-matching entry toinvestigate next. We may possibly alsostore some guards in the guard set. Atthe next level this procedure is repeatedrecursively, this time taking the storedguards into account. Before followingthe best-matching entry down to thenext level, the guard set is updated bymerging the matching new guards withthe existing ones. Two guards at thesame level are merged by discarding thepoorer match. This search continues re-cursively until we reach the leaf level.Note that for point queries, the lengthof the search path is equal to the heightof the BV-tree because each region inspace is represented by a unique nodeentry.
Figure 24 shows a BV-tree and thecorresponding space partitioning for therunning example. For illustration pur-poses we confine the grouped regions orobjects not by a tight polyline, but by aloosely wrapped boundary. In this ex-ample, the region D0 acts as a guard. Itis clear from the space partitioning thatD0 originally belongs to the bottom in-dex level (i.e., the middle level in thefigure). Since it functions as a guard forthe enclosed region S1, however, it hasbeen promoted to the root level. Sup-pose we are interested in all objectsintersecting the black rectangle X.Starting at the root, we place D0 in theguard set and investigate S1. Becauseinspection of S1 reveals that the search
Figure 24. BV-tree.
198 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

region is included neither in P0 nor inN0 or M0, we backtrack to D0 and in-spect the entries for D0. In our example,no entry satisfies the query.
In a later paper, Freeston [1997] dis-cusses complexity issues related to up-dates of guards. In the presence of suchupdates, it is necessary to “downgrade”(demote) entries that are no longerguards, which may in turn affect theoverall structure negatively. Freeston’sconclusion is that the logarithmic accessperformance and the minimum storageutilization of the BV-tree can be pre-served by postponing the demotion ofsuch entries, which may lead to (very)large index nodes.
4.3 Space-Filling Curves for Point Data
We already mentioned the main reasonwhy the design of multidimensional ac-cess methods is so difficult compared tothe one-dimensional case: There is nototal order that preserves spatial prox-imity. One way out of this dilemma is tofind heuristic solutions, that is, to lookfor total orders that preserve spatialproximity at least to some extent. Theidea is that if two objects are locatedclose together in original space, thereshould at least be a high probabilitythat they are close together in the totalorder, that is, in the one-dimensionalimage space. For the organization ofthis total order one could then use aone-dimensional access method (such asa B1-tree), which may provide good per-formance at least for point queries.Range queries are somewhat more com-plicated; a simple mapping from multi-dimensional to one-dimensional rangequeries often implies major performancepenalties. Tropf and Herzog [1981]present a more sophisticated and effi-cient algorithm for this problem.
Research on the underlying mappingproblem goes back well into the lastcentury; see Sagan [1994] for a survey.With regard to its relevance for spatialsearching, Samet [1990b] provides agood overview of the subject. One thingall proposals have in common is that
they first partition the universe with agrid. Each of the grid cells is labeledwith a unique number that defines itsposition in the total order (the space-filling curve). The points in the givendata set are then sorted and indexedaccording to the grid cell in which theyare contained. Note that although thelabeling is independent of the givendata, it is obviously critical for the pres-ervation of proximity in one-dimen-sional address space. That is, the waywe label the cells determines how clus-tered adjacent cells are stored on sec-ondary memory.
Figure 25 shows four common label-ings. Figure 25a corresponds to a row-wise enumeration of the cells [Samet1990b]. Figure 25b shows the cell enu-meration imposed by the Peano curve[Morton 1966], also called quad codes[Finkel and Bentley 1974], N-trees[White 1981], locational codes [Abel andSmith 1983], or z-ordering [Orensteinand Merrett 1984]. Figure 25c showsthe Hilbert curve [Faloutsos and Rose-man 1989; Jagadish 1990a], and Figure25d depicts Gray ordering [Faloutsos1986, 1988], which is obtained by inter-leaving the Gray codes of the x- andy-coordinates in a bitwise manner. Graycodes of successive cells differ in exactlyone bit.
Based on several experiments, Abeland Mark [1990] conclude that z-order-ing and the Hilbert curve are most suit-able as multidimensional access meth-ods. Jagadish [1990a] and Faloutsosand Rong [1991] all prefer the Hilbertcurve of those two.
Z-ordering is one of the few spatialaccess methods that has found its wayinto commercial database products. Inparticular, Oracle [1995] has adaptedthe technique and offered it for sometime as a product.
An important advantage of all space-filling curves is that they are practicallyinsensitive to the number of dimensionsif the one-dimensional keys can be arbi-trarily large. Everything is mapped intoone-dimensional space, and one’s favor-ite one-dimensional access method can
Multidimensional Access Methods • 199
ACM Computing Surveys, Vol. 30, No. 2, June 1998

be applied to manage the data. An obvi-ous disadvantage of space-filling curvesis that incompatible index partitionscannot be joined without recomputingthe codes of at least one of the twoindices.
5. SPATIAL ACCESS METHODS
All multidimensional access methodspresented in the previous section havebeen designed to handle sets of datapoints and support spatial searches onthem. None of those methods is directlyapplicable to databases containing ob-jects with a spatial extension. Typicalexamples include geographic databases,containing mostly polygons, or mechan-ical CAD data, consisting of three-di-mensional polyhedra. In order to handlesuch extended objects, point accessmethods have been modified using oneof the techniques:
(1) transformation (object mapping),(2) overlapping regions (object bound-
ing),(3) clipping (object duplication), or(4) multiple layers.
A simpler version of this classificationwas first introduced by Seeger and Krie-gel [1988]. Later on, Kriegel et al.[1991] added another dimension to thistaxonomy: a spatial access method’sbase type, that is, the spatial data typeit supports primarily. Table 2 shows theresulting classification of spatial accessmethods. Note that most structures usethe interval as a base type.
In the following sections, we presenteach of these techniques in detail, to-gether with several SAMs based on it.
5.1 Transformation
One-dimensional access methods (Sec-tion 3.1) and PAMs (Section 4) can oftenbe used to manage spatially extendedobjects, provided the objects are firsttransformed into a different representa-tion. There are essentially two options:one can either transform each objectinto a higher-dimensional point [Hin-richs 1985; Seeger and Kriegel 1988], ortransform it into a set of one-dimen-sional intervals by means of space-fill-ing curves. We discuss the two tech-niques in turn.
Figure 25. Four space-filling curves.
200 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998
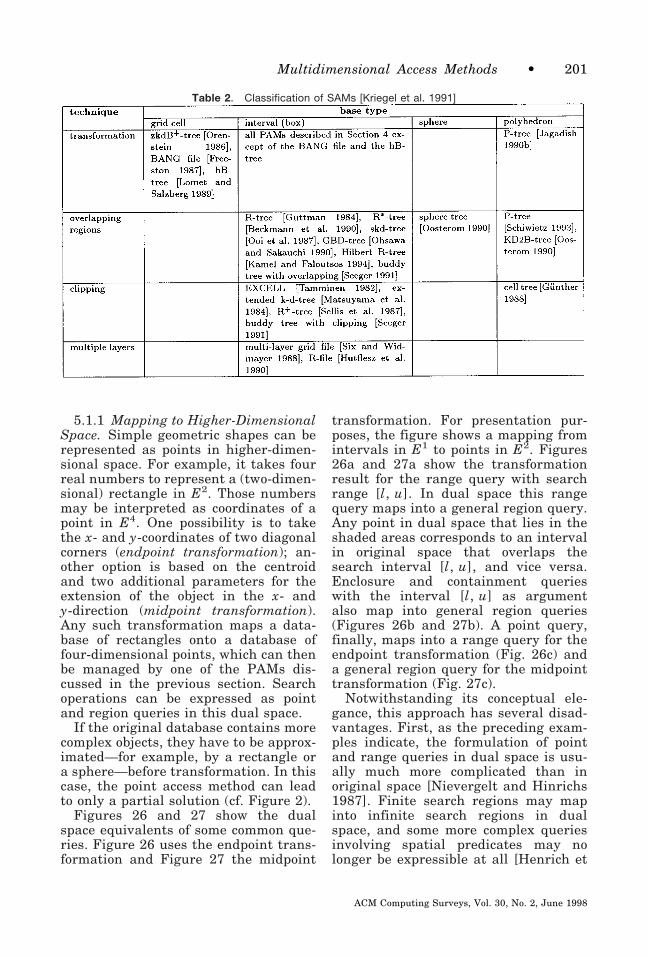
5.1.1 Mapping to Higher-DimensionalSpace. Simple geometric shapes can berepresented as points in higher-dimen-sional space. For example, it takes fourreal numbers to represent a (two-dimen-sional) rectangle in E2. Those numbersmay be interpreted as coordinates of apoint in E4. One possibility is to takethe x- and y-coordinates of two diagonalcorners (endpoint transformation); an-other option is based on the centroidand two additional parameters for theextension of the object in the x- andy-direction (midpoint transformation).Any such transformation maps a data-base of rectangles onto a database offour-dimensional points, which can thenbe managed by one of the PAMs dis-cussed in the previous section. Searchoperations can be expressed as pointand region queries in this dual space.
If the original database contains morecomplex objects, they have to be approx-imated—for example, by a rectangle ora sphere—before transformation. In thiscase, the point access method can leadto only a partial solution (cf. Figure 2).
Figures 26 and 27 show the dualspace equivalents of some common que-ries. Figure 26 uses the endpoint trans-formation and Figure 27 the midpoint
transformation. For presentation pur-poses, the figure shows a mapping fromintervals in E1 to points in E2. Figures26a and 27a show the transformationresult for the range query with searchrange [l, u]. In dual space this rangequery maps into a general region query.Any point in dual space that lies in theshaded areas corresponds to an intervalin original space that overlaps thesearch interval [l, u], and vice versa.Enclosure and containment querieswith the interval [l, u] as argumentalso map into general region queries(Figures 26b and 27b). A point query,finally, maps into a range query for theendpoint transformation (Fig. 26c) anda general region query for the midpointtransformation (Fig. 27c).
Notwithstanding its conceptual ele-gance, this approach has several disad-vantages. First, as the preceding exam-ples indicate, the formulation of pointand range queries in dual space is usu-ally much more complicated than inoriginal space [Nievergelt and Hinrichs1987]. Finite search regions may mapinto infinite search regions in dualspace, and some more complex queriesinvolving spatial predicates may nolonger be expressible at all [Henrich et
Table 2. Classification of SAMs [Kriegel et al. 1991]
Multidimensional Access Methods • 201
ACM Computing Surveys, Vol. 30, No. 2, June 1998

al. 1989; Orenstein 1990; Pagel et al.1993]. Second, depending on the map-ping chosen, the distribution of pointsin dual space may be highly nonuniformeven though the original data are uni-formly distributed. With the endpointtransformation, for example, there areno image points below the main diago-nal [Faloutsos et al. 1987]. Third, theimages of two objects that are close inthe original space may be arbitrarily farapart from each other in dual space.
To overcome some of these problems,Henrich et al. [1989], Faloutsos andRong [1991], as well as Pagel et al.[1993] have proposed special transfor-mation and split strategies. A structuredesigned explicitly to be used in connec-tion with the transformation techniqueis the LSD-tree (cf. Section 4.2.2). Per-formance studies by Henrich and Six[1991] confirm the claim that the LSD-tree adapts well to nonuniform distribu-tions, which is of particular relevance inthis context. It also contains a mecha-
nism to avoid searching large emptyquery spaces, which may occur as aresult of the transformation.
5.1.2 Space-Filling Curves for Ex-tended Objects. Space-filling curves (cf.Section 4.3) are a very different type oftransformation approach that seems tohave fewer of the drawbacks listed inthe previous section. Space-fillingcurves can be used to represent ex-tended objects by a list of grid cells or,equivalently, a list of one-dimensionalintervals that define the position of thegrid cells concerned. In other words, acomplex spatial object is approximatednot by only one simpler object, but bythe union of several such objects. Thereare different variations of this basicconcept, including z-ordering [Orensteinand Merrett 1984], the Hilbert R-tree[Kamel and Faloutsos 1994], and theUB-tree [Bayer 1996]. As an example,we discuss z-ordering in more detail.
Figure 26. Search queries in dual space—endpoint transformation: (a) intersection query; (b) contain-ment/enclosure queries; (c) point query.
Figure 27. Search queries in dual space—midpoint transformation: (a) intersection query; (b) contain-ment/enclosure queries; (c) point query.
202 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

For a discussion of the Hilbert R-tree,see Section 5.2.1.
Z-ordering [Orenstein and Merrett1984] is based on the Peano curve. Asimple algorithm to obtain the z-order-ing representation of a given extendedobject can be described as follows. Start-ing from the (fixed) universe containingthe data object, space is split recur-sively into two subspaces of equal sizeby (d 2 1)-dimensional hyperplanes. Asin the k-d-tree, the splitting hyper-planes are iso-oriented, and their direc-tions alternate in fixed order among thed possibilities. The subdivision contin-ues until one of the following conditionsholds.
(1) The current subspace does not over-lap the data object.
(2) The current subspace is fully en-closed in the data object.
(3) Some given level of accuracy hasbeen reached.
The data object is thus represented bya set of cells, called Peano regions orz-regions. As shown in Section 3.2.3,each such Peano region can be repre-sented by a unique bit string, calledPeano code, ST_MortonNumber, z-value,or DZ-expression. Using those bitstrings, the cells can then be stored in astandard one-dimensional index, suchas a B1-tree.
Figure 28 shows a simple example.Figure 28a shows the polygon to be ap-proximated, with the frame represent-
ing the universe. After several splits,starting with a vertical split line, weobtain Figure 28b. Nine Peano regionsof different shapes and sizes approxi-mate the object. The labeling of eachPeano region is shown in Figure 28c.Consider the Peano region z# in thelower left part of the given polygon. Itlies to the left of the first vertical hyper-plane and below the first horizontal hy-perplane, resulting in the first two bitsbeing 00. As we further partition thelower left quadrant, z# lies on the left ofthe second vertical hyperplane butabove the second horizontal hyperplane.The complete bit string accumulated sofar is therefore 0001. In the next roundof decompositions, z# lies to the right ofthe third vertical hyperplane and abovethe third horizontal hyperplane, result-ing in two additional 1s. The completebit string describing z# is therefore000111.
Figures 28b and 28c also give somebit strings along the coordinate axes,which describe only the splits orthogo-nal to the given axis. The string 01 onthe x-axis, for example, describes thesubspace to the left of the first verticalsplit and to the right of the second ver-tical split. By bit-interleaving the bitstrings that one finds when projecting aPeano region onto the coordinate axes,we obtain its Peano code. Note that if aPeano code z1 is the prefix of some otherPeano code z2, the Peano region corre-sponding to z1 encloses the Peano re-
Figure 28. Z-ordering of a polygon.
Multidimensional Access Methods • 203
ACM Computing Surveys, Vol. 30, No. 2, June 1998

gion corresponding to z2. The Peano re-gion corresponding to 00, for example,encloses the regions corresponding to0001 and 000. This is an important ob-servation, since it can be used for queryprocessing [Gaede and Riekert 1994].Figure 29 shows Peano regions for therunning example.
As z-ordering is based on an underly-ing grid, the resulting set of Peano re-gions is usually only an approximationof the original object. The terminationcriterion depends on the accuracy orgranularity (maximum number of bits)desired. More Peano regions obviouslyyield more accuracy, but they also in-crease the size and complexity of theapproximation. As pointed out by Oren-stein [1989b], there are two possiblyconflicting objectives: the number ofPeano regions to approximate the objectshould be small, since this results infewer index entries; and the accuracy ofthe approximation should be high, sincethis reduces the expected number offalse drops [Orenstein 1989a, b; Gaede1995b]. Objects are thus paged in fromsecondary memory, only to find out that
they do not satisfy the search predicate.A simple way to reduce the number offalse drops is to add a single bit to theencoding that reflects for each Peanoregion whether it is completely enclosedin the original object [Gaede 1995a]. Anadvantage of z-ordering is that localchanges of granularity lead to only localchanges of the corresponding encoding.
5.2 Overlapping Regions
The key idea of the overlapping regionstechnique is to allow different databuckets in an access method to corre-spond to mutually overlapping sub-spaces. With this method we can assignany extended object directly and as awhole to one single bucket region. Con-sider, for instance, the k-d-B-tree forthe running example, depicted in Figure19, and one of the polygons given in thescenario (Figure 9), say r10. r10 over-laps two bucket regions, the one con-taining p10, c1, and c2, and the otherone containing c10 and p9. If we extendone of those regions to accommodater10, this polygon could be stored in the
Figure 29. Z-ordering.
204 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

corresponding bucket. Note, however,that this extension inevitably leads toan overlap of regions.
Search algorithms can be applied al-most unchanged. The only differencesare due to the fact that the overlap mayincrease the number of search paths wehave to follow. Even a point query mayrequire the investigation of multiplesearch paths because there may be sev-eral subspaces at any index level thatinclude the search point. For range andregion queries, the average number ofsearch paths increases as well.
Hence, although functionality is not aproblem when using overlapping re-gions, performance can be. This is par-ticularly relevant when the spatial da-tabase contains objects whose size islarge relative to the size of the universe.Typical examples are known from geo-graphic applications where one mustrepresent objects of widely varying size(such as buildings and states) in thesame spatial database. Each insertionof a new data object may increase theoverlap and therefore the average num-ber of search paths to be traversed perquery. Eventually, the overlap betweensubspaces may become large enough torender the index ineffective because oneends up searching most of the index foreach single query. A well-known exam-ple where this degenerate behavior hasbeen observed is the R-tree [Guttman1984; Greene 1989]. Several modifica-tions have been presented to mitigatethese problems, including a technique tominimize the overlap [Roussopoulos andLeifker 1985]; see Section 5.2.1 for adetailed discussion.
A minor problem with overlapping re-gions concerns ambiguities during in-sertion. If we insert a new object, wecould in principle enlarge any subspaceto accommodate it. To optimize perfor-mance, there exist several strategies[Pagel et al. 1993]. For example, wecould try to find the subspace thatcauses minimal additional overlap, orthe one that requires the least enlarge-ment. If it takes too long to compute the
optimal strategy for every insertion,some heuristic may be used.
When a subspace needs to be split,one also tries to find a split that leads tominimal overall overlap. Guttman[1984], Greene [1989], and Beckmann etal. [1990] suggest some heuristics forthis problem.
5.2.1 The R-Tree [Guttman 1984]. AnR-tree corresponds to a hierarchy ofnested d-dimensional intervals (boxes).Each node n of the R-tree corresponds toa disk page and a d-dimensional inter-val Id(n). If n is an interior node thenthe intervals corresponding to the de-scendants ni of n are contained in Id(n).Intervals at the same tree level mayoverlap. If n is a leaf node, Id(n) is thed-dimensional minimum bounding boxof the objects stored in n. For each objectin turn, n stores only its MBB and areference to the complete object descrip-tion. Other properties of the R-tree in-clude the following.
—Every node contains between m andM entries unless it is the root. Thelower bound m prevents the degener-ation of trees and ensures an efficientstorage utilization. Whenever thenumber of a node’s descendants dropsbelow m, the node is deleted and itsdescendants are distributed amongthe sibling nodes (tree condensation).The upper bound M can be derivedfrom the fact that each tree node cor-responds to exactly one disk page.
—The root node has at least two entriesunless it is a leaf.
—The R-tree is height-balanced; that is,all leaves are at the same level. Theheight of an R-tree is at mostlogm (N) for N index records (N . 1).
Searching in the R-tree is similar tothe B-tree. At each index node n, allindex entries are tested to see whetherthey intersect the search interval Is. Wethen visit all child nodes ni with Id(ni) ùIs Þ À. Due to the overlapping regionparadigm, there may be several inter-vals Id(ni) that satisfy the search predi-cate. In the worst case, one may have to
Multidimensional Access Methods • 205
ACM Computing Surveys, Vol. 30, No. 2, June 1998

visit every index page. Figure 30 showsan R-tree for the running example. Re-member that the mi denote the MBBs ofthe polygonal data objects ri. A pointquery with search point X results in twopaths: R8 3 R4 3 m7 and R7 3 R3 3m5.
Because the R-tree only managesMBBs, it cannot solve a given searchproblem completely unless, of course,the actual data objects are interval-shaped. Otherwise the result of an R-tree query is a set of candidate objects,whose actual spatial extent has to betested for intersection with the searchspace (cf. Fig. 2). This step, which mayinvolve additional disk accesses andconsiderable computation, has not beentaken into account in most publishedperformance analyses [Guttman 1984;Greene 1989].
To insert an object o, we insert theminimum bounding interval Id(o) andan object reference into the tree. In con-trast to searching, we traverse only asingle path from the root to the leaf. Ateach level we choose the child node nwhose corresponding interval Id(n)needs the least enlargement to enclosethe data object’s interval Id(o). If sev-eral intervals satisfy this criterion,Guttman proposes selecting the descen-dant associated with the smallest inter-val. As a result, we insert the objectonly once; that is, the object is not dis-persed over several buckets. Once wehave reached the leaf level, we try toinsert the object. If this requires an
enlargement of the correspondingbucket region, we adjust it appropri-ately and propagate the change up-wards. If there is not enough space leftin the leaf, we split it and distribute theentries among the old and the new page.Once again, we adjust each of the newintervals accordingly and propagate thesplit up the tree.
As for deletion, we first perform anexact match query for the object inquestion. If we find it in the tree, wedelete it. If the deletion causes no un-derflow, we check whether the boundinginterval can be reduced in size. If so, weperform this adjustment and propagateit upwards. If the deletion causes nodeoccupation to drop below m, however,we copy the node content into a tempo-rary node and remove it from the index.We then propagate the node removal upthe tree, which typically results in theadjustment of several bounding inter-vals. Afterwards we reinsert all or-phaned entries of the temporary node.Alternatively, we can merge the or-phaned entries with sibling entries. Inboth cases, one may again have to ad-just bounding intervals further up thetree.
In his original paper, Guttman [1984]discusses various policies to minimizethe overlap during insertion. For nodesplitting, for example, Guttman sug-gests several algorithms, including asimpler one with linear time complexityand a more elaborate one with qua-dratic complexity. Later work by other
Figure 30. R-tree.
206 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

researchers led to the development ofmore sophisticated policies. The packedR-tree [Roussopoulos and Leifker 1985],for example, computes an optimal parti-tioning of the universe and a corre-sponding minimal R-tree for a givenscenario. However, it requires all datato be known a priori.
Other interesting variants of the R-tree include the sphere tree by Oosterom[1990] and the Hilbert R-tree by Kameland Faloutsos [1994]. The sphere treecorresponds to a hierarchy of nestedd-dimensional spheres rather than in-tervals. The Hilbert R-tree combines theoverlapping regions technique withspace-filling curves (cf. Section 4.3). Itfirst stores the Hilbert values of thedata rectangles’ centroids in a B1-tree,then enhances each interior B1-treenode by the MBB of the subtree below.This facilitates the insertion of new ob-jects considerably. Together with a re-vised splitting policy, Kamel and Fa-loutsos report good performance resultsfor both searches and updates. How-ever, since their splitting policy takesonly the objects’ centroids into account,the performance of the structure islikely to deteriorate in the presence oflarge objects.
Ng and Kameda [1993] discuss how tosupport concurrency in R-trees byadopting the lock-coupling technique ofB-trees [Bayer and Schkolnick 1977] toR-trees. Similarly, Ng and Kameda[1994] and Kornacker and Banks [1995]apply ideas of the B-link tree [Lehman
and Yao 1981] to R-trees, yielding twostructures both called the R-link tree.Kornacker and Banks empirically dem-onstrate that their R-link tree is supe-rior to the R-tree using lock-coupling.
5.2.2 The R*-Tree [Beckmann et al.1990]. Based on a careful study of R-tree behavior under different data dis-tributions, Beckmann et al. [1990] iden-tified several weaknesses of the originalalgorithms. In particular, they con-firmed the observation of Roussopoulosand Leifker [1985] that the insertionphase is critical for good search perfor-mance. The design of the R*-tree (seeFigure 31) therefore introduces a policycalled forced reinsert: If a node over-flows, it is not split right away. Rather,p entries are removed from the nodeand reinserted into the tree. The pa-rameter p may vary; Beckmann et al.suggest it should be about 30% of themaximal number of entries per page.
Another issue investigated by Beck-mann et al. concerns the node-splittingpolicy. Although Guttman’s R-tree algo-rithms tried only to minimize the areacovered by the bucket regions, the R*-tree algorithms also take the followingobjectives into account.
—Overlap between bucket regions atthe same tree level should be mini-mized. The less overlap, the smallerthe probability that one has to followmultiple search paths.
—Region perimeters should be mini-mized. The preferred rectangle is the
Figure 31. R*-tree.
Multidimensional Access Methods • 207
ACM Computing Surveys, Vol. 30, No. 2, June 1998

square, since this is the most compactrectangular representation.
—Storage utilization should be maxi-mized.
The improved splitting algorithm ofBeckmann et al. [1990] is based on theplane-sweep paradigm [Preparata andShamos 1985]. In d dimensions, its timecomplexity is O(d z n z log n) for a nodewith n intervals.
In summary, the R*-tree differs fromthe R-tree mainly in the insertion algo-rithm; deletion and searching are essen-tially unchanged. Beckmann et al. re-port performance improvements of up to50% compared to the basic R-tree. Theirimplementation also shows that reinser-tion may improve storage utilization. Inbroader comparisons, however, Hoeland Samet [1992] and Gunther andGaede [1997] found that the CPU timeoverhead of reinsertion can be substan-tial, especially for large page sizes; seeSection 6 for further details.
One of the major insights of the R*-tree is that node splitting is critical forthe overall performance of the accessmethod. Since a naive (exhaustive) ap-proach has time complexity O(d z 2n) forn given intervals, there is a need forefficient and optimal splitting policies.Becker et al. [1992] proposed a polyno-mial time algorithm that finds a bal-anced split, which also optimizes one ofseveral possible objective functions(e.g., minimum sum of areas or mini-mum sum of perimeters). They assumein their analysis that the intervals arepresorted in some specific order. Morerecently, Ang and Tan [1997] presenteda new linear node splitting algorithm,based on a simple heuristic. Accordingto the results reported, it outperformsits competitors.
Berchtold et al. [1996] proposed amodification of the R-tree called the X-tree that seems particularly well suitedfor indexing high-dimensional data. TheX-tree reduces overlap among directoryintervals by using a new organization: itpostpones node splitting by introducingsupernodes, that is, nodes larger than
the usual block size. In order to find asuitable split, the X-tree also maintainsthe history of previous splits.
5.2.3 The P-Tree [Jagadish 1990c]. Inmany applications, intervals are not agood approximation of the data objectsenclosed. In order to combine the flexi-bility of polygon-shaped containers withthe simplicity of the R-tree, Jagadish[1990c] and Schiwietz [1993] indepen-dently proposed different variations ofpolyhedral trees or P-trees. To distin-guish the two structures, we refer to theP-tree of Jagadish [1990c] as the JP-treeand to the P-tree of Schiwietz [1993] asthe SP-tree.
The JP-tree first introduces a variablenumber m of orientations in the d-di-mensional universe, where m . d. Forinstance, in two dimensions (d 5 2) wemay have four orientations (m 5 4):two parallel to the coordinate axes (i.e.,iso-oriented) and two parallel to the twomain diagonals. Objects are approxi-mated by minimum bounding polytopeswhose faces are parallel to these m ori-entations. Clearly, the quality of theapproximations is positively correlatedwith m. We can now map the originalspace into an m-dimensional orientationspace, such that each (d-dimensional)approximating polytope Pd turns intoan m-dimensional interval Im. Anypoint inside (outside) Pd maps onto apoint inside (outside) Im, whereas theopposite is not necessarily true. Tomaintain the m-dimensional intervals,a large selection of SAMs is available;Jagadish [1990c] suggests the R-tree orR1-tree (cf. Section 5.3.2) for this pur-pose.
An interesting feature of the JP-treeis the ability to add hyperplanes to theattribute space dynamically withouthaving to reorganize the structure. Byprojecting the new intervals of the ex-tended orientation space onto the oldorientation space, it is still possible touse the old structure. Consequently, wecan obtain an R-tree from a higher-dimensional JP-tree structure by drop-
208 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

ping all hyperplanes that are not iso-oriented.
The interior nodes of the JP-tree rep-resent a hierarchy of nested polytopes,similar to the R-tree or the cell tree (cf.Section 5.3.3). Polytopes correspondingto different nodes at the same tree levelmay overlap. For search operations wefirst compute the minimum boundingpolytope of the search region and map itonto an m-dimensional interval. Thesearch efficiency then depends on thechosen PAM. The same applies for dele-tion.
The introduction of additional hyper-planes yields a better approximation,but it increases the size of the entries,thus reducing the fanout of the interiornodes. Experiments reported by Jagad-ish [1990c] suggest that a 10-dimen-sional orientation space (m 5 10) is agood choice for storing 2-dimensionallines (d 5 2) with arbitrary orientation.This needs to be compared to a simpleMBB approach. Although the lattertechnique may sometimes render poorapproximations, the representation re-quires only four numbers per line. Stor-ing a 10-dimensional interval, on theother hand, requires 20 numbers, thatis, five times as many. Another draw-back of the JP-tree is the fixed orienta-tion of the hyperplanes. Figure 32shows the running example for m 5 4.
To overcome the problem of poor fil-tering, Brodsky et al. [1995] proposedmethods for effectively computing a setof optimal axes for separating polyhe-
dra. This work continues the line ofwork by Jagadish [1990c] in the use ofnonstandard axes for better filtering.
5.2.4 The P-Tree [Schiwietz 1993]. TheP-Tree of Schiwietz, here called the SP-tree, chooses a slightly different ap-proach for storing polygonal objects thattries to combine the advantages of thecell tree and the R*-tree for the two-dimensional case, while avoiding thedrawbacks of both methods. Basically,the SP-tree is an R-tree whose interiornodes correspond to a nesting of poly-topes rather than just rectangles. Ingeneral, the number of vertices (andtherefore the storage requirements) of apolytope are not bounded. Moreover,when used for approximating other ob-jects, the accuracy of the approximationis positively correlated with the numberof vertices of the approximating convexpolygon. On the other hand, when usedas index entries, there should be anupper bound in order to guarantee aminimum fanout of the interior nodes.To determine a reasonably good compro-mise between these conflicting objec-tives, extensive investigations havebeen conducted by Brinkhoff et al.[1993a] and Schiwietz [1993]. Accordingto these studies, pentagons or hexagonsseem to offer the best tradeoff betweenstorage requirements and approxima-tion quality.
If node splittings or insertions lead toadditional vertices such that somebounding polygons have more vertices
Figure 32. P-tree [Jagadish 1990c].
Multidimensional Access Methods • 209
ACM Computing Surveys, Vol. 30, No. 2, June 1998

than the threshold, the surplus verticesare removed one by one. This leads to alarger area and therefore to a decreaseof the quality of the approximation. Toreduce overlap between the convex con-tainers, Schiwietz suggests using amethod similar to the R*-tree. Further-more, in order to save storage space andto improve storage utilization, it is pos-sible to restrict the number of orienta-tions for the polygon edges (similar tothe JP-tree).
Figure 33 shows the SP-tree for therunning example. To our knowledge, noperformance results have been reportedso far for either of the two P-trees.
5.2.5 The SKD-Tree [Ooi et al. 1987;Ooi 1990]. A variant of the k-d-tree ca-pable of storing spatially extended ob-jects is the spatial k-d-tree or skd-tree.The skd-tree allows regions to overlap.To keep track of the mutual overlap, westore an upper and a lower bound witheach discriminator, representing themaximal extent of the objects in the twosubtrees. For example, consider thesplitting hyperplane (discriminator) hx1depicted in Figure 34 and its upper andlower bounds bx1 and bx2, respectively.The solid lines are the splitting hyper-planes and the dashed lines representthe upper and lower bounds of the cor-responding subtrees. m3 is the rectan-gle closest to hx1 without crossing it,thus determining the maximum extentbx1 of the objects in the left (lower)subspace. Similarly, m5 determines theminimum extent bx2 for the right (up-
per) subspace. If none of the objectsplaced in the corresponding subspacecrosses the splitting hyperplane, thelower bound of the upper interval isgreater than the discriminator, and theupper bound of the lower interval is lessthan dk. Leaf nodes of the binary treecontain the minimal bounds (dottedlines) of the objects in the correspondingdata page.
Prior to inserting an object o, we de-termine its centroid and its MBB. Bycomparing the centroid with the storeddiscriminators, we determine the nextchild to be inspected. Note that there isno ambiguity. During insertion, we haveto adjust the upper and lower boundsfor extended objects accordingly. Uponreaching the data node level, we testwhether there is enough space availableto accommodate the object. If so, weinsert the object; otherwise we split thedata node and insert the new discrimi-nator into the skd-tree. Likewise, thebounds of the new subspaces need to beadjusted.
As usual, searching starts at the rootand corresponds to a top-down tree tra-versal. At each interior node we checkthe discriminator and the boundaries todecide which child(ren) to visit next.
Deleting an object starts with an ex-act match query to determine the cor-rect leaf node. If a deletion causes anunderflow, we insert the remaining en-tries into the sibling data node and re-move the splitting hyperplane. If thisinsertion results in an overflow, we split
Figure 33. P-tree [Schiwietz 1993].
210 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

the page and insert the new hyperplaneinto the skd-tree. If no merge with asibling leaf node is possible, we deletethat leaf and its parent node. By redi-recting the reference of the latter to itssibling (interior) node, we extend thesubspace of the sibling. All affected en-tries are reinserted.
According to the results reported inOoi [1990] and Ooi et al. [1991], theskd-tree is competitive with the R-treeboth in storage utilization and searchefficiency.
5.2.6 The GBD-Tree [Ohsawa andSakauchi 1990]. The GBD-tree (gener-alized BD-tree) is an extension of theBD-tree [Ohsawa and Sakauchi 1983]that allows for secondary storage man-agement and supports the managementof extended objects. The BD-tree is abinary tree, but the GBD-tree is a bal-anced multiway tree that stores spatialobjects as a hierarchy of minimumbounding boxes. Each leaf node (bucket)stores the MBBs of those objects whosecentroids are contained in the corre-sponding bucket region. Each interiornode stores the MBB of the (usuallyoverlapping) MBBs of its descendants.The intervals are encoded using thesame DZ-expressions as described inSection 3.2.3.
The one advantage of the GBD-treeover the R-tree is that insertions anddeletions may be processed more effi-ciently, due to the encoding scheme andthe placement by centroid. The latter
point enables the GBD-tree to performan insertion along a single path fromthe root to a leaf. However, no apparentadvantage is gained in search perfor-mance. The reported performance ex-periments [Ohsawa and Sakauchi 1990]compare only storage utilization and in-sertion performance with the R-tree.The most important comparison, that ofsearch performance, is omitted.
Figure 35 depicts a GBD-tree for therunning example. The partitioning onthe left-hand side shows the minimumbounding boxes (dotted or dashed) andthe underlying intervals (Peano re-gions).
Among the approaches similar to theGBD-tree are an extension of the buddytree by Seeger [1991] and the extensionof the BANG file to handle extendedspatial objects [Freeston 1989b].
5.2.7 PLOP-Hashing [Kriegel andSeeger 1988; Seeger and Kriegel 1988].Piecewise linear order-preserving (PLOP)hashing [Seeger and Kriegel 1988] is avariant of hashing that allows the stor-age of extended objects without trans-forming them into points. An earlierversion of this structure [Kriegel andSeeger 1988] was only able to handlemultidimensional point data.
PLOP-hashing partitions the universein a similar way to the grid file: ex-tended objects may span more than onedirectory cell. Hyperplanes extend alongthe axes of the data space. For the orga-nization of these hyperplanes, PLOP-
Figure 34. SKD-tree.
Multidimensional Access Methods • 211
ACM Computing Surveys, Vol. 30, No. 2, June 1998

hashing uses d binary trees, where d isthe dimension of the universe. Each in-terior node of such a binary tree corre-sponds to a (d 2 1)-dimensional iso-oriented hyperplane. The leaf nodesrepresent d-dimensional subspacesforming slices of the universe.
Figure 36 depicts the binary trees forboth axes together with the slicesformed by them. By using the indexentries that are stored in the leaf nodes,we can easily identify the data page forwhich we are looking. To do this effi-ciently, we have to keep the d binarytrees in main memory, similar to thescales of the grid file. For furtherspeedup, the leaf nodes of each binarytree are linked to each other. In Figure36 this is suggested by the arrows at-tached to the leaves of the trees. Tohandle extended objects, we enlarge thestorage representation of each slice by alower and an upper bound. Thesebounds indicate the minimum and themaximum extension along the currentdimension of all objects stored in theslice at hand.
Insertion is straightforward and simi-lar to the grid file. To avoid ambiguities,PLOP-hashing uses the centroid of theobject to determine the data bucket inwhich to place the object. In the case ofnode splitting and deletion we have toadjust the respective upper and lowerbounds. It should be further noted thatPLOP-hashing can be easily modified sothat it supports clipping rather thanoverlapping regions.
Analytical experiments indicate thatPLOP-hashing is superior to the R-treeand R1-tree for uniform data distribu-tions [Seeger and Kriegel 1988].
5.3 Clipping
Clipping-based schemes do not allowany overlaps between bucket regions;they have to be mutually disjoint. Atypical access method of this kind is theR1-tree [Stonebraker et al. 1986; Selliset al. 1987], a variant of the R-tree thatallows no overlap between regions cor-responding to nodes at the same treelevel. As a result, point queries follow asingle path starting at the root, whichmeans efficient searches.
The main problems with clipping-based approaches relate to the insertionand deletion of data objects. During in-sertion, any data object that spans morethan one bucket region has to be subdi-vided along the partitioning hyper-planes. Eventually, several bucket en-tries have to be created for the sameobject. Each bucket stores either thegeometric description of the completeobject (object duplication) or the geo-metric description of the correspondingfragment with an object reference. Inany case, data about the object are dis-persed among several data pages (span-ning property). The resulting redun-dancy [Orenstein 1989a,b; Gunther andGaede 1997] may cause not only anincrease in the average search time, but
Figure 35. GBD-tree.
212 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

also an increase in the frequency ofbucket overflows.
A second problem applies to clipping-based access methods that do not parti-tion the complete data space. In thatcase, the insertion of a new data objectmay lead to the enlargement of severalbucket regions. Whenever the object (ora fragment thereof) is passed down to abucket (or, in the case of a tree struc-ture, an interior node) whose regiondoes not cover it, the region has to beextended. In some cases, such an en-largement is not possible without get-ting an overlap with other bucket re-gions; this is sometimes called thedeadlock problem of clipping. Becauseoverlap is not allowed, one has to com-pute a new region structure, which canbecome very complicated. It may in par-ticular cause further bucket overflowsand insertions, which can lead to achain reaction and, in the worst case, acomplete breakdown of the structure[Gunther and Bilmes 1991]. Accessmethods partitioning the complete dataspace do not suffer from this problem.
A final problem concerns the splittingof buckets. There may be situationswhere a bucket (and its correspondingregion) has to be split but there is nosplitting hyperplane that splits none (oronly a few) of the objects in that bucket.The split may then trigger other splits,which may become problematic with in-creasing size of the database. The moreobjects are inserted, the higher theprobability of splits and the smaller theaverage size of the bucket regions. Newobjects are therefore split into a largernumber of smaller fragments, whichmay in the worst case once again lead toa chain reaction. To alleviate theseproblems, Gunther and Noltemeier[1991] suggest storing large objects(which are more likely to be split into alarge number of fragments) in specialbuckets called oversize shelves, insteadof inserting them into the structure.
5.3.1 The Extended k-d-Tree [Mat-suyama et al. 1984]. One of the earliestextensions of the adaptive k-d-tree thatcould handle extended objects was the
Figure 36. PLOP-hashing.
Multidimensional Access Methods • 213
ACM Computing Surveys, Vol. 30, No. 2, June 1998

extended k-d-tree. In contrast to theskd-tree (Section 5.2.5), the extendedk-d-tree is based on clipping. Each inte-rior tree node corresponds to a (d 2 1)-dimensional partitioning hyperplane,represented by the dimension (e.g., x ory) and the splitting coordinate (the dis-criminator). A leaf node corresponds toa rectangular subspace and contains theaddress of the data page describing thatsubspace. Data pages may be referencedby multiple leaf nodes.
To insert an object, we start at theroot of the k-d-tree. At each interiornode, we test for intersection with thestored hyperplane. Depending on the lo-cation of the object relative to the hyper-plane, we either move on to the corre-sponding child node, or we clip theobject by the hyperplane and followboth branches. This procedure guaran-tees that we insert the object in alloverlapping bucket regions. If a datapage cannot accommodate the addi-tional object, we split the page by a newhyperplane. The splitting dimension isperpendicular to the dimension with thegreatest extension. After distributingthe entries of the data page among thetwo new pages, we insert the hyper-plane into the k-d-tree. Note that thismay in turn cause some objects to besplit, which may lead to further pageoverflows. To delete an object, we haveto visit all subspaces intersecting theobject and delete the stored object iden-tifier. If a data page is empty due todeletion, we remove it and mark all leaf
nodes pointing to that page as NIL. Nomerging of sibling nodes is performed.
Figure 37 depicts an extended k-d-tree for the running example. Rectanglem7 has been clipped and inserted intotwo nodes. Most partitions contain oneor two additional bounding hyperplanes(dotted lines) to provide a better local-ization of the objects in the correspond-ing subspace.
5.3.2 The R1-Tree [Stonebraker et al.1986; Sellis et al. 1987]. To overcomethe problems associated with overlap-ping regions in the R-tree, Sellis et al.[1987] introduced an access methodcalled the R1-tree. Unlike the R-tree,the R1-tree uses clipping; that is, thereis no overlap between index intervals Id
at the same tree level. Objects that in-tersect more than one index intervalhave to be stored on several differentpages. As a result of this policy, pointsearches in R1-trees correspond to sin-gle-path tree traversals from the root toone of the leaves. They therefore tend tobe faster than the corresponding R-treeoperation. Range searches usually leadto the traversal of multiple paths inboth structures.
When inserting a new object o, wemay have to follow multiple paths, de-pending on the number of intersectionsof the MBB Id(o) with index intervals.During the tree traversal, Id(o) may besplit into n disjoint fragments Ii
d(o)(øi51
n Iid(o) 5 Id(o)). Each fragment is
then placed in a different leaf node ni.
Figure 37. Extended k-d-tree.
214 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

Provided that there is enough space, theinsertion is straightforward. If thebounding interval Id(o) overlaps spacethat has not yet been covered, we haveto enlarge the intervals correspondingto one or more leaf nodes. Each of theseenlargements may require considerableeffort because overlaps must be avoided.In some rare cases, it may not be possi-ble to increase the current intervals insuch a way that they cover the newobject without some mutual overlap[Gunther 1988; Ooi 1990]. In case ofsuch a deadlock, some data intervalshave to be split and reinserted into thetree.
If a leaf node overflows it has to besplit. Node splittings work similarly tothe case of the R-tree. An importantdifference, however, is that splits maypropagate not only up the tree, but alsodown the tree. The resulting forced splitof the nodes below may lead to severalcomplications, including further frag-mentation of the data intervals; see, forexample, the rectangles m5 and m8 inFigure 38.
For deletion, we first locate all thedata nodes where fragments of the ob-ject are stored and remove them. If stor-age utilization drops below a giventhreshold, we try to merge the affectednode with its siblings or to reorganizethe tree. This is not always possible,which is the reason why the R1-treecannot guarantee a minimum space uti-lization.
5.3.3 The Cell Tree [Gunther 1988].The main goal in the design of the celltree [Gunther 1988; 1989] was to facili-tate searches on data objects of arbi-trary shapes, that is, especially on dataobjects that are not intervals them-selves. The cell tree uses clipping tomanage large spatial databases thatmay contain polygons or higher-dimen-sional polyhedra. It corresponds to adecomposition of the universe into dis-joint convex subspaces. The interiornodes correspond to a hierarchy ofnested polytopes and each leaf node cor-responds to one of the subspaces (Figure39). Each tree node is stored on one diskpage.
To avoid some of the disadvantagesresulting from clipping, the convex poly-hedra are restricted to be subspaces of aBSP (binary space partitioning). There-fore we can view the cell tree as acombination of a BSP- and an R1-tree,or as a BSP-tree mapped on paged sec-ondary memory. In order to minimizethe number of disk accesses that occurduring a search operation, the leafnodes of a cell tree contain all the infor-mation required for answering a givensearch query; we load no pages otherthan those containing relevant data.This is an important advantage of thecell tree over the R-tree and relatedstructures.
Before inserting a nonconvex object,we decompose it into a number of con-vex components whose union is the orig-
Figure 38. R1-tree.
Multidimensional Access Methods • 215
ACM Computing Surveys, Vol. 30, No. 2, June 1998

inal object. The components do not haveto be mutually disjoint. All componentsare assigned the same object identifierand inserted into the cell tree one byone. Due to clipping, we may have tosubdivide each component into severalcells during insertion, because it over-laps more than one subspace. Each cellis stored in one leaf node of the cell tree.If an insertion causes a disk page tooverflow, we have to split the corre-sponding subspace and cell tree nodeand distribute its descendants betweenthe two resulting nodes. Each split maypropagate up the tree.
For point searches, we start at theroot of the tree. Using the underlyingBSP partitioning, we identify the sub-space that includes the search point andcontinue the search in the correspond-ing subtree. This step is repeated recur-sively until we reach a leaf node, wherewe examine all cells to see whether theycontain the search point. The solutionconsists of those objects that contain atleast one of the cells that qualify. Asimilar algorithm exists for rangesearches. A performance evaluation ofthe cell tree [Gunther and Bilmes 1991]shows that it is competitive with otherpopular spatial access methods.
Figure 39 shows our running examplewith five partitioning hyperplanes, eachof them stored in the interior nodes.Even though the partitioning by meansof the BSP-tree offers more flexibilitythan rectilinear hyperplanes, clipping
objects may be inevitable. In Figure 39,we had to split r2 and insert the result-ing cells into two pages.
As do all structures based on clipping,the cell tree has to cope with the frag-mentation of space, which becomes in-creasingly problematic as more objectsare inserted into the tree. After sometime, most new objects will be split intofragments during insertion. To avoidthe negative effects of this fragmenta-tion, Gunther and Noltemeier [1991]proposed the concept of oversize shelves.Oversize shelves are special disk pagesattached to the interior nodes of the treethat accommodate objects which wouldhave been split into too many fragmentsif they had been inserted regularly. Theauthors propose a dynamically adjust-ing threshold for choosing between plac-ing a new object on an oversize shelf orinserting it regularly. Performance re-sults of Gunther and Gaede [1997] showsubstantial improvements compared tothe cell tree without oversize shelves.
5.4 Multiple Layers
The multiple layer technique can be re-garded as a variant of the overlappingregions approach, because data regionsof different layers may overlap. How-ever, there are several important differ-ences. First, the layers are organized ina hierarchy. Second, each layer parti-tions the complete universe in a differ-ent way. Third, data regions within a
Figure 39. Cell tree.
216 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

layer are disjoint; that is, they do notoverlap. Fourth, the data regions do notadapt to the spatial extensions of thecorresponding data objects.
In order to get a better understandingof the multilayer technique, we discusshow to insert an extended object. First,we try to find the lowest layer in thehierarchy whose hyperplanes do notsplit the new object. If there is such alayer, we insert the object into the cor-responding data page. If the insertioncauses no page to overflow, we are done.Otherwise, we must split the data re-gion by introducing a new hyperplaneand distribute the entries accordingly.Objects intersecting the hyperplanehave to be moved to a higher layer or anoverflow page. As the database becomespopulated, the data space of the lowerlayers becomes more and more frag-mented. As a result, large objects keepaccumulating on higher layers of thehierarchy or, even worse, it is no longerpossible to insert objects without inter-secting existing hyperplanes.
The multilayer approach seems to of-fer one advantage over the overlappingregions technique: a possibly higher se-lectivity during searching due to therestricted overlap of the different lay-ers. However, there are also several dis-advantages: the multilayer approachsuffers from fragmentation, which mayrender the technique inefficient forsome data distributions; certain queriesrequire the inspection of all existinglayers; it is not clear how to clusterobjects that are spatially close to eachother but in different layers; and thereis some ambiguity about the layer inwhich to place the object.
An early static multilayer accessmethod is the MX-CIF quadtree [Kedem1982; Abel and Smith 1983; Samet1990b]. This structure stores each ex-tended spatial object with the quadtreenode whose associated quadrant pro-vides the tightest fit without intersect-ing the object. Objects within a node areorganized by means of binary trees.
Sevcik and Koudas [1996] later pro-posed a similar SAM based on multiple
layers, called the filter tree. As in theMX-CIF quadtree, each layer is the re-sult of a regular subdivision of the uni-verse. A new object is assigned to aunique layer, depending on the object’sposition and extension. Objects withinone layer are first sorted by the Hilbertcode of their center, then packed intodata pages of a given size. Finally, thelargest Hilbert code of each data page,together with its reference, is insertedinto a B-tree.
We continue with a detailed descrip-tion of two dynamic SAMs based onmultiple layers.
5.4.1 The Multilayer Grid File [Sixand Widmayer 1988]. Yet another vari-ant of the grid file capable of handlingextended objects is the multilayer gridfile (not to be confused with the multi-level grid file of Whang and Krish-namurthy [1985]). The multilayer gridfile consists of an ordered sequence ofgrid layers. Each of these layers corre-sponds to a separate grid file (withfreely positionable splitting hyper-planes) that covers the whole universe.A new object is inserted into the firstgrid file in the sequence that does notimply any clipping of the object. This isan important difference from the twingrid file (see Section 4.1.4), where ob-jects can be moved freely between thetwo layers. If one of the grid files isextended by adding another splittinghyperplane, those objects that would besplit have to be moved to another layer.Figure 40 illustrates a multilayer gridfile with two layers for the running ex-ample.
In the multilayer grid file, the size ofthe bucket regions typically increaseswithin the sequence; that is, larger ob-jects are more likely to find their finallocation in later layers. If a new objectcannot be stored in any of the currentlayers without clipping, a new layer hasto be allocated. An alternative is to al-low clipping only for the last layer. Sixand Widmayer claim that d 1 1 layersare sufficient to store a set of d-dimen-
Multidimensional Access Methods • 217
ACM Computing Surveys, Vol. 30, No. 2, June 1998

sional intervals without clipping if thehyperplanes are cleverly chosen.
For an exact match query, we caneasily determine from the scales whichgrid file in the sequence is supposed tohold the search interval. Other searchqueries, in particular point and rangequeries, are answered by traversing thesequence of layers and performing a cor-responding search on each grid file. Theperformance results reported by Six andWidmayer [1988] suggest that the mul-tilayer grid file is superior to the con-ventional grid file, using clipping tohandle extended objects. Possible disad-vantages of the multilayer grid file in-clude low storage utilization and expen-sive directory maintenance.
5.4.2 The R-File [Hutflesz et al.1990]. To overcome some of the prob-lems of the multilayer grid file, Hutfleszet al. [1990] proposed an alternativestructure for managing sets of rectan-gles called the R-file; see Figure 41 foran example. In order to avoid the lowstorage utilization of the multilayer gridfile, the R-file uses a single directory.The universe is partitioned similarly tothe BANG file: splitting hyperplanescut the universe recursively into equalparts, and z-ordering is used to encodethe resulting bucket regions. In contrastto the BANG file, however, there are noexcisions. Bucket regions may overlap,and there is no clipping. Each data in-terval is stored in the bucket with thesmallest region that contains it entirely;
overflow pages may be necessary insome cases.
An interesting feature of the R-file isits splitting algorithm. Rather than cut-ting a bucket region into two halves, weretain the original bucket region andcreate a new bucket for one of the twohalves of that original region. Data in-tervals are then assigned to the newbucket if and only if they are completelycontained in the corresponding region.The half is chosen in such a way thatthe distribution of data intervals be-tween the two resulting buckets is mosteven. Once a region has been split, itmay subsequently be split again, usingthe same algorithm. Since objects thatare located near the middle of the uni-verse are likely to intersect the parti-tioning hyperplanes, they are often as-signed to the cell region correspondingto the whole universe. Thus objects inthat cell tend to cluster near the split-ting hyperplanes (cf. rectangle r5 in Fig-ure 41).
To avoid searching dead space, theR-file maintains minimum enclosingboxes of the stored objects, called searchregions. As shown by Hutflesz et al.[1990], this feature, together with thez-encoding of the partitions, make theR-file competitive to the R-tree. Onedrawback of the R-file is the fact that itpartitions the entire space, whereas theR-tree indexes only the part of the uni-verse that contains objects. For datadistributions that are nonuniform, the
Figure 40. Multilayer grid file.
218 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

R-file therefore often performs poorly.This disadvantage is something that theR-file shares with the grid file. Wid-mayer [1991] also notes that the R-fileis “algorithmically complicated.”
6. COMPARATIVE STUDIES
In this section, we give a brief overviewof theoretical and experimental resultson the comparison of different accessmethods. Unfortunately, the number ofsuch evaluations, especially theoreticalanalyses, is rather limited.
Greene [1989] compares the searchperformance of the R-tree, the k-d-B-tree, and the R1-tree for 10,000 uni-formly distributed rectangles of varyingsize. Query parameters include the sizeof the query rectangles and the pagesize. Greene’s study shows that the k-d-B-tree can never really compete withthe two R-tree variants. On the otherhand, there is not much difference be-tween the R1-tree and the R-tree, eventhough the former is significantly moredifficult to code. As expected, the R1-
tree performs better when there is lessoverlap between the data rectangles.
Kriegel et al. [1990] present an exten-sive experimental study of access-method performance for a variety ofpoint distributions. The study involvesfour point access methods: the hB-tree,the BANG file, the two-level grid file,and the buddy tree. The authors decidednot to include PLOP-hashing since itsperformance suffers considerably fornonuniform data. The zkdB1-tree ofOrenstein and Merrett [1984] was alsonot included since the authors consid-ered both the BANG file and the hB-tree as improvements of that strategy.Finally, Kriegel et al. did not includequantile hashing although they claim[Kriegel and Seeger 1987, 1989] thatthis structure is very efficient for non-uniform data.
According to the benchmarks, thebuddy tree and, to some degree, theBANG file outperform all other struc-tures. The reported results show in animpressive way how the performance of
Figure 41. R-file.
Multidimensional Access Methods • 219
ACM Computing Surveys, Vol. 30, No. 2, June 1998

the access methods studied varies withdifferent data distributions and queryrange sizes. For clustered data and aquery range of size 10% of the size ofthe universe, there is almost no perfor-mance difference between the buddytree and the BANG file. If the size of thequery range drops to only 0.1% of thesize of the universe; however, the buddytree performs about twice as fast.
For extended objects, Kriegel et al.[1990] compared the R-tree and PLOP-hashing with the buddy tree and theBANG file. The latter two techniqueswere enhanced by the transformationtechnique to handle rectangles. Onceagain, the buddy tree and the BANG fileoutperformed the other two accessmethods for nearly all data distribu-tions. Note that the benchmarks mea-sured only the number of page accessesbut not the CPU time.
Beckmann et al. [1990] compared theR*-tree with several variants of the R-tree for a variety of data distributions.Besides the performance of the differentstructures for point, intersection, andenclosure queries for varying query re-gion sizes, they also compared spatialjoin performance. The R*-tree is theclear winner for all data distributionsand queries, and it also has the beststorage utilization and insertion times.A comparison for point data confirmsthese results. Similarly to previous per-formance measurements, only the num-ber of disk accesses is measured. A re-lated study by Kamel and Faloutsos[1994] finds even better search resultsfor the Hilbert R-tree, whereas updatestake about the same time as for theR*-tree. The impact of global clusteringon the search performance of the R*-tree was investigated by Brinkhoff andKriegel [1994]. Kamel et al. [1996] useHilbert codes for bulk insertion into dy-namic R*-trees.
Seeger [1991] studied the relativeperformance of clipping, overlapping re-gions, and transformation techniquesimplemented on top of the buddy tree.He also included the two-level grid fileand the R*-tree in the comparison. The
buddy tree with clipping and the gridfile failed completely for certain distri-butions, since they produced unmanage-ably large files. The transformationtechnique supports fast insertions atthe expense of low storage utilization.The R*-tree, on the other hand, requiresfairly long insertion times but offersgood storage utilization. For intersec-tion and containment queries, thebuddy tree combined with overlappingregions is continuously superior to thebuddy tree with transformation. Theperformance advantage of the overlap-ping regions technique decreases forlarger query regions, even though thebuddy tree with transformation neveroutperforms the buddy tree with over-lapping regions. When the data set con-tains uniformly distributed rectanglesof varying size, the buddy tree withclipping outperforms the other tech-niques for intersection and enclosurequeries. For some queries the buddytree with overlapping performs slightlybetter than the R*-tree.
Ooi [1990] compares a static and adynamic variant of the skd-tree withthe packed R-tree described by Rousso-poulos and Leifker [1985]. For largepage sizes, the skd-tree clearly outper-forms the R-tree in terms of page ac-cesses per search operation. The spacerequirements of the skd-tree, however,are higher than those of the R-tree.Since the skd-tree stores the extendedobjects by their centroids, containmentqueries are answered more efficientlythan by the R-tree. This behavior isclearly reflected in the performance re-sults. A comparison with the extendedk-d-tree, enhanced by overflow pages,suggests that the skd-tree is superior,although the extended k-d-tree (whichis based on clipping) performs ratherwell for uniformly distributed data.
Gunther and Bilmes [1991] comparethe R-tree to two clipping-based accessmethods, the cell tree and the R1-tree.Unlike most studies, the data sets con-sist of convex polygons instead of justrectangles. The cell tree requires up totwice as much space as its competitors.
220 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

However, the average number of pageaccesses per search operation is lessthan for the other two access methods.Moreover, this advantage tends to in-crease with the size of the database andthe size of the query regions. Besidesmeasurements on the number of pagefaults, CPU time measurements arealso given.
Gunther and Gaede [1997] comparethe original cell tree as presented byGunther [1989] with the cell tree withoversize shelves [Gunther and Nolte-meier 1991], the R*-tree [Beckmann etal. 1990], and the hB-tree [Lomet andSalzberg 1989] for some real carto-graphic data. There is a slight perfor-mance advantage of the cell tree withoversize shelves compared to the R*-tree and the hB-tree, but a major differ-ence from the original cell tree. An ear-lier comparison using artificiallygenerated data can be found in Gunther[1991]. Both studies suggest that over-size shelves may lead to significant im-provements for access methods withclipping.
Oosterom [1990] compares the querytimes of his KD2B-tree and the spheretree with the R-tree for different que-ries. The KD2B-tree is a paged versionof the KD2-tree, which in turn is avariant of the BSP-tree. The two struc-tures differ in two aspects: each interiornode stores two iso-oriented lines to al-low for overlap and gaps, and the corre-sponding partition lines do not clip; thatis, an object is handled as a unit. TheKD2B-tree outperforms the R-tree forall queries, whereas the sphere tree isinferior to the R-tree.
Hoel and Samet [1992] compare theperformance of the PMR-quadtree [Nel-son and Samet 1987], the R*-tree, andthe R1-tree for indexing line segments.The R1-tree shows the best insertionperformance, whereas the R*-tree occu-pies the least space. However, the inser-tion behavior of the R1-tree heavily de-pends on the page size, unlike the PMR-quadtree. The performance of allstructures compared is about the same,even though the PMR-quadtree shows
some slight performance benefits. Al-though the R*-tree is more compactthan the other structures, its searchperformance is not as good as that ofthe R1-tree for line segments. Unfortu-nately, Hoel and Samet do not reportthe overall performance times for thedifferent queries.
Peloux et al. [1994] carried out a sim-ilar performance comparison of twoquadtree variants, a variant of the R1-tree, and the R*-tree. What makes theirstudy different is that all structureshave been implemented on top of a com-mercial object-oriented system usingthe application programmer interface. Afurther difference to Hoel and Samet[1992] is that Peloux et al. used poly-gons rather than line segments as testdata. Furthermore, they report the var-ious times for index traversal, loadingpolygons, and the like. Besides showingthat the R1-tree and a quadtree variantbased on Hierarchical EXCELL [Tam-minen 1983] outperform the R*-tree forpoint queries, they clearly demonstratethat the database system must providesome means for physical clustering.Otherwise, reading a single index pagemay induce several page faults.
Smith and Gao [1990] compare theperformance of a variant of the zkdB1-tree, the grid file, the R-tree, and theR1-tree for insertions, deletions, andsearch operations. They also measuredstorage utilization. The conclusion oftheir experiments is that z-ordering andthe grid file perform well for insertionsand deletions but deliver poor searchperformance. R- and R1-trees, in con-trast, offer moderate insertion and dele-tion performance but superior searchperformance. Although the R1-tree per-forms slightly better than the R-tree forsearch operations, the authors concludethat the R1-tree is not a good choice forgeneral-purpose applications, due to itspotentially poor space utilization.
Hutflesz et al. [1990] showed that theR-file has a 10 to 20% performance ad-vantage over the R-tree on a data setcontaining 48,000 rectangles with ahigh degree of overlap (each point in the
Multidimensional Access Methods • 221
ACM Computing Surveys, Vol. 30, No. 2, June 1998

database was covered by 5.78 rectangleson the average).
Further experimental studies on theR-tree and related structures can befound in Frank and Barrera [1989], Ka-mel and Faloutsos [1992], and Kolovsonand Stonebraker [1991].
Since the splitting of data buckets isan important operation in many struc-tures, Henrich and Six [1991] studiedseveral split strategies. Their theoreti-cal analysis is verified by means of theLSD-tree. They also provide some per-formance results for the R-tree thatuses their splitting strategy in compari-son to the otherwise unchanged R-tree.An empirical performance comparisonof the R-tree with an improved variantof z-hashing, called layered z-hashing orlz-hashing [Hutflesz et al. 1988a], canbe found in Hutflesz et al. [1991]. Theproposed structure needs significantlyless seek operations than the R-tree;average storage utilization is higher.
Jagadish [1990a] studies the proper-ties of different space-filling curves (z-ordering, Gray-coding, and Hilbert-curve). By means of theoreticalconsiderations as well as by experimen-tal tests, he concludes that the Hilbertmapping from multidimensional spaceto a line is superior to other space-filling curves. These results are in ac-cordance with those of Abel and Mark[1990].
When trying to summarize all thoseexperimental comparisons, the follow-ing multidimensional access methodsseem to be among the best-performingones (in alphabetical order):
—buddy (hash) tree [Seeger and Kriegel1990],
—cell tree with oversize shelves[Gunther and Gaede 1997],
—Hilbert R-tree [Kamel and Faloutsos1994],
—KD2B-tree [Oosterom 1990],—PMR-quadtree [Nelson and Samet
1987],—R1-tree [Sellis et al. 1987], and—R*-tree [Beckmann et al. 1990]
It cannot be emphasized enough, how-ever, that any such ranking needs to beused with great care. Clever program-ming can often make up for inherentdeficiencies of an access method andvice versa. Other factors of unpredict-able impact include the hardware used,the buffer size/page size, and the datasets. Note also that our list does nottake into account access methods forwhich no comparative analyses havebeen published.
As the preceding discussion shows,although numerous experimental stud-ies exist, they are hardly comparable.Theoretical studies may bring somemore objectivity to this discussion. Theproblem with such studies is that theyare usually very hard to perform if onewants to stick to realistic modeling as-sumptions. For that reason there areonly a few theoretical results on thecomparison of multidimensional accessmethods.
Regnier [1985] and Becker [1992] in-vestigated the grid file and some of itsvariants. The most complete theoreticalanalysis of range trees can be found inOvermars et al. [1990] and Smid andOvermars [1990]. Gunther and Gaede[1997] present a theoretical analysis ofthe cell tree. Recent analyses show thatthe theory of fractals seems to be partic-ularly suitable for modeling the behav-ior of SAMs if the data distribution isnonuniform.3
Some more analytical work exists onthe R-tree and related methods. A com-parison of the R-tree and the R1-treehas been published by Faloutsos et al.[1987]. Recently, Pagel et al. [1993a]presented an interesting probabilisticmodel of window query performance forthe comparison of different access meth-ods independent of implementation de-tails. Among other things, their modelreveals the importance of the perimeteras a criterion for node splitting, whichhas been intuitively anticipated by the
3 See Faloutsos and Kamel [1994], Belussi andFaloutsos [1995], Faloutsos and Gaede [1996], andPapadopoulos and Manolopoulos [1997].
222 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

inventors of the R*-tree [Beckmann etal. 1990]. The central formula of Pagelet al. [1993] to compute the number ofdisk accesses in an R-tree has beenfound independently by Kamel and Fa-loutsos [1993]. Faloutsos and Kamel[1994] later refined this formula by us-ing properties of the data set. Morerecently, Theodoridis and Sellis [1996]proposed a theoretical model to deter-mine the number of disk accesses in anR-tree that requires only two parame-ters: the amount of data and the densityin the data space. Their model also ex-tends to nonuniform distributions.
In pursuit of an implementation-inde-pendent comparison criterion for accessmethods, Pagel et al. [1995] suggest us-ing the degree of clustering. As a lowerbound they assume the optimal cluster-ing of the static situation, that is, if thecomplete data set has been exposed be-forehand. Incidentally, the significanceof clustering for access methods hasbeen demonstrated in numerous empir-ical investigations as well.4
In the area of constraint databasesystems (see Gaede and Wallace [1997]for a recent survey) a number of inter-esting papers related to multidimen-sional access methods have been pub-lished. Kanellakis et al. [1993], forexample, presented a semidynamic struc-ture that guarantees certain worst-casebounds for space, search, and insertion.Subramanian and Ramaswamy [1995]and Hellerstein et al. [1997] comple-ment this work by proving some impor-tant lower and upper bounds. Sexton[1997] and Stuckey [1997] look at index-ing from a language point of view. Theirwork can be regarded as a generaliza-tion of work by Hellerstein et al. [1995],who proposed a generic framework formodeling hierarchical access methods.
7. CONCLUSIONS
Research in spatial database systemshas resulted in a multitude of spatial
access methods. Even for experts it be-comes more and more difficult to recog-nize their merits and weaknesses, sinceevery new method seems to claim supe-riority to at least one access methodpreviously published. This survey didnot try to resolve this problem butrather to give an overview of the prosand cons of a variety of structures. Itwill come as no surprise to the readerthat at present no access method hasproven itself superior to all its competi-tors in whatever sense. Even if onebenchmark declares one structure asthe clear winner, another benchmarkmay prove the same structure inferior.
But why are such comparisons so dif-ficult? Because there are so many differ-ent criteria to define optimality, and somany parameters that determine per-formance. Both time and space effi-ciency of an access method strongly de-pend on the data processed and thequeries asked. An access method thatperforms reasonably well for iso-ori-ented rectangles may fail for arbitrarilyoriented lines. Strongly correlated datamay render an otherwise fast accessmethod irrelevant for any practical ap-plication. An index that has been opti-mized for point queries may be highlyinefficient for arbitrary region queries.Large numbers of insertions and dele-tions may deteriorate a structure that isefficient in a more static environment.
The initiative of Kriegel et al. [1990]to set up a standardized testbed forbenchmarking and comparing accessmethods under different conditions wasan important step in the right direction.The world wide web provides a conve-nient infrastructure to access and dis-tribute such benchmarks [Gunther etal. 1988]. Nevertheless, it remains farfrom easy to compare or rank differentaccess methods. Experimental bench-marks need to be studied with care andcan only be a first indicator for usabil-ity.
When it comes to technology transfer,that is, to the use of access methods incommercial products, most vendors re-sort to structures that are easy to un-
4 See Jagadish [1990a], Kamel and Faloutsos[1993], Brinkhoff and Kriegel [1994], Kumar[1994b], and Ng and Han [1994].
Multidimensional Access Methods • 223
ACM Computing Surveys, Vol. 30, No. 2, June 1998

derstand and implement. Quadtrees inSICAD [Siemens Nixdorf Informations-systeme AG 1997] and Smallworld GIS[Newell and Doe 1997], R-trees in Infor-mix [Informix Inc. 1997], and Z-orderingin Oracle [Oracle Inc. 1995] are typicalexamples. Performance seems to be ofminor importance in the selection,which comes as no surprise given therelatively small differences amongmethods in virtually all published anal-yses. Rather, the tendency is to take astructure that is simple and robust andto optimize its performance by a highlytuned implementation and tight inte-gration with other system components.
Nevertheless, the implementationand experimental evaluation of accessmethods is essential as it often revealsdeficiencies and problems that are notobvious from the design or a theoreticalmodel. In order to make such compara-tive evaluations both easier to performand easier to verify, it is essential toprovide platform-independent access tothe implementations of a broad varietyof access methods. Some extensions ofthe World Wide Web, including our ownMMM project [Gunther et al. 1997],may provide the right technologicalbase for such a paradigm change. Onceevery published paper includes a URL(uniform resource locator), that is, anInternet address that points to an im-plementation, possibly with a standard-ized user interface, transparency willincrease substantially. Until then, mostusers will have to rely on general wis-dom and their own experiments to se-lect an access method that provides thebest fit for their current application.
ACKNOWLEDGMENTS
While working on this survey, we had the plea-sure of discussions with many colleagues. Specialthanks go to D. Abel, A. Buchmann, C. Faloutsos,A. Frank, M. Freeston, J. C. Freytag, J. Heller-stein, C. Kolovson, H.-P. Kriegel, J. Nievergelt, J.Orenstein, P. Picouet, W.-F. Riekert, D. Rotem,J.-M. Saglio, B. Salzberg, H. Samet, M. Schiwietz,R. Schneider, M. Scholl, B. Seeger, T. Sellis, A. P.Sexton, and P. Widmayer. We would also like to
thank the referees for their detailed and insight-ful comments.
REFERENCES
ABEL, D. J. AND MARK, D. M. 1990. A compara-tive analysis of some two-dimensional order-ings. Int. J. Geograph. Inf. Syst. 4, 1, 21–31.
ABEL, D. J. AND SMITH, J. L. 1983. A data struc-ture and algorithm based on a linear key for arectangle retrieval problem. Comput. Vis. 24,1–13.
ANG, C. AND TAN, T. 1997. New linear nodesplitting algorithm for R-trees. In Advances inSpatial Databases, M. Scholl and A. Voisard,Eds., LNCS, Springer-Verlag, Berlin/Heidel-berg/New York.
AREF, W. G. AND SAMET, H. 1994. The spatialfilter revisited. In Proceedings of the SixthInternational Symposium on Spatial DataHandling, 190–208.
BAYER, R. 1996. The universal B-tree for multi-dimensional indexing. Tech. Rep. I9639,Technische Universitat Munchen, Munich,Germany. http://www.leo.org/pub/comp/doc/techreports/tum/informatik/report/1996/TUM-I9639.ps.gz.
BAYER, R. AND MCCREIGHT, E. M. 1972. Organi-zation and maintenance of large ordered indi-ces. Acta Inf. 1, 3, 173–189.
BAYER, R. AND SCHKOLNICK, M. 1977. Concur-rency of operations on B-trees. Acta Inf. 9,1–21.
BECKER, B., FRANCIOSA, P., GSCHWIND, S., OHLER,T., THIEM, F., AND WIDMAYER, P. 1992. En-closing many boxes by an optimal pair ofboxes. In Proceedings of STACS’92, A. Finkeland M. Jantzen, Eds., LNCS 525, Springer-Verlag, Berlin/Heidelberg/New York, 475–486.
BECKER, L. 1992. A new algorithm and a costmodel for join processing with the grid file.Ph.D. thesis, Universitat-GesamthochschuleSiegen, Germany.
BECKMANN, N., KRIEGEL, H.-P., SCHNEIDER, R., ANDSEEGER, B. 1990. The R*-tree: An efficientand robust access method for points and rect-angles. In Proceedings of ACM SIGMOD In-ternational Conference on Management ofData, 322–331.
BELUSSI, A. AND FALOUTSOS, C. 1995. Esti-mating the selectivity of spatial queries usingthe ‘correlation’ fractal dimension. In Proceed-ings of the 21st International Conference onVery Large Data Bases, 299–310.
BENTLEY, J. L. 1975. Multidimensional binarysearch trees used for associative searching.Commun. ACM 18, 9, 509–517.
BENTLEY, J. L. 1979. Multidimensional binarysearch in database applications. IEEE Trans.Softw. Eng. 4, 5, 333–340.
BENTLEY, J. L. AND FRIEDMAN, J. H. 1979. Data
224 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

structures for range searching. ACM Comput.Surv. 11, 4, 397–409.
BERCHTOLD, S., KEIM, D., AND KRIEGEL, H.-P.1996. The X-tree: An index structure forhigh-dimensional data. In Proceedings of the22nd International Conference on Very LargeData Bases, (Bombay) 28–39.
BLANKEN, H., IJBEMA, A., MEEK, P., AND VAN DEN
AKKER, B. 1990. The generalized grid file:Description and performance aspects. In Pro-ceedings of the Sixth IEEE International Con-ference on Data Engineering, 380–388.
BRINKHOFF, T. 1994. Der spatial join in geo-datenbanksystemen. Ph.D. Thesis, Ludwig-Maximilians-Universitat Munchen. Germany(in German).
BRINKHOFF, T. AND KRIEGEL, H.-P. 1994. Theimpact of global clustering on spatial data-base systems. In Proceedings of the TwentiethInternational Conference on Very Large DataBases, 168–179.
BRINKHOFF, T., KRIEGEL, H.-P., AND SCHNEIDER, R.1993a. Comparison of approximations ofcomplex objects used for approximation-basedquery processing in spatial database systems.In Proceedings of the Ninth IEEE Interna-tional Conference on Data Engineering, 40–49.
BRINKHOFF, T., KRIEGEL, H.-P., AND SEEGER, B.1993b. Efficient processing of spatial joinsusing R-trees. In Proceedings of ACM SIG-MOD International Conference on Manage-ment of Data, 237–246.
BRINKHOFF, T., KRIEGEL, H.-P., SCHNEIDER, R., AND
SEEGER, B. 1994. Multi-step processing ofspatial joins. In Proceedings of the ACM SIG-MOD International Conference on Manage-ment of Data, 197–208.
BRODSKY, A., LASSEZ, C., LASSEZ, J.-L., AND MAHER,M. J. 1995. Separability of polyhedra foroptimal filtering of spatial and constraintdata. In Proceedings of the Fourteenth ACMSIGACT–SIGMOD–SIGART Symposium onPrinciples of Database Systems (San Jose,CA), 54–64.
BURKHARD, W. 1984. Index maintenance fornon-uniform record distributions. In Proceed-ings of the Third ACM SIGACT–SIGMODSymposium on Principles of Database Sys-tems, 173–180.
BURKHARD, W. A. 1983. Interpolation-based in-dex maintenance. BIT 23, 274–294.
CHEN, L., DRACH, R., KEATING, M., LOUIS, S.,ROTEM, D., AND SHOSHANI, A. 1995. Accessto multidimensional datasets on tertiary stor-age systems. Inf. Syst. 20, 2, 155–183.
COMER, D. 1979. The ubiquitous B-tree. ACMComput. Surv. 11, 2, 121–138.
DANDAMUDI, S. P. AND SORENSON, P. G. 1986.Algorithms for BD-trees. Softw. Pract. Exper.16, 2, 1077–1096.
DANDAMUDI, S. P. AND SORENSON, P. G. 1991.Improved partial-match search algorithms forBD-trees. Comput. J. 34, 5, 415–422.
EGENHOFER, M. 1989. Spatial query languages.Ph.D. Thesis, University of Maine, Orono,ME.
EGENHOFER, M. 1994. Spatial SQL: A query andpresentation language. IEEE Trans. Knowl.Data Eng. 6, 1, 86–95.
EVANGELIDIS, G. 1994. The hBP-tree: A concur-rent and recoverable multi-attribute indexstructure. Ph.D. Thesis, Northeastern Univer-sity, Boston, MA.
EVANGELIDIS, G., LOMET, D., AND SALZBERG, B.1995. The hBP-tree: A modified hB-tree sup-porting concurrency, recovery and node con-solidation. In Proceedings of the 21st Interna-tional Conference on Very Large Data Bases,551–561.
FAGIN, R., NIEVERGELT, J., PIPPENGER, N., ANDSTRONG, R. 1979. Extendible hashing: Afast access method for dynamic files. ACMTrans. Database Syst. 4, 3, 315–344.
FALOUTSOS, C. 1986. Multiattribute hashing us-ing Gray-codes. In Proceedings of the ACMSIGMOD International Conference on Man-agement of Data, 227–238.
FALOUTSOS, C. 1988. Gray-codes for partialmatch and range queries. IEEE Trans. Softw.Eng. 14, 1381–1393.
FALOUTSOS, C. AND GAEDE, V. 1996. Analysis ofn-dimensional quadtrees using the Hausdorfffractal dimension. In Proceedings of the 22ndInternational Conference on Very Large DataBases, (Bombay), 40–50.
FALOUTSOS, C. AND KAMEL, I. 1994. Beyond uni-formity and independence: Analysis of R-treesusing the concept of fractal dimension. InProceedings of the Thirteenth ACM SIGACT–SIGMOD–SIGART Symposium on Principlesof Database Systems, 4–13.
FALOUTSOS, C. AND RONG, Y. 1991. DOT: A spa-tial access method using fractals. In Proceed-ings of the Seventh IEEE International Con-ference on Data Engineering, 152–159.
FALOUTSOS, C. AND ROSEMAN, S. 1989. Fractalsfor secondary key retrieval. In Proceedings ofthe Eighth ACM SIGACT–SIGMOD–SIGARTSymposium on Principles of Database Sys-tems, 247–252.
FALOUTSOS, C., SELLIS, T., AND ROUSSOPOULOS,N. 1987. Analysis of object-oriented spatialaccess methods. In Proceedings of the ACMSIGMOD International Conference on Man-agement of Data, 426–439.
FINKEL, R. AND BENTLEY, J. L. 1974. Quadtrees: A data structure for retrieval of com-posite keys. Acta Inf. 4, 1, 1–9.
FLAJOLET, P. 1983. On the performance evalua-tion of extendible hashing and trie searching.Acta Inf. 20, 345–369.
Multidimensional Access Methods • 225
ACM Computing Surveys, Vol. 30, No. 2, June 1998

FRANK, A. AND BARRERA, R. 1989. The fieldtree:A data structure for geographic informationsystems. In Design and Implementation ofLarge Spatial Database Systems, A. Buch-mann, O. Gunther, T. R. Smith, and Y.-F.Wang, Eds., LNCS 409, Springer-Verlag, Ber-lin/Heidelberg/New York, 29–44.
FREESTON, M. 1987. The BANG file: A new kindof grid file. In Proceedings of the ACM SIG-MOD International Conference on Manage-ment of Data,, 260–269.
FREESTON, M. 1989a. Advances in the design ofthe BANG file. In Proceedings of the ThirdInternational Conference on Foundations ofData Organization and Algorithms, LNCS367, Springer-Verlag, Berlin/Heidelberg/NewYork, 322–338.
FREESTON, M. 1989b. A well-behaved structurefor the storage of geometric objects. In Designand Implementation of Large Spatial Data-base Systems, A. Buchmann, O. Gunther,T. R. Smith, and Y.-F. Wang, Eds., LNCS 409,Springer-Verlag, Berlin/Heidelberg/New York,287–300.
FREESTON, M. 1995. A general solution of then-dimensional B-tree problem. In Proceedingsof the ACM SIGMOD International Confer-ence on Management of Data, 80–91.
FREESTON, M. 1997. On the complexity of BV-tree updates. In Proceedings of CDB’97 andCP’96 Workshop on Constraint Databases andtheir Application, V. Gaede, A. Brodsky, O.Gunther, D. Srivastava, V. Vianu, and M.Wallace, Eds., LNCS 1191, Springer-Verlag,Berlin/Heidelberg/New York, 282–293.
FUCHS, H., ABRAM, G. D., AND GRANT, E. D.1983. Near real-time shaded display of rigidobjects. Computer Graph. 17, 3, 65–72.
FUCHS, H., KEDEM, Z., AND NAYLOR, B. 1980. Onvisible surface generation by a priori treestructures. Computer Graph. 14, 3.
GAEDE, V. 1995a. Geometric information makesspatial query processing more efficient. InProceedings of the Third ACM InternationalWorkshop on Advances in Geographic Infor-mation Systems (ACM-GIS’95) (Baltimore,MD) 45–52.
GAEDE, V. 1995b. Optimal redundancy in spa-tial database systems. In Advances in SpatialDatabases, M. J. Egenhofer and J. R. Herring,Eds., LNCS 951, Springer-Verlag, Berlin/Hei-delberg/New York, 96–116.
GAEDE, V. AND RIEKERT, W.-F. 1994. Spatial ac-cess methods and query processing in theobject-oriented GIS GODOT. In Proceedingsof the AGDM’94 Workshop (Delft, The Nether-lands), Netherlands Geodetic Commission,40–52.
GAEDE, V. AND WALLACE, M. 1997. An informalintroduction to constraint databases. In Pro-ceedings of CDB’97 and CP’96 Workshop onConstraint Databases and their Application,
V. Gaede, A. Brodsky, O. Gunther, D. Srivas-tava, V. Vianu, and M. Wallace, Eds., LNCS1191, Springer-Verlag, Berlin/Heidelberg/New York, 7–52.
GARG, A. K. AND GOTLIEB, C. C. 1986. Order-preserving key transformation. ACM Trans.Database Syst. 11, 2, 213–234.
GREENE, D. 1989. An implementation and per-formance analysis of spatial data accessmethods. In Proceedings of the Fifth IEEEInternational Conference on Data Engineer-ing, 606–615.
GUNTHER, O. 1988. Efficient Structures for Geo-metric Data Management. LNCS 337, Spring-er-Verlag, Berlin/Heidelberg/New York.
GUNTHER, O. 1989. The cell tree: An object-ori-ented index structure for geometric data-bases. In Proceedings of the Fifth IEEE Inter-national Conference on Data Engineering,598–605.
GUNTHER, O. 1991. Evaluation of spatial accessmethods with oversize shelves. In GeographicDatabase Management Systems, G. Gambosi,M. Scholl, and H.-W. Six, Eds., Springer-Ver-lag, Berlin/Heidelberg/New York, 177–193.
GUNTHER, O. 1993. Efficient computation ofspatial joins. In Proceedings of the NinthIEEE International Conference on Data Engi-neering, 50–59.
GUNTHER, O. AND BILMES, J. 1991. Tree-basedaccess methods for spatial databases: Imple-mentation and performance evaluation. IEEETrans. Knowl. Data Eng. 3, 3, 342–356.
GUNTHER, O. AND BUCHMANN, A. 1990. Researchissues in spatial databases. SIGMOD Rec. 19,4, 61–68.
GUNTHER, O. AND GAEDE, V. 1997. Oversizeshelves: A storage management technique forlarge spatial data objects. Int. J. Geog. Inf.Syst. 11, 1, 5–32.
GUNTHER, O. AND NOLTEMEIER, H. 1991. Spatialdatabase indices for large extended objects. InProceedings of the Seventh IEEE Interna-tional Conference on Data Engineering, 520–526.
GUNTHER, O., MULLER, R., SCHMIDT, P., BHARGAVA,H., AND KRISHNAN, R. 1997. MMM: AWWW-based approach for sharing statisticalsoftware modules. IEEE Internet Comput. 1, 3.
GUNTHER, O., ORIA, V., PICOUET, P., SAGLIO, J.-M.,AND SCHOLL, M. 1998. Benchmarking spa-tial joins a la carte. In Proceedings of the 10thInternational Conference on Scientific andStatistical Database Management. IEEE, NewYork.
GUTING, R. H. 1989. Gral: An extendible rela-tional database system for geometric applica-tions. In Proceedings of the Fifteenth Interna-tional Conference on Very Large Data Bases,33–44.
GUTING, R. H. AND SCHNEIDER, M. 1993.
226 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

Realms: A foundation for spatial data types indatabase systems. In Advances in Spatial Da-tabases, D. Abel and B. C. Ooi, Eds., LNCS692, Springer-Verlag, Berlin/Heidelberg/NewYork.
GUTTMAN, A. 1984. R-trees: A dynamic indexstructure for spatial searching. In Proceedingsof the ACM SIGMOD International Confer-ence on Management of Data, 47–54.
HELLERSTEIN, J. M., KOUTSOUPIAS, E., AND PAPAD-IMITRIOU, C. H. 1997. Towards a theory ofindexability. In Proceedings of the SixteenthACM SIGACT–SIGMOD–SIGART Sympo-sium on Principles of Database Systems.
HELLERSTEIN, J. M., NAUGHTON, J. F., AND PFEF-FER, A. 1995. Generalized search trees fordatabase systems. In Proceedings of the 21stInternational Conference on Very Large DataBases, 562–573.
HENRICH, A. 1995. Adapting the transformationtechnique to maintain multidimensional non-point objects in k-d-tree based access struc-tures. In Proceedings of the Third ACM Interna-tional Workshop on Advances in GeographicInformation Systems (ACM-GIS’95) (Balti-more, MD) ACM Press, New York.
HENRICH, A. AND MOLLER, J. 1995. Extending aspatial access structure to support additionalstandard attributes. In Advances in SpatialDatabases, M. J. Egenhofer and J. R. Herring,Eds., LNCS 951, Springer-Verlag, Berlin/Hei-delberg/New York, 132–151.
HENRICH, A. AND SIX, H.-W. 1991. How to splitbuckets in spatial data structures. In Geo-graphic Database Management Systems, G.Gambosi, M. Scholl, and H.-W. Six, Eds.,Springer-Verlag, Berlin/Heidelberg/New York,212–244.
HENRICH, A., SIX, H.-W., AND WIDMAYER,P. 1989. The LSD tree: Spatial access tomultidimensional point and non-point objects.In Proceedings of the Fifteenth InternationalConference on Very Large Data Bases, 45–53.
HINRICHS, K. 1985. Implementation of the gridfile: Design concepts and experience. BIT 25,569–592.
HOEL, E. G. AND SAMET, H. 1992. A qualitativecomparison study of data structures for largesegment databases. In Proceedings of theACM SIGMOD International Conference onManagement of Data, 205–214.
HOEL, E. G. AND SAMET, H. 1995. Benchmark-ing spatial join operations with spatial out-put. In Proceedings of the 21st InternationalConference on Very Large Data Bases, 606–618.
HUTFLESZ, A., SIX, H.-W., AND WIDMAYER, P.1988a. Globally order preserving multidi-mensional linear hashing. In Proceedings ofthe Fourth IEEE International Conference onData Engineering, 572–579.
HUTFLESZ, A., SIX, H.-W., AND WIDMAYER, P.
1988b. Twin grid files: Space optimizing ac-cess schemes. In Proceedings of the ACM SIG-MOD International Conference on Manage-ment of Data, 183–190.
HUTFLESZ, A., SIX, H.-W., AND WIDMAYER, P.1990. The R-file: An efficient access struc-ture for proximity queries. In Proceedings ofthe Sixth IEEE International Conference onData Engineering, 372–379.
HUTFLESZ, A., WIDMAYER, P., AND ZIMMERMANN, C.1991. Global order makes spatial accessfaster. In Geographic Database ManagementSystems, G. Gambosi, M. Scholl, and H.-W.Six, Eds., Springer-Verlag, Berlin/Heidelberg/New York, 161–176.
INFORMIX INC. 1997. The DataBlade architec-ture. URL http://www.informix.com.
JAGADISH, H. V. 1990a. Linear clustering of ob-jects with multiple attributes. In Proceedingsof the ACM SIGMOD International Confer-ence on Management of Data, 332–342.
JAGADISH, H. V. 1990b. On indexing line seg-ments. In Proceedings of the Sixteenth Inter-national Conference on Very Large DataBases, 614–625.
JAGADISH, H. V. 1990c. Spatial search withpolyhedra. In Proceedings of the Sixth IEEEInternational Conference on Data Engineer-ing, 311–319.
KAMEL, I. AND FALOUTSOS, C. 1992. Parallel R-trees. In Proceedings of the ACM SIGMODInternational Conference on Management ofData, 195–204.
KAMEL, I. AND FALOUTSOS, C. 1993. On packingR-trees. In Proceedings of the Second Interna-tional Conference on Information and Knowl-edge Management, 490–499.
KAMEL, I. AND FALOUTSOS, C. 1994. Hilbert R-tree: An improved R-tree using fractals. InProceedings of the Twentieth InternationalConference on Very Large Data Bases, 500–509.
KAMEL, I., KHALIL, M., AND KOURAMAJIAN, V.1996. Bulk insertion in dynamic R-trees. InProceedings of the Seventh International Sym-posium on Spatial Data Handling (Delft, TheNetherlands), 3B.31–3B.42.
KANELLAKIS, P. C., RAMASWAMY, S., VENGROFF,D. E., AND VITTER, J. S. 1993. Indexing fordata models with constraints and classes. InProceedings of the Twelfth ACM SIGACT–SIGMOD–SIGART Symposium on Principlesof Database Systems, 233–243.
KEDEM, G. 1982. The quad-CIF tree: A datastructure for hierarchical on-line algorithms.In Proceedings of the Nineteenth Conferenceon Design and Automation, 352–357.
KEMPER, A. AND WALLRATH, M. 1987. An analy-sis of geometric modeling in database sys-tems. ACM Comput. Surv. 19, 1, 47–91.
KLINGER, A. 1971. Pattern and search statis-
Multidimensional Access Methods • 227
ACM Computing Surveys, Vol. 30, No. 2, June 1998

tics. In Optimizing Methods in Statistics, S.Rustagi, Ed., 303–337.
KNOTT, G. 1975. Hashing functions. Comput. J.18, 3, 265–278.
KOLOVSON, C. 1990. Indexing techniques formulti-dimensional spatial data and historicaldata in database management systems. Ph.D.Thesis, University of California at Berkeley.
KOLOVSON, C. AND STONEBRAKER, M. 1991. Seg-ment indexes: Dynamic indexing techniquesfor multi-dimensional interval data. In Pro-ceedings of the ACM SIGMOD InternationalConference on Management of Data, 138–147.
KRIEGEL, H.-P. 1984. Performance comparisonof index structures for multikey retrieval. InProceedings of the ACM SIGMOD Interna-tional Conference on Management of Data,186–196.
KRIEGEL, H.-P., HEEP, P., HEEP, S., SCHIWIETZ, M.,AND SCHNEIDER, R. 1991. An access methodbased query processor for spatial databasesystems. In Geographic Database Manage-ment Systems, G. Gambosi, M. Scholl, andH.-W. Six, Eds., Springer-Verlag, Berlin/Hei-delberg/New York, 273–292.
KRIEGEL, H.-P., SCHIWIETZ, M., SCHNEIDER, R., ANDSEEGER, B. 1990. Performance comparisonof point and spatial access methods. In Designand Implementation of Large Spatial Data-base Systems, A. Buchmann, O. Gunther,T. R. Smith, and Y.-F. Wang, Eds., LNCS 409,Springer-Verlag, Berlin/Heidelberg/New York,89–114.
KRIEGEL, H.-P. AND SEEGER, B. 1986. Multi-dimensional order preserving linear hashingwith partial expansions. In Proceedings of theInternational Conference on Database Theory,LNCS 243, Springer-Verlag, Berlin/Heidel-berg/New York.
KRIEGEL, H.-P. AND SEEGER, B. 1987. Multi-dimensional quantile hashing is very efficientfor non-uniform record distributions. In Pro-ceedings of the Third IEEE International Con-ference on Data Engineering, 10–17.
KRIEGEL, H.-P. AND SEEGER, B. 1988. PLOP-hashing: A grid file without directory. In Pro-ceedings of the Fourth IEEE InternationalConference on Data Engineering, 369–376.
KRIEGEL, H.-P. AND SEEGER, B. 1989. Multi-dimensional quantile hashing is very efficientfor non-uniform distributions. Inf. Sci. 48,99–117.
KORNACKER, M. AND BANKS, D. 1995. High-con-currency locking in R-trees. In Proceedings ofthe 21st International Conference on VeryLarge Data Bases, 134–145.
KUMAR, A. 1994a. G-tree: A new data structurefor organizing multidimensional data. IEEETrans. Knowl. Data Eng. 6, 2, 341–347.
KUMAR, A. 1994b. A study of spatial clusteringtechniques. In Proceedings of the Fifth Confer-
ence on Database and Expert Systems Appli-cations (DEXA’94), D. Karagiannis, Ed.,LNCS 856, Springer-Verlag, Berlin/Heidel-berg/New York, 57–70.
LARSON, P. A. 1980. Linear hashing with par-tial expansions. In Proceedings of the SixthInternational Conference on Very Large DataBases, 224–232.
LEHMAN, P. AND YAO, S. 1981. Efficient lockingfor concurrent operations on B-trees. ACMTrans. Database Syst. 6, 4, 650–670.
LIN, K.-I., JAGADISH, H., AND FALOUTSOS, C.1994. The TV-tree: An index structure forhigh-dimensional data. VLDB J. 3, 4, 517–543.
LITWIN, W. 1980. Linear hashing: A new toolfor file and table addressing. In Proceedings ofthe Sixth International Conference on VeryLarge Data Bases, 212–223.
LO, M. AND RAVISHANKAR, C. 1994. Spatial joinsusing seeded trees. In Proceedings of the ACMSIGMOD International Conference on Man-agement of Data, 209–220.
LOMET, D. B. 1983. Boundex index exponentialhashing. ACM Trans. Database Syst. 8, 1,136–165.
LOMET, D. B. 1991. Grow and post index trees:Role, techniques and future potential. In Ad-vances in Spatial Databases, O. Gunther andH. Schek, Eds., LNCS 525, Springer-Verlag,Berlin/Heidelberg/New York, 183–206.
LOMET, D. B. AND SALZBERG, B. 1989. The hB-tree: A robust multiattribute search struc-ture. In Proceedings of the Fifth IEEE Inter-national Conference on Data Engineering,296–304.
LOMET, D. B. AND SALZBERG, B. 1990. The hB-tree: A multiattribute indexing method withgood guaranteed performance. ACM Trans.Database Syst. 15, 4, 625–658. Reprinted inReadings in Database Systems, M. Stone-braker, Ed., Morgan-Kaufmann, San Mateo,CA, 1994.
LOMET, D. B. AND SALZBERG, B. 1992. Accessmethod concurrency with recovery. In Pro-ceedings of the ACM SIGMOD InternationalConference on Management of Data, 351–360.
LU, H. AND OOI, B.-C. 1993. Spatial indexing:Past and future. IEEE Data Eng. Bull. 16, 3,16–21.
MATSUYAMA, T., HAO, L. V., AND NAGAO, M. 1984.A file organization for geographic informationsystems based on spatial proximity. Int.J. Comput. Vis. Graph. Image Process. 26, 3,303–318.
MORTON, G. 1966. A computer oriented geodeticdata base and a new technique in file se-quencing. IBM Ltd.
NELSON, R. AND SAMET, H. 1987. A populationanalysis for hierarchical data structures. InProceedings of the ACM SIGMOD Interna-
228 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

tional Conference on Management of Data,270–277.
NEWELL, R. G. AND DOE, M. 1997. Discrete ge-ometry with seamless topology in a GIS. URLhttp://www.smallworld-us.com.
NG, R. T. AND HAN, J. 1994. Efficient and effec-tive clustering methods for spatial data min-ing. In Proceedings of the Twentieth Interna-tional Conference on Very Large Data Bases,144–154.
NG, V. AND KAMEDA, T. 1993. Concurrent ac-cesses to R-trees. In Advances in Spatial Da-tabases, D. Abel and B. C. Ooi, Eds., LNCS692, Springer-Verlag, Berlin/Heidelberg/NewYork, 142–161.
NG, V. AND KAMEDA, T. 1994. The R-link tree: Arecoverable index structure for spatial data.In Proceedings of the Fifth Conference on Da-tabase and Expert Systems Applications(DEXA’94), D. Karagiannis, Ed., LNCS 856,Springer-Verlag, Berlin/Heidelberg/New York,163–172.
NIEVERGELT, J. 1989. 762 criteria for assessingand comparing spatial data structures. In De-sign and Implementation of Large Spatial Da-tabase Systems, A. Buchmann, O. Gunther,T. R. Smith, and Y.-F. Wang, Eds., LNCS 409,Springer-Verlag, Berlin/Heidelberg/New York,3–27.
NIEVERGELT, J. AND HINRICHS, K. 1987. Storageand access structures for geometric databases. In Proceedings of the InternationalConference on Foundations of Data Organiza-tion, S. Ghosh, Y. Kambayashi, and K.Tanaka, Eds., Plenum, New York.
NIEVERGELT, J., HINTERBERGER, H., AND SEVCIK, K.1981. The grid file: An adaptable, symmetricmultikey file structure. In Proceedings of theThird ECI Conference, A. Duijvestijn and P.Lockemann, Eds., LNCS 123, Springer-Ver-lag, Berlin/Heidelberg/New York, 236–251.
NIEVERGELT, J., HINTERBERGER, H., AND SEVCIK,K. C. 1984. The grid file: An adaptable,symmetric multikey file structure. ACMTrans. Database Syst. 9, 1, 38–71.
OHSAWA, Y. AND SAKAUCHI, M. 1983. BD-tree: Anew n-dimensional data structure with effi-cient dynamic characteristics. In Proceedingsof the Ninth World Computer Congress, IFIP1983, 539–544.
OHSAWA, Y. AND SAKAUCHI, M. 1990. A new treetype data structure with homogeneous nodesuitable for a very large spatial database. InProceedings of the Sixth IEEE InternationalConference on Data Engineering, 296–303.
OOI, B. C. 1990. Efficient Query Processing inGeographic Information Systems. LNCS 471,Springer-Verlag, Berlin/Heidelberg/New York.
OOI, B. C., MCDONELL, K. J., AND SACKS-DAVIS,R. 1987. Spatial kd-tree: An indexingmechanism for spatial databases. In Proceed-
ings of the IEEE Computer Software and Ap-plications Conference, 433–438.
OOI, B. C., SACKS-DAVIS, R., AND MCDONELL,K. J. 1991. Spatial indexing by binary de-composition and spatial bounding. Inf. Syst.J. 16, 2, 211–237.
OOSTEROM, P. 1990. Reactive data structuresfor geographic information systems. Ph.D.Thesis, University of Leiden, The Nether-lands.
ORACLE INC. 1995. Oracle 7 multidimension:Advances in relational database technologyfor spatial data management. White paper.
ORENSTEIN, J. 1982. Multidimensional triesused for associative searching. Inf. Process.Lett. 14, 4, 150–157.
ORENSTEIN, J. 1983. A dynamic file for randomand sequential accessing. In Proceedings ofthe Ninth International Conference on VeryLarge Data Bases, 132–141.
ORENSTEIN, J. 1989a. Redundancy in spatialdatabases. In Proceedings of the ACM SIG-MOD International Conference on Manage-ment of Data, 294–305.
ORENSTEIN, J. 1989b. Strategies for optimizingthe use of redundancy in spatial databases. InDesign and Implementation of Large SpatialDatabase Systems, A. Buchmann, O. Gunther,T. R. Smith, and Y.-F. Wang, Eds., LNCS 409,Springer-Verlag, Berlin/Heidelberg/New York,115–134.
ORENSTEIN, J. 1990. A comparison of spatialquery processing techniques for native andparameter space. In Proceedings of the ACMSIGMOD International Conference on Man-agement of Data, 343–352.
ORENSTEIN, J. AND MERRETT, T. H. 1984. A classof data structures for associative searching.In Proceedings of the Third ACM SIGACT–SIGMOD Symposium on Principles of Data-base Systems, 181–190.
ORENSTEIN, J. A. 1986. Spatial query process-ing in an object-oriented database system. InProceedings of the ACM SIGMOD Interna-tional Conference on Management of Data,326–333.
OTOO, E. J. 1984. A mapping function for thedirectory of a multidimensional extendiblehashing. In Proceedings of the Tenth Interna-tional Conference on Very Large Data Bases,493–506.
OTOO, E. J. 1985. Symmetric dynamic indexmaintenance scheme. In Proceedings of theInternational Conference on Foundations ofData Organization, Plenum, New York, 283–296.
OTOO, E. J. 1986. Balanced multidimensionalextendible hash tree. In Proceedings of theFifth ACM SIGACT–SIGMOD Symposium onPrinciples of Database Systems, 100–113.
OUKSEL, M. 1985. The interpolation based grid
Multidimensional Access Methods • 229
ACM Computing Surveys, Vol. 30, No. 2, June 1998

file. In Proceedings of the Fourth ACM SI-GACT–SIGMOD Symposium on Principles ofDatabase Systems, 20–27.
OUKSEL, M. AND SCHEUERMANN, P. 1983. Stor-age mappings for multidimensional linear dy-namic hashing. In Proceedings of the SecondACM SIGACT–SIGMOD Symposium on Prin-ciples of Database Systems, 90–105.
OUKSEL, M. A. AND MAYER, O. 1992. A robustand efficient spatial data structure. Acta Inf.29, 335–373.
OVERMARS, M. H., SMID, M. H., BERG, T., AND VAN
KREVELD, M. J. 1990. Maintaining rangetrees in secondary memory: Part I: Partitions.Acta Inf. 27, 423–452.
PAGEL, B. U., SIX, H.-W., AND TOBEN, H. 1993a.The transformation technique for spatial ob-jects revisited. In Advances in Spatial Data-bases, D. Abel and B. C. Ooi, Eds., LNCS 692,Springer-Verlag, Berlin/Heidelberg/New York,73–88.
PAGEL, B. U., SIX, H.-W., AND WINTER, M. 1995.Window query optimal clustering of spatialobjects. In Proceedings of the Fourteenth ACMSIGACT–SIGMOD–SIGART Symposium onPrinciples of Database Systems, 86–94.
PAGEL, B. U., SIX, H.-W., TOBEN, H., AND WID-MAYER, P. 1993b. Towards an analysis ofrange query performance in spatial datastructures. In Proceedings of the Twelfth ACMSIGACT–SIGMOD–SIGART Symposium onPrinciples of Database Systems, 214–221.
PAPADIAS, D., THEODORIDIS, Y., SELLIS, T., AND
EGENHOFER, M. J. 1995. Topological rela-tions in the world of minimum bounding rect-angles: A study with R-trees. In Proceedingsof the ACM SIGMOD International Confer-ence on Management of Data, 92–103.
PAPADOPOULOS, A. AND MANOLOPOULOS, Y. 1997.Performance of nearest neighbor queries inR-trees. In Proceedings of the InternationalConference on Database Theory (ICDT’97), F.Afrati and P. Kolaitis, Eds., LNCS 1186,Springer-Verlag, Berlin/Heidelberg/New York,394–408.
PELOUX, J., REYNAL, G., AND SCHOLL, M. 1994.Evaluation of spatial indices implementedwith the O2 DBMS. Ingenierie des Systemesd’Information 6.
PREPARATA, F. P. AND SHAMOS, M. I. 1985. Com-putational Geometry. Springer-Verlag, NewYork.
REGNIER, M. 1985. Analysis of the grid file algo-rithms. BIT 25, 335–357.
ROBINSON, J. T. 1981. The K-D-B-tree: A searchstructure for large multidimensional dynamicindexes. In Proceedings of the ACM SIGMODInternational Conference on Management ofData, 10–18.
ROTEM, D. 1991. Spatial join indices. In Pro-
ceedings of the Seventh IEEE InternationalConference on Data Engineering, 10–18.
ROUSSOPOULOS, N. AND LEIFKER, D. 1984. An in-troduction to PSQL: A pictorial structuredquery language. In Proceedings of the IEEEWorkshop on Visual Languages.
ROUSSOPOULOS, N. AND LEIFKER, D. 1985. Directspatial search on pictorial databases usingpacked R-trees. In Proceedings of the ACMSIGMOD International Conference on Man-agement of Data, 17–31.
SAGAN, H. 1994. Space-Filling Curves. Spring-er-Verlag, Berlin/Heidelberg/New York.
SAMET, H. 1984. The quadtree and related hier-archical data structure. ACM Comput. Surv.16, 2, 187–260.
SAMET, H. 1988. Hierarchical representation ofcollections of small rectangles. ACM Comput.Surv. 20, 4, 271–309.
SAMET, H. 1990a. Applications of Spatial DataStructures. Addison-Wesley, Reading, MA.
SAMET, H. 1990b. The Design and Analysis ofSpatial Data Structures. Addison-Wesley,Reading, MA.
SAMET, H. AND WEBBER, R. E. 1985. Storing acollection of polygons using quadtrees. ACMTrans. Graph. 4, 3, 182–222.
SCHIWIETZ, M. 1993. Speicherung und anfrage-bearbeitung komplexer geo-objekte. Ph.D. The-sis, Ludwig-Maximilians-Universitat Munchen,Germany (in German).
SCHNEIDER, R. AND KRIEGEL, H.-P. 1992. TheTR*-tree: A new representation of polygonalobjects supporting spatial queries and opera-tions. In Proceedings of the Seventh Workshopon Computational Geometry, LNCS 553,Springer-Verlag, Berlin/Heidelberg/New York,249–264.
SCHOLL, M. AND VOISARD, A. 1989. Thematicmap modeling. In Design and Implementationof Large Spatial Database Systems, A. Buch-mann, O. Gunther, T. R. Smith, and Y.-F.Wang, Eds., LNCS 409, Springer-Verlag, Ber-lin/Heidelberg/New York.
SEEGER, B. 1991. Performance comparison ofsegment access methods implemented on topof the buddy-tree. In Advances in SpatialDatabases, O. Gunther and H. Schek, Eds.,LNCS 525, Springer-Verlag, Berlin/Heidel-berg/New York, 277–296.
SEEGER, B. AND KRIEGEL, H.-P. 1988. Tech-niques for design and implementation of spa-tial access methods. In Proceedings of theFourteenth International Conference on VeryLarge Data Bases, 360–371.
SEEGER, B. AND KRIEGEL, H.-P. 1990. The bud-dy-tree: An efficient and robust access methodfor spatial data base systems. In Proceedingsof the Sixteenth International Conference onVery Large Data Bases, 590–601.
SELLIS, T., ROUSSOPOULOS, N., AND FALOUTSOS, C.
230 • V. Gaede and O. Gunther
ACM Computing Surveys, Vol. 30, No. 2, June 1998

1987. The R1-tree: A dynamic index formulti-dimensional objects. In Proceedings ofthe Thirteenth International Conference onVery Large Data Bases, 507–518.
SEVCIK, K. AND KOUDAS, N. 1996. Filter treesfor managing spatial data over a range of sizegranularities. In Proceedings of the 22th In-ternational Conference on Very Large DataBases (Bombay), 16–27.
SEXTON, A. P. 1997. Querying indexed files. InProceedings of the CDB’97 and CP’96 Work-shop on Constraint Databases and Their Ap-plication, V. Gaede, A. Brodsky, O. Gunther,D. Srivastava, V. Vianu, and M. Wallace,Eds., LNCS 1191, Springer-Verlag, Berlin/Heidelberg/New York, 263–281.
SHEKHAR, S. AND LIU, D.-R. 1995. CCAM: A con-nectivity-clustered access method for aggre-gate queries on transportation networks: Asummary of results. In Proceedings of theEleventh IEEE International Conference onData Engineering, 410–419.
SIEMENS NIXDORF INFORMATIONSSYSTEME AG1997. URL http://www.sni.de.
SIX, H. AND WIDMAYER, P. 1988. Spatial search-ing in geometric databases. In Proceedings ofthe Fourth IEEE International Conference onData Engineering, 496–503.
SMID, M. H. AND OVERMARS, M. H. 1990. Main-taining range trees in secondary memory partII: Lower bounds. Acta Inf. 27, 453–480.
SMITH, T. R. AND GAO, P. 1990. Experimentalperformance evaluations on spatial accessmethods. In Proceedings of the Fourth Inter-national Symposium on Spatial Data Han-dling (Zurich), 991–1002.
STONEBRAKER, M. (ED.) 1994. Readings in Data-base Systems. Morgan-Kaufmann, San Mateo,CA.
STONEBRAKER, M., SELLIS, T., AND HANSON, E.1986. An analysis of rule indexing imple-mentations in data base systems. In Proceed-
ings of the First International Conference onExpert Data Base Systems.
STUCKEY, P. 1997. Constraint search trees. InProceedings of the International Conference onLogic Programming (CLP’97), L. Naish, Ed.,MIT Press, Cambridge, MA.
SUBRAMANIAN, S. AND RAMASWAMY, S. 1995. TheP-range tree: A new data structure for rangesearching in secondary memory. In Proceed-ings of the ACM-SIAM Symposium on DiscreteAlgorithms (SODA’95).
TAMMINEN, M. 1982. The extendible cell methodfor closest point problems. BIT 22, 27–41.
TAMMINEN, M. 1983. Performance analysis ofcell based geometric file organisations. Int.J. Comp. Vis. Graph. Image Process. 24, 160–181.
TAMMINEN, M. 1984. Comment on quad- and oc-trees. Commun. ACM 30, 3, 204–212.
THEODORIDIS, Y. AND SELLIS, T. K. 1996. Amodel for the prediction of R-tree perfor-mance. In Proceedings of the Fifteenth ACMSIGACT–SIGMOD–SIGART Symposium onPrinciples of Database Systems, 161–171.
TROPF, H. AND HERZOG, H. 1981. Multi-dimensional range search in dynamically bal-anced trees. Angewandte Informatik 2, 71–77.
WHANG, K.-Y. AND KRISHNAMURTHY, R. 1985.Multilevel grid files. IBM Research Labora-tory, Yorktown Heights, NY.
WHITE, M. 1981. N-trees: Large ordered in-dexes for multi-dimensional space. Tech. Rep.,Application Mathematics Research Staff, Sta-tistical Research Division, US Bureau of theCensus.
WIDMAYER, P. 1991. Datenstrukturen fur Geo-datenbanken. In Entwicklungstendenzen beiDatenbank-Systemen, G. Vossen and K.-U.Witt, Eds., Oldenbourg-Verlag, Munich,Chapter 9, 317–361 (in German).
Received August 1995; revised August 1997; accepted January 1998
Multidimensional Access Methods • 231
ACM Computing Surveys, Vol. 30, No. 2, June 1998















![Multidimensional ESPRIT for Damped and Undamped Signals: … · 2021. 7. 20. · difference between the N-D ESPRIT andthe multidimensional ESPRIT of [6], and other methods, such as](https://img.pdfslide.net/doc/110x75/61365ca60ad5d2067647f9b5/multidimensional-esprit-for-damped-and-undamped-signals-2021-7-20-difference.jpg)













