Embed Size (px)
Citation preview

Non-local features in Syntactic Parsing
Thesis submitted in partial fulfillment
of the requirements for the degree of
Master of Science by Research
in
Computer Science and Engineering
by
Sudheer Kolachina
Language Technologies Research Center
International Institute of Information Technology
Hyderabad - 500 032, INDIA
July 2012

Copyright c© Sudheer Kolachina, 2012
All Rights Reserved

International Institute of Information Technology
Hyderabad, India
CERTIFICATE
It is certified that the work contained in this thesis, titled “Non-local featuresin Syntactic Parsing” by
Sudheer Kolachina, has been carried out under my supervision and is not submitted elsewhere for a
degree.
Date Principal co-adviser: Prof. Rajeev Sangal
Date Principal co-adviser: Prof. Vineet Chaitanya

n corhAy� n c rAjhAy� n B}At� BA>y\ n c BArкAEr ।
&yy� к� t� vD t ev En(y\ Ev�ADn\ sv DnþDAnm ॥
That (wealth) which cannot be stolen by thieves, that which cannot be snatched by rulers, that
which cannot be divided amongst brothers, that which is not heavy to carry, that which when
spent only increases in quantity, that wealth of knowledge is the best of all wealths.
— Subhashitani, Bhartr.hari (5th century CE)

To Vijaya Kolachina, the first teacher of my life

Acknowledgments
“All things must pass”, said the wise Buddha. And it is time now for this thesis. On this happy
occasion, I would like to thank all those that helped me travel upto this point.
First and foremost, I would like to thank my advisors, Prof. Rajeev Sangaland Prof. Vineet Chai-
tanya, both of them pioneering figures who laid the foundations of language technology for Indian
languages. I consider myself incredibly lucky to have been able to work withthe two of them for my
thesis. Not only are they pioneers in language technology for Indian languages, they also spearheaded
efforts to apply theories from the Indian intellectual traditions to solve scientific and technological prob-
lems of current day India. Working with such stalwarts has inculcated in me asense of pride in what I
do. This thesis is only a by-product.
I must make a special note about Vineet Chaitanya ji who I also had the goodfortune of working with
for my under-grad thesis. His quiet dedication and silent ingenuity are a constant source of inspiration
to me. I will never forget the many thrilling and at the same time, illuminating hours of discussion spent
with him and others in theMahabharatareading group. I will also never forget the discussions on the
Ashtavakra Gita, one of the most interesting texts in Indian philosophy about the nature of mindand
consciousness. These experiences are lessons for life and I will cherish them for the rest of my time.
I would like to thank members of my thesis committee: Prof. Kishore Prahallad and Prof. Soma
Paul for their timely, detailed and favorable reviews.
Next, I would like to thank two individuals who were my constant go-to people at LTRC: Prof. Dipti
Misra Sharma and the late Prof. Lakshmi Bai. It was a great learning experience working on the Telugu
treebank and the Hindi discourse treebank with Dipti ma’am. And of Lakshmima’am who is no more
with us, I can only say that I don’t know if I could have reached this pointwithout her support and
encouragement. It is her inspiration that motivated me to work on Dravidian languages and I hope I
can do justice to her expectations from me. I cherish each and every momentspent with this absolutely
wonderful human being. I will never forget the numerous rides she gave me on our way back home.
Among my peers and co-workers, two people come first: Prasanth Kolachina and Taraka Rama Ka-
sicheyanula. Both of them stuck with me through thick and thin and taught me a lotof things: python
programming, phylogenetic inference algorithms, statistical machine translationand tolerance for Tol-
lywood movies and music. Again, I do not know where I would be without the support of these two
guys. I would also thank the following people for being such great colleagues: Viswanatha Naidu, Sruti
Rallapalli, Khushboo Jha, Gautam Varma, Parmeshwari, Sreenivas, Christopher, Avinesh Polisetty, Sri-
vi

vii
ram Venkatapathy, Anil Kumar Singh, Itishree Jena, Abhijeet Gupta, Arafat Ahsan, Radhika Mamidi,
Sukhada Sharma, Sriram Chaudhary, Sushant Kishore and Sanket Pathak. I would like to thank Harjin-
der SinghLaltu for his friendship during my final years at IIIT. I would also thank the numerous people
that helped me in my work, especially, the technical staff and administrative staff at LTRC. I feel that I
should also thank the people who did not co-operate with me and tried to createobstacles for me since
my experience of dealing with them taught me valuable lessons in life.
During the period 2009-2012, I had the good fortune of meeting and interacting with various es-
tablished researchers in the field, some of whom I had the good fortune ofworking with. I would
like to thank them here: Prof. Aravind Joshi, Rashmi Prasad, Srini Bangalore, the late Prof. Bhadri-
raju Krishnamurti, Amba Pradeep Kulkarni, Owen Rambow, Miriam Butt, RajeshBhatt and Bonnie
Webber. I would also like to thank the following for sharing information that proved to be useful in
my experiments- Joakim Nivre, Bernd Bohnet, Andre Martins, Jens Nilsson, Mihai Surdeanu, David
McClosky, Slav Petrov, Daniel Cer, Richard Johansson, David Vadas, Ivan Titov, John Judge, Jennifer
Foster, Grzegorz Chrupala,Ozlem Cetinoglu and Dip Sankar Banerjee.
Finally, I would like to thank my family- my mother, Vijaya for her thorough faith andsupport. It
is only because of her numerous sacrifices that I am able to pursue research. I would also like to thank
my aunt, Leela (Illu) and my cousin, Uthej (Teja) for their unconditional loveand support at all times.
Thanks to my dad for helping me realize some of the most important aspects of life. I would like to end
this note by thanking my brother, Prasanth Kolachina, who by his constant company, made this journey
worthwhile.

Abstract
Natural language parsers lie at the core of various natural language processing (NLP) systems such
as machine translation (MT), question answering (QA), information extraction/retrieval (IE/IR), etc.
Building accurate, wide-coverage parsers has been one of the main goals in NLP research for the last
two decades. As a result, there exist today highly accurate parsers based on a variety of approaches not
only for English but also for a few other languages. Statistical parsers have proven to be most effective
both in terms of coverage and precision. However, statistical parsers whether constituency-based or
dependency-based make certain independence assumptions about sentence structure. Simply put, statis-
tical parsers of all hues assume that sentence structure can be factored into smaller sub-structures which
can be predicted independently varying only in the type of factorization. Although such assumptions are
necessary in order to ensure tractability of parsing algorithms, they are not linguistically tenable since
we know that there is a significant amount of interaction among the factored sub-structures. There are a
number of linguistic phenomena such as subject-verb agreement, verb argument structure and corefer-
ence of noun phrases where information about the linguistic relationship is spread over more than one
sub-structure. In other words, in all these cases, the cues for parsing one sub-structure correctly can
come from another sub-structure. Most state-of-art statistical parsingmodels which make independence
assumptions about sentence structure fail to capture such non-local phenomena.
In this thesis, I study two approaches to overcome this limitation and make use of non-local features
that encode greater contextual information during parsing. The first approach is based on the technique
of discriminative reranking which consists of two steps: increasing the widthof the search beam to
allow more candidate parses and then employing a classifier that can use non-local features to rank the
candidate parses and pick the best among them. The second approach is based on the technique of
ensemble parsing whereby parsing models with complementary strengths/weaknesses can be combined
to obtain best possible parsing performance. In particular, I study the stacking approach to combining
parsers at learning time. The explored experimental setup allows for non-local features defined over the
output of one (or more) parser(s) to be used while training a graph-based parser. In my experiments on
discriminative reranking and ensemble parsing, I build several highly accurate parsers for English which
can be directly used in in-house large-scale English-to-Indian languagemachine translation systems. I
combine freely available parsers using the ensemble technique of re-parsing to build the best performing
model for dependency parsing of English. This high accuracy dependency parser for English is avail-
able under GPL and can be deployed in a wide array of NLP systems. In my experiments on stacking
viii

ix
dependency parsers, I build stacked parsing models with different combinations of non-local features
for three Indian languages– Hindi, Telugu and Bangla –to study the influence of each feature in im-
proving parsing performance. The accuracies of the best performingof these models are the state-of-art
accuracies for parsing these Indian languages. Although I do not comeup with a entirely new way of
overcoming the limitation of feature locality in statistical parsing frameworks, the insights gained from
the studies presented in this thesis can inform efforts aimed at development of contextually rich models
of syntactic parsing.

Contents
Chapter Page
1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.1 Syntactic parsing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1.1 Representation of Syntactic structure . . . . . . . . . . . . . . . . . . . . 31.1.2 Grammars, Treebanks and Parsing . . . . . . . . . . . . . . . . . . . . . . 5
1.2 Limitation of Feature locality . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.3 Non-local features in syntactic parsing . . . . . . . . . . . . . . . . . . . . . . . . 101.4 Thesis outline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 Discriminative reranking for Syntactic Parsing . . . . . . . . . . . . . . . . . . . . . . 122.1 Non-local features in discriminative reranking . . . . . . . . . . . . . . . . . . . . 132.2 Parsers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2.1 Berkeley Parser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2.2 Stanford parser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Treebanks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.4 Parser Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.5 Reranking Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.6 Results and Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.6.1 Reranking the Berkeley Parser . . . . . . . . . . . . . . . . . . . . . . . . 182.6.2 Reranking the Stanford Parser . . . . . . . . . . . . . . . . . . . . . . . . 22
2.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3 Ensemble models I: Parser combination at Inference time . . . . . . . . . . . . . . . . 253.1 Parser combination through Reparsing . . . . . . . . . . . . . . . . . . . . . . . . 263.2 Constituency-to-dependency conversion . . . . . . . . . . . . . . . . . . . . . . . 273.3 Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.3.1 Parsers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293.3.2 Reparsing experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.3.3 Datasets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 323.3.4 Dependency Parser Evaluation . . . . . . . . . . . . . . . . . . . . . . . . 33
3.4 Results and Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4 Ensemble models II: Parser combination during training . . . . . . . . . . . . . . . . . 394.1 Previous work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404.2 Stacked Dependency Parsing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
x

CONTENTS xi
4.3 Motivations for Stacked Parsing . . . . . . . . . . . . . . . . . . . . . . . . . . . . 434.4 Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.4.1 Non-local features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 444.4.2 Parsers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.4.3 IL dependency parsing datasets . . . . . . . . . . . . . . . . . . . . . . . . 47
4.5 Results and Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 484.6 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60

List of Figures
Figure Page
1.1 Analysis 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Analysis 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.3 Dependency trees for example sentence (1) . . . . . . . . . . . . . . . . . . . . . . 41.4 Dependency trees with labeled edges for example sentence (1) . . . . . . . . . . . 5
4.1 MST+MST-Hindi: Comparison of LAS and UAS score distributions of baselineand best stacked model scores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.2 MST+MST-Telugu: Comparison of UAS score distributions of baseline and beststacked model scores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.3 MST+MST-Bangla: Comparison of LAS and UAS score distributions of baselineand best stacked model scores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.4 MST+Malt-Hindi: Comparison of LAS and UAS score distributions of baselineand best stacked model scores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.5 MST+Malt-Telugu: Comparison of UAS score distributions of baseline and beststacked model scores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.6 MST+Malt-Bangla: Comparison of UAS score distributions of baseline and beststacked model scores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.7 MST+CBP-Hindi: Comparison of LAS and UAS score distributions of baselineand best coarse-grained stacked model . . . . . . . . . . . . . . . . . . . . . . . . 58
xii

List of Tables
Table Page
2.1 Summary of different parsers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.2 Parseval accuracies of baseline and reranked sm-6 models of the Berkeley parser:
LP - Labeled Precision, LR - Labeled Recall, F1 - f -score (Harmonic mean ofLP and LR), CM - Complete Match; * indicates significant increase; () indicatessignificant decrease . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.3 Parseval accuracies of baseline and reranked sm-5 models of the Berkeley parser:LP - Labeled Precision, LR - Labeled Recall, F1 - f -score (Harmonic mean ofLP and LR), CM - Complete Match; * indicates significant increase; () indicatessignificant decrease . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.4 Comparison of parseval scores of Berkeley reranked sm-6 models trained usingMaximum Entropy and Averaged Perceptron methods; * indicates significantincrease; () indicates significant decrease . . . . . . . . . . . . . . . . . . . . . . . 20
2.5 Leaf-Ancestor evaluation of the baseline and the reranked sm-6 models of theBerkeley parser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.6 Leaf-Ancestor evaluation of the baseline and the reranked sm-5 models of theBerkeley parser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.7 Comparison of leaf-ancestor scores of Berkeley reranked models trained usingMaximum Entropy and Averaged Perceptron methods . . . . . . . . . . . . . . . 22
2.8 Parseval accuracies of different versions of the Stanford parser: LP - LabeledPrecision, LR - Labeled Recall, F1 - f -score (Harmonic mean of LP and LR),CM - Complete Match; * indicates significant increase; () indicates significantdecrease . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.9 Leaf-Ancestor evaluation of the baseline and the reranked models of the Stanfordparser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.1 Comparison of dependencies extracted from section 02-21 of the Penn treebankusing the Stanford dependency extraction system and the Pennconverter . . . . . 29
3.2 Brief summary of parsers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.3 Summary of reparsing configurations . . . . . . . . . . . . . . . . . . . . . . . . . 333.4 Comparison of reparsed combination systems with Charniak-Johnson parser;
CoNLL dependencies; Different POS-tags in Berkeley and Stanford parsers . . . 343.5 Comparison of reparsed combination systems with Charniak-Johnson parser;
CoNLL dependencies; Stanford POS-tags in all parsers . . . . . . . . . . . . . . . 353.6 Comparison of reparsed combination systems with Charniak-Johnson parser;
Stanford dependencies; Different POS-tags in Berkeley and Stanford parsers . . . 36
xiii

xiv LIST OF TABLES
3.7 Comparison of reparsed combination systems with Charniak-Johnson parser;Stanford dependencies; Stanford POS-tags in all parsers . . . . . . . . . . . . . . 37
4.1 Non-local features derived from the level-0 parser . . . . . . . . . . . . . . . . . . 454.2 Combination of features enumerated in Table 4.1 used for stacking . . . . . . . . 454.3 MSTParser settings for different languages . . . . . . . . . . . . . . . . . . . . . . 464.4 Parsing algorithm and learner settings in MaltParser for different languages . . . 464.5 Indian language dependency parsing datasets . . . . . . . . . . . . . . . . . . . . 484.6 Results of stacking MST parser on level-0 MST parser for Hindi; ∗ indicates
significant increase; () indicate significant decrease . . . . . . . . . . . . . . . . . 494.7 Results of stacking MST parser on MST level-0 parser for Telugu; ∗ indicates
significant increase; () indicate significant decrease . . . . . . . . . . . . . . . . . 514.8 Results of stacking MST parser on MST level-0 parser for Bangla; ∗ indicates
significant increase; () indicate significant decrease . . . . . . . . . . . . . . . . . 524.9 Results of stacking MST parser on level-0 MaltParser for Hindi; ∗ indicates sig-
nificant increase; () indicate significant decrease . . . . . . . . . . . . . . . . . . . 524.10 Results of stacking MST parser on level-0 MaltParser for Telugu; ∗ indicates
significant increase; () indicates significant decrease . . . . . . . . . . . . . . . . . 554.11 Results of stacking MST parser on level-0 MaltParser for Bangla; ∗ indicates
significant increase; () indicate significant decrease . . . . . . . . . . . . . . . . . 564.12 Results of stacking a fine-grained MST parser on a coarse-grained constraint-
based parser (level-0) for Hindi . . . . . . . . . . . . . . . . . . . . . . . . . . . . 574.13 Results of stacking a coarse-grained MST parser on a coarse-grained constraint-
based parser (level-0) for Hindi; ∗ indicates significant increase; () indicates sig-nificant decrease . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57

Chapter 1
Introduction
Natural Language encodes information using structure. As a simple illustration, consider the follow-
ing English sentence,
(1) Ram saw the man with a telescope.
This sentence has two possible meanings. In the first interpretation, a telescope was used as an
instrument by Ram to see the man. There is also a second meaning that the man Ram saw was either
carrying or in possession of the telescope. Suchambiguity(more than one meaning) exists because this
sentence can be assigned more than one structural analysis. Figures 1.1and 1.2 show the two possible
structural analyses for this sentence corresponding to the two meanings.
Figure 1.1Analysis1 Figure 1.2Analysis2
The structure of the sentence is represented as a tree diagram in both the figures. Without getting
much into the details, it can be noticed that the substructure corresponding tothe string ‘with the tele-
scope’ (PP) is associated with the VP node corresponding to the verb SEE(Ram, man) in the tree in
figure 1.1 while in figure 1.2, it is associated with the NP ‘the man’. The associations shown in these
two trees predict correctly the two interpretations of this sentence mentioned above. Trees such as these
from which the meaning of the sentence can be computed are known asparse trees. The process of
structural analysis through which such trees are obtained is calledparsing. Parsing is of central impor-
1

tance in both computer science and linguistics. While linguists are concerned with building theories
of how humans parse and thereby comprehend natural language utterances, computer scientists work-
ing in the area of Natural Language Processing (NLP) and Artificial Intelligence (AI) attempt to build
parsers that can analyze natural language data just as humans do. Thus, the ultimate goal of NLP and
AI is also to model and replicate human language behavior. Although the goalof building a parser that
can pass the Turing test for language processing is still quite distant, research efforts in NLP / AI in
the last couple of decades in this direction have led to the development of parsers that can parse natu-
ral language text with reasonably high accuracy. Since parsing is a necessary step towards extracting
information encoded using natural language, such parsers are essential while building different kinds
of natural language processing applications of practical importance such as machine translation (MT),
question answering (QA) and information extraction/retrieval (IE / IR) systems.
The example discussed above illustrates how meaning/information is structurallyencoded at the
sentence level. The same is true at other levels of linguistic analysis too– sound structure (syllab-
ification in phonology), word structure (morphology) or text structure (discourse). And structural
analysis or parsing is required at all these levels to decode the information from the linguistic signal
(word/sentence/text). Structural analysis at the sentence level, usually referred to in literature assyntac-
tic parsingis the leitmotif of this thesis. The rest of this chapter is divided into3 sections– Section 1.1 is
a brief introduction to the task of syntactic parsing. This section is meant to discuss some basic concepts
about NL parsing by way of building a background to the ideas discussedin the rest of this thesis. It
does not add anything new to the vast amount of literature already existing on the subject. For a detailed
introduction to NL parsing, see [1, 2]. In section 1.2, I describe a fundamental limitation of the differ-
ent types of statistical parsing algorithms which represent the current state of the art in NL parsing. I
will discuss how these algorithms can only use very restricted information about the linguistic context
while parsing sentences due to this limitation and therefore, significantly fall short of modeling human
sentence processing. In section 1.3, I will present strategies exploredin the literature to address this lim-
itation of all kinds of parsing algorithms. I briefly introduce two techniques- discriminative reranking
and ensemble parsing that are studied in detail in this thesis. Finally, in section 1.4, I give a brief outline
of the thesis.
1.1 Syntactic parsing
As mentioned earlier, parsing is the task of automatic structural analysis of aninput string from
natural language. When the input string is a sentence from natural language, then this task is known as
syntactic parsing. In the example sentence discussed at the beginning of the chapter, the two meanings
of the sentence were shown to be computable from the corresponding parse trees. Syntactic parsing
thus, is the task of mapping from an input sentence, S (string of words in natural language) to a parse
tree, T from which the meaning of the sentence can be computed.
P : S −→ T (1.1)
2

1.1.1 Representation of Syntactic structure
Recall the parse trees shown in figures 1.1 and 1.2. The parse trees show substrings of the sentence
under nodes with different labels such as NP, VP, PP and V. These trees are based on one particular kind
of representation of syntactic structure known asPhrase structure(PS) representation orconstituency-
based representation. Phrase structure representation of syntactic structure goes back to the work of
Saussure [3] and other linguists from the structuralist era in the early twentieth century. The basic
idea underlying PS representation is that certain groupings of words in a sentence behave as syntactic
units. These groupings are known asphrasesor constituents. The structure of a sentence is made up of
different kinds of phrases. In the example sentence,
(2) The quick brown fox saw the lazy dog.
the words ‘The’, ‘quick’, ‘brown’ and ‘fox’ form one group. Similarly, the words ‘the’, ‘lazy’ and ‘dog’
form another group. In addition, the word ‘saw’ forms another group with the group of words ‘the
lazy dog’. These groups are the constituents (or basic syntactic units) ofthis sentence. Constituency
is established on the basis of different kinds ofconstituency tests- substitution, co-ordination, ellipsis
(omission), etc. For example, according to the substitution test for constituency, a group of words is a
constituent if it can be replaced by another group of words without affecting the grammaticality status
of the sentence. In the above example, the group of words ‘The quick brown fox’ can be replaced by
another group such as ‘The man’ and the sentence would still be grammatical.So, this group of words
forms a syntactic constituent. Similarly, ‘the lazy dog’ is a constituent since it is also substitutable. And
since the verb in the sentence, ‘saw’ can be replaced by another verb (such as ‘kill’), the string of words
‘saw the lazy dog’ is also a constituent.
As mentioned earlier, sentences contain different kinds of phrases. Inthe above example, the con-
stituents ‘The quick brown fox’ and ‘the lazy dog’ arenoun phrases(NPs) while the constituent ‘saw
the lazy dog’ is averb phrase(VP). What differentiates these phrases from one another is the syntactic
category of theheadwords in them. A head is one of the words in a phrase whose syntactic category
of the head determines the category of the phrase. For example, the noun ‘fox’ is the head of the noun
phrase ‘The quick brown fox’ and the verb ‘saw’ is the head in ‘saw thelazy dog’ making this group
of words a verb phrase. The head word in a phrase determines not onlythe syntactic category of the
phrase but also its semantics. For example, the verb phrase ‘saw the lazy dog’ refers to the set of entities
of which the event SEE(x, the lazy dog) (:=λx ∈ De.x saw the lazy dog) is true since the head of
this phrase is the verb SEE. Another important point to be noted is that in a phrase structure parse tree,
heads of phrases areterminalnodes or in other words, leaf nodes with no children. On the other hand,
phrases arenonterminalnodes which are internal to the tree. This can be seen in the parse trees shown
in figures 1.1 and 1.2.
In summary, phrase structure parsing of a sentence involves three steps- identifying the syntactic
category of each word in the sentence, identifying the different phrases in the sentence and finally,
identifying the structural relationships among different phrases.
3

Although phrase structure representation has been the dominant paradigm in both linguistics and
NLP through much of the last century, it is not the only means available for representing sentence struc-
ture. There exists another scheme for representing syntactic structure known asDependency structure
(DS) whose origin goes all the way back to the work of the ancient Indian linguist, Pan. ini [4]. In modern
linguistics, dependency representation is usually believed to have been introduced by the linguist Lu-
cian Tesniere [5]. Interestingly, in recent years, dependency representationof syntax has become very
popular in the NLP community and also to a certain extent, within linguistics. Two main reasons for
this preference can be gathered from the literature-
1. Dependency representation was found to be better-suited for languages that have relatively free
word order (non-configurational languages) such as Czech, Arabic and most Indian languages.
This is because the notion of phrase in PS representation assumes a certaindegree of configura-
tionality or fixedness of word order which is not true of these languages.
2. The simplicity of dependency representation makes it amenable for a variety of NLP tasks such as
relation extraction, semantic role labeling, etc. and also, for experimental psycholinguistic studies
on human sentence processing.
DS representation of syntax defines the structure of a sentence to be a directed acyclic graph con-
sisting of binary, asymmetrical relations between different words in the sentence known asdependency
relations(or simply,dependencies). Since dependencies are asymmetrical, one of the two words linked
by any dependency relation is syntactically subordinate to the other. The syntactically subordinate word
is known as themodifier (or dependent) and the word it is subordinate to is known as thehead. The
dependency parses for the ambiguous sentence discussed at the beginning of the chapter are shown
below.
sawprep with
Ram man telescope
the a
saw
Ram manprep with
the telescope
a
Figure 1.3Dependency trees for example sentence (1)
The dependency parses shown above are tree structures (directed acyclic graphs) where a word is
attached to the head word it modifies. It can be noticed that all the words in thesentence directly or
indirectly modify the verb ‘saw’. This is why in a dependency tree, the headof a sentence is always a
4

verb. Dependency representation schemes can also choose how to show certain kinds of information in
the tree diagram. For example, prepositions indicating relationships between the different content words
in a sentence can either be shown as nodes in the parse tree or simply as labels. This can be seen in the
above trees where the edge connecting ‘the telescope’ to the rest of the sentence is labeled ‘prepwith’.
In general, any dependency relation can be assigned a label to indicate the type of grammatical relation.
Examples of such dependency labels are ‘subj’ (subject), ‘dobj’ (direct object), ‘iobj’ (indirect object),
etc. The labeled versions of the dependency trees for the example sentence are as follows-
sawsubj
dobjprep with
Ram man telescope
the a
sawsubj
dobj
Ram manprep with
the telescope
a
Figure 1.4Dependency trees with labeled edges for example sentence (1)
The issue of equivalence and conversion between phrase structure (PS) and dependency structure
(DS) representations has also been studied in sufficient detail over the last two decades. On the surface,
the two kinds of representation seem to differ from each other in a number of ways. While dependency
representation of syntax defines structure only in terms of relations between words, phrase structure rep-
resentation involves postulation of internal XP (phrasal) nodes defined over groups of words. However,
when the heads of phrases are explicitly marked in a phrase structure tree, then it becomes very similar
to a dependency tree. This process known ashead percolationis central to the task of constituency-
to-dependency conversion. In recent years, a number of highly accurate constituency-to-dependency
conversion procedures have been developed and two of them are discussed in chapter 3 of this thesis.
For a detailed discussion about the comparison and conversion between phrase structure representation
and dependency representation, see [6].
1.1.2 Grammars, Treebanks and Parsing
In the previous section, we looked at two different kinds of representation of syntactic structure and
how they encode sentence meaning. But given a sentence in a natural language, how does the machine
(or a human, for that matter) parse it? What is the knowledge (or cognitive machinery) necessary to as-
sign parse trees to sentences and comprehend their meaning? AGrammaris a set of rules / constraints
5

that allows a machine (or a human) to analyze and assign a parse tree to a sentence1. A phrase structure
grammar for a language consists of a set of rules that can be used to assign a phrase structure parse
tree to a sentence in that language.Context-free grammar(CFG) defined by [7] is one of the early,
well-known types of phrase structure grammars. Similarly, a dependency grammar consists of a set of
rules that allow a sentence in natural language to be assigned a dependency parse tree. Examples of
dependency grammar formalisms are Functional generative description (FGD), Word grammar, Com-
putational Paninian grammar (CPG), etc. There also exist grammar formalisms that make use of hybrid
representations combining elements of both phrase structure and dependency representations. Tree Ad-
joining grammar (TAG) [8] and Lexical Functional grammar (LFG) are examples of such formalisms.
Therefore, an important point to note is that dependency and phrase structure representations are not
mutually exclusive or opposite approaches to syntax.
Most of the early work on parsing natural language was done using hand-crafted grammars. The
well-known CYK [9, 10, 11] and Earley [12] algorithms for phrase structure parsing were both based
on the CFG formalism. Similarly, Gaifman [13] and Hays [14] proposed a CFG-based dependency
parsing algorithm in the 1960s. Such approaches to parsing are referred to asgrammar -driven pars-
ing in literature. Grammar-driven approaches to parsing involve developing grammars for individual
languages. Practical experience has shown that the task of manually building high coverage grammars
for even a single language (like English) can take several human years [15]. An important reason for
grammar building being expensive is that syntactic (or generally speaking,linguistic) phenomena are
characterized by a Zipfian distribution with a very long tail. It is relatively straight-forward to build a
basic grammar that can handle constructions which occur with a frequencyabove a certain threshold
frequency. The bulk of the grammar-building effort is consumed by the task of expanding the coverage
of this grammar to handle constructions whose frequency is lower than this threshold frequency. And
given the open-ended nature of human linguistic creativity, it is impossible to construct a grammar that
can handle allpossibleconstructions. This is why even when a high coverage grammar is available,
grammar-driven parsing algorithms suffer from a lack of robustness asthey fail to analyze input sen-
tences for which rules do not exist in the grammar. Another issue with grammar-driven parsers is that
when more than one analysis is possible, they do not provide any way for selecting between the compet-
ing analyses. These drawbacks of grammar-driven parsers paved the way for probabilistic parsing. Both
these issues of robustness and disambiguation could be handled by using probabilistic versions of CFGs
for parsing. As a result, there was a major shift in the community towards probabilistic methods, espe-
cially for parsing. It must be noted that probabilistic parsing using PCFGs does not differ fundamentally
from the earlier CFG-based parsing models and retains most of the characteristics of CFG-based parsing
algorithms such as Earley and CYK. I will discuss more about this aspect in the next subsection.
1The term ‘grammar’ is also widely used in non-technical contexts to referto any aspect of structure in natural language.
In the context of parsing and formal language theory, however, it has a very restricted meaning of being the mathematical
formalism that can analyze / generate a language.
6

Another important development that strengthened the trend towards probabilistic parsing was the
creation of large-scaletreebankcorpora. Atreebankis a collection of sentences that are manually
annotated with syntactic analysis based on an carefully designed annotationscheme. The development
of the Penn treebank corpus (PTB) for English [16] marks the beginningof a new phase in NL parsing.
There were a number of attempts to develop methods to automatically learn probabilistic grammars
from treebanks. These methods were mostly machine-learning oriented andtreated the treebank as
given data. This approach to parsing soon came to be referred to asdata-drivenparsing. Since these
methods sought to estimate probabilities of rules from statistics in the treebank, there are also referred
to asstatisticalparsing algorithms.
Over the last decade, dependency treebanks have also been developed for a number of languages
such as Czech, Turkish, Arabic, etc. Currently, a large scale effortto develop dependency treebanks for
Indian languages such as Hindi, Telugu and Bangla using an annotation scheme inspired by Pan. inian
grammar is underway. The development of dependency treebanks has been followed by attempts to de-
velop statistical parsing algorithms that can automatically learn dependency parsing models from these
corpora. In recent years, there has been a growing interest in statistical dependency parsing approaches
such as the Maltparser and the MSTparser as they have been shown to work well for a number of
typologically different languages.
In general, a statistical parsing algorithm involves two steps-
• Learning: Given a treebankT , induce a parsing modelM that can parse new sentences
• Parsing: Given a parsing modelM and a sentenceS, assign a parseP to S with respect toM
It must be noted that a statistical or data-driven parsing model is heavily influenced by the annotation
scheme followed to create the treebank. Often times, treebank annotation schemes are based on ex-
plicit grammar formalisms. Even when they not, the annotation scheme can be seen as containing an
implicit treebank grammar. Hence, to describe grammar-driven and data-driven approaches to parsing
as opposite to each other is an over-simplification. In addition, another important point to be noted is
that the probability distribution obtained from a treebank corpus for a language isnot representative of
the entirety of that language. In fact, as we will see in chapter 2, there exist significant variations in the
nature of text across different domains of English.
At the time of writing this thesis, statistical parsing algorithms are the state of the artfor both
constituency (phrase structure) and dependency parsing. For constituency parsing, Charniak-Johnson
parser, Berkeley parser and the Stanford parser are the three most accurate parsers for English and all
three of them are studied in this thesis. Among dependency parsers, as mentioned earlier, Maltparser and
MSTparser give high parsing accuracies for a number of typologically different languages. I consider
both of them for study in this thesis.
7

1.2 Limitation of Feature locality
A fundamental design characteristic of all models of syntactic parsing, whether constituency or de-
pendency, is that they make certain independence assumptions about sentence structure.
Let us first consider the case of parsing based on context-free grammars (CFGs). Since the rewrite
rules in a CFG are context-free, in a parsing model based on this formalism, the rewrite operations
applicable at different stages in the parsing process are treated as being independent of each other. This
is also why CFG-based parsing models can be implemented using dynamic programming. The task
of predicting the structure of a sentence is broken down into subtasks of predicting the substructures
of smaller substrings within the sentence. During the parsing process, partial results are stored in a
chart (a data structure) rather than computed time and again. And once a substring is analyzed by the
parser and stored in the chart, the subtree is not used during the analysisof the rest of the sentence.
The partial subtree is revisited only if the parser fails to analyze the sentence completely. The analysis
of substrings is done in a strictly local manner without using any global information. Such a model
of parsing fails to account for syntactic phenomena such as agreement, co-indexation and argument
structure that are spread over larger structures. Due to the deterministic nature of CFG-based parsing
models, the parser either analyses the sentence completely or fails to do so. In this setup, it is difficult
to judge the impact of the independence assumption on the performance of theparser. Let us now look
at independence assumptions in parsing models based on probabilistic context-free grammars (PCFGs).
Probabilistic context-free grammars consist of context-free rules each of which is associated with an
emission probability such that the sum of these probabilities for rewriting any non-terminal symbol over
the entire grammar is1. PCFG-based parsing ensures that any input sentence is assigned a parse tree. In
a PCFG-based parsing model, a parse tree is also assigned a score whichcorresponds to the probability
of the tree. The probability of the parse tree is computed as the product of the probabilities of the rules
applied to build the tree. So, a tree,T built using the rules〈γi → βi〉 is assigned the probability,
P (T ) =
n∏
i=1
P (βi | γi) (1.2)
A PCFG-based parser implemented using dynamic programming is ahistory-based model which
searches for thedecision history, 〈d1d2...dn〉 that maximizes the parse tree probability. The decision
history is the sequence of decisions to construct the parse tree. Thus, ina history-based approach, a
one-to- one mapping can be defined between each pair〈T, S〉 and a decision sequence〈d1d2...dn〉-
P (T, S) =n∏
i=1
P (di|Φ(〈d1d2...di−1〉)) (1.3)
where 〈d1d2...di−1〉 is the history of theith decision. Φ is a function which groups histories into
equivalence classes, thereby making independence assumptions in the model. So, at any point in the
derivation, the parser chooses the decision that maximizes the probability ofthe tree given the decision
history upto that point. Hence, the assumption is that the quantityP (di|d1d2...di−1) depends only on
8

the non-terminal being expanded since decision history is fixed. Thus, thedecision taken is always
based an local optimum. This assumption is not linguistically tenable since there are phenomena which
are spread out in the tree. The agreement relationship between the subject and the verb in a sentence is
an example of one such phenomenon. Consider the following sentence,
(3) The boy who is standing over there is my brother.
The noun phrase ‘the boy’ controls the agreement on the verb in the main clause ‘is my brother’. This
is a non-local relationship which is not captured by the kind of parsing model discussed above. This
might not be a crucial inadequacy in a language like English which has an impoverished agreement
morphology (only a binary distinction between ‘is’ and ‘are’). But, in Indian languages, which have
rich agreement morphology, information pertaining to this relationship is crucial in determining the
relationships of noun phrases to the verb in the sentence. PCFGs underliemost current state of the
art constituency parsers such as Charniak-Johnson parser, Berkeley parser (latent PCFGs) and Stanford
parser.
As mentioned earlier, dependency parsing algorithms also make independence assumptions to achieve
tractability. The two main kinds of dependency parsing algorithms discussed inliterature aregraph-
basedmodels andtransition- basedmodels. In graph-based dependency parsing, dependency trees are
scored by factoring the tree into its edges, and parsing is performed by searching for the highest scoring
tree. The score of a tree is estimated as the sum of the scores of the edges due to this edge-factorization
assumption. Transition-based dependency parsers, on the other hand, model the sequence of decisions
of a shift-reduce parser, given previous decisions and current state. Parsing is performed using greedy
search or searching for the best sequence of transitions. This is exactly similar to the formulation dis-
cussed in the case of history-based models underlying PCFGs. As a result of these assumptions, the
features used for parsing are defined over a single edge or pair of edges in the case of graph-based
parsers and a single transition in the case of transition-based parsers.
This issue of locality of features is a fundamental limitation of current day parsing models. However,
one might question, ‘Why should we bother about non-locality when state-of-art parsing approaches
perform with significantly high accuracies ?’ My answer to this question is asfollows- It is important
to recognize this need to think of ways to overcome this fundamental limitation of parsing approaches
because it is well-known based on psychological and linguistic studies on language understanding that
humans use different kinds of contextual information to disambiguate the meaning of utterances. There
is no way to incorporate these additional kinds of contextual information into parsing models which are
based on such strict independence assumptions. Furthermore, am important goal in NLP / CL right now
is to extend the scope of grammars / parsers beyond the sentential domain. For discourse information to
become relevant in sentential parsing, there needs to be a way of incorporating this non-local information
into the parsing process.
9

1.3 Non-local features in syntactic parsing
In this thesis, I explore two approaches to address this limitation of feature locality of parsing models.
The first approach is based on the technique ofdiscriminative rerankingintroduced by Collins [17]. In
this approach, the limitation of feature locality is overcome by increasing the widthof the search beam
in the base parser to generate more than one parse for a given sentence. Next, a classifier trained using
non-local features is used to select the best parse from among the set of k-best parses generated by
the base parser. This combination of non-deterministic parsing and discriminative reranking has been
shown to significantly improve parsing accuracies [17, 18, 19] for phrase structure parsing. However,
there have not been any detailed studies of the kinds of constructions handled as a result of applying this
combination of k-best parsing and reranking. In this thesis, I apply this combination of k-best parsing
and discriminative reranking to incorporate information from non-local features into two well-known
state of art statistical constituency parsers. I experiment with a number of non-local features and study
their effect on improving parsing accuracies.
Reranking and k-best parsing techniques have been tried out for statistical dependency parsing
too [20] but the results have not been conclusive. Non-local features of the kind used to train rerankers
for phrase structure parsers do not seem to be very effective in the case of dependency parsing. This is
probably again due to the difference between the two kinds of representations of syntactic structure. De-
pendency structure is a relatively light-weight representation of syntacticstructure and therefore, struc-
turally oriented non-local features such as the ones used in phrase-structure parsing are not well-suited
for reranking dependency trees. So, for dependency parsing, I explore another way of incorporating
non-local features-ensemble parsing. Ensemble models for parsing are models that combine the out-
put of multiple parsers either at learning time or at inference time. Combining parsers at learning time
allows non-local features defined over the output of one (or more) parser(s) to be used while training
another parser. In my experiments on dependency parsing, I work on both English and Indian languages
and build parsers with state of the art accuracies.
1.4 Thesis outline
This thesis is organized as follows- In chapter 2, I present a study of thediscriminative reranking
technique to overcome the limitation of feature locality in PCFG-based parsers.I build rerankers using
a variety of non-local features for two widely used constituency parsers, Stanford [21] and Berkeley [22]
and evaluate them on corpora from different domains. In chapter 3, I study a technique to combine the
outputs of multiple dependency parsers. I convert the output of different constituency parsers for English
built in chapter 2 into dependency representation using two well-known constituency-to-dependency
conversion schemes. I combine these trees with the output of two freely available dependency parsers
for English. I compare the performance of the resulting ensemble parser tothe self-trained version of
the Charniak-Johnson parser [19], the state-of-art parser for English at the time of the writing of this
10

thesis. In chapter 4, I study another kind of technique for ensemble parsing- stacking, one that combines
dependency parsers at learning time. I discuss how the stacking architecture allows us to define non-
local features based on the output of one parser and use these features while training another parser. In
my experiments, I stack the graph-based MSTParser [23] on top of the transition-based MaltParser [24]
to build stacked dependency parsing models for three Indian languages-Hindi, Telugu and Bangla. I
present a detailed study of the usefulness of different kinds of non-local features. In addition, for Hindi,
I present an interesting study of stacking the MSTParser on top of a grammar-driven constraint-based
parser.
11

Chapter 2
Discriminative reranking for Syntactic Parsing
In this chapter, we present a study on discriminative reranking which is a relatively older technique to
incorporate non-local features that encode information about larger linguistic context into the syntactic
parsing process. Discriminative reranking was first introduced by Collins [17] who argued that due to
the dynamic programming formulation of generative parsing models such as PCFG-based parsing, the
task of predicting the structure of a sentence is broken down into subtasksof predicting the substructure
of smaller substrings within the sentence. The subtasks are assumed to be independent of each other.
In other words, the decision at each stage in the parsing process depends only on the terminal symbol
(node) being expanded given the derivational history upto that stage.
P (T, S) =
n∏
i=1
P (di|Φ(〈d1d2...di−1〉)) (2.1)
where 〈d1d2...di−1〉 is the history of theith decision. Φ is a function which groups histories into
equivalence classes, thereby making independence assumptions in the model. So, at any point in the
derivation, the parser chooses the decision that maximizes the probability ofthe tree given the decision
history upto that point. Hence, the assumption is that the quantityP (di|d1d2...di−1) depends only on
the non-terminal being expanded since decision history is fixed.
Collins [17] argues that it is awkward to encode some constraints in this framework. Although it is
possible to think of linguistic features that can be useful in discriminating between candidate parses of a
sentence, it is not straightforward to take them into account at parsing time since they are not restricted
to one substructure. The solution proposed by Collins to make use of such non-local features in parsing
is to break the parsing process into two steps. Instead of altering the PCFG-based parsing models to
take such features into account, allow the parsing model to generate multiple candidate parses with
associated probabilities in the first step. In the second step, introduce a new model to improve upon
the initial ranking among the candidate parses defined by the probabilities assigned by the base parser.
This new ranking model can be trained to use non-local features while discriminating among candidate
parses. I give a brief description of different kinds of non-local features explored in our experiments in
section 2.5.
12

2.1 Non-local features in discriminative reranking
Collins [17] applies boosting and log-linear models to rerank the output of a PCFG parser and shows
that this method of incorporating non-local information can improve parsing performance significantly
(relative decrease of13% in error rate). Following this success, Collins and Duffy [25] used the voted
Perceptron combined with Tree kernels to train reranking models. Shen et al. [26] show that LTAG-
based non-local features are more effective in discriminating between candidate parses. Collins and Koo
[18] is a comprehensive study that considers different kinds of learning algorithms and loss functions
for the task of parse reranking.
The Charniak-Johnson (CJ) parser is another reranking parser which does parsing in two stages [19].
The first stage of parsing is done using Charniak’s lexicalized history-based generative statistical parser [27].
In the second stage, Johnson’s discriminative reranker uses a large number of non-local features defined
over the entire parse tree to rerank the k-best parses produced by thefirst stage parser. Charniak’s parser
is reported to give an F-score of89.1 on section23 of the WSJ corpus. When combined with the John-
son reranker, the F-score on the same section significantly improved to91.3. This is the state-of-art
accuracy for constituency parsing of English text at the time of the writing ofthis thesis. The reranker
used in this parser a Maximum Entropy model although other parameter estimationtechniques have also
been studied [28]. In this study, we follow the procedure described in Gao et al. [28] to train reranking
models for two widely used constituency parsers. The non-local features used in our experiments are
the same as the ones reported by Charniak and Johnson [19] (section2.5).
2.2 Parsers
We consider two well-known statistical constituency parsers in this study on discriminative reranking-
the Berkeley parser [22] and the Stanford parser [21], both of whichare available under GPL.
2.2.1 Berkeley Parser
The Berkeley parser is an accurate constituency parser based on induction of latent PCFGs from
constituency treebanks. The latent non-terminal symbols in the PCFG are derived using an iterativesplit-
mergetechnique. The probabilities of the rules in the grammar are estimated using the EM-algorithm in
each iteration, followed by a smoothing step to reduce the risk ofover-fittingto the training data. The
number of split-merge cycles can be varied to learn grammars of different granularity. Petrov and Klein
[29] note that the sm-6 grammar (6 split-merge iterations) trained over the PTB could be overfitted to
the WSJ corpus. In our experiments, we consider both sm-5 and sm-6 grammars trained over sections
02-21 of the Penn treebank.
13

2.2.2 Stanford parser
Among the different parsing models available in the Stanford parser, I consider the lexicalized PCFG
parser1 in our benchmarking study [21]. This parser implements a factored product model, with separate
PCFG phrase structure and lexical dependency experts. The PCFG parser begins with a raw n-ary
treebank grammar obtained from the trees in the training data and performs a horizontal and vertical
markovization in order to capture the external context to deal with sparsity arising from infrequent or
unseen rule types. The probabilities over the sub-categorized grammar are estimated using maximum
likelihood estimation followed by smoothing.
In our reranking experiments, we combine these parsers with the discriminative reranker in the
Charniak-Johnson parser [19]. The reranker models are trained using a large pool of non-local lex-
ical and syntactic features which will be described in section 2.5. An important distinction between
these two parsers is with respect tolexicalization. While the latent PCFG in the Berkeley parser is an
unlexicalized grammar, the Stanford parser uses a lexicalized PCFG.
2.3 Treebanks
The standard practice in much of the statistical parsing literature is to train parsing models over
sections02-21 of the Penn treebank (PTB) [16] and report parsing performance in terms of Parseval
scores [30] on sections22 and23 of the same corpus. However, it is well-known that the performance
of any statistical model tends to be better on datasets that are similar in domain to thedataset used to
train the model. Owing to thisdomain-bias, the F-scores of PTB-trained parsers reported on test sets
drawn from the same corpus tend to be overestimates of the actual parsing performance of these models.
This gives rise to the need for evaluation of parsing performance on corpora from different domains. In
our study, we use treebank corpora from different domains available for English for evaluating parsing
performance. A detailed evaluation on test sets from different domains would give the complete picture
about the efficacy of reranking. The rest of this section contains a brief description of the different
treebanks used in our experiments.
The Penn treebank (PTB) consists of49207 sentences from the Wall Street Journal (WSJ) newspaper
corpus manually annotated with syntactic structure using a constituency-based annotation scheme. The
treebank is split into24 sections. Of these, sections02-21 (39832 sentences) are usually used to train
statistical parsers and sections22 (1700 sentences),23 (2416 sentences) and24 (1346 sentences) are
treated as development and test sets. All the parsing models studied in this work are trained using a
similar partitioning of the treebank.
The Brown corpus is a balanced corpus of English texts drawn from multipledomains and gen-
res [31]. A subset of this corpus, manually annotated using the PTB scheme, is distributed as part of
Treebank-3. This Brown parsed corpus consists of texts from different genres of fiction such as folk-
1Stanford Parser Version 1.6.4: 2010-11-30.
14

lore, memoirs, mystery, adventure, romance and humor. The difference indomain of these Brown parsed
texts compared to the WSJ qualify them as suitable test sets to study the out-of-domain performance of
parsers trained over the PTB. In addition, the diversity of genres within the Brown parsed corpus makes
it possible to study the variation of parsing performance across different genres.
The Questionbank [32] is a corpus of4000 questions annotated using the PTB annotation scheme.
In this study, the Questionbank is used as a test set to benchmark the performance of the parsers at
parsing questions. A few necessary corrections were made to the original annotations following the
steps mentioned here2.
Foster and van Genabith [33] created a parsed corpus of1000 sentences from the British National
Corpus (BNC). The sentences were assigned manually annotated constituent structures based on the
PTB annotation scheme. The sentences in this set were chosen such that each sentence contains a word
that appears as a verb in the BNC but not in the usual training sections of PTB. This corpus is also used
as a test set in this study as it was designed to be a difficult set for WSJ-trained statistical parsers.
Finally, we also use two treebanks from the biomedical domain as test sets in my experiments. It is
expected that the parsing performance on these two test sets would reflect the ability of parsers to ne-
gotiate texts from technical domains which have high incidence of unknown,out-of-domain vocabulary
items. The first test set is the Brown-Genia corpus [34] which contains215 sentences from the Genia
corpus [35]3. We also use the Genia treebank corpus [36] (18541 sentences) as a test set since it is
sufficiently large and therefore, accuracy reported on this dataset would be a more stable indicator of
parsing performance on this domain. It must be noted there is no overlap between these two treebanks.
2.4 Parser Evaluation
As mentioned earlier, in much of the statistical constituency parsing literature, parsing performance
is evaluated using the Parseval metric [37]. This metric calculates precision and recall over the con-
stituents identified by the parser. Since constituents are marked using the bracketing scheme of the Penn
treebank, this metric compares the bracketed groups and their labels between the parse tree and the
gold standard tree. Precision is the number of constituents correctly identified by the parser divided by
the total number of constituents identified by the parser. Recall is the number of constituents correctly
identified by the parser divided by the total number of constituents in the gold standard tree. F-score is
the harmonic mean of precision and recall. We use Sekine and Collins’ implementation of the Parse-
val metric4 [30] parsing performance in this study. However, a number of drawbacks of the Parseval
metric have also been noted in the literature. For this reason, we will also experiment with another
constituency-based evaluation metric in this study.
2http://nlp.stanford.edu/data/QuestionBank-Stanford. shtml
3Available fromhttp://www.cs.brown.edu/ ˜ mlease/parser-treebank.tgz
4Available fromhttp://nlp.cs.nyu.edu/evalb/EVALB.tgz
15

Leaf-Ancestor (LA) assessment [38] evaluates the parse tree by comparing thelineagesof individual
words between the parse tree and the gold standard tree. The lineage of aword is the sequence of non-
terminals (in other words, the path) between the word and the root node (S). The LA value of a word is
calculated as the Levenshtein distance between the lineage paths of the wordin the parse tree and the
gold standard tree. The LA value for a sentence is simply the average of theLA values of the words in
it. In our experiments, we use a recent implementation of the LA assessment metric [39] which comes
bundled with the Stanford parser. This implementation returns threes scores- micro-averaged (whole
corpus) LA score, macro-averaged (per sentence) LA score and also the percentage of exactly matching
lineages over the entire corpus.
2.5 Reranking Experiments
In our experiments, we train rerankers for both these parsers based on the reranking setup described
in [19]. Briefly, training a reranker model for any parser involves the following steps-
1. TrainN (10, 20, etc.) instances of the parser usingN folds of the training data in a leave-one-out
setting
2. Obtain the k-best parses on the left-out fold using the model trained over N − 1 folds
3. Extract non-local features from the k-best trees across the entiretraining corpus
4. Estimate feature weights using held-out data
A large set of lexical and syntactic features is used while training the rerankers. These features are
the main source of non-local information in the parser based on which the k-best parses of the parser on
unseen data are reranked. In our experiments, we used the following classes of non-local features.
• NLogP: This class of features indicate the negative log probability.
• CoPar: This class of features indicates conjunct parallelism at different depths. For example,
conjuncts which have the same label are parallel at depth 0, conjuncts with the same label and
whose children have the same label are parallel at depth 1, etc.
• CoLenPar: This class of features indicate the binned difference in length(in terms of number
of pre-terminals dominated) in adjacent conjuncts in the same coordinated structures, conjoined
with a boolean flag that indicates whether the pair is final in the coordinated phrase.
• RightBranch: This class of features enables the reranker to prefer right-branching trees. One
instance of this feature set returns the number of nonterminal nodes that lieon the path from
the root node to the right-most non-punctuation pre-terminal node, and theother instance of this
schema counts the number of the other nonterminal nodes in the parse tree.
16

• Heavy: This class of features classifies nodes by their category, their binned length (i.e., the
number of pre-terminals they dominate), whether they are at the end of the sentence and whether
they are followed by punctuation.
• Rule: The instances of this schema are local trees, annotated with varying amounts of contex-
tual information controlled by the feature parameters. This feature class is inspired by a similar
schema in [18]. The parameters to this schema control whether nodes are annotated with their
pre-terminal heads, their terminal heads and their ancestors categories.An additional parameter
controls whether the feature is specialized to embedded or non-embedded clauses, which roughly
corresponds to Emonds’ “non-root” and “root” contexts [40].
• NGram: The instances of this schema arel-tuples of adjacent children nodes of the same parent.
This schema was inspired by a similar schema in Collins and Koo [18]. This schema has the same
parameters as the Rule schema, plus the length of the tuples of children (l = 2 here).
• Heads: The instances of this schema are tuples of head-to-head dependencies, as mentioned
above. The category of the node that is the least common ancestor of the head and the depen-
dent is included in the instance (this provides a crude distinction between different classes of
arguments). The parameters of this schema are whether the heads involvedare lexical or func-
tional heads, the number of heads in an instance, and whether the lexical item or just the heads
part of speech are included in the instance.
• WProj: The instances of this schema are pre-terminals together with the categories of l of their
closest maximal projection ancestors. The parameters of this schema control the numberl of
maximal projections, and whether the pre-terminals and the ancestors are lexicalized.
• Word: The instances of this schema are lexical items together with the categories of l of their
immediate ancestor nodes, wherel is a schema parameter (l = 2 or l = 3 here). This feature was
inspired by a similar feature in [21].
• HeadTree: The instances of this schema are tree fragments consisting of the local trees consisting
of the projections of a pre-terminal node and the siblings of such projections. This schema is
parameterized by the head type (lexical or functional) used to determine the projections of a pre-
terminal, and whether the head pre-terminal is lexicalized.
• NGramTree: The instances of this schema are subtrees rooted in the least common ancestor of
l contiguous pre-terminal nodes. This schema is parameterized by the numberof contiguous
pre-terminals (l = 2 or l = 3 here) and whether these pre-terminals are lexicalized.
We also experiment with two different techniques to estimate the parameters of the reranker models-
Maximum Entropy (MaxEnt) withL2 regularization and Averaged Perceptron. In our experiments, We
train two different kinds of reranker models- one using sections02-21 of the PTB as the training data
17

and section24 as the development (final split) and the other using sections02-21 both for training and
development (non-finalsplit). The procedure to train the reranker using the non-final split of PTB is the
same as described in [41]. And as mentioned earlier, rerankers are trained for both the sm-5 and sm-6
parsing models in the Berkeley parser.
2.6 Results and Discussion
In this section, I will present the results of our experiments on reranking the Berkeley and the Stan-
ford parsers. The different versions of these parsers trained in our experiments are summarized in
table 2.1.
Parser Descriptionberkeley0 baseline sm-6 parsing model in the Berkeley parser trained over PTB sections 02-21berkeley1 baseline sm-5 model trained over PTB sections 02-21berkeley2 berkeley0 + MaxEnt reranker trained using non-final split of PTBberkeley3 berkeley1 + MaxEnt reranker trained using non-final split of PTBberkeley4 berkeley0 + MaxEnt reranker trained using final split of PTBberkeley5 berkeley0 + GAvPer reranker trained using final split of PTBstanford0 baseline model trained over PTB sections 02-21stanford1 stanford1 + MaxEnt reranker trained using non-final split of PTB
Table 2.1Summary of different parsers
2.6.1 Reranking the Berkeley Parser
In the first set of experiments, I build rerankers for the baseline 6-split(berkeley0) and 5-split (berke-
ley1) grammars in the Berkeley parser. A comparison of the accuracies ofthese baseline models with
their reranked versions is shown in tables 2.2 and 2.3. As can be noticed from these tables, discrim-
inative reranking using the non-local features described previously improves parsing performance on
most of the test sets except the question bank. In the case of the question bank, the 6-split baseline
model (berkeley0) outperforms the reranked 6-split model (berkeley2). In the 5-split model, reranking
improves recall on the question bank. Additionally, in both these pairs of models, reranking leads to a
sharp decrease in the complete match score on the question bank. This pattern of drop in performance
due to reranking is also found for the 6-split model (berkeley2) on section 24 of the PTB. On this corpus,
reranking, however, does seem to improve the precision.
As mentioned earlier, I also experiment with two different techniques to train reranker models- Max-
imum Entropy (ME) withL2 regularization and Averaged Perceptron. A comparison of the accuracies
of two 6-split reranking models trained using these two techniques is shown intable 2.4. Note that these
models are trained using a different partitioning of the PTB (final) compared to the 6-split (non-final)
18

corpusberkeley0 berkeley2
LP LR F1 CM(%) LP LR F1 CM(%)
wsj 22 90.97 90.64 90.80 39.84 91.37∗ 91.00∗ 91.19 40.15wsj 23 90.54 89.99 90.26 37.09 91.22∗ 90.49∗ 90.85 38.59wsj 24 90.12 89.09 89.60 31.45 90.51∗ (88.66) 89.58 31.29
brown cf 85.97 85.62 85.79 27.57 86.77∗ 86.13∗ 86.45 27.95brown cg 84.46 84.41 84.43 25.95 84.46 85.10 85.28 26.22brown ck 84.01 83.91 83.96 34.18 84.80 84.37∗ 84.59 34.72brown cl 84.40 83.97 84.18 32.84 85.02∗ 84.30∗ 84.66 33.03brown cm 86.28 85.95 86.12 34.35 86.68 86.22 86.45 34.20brown cn 86.11 85.63 85.87 36.07 86.48∗ 85.62 86.05 36.12brown cp 84.61 84.32 84.46 31.47 85.31∗ 84.56∗ 84.93 31.49brown cr 83.83 83.42 83.63 27.32 84.63∗ 84.11∗ 84.37 27.25
brown-genia 81.06 82.47 81.75 15.64 82.18 82.76 82.47 13.27genia 81.82 73.73 77.56 0.00 82.69∗ 74.12∗ 78.17 0.00
questionbank 85.16 86.49 85.82 36.77 (83.26) (86.07) 84.64 23.27
bnc 82.22 82.78 82.50 20.52 83.45∗ 83.97∗ 83.71 19.72
Table 2.2Parseval accuracies of baseline and reranked sm-6 models of the Berkeley parser: LP - LabeledPrecision, LR - Labeled Recall, F1 -f -score (Harmonic mean of LP and LR), CM - Complete Match; *indicates significant increase; () indicates significant decrease
corpusberkeley1 berkeley3
LP LR F1 CM(%) LP LR F1 CM(%)
wsj 22 90.07 89.80 89.94 38.02 91.46∗ 91.12∗ 91.29 40.88wsj 23 89.71 89.11 89.41 36.70 91.04∗ 90.42∗ 90.73 39.15wsj 24 89.13 87.95 88.54 30.63 90.76∗ 89.56∗ 90.16 33.53
brown cf 85.01 84.43 84.72 25.44 86.37∗ 85.63∗ 86.00 27.22brown cg 83.78 83.40 83.59 24.41 85.31∗ 84.78∗ 85.05 27.35brown ck 83.57 83.29 83.43 33.58 84.62∗ 84.17∗ 84.39 34.89brown cl 83.55 82.79 83.17 31.42 84.88∗ 84.19∗ 84.54 34.13brown cm 84.96 84.63 84.79 32.84 86.33∗ 85.71∗ 86.02 33.83brown cn 85.26 84.44 84.84 34.77 86.24∗ 85.41∗ 85.82 36.25brown cp 83.76 83.19 83.48 30.50 84.72∗ 84.07∗ 84.39 32.32brown cr 82.65 81.82 82.23 27.44 84.12∗ 83.41∗ 83.76 27.56
brown-genia 79.07 81.12 80.08 12.26 80.02 81.43 80.72 12.26genia 79.77 72.45 75.93 0.00 81.67∗ 73.46∗ 77.35 0.00
questionbank 85.68 86.39 86.03 43.18 (84.29) 86.94∗ 85.60 24.55
bnc 80.84 81.63 81.23 18.69 81.90∗ 82.45∗ 82.17 18.39
Table 2.3Parseval accuracies of baseline and reranked sm-5 models of the Berkeley parser: LP - LabeledPrecision, LR - Labeled Recall, F1 -f -score (Harmonic mean of LP and LR), CM - Complete Match; *indicates significant increase; () indicates significant decrease
19

corpusberkeley4 berkeley5
LP LR F1 CM(%) LP LR F1 CM(%)
wsj 22 91.02 91.47 91.27 41.84 91.09∗ 91.49∗ 91.29 41.01wsj 23 91.57 90.94 91.26 40.69 (90.99) 91.60∗ 91.29 39.65wsj 24 91.07 89.78 90.42 32.49 91.31∗ 90.07∗ 90.69 32.71
brown cf 87.35 86.53 86.94 28.34 (87.13) (86.32) 86.72 26.99brown cg 85.88 85.33 85.61 27.08 85.75 85.26 85.51 25.64brown ck 85.25 84.63 84.94 35.06 (84.92) 84.51 84.71 33.52brown cl 84.46 84.55 85.00 33.72 85.01∗ (84.34) 84.37 32.25brown cm 87.04 86.31 86.67 34.27 86.76 86.25 86.50 32.47brown cn 86.89 85.84 86.36 36.82 (86.58) 85.74 86.16 35.19brown cp 85.80 84.80 85.29 32.90 (85.20) (84.53) 84.86 30.98brown cr 85.12 84.45 84.78 29.51 84.94 84.35 84.65 27.28
brown-genia 82.60 83.13 82.86 15.17 (81.90) 82.74 82.31 15.17genia 83.16 74.21 78.43 0.00 83.04 74.28 78.41 0.00
questionbank 85.62 86.45 86.03 33.08 (84.28) (85.59) 84.93 31.36
bnc 84.00 84.29 84.15 22.43 84.09 84.50 84.30 20.93
Table 2.4Comparison of parseval scores of Berkeley reranked sm-6 models trained using MaximumEntropy and Averaged Perceptron methods; * indicates significant increase; () indicates significant de-crease
reranking model (berkeley2) discussed above. There is not much difference in performance between
these two models although if we look at the complete match score, the MaxEnt model (berkeley4) con-
sistently outperforms the Perceptron model (berkeley5). The Perceptron model (berkeley5) marginally
outperforms the MaxEnt model (berkeley4) on some test sets- the PTB sections and section cl of the
Brown corpus. This shows that the Perceptron model which is trained using an iterative learning algo-
rithm tends to overfit to the PTB corpus over which the parsing models are trained. Another important
point to note is that the Perceptron model took thrice the time required to train the MaxEnt model in
this experiment5. Therefore, since this difference in resource consumption is disproportionate to the
difference in parsing performance, the MaxEnt is to be preferred fortraining rerankers.
An additional observation is that comparing the accuracies of 6-splitnon-final reranking model
(berkeley2) andfinal reranking model (berkeley4) across tables 2.2 and 2.4, it can be noticedthat berke-
ley4 outperforms berkeley2 on almost all the test sets. This pattern suggests that rerankers trained using
the final split with a larger training set (39, 825 sentences) and a smaller development set (1345 sen-
tences) are more effective than ones trained using the non-final split withsmaller training set (35, 852
sentences) and larger development set (3, 976 sentences) at improving parsing performance. In other
words, a fine-grained model learnt from a larger training set with less tuning is better than a coarse-
grained model with more tuning. This probably indicates that the distribution of types of training exam-
ples does not vary much across different sections of the corpus.
5The reranker models were trained on a system with the following specs- Intel Xeon 3.1 GHz, 32 GB RAM
20

corpusberkeley0 berkeley2
Corpus-Avg Sentence-Avg Exact(%)Corpus-Avg Sentence-Avg Exact(%)
wsj 22 0.924 0.935 40.41 0.928 0.938 40.91wsj 23 0.913 0.921 37.83 0.918 0.926 39.49wsj 24 0.907 0.916 32.02 0.912 0.919 32.86
brown cf 0.868 0.886 28.07 0.875 0.891 28.65brown cg 0.846 0.871 26.60 0.852 0.878 26.89brown ck 0.842 0.862 34.67 0.851 0.872 35.40brown cl 0.856 0.861 33.53 0.857 0.865 33.87brown cm 0.862 0.862 35.15 0.868 0.868 35.27brown cn 0.869 0.873 36.48 0.872 0.880 36.65brown cp 0.845 0.855 32.25 0.850 0.860 32.23brown cr 0.835 0.864 28.15 0.838 0.866 28.36
brown-genia 0.851 0.863 15.64 0.860 0.865 13.27genia 0.855 0.862 10.31 0.859 0.864 10.74
questionbank 0.882 0.896 39.32 0.848 0.859 25.89
bnc 0.834 0.856 20.72 0.840 0.861 20.02
Table 2.5Leaf-Ancestor evaluation of the baseline and the reranked sm-6 models ofthe Berkeley parser
corpusberkeley1 berkeley3
Corpus-Avg Sentence-Avg Exact(%)Corpus-Avg Sentence-Avg Exact(%)
wsj 22 0.921 0.931 38.35 0.918 0.929 38.00wsj 23 0.907 0.918 37.46 0.906 0.918 37.21wsj 24 0.901 0.912 30.98 0.901 0.911 31.45
brown cf 0.864 0.885 26.13 0.861 0.881 25.75brown cg 0.841 0.872 25.15 0.837 0.869 24.87brown ck 0.843 0.867 34.00 0.840 0.865 34.02brown cl 0.849 0.858 32.21 0.846 0.857 31.66brown cm 0.851 0.859 33.64 0.852 0.859 33.07brown cn 0.867 0.876 35.43 0.864 0.873 35.09brown cp 0.838 0.854 31.21 0.835 0.853 31.13brown cr 0.831 0.864 28.32 0.826 0.859 28.11
brown-genia 0.837 0.848 12.26 0.841 0.851 10.85genia 0.853 0.860 9.47 0.849 0.857 9.26
questionbank 0.885 0.901 46.75 0.874 0.888 42.37
bnc 0.823 0.849 18.92 0.819 0.846 18.62
Table 2.6Leaf-Ancestor evaluation of the baseline and the reranked sm-5 models ofthe Berkeley parser
21

corpusberkeley4 berkeley5
Corpus-Avg Sentence-Avg Exact(%)Corpus-Avg Sentence-Avg Exact(%)
wsj 22 0.927 0.939 42.29 0.928 0.939 41.29wsj 23 0.920 0.929 41.68 0.920 0.928 40.65wsj 24 0.913 0.919 33.38 0.915 0.920 33.53
brown cf 0.877 0.894 29.06 0.875 0.892 27.70brown cg 0.855 0.881 27.79 0.854 0.880 26.44brown ck 0.852 0.874 35.40 0.850 0.871 33.99brown cl 0.862 0.867 34.31 0.858 0.863 32.91brown cm 0.862 0.866 35.15 0.866 0.866 33.18brown cn 0.875 0.882 37.37 0.873 0.880 35.59brown cp 0.852 0.863 33.65 0.849 0.860 31.74brown cr 0.842 0.869 30.45 0.842 0.866 28.15
brown-genia 0.861 0.867 15.17 0.854 0.863 15.17genia 0.858 0.863 10.64 0.858 0.863 10.40
questionbank 0.875 0.890 36.19 0.872 0.884 34.23
bnc 0.845 0.864 22.62 0.846 0.865 21.02
Table 2.7 Comparison of leaf-ancestor scores of Berkeley reranked models trained using MaximumEntropy and Averaged Perceptron methods
The leaf-ancestor scores for the same pairs of reranking models discussed above are shown in ta-
bles 2.5, 2.6 and 2.7. One main noticeable pattern is that the difference in the parsing performance for
these pairs of models is less when evaluated using the LA metric as compared to the parseval metrics.
Also, in the case of the 5-split model, the baseline model (berkeley1) performs better than the reranked
model (berkeley3) when we look at the LA scores. This is the complete opposite of the pattern with
the parseval scores discussed above. At this point, we take note of this puzzling observation about
the difference in parser performance when assessed using different evaluation metrics although a full
investigation of these two metrics is beyond the scope of this thesis.
2.6.2 Reranking the Stanford Parser
In this section, I report the results of our experiments on reranking the Stanford parser. A comparison
of the parsing performance of the baseline (stanford0) and rerankedmodels (stanford1) evaluated using
the parseval metrics are shown in table 2.8. In table 2.9, the performance ofthese two models is com-
pared using the Leaf-Ancestor evaluation. It can be noticed that reranking improves the performance
of the Stanford parser for all metrics on almost all the test sets, the only exception being the complete
match and the exact match scores on the question bank. It must be noted thatreranking failed to improve
parsing performance of the Berkeley parser on the same corpus. Indeed, this is why question construc-
tions have been the focus of recent works on improving parsing performance on specific domains [42].
The parsing model in the standard distribution of the Stanford parser is trained using additional training
22

corpusstanford0 stanford1
LP LR F1 CM(%) LP LR F1 CM(%)
wsj 22 86.07 84.80 85.43 27.18 89.87∗ 89.08∗ 89.47 39.89wsj 23 85.75 84.17 84.95 28.15 89.42∗ 88.12∗ 88.77 36.30wsj 24 81.75 81.22 81.48 23.94 84.92∗ 84.49∗ 84.70 31.97
brown cf 81.75 81.22 81.48 21.04 84.92∗ 84.49∗ 84.70 27.35brown cg 80.14 80.21 80.17 20.80 83.10∗ 83.21∗ 83.16 25.84brown ck 79.81 80.29 80.05 29.86 82.55∗ 83.00∗ 82.77 35.32brown cl 79.50 79.64 79.57 28.72 82.40∗ 82.58∗ 82.49 32.91brown cm 81.06 81.42 81.24 29.84 84.49∗ 84.81∗ 84.65 33.41brown cn 81.39 81.54 81.47 30.72 84.02∗ 84.12∗ 84.07 35.34brown cp 79.62 79.77 79.69 26.97 82.50∗ 82.68∗ 82.59 31.26brown cr 78.78 78.81 78.80 21.75 81.81∗ 81.80∗ 81.81 25.62
brown-genia 76.06 77.08 76.57 12.74 79.87∗ 80.32∗ 80.10 13.21genia 77.70 70.15 73.73 0.00 81.28∗ 73.01∗ 76.93 0.00
questionbank 76.04 81.00 78.44 24.40 80.06∗ 85.99∗ 82.92 22.12
bnc 78.07 78.74 78.40 16.18 81.62∗ 82.17∗ 81.89 20.42
Table 2.8Parseval accuracies of different versions of the Stanford parser: LP - Labeled Precision, LR- Labeled Recall, F1 -f -score (Harmonic mean of LP and LR), CM - Complete Match; * indicatessignificant increase; () indicates significant decrease
corpusstanford0 stanford1
Corpus-Avg Sentence-Avg Exact(%)Corpus-Avg Sentence-Avg Exact(%)
wsj 22 0.885 0.901 27.53 0.918 0.931 40.41wsj 23 0.876 0.891 28.60 0.906 0.917 37.33wsj 24 0.873 0.886 24.24 0.901 0.910 32.42
brown cf 0.843 0.865 21.63 0.861 0.882 28.02brown cg 0.820 0.850 21.14 0.839 0.867 26.21brown ck 0.823 0.847 29.99 0.842 0.863 35.28brown cl 0.825 0.835 28.90 0.843 0.851 33.18brown cm 0.836 0.845 30.65 0.852 0.858 35.07brown cn 0.845 0.858 30.88 0.864 0.873 35.31brown cp 0.818 0.835 27.32 0.835 0.850 31.86brown cr 0.808 0.836 22.26 0.835 0.850 31.86
brown-genia 0.826 0.836 12.74 0.844 0.853 13.21genia 0.831 0.840 8.09 0.850 0.858 10.60
questionbank 0.805 0.827 24.66 0.819 0.835 21.83
bnc 0.805 0.832 16.42 0.825 0.850 20.42
Table 2.9Leaf-Ancestor evaluation of the baseline and the reranked models of the Stanford parser
23

data from the question bank to address this deficiency of the parser. In our experiments, we studied a
different parsing model trained only using the PTB for the sake of comparison.
Another interesting observation is that the improvement in parsing performance (relative increase
in parseval scores) is more pronounced in the case of the Stanford parser than the Berkeley parser. It
must be noted that an important difference exists between the two parsers considered in our study- the
Stanford parser is a lexicalized parser while the Berkeley parser is not. This leads to the interesting
conclusion that reranking is more effective when the base parser is lexicalized.
Finally, in this set of experiments, we do not notice a difference in patterns of performance between
the two metrics unlike in the case of the Berkeley 5-split models. As mentioned earlier, a detailed
investigation is necessary to understand the difference in parsing performance with respect to these two
metrics.
2.7 Summary
In this chapter, I presented a study of the discriminative reranking technique as a way of incorporat-
ing non-local features into parsing. I built reranker models for the well-known Berkeley and Stanford
parsers using a wide array of non-local features described in the work of Charniak and Johnson [19].
I evaluated the reranker models on treebanks for different domains. The results of our experiments
show that rerankers trained using a basic set of non-local features improves the parsing performance
of both the parsers. An interesting result from our study is the insight thatdiscriminative reranking
brings about greater improvements in parsing performance when the baseparser is lexicalized as in the
Stanford parser. Ours is the first attempt at reranking the Stanford parser to the best of our knowledge
and the results of our experiments show this to be an extremely promising direction to pursue. Apart
from this main conclusion, we also note that question constructions seem to beparticularly challenging
for both these parsers. In the case of the Berkeley parser, reranking does not improve the performance
of the parser at parsing questions. Another puzzling observation that needs further investigation is the
difference in the behavior of the Berkeley 5-split parsing models when evaluated using the Parseval and
the Leaf-Ancestor metrics.
24

Chapter 3
Ensemble models I: Parser combination at Inference time
During the last decade of research on Natural language parsing, ensemble techniques (also known
as combination techniques) have been proposed to improve the parsing accuracies for a number of
languages. The common aim of all the different ensemble techniques discussed in the literature is
to integrate different parsing approaches with complementary strengths and weaknesses in order to
obtain the best possible parsing performance. Henderson and Brill [43] are the first to propose the
combination approach to achieve improved parsing accuracies for constituency parsing. Latter works
on combination techniques have focused on dependency parsing [44, 45, 46, 47], perhaps owing to its
growing popularity in recent years. In addition, there are approachesthe combine k-best parsers using
techniques such as discriminative reranking studied in the previous chapter [48, 49]. The different kinds
of combination techniques proposed in the dependency parsing literature can be broadly classified into
two types- techniques that integrate parsers at learning time, e.g, approach that involve training the
parsers using setups such asstacking[50, 51]. The other type of combination techniques are those
that combine independently trained parsers at parsing time, e.g, approaches such as the ones proposed
by Sagae and Lavie [45], Zhang et al. [48], Fossum and Knight [49]that combine the (1-best ork-
best) output of multiple base parsers. The former type of combination techniques that integrate parsers
at learning time are studied in the next chapter. In this chapter, we focus onthe second type, that is,
techniques that integrate parsers at inference (parsing) time.
The parser combination techniques proposed by Sagae and Lavie [45] bring about significant im-
provements in parsing performance. The dependency-based parsercombination technique proposed in
that work has been shown to be successful not only for multilingual parsing [47] but also for domain
adaptation [46]. In this chapter, we focus on this technique of parser combination. In our experiments,
we explore different ways to combine the output of multiple parsers to improveupon the existing state-
of-art accuracies for parsing English. We work with dependency parsers for English as our ultimate
goal is to create a high-quality parser for that language which can be deployed for analysis of source
sentences in an English-to-Indian language machine translation system, Anusaaraka. Since dependency
representation is well-suited for syntactic analysis of Indian languages that have relatively free word
order, transfer of syntactic information from source to target side is simplerif the source analysis is
25

dependency-based. Anusaaraka [52] is a large-scale machine translation system based on the principle
of cross-lingual information access. It is an open source system available under GNU General Pub-
lic License (GPL). The parsers chosen for this study are: the Stanfordparser, the Berkeley parser, the
mate-tools parser and the ISBN dependency parser, all of which are available under GPL. The first two
parsers are phrase-structure parsers which produce a phrase-based (constituency-based) analysis of sen-
tence structure while the latter two give a dependency-based analysis. The development of high quality
constituency-to-dependency conversion schemes in recent years makes it possible to combine parsers
across formalisms. Surdeanu and Manning [53] is an important work that addresses a number of im-
portant questions about the applicability and performance of ensemble models in the context of English
dependency parsing. They compare different aspects of the performance of the two different approaches
to parser integration mentioned earlier. Our study is in a similar vein with the main difference that we
consider not just dependency parsing models as they do but also constituent parsers which are widely
reported to represent the state of art for English parsing [54, 55, 56]even when a dependency-based
evaluation of parsers is carried out.
In fact, an important practical goal of this study is to build a GPL parser thatgives parsing performance
comparable to the constituency-based Charniak-Johnson parser [19], the best parser for English. A
novel feature of our study is that we experiment with different constituency-to-dependency conversion
schemes and POS-taggers for English to study the influence of these systems on the overall performance
of the parser combination technique. Evaluation of the parser combination technique on corpora from
different domains is another important aspect of our study.
3.1 Parser combination through Reparsing
The ensemble technique that we study in our work was proposed by Sagaeand Lavie [45]. This
technique combines parsers at inference time, that is, combine the output parses for a sentence from
multiple parsers to get a combined parse tree. In this section, we will describethis method in detail.
Whenm different parses are available for a sentence withn words, then the dependencies can be
combined using a simple voting scheme which is as follows- Each of them parsers votes for the head of
each of then words in the sentence. The head with most votes is assigned to each word. One such voting
scheme was tried out by Zeman andZabokrtsky [44] to combine dependency parsers for Czech. While
this scheme ensures that the final dependencies have as many votes as possible it does not guarantee
that the resultant structure will be a well-formed dependency tree. In fact, the resulting structure might
not even be connected. In order to overcome this limitation of simple word-based voting, Sagae and
Lavie [45] proposed the approach ofreparsing. Instead of a word-based voting for then words in the
sentence, they build a graph (multi-graph) from them initial dependency parses of the sentence. Each
node in this graph corresponds to a word in the sentence. Next, weighted directed edges are created
between pairs of nodes (words) which are connected by dependencies in the initial trees. Three different
weight configurations were explored by them-
26

1. Assign same weight to all dependencies.
2. Assign different weights to different dependencies based on whichparser generated the depen-
dency. This strategy considers that parsers have different accuracies and counts dependencies
proposed by more accurate parsers more heavily.
3. Assign different weights to different dependencies based on whichparser generated the depen-
dency and the POS-tag of the dependent word. This strategy attempts to capitalize on the specific
strengths of different parsers.
When an edge gets support from (exists in) more than one initialm structure, then the corresponding
weights are simply added. In this scheme, if at least one of the initial structures is a well-formed depen-
dency tree, then the graph will also be a well-formed dependency tree. Once a digraph is constructed
this way, the combined parse can be obtained by simply finding the maximum spanning tree (MST)
in this directed weighted graph. This step can be executed using efficient algorithms for finding MST
such as the Chu-Liu/Edmonds directed MST algorithm [57, 58] which is also used in the graph-based
dependency parsers such as the MSTParser [23].
Sagae and Lavie [45] apply this reparsing method to combine multiple unlabeled initial trees. How-
ever, latter versions of this method were equipped to combine labeled dependency parses as well. The
reparsing method has been shown to improve accuracies for a host of languages [47, 59]. It has also been
shown to be successful at the task of adapting parsers to new domains [46]. In the context of English
dependency parsing, Surdeanu and Manning [53] show that the simple reparsing method outperforms
ensemble techniques that combine parsers at learning time such as stacking.
3.2 Constituency-to-dependency conversion
The development of high quality constituency-to-dependency conversion procedures in recent years
has made comparisons of parsers across formalisms possible [54, 55]. The output parses of a con-
stituency parser are converted to dependency structures using a constituency-to-dependency converter.
The constituency-to-dependency conversion procedure is also usedto automatically convert constituency
treebanks into their dependency versions. Dependency parsers aretrained over such automatically con-
verted treebanks in case hand-crafted dependency treebanks do not exist. The performance of all parsers
is evaluated using the standard dependency evaluation metrics of labeled attachment score (LAS) and
unlabeled attachment score (UAS). Since the ensemble technique of reparsing described in the previous
section is a dependency graph-based technique, the parsers to be combined using this technique must be
dependency parsers. However, the best performing and widely-used parsers for English such as Stan-
ford parser, Berkeley parser, etc. are all constituency-based. Wetherefore, convert the output of these
constituency parsers to dependency trees using automatic constituency-to-dependency converters.
In our work, we study two different constituency-to-dependency conversion schemes.
27

• The Stanford typed dependency scheme [60] is a well-known constituency-to-dependency conver-
sion procedure that has been widely used in the NLP community as well as in thebiomedical text
processing community. Stanford dependencies are extracted from constituent parses by mapping
patterns in the parses (using the tree-expression syntax defined bytregex [61]) to grammatical
relations. A system to extract stanford typed dependencies is provided with the Stanford Parser.
Five variants of the typed dependency scheme are available in the system-basic, collapsed,
ccpropagated, tree andnoncollapsed [62]. In our experiments, we extract basic (projective)
dependencies using the extraction system in Stanford parser version1.6.4.
• The second conversion scheme is based on a constituency-to-dependency conversion procedure
proposed by Johansson and Nugues [63]. This procedure improvesupon earlier conversion pro-
cedures such as Yamada and Matsumoto [64] by using more sophisticated head-finding rules and
by making use of function tags and traces, if present, to recover long-distance dependencies and
non-projective dependencies. Thepennconverter1 (also known as the LTH converter) is an imple-
mentation of this conversion procedure and was used to create dependency versions of the Penn
treebank from which datasets were created for the CoNLL shared taskson dependency parsing
[65, 66]. For this reason, the dependencies extracted by this converter are also known as CoNLL
dependencies.
We use the constituency-to-dependency converters to create dependency versions of the Penn tree-
bank which is annotated with function tags. The dependency parsers used in our experiments are trained
over sections02-21 of this dependency version of the Penn treebank. For other corpora such as the Ques-
tionbank, BNC corpus and the biomedical treebanks, function tags are not available. In the absence of
function tags, the pennconverter is unable to recover all dependencies. Following Foster and van Gen-
abith [33], we handle this issue by applying a function tagger that assigns function tags to constituents
in these corpora. We use the state-of-art function tagger of Chrupala [67] in our experiments. The same
combination of function tagger and pennconverter is used to convert the output parses of constituency
parsers into dependency structures. In the case of Stanford dependencies, however, no such problem is
encountered as the system directly maps tree patterns to dependency relations. The Stanford dependency
system is applied to the output of constituency parsers as well to extract dependencies.
A brief comparison of the two different constituency-to-dependency conversion schemes considered
in our study is shown in table 3.1. The dependencies extracted using the Pennconverter are linguistically
richer in two noticeable ways. The number of edge labels is higher. Non-projective dependencies are
also extracted by this converter although their percentage in the Penn treebank is quite low.
1Available athttp://nlp.cs.lth.se/software/treebank_converter
28

Statistics Stanford Pennconverter# sent 39832 39832# dep labels 49 67% non-proj. deps 0 0.41% non-proj. sents 0 7.75% head left of modifier 51.6 60
Table 3.1 Comparison of dependencies extracted from section02-21 of the Penn treebank using theStanford dependency extraction system and the Pennconverter
3.3 Experiments
3.3.1 Parsers
In this section, we briefly describe the various parsers considered in our parser combination study.
As mentioned earlier, an important practical goal of our study is to combine freely available parsers for
English using the reparsing technique and build a parsing system that can beat the Charniak-Johnson
parser.
The Charniak-Johnson (CJ) parser is a reranking parser that doesparsing in two stages [19]. The first
stage of parsing is done using Charniak’s lexicalized history-based generative statistical parser [27]. In
the second stage, Johnson’s discriminative reranker uses a large number of non-local features defined
over the entire parse tree to rerank the k-best parses produced by thefirst stage parser. Charniak’s
parser is reported to give an F-score of89.1 on section23 of the WSJ corpus. When combined with the
Johnson reranker, the F-score on the same section significantly improvedto 91.3. McClosky et al. [68]
introduced self-training in this parsing setup as a result of which, the F-score improved to92.1 which is
the highest accuracy reported on that test set in the literature. In our experiments on parser combination,
we compare the performance of the combination systems against both the original CJ parser2 and its
self-trained version3.
We consider the well-known Stanford and Berkeley parsers (described in the previous chapter) in our
experiments on parser combination. Both these parsers contain pre-trained models for parsing English
text which are freely available. Following common practice, these pre-trainedmodels are trained over
sections02-21 of the Penn treebank. Apart from these baseline models, we also consider the reranked
versions of both the parsers built using non-local features describedin the previous chapter. For the
Berkeley parser, we include both sm-6 and sm-5 models as well as their reranked variants. The basic
idea underlying this study is to explore the possibility of building a powerful parser for English which
can parse text from any domain with high accuracy by combining the Berkeley and the Stanford parsers.
Since the ensemble technique of reparsing considered in our study is a dependency-based technique,
we consider both constituency and dependency parsers in our study onparser combination. Moreover,
2Available athttps://bitbucket.org/bllip/bllip-parser/get/tip.ta r.bz2
3Available fromhttp://cs.brown.edu/ ˜ dmcc/selftraining/selftrained.tar.gz
29

an important point to note is that the efficacy of ensemble techniques such asreparsing depends on the
diversity among the base parsers that are being combined [43, 45, 53].Since constituency parsers and
dependency parsers are traditionally thought of as based on different views on parsing natural language,
it might be worthwhile to combine the two to see if new insights can be gained. In thisstudy, we
consider two dependency parsers for English.
The MateTools parser [69] is an efficient implementation of a Maximum-spanning tree-based parsing
algorithm that uses second-order features. It uses the MIRA algorithmcombined with a hash kernel to
learn the dependency structures from a treebank. The parser includes a parallel feature extraction process
and a parsing algorithm to considerably improve the speed of the parser while still retaining the high
accuracy of graph-based dependency parsing approaches. TheMateTools parser contains a pre-trained
model for parsing English text trained over sections02-21 of the dependency version of the PTB.
The ISBN parser (also known as idparser) [70] is an implementation of a projective dependency
parsing algorithm similar to a standard shift-reduce algorithm for context-free grammars. The underly-
ing model is a latent-variable model for generative dependency parsing based on Incremental Sigmoid
Belief Networks. In other words, the features for parsing are inducedautomatically using latent vari-
ables. As inference is intractable in this class of graphical models, the parser uses a variational inference
method to compute the best parse for a given input sentence. A basic dependency parsing model was
trained over sections02-21 from the dependency version of the PTB. One serious issue with this parser
is the extremely high training time required to train a parsing model4. Due to lack of adequate resources,
this parser could not be used in all our experiments.
Of the two dependency parsers considered in our study, the matetools parser is a graph-based parser
while the idparser is a transition-based parser and therefore, represent the two main kinds of dependency
parsing algorithms. Both these parsers are available under GPL.
Table 3.2 contains a summary of the different parsers considered in our study. The output parses from
the constituency parsers are converted to dependency trees before applying the combination technique
to all the parsers. There are two sets of experiments in our study- one with Stanford dependency scheme
and the other with CoNLL dependencies. Since all the parses combined using the combination system
are dependency trees, the dependency evaluation metrics of labeled attachment score (LAS), unlabeled
attachment score (UAS) and label accuracy (LA) are used to measure parsing performance.
At this point, a clarification might be necessary. It may seem odd even ridiculous to combine8
different parsers to beat one parser (CJ). Even if the combination system outperforms the CJ parser,
due its very high parsing time complexity (Tc +∑
i Ti, whereTi is the runtime ofith parser in the
combination andTc is the runtime of the combination technique), it cannot be used to parse text in
online applications such as Machine Translation or Question Answering. What is the point then of
combining all these different parsers given this severe tradeoff between accuracy and parsing speed ? In
the context of our study, the answer to this question is as follows- our experiments on parser combination
4The baseline model trained over sections02-21 of PTB with CoNLL dependencies (67 edge labels) took nearly25 days
on a dual core system with4 GB memory.
30

Parser Descriptioncj0 pre-trained parsing and reranker modelscj1 Self-trained Charniak + MaxEnt rerankerberkeley0 pre-trained sm-6 parsing model in the Berkeley parserberkeley1 sm-5 model trained over PTB sections 02-21berkeley2 berkeley0 + MaxEnt reranker trained using final split of PTBberkeley3 berkeley1 + MaxEnt reranker trained using non-final split of PTBstanford0 pre-trained model trained only over PTB sections 02-21stanford1 stanford1 + MaxEnt reranker trained using non-final split of PTBmatetools pre-trained dependency parsing model in the MateTools parseridparser dependency parsing model trained over PTB sections02-21
Table 3.2Brief summary of parsers
using reparsing are aimed at achieving highest possible parsing accuracies with reduced concerns about
parsing time complexity of the ensemble parser. A highly accurate ensemble parsing system for English
such as the one being attempted here, although may not be directly deployablein an online system, can
be used in a self-training or the more recent up-training setup to train another fast and computationally
inexpensive parsing model such as in Petrov et al. [42]. This is especially relevant to the task of domain
adaptation where training data for a new domain might not exist. The highly accurate but relatively slow
ensemble parser can be used to create (noisy) training data that can be used to adapt parsers to this new
domain.
Another point in defense of our parser combination setup is that the self-trained Charniak-Johnson
parser (cj1 in table 3.2) against which we compare the ensemble parser is computationally expensive
to train. The iterative parsing and training process of self-training took several weeks on a dual core
system with4 GB of memory. The parsers considered for combination in our experiment are relatively
much less expensive (a reranked parsing model takes not more than a week to train) when seen from
this perspective of training time.
3.3.2 Reparsing experiments
In our experiments, we use an implementation of the reparsing approach by Hall et al. [47]. The
well-known Chu-Liu/Edmonds directed MST algorithm [57, 58] is used to search for the best parse in
the graph built from the output of the base parsers. This reparsing system has two kinds of parameters-
1. Weighting strategy with respect to parsers. This parameter (w) determines the weights to be
assigned to the base parsers. Three different values of this parameterare considered-
• Weigh all parsers equally (w = 1)
• Weigh parser according to its LAS (w = 2)
• Weigh parser according to LAS per POS-tag (w = 3)
31

2. Weighting strategy with respect to dependency relation labels. The values of this parameter (l)
are used to label the unlabeled trees obtained after reparsing. This parameter has four possible
values-
• Choose first best label (l = 1)
• Choose best among all (l = 2)
• Choose best among selected (l = 3)
• Choose labeled best among selected (l = 4)
There are12 possible parameter settings with which the reparsing system can be applied. The eight
parsers shown in table 3.2 are combined using all possible combinations of values of these two parame-
ters.
3.3.3 Datasets
Brown # sentences in # sentences insection original section modified dataset
cf 3164 3151cg 3279 3270ck 3881 3783cl 3714 3620cm 881 853cn 4415 4324cp 3942 3840cr 967 958
While comparing the combination systems against the Charniak-Johnson parser, we evaluate parsing
performance not only on sections of the WSJ corpus but also on a varietyof other treebank corpora.
These include the Brown corpus, the Questionbank, the BNC test set andthe biomedical treebanks-
Genia and Brown-Genia. A brief description of these corpora along with their sizes was given in the
previous chapter. In the multi-genre Brown corpus, the following issue was encountered in the parser
combination experiments- some of the parsers (Berkeley parser and its variants) fail to parse a few
sentences in each section of the Brown corpus. The parser combination system fails in such a scenario
when the number of sentences is not the same across parsers. We removethose sentences from all
the parsers before applying the combination technique. The relevant statistics are shown in table??.
Similarly, one sentence each had to removed from section24 of the WSJ corpus and the Questionbank
since the Berkeley parsers fail to parse them.
The argument for comparing the performance of the combination system on test sets from different
domains is similar to the one discussed for evaluating reranked versions of constituency parsers in the
previous chapter. Parsing performance needs to be measured on different test sets in order to verify if
the accuracy improvements obtained using the combination technique generalize across domain.
32

3.3.4 Dependency Parser Evaluation
Parsing performance evaluation for dependency representations is carried out using the standard
“labeled attachment score” (LAS) metric. The evaluator also computes “unlabeled attachment score”
(UAS) and “label accuracy” (LAcc) metrics across the dataset. The LAS score is estimated as the
accuracy of the parser in predicting the head word and label of the relation correctly when compared
with the gold standard tree. On the other hand, the UAS score is estimated as theaccuracy of the parser
in predicting the head word without considering the dependency labels assigned by the parser. Similarly,
LAcc is defined as the accuracy of predictions of the dependency labelsassigned to dependencies across
the dataset. While the attachment scores reflect the system’s ability to recoverthe structure correctly,
LAcc scores correspond to the system’s ability to correctly determine the nature of the dependencies.
In the experiments conducted in this chapter and the next, we report the parsing performance of different
parsers and our ensemble models using the attachment scores (both labeledand unlabeled).
3.4 Results and Discussion
In this section, I discuss the results of our experiments on using the reparsing technique to combine
the output of multiple dependency parsers. As mentioned earlier, the reparsing system studied in our
experiments has two kinds of weighting strategies- one with respect to parser and the other with respect
to the dependency relation labels. There are12 possible combinations of these parameters with which
the reparsing system can be applied. I study6 Of these12 possible combinations in my experiments to
see if this technique is useful in achieving the best accuracies for dependency parsing of English. The
different reparsing configuration explored in our experiments are summarized in table 3.3.
Model Parser weighting (w) Label weighting (l)reparsed1
equal weights (w = 2)best among all (l = 2)
reparsed2 best among selected (l = 3)reparsed3
parser LAS score (w = 3)best among all (l = 2)
reparsed4 best among selected (l = 3)reparsed5
parser LAS per POS tag (w = 4)best among all (l = 2)
reparsed6 best among selected (l = 3)
Table 3.3Summary of reparsing configurations
We combined the outputs of different parsers shown in table 3.2 using these6 reparsing configu-
rations. The outputs of the constituency parsers were converted to dependency trees using the basic
dependency scheme of the Stanford typed dependencies and also the pennconverter. In addition, we
also controlled for another variable- the part-of-speech (POS) tags used by the parsers. This is because
the original reparsing technique of Sagae and Lavie [45] to combine dependency parsers assumes that
the POS tags are the same across all the parsers. Therefore, we conduct another set of reparsing experi-
ments in which we give the same POS-tags as input to all the parsers. We usedthe latest version of the
33

Stanford POS-tagger5 in these experiments. In all our experiments, we compare the accuracies ofthe
reparsing systems to the self-trained version of the Charniak-Johnson (CJ) parser, the state-of-art parser
for English.
Dataset cj0 cj1 reparsed1 reparsed2 reparsed3 reparsed4 reparsed5 reparsed6
wsj 2287.60 87.63 87.94∗ 88.12∗ 88.03 88.09∗ 88.73∗ 88.79∗
91.63 91.88 92.17∗ 92.17∗ 92.17∗ 92.17∗ 92.18∗ 92.18∗
wsj 2387.80 88.15 88.23 88.39∗ 88.29 88.37∗ 88.72∗ 88.79∗
91.56 92.04 92.17 92.17 92.20 92.20 92.37∗ 92.37∗
wsj 2486.57 87.81 (87.35) 87.51 (87.36) 87.45 87.79 87.85∗
90.92 92.09 91.92 91.92 91.84 91.84 92.15∗ 92.15∗
QuestionBank87.36 88.20 (87.52) 87.99 87.97 88.17 88.37∗ 88.54∗
93.16 94.14 (93.95) (93.95) (93.70) (93.70) 94.02 94.02
Brown-Genia83.82 84.56 86.49∗ 84.85 85.00∗ 85.03∗ 85.76∗ 85.82∗
86.14 86.94 87.60∗ 87.32∗ 87.40∗ 87.32∗ 88.12∗ 88.12∗
Genia82.08 83.49 83.90∗ 84.19∗ 84.30∗ 84.49∗ 84.87∗ 84.96∗
84.25 85.61 86.43∗ 86.43∗ 86.59∗ 86.59∗ 87.03∗ 87.03∗
BNC84.18 85.27 85.01 85.42∗ 85.34 85.51∗ 86.03∗ 86.11∗
87.53 88.45 88.45 88.45 88.45 88.45 88.91∗ 88.91∗
Brown-cf84.13 84.96 (84.73) 84.85 85.02∗ 85.13∗ 85.56∗ 85.67∗
89.21 90.08 90.13 90.13 90.21∗ 90.21∗ 90.51∗ 90.51∗
Brown-cg82.76 83.64 83.71 83.92∗ 83.82∗ 83.95∗ 84.34∗ 84.42∗
88.08 89.04 89.95∗ 89.95∗ 89.67∗ 89.67∗ 90.02∗ 90.02∗
Brown-ck81.37 82.19 82.76∗ 82.84∗ 82.91∗ 82.94∗ 83.11∗ 83.18∗
87.36 88.18 89.21∗ 89.21∗ 89.84∗ 89.84∗ 90.45∗ 90.45∗
Brown-cl81.36 82.20 82.64∗ 82.71∗ 82.79∗ 82.86∗ 83.12∗ 83.19∗
87.54 88.36 89.13∗ 89.13∗ 89.67∗ 89.67∗ 89.91∗ 89.91∗
Brown-cm82.30 82.57 82.92∗ 82.96∗ 82.87∗ 82.91∗ 83.04∗ 83.12∗
87.61 87.78 89.03∗ 89.03∗ 89.03∗ 89.03∗ 89.47∗ 89.47∗
Brown-cn81.63 82.56 (82.18) (82.23) 82.55 82.59 82.78∗ 82.87∗
88.09 88.96 (88.42) (88.42) 88.98 88.98 89.21∗ 89.21∗
Brown-cp80.69 81.86 81.81 81.88 81.92 81.96∗ 82.15∗ 82.21∗
86.54 87.54 87.76∗ 87.76∗ 87.92∗ 87.92∗ 88.23∗ 88.23∗
Brown-cr80.31 81.06 81.09 81.14 81.26∗ 81.29∗ 81.48∗ 81.56∗
86.27 87.09 87.17 87.17 87.34∗ 87.34∗ 87.78∗ 87.78∗
Table 3.4Comparison of reparsed combination systems with Charniak-Johnson parser; CoNLL depen-dencies; Different POS-tags in Berkeley and Stanford parsers
The accuracies of the different ensemble models with default POS-tags in all the parsers when eval-
uated based on the pennconverter (CoNLL) dependencies are shownin table 3.4. All the ensemble
models outperform the self-trained version of the CJ parser on at least one test set. Among the different
ensemble models, the ones where the parsers are weighted by their LAS perPOS tag (reparsed5 and
reparsed6) outperform the rest by a significant margin. The ensemble model corresponding tow = 3
andl = 3 (reparsed6) significantly outperforms the self-trained version of the CJparser on all treebanks
except the question bank. In the case of the question bank, the self-trained CJ parser scores higher on
5version3.1.1 (released date:9th March,2012)
34

the UAS (unlabeled attachment score) metric. The improvement in LAS betweenthe reparsed6 model
and self-trained CJ is at least 1 point on all the test sets.
Dataset cj0 cj1 reparsed1 reparsed2 reparsed3 reparsed4 reparsed5 reparsed6
wsj 2287.60 87.63 88.02∗ 88.15∗ 88.08∗ 88.18∗ 88.78∗ 88.82∗
91.63 91.88 92.19∗ 92.19∗ 92.21∗ 92.21∗ 92.45∗ 92.45∗
wsj 2387.80 88.15 88.26 88.43∗ 88.58∗ 88.62∗ 88.91∗ 88.97∗
91.56 92.04 92.18 92.18 92.23∗ 92.23∗ 92.45∗ 92.45∗
wsj 2486.57 87.81 (87.42) (87.51) (87.41) (87.45) 87.78 87.8990.92 92.09 92.01 92.01 92.16∗ 91.84 92.18∗ 92.18∗
QuestionBank87.36 88.20 (87.49) (87.62) (87.97) 88.06 88.43∗ 88.59∗
93.16 94.14 (93.84) (93.84) (93.92) (93.92) 94.16 94.16
Brown-Genia83.82 84.56 84.47 84.51 84.91∗ 84.98∗ 85.46∗ 85.61∗
86.14 86.94 87.56∗ 87.56∗ 87.48∗ 87.48∗ 87.86∗ 87.86∗
Genia82.08 83.49 83.82∗ 83.89∗ 84.02∗ 84.13∗ 84.49∗ 84.56∗
84.25 85.61 86.27∗ 86.27∗ 86.34∗ 86.34∗ 86.88∗ 86.88∗
BNC84.18 85.27 85.06 85.36 85.65∗ 85.74∗ 86.12∗ 86.19∗
87.53 88.45 88.56 88.56 88.59 88.59 88.91∗ 88.91∗
Brown-cf84.13 84.96 (84.81) 84.87 85.02 85.11∗ 85.43∗ 85.51∗
89.21 90.08 90.19∗ 90.19∗ 90.23∗ 90.23∗ 90.51∗ 90.51∗
Brown-cg82.76 83.64 83.68 83.73 83.71 83.84∗ 84.21∗ 84.32∗
88.08 89.04 89.97∗ 89.97∗ 89.97∗ 89.97∗ 90.29∗ 90.29∗
Brown-ck81.37 82.19 82.69∗ 82.76∗ 82.95∗ 82.91∗ 83.13∗ 83.19∗
87.36 88.18 89.15∗ 89.15∗ 89.78∗ 89.78∗ 90.32∗ 90.32∗
Brown-cl81.36 82.20 82.68∗ 82.72∗ 82.71∗ 82.86∗ 83.04∗ 83.12∗
87.54 88.36 89.17∗ 89.17∗ 89.69∗ 89.69∗ 89.93∗ 89.93∗
Brown-cm82.30 82.57 82.84∗ 82.89∗ 82.85∗ 82.94∗ 83.04∗ 83.14∗
87.61 87.78 88.98∗ 88.98∗ 89.06∗ 89.06∗ 89.49∗ 89.49∗
Brown-cn81.63 82.56 (82.16) 82.83∗ 82.49 82.56 82.77∗ 82.83∗
88.09 88.96 (88.47) (88.47) (88.83) (88.83) 89.18∗ 89.18∗
Brown-cp80.69 81.83 81.89 81.94∗ 81.92 81.96∗ 82.16∗ 82.23∗
86.45 87.54 87.83∗ 87.83∗ 87.97∗ 87.97∗ 88.30∗ 88.30∗
Brown-cr80.31 81.06 81.12 81.17 81.26∗ 81.32∗ 81.49∗ 81.58∗
86.27 87.09 87.19 87.19 87.31∗ 87.31∗ 87.75∗ 87.75∗
Table 3.5Comparison of reparsed combination systems with Charniak-Johnson parser; CoNLL depen-dencies; Stanford POS-tags in all parsers
The accuracies of the different ensemble models with the same POS-tags in allthe parsers when
evaluated based on the pennconverter (CoNLL) dependencies are shown in table 3.5. The comparative
pattern is the same as in the previous set of ensemble models. The only difference is that the UAS of
reparsed6 is also higher than that of the self-trained CJ parser. Our expectation in this experiment was
that the accuracies of the ensemble models would show greater improvements ifthe POS tags in all the
parsers are the same. However, this is not borne out by the results of thisexperiment. There is only a
very slight improvement in LAS between the reparsed6 model built in this experiment and the one from
the previous experiment.
35

Dataset cj0 cj1 reparsed1 reparsed2 reparsed3 reparsed4 reparsed5 reparsed6
wsj 2289.04 88.93 89.52∗ 89.61∗ 89.52∗ 89.59∗ 89.91∗ 89.97∗
91.30 91.25 91.76∗ 91.76∗ 91.77∗ 91.77∗ 92.01∗ 92.01∗
wsj 2389.32 89.71 89.81 89.88∗ 89.84∗ 89.92∗ 90.14∗ 90.18∗
91.43 91.90 91.87 91.87 91.91 91.91 92.17∗ 92.17∗
wsj 2488.10 89.17 89.07 89.16 89.22 89.28∗ 89.74∗ 89.82∗
90.70 91.58 91.55 91.55 91.65 91.65 91.89∗ 91.89∗
QuestionBank78.75 78.61 78.50 78.86∗ 78.63 78.90∗ 79.03∗ 79.12∗
81.94 81.73 82.11∗ 82.11∗ 82.20∗ 82.20∗ 82.47∗ 82.47∗
Brown-Genia79.11 81.00 81.60∗ 81.65∗ 81.71∗ 81.79∗ 81.95∗ 82.03∗
85.38 86.36 87.31∗ 87.31∗ 87.25∗ 87.25∗ 87.57∗ 87.57∗
Genia78.34 80.08 80.77∗ 80.92∗ 80.87∗ 81.00∗ 81.32∗ 81.46∗
84.12 85.16 85.97∗ 85.97∗ 86.05∗ 86.05∗ 86.42∗ 86.42∗
BNC83.63 84.63 (84.21) (84.39) (84.33) 84.49 84.79∗ 84.86∗
87.30 88.16 (87.82) (87.82) (87.93) (87.93) 88.23∗ 88.23∗
Brown-cf86.11 87.05 (86.76) (86.84) 86.95 87.01 87.23∗ 87.29∗
88.91 89.77 (89.47) (89.47) 89.81 89.81 90.09∗ 90.09∗
Brown-cg84.76 85.74 85.69 85.76 85.83∗ 85.86∗ 86.02∗ 86.09∗
87.66 88.48 88.43 88.43 88.59∗ 88.59∗ 88.83∗ 88.83∗
Brown-ck83.22 84.38 84.42 84.45∗ 84.56∗ 84.59∗ 84.81∗ 84.93∗
86.66 87.73 87.89∗ 87.89∗ 87.96∗ 87.96∗ 88.18∗ 88.18∗
Brown-cl83.68 84.43 (84.25) (84.31) 84.51 84.53 84.82∗ 84.90∗
87.16 87.75 (87.64) (87.64) 87.83 87.83 87.98∗ 87.98∗
Brown-cm84.71 84.81 84.83 84.85 84.91∗ 84.93∗ 85.03∗ 85.08∗
87.68 87.65 87.71 87.71 87.91∗ 87.91∗ 88.07∗ 88.07∗
Brown-cn84.30 85.41 (84.91) (84.96) 85.48 85.51 85.80∗ 85.87∗
87.74 88.68 (88.34) (88.34) 88.78 88.78 88.97∗ 88.97∗
Brown-cp82.75 84.08 (83.68) (83.76) 84.11 84.16 84.47∗ 84.53∗
86.13 87.28 (86.98) (86.98) 87.30 87.30 87.76∗ 87.76∗
Brown-cr82.84 84.08 (83.74) (83.81) 84.11 84.17∗ 84.41∗ 84.49∗
86.25 87.27 87.03 87.03 87.30 87.30 87.71∗ 87.71∗
Table 3.6Comparison of reparsed combination systems with Charniak-Johnson parser; Stanford depen-dencies; Different POS-tags in Berkeley and Stanford parsers
The accuracies of the different ensemble models with default POS-tags in all the parsers when eval-
uated based on the Stanford typed dependencies are shown in table 3.6. The labeled attachment score
of all the parsers with this dependency scheme is higher than with the CoNLL dependencies. This is
expected since this dependency scheme excludes non-projective and long distance dependencies cov-
ered by the pennconverter. Again, all the ensemble models outperform theself-trained version of the CJ
parser on at least one test set. The ensemble models, reparsed5 and reparsed6 significantly outperform
the self-trained CJ parser on all the treebanks. The best performing parsing model built in this set of
experiments is reparsed6, which outperforms the self-trained CJ parserby almost1 point of LAS on all
the test sets.
The accuracies of the different ensemble models with the same POS-tags in allthe parsers when
evaluated based on the Stanford typed dependencies are shown in table 3.6. The comparative pattern
36

Dataset cj0 cj1 reparsed1 reparsed2 reparsed3 reparsed4 reparsed5 reparsed6
wsj 2289.04 88.93 89.44∗ 89.53∗ 89.67∗ 89.74∗ 90.03∗ 90.10∗
91.30 91.25 91.68∗ 91.68∗ 91.87∗ 91.87∗ 92.05∗ 92.05∗
wsj 2389.32 89.71 89.86∗ 89.91∗ 89.95∗ 89.99∗ 90.21∗ 90.27∗
91.43 91.90 91.89 91.89 91.93 91.93 92.19∗ 92.19∗
wsj 2488.10 89.17 89.09 89.13 89.22 89.28∗ 89.75∗ 89.81∗
90.70 91.58 91.51 91.51 91.67 91.67 91.87∗ 91.87∗
QuestionBank78.75 78.61 78.56 78.61 78.69 78.75∗ 78.93∗ 78.97∗
81.94 81.73 82.14∗ 82.14∗ 82.20∗ 82.20∗ 82.68∗ 82.68∗
Brown-Genia79.11 81.00 81.56∗ 81.65∗ 81.78∗ 81.83∗ 82.03∗ 82.11∗
85.38 86.36 87.21∗ 87.21∗ 87.54∗ 87.54∗ 87.87∗ 87.87∗
Genia78.34 80.08 80.83∗ 80.97∗ 81.03∗ 81.08∗ 81.39∗ 81.48∗
84.12 85.16 86.02∗ 86.02∗ 86.16∗ 86.16∗ 86.59∗ 86.59∗
BNC83.63 84.63 (84.19) (84.33) 84.63 84.69 84.83∗ 84.91∗
87.30 88.16 (87.89) (87.89) 88.13 88.13 88.39∗ 88.39∗
Brown-cf86.11 87.05 (86.83) (86.91) 87.03 87.06 87.31∗ 87.39∗
88.91 89.77 (89.59) (89.59) 89.93∗ 89.93∗ 90.09∗ 90.09∗
Brown-cg84.76 85.74 85.74 85.81 85.83 85.88∗ 86.04∗ 86.11∗
87.66 88.48 88.51 88.51 88.64∗ 88.64∗ 88.89∗ 88.89∗
Brown-ck83.22 84.38 84.46 84.49∗ 84.56∗ 87.59∗ 84.83∗ 84.91∗
86.66 87.73 87.91∗ 87.91∗ 87.96∗ 87.96∗ 88.20∗ 88.20∗
Brown-cl83.68 84.43 (84.21) (84.24) 84.37 84.53∗ 84.82∗ 84.90∗
87.16 87.75 (87.61) (87.61) 87.83 87.83 87.98∗ 87.98∗
Brown-cm84.71 84.81 84.87 84.94∗ 84.96∗ 85.05∗ 85.21∗ 85.27∗
87.68 87.65 87.73 87.73 87.94∗ 87.94∗ 88.11∗ 88.11∗
Brown-cn84.30 85.41 (84.91) (84.98) 85.64 85.71∗ 85.89∗ 85.94∗
87.74 88.68 (88.36) (88.36) 88.90 88.90 89.04∗ 89.04∗
Brown-cp82.75 84.08 (83.54) (83.62) 84.11 84.16 84.42∗ 84.49∗
86.13 87.28 (86.80) (86.54) 87.22 87.22 87.69∗ 87.69∗
Brown-cr82.84 84.08 (83.71) (83.81) 84.03 84.11 84.37∗ 84.42∗
86.25 87.27 (87.06) (87.06) 87.30 87.30 87.67∗ 87.67∗
Table 3.7Comparison of reparsed combination systems with Charniak-Johnson parser; Stanford depen-dencies; Stanford POS-tags in all parsers
is the same as in the previous experiment. The ensemble models reparsed5 andreparsed6 significantly
outperform the self-trained CJ parser on all the test sets. This shows that strategy of weighting according
to the LAS of parser per POS tag is the most effective of all the strategies explored in our combination
experiments. There is a slight improvement in LAS of the ensemble model reparsed6 as compared to
the previous experiment where all the parsers had different POS tags.
3.5 Summary
In this chapter, we studied the reparsing technique originally proposed bySagae and Lavie [45] to
combine dependency parsers at inference time. The results of our experiments show that this technique
is effective in building high accuracy ensemble models for dependency parsing of English by combining
37

freely available parsers for English. The models built in our experiments using the strategy of weighting
parsers according to their LAS per POS tag (w = 3) significantly outperform the self-trained version of
the Charniak-Johnson (CJ) parser, the state-of-art parser for English. We also study the effect of using
the same POS tags since the reparsing technique performs best when it weights parsers using accuracy
per POS tag. The results of our experiments show that there is no benefit of using the same POS tags in
all the parsers while combining them using the reparsing technique. Therefore, this additional step of
giving the same POS tags as manual input in all the parsers is unnecessary. The ensemble models built
in the experiments reported in this chapter represent the state-of-art fordependency parsing of English
to the best of our knowledge and built using parsers available under GPL. We deploy these models for
source analysis in a large-scale in-house English-to-Indian language MT system. One possible criticism
of the combination setup studied here is that too many parsers are combined to beat the self-trained CJ
parser and this combination system may not deployed online. Although we admitto this weakness of
the reparsing technique, we point out that the method of self-training to improve parsing performance is
also extremely resource intensive in comparison to reparsing. We also speculate that the accuracies of
the ensemble models would remain as high as reported here even if some of the parsers from table 3.2
are excluded from the combination.
38

Chapter 4
Ensemble models II: Parser combination during training
As mentioned earlier, ensemble techniques (or combination techniques) that combine parsers with
different syntactic behaviors have been shown in recent years to be successful at improving parsing
accuracies for a number of languages. The aim of any ensemble setup is toexploit diversity among
existing parsers to obtain the best possible parsing performance. Two kinds of ensemble models have
been studied in the literature on syntactic parsing so far. There are models that combine independently
trained parsers at inference time. The re-parsing approach of Sagaeand Lavie [45] studied in the pre-
vious chapter is an example of this kind of parser combination. The other kindof ensemble techniques
are those that combine parsers at learning time. Nivre and McDonald [50]first presented the integration
of two base dependency parsers at learning time using a setup which they refer to asguided parsing.
Martins et al. [51] introduced the generalized framework ofstackingfor dependency parsing as a way
of extending a parsing model’s feature space. Much of the theoretical discussion on stacking presented
in this chapter is based on that work.
As discussed at the beginning of this thesis, algorithms for syntactic parsingof natural language make
strong independence assumptions to achieve tractability. Graph-based and transition-based models are
the two main types of statistical dependency parsing approaches studied in the literature. In graph-based
dependency parsing, dependency trees are scored by factoring thetree into its edges, and parsing is per-
formed by searching for the highest scoring tree. The score of a tree isestimated as the sum of the
scores of the edges due to this edge-factorization assumption. Transition-based dependency parsers, on
the other hand, model the sequence of decisions of a shift-reduce parser, given previous decisions and
current state. Parsing is performed using greedy search or searching for the best sequence of transitions.
Thus, both these approaches to dependency parsing use different approximations to achieve tractability.
Transition-based approaches solve a sequence of local problems in sequence, ignoring global optimal-
ity. Graph-based methods although perform global inference, use score factorizations (edges scores) that
correspond to strong independence assumptions such as edge-factorization. Such strong independence
assumptions are untenable as a significant proportion of important linguistic relationships are non-local.
For example, linguistic relationships such as agreement and co-indexation (co-referentiality) are non-
local and spread across more than a single edge in the dependency graph. The strong independence
39

assumptions underlying current statistical dependency parsing approaches prevent them from learning
higher order models of syntax necessary to capture such important linguistic relationships. In the case of
Indian languages which have rich morphology, the adverse effects of making such strong independence
assumptions are perhaps more severe as such non-local linguistic relationships are morphologically re-
alized in these languages and have important consequences for syntax such as free word order. It is
therefore, necessary to find ways to incorporate non-local informationinto parsing models. Discrimina-
tive reranking studied in chapter 2 is one way to do this. Reranking and k-best parsing techniques were
tried out for statistical dependency parsing too [20] but the results havenot been conclusive. Non-local
features of the kind used to train rerankers for phrase structure parsers do not seem to be very effective
in the case of dependency parsing. This is probably again due to the difference between the two kinds of
representations of syntactic structure. Dependency structure is a relatively light-weight representation
of syntactic structure and therefore, structurally oriented non-local features such as the ones discussed
in chapter 2 are not well-suited for reranking dependency trees.
Martins et al. [51] present stacking dependency parsers as a successful way of incorporating non-
local features in dependency parsing. As mentioned earlier, stacking is an ensemble technique that
allows for parsing models to be combined at learning time. In the stacked learning architecture, a level-
1 parser is trained using not only the gold trees in the treebank but also the output of another level-0
parser (or multiple parsers). This setup for training dependency parsers extends the feature space of the
parsing model in two ways:
1. Addition of newstackedfeatures in the input to the level-1 parser. These new features are based
on combinations of the desired output and the output predicted by the level-0 parser.
2. Approximation of non-local features by using stacked features that make use of the structure pre-
dicted by the level-0 parser. This ability to incorporate non-local features allows for the learning
of higher order models of syntactic dependencies by the level-1 parsing model.
In this chapter, I study the usefulness of the approach of stacking dependency parsers based on the
framework discussed in Martins et al. [51] as a way to incorporate non-local features into parsing models
for three Indian languages: Hindi, Bangla and Telugu. We experiment withcombining a graph-based
dependency parser with different kinds of base parsers. A novelty inthis study is the combination of the
graph-based parser with a grammar-driven parser.
4.1 Previous work
As mentioned earlier, the method of guided parsing introduced by Nivre andMcDonald [50] is the
first attempt to integrate dependency parsers at learning time. They combineMaltParser and MSTParser
parsing models to achieve improvements in accuracy for a number of languages. Martins et al. [51]
presents stacked learning as a way of incorporating non-local features into dependency parsing. They
report improvements over the guided parsing setup for5 out of14 languages- Arabic, Danish, German,
40

Slovene and Swedish. The non-local features that they experiment with seem to be effective across
languages. Surdeanu and Manning [53] is an important work that compares different kinds of ensemble
techniques for dependency parsing of English. The results of their experiments show that methods
that combine parsers at runtime such as re-parsing outperform methods such as stacking that combine
parsers at learning time.
Since the focus of this chapter is on dependency parsing for Indian languages, I will also briefly
review existing literature in this area. The first attempt at building NL parsing systems for Indian lan-
guages was made using a grammar-driven constraint-based parsing approach [71, 72]. This approach
worked with a dependency-based representation of syntactic structureas Indian languages have rela-
tively free word order. The main intuition behind this approach was that, given the rich morphology
of these languages, morphological markers serve as strong cues for identifying the dependency rela-
tions between the words in a sentence. In recent times, the development of syntactically annotated
treebank corpora has paved the way for statistical (or data-driven) dependency parsing. Statistical ap-
proaches require less effort to build parsers, although their performance is directly related to the quality
and size of the treebank used to train the parsers. Most of the work on building dependency parsers
for Indian languages deals with feature engineering, in other words, searching for ways to incorporate
linguistic knowledge in the form of features that might prove to be beneficialfor parsing accuracies.
The two shared tasks on dependency parsing for Indian languages conducted as part of ICON [73, 74]
provided good momentum to efforts directed at feature engineering state-of-art dependency parsers to
parse Indian languages. The MaltParser [24] emerged as the most successful statistical parsing system
for parsing Indian languages in both the shared tasks and was closely followed by the MSTParser [75].
However, due to the small size of the datasets and the lack of significance testing, the results reported
in these contests are inconclusive. As a matter of fact, the absence of significance testing in Husain
[73], Husain et al. [74] brings into question the significance of the difference between the accuracies of
the different participating systems and the rankings assigned based on these differences.
Among the flurry of papers published on dependency parsing for Indian languages in the last few
years, only a few are coherent and allow for reproducibility of the reported experiments. Ambati et al.
[76] is a detailed study of the use of the transition-based parsing approach of the MaltParser for de-
pendency parsing of Hindi. They build on previous work such as Nivre[77] and Ambati et al. [78]
by exploring a common pool of features used by these systems. The resultsreported in this work are
claimed to be the state of the art for Hindi chunk parsing on the ICON-09 tools’ contest dataset. Am-
bati et al. [79] describe two methods to use local morpho-syntactic information such as chunk type,
head/non-head information, chunk boundary information, etc. during dependency parsing of Hindi sen-
tences. This work uses both MaltParser and MSTParser and is the first attempt at word level parsing
for Hindi using automatic features. Gadde et al. [80] report that the clause boundary feature improves
parsing accuracies for Hindi using the MSTParser.
Apart from these statistical dependency parsers, there is also recentwork on grammar-driven constraint-
based parsing for Indian languages [81, 82, 83, 84]. We consider this parser in our study on stacking
41

dependency parsers. This parser is an implementation of the framework for parsing Indian languages
laid out in Bharati and Sangal [72]. In this parser, lexical frames encode hard constraints (H-constraints)
that are used to generate candidate parses for an input sentence. Since lexical frames are ambiguous,
the parser generates more than one parse tree for a sentence. The parser also has soft constraints (S-
constraints) which are used to define an ordering among the candidate parses and thereby select the
best parse for a sentence. This parser provides a coarse-grainedsyntactic analysis with relatively fewer
number of dependency relations when compared to statistical parsers trained over the fine-grained de-
pendency treebanks. This issue will again be discussed briefly in section4.4.2. It must be mentioned
here that we noticed a problem with the way parsing performance is reported in the literature on this
parser [81, 82]. The constraint-based parser is evaluated using a coarse-grained version of the gold data.
In fact, the reference data used to evaluate the constraint-based hybridparser has fewer labels than the
coarse-grained gold dataset released for the ICON-2010 tools’ contest. This is because the contrast be-
tween certain labels is neutralized in the reference data used to evaluate the parser as it is not equipped
to make these distinctions. Parsing accuracy of the constraint-based parser computed using this mod-
ified reference data is juxtaposed to the accuracies of fine-grained statistical parsing models evaluated
using gold data from the fine-grained treebank. The fine-grained and the coarse-grained dependency
relation label sets used to create the ICON-2010 datasets are given in Appendix III. While the coarse-
grained treebank contains26 labels, the fine-grained dataset has well over70 labels. This difference in
the size of the label sets alone is enough to indicate the difference in complexitybetween coarse- and
fine-grained dependency parsing. In fact, accuracies of fine-grained parsers are at least3 LAS points
lower than coarse-grained ones for all three languages as observedin the shared task on dependency
parsing [73, 74]. However, this issue is completely glossed over and the performance of the constraint-
based parser is claimed to be comparable to fine-grained statistical parsers. The fact that the number of
dependency relations predicted varies across parsers remains obscure. This is a crucial aspect of parser
evaluation as accuracies of fine-grained parsers are at least3 LAS points lower than coarse-grained ones
for all three languages as observed in the shared task on dependencyparsing [73, 74]. Therefore, to
compare the accuracy of the coarse-grained constraint-based hybridparser (23 dependency relations)
against the accuracy of fine-grained statistical parsers (around 40 dependency relations) is misleading
to say the least.
In a recent work, Husain et al. [85] limit the search space in a graph-based parser to a constraint graph
generated by the lexical frames in the constraint-based parser. They focus on unlabeled attachment score
(UAS) alone and study the performance of encoding linguistic knowledge into MSTParser. Husain et al.
[86] consider an approach to encode linguistic information using a setup similar to stacking. Although it
is not clear from their description, the results they report are presumablyfor chunk-level parsing. Both
these works are somewhat similar to our experiments on stacking the MSTParser with non-local features
on the output of the constraint-based parser.
42

4.2 Stacked Dependency Parsing
Stacked dependency parsing is based on the machine-learning framework of Stacked Generalization
first proposed by Wolpert [87] and Breiman [88]. The main idea in this framework is to have two levels
of predictors. The first level (or level-0) consists of one or more predictors, g1, g2, ...gk : Rd → R;
each receives input x∈ Rd and outputs a predictiongk(x). The second level (or level-1) consists of
a single meta-predictor functionh : Rd+K → R that takes as input〈x, g1(x), ...gk(x)〉 and outputs a
final predictiony = h(x, g1(x), ...gk(x)). When the stacked learning framework is applied to the task
of parsing, the architecture of a stacked parser consists of two levels. The level-0 parser,g processes an
input sentence x and outputs the set of predicted edges that form a dependency graph,y0 = g(x). At
level-1, another dependency parser,h is applied that now uses in addition to basic (factored) features,
new features from the edges predicted by the level-0 parser while making its predictions. The overall
output of the stacked parser is therefore, of the formh(x, g(x)) and the total runtime is additive in
calculatingh(.) andg(.). Stacking as a framework is a general approach to building ensemble predictors
and does not impose any restrictions on the form of the predictorsg andh or on the methods used to
learn them.
The steps involved in training a stacked parser are as follows:
1. Split the training dataD = {〈xi, yi〉}i intoL partitions,D1, ....., Dl.
2. Train L instances of the level-0 parser g on these L partitions on a leave-one-out basis- thel-th
instance,gl is trained onD−l = D \Dl. Then usegl to output predictions on the unseen partition
Dl. This process leads to the creation of an augmented datasetD = {〈xi, g(xi), yi〉}i.
3. Train the level-0 parser on the original training data,D.
4. Train the level-1 parser on the augmented training data,D.
The total training time of the stacked parser isO(LT0+T1), whereT0 andT1 are individual training
times for the level-0 and the level-1 parsers respectively. At parsing time, similarly, the level-0 parser g
is run on the unseen test set, thus creating an augmented test set on which the level-1 parser is run to get
the final output of the stacked parser.
4.3 Motivations for Stacked Parsing
Martins et al. [51] discuss two main motivations for stacking dependency parsers- as a way of aug-
menting the feature space of the level-1 parser or as a way to approximate higher order models of
dependency syntax. We briefly summarize these two aspects as discussedin that work. For the sake of
this discussion, let us assume the level-1 parser to be a graph-based parser which makes the assumption
of edge-factorization. The feature vector of this parser is of the form
f(x, y) =∑
a∈Ay
fa(x) (4.1)
43

1. In the stacked learning framework, the feature vectors of this level-1 parser can be written as
f(x, y) = f1(x, y) ⌣ f2(x, y0, y)
=∑
a∈Ay
f1,a(x) ⌣ f2,a(x, g(x))
wheref1(x, y) =∑
a∈Ayf1,a(x) are regular edge-factored features, andf2(x, y0, y) =
∑
a∈Ayf2,a(x, g(x)) are thestacked featureswhich are additional features available to the level-1
parser as a result of stacking it on the level-0 parserg. An example of such a stacked feature is a
binary feature that fires if and only if the edgea is predicted by g, i.e, ifa ∈ Ag(x), used by Nivre
and McDonald [50].
2. The feature vector of a graph-based second order model where features decompose by edge and
by edge pair is:
f(x, y) =∑
a1∈Ay
fa1(x) ⌣∑
a2∈Ay
fa1,a2(x)
(4.2)
Exact parsing using this model is intractable when arbitrary second orderfeatures are consid-
ered [89]. For the stacked parsing model in which the level 0 parser outputs a parsey, the feature
vector can be written as
f(x, y) =∑
a1∈Ay
fa1(x) ⌣∑
a2∈Ay
fa1,a2(x)
(4.3)
The only difference between equations 4.2 and 4.3 is thatAy is replaced byAy in the index term
of the second summation. Sincey is given in the stacked model,f becomes edge-factored and
therefore, tractable. The modelf can be viewed as an approximation of the modelf which allows
for higher-order features.
4.4 Experiments
In this section, we describe our experiments on stacking dependency parsers for parsing Indian lan-
guages.
4.4.1 Non-local features
Similar to Martins et al. [51], we experiment with stacking a graph-based dependency parser on other
kinds of dependency parsers. We use the stacked version of the MSTParser presented in that work in
our experiments. We add three new non-local features to that parser. The set of non-local features used
in our experiments is summarized in table 4.1.
44

Feature DescriptionPredEdge Indicate whether the candidate edge was present, and what was its label.Sibling Lemma, POS, link label, distance and direction of attachment of the previous and next predicted siblings.GrandParents Lemma, POS, link label, distance and direction of attachment of the grandparent of the current modifier.PredHead Predicted head of the candidate modifier (if PredEdge=0).AllChildren Sequence of POS and link labels of all the predicted children of the candidate head.Valency Number of predicted children.Depth Depth of a node in the tree.Path Sequence of Lemma, POS on the path from the root of the tree to a node.
Table 4.1Non-local features derived from the level-0 parser
stacked model Combination of non-local featuresmodel1 PredEdgemodel2 PredEdge +Siblingmodel3 PredEdge + Sibling +GrandParentsmodel4 PredEdge + Sibling + GrandParents +PredHeadmodel5 PredEdge + Sibling + GrandParents + PredHead +AllChildrenmodel6 PredEdge + Sibling + GrandParents + PredHead + AllChildren +Valencymodel7 PredEdge + Sibling + GrandParents + PredHead + AllChildren +Valency +Depthmodel8 PredEdge + Sibling + GrandParents + PredHead + AllChildren +Valency + Depth +Path
Table 4.2Combination of features enumerated in Table 4.1 used for stacking
In our experiments, we build stacked MST models that use different combinations of these non-local
features. Table 4.2 shows the feature combination for each stacked model.The stacked models are
trained on different base parsers described in the next section.
Just like the MSTParser, the stacked MSTParser can learn both projective and non-projective parsing
models. It also has an option to vary the order of features- first order or second order while learning the
parsing models. As in the case of the MSTParser, a parsing model trained using a certain value of the
projectivity parameter has to be applied using the same value at inference time.The same holds true in
the case of the feature order parameter. In our experiments, we train stacked models for all four possible
combinations of these two parameters.
4.4.2 Parsers
In our stacking experiments, we consider three parsers at level-0 -MSTParser, MaltParser and a
grammar-driven constraint-based parser. A brief description of eachof these systems is given in this
section.
The MSTParser is based on a probabilistic graph-based model of dependency parsing proposed by
Eisner [90]. The basic idea of this model is as follows- if all the words in a sentence are connected by
dependency links to form a fully connected graph, then the maximally orientedspanning tree of this
graph is the parse tree for the sentence. This model of dependency parsing makes the assumption of
edge (arc) factorization, that is, factoring sentence structure into edges. Parsing is the task of finding
the Maximum spanning tree (tree with maximum sum of edge scores) from a graph with edge scores
45

that are learnt from a dependency treebank. McDonald et al. [23] presented a first-order maximum
spanning tree-based parsing algorithm which uses features defined over dependency edges such as head,
dependent (child) and edge label. McDonald and Pereira [75] present a second order parsing algorithm
which can handle additional features defined over pairs of adjacent edges. Both these algorithms are
available in version0.4b of the MSTParser which we use in our experiments. We use settings reported
in previous work on parsing Indian languages with the MSTParser [78] inour experiments (shown in
table 4.3). We could not explore the entire parameter space for the MSTParser at level-0 due to lack of
adequate resources.
Language Algorithm Training-k OrderBangla Arc-standard 5 2Hindi Non-projective 5 2Telugu Non-projective 1 1
Table 4.3MSTParser settings for different languages
The MaltParser [24] is a language independent system for data-driven dependency parsing that can
be used to induce a dependency parsing model for any language which has a dependency treebank. It
contains several different transition-based parsing algorithms with different levels of complexity. Al-
gorithms such as arc-eager and arc-standard are among the fastest (linear time parsing complexity)
and also, most accurate for a number of languages [91]. They have been shown to give the best ac-
curacies for parsing Indian languages too [77]. In our experiments onstacking, we study these two
parsing algorithms using learner settings and feature models reported in previous work [59]. The
learner and parsing algorithm settings are shown in table 4.4. The feature models used in our ex-
periments can be downloaded fromhttp://researchweb.iiit.ac.in/ ˜ sudheer.kpg08/
icon10-maltexperiments-featuremodels.tgz . MaltParser version1.4.1 was used in our
experiments.
Language Algorithm SVM settingsBangla Arc-standard s0t1d2g0.2c0.25r0.3e1.0Hindi Arc-eager s0t1d2g0.12c0.7r0.3e0.5Telugu Arc-eager s0t1d2g0.1c0.5r0.6e1.0
Table 4.4Parsing algorithm and learner settings in MaltParser for different languages
In addition to statistical dependency parsers, we also experiment with a grammar-driven constraint-
based parser for Indian languages based on the framework described in Bharati and Sangal [72]. The
implementation of this parser for Hindi is described in Bharati et al. [81]. Inthis parser, the parsing task
is divided into two stages, intra-clausal and inter-clausal, which allows forthe selective identification
and resolution of specific dependency relations at the appropriate stage. The H-constraints (hard con-
straints) in this parsing setup encode language-specific knowledge suchas argument structure, lexical
preferences, etc. These H-constraints are fed to an Integer Programming (IP) module that solves the
46

constraint graph to produce the solution graphs i.e., the output parse trees. Since H-constraints are not
unambiguous, more than one solution graph (candidate parse) is generated by the IP module. The best
parse is selected from among these candidate parses using S-constraints(soft constraints) defined in this
parsing setup. S-constraints are used for prioritization among the output parses. It is not clear how S-
constraints were implemented in this work. Moreover, the best parse selected using these S-constraints
is shown to have a significantly lower accuracy than the oracle1 accuracy of the parser. Husain [84]
replaces these S-constraints with a new approach to prioritization of parses in this parser. He applies
a Maximum Entropy labeler to the unlabeled parses obtained from the parser. The label probabilities
assigned to the edges by the labeler are used to obtain tree probabilities (scores) to rank the parses.
This ranking model is erroneously referred to as an edge-factored model as features spread over mul-
tiple edges such as depth and sibling information are also used to train the labeler. In our experiments
with the constraint-based parser2, we completely remove this dubious S-constraints / prioritization
module from the parser and use only the first parse generated by the parser to train a stacked MST-
Parser at level-1. Another important point to be noted is that the constraint-based parser provides only
a coarse-grained analysis (maximum of26 labels ) as opposed to the statistical parsers that are trained
over fine-grained treebanks with more than70 labels. On the testing dataset used in our experiments,
MSTParser, MaltParser and the constraint-based parser output36, 34 and23 labels respectively. In our
stacking experiments, we trained both fine-grained and coarse-grainedstacked parsing models over the
coarse-grained analysis of the constraint-based parser at level-0.
4.4.3 IL dependency parsing datasets
The datasets used in our experiments were all released for the shared task on dependency parsing of
Indian languages [74] organized as part of ICON 2010 Tools contest.The datasets are all drawn from
dependency treebanks for Indian languages [92, 93] which are being developed based on an annotation
scheme [94] inspired by Pan. inian theory of syntax. Table 4.5 contains information about the size of
these datasets.
An important point to be noted is that the Hindi dataset contains full dependency trees that is, de-
pendencies are marked among the words in the sentence. While in the Telugu and Bangla datasets,
dependencies are marked only between heads of chunks. In our initial experiments, we observed that
it was extremely expensive to build stacked models for Hindi using the full dependency trees3. This
is because the number of dependency relations becomes extremely high when word-level dependen-
cies are considered. Dependency relations within a chunk also differ from those outside in the level of
complexity of the relations they encode. In fact, in the annotation pipeline followed to create the Hindi
1best parse available in the output2Available from http://researchweb.iiit.ac.in/ ˜ samar/tools/GH-CBP-Hindi-release_
version-1.6.tgz3In fact, we could not train any stacked model over the full dependencytrees for Hindi on the system (Dual core processor
with 4GB memory) we used in our experiments.
47

Language Dataset Sentence count
HindiTraining 2,972Development 543Test 320
TeluguTraining 1,300Development 150Test 150
BanglaTraining 980Development 150Test 150
Table 4.5Indian language dependency parsing datasets
treebank, only inter-chunk relations are manually annotated. Intra-chunk relations in the treebank are
obtained automatically using a small set of rules [95]. For these reasons, we work with a chunk-level
version of the Hindi dataset in our experiments. Recent works such In our stacking experiments with
the constraint-based parser, the size of the training and development datacombined together is3092
sentences while the size of the test data is302 sentences. The parser failed to parse the rest of the
sentences.
4.5 Results and Discussion
In this section, we describe the results of our experiments on stacking the MSTParser on different
parsers at level-0 to build stacked parsing models for three Indian languages- Hindi, Telugu and Bangla.
As mentioned earlier, stacked models are built for all four possible combinations of the values of the
projectivity and feature order parameters. The stacked learning architecture allows the level-1 MST-
Parser to be trained using non-local features derived from the structure predicted by the level-0 parser.
We train stacked MSTParser models using the different combinations of non-local features described in
section 4.4.1. Of the three new non-local features compared to Martins et al. [51] we introduced into
the stacked MSTParser, we were able to successfully experiment only withthe valency feature for all
the three languages. The depth and POS-path feature could be successfully tried out only for Telugu
and Bangla whose datasets are small. On the Hindi dataset, we could not trainany stacked model that
could use one of these two non-local features. Due to the small size of the datasets, significance testing
is an important issue (as discussed in section 4.1). In our experiments, statistical significance between
accuracies is measured using Dan Bikel’s randomized parsing evaluation comparator with 10,000 it-
erations4. In all our experiments, we test the significance of the difference between accuracies of the
stacked models and the level-0 parser which is also the baseline system.
4http://www.cis.upenn.edu/ ˜ dbikel/software.html
48

MST+MST for Hindi:
level-0 LAS UASMST 66.09 88.25
stacked model1O proj 1O non-proj 2O proj 2O non-proj
LAS UAS LAS UAS LAS UAS LAS UAS
Model-1 65.83 (87.76) 66.60 88.47 65.93 87.89 66.60 88.31Model-2 65.96 (87.80) 66.99 88.73 65.90 (87.70) 66.92 88.60Model-3 66.28 87.96 66.63 88.38 65.93 (87.83) 67.05∗ 88.73Model-4 66.38 88.12 66.76 88.44 65.86 87.80 66.70 88.47Model-5 66.22 (87.93) 66.80 88.38 66.41 (88.31) 66.92 88.82Model-6 66.35∗ (87.89) 66.89∗ 88.41∗ (65.96) (87.76) 66.99∗ 88.79∗
Table 4.6 Results of stacking MST parser on level-0 MST parser for Hindi;∗ indicates significantincrease;() indicate significant decrease
Our first set of experiments dealt with stacking the MSTParser on itself forHindi. The accuracies of
the models built in these experiments on the test set are shown in table 4.6. The level-0 MSTParser has
LAS and UAS of66.09 and88.25 respectively. LAS of this baseline model is lower in comparison with
previous work on parsing Hindi with the MSTParser [78, 80] while UAS is comparable. Note that we
use settings reported in these previous works while training the parser. Wealso broke down the task of
dependency parsing into two steps- predicting the unlabeled tree first andthen using a labeler to assign
dependency relation labels to the predicted edges. As can be noticed fromthe table, stacking does not
bring about any drastic improvements in parsing performance over the baseline model. A significant
improvement in LAS or UAS is noticed only in4 out of the24 stacking configurations explored in our
experiments. In fact, stacking leads to a significant drop in performance more times (7 out of24) than it
improves. This is similar to the scenario reported by Martins et al. [51] wherestacking the MSTParser
on itself brings about only slight improvements in accuracy (less than0.5 LAS points) for9 out of 12
languages. The best improvements in LAS and UAS in comparison to the level-0 parser obtained in
our experiments are0.94 and0.54 respectively. Such low values could be because this stacking setup
combines models that are very similar to each other. It is widely reported in literature that the success of
ensemble techniques depends on the diversity among the parsers to be combined [51, 53, 50, 45, 43].
This claim seems to be supported by the results of this set of experiments. Another observation from
table 4.6 is that this stacking setup improves LAS more often than it improves UAS.Apart from this,
the combination of non-local features corresponding to Model-6 improves parsing performance in3 out
of 4 configurations of that model. The non-local feature of valency introduced in this model seems to
be successful at facilitating the learning of a higher order model of dependencies. Figure 4.1 shows
a comparison of the level-0 baseline MSTParser and the stacked models with best LAS (model-3, 2O
non-proj) on the left and UAS (model 6, 2O non-proj) on the right respectively. The plot comparing
the LAS distribution shows the improvements in the labelled attachment scores pereach dependency
relation in the stacked model relative to the base level-0 parser. Similarly, the plot on the right shows
49

the comparative unlabeled attachment accuracy in predicting the correct head per part-of-speech tag.
Hence, one can infer from the figure that the attachment accuracies of chunks with a “NN” (noun) head
improves by0.31 points and by1.66 points for chunks with a “VM” (main verb) head.
0
20
40
60
80
100
Accu
racy p
er de
pend
ency
relat
ion
k1 k2 r6 ccof
main pof k7 k7p k7tvm
odnmod adv
r6-k2 k1s rt
0.800.79
1.023.63
0.31
-0.33
-4.15
-4.94
1.426.15
11.133.32
4.00
-6.59
12.83
0
20
40
60
80
100
Attac
hmen
t acc
uracy
per p
art-of
-spee
ch ta
g
NN VM NNP CC PRP JJ RB NST QC DEM
0.31 1.66 -0.22
-1.37
-0.950.76
9.09
25.00
25.00
50.00
Figure 4.1 MST+MST-Hindi: Comparison of LAS and UAS score distributions of baseline and beststacked model scores
MST+MST for Telugu:
In the next set of experiments, we explore the same setup of stacking MSTParser on itself for Telugu.
The accuracies of the models built in these experiments on the test set are shown in table 4.7. In the
case of Telugu, stacking the MSTParser on itself seems to be more ineffective than for Hindi. We were
able to build stacked models using all the non-local features in this set of experiments. However, no
combination of non-local features seems to be helpful in improving parsing performance. Significant
improvements were observed only in UAS for two out of the32 stacking configurations explored. How-
50

level-0 LAS UASMST 64.11 89.15
stacked model1O proj 1O non-proj 2O proj 2O non-proj
LAS UAS LAS UAS LAS UAS LAS UAS
Model-1 63.94 88.81 65.11 90.48∗ 64.45 89.65 64.94 89.98Model-2 64.94 90.32 64.94 90.48 64.77 89.98 64.61 89.82Model-3 64.11 89.32 64.44 89.82 64.27 89.65 64.11 89.15Model-4 63.94 89.32 65.11 90.48 64.94 90.48 65.28 90.32Model-5 64.77 90.32 64.77 90.32 64.27 89.65 64.61 89.82Model-6 64.11 89.48 63.94 89.15 64.77 90.32 64.27 89.32Model-7 64.44 89.98 64.77 90.15∗ 64.44 89.82 63.77 88.98Model-8 64.44 89.82 65.28 90.48 64.11 89.65 64.27 89.65
Table 4.7 Results of stacking MST parser on MST level-0 parser for Telugu;∗ indicates significantincrease;() indicate significant decrease
ever, unlike Hindi, the parsing performance does not drop for any of the stacked models. Stacked model
with non-local feature combination of model-1 (1O non-proj) improves the UAS by1.35 points. There
is no significant improvement in the LAS for any of the stacked models for Telugu. The distribution of
UAS scores per part-of-speech tag for the baseline parser and the stacked model with the best UAS are
shown in figure 4.2.
0
20
40
60
80
100
Attac
hmen
t acc
uracy
per p
art-of
-spee
ch ta
g
NN VM NNP PRP NST RB
1.840.97
2.44
-3.85
6.25
12.50
Figure 4.2 MST+MST-Telugu: Comparison of UAS score distributions of baseline andbest stackedmodel scores
MST+MST for Bangla:
In the case of Bangla, the setup of stacking MSTParser on itself significantly improves parsing
accuracies across the board. This can be seen from table 4.8. Improvements are observed in either
51

level-0 LAS UASMST 63.48 86.89
stacked model1O proj 1O non-proj 2O proj 2O non-proj
LAS UAS LAS UAS LAS UAS LAS UAS
Model-1 65.45∗ 87.62 66.29∗ 88.35∗ 65.97∗ 88.55∗ 65.24∗ 87.72Model-2 65.56∗ 88.14∗ 65.45∗ 87.83 65.66∗ 88.35∗ 64.93∗ 87.83Model-3 65.14∗ 87.72 65.24∗ 87.62 65.14∗ 87.62 63.79 85.95Model-4 65.04∗ 87.41 65.66∗ 87.93 65.45∗ 88.66∗ 64.93 87.83Model-5 65.04∗ 87.41 65.14∗ 87.62 65.76∗ 88.24 65.24∗ 87.83Model-6 65.45∗ 87.62 65.87∗ 88.03∗ 65.56∗ 88.24∗ 64.72 87.30Model-7 65.04∗ 87.51 65.97∗ 88.14 65.56∗ 88.14∗ 65.04∗ 87.72Model-8 64.93 87.41 65.66∗ 88.03 65.45∗ 88.24∗ 65.35∗ 87.83
Table 4.8 Results of stacking MST parser on MST level-0 parser for Bangla;∗ indicates significantincrease;() indicate significant decrease
LAS or UAS in 30 out of the32 stacked configurations. Improvements in LAS are observed more
often than in UAS. The improvement in LAS is a little below3 points while in the case of UAS, the
improvement is slightly less than2 points. So, it does not seem to be the case that stacked models benefit
from higher order combinations of non-local features. The best LAS and UAS accuracies are obtained
using stacked-feature combinations from model-1 (1O non-proj) and model-4 (2O proj) respectively.
Figure 4.3 shows a comparison of the level-0 baseline MSTParser and the stacked models with the best
LAS and UAS scores.
MST+Malt for Hindi:
level-0 LAS UASMalt 75.69 89.18
stacked model1O proj 1O non-proj 2O proj 2O non-proj
LAS UAS LAS UAS LAS UAS LAS UAS
Model-1 (74.63) 88.86 75.34 89.40 (74.66) 89.02 75.50 89.72Model-2 (74.79) 89.11 75.56 89.79 74.95 89.15 75.79 89.92∗
Model-3 (74.89) 89.08 75.66 89.88 (74.86) 89.11 75.66 89.88∗
Model-4 (74.86) 89.15 75.95∗ 90.01 (74.92) 89.15 75.72 89.95∗
Model-5 (74.79) 89.08 75.85 89.92∗ 74.98 89.15 75.59 89.69Model-6 (74.73) 89.24 75.72 89.82 75.05 89.27 75.95 90.08∗
Table 4.9Results of stacking MST parser on level-0 MaltParser for Hindi;∗ indicates significant in-crease;() indicate significant decrease
In this set of experiments, we stack the MSTParser on the MaltParser for Hindi. As mentioned
earlier, a MaltParser model is claimed to give the state of the art parsing accuracy for Hindi. The best
results on the test set used in our experiments were reported using the MaltParser albeit for word-level
52

0
20
40
60
80
100
Accu
racy p
er de
pend
ency
relat
ion
k1 main k2vm
od r6 pofk7p
ccof k7t k7 k1s
adv
nmod__relc
sent_adv k4a
4.69
2.00
3.465.94
-1.912.79
-0.55
11.91
1.90
0.59
5.41
5.15-10.89
-11.67
-80.00
0
20
40
60
80
100
Attac
hmen
t acc
uracy
per p
art-of
-spee
ch ta
g
NN VM PRP NNP JJ RB WQ NULL
1.49 2.34 0.79 7.418.33
-4.17 6.25
7.69
Figure 4.3 MST+MST-Bangla: Comparison of LAS and UAS score distributions of baseline and beststacked model scores
parses. This stacking combination of MST + Malt gives the best accuracies for a number of languages
[50, 51] and outperforms both MST and Malt parsing models. So, this is the combination for which
the maximum improvements are expected due to stacking. The accuracies of themodels built in these
experiments are shown in table 4.9. Contrary to our expectation, the accuracies of the stacked models
are only marginally better than those of the baseline model. There is improvementin UAS in 5 out of the
24 stacking configurations. Most of these improvements are with second order non-projective models.
The maximum improvement observed in UAS is0.9 points. There is a slight improvement (< 0.5) in
LAS for just one configuration. In fact, there is a drop in LAS for many configurations (9 out of 24).
The results indicate that stacking models do not benefit from higher ordercombinations of non-local
features. No significant increase in accuracies can be observed as we move from model-1 to model-6.
A comparison of distribution of accuracies of the base parser and the stacked models with the best LAS
and UAS is shown in figure 4.4.
53

0
20
40
60
80
100
Accu
racy p
er de
pend
ency
relat
ion
k1 k2 r6 ccof
main pof k7 k7p k7tvm
odnmod adv
r6-k2 k1s rt
-2.56-1.08
1.210.20
7.25
0.37
1.37-2.330.25
1.30-4.86
-3.96
2.34
2.84
-1.95
0
20
40
60
80
100
Attac
hmen
t acc
uracy
per p
art-of
-spee
ch ta
g
NN VM NNP CC PRP JJ RB NST QC
1.25 0.28 -0.89
4.57
1.900.76
-3.039.09
-25.00
Figure 4.4 MST+Malt-Hindi: Comparison of LAS and UAS score distributions of baselineand beststacked model scores
MST+Malt for Telugu:
In this set of experiments, we stacked the MSTParser on the MaltParser for Telugu. The best parsing
accuracies for Telugu are reported using MaltParser models. The accuracies of the different stacking
models built in these experiments are shown in table 4.10. Again, as in the case of MST + MST
combination, stacking is completely ineffective in improving upon the parsing performance of the level-
0 parser. There is an increase in UAS for3 stacking configurations. However, the increase is higher (2.6
points) when compared to the MST + MST combination. There is no drop in LAS as in the case of Hindi.
Models with higher order combinations of non-local features do not perform better. A comparison of
the distribution of UAS scores per part-of-speech tag of the level-0 model and the stacked model with
best UAS is shown in figure 4.5.
54

level-0 LAS UASMalt 67.78 88.31
stacked model1O proj 1O non-proj 2O proj 2O non-proj
LAS UAS LAS UAS LAS UAS LAS UAS
Model-1 66.94 89.82 67.28 89.98 66.78 89.82 66.78 89.48Model-2 67.28 89.98 67.78 90.48 67.11 89.82 66.94 89.48Model-3 67.28 90.32 67.95 90.98∗ 67.45 90.32 67.11 89.65Model-4 67.11 89.82 67.45 90.32 67.11 89.65 67.11 89.65Model-5 67.61 90.65 67.45 90.48∗ 67.45 90.15 67.78 90.48Model-6 66.94 89.82 67.61 90.48∗ 66.94 89.98 67.28 89.82
Table 4.10Results of stacking MST parser on level-0 MaltParser for Telugu;∗ indicates significantincrease;() indicates significant decrease
0
20
40
60
80
100
Attac
hmen
t acc
uracy
per p
art-of
-spee
ch ta
g
NN VM NNP PRP NST RB CC
-0.46 3.86 5.00 3.85
25.00
12.50
14.29
Figure 4.5 MST+Malt-Telugu: Comparison of UAS score distributions of baseline and best stackedmodel scores
MST+Malt for Bangla:
Next, we stack the MSTParser on a level-0 MaltParser model for Bangla. The results of this set
of experiments are shown in table 4.10. Unlike the setup of stacking the MSTParser on itself, which
improved the parsing accuracy significantly for a number of stacking configurations, this combination
does not improve the parsing performance in any way. Improvements in UASwere observed in two
cases-2O projective model-6 (1.8 points) and2O non-projective model-5 (2.5 points). Stacking does
not lead to a decrease in accuracies for any of the stacking configurations. A comparison of the label
attachments of the level-0 model and the stacked model with best UAS is shown in figure 4.6.
55
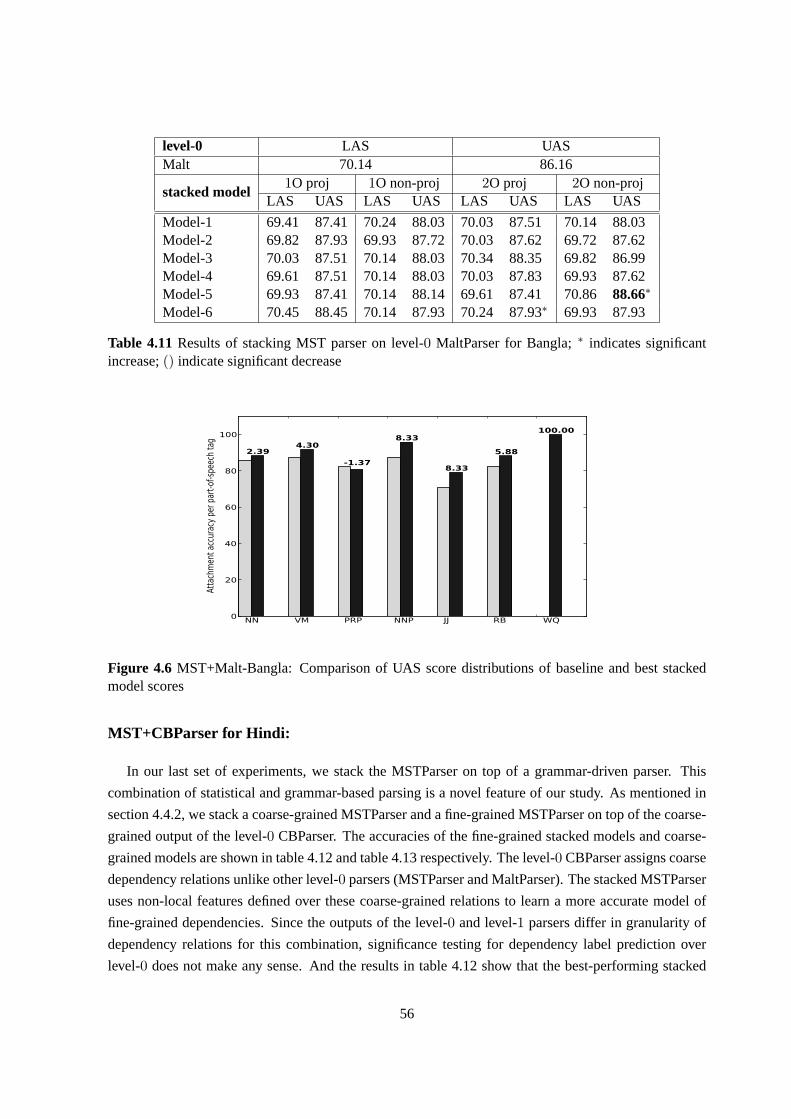
level-0 LAS UASMalt 70.14 86.16
stacked model1O proj 1O non-proj 2O proj 2O non-proj
LAS UAS LAS UAS LAS UAS LAS UAS
Model-1 69.41 87.41 70.24 88.03 70.03 87.51 70.14 88.03Model-2 69.82 87.93 69.93 87.72 70.03 87.62 69.72 87.62Model-3 70.03 87.51 70.14 88.03 70.34 88.35 69.82 86.99Model-4 69.61 87.51 70.14 88.03 70.03 87.83 69.93 87.62Model-5 69.93 87.41 70.14 88.14 69.61 87.41 70.86 88.66∗
Model-6 70.45 88.45 70.14 87.93 70.24 87.93∗ 69.93 87.93
Table 4.11Results of stacking MST parser on level-0 MaltParser for Bangla;∗ indicates significantincrease;() indicate significant decrease
0
20
40
60
80
100
Attac
hmen
t acc
uracy
per p
art-of
-spee
ch ta
g
NN VM PRP NNP JJ RB WQ
2.394.30
-1.37
8.33
8.33
5.88
100.00
Figure 4.6 MST+Malt-Bangla: Comparison of UAS score distributions of baseline and best stackedmodel scores
MST+CBParser for Hindi:
In our last set of experiments, we stack the MSTParser on top of a grammar-driven parser. This
combination of statistical and grammar-based parsing is a novel feature of our study. As mentioned in
section 4.4.2, we stack a coarse-grained MSTParser and a fine-grained MSTParser on top of the coarse-
grained output of the level-0 CBParser. The accuracies of the fine-grained stacked models and coarse-
grained models are shown in table 4.12 and table 4.13 respectively. The level-0 CBParser assigns coarse
dependency relations unlike other level-0 parsers (MSTParser and MaltParser). The stacked MSTParser
uses non-local features defined over these coarse-grained relations to learn a more accurate model of
fine-grained dependencies. Since the outputs of the level-0 and level-1 parsers differ in granularity of
dependency relations for this combination, significance testing for dependency label prediction over
level-0 does not make any sense. And the results in table 4.12 show that the best-performing stacked
56
level-0 LAS UASCB parser (first parse) 64.42 85.20
stacked model1O proj 1O non-proj 2O proj 2O non-proj
LAS UAS LAS UAS LAS UAS LAS UAS
Model-1 72.39 89.24 73.17 89.98 72.42 89.45 73.10 89.73Model-2 72.35 89.27 73.24 90.02 72.71 89.70 73.52 90.37Model-3 72.42 89.31 73.38 90.37 72.81 89.91 73.73 90.65Model-4 72.39 89.24 73.17 89.91 72.96 89.95 73.24 90.09Model-5 72.50 89.24 73.10 89.84 73.13 90.12 73.77 90.73Model-6 72.32 89.24 73.49 90.30 72.71 89.77 73.56 90.37
Table 4.12Results of stacking a fine-grained MST parser on a coarse-grained constraint-based parser(level-0) for Hindi
model has a UAS of90.73. The UAS scores reported on all the stacked models are higher than those
of the MST+Malt and MST+MST configurations. Thus, it is this combination that gives the best scores
with respect to attachment. There is no improvement in LAS over the MST+Malt models. However, If
we compare the accuracies of this fine-grained stacked MST model to the fine-grained baseline MST
model, there is a huge improvement of over7 LAS points and2.5 UAS points. This shows that non-local
features defined using the coarse-grained analysis of the CBParser are quite effective at improving the
performance of the stacked parsing models.
level-0 LAS UASCB parser (first parse) 64.99 85.20
stacked model1O proj 1O non-proj 2O proj 2O non-proj
LAS UAS LAS UAS LAS UAS LAS UAS
Model-1 72.85∗ 85.20 73.31∗ 85.31 72.46∗ 84.74 73.49∗ 85.77Model-2 73.52∗ 86.05 73.24∗ 85.49 72.67∗ 84.99 73.70∗ 86.27Model-3 73.73∗ 86.27 73.59∗ 85.84 72.78∗ 85.24 74.09∗ 86.73Model-4 75.08∗ 87.58∗ 74.90∗ 87.47∗ 73.56∗ 85.98 74.37∗ 87.01∗
Model-5 75.01∗ 87.72∗ 74.90∗ 87.26∗ 73.31∗ 85.77 74.37∗ 86.97Model-6 75.43∗ 88.07∗ 75.08∗ 87.43∗ 73.49∗ 86.23 74.83∗ 87.58∗
Table 4.13Results of stacking a coarse-grained MST parser on a coarse-grained constraint-based parser(level-0) for Hindi; ∗ indicates significant increase;() indicates significant decrease
In the case of coarse-grained level-1 MSTParser, we observed (table 4.13) significant improvements
in terms of LAS in all the stacking configurations and in8 of the24 configurations in terms of UAS.
The improvements obtained in comparison to the level-0 parser are significantly high-10.44 points
and2.87 points in LAS and UAS scores. However, the scores from these models can not be directly
compared to the scores on the fine-grained test set reported earlier. Such high improvements of stacked
models over the first parse of the CBParser indicate that the stacked parsing framework explored here
is much more effective than the S-constraints of Husain [84] in arriving atan accurate parse based on
the grammar in the CBParser. In the stacking setup, even the first parse generated by the CBParser can
57

be used to train an accurate coarse-grained stacked parsing model. Another interesting point about this
combination is that the improvements in UAS from the coarse-grained and fine-grained stacked models
differ significantly. While the average improvement in UAS for different configurations of the coarse-
grained stacked models is1.18 points, the fine-grained stacked models improve UAS by4.66 points
on an average. This is possibly because the stacked MSTParser makes use of dependency relations of
the level-0 parser in the form of the non-local features to predict attachments. A comparison of the
accuracies of the level-0 model and the best stacked model (model-6, 1O proj) is shown in figure 4.7.
0
20
40
60
80
100
Accu
racy p
er de
pend
ency
relat
ion
k1 k7 r6 k2 ccof
main pofvm
odnmod
r6-k2 k1s rt k4 rh k5
2.184.13
2.84
23.05
5.008.97
12.02
14.25
5.82
32.78
27.992.6012.6017.60
4.74
0
20
40
60
80
100
Attac
hmen
t acc
uracy
per p
art-of
-spee
ch ta
g
NN VM NNP CC PRP JJ RB NST QC DEM UNK PSP NP
1.90 3.70 1.20
7.00
1.064.03
3.45
7.6912.50
75.00
25.0033.3333.33
Figure 4.7 MST+CBP-Hindi: Comparison of LAS and UAS score distributions of baseline and bestcoarse-grained stacked model
58

4.6 Summary
We presented a study of the stacking architecture for dependency parsers [51] when applied to pars-
ing three Indian languages. We experimented with two dependency parsers at level-0: MSTParser and
MaltParser for all three languages. We additionally use a grammar-drivenparser in our experiments
on Hindi. The level-1 parser is a graph-based dependency parser that uses non-local features extracted
from the output of the base parser. We experimented with6 different combinations of non-local features
in the level-1 parser. We also found that the newly introduced non-local feature of valency significantly
improves the parsing performance across languages.
Due to the small size of the test datasets, significance testing is a crucial step indetermining the impact
of non-local features in stacking. The results of our experiments show that stacked models bring about
small improvements when the MSTParser is stacked over itself. While parser performance for Telugu
in terms of UAS improved only marginally, the Bangla stacked models resulted in significantly better
parsing performance. There were also a few cases when parsing performance dropped significantly due
to stacking most notably, for Hindi.
Stacking the MSTParser on top of the transition-based MaltParser gave modest improvements in
terms of LAS and UAS for the case of Hindi, and far less improvements in caseof both Telugu and
Bangla. Observed differences of0.5-1 points in terms of LAS and1-2 points in terms of UAS on the
Telugu and Bangla datasets were insignificant. Once again, a drop in parsing performance was observed
in some of the Hindi MST+Malt stacked models. It is puzzling why this combinationwhich achieves
best parsing accuracies for a host of languages fails completely in our experiments.
Finally, we also stacked MSTParser on top of a grammar-driven parser for Hindi, which gives a de-
pendency analysis with coarse-grained dependency relations. Thesestacked models give improvements
of about4-5 points in terms of UAS, giving the best reported UAS scores for Hindi. These results
are promising in the sense that improving the coverage of the grammar-basedparser is one straight-
forward way to improve parsing accuracies. Another interesting point to note is that this combination
outperforms the MST+MST combination by a significant margin although the level-0 accuracies are
comparable. This suggests that dependency relations from the constraint-based grammar-based parser
are more beneficial than those from the MSTParser while learning models withnon-local features. [51]
have an interesting discussion on the information gain associated with each stacked feature and this dif-
ference between the usefulness of non-local features defined overgrammar-driven and statistical parsers
can be explored within that framework in future work.
59

Chapter 5
Conclusions
In this thesis, I focus on the problem of incorporating non-local information into syntactic parsing.
Statistical parsers, whether constituency or dependency-based make certain independence assumptions
about sentence structure in order to achieve tractability. However, theseindependence assumptions
impose a limitation on the kind of features that can be used by the parsing algorithm. In this thesis, I
study techniques to overcome this limitation of feature locality- discriminative reranking in the case of
constituency parsing and the techniques of reparsing and stacking in the case of dependency parsing.
I presented a study of the discriminative reranking technique introduced by Collins [17] as a way of
incorporating non-local information into two well-known PCFG-based constituency parsers, Berkeley
parser and Stanford parser. I use a wide array of non-local features such as those discussed by Charniak
and Johnson [19]. I also study two different kinds of learning algorithmsto train the reranker models-
Maximum Entropy (MaxEnt) withL2 regularization and Averaged Perceptron. The results of our ex-
periments show that rerankers trained using non- local features do improve the performance of both the
parsers at parsing texts from different domains. The relative improvements in accuracy due to reranking
are greater in the case of the Stanford parser which is lexicalized as compared to the Berkeley parser
which is unlexicalized. This observation leads us to the most important conclusion from this study- dis-
criminative reranking as a way of incorporating non-local information is more effective when the base
parser is lexicalized. The study reported in this thesis is the first attempt at reranking the Stanford parser
and the results show this to be an extremely promising direction to pursue. Question constructions seem
to pose a particular problem for both these parsers. In the case of the Berkeley parser, reranking fails to
improve performance of parser on the question bank. Another important novelty of the study reported
in this chapter is the use of multiple parser evaluation metrics although at this point,there is need for
further investigation to understand the behavior of parsers when characterized using these two metrics.
Next, I studiedensemblemethods to integrate parsers as ways of incorporating non-local information.
Two different kinds of parser combination techniques have been studiedin the dependency parsing
literature- techniques such as reparsing [45] and voting that combine independently trained parsers at
inference time and techniques such as stacking [51] that combine parsersat learning time.
60

I consider the reparsing technique to combine dependency parsers in thefirst part of my study on
ensemble methods. This simple, computationally inexpensive was shown in previous work to be very
effective at improving parsing performance by combining a variety of parsers. An important practical
goal of this study was to use this technique to combine GPL parsers for English to build the best freely
available dependency parser for English. I consider the outputs of the highly accurate reranked models of
Berkeley and Stanford parsers built in the first part of my thesis on all thedifferent treebanks and convert
them to dependency trees using two well-known constituency-to-dependency converters. I combine
these parsers with two other dependency parsers for English using the reparsing technique to build6
different ensemble models. I compare these ensemble models to the Charniak-Johnson (CJ) parser,
the state-of-art parser for English using dependency-based LAS and UAS metrics. The results of my
experiments show that the ensemble models built using the reparsing techniquesignificantly outperform
the CJ parser on all the test sets by a margin of around1 LAS point for all the settings considered. The
ensemble parser built in my experiments is the state-of-art parser for dependency parsing of English
and is also built wholly from freely available tools and resources. This parser can be used for analysis
of source sentences in a large-scale English-to-Indian language MT system such as Anusaaraka. In
addition, this parser can be deployed in a variety of NLP systems. Another interesting direction to
pursue in future work is use this ensemble parser which is computationally expensive to create additional
training touptrain fast parsers for new domains [42].
Continuing my exploration of ensemble methods for syntactic parsing, I also presented a study of
the stacking architecture for dependency parsers [51] when applied toparsing three Indian languages. I
experiment with two dependency parsers at level-0: MSTParser and MaltParser for all three languages.
I additionally use a grammar-driven parser in the experiments on Hindi. Due tothe small size of the test
datasets, significance testing is a crucial step in determining the impact of stacking. The results of my
experiments show that stacked models bring about small improvements when theMSTParser is stacked
over itself. There are also a few cases when parsing performance dropped significantly due to stacking,
mainly for Hindi. The newly introduced non-local feature of valency significantly improves the parsing
performance for all3 languages. Stacking the MSTParser on top of the transition-based MaltParser
gave modest improvements in LAS and UAS for Hindi, and much less improvementsin case of both
Telugu and Bangla. Once again, a drop in parsing performance was observed in some of the Hindi
MST+Malt stacked models. It is puzzling why this combination performs well for a host of languages
fails completely for Indian languages.
Finally, I also stacked the MSTParser on top of a grammar-driven parserfor Hindi, which gives a
dependency analysis with coarse-grained dependency relations. Thefine-grained stacked model trained
using this setup gives the best reported UAS for Hindi. In addition, if we compare the accuracies of this
fine-grained stacked MST model to the fine-grained baseline MST model, there is a huge improvement
of over7 LAS points and2.5 UAS points. This shows that non-local features defined using the coarse-
grained analysis of the CBParser are quite effective at improving the performance of the stacked parsing
models. Similar improvement are obtained with the coarse-grained stacked model trained over the
61

coarse-grained analysis of the CBParser. This gives rise to the possibility that the stacked parsing setup
can completely replace the dubious ranking module of the CBParser as it canleverage information
present in a single parse of the CBParser to build a relatively more accurate coarse-grained parsing
model. Martins et al. [51] have an interesting discussion on the information gain associated with each
stacked feature and this difference between non-local features defined over the outputs of grammar-
driven and statistical parsers can be explored within that framework in future work.
62

Related Publications
1. Sudheer Kolachinaand Prasanth Kolachina, “Parsing Any Domain English text to CoNLL De-
pendencies” inProceedings of the Eight International Conference on Language Resources and
Evaluation (LREC’12). European Language Resources Association (ELRA), 2012.
2. Sudheer Kolachina, Prasanth Kolachina, Manish Agarwal and Samar Husain, “Experiments with
MaltParser for parsing Indian Languages” inProceedings of ICON 2010 NLP Tools Contest on
Indian Language Dependency Parsing. Macmillan Publishers, India 2012, pp. 32–38
63

Bibliography
[1] C. D. Manning and H. Schutze,Foundations of Statistical Natural Language Processing. Cam-
bridge, MA, USA: MIT Press, 1999.
[2] D. Jurafsky and J. Martin,Speech and Language Processing: An Introduction to Natural Lan-
guage Processing, Computational Linguistics, and Speech Recognition, ser. Prentice Hall Series
in Artificial Intelligence. Pearson Prentice Hall, 2009.
[3] F. De Saussure, “Cours de linguistique generale (1908-1909),”Cahiers Ferdinand de Saussure, pp.
3–103, 1957.
[4] A. Bharati, V. Chaitanya, and R. Sangal,Natural language processing: a Paninian perspective.
Prentice-Hall of India, 1994.
[5] L. Tesniere and J. Fourquet,Elements de syntaxe structurale. Klincksieck Paris, 1959, vol. 1965.
[6] O. Rambow, “The simple truth about dependency and phrase structure representations: An opinion
piece,” inHuman Language Technologies: The 2010 Annual Conference of the North American
Chapter of the Association for Computational Linguistics. Association for Computational Lin-
guistics, 2010, pp. 337–340.
[7] N. Chomsky, “Three models for the description of language,”IRI Transactions on Information
Theory, vol. 2, no. 3, pp. 113–124, September 1956.
[8] A. Joshi, L. Levy, and M. Takahashi, “Tree adjunct grammars,”Journal of Computer
Systems Science, vol. 10, pp. 136–163, February 1975. [Online]. Available: http:
//dx.doi.org/10.1016/S0022-0000(75)80019-5
[9] T. Kasami, “An efficient recognition and syntax analysis algorithm forcontext-free languages,”
DTIC Document, Tech. Rep., 1965.
[10] D. Younger, “Recognition and parsing of context-free languages in time¡ i¿ n¡/i¿¡ sup¿ 3¡/sup¿,”
Information and control, vol. 10, no. 2, pp. 189–208, 1967.
[11] J. Cocke and J. Schwartz, “Programming languages and their compilers: Preliminary notes, 2nd
rev. version, new york, ny: Courant inst. of math,” 1970.
64

[12] J. Earley, “An efficient context-free parsing algorithm,”Communications of the ACM, vol. 13,
no. 2, pp. 94–102, 1970.
[13] H. Gaifman, “Dependency systems and phrase-structure systems,” Information and Control, vol. 8,
no. 3, pp. 304–337, 1965.
[14] D. Hays, “Dependency Theory: A Formalism and Some Observations,” Language, vol. 40, no. 4,
pp. 511–525, 1964.
[15] XTAG, “A Lexicalized Tree Adjoining Grammar for English,” IRCS, University of Pennsylvania,
Tech. Rep. IRCS-01-03, 2001.
[16] M. Marcus, G. Kim, M. Marcinkiewicz, R. MacIntyr, A. Bies, M. Ferguson, K. Katz,
and B. Schasberger, “The Penn Treebank: Annotating Predicate Argument Structure,” in
Proceedings of the workshop on Human Language Technology, ser. HLT ’94. Stroudsburg,
PA, USA: Association for Computational Linguistics, 1994, pp. 114–119.[Online]. Available:
http://dx.doi.org/10.3115/1075812.1075835
[17] M. Collins, “Discriminative reranking for natural language parsing,” in Proceedings of the Inter-
national Conference for Machine Learning, 2000, pp. 175–182.
[18] M. Collins and T. Koo, “Discriminative reranking for natural language parsing,”Computational
Linguistics, vol. 31, no. 1, pp. 25–70, 2005.
[19] E. Charniak and M. Johnson, “Coarse-to-Fine n-best Parsingand MaxEnt Discriminative
Reranking,” inProceedings of the 43rd Annual Meeting of the Association for Computational
Linguistics (ACL’05). Ann Arbor, Michigan: Association for Computational Linguistics, June
2005, pp. 173–180. [Online]. Available: http://www.aclweb.org/anthology/P05-1022
[20] K. Hall, “K-best spanning tree parsing,” inProceedings of the 45th Annual Meeting of
the Association of Computational Linguistics. Prague, Czech Republic: Association for
Computational Linguistics, June 2007, pp. 392–399. [Online]. Available:http://www.aclweb.org/
anthology/P07-1050
[21] D. Klein and C. Manning, “Accurate Unlexicalized Parsing,” inProceedings of the
41st Annual Meeting of the Association for Computational Linguistics. Sapporo, Japan:
Association for Computational Linguistics, July 2003, pp. 423–430. [Online]. Available:
http://www.aclweb.org/anthology/P03-1054
[22] S. Petrov, L. Barrett, R. Thibaux, and D. Klein, “Learning Accurate, Compact, and Interpretable
Tree Annotation,” in Proceedings of the 21st International Conference on Computational
Linguistics and 44th Annual Meeting of the Association for Computational Linguistics. Sydney,
Australia: Association for Computational Linguistics, July 2006, pp. 433–440. [Online].
Available: http://www.aclweb.org/anthology/P06-1055
65

[23] R. McDonald, K. Crammer, and F. Pereira, “Online large-margin training of dependency parsers,”
in Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics
(ACL’05). Ann Arbor, Michigan: Association for Computational Linguistics, June 2005, pp.
91–98. [Online]. Available: http://www.aclweb.org/anthology/P05-1012
[24] J. Nivre, J. Hall, J. Nilsson, A. Chanev, G. Eryigit, S. Kubler, S. Marinov, and E. Marsi, “Malt-
parser: A language-independent system for data-driven dependency parsing,”Natural Language
Engineering, vol. 13, no. 02, pp. 95–135, 2007.
[25] M. Collins and N. Duffy, “New ranking algorithms for parsing and tagging: Kernels over discrete
structures, and the voted perceptron,” inProceedings of the 40th Annual Meeting on Association
for Computational Linguistics. Association for Computational Linguistics, 2002, pp. 263–270.
[26] L. Shen, A. Sarkar, and A. Joshi, “Using ltag based features in parse reranking,” inProceedings
of the 2003 conference on Empirical methods in natural language processing. Association for
Computational Linguistics, 2003, pp. 89–96.
[27] E. Charniak, “A Maximum-Entropy-Inspired Parser,” inProceedings of the 1st conference on
North American Chapter of the Association for Computational Linguistics. Association for
Computational Linguistics, June 2000, pp. 132–139. [Online]. Available:http://acl.ldc.upenn.edu/
A/A00/A00-2018.pdf
[28] J. Gao, G. Andrew, M. Johnson, and K. Toutanova, “A Comparative Study of Parameter
Estimation Methods for Statistical Natural Language Processing,” inProceedings of the 45th
Annual Meeting of the Association of Computational Linguistics. Prague, Czech Republic:
Association for Computational Linguistics, June 2007, pp. 824–831. [Online]. Available:
http://www.aclweb.org/anthology/P07-1104
[29] S. Petrov and D. Klein, “Improved Inference for Unlexicalized Parsing,” in Human Language
Technologies 2007: The Conference of the North American Chapter of the Association for
Computational Linguistics; Proceedings of the Main Conference. Rochester, New York:
Association for Computational Linguistics, April 2007, pp. 404–411. [Online]. Available:
http://www.aclweb.org/anthology/N/N07/N07-1051
[30] S. Sekine and M. Collins, “Evalb bracket scoring program,” 1997. [Online]. Available:
http://nlp.cs.nyu.edu/evalb/EVALB.tgz
[31] F. W. Nelson and H. Kucera,Manual of Information to accompany a Standard Corpus of present-
day edited American English, for use with digital computers. Brown University, Department of
Lingustics, 1979.
[32] J. Judge, A. Cahill, and J. van Genabith, “QuestionBank: Creatinga Corpus of Parse-Annotated
Questions,” inProceedings of the 21st International Conference on Computational Linguistics
66

and 44th Annual Meeting of the Association for Computational Linguistics. Sydney, Australia:
Association for Computational Linguistics, July 2006, pp. 497–504. [Online]. Available:
http://www.aclweb.org/anthology/P06-1063
[33] J. Foster and J. van Genabith, “Parser Evaluation and the BNC: Evaluating 4 constituency parsers
with 3 metrics,” inProceedings of the Sixth conference on International Language Resources and
Evaluation (LREC’08), 2008.
[34] M. Lease and E. Charniak, “Parsing Biomedical Literature,” inProceedings of 2nd International
Joint Conference on Natural Language Processing. Asian Federation of Natural Language Pro-
cessing, 2005, pp. 58–69.
[35] J. Kim, T. Ohta, Y. Tateisi, and J. Tsujii, “Genia corpus- A Semantically Annotated Corpus for
Bio-Textmining,”Bioinformatics, vol. 19, no. suppl 1, p. i180, 2003.
[36] Y. Tateisi, A. Yakushiji, T. Ohta, and J. Tsujii, “Syntax Annotation forthe GENIA corpus,” in
Proceedings of 2nd International Joint Conference on Natural Language Processing. Asian
Federation of Natural Language Processing, 2005, pp. 222–227.
[37] S. Abney, S. Flickenger, C. Gdaniec, C. Grishman, P. Harrison,D. Hindle, R. Ingria, F. Jelinek,
J. Klavans, M. Liberman, M. Marcus, S. Roukos, B. Santorini, and T. Strzalkowski, “Procedure
for quantitatively comparing the syntactic coverage of english grammars,” inProceedings of
the workshop on Speech and Natural Language, ser. HLT ’91, E. Black, Ed. Stroudsburg,
PA, USA: Association for Computational Linguistics, 1991, pp. 306–311.[Online]. Available:
http://dx.doi.org/10.3115/112405.112467
[38] G. Sampson and A. Babarczy, “A test of the leaf-ancestor metric for parse accuracy,”Natural
Language Engineering, vol. 9, no. 4, pp. 365–380, 2003.
[39] S. Green and C. Manning, “Better arabic parsing: Baselines, evaluations, and analysis,” inPro-
ceedings of the 23rd International Conference on Computational Linguistics. Association for
Computational Linguistics, 2010, pp. 394–402.
[40] J. Emonds,A transformational approach to English syntax: Root, structure-preserving, and local
transformations. Academic Press New York, 1976.
[41] M. Johnson and A. Ural, “Reranking the Berkeley and Brown Parsers,” in Human Language
Technologies: The 2010 Annual Conference of the North American Chapter of the Association for
Computational Linguistics. Los Angeles, California: Association for Computational Linguistics,
June 2010, pp. 665–668. [Online]. Available: http://www.aclweb.org/anthology/N10-1095
[42] S. Petrov, P. Chang, M. Ringgaard, and H. Alshawi, “Uptraining for Accurate Deterministic
Question Parsing,” inProceedings of the 2010 Conference on Empirical Methods in Natural
67

Language Processing. Cambridge, MA: Association for Computational Linguistics, October
2010, pp. 705–713. [Online]. Available: http://www.aclweb.org/anthology/D10-1069
[43] J. Henderson and E. Brill, “Exploiting diversity in natural languageprocessing: Combining
parsers,” inProceedings of the Fourth Conference on Empirical Methods in Natural Language
Processing, 1999, pp. 187–194.
[44] D. Zeman and Z.Zabokrtsky, “Improving parsing accuracy by combining diverse dependency
parsers,” inProceedings of the Ninth International Workshop on Parsing Technology. Association
for Computational Linguistics, 2005, pp. 171–178.
[45] K. Sagae and A. Lavie, “Parser combination by reparsing,” inProceedings of the Human
Language Technology Conference of the NAACL, Companion Volume: Short Papers. New
York City, USA: Association for Computational Linguistics, June 2006, pp.129–132. [Online].
Available: http://www.aclweb.org/anthology/N/N06/N06-2033
[46] K. Sagae and J. Tsujii, “Dependency parsing and domain adaptationwith lr models and parser
ensembles,” inProceedings of the CoNLL Shared Task Session of EMNLP-CoNLL, vol. 7, 2007,
pp. 1044–1050.
[47] J. Hall, J. Nilsson, J. Nivre, G. Eryigit, B. Megyesi, M. Nilsson, and M. Saers,
“Single malt or blended? a study in multilingual parser optimization,” inProceedings
of the CoNLL Shared Task Session of EMNLP-CoNLL 2007. Prague, Czech Republic:
Association for Computational Linguistics, June 2007, pp. 933–939. [Online]. Available:
http://www.aclweb.org/anthology/D/D07/D07-1097
[48] H. Zhang, M. Zhang, C. L. Tan, and H. Li, “K-best combination ofsyntactic parsers,” in
Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing.
Singapore: Association for Computational Linguistics, August 2009, pp. 1552–1560. [Online].
Available: http://www.aclweb.org/anthology/D/D09/D09-1161
[49] V. Fossum and K. Knight, “Combining constituent parsers,” inProceedings of Human
Language Technologies: The 2009 Annual Conference of the North American Chapter of
the Association for Computational Linguistics, Companion Volume: Short Papers. Boulder,
Colorado: Association for Computational Linguistics, June 2009, pp. 253–256. [Online].
Available: http://www.aclweb.org/anthology/N/N09/N09-2064
[50] J. Nivre and R. McDonald, “Integrating graph-based and transition-based dependency parsers,”
in Proceedings of ACL-08: HLT. Columbus, Ohio: Association for Computational Linguistics,
June 2008, pp. 950–958. [Online]. Available: http://www.aclweb.org/anthology/P/P08/P08-1108
[51] A. F. T. Martins, D. Das, N. A. Smith, and E. P. Xing, “Stacking dependency parsers,” in
Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing.
68

Honolulu, Hawaii: Association for Computational Linguistics, October 2008,pp. 157–166.
[Online]. Available: http://www.aclweb.org/anthology/D08-1017
[52] S. Chaudhury, A. Rao, and D. Sharma, “Anusaaraka: An Expert system based Machine Transla-
tion System,” in2010 International Conference on Natural Language Processing andKnowledge
Engineering (NLP-KE). IEEE, 2010, pp. 1–6.
[53] M. Surdeanu and C. D. Manning, “Ensemble models for dependency parsing: Cheap and
good?” in Human Language Technologies: The 2010 Annual Conference of the North
American Chapter of the Association for Computational Linguistics. Los Angeles, California:
Association for Computational Linguistics, June 2010, pp. 649–652. [Online]. Available:
http://www.aclweb.org/anthology/N10-1091
[54] D. Cer, M. De Marneffe, D. Jurafsky, and C. Manning, “Parsing to Stanford Dependencies: Trade-
offs between speed and accuracy,” inProceedings of the Seventh conference on International
Language Resources and Evaluation (LREC’10). European Language Resources Association
(ELRA), May 2010.
[55] O. Cetinoglu, J. Foster, J. Nivre, D. Hogan, A. Cahill, and J. van Genabith, “LFG without C-
structures,” inProceedings of the 9th International Workshop on Treebanks and Linguistic Theo-
ries, 2010.
[56] S. Kolachina and P. Kolachina, “Parsing any domain english text to conll dependencies,” in
Proceedings of the Eight International Conference on Language Resources and Evaluation
(LREC’12), N. C. C. Chair), K. Choukri, T. Declerck, M. U. Doan, B. Maegaard, J. Mariani,
J. Odijk, and S. Piperidis, Eds. Istanbul, Turkey: European Language Resources Association
(ELRA), may 2012.
[57] Y. Chu and T. Liu, “On the shortest arborescence of a directed graph,”Science Sinica, vol. 14, no.
1396-1400, p. 270, 1965.
[58] J. Edmonds, “Optimum branchings,”Journal of Research of the National Bureau of Stan-
dards(71B), pp. 233–240, 1967.
[59] S. Kolachina, P. Kolachina, M. Agarwal, and S. Husain, “Experiments with maltparser for parsing
indian languages,”Proceedings of the ICON2010 NLP Tools Contest: Indian Language Depen-
dency Parsing, pp. 32–39, 2010.
[60] M. De Marneffe, B. MacCartney, and C. Manning, “Generating typed dependency parses from
phrase structure parses,” inProceedings of Fifth International conference on Language Resources
and Evaluation (LREC 2006), vol. 6, 2006, pp. 449–454.
69

[61] R. Levy and G. Andrew, “Tregex and tsurgeon: tools for querying and manipulating tree data struc-
tures,” inProceedings of the Fifth International conference on Language Resources and Evaluation
(LREC 2006), 2006, pp. 2231–2234.
[62] M. De Marneffe and C. Manning, “Stanford typed dependenciesmanual,”
http://nlp.stanford.edu/software/dependenciesmanual.pdf, 2008.
[63] R. Johansson and P. Nugues, “Extended Constituent-to-Dependency Conversion for English,” in
Proceedings of the 16th Nordic Conference on Computational Linguistics (NODALIDA). Citeseer,
2007.
[64] H. Yamada and Y. Matsumoto, “Statistical Dependency Analysis with Support Vector Machines,”
in Proceedings of the Eighth International Conference on Parsing Technologies. Association for
Computational Linguistics, 2003.
[65] J. Nivre, J. Hall, S. Kubler, R. McDonald, J. Nilsson, S. Riedel, and D. Yuret, “The CoNLL
2007 Shared Task on Dependency Parsing,” inProceedings of the CoNLL Shared Task Session of
EMNLP-CoNLL 2007. Association for Computational Linguistics, 2007.
[66] M. Surdeanu, R. Johansson, A. Meyers, L. Marquez, and J. Nivre, “The CoNLL 2008 Shared
Task on Joint Parsing of Syntactic and Semantic Dependencies,” inCoNLL 2008: Proceedings
of the Twelfth Conference on Computational Natural Language Learning. Manchester,
England: Coling 2008 Organizing Committee, August 2008, pp. 159–177. [Online]. Available:
http://www.aclweb.org/anthology/W08-2121
[67] G. Chrupala, “Better Training for Function Labeling,” inProceedings of the International Confer-
ence RANLP-2007, Borovets, Bulgaria, 2007.
[68] D. McClosky, E. Charniak, and M. Johnson, “Effective Self-training for Parsing,” inProceedings
of the Human Language Technology Conference of the NAACL, Main Conference. New York
City, USA: Association for Computational Linguistics, June 2006, pp. 152–159. [Online].
Available: http://www.aclweb.org/anthology/N/N06/N06-1020
[69] B. Bohnet, “Very High Accuracy and Fast Dependency Parsingis not a Contradiction,” in
Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010).
Beijing, China: Coling 2010 Organizing Committee, August 2010, pp. 89–97.[Online]. Available:
http://www.aclweb.org/anthology/C10-1011
[70] I. Titov and J. Henderson, “A latent variable model for generative dependency parsing,” in
Proceedings of the Tenth International Conference on Parsing Technologies. Prague, Czech
Republic: Association for Computational Linguistics, June 2007, pp. 144–155. [Online].
Available: http://www.aclweb.org/anthology/W/W07/W07-2218
70

[71] A. Bharati and R. Sangal, “A karaka based approach to parsingof indian languages,” inProceed-
ings of the 13th conference on Computational linguistics-Volume 3. Association for Computa-
tional Linguistics, 1990, pp. 25–29.
[72] ——, “Parsing free word order languages in the paninian framework,” in Proceedings of the 31st
annual meeting on Association for Computational Linguistics. Association for Computational
Linguistics, 1993, pp. 105–111.
[73] S. Husain, “Dependency parsers for indian languages,”Proceedings of ICON09 NLP Tools Con-
test: Indian Language Dependency Parsing, 2009.
[74] S. Husain, P. Mannem, B. Ambati, and P. Gadde, “The icon-2010 tools contest on indian language
dependency parsing,”Proceedings of ICON-2010 Tools Contest on Indian Language Dependency
Parsing, ICON, vol. 10, pp. 1–8, 2010.
[75] R. McDonald and F. Pereira, “Online learning of approximate dependency parsing algorithms,” in
Proceedings of the 11th Conference of the European Chapter of the ACL(EACL 2006). Trento,
Italy: Association for Computational Linguistics, April 2006, pp. 81–88. [Online]. Available:
http://aclweb.org/anthology-new/E/E06/E06-1011
[76] B. Ambati, S. Husain, J. Nivre, and R. Sangal, “On the role of morphosyntactic features in Hindi
dependency parsing,” inThe First Workshop on Statistical Parsing of Morphologically Rich Lan-
guages (SPMRL 2010), 2010, p. 94.
[77] J. Nivre, “Parsing indian languages with maltparser,”Proceedings of the ICON09 NLP Tools Con-
test: Indian Language Dependency Parsing, pp. 12–18, 2009.
[78] B. Ambati, P. Gadde, and K. Jindal, “Experiments in indian language dependency parsing,”Pro-
ceedings of the ICON09 NLP Tools Contest: Indian Language Dependency Parsing, pp. 32–37,
2009.
[79] B. Ambati, S. Husain, S. Jain, D. Sharma, and R. Sangal, “Two methods to incorporate local
morphosyntactic features in Hindi de-pendency parsing,” inThe First Workshop on Statistical
Parsing of Morphologically Rich Languages (SPMRL 2010), 2010, p. 22.
[80] P. Gadde, K. Jindal, S. Husain, D. Sharma, and R. Sangal, “Improving data driven dependency
parsing using clausal information,” inHuman Language Technologies: The 2010 Annual Confer-
ence of the North American Chapter of the Association for Computational Linguistics. Associa-
tion for Computational Linguistics, 2010, pp. 657–660.
[81] A. Bharati, S. Husain, D. Misra, and R. Sangal, “Two stage constraint based hybrid approach to
free word order language dependency parsing,” inProceedings of the 11th International Confer-
ence on Parsing Technologies. Association for Computational Linguistics, 2009, pp. 77–80.
71

[82] A. Bharati, S. Husain, M. Vijay, K. Deepak, D. Sharma, and R. Sangal, “Constraint based hybrid
approach to parsing indian languages,” inProceedings of The 23rd Pacific Asia Conference on
Language, Information and Computation (PACLIC 23). Hong Kong, 2009.
[83] S. Kesidi, P. Kosaraju, M. Vijay, and S. Husain, “A constraint-based hybrid dependency parser for
telugu,” IJCLA, vol. 2, 2011.
[84] S. Husain, “A generalized parsing framework based on computational paninian grammar,” Ph.D.
dissertation, PhD thesis, IIIT-Hyderbad, India, 2011.
[85] S. Husain, R. P. Gade, and R. Sangal, “Linguistically rich graph based data driven parsing for
hindi,” in Proceedings of the Second Workshop on Statistical Parsing of Morphologically Rich
Languages. Dublin, Ireland: Association for Computational Linguistics, October 2011, pp.
56–61. [Online]. Available: http://www.aclweb.org/anthology/W11-3807
[86] S. Husain, P. Gadde, J. Nivre, and R. Sangal, “Clausal parsing helps data-driven dependency
parsing: Experiments with hindi,” inProceedings of 5th International Joint Conference on Natural
Language Processing. Chiang Mai, Thailand: Asian Federation of Natural Language Processing,
November 2011, pp. 1279–1287. [Online]. Available: http://www.aclweb.org/anthology/I11-1143
[87] D. Wolpert, “Stacked generalization,”Neural Networks, vol. 5, no. 2, pp. 241–259, 1992.
[88] L. Breiman, “Stacked regressions,”Machine learning, vol. 24, no. 1, pp. 49–64, 1996.
[89] R. McDonald and G. Satta, “On the complexity of non-projective data-driven dependency
parsing,” inProceedings of the Tenth International Conference on Parsing Technologies. Prague,
Czech Republic: Association for Computational Linguistics, June 2007, pp. 121–132. [Online].
Available: http://www.aclweb.org/anthology/W/W07/W07-2216
[90] J. Eisner, “Three new probabilistic models for dependency parsing: An exploration,” in
Proceedings of the 16th International Conference on Computational Linguistics. Copenhagen,
Denmark: Association for Computational Linguistics, August 1996, pp. 340–345. [Online].
Available: http://acl.ldc.upenn.edu/C/C96/C96-1058
[91] J. Hall, J. Nilsson, and J. Nivre, “Single malt or blended? a study in multilingual parser optimiza-
tion,” Trends in Parsing Technology, pp. 19–33, 2011.
[92] R. Bhatt, B. Narasimhan, M. Palmer, O. Rambow, D. Sharma, and F. Xia, “A multi-
representational and multi-layered treebank for hindi/urdu,” inProceedings of the Third Linguistic
Annotation Workshop. Suntec, Singapore: Association for Computational Linguistics, August
2009, pp. 186–189. [Online]. Available: http://www.aclweb.org/anthology/W/W09/W09-3036
[93] S. Kolachina, D. Sharma, P. Gadde, M. Vijay, R. Sangal, and A. Bharati, “External sandhi and its
relevance to syntactic treebanking,”Polibits, vol. 43, pp. 67–74, 2011.
72

[94] R. Begum, S. Husain, A. Dhwaj, D. Sharma, L. Bai, and R. Sangal, “Dependency Annotation
Scheme for Indian languages,” inProceedings of the 3rd International Joint Conference on
Natural Language Processing (IJCNLP-08). Association for Computational Linguistics, January
2008, pp. 721–726. [Online]. Available: http://aclweb.org/anthology-new/I/I08/I08-2099
[95] P. Kosaraju, B. R. Ambati, S. Husain, D. M. Sharma, and R. Sangal,“Intra-chunk dependency
annotation : Expanding hindi inter-chunk annotated treebank,” inProceedings of the Sixth
Linguistic Annotation Workshop. Jeju, Republic of Korea: Association for Computational
Linguistics, July 2012, pp. 49–56. [Online]. Available: http://www.aclweb.org/anthology/
W12-3607
73





























