Embed Size (px)
Citation preview

Chapter �
Associative Models
Association is the task of mapping input patterns to tar�
get patterns ��attractors��� For instance� an associative
memory may have to complete �or correct� an incom�
plete �or corrupted� pattern� Unlike computer memo�
ries� no �address� is known for each pattern�
Learning consists of encoding the desired patterns as
a weight matrix �network�� retrieval �or �recall�� refers
to the generation of an output pattern when an input
pattern is presented to the network�
�� Hetero�association mapping input vectors to output
vectors that range over a dierent vector space� e�g��
translating English words to Spanish words�
�

� CHAPTER �� ASSOCIATIVE MODELS
�� Auto�association input vectors and output vectors
range over the same vector space� e�g�� character
recognition� eliminating noise from pixel arrays� as
in Figure ����
�
�
�or�
Noisy Input Stored Image
Stored Image Stored Image
Figure ���� Noisy input pattern resembles � � and ���� but
not ����
This example illustrates the presence of noise in the
input� and also that more than one �but not all� target
patterns may be reasonable for an input pattern� The
dierence between input and target patterns allows us

���� NON�ITERATIVE PROCEDURES �
to evaluate network outputs�
Many associative learning models are based on varia�
tions of Hebb�s observation �When one cell repeatedly
assists in �ring another� the axon of the �rst cell de�
velops synaptic knobs �or enlarges them if they already
exist� in contact with the soma of the second cell��
We �rst discuss non�iterative� �one�shot� procedures
for association� then proceed to iterative models with
better error�correction capabilities� in which node states
may be updated several times� until they �stabilize��
��� Non�iterative Procedures
In non�iterative association� the output pattern is gener�
ated from the input pattern in a single iteration� Hebb�s
law may be used to develop associative �matrix mem�
ories�� or gradient descent can be applied to minimize
recall error�
Consider hetero�association� using a two�layer network

CHAPTER �� ASSOCIATIVE MODELS
developed using the training set
T � f�ip� dp� p � �� � � � � Pg
where ip � f��� �gn� dp � f��� �gm� Presenting ip atthe �rst layer leads to the instant generation of dp at
the second layer�
Each node of the network corresponds one component
of input �i� or desired output �d� patterns�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Matrix Associative Memories A weight matrix W is
�rst used to premultiply the input vector y � WX����
If output node values must range over f��� �g� then thesignum function is applied to each coordinate
X���j � sgn�yj�� for j � �� � � � �m�
The Hebbian weight update rule is
�wj�k � ip�kdp�j�
If all input and output patterns are available at once�

���� NON�ITERATIVE PROCEDURES
we can perform a direct calculation of weights
wj�k � cPXp��
ip�kdp�j� for c � ��
Each wj�k measures the correlation between the kth
component of the input vectors and the jth component
of the associated output vectors� The multiplier c can
be omitted if we are only interested in the sign of each
component of y� so that
W �
PXp��
dp �ip�T � DIT �
where rows of matrix I are input patterns ip� and rowsof D are desired output patterns dp�Non�iterative procedures have low error�correction ca�
pabilities multiplyingW with even a slightly corrupted
input vector often results in �spurious� output that dif�
fers from the patterns intended to be stored�
Example ��� Associate input vector ��� �� with output
vector ���� ��� and ������ with ��������

� CHAPTER �� ASSOCIATIVE MODELS
W �
�� �� ��
� ��
�A�� � �
� ��
�A �
�� �� �
� �
�A �
When the original input pattern ����� is presented�
y �WX��� �
�� �� �
� �
�A�� ��
�A �
�� ��
�
�A �
and sgn�y� � X���� the correct output pattern associ�
ated with ��� ��� If the stimulus is a new input pattern
�������� for which no stored association exists� the re�sulting output pattern is
y �WX��� �
�� �� �
� �
�A�� ����
�A �
�� �
��
�A �
and sgn�y� � ������� dierent from the stored patterns�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Least squares procedure �Widrow�Ho rule� When ip
is presented to the network� the resulting output �ip
must be as close as possible to the desired output pat�

���� NON�ITERATIVE PROCEDURES �
tern dp� Hence � must be chosen to minimize
E �PXp��
jjdp � �ipjj�
�PXp��
��dp�� �Xj
���jip�j�� � � � � � �dp�m �
Xj
�m�jip�j���
Since E is a quadratic function whose second deriva�
tive is positive� we obtain the weights that minimize E
by solving
�E
��j��
� ��PXp��
�dp�j �
nXk��
�j�k ip�k
�ip�� � ��
for each �� j� obtaining
PXp��
dp�j ip�� �PXp��
nXk��
�j�k ip�k ip��
�
nXk��
�j�k
�� PX
p��
ip�k ip��
�A
� �jth row of �� � ��th column of IIT��Combining all such equations�
DIT � ��IIT ��
When �IIT � is invertible� mean square error is mini�

� CHAPTER �� ASSOCIATIVE MODELS
mized by
� � DIT �IIT ��� �����
The least squares method �normalizes� the Hebbian
weight matrix DIT using the inverse of �IIT ���� Forauto�association� � � IIT�IIT ��� is the identity matrixthat maps each vector to itself�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
What if IIT has no inverse� EverymatrixA has a unique�pseudo�inverse�� de�ned to be a matrix A� that satis�es
the following conditions
AA�A � A
A�AA� � A�
A�A � �A�A�T
AA� � �AA��T �
The Optimal Linear Associative Memory �OLAM� gen�
eralizes Equation ��� � � D �I�� �For autoassociation� I � D� so that � � I �I�� �

���� NON�ITERATIVE PROCEDURES
When I is a set of orthonormal unit vectors�
ip � ip� �
��� � if p � p�
� otherwise
hence I �I�T � �I�T I � I� the identity matrix� so that
all conditions de�ning the pseudo�inverse are satis�ed
with �I�� � �I�T � Then
� � D �I�� � D �I�T �
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Example ��� Hetero�association� with three �i� d� pairs
��� �� ����� ��� ������ �������� �� ���� �� �� ������ Inputand output matrices are
I �
�BBBB�� � ��� �� �
� � �
�CCCCA and D �
�� �� �� �
� �� ��
�A �
The inverse of I�I�T exists� and � � D�I�T �I�I�T ���
�
�� �� �� �
� �� ��
�A�BBBB�
� � �
� �� ��� � �
�CCCCA
�BBBB����� ���� ����
���� ���� ����
���� ���� ����
�CCCCA

�� CHAPTER �� ASSOCIATIVE MODELS
�
�� �� � �
� � ��
�A �
An input pattern ���������� yields ���� �� on premul�tiplying by ��
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Example �� Consider hetero�association where four in�
put�output patterns are ��� ������������ ��������� ����� ��������� �� �� ��� and ���� �� ����� ���
I �
�BBBB�
� � �� ��� �� �� �
�� �� � �
�CCCCA and D �
�� �� � � ���� �� � �
�A �
�I�I�T � ��BBBB����� ���� ����
���� ���� ����
���� ���� ����
�CCCCA �

���� NON�ITERATIVE PROCEDURES ��
� �
�� �� � � ���� �� � �
�A
�BBBBBBB�
� � ��� �� ��
�� �� �
�� � �
�CCCCCCCA
�BBBB����� ���� ����
���� ���� ����
���� ���� ����
�CCCCA
�
�� � �� ��� � �
�A �
For input vector ��� ������ the output is
�� � �� ��� � �
�A�BBBB�
�
�
��
�CCCCA �
�� ����
�A �
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Noise Extraction Given I� a vector x can be written asthe sum of two components
x � Ix �Wx � �I �W �x � �x � �a �mXi��
ciii � �a
where �x is the projection of x onto the vector space
spanned by I� and �a is the noise component orthonor�mal to this space�

�� CHAPTER �� ASSOCIATIVE MODELS
Matrix multiplication by W thus projects any vector
onto the space of the stored vectors� whereas �I �W �
extracts the noise component to be minimized�
Noise is suppressed if the number of patterns being
stored is less than the number of neurons� otherwise�
the noise may be ampli�ed�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Nonlinear Transformations
X��� � f�W X������
�BBBB�
f�w��� X���� � � � ��w��n X���
n �
���
f�wm�� X���� � � � ��wm�n X���
n �
�CCCCA �
where f is dierentiable� Error E is minimized w�r�t�
each weight wj�� by solving
�E
�wj��
PXp��
�dp�j �X���p�j � f
��nX
k��
wj�k ip���ip�� � �
where X���p�j � f�
nXk��
wj�k ip��� and f ��Z� � df�Z��dZ�
Iterative procedures are needed to solve these nonlin�
ear equations�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��

���� HOPFIELD NETWORKS ��
��� Hop�eld Networks
Hop�eld networks are auto�associators in which node
values are iteratively updated based on a local compu�
tation principle the new state of each node depends
only on its net weighted input at a given time�
The network is fully connected� as shown in Figure
���� and weights are obtained by Hebb�s rule�
The system may undergo many state transitions be�
fore converging to a stable state�
� �
�
w��� � w���
w��� � w���
w��� � w���
w��� � w���
w��� � w���
Figure ���� Hop�eld network with �ve nodes�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Discrete Hop�eld networks
One node corresponds to each vector dimension�

� CHAPTER �� ASSOCIATIVE MODELS
taking values � f��� �g� Each node applies a step func�tion to the sum of external inputs and the weighted
outputs of other nodes� Node output values may change
when an input vector is presented� Computation pro�
ceeds in �jumps� the values for the time variable range
over natural numbers� not real numbers�
NOTATION
T � fi�� � � � � iPg training set�xp�j�t� value generated by the jth node at time t� for
pth input pattern�
wk�j weight of connection from jth to kth node�
Ip�k external input to kth node� for pth input vector
�includes threshold term��
The node output function is described by
xp�k�t� �� � sgn
�� nX
j��
wk�jxp�j�t� � Ip�k
�A
where sgn�x� � � if x � � and sgn�x� � �� if x � ��Asynchronicity at every time instant� precisely one
node�s output value is updated� Node selection may be

���� HOPFIELD NETWORKS �
cyclic or random� each node in the system must have
the opportunity to change state�
Network Dynamics Select a node k � f�� � � � � ng tobe updated�
xp���t� �� �
���xp���t� if � �� k
sgn
�� nX
j��
w��jxp�j�t� � Ip��
�A if � � k�
�����
By contrast� in Little�s synchronous model� all nodes
are updated simultaneously� at every time instant� Cyclic
behavior may result when two nodes update their val�
ues simultaneously� each attempting to move towards a
dierent attractor� The network may then repeatedly
shuttle between two network states� Any such cycle
consists of only two states and hence can be detected
easily�
The Hop�eld network can be used to retrieve a stored
pattern when a corrupted version of the stored pat�
tern is presented� The Hop�eld network can also be
used to �complete� a pattern when parts of the pat�

�� CHAPTER �� ASSOCIATIVE MODELS
X
Y
�c��a� �b�X X
YY
Y
X
O
O
O
�d� �e�
YO
XO
Figure ���� Initial network state �O� is equidistant from at�
tractors X and Y � in �a�� Asynchronous computation
instantly leads to one of the attractors� �b� or �c�� In syn�
chronous computation� the object moves instead from
the initial position to a non�attractor position �d�� Cy�
cling behavior results for the synchronous case� with
network state oscillating between �d� and �e��

���� HOPFIELD NETWORKS ��
tern are missing� e�g�� using � for an unknown node in�
put�activation value�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Example ��� Consider a ��node Hop�eld network whose
weights store patterns ��� �� �� �� and ��������������Each weight w��j � �� for � �� j� and wj�j � � for all j�
I� Corrupted Input Pattern ��� �� ����� I� � I� � I� �
� and I� � �� are the initial values for node outputs�
�� Assume that the second node is randomly selected
for possible update� Its net input is w���x��w���x��
w���x�� I� � ����� � � � �� Since sgn��� � �� this
node�s output remains at ��
�� If the fourth node is selected for possible update� its
net input is ������� � �� and sgn��� � � implies
that this node changes state to ��
� No further changes of state occur from this network
con�guration ��� �� �� ��� Thus� the network has suc�
cessfully recovered one of the stored patterns from

�� CHAPTER �� ASSOCIATIVE MODELS
the corrupted input vector�
II� Equidistant Case ��� �������� Both stored patternsare equally distant� one is chosen because the node func�
tion yields � when the net input is ��
�� If the second node is selected for updating� its net
input is �� hence state is not changed from ��
�� If the third node is selected for updating� its net
input is �� hence state is changed from �� to ��
� Subsequently� the fourth node also changes state� re�
sulting in the network con�guration ��� �� �� ���
Missing Input Element Case ��� �������� If the sec�ond node is selected for updating� its net input isw��x��
w��x� � w��x� � I� � ����� � � � �� implying the up�dated node output is �� for this node� Subsequently�the �rst node also switches state to ��� resulting in thenetwork con�guration ���� ��� ��� ����Multiple Missing Input Element Case ��� �� ����� Thoughmost of the initial inputs are unknown� the network suc�

���� HOPFIELD NETWORKS �
ceeds in switching states of three nodes� resulting in the
stored pattern ���� ��� ��� ����Thus� a signi�cant amount of corruption� noise or
missing data can be successfully handled in problems
with a small number of stored patterns�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Energy Function The Hop�eld network dynamics at�
tempt to minimize an �energy� �cost� function derived
as follows� assuming each desired output vector is the
stored attractor pattern nearest the input vector�
� If w��j is positive and large� then we expect that the
�th and jth nodes are frequently ON or OFF to�
gether in the attractor patterns� i�e��PP
p���ip�� ip�j�
is positive and large�
� Similarly� w��j is negative and large when the �th and
jth nodes frequently have opposite activation values
for dierent attractor patterns� i�e��PP
p���ip�� ip�j� is
negative and large�

�� CHAPTER �� ASSOCIATIVE MODELS
� So w��j should be proportional toPP
p���ip�� ip�j�� For
strong positive or negative correlation� w��j andP
p�ip�� ip�j�
have the same sign� hencePP
p�� w��j�ip�� ip�j� � ��
� Self�excitation coe cient wj�j � �� often ���
� Summing over all pairs of nodes� P�
Pjw��jip��ip�j is
positive and large for input vectors almost identical
to some attractor�
� We expect that node correlations present in the at�tractors are absent in an input vector i distant from
all attractor patterns� so thatP
�
Pjw��ji�ij is then
low or negative�
� Therefore� the energy function contains a term
���X
�
Xj
w��jx�xj
�A �
When this is minimized� the �nal values of various
node outputs are expected to correspond to an at�
tractor pattern�
� Network output should be close to the input vector�

���� HOPFIELD NETWORKS ��
when presented with a corrupted image of � �� we
do not want the system to generate an output cor�
responding to ���� For external inputs I�� another
term �P�I�x� is included in the energy expression�
I�x� � � i input�output for the �th node�
Combining the two terms� the following �energy� or
Lyapunov function must be minimized by modifying x�
values�
E � �aX�
Xj
w��jx�xj � bX�
I�x�
where a� b � �� The values a � ��� and b � � corre�
spond to reduction in energy whenever a node update
occurs� as described below�
Even if each I� � �� we can select initial node inputs
x���� so that the network settles into a state close to the
input pattern components�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Energy Minimization Steadily reducing E will result in
convergence to a stable state �which may or may not be

�� CHAPTER �� ASSOCIATIVE MODELS
one of the desired attractors��
Let the kth node be selected for updating at time
t� For the node update rule in Eqn� ���� the resulting
change of energy is
�E�t� � E�t � ��� E�t�
� �aX�
Xj ���
w��j �x��t � ��xj�t� ��� x��t�xj�t��
�bX�
I��x��t� ��� x��t��
� �aXj ��k
��wk�j �wj�k� �xk�t � ��� xk�t��xj�t��
�bIk �xk�t� �� � xk�t�� �
because xj�t � �� � xj�t� for every node �j �� k� not
selected for updating at this step� Hence�
�E�t� � ���aX
j ��k
�wk�j � wj�k�xj�t� � bIk
� �xk�t � ��� xk�t�� �
For �E�t� to be negative� �xk�t � ��� xk�t�� and
�aP
j ��k �wk�j � wj�k�xj�t� � bIk� must have the same sign�
The weights are chosen to be proportional to corre�
lation terms� i�e�� w��j �PP
p�� ip��ip�j�P � Hence wj�k �
wk�j� i�e�� the weights are symmetric� and for the choice

���� HOPFIELD NETWORKS ��
of the constants a � ��� b � �� the energy change expres�
sion simpli�es to
�E�t� � ���X
j ��k
wj�kxj�t� � Ik
�A �xk�t� ��� xk�t��
� �netk�t��xk�t��
where netk�t� �
��X
j ��k
wj�kxj�t� � Ik
�A is the net input
to the kth node at time t�
To reduce energy� the chosen �kth� node changes state
i current state diers from the sign of the net input�
i�e��
netk�t� ��xk�t� � ��
Repeated applications of this update rule results in a
�stable state� in which all nodes stop changing their cur�
rent values� Stable states may not be the desired at�
tractor states� but may instead be �spurious��
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Example ��� The patterns ��� ��������� ��� �� �� �� and������� �� �� are to be stored in a ��node network� The

� CHAPTER �� ASSOCIATIVE MODELS
�rst and second nodes have exactly the same values in
every stored pattern� hence w��� � �� Similarly� w��� �
�� The �rst and third nodes agree in one stored pattern
but disagree in the other two stored patterns� hence
w��� ��no� of agreements� � �no� of disagreements�
no� of patterns��� �
�
Similarly� w��� � w��� � w��� � ��� �
� If the input vector is �������������� and the fourthnode is selected for possible node update� its net in�
put is w���x� �w���x� �w���x� � I� � ���� ����� ����� ����� � ���� � ���� � ��� � �� hence thenode does not change state� The same holds for ev�
ery node in the network� so that the network con�g�
uration remains at �������������� dierent fromthe patterns that were to be stored�
� If the input vector is ���������� ��� representingthe case when the fourth input value is missing� and
the fourth node is selected for possible node up�
date� its net input is w���x� �w���x� �w���x� � I� �

���� HOPFIELD NETWORKS �
���� ���������� �������������� � ��� � ��and the node changes state to ��� resulting in thespurious pattern ��������������
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Example ��� Images of four dierent objects are shown
in Figure ���� We treat each image as a �!� �! binarypixel array� as in Figure ���� stored using a Hop�eld
network with �!� �! neurons�
XII
VI
IIIIX
Figure ��� Four images stored in a Hop�eld network�
Figure ��� Binary representation of objects in Fig� ����

�� CHAPTER �� ASSOCIATIVE MODELS
Figure ���� Corrupted versions of objects in Fig� ����
The network is stimulated by a distorted version of
a stored image� shown in Figure ���� In each case� as
long as the total amount of distortion is less than �" of
the number of neurons� the network recovers the correct
image� even when big parts of an image are �lled with
ones or zeroes�
Poorer performance would be expected if the network
is much smaller� or if the number of patterns to be
stored is much larger�
One drawback of a Hop�eld network is the assumption
of full connectivity a million weights are needed for a
thousand�node network� such large cases arise in image�
processing applications with one node per pixel�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��

���� HOPFIELD NETWORKS ��
Storage capacity refers to the quantity of information
that can be stored and retrieved without error� and may
be measured as
C �no� of stored patterns
no� of neurons�
Capacity depends on the connection weights� the stored
patterns� and the dierence between the stimulus pat�
terns and stored patterns�
Let the training set contain P randomly chosen vec�
tors i�� � � � � iP where each ip � f����gn� These vectorsare stored using the connection weights
w��j ��
n
PXp��
ip�� ip�j�
� How large can P be� so that the network responds
to each i� by correctly retrieving i��
Theorem ��� The maximum capacity of a Hop�eld neu�
ral network �with n nodes� is bounded above by �n�� lnn��
In other words� if
� � Prob�� ��th bit of p�th stored vector is correctly
retrieved for each �� p��

�� CHAPTER �� ASSOCIATIVE MODELS
then limn�� � � � whenever P � n��� ln�n���
Proof
� For stimulus i�� the output of the �rst node is
o� �nXj��
w��ji��j ��
n
nXj��
PXp��
ip��ip�ji��j�
This output will be correctly decoded if o�i��� � ��
� Algebraic manipulation yields
o�i��� � � � Z � �n
where Z � ���n�Pn
j��
PPp�� ip��ip�ji��ji����
� Probability of correct retrieval for the �rst bit is
� � Prob�o� i��� � �� � Prob�� � Z � �n� ��
� Prob�Z � ���
� By assumption� E�i��j� � � and
E�i��ji��j�� �
��� � if � � ��� j � j�
� otherwise
� By the central limit theorem� Z would be distributedas a Gaussian random variable with mean � and vari�
ance �P����n����n� � P�n for large n and P � with

���� HOPFIELD NETWORKS �
density function ��P�n����� exp��nx���P �� and
Prob�Z � a� �
Z �
a
��P�n����� exp��nx���P �dx
� �
pnp�P
Z �
��
e��nx
�
�P�dx
�
pnp�P
Z �
��
e��nx
�
�P�dx
since the density function of Z is symmetric�
� If �n�P � is large� � � ��q
P�� n
exp�� n
�P
�
� The same probability expression � applies for eachbit of each pattern� Therefore� if p n� the prob�
ability of correct retrieval of all bits of all stored
patterns is given by
� � ���nP ����
rP
� ne��n��P �
�nP
� �� nP
rP
� ne��n��P ��
� If P�n � ���� lnn�� for some � �� then
exp�� n
�P� � exp��� lnn
�� � n���

�� CHAPTER �� ASSOCIATIVE MODELS
which converges to zero as n�� so that
nP
rP
� nexp�� n
�P� � n���
�� lnn����p�
which converges to zero if � ��
�
A better bound can be obtained by considering the
correction of errors during the iterative evaluations�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Hop�eld network dynamics are not deterministic the
node to be updated at any given time is chosen ran�
domly� Dierent sequences of choices of nodes to be
updated may lead to dierent stable states�
Stochastic version �of Hop�eld network� Output of node
� is �� with probability ���� � exp����net���� for netnode input net�� Retrieval of stored patterns is then
eective if P � ��� �n�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Continuous Hop�eld networks
�� Node outputs � a continuous interval�

���� HOPFIELD NETWORKS ��
�� Time is continuous each node constantly examines
its net input and updates its output�
� Changes in node outputs must be gradual over time�
For ease of implementation� assurance of convergence�
and biological plausibility� we assume each node�s out�
put � ���� ��� with the modi�ed node update rule
�x��t�
�t�
����� if x� � � and f�
Pj wj��xj�t� � I�� � ��
�� if x� � �� and f�P
j wj��xj�t� � I�� � ��
� f�P
j wj��xj�t� � I��� otherwise�
Proof of convergence is similar to that for the dis�
crete Hop�eld model� An energy function with a lower
bound is constructed� and it is shown that every change
made in a node�s output decreases energy� assuming
asynchronous dynamics� The energy function
E � ������X�
Xj ���
w��jx��t�xj�t��X�
I�x��t�
is minimized as x��t�� � � � � xn�t� vary with time t� Given
the weights and external inputs� E has a lower bound
since x��t�� � � � � xn�t� have upper and lower bounds�

�� CHAPTER �� ASSOCIATIVE MODELS
Since �����w��jx�xj������wj��xjx� � w��jx�xj for sym�
metric weights� we have
�E
�x��t�� ��
Xj
w��jxj � I��� �����
The Hop�eld net update rule requires
�x�
�t� � i f�
Xj
wj��xj � I�� � �� �����
Equivalently� the update rule may be expressed in terms
of changes occurring in the net input to a node� instead
of node output �x���
Whenever f is a monotonically increasing function
�such as tanh�� with f��� � ��
f�Xj
wj��xj � I�� � � i �Xj
wj��xj � I�� � �� �����
From Equations �� � ���� and ����
�x�
�t� � i
��X
j
wj�x� � I� � �
�A � i�e��
�E
�x�� �
����x�
�t
���E
�x�
�� �� for each i
�� �E
�t�X�
��x�
�t
���E
�x�
�� ��

���� HOPFIELD NETWORKS ��
Computation terminates� since
�a� each node update decreases �lower�bounded� E�
�b� the number of possible states is �nite�
�c� the number of possible node updates is limited�
�d� and node output values are bounded�
The continuous model generalizes the discrete model�
but the size of the state space is larger and the energy
function may have many more local minima�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Cohen�Grossberg Theorem gives su cient conditions for
a network to converge asysmptotically to a stable state�
Let u� be the net input to the �th node� f� its node
function� aj the rate of change� and bj a �loss� term�
Theorem ��� Let aj�uj� � �� �dfj�uj��duj� � �� whereuj is the net input to the jth node in a neural network
with symmetric weights wj�� � w��j� whose behavior is
governed by the following dierential equation
duj
dt� aj�uj�
�bj�uj��
NXi��
wj�� f��u��
�� for j � �� � � � � n�

� CHAPTER �� ASSOCIATIVE MODELS
Then� there exists an energy function E for which
�dE�dt� � for uj �� �� i�e�� the network dynamics leadto a stable state in which energy ceases to change�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
�� Brain�State�in�a�Box �BSB� Network
BSB is similar to the Hop�eld model� but all nodes are
updated simultaneously� The node function used is a
ramp function
f�net� � min��� max���� net��
which is bounded� continuous� and piecewise linear� as
shown in Figure ��#�
��
��
f�x�
x
Figure ���� Ramp function� with output values � ���� ���

���� BRAIN�STATE�IN�A�BOX �BSB� NETWORK �
Node update rule initial activation is steadily ampli�ed
by positive feedback until saturation� jx�j ��
x��t � �� � f
�� nX
j��
w��jxj�t�
�A
w��� may be �xed to equal ��
The state of the network always remains inside an n�
dimensional �box�� giving rise to the name of the net�
work� �Brain�State�in�a�Box�� Network state steadily
moves from an arbitrary point inside the box �A in Fig�
ure ����a�� towards one side of the box �B in �gure��
and then crawls along the side of the box to reach a
corner of the box �C in �gure�� a stored pattern�
Connections between nodes are Hebbian� represent�
ing correlations between node activations� and can be
obtained by the non�iterative computation
w��j ��
P
PXp��
�ip�� ip�j��
where each ip�j � f��� �g�If the training procedure is iterative� training patterns
are repeatedly presented to the network� and weights

�� CHAPTER �� ASSOCIATIVE MODELS
�a� �b�
�
���
x�
���
x� x�
B
��� �� ��C
���������
A����������
Figure ���� State change trajectory �A B C� in a BSB
�a� the network� with nodes� �b� three stored patterns�
indicated by darkened circles�
are successively modi�ed using the weight update rule
�w��j � �ip�j�ip�� �Xk
w��kip�k�� for p � �� � � � � P�
where � � �� This rule steadily reduces
E �
PXp��
nX���
�ip�� �Xk
w��kip�����
and is applied repeatedly for each pattern until E � ��When training is completed� we expect
Pp�w��j � ��
implying that
Xp
ip�j�ip�� �Xk
w��kip�k� � ��

���� BRAIN�STATE�IN�A�BOX �BSB� NETWORK ��
i�e��Xp
�ip�j ip��� �Xp
ip�jXk
�w��k ip�k��
an equality satis�ed when
ip�� �Xk
�w��k ip�k��
The trained network is hence �stable� for the trained
patterns� i�e�� presentation of a stored pattern does not
result in any change in the network�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Example ��# Let the training set contain patterns
f��� �� ��� ����������� ���������g�
as in Figure ���� with network connection weights
w��� � w��� � �� � �� ��� � �� �
w��� � w��� � �� � �� ��� � �� �
w��� � w��� � �� � � � ��� � ��
� If an input pattern ����� ���� ���� is presented� thenext network state is�f
���� �
���
����
�� f
���� �
���
� ���
�� f �� � ��
�

�� CHAPTER �� ASSOCIATIVE MODELS
� ���# � ��!#� ��!#�
where f is the ramp function described earlier� Note
that the second and third nodes exhibit identical
states� since w��� � �� The very next network state
is ��� �� ��� a stored pattern�
� If ����� �������#� is the input pattern� network statechanges to ����#� ���#� ���#� then to ������ �� � �� ��
eventually converging to the stable memory ��� �� ���
� If the input pattern presented is ��� ���������� net�work state changes instantly to ��� �� ��� and does
not change thereafter�
Network state may converge to a pattern which was
not intended to be stored� E�g�� if a �dimensional BSB
network was intended to store only the two patterns
f��� �� ��� ���������g� with weights
w��� � w��� � ��� ���� � ��w��� � w��� � ��� ���� � ��
and w��� � w��� � �� � ���� � ��

���� BRAIN�STATE�IN�A�BOX �BSB� NETWORK �
then ���������� is such a spurious attractor�BSB computations steadily reduce �P�
Pj w��jx�xj�
when the weight matrix is symmetric and positive de��
nite �i�e�� all eigenvalues of W are positive��
Stability and the number of spurious attractors tends
to increase with the self�excitatory weights wj�j� If the
weight matrix is �diagonal�dominant�� with
wj�j �X���j
w��j for each j � f�� � � � � ng�
then every vertex of the �box� is a stable memory�
The hetero�associative version of the BSB network
contains two layers of nodes� the connection from the
jth node of the input layer to the �th node of the out�
put layer carries the weight
w��j ��
P
PXp��
ip�jdp���
Example application clustering radar pulses� distinguish�
ing meaningful signals from noise in a radar surveillance
environment where a detailed description of the signal
sources is not known�

� CHAPTER �� ASSOCIATIVE MODELS
��� Hetero�associators
A hetero�associator maps input patterns to a dierent
set of output patterns�
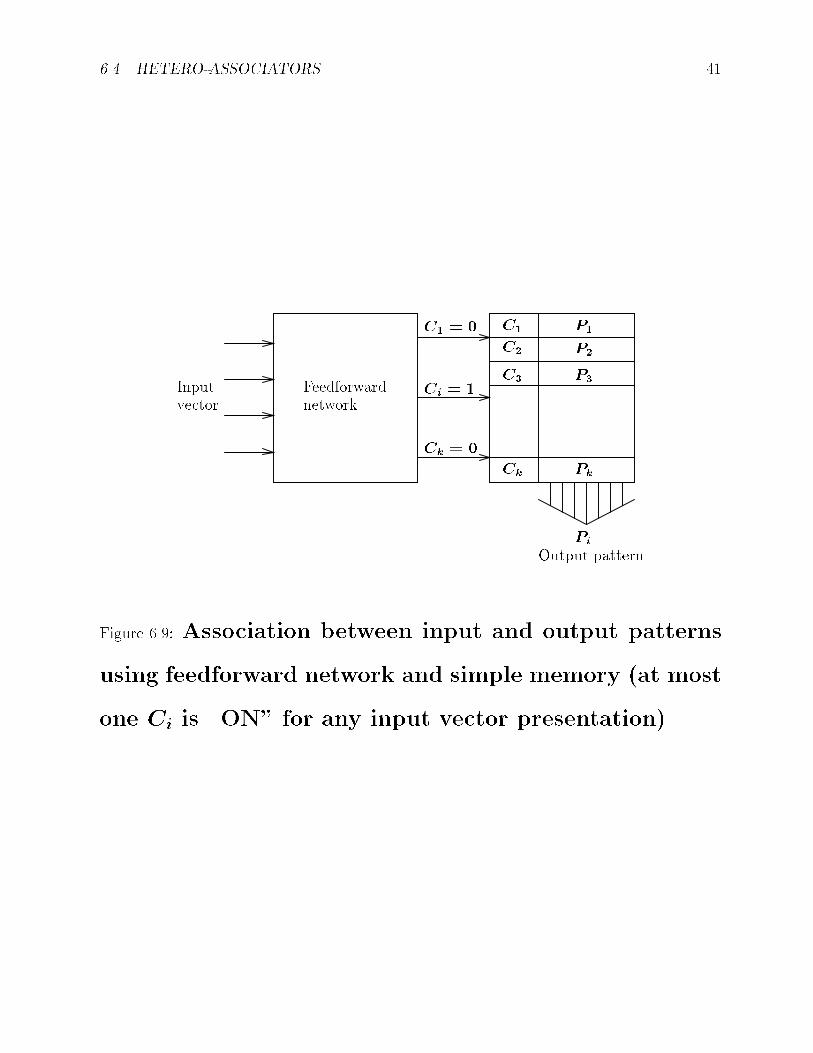
Consider the task of translating English word inputs
into Spanish word outputs� A simple feedforward net�
work trained by backpropagation may be able to assert
that a particular word supplied as input to the system
is the ���th word in the dictionary� The desired output
pattern may be obtained by concatenating the feedfor�
ward network function f �n � fC�� � � � � Ckg with alookup table mapping g fC�� � � � � Ckg � fP�� � � � � Pkgthat associates each �address� Ci with a pattern Pi� as
shown in Figure ��!�
Two�layer networks with weights determined by Hebb�s
rule are much less computationally expensive� In a non�
iterative model� output layer node activations are given
by
x���� �t� �� � f�
Xj
w��jx���j �t� � ��
���� HETERO�ASSOCIATORS �
Ck
C�
C�
C�
���
Feedforwardnetwork
Inputvector
C� �
Ck �
Output patternPi
���
���
P�
P�
Pk
P�
���
Ci � �
Figure �� � Association between input and output patterns
using feedforward network and simple memory �at most
one Ci is �ON� for any input vector presentation��

� CHAPTER �� ASSOCIATIVE MODELS
For error correction� iterative models are more useful
�� Compute output node activations using the above
�non�iterative� update rule� and then perform itera�
tive auto�association within the output layer� leading
to a stored output pattern�
�� Perform iterative auto�association within the input
layer� resulting in a stored input pattern� which is
then fed into the second layer of the hetero�associator
network�
� Bidirectional Associative Memory �BAM� with no
intra�layer connections� as in Figure ����
REPEAT
�a� x���� �t � �� � f�
Pj w��jx
���j �t� �
���� ��
�b� x���� �t � �� � f�
Pj w��jx
���j �t� �� �
���� �
UNTIL x���� �t��� � x
���� �t�� and x
���� �t��� � x
���� �t��
Weights can be chosen to be Hebbian �correlation�
terms w��j � cPP
p�� ip�j dp�� Sigmoid node functions
can be used in continuous BAM models�

���� HETERO�ASSOCIATORS �
First layer Second layer
Figure ����� Bidirectional Associative Memory �BAM�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Example ��� The goal is to establish the following three
associations between ��dim� and ��dim� patterns
���� ��� ��� ��� ���� ����
���� ��� ��� ��� ���� �������� ��� ��� ��� ���� ����
By the Hebbian rule �with c � ��P � �� ��
w��� ��P�
p�� ip��dp���
� ��

CHAPTER �� ASSOCIATIVE MODELS
Likewise� w��� � � and every other weight � ���� e�g��
w��� ��P�
p�� ip��dp���
� ��
�
These weights constitute the weight matrix
W �
�� � � ��� ��� ��� ��� ��� ���
�A �
When an input vector such as i � ������������� ispresented at the �rst layer� x
���� � sgn�x
���� w����x
���� w����
x���� w��� � x
���� w���� � sgn��� � � � �� � �� � � ��
and x���� � sgn�x
���� w��� � x
���� w��� � x
���� w��� � x
���� w���� �
sgn��� � �� � �� � �� � � �� The resulting vector is
���� ��� one of the stored ��dim� patterns� The corre�sponding �rst layer pattern generated is ������� �� ���following computations such as
x���� � sgn�x
���� w��� � x
���� w���� � sgn���� �� � � ���
No further changes occur�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
The �additive� variant of the BAM separates out the
eect of the previous activation value and the external

���� HETERO�ASSOCIATORS
input I� for the node under consideration� using the fol�
lowing state change rule
x���� �t � �� � a�x
���� �t� � b�I� � f�
Xj ���
w��jx���j �t��
where ai� bi are frequently chosen from f�� �g� If theBAM is discrete� bivalent� as well as additive� then
x���i �t��� �
��� � if �aix
���i �t� � biIi �
Pj ��iwi�jx
���j �t�� � i
� otherwise�
where i is the threshold for the ith node� A similar
expression is used for the �rst layer updates�
BAM models have been shown to converge using a
Lyapunov function such as
L� � �X�
Xj
x���� �t�x
���j �t�w��j�
This energy function can be modi�ed� taking into ac�
count external node inputs Ik� as well as thresholds �k��
for nodes
L� � L� ��X
k��
N�k�X���
x�k�� �I
k� �
�k�� ��

� CHAPTER �� ASSOCIATIVE MODELS
where N�k� denotes the number of nodes in the kth
layer� As in Hop�eld nets� there is no guarantee that
the system stabilizes to a desired output pattern�
Stability is assured if nodes of one layer are unchanged
while nodes of the other layer are being updated� All
nodes in a layer may change state simultaneously� allow�
ing greater parallelism than Hop�eld networks�
When a new input pattern is presented� the rate at
which the system stabilizes depends on the proximity of
the new input pattern to a stored pattern� and not on
the number of patterns stored� The number of patterns
that can be stored in a BAM is limited by network size�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Importance Factor The relative importance of dier�
ent pattern�pairs may be adjusted by attaching a �sig�
ni�cance factor� ��p� to each pattern ip being used to
modify the BAM weights
wj�i � wi�j �PXp��
��p ip�i dp�j��

���� HETERO�ASSOCIATORS �
Decay Memory may change with time� allowing pre�
viously stored patterns to decay� using a monotonically
decreasing function for each importance factor
�p�t� � ��� ���p�t� ���
or �p�t� � max��� �p�t� ��� ��
where � � � � � represents the �forgetting� rate�
If �ip� dp� is added to the training set at time t� then
wi�j�t� � ��� ��wi�j�t� �� � �p�t� ��ip�j dp�i
where �� � �� is the attenuation factor� Alternatively�
the rate at which memory fades may be �xed to a global
clock
wi�j�t� � ��� ��wi�j�t� �� ���t�Xp��
�p�t� ��ip�j dp�i
where ��t� � � is the number of new patterns being
stored at time t� There may be many instants at which
��t� � �� i�e�� no new patterns are being stored� but
existing memory continues to decay�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��

� CHAPTER �� ASSOCIATIVE MODELS
��� Boltzmann Machines
Memory capacity of Hop�eld models can be increased
by introducing hidden nodes� A stochastic learning pro�
cess is needed to allow the weights between hidden nodes
and other ��visible�� nodes to change to optimal values�
beginning from randomly chosen values�
Principles of simulated annealing are invoked to min�
imize the energy function E de�ned earlier for Hop�
�eld networks� A node is randomly chosen� and changes
state with a probability that depends on ��E�� �� where
temperature � � � is steadily lowered� The state change
is accepted with probability ���� � exp��E�� ��� An�
nealing terminates when � � ��
Many state changes occur at each temperature� If
such a system is allowed to reach equilibrium at any tem�
perature � � the ratio of the probabilities of two states
a� b with energiesEa and Eb will be given by P �a��P �b� �
exp�Eb�Ea��� � This is the Boltzmann distribution� and

��� BOLTZMANN MACHINES
does not depend on the initial state or the path followed
in reaching equilibrium�
Figure ���� describes the learning algorithm for het�
eroassociation problems� For autoassociation� no nodes
are �clamped� in the second phase of the algorithm�
The Boltzmann machine weight change rule conducts
gradient descent on relative entropy �cross�entropy��
H�P� P �� �Xs
Ps ln�Ps�P�s�
where s ranges over all possible network states� Ps is the
probability of network state s when the visible nodes
are clamped� and P �s is the probability of network state
s when no nodes are clamped� H�P� P �� compares the
probability distributions P and P �� note thatH�P� P �� �
� when P � P �� the desired goal�
In using the BM� we cannot directly compute output
node states from input node states since initial states
of the hidden nodes are undetermined� Annealing the
network states would result in a global optimum of the
energy function� which may have nothing in common

� CHAPTER �� ASSOCIATIVE MODELS
Algorithm Boltzmann�
while weights continue to change
and computational bounds are not exceeded� do
Phase �
for each training pattern� do
Clamp all input and output nodes�
ANNEAL� changing hidden node states�
Update f� � � pi�j � � �g� the equilibrium probs�with which nodes i� j have same state�
end�for�
Phase �
for each training pattern� do
Clamp all input nodes�
ANNEAL� changing hidden $ output nodes�
Update f� � � p�i�j � � �g� the equilibrium probs�with which nodes i� j have same state�
end�for�
Increment each wi�j by ��pi�j � p�i�j��
end�while�
Figure ����� BM Learning Algorithm

��� BOLTZMANN MACHINES �
with the input pattern� Since the input pattern may
be corrupted� the best approach is to initially clamp in�
put nodes while annealing from a high temperature to
an intermediate temperature �I � This leads the network
towards a local minimum of the energy function near the
input pattern� The visible nodes are then unclamped�
and annealing continues from �I to � � �� allowing visi�ble node states also to be modi�ed� correcting errors in
the input pattern�
The cooling rate with which temperature decreases
must be extremely slow to assure convergence to global
minima of E� Faster cooling rates are often used due to
computational limitations�
The BM learning algorithm is extremely slow many
observations have to be made at many temperatures
before computation concludes�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��
Mean �eld annealing improves on the speed of execu�
tion of the BM� using a �mean �eld� approximation in

� CHAPTER �� ASSOCIATIVE MODELS
the weight change rule� e�g�� approximating the weight
update rule
�w��j � ��p��j � p���j��
�where p��j � E�x�xj� when the visible nodes are clamped�while p���j � E�x�xj� when no nodes are clamped�� by
�w��j � ��q�qj � q��q�j��
where average output of �th node is q� when visible
nodes are clamped� and q�� without clamping�
For the Boltzmann distribution� the average output is
q� � tanh�Xj
w��jxj�� ��
The mean �eld approximation suggests replacing the
random variable xj by its expected value E�xj�� so that
q� � tanh�Xj
w��jE�xj��� ��
These approximations improve the speed of execu�
tion of the Boltzmann machine� but convergence of the
weight values to global optima is not assured�
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � ��

���� CONCLUSION �
��� Conclusion
The biologically inspired Hebbian learning principle shows
how to make connection weights represent the simi�
larities and dierences inherent in various attributes
or input dimensions of available data� No extensive
slow �training� phase is required� the number of state�
changes executed before the network stabilizes is roughly
proportional to the number of nodes�
Associative learning reinforces the magnitudes of con�
nections between correlated nodes� Such networks can
be used to respond to a corrupted input pattern with
the correct output pattern� In autoassociation� the in�
put pattern space and output space are identical� these
spaces are distinct in heteroassociation tasks� Heteroas�
sociative systems may be bidirectional� with a vector
from either vector space being generated when a vector
from the other vector space is presented� These tasks
can be accomplished using one�shot� non�iterative pro�

CHAPTER �� ASSOCIATIVE MODELS
cedures� as well as iterative mechanisms that repeatedly
modify the weights as new samples are presented�
In dierential Hebbian learning� changes in a weight
wi�j are caused by the change in the stimulation of the
ith node by the jth node� at the time the output of the
ith node changes� also� the weight change is governed
by the sum of such changes over a period of time�
Not too many pattern associations can be stably stored
in these networks� If few patterns are to be stored� per�
fect retrieval is possible even when the input stimulus
is signi�cantly noisy or corrupted� However� such net�
works often store spurious memories�





























