Embed Size (px)
Citation preview

NineOneOne:Recognizing and Classifying Speech
for Handling Minority Language Emergency Calls
Udhay Nallasamy, Alan W Black,
Tanja Schultz, Robert Frederking,
[Jerry Weltman, Julio Schrodel]
May 2008

Outline
• Overview– System design– ASR design– MT design
• Current results– ASR results– Classification-for-MT results
• Future plans

Project overview
• Problem: Spanish 9-1-1 calls handled in slow, unreliable fashion
• Tech base: SR/MT far from perfect, but usable in limited domains
• Science goal: Speech MT that really gets used– 9-1-1 as likeliest route:
• Naturally limited, important, civilian domain• Interested user partner who will really try it
– (vs. Diplomat experience…)

Domain Challenges/Opportunities
• Challenges:– Real-time required– Random phones– Background noise– Stressed speech– Multiple dialects– Cascading errors
• Opportunities:– Speech data source– Strong task constraints– One-sided speech– Human-in-the-loop– Perfection not required

System flow
Spanish caller
English Text
I need ambulance
Spanish speech
English Dispatcher
Nueve uno uno, ¿cuál es su emergencia?
Necessito una ambulancia
SpanishASR
DAClassifier
Spanish-To-English MT
DispatchBoard
SpanishTTS

Overall system design
• Spanish to English: [no TTS!]– Spanish speech recognized– Spanish text classified (context-dependent?) into
DomainActs, arguments spotted and translated– Resulting text displayed to dispatcher
• English to Spanish: [no ASR!]– Dispatcher selects output from tree, typing/editing arg
• Very simple “Phraselator”-style MT
– System synthesizes Spanish output• Very simple limited-domain synthesizer
• HCI work: keeping human in the loop!– role-playing & shadow use

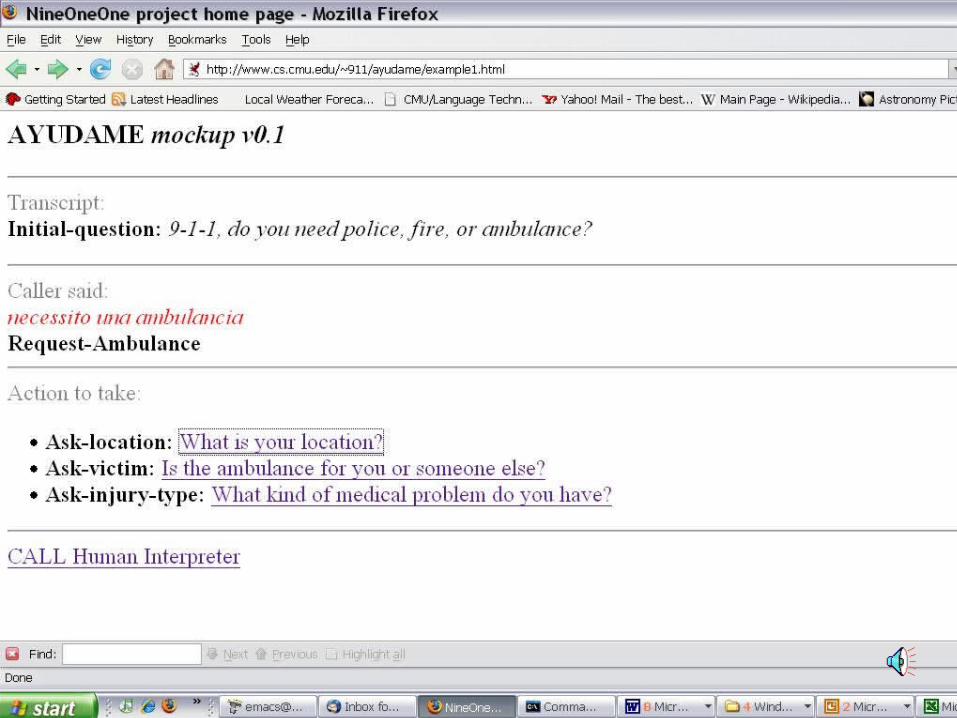
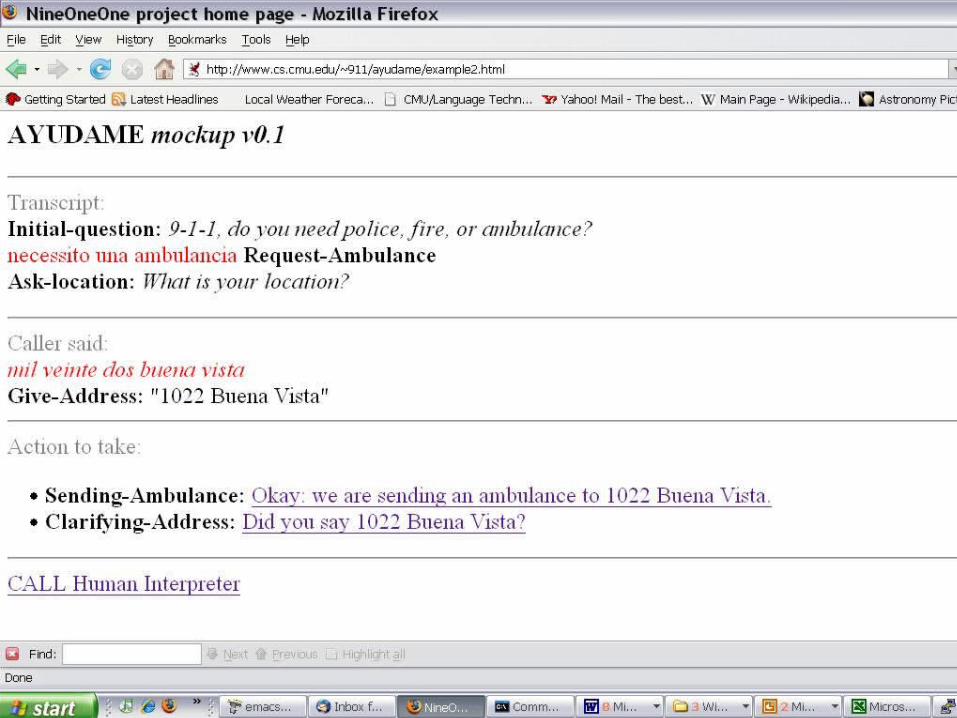
“Ayudame” system mock-up
• We plan to interface with call-takers via web browser
• Initial planned user scenario follows
• The first version will certainly be wrong– One of the axioms of HCI
• But iterating through user tests is the best way to get to the right design

Technical plans: ASR
• ASR challenges:– Disfluencies– Noisy emotional speech– Multiple dialects, some English
• Planned approaches:– Noisy-channel model [Honal et al,
Eurospeech03]– Articulatory features– Multilingual grammars, multilingual front end

Technical plans: MT
• MT challenges:– Disfluencies in speech– ASR errors– Accuracy/transparency vs. Development costs
• Planned approaches: adapt and extend– Domain Act classification from Nespole!
• Shallow interlingua, speaker intent (not literal)• Report-fire, Request-ambulance, Don’t-know, …
– Transfer rule system from Avenue– (Both NSF-funded.)

Nespole! Parsing and Analysis Approach
• Goal: A portable and robust analyzer for task-oriented human-to-human speech, parsing utterances into interlingua representations
• Our earlier systems used full semantic grammars to parse complete DAs– Useful for parsing spoken language in restricted domains
– Difficult to port to new domains
• Nespole! focus was on improving portability to new domains (and new languages)
• Approach: Continue to use semantic grammars to parse domain-independent phrase-level arguments and train classifiers to identify DAs

Example Nespole! representation
• Hello. I would like to take a vacation in Val di Fiemme.
• c:greeting (greeting=hello)
c:give-information+disposition+trip
(disposition=(who=i, desire),
visit-spec=(identifiability=no, vacation),
location=(place-name=val_di_fiemme))

MT differences from Nespole!
• Hypothesis: Simpler domain can allow simpler (less expensive) MT approach
• DA classification done without prior parsing– We may add argument-recognizers as
features, but still cheaper than parsing
• After DA classification, identify, parse, and translate simple arguments (addresses, phone numbers, etc.)

Currently-funded NineOneOne work
• Full proposal was not funded– But SGER was funded
• Build targeted ASR from 9-1-1 call data• Build classification part of MT system• Evaluate on unseen data, hopefully
demonstrating sufficient ASR and classification quality to get follow-on
• 18 months, began May 2006– No-Cost Extension to 24 months

Spanish ASR Details
• Janus Recognition Toolkit (JRTk)• CI models initialized from GlobalPhone
data (39 Phones)• CD models are 3 state, semi-continuous
models with 32 gaussians per state• LM trained on Global Phone text corpus
(Spanish news – 1.5 million words)• LM is interpolated with the training data
transcriptions

ASR Evaluation
• Training data – 50 calls (4 hours of speech)
• Dev set – 10 calls (for LM interpolation)
• Test set – 15 calls (1 hour of speech)
• Vocabulary size – 65K words
• Test set perplexity – 96.7
• Accuracy of ASR on test set – 76.5%– Good for spontaneous, multi-speaker
telephone speech

Utterance Classification/Eval
• Can we automatically classify utterances into DAs?
• Manually classified turns into DAs– 10 labels, 845 labelled turns
• WEKA toolkit SVM with simple bag-of- words binary features
• Evaluated using 10-fold cross-validation • Overall accuracy 60.1%
– But increases to 68.8% ignoring “Others”
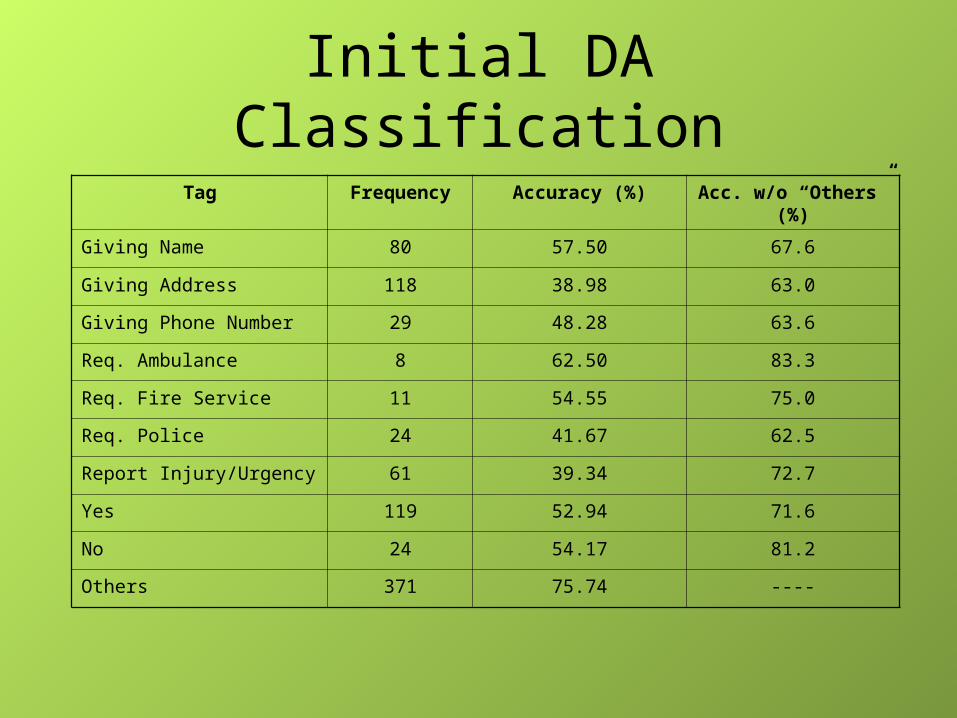
Initial DA Classification
Tag Frequency Accuracy (%) Acc. w/o “Others” (%)
Giving Name 80 57.50 67.6
Giving Address 118 38.98 63.0
Giving Phone Number 29 48.28 63.6
Req. Ambulance 8 62.50 83.3
Req. Fire Service 11 54.55 75.0
Req. Police 24 41.67 62.5
Report Injury/Urgency 61 39.34 72.7
Yes 119 52.94 71.6
No 24 54.17 81.2
Others 371 75.74 ----

DA classification caveat
• But DA classification was done on human transcriptions (also human utterance segmentation)
• Classifier accuracy on current ASR transcriptions is 40% (49% w/o “Others”)
• Probably needs to be better than that

Future work
• Improving ASR
• Improving classification on real output:– More labelled training data– Use discourse context in classification– “Query expansion” via synsets from Spanish
EuroWordNet– Engineered phone-number-recognizer etc.
• Partial (simpler) return to Nespole! approach
– Better ASR/classifier matching
• Building and user-testing full pilot system

Questions?
http://www.cs.cmu.edu/~911/

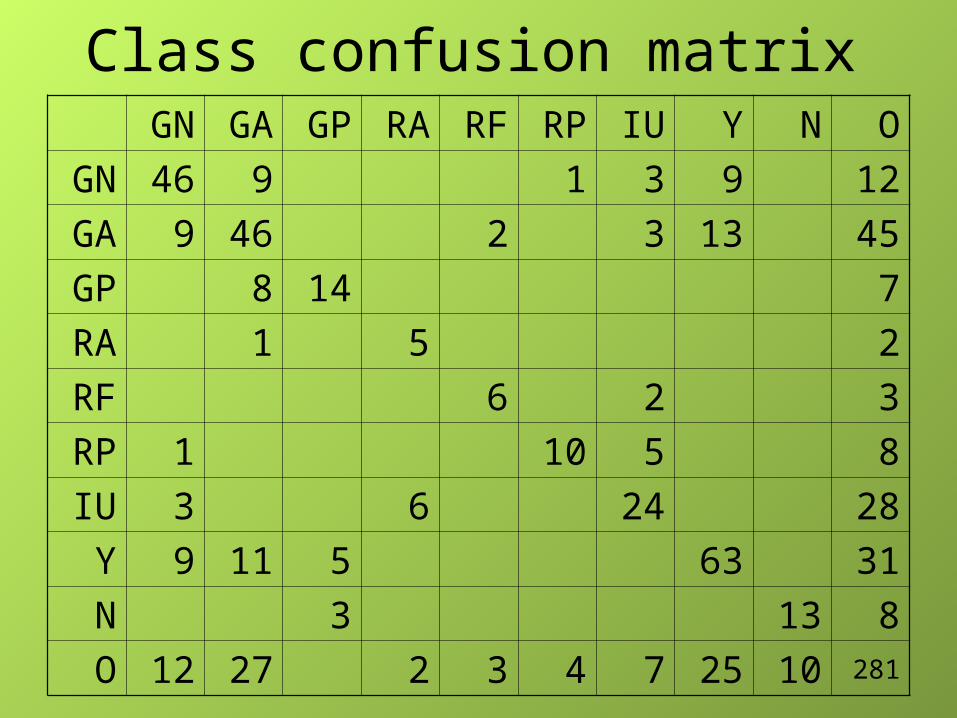
Class confusion matrixGN GA GP RA RF RP IU Y N O
GN 46 9 1 3 9 12
GA 9 46 2 3 13 45
GP 8 14 7
RA 1 5 2
RF 6 2 3
RP 1 10 5 8
IU 3 6 24 28
Y 9 11 5 63 31
N 3 13 8
O 12 27 2 3 4 7 25 10 281

Argument Parsing
• Parse utterances using phrase-level grammars
• Nespole! used SOUP Parser (Gavaldà, 2000): Stochastic, chart-based, top-down robust parser designed for real-time analysis of spoken language
• Separate grammars based on the type of phrases that the grammar is intended to cover

Domain Action Classification
• Identify the DA for each SDU using trainable classifiers
• Nespole! used two TiMBL (k-NN) classifiers:– Speech act– Concept sequence
• Binary features indicate presence or absence of arguments and pseudo-arguments

Current status: March 2008 (1)
(At end of extended SGER…)
• Local Spanish transcribers transcribing HIPAA-sanitized 9-1-1 recordings
• CMU grad student (Udhay)– managing transcribers via internal website, – built and evaluated ASR and utt. classifier,– building labelling webpage, prototype, etc.
• Volunteer grad student (Weltman, LSU) analyzing, refining, and using classifier labels

Current status: March 2008 (2)
• “SGER worked.”• Paper on ASR and classification accepted to
LREC-2008• Two additional 9-1-1 centers sending us data• Submitted follow-on small NSF proposal in
December 07: really build and user-test pilot– Letters of Support from three 9-1-1 centers
• Will submit to COLING workshop on safety-critical MT systems

Additional Police Partners
• Julio Schrodel (CCPD) successes:– Mesa PD, Arizona– Charlotte-Mecklenburg PD, NC
• Much larger cities than Cape Coral– (Each is now bigger than Pittsburgh!)
• Uncompressed recordings!• Much larger, more automated 9-1-1
operations– Call-taker vs. dispatcher– User-defined call types logged
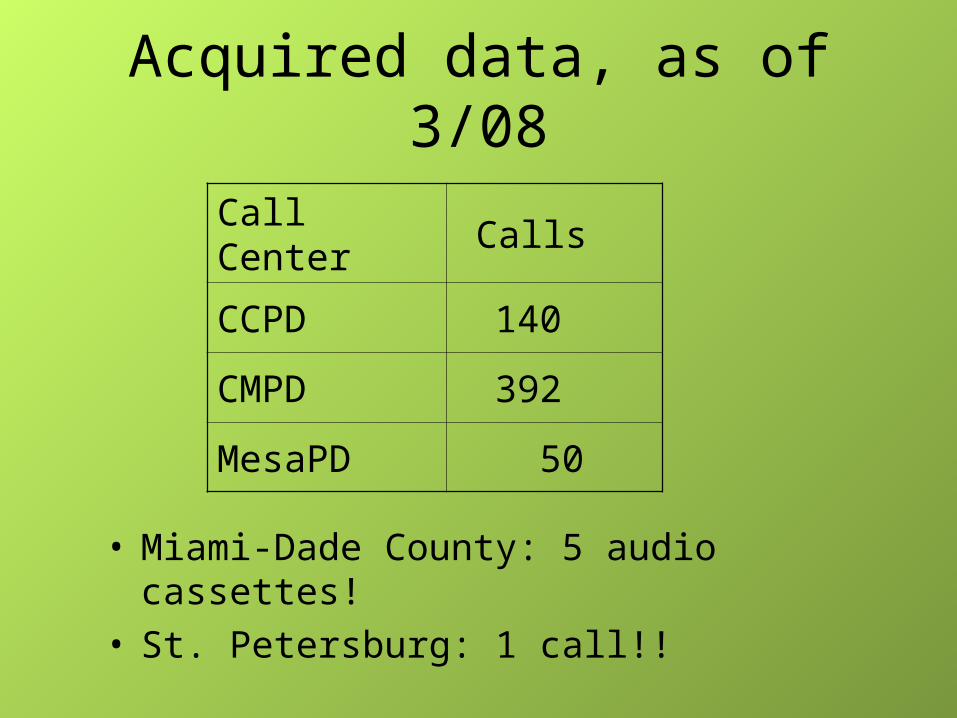
Acquired data, as of 3/08
• Miami-Dade County: 5 audio cassettes!• St. Petersburg: 1 call!!
Call Center Calls
CCPD 140
CMPD 392
MesaPD 50

Transcription Status
• VerbMobil transcription conventions
• TransEdit software (developed by Susi Burger and Uwe Meier)
• Transcribed calls: – 97 calls from Cape Coral PD– 13 calls from Charlotte
• Transcribed calls playback time: 9.7 hours

LSU work: Better DA tags
• Manually analyzed 30 calls to find DAs with widest coverage
• Current proposal adds 25 new DAs• Created guidelines for tagging. E.g.:
– If the caller answers an open-ended question with multiple pieces of information, tag each piece of information
• Currently underway: Use web-based tagging tool to manually tag the calls
• Determine inter-tagger agreement
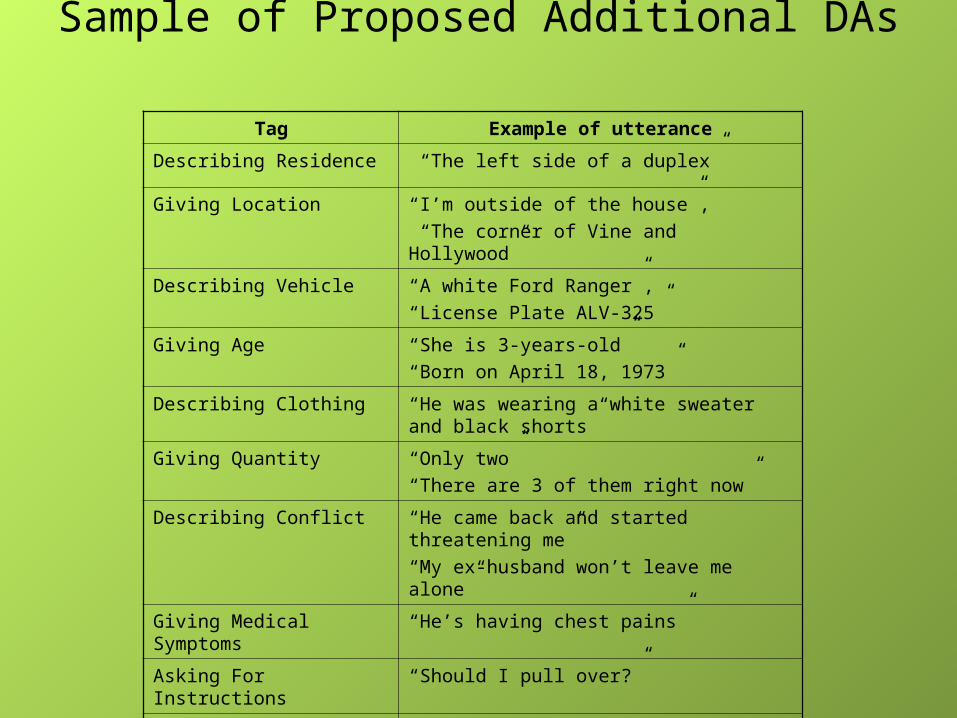
Sample of Proposed Additional DAs Tag Example of utterance
Describing Residence “The left side of a duplex”
Giving Location “I’m outside of the house”,
“The corner of Vine and Hollywood”
Describing Vehicle “A white Ford Ranger”,
“License Plate ALV-325”
Giving Age “She is 3-years-old”
“Born on April 18, 1973”
Describing Clothing “He was wearing a white sweater and black shorts”
Giving Quantity “Only two”
“There are 3 of them right now”
Describing Conflict “He came back and started threatening me”
“My ex-husband won’t leave me alone”
Giving Medical Symptoms “He’s having chest pains”
Asking For Instructions “Should I pull over?”
Asking About Response “How long will it take someone to get here?”

Project origin• Contacted by Julio Schrodel of Cape Coral
PD (CCPD) in late 2003– Looking for technological solution to shortage
of Spanish translation for 9-1-1 calls
• Visited CCPD in December 2003– CCPD very interested in cooperating– Promised us access to 9-1-1 recordings
• Designed system, wrote proposal– CCPD letter in support of proposal– Funded starting May 2006
• (SGER, only for ASR and preparatory work)

Articulatory features
• Model phone as a bundle of articulatory features such as voiced or bilabial
• Less fragmentation of training data
• More robust in handling hyper-articulation– Error-rate reduction of 25% [Metze et al,
ICSLP02]
• Multilingual/crosslingual articulatory features for multilingual settings– Error-rate reduction of 12.3% [Stuecker et al,
ICASSP03]

Grammars plus N-grams
• Grammar-based concept recognition
• Multilingual grammars plus n-grams for efficient multi-lingual decoding [Fuegen et al, ASRU03]
• Multilingual acoustic models

Interchange Format
• Interchange Format (IF) is a shallow semantic interlingua for task-oriented domains
• Utterances represented as sequences of semantic dialog units (SDUs)
• IF representation consists of four parts– Speaker– Speech Act– Concepts– Arguments
speaker : speech act +concept* +arguments*
} Domain Action


Hybrid Analysis Approach
Hello. I would like to take a vacation in Val di Fiemme.c:greeting (greeting=hello)c:give-information+disposition+trip (disposition=(who=i, desire), visit-spec=(identifiability=no, vacation), location=(place-name=val_di_fiemme))
hello i would like to take a vacation in val di fiemme
SDU1 SDU2
greeting= disposition= visit-spec= location=
hello i would like to take a vacation in val di fiemme
greeting give-information+disposition+trip
greeting= disposition= visit-spec= location=
hello i would like to take a vacation in val di fiemme

Hybrid Analysis Approach
Text
Argument
Parser
Text
Arguments
SDU
Segmenter
Text
Arguments
SDUs
DA
Classifier
IF
Use a combination of grammar-based phrase-level parsing and machine learning to produce interlingua (IF) representations

Grammars (1)
• Argument grammar– Identifies arguments defined in the IFs[arg:activity-spec=]
(*[object-ref=any] *[modifier=good] [biking])
– Covers "any good biking", "any biking", "good biking", "biking", plus synonyms for all 3 words
• Pseudo-argument grammar– Groups common phrases with similar meanings into
classess[=arrival=] (*is *usually arriving)
– Covers "arriving", "is arriving", "usually arriving", "is usually arriving", plus synonyms

Grammars (2)
• Cross-domain grammar– Identifies simple domain-independent DAss[greeting]
([greeting=first_meeting] *[greet:to-whom=])
– Covers "nice to meet you", "nice to meet you donna", "nice to meet you sir", plus synonyms
• Shared grammar– Contains low-level rules accessible by all
other grammars

Using the IF Specification
• Use knowledge of the IF specification during DA classification– Ensure that only legal DAs are produced– Guarantee that the DA and arguments
combine to form a valid IF representation
• Strategy: Find the best DA that licenses the most arguments– Trust parser to reliably label arguments– Retaining detailed argument information is
important for translation

Avenue Transfer Rule Formalism (I)
Type information
Part-of-speech/constituent information
Alignments
x-side constraints
y-side constraints
xy-constraints,
e.g. ((Y1 AGR) = (X1 AGR))
;SL: the old man, TL: ha-ish ha-zaqen
NP::NP [DET ADJ N] -> [DET N DET ADJ]((X1::Y1)(X1::Y3)(X2::Y4)(X3::Y2)
((X1 AGR) = *3-SING)((X1 DEF = *DEF)((X3 AGR) = *3-SING)((X3 COUNT) = +)
((Y1 DEF) = *DEF)((Y3 DEF) = *DEF)((Y2 AGR) = *3-SING)((Y2 GENDER) = (Y4 GENDER)))

Avenue Transfer Rule Formalism (II)
Value constraints
Agreement constraints
;SL: the old man, TL: ha-ish ha-zaqen
NP::NP [DET ADJ N] -> [DET N DET ADJ]((X1::Y1)(X1::Y3)(X2::Y4)(X3::Y2)
((X1 AGR) = *3-SING)((X1 DEF = *DEF)((X3 AGR) = *3-SING)((X3 COUNT) = +)
((Y1 DEF) = *DEF)((Y3 DEF) = *DEF)((Y2 AGR) = *3-SING)((Y2 GENDER) = (Y4 GENDER)))





























