Embed Size (px)
Citation preview

NUMA obliviousness through memory mapping Mrunal Gawade Martin Kersten
CWI, Amsterdam
DaMoN 2015 (1st June 2015) Melbourne, Australia

NUMA architecture
Intel Xeon E5-4657L v2 @2.40GHz

Memory mapping
What is it?
Operating system maps disk files to memory
E.g. Executable file mapping
How is it done?
System call – mmap(), munmap()
Relevance for the Database world?
In memory columnar storage disk files mapped to memory

Motivation
Memory mapped columnar storage and
NUMA effects, in analytic workload

TPC-H Q1 … (4 sockets, 100GB, MonetDB)
0
5
10
15
20
25
30
35
0,1 0 0,2 1,2 2 0,3 3
Tim
e (s
ec)
Sockets on which memory is allocated
numactl -N 0,1 -m “Varied between sockets 0-3” “Database server process”

Contributions
NUMA oblivious (shared-everything) is relatively good compared to NUMA aware (shared-nothing). (using SQL workload)
Effect of memory mapping on NUMA obliviousness insights. (using micro-benchmarks)
Distributed database system using multi-sockets (shared-nothing) reduces remote memory accesses.

NUMA oblivious vs NUMA aware plans NUMA_Obliv- (shared
everything)
Default parallel plans in MonetDB
Only “Lineitem” table is sliced
NUMA_Shard- (Variation of NUMA_Obliv)
Shard aware plans in MonetDB
“Lineitem” and “Orders” table sharded in 4 pieces (orderkey) and sliced
NUMA_Distr- (shared nothing)
Socket aware plans in MonetDB
“Lineitem” and “Orders” table sharded in 4 pieces(orderkey), and sliced
Dimension tables replicated

System configuration
Intel Xeon E5-4657L v2 @2.40GHz, 4 sockets, 12 cores per socket (total 96 threads with Hyper-threading)
Cache - L1=32KB, L2 =256KB, shared L3=30MB.
1TB four channel DDR3 memory, (256 GB memory / socket).
O.S. - Fedora 20 Data-set- TPC-H 100GB
Tools – numactl, Intel PCM, Linux Perf
MonetDB open-source system with memory mapped columnar storage

TPC-H performance
0
1
2
3
4
5
6
4 6 15 19
Tim
e (s
ec)
TPC-H Queries
NUMA_OblivNUMA_Shard
NUMA_Distr
NUMA_Shard is a variation of NUMA_Obliv with sharded & partitioned “orders” table.

Micro-experiments on modified Q6
Why Q6? - select count(*) from lineitem where l_quantity > 24000000;
Selection on “lineitem” table
Easily parallelizable
NUMA effects analysis is easy (read only query)

Process and memory affinity
Socket 0 Socket 1 Socket 2 Socket 3
cores 0-11 12-23 24-35 36-47
cores 48-59 60-71 72-83 84-95
Example:numactl -C 0-11,12-23,24-35 -m 0,1,2 “Database Server”

NUMA_OblivMicro-experiments on Q6

01020304050607080
12 24 36 48 60 72 84 96
Mem
ory
acce
sses
in M
illion
s
Number of threads
Local memory accessRemote memory access
Local vs Remote memory access
01020304050607080
12 24 36 48 60 72 84 96
Mem
ory
acce
sses
in M
illion
s
Number of threads
Local memory accessRemote memory access
01020304050607080
12 24 36 48 60 72 84 96
Mem
ory
acce
sses
in M
illion
s
Number of threads
Local memory accessRemote memory access
Process and memory affinity = PMABuffer cache cleared = BCC (echo 3 | sudo /usr/bin/tee /proc/sys/vm/drop caches)
PMA= yes, BCC=yes PMA= no, BCC=yes PMA= no, BCC=no

Execution time (Robustness)
0
50
100
150
200
250
300
350
12 24 36 48 60 72 84 96
Time (
milli-
seco
nd
Number of threads
0
50
100
150
200
250
300
350
12 24 36 48 60 72 84 96
Time (
milli-
seco
nds)
Number of threads
0
50
100
150
200
250
300
350
12 24 36 48 60 72 84 96
Tim
e (m
illi-s
econ
ds)
Number of threads
PMA= yes, BCC=yes PMA= no, BCC=yes PMA= no, BCC=noMost robust Less robust Least robust
Process and memory affinity = PMABuffer cache cleared = BCC (echo 3 | sudo /usr/bin/tee /proc/sys/vm/drop caches)

Increase in threads = more remote accesses?

Distribution of mapped pages
0
20
40
60
80
100
12 24 36 48
Prop
ortio
n of
map
ped
page
s
Number of threads
socket 0socket 1socket 2socket 3
/proc/process id/numa maps
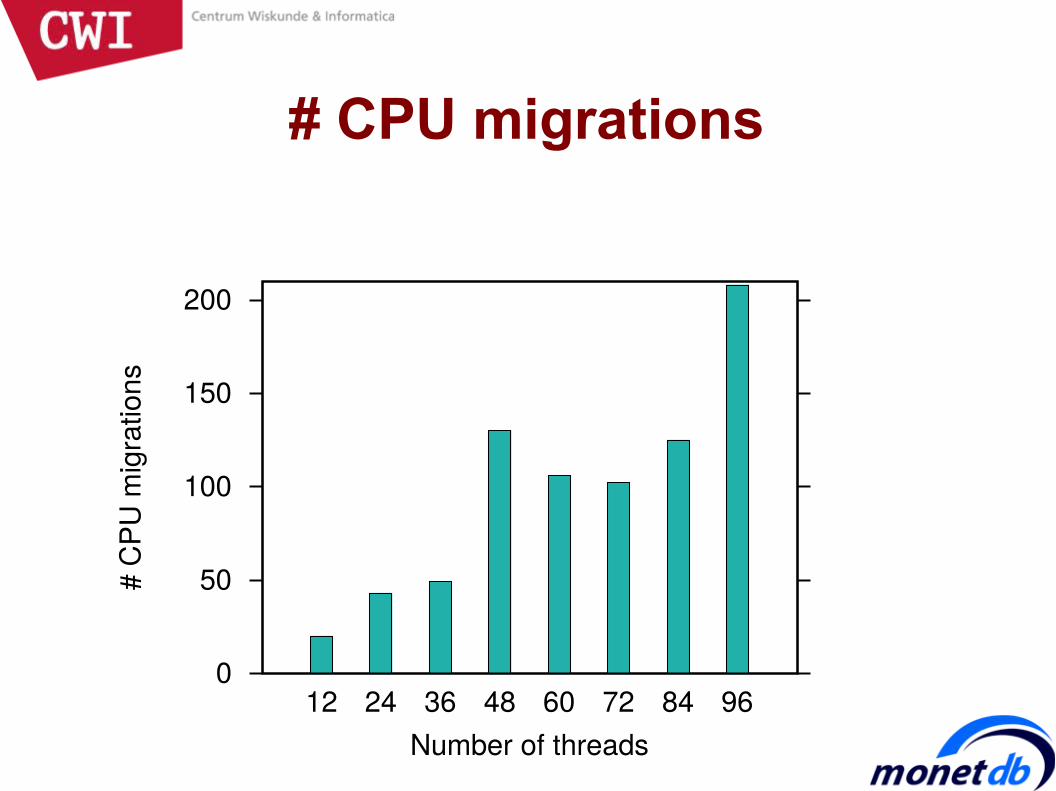
# CPU migrations
0
50
100
150
200
12 24 36 48 60 72 84 96
# C
PU m
igra
tions
Number of threads

Why remote accesses are bad?
020406080
100120140160
NUMA_Obliv NUMA_Distr
Tim
e (m
illi-s
econ
ds)
Modified TPC-H Q6
#Local Access # Remote Access
NUMA_Obliv 69 Million (M) 136 M
NUMA_Distr 196 M 9 M

NUMA_Distr to minimize remote accesses ?

Comparison with Vectorwise
0
1
2
3
4
5
6
4 6 15 19
Tim
e (s
ec)
TPC-H Queries
MonetDB NUMA_ShardMonetDB NUMA_Distr
Vector_DefVector_Distr
Vectorwise has no NUMA awareness and also uses a dedicated buffer manager
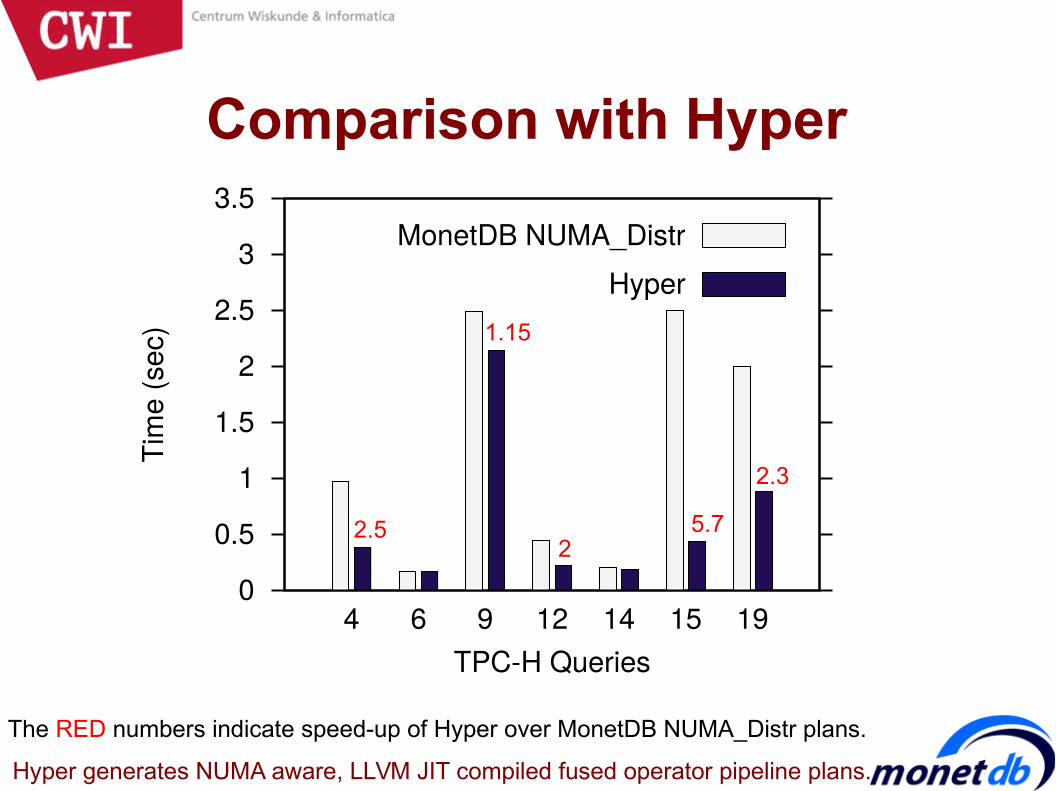
Comparison with Hyper
0
0.5
1
1.5
2
2.5
3
3.5
4 6 9 12 14 15 19
Tim
e (s
ec)
TPC-H Queries
MonetDB NUMA_DistrHyper
2.5 2
1.15
5.7
2.3
The RED numbers indicate speed-up of Hyper over MonetDB NUMA_Distr plans.
Hyper generates NUMA aware, LLVM JIT compiled fused operator pipeline plans.

Conclusion
● NUMA obliviousness fares reasonably to NUMA awareness.
● Process and memory affinity helps NUMA oblivious plans to perform robustly.
● Simple distributed shared nothing database configuration can compete with the state of the art database.

Thank you





























