Embed Size (px)
Citation preview

ĐẠI HỌC SƯ PHẠM HÀ NỘI
NGUYỄN CHÍ TRUNG NGUYỄN THỊ THU THỦY
PHÂN TÍCH THIẾT KẾ THUẬT TOÁN VÀ ĐÁNH GIÁ ĐỘ PHỨC TẠP GIẢI THUẬT
HÀ NỘI 2010

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
2
MỤC LỤC
TÀI LIỆU THAM KHẢO...............................................................................................................4 Chương 1. CÁC KHÁI NIỆM CƠ BẢN ........................................................................................5
1. Thuật toán (giải thuật, thuật giải) ............................................................................................5 1.1. Định nghĩa ........................................................................................................................5 1.2. Các đặc trưng của thuật toán ............................................................................................5
2. Phân tích thuật toán .................................................................................................................5 2.1. Tại sao phải phân tích thuật toán....................................................................................10 2.2. Thời gian thực hiện thuật toán .......................................................................................11
2.3. Khái niệm độ ph1độ phức tạp thuật toán ...........................................................................15 3.1. Qui tắc hằng số ...............................................................................................................15 3.2. Qui tắc cộng ...................................................................................................................16 3.3. Qui tắc lấy max ..............................................................................................................16 3.4. Qui tắc nhân ...................................................................................................................17
3. Các kỹ thuật đánh giá độ phức tạp thuật toán .......................................................................17 3.1. Câu lệnh đơn ..................................................................................................................17 3.2. Câu lệnh hợp thành.........................................................................................................17 3.3. Câu lệnh lặp với số lần lặp biết trước for-do..................................................................18 3.4. Câu lệnh rẽ nhánh if .......................................................................................................19 3.5. Câu lệnh lặp với số lần lặp chưa biết trước while, repeat ..............................................19
4. Một số ví dụ minh họa thiết kế thuật toán và đánh giá độ phức tạp......................................21 Bài toán 1.1. Tính giá trị gần đúng của exp(x) theo khai triển Taylor..................................21 Bài toán 1.2 Thuật toán tìm kiếm tuần tự..............................................................................22 Bài toán 1.3 Thuật toán tìm kiếm nhị phân ...........................................................................22 Bài toán 1.4 Thuật toán sắp xếp chọn lựa .............................................................................23
5. Phân tích chương trình (con) đệ qui ......................................................................................24 5.1. Khái niệm về đệ qui .......................................................................................................24 5.2. Chương trình (con) đệ qui ..............................................................................................25 5.3. Xây dựng phương trình (công thức) đệ qui....................................................................25 5.4. Giải phương trình đệ qui và Định lí Thợ........................................................................26
BÀI TẬP CHƯƠNG 1 ..............................................................................................................30 Chương 2 CHIA ĐỂ TRỊ ..............................................................................................................33
1. Sơ đồ chung của thuật toán chia để trị ..................................................................................33 1.1. Thuật toán β ...................................................................................................................33 1.2. Thuật toán γ ....................................................................................................................34 1.3. Thuật toán γ tổng quát ....................................................................................................35
2. Một số ví dụ minh họa Chia để trị.........................................................................................35 2.1. Thuật toán sắp xếp trộn (Merge Sort) ............................................................................35 2.2. Thuật toán sắp xếp nhanh (QuickSort)...........................................................................37 2.3. Nhân số nguyên lớn........................................................................................................39 2.4. Mảng con trọng số lớn nhất............................................................................................40
BÀI TẬP CHƯƠNG 2 ..............................................................................................................43 Chương 3. QUY HOẠCH ĐỘNG ................................................................................................45
1. Giới thiệu phương pháp qui hoạch động...............................................................................45 2. Phương pháp chung của qui hoạch động...............................................................................45 3. Một số ví dụ minh họa...........................................................................................................46
3.1. Dãy con tăng dần dài nhất ..............................................................................................46

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
3
3.2. Trở lại bài toán mảng con trọng số lớn nhất ..................................................................51 3.3. Xâu con chung dài nhất ..................................................................................................52 3.4. Bài toán cái túi................................................................................................................55 3.5. Nhân ma trận ..................................................................................................................57
BÀI TẬP CHƯƠNG 3 ..............................................................................................................62 Chương 4. THUẬT TOÁN THAM LAM.....................................................................................64
1. Giới thiệu thuật toán tham lam..............................................................................................64 1.1. Đặc điểm của thuật toán tham lam.................................................................................64 1.2. Sơ đồ chung của thuật toán tham lam ............................................................................65 1.3. Chứng minh thuật toán đúng..........................................................................................65
2. Một số ví dụ minh họa...........................................................................................................66 2.1. Bài toán tập các đoạn thẳng không giao nhau................................................................66 2.2. Tìm hiểu các thuật toán tham lam đối với bài toán cái túi .............................................69 2.3. Bài toán người du lịch (TSP - Travelling Salesman Problem).......................................70 2.4. Bài toán mã hóa Huffman ..............................................................................................71
BÀI TẬP CHƯƠNG 4 ..............................................................................................................75 Chương 5. CÁC THUẬT TOÁN ĐỒ THỊ CƠ BẢN....................................................................77
1. Các khái niệm cơ bản ............................................................................................................77 1.1. Đồ thị..............................................................................................................................77 1.2. Các khái niệm.................................................................................................................77
2. Các phương pháp biểu diễn đồ thị.........................................................................................78 1.1. Biểu diễn đồ thị bằng ma trận kề....................................................................................78 1.2. Biểu diễn đồ thị bằng danh sách cạnh ............................................................................78 1.3. Biểu diễn đồ thị bằng danh sách kề................................................................................79 1.4. Biểu diễn đồ thị bằng danh sách liên thuộc....................................................................81
3. Thuật toán tìm kiếm theo chiều rộng ....................................................................................81 3.1. Nguyên tắc tô màu..........................................................................................................81 2.2. Breadth – First Tree........................................................................................................81 3.3. Mô tả thuật toán..............................................................................................................82
4. Thuật toán tìm kiếm theo chiều sâu ......................................................................................84 4.1. Giới thiệu thuật toán.......................................................................................................84 4.2. Thủ tục tìm kiếm theo chiều sâu ....................................................................................85 4.3. Đánh giá độ phức tạp thuật toán DFS và DFS-Visit ......................................................86
5. Bài toán tìm đường đi ngắn nhất ...........................................................................................87 5.1. Một số khái niệm cơ bản ................................................................................................87 5.2. Thuật toán Dijkstra.........................................................................................................88
6. Bài toán về cây khung nhỏ nhất ............................................................................................90 6.1. Các khái niệm cơ bản .....................................................................................................90 6.2. Thuật toán Kruskal .........................................................................................................91 6.3. Thuật toán Prim..............................................................................................................92
BÀI TẬP CHƯƠNG 5 ..............................................................................................................94 CÁC CHUYÊN ĐỀ MÔN HỌC...................................................................................................96

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
4
TÀI LIỆU THAM KHẢO
1. Vũ Đình Hòa, “Giải thuật và đánh giá độ phức tạp giải thuật”, Gói giáo trình môn học theo chuẩn SCORM, Trường ĐHSP HN.
2. Hồ Sỹ Đàm (chủ biên), Đỗ Đức Đông, Lê Minh Hoàng, Nguyễn Thanh Hùng, “Tài liệu giáo khoa Chuyên Tin” Quyển 1 và 2, Nhà xuất bản giáo dục, 2009.
3. Nguyễn Đức Nghĩa, Nguyễn Tô Thành, “Toán rời rạc”, Nhà xuất bản giáo dục, tài bản 2005.
4. Larry Nyhoff, “Lập trình nâng cao bằng Pascal với các cấu trúc dữ liệu”, Dịch giả Lê Minh Trung, Công ty liên doanh tư vấn và dịch vụ khoa học kỹ thuật SCITEC, 1991.
5. Nguyễn Chí Trung, “Giáo trình Thuật toán và kĩ thuật lập trình Pascal”, Nhà xuất bản Hà Nội, 2005.

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
5
Chương 1. CÁC KHÁI NIỆM CƠ BẢN
1. Thuật toán (giải thuật, thuật giải)
1.1. Định nghĩa Một thuật toán là một danh sách từng bước các chỉ dẫn để giải quyết cho một bài toán cụ thể. 1 Ở góc độ lập trình, thuật toán còn được gọi là thuật giải hay giải thuật, là một danh sách các thao tác (câu lệnh) theo đó máy tính thực hiện để sau một số hữu hạn bước, từ input là dữ liệu vào của bài toán, sẽ thu được output là dữ liệu ra cần tìm của bài toán.
1.2. Các tính chất cơ bản của thuật toán 1.2.1. Tính dừng Thuật toán phải kết thúc sau một số hữu hạn lần thực hiện các thao tác.
Ví dụ: thuật toán sau đây vi phạm tính dừng
Bước 1: S 0; i 0;
Bước 2: i i + 1;
Bước 3: S S + i*i;
Bước 4: Quay về bước 2;
Bước 5: Đưa ra S và kết thúc thuật toán
Thuật toán được sửa lại để nó có tính dừng (trở thành thuật toán tính tổng các bình phương của n số tự nhiên đầu tiên) như sau:
Bước 1: Nhập N;
Bước 2: S 0; i 0;
Bước 3: Nếu i ≥ N thì chuyển đến Bước 7;
Bước 4: i i + 1;
Bước 5: S S + i*i;
Bước 6: Quay về bước 3;
Bước 7: Đưa ra S và kết thúc thuật toán
1 Từ “thuật toán” (algorithm) xuất phát từ tên của quốc gia châu Á trung tâm cổ xưa là Khorezm, về sau là các nước cộng hòa xã hội chủ nghĩa Kazakh, Turkmen, and Uzbek. Vào khoảng năm 825 sau công nguyên, nghiên cứu chính về đại số và hệ thống khái niệm số học Ấn Độ được viết bởi Mohammed, là con trai của Musa (Khorez); tiếng Lattinh nghĩa là bởi “Mohamed ibn Musa al-Khowarizmi.” Vào năm 857, đoạn văn bản tiếng này được dịch sang tiếng Anh là "Algoritmi”. Từ đây, xuất phát từ cụm từ al-Khowarizmi, Hisab al-jabrw'sal-muqabalah (Mathematics-al-jabrw'sal muqabalah) mà chúng ta có tù algebra (đại số)

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
6
1.2.2. Tính xác định
Thuật toán phải đảm bảo sau khi thực hiện một thao tác thì hoặc thuật toán kết thúc hoặc có đúng một thao tác hoàn toàn xác định để thực hiện tiếp theo.
Ví dụ: thuật toán sau đây vi phạm tính xác định:
Bước 1: Nhập a, b;
Bước 2: Tính diện tích hình chữ nhật kích thước a, b hoặc tính thể tính hình nón đường cao a và bán kính hình tròn đáy là b. Tức là:
S a * b hoặc S (1/3)π.a.b2
Bước 3: Đưa ra S và kết thúc thuật toán
Sửa lại Bước 1: Nhập a, b, nhập chọn lựa choice; //Qui ước choice = 1 là tính diện tích hình chữ nhật, ngược lại, tính thể tích hình nón
Bước 2: Nếu choice = 1 thì S a * b và thực hiện bước 4; Bước 3: S (1/3)π.a.b2
Bước 4: Đưa ra S và kết thúc thuật toán; Ví dụ khác: thuật toán ”Tìm số hạng Fibonacci thứ N” dưới đây vi phạm tính xác định
Bước 1: Nhập số dương N
Bước 2: Nếu N ≤ 2 thì c 1, kết thúc thuật toán
Bước 3: a 1; b 1; k 2;
Bước 4: Nếu k = N thì đưa ra c và kết thúc thuật toán,
Bước 5: k k + 1; Thực hiện bước 6 hoặc bước 7 sau đây:
Bước 6: c a + b; a b; b c; Quay về bước 4;
Bước 7: c a + b;
Bước 8: a b; b c; Quay về bước 4;
Sửa lại: Bước 1: Nhập số dương N
Bước 2: Nếu N ≤ 2 thì c 1, đưa ra c và kết thúc thuật toán
Bước 3: a 1; b 1; k 2;
Bước 4: Nếu k = N thì đưa ra c và kết thúc thuật toán,
Bước 5: k k + 1;
Bước 6: c a + b; a b; b c; Quay về bước 4;
1.2.3. Tính đúng đắn Một thuật toán phải đảm bảo cho ra Output luôn đúng đối với mọi dữ liệu vào của Input.

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
7
Ta định nghĩa một bộ dữ liệu vào đầy đủ là nó bao phủ hết (cover all the cases) tất cả các trường hợp cần xem xét.
Ví dụ, để giải phương trình bậc 2: ax2 + bx + c = 0 (với a ≠0). Bộ Input đầy đủ là các giá trị tùy ý của a, b, c nhưng phải đủ trường hợp sau (với d = b2 - 4ac)
d = 0, ví dụ (a, b, c) = (1, -2, 1)
d > 0, ví dụ (a, b, c) = (1, 5, 4)
d < 0, ví dụ (a, b, c) = (9, 2, 5)
Như vậy, thuật toán đảm bảo tính đúng đắn nếu nó luôn cho kết quả (output) đúng đắn đối với một bộ dữ liệu vào đầy đủ.
Ví dụ: Xét tính đúng đắn của thuật toán tính m = max (a, b,c) dưới đây:
Bước 1: Nhập a, b, c;
Bước 2: Nếu a < b thì m b
Không thì
Nếu a < c thì m c;
Bước 3: Đưa ra m và kết thúc thuật toán;
Rõ ràng thuật toán trên sai tại một số bộ dữ liệu, ví dụ nếu bộ dữ liệu vào là (a, b, c) = (1, 2, 3) thì thuật toán cho kết quả m = 2, không đúng yêu cầu của đề bài; nếu bộ dữ liệu vào là (a, b, c) = (2, 1, 3) thì không có chỉ thị nào trong thuật toán tác động vào m, do đó m không xác định và không tính được m như yêu cầu đề bài.
Có thể sửa lại thuật toán như sau:
Bước 1: Nhập a, b, c;
Bước 2: m a;
Bước 3: Nếu m < b thì m b;
Bước 4: Nếu m < c thi m c;
Bước 5: Đưa ra m và kết thúc thuật toán;
1.2.4. Tính phổ dụng Thuật toán phải đảm bảo giải được một lớp bài toán.
Ví dụ thay vì xây dựng thuật toán và viết chương trình giải các phương trình:
1) 5x2 + 12x - 1 = 0
2) 2x2 -6x +2 = 0
3) 7x + 100 = 0
4) -50x2 +112x - 11 = 0

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
8
Người ta tiến hành xây dựng thuật toán và viết chương trình giải phương trình:
ax2 + bx + c = 0 với mọi số thực a, b, c cho trước.
1.3. Các tính quan trọng của thuật toán
Các tính chất này liên quan đến việc nhấn mạnh ưu điểm của "thuật toán tin học" là có thể giao cho máy tính thực hiện. Một "thuật toán toán học" thuần túy có thể “rất đẹp” nhưng chưa chắc đã cài đặt dễ dàng trên máy tính, và nếu cài đặt được thì thuật toán đó chưa chắc ổn định và khả thi. Nói ở góc độ tương tự, hai tính chất sau đây thể hiện sự khác biệt giữa toán lí thuyết và toán tính.
- Toán lí thuyết quan tâm đến các vấn đề định tính của bài toán: tồn tại, duy nhất, tính chất nghiệm của các bài toán.
- Toán tính quan tâm đến xây dựng phương pháp, thuật toán để để tìm nghiệm bài toán trên máy tính.
Thuật toán được xây dựng phải thỏa mãn yêu cầu về tính khả thi và tính ổn định.
1.3.1. Tính khả thi
Một thuật toán là khả thi nếu nó thực hiện được trên máy tính trong một thời gian chấp nhận được. Thòi gian ở đây không tính đến kiểu CPU và chưa tính đến dung lượng bộ nhớ cần cấp phát.
Ví dụ (tính khả thi). Cho hệ phương trình đại số tuyến tính
bAx = , (1)
trong đó A là ma trận vuông cấp n với định thức khác 0.
Về lý thuyết, có thể giải hệ trên bằng thuật toán mà ý tưởng của nó dựa vào công thức Cramer:
∆∆
= iix , (i =1,..., n), (2)
trong đó , còn là định thức của ma trận A sau khi thay cột i bởi cột tự do b. Nhưng
việc tính toán ra nghiệm bằng số cụ thể lại là một việc không đơn giản. Theo công thức (2) cần phải tính n +1 định thức cấp n. Mỗi định thức là tổng của n! số hạng, mỗi số hạng là tích của n thừa số. Do vậy, để tính mỗi số hạng cần thực hiện n – 1 phép nhân. Như vậy, tất cả số phép tính nhân cần thực hiện trong (2) là Q = n!(n+1)(n-1).
Adet=∆ i∆
Giả sử n = 20. Khi đó . Nếu tốc độ của máy tính là 100 triệu phép tính/giây thì
thời gian để thực hiện khối lượng tính toán trên là giờ = năm. Một thời gian lớn vô cùng! Và như vậy, thuật toán dựa vào công thức Cramer là hoàn toàn không khả thi cho dù máy tính có tăng tốc độ lên gấp hàng nghìn, hàng vạn lần.
2010*7073.9≈Q910*2.6965 510*0782.3
Ở trên ta mới chỉ xét việc giải một hệ cỡ 20, mà thực tế khoa học và công nghệ đòi hỏi phải giải các hệ phương trình đại số tuyến tính cỡ hàng vạn, hàng triệu hoặc hơn thế nữa. Vì thế, cần phải

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
9
nghiên cứu đề xuất các phương pháp hiệu quả để có thể giải được các hệ thống phương trình cỡ lớn.
1.3.2. Tính ổn định
Một thuật toán gọi là ổn định nếu sai số tính toán (do máy tính làm tròn số) không bị khuếch đại trong quá trình tính.
Ví dụ (tính ổn định). Giả sử cần tính tích phân
)1(11
0
≥= −∫ ndxexI xnn .
Tích phân từng phần: đặt u = xn thì du = nxn-1dx; đặt dv = ex-1dx thì v = ex-1 ta được
.1 11
1
0
110
1−
−−− −=−= ∫ nxnxn
n nIdxexnexI
Ngoài ra ta có
.3679.01)1( 1
011
1
01 ≈=−== −−∫ e
xedxexI xx
Như vậy, để tính ta thu được công thức truy hồi tính được In về mặt lý thuyết: nI
.3679.0,2,1
1
1
=≥−= −
InnII nn
Về mặt thực tế tính trên máy tính không cho kết quả mong muốn khi n lớn. Cụ thể là tính trên máy tính với n = 25 ta được bảng kết quả sau (liệt kê theo từng hàng)
0.3679 0.2642 0.2073 0.1709 0.1455
0.1268 0.1124 0.1009 0.0916 0.0839
0.0774 0.0718 0.0669 0.0627 0.0590
0.0555 0.0572 -0.0295 1.5596 -30.1924
635.0403 -13969.8864 321308.3881 -7711400.3133 192785008.8325
Kết quả giảm dần từ 0.3679 (khi n = 1) đến 0.0555 (khi n=16).
Kết quả sau đó kết quả thay đổi thất thường và giá trị tuyệt đối tăng rất nhanh.
Điều này hoàn toàn không phù hợp với lý thuyết vì theo lý thuyết thì khi 0→nI ∞→n do đó
.1
101
0 +=≤≤ ∫ n
dxxI nn

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
10
Hiện tượng kết quả tính toán nêu trên là sự không ổn định của thuật toán: sai số ban đầu khi
tính
nI
3679.011 ≈=
eI đã bị khuyếch đại trong quá trình tính. Cụ thể như sau: Thay vì tính chính
xác e
I 11 = ta tính xấp xỉ của nó là δ+= 11
~ II , trong đó δ là sai số. Giả sử các tính toán tiếp theo
không mắc phải sai số. Với n = 2 ta được
.22)21()(21~21~21112 δδδ −=−−=+−=−= IIIII
Thu được 2~I với sai số δ2|~| 22 =− II . Tương tự, ở bước thứ n thay cho giá trị đúng ta thu
được giá trị gần đúng với sai số . Do đó, dù nI
nI~ δ!|~| nII nn =− δ có bé thì khi n đủ lớn, sai số vẫn
đủ lớn và ta không thể nhận được giá trị chấp nhận được là gần đúng cho . nI
2. Phân tích thuật toán
2.1. Tại sao phải phân tích thuật toán Xét một thuật toán nhân 2 số phức
z1 = a + bi; z2 = c + di
z = z1 * z2 = (ac – bd) + (ad + bc)i
Khi tiến hành thuật toán: máy tính thực hiện 4 phép nhân và 3 phép cộng (ở đây là phép cộng đại số, nghĩa là phép trừ được xem là cộng với số âm).
Giả sử phép nhân thực hiện mất 1 giây, phép cộng thực hiện mất 0.01 giây, phép gán thực hiện mất 0.005 giây. Khi đó phép nhân hai số phức trên thực hiện mất 4*1 + 3*0.01 + 0.005 = 4.035 giây. Để giảm thời gian tính toán, ta có thể giảm phép nhân nhờ các tính toán sau đây:
ac - bd và ad + bc = (a + b)*(c + d) - ac - bd
Do đó nếu đặt p := ac; q := bd; Thì z := (p - q) + ((a +b)*(c+d) - p - q)i
Khi đó việc tính z gồm 3 phép nhân, 6 phép cộng và 3 phép gán; mất khoảng thời gian là 3*1 + 6*0.01 + 3*0.005 = 3.075 giây, giảm được 4.04 - 3.09 = 0.96 giây.
Ví dụ trên cho thấy một bài toán có thể tồn tại nhiều thuật toán để giải, do đó cần lựa chọn thuật toán tốt nhất. Điều này cũng dẫn đến việc phân tích thuật toán. Ngoài ra, một bài toán được cài đặt bằng một thuật toán đúng, nhưng chưa chắc cho kết quả mong muốn. Vì các lí do sau:
• Thời gian thực hiện quá lâu
• Tốn nhiều bộ nhớ
Điều này cũng dẫn đến cần phân tích thuật toán. Khi phân tích thuật toán, ta thường xem xét về thời gian và bộ nhớ chi phí cho thuật toán, trong đó chủ yếu phân tích về mặt thời gian.

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
11
2.2. Thời gian thực hiện thuật toán Thời gian thực hiện thuật toán phụ thuộc vào các yếu tố sau:
1. Kích thước dữ liệu đầu vào (ở đây ta sẽ kí hiệu là n).
2. Tốc độ máy tính
3. Ngôn ngữ lập trình
4. Kĩ thuật lập trình
Các yếu tố (2), (3), (4) không đồng nhất đối với từng loại máy tính và ngôn ngữ lập trình. Vì thế thời gian thực hiện thuật toán được đánh giá chủ yếu dựa vào yếu tố (1) là kích thước dữ liệu đầu vào.
Định nghĩa 1.1. Ta gọi T(n) là hàm thời gian phụ thuộc vào kích thước dữ liệu đầu vào n.
Định nghĩa 1.2. Đơn vị tính của hàm T(n) không phải là đơn vị thời gian thực mà là số lần thực hiện các phép tính cơ bản. Các phép tính cơ bản là các phép toán có thời gian thực hiện bị chặn bởi một hàm số.
Các phép tính cơ bản bao gồm:
1. Lời gọi thủ tục như read, write, và lời gọi hàm như sqr, sqrt,..
2. Câu lệnh gán
3. Phép tính số học (+, -, *, /)
4. Phép toán logic và phép toán so sánh
Chú ý: Ở đây ta không xem xét thời gian thực hiện đối với các câu lệnh điều khiển (rẽ nhánh if-then, case-of, lặp for-do, while-do, và repeat-until) vì chúng không được xem là các phép tính cơ bản. Việc bỏ qua các câu lệnh điều khiển mặc dù không cho kết quả chính xác về thời gian tính (khác nhau một cơ số lần giá trị của n, với n là kích thước dữ liệu vào), nhưng thường không ảnh hưởng đến độ phức tạp cần đánh giá. Vài trường hợp, câu lệnh rẽ nhánh khi kiểm tra điều kiện được quan tâm và thời gian của việc kiểm tra điều kiện này được tính là một hằng số nào đó. Một cách tổng quát, nếu mục đích là tính thời gian thực hiện thuật toán thì nên xem xét đầy đủ cả các câu lệnh điều khiển, nếu mục đích là đánh giá độ phức tạp thuật toán thì có thể bỏ qua các câu lệnh điều khiển.
Ví dụ 1.1 Tính trung bình cộng của n số nhập từ bàn phím
Số lần thực hiện
1. write(‘n = ‘); 1
2. readln(n); 1
3. T := 0; 1
for i := 1 to n do begin

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
12
4. write(‘x = ‘); n
5. readln(x); n
6. T := T + x; n
end;
7. T := T/n; 1
Phân tích và đánh giá: Các lệnh 1, 2, 3 và 7 được thực hiện một lần. Thân vòng lặp gồm các lệnh 4, 5, 6 được thực hiện n lần. Vậy T(n) = 3n + 4.
Định nghĩa 1.3. Có ba loại thời gian tính:
• Thời gian tính tốt nhất: Là thời gian thực hiện nhanh nhất của thuật toán với một bộ dữ liệu vào nào đó.
• Thời gian tính tồi nhất: Là thời gian thực hiện chậm nhất của thuật toán với một bộ dữ liệu vào nào đó.
• Thời gian tính trung bình: Là trung bình cộng của các thời gian thực hiện thuật toán đối với tất cả các trường hợp thực hiện thuật toán (ứng với một bộ dữ liệu vào đầy đủ).
Ví dụ 1.2 Tìm kiếm tuần tự
Cho dãy số (a) gồm n phần tử a1, a2, ..., an. Hãy tìm vị trí của phần tử có giá trị bằng x cho trước trong dãy.
1. i := 1; 1 lần
2. found := false; 1 lần
while (i <= n) and not found do
if x = ai then
3. found := true;
else
4. i := i + 1;
if found then
5. writeln(‘vi tri ‘,i)
else
6. writeln(‘khong tim thay’);
1 lần
Phân tích và đánh giá: Mỗi câu lệnh 1, 2 luôn thực hiện 1 lần. Một trong hai lệnh 5 hoặc 6 thực hiện một lần. Vậy thời gian thực hiện thuật toán luôn có dạng T(n) = 3 + k, trong đó k là số lần thực hiện các câu lệnh 3 và 4. Khi đó ta có thể tạm thời không cần xem xét các câu lệnh 1, 2, 5, 6 nữa mà chỉ cần xem xét các câu lệnh 3 và 4.

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
13
Thời gian tính tốt nhất khi x = a1: Câu lệnh 3 thực hiện một lần, câu lệnh 4 thực hiện không lần, do đó k = 1 và :
T(n) = 3 + 1
Thời gian tính tồi nhất xảy ra khi không có x trong dãy (không tìm thấy). Câu lệnh 3 thực hiện không lần, câu lệnh 4 thực hiện n lần. Do đó k = n và
T(n) = 3 + n
Thời gian tính trung bình được tính như sau:
Nếu x = a1: T(n) = 3 + 1 (lệnh 3 một lần; lệnh 4 không lần)
Nếu x = a2: T(n) = 3 + 2 (lệnh 3 một lần, lệnh 4 một lần)
Nếu x = a3: T(n) = 3 + 3 (lệnh 3 một lần, lệnh 4 hai lần)
….
Nếu x = an: T(n) = 3 + n (lệnh 3 một lần, lệnh 4 thực hiện n-1 lần)
Nếu không thấy: T(n) = 3 + n (lệnh 3 không lần, lệnh 4 thực hiện n lần)
Suy ra thời gian tính trung bình là :
)1(2
691
32
)1(3)(
2
+++
=+
+++
+=
nnn
n
nnnnnT
Phân tích thuật toán theo nghĩa hẹp ở đây là xác định T(n) trong trường hợp xấu nhất. Phân tích thuật toán theo nghĩa rộng là việc lựa chọn thuật toán tốt: tốn ít bộ nhớ, và có thời gian tính trong trường hợp xấu nhất là chấp nhận được (tức là thỏa mãn tính khả thi).
Một số vấn đề đặt ra: Khi phân tích thuật toán, người ta ít khi quan tâm đến tính chính xác của hàm thời gian tính mà thường quan tâm đến độ tăng của hàm này.
Ví dụ 1.3 Đánh giá hàm thời gian khi n tăng
Xét hàm thời gian T(n) = 60n2 + 9n + 19. Khi n tăng rất lớn thì T(n) ≈ 60n2
Giả sử T(n) được tính bằng giây, khi đó hàm T(n) trên đây tính bằng phút có dạng:
T = n2 + 0,15n + 0,316.
Khi n tăng rất lớn thì T(n) ≈ n2.
Khi đó ta nói rằng T(n) có thời gian tính tương đương với hàm n2 , hay T(n) là VCL (vô cùng lớn) cùng bậc với n2, và ta viết T(n) = O(n2). Kí hiệu O đọc là kí hiệu big-O. Ở dưới đây ta có cách gọi khác, đó là T(n) có bậc không quá n2.
Vậy trong quá trình phân tích thuật toán, ta cần tính T(n) theo kí hiệu Big-O.

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
14
2.3. Khái niệm độ phức tạp của thuật toán, kí hiệu big-O Định nghĩa 1.4. Cho f và g là hai hàm đối số nguyên dương.
• Ta viết f(n) = O(g(n)) và nói f(n) có bậc không quá g(n) nếu tồn tại hằng số dương C1 và số nguyên N1 sao cho
f(n) ≤ C1.g(n) với ∀n ≥ N1
Theo cách viết giới hạn, điều này nghĩa là: ∞→
=
n
Cngnf
1)()(lim
• Ta viết f(n) = Ω(g(n)) và nói f(n) có bậc ít nhất là g(n) nếu tồn tại hằng số dương C2 và số nguyên dương N2 sao cho
f(n) ≥ C2.g(n) với ∀ n ≥ N2
Theo cách viết giới hạn, điều này nghĩa là: ∞=∞→ )(
)(limngnf
n
• Ta viết f(n) = θ(g(n)) và nói f(n) có bậc là g(n) nếu f(n) = O(g(n)) và f(n) = Ω(g(n))
Theo cách viết giới hạn, điều này nghĩa là: 0)()(lim =
∞→ ngnf
n
Theo định nghĩa trên, đánh giá thời gian tồi nhất của thuật toán chính là việc tính O(.), đánh giá thời gian tốt nhất của thuật toán là việc tính Ω(.).
Định nghĩa 1.5. Khi hàm thời gian tính T(n) của thuật toán được biểu diễn qua kí hiệu big-O thì T(n) được gọi là độ phức tạp thuật toán (Complexity of Algorithms).
Ví dụ 1.4 Biểu diễn hàm thời gian theo các kí pháp big-O, omega, theta
Xét hàm T(n) = 60n2 + 9n + 1,
1) Tính O(.)
Ta có 60n2 + 9n + 1 ≤ 60n2 + 9n2 + n2 = 70n2 với ∀ n ≥ 1
Chọn C1 = 70, g(n) = n2, N1 = 1 T(n) ≤ C1.g(n) hay T(n) = O(n2)
2) Tính Ω(.)
Ta có 60n2 ≤ 60n2 + 9n + 1 với ∀ n ≥ 1
Chọn C2 = 60 , N2 = 1 T(n) = Ω(n2)
3) Tính θ(.)
Vì O(n2) = T(n) = Ω(n2) T(n) = θ(n2).
Các hàm đánh giá thông dụng:

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
15
STT Hàm Tên gọi: độ phức tạp Đánh giá
1 O(C), O(1) Hằng số
2 O(log2n) logarit
3 O(n) tuyến tính
4 O(nlogn) nlog2n
5 O(n2) bậc 2
6 O(n3) bậc 3
7 O(nk) đa thức
Chấp nhận được
8 O(an) hàm mũ
9 O(n!) giai thừa
Không chấp nhận được
Ví dụ 1.5 Dùng kí hiệu θ đánh giá tốc độ tăng của hàm
a) 222
)1()(2 nnnnnf +=
+=
Chọn C1 = 1; N1 = 1; C2 = 1/2; N2 = 1, g(n) = n2, ta có:
f(n) ≤ n2/2 +n2/2 = n2 với ∀ n ≥ N1 f(n) ≤ C1.g(n) f(n) = O(n2)
f(n) = n2/2 + n/2 ≥ n2/2 với ∀ n ≥ N2 f(n) ≥ C2.g(n) f(n) = Ω(n2)
Do đó f(n) = θ(n2).
b) 1
2111)(
2
++−=
++
=n
nnnnf
Ta có 11
21 ≥∀≤+
+− nnn
n , đó đặt C1=1; N1=1 thì f(n) = O(n)
Và vì 11
2121
≥∀+
+−≤ nn
nn nên đặt C2 = 1/2; N2=2 thì f(n) = Ω(n)
Suy ra f(n) = θ(n).
3. Các qui tắc xác định độ phức tạp thuật toán
3.1. Qui tắc hằng số Nếu một thuật toán T có thời gian thực hiện T(n) = O(C.f(n)) với C là hằng số dương thì có thể coi thuật toán T có độ phức tạp tính toán là O(f(n)).

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
16
Chứng minh: Vì T(n) = O(C.f(n)) nên tồn tại số dương C1 và số nguyên N1 sao cho T(n) ≤ C.C1.f(n) với ∀ n ≥ N1. Khi đó chọn C2 = C.C1 thì T(n) ≤ C2.f(n) với ∀ n ≥ N1, hay T(n) = O(f(n)).
3.2. Qui tắc cộng Giả sử một thuật toán T gồm hai phần liên tiếp T1 và T2. Và, giả sử phần T1 có thời gian thực hiện là T1(n) = O(f(n)); phần T2 có thời gian thực hiện là T2(n) = O(g(n)). Khi đó thời gian thực hiện thuật toán sẽ là T(n) = T1(n) + T2(n) = O(f(n) + g(n))
Chứng minh: Vì T1 = O(f(n)) nên tồn tại hằng số dương C1 và số nguyên N1 sao cho T1(n) ≤ C1.f(n) với ∀ n ≥ N1. Và vì T2 = O(g(n)) nên tồn tại hằng số dương C2 và số nguyên N2 sao cho T2(n) ≤ C2.g(n) với ∀ n ≥ N2. Chọn C0 = max(C1, C2) và N0 = max(N1, N2) thì với ∀ n ≥ N0 ta có: T(n) = T1(n) + T2(n) ≤ C1.f(n) + C2.g(n) ≤ C0.f(n) + C0.g(n) = C0(f(n)+g(n)).
Do đó T(n) = O(f(n) + g(n)).
3.3. Qui tắc lấy max Nếu thuật toán T có thời gian thực hiện T(n) = O(f(n) + g(n)) thì có thể coi thời gian thực hiện thuật toán T có độ phức tạp là T(n) = O(max(f(n), g(n)).
Chứng minh: Vì T(n) = O(f(n) + g(n)) nên tồn tại số dương C1 và số nguyên N1 sao cho với ∀ n ≥ N1 thì T(n) ≤ C1.(f(n) + g(n)) = C1.f(n) + C1.g(n) ≤ 2C1.max(f(n), g(n)). Do đó T(n) = O(max(f(n), g(n))).
Chú ý: Qui tắc max rất hay được sử dụng. Với qui tắc này:
• Nếu T(n) là một đa thức thì có thể khẳng định các toán hạng bậc thấp là không quan trọng, có thể bỏ qua khi đánh giá độ phức tạp thuật toán.
• Trong một đoạn chương trình, câu lệnh được thực hiện nhiều nhất (được gọi là câu lệnh đặc trưng) sẽ được sử dụng để đánh giá độ phức tạp thuật toán của đoạn chương trình đó, mà không cần quan tâm đến các câu lệnh khác (điều này không đúng nếu tính thời gian thực hiện thuật toán cho toàn bộ đoạn chương trình). Câu lệnh đặc trưng thường là câu lệnh đơn nằm trong một vòng lặp ở mức sâu nhất. Việc đánh giá độ phức tạp thuật toán sử dụng câu lệnh đặc trưng sẽ được dùng đến từ phần áp dụng của chương 3, hiện tại không dùng đến để rèn luyện việc phân tích thuật toán.
Ví dụ 1.6. Minh họa qui tắc max
a) T(n) = 3n + 4 (Trong Ví dụ 1.1). Ta có T(n) = 3n + 4n0 T(n) = O(n).
Vậy thuật toán tính giá trị trung bình có độ phức tạp tuyến tính.
b) )1(2
69)(2
+++
=n
nnnT (Trong Ví dụ 1.2). Ta có

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
17
696969)1(2
69)( 00
22
=≥∀+≤++=++
≤+
++= Nnnn
nn
nnn
nnnnT
)()( nOnT =→
Vậy thuật toán tìm kiếm tuần tự có độ phức tạp tuyến tính.
c) T(n) = 60n2 + 9n + 9 (Trong Ví dụ 1.3). Ta có T(n) = O(n2)
Vì chọn N0 = 9 và C0 = 70 thì với ∀ n ≥ N0 ta có 60n2 + 9n + 9 ≤ 60n2 + 9n2 + n2 = 70n2. Do đó T(n) ≤ C0.n2 với ∀n ≥ N0 hay T(n) = O(n2).
3.4. Qui tắc nhân Nếu đoạn thuật toán T có thời gian thực hiện T(n) = O(f(n)). Khi đó nếu thực hiện k(n) lần đoạn thuật toán T với k(n) = O(g(n)) thì độ phức tạp tính toán của quá trình lặp này là: T(n) = O(f(n).g(n)).
Chứng minh: Thời gian thực hiện k(n) đoạn thuật toán T sẽ là k(n).T(n). Theo định nghĩa big-O ta có:
- Tồn tại hằng số dương Ck và số nguyên Nk sao cho k(n) ≤ Ck.g(n) với ∀ n ≥ Nk
- Tồn tại hằng số dương Cr và số nguyên Nr sao cho T(n) ≤ Cr.f(n) với ∀ n ≥ Nr.
Vậy nếu đặt N0 = max(Nk, Nr) và C0 = Ck.Cr thì với ∀ n ≥ N0 ta có: k(n).T(n) ≤ C0.f(n).g(n) hay độ phức tạp tính toán của quá trình lặp là T(n) = O(f(n).g(n)).
4. Các kỹ thuật đánh giá độ phức tạp thuật toán
4.1. Câu lệnh đơn Câu lệnh đơn là câu lệnh thực hiện một thao tác, ví dụ câu lệnh gán đơn giản (không chứa lời gọi hàm trong biểu thức), câu lệnh vào/ra đơn giản, câu lệnh chuyển điều khiển đơn giản như break, goto, continue, return.
Thời gian thực hiện một câu lệnh đơn không phụ thuộc vào kích thước dữ liệu nên sẽ là O(1). Nói cách khác, các câu lệnh đơn có thời gian tính bị chặn bởi hàm số O(1) (hay O(c)). Ví dụ mỗi câu lệnh sau đều có thời gian thực hiện là O(1): readln; writeln; readln(x); writeln(k);
4.2. Câu lệnh hợp thành Thời gian thực hiện một câu lệnh hợp thành sẽ được tính theo qui tắc cộng và qui tắc max.
Ví dụ 1.7 Minh họa qui tắc cộng
if n > 1 then begin
1. s := sqrt(n) 1 lần
2. readln(x); 1 lần

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
18
if s > x then
3. s := s - x;
else
4 s := x - s;
1 lần
end; Hiển nhiên T(n) = 1 + 1 + 1 = 3 (đúng như qui tắc cộng) T(n) = O(1)
Ví dụ 1.8 Minh họa qui tắc max đối với câu lệnh hợp thành
if n > 1 then begin
for i :=1 to n do
1. write(i*i:6);
n lần
2. writeln; 1 lần
end; Dễ thấy T(n) = 1 + n T(n) = O(n) Đúng như qui tắc max: T(n) = O(max(1, n)) = O(n)
3.3. Câu lệnh lặp với số lần lặp biết trước for-do
for i := 1 to n do
P(i);
Trong đó P(i) là một câu lệnh hoặc một khối lệnh (câu lệnh hợp thành) trong thân vòng lặp. Có hai trường hợp:
Trường hợp 1: Thời gian thực hiện P(i) là một hằng số và không phụ thuộc vào i, nghĩa là T(P(i)) = t , với t là hằng số. Khi đó thời gian thực hiện câu lệnh lặp là n lần thực hiện P(i), tức là:
tnnT .)( =
Ví dụ 1.9. Đánh giá thời gian tính của vòng lặp khi P(i) là hằng số
for i := 1 to n do begin
1. write(‘x = ‘);
2. readln(x);
3. S := S + x;
end; ⎪⎪⎭
⎪⎪⎬
⎫
P(i)
T(P(i)) = 3. Do đó T(n) = n.3 T(n) = O(n)

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
19
Trường hợp 2: Thời gian thực hiện của P(i) phụ thuộc vào i, nghĩa là T(P(i)) = t(i). Khi đó thời gian thực hiện câu lệnh lặp “for i” với i lần lượt nhận giá trị từ 1 đến n là T(n) = t(1) + t(2) + … + t(n), hay ta có:
∑=
=n
iitnT
1)()(
Ví dụ 1.10. Đánh giá thời gian tính của vòng lặp khi P(i) phụ thuộc i
for i := 1 to n do begin
for j:=1 to i do
1. write(j:5);
2. writeln;
end; ⎪⎪⎭
⎪⎪⎬
⎫
P(i)
)()(21
21
2)1()1()(
1))((
21
2
1
nOnT
nnnnnininT
iiPTn
i
n
i
=→
+=+
+=+=+=→
+=
∑ ∑= =
3.4. Câu lệnh rẽ nhánh if Giả sử thời gian thực hiện hai câu lệnh thành phần của câu lệnh if dạng đủ là f(n) và g(n). Khi đó thời gian thực hiện câu lệnh if sẽ được tính theo qui tắc max, tức là sẽ bằng
O(max(f(n), g(n)).
Thời gian kiểm tra điều kiện thường là hằng số, tức là O(1).
Ví dụ 1.11. Minh họa thời gian tính của câu lệnh rẽ nhánh
if n < 1 then
1. writeln(‘hay nhap so nguyen duong’) 1 lần
else
for i :=1 to n do
2. write(i : 5); ⎭⎬⎫
n lần
T(n) = max (1, n) = n T(n) = O(n)
3.5. Câu lệnh lặp với số lần lặp chưa biết trước while, repeat Để đánh giá thời gian thực hiện câu lệnh lặp này ta dựa vào kinh nghiệm:
Ví dụ 1.12 Thời gian tính đối với vòng lặp while đơn giản
1. i := n; 1 lần

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
20
2. S := 0; 1 lần
while i > 0 do begin
3. write(‘x = ‘);
4. readln(x);
5. S := S + x;
6. i : = i - 1; end;
P(i) lần
T((P(i)) = 4 T(n) = 2 + 4.T(P(i)) = 2 + 4n T(n) = O(n)
Ví dụ 1.13 Độ phức tạp của vòng while mà biến điều khiển thay đổi không liên tục
1. i := n; 1 lần
2. S := 0; 1 lần
while i > 0 do begin
3. write(‘x = ‘);
4. readln(x);
5. S := S + x;
6. i : = i div 2;
P(i)
gồm 4 câu lệnh cơ bản
end;
Phân tích, đánh giá: P(i) gồm 4 câu lệnh cơ bản 3, 4, 5, và 6
- i = n/20 P(i) thực hiện lần thứ nhất
- i = n/21 P(i) thựchiện lần thứ hai
- i = n/22 P(i) thựchiện lần thứ ba
- …
- i = n/2k-1 P(i) thực hiện lần thứ k
Nếu đây là lần thực hiện cuối cùng thì n/2k-1 = 1 n = 2k-1 k = log2n + 1
Khi đó T(n) = 2 + 4k = 2 +4(log2n + 1) = 4log2n + 6
với ∀ n ≥ 2 thì T(n) ≤ 4log2n + 6log2n = 10log2n
Chọn f(n) = log2n, N0 = 2; C0 = 10 ta có T(n) ≤ C0f(n) với ∀ n ≥ N0.
Do đó: T(n) = O(log2n).
Ví dụ 1.14 Độ phức tạp của vòng lặp while phức tạp hơn
1. i := n; 1 lần

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
21
2. S := 0; l lần
while i > 0 do begin
3. for j := 1 to i do
4. write(j:5);
5. writeln;
6. i := i div 2;
)(iP⎪⎭
⎪⎬
⎫
end;
Phân tích, đánh giá: P(i) gồm hai câu lệnh cơ bản 5 và 6, và một câu lệnh cơ bản 4 thực hiện i lần.
- Lần 1: i = n/20 thực hiện n + 2 câu lệnh cơ bản
- Lần 2: i = n/21 thực hiện n/2 + 2 câu lệnh cơ bản
- Lần 3 i = n/22 thực hiện n/22 + 2 câu lệnh cơ bản
- …
- Lần k: i = n/2k-1 thực hiện n/2k + 2 câu lệnh cơ bản
Nếu đây là lần thực hiện cuối cùng thì n/2k-1 = 1 n = n/2k-1 k = log2n + 1. Khi đó:
12
2
12
22log24
211211
2log22
)2
1...21
211(22)(
−
−
−++=
−
−+++=
++++++=
k
k
k
nnn
nn
nknT
Do đó T(n) ≤ 2n + 2log2n + 4 ≤ 2n + 2n + 4n = 8n (vì khi n tăng thì log2n ≤ log22n =n).
Vậy T(n) = O(n).
5. Một số ví dụ minh họa thiết kế thuật toán và đánh giá độ phức tạp
Bài toán 1.1. Tính giá trị gần đúng của exp(x) theo khai triển Taylor
!...
!2!11
2
nxxxe
nx ++++=
a) Thiết kế giải thuật
b) Đánh giá độ phức tạp
Giải

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
22
a)
1, 2 s := 1; p := 1;
for i :=1 to n do begin
3. p := p * x/i;
4. s := s + p; ⎭⎬⎫
P(i)
end;
b) T(n) = 2 + 2*n T(n) = O(n)
Bài toán 1.2 Thuật toán tìm kiếm tuần tự Cho dãy gồm n phần tử a1, a2, ..., an. Hãy đưa ra vị trí của phần tử đầu tiên bằng phần tử đứng ngay trước đó trong dãy.
a) Thiết kế giải thuật
b) Đánh giá độ phức tạp
Giải
Ví dụ 6, 7, 3, 4, 9, 8, 1, 5, 2, 5, 4, 3 Đáp số là vị trí 7
a)
1, 2 i := 2; found := false; 1 lần
while (i<=n) and not found do
3. if a[i] = a[i-1] then found := true
4. else i := i + 1; ⎭⎬⎫
P(i)
5. if found then write(‘Vi tri can tim: ‘, i)
6. else write(‘khong co phan tu nao nhu vay’);
1 lần
Trong trường hợp xấu nhất, lệnh rẽ nhánh đủ - thân vòng lặp while thực hiện n-1 lần. Do đó ta có T(n) = 2 + (n-1) + 1 = n + 2 T(n) = O(n).
Bài toán 1.3 Thuật toán tìm kiếm nhị phân Cho dãy n số a1, a2, ..., an đã được sắp xếp tăng. Hãy đưa ra vị trí của phần tử trong dãy có giá trị bằng x cho trước.
Giải
1. d := 1; 1 lần
2. c := n; 1 lần
3. found := false; 1 lần

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
23
while (d <= c) and not found do begin
4. k := (d+c) div 2;
5. if x < a[k] then c := k - 1
6. else if x > a[k] then d := k + 1
7. else found := true; ⎪⎪⎭
⎪⎪⎬
⎫
P(i)
end;
8. if found then write(‘Tim thay o vi tri ‘, k)
9. else write(‘khong co x trong day’); 1 lần
Trong trường hợp xấu nhất, không có x trong dãy, ta cần tính số lần thực hiện khối lệnh P(i) trong thân vòng lặp, gồm 2 lệnh cơ bản. Vì mỗi lần đi qua vòng lặp độ dài của dãy giảm đi một nửa, nên sau vòng lặp thứ k độ dài của dãy còn là n/2k
. Vòng lặp kết thúc tại lần thứ k mà độ dài còn lại của dãy là n/2k
= 1 hay k = log2n. Khi đó:
T(n) = 4 + 2k = 4 + 2log2n ≤ log2n + 2log2n với ∀ n ≥ N0 = 3. T(n) ≤ 3log2n T(n) = O(log2n).
Bài toán 1.4 Thuật toán sắp xếp chọn lựa Cho dãy (a) gồm n số a1, a2, ..., an. Hãy sắp xếp dãy (a) theo thứ tự không giảm.
Thuật toán sắp xếp chọn trực tiếp kinh điển (chưa tối ưu)
for i :=1 to n-1 do begin
(* chọn phần tử nhỏ nhất trong dãy a[i] đến a[n]*)
1. k := i ; (*vị trí của phần tử nhỏ nhất*) n-1 lần
2. min := a[i] (*giá trị phần tử nhỏ nhất*) n-1 lần
for j := i + 1 to n do
if a[j] < min then begin
3. k := j;
4. min := a[j]; end; ⎪⎪⎭
⎪⎪⎬
⎫
P(i)
if (k<>i) then begin
5. a[k] := a[i]; n-1 lần
6. a[i] := min; end; end; n-1 lần
Xét thuật toán trong trường hợp tồi nhất: dãy (a) đã được sắp xếp không tăng. Ta cần đánh giá được số lần thực hiện hai câu lệnh cơ bản 3 và 4, do đó tính được thời gian P(i) để thực hiện các câu lệnh for j phụ thuộc vào i.

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
24
- i = 1: hai câu lệnh 3 và 4 thực hiện n - 1 lần
- i = 2: hai câu lệnh 3 và 4 thực hiện n - 2 lần
- …
- i = n-1: hai câu lệnh 3 và 4 thực hiện n- (n-1) = 1 lần
Vậy T(P(i)) = 1 + 2 + … + (n-2) + (n-1) = n(n-1)/2 (ta đặt bằng p)
Do đó T(n) = 4(n-1) + n(n-1)/2 = (1/2)n2 + (7/2)n - 4.
Vậy T(n) = O(n2).
Thuật toán sắp xếp chọn trực tiếp cải tiến (tối ưu hơn)
for i :=1 to n-1 do begin
(* chọn phần tử nhỏ nhất trong dãy a[i] đến a[n]*)
1. k := i ; (*vị trí của phần tử nhỏ nhất*) n-1 lần
for j := i + 1 to n do
2. if a[j] < a[k] then k := j;
p lần
3. if k<> i then begin
4. tg := a[i];
5. a[i] := a[k];
6. a[k] := tg; end;
n-1 lần
end;
Do đó T2(n) = 2(n-1) + n(n-1)/2 = (1/2)n2 + (3/2)n - 2.
Vậy T2(n) = O(n2).
Ta thấy khi thay đổi thuật toán, độ phức tạp không thay đổi nhưng thời gian tính toán ít hơn.
6. Phân tích chương trình (con) đệ qui
6.1. Khái niệm về đệ qui Khái niệm về đề qui dẫn đến một loạt các khái niệm như bài toán đệ qui, lời giải đệ qui, thuật toán đệ qui và cuối cùng là chương trình con đệ qui.
Ta nói: một đối tượng là đệ qui khi nó bao gồm chính nó như một bộ phận hoặc nó được định nghĩa dưới dạng chính nó.
Bài toán T gọi là bài toán đệ qui nếu nó được giải bằng một bài toán T’ có dạng giống như T, nói cách khác T là bài toán được giải bằng một thuật toán đệ qui.

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
25
Ví dụ về hình ảnh đệ qui: giả sử cần xác định một cái túi: Cần lấy một cái túi mà nó đựng trong một cái túi thứ hai mà cái túi thứ hai này là một cái túi mà nó đựng trong một cái túi thứ ba, cái túi thứ ba là một cái túi mà nó đựng trong cái túi thứ tư, ... Tuy nhiên quá trình các cái túi chứa trong nhau ấy không thể vô hạn, đến một cái túi thứ n hữu hạn nào đó thì nó không đựng trong một cái túi nào nữa. Cái túi thứ n này gọi là cái túi “neo”, các cái túi còn lại gọi là các cái túi được xác định một cách đệ qui.
Trong toán học, ta gặp rất nhiều định nghĩa đệ qui mà thường là các công thức để tính giá trị cho một hàm số nào đó có thể tính được bằng qui nạp toán học (hay công thức truy hồi).
Ví dụ 1.15 Định nghĩa đệ qui hàm tính n!
Ta có thể định nghĩa f(n) = n! như sau:
⎩⎨⎧
>−=
=0)1(.
01)(
nifnfnnif
nf
Như vậy bài toán T tính f(n) được giải dựa vào bài toán T’ tính f(n-1) có dạng giống như T. Bài toán T’ tính f(n-1) lại được giải dựa vào bài toán T” tính f(n-2) có dạng giống như T’ (hoặc như T), cứ tiếp tục quá trình đệ qui đó và cuối cùng đến phần “neo”, ta nhận được bài toán Tn’ được giải hoàn toàn khác, đó là f(0) = 1.
6.2. Chương trình (con) đệ qui Chương trình con thể hiện một thuật toán đệ qui gọi là chương trình (con) đệ qui. Định nghĩa một chương trình con đệ qui phản ánh chính xác định nghĩa công thức đệ qui, nghĩa là gồm hai phần
• Phần neo: Lời gọi hàm hay thủ tục được thực hiện bằng một lời giải đã biết.
• Phần đệ qui: Lời gọi chính hàm hay thủ tục đó nhưng có kích thước dữ liệu đầu vào thay đổi theo xu hướng (thường là nhỏ hơn) để quá trình đệ qui dẫn đến phần neo.
Ví dụ 1.16 Chương trình (con) đệ qui tính hàm giaithua(n) = n!
function giaithua(n:integer): longint;
begin
if n = 0 then giaithua := 1
else giaithua := n*giaithua(n-1);
end;
6.3. Xây dựng phương trình (công thức) đệ qui Phương trình đệ qui là phương trình thể hiện mối quan hệ giữa T(n) và T(k). Trong đó T(n) là thời gian thực hiện thuật toán với dữ liệu vào kích thước là n, T(k) là thời gian thực hiện chính thuật toán đó nhưng với dữ liệu kích thước là k.
Ví dụ 1.17 Xây dựng phương trình đệ qui tính hàm giaithua(n)

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
26
Gọi T(n) là thời gian thực hiện thuật toán tính hàm giaithua(n). Ta có
- n = 0: T(n) = 2 (là thời gian thực hiện việc kiểm tra điều kiện và lệnh gán giaithua := 1)
- n > 0: Hàm gọi tới hàm giaithua(n-1) để tính (n-1)! mất thời gian là T(n-1). Sau khi có kết quả của giaithua(n-1) thì cần thực hiện thêm một phép nhân và một phép gán, mất một thời gian là một hằng số c, do đó T(n) = T(n-1) + c;
Vậy phương trình đệ qui tính hàm giaithua(n) là:
⎩⎨⎧
>+−=
=0)1(
02)(
nifcnTnif
nT
Ví dụ 1.18 Viết phương trình đệ quy tính số hạng Fibonaci thứ n
Dãy Fibonaci có dạng 1, 1, 2, 3, 5, 8, 13, 21, 35, …
Gọi f(n) là giá trị của số hạng Fibonaci thứ n.
a) Định nghĩa qui tính hàm f(n) như sau:
⎩⎨⎧
>−+−≤
=2)2()1(
21)(
nifnfnfnif
nf
b) Chương trình con đệ qui tính hàm fibonaci(n):
function fibonaci(n: integer) : longint;
begin
if n <= 2 then fibonaci := 1
else fibonaci := fibonaci(n-1) + fibonaci(n-2);
end;
c) Phương trình đệ qui tính hàm fibonaci(n):
⎩⎨⎧
>+−+−≤
=2)2()1(
22)(
nifcnTnTnif
nT
Trong đó hằng số dương c là thời gian thực hiện phép cộng và phép gán.
6.4. Giải phương trình đệ qui và Định lí Thợ Giải phương trình đệ qui thực chất là tiến hành đánh giá độ phức tạp của thuật toán đệ qui.
a) Phương pháp thế Ý tưởng của phương pháp thể là thay dần các công thức đệ qui của hàm thời gian ở vế phải cho đến khi thu được các hàm thời gian mà chúng nhận được các giá trị cụ thể.
Ví dụ 1.19 Tính độ phức tạp của thuật toán đệ qui tính n!

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
27
⎩⎨⎧
>+−=
=0)1(
02)(
nifcnTnif
nT
Giải:
T(n) = T(n-1) + c
= T(n-2) + 2c
= T(n-3) + 3c
= …
= T(n-n) + n.c = T(0) + nc = 2 + n.c
T(n) = O(n).
Ví dụ 1.20 Độ phức tạp đệ qui khi lời gọi đệ qui giảm 1/2 kích thước dữ liệu đầu vào
Giải phương trình đệ qui ⎩⎨⎧
>+=
=1)2/(
1)( 1
nifcnTnifc
nT
Giải
bước 1 : T(n) = T(n/2) + c
bước 2 : = T(n/22) + 2c
bước 3 : = T(n/23) + 3c
… …
bước k = T(n/2k) + k.c
= T(1) + k.c
Giả sử k là bước cuối cùng thì n/2k = 1 k = log2n và T(n) = c1 + k.c = c1 + c.log2n.
Do đó T(n) = O(log2n).
Ví dụ 1.21 Thuật toán đệ qui có độ phức tạp O(nlog2n)
Giải phương trình đệ qui ⎩⎨⎧
>+=
=1.)2/(2
1)( 1
nifncnTnifc
nT
Giải
bước 1 : T(n) = 2T(n/2) + c.n
bước 2 : = 22T(n/22) + 2c.n
bước 3 : = 23T(n/23) + 3c.n
… …
bước k = 2kT(n/2k) + k.c.n
Giả sử k là bước cuối cùng thì n/2k = 1 k = log2n. Khi đó T(n/2k) = T(1) = c1 và

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
28
T(n) = c1.2k + k.c = c1.2log2(n) + c.n.log2n = c1.n + c.n.log2n
Do đó theo qui tắc cộng và qui tắc max ta có T(n) = O(nlog2n).
b) Sử dụng phương trình đặc trưng
Định nghĩa phương trình đặc trưng
Cho phương trình đệ qui có dạng
T(n) = c1.T(n-1) + c2.T(n-2) (1)
Khi đó, phương trình đặc trưng của (1) được định nghĩa là phương trình dạng
r2 - c1r - c2 = 0 (2)
Sử dụng phương trình đặc trưng (2) để đánh giá độ phức tạp của thuật toán đệ qui có phương trinh đệ qui (1) dựa vào hai trường hợp sau đây :
• Nếu phương trình (2) có hai nghiệm phân biệt r1 và r2 thì phương trình đệ qui có dạng :
T(n) = α.r1n + β.r2
n (3)
• Nếu phương trình (2) có nghiệm kép r0 thì phương trình đệ qui có dạng:
T(n) = α.r0n + β.n.r0
n (4)
trong đó α, β là các số được xác định bởi điều kiện “ neo” và điều kiện đầu.
Ví dụ 1.22 Đánh giá độ phức tạp thuật toán đệ qui bằng phương trình đặc trưng
Giải phương trình đệ qui sau
⎪⎩
⎪⎨
⎧
>−−−==
=1)2(6)1(5
1602
)(nifnTnT
nifnif
nT
Giải
Xét phương trình đệ qui
T(n) = 5T(n-1) - 6T(n-2) (1)
Phương trình (1) có phương trình đặc trưng là :
r2 -5r + 6 = 0 (2)
Phương trình (2) có hai nghiệm phân biệt r1 = 2 và r2 = 3. Do đó phương trình đệ qui (1) có thể viết dưới dạng
T(n) = α r1n + β r2
n
Các hệ số α, β được xác định bởi các điều kiện “neo” và điều kiện đầu
Vì T(0) = 2, T(1) = 6, do đó:

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
29
⎩⎨⎧
=+==+=
6)1(2)0(
12
11
02
01
rrTrrT
βαβα
⎩⎨⎧
=+=+
6322
βαβα
⎩⎨⎧
==
20
βα
Vậy T(n) = 0. 2n + 2.3n = 2.3n T(n) = O(3n)
Ví dụ 1.22 Đánh giá độ phức tạp thuật toán đệ qui bằng phương trình đặc trưng
Giải phương trình đệ qui sau:
⎪⎩
⎪⎨
⎧
>−−−==
=1)2(9)1(6
1701
)(nifnTnT
nifnif
nT
Giải
Xét phương trình đệ qui
T(n) = 6T(n-1) - 9T(n-2) (1)
Phương trình (1) có phương trình đặc trưng là :
r2 -6r + 9 = 0 (2)
Phương trình (2) có hai nghiệm kép r0 = 3. Do đó phương trình đệ qui (1) có thể viết dưới dạng
T(n) = α.r0n + β.n.r0
n
Các hệ số α, β được xác định bởi các điều kiện “neo” và điều kiện đầu
Vì T(0) = 1, T(1) = 7, do đó:
⎩⎨⎧
=+==+=7.1.)1(1.0.)0(
12
11
02
01
rrTrrT
βαβα
⎩⎨⎧
=+=
7.1.331βα
α
⎩⎨⎧
==
3/41
βα
Vậy T(n) = 1. 3n + (4/3).n.3n T(n) = O(n3n)
c) Sử dụng định lí thợ
Định lí thợ
Cho a ≥ 1, b > 1 và hàm thời gian T(n) thỏa mãn điều kiện:
T(n) = a.T(n/b) + c.nk (1)
• Trường hợp 1: Nếu a > bk thì )()( log abnnT θ=
• Trường hợp 2: Nếu a = bk thì )log.()( 2 nnnT kθ=
• Trường hợp 3: Nếu a < bk thì )()( knnT θ=
Ví dụ 1.24 Minh họa vận dụng định lí thợ trường hợp 1
Giải phương trình đệ qui

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
30
T(n) =4.T(n/2) + c.n (c là hằng số cho trước)
Giải
Phương trình đệ qui thỏa mãn điều kiện của định lí thợ, có dạng
T(n) = a.T(n/b) + c.nk
với a = 4, b = 2 và k = 1.
Vì a > bk nên trường hợp 1 của định lí thợ được áp dụng, ta có )()( log abnnT θ=
hay .)()()( 24log2 nnnT θθ ==
Ví dụ 1.25 Minh họa vận dụng định lí thợ trường hợp 2
Giải phương trình đệ qui
T(n) = 2.T(n/2) + c.n (c là hằng số cho trước)
Giải
Phương trình đệ qui thỏa mãn điều kiện của định lí thợ, có dạng
T(n) = a.T(n/b) + c.nk
với a = 2, b = 2 và k = 1.
Vì a = bk nên trường hợp 2 của định lí thợ được áp dụng, ta có )log.()( 2 nnnT kθ=
hay T(n) = θ(n.log2n).
Ví dụ 1.26 Minh họa vận dụng định lí thợ trường hợp 3
Giải phương trình đệ qui
T(n) =2.T(n/2) + c.n3 (c là hằng số cho trước)
Giải
Phương trình đệ qui thỏa mãn điều kiện của định lí thợ, có dạng
T(n) = a.T(n/b) + c.nk
với a = 2, b = 2 và k = 3.
Vì a < bk nên trường hợp 3 của định lí thợ được áp dụng, ta có )()( knnT θ=
hay . )()( 3nnT θ=
BÀI TẬP CHƯƠNG 1 Phân tích thời gian thực hiện thuật toán và đánh giá độ phức tạp thuật toán của các đoạn chương trình sau:
1.

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
31
for i := 1 to n do
if i mod 2 = 0 then c := c + 1;
2.
for i := 1 to n do
if i mod 2 = 0 then c1 := c1 + 1
else c 2 :+ c2 + 1;
3.
for i :=1 to n do
if i mod 20 = 0 then
for j := 1 to n do c := c + 1;
4.
a := 0;
b := 0;
c := 0;
for i :=1 to n do
begin a := a + 1;
b := b + i;
c := c + i*i;
end;
5.
i := n;
d := 0;
while i > 0 do
begin i := i - 1;
d := d + i;
end;
6.
i := 0;
d := 0;
repeat

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
32
i := i + 1;
if i mod 3 = 0 then d := d + 1;
until i > n;
7.
d := 0;
for i := 1 to n - 1 do
for j := i + 1 to n do d := d + 1;
8.
d := 0;
for i := 1 to n - 2 do
for j := i + 1 to n - 1 do
for k := j + 1 to n do d := d + 1;
9.
d := 0;
while n > 0 do
begin n := n div 2;
d := d + 1;
end;
10. Đưa ra một thuật toán tìm phần tử lớn nhất của một dãy hữu hạn số thực.
a) Mô tả thuật toán của bạn bằng các cách khác nhau (mô tả, sơ đồ khối, ngôn ngữ tựa Pascal). b) Xác định số phép tính nhiều nhất phải thực hiện trong thuật toán trên.
11. Mô tả thuật toán xếp lại một dãy theo thứ tự tăng dần.
a) Mô tả thuật toán của bạn bằng các cách khác nhau (mô tả, sơ đồ khối, ngôn ngữ tựa Pascal). b) Xác định số phép tính nhiều nhất phải thực hiện trong thuật toán trên.
12. Mô tả thuật toán tìm một dãy các số liên tiếp nhau có tổng dương trong một dãy số thực cho trước.
a) Mô tả thuật toán của bạn bằng các cách khác nhau (mô tả, sơ đồ khối, ngôn ngữ tựa Pascal).
b) Xác định số phép tính nhiều nhất phải thực hiện trong thuật toán trên.

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
33
Chương 2 CHIA ĐỂ TRỊ
Ý tưởng của phương pháp chia để trị (Divide & Conquer) là giải quyết bài toán thành 3 bước
- Chia: Chia bài toán thành các bài toán con có kích thước nhỏ hơn.
- Trị: Giải các bài toán con một cách độc lập.
- Tổng hợp: Tổng hợp các kết quả của các bài toán con để thu được lời giải của bài toán ban đầu.
1. Sơ đồ chung của thuật toán chia để trị
1.1. Thuật toán β Ta xét bài toán tổng quát P với kích thước dữ liệu vào là n.
Giả sử có thuật toán α để giải bài toán P với thời gian bị chặn bởi c.n2.
Xét một thuật toán β khác giải chính bài toán P đã cho theo ba bước sau:
- Chia: Chia bài toán thành 3 bài toán con kích thước n/2
- Trị: giải 3 bài toán con theo thuật toán α
- Tổng hợp lời giải các bài toán con
Giả sử thời gian chia và tổng hợp các bài toán con là tuyến tính, tức là có độ phức tạp đa thức O(n) hay d.n.
Khi đó:
Tα = cn2 = (3/4)cn2 + (1/4)cn2 T(n) = O(n2)
Tβ = 3Tα + dn = 3c(n/2)2 + dn = (3/4)cn2 + dn T(n) = O(n2)
(Tức là Tβ bằng tổng của thời gian trị (3/4)cn2 + thời gian tổng hợp dn).
Từ đó, nếu dn < (1/4)cn2 d < cn2/4 n > 4d/c thì thuật toán β nhanh hơn thuật toán α. Điều này luôn đúng với n đủ lớn. Tuy nhiên ta thấy thuật toán β mới chỉ thay đổi được nhân tử hằng số chưa thay đổi được bậc nhưng cũng hiệu quả khi n lớn. Nói cách khác, độ phức tạp thuật toán không thay đổi, nhưng thời gian thực hiện thuật toán được cải thiện.
Thủ tục Beta dưới đây thể hiện thuật toán β
procedure Beta(n) (* n là kích thước bài toán *)
begin
i. Chia bài toán thành ba bài toán con kích thước n/2;
ii. Giải mỗi bài toán con bằng thuật toán α;
iii. Tổng hợp lời giải của các bài toán con;

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
34
end;
Việc chia để trị rõ ràng có xu hướng làm giảm thời gian tính toán. Vì thế các bài toán con nên tiếp tục được chia nhỏ như thế khi còn có lợi, tức là khi còn thỏa mãn điều kiện n > 4dc. Nói cách khác, các bài toán con sẽ tiếp tục được chia nhỏ cho đến khi việc chia đó không làm giảm thời gian tính (tức là khi n ≤ 4dc) thì dừng lại. Điều này được thể hiện trong thuật toán γ dưới đây.
1.2. Thuật toán γ Thủ tục Gamma dưới đây thể hiện thuật toán γ
procedure Gamma(n) (* n là kích thước bài toán; đặt n0 = 4d/c *)
begin
if n ≤ n0 then việc chia không còn lợi nữa thì giải trực tiếp
Giải bài toán một cách trực tiếp, bằng thuật toán α
else begin
i. Chia bài toán thành ba bài toán con kích thước n/2;
ii. Giải mỗi bài toán con bằng thuật toán γ;
iii. Tổng hợp lời giải của các bài toán con;
end;
end;
Nhận xét:
- Nếu bài toán P giải bởi thuật toán α thì không có chia để trị.
- Nếu bài toán P giải bằng thuật toán β thì được việc chia để trị được thực hiện một lần, trong đó có 3 bài toán con được chia, và được giải bằng thuật toán α.
- Nếu bài toán P được giải bằng thuật toán γ (thay vì thuật toán β) thì quá trình chia để trị được thực hiện nhiều lần nếu thời gian tính vẫn tốt hơn, mỗi bài toán con sử dụng chính thuật toán γ của bài toán mẹ, tức là thực hiện bởi một lời giải đệ qui.
Ta có phương trình đệ qui sau:
⎪⎩
⎪⎨
⎧
>+
≤=
cdnifdnnT
cdnifcn
nT 4)2
(3
4
)(2
γ
γ

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
35
Phương trình đệ qui có dạng Tγ(n) = a.Tγ(n/b) + c.nk thỏa mãn điều kiện của định lí thợ với a = 3, b = 2, c = d và k = 1. Mặt khác, vì 3 = a > bk = 2 nên định lí thợ rơi vào trường hợp thứ nhất,
do đó . )()( log abnnT θ= )()()( ...589.13log2 nnnT θθ ≈=
Thuật toán γ thu được có thời gian tính là tốt hơn cả thuật toán α và thuật toán β. Hiệu quả thu được trong thuật toán γ có được là nhờ ta đã khai thác triệt để hiệu quả của việc sử dụng thuật toán β.
1.3. Thuật toán γ tổng quát Để có được một mô tả chi tiết thuật toán chia để trị chúng ta cần phải xác định 4 tham số:
1. n0: giá trị neo, là điểm kết thúc quá trình chia bài toán con
2. k: kích thước của mỗi bài toán con trong cách chia.
3. r: số lượng các bài toán con được chia tại mỗi lần thực hiện.
4. Thuật toán tổng hợp lời giải của các bài toán con.
Chia như thế nào (xác định r và k) là căn cứ vào mục đích thời gian thực hiện thuật toán tổng hợp là nhỏ (thường là tuyến tính).
Ta có thủ tục DivideAndConquer thể hiện thuật toán γ tổng quát như sau:
procedure DivideAndConquer(n) (* n là kích thước bài toán; đặt n0 = 4d/c *)
begin
if n <= n0 then
Giải bài toán một cách trực tiếp, bằng thuật toán α
else begin
i. Chia bài toán thành r bài toán con kích thước n/k;
ii. for (r bài toán con) do DivideAndConquer(n/k);
iii. Tổng hợp lời giải của các bài toán con;
end;
end;
2. Một số ví dụ minh họa Chia để trị
2.1. Thuật toán sắp xếp trộn (Merge Sort) Bài toán 2.1 Cho dãy (a) gồm n phần tử a1, a2, ..., an. Hãy sắp xếp dãy (a) theo thứ tự không giảm bằng thuật toán sắp xếp kiểu trộn.
Thuật toán γ được vận dụng giải bài toán như sau
procedure MergeSort(a, n) ;

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
36
begin
if n = 1 then
return a;
else
begin
(* Chia *) a1 := a[1..n/2]; a2 := a[(n/2 + 1) .. n];
(* Trị *) MergeSort(a1, n/2); MergeSort(a2, n/2);
(* Tổng hợp*) Merge(a1, a2, a);
end;
end;
Thuật toán Tổng hợp được thể hiện qua thủ tục Merge (“trộn”) sau đây:
procedure Merge(U[1..m+1], V[1..n+1], T[1..m+n]);
(*Trộn 2 mảng U[1..m+1] và V[1..n+1] thành mảng T[1..m+n]);
U[m+1],V[n+1] được dùng để chứa các giá trị cầm canh*)
begin i:=1; j:=1; k := 0;
while ( i <= m or j <= n) do
begin k := k + 1;
if U[i]<V[j] then
begin T[k]:=U[i];
i:=i+1;
end else
begin
T[k]:=V[j];
j:=j+1;
end;
end;
if n < m then <Nối đoạn còn lại của mảng V vào cuối mảng T>
else <Nối đoạn còn lại của mảng U vào cuối mảng T>;
end;
Giải thuật sắp xếp này minh hoạ tất cả các khía cạnh của chia để trị. Khi số lượng các phần tử cần sắp là nhỏ thì ta thường sử dụng các giải thuật sắp xếp đơn giản. Khi số phần tử đủ lớn thì ta chia mảng ra hai phần, tiếp đến trị từng phần một và cuối cùng là kết hợp các lời giải.

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
37
Giả sử T(n) là thời gian cần thiết để giải thuật này sắp xếp một mảng n phần tử. Việc tách T thành U và V là tuyến tính. Ta cũng dễ thấy merge(U,V,T) cũng tuyến tính. Dễ viết được phương trình đệ qui:
⎪⎩
⎪⎨⎧
>+
== 1)
2(2
1)( nifdnnT
nifcnT
Phương trình đệ qui có dạng T(n) = a.T(n/b) + c.nk thỏa mãn điều kiện của định lí thợ với a = 2, b = 2, c = d và k = 1. Mặt khác, vì 2 = a = bk = 2 nên định lí thợ rơi vào trường hợp thứ hai, do đó )log.()( 2 nnnT kθ= )log()( 2 nnnT θ= .
Khi xét thuật toán sắp xếp kiẻu vun đống (HeapSort) ta thấy hiệu quả của MergeSort tương tự HeapSort. Trong thực tế sắp xếp trộn có thể nhanh hơn vun đống một ít nhưng nó cần nhiều bộ nhớ hơn cho các mảng trung gian U và V. Ta nhớ lại HeapSort có thể sắp xếp tại chỗ (in-place), và cảm giác nó chỉ sử dụng một ít biến phụ. Theo lý thuyết, MergeSort cũng có thể làm được như vậy, tuy nhiên chi phí về thời gian sắp xếp có tăng một chút.
2.2. Thuật toán sắp xếp nhanh (QuickSort) Bài toán 2.2 Cho dãy (a) gồm n phần tử a1, a2, ..., an. Hãy sắp xếp dãy (a) theo thứ tự không giảm bằng thuật toán sắp xếp kiểu QuickSort.
QuickSort được phát minh bởi Hoare, dựa theo nguyên tắc chia để trị. Không giống như MergeSort, QuickSort quan tâm đến việc giải các bài toán con hơn là sự kết hợp giữa các lời giải của chúng.
Ý tưởng của thuật toán QuickSort như sau: Nếu đoạn cần sắp xếp chỉ có một phần tử thì đoạn đó đã được sắp xếp, ngược lại ta chọn một phần tử x trong đoạn làm phần tử “chốt”, mọi phần tử nhỏ hơn chốt được xếp vào vị trí đứng trước chốt, mọi phần tử lớn hơn chốt được xếp vào vị trí đứng sau chốt. Sau phép toán chuyển như vậy thì đoạn được chia thành hai đoạn con mà đoạn trước gồm các phần tử nhỏ hơn chốt, đoạn sau gồm các phần tử lớn hơn chốt. Tiếp tục áp dụng thuật toán đã làm (như đối với đoạn đầu tiên) cho hai đoạn con, và cứ tiếp tục một cách đệ qui như thế ta sẽ thu được toàn đoạn được sắp.
Ý tưởng cụ thể như sau: Giả sử cần sắp xếp đoạn có chỉ số từ L (Left) đến R (Right):
- Chọn x làm phần tử ngẫu nhiên trong đoạn L ..R, có thể chọn x là phần tử ở giữa đoạn, tức là phần tử x = a[(L+R) div 2]
- Cho i chạy từ L sang phải; j chạy từ R sang trái, nếu gặp một cặp phải tử sai thứ tự, tức i ≤ j mà a[i] > x và a[j] < x thì tiến hành đổi chỗ hai phần tử đó. Quá trình này còn tiếp tục khi i > j thì dừng.
- Tiếp tục làm như thế đối với 2 đoạn từ L đến j và từ i đến R.
Thuật toán γ vận dụng cho thuật toán QuickSort được diễn tả trong thủ tục QuickSort sau đây đối với mảng a từ vị trí L đến R:

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
38
procedure Quicksort(L, R); (* Sắp xếp theo thứ tự không giảm *)
begin
i := L; j := R;
x := a[(L + R) div 2];
while i <= j do
begin
while (a[i] < x) and (i < R) do i := i + 1;
while (a[j] > x) and (j > L) do j := j -1;
if i <= j then
begin
tmp := a[i]; a[i] := a[j]; a[j] := tmp;
i := i + 1; j := j - 1;
end;
end;
if L < j then QuickSort(L, j);
if i < R then QuickSort(i, R);
end;
Việc chọn phần tử chốt để phân đoạn sẽ quyết định hiệu quả của thuật toán. Trong trường hợp xấu nhất (đoạn được chia thành một đoạn con 1 phần tử và đoạn con kia có n-1 phần tử) thì độ phức tạp thuật toán cỡ O(n2).
Gọi T(n) là thời gian trung bình dùng Quicksort để sắp mảng n phần tử a[1..n]. Trường hợp riêng như thuật toán trên, thời gian để xác định phần tử chốt ở vị trí m = (L+R) div 2 bằng hằng số c; trường hợp tổng quát, phần tử chốt ở vị trí m nằm trong đoạn từ 1 đến n, có xác suất là 1/n, và thời gian để tìm m có thể xác định bởi một hàm tuyến tính g(n). Giả sử thời gian dùng đệ qui để sắp xếp hai mảng con kích thước (m - 1) và (n - m) tương ứng là T(m-1) và T(n-l). Như vậy với n đủ lớn ta có:
∑∑∑−
===
+=−+−+=mn
k
n
m
n
mkT
nng
nmnTmTng
nnT
011
)(2)(1))()1()((1)(
Nếu chọn n0 là giá trị đủ lớn để sử dụng công thức trên. Nghĩa là nếu n ≤ n0 thì ta dùng thuật toán sắp xếp khác, ví dụ thuật toán sắp xếp chèn trực tiếp. Với n > n0 ta gọi d là hằng số sao cho g(n) ≤ dn. Khi đó ta có đánh giá
∑−
=
+≤mn
kkT
ndnnT
0
)(2)( với ∀ n > n0.

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
39
Công thức như trên khó phân tích độ phức tạp, vì thế ta thừa nhận kết quả sau: Thời gian trung bình để thực hiện thuật toán QuickSort là T(n) = O(nlog2n).
2.3. Nhân số nguyên lớn Bài toán 2.3. Cho hai số nguyên lớn (có n chữ số, n đủ lớn) X và Y. Hãy xây dựng thuật toán chia để trị để tìm kết quả của phép nhân Z = X * Y.
Giả sử X = x1x2...xn và Y = y1y2…yn
Nếu thực hiện thuật toán mô phỏng phép nhân X*Y như việc thực hiện phép nhân bằng tay thông thường thì độ phức tạp tính toán dễ tìm được là O(n2).
Ta sẽ tìm cách xây dựng thuật toán chia để trị cho việc thực hiện phép nhân X*Y để có được độ phức tạp tính toán nhỏ hơn.
Chia đôi mỗi số ta được:
X1 = x1x2…xn/2 và X2 = xn/2…xn
Y1 = y1y2…yn/2 và Y2 = yn/2…yn.
Ta có X = X110n/2 + X2 và Y = Y110n/2 + Y2. Do đó
Z = X*Y = (X110n/2 + X2)*(Y110n/2 + Y2) = = X1Y110n + (X1Y2 + X2Y1)10n/2 + X2Y2 (1)
Thủ tục Nhân sau đây thể hiện thuật toán chia để chị
procedure Nhan(X, Y, n) ;
begin
if n = 1 then return X*Y
else
begin
X1 := X[1..n/2]; X2 := X[n/2..n];
Y1 := Y[1..n/2]; Y2 := Y[n/2..n];
M := Nhan(X1, Y1, n/2);
N := Nhan(X1, Y2, n/2);
P := Nhan(X2, Y1, n/2);
Q := Nhan(X2, Y2, n/2);
return M*10n + (N + P)*10n/2 + Q;
end;
end;
Gọi T(n) là thời gian thực hiện thuật toán Nhan(X, Y, n) thực hiện phép nhân hai số X và Y với số chữ số n; Thời gian giải mỗi bài con (4 bài toán con) thực hiện phép nhân hai số X và Y với

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
40
số chữ số n/2 sẽ là T(n/2); Thời gian tổng hợp kết quả là dn. Khi đó ta có phương trình đệ qui tính T(n) là:
⎩⎨⎧
>+=
=1)2/(4
1)(
nifdnnTnifc
nT
Phương trình đệ qui có dạng T(n) = a.T(n/b) + c.nk thỏa mãn điều kiện của định lí thợ với a = 4, b = 2, c = d và k = 1. Mặt khác, vì 4 = a > bk = 2 nên định lí thợ rơi vào trường hợp thứ nhất, do đó . )()( log abnnT θ= )()()( 24log2 nnnT θθ ==
Nhận xét: Việc tính Z trong công thức (1) dẫn đến cần giải 4 bài toán con tính M, N, P, Q. Ta có thể thay 4 bài toán con này bằng 3 bài toán con sau đây:
U := X1.Y1;
V := X2*Y2 và
W := (X1 + X2) * (Y1 + Y2)
và khi đó công thức (1) có thể viết lại dưới dạng :
Z = U.102 + (W-U-V).10n/2 + V
Khi đó phương trình đệ quy của thuật toán Chia thành 3 bài toán để Trị sẽ là:
⎩⎨⎧
>+=
=1)2/(3
1)(
nifdnnTnifc
nT
Phương trình đệ qui có dạng T(n) = a.T(n/b) + c.nk thỏa mãn điều kiện của định lí thợ với a = 3, b = 2, c = d và k = 1. Mặt khác, vì 3 = a > bk = 2 nên định lí thợ vẫn rơi vào trường hợp thứ nhất, và . )()( log abnnT θ= )()()( 23log2 nnnT θθ <=
2.4. Mảng con trọng số lớn nhất Bài toán 2.4. Cho mảng (a) gồm n số a[1..n]. Ta gọi một mảng con của mảng a là một đoạn a[p..q] (1 ≤ p ≤ q ≤ n). Hãy tìm mảng con có trọng số lớn nhất, tức là có tổng giá trị của các phần tử lớn nhất.
Cách thứ nhất: Phương pháp liệt kê toàn bộ (duyệt toàn bộ)
procedure maxsub(n, var p, q);
begin
max := -∞;
for i := 1 to n do
for j := i to n do
begin (*xet mảng con a[i..j]*)
s := 0;

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
41
for k := i to j do
s := s + a[k]; (* câu lệnh đặc trưng 2*)
if max < s then
begin
max := s; p := i; q := j:
end;
end;
end;
Theo qui tắc max, ta có thể đánh giá độ phức tạp của thuật toán trên bằng cách chỉ dựa vào câu lệnh đặc trưng (là câu lệnh có số lần thực hiện nhiều nhất):
∑∑∑= = =
=n
i
n
ij
j
iknT
1
1)( T(n) = O(n3).
Cách thứ hai: Cải tiến việc liệt kê toàn bộ (cải tiến duyệt toàn bộ)
procedure maxsub(n, var p, q);
begin
max := -∞;
for i := 1 to n do
begin
s := 0;
for j := i to n do
begin (*xet mảng con a[i..j]*)
s := s + a[j]; (*câu lệnh đặc trưng*)
if max < s then
begin
max := s; p := i; q := j:
end;
end;
end;
end;
Theo qui tắc max, độ phức tạp của kĩ thuật thứ hai vào câu lệnh đặc trưng được đánh giá bởi
2 Câu lệnh đặc trưng của một (đoạn) thuật toán là câu lệnh có số lần thực hiện nhiều nhất.

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
42
∑∑= =
=n
i
n
ijnT
11)( T(n) = O(n2).
Cách thứ ba: Dùng phương pháp chia để trị
Ý nghĩa của các công việc Chia, Trị và Tổng hợp như sau:
- Chia: Ta chia mảng thành 2 mảng con có kích thước khác nhau ít nhất 1 đơn vị, kí hiệu là aL và aR. Để đơn giản, ta chỉ quan tâm đến đến tính trọng số lớn nhất của mảng con.
- Trị: Tìm các mảng con có trọng số lớn nhất của mỗi nửa một cách đệ qui aL và aR, giả sử các trọng số tìm được là WL, WR
- Tổng hợp: trọng số lớn nhất của mảng con trong mảng đã cho là
+ Kết quả ban đầu cần tìm là max (WL, WR)
+ Ta cần xét khả năng mảng con có trọng lượng lớn WM (Weight of Median Array) có thể là mảng con nằm đè lên các điểm chia. Để tính WM, ta chỉ cần tính trọng lượng WML của mảng con lớn nhất trong nửa aL kết thúc ở điểm chia, và trọng lượng WMR của mảng con lớn nhất trong nửa aR bắt đầu ngay sau điểm chia. Tức là ta có
WM = WML + WMR.
+ Vậy trọng lượng lớn nhất của mảng con tìm được là max(WL, WR, WM)
Cài đặt thuật toán
function MaxSubArray(a,i,j);
begin
if ( i = j) return a[i]
else
begin
M := (i+j)/2;
WL := MaxSubArray(a,i,m);
WR := MaxSubArray(a,m+1,j);
WM := MaxLeftArray(a,i,M) + MaxRight Array(a,M+1,j);
Return Max(WL, WR, WM );
end
end;
Các hàm MaxLeftArray, Max RightArray được cài đặt như sau :
function MaxLeftArray(a,i,j);
begin

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
43
MaxSum := - ∞; Sum := 0;
for k := j downto i do
begin
Sum := Sum + a[k];
MaxSum := Max(Sum,MaxSum)
end;
return MaxSum;
end;
Tương tự với hàm MaxLeftArray, dễ dàng xây dựng được hàm MaxRightArray: Thay vòng for ở thủ tục trên bằng vòng for sau
for k := i to j do
begin
Sum := Sum + a[k];
MaxSum := MaxSum(Sum, MaxSum)
end;
Phân tích độ phức tạp
Thời gian chạy thủ tục MaxLeftArray và MaxRightArray là O(m) với m = j-i+1
Gọi T(n) là thời gian tính, giả thiết n = 22. Ta có :
- n = 1 thì T(n) = 1
- n > 1 thì việc tính WM đòi hỏi thời gian n/2 + n/2 = n T(n) = 2T(n/2) + n
Phương trình đệ qui có dạng T(n) = a.T(n/b) + c.nk thỏa mãn điều kiện của định lí thợ với a = 2, b = 2, c = 1 và k = 1. Mặt khác, vì 2 = a = bk = 2 nên định lí thợ rơi vào trường hợp thứ hai, do đó )log.()( 2 nnnT kθ= )log()( 2 nnnT θ= . Vậy rõ ràng phương pháp chia để trị có độ phức tạp thuật toán nhỏ hơn các phương pháp liệt kê.
BÀI TẬP CHƯƠNG 2 1. Cho mảng số liệu sau :
10, 4, -5, 7, -45, 14, 30, -2, 50
Hãy minh họa các bước của thuật toán để tìm mảng con lớn nhất.
2. Cho dãy số liệu
80, 12, 47, 16, 7, 56, 14, 19, 100
Hãy minh họa các bước của thuật toán MergeSort, QuickSort để sắp xếp dãy khóa trên theo thứ tự tăng dần.

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
44
3. Thiết kế thuật toán nhân 2 số nguyên dương, sử dụng thuật toán chia để trị, trong đó mỗi số nguyên dương được chia làm ba phần, và tích của hai số đó sẽ tìm được sau 5 phép nhân số này với độ xấp xỉ n/3. Phân tích độ phức tạp tính toán trong thuật toán thu được.

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
45
Chương 3. QUY HOẠCH ĐỘNG
1. Giới thiệu phương pháp qui hoạch động Quy hoạch động có những nét giống như phương pháp “Chia để trị”, nó đòi hỏi việc chia bài toán thành những bài toán con kích thước nhỏ hơn. Phương pháp chia để trị chia bài toán cần giải ra thành các bài toán con độc lập, sau đó các bài toán con này được giải một cách đệ quy, và cuối cùng tổng hợp các lời giải của các bài toán con ta thu được lời giải của bài toán đặt ra. Trong tình huống các bài toán con là không độc lập với nhau, nghĩa là các bài toán con cùng có chung các bài toán con nhỏ hơn thì phương pháp chia để trị sẽ tỏ ra không hiệu quả, vì nó phải lặp đi lặp lại việc giải các bài toán con chung đó. Quy hoạch động sẽ giải một bài toán con một lần và lời giải của các bài toán con sẽ được ghi nhận, giữ lại để sử dụng cho việc giải các bài toán con cỡ lớn hơn.
Quy hoạch động thường được áp dụng để giải các bài toán tối ưu. Trong các bài toán tối ưu, ta có một tập các lời giải, mà mỗi lời giải như vậy được gán với một giá trị số. Ta cần tìm lời giải với giá trị số tối ưu (nhỏ nhất hoặc lớn nhất). Lời giải như vậy ta sẽ gọi là lời giải tối ưu.
2. Phương pháp chung của qui hoạch động Trước khi có được các bước cụ thể để xây dựng thuật toán qui hoạch động, ta có thể tiến hành các phân tích sau đây:
• Phân rã: Tìm cách chia bài toán cần giải thành những bài toán con nhỏ hơn có cùng dạng với bài toán ban đầu thành các bài toán có kích thước nhỏ hơn, sao cho bài toán con kích thước nhỏ nhất có thể giải một cách trực tiếp. Bản thân bài toán xuất phát có thể coi là bài toán con có kích thước lớn nhất trong họ các bài toán con này.
• Ghi nhận lời giải: Chọn cách lưu trữ lời giải của các bài toán con vào một bảng để có thể dùng lại lời giải của chúng cho các bài toán con cỡ lớn hơn.
• Tổng hợp lời giải: Tìm cách truy vết, nghĩa là lần lượt đi từ lời giải của các bài toán con kích thước nhỏ hơn, tìm cách xây dựng lời giải của bài toán kích thước lớn hơn, cho đến khi thu được lời giải của bài toán xuất phát (là bài toán con có kích thước lớn nhất). Kỹ thuật giải các bài toán con của quy hoạch động là quá trình đi từ dưới lên (bottom – up) là điểm khác quan trọng với phương pháp chia để trị, trong đó các bài toán con được trị một cách đệ quy (top – down).
Yêu cầu quan trọng nhất trong việc thiết kế thuật toán nhờ quy hoạch động là thực hiện khâu phân rã, tức là xác định được cấu trúc của bài toán con. Việc phân rã cần được tiến hành sao cho không những bài toán con kích thước nhỏ nhất có thể giải được một cách trực tiếp mà còn có thể dễ dàng việc thực hiện tổng hợp lời giải.

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
46
Không phải lúc nào việc áp dụng phương pháp quy hoạch động đối với bài toán tối ưu hoá cũng dẫn đến thuật toán hiệu quả. Có hai tính chất quan trọng mà một bài toán tối ưu cần phải thoả mãn để có thể áp dụng quy hoạch động để giải nó là:
• Cấu trúc con tối ưu: Tính chất này còn được gọi là tiêu chuẩn tối ưu và có thể phát biểu như sau: Để giải được bài toán đặt ra một cách tối ưu, mỗi bài toán con cũng phải được giải một cách tối ưu. Mặc dù sự kiện này có vẻ là hiển nhiên, nhưng nó thường không được thoả mãn do các bài toán con là giao nhau. Điều đó dẫn đến là một lời giải có thể là “kém tối ưu hơn” trong một bài toán con này nhưng lại có thể là lời giải tốt trong một bài toán con khác.
• Số lượng các bài toán con phải không quá lớn. Rất nhiều các bài toán NP – khó có thể giải được nhờ quy hoạch động, nhưng việc làm này là không hiệu quả do số lượng các bài toán con tăng theo hàm mũ. Một đòi hỏi quan trọng đối với quy hoạch động là tổng số các bài toán con cần giải là không quá lớn, cùng lắm phải bị chặn bởi một đa thức của kích thước dữ liệu vào.
Sau bước phân rã, có thể hình thức hóa chi tiết hơn các bước giải bài toán qui hoạch động như sau:
Bước 1: Đặt giả thiết về hàm qui hoạch động. Hàm qui hoạch động là hàm hình thức hóa cho bài toán con tổng quát cần định lượng, thể hiện trực tiếp hoặc gián tiếp yêu cầu của cho bài toán đã cho. Mục đích của bước này là nêu được ý nghĩ của hàm qui hoạch động mà chưa cần phải tìm dạng biểu diễn cụ thể của nó như thế nào.
Bước 2: Tìm nghiệm các bài toán con nhỏ nhất. Ở bước này ta tính hàm qui hoạch động tại các trường hợp đơn giản nhất hoặc các trường hợp đặc biệt mà dễ dàng tính toán được.
Bước 3: Xây dựng công thức qui hoạch động, tìm nghiệm cho bài toán con tổng quát. Đây là bước quan trọng nhất của qui hoạch động, thu được nhờ quá trình phân rã. Tại đây ta cần định nghĩa cụ thể hàm qui hoạch động, tức là tìm dạng biểu diễn của nó. Nói cách khác, ta cần xây dựng được công thức truy hồi để tìm nghiệm của bài toán con tổng quát dựa vào tập nghiệm của các bài toán con cỡ nhỏ hơn đã giải, công thức này gọi là công thức qui hoạch động.
Khi đã định nghĩa được công thức qui hoạch động thì tức là ta đã giải xong một họ các bài toán con, trong đó có bài toán cần giải với kích thước lớn nhất.
Chú ý: Ở bước 2 và bước 3, tập hợp nghiệm của các bài toán con phải được lưu trong một bảng. Bảng này thường là biểu diễn trực tiếp hàm qui hoạch động.
Bước 4. Tìm nghiệm cho bài toán. Bước này chính ta công việc Tổng hợp lời giải, tức là dựa vào bảng lưu nghiệm để từ các bài toán con, tìm nghiệm của bài toán ban đầu.
3. Một số ví dụ minh họa
3.1. Dãy con tăng dần dài nhất Bài toán 3.1: Cho dãy (a) gồm n phần từ a1, a2, ..., an. Hãy tìm dãy con không giảm có độ dài lớn nhất (nhiều phần tử nhất).

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
47
a) Giải bài toán bằng qui hoạch động
Bước 1: Nêu giả thiết hàm qui hoạch động. Gọi giá trị hàm f(i) là độ dài dãy con tăng dần lớn nhất tính từ a1 đến ai (lấy cả ai), với i = 1, 2, ... n.
Hàm này biểu diễn giá trị của nghiệm cần tìm. Nghiệm cần tìm có thể tìm lại được ở bước 4 nhờ chính hàm này khi nó được cài đặt bởi một mảng một chiều.
Bước 2. Tìm nghiệm các bài toán con nhỏ nhất. Dễ thấy dãy con tăng dần dài nhất từ a1 đến a1 chỉ có một phần tử là chính a1. Do đó ta có:
f(1) = 1;
Bước 3. Xây dựng công thức qui hoạch động. Ta cần phải tính f(i) với i ≥ 2. Nói cách khác khi đã biết f(1), f(2), ... , f(i-1) thì f(i) được tính như thế nào?
Ví dụ: ta thử tìm cách tính f(2), f(3), ..., f(10) đối với dãy (a) trong bảng sau:
i 1 2 3 4 5 6 7 8 9 10
ai 9 3 7 4 4 6 5 6 2 3
f(i) 1 1 2 2 3 4 4 5 1 2
Vì f(i) chắc chắn lấy cả ai nên f(i) sẽ là tổng của độ dài 1 sẵn có cộng với một lượng p nào đó. Ta tính lượng p này như sau: Xét tất cả các phần tử aj đứng trước ai mà nhỏ hơn hoặc bằng ai, với mỗi phần tử aj đó ta nhìn xuống giá trị của f(j) tương ứng đã tính (j = 1, 2, ..., i-1) và chọn giá trị f(j) lớn nhất, là lượng p cần tìm. Một cách hình thức, ta có công thức qui hoạch động:
f(i) = 1 + max f(j) : aj ≤ ai , j = i-1, i-2, ...., 1 (1)
Vậy độ dài dãy con tăng dần lớn nhất từ a1 đến an lấy cả an là f(n); Độ dài dãy con tăng dần lớn nhất cần tìm chính là
max f(i); i = n, n-1, …, 1
Rõ ràng việc phân rã bài toán đã cho thành các bài toán con luôn đảm bảo cấu trúc tối ưu (nghĩa là từng bài toán con là tối ưu) và số lượng các bài toán con là hữu hạn. Nói cách khác, quá trình tính dần giá trị của hàm f(i) từ trái sang phải luôn cho kết quả f(i) là độ dài dãy con lớn nhất a1 đến ai lấy cả ai.
Hàm f(i) có thể biểu diễn bởi mảng f[1..n]. Thủ tục tính giá trị của mảng này như sau:
procedure DayconTangdan;
begin
f[1] := 1;
for i:= 2 to n do
begin max := 0;
for j:= i-1 downto 1 do

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
48
if a[j] <= a[i] then
if f[j] > max then m := f[j];
f[i] := 1 + max;
end;
end;
Bước 4. Tìm nghiệm cho bài toán. Dựa vào mảng lưu giá trị nghiệm các bài toán con là f[1..n] ta có thể tìm nghiệm của bài toán ban đầu như sau:
Dãy con dài nhất cần tìm, in ra theo thứ tự ngược có thể thực hiện như sau:
1. Tìm f[k] = max f[i]; i = n, n-1, …, 1. Đặt p = a[k];
2. Lặp quá trình sau khi p > 0
2.1. In ra a[k];
2.2. Tìm f[k] sát bên trái p mà bằng p - 1
2.3. Gán p := p - 1 trước khi quay về đầu vòng lặp
i 1 2 3 4 5 6 7 8 9 10
3 4 4 5 6 ai 8 7 6 4 3
Để không phải in ra nghiệm theo thứ tự ngược, ở bước 2.1. ta tích lũy dần các thành phần của nghiệm vào một mảng x. Sau khi tìm xong các thành phần của nghiệm, ta sẽ in ra mảng x theo thứ tự từ cuối mảng về đầu mảng. Thủ tục tìm lại nghiệm có thể viết như sau:
procedure TimNghiem;
begin
(* 1. Tìm f[k] = max f[i]; i = n, n-1, …, 1. Đặt p = a[k]; *)
k := 1 ;
for i := 1 to n do
if f[i] > f[k] then k := i;
p := f[k];
r := 0;
while p > 0 do
begin
(* 2.1. tích lũy a[k] vào nghiệm x*)
r := r + 1; x[r] := a[k];
f(i) 1 1 2 3 4 5 2 4 4 2

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
49
(* 2.2. tìm f[k] sát bên trái p mà bằng p - 1 *)
while f[k] <> p-1 do k := k - 1;
(* 2.3. Gán p := p - 1 trước khi quay về đầu vòng lặp *)
p := p - 1;
end;
writeln(‘Output: ‘);
for i := r downto 1 do write(x[i]:5);
end;
b) Kỹ thuật mảng lưu vết
Để dễ dàng tìm lại nghiệm, ta thường sử dụng mảng lưu vết để đánh dấu chỉ số của các nghiệm tối ưu trong quá trình giải các bài toán con cỡ lớn dần. Ở đây ta dùng một mảng lưu vết pred[1..n] trong đó pred[i] = j nghĩa là ngay trước ai trong dãy con lớn nhất đang xét từ a1 đến ai
là phần tử aj. Ban đầu pred[1] := -1 và trong (1) nếu tìm được giá trị max > 0 thì ta gán pred[i] := j, ngược lại nếu max = 0 tức là không có phần tử nào đứng trước ai mà nhỏ hơn hoặc bằng ai thì ta cũng gán pred[i] := -1;
i 1 2 3 4 5 6 7 8 9 10
3 4 4 5 6 ai 8 7 6 4 3
Các thủ tục QHĐ và TìmNghiem sẽ được viết lại như sau;
procedure DayconTangdan2;
begin
f[1] := 1; pred[1]:=-1;
for i:= 2 to n do
begin max := 0; j0:=i;
for j:= i-1 downto 1 do
if a[j] <= a[i] then
if f[j] > max then
begin max := f[j];
j0 := j;
end;
f[i] := 1 + max;
f(i) 1 1 2 3 4 5 2 4 4 2
-1 2 4 5 7 pred[i] -1 2 5 5 2

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
50
if max > 0 then pred[i] := j0
else pred[i] := -1;
end;
end;
procedure TimNghiem2;
begin
k := 1; for i := 1 to n do if f[i] > f[k] then k := i;
r := 0;
while k > -1 do
begin
r := r + 1; x[r] := a[k];
k := pred[k];
end;
writeln(‘Output: ‘);
for i := r downto 1 do write(x[i]:5);
end;
c) Cải tiến hàm qui hoạch động
Để ý thấy rằng độ dài dãy con tăng dần lớn nhất tính từ a1 đến ai và lấy cả ai như đã tính chưa chắc đã lớn hơn độ dài dãy con tăng dần lớn nhất từ a1 đến ai mà không lấy ai. Ví dụ f(10) = 2 nếu lấy cả a10 và f(10) = 5 nếu không lấy a10 mà chỉ lấy đến a8. Điều này là do ở bước 1 (do đó ảnh hưởng đến các bước còn lại) ta đặt ra giả thiết hàm qui hoạch động quá cứng nhắc, là lấy cả ai. Kết quả là giá trị nghiệm tối ưu phải tính lại bằng cách tính max f(i), i = 1, 2, ..., n. Trong những tính huống kiểu này, thường thì hàm qui hoạch động được định nghĩa tốt hơn như sau.
Bước 1: Nêu giả thiết hàm qui hoạch động: Gọi f(i) là độ dài dãy con tăng dần lớn nhất tính từ a1 đến ai (có thể lấy hoặc không lấy ai), với i = 1, 2, ... n. Với giả thiết này thì độ dài dãy con tăng dần lớn nhất cần tìm sẽ là f(n).
Bước 2. Tìm nghiệm bài toán con nhỏ nhất. f(1) := 1;
Bước 3. Xây dựng công thức qui hoạch động.
Ta có nhận xét sau đây:
⎩⎨⎧
−−−=≤+
=][)1(
][1,...,2,1],[][:)(max1)(
iaincludenotififiaincludeifiijiajajf
if (2)
Kết hợp 2 khả năng trên, ta có thể xây dựng được công thức qui hoạch động tính f(i) là độ dài dãy con lớn nhất tính từ a1 đến ai với i ≥ 2 như sau:

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
51
)1(,...,3,2),1(),(max)( niificif =−= (3)
Với c(i) là độ dài dãy con tăng dần lớn nhất tính từ a1 đến ai và lấy cả ai. Việc tính c(i) được xác định như sau:
⎩⎨⎧
>−−=≤+=
=1,1,...,2,1],[][:)(max1
1,1)(
iifiijiajajfiif
ic (4)
Mảng lưu vết pred[1..n] được tính tương tự như trên, tuy nhiên pred[i] := j với j lấy theo max của c(j) hay lấy theo max của d(j) là tùy theo cái nào lớn hơn, và nếu hai giá trị này bằng nhau thì ưu tiên lấy theo c(j)
3.2. Trở lại bài toán mảng con trọng số lớn nhất Bài toán 3.2. Trong chương 2 ta đã trình bày thuật toán chia để trị để giải bài toán tìm dãy con (mảng con) có trọng số nhất với thời gian tính cỡ O(nlog2n). Bây giờ ta xét cách tiếp cận bằng quy hoạch động để giải bài toán này.
a) Các bước qui hoạch động
Bước 1: Nêu giả thiết hàm qui hoạch động.
Gọi s(i) là tổng của dãy con lớn nhất trong dãy:
a1, a2, …., ai, i = 1,2,…, n.
Rõ ràng s(n) là giá trị cần tìm.
Bước 2: Giải các bài toán đơn giản Hiển nhiên ta có s(1) = a1.
Bước 3: Xây dựng công thức qui hoạch động
Giả sử i > 1 và s(k) đã biết với k = 1,2,…, i - 1. Ta cần tính s(i) là tổng của dãy con lớn nhất của dãy con lớn nhất của dãy a1, a2, …, ai-1, ai.
Rõ ràng dãy con lớn nhất của dãy này hoặc là có chứa phần tử ai hoặc là không chứa phần tử ai, vì thế chỉ có thể là một trong hai dãy sau đây:
• Dãy con lớn nhất của dãy a1, a2, …, ai-1.
• Dãy con lớn nhất của dãy a1, a2, …, ai kết thúc tại ai.
Từ đó suy ra

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
52
s(i) = max s(i-1), e(i),
Trong đó e(i) là tổng của dãy con lớn nhất của dãy a1, a2, …, ai kết thúc tại ai.
Lưu ý rằng để tính e(i), i = 1, 2, …, n, ta cũng có thể sử dụng công thức đệ quy sau:
e(1) = a1;
e(i) = max ai, e(i-1) + ai , i > 1.
b) Mô phỏng Pascal
Ta có thuật toán sau để giải bài toán đặt ra:
procedure Maxsub(a);
begin
e := a[1]; (* e là tổng của dãy con lớn nhất *)
s[1] := a[1]; (* s là mảng qui hoạch động*)
imax : = 1; (* imax là vị trí kết thúc của dãy con lớn nhất *)
for i: = 2 to n do
begin
u := e + a[i];
v := a[i];
if (u > v) then e := u else e := v;
if (e > s[i-1]) then
begin
s[i] = e;
imax: = i;
end
else s[i] := s[i-1]
end;
end;
Dễ thấy thuật toán Maxsub có thời gian tính là O(n).
3.3. Xâu con chung dài nhất Bài toán 3.3. Ta gọi xâu con của một xâu cho trước là xâu thu được bằng việc loại bỏ một số kí tự của xâu đã cho. Một cách hình thức, giả sử cho xâu X = x1 x2 … xm, thì xâu Z = z1z2…zk được gọi là xâu con X nếu tìm được dãy các chỉ số 1≤ i1 < i2 < … < ik ≤ n sao cho , j = 1, 2, …,
k. Chẳng hạn dãy Z = ‘BCDB’ là xâu con xâu X = ‘AABCBCDABDAB’ với dãy chỉ số là <3, 4, 7, 9>.
jij xz =

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
53
Cho hai xâu X và Y ta nói xâu Z là xâu con chung của X và Y nếu Z là xâu con của cả hai xâu X và Y. Ví dụ, nếu X = ‘ABCDEFG’ và Y = ‘CCEDEGF’ thì Z = ‘CDF’ là một xâu con chung của hai xâu X và Y, còn xâu ‘BFG’ không là xâu con chung của chúng. Xâu ‘CDF’ không là xâu con chung dài nhất vì nó có độ dài 3 (số phần tử trong xâu), trong khi đó xâu ‘CDEG’ là xâu con chung của X và Y có độ dài 4, đồng thời đó là xâu con chung dài nhất vì không tìm được xâu con chung có độ dài 5.
Bài toán đặt ra như sau: Cho xâu X = ‘x1x2…xm’ và Y = ‘y1y2…yn’. Cần tìm xâu con chung dài nhất của X và Y.
a) Phương pháp duyệt toàn bộ
Thuật toán trực tiếp để giải là duyệt tất cả các xâu con của X và kiểm tra xem mỗi xâu như vậy có là xâu con của Y, và giữ lại xâu con dài nhất. Mỗi xâu con của X tương ứng với dãy chỉ số <i1,i2, …, ik> là tập con k phần tử của tập chỉ số 1, 2, …, m, vì thế có tất cả 2m xâu con của X. Như vậy thuật toán trực tiếp đòi hỏi thời gian hàm mũ và không thể ứng dụng được trên thực tế. Ta sẽ áp dụng quy hoạch động để xây dựng thuật toán giải bài toán này.
b) Phương pháp quy hoạch động
Bước 1. Nêu giả định về hàm qui hoạch động
Gọi C(i, j) là độ dài của xâu con chung dài nhất của hai xâu:
Xi = ‘x1x2…xi’ và Yj = ‘y1y2…yj’
với mỗi 0 ≤ i ≤ m và 0 ≤ j ≤ n
Như vậy ta đã phân bài toán cần giải ra thành (m + 1)(n + 1) bài toán con. Bản thân bài toán xuất phát là bài toán con có kích thước lớn nhất c(m, n).
Bước 2: Tìm nghiệm của các bài toán con đơn giản
Để thuận lợi, ta đồng nhất hàm c(i,j) với mảng C[0..m, 0..n]. Rõ ràng nếu một trong hai xâu rỗng, không có phần tử chung thì xâu con chung cũng là rỗng. Vì vậy ta có
C[0, j] = 0 ∀j, j = 0, 1,…, n và
C[i, 0] = 0 ∀i, i = 0, 1,…, m.
Bước 3: Xây dựng công thức qui hoạch động
Giả sử i > 0, j > 0 ta cần tính C[i, j] là độ dài của xâu con chung lớn nhất của hai xâu Xi và Yj. Có hai trường hợp:
Nếu xi = yj thì xâu con chung dài nhất của Xi và Yj sẽ thu được bằng việc bổ sung xi (hoặc yj) vào xâu con chung dài nhất của hai xâu Xi-1và Yj-1
Nếu xi ≠ yj thì xâu con chung dài nhất của Xi và Yj sẽ là xâu con dài nhất trong hai xâu con chung dài nhất của (Xi-1 và Yj) và của (Xi-1 và Yj).
Từ đó ta có công thức qui hoạch động sau để tính C[i, j]:

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
54
⎪⎩
⎪⎨
⎧
≠>−−=−−+
===
ji
ji
yxandjiifjiCjiCyxifjiC
joriifjiC
0,],1[],1,[max]1,1[1
00,0],[
với i = 0, 1,…, m và j = 0, 1,…, n.
Hoặc ngắn gọn hơn là với i =0, 1,…, m và j = 0, 1,…, n thì
C[i, j] = max C[i, j-1], C[i-1, j], C[i-1, j - 1] + x
với x = 0 nếu xi = yj và x = 1 nếu xi ≠ yj
Bước 4. Việc tìm lại nghiệm
Dễ dàng lần vết dựa vào mảng C ,bắt đầu từ vị trí C[m, n].
1. Khởi tạo i := m, j := n; z := ‘’;
2. Lặp trình sau khi i > 0 và j > 0
2.1. Nếu x[i] = y[j] thì thêm x[i] vào cuối xâu z và đồng thời giảm 1 đơn vị cho cả i và j
2.2. Ngược lại, nếu x[i] ≠ y[j] thì
Nếu C[i, j] = C[i-1, j] thì lùi về hàng trên bằng lệnh giảm i := i - 1
Ngược lại, nếu C[i, j] = C[i, j - 1] lùi về cột trái bằng lệnh giảm j := j - 1
c) Mô phỏng Pascal
Thuật toán qui hoạch động tìm độ dài xâu con chung dài nhất có thể mô tả như sau.
procedure XauConChungMax(x,y : string; var z : string);
begin
for i :=1 to m do c[i,0]:=0;
forj: =1 to n do c[0,j]:=0;
z := ‘’;
for i: =1 to m do
for j: = 1 to n do
if x[i] = y[j] then
begin
c[i,j]:=c[i-1,j-1]+1;
z := z + x[i];
end
else
if c [i-1,j] < c[i,j-1] then c[i,j]:=c[i-1,j]

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
55
else c[i,j]:=c[i,j-1];
end;
Trong thủ tục mô tả ở trên ta sử dụng biến b[i, j] để ghi nhận tình huống tối ưu khi tính giá trị c[i, j]. Sử dụng biến này ta có thể đưa ra dãy con chung dài nhất của hai dãy X và Y nhờ thủ tục sau đây:
Dễ dàng đánh giá được thời gian tính của thuật toán LCS là O(mn).
3.4. Bài toán cái túi Bài toán 3.4. Cho n đồ vật (n ≤ 100), đồ vật thứ i có trọng lượng là wi (wi ≤ 100) và có giá trị sử dụng là ci (ci ≤ 100). Cần xếp đồ vật vào một cái túi sao cho tổng giá trị sử dụng được xếp vào túi là lớn nhất. Biết rằng cái túi chỉ có thể mang được trọng lượng không vượt quá b (b ≤ 100).
a) Phương pháp qui hoạch động
Bước 1. Nêu giả định về hàm qui hoạch động
Gọi f(i, j) là giá trị sử dụng lớn nhất của của các đồ vật được xếp vào túi khi chọn các đồ vật 1, 2, …, i và trọng lượng giới hạn của túi là j. Khi đó giá trị nghiệm tốt nhất của bài toán là f(n, m).
Bước 2: Tìm nghiệm của các bài toán con đơn giản
Dễ thấy f(0, j) = 0 với mọi j = 1, 2, …, b
Bước 3: Xây dựng công thức qui hoạch động
Với giới hạn trọng lượng j, việc chọn tối ưu trong các đồ vật 1, 2, …, i - 1, i để có giá trị lớn nhất có hai khả năng:
• Nếu không chọn đồ vật thứ i thì f(i, j) là giá trị sử dụng lớn nhất có thể bằng cách chọn trong các đồ vật 1, 2, …, i - 1 với trọng lượng j, tức là
f(i, j) = f (i-1, j)
• Nếu có chọn đồ vật i (với wi ≤ j) thì f(i, j) bằng giá trị sử dụng của đồ vật thứ i cộng với giá trị sử dụng lớn nhất có thể được bằng cách chọn trong số các gói 1, 2, …, i - 1 với giới hạn trọng lượng là j - wi. Nói cách khác ta có công thức:
f(i, j) = ci + f(i-1, j - wi)
Kết hợp hai khả năng trên ta có công thức qui hoạch động:
f(i, j) = max f(i-1, j) , ci + f(i-1, j - wi)
với i = 1, 2, …, n và j = 0, 1, 2, .., M.
Bước 4. Tìm lại nghiệm
Ta đồng nhất hàm f(i,j) với bảng F[1..n, 1..b] (còn gọi là bảng qui hoạch động). Sau khi tính xong mảng F, việc truy vết trên F để tìm nghiệm như sau:

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
56
Chú ý rằng F[n, b] là giá trị sử dụng lớn nhất của các đồ vật được xếp vào túi khi xem xét tất cả n đồ vật và giới hạn trọng lượng của túi là b.
Nếu F[n , b] = F[n - 1, b] thì tức là không chọn đồ vật thứ n, ta truy tiếp F[n - 1, b]. Còn nếu F[n, b] ≠ F[n-1, b] thì chứng tỏ đồ vật thứ n được chọn, ta ghi nhận thành phần đó vào nghiệm và truy tiếp F[n-1, b-wn]. Cứ tiếp tục quá trình đó cho đến khi truy lên tới hàng thứ 0 của bảng F.
b) Mô phỏng Pascal
procedure Caitui;
begin
for j := 0 to b do F[0, j] := 0;
for i := 1 to n do
for j := 1 to b do
begin
F[i, j] := F[i-1, j];
if (j > wi) and (F[i, j] < F[i-1, j-wi] + ci then
F[i, j] := F[i, j] < F[i-1, j-wi] ;
end;
end;
procedure Trace;
begin
write(‘Max value: ‘, F[n, b]);
while n ≠ 0 do
begin
if F[n, b] ≠ F[n-1, b] then
begin
write(‘Chon do vat ‘, n, ‘ w = ‘, wn, ‘ value = ‘, vn);
b := b - wn;
end;
n := n - 1;
end;
end;

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
57
3.5. Nhân ma trận Bài toán 3.5. Cần tính tích của n ma trận M1M2...Mn, (n ≤ 100) với số lượng ít nhất các phép nhân. Biết rằng ma trận Mi có kích thước di-1, × di (i =1, 2, .., n).
Như đã biết, tính của ma trận A = (aik) kích thước p × q với ma trận B = (bkj) kích thước q × r là ma trận C = (cij) kích thước p × r với các phần tử được tính theo công thức:
.1,1,1
qjpibacq
kkjikij ≤≤≤≤= ∑
=
(1)
Chúng ta có thể sử dụng đoạn chương trình sau đây để tính tích của hai ma trận A,B:
for i : =1 to p do
for j : =1 to r do
begin
c [i,j] = 0;
for k : = 1 to q do c[i,j] :=c[i,j] +a[i,k] *b[k,j];
end;
Rõ ràng , đoạn chương trình trên đòi hỏi thực hiện tất cả p.q.r phép nhân để tính tích của hai ma trận.
a) Phân tích bài toán
Giả sử ta phải tính tích của nhiều hơn là hai ma trận. Chú ý rằng do tích ma trận không có tính chất giao hoán, nên ta không được thay đổi thứ tự của các ma trận trong biểu thức đã cho. Do phép nhân ma trận có tính kết hợp, ta có thể tính tích của các ma trận theo nhiều cách khác nhau.
Ví dụ 3.1. Nhân nhiều ma trận
Giả sử cần tính tích M = ABCD của bốn ma trận, trong đó A có kích thước 13 x 5, B có kích thước 5 x 89, C có kích thước 89 x 3 và D có kích thước 3 x 34. Sử dụng cách tính
M = ((AB)C)D),
Ta phải thực hiện lần lượt tính
AB 5785 phép nhân
(AB)C 3271 phép nhân
((AB)C)D 1326 phép nhân
Và tổng cộng là 10582 phép nhân
Tất cả có 5 phương pháp khác nhau để tính tích ABCD:
1. ((AB)C)D 10582
2. (AB)(CD) 54201

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
58
3. (A(BC))D 2856
4. A((BC)D) 4055
5. A(B(CD)) 26418
Phương pháp hiệu quả nhất (phương pháp 3) đòi hỏi khối lượng phép nhân ít hơn gần 19 lần so với phương pháp tồi nhất (phương pháp 5).
Mỗi cách tính tích các ma trận đã cho đòi hỏi một thời gian tính khác nhau. Số lượng phép nhân là một yếu số đánh giá khá chính xác hiệu quả của phương pháp. Để tìm phương pháp hiệu quả nhất, chúng ta có thể liệt kê tất cả các cách điền dấu ngoặc vào biểu thức tích ma trận đã cho và tính số lượng phép nhân đòi hỏi theo mỗi cách.
Gọi T(n) là số cách điền các dấu ngoặc vào biểu thức tích của n ma trận. Giả sử ta định đặt cặp dấu ngoặc )( phân tách đầu tiên vào giữa ma trận thứ i và ma trận thứ (i + 1) trong biểu thức tích, tức là:
M = (M1 M2 … Mi)(Mi+1 Mi+2 … Mn)
Khi đó có T(i) cách đặt dấu ngoặc cho thừa số thứ nhất (M1 M2 … Mi) và T(n-i) cách đặt dấu ngoặc cho thừa số thứ hai (Mi+1 Mi+2 … Mn) và từ đó có T(i)T(n-i) cách tính biểu thức (M1 M2 … Mi)(Mi+1 Mi+2 … Mn). Do i có thể nhận bất cứ giá trị nào trong khoảng từ 1 đến n-1, suy ra ta có công thức truy hồi sau để tính T(n):
∑−
=
−=1
1
)()()(n
i
inTiTnT (2)
Kết hợp với điều kiện đầu hiển nhiên T(1) = 1, ta có thể tính các giá trị của T(n) với mọi n. Giá trị của T(n) được gọi là số Catalan. Công thức sau đây cho phép tính T(n) qua hệ số tổ hợp với n ≥ 2
21
22 ))!1(()!22(1)(
−−
== −− n
nCn
nT nn (3)
Từ đó T(n) = 4nn2. Như vậy, phương pháp duyệt toàn bộ không thể sử dụng để tìm cách tính hiệu quả biểu thức tính của n ma trận, khi n lớn.
Bây giờ, ta xét cách áp dụng quy hoạch động để giải bài toán đặt ra.
b) Phân rã (Xác định cấu trúc con tối ưu)
Nếu cách tính tối ưu tích của n ma trận đòi hỏi đặt dấu ngoặc tách đầu tiên giữa ma trận thứ i và thứ (i+1) của biểu thức tích, thì khi đó cả hai tích con (M1 M2 … Mi) và (Mi+1 Mi+2 … Mn) cũng phải được tính một cách tối ưu. Khi đó số phép nhân cần phải thực hiện để nhân dãy ma trận sẽ bằng tổng số phép nhân cần thực hiện để nhân hai dãy con (M1 M2 … Mi) và (Mi+1 Mi+2 … Mn) cộng với số phép nhân cần thực hiện để nhân hai ma trận kết quả tương ứng với hai dãy con này. Vì vậy để xác định cách thực hiện nhân tối ưu ta cần giải quyết hai vấn đề sau:
1) Cần đặt dấu ngoặc phân tách đầu tiên vào vị trí nào (xác định i) ?

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
59
2) Thực hiện việc tính tối ưu hai tích con (M1 M2 … Mi) và (Mi+1 Mi+2 … Mn) bằng cách nào?.
Trả lời câu hỏi thứ nhất: Xét tất cả các giá trị có thể được của i. Trả lời câu hỏi thứ hai: việc tính mỗi tích con rõ ràng có dạng giống như bài toán ban đầu, vì thế có thể giải một cách đệ quy bằng cách áp dụng cách giải như đối với dãy xuất phát. Như vậy, bài toán nhân dãy ma trận thoả mãn đòi hỏi về cấu trúc con tối ưu: Để tìm cách tính tối ưu việc nhân dãy ma trận (M1 M2 … Mn) chúng ta có thể sử dụng cách tính tối ưu của hai tích con (M1 M2 … Mi) và (Mi+1 Mi+2 … Mn). Nói cách khác, những bài toán con phải được giải một cách tối ưu cũng như bài toán ban đầu. Phân tích này cho phép ta sử dụng quy hoạch động để giải bài toán đặt ra.
c) Các bước qui hoạch động
Bước 1: Đặt giải thiết hàm qui hoạch động: Gọi giá trị hàm f(i, j) là số phép nhân ít nhất cần thực hiện để tính tích (Mi+1 Mi+2 … Mj), với 1 ≤ i ≤ j ≤ n
Số lượng phép nhân ít nhất cần tìm sẽ là f(1,n). Và tập tất cả các f(i,j) là tập các lời giải của các bài toán con, hay ngắn gọn là họ các bài toán con.
Bước 2. Tìm nghiệm bài toán con nhỏ nhất
Theo đầu bài, kích thước của các ma trận được cho bởi mảng d[0 … n], trong đó ma trận Mi có kích thước di-1 × di, i = 1, 2, 3, … n.
- Trường hợp rất đặc biệt, f(i,i) = 0, vì tích của một ma trận có số lượng phép nhân là 0.
- Số lượng phép nhân của tích của hai ma trận liên tiếp được biết qua định nghĩa phép nhân hai ma trận, do đó f(i, i+1) = di-1didi+1
Bước 3. Xây dựng công thức qui hoạch động.
Hàm f(i,j) với 1 ≤ i ≤ j ≤ n có thể biểu diễn trong bảng (mảng hai chiều) lưu các giá nghiệm của các bài toán con f[1..n, 1..n]. Ta có thể xây dựng bảng giá trị f(i, j) lần lượt theo từng đường chéo của nó, trong đó đường chéo thứ s chứa các phần tử f(i, j) với chỉ số thoả mãn j – i = s.
Ta đã có
- Đường chéo s = 0 sẽ chứa các phần tử f(i, i) = 0, với i = 1, 2, … n.
- Đường chéo s = 1 chứa các phần tử f(i, i+1) = di-1didi+1 tương ứng với tích MiMi + 1, i = 1, 2, …, n - 1
- Ở bước 3 này ta phải tính f(i, j) trên các đường chéo s > 1.
Ta thấy đường chéo thứ s chứa các phần tử f(i, j + s) tương ứng với tích Mi Mi+1 … Mi+s. Ta có thể lựa chọn việc đặt dấu ngoặc tách đầu tiên sau một trong số các ma trận Mi,Mi+1, …,Mi+s-1. Nếu đặt dấu ngoặc đầu tiên sau Mk, với i ≤ k < i+s, ta cần thực hiện f(i, k) phép nhân để tính thừa số thứ nhất, f(k+1, i + s) phép nhân để tính thừa số thứ hai, và cuối cùng là di-1dkdi+s phép nhân để tính tích của hai ma trận thừa số để thu được ma trận kết quả. Để tìm cách tính tối ưu, ta cần chọn cách đặt dấu ngoặc tách đòi hỏi ít phép nhân nhất. Một cách hình thức, ta có công thức qui hoạch động cần tìm:

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
60
f(i, j + s) = minf(i, k) + f(k+1, i + s) + di-1dkdi+s: 1 ≤ k < i+s, i = 1, 2, …, n – s.
Lưu ý rằng, để dễ theo dõi, ta viết cả công thức cho trường hợp s = 1, mà dễ thấy là công thức cho trường hợp tổng quát vẫn đúng cho s = 1.
Ví dụ 3.2. Tìm cách tính tối ưu cho tích của bốn ma trận cho trong ví dụ 1.
j=1 2 3 4
i=1 0 5785 1530 2856
2 0 1335 1845 s=3
3 0 9078 s=2
4 0 s=1
s=0
Ta có d = (13, 5, 89, 3, 34).
Với s = 1, f(1,2) = 5785, f(2,3) = 1335 và f(3,4) = 9078.
Với s = 2 ta thu được
- f(1,3) = min f(1,1) + f(2,3) + 13 x 5 x 3, f(1, 2) + f(3, 3) + 13 x 89 x 3
= min1530, 9256 = 1530
- f(2, 4) = minf(2,2) + f(3, 4) + 5 x 89 x 34, f(2, 3) + f(4, 4) + 5 x 3 x 34
= min24208, 1845 = 1845
Với s = 3 ta có
- f(1, 4) = minf(1, 1) + f(2, 4) + 13 x 5 x 34), k = 1
f(1, 2) + f(3, 4) + 13 x 89 x 34, k = 2
f(1, 3) + f(4, 4) + 13 x 3 x 34, k = 3
= min4055, 54201, 2856 = 2856.
Bước 4. Tìm nghiệm cho bài toán. Dựa vào mảng f[1..n, 1..n] lưu giá trị nghiệm của các bài toán con, ta có thể tìm nghiệm của bài toán đã (cách đặt các dấu ngoặc).
Ta sử dụng kỹ thuật lưu vết bằng bảng h[i, j] ghi nhận cách đặt dấu ngoặc tách đầu tiên cho giá trị f(i, j). Cùng với việc tính các giá trị f(i, j) ta sẽ tính h[i, j] theo quy tắc:
Với s = 1: f(i, i +1), ta đặt h[i, i +1 ] := i + 1;
Với 1 < s < n:
Biểu thức f(i, j + s) = minf(i, k) + f(k+1, i + s) + di-1dkdi+s: 1 ≤ k < i+s, i = 1, 2, …, n – s đạt giá trị min tại k = t, ta đặt h[i, j + s] = t;
Ví dụ 3.3. Các giá trị của mảng lưu vết h[i,j] theo ví dụ 1

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
61
j=1 2 3 4
i=1 1 2 1 3
2 2 3 3 s=3
3 3 4 s=2
4 4 s=1
s=0
Ta có số phép nhân cần thực hiện là f(1, 4) = 2856. Dấu ngoặc đầu tiên cần đặt sau vị trí h[1, 4] = 3, tức là M = (ABC)D. Ta tìm cách đặt dấu ngoặc đầu tiên để có f(1, 3) tương ứng với tích ABC. Ta có h[1, 3] = 1, tức là tích ABC được tính tối ưu theo cách: ABC = A(BC). Từ đó suy ra, lời giải tối ưu là: M = (A(BC))D.
d) Đánh giá độ phức tạp giải thuật
Bây giờ, ta tính số phép toán cần thực hiện theo thuật toán vừa trình bày. Với mỗi s > 0, có n – s phần tử trên đường chéo cần tính, để tính mỗi phần tử đó ta cần so sánh s giá trị số tương ứng với các giá trị có thể của k. Từ đó suy ra số phép toán cần thực hiện theo thuật toán là cỡ
)(6/)(
6/)12)(1(2/)1(
)(
3
3
2
1
1
21
1
1
1
nOnn
nnnnn
ssnssnn
s
n
s
n
s
=
−=
−−−−=
−=− ∑∑∑−
=
−
=
−
=
e) Mô phỏng Pascal cài đặt thuật toán
Các thủ tục qui hoạch động và tìm lại nghiệm có thể mô tả trong hai thủ tục sau:
procedure NhanMatrand,n)
f[i,j] - chi phí tối ưu thực hiện nhân dãy Mi . . . Mj;
h[i,j] - ghi nhận vị trí đặt dấu ngoặc đầu tiên trong cách thực hiện nhân dãy Mi . . . Mj
begin
for i: = 1 to n do m[i,j]: = 0; //khởi tạo
for s: = 1 to n do // s = chỉ số của đường chéo
for i: = 1 to n - s do
begin
j: = i + s - 1; m[i,j] = +∞;
for k: = i to j - 1 do
begin

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
62
q: = m[i,k] + m[k+1,j] + d[i-1]*d[k]*d[j];
if(q<m[i,j]) then
begin
m[i,j] = q; h[i,j] = k;
end;
end;
end;
end;
Thủ tục đệ quy sau đây sử dụng mảng ghi nhận h để đưa ra trình tự nhân tối ưu.
procedure Mult(i,j);
begin
if(i<j) then
begin
k = h[i,j];
X = Mult(i,k); X = M[i] / . . . M[k]
Y = Mult(k+1,j); Y = M[k+1] . . . M[j]
return X*Y; Nhân ma trận X và Y
end
else
return M[i];
end;
BÀI TẬP CHƯƠNG 3 1. Tìm trình tự nhân tối ưu để tính tích của dãy ma trận A1x A2 x A3 x A4 x A5 trong đó kích thước của A1 là 10 x 4, A2 - 4 x 5, A3 - 5 x 20, A4 - 20 x 2, và A5 -2 x 50.
2.Xét Bài toán về các đoạn thẳng không giao nhau có trọng số.
Đầu vào: Cho họ các đoạn thẳng mở: C = (a1, b1), (a2,b2),…,(an,bn). Đoạn thẳng (ai,bi) được gán với trọng số ci , i = 1,2,…n.
Đầu ra: Tập các đoạn không giao nhau có tổng các trọng số là lớn nhất.
Thiết kế thuật toán giải bài toán đặt ra. Phân tích thời gian tính của thuật toán.
3. Phát triển thuật toán đa thức giải bài toán tìm xâu con chung dài nhất của ba xâu A,B,C; Input: 3 xâu A,B và C,
Output: Xâu con chung dài nhất S của 3 xâu A,B và C.

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
63
4. Phát triển thuật toán đa thức giải bài toán tìm xâu ngắn nhất phủ hai xâu A và B. Xâu C được gọi là xâu phủ của A nếu A là xâu con của C.
5. Có n cuộc họp, cuộc họp thứ i bắt đầu vào thời điểm ai và kết thúc ở thời điểm bi. Do chỉ có một phòng hội thảo nên 2 cuộc họp bất kì sẽ được cùng bố trí phục vụ nếu khoảng thời gian làm việc của chúng chỉ giao nhau tại đầu mút. Hãy bố trí phòng họp để phục vụ được nhiều cuộc họp nhất.
6.Cho n gói kẹo, gói thứ i có ai viên. Hãy chia các gói thành 2 phần sao cho chênh lệch giữa 2 phần là ít nhất.
7. Một xâu gọi là xâu đối xứng (palindrom) nếu xâu đó đọc từ trái sang phải hay từ phải sang trái đều như nhau. Cho một xâu S, hãy tìm số kí tự ít nhất cần thêm vào S để S trở thành xâu đối xứng.
8. Ở đất nước Omega người ta chỉ tiêu tiền xu. Có N loại tiền xu, loại thứ i có mệnh giá là ai đồng. Một người khách du lịch đến Omega du lịch với số tiền M đồng. Ông ta muốn đổi số tiền đó ra tiền xu Omega để tiện tiêu dùng. Ông ta cũng muốn số đồng tiền đổi được là ít nhất (cho túi tiền đỡ nặng khi đi đây đi đó). Bạn hãy giúp ông ta tìm cách đổi tiền.

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
64
Chương 4. THUẬT TOÁN THAM LAM
Toàn bộ phương pháp tối ưu có thể đạt được từ việc chọn tối ưu trong từng bước chọn. Về khía cạnh này giải thuật tham lam khác với giải thuật quy hoạch động ở chỗ: Trong qui hoạch động chúng ta thực hiện chọn cho từng bước, nhưng việc lựa chọn này phụ thuộc vào cách giải quyết các bài toán con. Với giải thuật tham lam, tại mỗi bước chúng ta chọn bất cứ cái gì là tốt nhất vào thời điểm hiện tại, và sau đó giải quyết các vấn đề phát sinh từ việc chọn này. Vấn đề chọn thực hiện bởi giải thuật tham lam không phụ thuộc vào việc lựa chọn trong tương lai hay cách giải quyết các bài toán con. Vì vậy khác với quy hoạch động, giải quyết các bài toán con theo kiểu bottom up (từ dưới lên), giải thuật tham lam thường sử dụng giải pháp top-down (từ trên xuống). Chúng ta phải chứng minh rằng với giải thuật tham lam, toàn bộ bài toán được giải quyết một cách tối ưu nếu mỗi bước việc chọn được thực hiện tối ưu. Các bước chọn tiếp theo được thực hiện tương tự như bước đầu tiên, nhưng với bài toán nhỏ hơn. Phương pháp qui nạp được ứng dụng trong giải thuật tham lam có thể được sử dụng cho tất cả các bước chọn.
1. Giới thiệu thuật toán tham lam
1.1. Đặc điểm của thuật toán tham lam Mục đích của phương pháp tham lam (Greedy) là xây dựng bài toán giải nhiều lớp bài toán khác nhau, đưa ra quyết định dựa ngay vào thuật toán đang có, và trong tương lai sẽ không xem xét lại quyết định trong quá khứ. Do vậy thuật toán tham lam có ưu điểm:
• Dễ đề xuất,
• Thời gian tính nhanh,
• Thường không cho kết quả đúng.
Thuật toán tham lam có những đặc điểm sau đây:
- Lời giải của bài toán là một tập hữu hạn S các phần tử thoả mãn điều kiện nào đó, ta phải giải quyết bài toán một cách tối ưu. Nói cách khác, nghiệm S phải được xây dựng sao cho hàm mục tiêu f(S) có giá trị tốt nhất (lớn nhất hay nhỏ nhất) có thể được.
- Có một tập các ứng cử viên C để chọn cho các thành phần của nghiệm tại mỗi bước.
- Xuất phát từ lời giải rỗng S, tại mỗi bước của thuật toán, ta sẽ lựa chọn một ứng cử viên trong C để bổ sung vào lời giải S hiện có.
- Xây dựng được hàm Select(C) để lựa chọn một ứng cử viên có triển vọng nhất để đưa vào lời giải S.
- Xây dựng được hàm Feasible(S ∪ x) để kiểm tra tính chấp nhận được của ứng cử viên x khi đưa vào tập nghiệm S. (Feasible (adj): có thể được, khả thi, xuôi tai)
- Xây dựng hàm Solution(S) để kiểm tra tính chấp nhận được của lời giải S

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
65
1.2. Sơ đồ chung của thuật toán tham lam procedure Greedy;
begin
C := Tập các ứng cử viên;
S := ∅ S là lời giải cần xây dựng theo thuật toán
while (C ≠ ∅) and not Solution(S) do
begin
x Select(C);
C := C \ x;
if feasible(S ∪ x) then S := S ∪ x;
end;
if Solution(S) then Return S
end;
1.3. Chứng minh thuật toán đúng Công việc này không phải đơn giản. Ta sẽ nêu một lập luận được sử dụng để chúng minh tính đúng đắn.
- Để chỉ ra thuật toán không cho lời giải đúng chỉ cần đưa ra một phản ví dụ
- Việc chứng minh thuật toán đúng khó hơn, và dựa vào hai cách chứng minh lập luận biến đổi dưới đây.
Lập luận biến đổi (Exchange Argument)
Giả sử A là thuật toán tham lam và I là một bộ dữ liệu vào. Ta gọi A(I) là lời giải tìm được bởi thuật toán A đối với bộ dữ liệu I. Vấn đề đặt ra là tìm cách trả lời câu hỏi: Thuật toán A có đúng hay không?
Ta gọi O là lời giải tối ưu của bài toán đối với bộ dữ liệu này.
Ta cần tìm cách xây dựng phép biến đổi ϕ để biến đổi O thành O’ sao cho:
. O’ cũng tốt không kém gì O (Nghĩa là O’ vẫn tối ưu)
. O’ giống với A(I) nhiều hơn O.
Nếu tồn tại phép biến đổi ϕ như thế thì thuật toán A cho lời giải đúng.
Thật vậy, giả sử đã xây dựng được phép biến đổi ϕ vừa nêu. Ta sẽ chứng minh thuật toán A là đúng đắn.
1) Chứng minh bằng phản chứng: Giả sử A không đúng đắn, hãy tìm bộ dữ liệu I sao cho A(I) khác với lời giải tối ưu của bài toán. Gọi O là lời giải tối ưu giống với A(I) nhất (do giả sử, A(I)

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
66
vẫn phải khác O). Dùng phép biến đổi ϕ đã xây dựng được, theo cách xây dựng ϕ, ta có thể biến đổi O → O’ sao cho O’ vẫn tối ưu và O’ giống với A(I) hơn. Điều này mâu thuẫn giả thiết O là lời giải tối ưu giống với A(I) nhất.
2) Chứng minh trực tiếp: Gọi O là lời giải tối u. Ta biến đổi O → O’ giống với A(I) hơn là O. Nếu O’ = A(I) thì A(I) chính là phương án tối ưu, ngược lại ta biến đổi O’ → O’’ giống với A(I) hơn. Cứ thế ta thu được dãy O’, O’’ ,O’’’ ….. ngày càng giống A(I) hơn, và chỉ có một số hữu hạn điều kiện để so sánh nên chỉ sau một số hữu hạn lần, phép biến đổi sẽ kết thúc tại A(I).
2. Một số ví dụ minh họa
2.1. Bài toán tập các đoạn thẳng không giao nhau Phát biểu bài toán
Input: Cho họ các đoạn thẳng mở C = (a1, b1), (a2, b2), ..., (an, bn)
Output: Tập các đoạn thẳng không giao nhau có lực lượng lớn nhất.
Ứng dụng thực tế: Bài toán xếp thời gian biểu cho các hội thảo, bài toán phục vụ khách hành trên một máy, bài toán lựa chọn hành động (Ví dụ có n cuộc họp dùng chung một phòng họp. Cuộc họp thứ i bắt đầu tại thời điểm ai và kết thúc tại thời điểm bi. Hãy lựa chọn các cuộc họp sao cho có nhiều cuộc họp được tổ chức nhất. Biết rằng tại một thời điểm phòng họp chỉ có thể diễn ra một cuộc họp).
Thuật toán tham lam 1:
- Ý tưởng: Bắt đầu sớm thì chọn trước.
- Sắp xếp các đoạn thẳng theo thứ tự tăng dần của đầu mút trái. Bắt đầu từ tập S là tập rỗng, ta lần lượt bổ sung các đoạn thẳng theo thứ tự đã sắp vào S nếu nó không có điểm chung với bất cứ đoạn nào trong S. Ví dụ:
Input Output 1
S = 1, 3 2
3
procedure Greedy1;
begin
C Tập các đoạn thẳng được sắp tăng dần theo đầu mút trái;
S := ∅;
while C ≠ ∅ do
begin (ai, bi) đoạn đầu tiên trong C;

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
67
C := C \ (ai, bi)
if <(ai, bi) không giao với bất cứ đoạn nào trong S> then
S := S ∪ (ai, bi)
end;
return S;
end;
Độ phức tạp của thuật toán là O(nlog2n).
Chứng minh sai: Greedy1 không cho lời giải tối ưu đối với bộ dữ liệu sau:
Input Output Trong khi lời giải tối ưu là 1
S = 1 S = 2, 32
3
Thuật toán tham lam 2:
- Ý tưởng: Đoạn thẳng ngắn nhất thì được lựa chọn trước.
- Sắp xếp các đoạn thẳng theo thứ tự không giảm của độ dài. Bắt đầu từ tập S là tập rỗng, ta lần lượt bổ sung các đoạn thẳng theo thứ tự đã sắp vào S nếu nó không có điểm chung với bất cứ đoạn nào trong S.
procedure Greedy2;
begin
C Tập các đoạn thẳng được sắp tăng dần theo độ dài;
S := ∅;
while C ≠ ∅ do
begin (ai, bi) đoạn đầu tiên trong C;
C := C \ (ai, bi)
if <(ai, bi) không giao với bất cứ đoạn nào trong S> then
S := S ∪ (ai, bi)
end;
return S;
end;
Chứng minh sai: Greedy2 không cho lời giải tối ưu đối với bộ dữ liệu sau:

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
68
Input Output Trong khi lời giải tối ưu là 1
S = 1 S = 2, 32
3
Thuật toán tham lam 3:
- Ý tưởng: Kết thúc sớm thì lựa chọn trước.
- Sắp xếp các đoạn thẳng theo thứ tự không giảm của đầu mút phải. Bắt đầu từ tập S là tập rỗng, ta lần lượt bổ sung các đoạn thẳng theo thứ tự đã sắp vào S nếu nó không có điểm chung với bất cứ đoạn nào trong S.
procedure Greedy2;
begin
C Tập các đoạn thẳng được sắp tăng dần theo đầu mút phải;
S := ∅;
while C ≠ ∅ do
begin (ai, bi) đoạn đầu tiên trong C;
C := C \ (ai, bi)
if <(ai, bi) không giao với bất cứ đoạn nào trong S> then
S := S ∪ (ai, bi)
end;
return S;
end;
Chứng minh thuật toán đúng: Giả sử Greedy3 không cho lời giải đúng. Phải tìm bộ dữ liệu đầu vào C sao cho thuật toán không cho lời giải tối ưu. Giả sử G3(C) là lời giải tìm được bởi Greedy3. Gọi O là lời giải tối ưu có số đoạn thẳng chung với G3(C) là lớn nhất. Gọi X là đoạn thẳng đầu tiên có trong G3(C) nhưng không có trong O. Đoạn này là tồn tại, vì nếu trái lại thì hoặc G3(C) ≡ O (mâu thuẫn vì đã giả thiết G3(C) ≠ O) hoặc G3(C) ∈ O (cũng mâu thuẫn vì khi đó thuật toán phải chọn đoạn thẳng X cho O, vì O cũng được sắp xếp giống G3(C)).
Gọi Y là đoạn đầu tiên kể từ bên trái của O không có mặt trong G3(C). Đoạn Y cũng phải tồn tại (Chứng minh tương tự như trên).
Khi đó đầu mút phải của đoạn X phải ở bên trái (nhỏ hơn) mút phải của đoạn Y, vì nếu trái lại thuật toán sẽ chọn Y thay vì X.

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
69
Xét tập lời giải O' sau đây:
O’ = O \ Y ∪ X
Rõ ràng:
- O’ gồm các đoạn thẳng không giao với nhau, bởi vì X không giao với bất kì đoạn nào ở bên trái nó trong O’ (do G3(C) là chấp nhận được) cũng như không giao với bất cứ đoạn nào ở bên phải nó trong O’ (Do mút phải của X nhỏ hơn mút phải của Y và Y không giao với bất cứ đoạn nào ở bên phải Y trong O’).
- Do O’ có cùng lực lượng với O nên O’ cũng là tối ưu.
- Tuy nhiên ta thấy rằng O’ giống với G3(C) hơn là O, điều này mâu thuẫn với giả thiết O là lời giải tối ưu có số đoạn thẳng chung với G3(C) là lớn nhất.
2.2. Tìm hiểu các thuật toán tham lam đối với bài toán cái túi Ta quay lại bài toán cái túi đã được phát biểu ở chương trước. Ta có thể tóm tắt bài toán như sau:
C = 1, 2, ..., n là tập chỉ số các đồ vật. Cần tìm nghiệm I trong C sao cho:
bwIi
i ≤∑∈
(1) (ràng buộc nghiệm)
max)( →= ∑∈Ii
icIf (2) (hàm mục tiêu)
Đề xuất thuật toán tham lam
Greedy1: Sắp xếp theo thứ tự không tăng của giá trị sử dụng của các đồ vật. Xét các đồ vật theo thứ tự đã xếp, lần lượt chất từng đồ vật đang xét vào túi nếu dung lượng còn lại trong túi đủ chứa nó. Thuật toán tham lam này không cho lời giải tối ưu. Sau đây là phản ví dụ :
Tham số của bài toán là n = 3; b = 19.
Đồ vật 1 2 3
Giá trị 20 16 8 (Giá trị lớn nhưng trọng lượng cũng rất lớn)
Trọng lượng 14 6 10
Thuật toán sẽ lựa chọn đồ vật 1 với tổng giá trị là 20, trong khi lời giải tối ưu của bài toán là lựa chọn đồ vật 2, đồ vật 3 với tổng giá trị là 24.
Greedy2: Sắp xếp đồ vật không giảm của trọng lượng. Lần lượt chất các đồ vật vào túi theo thứ tự đã sắp xếp. Thuật toán tham lam này cũng không cho kết quả tối ưu. Sau đây là phản ví dụ:
Tham số của bài toán là n = 3; b = 11
Đồ vật 1 2 3
Giá trị 10 16 28 (Đồ vật nhẹ nhưng giá trị sử dụng cũng rất ít)

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
70
Trọng lượng 5 6 10
Thuật toán sẽ lựa chọn (đồ vật 1, đồ vật 2) với tổng giá trị là 26, trong khi lời giải tối ưu của bài toán là (đồ vật 3) với tổng giá trị là 28.
Greedy3: Sắp xếp các đồ vật theo thứ tự không tăng của giá trị một đơn vị trọng lượng, tức là sắp theo thứ tự ≥ của dãy ci/wi. Ta lần lượt đưa các đồ vật vào túi theo thứ tự:
n
n
wc
wc
wc
≥≥≥ ...2
2
1
1
Tuy nhiên Greedy3 cũng không cho lời giải tối ưu. Sau đây là phản ví dụ của thuật toán.
Tham số của bài toán : n = 2; b ≥ 2.
Đồ vật 1 2
Giá trị 10 10b-1
Trọng lượng 1 b
Vì 2
2
1
1 1101
10wc
bb
wc
=−
≥= nên thuật toán chỉ lựa chọn được đồ vật 1 với tổng giá trị là 10,
trong khi lời giải tối ưu của bài toán lựa chọn đồ vật 2 với tổng giá trị là 10b-1 ( ≥ 10.2-1 = 19 > 10).
Greedy4 : Gọi Ij là lời giải thu được theo các thuật toán Greedyj đã giải ở trên (j = 1, 2, 3). Gọi I là phương án làm cho hàm mục tiêu đạt giá trị max, tức là:
∑∑∑∈∈∈
=3
4 ,,max21 Ii
iIi
iIi
i cccI
Định lý: Lời giải I4 thoả mãn bất đẳng thức
∑∈
≥4
*21
Iii fc
Trong đó f* là giá trị tối u của bài toán.
Định lí này chứng tỏ thuật toán tham lam thứ tư này cũng không cho lời giải tối ưu.
2.3. Bài toán người du lịch (TSP - Travelling Salesman Problem) Phát biểu bài toán: Cho n thành phố đánh số thứ tự từ 1 đến n và các tuyến đường giao thông hai chiều giữa chúng, mạng lưới giao thông này cho bởi mảng C[1..n, 1..n], ở đây C[i, j] = C[j, i] là chi phí đi lại trên đoạn đường trực tiếp giữa thành phố i và thành phố j.
Một người du lịch từ thành phố 1, muốn đi thăm tất cả các thành phó còn lại, mỗi thành phố thăm đúng một lần và cuối cùng quay trở lại thành phố xuất phát 1. Hãy chỉ ra cho người du lịch một hành trình với (tổng) chi phí ít nhất.

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
71
Greedy: Ý tưởng đơn giản như sau: Xuất phát từ thành phố 1, tại mỗi bước ta sẽ chọn thành phố tiếp theo là thành phố chưa thăm mà chi phí từ thành phố hiện tại đến thành phố đó là ít nhất (tối ưu cục bộ), ta gọi thành phố đó là thành phố “gần nhất”. Cụ thể như sau:
- Hành trình cần tìm có dạng: S = (x1 = 1, x2, ..., xn, xn+1 = 1), trong đó dãy (x1, x2, ..., xn) là một hoán vị của (1, 2, ..., n).
- Ta xây dựng nghiệm từng bước, bắt đầu từ x1, chọn x2 là thành phố gần x1 nhất, sau đó chọn x3 là thành phố gần x2 nhất (x3 khác x1), ... Tổng quát, chọn xi là thành phố chưa đi qua mà gần xi-1 nhất.
2.4. Bài toán mã hóa Huffman Phát biểu bài toán: Giả sử C là bảng chữ cái. Với mỗi chữ cái c ∈ C, ta biết tần suất xuất hiện của nó trong văn bản là f(c). Có rất nhiều cách mã hóa văn bản.
Mã hóa với độ dài cố định: Mỗi kí tự được mã hóa bởi một xâu nhị phân độ dài như nhau. Mã hóa độ dài cố định có ưu điểm dễ mã hóa, dễ giải mã nhưng tốn bộ nhớ.
Mã phi tiền tố (Prefix Free Code) là cách mã hóa mỗi kí tự c bởi một xâu nhị phân Code(c) sao cho mã của một kí tự bất kì không là đoạn đầu của bất cứ mã của kí tự nào trong số các kí tự còn lại. Mã phi tiền tố phức tạp trong mã hóa và giải mã nhưng ít tốn bộ nhớ.
Mỗi mã phi tiền tố có thể biểu diễn bởi cây nhị phân T, mỗi lá của cây tương ứng với một chữ cái và cạnh của nó được gán cho một trong hai số 0,1. Mã của chữ cái c là một dãy nhị phân gồm các số gán cho các cạnh trên đường đi từ gốc tới lá.
Yêu cầu của bài toán: Tìm cây nhị phân tối thiểu hóa tổng độ dài có trọng số:
∑∈
=Cc
cdepthcfTB )()()(
Sử dụng thuật toán tham lam: Chữ cái có tần suất nhỏ hơn cần được gán cho lá có khoảng cách đến gốc là lớn hơn, và ngược lại. Đó chính là tư tưởng của thuật toán Huffman.
procedure Huffman(C, f);
begin
n ← |C|;
Q ← C; Xử lí, thay đổi trên Q, giữ lại Input C
for i := 1 to n -1 do
begin
x, y ← 2 chữ cái có tần suất xuất hiện nhỏ nhất trong Q;
Tạo nút P với hai con x, y ;
f(P) := f(x) + f(y);
Q ← Q \ x,y ∪ P
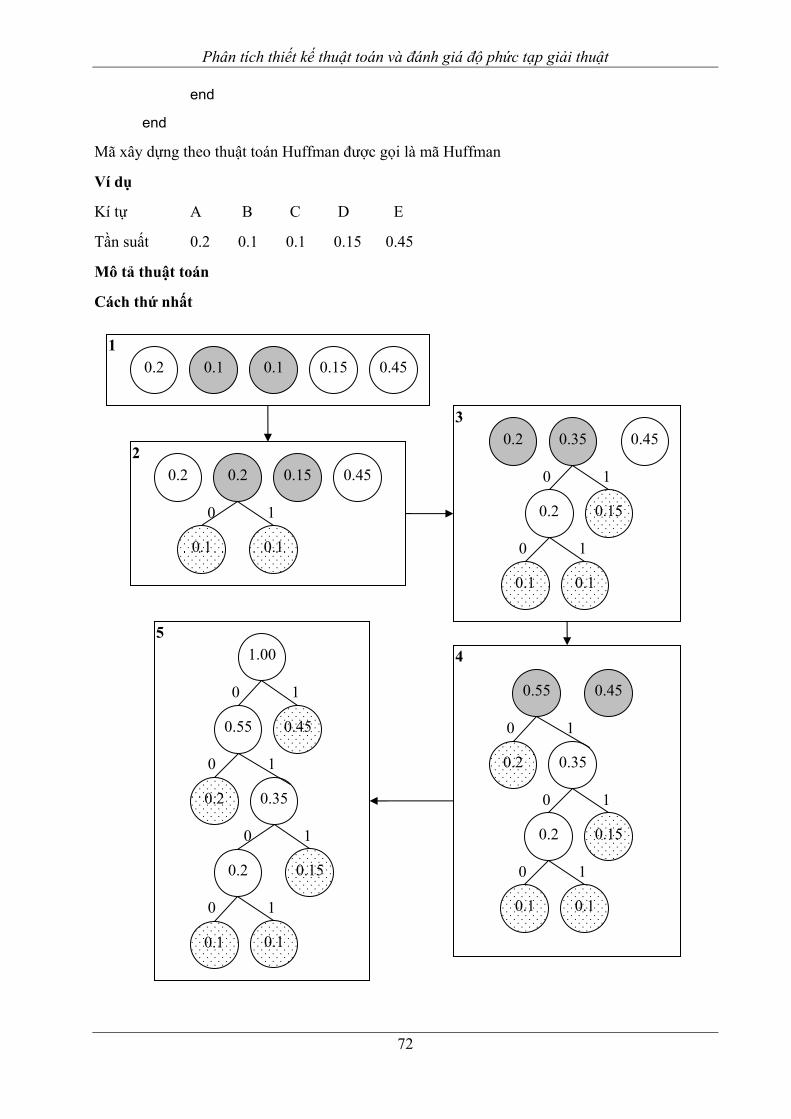
Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
72
end
end
Mã xây dựng theo thuật toán Huffman được gọi là mã Huffman
Ví dụ
Kí tự A B C D E
Tần suất 0.2 0.1 0.1 0.15 0.45
Mô tả thuật toán
Cách thứ nhất
1 0.2 0.1 0.1 0.15 0.45
0.2 0.2 0.15 0.45
0.1 0.1
0 1 0.2 0.15
0.45
0.1 0.1
0.35 0.2
0 1
0 1
0.2 0.15
0.45
0.1 0.1
0.35 0.2
0.55
0 1
0 1
0 1
3
2
5 4
0.2 0.15
0.45
0.1 0.1
0.35 0.2
0.55
1.00
0 1
0 1
0 1
0 1
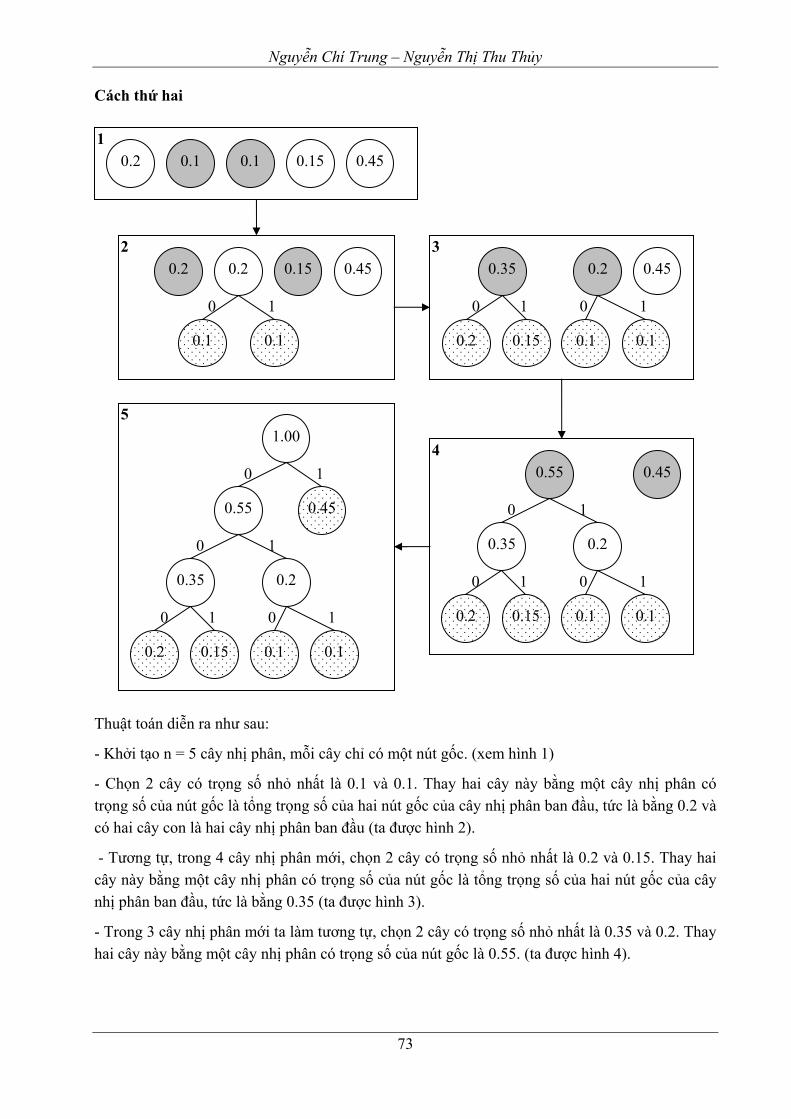
Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
73
Cách thứ hai
1 0.2 0.1 0.1 0.15 0.45
Thuật toán diễn ra như sau:
- Khởi tạo n = 5 cây nhị phân, mỗi cây chỉ có một nút gốc. (xem hình 1)
- Chọn 2 cây có trọng số nhỏ nhất là 0.1 và 0.1. Thay hai cây này bằng một cây nhị phân có trọng số của nút gốc là tổng trọng số của hai nút gốc của cây nhị phân ban đầu, tức là bằng 0.2 và có hai cây con là hai cây nhị phân ban đầu (ta được hình 2).
- Tương tự, trong 4 cây nhị phân mới, chọn 2 cây có trọng số nhỏ nhất là 0.2 và 0.15. Thay hai cây này bằng một cây nhị phân có trọng số của nút gốc là tổng trọng số của hai nút gốc của cây nhị phân ban đầu, tức là bằng 0.35 (ta được hình 3).
- Trong 3 cây nhị phân mới ta làm tương tự, chọn 2 cây có trọng số nhỏ nhất là 0.35 và 0.2. Thay hai cây này bằng một cây nhị phân có trọng số của nút gốc là 0.55. (ta được hình 4).
0.2 0.2 0.15
2 3 0.45
0.1 0.1
0 1
4
5
0.1 0.1
0.450.2
0 1
0.35
0 1
0.2 0.15
0.1 0.1
0.45
0.2
0 1 0 1
0.35
0.2 0.15
0.55
0 1
0.1 0.1
0.45
0.2
0 1 0 1
0.35
0.2 0.15
0.55
0 1
1.00
0 1

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
74
- Cuối cùng, thay 2 cây còn lại bởi một cây có trọng số 0.55 và 0.45 bởi một cây nhị phân duy nhất có trọng số của nút gốc là 1.00 (ta được hình 5).
Các nút lá của cây được gán thêm nhãn là kí tự có tần suất tương ứng. Mã của một kí tự là đường đi từ nút gốc đến nút lá tương ứng. Mã này thể hiện bởi dãy bit ghi trên các cạnh của đường đi.
Kí tự Tần suất Mã cách 1 Mã cách 2
A 0.2 00 000
B 0.1 0100 010
C 0.1 0101 011
D 0.15 011 001
E 0.45 1 1
Mặc dù cả hai cách đều thỏa mãn mã của một kí tự là xác định duy nhất (tức là mã của một kí tự không là đoạn đầu của mã của kí tự khác), nhưng cách thứ nhất phù hợp với ý tưởng thuật toán đã nêu. Trong cách thứ nhất: Kí tự B và C cùng có tần suất nhỏ nhất, có mã dài nhất gồm 4 bit. Kí tự D có tần suất nhỏ thứ nhì, có mã ngắn hơn gồm 3 bit. Kí tự A có tần suất lớn hơn nên có mã ngắn hơn, gồm 2 bit. Cuối cùng, kí tự E có tần suất lớn nhất nên có có mã ngắn nhất chỉ gồm 1 bit. Từ đó có một lưu ý khi mã hóa là khi có hai cách hòa nhập hai cây ta ưu tiên chọn cây có nhiều mức hơn.
Thuật toán xây dựng cây Huffman:
Bước 1: Khởi tạo n cây nhị phân, mỗi cây chỉ có một nút gốc có trọng số là tần suất của kí tự tương ứng. Mỗi nút đều gắn thêm một nhãn là kí tự tương ứng với tần số của nó.
Bước 2: Giảm n một đơn vị.
Bước 3. Nếu n = 1 thì kết thúc thuật toán xây dựng cây Huffman (Để chuyển sang thuật toán xây dựng mã hóa Huffman cho các kí tự).
Bước 4: Xét n cây nhị phân còn lại: Chọn hai nhị phân mà nút gốc có trọng số nhỏ nhất. Nếu có nhiều hơn một cách chọn thì ưu tiên chọn các cây có nhiều mức. Thay hai cây này bằng một cây nhị phân có trọng số của nút gốc là tổng trọng số của hai nút gốc của cây nhị phân ban đầu, và có hai cây con là hai cây nhị phân ban đầu.
Bước 5: Quay về bước 3.
Định lý: Thuật toán mã hóa Huffman xây dựng được cây mã phi tiền tố tối ưu sau thời gian O(nlogn).
Chứng minh : Trong vòng for-do có hai thao tác 1, và 2 là thực hiện nhiều nhất, còn các thao tác còn lại bị chặn bởi hằng số.
Thao tác 1 : tạo một heapmin là một cây tìm kiếm nhị phân đòi hỏi thời gian tính O(logn), lấy hai phần tử nhỏ nhất mất thời gian O(logn)

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
75
Thao tác 2 : Bổ sung nút P vào Q mất thời gian là O(logn)
Việc cài đặt thuật toán Huffman O(nlogn)
Một văn bản được mã hóa Huffman có thể giải mã nhờ thuật toán sau
procedure Huffman_Decode(B);
(*B là xâu mã hóa văn bản theo mã Huffman*)
begin
<Khởi động con trỏ P trỏ vào gốc của cây Huffman>
while <Chưa đạt đến kết thúc của B> do
begin
X ← bit tiếp theo trong xâu B;
If x = 0 then
P ← con trái của P
else
P ← con phải của P
If ( P là nút lá) then
begin
<Hiển thị kí tự tương ứng với nút lá>
<Đặt lại P tại gốc của cây Huffman>
end
end
end
BÀI TẬP CHƯƠNG 4 1. Đầu vào : Tập S = (xi, yi) | 1 ≤ i ≤ n
Đầu ra : Tập con với lực lượng lớn nhất S* của S sao cho không có hai khoảng nào trong S* có điểm chung.
Xét thuật toán sau :
Lặp lại cho đến khi S là rỗng các thao tác sau :
1. Chọn khoảng I có số điểm chung với một số ít nhất các khoảng khác
2. Bổ sung I vào tập cần tìm S*
3. Loại bỏ mọi khoảng có điểm chung với
Hãy chứng minh tính đúng đắn hoặc nêu phản ví dụ cho nó.

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
76
2. Xét bài toán tô màu khoảng (Interval Coloring Problem)
Đầu vào : Tập S = (xi, yi) | 1 ≤ i ≤ n
Hãy coi rằng mỗi khoảng (xi, yi) tương ứng với một yêu cầu sử dụng phòng học bắt đầu từ thời điểm xi , kết thúc tại yi.
Đầu ra : Tìm các phân bổ lớp vào phòng sao cho số phòng cần sử dụng là ít nhất. Chú ý là mỗi yêu cầu sử dụng phòng cần được thỏa mãn và không có hai lớp nào sử dụng cùng một phòng tại cùng một thời điểm.
a. Xét thuật toán lặp sau : Phân bổ một số nhiều nhất có thể được các lớp phòng thứ nhất, sau đó phân bổ một số nhiều nhất có thể các lớp vào phòng thứ hai, rồi đến phòng thứ 3, … Hỏi rằng thuật toán vừa nêu có cho lời giải đúng của bài toán tô màu khoảng? Giải thích câu trả lời của bạn.
b. Xét thuật toán sau : Lần lượt xét các lớp theo thứ tự tăng dần của thời điểm bắt đầu. Giả sử đang xét lớp C, nếu có phòng R đã được sử dụng để xếp một lớp nào đấy và C có thể xếp vào phòng này mà không mâu thuẫn với các lớp đã xếp vào R trước đó thì xếp C vào R. Nếu trái lại xếp C vào phòng mới. Hỏi rằng thuật toán vừa nêu có cho lời giải đúng của bài toán tô màu khoảng? Giải thích câu trả lời của bạn.
3. Xét bài toán đổi tiền sau : Đầu vào là một số nguyên L. Đầu ra là số lượng ít nhất các đồng tiền để đổi lượng tiền L. Các đồng tiền có mệnh giá là 1, 2, 22, …, 21000. Giả thiết rằng số lượng đồng tiền của mỗi mệnh giá là không hạn chế. Xét thuật toán đổi tiền sau đây: Sử dụng nhiều nhất đồng tiền có mệnh giá cao nhất. Ví dụ L = 31 : sử dụng một đồng tiền 24; còn lại giá trị 15, lại lấy một đồng tiền 23; còn lại giá trị 7, lấy 1 đồng tiền 22; giá trị còn lại 3 cần đổi bởi một đồng 21 và 1 đồng 20.
Hỏi thuật toán này có cho lời giải tối ưu của bài toán không? giải thích câu trả lời của bạn?

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
77
Chương 5. CÁC THUẬT TOÁN ĐỒ THỊ CƠ BẢN
1. Các khái niệm cơ bản
1.1. Đồ thị Đồ thị là mô hình biểu diễn một tập các đối tượng và mối quan hệ hai ngôi giữa các đối tượng. Có thể biểu diễn đồ thị G là một cặp gồm hai thành phần V và E, kí hiệu G = (V, E), trong đó V là tập các đỉnh biểu diễn các đối tượng, E là tập các cung biểu thị mối quan hệ giữa các đối tượng.
Ví dụ đồ thị biểu diễn một sơ đồ giao thông, cấu trúc phân tử, mạng máy tính.
Một số loại đồ thị
- Đơn đồ thị: giữa hai đỉnh có duy nhất một cạnh.
- Đa đồ thị: giữa hai đỉnh có thể có nhiều hơn một cạnh.
- Đồ thị vô hướng: các cạnh trong E không định hướng.
- Đồ thị có hướng: các cạnh trong E định hướng.
- Đồ thị không trọng số: các cạnh không gán trọng số.
- Đồ thị có trọng số: các cạnh gắn với một trọng số nào đó, còn gọi là “giá” của cạnh.
1.2. Các khái niệm Cho đồ thị G= (V, E),
a) Bậc của đỉnh: bậc của đỉnh v ∈ V, kí hiệu là deg(v), là số cạnh kề với v.
Định lí 5.1. Trong đồ thị vô hướng, tổng bậc của tất cả các đỉnh bằng hai lần số cạnh.
Hệ quả 5.2. Trong đồ thị vô hướng, số đỉnh bậc lẻ là một số chẵn.
b) Bán bậc ra và bán bậc vào: Nếu G là có hướng, định nghĩa bán bậc ra của đỉnh v ∈ E, kí hiệu là deg+(v) là số cung đi ra khỏi nó; định nghĩa bán bậc vào của đỉnh v ∈ E, kí hiệu là deg-(v) là số cung đi vào nó.
Định lí 5.2. Trong đồ thị có hướng tổng các bán bậc ra của tất cả các đỉnh bằng tổng các bán bậc vào của tất cả các đỉnh và bằng số cung của đồ thị.
c) Đường đi và chu trình
- Một dãy các đỉnh P = v0, v1, .., vk sao cho (vi-1, vi) ∈ E, i = 1, 2, ..., k, gọi là một đường đi. Đường đi P trên đi qua k+1 đỉnh và k cạnh.
- Đường đi P = v0, v1, .., vk là một chu trình nếu vk = v0.
- Đường đi hay chu trình được gọi là đơn nếu không có cạnh nào được lặp lại.

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
78
d) Tính liên thông
- Một đồ thị gọi là liên thông nếu giữa hai đỉnh bất kỳ của đồ thị luôn tồn tại đường đi.
- Đồ thị có hướng gọi là liên thông mạnh nếu giữa hai đỉnh bất kỳ của đồ thị luôn tồn tại đường đi. Đồ thị có hướng gọi là liên thông yếu nếu đồ thị vô hướng của nó là một đồ thị liên thông.
2. Các phương pháp biểu diễn đồ thị
1.1. Biểu diễn đồ thị bằng ma trận kề Cho đơn đồ thị đồ thị G = (V, E), trong đó |V| =n, có thể đánh số thứ tự các đỉnh từ 1 đến n và đồng nhất mỗi đỉnh với số thứ tự của nó. Ma trận kề của G là ma trận vuông A = (aij)n x n trong đó:
⎩⎨⎧
∉∈
=EjiifEjiif
aij ),(0),(1
Nhận xét
- Ma trận kề của đồ thị yêu cầu O(V2) bộ nhớ, không phụ thuộc vào số cạnh trong đồ thị.
- Ma trận kề của đồ thị vô hướng thì đối xứng, do đó chỉ cần lưu phần tam giác trên (hoặc dưới) của ma trận, do đó bộ nhớ được giảm một nửa.
- Ưu điểm của ma trận kề là trực quan, dễ cài đặt trên máy, dễ kiểm tra xem hai đỉnh u, v của đồ thị có kề nhau hay không
- Hạn chế của ma trận kề là tốn bộ nhớ, luôn tốn một ma trận n x n cho dù chỉ có rất ít cạnh.
Biểu diễn ma trận kề trên Pascal
var a : array[1..n, 1..n] of boolean
1.2. Biểu diễn đồ thị bằng danh sách cạnh Cho đồ thị G = (V, E), giả sử có n đỉnh và m cạnh, tức n = |V|, m = |E|. Khi đó G có thể cho bởi danh sách m cạnh trong E.
Nhận xét:
- Ưu điểm của biểu diễn đồ thị bằng danh sách cạnh là thích hợp đối với đồ thị thưa, thích hợp đối với các thuật toán đồ thị mà cần duyệt trên các cạnh (ví dụ thuật toán Kruscal)
- Hạn chế của danh sách cạnh là không thích hợp khi cần duyệt đồ thị theo đỉnh.
Biểu diễn danh sách cạnh trên Pascal
type Canh = record x, y : integer; end;
var e : array[1..m] of Canh;

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
79
1.3. Biểu diễn đồ thị bằng danh sách kề Biểu diễn đồ thị bằng danh sách kề (adjacency list) khắc phục được những hạn chế của ma trận kề và danh sách cạnh; tuy nhiên nó có hạn chế trong việc kiểm tra một cặp đỉnh có phải là một cạnh hay không (vì phải duyệt trên tập các đỉnh kề). Trong cách biểu diễn này, với mỗi đỉnh v của đồ thị, ta cho tương ứng với nó một danh sách các đỉnh kề với đỉnh v.
Cho đồ thị có hướng G = (V, E), V gồm n đỉnh và E gồm cung. Có hai cách cài đặt danh sách kề:
Danh sách trỏ trước: Với mỗi đỉnh u, lưu trữ một danh sách adj[u] chứa các đỉnh kề với đỉnh u:
adj[u] = v : (u, v) ∈ E
Danh sách trỏ sau: Với mỗi đỉnh u, lưu trữ một danh sách adj[u] chứa các đỉnh v mà u kề với v:
adj[u] = v : (v, u) ∈ E
a) Biểu diễn danh sách kề bằng mảng
Dùng mảng adj[1..n] chứa các đỉnh, mảng được chia thành n đoạn, đoạn thứ u trong mảng lưu các đỉnh kề với đỉnh u.
Để biết một đoạn nằm từ chỉ số nào đến chỉ số nào, dùng thêm một mảng head[1...n + 1] để đánh dấu vị trí phân đoạn: head[u] bằng chỉ số (vị trí) cuối cùng của đoạn ngay trước đoạn u, qui ước head[n+1] = 2m, với m là số cung của đồ thị (lưu ý việc biểu diễn danh sách kề bằng mảng sẽ nhân đôi số cung của đồ thị).
Vậy đoạn thứ u bắt đầu từ chỉ số head[u] + 1 cho đến head[u+1]. Nói cách khác, các đỉnh kề của u thuộc phân đoạn từ adj[head[u]+1] đến adj[head[u+1]]. Ví dụ như hình dưới đây, các đỉnh kề của u = 2 thuộc phân đoạn từ adj[head[2]+1] đến adj[head[3]], cụ thể là từ adj[3] đến adj[6], phân đoạn này tương ứng với các đỉnh 1, 3, 4, 5.
Biểu diễn danh sách kề bằng mảng trên Pascal
var adj : array[1..2*m] of integer;
head : array[1..n + 1 ] of integer;
Đoạn trình chuyển đổi từ ma trận kề sang danh sách kề
1. head[n +1] := 2*m;
2. for i := n downto 1 do begin
3. head[i] := head[i+1];
1 2 3
4 5
1 2 3 4 5 6 7 8 9 10 11 12 13 14adj 2 4 1 3 4 5 2 5 1 2 5 2 3 4 1 2 3 4 5 1 2 3 4 5 6 head 0 2 6 8 11 14

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
80
4. for j := n downto 1 do
5. if a[i, j] then begin
6. adj[head[i]] := j;
7. head[i] := head[i] - 1;
8. end; 9. end;
Để hiểu được thuật toán trên, ta mô phỏng vài thao tác ban đầu dựa vào ví dụ đã nêu. Ta có head[6] = 14. Với i = 5, ban đầu head[5] = 14. Ta thấy câu lệnh 7 sẽ được thực hiện 3 lần, bằng độ dài của phân đoạn 5, tức là cuối cùng head[5] = 12. Cùng với câu lệnh 7, câu lệnh 6 sẽ lần lượt gán adj[14] = 4 (vì tồn tại a[5,4]), adj[13] = 3 (vì tồn tại a[5, 3]), adj[12] = 2 (vì tồn tại a[5,2]). Vậy là xong phân đoạn 5.
Với i = 4 tiếp theo, câu lệnh 3 khởi gán head[4] = 11, rồi việc tính lại head và tính mảng adj thuộc phân đoạn 4 lại diễn ra tương tự. Cuối cùng head[4] giảm 3 lần còn 8, phân đoạn 4 được tính với adj[11, 10, 9] = [5, 2, 1].
Đoạn trình chuyển đổi từ danh sách kề sang ma trận kề
for i := 1 to n do
for j :=1 to n do a[i,j] := false;
for u :=1 to n do
for k := head[u] + 1 to head[u+1] do a[u, adj[k]] := true;
b) Biểu diễn danh sách kề bằng danh sách móc nối
Trong biểu diễn này, ta cho mỗi đỉnh u của đồ thị tương ứng với list[u] là chốt của một danh sách móc nối (hay danh sách liên kết) gồm các đỉnh kề u.
Nếu G là đồ thị có hướng, tổng chiều dài của tất cả các danh sách kề là |E|, do có cạnh nối (u,v) chỉ khi đỉnh v xuất hiện trong adj[u]. Nếu G là một đồ thị vô hướng, tổng độ dài của tất cả các danh sách kề là 2|E|, do tồn tại cạnh vô hướng (u,v) chỉ khi đỉnh u xuất hiện trong danh sách các đỉnh kề của v và đỉnh v xuất hiện trong danh sách các đỉnh kề của u. Dù đồ thị có hướng hay vô
1 2 3
4 5
list[1] 2 4
list[2] 1 3 4
list[3] 2 5
list[4] 1 2
list[5] 2 3
5
5
4

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
81
hướng, việc biểu diễn qua danh sách kề chiếm một vùng bộ nhớ có kích thước là O(max(V,E)) = O(V + E).
Các danh sách các đỉnh kề có thể dễ dàng được sử dụng để biểu diễn các đồ thị có trọng số. Đó là đồ thị mà mỗi cạnh đều có một trọng số riêng, được tính bằng hàm trọng số w: E → R.
1.4. Biểu diễn đồ thị bằng danh sách liên thuộc Cho đồ thị G = (V, E). Với cạnh e = (u, v) ∈ E, ta nói u và v là hai đỉnh kề nhau; cạnh e là cạnh liên thuộc (incdent) với đỉnh u và đỉnh v.
Danh sách liên thuộc là mở rộng của danh sách kề. Nếu như trong danh sách kề, mỗi đỉnh được cho tương ứng với một danh sách các đỉnh kề, thì trong danh sách liên thuộc, mỗi đỉnh được cho bởi danh sách các cạnh liên thuộc.
3. Thuật toán tìm kiếm theo chiều rộng Duyệt theo chiều rộng (Breadth – First search, BFS) là một trong những thuật toán quan trọng trong việc duyệt và tìm kiếm trên đồ thị. Trên cơ sở của thuật toán này mà nhiều các thuật toán đồ thị quan trọng khác đã ra đời, như là: Thuật toán Dijkstra giải bài toán đường đi ngắn nhất;
Thuật toán Prim giải bài toán cây khung nhỏ nhất.
3.1. Nguyên tắc tô màu - cách hoạt động của BFS Sở dĩ thuật toán BFS có tên gọi như vậy là do tại mỗi một bước của thuật toán, nó mở rộng biên giới giữa các đỉnh được thăm và chưa được thăm theo một quy tắc nhất định: thuật toán lần lượt thăm các đỉnh có khoảng cách từ đỉnh xuất phát s đến chúng là k (có nghĩa là số cạnh từ s tới các đỉnh này là k) trước khi thăm bất cứ một đỉnh nào có khoảng cách từ đỉnh s tới nó là k+1.
Trong quá trình hoạt động, thuật toán tiến hành bôi màu các đỉnh với một trong 3 màu - màu trắng, xám hoặc đen theo nguyên tắc sau:
- Tại bước khởi động tất cả các đỉnh của đồ thị đều có màu trắng.
- Tất cả các đỉnh đã được thăm đều có màu xám hoặc đen.
- Thuật toán BFS phân biệt giữa các đỉnh có màu xám và màu đen để đảm bảo tính chất duyệt theo chiều rộng của mình.
- Khi đỉnh v được thăm lần đầu tiên, nó được bôi màu xám (ta nói rằng v là đỉnh đã được duyệt đến). Các đỉnh này biểu hiện biên giới giữa các đỉnh đã được thăm và chưa được thăm. Sau đó thuật toán tiến hành duyệt các đỉnh kề với đỉnh v.
- Đỉnh v được bôi màu đen (ta nói rằng v là đỉnh đã duyệt xong) chỉ khi đã duyệt xong (thăm) tất cả các đỉnh kề với v.
2.2. Breadth – First Tree Với ý tưởng tô mầu nói trên, thuật toán BFS có thể cho phép xây dựng một cây tìm kiếm theo chiều rộng T (breadth – first tree) như sau:

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
82
- Ban đầu cây này chỉ có mỗi một gốc là đỉnh s.
- Trong quá trình duyệt, giả sử thuật toán đã duyệt đến đỉnh chưa được thăm u. Khi đó u trở thành đỉnh được duyệt đến và thuật toán sẽ tiến hành duyệt danh sách các đỉnh kề với đỉnh u. Nếu gặp phải đỉnh v kề với u, mà đỉnh v chưa dược thăm lần nào cả, thì đỉnh v và cạnh (u, v) được bổ sung vào trong cây. Điều này có nghĩa là nút tương ứng với đỉnh u là nút cha của nút tương ứng với đỉnh v, còn đỉnh u được gọi là đỉnh trước của đỉnh v trong thứ tự duyệt theo chiều rộng.
Do các đỉnh được thăm nhiều nhất là một lần, nên nút trong cây T tương ứng với đỉnh này chỉ có một cha.
3.3. Mô tả thuật toán Thuật toán tô màu đồ thị - BFS được mô tả như sau:
Đầu vào:
- Cho đồ thị vô hướng hoặc có hướng G=(V,E) được biểu diễn bằng danh sách kề.
- Màu của đỉnh u∈V được lưu trong mảng color[u].
- Đỉnh trước của đỉnh u được lưu trong mảng pred[u]. Nếu đỉnh u không có đỉnh trước, khi đó pred[u]=NIL.
- Khoảng cách từ đỉnh xuất phát s tới đỉnh u được lưu trong mảng d[u].
- Thuật toán sử dụng hàng đợi Q (theo nguyên tắc FIFO – vào trước ra trước) để quản lý tập các đỉnh có màu xám.
Mô phỏng thuật toán BFS bằng ngôn ngữ giả Pascal:
procedure BFS (G,s)
1 begin for each u∈V[G] \ s do 1 2
3 4
5
V
6
2 begin color[u] ←WHITE
3 d[u]← ∞ S 4 pred[u]←NIL end;
5 colors[s] ← GRAY;
6 d[s]←0;
7 pred[s]←NIL;
8 Q ← s
9 while Q ≠ ∅ do
10 begin u ←head[Q];
11 for each v∈Adj[u] do

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
83
12 if color[v] = WHITE then
13 begin color[v]←GRAY
14 d[v]←d[u]+1;
15 pred[v]←u;
16 Q v; end;
17 colors[u] ← BLACK;
end;
Phân tích thủ tục:
Bước 1 (dòng 1 cho đến dòng 4):
Thực hiện vòng lặp for để khởi tạo các giá trị ban đầu cho tất cả các đỉnh khác với đỉnh xuất phát s của đồ thị (each vertex u ∈ V[G] - s):
- gán màu trắng cho mọi đỉnh của đồ thị G trừ đỉnh s (color [u] ← white)
- Do tại bước đầu chưa tiến hành duyệt đồ thị, nên gán khoảng cách từ đỉnh s tới các đỉnh còn lại bằng vô cùng (d[u] ← ∞)
- pred[u] ← NIL, có nghĩa là chưa xác định được đỉnh đứng trước đỉnh u trong thứ tự duyệt theo chiều rộng.
Bước 2 (dòng 5 cho đến dòng 8):
Khởi tạo cho đỉnh xuất phát s:
- gán màu xám cho s color[s] ← gray
- gán d[u] ← 0 (khoảng cách từ s tới chính nó là 0)
- gán pred[s] ← nil
- đẩy đỉnh s vào hàng đợi Q ( s trở thành phần tử đầu của Q)
Bước 3 (dòng 9 cho đến 17):
Đây là bước chính của thuật toán. Nó được lặp đi lặp lại khi trên đồ thị vẫn còn các đỉnh có màu xám, có nghĩa là khi còn có các đỉnh mà danh sách kề của chúng vẫn chưa được duyệt:
1) Kiểm tra hàng đợi Q có rỗng không. Nếu rỗng, kết thúc thuật toán. Ngược lại, chuyển sang bước 2.
2) Lấy phần tử u đầu từ Q.
3) Duyệt lần lượt danh sách các đỉnh kề của đỉnh u.
4) Với mỗi phần tử v của danh sách kề này kiểm tra xem v đã được thăm chưa
(đỉnh v chưa được thăm khi color[v] ← WHITE). Nếu v chưa được thăm thì:

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
84
- gán color[v] ← GRAY
- gán giá trị mới cho khoảng cách tử đỉnh xuất phát s tới v: d[v] ← d[u]+1
- ghi nhớ lại đỉnh đứng trước đỉnh v: pred[v] ← u
- Đẩy đỉnh v vào cuối của hàng đợi Q (dòng 16).
5) Vì các đỉnh kề với u đã duyệt xong: Gán màu đen cho u: color[u] ← BLACK
Chú ý: Thuật toán BFS trên sẽ không duyệt hết tất cả các đỉnh của đồ thị G nếu đồ thị này gồm nhiều thành phần liên thông khác nhau. Để duyệt được hết các thành phần liên thông của đồ thị G, thuật toán được điều chỉch lại như sau: Thêm một vòng lặp for ở ngoài cùng để duyệt mọi đỉnh s của G, nếu gặp đỉnh s chưa được thăm thì tiến hành thủ tục BFS(G, s).
Đánh giá độ phức tạp tính toán của thuật toán BFS
- Sau khi được khởi tạo, các đỉnh đều được gán màu trắng, nên mỗi một đỉnh sẽ được đưa vào trong hàng đợi Q nhiều nhất là một lần, và hiển nhiên là cũng được đưa ra khỏi hàng đợi nhiều nhất là một lần. Thao tác đẩy vào và lấy ra khỏi hàng đợi Q sẽ mất thời gian là O(1), vì vậy, thời gian tổng cộng dành cho các phép toán với hàng đợi là O(V).
- Do danh sách kề của mỗi một đỉnh được duyệt chỉ khi đỉnh này được đưa vào trong hành đợi, nên danh sách kề của mỗi một đỉnh cũng được duyệt nhiều nhất là một lần. Chiều dài của tất cả các danh dách kề là O(E). Do vậy, thời gian dành cho việc duyệt toàn bộ các danh sách kề là O(E).
Vậy, độ phức tạp tính toán của thuật toán BFS là O(V+E). Từ đó cũng suy ra thời gian tính toán của BFS tỷ lệ tuyến tính với kích thước của danh sách kề của đồ thị G.
4. Thuật toán tìm kiếm theo chiều sâu
4.1. Giới thiệu thuật toán Ý tưởng thuật toán: Thuật toán toán tìm kiếm theo chiều sâu (Deapth First Seach - DFS) tìm kiếm sâu dần trên đồ thị chừng nào còn có thể. Ý tưởng của DFS như sau: Bắt đầu tìm kiếm từ một đỉnh v0 nào đó của đồ thị. Sau đó chọn u là một đỉnh kề với v0 và lặp lại quá trình như thế đối với đỉnh u. Giả sử ta đang xét đỉnh v ở một bước nào đó, khi đó các cạnh đến được đỉnh v sẽ chưa được thăm cho đến khi nào v còn cạnh (đi ra từ nó) chưa được thăm. Khi tất cả các cạnh của v đã được thăm, thì ta nói rằng đỉnh v đã được duyệt xong và quay trở lại tìm kiếm từ đỉnh mà trước đó ta đến được đỉnh v. Quá trình này tiếp tục cho đến khi v = v0 thì kết thúc nghĩa là tất cả các cạnh của đồ thị đã được thăm.
Đồ thị con trước đó: Trong thuật toán tìm kiếm theo chiều sâu, với u là một đỉnh đã được thăm, thì mỗi khi một đỉnh v thuộc danh sách kề của u được thăm, thuật toán sẽ đánh dấu bằng cách đặt trước v một trường π(v) có giá trị là u. Khác với thuật toán tìm kiếm theo chiều rộng (toàn bộ đồ thị con trước đó - predecessor subgraph – là đồ thị tạo ra khi thăm các đỉnh trước đó trong quá trình tìm kiếm) xác định một cây tìm kiếm duy nhất, trong thuật toán tìm kiếm theo chiều sâu, đồ

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
85
thị con trước đó có thể xác định nhiều cây tìm kiếm khác nhau và có thể được lặp lại từ nhiều đỉnh khác nhau. Vì vậy đồ thị con trước đó trong thuật toán tìm kiếm theo chiều sâu được định nghĩa hơi khác một chút so với trong thuật toán tìm kiếm theo chiều rộng. Ta định nghĩa như sau:
Gπ = (V, Eπ) trong đó Eπ = ( π[v], v) : v ∈ V và π[v] # Nil
Đồ thị con trước đó trong thuật toán tìm kiếm theo chiều sâu sẽ xác định một rừng cây tìm kiếm theo chiều sâu (a depth-first forest ) là tập hợp của các cây tìm kiếm theo chiều sâu (deepth- first trees ). Các cạnh thuộc Eπ gọi là các cạnh của cây (tree edges).
Tô màu theo chiều sâu: Trong thuật toán tìm kiếm theo chiều sâu, các đỉnh của đồ thị có thể được tô màu để mô tả trạng thái của nó tại mỗi thời điểm. Các đỉnh ban đầu chưa được thăm sẽ được khởi tạo là màu trắng, khi được thăm sẽ tô màu xám và tô màu đen khi đã duyệt xong. Giải thuật tô màu trên sẽ đảm bảo chính xác mỗi đỉnh chỉ được duyệt một lần, vì vậy mà các cây tìm kiếm theo chiều sâu phân biệt được với nhau.
Thứ tự duyệt đến và duyệt xong: Bên cạnh việc tạo ra một rừng cây tìm kiếm theo chiều sâu, thuật toán tìm kiếm theo chiều sâu còn gán cho mỗi đỉnh một tem thời gian (timestamps). Mỗi đỉnh v sẽ có 2 tem thời gian:
• Khi đỉnh v bắt đầu được thăm lần đầu tiên, ta nói rằng v được duyệt đến và được gán tem thứ nhất d[v] (được tô màu xám).
• Khi chuẩn bị khi lùi về đỉnh trước đỉnh v, tức là các đỉnh trong danh sách kề của v đã được duyệt, ta nói rằng đỉnh v được duyệt xong, và v được gán tem thứ hai f[v] (tô màu đen).
Các tem thời gian này giúp ích rất nhiều cho việc mô tả quá trình thực hiện các bước trong thuật toán tìm kiếm theo chiều sâu; được sử dụng nhiều trong các thuật toán đồ thị như tìm thành phần liên thông mạnh, thuật toán sắp xếp topo.
4.2. Thủ tục tìm kiếm theo chiều sâu Thủ tục DFS dưới đây khởi tạo mọi đỉnh của đồ thị có màu trắng, mỗi đỉnh đều chưa có đỉnh đi trước (π(u) = nill) và khởi tạo biến thời gian bằng 0. Khi đồ thì không liên thông thì đoạn trình tiếp theo (dòng 5, 6, 7) sẽ lần lượt tìm các cây tìm kiếm theo chiều sâu bằng thủ tục DFS-Visit(u) trong đó u là đỉnh gốc của cây (chưa thăm - màu trắng).
procedure DFS(G)
1 begin for u ∈ V[G] do begin
2 color[u] ← WHITE;
3 π [u] ← NIL; end;
4 time ← 0;
5 for u ∈ V[G] do

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
86
6 if color[u] = WHITE then
7 DFS-Visit(u); end;
procedure DFS-Visit(u)
1 begin color[u] ←GRAY Trong khi mọi đỉnh v kề u chưa được thăm
2 d[u] ← (time ← time + 1);
3 for v ∈ Adj[u] do thăm cạnh (u,v)
4 if color[v] = WHITE then
5 begin π [v] ← u;
6 DFS-Visit(v);
end;
7 color[u] ← BLACK Tô màu đen cho đỉnh u khi đã duyệt xong
8 f[u] ← (time ← time + 1);
end;
Tại mỗi lần gọi thủ tục DFS-Visit(u):
Đỉnh u ban đầu đang được tô màu trắng.
Khi thực hiện, dòng 1 sẽ tô màu xám cho đỉnh u
Dòng 2 ghi lại thời điểm đỉnh u bắt đầu được thăm lần đầu tiên vào biến time sau khi tăng nó lên 1.
Dòng 3-6 kiểm tra các đỉnh v kề với đỉnh u và thực hiện thăm v một cách đệ quy nếu nó vẫn là đỉnh trắng. Với mỗi đỉnh v được xét tại dòng 3, ta nói rằng cạnh (u,v) đã được thăm trong thuật toán tìm kiếm theo chiều sâu .
Khi tất cả các cạnh đi từ u đã được thăm, dòng 7-8 sẽ tô màu đen cho đỉnh u và ghi lại thời điểm đỉnh u đã duyệt xong trong biến f[u].
4.3. Đánh giá độ phức tạp thuật toán DFS và DFS-Visit Thủ tục DFS: Số phép toán cần thực hiện trong hai chu trình của thuật toán (hai vòng for-do ở dòng 1-2 và 5-7) là cỡ O(V).
Thủ tục DFS-Visit: sẽ được gọi chính xác chỉ một lần cho mỗi đỉnh thuộc V và mỗi lần thực hiện không quá ⎥A[v]| phép toán. Trong đó :
∑∈
=Vv
EOvA )(][
nghĩa là tổng số phép toán cần thực hiện tại các dòng 2-5 của thủ tục DFS-Visit là O(E).
Vì vậy độ phức tạp tính toán của thủ tục DFS sẽ là O (V+E).

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
87
5. Bài toán tìm đường đi ngắn nhất
5.1. Một số khái niệm cơ bản Cho đồ thị có trọng số G = (V, E, w), trong đó G = (V, E) là một đồ thị, w là một hàm trọng số từ E đến R, gán mỗi cung e ∈ E với một giá nào đó w(e) ∈ R.
Định lí 5.3. Cho đồ thị có trọng số G = (V, E, w). Nếu P = (v1, v2, …, vk) là một đường đi ngắn nhất trên từ đỉnh v1 đến đỉnh vk thì mọi dãy con từ đỉnh vi đến đỉnh vj (1 ≤ i ≤ j ≤ k) trên đường đi đó đều là đường đi ngắn nhất từ đỉnh vi đến đỉnh vj.
Hầu hết các thuật toán tìm đường đi ngắn nhất đều dùng qui hoạch động (ví dụ các thuật toán Floyd và Dijkstra dùng kết quả của định lí trên) hoặc phương pháp tham lam đúng (ví dụ thuật toán Kruskal).
Bài toán đo khoảng cách
Phát biểu bài toán: Giả sử đồ thị không có chu trình âm và có ma trận trọng số là c[1..n, 1..n]. Hãy tìm đường đi ngắn nhất từ đỉnh xuất phát s đến đỉnh kết thúc t.
Để giải bài toán, ta sử dụng kí hiệu δ(u, v) để chỉ độ dài đường đi từ đỉnh u đến đỉnh v trong đồ thị.
Ý tưởng của thuật toán: Trước tiên tìm đỉnh v1 ≠ t mà δ(s, t) = δ(s, v1) + c[v1, t]. Dễ thấy luôn tồn tại đỉnh v1 đó và v1 là đỉnh đứng ngay trước đỉnh t trên đường đi ngắn nhất từ s đến t. Nếu v1 = s thì đường đi ngắn nhất cần tìm chính là cạnh (s, t). Nếu không thì vấn đề trở thành tìm đường đi ngắn nhất từ s đến v1 và ta lại tìm đỉnh v2 ≠ t, v1 mà δ(s, v1) = δ(s, v2) + c[v1, v2], … Cứ tiếp tục như vậy, sau một số hữu hạn bước, ta có dãy t = v0 , v1, v2, …, vk = s không chứa các đỉnh lặp lại. Lật ngược thứ tự dãy như vậy ta có đường đi ngắn nhất từ s đến t.
Nhãn khoảng cách và phép co
Các bài toán tìm đường đi ngắn nhất xuất phát từ một đỉnh s xác định đều sử dụng kĩ thuật gán nhãn khoảng cách. Hiểu "nhãn khoảng cách" theo nghĩa như sau: Với mỗi đỉnh v ∈ V, nhãn khoảng cách d[v] là độ dài của một đường đi nào đó từ đỉnh xuất phát s đến đỉnh v.
Ban đầu ta chưa xác định được bất kỳ đường đi nào từ s đến các đỉnh khác nên nhãn d[v] được khởi tạo như sau: Với ∀ v ∈ V thì
⎩⎨⎧
≠∞+=
=,
0][
svifsvif
vd
Do định nghĩa của nhãn khoảng cách nên ta có d[v] ≥ δ(s, v) với ∀v ∈ V. Các thuật toán tìm đường đi ngắn nhất từ s đến v sẽ tìm cách cực tiểu hóa dần các nhãn khoảng cách d[v] cho đến khi d[v] = δ(s, v) với ∀ v ∈ V bằng cách sử dụng các phép co.
Phép co theo cạnh (u, v) ∈ E, gọi tắt là phép co (u, v), được thực hiện như sau:

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
88
Giả sử đã xác định được d[u]. Xét đường đi từ s đến u. Ta nối thêm cạnh (u,v) (nếu có cạnh này) để được đường đi từ s đến v, và có độ dài là d[u] + c[u,v]. Nếu xảy ra bất đẳng thức:
d[u] + c[u, v] < d[v]
thì ta cần thay đường đi từ s đến v bằng đường đi từ s đến v mà ngay trước đỉnh v là đỉnh u cần đi qua, tức là:
d[v] = d[u] + c[u, v]
Khi đó ta nói rằng d[v] được giảm bởi phép co (u, v).
5.2. Thuật toán Dijkstra Chú ý rằng thuật toán Dijkstra chỉ áp dụng đối với đồ thị G có trọng số không âm.
Định nghĩa: Một nhãn khoảng cách d[v] là cố định nếu ta đã biết d[v] = δ(s, v) và không thể giảm d[v] được nữa thông quan một phép co, ngược lại ta nói nhãn d[v] là tự do.
Thuật toán
Bước 1: Khởi tạo
- Khởi tạo nhãn khoảng cách d[s] := 0;
- d[v] := a[s, v], ∀ v ≠ s (a là ma trận kề của đồ thị).
- Khởi tạo mọi trạng thái nhãn là tự do: avail[v] := true, ∀ v ≠ s.
Bước 2: Lặp hai thao tác sau
- Cố định nhãn: Chọn trong số các định có nhãn tự do, lấy ra đỉnh u có d[u] nhỏ nhất, ghi nhận nó trở thành đỉnh cố định, tức avail[u] := false;
- Sửa nhãn: Dùng đỉnh u, xét tất cả các đỉnh v kề đỉnh u và thực hiện phép co theo cạnh (u, v) để cực tiểu hóa d[v]. Tại bước này, nếu dùng phép co (u, v), ta nên lưu vết bằng mảng pred bởi lệnh pred[v] := u. Việc lưu vết này giúp lần lại đường đi ngắn nhất dựa vào mảng pred sau khi thuật toán Dijkstra hoàn tất.
Bước 3: Truy vết
Sử dụng mảng lưu vết pred để tìm lại đường đi ngắn nhất từ s đến t với độ dài đường đi ngắn nhất là d[t].
Mô phỏng thuật toán Dijkstra trên Pascal
procedure Dijkstra;
s
u
vd[v]
d[u] c[u,v]

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
89
begin
(*Khởi tạo*)
for v ∈ V do
begin
d[v] := a[s, v];
pred[v] := s;
avail[v] := true;
end;
d[s] := 0;
avail[s]:= false;
stop := false;
(*Bước lặp*)
while not stop do
begin
(*Cố định nhãn*)
d[u] := min d[v] : ∀ v ∈ V và avail[v] = true;
avail[u] := false ;
(*Sửa nhãn*)
for v ∈ V do
if avail[v] then
if d[v] > d[u] +a[u, v] then
begin
d[v] := d[u] +a[u, v];
pred[v] := u;
end;
end;
(* kiếm tra điều kiện kết thúc lặp*)
stop := true;
for v ∈ V do
if avail[v] then stop := false;
end;
end;

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
90
6. Bài toán về cây khung nhỏ nhất
6.1. Các khái niệm cơ bản Định nghĩa 1. Cầu là một cạnh của đồ thị mà nếu xóa nó thì làm tăng số thành phần liên thông của đồ thị.
Định nghĩa 2. Cây là đồ thị vô hướng, liên thông và không có chu trình. Đồ thị không có chu trình gọi là rừng.
Như vậy một rừng có thể có từ 1 đến nhiều cây.
Ví dụ: Dưới đây gồm một rừng có 3 cây:
Định lí 5.4. Giả sử T = (V, E) là đồ thị có n đỉnh. Khi đó các mệnh đề sau là tương đương:
(1) T là cây
(2) T không chứa chu trình và có n - 1 cạnh
(3) T liên thông và có n - 1 cạnh
(4) T liên thông và mỗi cạnh của nó đều là cầu.
(5) Hai đỉnh bất kì của T được nối với nhau bởi đúng một đường đi đơn.
(6) T không chứa chu trình, nhưng nếu cứ thêm vào nó một cạnh thì ta thu được đúng một chu trình.
Định nghĩa 3. Giả sử G = (V, E) là đồ thị vô hướng liên thông. Cây T = (V, F) với F ⊂ E, được gọi là một cây khung của đồ thị G.
Nói cách khác, cây khung của một đồ thị trước hết là một cây, sau đó cần thêm điều kiện số đỉnh của nó bằng số đinh của đồ thị.
Với một đồ thị, người ta có thể xây dựng nhiều cây khung khác nhau.
Định lí 5.5. Số lượng cây khung của đồ thị là nn-2.
Định nghĩa 4. Trong số các cây khung xây dựng từ một đồ thị, cây khung có tổng trọng số trên các cạnh nhỏ nhất gọi là cây khung cực tiểu.
Có hai thuật toán để tìm cây khung cực tiểu: Kruskal và Prim.

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
91
6.2. Thuật toán Kruskal Thuật toán sẽ xây dựng tập cạnh T của cây khung T nhỏ nhất H = (V, T) theo từng bước. Trước hết xếp các cạnh của đồ thị G theo thứ tự không giảm của trọng số. Bắt đầu từ tập T = ∅, ở mỗi bước ta sẽ lần lượt duyệt trong danh sách cạnh đã sắp xếp, từ cạnh có độ dài nhỏ nhất đến cạnh có độ dài lớn hơn, để tìm ra cạnh mà việc bổ sung nó vào tập T không tạo thành chu trình trong tập này. Thuật toán kết thúc khi thu được tập T gồm n - 1 cạnh.
procedure Kruscal;
begin
T := ∅;
while |T| < (n-1) and (E ≠ ∅) do
begin
Chọn e là cạnh có độ dài nhỏ nhất trong E;
E := E \ e;
if T ∪ e không chứa chu trình then T := T ∪ e;
end;
if |T| < n - 1) then Đồ thị không liên thông;
end;
Ví dụ
2 4
Bước khởi tạo: T := ∅. Sắp xếp các cạnh của đồ thị theo thứ tự không giảm của đồ thị, ta có dãy
(3, 5), (4, 6), (4, 5), (5, 6), (3, 4), (1, 3), (2, 3), (2, 4), (1, 2)
dãy độ dài tương ứng của chúng là:
4, 8, 9, 14, 16, 17, 18, 20, 33
Ở ba lần lặp đầu tiên, ta bổ sung được vào T các cạnh (3, 5), (4, 6), (4, 5). Nếu tiếp tục bổ sung cạnh (5, 6) vào T thì sẽ tạo thành với hai cạnh (4, 5) và (4, 6) đã có trong T chu trình. Tình huống tiếp theo cũng tương tự xảy ra đối với cạnh (3, 4) trong dãy. Tiếp theo, ta bổ sung cạnh (1, 3) và (2, 3) vào T và thu được cây khung T cực tiểu cần tìm gồm 5 cạnh:
T = (3, 5), (4, 6), (4, 5), (1, 3), (2, 3)
Vấn đề chọn cạnh e đưa vào T để không tạo thành chu trình
1
3 5
33 20 8
6 18 16 9
1417 4

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
92
Để ý rằng các cạnh trong T ở các bước lặp trung gian sẽ tạo thành một rừng. Cạnh e cần khảo sát sẽ tạo thành một chu trình với các cạnh trong T nếu hai đầu của nó cùng thuộc vào một cây con của rừng nói trên. Do đó, nếu cạnh e không tạo thành chu trình trong T thì nó phải nối hai cây khác nhau trong T. Vì thế để kiểm tra xem có thể bổ sung cạnh e vào T ta chỉ cần kiểm tra xem nó có nối với hai cây khác nhau trong T hay không.
Để làm được điều này, ta có thể phân hoạch tập các đỉnh của đồ thị thành các tập con không giao nhau, mỗi tập xác định một cây con trong T (được hình thành do bổ sung cạnh vào T). Xét đồ thị trong ví dụ trên, đầu tiên ta có sáu tập con 1 phần tử
1, 2, 3, 4, 5, 6.
Sau khi bổ sung cạnh (3, 5) ta có 5 tập con
1, 2, 3, 5, 4, 6
Tiếp theo, khi cạnh (4, 6) được chọn ta có 4 tập con
1, 2, 3, 5, 4, 6
Ở bước 3, ta chọn cạnh (4, 5), khi đó hai tập con được nối lại với nhau, ta thu được 3 tập con:
1, 2, 3, 4, 5, 6
Rõ ràng tiếp theo ta không thể chọn (4, 6) hoặc (3, 4) vì chúng thuộc một tập con, nên sẽ tạo thành chu trình trong T.
Bởi vậy các cạnh còn lại là (1, 3) và (2, 3) nối các cây con nói trên sẽ lần lượt được chọn.
6.3. Thuật toán Prim Thuật toán Kruskal làm việc kém hiệu quả đối với đồ thị dày. Để khắc phục ta sử dụng thuật toán Prim (còn gọi là phương pháp lân cận gần nhất, hay “Người láng giềng gần nhất”).
Ý tưởng của thuật toán Prim
Ý tưởng của thuật toán Prim như sau: Bắt đầu từ một đỉnh s tùy ý của đồ thị, đầu tiên ta nối đỉnh s với đỉnh lân cận gần nó nhất, chẳng hạn là đỉnh y. Nghĩa là trong số các đỉnh kề đỉnh s, cạnh (s, y) có trọng số nhỏ nhất. Tiếp theo, trong số các cạnh kề với hai đỉnh s hoặc y, ta tìm cạnh có trọng số nhỏ nhất, cạnh này dẫn đến đỉnh thứ ba z, và ta thu được cây gồm ba đỉnh và hai cạnh. Quá trình này cứ tiếp tục cho đến khi ta thu được cây gồm n đỉnh và n - 1 cạnh thì nó chính là cây khung cực tiểu cần tìm.
Giả sử đồ thị cho bởi ma trận trọng số C = c[i, j], i, j = 1, 2, …, n. Trong quá trình thực hiện thuật toán, ở mỗi bước để có thể nhanh chóng chọn đỉnh và cạnh cần bổ sung vào cây khung, các đỉnh của đồ thị sẽ được gán nhãn. Nhãn của đỉnh v gồm hai phần và có dạng (d[v], near[v]), trong đó d[v] dùng để ghi nhận độ dài cạnh nhỏ nhất trong số các cạnh nối đỉnh v với các đỉnh của cây khung đang xây dựng (ta sẽ gọi là khoảng cách từ đỉnh v đến tập các đỉnh của cây khung), nói một cách chính xác:
d[v] = min c[v, w] : w ∈ VH ( = c[v, z])

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
93
còn near[v] ghi nhận đỉnh của cây khung gần v nhất (near[v] := z)
Mô phỏng thuật toán Prim trên Pascal
procedure Prim;
begin
(*Bước khởi tạo*)
chọn s là đỉnh nào đó của đồ thị;
VH := s; T := ∅; d[s] := 0; near[s] := s;
for v ∈ V \ VH do
begin d[v] := c[s, v]; near[v] := s;
end;
(* Bước lặp*)
stop := false;
while not stop do
begin
Tìm đỉnh u ∈ V \ VH thỏa mãn
d[u] = min d[v] : v ∈ V \ VH ;
VH := VH ∪ u ; T := T ∪ (u, near[u] ;
if |VH| = n then
begin
H := (VH , T ) là cây khung cực tiểu ;
stop := true ;
end
else
for v ∈ V \VH do
if d[v] > c[u, v] then
begin
d[v] := c[u, v];
near[v] := u;
end;
end;
end;
Ví dụ: Tìm cây khung nhỏ nhất của đồ thị cho bởi ma trận trọng số sau:

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
94
1 2 3 4 5 6
1 0 33 17 ∞ ∞ ∞
2 0 18 20 ∞ ∞
3 0 16 4 ∞
4 0 9 8
5 0 14
C =
6 0
Bảng dưới đây ghi nhãn của các đỉnh trong các bước lặp của thuật toán, đỉnh đánh dấu * là đỉnh được chọn để bổ sung vào cây khung (khi đó nhãn của nó không bị biến đổi trong các bước tiếp theo, vì thế ta đánh dấu “-“ để ghi nhận điều đó.
Bước lặp Đỉnh 1 Đỉnh 2 Đỉnh 3 Đỉnh 4 Đỉnh 5 Đỉnh 6 VH T
Khởi tạo [0, 1] [33, 1] [17, 1]* [∞, 1] [∞, 1] [∞, 1] 1 ∅
1 - [18, 3] - [16, 3] [4, 3]* [∞, 1] 1, 3 (3, 1)
2 - [18, 3] - [9, 5]* - [14, 5] 1, 3, 5 (3,1),(5,3)
3 - [18, 3] - - - [8, 4]* 1,3,5,4 (3,1),(5,3), (4,5)
4 - [18,3]* - - - - 1,3,5,4, 6 (3,1),(5,3), (4,5),(6,4)
5 - - - - - - 1,3,5,4,6,2 (3,1),(5,3), (4,5),(6,4), (2,3)
BÀI TẬP CHƯƠNG 5 1. Cho đồ thị sau:
Hãy biểu diễn đồ thị bằng
a). Ma trận kề
b). Danh sách kề
2. Cho đồ thị sau
Hãy biểu diễn đồ thị bằng
c) Ma trận trọng số b) Danh sách kề

Nguyễn Chí Trung – Nguyễn Thị Thu Thủy
95
3. Cho các đồ thị
Hãy minh họa các bước của thuật toán
a) Tìm kiếm theo chiều sâu
b) Tìm kiếm theo chiều rộng
4. Cho đồ thị
Nêu cách sắp xếp thứ tự các đỉnh do thuật toán Topological-Sort tạo ra cho hình trên. Minh họa thuật toán.
5. Cho đồ thị
Xác định các thành phần liên thông mạnh của đồ thị.

Phân tích thiết kế thuật toán và đánh giá độ phức tạp giải thuật
96
CÁC CHUYÊN ĐỀ MÔN HỌC
1. Hash table
2. Balanced Tree
3. B – Tree
4. Red – Black Trees
5. AVL Trees
6. Splay Trees
7. Skip List
8. Heap
9. Priority Queue
10. Deapth First Search, Breadth First Search
11. Shorted Path (Đường đi ngắn nhất)
12. Minimum Spanning Tree (cây khung tối thiểu)
13. Flow Network (luồng trong mạng)
14. Topological Sort
15. Probabilistic Algorithm
16. The class P, NP, and NP – complete, Co-NP (Độ phức tạp bài toán)
Ghi chú
• Chuyên đề từ 1 đến 9: đề cập đến các cấu trúc dữ liệu nâng cao: Định nghĩa cấu trúc dữ liệu trừu tượng; Các phép toán (khởi tạo, thêm, xóa, sửa, …); Các ứng dụng (những ứng dụng nào dùng nó?). Có thể tham khảo tài liệu trên wikipedia.
• Chuyên đề 13: Đề cập đến các nội dung: Luồng trong mạng; Luồng chi phí tối thiểu; Đa luồng;
• Chuyên đề từ 10 đến 14: Lưu ý đề cập đến các nội dung: Nêu bài toán cần giải quyết; Các thuật toán * (ví dụ thuật toán A*) ; Các ứng dụng. Các chuyên đề từ 1 đến 13 có thể tham khảo tài liệu “Toán rời rạc” của Nguyễn Đức Nghĩa (ĐH BK HN).
• Chuyên đề 15: Đề cập đến các nội dung: Tư tưởng chung của thuật toán là gì? Ví dụ minh họa.
• Chuyên đề 16: Đề cập đến việc chứng minh độ phức tạp của bài toán: Thế nào là lớp P (tồn tại thuật toán đa thức để giải)? lớp NP? NP-complete? (không tồn tại thuật toán đa thức để giải); Chứng minh một thuật toán thuộc lớp NP-C. Chú ý độ phức tạp thuật toán (tính O(?)) khác với độ phức tạp bài toán (Có thể giải được hay không thể giải được).





























