Embed Size (px)
Citation preview

Operating Systems 11/21/2013
CSC 256/456 1
11/21/2013 CSC 256/456 23
Multiprocessor Operating
Systems
CS 256/456
Dept. of Computer Science, University
of Rochester
11/21/2013 CSC 256/456 24
Multiprocessor Hardware • A computer system in which two or more CPUs share full
access to the main memory
• Each CPU might have its own cache and the coherence among multiple caches is maintained
– write operation by a CPU is visible to all other CPUs
– writes to the same location is seen in the same order by all CPUs (also called write serialization)
– bus snooping and cache invalidation
… … … Cache
CPU
Cache
CPU
Cache
CPU
Memory
Memory bus
11/21/2013 CSC 256/456 25
Multiprocessor Applications
• Multiprogramming
– Multiple regular applications running concurrently
• Concurrent servers
– Web servers, … …
• Parallel programs
– Utilizing multiple processors to complete one task (parallel matrix multiplication, Gaussian elimination)
– Strong synchronization
x = A B C
11/21/2013 CSC 256/456 26
Single-processor OS vs. Multiprocessor
OS • Single-processor OS
– easier to support kernel synchronization • coarse-grained locking vs. fine-grain locking
• disabling interrupts to prevent concurrent executions
– easier to perform scheduling • which to run, not where to run
• Multiprocessor OS
– evolution of OS structure
– synchronization
– scheduling
Operating Systems 11/21/2013
CSC 256/456 2
11/21/2013 CSC 256/456 27
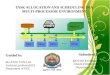
Multiprocessor OS
• Each CPU has its own operating system
– quick to port from a single-processor OS
• Disadvantages
– difficult to share things (processing cycles, memory, buffer cache)
Bus
11/21/2013 CSC 256/456 28
Multiprocessor OS – Master/Slave
Bus
• All operating system functionality goes to one CPU
– no multiprocessor concurrency in the kernel
• Disadvantage
– OS CPU consumption may be large so the OS CPU becomes the bottleneck (especially in a machine with many CPUs)
11/21/2013 CSC 256/456 29
Multiprocessor OS – Shared OS
• A single OS instance may run on all CPUs
• The OS itself must handle multiprocessor synchronization
– multiple OS instances from multiple CPUs may access shared data structure
Bus
11/21/2013 CSC 256/456 30
Preemptive Scheduling
• Use timer interrupts or signals to trigger involuntary yields
• Protect scheduler data structures by locking ready list, disabling/reenabling prior to/after rescheduling
yield:
disable_signals
enqueue(ready_list, current)
reschedule
re-enable_signals

Operating Systems 11/21/2013
CSC 256/456 3
11/21/2013 CSC 256/456 31
Synchronization (Fine/Coarse-Grain
Locking)
• Fine-grain locking – lock only what is necessary for critical section
• Coarse-grain locking – locking large piece of code, much of which is unnecessary – simplicity, robustness – prevent simultaneous execution
Simultaneous execution is not possible on uniprocessor
anyway
11/21/2013 CSC 256/456 32
Anderson et al. 1989 (IEEE TOCS)
• Raises issues of
– Locality (per-processor data structures)
– Granularity of scheduling tasks
– Lock overhead
– Tradeoff between throughput and latency
• Large critical sections are good for best-case
latency (low locking overhead) but bad for
throughput (low parallelism)
11/21/2013 CSC 256/456 33
Performance Measures
• Latency
– Cost of thread management under the best
case assumption of no contention for locks
• Throughput
– Rate at which threads can be created, started,
and finished when there is contention
11/21/2013 CSC 256/456 34
Optimizations
• Allocate stacks lazily
• Store deallocated control blocks and stacks in
free lists
• Create per-processor ready lists
• Create local free lists for locality
• Queue of idle processors (in addition to queue of
waiting threads)
Operating Systems 11/21/2013
CSC 256/456 4
11/21/2013 CSC 256/456 35
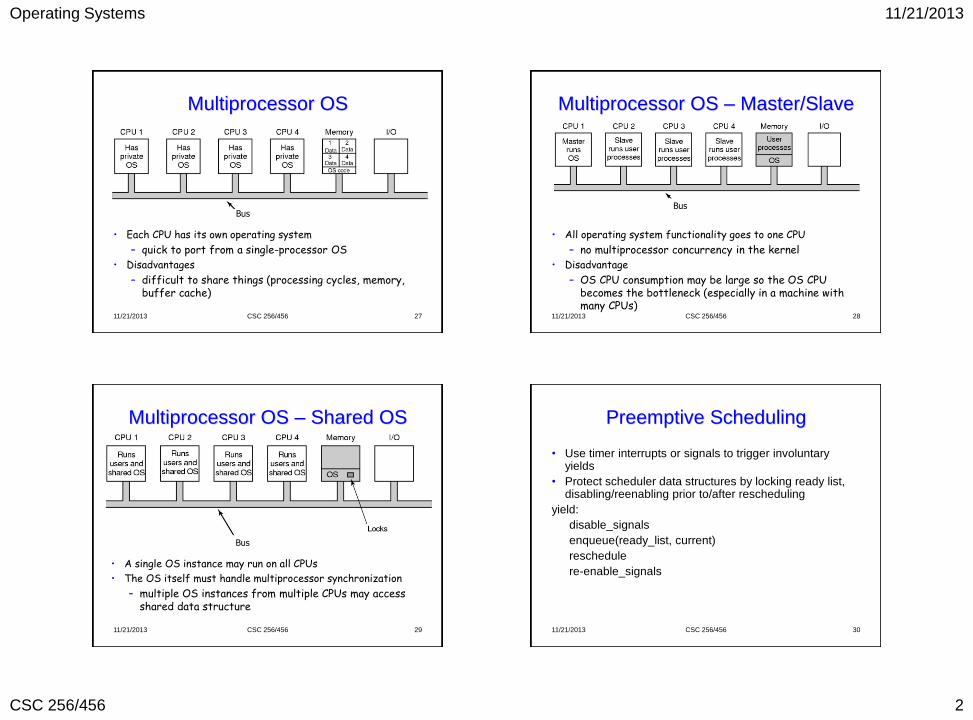
Ready List Management
• Single lock for all data structures
• Multiple locks, one per data structure
• Local freelists for control blocks and stacks, single shared locked ready list
• Queue of idle processors with preallocated control block and stack waiting for work
• Local ready list per processor, each with its own lock
11/21/2013 CSC 256/456 36
Multiprocessor Scheduling • Timesharing
– similar to uni-processor scheduling – one queue of ready tasks (protected by synchronization), a task is dequeued and executed when a processor is available
• Space sharing • cache affinity
– affinity-based scheduling – try to run each process on the processor that it last ran on
• cache sharing and synchronization of parallel/concurrent applications – gang/cohort scheduling – utilize all CPUs for one
parallel/concurrent application at a time CPU 0
CPU 1
web server parallel Gaussian elimination
client/server game (civ)
11/21/2013 CSC 256/456 37
SMP-CMP-SMT Multiprocessor
Image from http://www.eecg.toronto.edu/~tamda/papers/threadclustering.pdf 11/21/2013 CSC 256/456 38
Resource Contention-Aware
Scheduling I • Hardware resource sharing/contention in multi-processors
– SMP processors share memory bus bandwidths
– Multi-core processors share L2 cache
– SMT processors share a lot more stuff
• An example: on an SMP machine
– a web server benchmark delivers around 6300 reqs/sec on one processor, but only around 9500 reqs/sec on an SMP with 4 processors
• Contention-reduction scheduling
– co-scheduling tasks with complementary resource needs (a computation-heavy task and a memory access-heavy task)
– In [Fedorova et al. USENIX2005], IPC is used to distinguish computation-heavy tasks from memory access-heavy tasks

Operating Systems 11/21/2013
CSC 256/456 5
11/21/2013 CSC 256/456 39
Resource Contention-Aware
Scheduling II • What if contention on a resource is unavoidable?
• Two evils of contention
– high contention ⇒ performance slowdown
– fluctuating contention ⇒ uneven application progress over the same amount of time ⇒ poor fairness
• [Zhang et al. HotOS2007] Scheduling so that:
– very high contention is avoided
– the resource contention is kept stable
CPU 0
CPU 1
high resource usage
low resource usage
high resource usage
low resource usage
medium resource usage
medium resource usage
Multi-Core Cache Challenges
• Cache performance is critical to computer
systems.
– memory access: several hundred cycles
– cache hit: L1 several cycles; L2 10~20 cycles
• Cache performance is poor.
– more than half of CPU’s area is dedicated to cache
– 30% of total execution time is due to
L2 cache miss [Basu, MICRO’06]
– low utilization:
more than 40% of lines are evicted
before reuse [Qureshi, ISCA’07]
source: http://www.intel.com
Multi-Core Cache Challenges
(cont.)
• Hardware manages cache at the grain of cache
lines.
– single program: data with different locality are mixed
together
– shared cache: uncontrolled sharing threads
– compete for space -> interference
• Using OS as an auxiliary to manage cache
– high-level knowledge of program
– running state of the entire system
– how? page coloring
Address Mapping in Cache
• physical memory address and cache
– cache size = line size * way size * # of set
– 512KB, 16-way, 64B line size L2 cache: 512
sets (9 bits to index)
32 bits addr. set index line offset
5 bits 9 bits
L2 Cache
cache set
Way-1 Way-16 …………
Operating Systems 11/21/2013
CSC 256/456 6
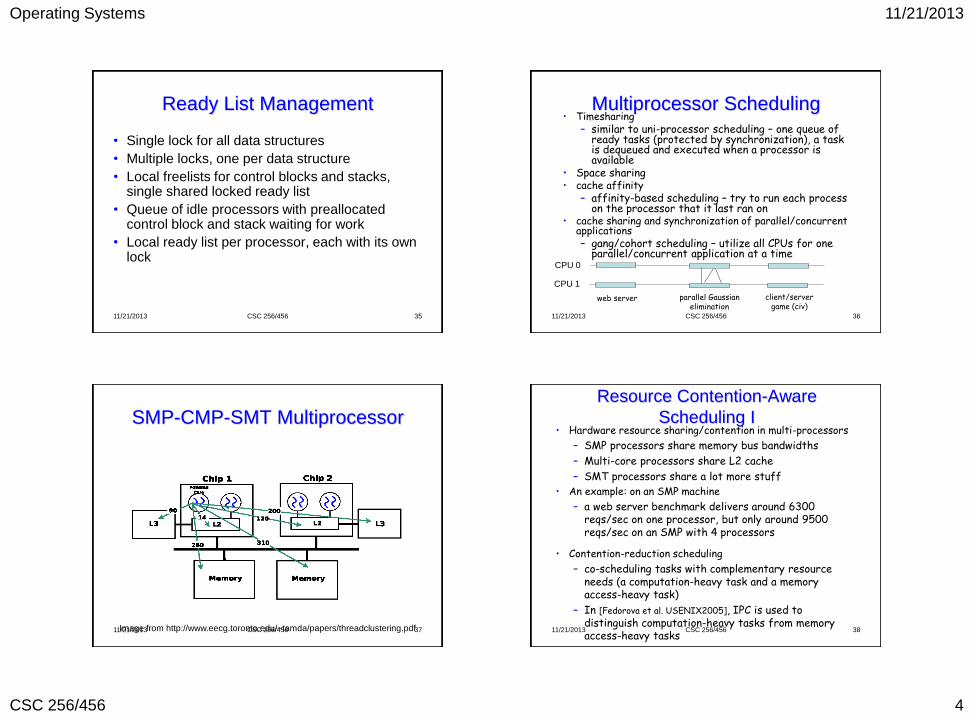
•color:
– cache: a group of cache sets
– memory: a group of physical pages
– (page N, N+4, N+8, … )
•page color:
– data belonging to a page color can only be cached by cache sets with same color
physical addr. page offset (12bits)
5 bits line off. 9 bits set index
physical page #
physical
mem pages
color index (2 bits-> 4 colors)
L2 Cache
What is a Page Color? Software partitioning by page
coloring
OS and Page Coloring
• What is the rule of OS?
– control the mapping between virtual memory
pages and physical pages via page table
physical addr. page offset physical page #
virtual addr. page offset virtual page #
page table
under the
control of OS
OS and Page Coloring (cont.)
• Color a page: map a virtual page to a physical
page with a particular color (lower bits of page #)
• Re-color a page: change the color in runtime
– flush TLB, copy page data, modify page table
– overhead
physical pages
virtual addr. page offset virtual page number

Operating Systems 11/21/2013
CSC 256/456 7
Shared Caches on Multicore Systems
[Tam et al. WIOSCA’97]
– Uncontrolled sharing threads
run mcf,art on Dual Core Power 5
Page Coloring Based Cache
Partitioning • Hardware partitioning mechanisms, not available
today
• Page coloring based cache partitioning
– Implemented on real system
– Guided phys pages allocation
-> controlled L2 cache usage
– Goal: optimize system overall
performance
Benefits of Cache Partitioning [Tam
et al. WIOSCA’07]
base:
multi-prg, no partitioning
Big Picture
A B D C
Select which applications run
together
X ………
…..
Control resource usage of co-running
applications
Resource-aware scheduling
Page coloring or Hardware throttling
Operating Systems 11/21/2013
CSC 256/456 8
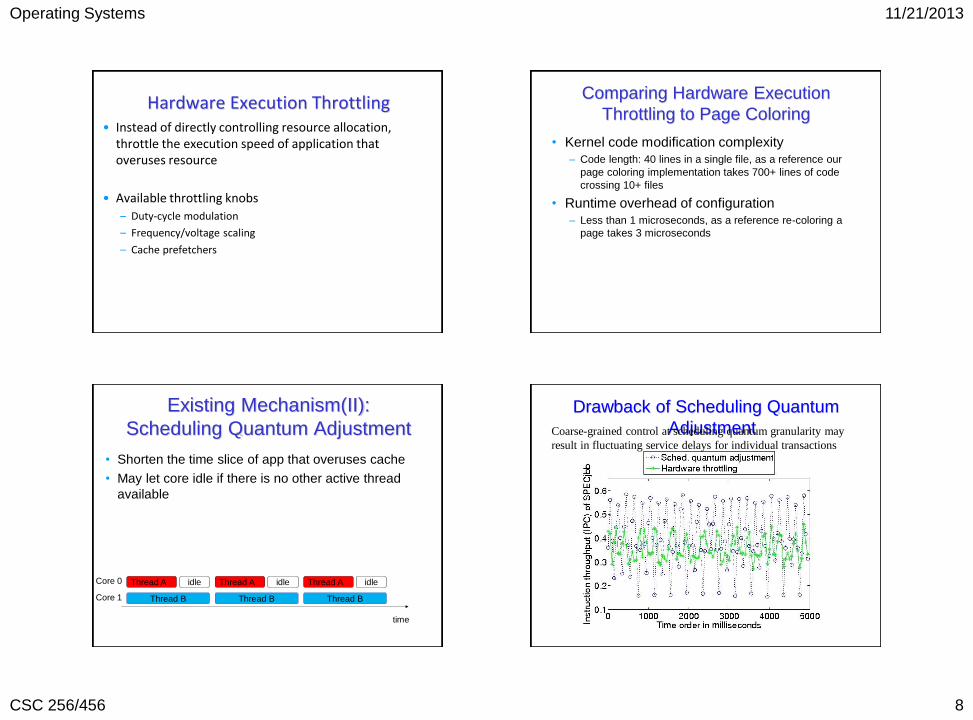
Hardware Execution Throttling • Instead of directly controlling resource allocation,
throttle the execution speed of application that overuses resource
• Available throttling knobs
– Duty-cycle modulation
– Frequency/voltage scaling
– Cache prefetchers
Comparing Hardware Execution
Throttling to Page Coloring
• Kernel code modification complexity
– Code length: 40 lines in a single file, as a reference our
page coloring implementation takes 700+ lines of code
crossing 10+ files
• Runtime overhead of configuration
– Less than 1 microseconds, as a reference re-coloring a
page takes 3 microseconds
Existing Mechanism(II):
Scheduling Quantum Adjustment
• Shorten the time slice of app that overuses cache
• May let core idle if there is no other active thread
available
Thread B
Thread A idle
Thread B
Thread A idle
Thread B
Thread A idle Core 0
Core 1
time
Drawback of Scheduling Quantum
Adjustment Coarse-grained control at scheduling quantum granularity may
result in fluctuating service delays for individual transactions

Operating Systems 11/21/2013
CSC 256/456 9
New Mechanism:
Hardware Execution Throttling [Usenix’09]
• Throttle the execution speed of app that overuses cache
– Duty cycle modulation
• CPU works only in duty cycles and stalls in non-duty cycles
• Different from Dynamic Voltage Frequency Scaling
– Per-core vs. per-processor control
– Thermal vs. power management
– Enable/disable cache prefetchers
• L1 prefetchers
– IP: keeps track of instruction pointer for load history
– DCU: when detecting multiple loads from the same line within a time limit,
prefetches the next line
• L2 prefetchers
– Adjacent line: Prefetches the adjacent line of required data
– Stream: looks at streams of data for regular patterns
Comparison of Hardware Execution
Throttling to other two mechanisms
• Comparison to page coloring
– Little complexity to kernel • Code length: 40 lines in a single file, as a reference our page coloring implementation
takes 700+ lines of code crossing 10+ files
– Lightweight to configure • Read plus write register: duty-cycle 265 + 350 cycles, prefetcher 298 + 2065 cycles
• Less than 1 microseconds, as a reference re-coloring a page takes 3 microseconds
• Comparison to scheduling quantum adjustment
– More fine-grained controlling
Thread B
Core 0
Core 1
Thread A idle
Quantum adjustment Hardware execution throttling
time
57
Fairness Comparison
• On average all three mechanisms are effective in improving fairness
• Case {swim, SPECweb} illustrates limitation of page coloring
• Unfairness factor: coefficient of variation (deviation-to-mean ratio, σ / μ) of co-running apps’ normalized performances (normalization base is the execution-time/throughput when the application monopolizes the whole chip)
58
Performance Comparison
• System efficiency: geometric mean of co-running apps’ normalized performances
• On average all three mechanisms achieve system efficiency comparable to default sharing
• Case where severe inter-
thread cache conflicts exist
favors segregation, e.g.
{swim, mcf}
• Case where well-interleaved
cache accesses exist favors
sharing, e.g. {mcf, mcf}

Operating Systems 11/21/2013
CSC 256/456 10
Policies for Hardware Throttling-
Enabled Multicore Management
• User-defined service level agreements (SLAs) – Proportional progress among competing threads
• Unfairness metric: coefficient of variation of threads’ performance
– Quality of service guarantee for high-priority application(s)
• Key challenge
– Throttling configuration space grows exponentially as
the number of cores increases
– Quickly determining optimal or close to optimal
throttling configurations is challenging
TEMM: A Flexible Framework for
Throttling-Enabled Multicore
Management [ICPP’12] • Customizable performance estimation model
• Reference configuration set and linear approximation
• Currently incorporates duty cycle modulation and
frequency/voltage scaling
• Iterative refinement
• Prediction accuracy gets improved over time as more
configurations are added into reference set