Embed Size (px)
Citation preview

Neural NetworksChapter 6
Joost N. Kok
Universiteit Leiden
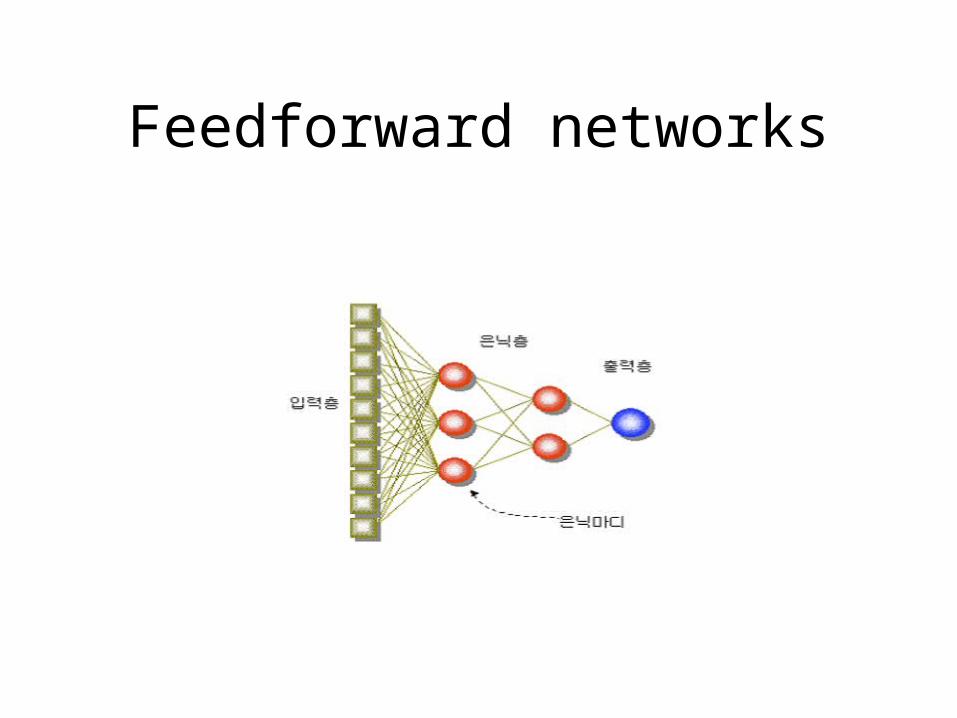
Feedforward networks

Feedforward networks
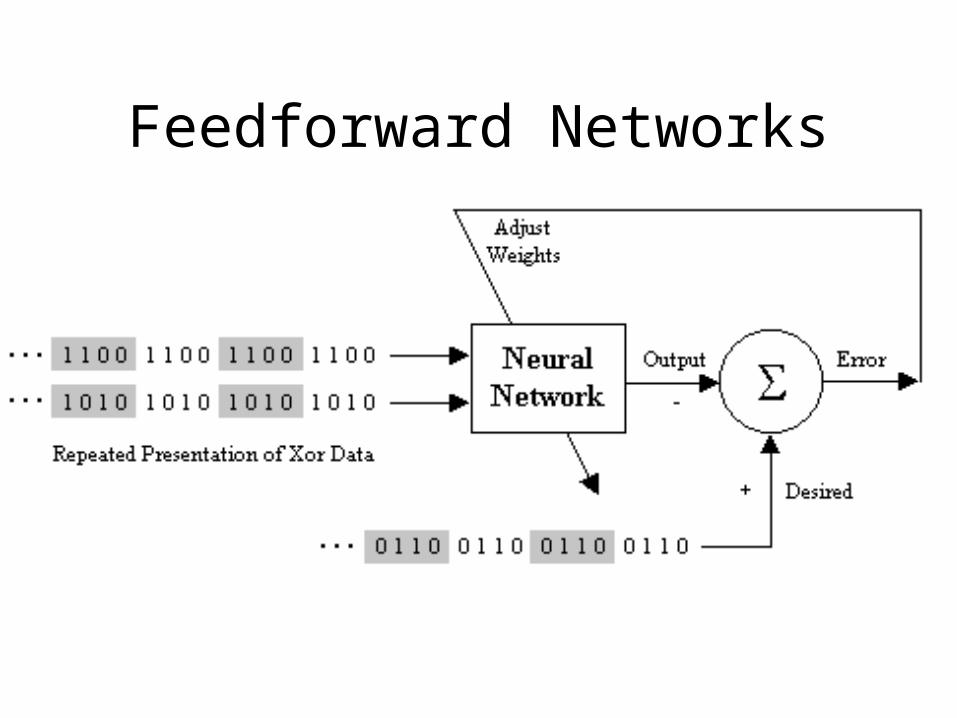
Feedforward Networks

Feedforward Networks

NetTalk

NetTalk

Feedforward Networks
• A network to pronounce English text
• 7 x 29 input units
• 1 hidden layer with 80 hidden units
• 26 output units encoding phonemes
• Trained by 1024 words with context
• Produces intelligible speech after 10 training epochs

Feedforward Networks
• Functionally equivalent to DEC-talk
• Rule-based DEC-talk is the result of a decade of efforts by many linguists
• NETtalk learns from examples, and requires no linguistic knowledge

Back-Propagation
1 2 34 5
1O 2O
1V 2V 3V jV
iO
k
jkw
ijW23W
35w

Back-Propagation
ik ,
k
kjkj wh
k
kjkjj wghgV )()(

Back-Propagation
j k
kjkijj
jiji wgWVWh )(
)()( j
jijii VWghgO
))(( j k
kjkij wgWg

Back-Propagation
patterns
inputoutputpq Vw

Back-Propagation
• Initialize the weights to small random values
• Choose a pattern and apply it to the input layer
• Propagate the signal forwards through the network
• Compute the deltas for the output layer
])[( iiii Ohg

Back-Propagation
• Compute the deltas for the preceding layers by propagating the errors backwards
• Update all the connections
• Go back to the second step for the next pattern
ii
ijjj Whg )(
jiij VW kjjkw

Feedforward Networks

Feedforward Networks

Navigation of a Car
• Carnegie-Mellon
• 30 times 32 pixel image
• 8 times 32 range finder
• 29 hidden units, 45 output units
• 1200 simulated road images, 40 training cycles
• 5km/hr

Feedforward Networks

Backgammon
• Score from –100 to +100
• 3000 examples
• 459 inputs
• Two hidden layers of 24 nodes
• Neurogammon vs. Gammontool: 59 percent
• Without precomputed features: 41 percent
• Without noise: 45 percent

Feedforward Networks

Feedforward Networks


Parity Problem
• Parity Problem: Output is on if an odd number of inputs is on
0.5
0.50.5
1 1 1 1
1 -2

Back-Propagation
2][2
1][
ii
i OwE
2))](([2
1][
kkjk
jij
ii wgWgwE

Back-Propagation
jiiiij
ij VhgOW
EW )(][
jV
])[( iiii Ohg

Back-Propagation
jk
j
jjk w
V
V
Ew
kji
ijiii hgWhgO )()(][
kj
ii
ijjj Whg )(

Back-Propagation
)2exp(1
1)()(
hhfhg
))(1)((2)( hghghg

Back-Propagation
• The update rule is local
• Incremental weight updating vs. batch mode
• Momentum: accelerate the long term trend by a factor
)()1( tww
Etw pq
pqpq
)1/(1

Back-Propagation
• Adaptive parameters
otherwise
Eif
lyconsistentEif
b 0
0
0

Feedforward Networks
• Process Modeling and Control • Machine Diagnostics • Portfolio Management• Target Recognition • Medical Diagnosis• Credit Rating

Feedforward Networks
• Targeted Marketing
• Voice Recognition
• Financial Forecasting
• Quality Control
• Intelligent Searching
• Fraud Detection

Optimal Network Architectures
• Optimization
• Use as few units as possible:– Improve computational costs and training time– Improve generalization
• Search through space of possible architectures, for example using Back-Propagation and Evolutionary Algorithms

Optimal Network Architectures
• Construct or modify architecture– Start with too many nodes and take some away– Start with too few and add some more

Optimal Network Architectures
• Pruning and weight decay
oldij
newij ww )1(
)(
20
ijijwEE
2/

Optimal Network Architectures
• Small weights decay more rapidly than large ones:
22)1(
2/
ijij w
)(2
2
0 1ij ij
ij
w
wEE

Optimal Network Architectures
• We want to remove units: use same for all connections feeding unit i:
22)1(
2/
jij
i w
i

Optimal Network Architectures
• Start with small network and gradually grow one of the appropriate size
• Boolean function from N binary inputs to single binary output

Optimal Network Architectures

Optimal Network Architectures
• Choose hidden units such that– Same output for all remaining patterns with one
target– Opposite output for at least one of the
remaining patterns with opposite target and remove these patterns
• Linearly separable problem

Optimal Network Architectures
+
+
+-
-
-

Optimal Network Architectures
• We do the best we can with single node
• Correct with two nodes– One for wrongly on patterns– One for wrongly off patterns
• Each additional unit reduces the number of incorrectly classified patterns by at least one

Optimal Network Architectures

Optimal Network Architectures
• Faithful representation: two patterns with different targets should have different representations
• Master unit: does as well as possible on the task
• Ancillary units: added to obtain faithful representation





























