Embed Size (px)
Citation preview

ARTICLE IN PRESS
0952-1976/$ - se
doi:10.1016/j.en
�CorrespondE-mail addr
Aradhya), naw
Engineering Applications of Artificial Intelligence 21 (2008) 658–668
www.elsevier.com/locate/engappai
Multilingual OCR system for South Indian scripts andEnglish documents: An approach based on Fourier transform
and principal component analysis
V.N. Manjunath Aradhya�, G. Hemantha Kumar, S. Noushath
Department of Studies in Computer Science, University of Mysore, Mysore 570006, Karnataka, India
Received 5 May 2006; received in revised form 20 May 2007; accepted 28 May 2007
Available online 12 July 2007
Abstract
Character recognition lies at the core of the discipline of pattern recognition where the aim is to represent a sequence of characters
taken from an alphabet [Kasturi, R., Gorman, L.O., Govindaraju, V., 2002. Document image analysis: a primer. Sadhana 27 (Part 1),
3–22]. Though many kinds of features have been developed and their test performances on standard database have been reported, there is
still room to improve the recognition rate by developing improved features. In this paper, we present a multilingual character recognition
system for printed South Indian scripts (Kannada, Telugu, Tamil and Malayalam) and English documents. South Indian languages are
most popular languages in India and around the world. The proposed multilingual character recognition is based on Fourier transform
and principal component analysis (PCA), which are two commonly used techniques of image processing and recognition. PCA and
Fourier transforms are classical feature extraction and data representation techniques widely used in the area of pattern recognition and
computer vision. Our experimental results show the good performance over the data sets considered.
r 2007 Elsevier Ltd. All rights reserved.
Keywords: Document analysis; Multi-lingual character recognition; South Indian languages; Fourier transform; Principal component analysis (PCA)
1. Introduction
Optical character recognition (OCR) is one of thevirtually eminent applications of automatic pattern recog-nition. Research in OCR is very popular for variousapplication potentials in banks, post offices, defenseorganizations, reading aid for the blind, library automa-tion, language processing and multi-media design. India isa multi-lingual multi-script country, where a single docu-ment page (e.g., passport application form, an examinationquestion paper, a money order form, bank accountopening application form, train reservation form, etc.)may contains text in two or more language scripts. OCR isof special significance for a multilingual country like Indiahaving 16 major state languages and over 100 regionallanguages.
e front matter r 2007 Elsevier Ltd. All rights reserved.
gappai.2007.05.009
ing author.
esses: [email protected] (V.N. Manjunath
[email protected] (S. Noushath).
The current challenges in the filed of OCR technology isto take care of poor quality documents, recognizingcharacters with various noise types, recognition of multi-lingual characters and development of OCR which canhandle different fonts and sizes.For Indian and many other oriental languages, OCR
systems are not yet able to successfully recognize printeddocument images of varying scripts, quality, size, style, andfont. In contrast to European languages, Indian languagespose many additional challenges. Such as: (i) large numberof vowels, consonants, and conjuncts, (ii) most scriptsspread over several zones, (iii) inflectional in nature andhaving complex character grapheme, (iv) lack of standardtest databases for the Indian languages.However, most of the available systems work on
European scripts which are based on Roman alphabet(Bozinovic and Srihari, 1989; Casey and Nagy, 1968; Wanget al., 1982; Mori et al., 1992; Kahan et al., 1987). Researchreports on oriental language scripts are few, except forKorean, Chinese and Japanese scripts (Govindan and

ARTICLE IN PRESSV.N. Manjunath Aradhya et al. / Engineering Applications of Artificial Intelligence 21 (2008) 658–668 659
Shivaprasad, 1990). Focused documentation of the activ-ities in this area may also be seen in Indian languagedocument analysis and understanding (2002).1 Thesetechnical articles reveal the academic contributions to thedevelopment of OCR system for Indian scripts and discussspecific issues to be addressed in Indian scripts. One of themajor contributions in this area is the Devnagari OCRsystem developed by Chaudhuri B.B. Chaudhuri and Pal(1998), which is commercially available. This is the firstOCR system among all script forms used in the Indian sub-continent. Performance of the system on documents with avaried degree of noise is being studied and that on size andstyle variations is also studied. Another important OCRsystem is also proposed in the literature that can read twoIndian language scripts: Bangla and Devnagari (Hindi), themost popular ones in Indian sub-continent by Chaudhuriand Pal (1997). Stroke features are used for characterrecognition. Feature based tree classifiers is initially usedand efficient template matching approach is employed torecognize individual character. The performance of thesystem is quite satisfactory on single font clear documents.An OCR system to read South Indian language of Teluguis presented in Negi et al. (2001). The simple and mostobvious approach for recognizing Telugu characters is tobreak each character into glyphs and recognize them. Theyuse fringe distance for the comparison of Telugu characterbinary images. The overall performance of the proposedmethod is 92%. A multi-font OCR system for printedTelugu text is also described in Vasantha Lakshmi andPatvardhan (2002).
The character recognition process from printed docu-ments containing Hindi and Telugu text is presented inJawahar et al. (2003). The bilingual recognizer is based onprincipal component analysis (PCA) followed by supportvector classification. Basically principal components areused for dimensionality reduction and can give superiorperformance for font independent OCR. Support vectormachines (SVM) are pair-wise discriminating classifierswith the ability to identify the decision boundary withmaximal margin. The overall accuracy of the method is96.7%. In Hanmandlu et al. (2003) an approach based onFuzzy for unconstrained handwritten character recognitionis presented. Binary image of a character is partitioned intofixed number of sub-images called boxes. The featuresconsist of normalized vector distances and angles fromeach box. They have devised a new fuzzification functioninvolving parameters, which take into account of thevariations in the fuzzy sets. A recognition rate of almost99% was achieved with the new fuzzification function.
An OCR system for printed Urdu script is described inPal and Sarkar (2003). The method uses topologicalfeatures, contour features as well as features obtainedfrom the concept of water reservoir. The topologicalfeatures include existence of holes, ratio of hole height to
1For further information please visit the link: www.iiit.net/itrc/
index.html.
character height, etc. Contour features include character-istics of different profiles obtained from a portion ofcontour. Water reservoir based features include number ofreservoirs, position of reservoirs, height of reservoir, etc.These features are used for further recognition purpose.The method was tested in a variety of printed Urdudocuments. The system identifies individual text line withan accuracy of 98.3% and the system recognizes basiccharacters and numerals with an accuracy of about 97.8%.OCR for printed Tamil text using Unicode is presented inSeethalakshmi et al. (2005). The method uses variousfeatures that are considered for classification are thecharacter height, width, number of horizontal and verticallines, etc. Back propagation and SVM based classifiers areused for subsequent classification purpose. Automaticrecognition of printed Oriya script is presented inChaudhuri et al. (2002). The digitized document image isfirst passed through preprocessing modules like skewcorrection, line segmentation, character segmentation,etc. Next, individual characters are recognized usingcombination of stroke and run-number based featuresalong with features obtained from the concept of waterreservoir. In the recognition stage, modifiers are recognizedin the first part and remaining characters are recognized inthe second part. The system has been tested on a variety ofprinted Oriya documents. Recognition of individual textlines is about 97.5% whereas character segmentationaccuracy is about 97.2%. On average the system recognizescharacters with an accuracy of about 96.3%. A font andsize independent OCR system for printed Kannadadocuments is presented in Ashwin and Sastry (2002). Thesystem first extracts words from the document image andthen segments these into sub-character level pieces. A set ofzone features is extracted after normalization of thecharacters for further recognition purpose. A survey onIndian script character recognition is presented in Pal andChaudhuri (2004). The paper discusses a review of OCRwork done on Indian language scripts and differentmethodologies applied in OCR development in interna-tional scenario.To the best of our knowledge, this is the first report of its
kind on multiple Indian scripts character recognition. Theproposed multilingual character recognition system worksbased on Fourier transform and PCA (Fourier-PCA).Fourier transform is a widely used image processingtechnique, which is often applied to the enhancement ofimage description information and visual effect. In thispaper, we combine it with popular PCA to enhance theclassification information and improve the recognitioneffect. We first obtain filtered images (pre-processed) by theselection of appropriate Fourier frequency bands ofcharacter images. We then propose to carry out characterclassification/recognition by using the PCA method.The organization of this paper is as follows. In Section 2,
brief overview of South Indian scripts are presented.In Section 3, preprocessing procedures such as skewestimation and segmentation are presented. In Section 4,

ARTICLE IN PRESSV.N. Manjunath Aradhya et al. / Engineering Applications of Artificial Intelligence 21 (2008) 658–668660
we describe our proposed technique. Experimental resultsand comparative study are reported in Section 5. Finally,conclusions are drawn in Section 6.
2. Brief overview of South Indian scripts
In this section, we give the brief explanation over theproperties of South Indian scripts. Figures containing ofvowels, consonants, and conjunct consonant characterpertaining to South Indian scripts are separately shown inAppendix A.
2.1. Kannada script
Kannada is one of the major Dravidian languages ofsouthern India and one of the earliest languages evidencedepigraphically in India and spoken by about 50 millionpeople in the Indian states of Karnataka. The script has 49characters in its alphasyllabary and is phonemic. TheKannada character set is almost identical to that of otherIndian languages. The characters are classified into threecategories: swaras (vowels), vyanjanas (consonants) andyogavaahas (part vowel, part consonants).
2.2. Tamil script
Tamil is a Dravidian language spoken predominantly byTamils in India and Sri Lanka, of speakers in many othercountries. It is the official language of the Indian state ofTamil Nadu, and also has official status in Sri Lanka andSingapore and having more than 7 million speakers. Tamilis one of the major languages of the world. The Tamilscript has 12 vowels, 18 consonants and five grantha letters.The script, however, is syllabic and not alphabetic. Thecomplete script, therefore, consists of the 31 letters in theirindependent form, and an additional 216 combinant lettersrepresenting every possible combination of a vowel and aconsonant.
2.3. Telugu script
Telugu, another Dravidian language spoken by about 5million people in the southern Indian state of AndhraPradesh and neighboring states, and also in Bahrain, Fiji,Malaysia, Mauritius, Singapore and the UAE. Telugu is asyllabic language. Similar to most languages of India, eachsymbol in Telugu script represents a complete syllable.Officially, there are 18 vowels, 36 consonants, and threedual symbols. Of these, 13 vowels, 35 consonants are incommon usage.
2.4. Malayalam script
Malayalam is the language spoken predominantly inthe state of Kerala, in southern India. It is one of the 23official languages of India, spoken by around 37 millionpeople. The language belongs to the family of Dravidian
languages. Both the language and its writing system areclosely related to Tamil; however, Malayalam has a scriptof its own. Malayalam language script consists of 51 lettersincluding 16 vowels and 37 consonants. The earlier style ofwriting is now substituted with a new style and this newscript reduces the different letters for typeset from 900 toless than 90.
3. Preprocessing
Preprocessing plays an important role in any OCRsystem. In this section we explain two major preprocessingsteps that are crucial for successful development of OCRsystem: (1) skew estimation and (2) segmentation.The digitized images are in gray tone and we have used
histogram based thresholding approach to convert theminto two-tone images. For a clear document the histogramshows two-prominent peaks corresponding to white andblack regions. The threshold value is chosen as themidpoint of the two-histogram peaks. The two-tone imageis converted into 0-1 labels where the label 1 represents theobject and 0 represents the background.
3.1. Skew estimation
Skew angle detection is an important component of anyOCR and document analysis system. When a document isfed to a scanner either mechanically or by a humanoperator for digitization, it suffers some degrees of skew ortilt. Hence, in this work we have applied skew detectionmethod described in Nagabhushan et al. (2006), which isspecially designed to handle South Indian scripts docu-ments. The technique is based on boundary growing (BG),nearest neighboring clustering (NNC) and moments todetermine the inclination of the scanned document. First,the method excludes those components whose height isvery small. In doing so, dots of the character like ‘i’ and ‘j’,punctuation marks like full stop, comma, hyphen, etc. areremoved. If height of a character is greater than theaverage height, then the character height is reduced toaverage height. In this way, the method obtains heightnormalized character document. Using BG, the methodextracts top-left, bottom-right and centriod coordinatepoints present in each text line. However, the BG alonedoes not give accuracy for South Indian languagedocuments because of the modifiers that often gets pluggedinto the characters. Hence the method uses NNC and BGto extract the coordinates of the compound characters bydrawing a single boundary. The extracted coordinatepoints are then passed to moments to estimate skew angle.Fig. 1(a) shows the sample text lines of four South
Indian scripts. Fig. 1(b) shows the results of applying BGalone, and finally the results of BG+NNC is shown inFig. 1(c). Skew angle obtained for the document shown inFig. 2(a) is 4.891, whereas actual skew angle is 51. Afterdetecting the skew, it is necessary to deskew the document.To deskew the document, nearest neighbor interpolation

ARTICLE IN PRESS
Fig. 1. Results of BG+NNC for sample images of Kannada, Malayalam, Tamil and Telugu.
Fig. 2. Input skewed document and its corresponding deskewed docu-
ment.
Fig. 3. A sample Kannada word is divided into three lines.
Fig. 4. Showing the working procedure of the proposed segmentation
method.
V.N. Manjunath Aradhya et al. / Engineering Applications of Artificial Intelligence 21 (2008) 658–668 661
technique is applied for the document. Result of deskeweddocument is shown in Fig. 2(b).
3.2. Segmentation
Segmentation of a document into lines, and subsequentlyextracting individual characters constitute an important taskin the optical reading of texts. Presently most recognitionerrors are due to character segmentation errors (Bansal andSinha, 2002). To segment the word into individual characters,proposed system also incorporates a segmentation techniqueto segment the individual characters of South Indian andEnglish alphabets. As South Indian script is a non-cursivescript, the individual characters in a word are isolated.Spacing between the characters can be used for segmentation.But, there will not be any zero-valued valleys, due to thepresence of conjunct consonants. Hence, in such cases theusual method of vertical projection profile to separatecharacters fails. To segment the characters of these types,we propose a new technique based on their structure. Theproposed segmentation technique has two stages as follows:
Stage 1: consider the sample word as shown in Fig. 3.The height of the word is divided into three lines: upper,
lower and middle line. Upper line is drawn such that itpasses through the upper most pixels present in theword. In the similar way, the lower line is drawn whichpasses through the lower most pixel present in the word.Finally, the middle line is drawn corresponding to upperand lower line.Stage 2: beginning from the middle line, label aconnected component by searching in the upwarddirection. This search is confined within the image areaencompassed by the upper and middle lines. (ReferFig. 4). If any component is encountered along the middleline of the image, label the corresponding component.Now, within the image area of the previously labeledcomponent continue searching process as mentionedearlier (i.e., in upward direction). If any component isencountered within that area, the current componentalong with the previously labeled component is consideredas one single component. This labeling process iscontinued till we reach the end of the middle line. If anycomponent is present within the middle and lower linethen that component is labeled as modifier. Fig. 5 showsthe final segmentation of the individual characters of thesample word considered, where the numbers indicate theorder by which the components are extracted.

ARTICLE IN PRESS
Fig. 5. Showing the final segmentation of characters.
Fig. 6. Illustration of Fourier frequency spectrums with different
frequency bands.
V.N. Manjunath Aradhya et al. / Engineering Applications of Artificial Intelligence 21 (2008) 658–668662
This algorithm is a general algorithm which is indepen-dent of language and size. The proposed segmentationalgorithm is tested on verity of South Indian scripts andperformed well in all conditions. After successfullysegmenting words into individual characters, each of thesecomponents are scaled to a standard size before featureextraction. In the final implementation, it turned out to 220classes for Kannada, 200 classes for Tamil, 225 classes forTelugu, 85 classes for Malayalam and 62 in case of English.
4. Overview of PCA
Feature extraction is the identification of appropriatemeasures to characterize the component images distinctly.There are many popular methods to extract features.Amongst which PCA is one of the state-of-the art methodsfor feature extraction and data representation techniquewidely used in the area of computer vision and patternrecognition. Using these techniques, an image can beefficiently represented as a feature vector of low dimen-sionality. The features in such subspace provide moresalient and richer information for recognition than the rawimage. In this section, we have briefly explained PCAmethod for the sake of continuity and completeness.
4.1. The PCA method
The PCA technique (Turk and Pentland, 1991) regardseach image as a feature vector in a high dimensional spaceby concatenating the rows of the image and using theintensity of each pixel as a single feature vector. Moreformally, let us consider a set of N sample training images{A1, A2,y,AN} taking values in n-dimensional imagespace, and assume that each belongs to one of c classes{B1, B2,y, Bc}. Now the average matrix A of all trainingsamples has to be calculated then subtracted from theoriginal characters Ai and the result is stored in Fi:
A ¼1
N
XN
i¼1
Ai, (1)
Fi ¼ Ai � A. (2)
In the next step, the covariance matrix C is calculated
according to C ¼ 1=NPNi¼1
FiFTi . Now the eigenvectors
Ui(i ¼ 1,y,N) and the corresponding eigenvalues
li(i ¼ 1,y,N) are calculated. From the above N eigenvec-tors, only k should be chosen corresponding to largesteigenvalues. The highest the eigenvalues, the more char-acteristic features of a character does the particulareigenvector describe. Using the k eigenvectors Uk, featureextraction done by PCA is as follows:
Fi ¼ UTk ðAi � AÞ i ¼ 1; . . . ;N, (3)
4.2. Fourier approach description
Suppose that the original image sample set is X, eachimage matrix is sized m-by-n and expressed by f(x,y), where1pxpm,1pypn and mXn. Assuming there are c knownpattern classes (w1,w2,y,wc) in X. Perform a two-dimen-sional discrete Fourier transform on each image by
F ðu; vÞ ¼1
mn
Xm
x¼1
Xn
y¼1
f ðx; yÞ exp �j2pux
mþ
vy
n
� �h i, (4)
where j ¼ffiffiffiffiffiffiffi�1p
, exp() denotes the exponential function,and F(u,v) is sized mxn. Let F(u0,v0) indicates zero-frequency band. Shift F(u0,v0) to the center of imagematrix, that is, the point (m/2,n/2). Since the frequencydomain is represented by the matrix form, we use a squarebox Box (l) to represent the lth frequency band, where0plpm/2. The four vertices of the Box (l) are (u0�l,v0�l),(u0+l,v0�l), (u0�l,v0+l) and (u0+l,v0+l), respectively. So,the lth frequency band denotes:
F ðu; vÞ 2 BoxðlÞ.
The Fourier spectrum with different frequency bandsare shown in Fig. 6. If we select the lth frequency band,retain the values of F(u,v), otherwise set the values of F(u,v)to zero. But, which principle should we follow to select theappropriate bands? Here, we propose a simple two-dimen-sional discriminatory criterion to evaluate the discriminatory

ARTICLE IN PRESSV.N. Manjunath Aradhya et al. / Engineering Applications of Artificial Intelligence 21 (2008) 658–668 663
power of the frequency band and select the appropriatebands:
(i)
Fig.
imag
Use the lth frequency band:
F ðu; vÞ
¼retain original values if F ðu; vÞ 2 BoxðlÞ
0 if F ðu; vÞeBoxðlÞ
(,
ð5Þ
and perform an inverse Fourier transform on thecurrent F(u,v) values as follows:
f ðx; yÞ
¼1
mn
Xm
u¼1
Xn
v¼1
F ðu; vÞ exp j2pux
mþ
vy
n
� �h i. ð6Þ
Hence, for all the images in X, we obtain thecorresponding filtered images, which construct a newsamples set Yl. Note that the Yl have the same valuesof the number of samples and number of classes as thatof X. Let W denotes the total mean value of Yl. Nowwith regard to Yl, the scatter matrix is defined asfollows:
S ¼ E½ðY l �W ÞT ðY l �W Þ�. (7)
(ii)
We evaluate the discriminatory power of Yl, J(Yl),using the following judgment:JðY lÞ ¼ trðSÞ, (8)
where tr() represents the trace of the matrix. Nowthose frequency bands, which maximize the abovecriteria, will have the better discriminatory power.Hence, we chose those frequency bands that maximizeEq. (8), perform the inverse Fourier transform andobtain the band-pass filtered images.
After deriving these band-pass filtered (i.e., prepro-cessed) images we apply PCA (as explained in Section 4.1)to build the corresponding eigenspaces for subsequentrecognition process. NNC is used for subsequent classifica-tion purpose. Here we call, the method applying PCA on Yl
as Fourier-PCA (F-PCA). Fig. 7 displays four originalsamples of images of the character and the correspondingfiltered images.
7. Typical character images (Top) and their corresponding filtered
es (Bottom).
5. Experimental results
In this section, we experimentally evaluate our proposedmethod with a data set containing various characterspertaining to South Indian languages and English. Eachexperiment is repeated 25 times by varying number ofprojection vectors t (where t ¼ 1,y,20, 25, 30, 35, 40, and45). Since t, has a considerable impact on recognitionaccuracy, we chose the value that corresponds to bestclassification result on the image set. All of our experimentsare carried out on a PC machine with P4 3GHz CPU and512MB RAM memory under Matlab 7.0 platform.
5.1. Experimentation on printed South Indian and English
text documents
We have evaluated the performance of the proposedsystem of the recognition process on different realdocuments. The characters are collected in a systematicmanner from the printed pages scanned on a HP 2400Scanjet Scanner. Documents were skew correctedand components were extracted. Subsets from this dataset were used for training and testing. The size of theinput character is normalized to 50� 50. Totally wehave conducted four different types of experimentation:(1) clear and degraded characters (2) scale independence(3) font independence (4) noisy characters. In the firstexperimentation, we considered the font-specific perfor-mance of South Indian languages and English. Weconsidered two fonts each for these languages and weconsidered 50,000 samples for this experiment. Resultsare reported in Table 1. From Table 1 it is noticed that forclear and degraded characters the recognition rate achievedis 99.01%. Some of the misclassifications were present dueto the distortions created by skew correction.Performance of the system is usually influenced by scale
and resolution of the characters. We considered samples ofprinted characters at various sizes and scanned at variousscales for the next experiment. Totally we collected about20,000 samples of different size characters and scannedwith different resolution. From the experimentation therecognition rate achieved for scale independence charactersis about 95%.A font is a set of printable or displayable text characters
in a specific style and size. Recognizing different font whenthe character class is huge is really interesting andchallenging. In this experimentation, we have considereddifferent font independent characters of South Indianscripts and English. Totally, we considered around 37,500samples for font independence and we achieved around92.4%.Noise plays a very important role in the field of
document image processing. To check the robustnessof the proposed method, we conducted series of experi-mentation on noisy characters by varying noise densityfrom 0.01 to 0.5 in step of 0.01. For this, we randomlyselect one character image from each class and generate

ARTICLE IN PRESS
Table 1
Recognition rate of the proposed system and comparative study with PCA method
Experimental details Language Font F-PCA (%) PCA (%)
Clear and degraded Kannada Kailasam 99.01 96.9
Kannada Kasturi
Tamil BRH Tamil
Tamil BRH Tamil RN
Telugu BRH Telugu
Telugu BRH Telugu RN
Malayalam BRH Malayalam
Malayalam BRH Malayalam RN
English Times New Roman
English Arial
Scale independence Kannada Kailasam 95 93.45
Kannada Kasturi
Tamil BRH Tamil
Tamil BRH Tamil RN
Telugu BRH Telugu
Telugu BRH Telugu RN
Malayalam BRH Malayalam
Malayalam BRH Malayalam RN
English Times New Roman
English Arial
Font independence South Indian N.A 92.4 90.8
English N.A
Noisy data Kannada Kailasam 94 92.56
Kannada Kasturi
Tamil BRH Tamil
Tamil BRH Tamil RN
Telugu BRH Telugu
Telugu BRH Telugu RN
Malayalam BRH Malayalam
Malayalam BRH Malayalam RN
English Times New Roman
English Arial
Fig. 8. Some of the sample images of English handwritten characters.
V.N. Manjunath Aradhya et al. / Engineering Applications of Artificial Intelligence 21 (2008) 658–668664
50 corresponding noisy images (here ‘‘salt and pepper’’noise is considered). We tested our proposed system withapproximately 30,000 character images of South Indianscripts and English. We noticed that the proposed systemachieves 94% recognition rate and remained robust tonoise by withstanding upto 0.3 noise density.
We also compared our proposed method with Eigen-character (PCA) based technique (Jawahar et al., 2003).Table 1 shows the performance accuracy of the PCA basedtechnique with clear and degraded characters, scaleindependence, font independence, and noisy characters.From Table 1 it is clear that the proposed Fourier-PCAbased technique performs well for all the conditionsconsidered.
5.2. Experimentation on handwritten characters
Handwritten recognition is an active topic in OCRapplication and pattern classification/learning research. InOCR applications, English alphabets recognition is dealtwith postal mail sorting, bank cheque processing, formdata entry, etc. For these applications, the performance ofhandwritten English alphabets recognition is crucial to the
overall performance. In this work, we have also extendedour experiment to handwritten characters of Englishalphabets. For experimentation, we considered samplesfrom 200 individual writers and total of 12,400 characterset is considered. Some of the sample images of hand-written characters are shown in Fig. 8. We trained thesystem by varying the training sample number by 50, 75,125, 175 and remaining samples of each character class areused during testing. Table 2 shows the best recognitionaccuracy obtained from the proposed system and the PCA

ARTICLE IN PRESSV.N. Manjunath Aradhya et al. / Engineering Applications of Artificial Intelligence 21 (2008) 658–668 665
based technique for varying number of samples. FromTable 2 it is clear that the highest recognition rate achievedis 93.8% when 175 samples are used for training andremaining 25 samples used for testing.
6. Conclusion
In this paper, the potentiality of PCA method is furtherexplored by combining it with Fourier transform. A simplecriterion for selecting appropriate Fourier frequency bandsis proposed. After choosing the appropriate frequencybands, we have performed inverse Fourier transform toobtain alternate band-pass filtered (preprocessed) trainingset. We have then applied conventional PCA scheme for
Table 2
Best recognition accuracy for handwritten characters
No. of training samples/
character class
Best recognition accuracy
F-PCA (%) PCA (%)
50 59 57.5
75 79.6 76.7
125 88.9 86
175 93.8 90.8
Fig. A.2. Kannad
Fig. A.1. Kannada vow
Fig. A.3. A few examples o
subsequent recognition purpose. This preprocessing stepmakes the training image set more salient by fading outthe unimportant features and enhancing the essentialvisual information, which will be useful for recognitiontask. The proposed system recognizes all basic characters,vowel–consonants combinations, and modifiers of SouthIndian script texts and upper case, lower case, andnumerals in case of English language with an averagerecognition accuracy of 95.1%. The system is also testedon English handwritten characters and achieved recogni-tion accuracy of about 93.8%. The system is tested onvariety of images containing noise, sizes, mulit fonts anddegraded characters. Hence, our proposed work hasgreater advantages and meets the current challenges inthe field of OCR. We have also compared our systemwith conventional PCA method and ascertained thesuperiority of the proposed method over PCA method inall aspects. Further, we plan to extend this work for otherIndian scripts.
Appendix A. South Indian scripts
Kannada script: Figs. A.1–A.3; Tamil script: Figs. A.4and A.5; Telugu script: Figs. A.6–A.8; Malayalam script:Figs. A.9–A.11.
a consonants.
els and its diacritics.
f conjunct consonants.
ARTICLE IN PRESS
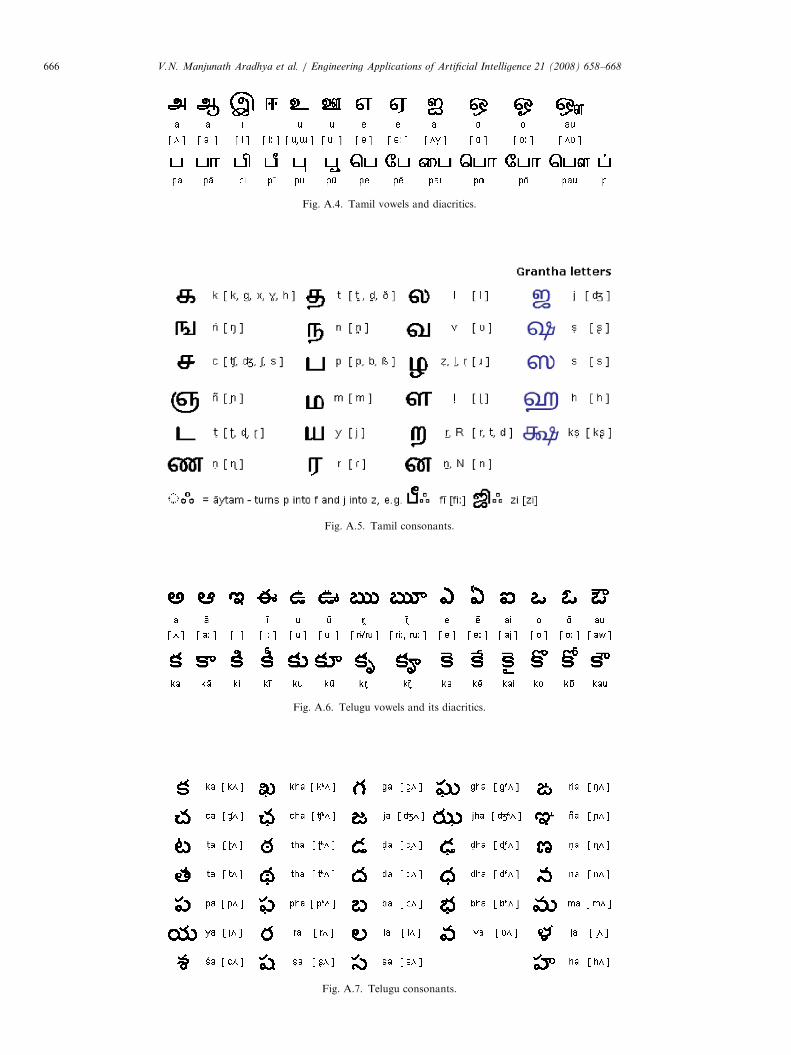
Fig. A.4. Tamil vowels and diacritics.
Fig. A.5. Tamil consonants.
Fig. A.6. Telugu vowels and its diacritics.
Fig. A.7. Telugu consonants.
V.N. Manjunath Aradhya et al. / Engineering Applications of Artificial Intelligence 21 (2008) 658–668666

ARTICLE IN PRESS
Fig. A.9. Malayalam vowels and its diacrtitics.
Fig. A.8. Example of some of the conjunct consonants.
Fig. A.10. Malayalam consonants.
Fig. A.11. Example of some of the conjunct consonants and its diacritics.
V.N. Manjunath Aradhya et al. / Engineering Applications of Artificial Intelligence 21 (2008) 658–668 667

ARTICLE IN PRESSV.N. Manjunath Aradhya et al. / Engineering Applications of Artificial Intelligence 21 (2008) 658–668668
References
Ashwin, T.V., Sastry, P.S., 2002. A font and size-independent OCR system
for printed Kannada documents using support vector machines.
Sadhana 27 (Part 1), 35–58.
Bansal, V., Sinha, R.M.K., 2002. Segmentation of touching and fused
Devnagari characters. Pattern Recognition 35, 593–875.
Bozinovic, R.M., Srihari, S.N., 1989. Offline cursive script word
recognition. IEEE Transactions on Pattern Recognition and Machine
Intelligence 11, 68–83.
Casey, R., Nagy, G., 1968. Automatic reading machine. IEEE Transac-
tions on Computers. 17, 492–503.
Chaudhuri, B.B., Pal, U., 1997. An OCR system to read two Indian
language scripts: Bangla and Devnagari (Hindi). Proceedings of
ICDAR, 1011–1015.
Chaudhuri, B.B., Pal, U., 1998. A complete Bangla OCR system. Pattern
Recognition 31 (5), 531–549.
Chaudhuri, B.B., Pal, U., Mitra, M., 2002. Automatic recognition of
printed Oriya script. Sadhana 27 (Part 1), 23–34.
Govindan, V.K., Shivaprasad, A.P., 1990. Character recognition—
a survey. Pattern Recognition 23, 671–683.
Hanmandlu, M., Mohan, A., Goyal, C., Roy, D., 2003. Unconstrained
handwritten character recognition based on fuzzy logic. Pattern
Recognition 36 (3), 603–623.
Indian language document analysis and understanding, 2002. Special issue
of Sadhana, February.
Jawahar, C.V., Pavan Kumar, M.N.S.S.K., Ravi Kiran, S.S., 2003.
A bilingual OCR for Hindi–Telugu documents and its applications.
In: Proceedings of ICDAR, 3–6 August, Edinburgh, pp. 656–660.
Kahan, S., Pavildis, T., Baird, H.S., 1987. On the recognition of printed
character of any font and size. IEEE Transactions on Pattern Analysis
and machine Intelligence 9, 274–288.
Kasturi, R., Gorman, L.O., Govindaraju, V., 2002. Document image
analysis: a primer. Sadhana 27 (Part 1), 3–22.
Mori, S., Suen, C.Y., Yamamoto, K., 1992. Historical review of
OCR research and development. Proceedings of the IEEE 80,
1029–1058.
Nagabhushan, P., Hemantha Kumar, G., Shivakumara, P., Manjunath
Aradhya, V.N., 2006. Skew estimation by improved boundary growing
for text documents in South Indian languages. Journal of
Vivek Special Issue on Document Analysis of Indian Scripts 16 (2),
16–21.
Negi, A., Bhagvati, C., Krishna, B., 2001. An OCR system for Telugu. In:
Proceedings of ICDAR, 10–13 September, Seattle, pp. 1110–1113.
Pal, U., Chaudhuri, B.B., 2004. Indian script character recognition: a
survey. Pattern Recognition 37, 1887–1899.
Pal, U., Sarkar, A., 2003. Recognition of printed Urdu Script. In:
Proceedings of ICDAR, 3–6 August, Edinburgh 2003, pp. 598–602.
Seethalakshmi, R., Sreeranjani, T.R., Balachandar, T., 2005. Optical
Character recognition for printed Tamil text using unicode. Journal of
Zhejiang University Science 6A (11), 1297–1305.
Turk, M., Pentland, A., 1991. Eigenfaces for recognition. Journal of
Cognitive Neuroscience 3 (1), 71–86.
Vasantha Lakshmi, C., Patvardhan, C., 2002. A multi-font OCR system
for printed Telugu text. Proceedings of the Language Engineering
Conference (LEC), 1–17.
Wang, K.Y., Casey, R.G., Wahl, F.M., 1982. Document analysis system.
IBM Journal of Research and Devlopment 26, 647–656.