Embed Size (px)
Citation preview

Massively Multilingual Neural Machine Translationin the Wild: Findings and Challenges
Naveen Arivazhagan ∗ Ankur Bapna ∗ Orhan Firat ∗
Dmitry Lepikhin Melvin Johnson Maxim Krikun Mia Xu Chen Yuan Cao
George Foster Colin Cherry Wolfgang Macherey Zhifeng Chen Yonghui Wu
Google AI
Abstract
We introduce our efforts towards building auniversal neural machine translation (NMT)system capable of translating between anylanguage pair. We set a milestone towardsthis goal by building a single massivelymultilingual NMT model handling 103 lan-guages trained on over 25 billion examples.Our system demonstrates effective trans-fer learning ability, significantly improv-ing translation quality of low-resource lan-guages, while keeping high-resource lan-guage translation quality on-par with com-petitive bilingual baselines. We provide in-depth analysis of various aspects of modelbuilding that are crucial to achieving qual-ity and practicality in universal NMT. Whilewe prototype a high-quality universal trans-lation system, our extensive empirical anal-ysis exposes issues that need to be furtheraddressed, and we suggest directions for fu-ture research.
1 Introduction
Sequence-to-sequence neural models (seq2seq)(Kalchbrenner and Blunsom, 2013; Sutskeveret al., 2014; Cho et al., 2014; Bahdanau et al.,2014) have been widely adopted as the state-of-the-art approach for machine translation, bothin the research community (Bojar et al., 2016a,2017, 2018b) and for large-scale production sys-tems (Wu et al., 2016; Zhou et al., 2016; Cregoet al., 2016; Hassan et al., 2018). As a highly ex-pressive and abstract framework, seq2seq modelscan be trained to perform several tasks simulta-neously (Luong et al., 2015), as exemplified bymultilingual NMT (Dong et al., 2015; Firat et al.,
∗ Equal contribution. Correspondence tonavari,ankurbpn,[email protected]
2016a; Ha et al., 2016c; Johnson et al., 2017) - us-ing a single model to translate between multiplelanguages.
Multilingual NMT models are appealing forseveral reasons. Let’s assume we are interested inmapping between N languages; a naive approachthat translates between any language pair fromthe given N languages requires O(N2) individ-ually trained models. When N is large, the hugenumber of models become extremely difficult totrain, deploy and maintain. By contrast, a mul-tilingual model, if properly designed and trained,can handle all translation directions within a sin-gle model, dramatically reducing the training andserving cost and significantly simplifying deploy-ment in production systems.
Apart from reducing operational costs, multi-lingual models improve performance on low andzero-resource language pairs due to joint train-ing and consequent positive transfer from higher-resource languages (Zoph et al., 2016; Firat et al.,2016b; Nguyen and Chiang, 2017; Johnson et al.,2017; Neubig and Hu, 2018; Aharoni et al., 2019;Escolano et al., 2019; Arivazhagan et al., 2019;Hokamp et al., 2019). Unfortunately, this si-multaneously results in performance degradationon high-resource languages due to interferenceand constrained capacity (Johnson et al., 2017;Tan et al., 2019). Improving translation perfor-mance across the board on both high and low re-source languages is an under-studied and chal-lenging task.
While multilingual NMT has been widely stud-ied, and the above benefits realized, most ap-proaches are developed under constrained set-tings; their efficacy is yet to be demonstrated inreal-world scenarios. In this work, we attemptto study multilingual neural machine translationin the wild, using a massive open-domain dataset
arX
iv:1
907.
0501
9v1
[cs
.CL
] 1
1 Ju
l 201
9

containing over 25 billion parallel sentences in103 languages.
We first survey the relevant work in various ar-eas: vocabulary composition, learning techniques,modeling and evaluation. In each area, we iden-tify key determinants of performance and assesstheir impact in our setting. The result is a mapof the landscape on this still largely unexploredfrontier of natural language processing (NLP) andmachine learning (ML). To the best of our knowl-edge, this is the largest multilingual NMT sys-tem to date, in terms of the amount of trainingdata and number of languages considered at thesame time. Based on experiments centered arounddifferent aspects of multilingual NMT we high-light key challenges and open problems on theway to building a real-world massively multilin-gual translation system.
2 Towards Universal MachineTranslation
Enabling a single model to translate between anarbitrary language pair is the ultimate goal of uni-versal MT. In order to reach this goal, the under-lying machinery, the learner, must model a mas-sively multi-way input-output mapping task understrong constraints: a huge number of languages,different scripting systems, heavy data imbalanceacross languages and domains, and a practicallimit on model capacity. Now let us take a lookat the problem from a machine learning perspec-tive.
Machine learning algorithms are built on induc-tive biases in order to enable better generaliza-tion (Mitchell, 1997). In the setting of multilin-gual NMT, the underlying inductive bias is that thelearning signal from one language should bene-fit the quality of other languages (Caruana, 1997).Under this bias, the expectation is that as we in-crease the number of languages, the learner willgeneralize better due to the increased amount ofinformation1 added by each language (or task).This positive transfer is best observed for low-resource languages (Zoph et al., 2016; Firat et al.,2016a; Neubig and Hu, 2018). Unfortunately theabove mentioned constraints prevent these gains
1Which can be sharing of semantic and/or syntactic struc-ture, or ease of optimization via shared error signals etc.
from being progressively applicable: as we in-crease the number of languages with a fixed modelcapacity2, the positive/negative transfer boundarybecomes salient, and high resource languages startto regress due to a reduction in per-task capacity.
From a function of mapping perspective, thereare three common categories of multilingual NMTmodels in the literature, depending on the lan-guages covered on the source and target sides:many-to-one, one-to-many and many-to-manymodels (Dong et al., 2015; Firat et al., 2016a;Johnson et al., 2017). Many-to-one multilingualNMT models learn to map any of the languagesin the source language set into the selected targetlanguage, usually chosen to be English due to theeasy availability of parallel corpora with Englishon one side. Similarly, one-to-many multilingualNMT models aim to translate a single source lan-guage into multiple target languages. Many-to-one multilingual NMT can be categorized as amulti-domain3 learning problem (Dredze et al.,2010; Joshi et al., 2012; Nam and Han, 2015),where the task of translating into a selected lan-guage remains the same, but the input distributionis different across source languages (Arivazhaganet al., 2019). On the other hand, one-to-manymultilingual NMT can be considered a multi-taskproblem (Caruana, 1997; Thrun and Pratt, 1998;Dong et al., 2015), where each source-target pairis a separate task. Many-to-many translation isthe super-set of both these tasks. Regardless ofthe number of languages considered on the sourceor the target side, improvements in multilingualNMT are expected to arise from positive trans-fer between related domains and transferabletasks.
Multi-domain and multi-task learning across avery large number of domains/tasks, with widedata imbalance, and very heterogeneous inter-task relationships arising from dataset noise andtopic/style discrepancies, differing degrees of lin-guistic similarity, etc., make the path towards uni-versal MT highly challenging. These problemsare typically approached individually and in con-
2Loosely measured in terms of the number of free param-eters for neural networks.
3Note that we use the machine learning notion of domainhere where each domain refers to a particular distribution ofthe input, while the target distribution remain unchanged.
2

strained settings. Here we approach this challengefrom the opposite end of the spectrum, determin-ing what is possible with our current technologyand understanding of NMT and ML, and probingfor the effect of various design strategies in an ex-treme, real-world setting.
Our desired features of a truly multilingualtranslation model can be characterized as:
• Maximum throughput in terms of the num-ber of languages considered within a singlemodel.
• Maximum inductive (positive) transfer to-wards low-resource languages.
• Minimum interference (negative transfer) forhigh-resource languages.
• Robust multilingual NMT models that per-form well in realistic, open-domain settings.
In the next sections we analyze different aspectsof multilingual NMT, and investigate the implica-tions of scaling up the dataset size and the numberof languages considered within a single model. Ineach section we first discuss approaches describedin recent literature, followed by our experimentalsetup, findings, and analysis. We also highlightsome challenges and open problems identified inrecent literature or as a result of our analyses. Westart by describing our data setup, followed by ananalysis of transfer and interference in the mas-sively multilingual setting. We then analyze thepre-processing and vocabulary problems in mul-tilingual NLP, discuss modeling approaches andthe effect of increasing model capacity. We closewith a discussion of evaluation and open problemsin massively multilingual NMT.
3 Data and Baselines
As with any machine learning problem, the qual-ity and the amount of the data has significant im-pact on the systems that can be developed (Good-fellow et al., 2016). Multilingual NMT is typi-cally studied using various public datasets or com-binations of them. The most commonly useddatasets include: (i) TED talks (Cettolo et al.,2012) which includes 59 languages (Qi et al.,2018) with around 3k to 200k sentence pairs per
Figure 1: Per language pair data distribution ofthe training dataset used for our multilingual ex-periments. The x-axis indicates the language pairindex, and the y-axis depicts the number of train-ing examples available per language pair on a log-arithmic scale. Dataset sizes range from 35k forthe lowest resource language pairs to 2 billion forthe largest.
language pair. (ii) European parliamentary doc-uments (Koehn, 2005) which include versions in21 European languages having 1M to 2M sentencepairs. (iii) The UNCorpus (Ziemski et al., 2016) isanother multilingual dataset of parliamentary doc-uments of United Nations, consisting of around11 million sentences in 6 languages. (iv) A com-pilation of the datasets used for the WMT NewsTranslation shared task from 2005-19 (Bojar et al.,2016b, 2018a) covers a broader set of domainsin around 15 languages, each containing between10k to 50M sentence pairs. (v) Other smaller par-allel corpora for specific domains are indexed byOPUS (Tiedemann, 2012) for various languagepairs. (vi) The Bible corpus is perhaps the mostmultilingual corpus publicly available, containing30k sentences in over 900 languages (Tiedemann,2018).
The results of various works on these datasetshave greatly contributed to the progress of mul-tilingual NMT. However, methods developed onthese datasets and the consequent findings are notimmediately applicable to real world settings out-side those datasets due to their narrow domains,the number of languages covered or the amount oftraining data used for training.
3

3.1 Our Data Setup
Our problem significantly extends those studiedby these previous works: we study multilingualNMT on a massive scale, using an in-house cor-pus generated by crawling and extracting parallelsentences from the web (Uszkoreit et al., 2010).This corpus contains parallel documents for 102languages, to and from English, containing a to-tal of 25 billion sentence pairs.4 The numberof parallel sentences per language in our cor-pus ranges from around tens of thousands toalmost 2 billion. Figure 1 illustrates the datadistribution across language pairs for all 204 lan-guage pairs we study. The following specifics ofour dataset distinguish our problem from previouswork on multilingual NMT:
• Scale: Even on our lowest resource lan-guages we often exceed the amount of dataavailable in a majority of the previously stud-ied datasets. Given the amount of data, tech-niques developed in relatively low-resourcesetups may not be as effective.
• Distribution: The availability of quality par-allel data follows a sharp power law, and databecomes increasingly scarce as we expandthe scope of the system to more languages.There is a discrepancy of almost 5 orders ofmagnitude between our highest and our low-est resource languages. Balancing betweenthese different language pairs now becomesa very challenging problem.
• Domain and Noise: Having been mined fromthe web, our dataset spans a vast range ofdomains. However, such web crawled datais also extremely noisy; this problem getsworse in the multilingual setting where thelevel of noise might be different across dif-ferent languages. While clean sources of par-allel data are also available, they are oftenlimited to narrow domains and high resourcelanguages.
To summarize, the training data used in ourstudy is drawn from 102 languages (+ English),
4Limited to approximately this amount for experimenta-tion.
exhibits a power-law in terms of number of train-ing examples across language pairs, and spans arich set of domains with varying noise levels—making our overall attempt as realistic as possible.Please see Table 8 in the Appendix for the full listof languages.
3.2 Experiments and BaselinesThroughout this paper we perform several exper-iments on the training dataset described above, tohighlight challenges associated with different as-pects of multilingual models. We first train ded-icated bilingual models on all language pairs toground our multilingual analyses. We performall our experiments with variants of the Trans-former architecture (Vaswani et al., 2017), usingthe open-source Lingvo framework (Shen et al.,2019). For most bilingual experiments, we usea larger version of Transformer Big (Chen et al.,2018a) containing around 375M parameters, and ashared source-target sentence-piece model (SPM)(Kudo and Richardson, 2018) vocabulary with32k tokens. We tune different values of regular-ization techniques (e.g. dropout (Srivastava et al.,2014)) depending on the dataset size for each lan-guage pair. For most medium and low resourcelanguages we also experiment with TransformerBase. All our models are trained with Adafactor(Shazeer and Stern, 2018) with momentum factor-ization, a learning rate schedule of (3.0, 40k),5 anda per-parameter norm clipping threshold of 1.0.For Transformer Base models, we use a learningrate schedule of (2.0, 8k), unless otherwise neces-sary for low-resource experiments.
In order to minimize confounding factors andcontrol the evaluation set size and domain, we cre-ated our validation (development) and test sets asmulti-way aligned datasets containing more than3k and 5k sentence pairs respectively for all lan-guages. For our bilingual baselines, BLEU scoresare computed on the checkpoint with the best val-idation set performance, while we compute testBLEU on the final checkpoint (after training foraround 1M steps) for our multilingual models, ontrue-cased output and references6. For all our
5(3.0, 40k) schedule is the shorthand for a learning rateof 3.0, with 40k warm-up steps for the schedule, which is de-cayed with the inverse square root of the number of trainingsteps after warm-up.
6We used an in-house implementation of mteval-v13a.pl
4
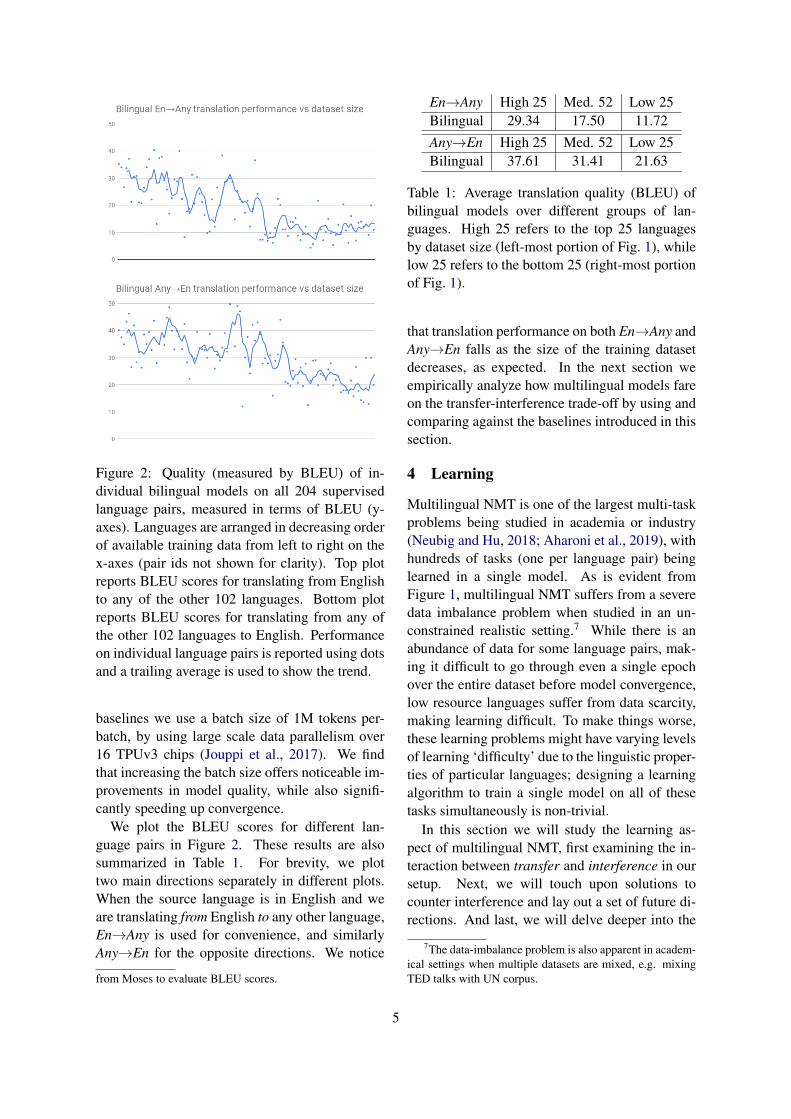
Figure 2: Quality (measured by BLEU) of in-dividual bilingual models on all 204 supervisedlanguage pairs, measured in terms of BLEU (y-axes). Languages are arranged in decreasing orderof available training data from left to right on thex-axes (pair ids not shown for clarity). Top plotreports BLEU scores for translating from Englishto any of the other 102 languages. Bottom plotreports BLEU scores for translating from any ofthe other 102 languages to English. Performanceon individual language pairs is reported using dotsand a trailing average is used to show the trend.
baselines we use a batch size of 1M tokens per-batch, by using large scale data parallelism over16 TPUv3 chips (Jouppi et al., 2017). We findthat increasing the batch size offers noticeable im-provements in model quality, while also signifi-cantly speeding up convergence.
We plot the BLEU scores for different lan-guage pairs in Figure 2. These results are alsosummarized in Table 1. For brevity, we plottwo main directions separately in different plots.When the source language is in English and weare translating from English to any other language,En→Any is used for convenience, and similarlyAny→En for the opposite directions. We notice
from Moses to evaluate BLEU scores.
En→Any High 25 Med. 52 Low 25Bilingual 29.34 17.50 11.72Any→En High 25 Med. 52 Low 25Bilingual 37.61 31.41 21.63
Table 1: Average translation quality (BLEU) ofbilingual models over different groups of lan-guages. High 25 refers to the top 25 languagesby dataset size (left-most portion of Fig. 1), whilelow 25 refers to the bottom 25 (right-most portionof Fig. 1).
that translation performance on both En→Any andAny→En falls as the size of the training datasetdecreases, as expected. In the next section weempirically analyze how multilingual models fareon the transfer-interference trade-off by using andcomparing against the baselines introduced in thissection.
4 Learning
Multilingual NMT is one of the largest multi-taskproblems being studied in academia or industry(Neubig and Hu, 2018; Aharoni et al., 2019), withhundreds of tasks (one per language pair) beinglearned in a single model. As is evident fromFigure 1, multilingual NMT suffers from a severedata imbalance problem when studied in an un-constrained realistic setting.7 While there is anabundance of data for some language pairs, mak-ing it difficult to go through even a single epochover the entire dataset before model convergence,low resource languages suffer from data scarcity,making learning difficult. To make things worse,these learning problems might have varying levelsof learning ‘difficulty’ due to the linguistic proper-ties of particular languages; designing a learningalgorithm to train a single model on all of thesetasks simultaneously is non-trivial.
In this section we will study the learning as-pect of multilingual NMT, first examining the in-teraction between transfer and interference in oursetup. Next, we will touch upon solutions tocounter interference and lay out a set of future di-rections. And last, we will delve deeper into the
7The data-imbalance problem is also apparent in academ-ical settings when multiple datasets are mixed, e.g. mixingTED talks with UN corpus.
5

transfer dynamics towards universal NMT.
4.1 Transfer and Interference
Multitask learning (Caruana, 1997) has been suc-cessfully applied to multiple domains, includ-ing NLP, speech processing, drug discovery andmany others (Collobert and Weston, 2008; Denget al., 2013; Ramsundar et al., 2015; Maurer et al.,2016; Ruder, 2017; Kaiser et al., 2017). Otherproblems closely related to multitask learning in-clude zero or few-shot learning (Lake et al., 2011;Romera-Paredes and Torr, 2015; Vinyals et al.,2016; Pan and Yang, 2010), meta-learning andlife-long learning (Thrun and Mitchell, 1995; Sil-ver et al., 2013; Chen and Liu, 2016; Parisi et al.,2018; Golkar et al., 2019; Sodhani et al., 2018;Lopez-Paz et al., 2017). Although these learningparadigms make different assumptions about theunderlying problem setting, they share the com-mon goal of leveraging the inductive bias and reg-ularization from a set of tasks to benefit anotherset of tasks. This inductive transfer could be par-allel or sequential.
Multilingual NMT has been studied undermany of these settings to various extents. Mostexisting literature deals with sequential transfer,where the goal is to leverage a set of high re-source tasks that are already mastered, to improvethe performance on a new (predominantly) low re-source task (Zoph et al., 2016). We consider theparallel learning problem, where the goal is tolearn a single multi-task model trained concur-rently on all tasks and hence is capable of per-forming all tasks simultaneously once the train-ing is accomplished.
In this section we investigate the effect of dataimbalance across languages on these learning dy-namics, particularly through the lens of trans-fer and interference (Caruana, 1997; Rosensteinet al., 2005). Reiterating from Section 2, twodesired characteristics of our universal machinetranslation model are (1) maximum (positive)transfer to low-resource languages and (2) min-imum interference (negative transfer) for high-resource languages. Now let us examine the inter-action between variables considered. For the base-line experiment, we start by following commonconventions in literature on multilingual NMT(Firat et al., 2017; Lee et al., 2017; Johnson et al.,
2017). We compare the performance of two train-ing approaches against bilingual baselines follow-ing two strategies:
(i) all the available training data is combined asit is, with the data distribution in Figure 1,
(ii) we over-sample (up-sample) low-resourcelanguages so that they appear with equalprobability in the combined dataset.
In order to guide the translation with the in-tended target language, we pre-pend a target lan-guage token to every source sequence to be trans-lated (Johnson et al., 2017). Further, to studythe effect of transfer and interference at its limit,we shared a single encoder and decoder acrossall the language pairs. During training, mini-batches are formed by randomly sampling exam-ples from the aggregated dataset following strate-gies (i) or (ii), as described above. We train asingle Transformer-Big with a shared vocabularyof 64k tokens, all Transformer dropout optionsturned on with probability 0.1, and the same val-ues as the bilingual baselines used for other hyper-parameters. We use batch sizes of 4M tokens forall our multilingual models to improve the rateof convergence. All Transformer-Big runs utilizedata parallelism over 64 TPUv3 chips. The resultsare depicted in Figure 3.
The performance of these two models high-lights the trade-off between transfer and interfer-ence. If we sample equally from all datasets byover-sampling low-resource languages (strategy(ii)), we maximize transfer (right-most portion ofFigure 3) and beat our bilingual baselines by largemargins, especially in the Any→En direction.However, this also has the side-effect of signifi-cantly deteriorated performance on high resourcelanguages (left-most portion of Figure 3). On theother hand, sampling based on the true data dis-tribution (strategy (i)) retains more performanceon high resource languages, at the cost of sacrific-ing performance on low resource languages. Wealso note that the transfer-interference trade-off is more pronounced in the Any→En direc-tion: the cost-benefit trade-off between low andhigh-resource languages is more severe thanthat for the En→Any direction.
Another interesting finding is the performancedeterioration on high resource languages when
6

Figure 3: Effect of sampling strategy on the per-formance of multilingual models. From left toright, languages are arranged in decreasing orderof available training data. While the multilingualmodels are trained to translate both directions,Any→En and En→Any, performance for each ofthese directions is depicted in separate plots tohighlight differences. Results are reported rela-tive to those of the bilingual baselines (2). Per-formance on individual language pairs is reportedusing dots and a trailing average is used to showthe trend. The colors correspond to the followingsampling strategies: (i) Blue: original data distri-bution, (ii) Green: equal sampling from all lan-guage pairs. Best viewed in color.
translating from Any→En, contrary to existing re-sults in multilingual NMT (Firat et al., 2016a;Johnson et al., 2017), exaggerated by the limitedmodel capacity and the scale and imbalance ofour dataset. All these observations again under-score the difficulty in multitask learning, espe-cially when hundreds of tasks are to be learnedsimultaneously, each of which may come froma different distribution. Although (Maurer et al.,2016) demonstrates the benefit of multitask learn-ing when invariant features can be shared acrossall tasks, such a premise is not guaranteed when
hundreds of languages from different families arejointly considered.
4.2 Countering Interference: Baselines andOpen Problems
The results in Figure 3 indicate that, in a largemulti-task setting, high resource tasks are starvedfor capacity while low resource tasks benefit sig-nificantly from transfer, and the extent of inter-ference and transfer are strongly related. How-ever, this trade-off could be controlled by applyingproper data sampling strategies.
To enable more control over sampling, we in-vestigate batch balancing strategies (Firat et al.,2017; Lee et al., 2017), along the lines of the tem-perature based variant used for training multilin-gual BERT (Devlin et al., 2018). For a given lan-guage pair, l, let Dl be the size of the availableparallel corpus. Then if we adopt a naive strat-egy and sample from the union of the datasets, theprobability of the sample being from language l ispl =
DlΣkDk
. However, this strategy would starvelow resource languages. To control the ratio ofsamples from different language pairs, we sam-ple a fixed number of sentences from the trainingdata, with the probability of a sentence belong-
ing to language pair l being proportional to p1Tl ,
where T is the sampling temperature. As a result,T = 1 corresponds to true data distribution andT = 100 corresponds to (almost) equal numberof samples for each language (close to a uniformdistribution with over-sampled low-resource lan-guages). Please see Figure 4 for an illustration ofthe effect of temperature based sampling overlaidon our dataset distribution.
Figure 4: Temperature based data sampling strate-gies overlaid on the data distribution.
We repeat the experiment in Section 4.1 withtemperature based sampling, setting T = 5 for
7

Figure 5: Effect of varying the sampling temper-ature on the performance of multilingual models.From left to right, languages are arranged in de-creasing order of available training data. Resultsare reported relative to those of the bilingual base-lines (2). Performance on individual languagepairs is reported using dots and a trailing aver-age is used to show the trend. The colors cor-respond to the following sampling strategies: (i)Green: True data distribution (T = 1) (ii) Blue:Equal sampling from all language pairs (T = 100)(iii) Red: Intermediate distribution (T = 5). Bestviewed in color.
a balanced sampling strategy, and depict our re-sults in Figure 5. Results over different languagegroups by resource size are also summarized inTable 2. We notice that the balanced samplingstrategy improves performance on the high re-source languages for both translation directions(compared to T = 100), while also retaining hightransfer performance on low resource languages.However, performance on high and medium re-source languages still lags behind their bilingualbaselines by significant margins.
We unveiled one of the factors responsible forinterference while training massively multilingualNMT models under heavy dataset imbalance, and
En→Any High 25 Med. 52 Low 25Bilingual 29.34 17.50 11.72T=1 28.63 15.11 6.24T=100 27.20 16.84 12.87T=5 28.03 16.91 12.75Any→En High 25 Med. 52 Low 25Bilingual 37.61 31.41 21.63T=1 34.60 27.46 18.14T=100 33.25 30.13 27.32T=5 33.85 30.25 26.96
Table 2: Average translation quality (BLEU) ofmultilingual models using different sampling tem-peratures, over different groups of languages.High 25 refers to the top 25 languages by datasetsize, while low 25 refers to the bottom 25.
hinted that an appropriate data sampling strategycan potentially mitigate the interference. But theimbalance in dataset across tasks is not the onlyvariable interacting with the transfer - interfer-ence dilemma. In all the experiments describedabove, multilingual models have the same capac-ity as the baselines, a strategy which could be in-terpreted as reducing their per-task capacity. Tohighlight the exacerbating effect of interferencewith increasing multilinguality, we train three ad-ditional models on a growing subset of 10, 25, and50 languages. The specific languages are chosento get a mixed representation of data size, script,morphological complexity and inter-language re-latedness. Results for the 10 languages, with adata sampling strategy T = 5, that are com-mon across all subsets are reported in Figure 6and clearly highlight how performance degradesfor all language pairs, especially the high andmedium resource ones, as the number of tasksgrows.
While simple data balancing/sampling strate-gies might reduce the effects of interference with-out reducing transfer, our experiments also high-light a few research directions worth further ex-ploration. Most notably, Should we be usingthe same learning algorithms for multilingual andsingle language pair models? Can we still relyon data-sampling heuristics when the number oftasks are excessively large? We highlight a fewopen problems along these lines:
8

Figure 6: Effect of increasing the number of lan-guages on the translation performance of multi-lingual models. From left to right, languages arearranged in decreasing order of available trainingdata. Results are reported relative to those of thebilingual baselines (2). The colors correspond tothe following groupings of languages: (i) Blue:10 languages↔ En, (ii) Red: 25 languages↔ En,(iii) Yellow: 50 languages↔ En (yellow), and (iv)Green: 102 languages↔ En. Note that, we onlyplot performance on the 10 languages commonacross all the compared models while keeping thex-axis intact for comparison with other plots. Bestviewed in color.
Task Scheduling: Scheduling tasks has beenwidely studied in the context of multitask learningand meta-learning, but remains relatively under-explored for multilingual NMT (Bengio et al.,2009; Pentina et al., 2015). The scheduling ofthe tasks, or the scheduling of the correspond-ing data associated with the task can be studiedunder two distinct categories, static and dynamic(curriculum learning). Temperature based sam-pling or co-training with related languages to im-prove adaptation (Zoph et al., 2016; Neubig andHu, 2018) fall within the class of static strate-gies. On the other hand, dynamic or curriculum
learning strategies refine the ratio of tasks simul-taneously with training, based on metrics derivedfrom the current state of the learner (Graves et al.,2017). In the context of NMT, (Kumar et al.,2019) learn a RL agent to schedule between dif-ferent noise levels in the training data, while (Pla-tanios et al., 2019) combined heuristics into a datacurriculum. (Kiperwasser and Ballesteros, 2018)designed schedules favoring one target languageand (Jean et al., 2018) learn an adaptive schedulerfor multilingual NMT. Similar approaches couldbe extended in the context of learning differentlanguage pairs in massively multilingual settings.
Optimization for Multitask Learning: Whiletask scheduling alters the data distribution or thedynamics of the data distribution seen by thelearner, optimization algorithms, regularizationand loss formulations determine how these exam-ples effect the learning process. While most lit-erature in multilingual NMT, including our work,relies on the same monolithic optimization ap-proach for single and multitask models,8 thischoice might be far from optimal. There is nodearth of literature exploring loss formulations orregularization techniques that unravel and exploittask relatedness, reformulate loss functions to ac-count for adaptation and exploit meta-learning ap-proaches in multitask models (Vilalta and Drissi,2002; Zhang and Yang, 2017). Applying op-timization approaches designed specifically formultitask models to multilingual NMT might bea fruitful avenue for future research.
4.3 Understanding Transfer
From our experiments on data sampling, we no-tice that multilingual training with shared weightshelps promote transfer to low-resource languages.However, these improvements are imbalanced inhow they affect languages when translating to orfrom English. To better understand transfer inmultilingual models we individually inspect threedifferent settings: 1) translation from English(En→Any), 2) translation to English (Any→En),and 3) translation between non-English languagepairs (Any→Any).
We compare the performance of our model
8One adaptive optimizer e.g. Adam, Adafactor withshared accumulators for gradient moments across all tasks.
9
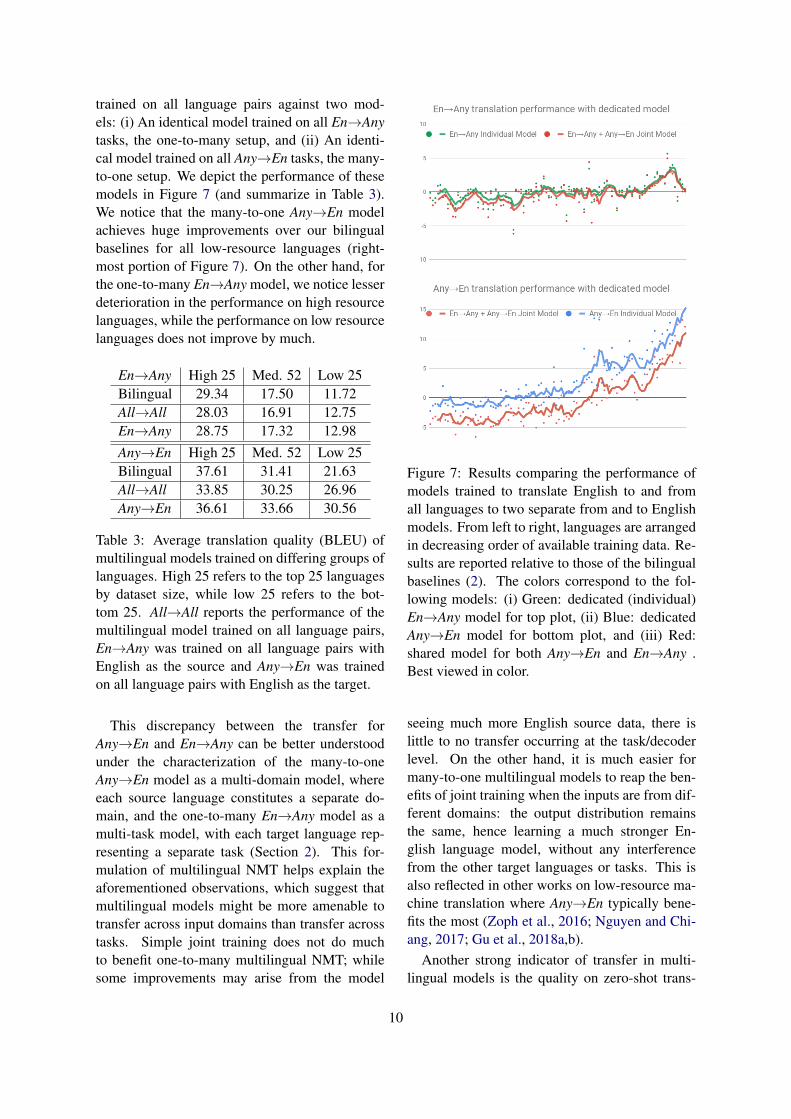
trained on all language pairs against two mod-els: (i) An identical model trained on all En→Anytasks, the one-to-many setup, and (ii) An identi-cal model trained on all Any→En tasks, the many-to-one setup. We depict the performance of thesemodels in Figure 7 (and summarize in Table 3).We notice that the many-to-one Any→En modelachieves huge improvements over our bilingualbaselines for all low-resource languages (right-most portion of Figure 7). On the other hand, forthe one-to-many En→Any model, we notice lesserdeterioration in the performance on high resourcelanguages, while the performance on low resourcelanguages does not improve by much.
En→Any High 25 Med. 52 Low 25Bilingual 29.34 17.50 11.72All→All 28.03 16.91 12.75En→Any 28.75 17.32 12.98Any→En High 25 Med. 52 Low 25Bilingual 37.61 31.41 21.63All→All 33.85 30.25 26.96Any→En 36.61 33.66 30.56
Table 3: Average translation quality (BLEU) ofmultilingual models trained on differing groups oflanguages. High 25 refers to the top 25 languagesby dataset size, while low 25 refers to the bot-tom 25. All→All reports the performance of themultilingual model trained on all language pairs,En→Any was trained on all language pairs withEnglish as the source and Any→En was trainedon all language pairs with English as the target.
This discrepancy between the transfer forAny→En and En→Any can be better understoodunder the characterization of the many-to-oneAny→En model as a multi-domain model, whereeach source language constitutes a separate do-main, and the one-to-many En→Any model as amulti-task model, with each target language rep-resenting a separate task (Section 2). This for-mulation of multilingual NMT helps explain theaforementioned observations, which suggest thatmultilingual models might be more amenable totransfer across input domains than transfer acrosstasks. Simple joint training does not do muchto benefit one-to-many multilingual NMT; whilesome improvements may arise from the model
Figure 7: Results comparing the performance ofmodels trained to translate English to and fromall languages to two separate from and to Englishmodels. From left to right, languages are arrangedin decreasing order of available training data. Re-sults are reported relative to those of the bilingualbaselines (2). The colors correspond to the fol-lowing models: (i) Green: dedicated (individual)En→Any model for top plot, (ii) Blue: dedicatedAny→En model for bottom plot, and (iii) Red:shared model for both Any→En and En→Any .Best viewed in color.
seeing much more English source data, there islittle to no transfer occurring at the task/decoderlevel. On the other hand, it is much easier formany-to-one multilingual models to reap the ben-efits of joint training when the inputs are from dif-ferent domains: the output distribution remainsthe same, hence learning a much stronger En-glish language model, without any interferencefrom the other target languages or tasks. This isalso reflected in other works on low-resource ma-chine translation where Any→En typically bene-fits the most (Zoph et al., 2016; Nguyen and Chi-ang, 2017; Gu et al., 2018a,b).
Another strong indicator of transfer in multi-lingual models is the quality on zero-shot trans-
10

De→ Fr Be→ Ru Y i→ De Fr → Zh Hi→ Fi Ru→ Fi
10 langs 11.15 36.28 8.97 15.07 2.98 6.02102 langs 14.24 50.26 20.00 11.83 8.76 9.06
Table 4: Effect of increasing the number of languages on the zero-shot performance of multilingualmodels.
lation. Multilingual models possess a unique ad-vantage over single task models, in that they arecapable of translating between any pair of sup-ported input and output languages, even whenno direct parallel data is available (Firat et al.,2016b). However, without supervision from par-allel data between non-English language pairs,zero-shot translation quality often trails the per-formance of pivoting/bridging through a commonlanguage (Johnson et al., 2017). Given the lackof transfer across different En→Any translationtasks, it isn’t hard to imagine why transferringacross Yy→En and En→Xx , to learn Yy→Xx , isan even more challenging task.
Enabling direct translation between arbitrarylanguages has been widely studied, and has thepotential to obviate the need for two-step pivotingwhich suffers from higher latency and accumu-lated errors. The most effective approach has beento simply synthesize parallel data (Firat et al.,2016b; Chen et al., 2017, 2018b) and incorporatethat into the training process. However, this two-stage approach becomes intractable when dealingwith a large number of languages; the amountof synthesized data required to enable zero-shottranslation grows quadratically with the numberof languages. More recent work has demon-strated that direct translation quality may be im-proved even in a zero-shot setting, by incorporat-ing more languages (Aharoni et al., 2019), addingregularization to promote cross-lingual transfer(Arivazhagan et al., 2019; Gu et al., 2019; Al-Shedivat and Parikh, 2019), and modeling strate-gies that encourage shared cross-lingual represen-tations (Lu et al., 2018; Escolano et al., 2019).
We report the zero-shot performance of our 10language and 102 language models, discussed inSection 4.2, on selected language pairs in Table4. We observe that zero-shot performance on sim-ilar languages, in this case Be→Ru and Yi→De ,is extremely high. We also notice that the zero-shot performance for most language pairs in-
creases as we move from the 10 language modelto the 102 language model, possibly due to theregularization effect in the capacity constrainedsetting, similar to what was observed in (Aharoniet al., 2019). This also indicates why methods thatexplicitly force languages to share the same rep-resentation space (Arivazhagan et al., 2019; Guet al., 2019; Lu et al., 2018) may be key to im-proving zero-shot translation performance.
We next delve into pre-processing and vocab-ulary generation when dealing with hundreds oflanguages.
5 Pre-processing and Vocabularies
Pre-processing and vocabulary construction laycentral to the generalization ability of natural lan-guage processing systems.
To generalize to unseen examples, machinelearning algorithms must decompose the inputdata into a set of basic units (e.g. pixels, char-acters, phonemes etc.) or building blocks. Fortext, this set of basic units or building blocks isreferred to as the vocabulary. Given some textand a vocabulary, a segmentation algorithm or apre-processor is applied to fragment the text to itsbuilding blocks upon which the learner may thenapply inductive reasoning.
In essence, a properly defined vocabulary needsto (i) maintain a high coverage by being able tocompose most text and produce minimal numberof Out-of-Vocabulary (OOV) tokens during seg-mentation, (ii) have tractable size to limit compu-tational and spatial costs, and (iii) operate at theright level of granularity to enable inductive trans-fer with manageable sequence lengths which in-crease computational costs.
Early NMT models operated at the word level(Sutskever et al., 2014; Cho et al., 2014; Bahdanauet al., 2014). Coverage issues arising from diffi-culty capturing all words of a language within alimited vocabulary budget promoted the develop-ment of character level systems (Ling et al., 2015;
11

Luong and Manning, 2016; Chung et al., 2016;Costa-jussà and Fonollosa, 2016; Lee et al., 2017;Cherry et al., 2018). These trivially achieve highcoverage, albeit with the downside of increasedcomputational and modeling challenges due to in-creased sequence lengths. Sub-word level vocab-ularies (Sennrich et al., 2016) have since found amiddle ground and are used in most state-of-the-art NMT systems.
Constructing vocabularies that can model hun-dreds of languages with vast number of charac-ter sets, compositional units, and morphologicalvariance is critical to developing massively multi-lingual systems, yet remains challenging. Earlymultilingual NMT models utilized separate vo-cabularies for each language (Dong et al., 2015;Luong et al., 2015; Firat et al., 2016a); later onesused shared multilingual vocabularies (Sennrichet al., 2016; Ha et al., 2016c; Johnson et al., 2017)which are shared across languages. Recently, hy-brid (Shared + Separate) multilingual vocabular-ies and approaches for adding new languages toexisting vocabularies (Lakew et al., 2018) havealso been explored.
In this section we describe the simplistic ap-proach to multilingual vocabulary constructionused in our setup, inspect implicit characteris-tics of such vocabularies, and finally evaluatethe downstream effects on multilingual machinetranslation.
5.1 Vocabulary Construction andCharacteristics
We construct all our vocabularies using Sen-tence Piece Model (SPM) (Kudo and Richard-son, 2018) to remove complexity that may arisefrom language specific pre-processing (e.g. to-kenization, special character replacements etc.).The large number of languages used in our setupmakes separate per-language vocabularies infea-sible. Therefore, we picked shared sub-word vo-cabularies. While using a single shared vocabu-lary across all languages reduces complexity, it in-troduces other challenges that we discuss below.
With the large number of scripts introduced ina multilingual setting, the chance of a vocabu-lary producing unknowns (OOV) increases. Notethat since only unrecognized characters will beencoded as OOV, if the vocabulary provides suf-
Figure 8: Average number of sentence-piece to-kens per sentence on random samples drawn fromthe training set. We compare the increase in num-ber of tokens per sentence for different languages,when moving from a standard monolingual vo-cabulary with 32k tokens to a multilingual vo-cabulary for which we vary the vocabulary size(size={32k, 64k, 128k} tokens) and the vocabu-lary sampling temperature (T = {1, 5, 100}).
ficient coverage over the alphabet from variousscripts, OOV rates will be low. For SPMs, this istuned using the character_coverage option and weto a high value of 1 − (5 ∗ 10−6) which yields analphabet size of around 12000, ensuring very lowunknown rates for all the languages in our study.
While ensuring low unknown rates, the shift to-wards a vocabulary which largely consists of char-acters or short sub-words (in terms of the numberof characters that they consist of) results in longersequences after tokenization (Chung et al., 2016;Costa-jussà and Fonollosa, 2016). Longer se-quence lengths, however, increase computationalcomplexity and may also introduce optimizationchallenges due to longer range dependencies andrequire the learner to model a more complex map-ping function from a finer grained sequence tomeaning. To avoid exceedingly long sequence
12
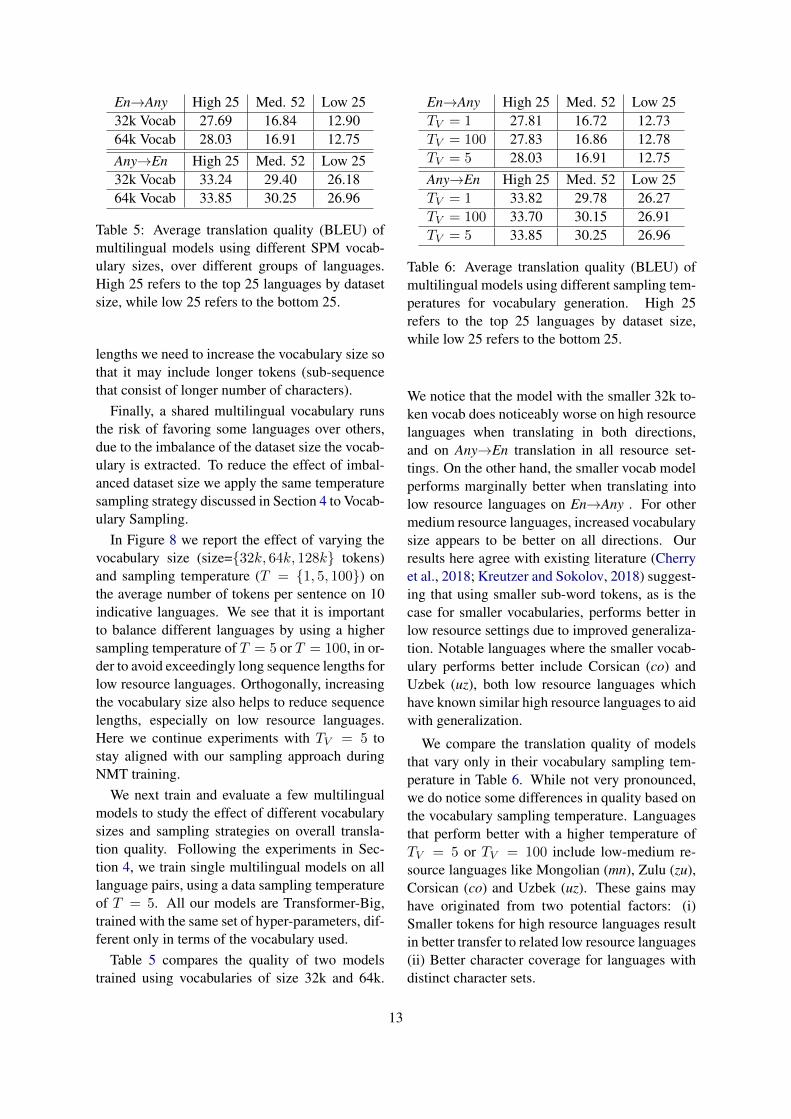
En→Any High 25 Med. 52 Low 2532k Vocab 27.69 16.84 12.9064k Vocab 28.03 16.91 12.75Any→En High 25 Med. 52 Low 2532k Vocab 33.24 29.40 26.1864k Vocab 33.85 30.25 26.96
Table 5: Average translation quality (BLEU) ofmultilingual models using different SPM vocab-ulary sizes, over different groups of languages.High 25 refers to the top 25 languages by datasetsize, while low 25 refers to the bottom 25.
lengths we need to increase the vocabulary size sothat it may include longer tokens (sub-sequencethat consist of longer number of characters).
Finally, a shared multilingual vocabulary runsthe risk of favoring some languages over others,due to the imbalance of the dataset size the vocab-ulary is extracted. To reduce the effect of imbal-anced dataset size we apply the same temperaturesampling strategy discussed in Section 4 to Vocab-ulary Sampling.
In Figure 8 we report the effect of varying thevocabulary size (size={32k, 64k, 128k} tokens)and sampling temperature (T = {1, 5, 100}) onthe average number of tokens per sentence on 10indicative languages. We see that it is importantto balance different languages by using a highersampling temperature of T = 5 or T = 100, in or-der to avoid exceedingly long sequence lengths forlow resource languages. Orthogonally, increasingthe vocabulary size also helps to reduce sequencelengths, especially on low resource languages.Here we continue experiments with TV = 5 tostay aligned with our sampling approach duringNMT training.
We next train and evaluate a few multilingualmodels to study the effect of different vocabularysizes and sampling strategies on overall transla-tion quality. Following the experiments in Sec-tion 4, we train single multilingual models on alllanguage pairs, using a data sampling temperatureof T = 5. All our models are Transformer-Big,trained with the same set of hyper-parameters, dif-ferent only in terms of the vocabulary used.
Table 5 compares the quality of two modelstrained using vocabularies of size 32k and 64k.
En→Any High 25 Med. 52 Low 25TV = 1 27.81 16.72 12.73TV = 100 27.83 16.86 12.78TV = 5 28.03 16.91 12.75Any→En High 25 Med. 52 Low 25TV = 1 33.82 29.78 26.27TV = 100 33.70 30.15 26.91TV = 5 33.85 30.25 26.96
Table 6: Average translation quality (BLEU) ofmultilingual models using different sampling tem-peratures for vocabulary generation. High 25refers to the top 25 languages by dataset size,while low 25 refers to the bottom 25.
We notice that the model with the smaller 32k to-ken vocab does noticeably worse on high resourcelanguages when translating in both directions,and on Any→En translation in all resource set-tings. On the other hand, the smaller vocab modelperforms marginally better when translating intolow resource languages on En→Any . For othermedium resource languages, increased vocabularysize appears to be better on all directions. Ourresults here agree with existing literature (Cherryet al., 2018; Kreutzer and Sokolov, 2018) suggest-ing that using smaller sub-word tokens, as is thecase for smaller vocabularies, performs better inlow resource settings due to improved generaliza-tion. Notable languages where the smaller vocab-ulary performs better include Corsican (co) andUzbek (uz), both low resource languages whichhave known similar high resource languages to aidwith generalization.
We compare the translation quality of modelsthat vary only in their vocabulary sampling tem-perature in Table 6. While not very pronounced,we do notice some differences in quality based onthe vocabulary sampling temperature. Languagesthat perform better with a higher temperature ofTV = 5 or TV = 100 include low-medium re-source languages like Mongolian (mn), Zulu (zu),Corsican (co) and Uzbek (uz). These gains mayhave originated from two potential factors: (i)Smaller tokens for high resource languages resultin better transfer to related low resource languages(ii) Better character coverage for languages withdistinct character sets.
13

While the effects of vocabulary are muchsmaller than the trends observed for data sam-pling, failure to ensure careful character coverageand fair representation from all languages couldnonetheless significantly impact translation qual-ity.
So far in our study, we have presented our anal-ysis and experimentation with data, training andvocabulary in multilingual scenarios. We next an-alyze the effect of several architectural choices onthe quality of our massively multilingual NMTmodel.
6 Modeling
The quality of any neural network is largely de-pendent on its architecture and parametrization.The choice of the model, and the constraints onits parameters determine the extent of the transfer-interference trade-off, the learning dynamics and,ultimately, the performance limits of the model.In this section we analyze how choices regardingparameter sharing and model capacity can impacttranslation quality in the setting of massively mul-tilingual NMT.
6.1 Architecture
In recent years, several revolutionary architec-tures have been developed to improve MT quality(Gehring et al., 2017; Vaswani et al., 2017; Chenet al., 2018a; Wu et al., 2019). However, in thecontext of multilingual NMT, the most commonprior imposed on models is typically in the form of(hard or soft) parameter sharing constraints acrossdifferent languages pairs. In designing a multi-ingual NMT model, we would like to take ad-vantage of the common structures and featuresshared by multiple languages, which imposes con-straints on the model architecture. These con-straints range from sharing a fixed length repre-sentation across all source and target pairs (Lu-ong et al., 2015), sharing small network mod-ules, for example the attention parameters (Firatet al., 2016a), and sharing everything except theattention parameters (Ha et al., 2016b; Blackwoodet al., 2018), to sharing all parameters in the modelacross all language pairs (Johnson et al., 2017; Haet al., 2016c). Some studies also explore partialparameter sharing strategies tailored for specificarchitectures (Sachan and Neubig, 2018; Wang
et al., 2018b). More recently, with the increasednumber of languages (Qi et al., 2018; Aharoniet al., 2019), there has been work along the linesof applying soft sharing for MT, in the form ofa shared set of meta-learned parameters used togenerate task level parameters (Platanios et al.,2018). All of these sharing strategies come pairedwith their associated set of transfer-interferencetrade-offs, and regardless of the sharing strategy,in the absence of a complete and accurate atlas oftask relatedness, more transferrability also impliesmore interference. This phenomenon is knownto be a common problem for multitask learning,and is also related to the stability vs plasticitydilemma (Carpenter and Grossberg, 1987; Gross-berg, 1988). See (Parisi et al., 2018) for a catego-rization of such work.
Considering the scale of our experimental setupand end-goal, combinatorial approaches for pa-rameter sharing do not emerge as plausible so-lutions. While “learning to share” approaches(Kang et al., 2011; Ruder et al., 2017; Platanioset al., 2018) are promising alternatives, a morestraightforward solution could be implicitly in-creasing the per-task capacity by increasing over-all model capacity. Next we look into a brute-force approach to mitigate interference by enhanc-ing model capacity.
6.2 Capacity
Over the last few years, scaling up model capac-ity has been shown to demonstrate huge improve-ments on several supervised and transfer learningbenchmarks, including MT (Brock et al., 2018;Devlin et al., 2018; Radford et al.; Shazeer et al.,2018). Scale often comes bundled with new hard-ware, infrastructure, and algorithmic approachesmeant to optimize accelerator memory utilizationand benefit faster computation, including meth-ods like gradient checkpointing and low preci-sion training (Courbariaux et al., 2014; Ott et al.,2018), memory efficient optimizers (Shazeer andStern, 2018; Gupta et al., 2018) and frameworkssupporting model parallelism (Shazeer et al.,2018; Harlap et al.; Huang et al., 2018).
While massive models have been shown to im-prove performance in single task settings (Shazeeret al., 2018), we would expect the gains to be evenlarger on a capacity-constrained massively multi-
14

En→Any High 25 Med. 52 Low 25Bilingual 29.34 17.50 11.72400M 28.03 16.91 12.751.3B Wide 28.36 16.66 11.141.3B Deep 29.46 17.67 12.52Any→En High 25 Med. 52 Low 25Bilingual 37.61 31.41 21.63400M 33.85 30.25 26.961.3B Wide 37.13 33.21 27.751.3B Deep 37.47 34.63 31.21
Table 7: Average translation quality (BLEU)of multilingual models with increasing capacity.High 25 refers to the top 25 languages by datasetsize, while low 25 refers to the bottom 25.
lingual task. We next try to quantify how the per-formance of our model scales with capacity. Ad-ditionally, we also compare two dimensions alongwhich model capacity can be increased—depthand width—and compare how performance acrossdifferent tasks is affected when scaling along thesetwo dimensions.
We start with our Transformer-Big baselinewith a 64k vocabulary, trained with a data sam-pling temperature of T = 5. This model hasaround 400M parameters, including the embed-dings and the softmax layers. We compare theperformance of two scaled up models with around1.3B parameters. Our first model is the widemodel, with 12 layers in both the encoder and thedecoder (24 layers in total), feed-forward hiddendimensions set to 16384, 32 attention heads and anattention hidden dimension set to 2048 (Shazeeret al., 2018). The deep model has 24 layers inthe encoder and the decoder (48 layers in total),with all other hyper-parameters being equivalentto the Transformer-Big. To avoid trainability hur-dles, both these models are trained with transpar-ent attention (Bapna et al., 2018). Further, in orderto enable training these massive models, we utilizeGPipe (Huang et al., 2018) to incorporate efficientmodel parallelism. Both 1.3B param wide anddeep models are trained with 128 TPUv3 chips,parallelized over 2 and 4 cores respectively.9 Weuse the same 4M token batch size used for all ourmultilingual experiments.
9Note, each TPUv3 chip has 2 cores.
Figure 9: Effect of increasing capacity on the per-formance of multilingual models. From left toright, languages are arranged in decreasing or-der of available training data. Results are re-ported relative to those of the bilingual baselines(2). The plots correspond to the following mod-els: blue: 400M param ‘Transformer-Big’, green:1.3B param, 12 layer wide model and red: 1.3Bparam, 24 layer model. Best viewed in color.
The performance of these two models and thebaseline Transformer-Big is depicted in Figure 9(also summarized in Table 7). We notice thatboth these models improve performance by sig-nificant amounts on the high resource languages,when compared against the capacity constrainedmassively multilingual baseline (blue curves inFigure 9). However, the deep model handilybeats both, the baseline and the equivalent capac-ity wide model, by significant margins on most ofthe language pairs. We also notice that, unlike thewide model, the deep model does not overfit inlow resource languages and, in fact, significantlyenhances transfer to low resource languages onthe Any→En translation tasks.
Our results suggest that model capacity might
15

be one of the most important factors determin-ing the extent of the transfer-interference trade-off. However, naively scaling capacity mightresult in poor transfer performance to low re-source languages. For example, our wide Trans-former while significantly improving performanceon the high resource languages, fails to showsimilar gains in the low resource setting. Whiledeeper models show great performance improve-ments, they come bundled with high decoding la-tency, a significantly larger computational foot-print, and trainability concerns including van-ishing/exploding gradients, early divergence, ill-conditioned initial conditions etc. (Hestness et al.,2017). Further research into various aspects ofscalability, trainability and optimization dynamicsis expected to be a fruitful avenue towards univer-sal NMT.
We next delve into evaluation challenges posedby multilingual models.
7 Evaluation
Metrics for automatic quality evaluation (Pap-ineni et al., 2002) have been critical to the rapidprogress in machine translation, by making eval-uation fast, cheap and reproducible. For multilin-gual NMT, new concerns arise due to the multi-objective nature of the problem and the inherentquality trade-offs between languages.
Inter-language quality trade-offs arise due tovarious decisions made while constructing, train-ing and selecting a model. When constructingthe model, the vocabulary may be constructedto favor a certain script or group of languages,or the language specific parameters may be un-evenly distributed across languages. During train-ing, the optimization settings or the rate at whichtraining data from different languages are sam-pled strongly influence the eventual performanceon different languages. Finally, when selecting acheckpoint10, the model may perform better onhigh resource languages at later checkpoints butmay have regressed on low resource languages bythat time due to over-training (or under-trainingfor the opposing case). Each of these choices nat-urally may favor certain languages over others.
To choose between the aforementioned trade-offs, we need a translation quality metric that is
10Certain snapshot of the model parameters.
both effective and comparable across languages.This in and of itself is a hard problem with anever growing list of hundreds of metrics to choosefrom. Oftentimes these metrics vary in their effec-tiveness across languages; WMT shared tasks (Maet al., 2018b) report that the specific language,dataset, and system significantly affect which met-ric has the strongest correlation with human rat-ings. When metrics are sufficiently effectiveacross languages they are not always comparable.N-gram based metrics (Papineni et al., 2002; Dod-dington, 2002; Wang et al., 2016; Popovic, 2015)that measure lexical overlap require tokenizationwhich is highly affected by language specific fac-tors such as alphabet size and morphological com-plexity. In fact, even within the same language,tokenization discrepancies pose significant chal-lenges to reliable evaluation (Post, 2018). Embed-ding based approaches (Stanojevic and Sima’an,2014) may be language agnostic and help addressthese issues.
Equally important to choosing a metric ischoosing an evaluation set. Most existing met-rics are not consistent (Banerjee and Lavie, 2005)and for the same model vary based on the domainor even the specific sentences that they are beingevaluated on. For example, there are significantdifferences of 3-5 BLEU between the WMT devand test sets for the same language pair. Suchconsistency issues may further exacerbate the dif-ficulty of comparing system quality across lan-guages if we use different test sets for each lan-guage. This may be addressed by ensuring thatevaluation is performed on the same corpora thathas been translated to all the languages, i.e. multi-way parallel data. Even so, attention must be paidto the original language (Freitag et al., 2019) anddomain such data is collected from.
8 Open Problems in MassivelyMultilingual NMT
Data and Supervision Whereas we focus solelyon supervised learning, for many low resourcelanguages it becomes essential to learn frommonolingual data. There has been a lot ofrecent work on incorporating monolingual datato improve translation performance in low andzero resource settings, including research onback-translation (Sennrich et al., 2015; Edunov
16

et al., 2018), language model fusion (Gulcehreet al., 2015; Sriram et al., 2017), self-supervisedpre-training (Dai and Le, 2015; Ramachandranet al., 2016; Zhang and Zong, 2016; Song et al.,2019) and unsupervised NMT (Lample et al.,2017; Artetxe et al., 2017). Languages wherelarge swathes of monolingual data are not eas-ily available might require more sample effi-cient approaches for language modeling, includ-ing grounding with visual modalities or sourcesof information (Huang et al., 2016), and learningfrom meta-data or other forms of context. Be-ing able to represent and ground information frommultiple modalities in the same representationalspace is the next frontier for ML research.
The scope of our study is limited to 103 lan-guages, a minuscule fraction of the thousands ofexisting languages. The heuristics and approacheswe develop will be less and less applicable aswe include more languages and incorporate otherforms of data. As we scale up model sizes andthe number of languages learned within a singlemodel, approaches that require multi-stage train-ing or inference steps will likely become infea-sible. Work towards better integration of self-supervised learning with the supervised trainingprocess is more likely to scale well with largermodel capacities and increasing number of lan-guages.
Learning Developing learning approaches thatwork well for multitask models is essential to im-proving the quality of multilingual models. Ouranalysis from Section 4 demonstrates that evensimple heuristics for data sampling/balancing cansignificantly improve the extent of transfer andinterference observed by individual tasks. How-ever, our heuristic strategy only takes dataset sizeinto account when determining the fraction ofper-task samples seen by the model. Researchon exploiting task-relatedness (Lee et al., 2016;Neubig and Hu, 2018), curriculum learning onnoisy data (van der Wees et al., 2017; Wanget al., 2018a), and automated curriculum learn-ing from model state (Bengio et al., 2009; Graveset al., 2017) have demonstrated success in mul-titask learning, including for NMT. Other rele-vant threads of work include research on meta-learning to learn model hyper-parameters (Nicholet al., 2018; Baydin et al., 2017), model parame-
ters (Ha et al., 2016a; Platanios et al., 2018) andmodels that learn new tasks with high sample ef-ficiency (Finn et al., 2017) without forgetting ex-isting tasks or languages (Rusu et al., 2016; Kirk-patrick et al., 2017; Lakew et al., 2018). Whenscaling to thousands of languages, approaches thatcan automatically learn data sampling, curricula,model hyper-parameters and parameters, to trainmodels that quickly adapt to new tasks, is againexpected to become increasingly important.
Increasing Capacity Increasing the model ca-pacity has been demonstrated to be a sure-shotapproach to improving model quality in the pres-ence of supervised data for several tasks, includ-ing Image Generation (Brock et al., 2018), Lan-guage Modeling and transfer learning (Radfordet al.; Devlin et al., 2018) and NMT (Shazeeret al., 2018). Validating this trend, one key re-sult from our study is the need for sufficientmodel capacity when training large multitask net-works. Other than the systems and engineeringchallenges (Jouppi et al., 2017; Huang et al., 2018;Shazeer et al., 2018), training deep and high ca-pacity neural networks poses significant trainabil-ity challenges (Montavon et al., 2018). A bet-ter theoretical understanding of the generalizationability of deep and wide models (Raghu et al.,2017; Arora et al., 2018), trainability challengesincluding exploding and vanishing gradients (Glo-rot and Bengio, 2010; Balduzzi et al., 2017) andempirical approaches to counter these challenges(Bapna et al., 2018; Zhang et al., 2019) are criticalto further scaling of model capacity.
Architecture and Vocabulary Extending exist-ing approaches for vocabulary construction andneural modeling to work better in multitask set-tings (Ma et al., 2018a; Houlsby et al., 2019) in or-der to strike the right balance between shared andtask-specific capacity, or learning network struc-ture in order to maximally exploit task relatedness(Li et al., 2019) are exciting avenues for futureresearch. As we scale up to thousands of lan-guages, vocabulary handling becomes a signifi-cantly harder challenge. Successfully represent-ing thousands of languages might require charac-ter (Lee et al., 2017; Cherry et al., 2018), byte(Gillick et al., 2015) or even bit level modeling.Modeling extremely long sequences of bit/byte-
17

level tokens would present its own set of model-ing challenges. Finally, while scaling up existingapproaches is one way to improve model quality,some approaches or architectures are more effi-cient to train (Shazeer et al., 2017; Vaswani et al.,2017; Wu et al., 2019), more sample efficient, orfaster at inference (Gu et al., 2017; Roy et al.,2018). As models get larger, improving trainingand inference efficiency become more importantto keep training and inference times within rea-sonable limits from both a practical and environ-mental perspective (Strubell et al., 2019).
9 Conclusion
Although we believe that we have achieved a mile-stone with the present study, building on five yearsof multilingual NMT research, we still have a longway to go towards truly universal machine trans-lation. In the open problems and future directionsenumerated above, many promising solutions ap-pear to be interdisciplinary, making multilingualNMT a plausible general test bed for other ma-chine learning practitioners and theoreticians.
Acknowledgments
We would like to thank the Google Translate andGoogle Brain teams for their useful input anddiscussion, and the entire Lingvo developmentteam for their foundational contributions to thisproject. We would also like to thank KatherineLee, Thang Luong, Colin Raffel, Noam Shazeer,and Geoffrey Hinton for their insightful com-ments.
References
Roee Aharoni, Melvin Johnson, and Orhan Firat.2019. Massively multilingual neural machinetranslation. CoRR, abs/1903.00089.
Maruan Al-Shedivat and Ankur P Parikh. 2019.Consistency by agreement in zero-shot neu-ral machine translation. arXiv preprintarXiv:1904.02338.
Naveen Arivazhagan, Ankur Bapna, Orhan Fi-rat, Roee Aharoni, Melvin Johnson, and Wolf-gang Macherey. 2019. The missing ingredient
in zero-shot neural machine translation. arXivpreprint arXiv:1903.07091.
Sanjeev Arora, Nadav Cohen, and Elad Hazan.2018. On the optimization of deep networks:Implicit acceleration by overparameterization.arXiv preprint arXiv:1802.06509.
Mikel Artetxe, Gorka Labaka, Eneko Agirre,and Kyunghyun Cho. 2017. Unsupervisedneural machine translation. arXiv preprintarXiv:1710.11041.
Dzmitry Bahdanau, Kyunghyun Cho, and YoshuaBengio. 2014. Neural machine translation byjointly learning to align and translate. arXivpreprint arXiv:1409.0473.
David Balduzzi, Marcus Frean, Lennox Leary,JP Lewis, Kurt Wan-Duo Ma, and BrianMcWilliams. 2017. The shattered gradientsproblem: If resnets are the answer, then whatis the question? In Proceedings of the 34th In-ternational Conference on Machine Learning-Volume 70, pages 342–350. JMLR. org.
Satanjeev Banerjee and Alon Lavie. 2005. Me-teor: An automatic metric for mt evaluationwith improved correlation with human judg-ments. In Proceedings of the acl workshopon intrinsic and extrinsic evaluation measuresfor machine translation and/or summarization,pages 65–72.
Ankur Bapna, Mia Xu Chen, Orhan Firat,Yuan Cao, and Yonghui Wu. 2018. Train-ing deeper neural machine translation mod-els with transparent attention. arXiv preprintarXiv:1808.07561.
Atilim Gunes Baydin, Robert Cornish,David Martinez Rubio, Mark Schmidt,and Frank Wood. 2017. Online learning rateadaptation with hypergradient descent. arXivpreprint arXiv:1703.04782.
Yoshua Bengio, Jérôme Louradour, Ronan Col-lobert, and Jason Weston. 2009. Curriculumlearning. In Proceedings of the 26th annualinternational conference on machine learning,pages 41–48. ACM.
18

Graeme Blackwood, Miguel Ballesteros, andTodd Ward. 2018. Multilingual neural machinetranslation with task-specific attention. arXivpreprint arXiv:1806.03280.
Ondrej Bojar, Rajen Chatterjee, Christian Feder-mann, et al. 2018a. Proceedings of the thirdconference on machine translation: Researchpapers. Belgium, Brussels. Association forComputational Linguistics.
Ondrej Bojar, Rajen Chatterjee, Christian Feder-mann, et al. 2017. Findings of the 2017 confer-ence on machine translation (wmt17). In Pro-ceedings of the Second Conference on MachineTranslation, pages 169–214.
Ondrej Bojar, Rajen Chatterjee, Christian Feder-mann, et al. 2016a. Findings of the 2016 con-ference on machine translation. In ACL 2016FIRST CONFERENCE ON MACHINE TRANS-LATION (WMT16), pages 131–198. The Asso-ciation for Computational Linguistics.
Ondrej Bojar, Christian Federmann, Mark Fishel,Yvette Graham, Barry Haddow, Philipp Koehn,and Christof Monz. 2018b. Findings ofthe 2018 conference on machine translation(wmt18). In Proceedings of the Third Confer-ence on Machine Translation: Shared Task Pa-pers, pages 272–303, Belgium, Brussels. Asso-ciation for Computational Linguistics.
Ondrej Bojar, Christian Federmann, Barry Had-dow, Philipp Koehn, Matt Post, and Lucia Spe-cia. 2016b. Ten years of wmt evaluation cam-paigns: Lessons learnt. In Proceedings of theLREC 2016 Workshop âAIJTranslation Evalua-tion âAS From Fragmented Tools and Data Setsto an Integrated EcosystemâAI, pages 27–34.
Andrew Brock, Jeff Donahue, and Karen Si-monyan. 2018. Large scale gan training forhigh fidelity natural image synthesis. arXivpreprint arXiv:1809.11096.
Gail A Carpenter and Stephen Grossberg. 1987.Art 2: Self-organization of stable categoryrecognition codes for analog input patterns. Ap-plied optics, 26(23):4919–4930.
Rich Caruana. 1997. Multitask learning. MachineLearning, 28(1):41–75.
Mauro Cettolo, C Girardi, and M Federico. 2012.Wit3: Web inventory of transcribed and trans-lated talks. Proceedings of EAMT, pages 261–268.
Mia Xu Chen, Orhan Firat, Ankur Bapna, et al.2018a. The best of both worlds: Combin-ing recent advances in neural machine transla-tion. In Proceedings of the 56th Annual Meet-ing of the Association for Computational Lin-guistics (Volume 1: Long Papers), pages 76–86,Melbourne, Australia. Association for Compu-tational Linguistics.
Yun Chen, Yang Liu, Yong Cheng, and Vic-tor OK Li. 2017. A teacher-student frame-work for zero-resource neural machine transla-tion. arXiv preprint arXiv:1705.00753.
Yun Chen, Yang Liu, and Victor OK Li. 2018b.Zero-resource neural machine translation withmulti-agent communication game. In Thirty-Second AAAI Conference on Artificial Intelli-gence.
Zhiyuan Chen and Bing Liu. 2016. Lifelong ma-chine learning. Synthesis Lectures on ArtificialIntelligence and Machine Learning, 10(3):1–145.
Colin Cherry, George Foster, Ankur Bapna, OrhanFirat, and Wolfgang Macherey. 2018. Revisit-ing character-based neural machine translationwith capacity and compression. In Proceedingsof the 2018 Conference on Empirical Methodsin Natural Language Processing, pages 4295–4305, Brussels, Belgium. Association for Com-putational Linguistics.
Kyunghyun Cho, Bart van Merrienboer, CaglarGulcehre, Dzmitry Bahdanau, Fethi Bougares,Holger Schwenk, and Yoshua Bengio. 2014.Learning phrase representations using rnnencoder–decoder for statistical machine trans-lation. In Proceedings of the 2014 Conferenceon Empirical Methods in Natural LanguageProcessing (EMNLP), pages 1724–1734, Doha,Qatar. Association for Computational Linguis-tics.
Junyoung Chung, Kyunghyun Cho, and YoshuaBengio. 2016. A character-level decoder with-
19

out explicit segmentation for neural machinetranslation. arXiv preprint arXiv:1603.06147.
Ronan Collobert and Jason Weston. 2008. A uni-fied architecture for natural language process-ing: Deep neural networks with multitask learn-ing. In Proceedings of the 25th InternationalConference on Machine Learning, pages 160–167.
Marta R. Costa-jussà and José A. R. Fonollosa.2016. Character-based neural machine transla-tion. CoRR, abs/1603.00810.
Matthieu Courbariaux, Yoshua Bengio, and Jean-Pierre David. 2014. Training deep neuralnetworks with low precision multiplications.arXiv preprint arXiv:1412.7024.
Josep Maria Crego, Jungi Kim, Guillaume Klein,et al. 2016. Systran’s pure neural machinetranslation systems. CoRR, abs/1610.05540.
Andrew M Dai and Quoc V Le. 2015. Semi-supervised sequence learning. In Advances inneural information processing systems, pages3079–3087.
L. Deng, G. Hinton, and B. Kingsbury. 2013.New types of deep neural network learning forspeech recognition and related applications: anoverview. In 2013 IEEE International Confer-ence on Acoustics, Speech and Signal Process-ing, pages 8599–8603.
Jacob Devlin, Ming-Wei Chang, Kenton Lee,and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformersfor language understanding. arXiv preprintarXiv:1810.04805.
George Doddington. 2002. Automatic evaluationof machine translation quality using n-gram co-occurrence statistics. In Proceedings of the sec-ond international conference on Human Lan-guage Technology Research, pages 138–145.Morgan Kaufmann Publishers Inc.
Daxiang Dong, Hua Wu, Wei He, Dianhai Yu, andHaifeng Wang. 2015. Multi-task learning formultiple language translation. In Proceedingsof the 53rd Annual Meeting of the Association
for Computational Linguistics and the 7th In-ternational Joint Conference on Natural Lan-guage Processing (Volume 1: Long Papers),volume 1, pages 1723–1732.
Mark Dredze, Alex Kulesza, and Koby Crammer.2010. Multi-domain learning by confidence-weighted parameter combination. Mach.Learn., 79(1-2):123–149.
Sergey Edunov, Myle Ott, Michael Auli,and David Grangier. 2018. Understandingback-translation at scale. arXiv preprintarXiv:1808.09381.
Carlos Escolano, Marta R Costa-jussà, andJosé AR Fonollosa. 2019. Towards interlin-gua neural machine translation. arXiv preprintarXiv:1905.06831.
Chelsea Finn, Pieter Abbeel, and Sergey Levine.2017. Model-agnostic meta-learning for fastadaptation of deep networks. In Proceedings ofthe 34th International Conference on MachineLearning-Volume 70, pages 1126–1135. JMLR.org.
Orhan Firat, Kyunghyun Cho, and Yoshua Ben-gio. 2016a. Multi-way, multilingual neural ma-chine translation with a shared attention mech-anism. arXiv preprint arXiv:1601.01073.
Orhan Firat, Kyunghyun Cho, BaskaranSankaran, Fatos T. Yarman Vural, andYoshua Bengio. 2017. Multi-way, multilingualneural machine translation. Computer Speech& Language, 45:236 – 252.
Orhan Firat, Baskaran Sankaran, Yaser Al-Onaizan, Fatos T Yarman Vural, andKyunghyun Cho. 2016b. Zero-resourcetranslation with multi-lingual neural machinetranslation. In Proceedings of the 2016Conference on Empirical Methods in NaturalLanguage Processing, pages 268–277.
Markus Freitag, Isaac Caswell, and Scott Roy.2019. Text repair model for neural machinetranslation. arXiv preprint arXiv:1904.04790.
Jonas Gehring, Michael Auli, David Grangier,Denis Yarats, and Yann N. Dauphin. 2017.
20

Convolutional sequence to sequence learning.CoRR, abs/1705.03122.
Dan Gillick, Cliff Brunk, Oriol Vinyals, andAmarnag Subramanya. 2015. Multilingual lan-guage processing from bytes. arXiv preprintarXiv:1512.00103.
Xavier Glorot and Yoshua Bengio. 2010. Under-standing the difficulty of training deep feedfor-ward neural networks. In Proceedings of thethirteenth international conference on artificialintelligence and statistics, pages 249–256.
Siavash Golkar, Michael Kagan, and KyunghyunCho. 2019. Continual learning via neural prun-ing. CoRR, abs/1903.04476.
Ian Goodfellow, Yoshua Bengio, and AaronCourville. 2016. Deep Learning. The MITPress.
Alex Graves, Marc G Bellemare, Jacob Menick,Remi Munos, and Koray Kavukcuoglu. 2017.Automated curriculum learning for neural net-works. In Proceedings of the 34th InternationalConference on Machine Learning-Volume 70,pages 1311–1320. JMLR. org.
Stephen Grossberg. 1988. Neurocomputing:Foundations of research. chapter How Does theBrain Build a Cognitive Code?, pages 347–399.MIT Press, Cambridge, MA, USA.
Jiatao Gu, James Bradbury, Caiming Xiong,Victor OK Li, and Richard Socher. 2017.Non-autoregressive neural machine translation.arXiv preprint arXiv:1711.02281.
Jiatao Gu, Hany Hassan, Jacob Devlin, and Vic-tor O.K. Li. 2018a. Universal neural machinetranslation for extremely low resource lan-guages. In Proceedings of the 2018 Conferenceof the North American Chapter of the Associ-ation for Computational Linguistics: HumanLanguage Technologies, Volume 1 (Long Pa-pers), pages 344–354, New Orleans, Louisiana.Association for Computational Linguistics.
Jiatao Gu, Yong Wang, Yun Chen, KyunghyunCho, and Victor OK Li. 2018b. Meta-learningfor low-resource neural machine translation.arXiv preprint arXiv:1808.08437.
Jiatao Gu, Yong Wang, Kyunghyun Cho, and Vic-tor OK Li. 2019. Improved zero-shot neuralmachine translation via ignoring spurious cor-relations. arXiv preprint arXiv:1906.01181.
Caglar Gulcehre, Orhan Firat, Kelvin Xu,Kyunghyun Cho, Loic Barrault, Huei-Chi Lin,Fethi Bougares, Holger Schwenk, and YoshuaBengio. 2015. On using monolingual corporain neural machine translation. arXiv preprintarXiv:1503.03535.
Vineet Gupta, Tomer Koren, and Yoram Singer.2018. Shampoo: Preconditioned stochas-tic tensor optimization. arXiv preprintarXiv:1802.09568.
David Ha, Andrew Dai, and Quoc V Le.2016a. Hypernetworks. arXiv preprintarXiv:1609.09106.
Thanh-Le Ha, Jan Niehues, and AlexanderWaibel. 2016b. Toward multilingual neural ma-chine translation with universal encoder and de-coder. arXiv preprint arXiv:1611.04798.
Thanh-Le Ha, Jan Niehues, and Alexander H.Waibel. 2016c. Toward multilingual neural ma-chine translation with universal encoder and de-coder. CoRR, abs/1611.04798.
Aaron Harlap, Deepak Narayanan, Amar Phan-ishayee, Vivek Seshadri, Gregory R Ganger,and Phillip B Gibbons. Pipedream: Pipelineparallelism for dnn training.
Hany Hassan, Anthony Aue, Chang Chen, et al.2018. Achieving human parity on automaticchinese to english news translation. arXivpreprint arXiv:1803.05567.
Joel Hestness, Sharan Narang, Newsha Ardalani,Gregory Diamos, Heewoo Jun, Hassan Kian-inejad, Md. Mostofa Ali Patwary, Yang Yang,and Yanqi Zhou. 2017. Deep learning scal-ing is predictable, empirically. arXiv preprintarXiv:1712.00409.
Chris Hokamp, John Glover, and DemianGholipour. 2019. Evaluating the super-vised and zero-shot performance of multi-lingual translation models. arXiv preprintarXiv:1906.09675.
21

Neil Houlsby, Andrei Giurgiu, Stanislaw Jas-trzebski, Bruna Morrone, Quentin de Larous-silhe, Andrea Gesmundo, Mona Attariyan,and Sylvain Gelly. 2019. Parameter-efficienttransfer learning for nlp. arXiv preprintarXiv:1902.00751.
Po-Yao Huang, Frederick Liu, Sz-Rung Shiang,Jean Oh, and Chris Dyer. 2016. Attention-based multimodal neural machine translation.In Proceedings of the First Conference on Ma-chine Translation: Volume 2, Shared Task Pa-pers, volume 2, pages 639–645.
Yanping Huang, Yonglong Cheng, Dehao Chen,HyoukJoong Lee, Jiquan Ngiam, Quoc V Le,and Zhifeng Chen. 2018. Gpipe: Efficienttraining of giant neural networks using pipelineparallelism. arXiv preprint arXiv:1811.06965.
Sébastien Jean, Orhan Firat, and Melvin John-son. 2018. Adaptive scheduling for multi-tasklearning. In Advances in Neural InformationProcessing Systems, Workshop on ContinualLearning, Montreal, Canada.
Melvin Johnson, Mike Schuster, Quoc V Le, et al.2017. Google’s multilingual neural machinetranslation system: Enabling zero-shot transla-tion. Transactions of the Association of Com-putational Linguistics, 5(1):339–351.
Mahesh Joshi, Mark Dredze, William W. Cohen,and Carolyn Rose. 2012. Multi-domain learn-ing: When do domains matter? In Proceed-ings of the 2012 Joint Conference on Empiri-cal Methods in Natural Language Processingand Computational Natural Language Learn-ing, pages 1302–1312, Jeju Island, Korea. As-sociation for Computational Linguistics.
Norman P. Jouppi, Cliff Young, Nishant Patil,et al. 2017. In-datacenter performance analy-sis of a tensor processing unit.
Lukasz Kaiser, Aidan N. Gomez, Noam Shazeer,Ashish Vaswani, Niki Parmar, Llion Jones, andJakob Uszkoreit. 2017. One model to learnthem all. CoRR, abs/1706.05137.
Nal Kalchbrenner and Phil Blunsom. 2013. Re-current continuous translation models. In Pro-
ceedings of the 2013 Conference on Empiri-cal Methods in Natural Language Processing,pages 1700–1709, Seattle, Washington, USA.Association for Computational Linguistics.
Zhuoliang Kang, Kristen Grauman, and Fei Sha.2011. Learning with whom to share in multi-task feature learning. In Proceedings of the28th International Conference on InternationalConference on Machine Learning, ICML’11,pages 521–528, USA. Omnipress.
Eliyahu Kiperwasser and Miguel Ballesteros.2018. Scheduled multi-task learning: Fromsyntax to translation. Transactions of the Asso-ciation for Computational Linguistics, 6:225–240.
James Kirkpatrick, Razvan Pascanu, Neil Ra-binowitz, et al. 2017. Overcoming catas-trophic forgetting in neural networks. Pro-ceedings of the national academy of sciences,114(13):3521–3526.
Philipp Koehn. 2005. Europarl: A Parallel Corpusfor Statistical Machine Translation. In Confer-ence Proceedings: the tenth Machine Transla-tion Summit, pages 79–86, Phuket, Thailand.AAMT, AAMT.
Julia Kreutzer and Artem Sokolov. 2018.Learning to segment inputs for NMT fa-vors character-level processing. CoRR,abs/1810.01480.
Taku Kudo and John Richardson. 2018. Senten-cePiece: A simple and language independentsubword tokenizer and detokenizer for neuraltext processing. In Proceedings of the 2018Conference on Empirical Methods in NaturalLanguage Processing: System Demonstrations,pages 66–71, Brussels, Belgium. Associationfor Computational Linguistics.
Gaurav Kumar, George Foster, Colin Cherry, andMaxim Krikun. 2019. Reinforcement learningbased curriculum optimization for neural ma-chine translation. CoRR, abs/1903.00041.
Brenden M. Lake, Ruslan R. Salakhutdinov, Ja-son Gross, and Joshua B. Tenenbaum. 2011.One shot learning of simple visual concepts. InCogSci.
22

Surafel Melaku Lakew, Aliia Erofeeva, MatteoNegri, Marcello Federico, and Marco Turchi.2018. Transfer learning in multilingual neuralmachine translation with dynamic vocabulary.CoRR, abs/1811.01137.
Guillaume Lample, Ludovic Denoyer, andMarc’Aurelio Ranzato. 2017. Unsupervisedmachine translation using monolingual corporaonly. arXiv preprint arXiv:1711.00043.
Giwoong Lee, Eunho Yang, and Sung Hwang.2016. Asymmetric multi-task learning basedon task relatedness and loss. In InternationalConference on Machine Learning, pages 230–238.
Jason Lee, Kyunghyun Cho, and Thomas Hof-mann. 2017. Fully character-level neural ma-chine translation without explicit segmentation.Transactions of the Association for Computa-tional Linguistics, 5:365–378.
Xilai Li, Yingbo Zhou, Tianfu Wu, RichardSocher, and Caiming Xiong. 2019. Learn togrow: A continual structure learning frame-work for overcoming catastrophic forgetting.
Wang Ling, Isabel Trancoso, Chris Dyer, andAlan W Black. 2015. Character-based neu-ral machine translation. arXiv preprintarXiv:1511.04586.
David Lopez-Paz et al. 2017. Gradient episodicmemory for continual learning. In Advances inNeural Information Processing Systems, pages6467–6476.
Yichao Lu, Phillip Keung, Faisal Ladhak, VikasBhardwaj, Shaonan Zhang, and Jason Sun.2018. A neural interlingua for multilin-gual machine translation. arXiv preprintarXiv:1804.08198.
Minh-Thang Luong, Quoc V Le, Ilya Sutskever,Oriol Vinyals, and Lukasz Kaiser. 2015. Multi-task sequence to sequence learning. arXivpreprint arXiv:1511.06114.
Minh-Thang Luong and Christopher D Manning.2016. Achieving open vocabulary neural ma-chine translation with hybrid word-charactermodels. arXiv preprint arXiv:1604.00788.
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen,Lichan Hong, and Ed H. Chi. 2018a. Modelingtask relationships in multi-task learning withmulti-gate mixture-of-experts. In Proceedingsof the 24th ACM SIGKDD International Con-ference on Knowledge Discovery & DataMining, KDD ’18, pages 1930–1939, NewYork, NY, USA. ACM.
Qingsong Ma, Ondrej Bojar, and Yvette Graham.2018b. Results of the wmt18 metrics sharedtask: Both characters and embeddings achievegood performance. In Proceedings of the ThirdConference on Machine Translation: SharedTask Papers, pages 671–688.
Andreas Maurer, Massimiliano Pontil, andBernardino Romera-Paredes. 2016. The benefitof multitask representation learning. Journal ofMachine Learning Research, 17:81:1–81:32.
Tom M. Mitchell. 1997. Machine learning. Mc-Graw Hill series in computer science. McGraw-Hill.
Grégoire Montavon, Wojciech Samek, and Klaus-Robert Müller. 2018. Methods for interpretingand understanding deep neural networks. Digi-tal Signal Processing, 73:1–15.
Hyeonseob Nam and Bohyung Han. 2015.Learning multi-domain convolutional neu-ral networks for visual tracking. CoRR,abs/1510.07945.
Graham Neubig and Junjie Hu. 2018. Rapid adap-tation of neural machine translation to new lan-guages. In Proceedings of the 2018 Confer-ence on Empirical Methods in Natural Lan-guage Processing, pages 875–880. Associationfor Computational Linguistics.
Toan Q. Nguyen and David Chiang. 2017. Trans-fer learning across low-resource, related lan-guages for neural machine translation. In Proc.IJCNLP, volume 2, pages 296–301.
Alex Nichol, Joshua Achiam, and John Schulman.2018. On first-order meta-learning algorithms.arXiv preprint arXiv:1803.02999.
23

Myle Ott, Sergey Edunov, David Grangier, andMichael Auli. 2018. Scaling neural machinetranslation. arXiv preprint arXiv:1806.00187.
S. J. Pan and Q. Yang. 2010. A survey on trans-fer learning. IEEE Transactions on Knowledgeand Data Engineering, 22(10):1345–1359.
Kishore Papineni, Salim Roukos, Todd Ward,and Wei-Jing Zhu. 2002. Bleu: a methodfor automatic evaluation of machine transla-tion. In Proceedings of 40th Annual Meetingof the Association for Computational Linguis-tics, pages 311–318, Philadelphia, Pennsylva-nia, USA. Association for Computational Lin-guistics.
German Ignacio Parisi, Ronald Kemker, Jose L.Part, Christopher Kann, and Stefan Wermter.2018. Continual lifelong learning with neuralnetworks: A review. CoRR, abs/1802.07569.
Anastasia Pentina, Viktoriia Sharmanska, andChristoph H. Lampert. 2015. Curriculum learn-ing of multiple tasks. In The IEEE Conferenceon Computer Vision and Pattern Recognition(CVPR).
A. Phillips and M Davis. 2009. Tags for Identify-ing Languages. RFC 5646, RFC Editor.
Emmanouil Antonios Platanios, MrinmayaSachan, Graham Neubig, and Tom Mitchell.2018. Contextual parameter generation foruniversal neural machine translation. arXivpreprint arXiv:1808.08493.
Emmanouil Antonios Platanios, Otilia Stretcu,Graham Neubig, Barnabás Póczos, and Tom M.Mitchell. 2019. Competence-based curriculumlearning for neural machine translation. CoRR,abs/1903.09848.
Maja Popovic. 2015. chrf: character n-gram f-score for automatic mt evaluation. In Proceed-ings of the Tenth Workshop on Statistical Ma-chine Translation, pages 392–395.
Matt Post. 2018. A call for clarity in reportingbleu scores. arXiv preprint arXiv:1804.08771.
Ye Qi, Sachan Devendra, Felix Matthieu, Pad-manabhan Sarguna, and Neubig Graham. 2018.
When and why are pre-trained word embed-dings useful for neural machine translation. InHLT-NAACL.
Alec Radford, Karthik Narasimhan, Tim Sali-mans, and Ilya Sutskever. Improving languageunderstanding by generative pre-training.
Maithra Raghu, Ben Poole, Jon Kleinberg, SuryaGanguli, and Jascha Sohl Dickstein. 2017. Onthe expressive power of deep neural networks.In Proceedings of the 34th International Con-ference on Machine Learning-Volume 70, pages2847–2854. JMLR. org.
Prajit Ramachandran, Peter J Liu, and Quoc VLe. 2016. Unsupervised pretraining for se-quence to sequence learning. arXiv preprintarXiv:1611.02683.
Bharath Ramsundar, Steven Kearnes, Patrick Ri-ley, Dale Webster, David Konerding, and VijayPande. 2015. Massively multitask networks fordrug discovery. arXiv:1502.02072.
Bernardino Romera-Paredes and Philip H. S. Torr.2015. An embarrassingly simple approach tozero-shot learning. In ICML.
Michael T Rosenstein, Zvika Marx, Leslie PackKaelbling, and Thomas G Dietterich. 2005. Totransfer or not to transfer. In NIPS 2005 work-shop on transfer learning, volume 898, pages1–4.
Aurko Roy, Ashish Vaswani, Arvind Neelakan-tan, and Niki Parmar. 2018. Theory and experi-ments on vector quantized autoencoders. arXivpreprint arXiv:1805.11063.
Sebastian Ruder. 2017. An overview of multi-task learning in deep neural networks. CoRR,abs/1706.05098.
Sebastian Ruder, Joachim Bingel, Isabelle Au-genstein, and Anders Søgaard. 2017. Learn-ing what to share between loosely related tasks.arXiv preprint arXiv:1705.08142.
Andrei A Rusu, Neil C Rabinowitz, GuillaumeDesjardins, Hubert Soyer, James Kirkpatrick,Koray Kavukcuoglu, Razvan Pascanu, and RaiaHadsell. 2016. Progressive neural networks.arXiv preprint arXiv:1606.04671.
24

Devendra Singh Sachan and Graham Neubig.2018. Parameter sharing methods for multilin-gual self-attentional translation models. Pro-ceedings of the Third Conference on MachineTranslation.
Rico Sennrich, Barry Haddow, and AlexandraBirch. 2015. Improving neural machine trans-lation models with monolingual data. arXivpreprint arXiv:1511.06709.
Rico Sennrich, Barry Haddow, and AlexandraBirch. 2016. Neural machine translation ofrare words with subword units. In Proceedingsof the 54th Annual Meeting of the Associationfor Computational Linguistics (Volume 1: LongPapers), volume 1, pages 1715–1725.
Noam Shazeer, Youlong Cheng, Niki Parmar,et al. 2018. Mesh-tensorflow: Deep learningfor supercomputers. In Advances in Neural In-formation Processing Systems, pages 10414–10423.
Noam Shazeer, Azalia Mirhoseini, KrzysztofMaziarz, Andy Davis, Quoc Le, GeoffreyHinton, and Jeff Dean. 2017. Outrageouslylarge neural networks: The sparsely-gatedmixture-of-experts layer. arXiv preprintarXiv:1701.06538.
Noam Shazeer and Mitchell Stern. 2018.Adafactor: Adaptive learning rates withsublinear memory cost. arXiv preprintarXiv:1804.04235.
Jonathan Shen, Patrick Nguyen, Yonghui Wu,et al. 2019. Lingvo: a modular and scalableframework for sequence-to-sequence modeling.arXiv preprint arXiv:1902.08295.
Daniel L. Silver, Qiang Yang, and Lianghao Li.2013. Lifelong machine learning systems: Be-yond learning algorithms. In AAAI Spring Sym-posium: Lifelong Machine Learning.
Shagun Sodhani, Sarath Chandar, and YoshuaBengio. 2018. On training recurrent neu-ral networks for lifelong learning. CoRR,abs/1811.07017.
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, andTie-Yan Liu. 2019. Mass: Masked sequence to
sequence pre-training for language generation.arXiv preprint arXiv:1905.02450.
Anuroop Sriram, Heewoo Jun, Sanjeev Satheesh,and Adam Coates. 2017. Cold fusion: Trainingseq2seq models together with language models.arXiv preprint arXiv:1708.06426.
Nitish Srivastava, Geoffrey Hinton, AlexKrizhevsky, Ilya Sutskever, and RuslanSalakhutdinov. 2014. Dropout: a simple wayto prevent neural networks from overfitting.The Journal of Machine Learning Research,15(1):1929–1958.
Milos Stanojevic and Khalil Sima’an. 2014.BEER: BEtter evaluation as ranking. In Pro-ceedings of the Ninth Workshop on Statisti-cal Machine Translation, pages 414–419, Bal-timore, Maryland, USA. Association for Com-putational Linguistics.
Emma Strubell, Ananya Ganesh, and Andrew Mc-Callum. 2019. Energy and policy considera-tions for deep learning in nlp.
Ilya Sutskever, Oriol Vinyals, and Quoc V Le.2014. Sequence to sequence learning with neu-ral networks. In Advances in neural informa-tion processing systems, pages 3104–3112.
Xu Tan, Yi Ren, Di He, Tao Qin, Zhou Zhao, andTie-Yan Liu. 2019. Multilingual neural ma-chine translation with knowledge distillation.arXiv preprint arXiv:1902.10461.
Sebastian Thrun and Tom M. Mitchell. 1995.Lifelong robot learning. Robotics and Au-tonomous Systems, 15(1):25 – 46. The Biol-ogy and Technology of Intelligent AutonomousAgents.
Sebastian Thrun and Lorien Pratt, editors. 1998.Learning to Learn. Kluwer Academic Publish-ers, Norwell, MA, USA.
Jörg Tiedemann. 2012. Parallel data, tools andinterfaces in OPUS. In Proceedings of theEighth International Conference on LanguageResources and Evaluation (LREC-2012), pages2214–2218, Istanbul, Turkey. European Lan-guage Resources Association (ELRA).
25

Jörg Tiedemann. 2018. Emerging languagespaces learned from massively multilingual cor-pora. arXiv preprint arXiv:1802.00273.
Jakob Uszkoreit, Jay M Ponte, Ashok C Popat,and Moshe Dubiner. 2010. Large scale par-allel document mining for machine transla-tion. In Proceedings of the 23rd Interna-tional Conference on Computational Linguis-tics, pages 1101–1109. Association for Compu-tational Linguistics.
Ashish Vaswani, Noam Shazeer, Niki Parmar,Jakob Uszkoreit, Llion Jones, Aidan N Gomez,Łukasz Kaiser, and Illia Polosukhin. 2017. At-tention is all you need. In Advances in NeuralInformation Processing Systems, pages 5998–6008.
Ricardo Vilalta and Youssef Drissi. 2002. A per-spective view and survey of meta-learning. Ar-tificial intelligence review, 18(2):77–95.
Oriol Vinyals, Charles Blundell, Timothy Lilli-crap, Koray Kavukcuoglu, and Daan Wierstra.2016. Matching networks for one shot learning.In Proceedings of the 30th International Con-ference on Neural Information Processing Sys-tems, NIPS’16, pages 3637–3645, USA. CurranAssociates Inc.
Wei Wang, Taro Watanabe, Macduff Hughes, Tet-suji Nakagawa, and Ciprian Chelba. 2018a.Denoising neural machine translation trainingwith trusted data and online data selection.arXiv preprint arXiv:1809.00068.
Weiyue Wang, Jan-Thorsten Peter, HendrikRosendahl, and Hermann Ney. 2016. Char-acter: Translation edit rate on character level.In Proceedings of the First Conference on Ma-chine Translation: Volume 2, Shared Task Pa-pers, volume 2, pages 505–510.
Yining Wang, Jiajun Zhang, Feifei Zhai, Jing-fang Xu, and Chengqing Zong. 2018b. Threestrategies to improve one-to-many multilingualtranslation. In Proceedings of the 2018 Con-ference on Empirical Methods in Natural Lan-guage Processing, pages 2955–2960, Brussels,Belgium. Association for Computational Lin-guistics.
Marlies van der Wees, Arianna Bisazza, andChristof Monz. 2017. Dynamic data selectionfor neural machine translation. arXiv preprintarXiv:1708.00712.
Felix Wu, Angela Fan, Alexei Baevski, Yann NDauphin, and Michael Auli. 2019. Pay less at-tention with lightweight and dynamic convolu-tions. arXiv preprint arXiv:1901.10430.
Yonghui Wu, Mike Schuster, Zhifeng Chen,et al. 2016. Google’s neural machine trans-lation system: Bridging the gap between hu-man and machine translation. arXiv preprintarXiv:1609.08144.
Hongyi Zhang, Yann N Dauphin, and TengyuMa. 2019. Fixup initialization: Residual learn-ing without normalization. arXiv preprintarXiv:1901.09321.
Jiajun Zhang and Chengqing Zong. 2016. Ex-ploiting source-side monolingual data in neu-ral machine translation. In Proceedings of the2016 Conference on Empirical Methods in Nat-ural Language Processing, pages 1535–1545.
Yu Zhang and Qiang Yang. 2017. A sur-vey on multi-task learning. arXiv preprintarXiv:1707.08114.
Jie Zhou, Ying Cao, Xuguang Wang, Peng Li,and Wei Xu. 2016. Deep recurrent modelswith fast-forward connections for neural ma-chine translation. Transactions of the Associa-tion for Computational Linguistics, 4:371–383.
MichaÅC Ziemski, Marcin Junczys-Dowmunt,and Bruno Pouliquen. 2016. The united na-tions parallel corpus v1.0. In Proceedings of theTenth International Conference on LanguageResources and Evaluation (LREC 2016), Paris,France. European Language Resources Associ-ation (ELRA).
Barret Zoph, Deniz Yuret, Jonathan May, andKevin Knight. 2016. Transfer learning for low-resource neural machine translation. In Pro-ceedings of the 2016 Conference on Empiri-cal Methods in Natural Language Processing,pages 1568–1575.
26
Language Id Language Id Language IdAfrikaans af Hebrew iw Polish plAlbanian sq Hindi hi Portuguese ptAmharic am Hmong hmn Punjabi paArabic ar Hungarian hu Romanian roArmenian hy Icelandic is Russian ruAzerbaijani az Igbo ig Samoan smBasque eu Indonesian id Scots_Gaelic gdBelarusian be Irish ga Serbian srBengali bn Italian it Sesotho stBosnian bs Japanese ja Shona snBulgarian bg Javanese jw Sindhi sdBurmese my Kannada kn Sinhalese siCatalan ca Kazakh kk Slovak skCebuano ceb Khmer km Slovenian slChinese zh Korean ko Somali soCorsican co Kurdish ku Spanish esCroatian hr Kyrgyz ky Sundanese suCzech cs Lao lo Swahili swDanish da Latvian lv Swedish svDutch nl Lithuanian lt Tajik tgEsperanto eo Luxembourgish lb Tamil taEstonian et Macedonian mk Telugu teFilipino/Tagalog tl Malagasy mg Thai thFinnish fi Malay ms Turkish trFrench fr Malayalam ml Ukrainian ukFrisian fy Maltese mt Urdu urGalician gl Maori mi Uzbek uzGeorgian ka Marathi mr Vietnamese viGerman de Mongolian mn Welsh cyGreek el Nepali ne Xhosa xhGujarati gu Norwegian no Yiddish yiHaitian_Creole ht Nyanja ny Yoruba yoHausa ha Pashto ps Zulu zuHawaiian haw Persian fa
Table 8: List of BCP-47 language codes used throughout this paper (Phillips and Davis, 2009)..
27


![arXiv:1909.02197v2 [cs.CL] 11 Sep 2019 · Investigating Multilingual NMT Representations at Scale Sneha Kudugunta Ankur Bapna Isaac Caswell Naveen Arivazhagan Orhan Firat Google AI](https://img.pdfslide.net/doc/110x75/5e1fb6fda2590d5ca01de224/arxiv190902197v2-cscl-11-sep-2019-investigating-multilingual-nmt-representations.jpg)


























