Embed Size (px)
Citation preview

Numerische Mathematik fur das Lehramt
Skriptum zur Vorlesung im SS 2009 †
PD Dr. Markus NeherUniversitat Karlsruhe (TH)Forschungsuniversitat · gegrundet 1825
Institut fur Angewandte und Numerische Mathematik
14. Mai 2009
† c©2007-2009 by Markus Neher. Dieses Skriptum ist urheberrechtlich geschutzt. Weiterverbreitung
und Einsatz in anderen Lehrveranstaltungen (auch von Teilen des Skriptums) ist ohne vorherige schrift-
liche Genehmigung des Autors untersagt. Insbesondere ist es nicht gestattet, das Skriptum oder Teile
davon in elektronischer Form im Internet zuganglich zu machen.

Inhaltsverzeichnis
1 Einfuhrung 7
1.1 Symbolisches und numerisches Rechnen . . . . . . . . . . . . . . . . . . . . . . 8
1.2 Gleitpunktzahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.3 Gleitpunktarithmetik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.4 Algorithmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.5 Maple . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.5.1 Schleifen in Maple . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.5.2 Auswahlanweisungen in Maple . . . . . . . . . . . . . . . . . . . . . . . . 16
1.5.3 Prozeduren in Maple . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
1.6 Landau-Symbole . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.7 Ziele dieser Vorlesung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2 Iterationsverfahren 25
2.1 Fixpunktiteration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.2 Lokale Fixpunktsatze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.3 Relaxation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.4 Das Newton-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.5 Verwandte Iterationsverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.5.1 Vereinfachtes Newton-Verfahren . . . . . . . . . . . . . . . . . . . . . . . 36
2.5.2 Sekantenverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.5.3 Das Bisektionsverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.6 Vektor- und Matrixnormen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
2.7 Iterationsverfahren im Rn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3 Lineare Gleichungssysteme 47
3.1 Gauß-Elimination ohne Zeilentausch: LU-Zerlegung . . . . . . . . . . . . . . . . 47
3.1.1 Eliminationsmatrizen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.1.2 LU-Zerlegung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.1.3 Aufwand des Gauß-Algorithmus . . . . . . . . . . . . . . . . . . . . . . . 52
3.2 Gauß-Elimination mit Zeilentausch: PALU-Zerlegung . . . . . . . . . . . . . . . . 53
3

4 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
3.2.1 Permutationsmatrizen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
3.2.2 Pivotisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.3 Fehlerabschatzungen fur lineare Gleichungssysteme . . . . . . . . . . . . . . . . 57
3.4 Iterationsverfahren fur lineare Gleichungssysteme . . . . . . . . . . . . . . . . . 60
3.4.1 Fixpunktiteration fur lineare Gleichungssysteme . . . . . . . . . . . . . . 60
3.4.2 Gesamt- und Einzelschrittverfahren . . . . . . . . . . . . . . . . . . . . . 62
3.4.3 Die Methode des steilsten Abstiegs . . . . . . . . . . . . . . . . . . . . . 66
3.4.4 Das cg-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
3.4.5 Vorkonditionierung beim cg-Verfahren . . . . . . . . . . . . . . . . . . . . 73
3.5 Die QR-Zerlegung einer Matrix . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
3.5.1 Orthogonale Matrizen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
3.5.2 Gram-Schmidt-Orthogonalisierung . . . . . . . . . . . . . . . . . . . . . . 76
3.5.3 Householder-Matrizen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
3.5.4 QR-Zerlegung durch Householder-Transformationen . . . . . . . . . . . . 77
3.6 Uber- und unterbestimmte lineare Gleichungssysteme . . . . . . . . . . . . . . . 80
3.6.1 Uberbestimmte lineare Gleichungssysteme . . . . . . . . . . . . . . . . . 80
3.6.2 Unterbestimmte lineare Gleichungssysteme . . . . . . . . . . . . . . . . . 83
4 Das Eigenwertproblem fur Matrizen (entfallt 2009) 85
5 Approximation und Interpolation 87
6 Numerische Integration 89
7 Numerische Behandlung gewohnlicher Differentialgleichungen (entfallt 2009) 91
8 Gleitpunktrechnung, Kondition, Stabilitat 93

Kapitel 1
Einfuhrung
Viele technische Aufgabenstellungen lassen sich experimentell losen. Klassische Beispiele ex-
perimentellen Losens sind der Bau gotischer Kathedralen im Mittelalter oder die Bestimmung
optimaler Wirkstoffkonzentrationen in der Medikamentenentwicklung.
Manchmal sind Experimente aber teuer (insbesondere Misserfolge wie der Einsturz einer feh-
lerhaft gebauten Kathedrale) oder zu zeitaufwandig (wenn z.B. beim Auftreten eines neuen
Krankheitserregers moglichst schnell neue Medikamente benotigt werden). In diesen Fallen
versucht man, durch Modellbildung ein mathematisches Problem zu formulieren, aus dessen
mathematischer Losung sich eine Losung des praktischen Problems ableiten lasst. Dabei soll
die mathematische Losung einerseits moglichst gut mit der Losung des praktischen Problems
ubereinstimmen (geringer Modellfehler), andererseits aber nicht zu aufwandig zu berechnen
sein.
Als einfaches Anwendungsbeispiel betrachten wir den freien Fall eines Tennisballs aus 1,50
m Hohe. Bei der ublichen Modellierung mit Hilfe des Gravitationsgesetzes nimmt man unter
anderem die folgenden Modellfehler in Kauf:
• Vernachlassigung des Luftwiderstands beim Fall,
• Annahme einer konstanten Erdbeschleunigung (die in Wahrheit vom Ort auf der Erd-
oberflache und von der Hohe abhangt),
• Vernachlassigung der Corioliskraft,
• Vernachlassigung relativistischer Effekte.
Die vorgenommenen Vereinfachungen sind hier dadurch gerechtfertigt, dass sie die berech-
nete Fallzeit des Tennisballs nur unwesentlich beeinflussen.
Außerdem rundet man – insbesondere in Ubungsaufgaben – gern Naturkonstanten, wenn man
nicht an prazisen Ergebniswerten, sondern nur an uberschlagenen Naherungen interessiert ist
und die Rechnung dadurch einfacher wird. Z.B. verwendet man beim freien Fall haufig g = 10
m/s2 oder g = 9.81 m/s2.
In der Regel lasst sich die durch Modellbildung entstandene mathematische Aufgabenstellung
nicht exakt (symbolisch, analytisch) losen. An dieser Stelle setzt die Numerik ein. Die Nume-
rische Mathematik befasst sich mit der Konstruktion und Analyse von (endlichen) Algorithmen
fur kontinuierliche mathematische Probleme.
7

8 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
1.1 Symbolisches und numerisches Rechnen
Symbolisches Rechnen ist das aus der Analysis und der Linearen Algebra bekannte exakte
Rechnen mit Variablen (Symbolen):
(a + b)2 = a2 + 2ab + b2,
sinπ
3=
1
2
√3,
d
dxtanx = 1 + tan2 x.
Wenn eine symbolische Rechnung durchfuhrbar ist, liefert sie die exakte Losung des mathe-
matischen Problems. Allerdings konnen bei der Losung praktischer Probleme die folgenden
Schwierigkeiten auftreten:
• Es gibt Probleme, die nicht geschlossen losbar sind. Beispielsweise existiert keine allge-
meine Losungsformel fur Nullstellen von Polynomen vom Grad n ≥ 5 (die Unmoglichkeit
einer allgemeinen geschlossenen Losungsformel wird in der Algebra bewiesen).
• Manchmal ist unklar, ob eine symbolische Losung existiert. Ist z.B.
2x4 − 4x3 − 25x2 − x − 58ex2−x−1
x2+x+5
(x2 + x + 5)3
elementar integrierbar?
• Eventuell ist die symbolische Losung des gestellten Problems zu aufwendig.
Beispiel: Die Berechnung der Determinante einer Matrix der Dimension 1000.
• Das Ergebnis der symbolischen Berechnung kann unubersichtlich sein.
Beispiel: Eine Nullstelle von x3 − 4x2 − 6x + 11 ist
3√
188 + 12i√
17223
6+
68
33√
188 + 12i√
17223+
4
3.
Die Lage dieser Zahl in der komplexen Ebene lasst sich nur mit aufwandigen Betrach-
tungen bestimmen.
Salopp gesprochen besteht das numerische Rechnen aus der Rechnung mit Naherungswer-
ten. In der Regel verwendet man dezimale Naherungen in Form von Gleitpunktzahlen:
1
7≈ 0.143;
√2 ≈ 1.414;
∫ 1
0e−x2
dx ≈ 0.747.
Bei der Losung praktischer Probleme besitzt das numerischen Rechnen die folgenden Vorteile
gegenuber dem symbolischen Rechnen:
• Eine numerische Rechnung ist oft noch durchfuhrbar, wenn die symbolische Rechnung
versagt.
Beispiel: Nullstellen von Polynomen vom Grad n ≥ 5 lassen sich naherungsweise mit
dem Newton-Verfahren bestimmen.

Numerische Mathematik fur das Lehramt · SS 2009 9
• Das Ergebnis einer numerischen Berechnung kann ubersichtlicher als ein exaktes Er-
gebnis sein.
Beispiel: Eine Nullstelle von x3−4x2−6x+11 ist (genauer: liegt in der Nahe von) 4.774153.
Die Lage dieser Nullstelle ist sofort ersichtlich.
Andererseits muss man beim numerischen Rechnen auch gewisse Nachteile in Kauf nehmen:
• Eine numerische Rechnung liefert in der Regel kein exaktes Ergebnis.
• Nicht exakte Zwischenergebnisse konnen zu Folgefehlern fuhren.
Beispiel:√
2 ≈ 1.414, 1.4142 = 1.999396 ≈ 1.999 6= 2.
Durch Fehlerfortpflanzung kann man am Ende einer langeren numerischen Rechnung
ein grob falsches Ergebnis erhalten, auch wenn in den einzelnen Teilschritten immer
bestmoglich gerundet wurde.
Aus diesem Grund muss man sich bei jeder numerischen Rechnung Gedanken uber die dabei
auftretenden Fehler machen. Welche Fehlerarten auftreten konnen und wie diese abgeschatzt,
verringert oder sogar vermieden werden konnen, wird im Lauf der Vorlesung behandelt.
1.2 Gleitpunktzahlen
Numerische Berechnungen werden in der Regel nicht mit Variablen, sondern mit Gleitpunkt-
zahlen der Bauart
±m · be (1.1)
mit der Mantisse m, der festen Basis b und dem Exponenten e durchgefuhrt. Dabei ist die Basis
b des b-adischen Zahlensystems eine naturliche Zahl großer als 1, der Exponent e eine ganze
Zahl und die Mantisse m eine rationale Zahl mit endlicher b-adischer Darstellung. Beispiele
solcher Zahlen sind
3.1416 · 100, −44.123 · 53, 0.0001101 · 2−1011.
Menschen bevorzugen die Basis b = 10, wohingegen heutige Computer Binarzahlen mit b = 2verwenden.
Die angegebene Gleitpunktdarstellung (1.1) einer Zahl ist nicht eindeutig. Beispielsweise gilt
3.1416 · 100 = 3141600.00 · 10−6 = 0.00000000000000000000031416 · 1022.
Beim Rechnen ist diese Mehrdeutigkeit unpraktisch. Deshalb fordern wir in (1.1) zusatzlich,
dass – außer fur die Zahl Null – die Mantisse im Intervall [1, b) liegt. Durch eine Anpassung des
Exponenten (bei der im Gegenzug der Dezimalpunkt gleitet) existiert fur jede Gleitpunktzahl
z 6= 0 eine eindeutig bestimmte normalisierte Darstellung
z = ±m1.m2m3 . . .ml · be
mit m1, m2, . . . ,ml ∈ {0, 1, . . . , b−1}, m1 6= 0, e ∈ Z. Die Menge aller normalisierten Gleitpunkt-
zahlen zur Basis b mit fester Mantissenlange l ≥ 1 und Exponentenbereich emin ≤ e ≤ emax,
vereinigt mit der Zahl Null, bildet das Gleitpunktsystem Snorm(b, l, emin, emax) ⊂ Q.

10 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
Beispiel 1.1 Das normalisierte dezimale Gleitpunktsystem S := Snorm(10, 4,−9, 9) mit vier
dezimalen Mantissenstellen und einer Dezimalstelle fur den Exponenten umfasst die folgenden
Zahlen:
0,
+1.000 · 10−9, −1.000 · 10−9, +1.001 · 10−9, −1.001 · 10−9, . . . ,+9.999 · 10−9, −9.999 · 10−9,
+1.000 · 10−8, −1.000 · 10−8, +1.001 · 10−8, −1.001 · 10−8, . . . ,+9.999 · 10−8, −9.999 · 10−8,
...
+1.000 · 109, −1.000 · 109, +1.001 · 109, −1.001 · 109, . . . ,+9.999 · 109, −9.999 · 109.
Die kleinste darstellbare positive normalisierte Gleitpunktzahl heißt mininorm, die großte heißt
maxreal. In S gilt:
mininorm = 1.000 · 10−9, maxreal = 9.999 · 109
Man beachte, dass die Gleitpunktzahlen in S nicht gleichabstandig verteilt sind. Der Abstand
der Nachbarzahlen 9.998 · 109 und 9.999 · 109 betragt 106, der Abstand der Nachbarzahlen
1.000 · 10−9 und 1.001 · 10−9 nur 10−12. Normalisierte Gleitpunktzahlen besitzen die wertvolle
Eigenschaft, dass der relative Fehler zweier benachbarter Gleitpunktzahlen zueinander un-
gefahr konstant ist.
1.3 Gleitpunktarithmetik
Ein normalisiertes Gleitpunktsystem enthalt nur endlich viele (und ausschließlich rationale)
Zahlen. Tritt in einer Gleitpunktrechnung eine nicht exakt darstellbare Zahl (wie z.B.√
2 oder
π) auf, wird diese gerundet und die Rechnung mit der gerundeten Große durchgefuhrt.
Beim Rechnen mit Gleitpunktzahlen ergibt sich eine weiteres Problem: eine nichttriviales nor-
malisiertes Gleitpunktsystem ist bezuglich der arithmetischen Grundoperationen Addition und
Multiplikation nicht abgeschlossen. Addiert oder multipliziert man zwei Gleitpunktzahlen mit-
einander, muss das Ergebnis nicht im selben Gleitpunktsystem darstellbar sein. Eine genaue
Beschreibung und Analyse von Gleitpunktarithmetik nehmen wir erst in Kapitel 8 vor. Vorerst
halten wir nur fest, dass bei der Approximation reeller Zahlen durch Gleitpunktzahlen Run-
dungsfehler auftreten und diese auch bei jeder arithmetischen Operation zwischen Gleitpunkt-
zahlen vorkommen konnen.
Rundungsfehler treten haufig, aber sehr unregelmaßig auf. Einer systematischen Fehlerana-
lyse sind sie kaum zuganglich. Der Einfluss von Rundungsfehlern wird von vielen Anwendern
unterschatzt, da einzelne Rundungsfehler klein sind und haufig vermutet wird, dass sich Mil-
lionen von Rundungfehlern im Verlauf einer langeren Rechnung gegenseitig ausmitteln. Weil
die Rundung aber arithmetische Grundgesetze der reellen Zahlen außer Kraft setzt, haben
Rundungsfehler durchaus das Potential, Ergebnisse numerischer Rechnungen gravierend zu
verfalschen. Beispielsweise gilt in Gleitpunktrechnung das Assoziativgesetz bezuglich Additi-
on und Multiplikation im Allgemeinen nicht. Ebenso kann das Distributivgesetz verletzt werden.
Wir illustrieren dies an einem Beispiel.
Im Folgenden bezeichnen wir mit 2 die kaufmannische Rundung einer Zahl zur nachstge-
legenen Gleitpunktzahl in S und mit 2◦ die Ausfuhrung der arithmetischen Grundoperation
◦ ∈ {+,−, ·, /} in S, wobei jedes Ergebnis wieder kaufmannisch zur nachstgelegenen Gleit-
punktzahl gerundet wird.
Beispiel 1.2 Verletzung des Assoziativgesetzes der Addition in S.

Numerische Mathematik fur das Lehramt · SS 2009 11
1. Es seien x = 7.501 · 109, y = −7.499 · 109, z = −7.500 · 109. Dann gilt
(x 2+ y) 2+ z = 2.000 · 1062+ z = −7.498 · 109,
aber x 2+ (y 2+ z) ist nicht berechenbar, da bei der Berechnung von y 2+ z Uberlauf auftritt
(das Ergebnis ist betragsmaßig großer als die großte in S darstellbare Zahl).
2. Es seien x = 7.501 · 104, y = −7.499 · 104, z = 1.234 · 100. Dann gilt
(x 2+ y) 2+ z = 2.000 · 1012+ 1.234 · 100 = 2.123 · 101,
aber wegen
y 2+ z = −7.499 · 1042+ 1.234 · 100 = 2(−7.4988 . . . · 104) = −7.499 · 104 = y
ist
x 2+ (y 2+ z) = x 2+ y = 2.000 · 101.
Man beachte, dass sich die beiden Ergebnisse um ca. 6% voneinander unterscheiden,
obwohl jeweils nur zwei Gleitpunktadditionen ausgefuhrt wurden.
1.4 Algorithmen
Unter einem endlichen Algorithmus versteht man eine genau definierte Folge von ausfuhrbaren
Einzelschritten zur Losung eines Problems. In der Mathematik bestehen die einzelnen Schritte
in der Regel aus Berechnungen. Im taglichen Leben kann sich ein Algorithmus auch aus fur
den Ausfuhrenden verstandlichen Handlungsanweisungen zusammensetzen. Ein Kochrezept
ist beispielsweise ein alltaglicher Algorithmus, sofern es detailliert genug ist und die einzelnen
Schritte durchfuhrbar sind (was eventuell spezielle Kenntnisse erfordern kann).
In der ersten Halfte des 20. Jahrhunderts wurden verschiedene Ansatze entwickelt, um den
Begriff des Algorithmus auf eine mathematisch strenge Grundlage zu stellen. Die folgende
formale Definition eines Algorithmus benutzt die 1936 von dem englischen Mathematiker Alan
Turing entwickelte Turing-Maschine:
Definition 1.3 Eine Berechnungsvorschrift zur Losung eines Problems heißt genau dann Al-
gorithmus, wenn eine zu dieser Berechnungsvorschrift aquivalente Turing-Maschine existiert,
die fur jede Eingabe, die eine Losung besitzt, stoppt.
Die Definition eines Algorithmus wird damit auf die Definition der Turing-Maschine verlagert.
Zum Verstandnis ist dies nicht besonders hilfreich, da eine Beschreibung der Turing-Maschine
Begriffe aus der Informatik benotigt, die wir an dieser Stelle weder als bekannt voraussetzen
noch erlautern konnen. Wir erwahnen daher lediglich, dass die Turing-Maschine von Turing so
formalisiert wurde, dass die obige Definition den Begriff des Algorithmus in geeigneter Weise
festlegt.
Aus Definition 1.3 lassen sich die folgenden charakteristischen Merkmale ableiten, welche die
Eigenschaften von Algorithmen fur unsere Zwecke hinreichend beschreiben:
1. Das Verfahren muss in einem endlichen Text eindeutig formulierbar sein.

12 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
2. Jeder Schritt des Verfahrens muss durchfuhrbar sein.
3. Das Verfahren darf nur endlich viele Schritte (mit jeweils endlicher Ausfuhrungszeit)
benotigen.
4. Das Verfahren darf nur endlich viel Speicherplatz benotigen.
Die beiden letzten Eigenschaften sind fur die Implementierung von Algorithmen auf Computern
wichtig. Wenn ein mathematischer Algorithmus unendlich viele Schritte enthalt, muss man ihn
fur die praktische Durchfuhrung mit einem geeigneten Abbruchkriterium versehen, das nach
spatestens endlich vielen Schritten erfullt ist. Die vierte Eigenschaft erlaubt das Rechnen mit
unendlichen Großen, sofern diese durch endlich viele Zeichen dargestellt werden.
Weitere wichtige Begriffe sind die Determiniertheit und der Determinismus eines Algorithmus.
Ein Algorithmus heißt determiniert, wenn er bei jeder Ausfuhrung mit gleichen Startwerten
gleiche Ergebnisse liefert. Ein Algorithmus heißt deterministisch, wenn zu jedem Ausfuhrungs-
zeitpunkt der nachste Handlungsschritt eindeutig definiert ist.
Beispiel 1.4 Nicht-deterministischer Gauß-Jordan-Algorithmus mit beliebiger Wahl des Pivot-
Elements.
Als erstes konkretes Beispiel eines Algorithmus betrachten wir den Gauß-Jordan-Algorithmus
zur Losung eines linearen Gleichungssystems
Ax = b, (1.2)
den wir als bekannt voraussetzen.
Beschrankt man sich auf quadratische nichtsingulare Koeffizientenmatrizen, liefert der Gauß-
Jordan-Algorithmus nach endlich vielen arithmetischen Grundoperationen (Additionen, Sub-
traktionen, Multiplikationen, Divisionen) und Zeilenvertauschungen zu gegebener rechter Sei-
te b die eindeutige Losung x von (1.2). Dieser Algorithmus ist also determiniert. Er muss
aber nicht deterministisch sein, wenn die Zeilenvertauschungen beliebig vorgenommen wer-
den durfen: “Falls im k-ten Schritt akk = 0 gilt, vertausche die k-te Zeile der Matrix mit einer
beliebigen i-ten Zeile, fur die i > k und aik 6= 0 gilt.”
Fur das LGS
0 1 1
1 1 0
1 0 1
x1
x2
x3
=
5
3
4
erlaubt dieser Algorithmus die folgenden Losungswege:
Variante 1: Tausch von erster und zweiter Zeile in Schritt 1:
(A | b) →
1 1 0 3
0 1 1 5
1 0 1 4
→
1 1 0 3
0 1 1 5
0 −1 1 1
→
1 1 0 3
0 1 1 5
0 0 2 6
→
1 1 0 3
0 1 0 2
0 0 1 3
→
1 0 0 1
0 1 0 2
0 0 1 3
Variante 2: Tausch von erster und dritter Zeile in Schritt 1:
(A | b) →
1 0 1 4
1 1 0 3
0 1 1 5
→
1 0 1 4
0 1 −1 −1
0 1 1 5
→
1 0 1 4
0 1 −1 −1
0 0 2 6
→
1 0 0 1
0 1 0 2
0 0 1 3

Numerische Mathematik fur das Lehramt · SS 2009 13
Man beachte, dass der Algorithmus in beiden Fallen die gleiche (eindeutige) Losung liefert,
also fur regulare Koeffizientenmatrizen determiniert, aber bei freier Pivotwahl fur das gleiche
LGS nicht nur unterschiedliche, sondern sogar verschieden viele Schritte benotigen kann.
Nach Definition 1.3 sind eindeutige Beschreibung und Ausfuhrbarkeit zwei wesentliche Merk-
male eines Algorithmus. In der Praxis ware es aber viel zu umstandlich, jeden einzelnen, tri-
vialen Teilschritt einer Berechnung detailliert zu beschreiben. Haufig werden Algorithmen in
Schritten formuliert, die selbst eigenstandige Algorithmen darstellen, und fur deren Ausfuhrung
Expertenwissen vorausgesetzt wird. Im obigen Gauß-Jordan-Algorithmus haben wir beispiels-
weise den Prozess der (aus mehreren Einzelschritten bestehenden) Vertauschung zweier Zei-
len einer Matrix als bekannt angenommen.
Bei der Losung praktischer Probleme tritt ein weiteres Phanomen auf. Haufig ist man nicht
an einer exakten Losung interessiert (wenn z.B. bekannt ist, dass diese nicht oder nur mit
unvertretbar hohem Aufwand berechnet werden kann), sondern nur an einer hinreichend guten
Naherungslosung. In solchen Fallen ubertragt sich die Unscharfe in der Naherungslosung
auf den Algorithmus, der dem Ausfuhrenden gewisse Freiheiten lasst und damit im Sinn der
obigen Definition keinen mathematisch strengen Algorithmus mehr darstellt. Wir erlautern dies
an Hand von praktischen Beispielen.
Beispiel 1.5 Kochrezept fur Nudeln.
Nudeln in kochendes Salzwasser geben und weichkochen (ca. 8-10 min).
Dieser Algorithmus ist zum einen unvollstandig: die Herstellung von kochendem Salzwasser
wird nicht beschrieben. Außerdem ist er unprazise: die Zeitangabe ist vage und uber die Men-
genverhaltnisse von Nudeln und Wasser wird nichts ausgesagt. Dennoch sollte das Ergebnis
seiner Ausfuhrung genießbar sein.
Beispiel 1.6 Kochrezept fur Nudeln.
Nudeln in kochendes Salzwasser geben und weichkochen (ca. 8-10 min). Bei Spaghetti keinen
zu kleinen Topf wahlen und bestandig ruhren. Damit die Nudeln nicht verklumpen, etwas Ol
zum Kochwasser geben.
Auch dieser Algorithmus verschweigt die Herstellung von kochendem Salzwasser und enthalt
nur vage Zeit- und Mengenangaben. Durch die Erganzung wichtiger Details ist dieses Rezept
fur Anfanger am Herd aber besser geeignet als das obige. Aus mathematischer Sicht ist die
Formulierung allerdings ungenugend. Folgt man den Anweisungen Schritt fur Schritt und sind
die Spaghetti nach 8-10 Minuten im zu kleinen Topf verklumpt, helfen weder Umfullen in ein
großeres Gefaß noch die nachtragliche Zugabe von Ol.
Beispiel 1.7 Kochrezept fur Lamm-Ragout.
Fur 6 Personen:
900 g Lammhufte
1/2 Knolle Sellerie
1 Stange Lauch (Porree)
2 Karotten
100 g Tomatenmark
1/2 l Rotwein
Salz, Pfeffer
Olivenol zum Braten

14 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
Die Lammhufte von Fett befreien, in Wurfel mit ca. 2cm Kantenlange schneiden, mit Salz
und Pfeffer wurzen und in Olivenol scharf anbraten. Das Fleisch aus der Pfanne nehmen und
beiseite stellen. Das Gemuse wurfeln und ebenfalls in Olivenol dunsten. Mit Salz und Pfef-
fer wurzen. Fleisch und Tomatenmark dazugeben. Den Rotwein angießen und alles ca. eine
Stunde weichschmoren.
Beilage: Reis oder Kartoffelgratin.
An diesem Beispiel wollen wir Varianten des Algorithmus und ihre Auswirkung auf das Er-
gebnis diskutieren. Offensichtlich kann man das Gemuse wurfeln, bevor das Fleisch ange-
braten wird (Anderung der Reihenfolge von Anweisungen), ohne dass sich geschmacklich
etwas andert. Ebenso konnte man Fleisch und Gemuse nicht nacheinander, sondern gleich-
zeitig in zwei Pfannen anbraten (Parallelisierung von Teilschritten). Dies wurde einerseits zum
Zeitgewinn fuhren, andererseits aber mehr Resourcen (zweite Pfanne, zusatzliche Herdplatte)
erfordern. Alternative Algorithmen ergeben sich, wenn das Gericht im Backofen oder in der
Mikrowelle zubereitet werden soll. Ein verwandter Algorithmus entsteht, falls Sellerie, Lauch
und Karotten durch Tomaten und Zucchini ersetzt werden. Im letzten Fall losen wir (in mathe-
matischer Sprechweise) ein anderes Problem, aber welche Methode bevorzugt werden soll,
ist im wahrsten Sinn des Wortes Geschmacksache.
Die in den Beispielen angesprochenen Merkmale von Kochrezepten treten bei mathemati-
schen Algorithmen ahnlich auf. In der Mathematik ist es sogar haufig so, dass mehrere sehr
unterschiedliche Algorithmen fur ein gegebenes Problem zur Verfugung stehen. Die Eignung
eines speziellen Algorithmus hangt dann unter anderem davon ab,
• wie genau die gesuchte Losung berechnet wird,
• wieviel Aufwand die Berechnung erfordert,
• ob Fehlerschranken fur die berechnete Naherungslosung verfugbar sind,
• ob der Algorithmus fur allgemeine oder nur fur spezielle Eingangsdaten durchfuhrbar ist.
Bevor wir mathematische Algorithmen formulieren konnen, mussen wir eine geeignete Spra-
che entwickeln, in der jede Anweisung eine prazise Handlungs- oder Rechenvorschrift aus-
druckt. Erstaunlicherweise muss eine solche Sprache nicht besonders machtig sein. Sie sollte
aber zumindest
• Symbole zur Beschreibung mathematischer Objekte (Zahlen, Vektoren, Matrizen, . . . ),
die arithmetischen Grundoperationen +, - ·, / und die ublichen Standardfunktionen ent-
halten,
• uber Variablen verfugen, in die Zwischenergebnisse gespeichert werden konnen,
• Befehle zur Ablaufsteuerung umfassen, damit eine numerische Rechnung in Abhangig-
keit von Zwischenergebnissen unterschiedlich fortgesetzt werden kann.
Fur die Ablaufsteuerung von Algorithmen sind insbesondere zwei Konstrukte erforderlich:
Schleifen und Verzweigungen. Ihre Funktionsweisen erlautern wir im nachsten Abschnitt.
Da das Praktikum zu dieser Vorlesung mit Maple durchgefuhrt wird, werden alle im folgenden
auftretenden Algorithmen in der aktuellen Maple-Syntax formuliert. Soll ein Algorithmus in ei-
ner anderen Programmiersprache als Maple implementiert werden, muss die Befehlssyntax
entsprechend angepasst werden. Inhaltliche Anderungen am Algorithmus sind dabei in der
Regel nicht oder nur in geringem Umfang erforderlich, weil die in dieser Vorlesung behandel-
ten Algorithmen ausschließlich Anweisungen verwenden, die in jeder modernen Programmier-
sprache zur Verfugung stehen.

Numerische Mathematik fur das Lehramt · SS 2009 15
1.5 Maple
Maple wurde ab 1980 an der Universitat Waterloo in Kanada als interaktives Computeralgebra-
system (CAS) fur symbolisches Rechnen entwickelt. Das System ist leicht zuganglich, aller-
dings vergleichsweise langsam (Interpreter), und enthalt inzwischen auch viele numerische
Routinen. Im Praktikum verwenden wir die aktuelle Version Maple 12 unter Windows. Fur Stu-
dierende der Universitat steht Maple 12 kostenlos als Campuslizenz zur Verfugung (Bezug
beim Rechenzentrum).
Eine Maple-Sitzung arbeitet mit sogenannten Worksheets, in denen der Benutzer Maple-
Befehle eingibt. Die von Maple berechneten Ergebnisse werden im selben Worksheet ausge-
geben. Seit Maple 10 verfugen die Worksheets uber zwei Anzeigeformate, den Worksheet-
Modus und den Document-Modus. Wir benutzen in dieser Vorlesung die Syntax des
Worksheet-Modus, in dem jedes Kommando durch ein Semikolon abgeschlossen wird. Meh-
rere Maple-Befehle konnen in eine Zeile geschrieben werden. Fur mathematische Formeln gilt
die ubliche Notation. Die Exponentialfunktion wird mit exp bezeichnet, die Wurzelfunktion mit
sqrt. Bei numerischen Berechnungen verwendet Maple standardmaßig zehn Nachkomma-
stellen. Zur besseren Lesbarkeit geben wir in den folgenden Beispielen aber weniger Stellen
an.
Einfache Beispiele gultiger Maple-Kommandos:
Eingabe Ergebnis
3+5; 8
3.0/2; exp(1.0); 1.500; 2.718
a := exp(1.0); Der Variable a wird der Wert 2.718 zugewiesen.
b := a+1; Der Variable b wird der um 1 erhohte Wert der Variable
a zugewiesen. Der Wert der Variable a wird dabei nicht
verandert.
print( a ); Der Wert der Variable a wird auf dem Bildschirm
ausgegeben.
print( "Division durch 0!" ); Ausgabe einer Fehlermeldung auf dem Bildschirm.
1.5.1 Schleifen in Maple
Eine Schleife in einem Algorithmus bzw. Computerprogramm besteht aus einer oder mehreren
wiederkehrenden Rechenoperationen. Wir erlautern die Verwendung einer Schleife bei der
Berechnung einer Summe s von funf reellen Zahlen a1, . . . , a5:
s :=5∑
k=1
ak = a1 + a2 + a3 + a4 + a5.
Ein Computer berechnet diese Summe auf die gleiche Weise, wie Menschen ein Bundel Geld-
scheine zahlen: durch Bildung von Partialsummen. Zunachst wird a1 gezahlt. Im ersten Sum-
mationsschritt wird a2 addiert und so die erste Teilsumme gebildet. Zur aktuellen Teilsumme
werden nacheinander a3, a4 und a5 addiert. Der Wert der Summe wird dabei fortlaufend uber-

16 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
schrieben:s := a1
s := s + a2...
s := s + a5
Hier wird also immer wieder die gleiche Operation durchgefuhrt: “addiere den nachsten Sum-
manden zu s”. In der Maple-Notation wurde man dies folgendermaßen formulieren (die eckigen
Klammern beschreiben in Maple Indizes):
s := a[1];
for k from 2 to 5 do
s := s + a[k];
end do;
Die Schleifenanweisung in Maple lautet also
for <schleifenzahler> from <startwert> to <endwert> do
<beliebige Anweisung(en)>
end do;
Der Schleifenzahler ist eine beliebige Variable (im obigen Beispiel k), die beim ersten Durchlauf
mit dem Startwert besetzt ist und deren Wert bei jedem weiteren Schleifendurchlauf um 1
erhoht wird, bis der Endwert erreicht ist.
Zehn Schritte des Newton-Verfahrens zur Bestimmung einer Nullstelle der differenzierbaren
Funktion f , ausgehend von einem gegebenen Startwert x0, lassen sich in dieser Notation wie
folgt beschreiben:
for k from 1 to 10 do
x[k] := x[k-1] - f(x[k-1])/df(x[k-1]);
end do;
Diese Darstellung enthalt die Metaelemente f(.) und df(.) als Platzhalter fur die Berechnung
von f und f ′. Die Metaelemente reprasentieren das oben angesprochene Expertenwissen. Ist
man beim Newton-Verfahren nicht an den Zwischenwerten interessiert, kann man anstelle der
Iterierten xk immer wieder die gleiche Variable uberschreiben, die am Ende der Schleife den
Wert von x10 enthalt:
x := x[0]
for k from 1 to 10 do
x := x - f(x)/df(x);
end do;
1.5.2 Auswahlanweisungen in Maple
Das Newton-Verfahren ist nur so lange definiert, wie keine Division durch Null auftritt. Divi-
sion durch Null ist nicht nur in der Mathematik verboten, sondern auch in einem Computer-
programm. Falls im Newton-Verfahren ein Ableitungswert Null auftritt, muss die Berechnung
ergebnislos abgebrochen werden. Dies erfordert die Moglichkeit einer Verzweigung und den
vorzeitigen Abbruch einer Schleife.
Der Abbruch einer Schleife wird mit dem Kommando break erzwungen. Die Auswahlanwei-
sung in Maple besitzt die folgende Syntax:

Numerische Mathematik fur das Lehramt · SS 2009 17
if <bedingung> then
<beliebige Anweisung(en)>
end if;
Die zwischen if und end if stehenden Anweisungen werden nur ausgefuhrt, wenn die ge-
nannte Bedingung erfullt ist. Ist die Bedingung nicht erfullt, wird dieser Anweisungsblock uber-
sprungen und das Computerprogramm mit dem ersten Befehl nach der Auswahlanweisung
fortgesetzt.
Das Newton-Verfahren mit Abbruchbedingung lautet:
x := x[0]
for k from 1 to 10 do
if df(x) = 0 then
print( "Fehler: Division durch Null" );
break;
end if;
x := x - f(x)/df(x);
end do;
Manchmal mochte man auch (andere) Befehle ausfuhren, wenn die Auswahlbedingung nicht
erfullt ist. In Maple gibt es dazu in der if-Anweisung den optionalen else-Zweig. Die erweiterte
Auswahlanweisung lautet:
if <bedingung> then
<beliebige Anweisung(en) 1>
else
<beliebige Anweisung(en) 2>
end if;
Ein typisches Anwendungsbeispiel ist die Berechnung von Funktionswerten einer abschnitts-
weise definierten Funktion. Die Betragsfunktion kann in Maple beispielsweise folgendermaßen
implementiert werden:
if x >= 0 then
betrag := x;
else
betrag := -x;
end if;
Schleifen und Auswahlanweisungen konnen in Maple beliebig verschachtelt werden. Eine
Schleife kann weitere (innere) Schleifen und Auswahlanweisungen enthalten, ebenso eine
Auswahlanweisung weitere Auswahlanweisungen und Schleifen. Damit sind auch komplexe
Aufgabenstellungen ubersichtlich in Algorithmen formulierbar. Der folgende Algorithmus be-
rechnet Funktionswerte der Signumsfunktion:
if x > 0 then
sig := 1;
else
if x = 0 then
sig := 0;
else
sig := -1;
end if;
end if;

18 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
Auswahlanweisungen mit mehr als zwei Alternativen kommen so haufig vor, dass Maple eine
Syntaxvariante anbietet, bei der else if zu elif verkurzt wird und bei der insgesamt nur ein
abschließendes end if benotigt wird. Die Kurzfassung der Signumsfunktion lautet:
if x > 0 then
sig := 1;
elif x = 0 then
sig := 0;
else
sig := -1;
end if;
Abschließend prasentieren wir als anspruchsvolleres Beispiel die praktische Implementierung
des Newton-Verfahrens, bei der bis zur Konvergenz iteriert wird. Konvergenz wird angenom-
men, wenn sich die Iterierten nicht mehr wesentlich andern. Um im Fall der Divergenz nicht
unendlich lange zu iterieren, werden maximal 100 Iterationen zugelassen. In jedem Schritt des
Newton-Verfahrens besitzt x den Wert der alten Iterierten und y den Wert der neuen Iterier-
ten. Die mit # beginnenden Zeilen enthalten Kommentare, die das Programm fur den Benutzer
verstandlich machen und die bei der Ausfuhrung des Algorithmus ignoriert werden.
x := x[0]
for k from 1 to 100 do
if df(x) = 0 then
print( "Fehler: Division durch Null" );
break;
else
y := x - f(x)/df(x);
if | y - x | < 10 (-8) then
print( "Gefundene Nullstelle: ", y );
break;
end if;
# Umspeichern der letzten Iterierten
# zur Fortsetzung der Iteration
x := y;
end if;
if k = 100 then
print( "Keine Konvergenz nach 100 Schritten." );
end if;
end do;
1.5.3 Prozeduren in Maple
Ublicherweise fasst man in jedem Computerprogramm mehrere Rechenschritte, die immer in
der gleichen Kombination ausgefuhrt werden sollen, in einer Prozedur zusammen. Prozeduren
werden vor allem genutzt, wenn eine komplexe Aufgabenstellung so in einfache Teilprobleme
zerlegt werden kann, dass jedes Teilproblem unabhangig von den anderen losbar ist. Ist eine
Prozedur in Maple erfolgreich implementiert und getestet worden, kann sie auch in andere
Maple-Worksheets eingebunden und somit wiederverwendet werden.
Einer Prozedur konnen Eingabedaten in einer Liste von Parameterwerten ubergeben werden.
Eine Prozedur kann selbst andere Prozeduren aufrufen, die im gleichen Maple-Worksheet

Numerische Mathematik fur das Lehramt · SS 2009 19
definiert sind oder die von diesem eingebunden werden. Nach der Ausfuhrung der Prozedur
wird das berechnete Ergebnis an das aufrufende Programm oder den Benutzer zuruckgeliefert.
Eine Maple-Prozedur wird durch das Gerust
<procname> := proc( <parameterliste> )
global <globale variablen>;
local <lokale variablen>;
<beliebige Anweisung(en)>
return <ergebniswert>;
end proc;
definiert. <procname> ist ein beliebig gewahlter Name der Prozedur, unter dem die Prozedur
anschließend aufgerufen wird. Die erste Zeile und die (optionalen) Zeilen mit den Listen der
globalen und der lokalen Variablen heißen Kopf der Prozedur, der Anweisungsteil heißt Rumpf
der Prozedur. Die Bedeutung der einzelnen Elemente erklaren wir an Beispielen.
Beispiel 1.8 Maple-Prozedur zur Berechnung der Fakultatsfunktion
Die Berechnung von n! lasst sich in Maple mit der folgenden Prozedur bewerkstelligen:
fak := proc( n )
local i, prod;
prod := 1;
for i from 2 to n do
prod := prod*i;
end do;
return prod;
end proc;
Der Aufruf der Prozedur liefert die folgenden Ergebnisse:
Eingabe Ergebnis
fak(3); 6
fak(4); 24
fak(3.14); 6
fak(-2); 1
fak(A); Error, (in fak) final value
in for loop must be numeric.
Hier sind einige Erklarungen angebracht:
1. Der Prozedurname darf nur beinahe beliebig gewahlt werden. Vordefinierte Be-
fehlsworter wie end, for, global, . . . , sind unzulassige Prozedurnamen.
2. Wenn eine Prozedur interne Variablen benutzt (im obigen Beispiel i und prod), durfen
diese Variablen nicht gleichzeitig an einer anderen Stelle des aufrufenden Computer-
programms verwendet werden, da deren Werte sonst bei der Ausfuhrung der Prozedur
verandert wurden. Allerdings ist bei der Programmierung einer Prozedur haufig nicht be-
kannt, in welche Computerprogramme sie spater eingebunden werden soll und welche
Variablennamen in den einbindenden Programmen bereits vergeben sind.

20 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
Um Konflikte zu vermeiden, werden daher alle nur innerhalb der Prozedur verwendeten
Variablen im Prozedurkopf als lokale Variablen deklariert. Der Computer legt dann beim
Aufruf der Prozedur neue Variablen mit internen (fur den Benutzer unsichtbaren) Namen
an und fuhrt die Rechnung mit diesen aus. Wenn die Prozedur beendet ist, werden die
internen Variablen wieder geloscht.
Manchmal gibt es in einem Computerprogramm auch Variablen, die im Hauptprogramm
und in verschiedenen Prozeduren die gleiche Bedeutung haben und auch den selben
Wert besitzen. Derartige Variablen konnen im Prozedurkopf als global deklariert werden.
Wird der Wert einer globalen Variablen innerhalb einer Prozedur geandert, bleibt die
Anderung nach dem Ende der Prozedur bestehen.
3. Die Vereinbarung lokaler und globaler Variablen im Prozedurkopf ist optional. Wenn sol-
che Variablen deklariert werden, darf nach proc( <parameterliste> ) kein Semikolon
stehen.
4. Das Ergebnis einer Maple-Prozedur wird mit dem return-Befehl an das aufrufende Pro-
gramm zuruckgeliefert.
Bei Verzweigungen innerhalb einer Prozedur kann diese auch mehrere return-Befehle
enthalten. Nach der Ausfuhrung eines return-Befehls wird die Prozedur sofort beendet.
Eventuell nachfolgende Anweisungen werden nicht mehr bearbeitet.
5. Die oben aufgefuhrten numerischen Ergebnisse kommen folgendermaßen zustande:
• fak(3) und fak(4) werden wie erwartet berechnet.
• Bei fak(3.14) besitzt n den Wert 3.14 und der Schleifenzahler i nacheinander die
Werte 2, 3, 4. Vor jedem Schleifendurchlauf wird die Bedingung i < n uberpruft.
Die Bedingungen 2 < 3.14 und 3 < 3.14 sind erfullt, also wird die Schleife jeweils
durchlaufen und der Wert von i anschließend um 1 erhoht. Die Bedingung 4 < 3.14
ist falsch, so dass die Schleife an dieser Stelle abgebrochen wird.
• Bei fak(-2) besitzt n den Wert -2. Der erste Test des Schleifenzahlers lautet 2 < -2.
Da diese Bedingung nicht erfullt ist, wird die Schleife nicht durchlaufen. Der Variable
prod wurde aber bereits zuvor der Wert 1 zugewiesen. Dieser ist somit Ergebniswert
der Prozedur.
• Der Aufruf fak(A) fuhrt zu Beginn der Schleife zum Test der Bedingung 2 < A.
Falls A einen Zahlenwert besitzt, wird die Zahl 2 mit diesem Wert verglichen. Falls A
keinen Zahlenwert besitzt, kann Maple die Bedingung nicht auflosen und bricht mit
einer Fehlermeldung ab.
Beispiel 1.9 Binomialkoeffizienten.
Die Binomialkoeffizienten konnen mit Hilfe der Fakultat definiert werden:
(nk
)=
n!
k!(n − k)!. (1.3)
Die folgende Maple-Prozedur berechnet die Binomialkoeffizienten mit Hilfe der Prozedur fak.
binom := proc( n, k );
return fak(n) / ( fak(k) * fak(n-k) );
end proc;

Numerische Mathematik fur das Lehramt · SS 2009 21
Die Prozedur liefert die folgenden Ergebnisse:
Eingabe Ergebnis
binom(2,0); binom(2,1); binom(2,2); 1 2 1
binom(3,1); 3
binom(1,3); 1/6
Der zuletzt ausgegebene Wert beruht nicht auf einem Fehler des Computers, sondern der
Programmierung. Berechnet wird
fak(1)
fak(3) ∗ fak(1-3) =fak(1)
fak(3) ∗ fak(-2) =1
6 * 1=
1
6.
Bei der Programmierung wurde ubersehen, dass die Formel (1.3) nur im Fall n, k ∈ N0, n ≥ k
gilt. Unter der Voraussetzung k ∈ N0, α ∈ R werden die Binomialkoeffizienten
(αk
)mit der
folgenden Prozedur korrekt berechnet (welche Berechnungsformel fur Binomialkoeffizienten
wird hier implementiert?):
binom := proc( alpha, k )
local alphaloc, i, prod;
alphaloc := alpha;
prod := 1;
for i from 1 to k do
prod := prod*alphaloc;
alphaloc := alphaloc-1;
end do;
return prod / fak(k);
end proc;
Diese Prozedur liefert die folgenden Ergebnisse:
Eingabe Ergebnis
binom(2,0); binom(2,1); binom(2,2); 1 2 1
binom(1,3); 0
binom(3.14,0); binom(3.14,1); binom(3.14,2); 1 3.14 3.3598
binom(0.5,2); -0.125
Bei der Analyse der Prozedur mag es verwundern, dass der Parameter alpha in eine lokale
Variable umgespeichert wird, nicht aber der Parameter k. Dies liegt daran, dass der Wert von
alpha innerhalb der Prozedur (in Zeile 7) verandert wird. Wurde man den Inhalt der Speicher-
zelle von alpha uberschreiben, hatte dies Auswirkungen auf den Wert von alpha im aufrufen-
den Programm (in dem alpha eventuell unverandert gebraucht wird). Deshalb muss fur alpha
eine lokale Variable angelegt werden. Wird der Wert von alphaloc verandert, hat dies keinen
Einfluss auf den Wert von alpha. Fur k wird keine Wertzuweisung vorgenommen, so dass
auch keine lokale Variable kloc benotigt wird.
Mit diesen Beispielen schließen wir die Einfuhrung in Maple an dieser Stelle ab. Vertiefte Pro-
grammierkenntnisse werden im Praktikum zur Vorlesung vermittelt.

22 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
1.6 Landau-Symbole
Landau-Symbole beschreiben das asymptotische Verhalten von Funktionen. Genauer verglei-
chen sie das gesuchte asymptotische Verhalten einer Funktion f mit dem bekannten asympto-
tischen Verhalten einer Referenzfunktion g. Ist x0 ∈ R oder x0 = ∞ und sind f und g in einer
Umgebung von x0 definierte reellwertige Funktionen, wobei g(x) > 0 vorausgesetzt wird, dann
haben die Symbole O(.) und o(.) die folgenden Bedeutungen:
• f(x) = O(g(x)
)fur x → x0 ⇐⇒ f(x)
g(x)ist beschrankt fur x → x0,
• f(x) = o(g(x)
)fur x → x0 ⇐⇒ lim
x→x0
f(x)
g(x)= 0.
Wenn x0 aus dem Zusammenhang bekannt ist, schreibt man haufig nur f(x) = O(g(x)
)bzw.
f(x) = o(g(x)
). Die gleichen Symbole werden sinngemaß auch fur das Wachstum von Folgen
fur n → ∞ verwendet.
Beispiel 1.10 Landau-Symbole.
1. f(x) = O(1): f ist eine beschrankte Funktion.
Z.B. sinx = O(1).
2. f(x) = O(x): f wachst hochstens linear (fur x → ∞).
Z.B.√
1 + x2 = O(x); lnx = O(x).
3. f(x) = o(x): f wachst langsamer als jede lineare Funktion (fur x → ∞).
Z.B.√
x = o(x); lnx = o(x).
4.1√x
= O(1
x) fur x → 0;
1√x
= o(1
x) fur x → 0.
5.
n∑
k=1
k =1
2n(n + 1) = O(n2);
√n + 1 −
√n = O(
1√n
).
In der Numerik werden Landau-Symbole haufig verwendet, um den Aufwand eines Algorith-
mus abzuschatzen.
Beispiel 1.11
1. Die Berechnung eines Skalarprodukts zweier Vektoren x, y ∈ Rn erfordert n Produkte
und n − 1 Additionen:
xT y =n∑
i=1
xiyi.
Zahlt man jede Addition und jedes Produkt als gleich aufwandige Gleitpunktoperation,
ergeben sich 2n− 1 Operationen. Diese genaue Zahl ist aber weniger interessant als die
Tatsache, dass der Gesamtaufwand linear mit der Dimension steigt: verdoppelt man die
Lange der Vektoren, verdoppelt sich (ungefahr!) der Aufwand. Man sagt: das Skalarpro-
dukt besitzt die Komplexitat O(n).

Numerische Mathematik fur das Lehramt · SS 2009 23
2. Die Multiplikation zweier Matrizen A, B ∈ Rn×n erfolgt durch die Berechnung von n2
Elementen des Produkts. Jedes Element wird mit Hilfe eines Skalarprodukts berechnet.
Die gesamte Rechnung benotigt also n2(2n − 1) = O(n3) Gleitpunktoperationen.
1.7 Ziele dieser Vorlesung
Vordringliches Ziel dieser Vorlesung ist eine Einfuhrung in die Arbeitsweise der Numerik. Aus-
gangspunkt jedes behandelten Themengebiets ist die durch Modellierung eines Anwendungs-
problems entstandene mathematische Fragestellung. Auf die Modellierung selbst gehen wir
dabei in der Regel nicht ein, da der Modellfehler nach unserem Verstandnis außerhalb der
Numerischen Mathematik entsteht und nicht durch numerische Methoden zu bekampfen ist.
Fur die mathematischen Aufgabenstellungen prasentieren und analysieren wir Algorithmen,
mit denen nach endlich vielen Rechenoperationen Naherungslosungen berechnet werden. Als
unentbehrliches Hilfsmittel setzen wir dazu einen Taschenrechner oder Computer voraus, der
in der Lage ist, zu jeder in dieser Vorlesung auftretenden Funktion fur ein beliebiges Argument
einen Naherungswert fur den Funktionswert mit einer gewunschten Genauigkeit (d.h. Anzahl
gultiger Dezimalstellen) zu liefern.†
Zum Einstieg stellen wir im nachsten Kapitel Iterationsverfahren fur nichtlineare Gleichungen
und Gleichungssysteme vor. Methoden zur Losung von linearen Gleichungssystemen disku-
tieren wir in Kapitel 3. Im nachfolgenden Kapitel werden Approximation und Interpolation von
Funktionen und Messwerten behandelt. Kapitel 6 ist der numerischen Integration gewidmet.
Wir beschließen die Vorlesung mit einer Analyse der Fehlerfortpflanzung in numerischen Al-
gorithmen, unter Einbeziehung der beim Rechnen in Gleitpunktarithmetik auftretenden Run-
dungsfehler.
†Einige Algorithmen zur Programmierung eines solchen Computers werden wir im Lauf der Vorlesung behan-
deln.

24 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
Kapitel 2
Iterationsverfahren
Zur Motivation der iterativen Losung von Gleichungen betrachten wir eine Extremwertaufgabe.
Gesucht sei das Maximum der Funktion
f(x) =3
4x2 + ln(cos x), x ∈ I = [
π
4,π
3].
Als stetige Funktion nimmt f auf dem kompakten Intervall I Maximum und Minimum an. Dafur
kommen die Randwerte
f(π
4) =
3π2
64+
1
2ln
1
2, f(
π
3) =
π2
12+ ln
1
2.
oder eventuelle lokale Extrema im Innern von I in Frage. Da f differenzierbar ist, muss f ′
an der Stelle eines lokalen Extremwerts im Innern von I verschwinden. Gesucht sind also
Nullstellen von f ′, d.h. Losungen der Gleichung
3
2x − tanx = 0, x ∈ (
π
4,π
3). (2.1)
Die Gleichung (2.1) ist nicht nach x auflosbar. Man kann sich aber auf verschiedene Weise
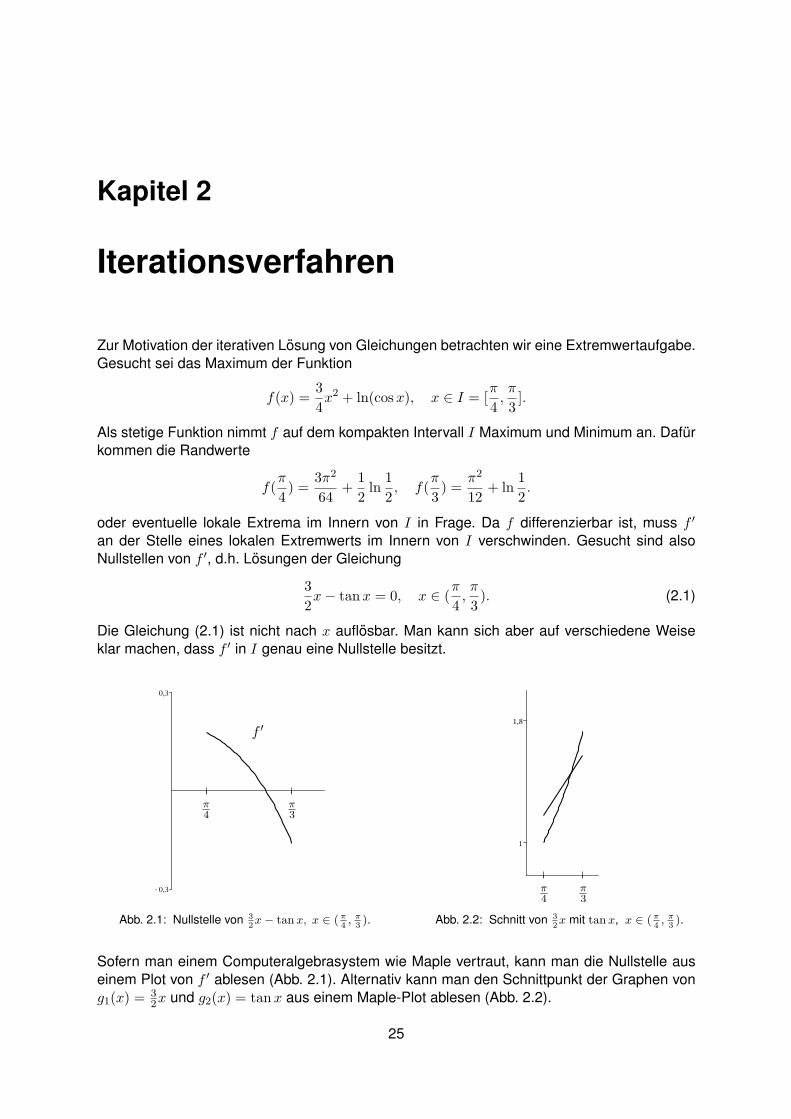
klar machen, dass f ′ in I genau eine Nullstelle besitzt.
π4
π3
f ′
Abb. 2.1: Nullstelle von 3
2x − tan x, x ∈ (π
4, π
3).
π4
π3
Abb. 2.2: Schnitt von 3
2x mit tan x, x ∈ (π
4, π
3).
Sofern man einem Computeralgebrasystem wie Maple vertraut, kann man die Nullstelle aus
einem Plot von f ′ ablesen (Abb. 2.1). Alternativ kann man den Schnittpunkt der Graphen von
g1(x) = 32x und g2(x) = tanx aus einem Maple-Plot ablesen (Abb. 2.2).
25

26 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
Die Existenz von genau einer Nullstelle von f ′ in I lasst sich in diesem Beispiel auch durch
elementare Rechnung mathematisch streng begrunden. f ′ ist stetig. Es ist f ′(π4 ) > 0, f ′(π
3 ) <0. Aus dem Zwischenwertsatz folgt, dass f ′ im Innern von I mindestens eine Nullstelle besitzt.
Da f ′′(x) = 12 − tan2 x ≤ −1
2 < 0 in I gilt, ist f ′ streng monoton fallend. Also besitzt f ′ in I nur
eine Nullstelle ξ und f nimmt auf ξ das absolute Maximum auf I an.
Nachdem die Existenz von ξ bewiesen ist, soll nun eine moglichst gute Naherung fur ξ gefun-
den werden. Dazu bringen wir die Gleichung (2.1) in eine iterationsfahige Gestalt, indem wir
die Gleichung so umformen, dass auf einer Seite nur x steht:
x =2
3tanx, x ∈ (
π
4,π
3). (2.2)
Nun betrachten wir das Iterationsverfahren
x0 ∈ I,
xk+1 =2
3tanxk, k = 0, 1, . . . ,
wobei wir vereinbaren, dass die Iteration abgebrochen wird, wenn xk nicht mehr in I liegt.
Wahlt man x0 = 7π24 (Mittelpunkt von I), so erhalt man die folgenden Iterierten (gerundet auf 4
Nachkommastellen):
x0 = 0.9163,x1 = 0.8688,x2 = 0.7883,x3 = 0.6705.
x3 liegt nicht mehr in I, so dass die Iteration hier abbricht, ohne dass man eine zufriedenstel-
lende Naherung fur ξ gefunden hatte.
Andererseits kann man die Gleichung (2.1) auch folgendermaßen in eine iterationsfahige Ge-
stalt uberfuhren:
x = arctan(3
2x), x ∈ (
π
4,π
3). (2.3)
Das Iterationsverfahren
x0 ∈ I,
xk+1 = arctan(3
2xk), k = 0, 1, . . .
liefert fur x0 =7π
24die Iterierten
x0 = 0.9163,x1 = 0.9418,x2 = 0.9548,x3 = 0.9617,...
x10 = 0.9674.
Auf 4 Stellen gerundet gilt x10 = x11 = x12 = · · · = 0.9674. Anscheinend konvergieren diese
Iterierten gegen ξ ≈ 0.9674. Naherungen fur ξ mit hoherer Genauigkeit lassen sich analog
durch Rechnung mit mehr Dezimalstellen aus hinreichend vielen Iterationsschritten gewinnen.
Aus diesem Beispiel ergeben sich unter anderem die folgenden mathematischen Fragestellun-
gen zur Losung einer transzendenten Gleichung in einem Intervall I:
1. Wie kann man erkennen, ob die Gleichung in I losbar ist?

Numerische Mathematik fur das Lehramt · SS 2009 27
2. Wie soll man eine losbare Gleichung in eine iterationsfahige Gestalt uberfuhren, so dass
das Iterationsverfahren (moglichst fur jeden Startwert aus I) konvergiert?
3. Was kann man uber die Konvergenzgeschwindigkeit des Verfahrens aussagen? Nach
wievielen Schritten soll man die Iteration abbrechen?
4. Wie lasst sich das Iterationsverfahren auf hoherdimensionale Probleme verallgemei-
nern?
Eine systematische Herleitung und Untersuchung von Iterationsverfahren wird diese Fragen
zunachst fur eindimensionale Probleme beantworten. Anschließend diskutieren wir den Fall
von n Gleichungen mit n Unbekannten fur n > 1.
2.1 Fixpunktiteration
Nichtlineare Gleichungen der Bauart
f(x) = g(x), x ∈ D ⊂ R,
oder der Gestalt
g(x) = 0, x ∈ D ⊂ R,
oder von der Form
f(x) = x, x ∈ D ⊂ R, (2.4)
mit reellwertigen Funktionen f und g lassen sich beliebig ineinander uberfuhren, so dass diese
drei Formulierungen als aquivalent betrachtet werden konnen. Im Folgenden untersuchen wir
das zu (2.4) gehorende Iterationsverfahren
{x0 ∈ D,
xk+1 = f(xk), k = 0, 1, . . . .(2.5)
Dazu benotigen wir zunachst die Begriffe Selbstabbildung und Fixpunkt. Man sagt, die Funkti-
on f bildet die Menge D in sich ab, wenn f fur alle x ∈ D definiert ist und wenn f(x) ∈ D fur
alle x ∈ D gilt. f heißt dann Selbstabbildung auf D. Ein Punkt x ∈ D, fur den f(x) = x gilt,
heißt Fixpunkt von f .
Satz 2.1 Vor.: Seien I = [a, b] ⊂ R ein kompaktes Intervall und f : I → R eine stetige Selbst-
abbildung von I in sich.
Beh.: Dann besitzt f in I einen Fixpunkt.
a ξ b
f
Abb. 2.3: Selbstabbildung
Beweis: Die Funktion
h(x) = x − f(x), x ∈ I,
ist stetig. Aufgrund der Selbstabbildungseigenschaft gelten
h(a) = a − f(a) ≤ 0, h(b) = b − f(b) ≥ 0.
Nach dem Zwischenwertsatz besitzt h in I eine Nullstelle ξ,
die nach Definition von h einem Fixpunkt von f entspricht.
2

28 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
Bemerkung 2.2 Fur eine stetige Selbstabbildung f auf I gilt:
1. Das Iterationsverfahren (2.4) ist fur beliebiges x0 ∈ I durchfuhrbar, d.h. die Iteration
bricht nicht ab.
2. Falls limk→∞
= ξ gilt, ist ξ ein Fixpunkt von f . Aufgrund der Stetigkeit von f folgt namlich
ξ = limk→∞
xk+1 = limk→∞
f(xk) = f( limk→∞
xk) = f(ξ).
3. Eine Funktion f kann in einem Intervall I auch einen Fixpunkt besitzen, wenn sie I nicht
auf sich abbildet.
4. Unter den Voraussetzungen von Satz 2.1 kann f in I mehrere Fixpunkte besitzen.
a b
f
Abb. 2.4: Nicht-Selbstabb. mit Fixpunkt
a b
f
Abb. 2.5: Mehrere Fixpunkte
Definition 2.3 Sei I = [a, b] ein kompaktes Intervall. Eine Funktion f : I → R heißt Kontraktion
oder kontrahierende Abbildung auf I, wenn es eine Konstante L < 1 gibt, so dass
|f(x) − f(y)| ≤ L |x − y| fur alle x, y ∈ I
gilt.
Bemerkung 2.4
1. Eine kontrahierende Abbildung ist stetig, denn fur x0 ∈ I gilt
|f(x) − f(x0)| ≤ L |x − x0| → 0 fur x → x0.
2. Ist die Kontraktion f in I stetig differenzierbar, existiert zu x, y ∈ I nach dem Mittelwert-
satz ein η zwischen x und y, fur welches die Ungleichungskette
∣∣f ′(η)∣∣ =
|f(x) − f(y)||x − y| ≤ L |x − y|
|x − y| = L
erfullt ist. Aufgrund von Stetigkeitsuberlegungen kann man hieraus folgern, dass die
kleinstmogliche Kontraktionskonstante zu f gegeben ist durch
Lmin := maxη∈I
∣∣f ′(η)∣∣ .

Numerische Mathematik fur das Lehramt · SS 2009 29
3. Eine auf I kontrahierende Abbildung muss I nicht in sich abbilden. Z.B. die Funktion
f(x) =3
4x + 1, x ∈ [1, 2]
ist wegen
|f(x) − f(y)| =3
4|x − y|
kontrahierend mit Kontraktionskonstante3
4, besitzt aber den Wertebereich
Wf = [7
4,5
2] 6⊂ I.
Fur kontrahierende Selbstabbildungen gilt der Banach’sche Fixpunktsatz, den wir hier speziell
fur reellwertige Funktionen auf kompakten Intervallen formulieren.
Satz 2.5 (Banach’scher Fixpunktsatz im R1) Vor.: Seien I = [a, b] ⊂ R ein kompaktes Inter-
vall und f : I → R eine kontrahierende Selbstabbildung auf I mit Kontraktionskonstante L < 1.
Beh.: Dann gilt:
1. f besitzt in I genau einen Fixpunkt ξ.
2. Das Iterationsverfahren
(IV)
{x0 ∈ I,
xk+1 = f(xk), k = 0, 1, . . .
konvergiert fur jeden Startwert x0 ∈ I gegen ξ.
3. Fur k ∈ N gilt die a priori-Abschatzung
|xk − ξ| ≤ Lk
1 − L|x1 − x0| .
4. Fur k ∈ N gilt die a posteriori-Abschatzung
|xk − ξ| ≤ L
1 − L|xk − xk−1| .
Beweis:
von 1.: Nach Satz 2.1 besitzt f mindestens einen Fixpunkt. Wir nehmen nun an, dass f in Izwei verschiedene Fixpunkte ξ1 6= ξ2 besitzt. Dann folgt
|ξ1 − ξ2| = |f(ξ1) − f(ξ2)| ≤ L |ξ1 − ξ2| < |ξ1 − ξ2| .
Die letzte Ungleichung ist offenbar ungultig, so dass unsere Annahme von der Existenz
verschiedener Fixpunkte nicht zutreffen kann.
von 2.: Zunachst ist
|xk − ξ| = |f(xk−1) − f(ξ)| ≤ L |xk−1 − ξ| .Vollstandige Induktion ergibt
|xk − ξ| ≤ Lk |x0 − ξ| . (2.6)
Da die rechte Seite dieser Ungleichung fur k → ∞ gegen Null strebt, folgt die Behauptung.

30 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
von 3.: Aus
|x0 − ξ| ≤ |x0 − x1| + |x1 − ξ| = |x0 − x1| + |f(x0) − f(ξ)| ≤ |x0 − x1| + L |x0 − ξ|
erhalten wir
|x0 − ξ| ≤ 1
1 − L|x1 − x0| .
Die a priori-Abschatzung folgt nun aus (2.6). Die a posteriori-Abschatzung ergibt sich un-
mittelbar aus der Anwendung der a priori-Abschatzung auf xk−1 anstelle von x0.
2
Bemerkung 2.6
1. Der Banach’sche Fixpunktsatz gilt allgemeiner fur kontrahierende Selbstabbildungen auf
abgeschlossenen reellen Intervallen. Diese mussen nicht notwendig beschrankt sein.
Beim Fixpunktsatz 2.1 kann auf die Beschranktheit des Intervalls I nicht verzichtet wer-
den, wie das Beispiel der fixpunktfreien Selbstabbildung f(x) = x + 1 auf den abge-
schlossenenen Intervallen I1 = R und I2 = [0,∞) zeigt.
2. Die a priori-Abschatzung wird verwendet, um den Rechenaufwand abzuschatzen, der fur
eine gewunschte Genauigkeit der Fixpunktnaherung notig ist.
Fur eine vorgegebene Fehlerschranke ε > 0 ist
Lk
1 − L|x1 − x0| ≤ ε
genau dann erfullt, wenn
Lk ≤ (1 − L)ε
|x1 − x0|bzw.
k lnL ≤ ln(1 − L) + ln ε − ln |x1 − x0|
gelten. Auflosung nach k liefert wegen lnL < 0 die hinreichende Bedingung
k ≥ ln(1 − L) + ln ε − ln |x1 − x0|lnL
.
Spatestens fur
k =
⌊ln(1 − L) + ln ε − ln |x1 − x0|
lnL
⌋+ 1
(wobei ⌊x⌋ die großte ganze Zahl kleiner oder gleich x bezeichnet) gilt also
|xk − ξ| ≤ ε.
3. In der Regel ist die a posteriori-Abschatzung wesentlich genauer als die a priori-
Abschatzung, aber sie erfordert die Berechnung der Iterierten.

Numerische Mathematik fur das Lehramt · SS 2009 31
Beispiel 2.7 Die Funktion
f(x) = ln(3x), x ∈ I = [1.25, 3]
besitzt einen Fixpunkt, der mit der Fixpunktiteration (IV) bestimmt werden soll (Abb. 2.6).
1.25
ξ
3
f
Abb. 2.6: Fixpunkt von ln(3x)
Als Kontraktionskonstante verwenden wir
L = maxx∈I
∣∣f ′(x)∣∣ = max
x∈I
1
x= 0.8.
Wir suchen eine Iterierte xk, fur die bei Wahl von x0 = 2
|xk − ξ| ≤ 10−2
garantiert ist. Zunachst liefert die a priori-Abschatzung mit
x1 = ln 6
k ≥ ln(0.2) + ln(0.01) − ln |ln 6 − 2|ln 0.8
≈ 20.819.
Die vorgegebene Fehlerschranke wird also spatestens ab
k = 21 unterschritten.
Nach der Berechnung von
x10 = 1.51750, x11 = 1.51567,
zeigt die a posteriori-Abschatzung fur k = 11,
|x11 − ξ| ≤ 0.8
0.2|x11 − x10| ≈ 0.00732 < 10−2,
dass bereits x11 eine hinreichend genaue Naherung darstellt.
2.2 Lokale Fixpunktsatze
Definition 2.8 Ein Fixpunkt ξ von f heißt anziehend, wenn es eine Umgebung U um ξ gibt, so
dass die Fixpunktiteration (IV) fur alle x0 ∈ U gegen ξ konvergiert.
Ein Fixpunkt ξ von f heißt abstoßend, wenn es eine Umgebung U um ξ gibt, so dass die
Fixpunktiteration (IV) fur alle x0 ∈ U\{ξ} aus U ausbricht (d.h. dass fur alle x0 ∈ U\{ξ} ein
Index k ∈ N existiert, so dass xk 6∈ U gilt).
Bemerkung 2.9 Es gibt Fixpunkte, die weder anziehend noch abstoßend sind.
Satz 2.10 Vor.: f : I = [a, b] → R sei in I stetig differenzierbar und besitze einen Fixpunkt
ξ ∈ (a, b).
Beh.: Dann ist ξ
a) anziehender Fixpunkt , falls |f ′(ξ)| < 1 gilt,
b) abstoßender Fixpunkt , falls |f ′(ξ)| > 1 gilt.
Im Fall |f ′(ξ)| = 1 ist keine allgemein gultige Aussage moglich.
Beweis:

32 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
von a): Sei |f ′(ξ)| = 1− 2δ, δ > 0. Dann gibt es eine abgeschlossene ε-Umgebung U = U ε =[ξ − ε, ξ + ε] um ξ, so dass |f ′(x)| ≤ 1 − δ =: L fur alle x ∈ U gilt.
Weiter gibt es nach dem Mittelwertsatz zu jedem x ∈ U ein η ∈ U , so dass die Abschatzung
|f(x) − f(ξ)| =∣∣f ′(η)
∣∣ |x − ξ| ≤ L |x − ξ| ≤ Lε < ε
erfullt ist. Somit ist der Wertebereich von f auf U eine Teilmenge von U und f ist eine
kontrahierende Selbstabbildung auf U . Die Behauptung folgt nun aus dem Fixpunktsatz
2.5.
von b): Als Ubungsaufgabe. 2
Abb. 2.7 veranschaulicht Konvergenz und Divergenz der Fixpunktiteration fur verschiedene
Werte von f ′(ξ).
ax0x1
b
f
Abb. 2.7a: anziehender FP, f ′ > 0
ax0 x1
b
f
Abb. 2.7b: anziehender FP, f ′ < 0
ax0 x1
b
f
Abb. 2.7c: abstoßender FP, f ′<−1
2.3 Relaxation
Definition 2.11 Eine gegen ξ konvergierende Folge {xk}∞k=0 heißt
a) (mindestens) linear konvergent, wenn eine Konstante 0 ≤ C < 1 sowie ein Index k0 ∈ N
existieren, so dass
|xk+1 − ξ| ≤ C |xk − ξ| fur k ≥ k0 (2.7)
gilt,
b) konvergent von (mindestens) der Ordnung p > 1, wenn ein C ≥ 0 existiert, so dass
|xk+1 − ξ| ≤ C |xk − ξ|p fur k = 0, 1, . . .
gilt.
Die Konvergenzordnung eines Iterationsverfahrens ist durch die minimale Konvergenzordnung
der von ihm erzeugten Folgen festgelegt.
Bemerkung 2.12
1. Offensichtlich ist die Konvergenz umso schneller, je großer p ist. Fur linear konvergente
Verfahren sind kleine Werte von C gunstig. C = 12 bedeutet bei linearer Konvergenz,
dass sich der Fehler in jedem Iterationsschritt (mindestens) halbiert.

Numerische Mathematik fur das Lehramt · SS 2009 33
2. Unter den Voraussetzungen des Fixpunksatzes 2.5 konvergiert das Iterationsverfahren
(IV) mindestens linear.
In der hinreichend kleinen Umgebung U eines Fixpunkts ξ der stetig differenzierbaren Funktion
f gilt nach dem Mittelwertsatz fur die Iterierten von (IV) und ein η aus U :
|xk+1 − ξ||xk − ξ| =
|f(xk) − f(ξ)||xk − ξ| =
∣∣f ′(η)∣∣ ≈
∣∣f ′(ξ)∣∣ .
Da |f ′(ξ)| eine Unterschranke fur C in (2.7) darstellt, andererseits ξ im Fall |f ′(ξ)| < 1 nach
Satz 2.10 anziehender Fixpunkt ist, hangt die Konvergenzgeschwindigkeit von (IV) in der Um-
gebung eines Fixpunkts ξ im Wesentlichen von |f ′(ξ)| ab. Die Idee der Relaxation besteht nun
darin, f so abzuandern, dass (IV) immer noch gegen ξ konvergiert, aber fur die geanderte
Iterationsfunktion h der Betrag von h′(ξ) moglichst klein wird.
Ausgangspunkt unserer Uberlegungen ist (IV) mit einer stetig differenzierbaren Funktion f , die
in I einen Fixpunkt besitzen moge. Fur eine Zahl λ ∈ R betrachten wir nun anstelle von (IV)
die sogenannte relaxierte Iteration
xk+1 = λf(xk) + (1 − λ)xk =: h(xk). (2.8)
Falls die Folge {xk}∞k=0 aus (2.8) gegen ξ strebt, liefert der Ansatz
h′(ξ) = λf ′(ξ) + 1 − λ!= 0
im Fall f ′(ξ) 6= 1 den optimalen Parameterwert
λ =1
1 − f ′(ξ). (2.9)
Im Fall f ′(ξ) = 1 versagt die Relaxation. Unabhangig von λ gilt dann namlich h′(ξ) = 1, so
dass die Konvergenzfrage fur h ebenso offen ist wie fur f . Falls das Iterationsverfahren unter
diesen Umstanden uberhaupt konvergiert, ist die Konvergenz im Allgemeinen sehr langsam.
Wir setzen nun f ′(ξ) 6= 1 voraus. Einsetzen des Wertes aus (2.9) in (2.8) liefert das Iterations-
verfahren
x0 ∈ I,
xk+1 = xk +f(xk) − xk
1 − f ′(ξ), k = 0, 1, . . . ,
(2.10)
welches zumindest lokal (d.h. in einer hinreichend kleinen Umgebung von ξ) konvergiert. Im
nachsten Abschnitt werden wir zeigen, dass die Konvergenz sogar quadratisch ist.
Setzt man noch
g(x) = f(x) − x,
dann lautet (2.10)
x0 ∈ I,
xk+1 = xk − g(xk)
g′(ξ), k = 0, 1, . . . .
(2.11)
Der Fixpunkt ξ von f ist Nullstelle von g. Im Fall von g′(ξ) 6= 0 wird durch (2.11) also ein lokal
konvergentes Iterationsverfahren zur Bestimmung einer Nullstelle von g definiert.

34 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
2.4 Das Newton-Verfahren
Die Iteration (2.11) ist praktisch nicht durchfuhrbar, da man ξ kennen musste, um g′(ξ) zu
berechnen. Falls g stetig differenzierbar ist, gilt aber fur xk hinreichend nahe bei ξ
g′(xk) ≈ g′(ξ).
Diese Beobachtung fuhrt auf das Newton-Verfahren.
Definition 2.13 Fur eine im Intervall I differenzierbare Funktion g heißt das Iterationsverfahren
(NV)
x0 ∈ I,
xk+1 = xk − g(xk)
g′(xk), k = 0, 1, . . .
(2.12)
Newton-Verfahren.
Satz 2.14 Vor.: Sei I = [a, b] ⊂ R ein beschranktes Intervall. g : I → R sei in (a, b) zweimal
stetig differenzierbar und besitze eine Nullstelle ξ ∈ (a, b). Weiter gelte g′(ξ) 6= 0.
Beh.: Dann konvergiert das Newton-Verfahren lokal mindestens quadratisch gegen ξ.
Beweis: Zunachst gibt es ein δ1 > 0 so dass g′(η) 6= 0 fur alle
η ∈ W := [ξ − δ1, ξ + δ1] ⊆ I
gilt. Fur dieses Intervall W definieren wir die Konstanten
M1 := maxη∈W
∣∣g′′(η)∣∣ , M2 := min
η∈W
∣∣g′(η)∣∣ , δ := min{δ1,
M2
3M1}
sowie das Intervall
U = [ξ − δ, ξ + δ].
Wir wahlen x0 ∈ U . Unter der Voraussetzung, dass xk in U liegt, wollen wir
|xk+1 − ξ||xk − ξ| =
∣∣∣∣xk − g(xk)
g′(xk)− ξ
∣∣∣∣|xk − ξ| =
∣∣∣∣g′(xk)(xk − ξ) − g(xk)
g′(xk)(xk − ξ)
∣∣∣∣
geeignet abschatzen. Wegen g(ξ) = 0 gilt die Taylor-Entwicklung
g(xk) = g(ξ) + g′(ξ)(xk − ξ) +1
2g′′(η1)(xk − ξ)2 = g′(ξ)(xk − ξ) +
1
2g′′(η1)(xk − ξ)2
fur ein η1 zwischen ξ und xk, woraus
∣∣∣∣g′(xk)(xk − ξ) − g(xk)
g′(xk)(xk − ξ)
∣∣∣∣ =
∣∣∣∣∣(g′(xk) − g′(ξ))(xk − ξ) − 1
2g′′(η1)(xk − ξ)2
g′(xk)(xk − ξ)
∣∣∣∣∣
folgt. Weiter existiert nach dem Mittelwertsatz ein η2 zwischen ξ und xk, so dass
g′(xk) − g′(ξ) = g′′(η2)(xk − ξ)
Numerische Mathematik fur das Lehramt · SS 2009 35
gilt. Somit erhalt man schließlich
|xk+1 − ξ||xk − ξ| =
∣∣∣∣∣g′′(η2) − 1
2g′′(η1)
g′(xk)
∣∣∣∣∣ |xk − ξ| ≤32M1
M2· δ ≤ 1
2. (2.13)
Aus
|xk+1 − ξ| ≤ 1
2|xk − ξ|
folgt insbesondere xk+1 ∈ U . Mit vollstandiger Induktion ergibt sich
|xk − ξ| ≤(
1
2
)k
|x0 − ξ| ,
so dass die Folge {xk} unabhangig von x0 gegen ξ strebt. Die lokal mindestens quadratische
Konvergenzordnung des Newton-Verfahrens folgt schließlich aus (2.13) mittels
|xk+1 − ξ| =
∣∣∣∣∣g′′(η2) − 1
2g′′(η1)
g′(xk)
∣∣∣∣∣ |xk − ξ|2 ≤ 3M1
2M2|xk − ξ|2 .
2
Bemerkung 2.15
ξ
x2 x1 x0
g
Abb. 2.8: Newton-Verfahren
1. Geometrische Interpretation des Newton-Verfahrens:
im (k+1)-ten Iterationsschritt bestimmt man eine Null-
stelle der Tangente an g im Punkt (xk, g(xk)) (lineare
Gleichung, fur g′(xk) 6= 0 eindeutig losbar).
2. Quadratische Konvergenz bedeutet anschaulich,
dass sich die Zahl gultiger Dezimalstellen in jedem
Iterationsschritt ungefahr verdoppelt. Dies gilt aber
nur in der Nahe von ξ.
Dazu ein Zahlenbeispiel: Berechnung einer Nullstelle
von
g(x) = ln(3x) − x
mit dem Newton-Verfahren. Der Startwert x0 = 2 liefert die folgenden Iterierten (gultige
Dezimalstellen sind jeweils unterstrichen):
x1 = 1.583
x2 = 1.5149
x3 = 1.5121397
x4 = 1.512134551675
3. Beispiel fur sehr langsame Konvergenz (am Anfang) des Newton-Verfahrens: Bestim-
mung der Nullstelle ξ = 1 von
g(x) = xn − 1 (n ∈ N).
Das Newton-Verfahren lautet
xk+1 = xk − xnk − 1
nxn−1= (1 − 1
n)xk +
1
nxn−1.
36 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
Fur xk > 0 gilt also
xk+1 > (1 − 1
n)xk.
Mit vollstandiger Induktion zeigt man leicht, dass fur n > 2 und x0 = n nach n − 2Schritten immer noch xn−2 > 2 gilt.
2.5 Verwandte Iterationsverfahren
2.5.1 Vereinfachtes Newton-Verfahren
ξ
x2 x1 x0
g
Abb. 2.9: Vereinfachtes Newton-V.
In der Nahe einer Nullstelle ξ andert sich g′ nicht mehr
stark, falls g stetig differenzierbar ist. Statt die Ableitung in
jedem Iterationsschritt neu zu berechnen, verwendet man
beim vereinfachten Newton-Verfahren einen festen Wert.
Varianten des vereinfachten Newton-Verfahrens berechnen
die Ableitung jeweils nach n Schritten neu oder immer
dann, wenn die Differenz von xk und xk+1 einen heuristisch
gewahlten Wert uberschreitet. Im einfachsten Fall verwen-
det man anstelle von g′(xk) stets g′(x0):
xk+1 = xk − g(xk)
g′(x0), k = 0, 1, . . . . (2.14)
Das vereinfachte Newton-Verfahren ist zwar nur linear konvergent, aber falls g′(x0) tatsachlich
eine gute Naherung von g′(xk) darstellt, ist die zugehorige Kontraktionskonstante sehr klein.
2.5.2 Sekantenverfahren
ξ
x2 x1 x0
g
Abb. 2.10: Sekantenverfahren
Beim Sekantenverfahren ersetzt man die Ableitung g′(xk)durch Sekantensteigungen. Dies ist insbesondere dann von
Interesse, wenn die Ableitung nicht oder nur schwer be-
rechnet werden kann. Beim Sekantenverfahren startet man
mit zwei Startnaherungen x0 und x1. Die Sekantensteigun-
gen erhalt man aus Differenzenquotienten nachfolgender
Iterationsschritte:
x0, x1 ∈ I
xk+1 = xk − g(xk)
g(xk) − g(xk−1)
xk − xk−1
k = 1, 2, . . . . (2.15)
Das Sekantenverfahren besitzt die gebrochene Konvergenzordnung (1 +√
5)/2 ≈ 1.618,
benotigt aber pro Iterationsschritt nur eine Funktionsauswertung. Zwei Schritte des Sekanten-
verfahrens sind also ungefahr so aufwandig wie ein Schritt des Newton-Verfahrens. Bezogen
auf den Rechenaufwand konvergiert das Sekantenverfahren daher sogar schneller als das
Newton-Verfahren.

Numerische Mathematik fur das Lehramt · SS 2009 37
2.5.3 Das Bisektionsverfahren
Beim Bisektionsverfahren ist die Nullstelle einer stetigen Funktion g im Intervall I0 = [a0, b0]gesucht. Dabei wird vorausgesetzt, dass g(a0)g(b0) < 0 gilt, wodurch die Existenz einer Null-
stelle in I0 nach dem Zwischenwertsatz gesichert ist. Durch fortgesetzte Intervallhalbierung
wird eine Nullstelle von g in eine Intervallschachtelung eingeschlossen:
Algorithmus 2.1: Bisektionsverfahren
Fur k = 1, 2, . . . :
mk =1
2(ak−1 + bk−1)
Falls
– g(mk) = 0 : ξ = mk ist Nullstelle von g
– g(ak−1)g(mk) < 0 : Ik = [ak−1, mk]
– g(ak−1)g(mk) > 0 : Ik = [mk, bk−1]
Das Bisektionsverfahren wird durch die folgende Maple-Prozedur implementiert:
Maple-Prozedur 2.1: Bisektionsverfahren
bisekt := proc( A, B, g )
local a, b, k, m;
a := A; b := B;
for k from 1 to 100 while abs(b-a) > 1.0E-12 do
m := ( a + b ) / 2;
if g(m) = 0 then
return m;
elif g(a)*g(m) < 0 then
b := m;
else
a := m;
end if;
end do;
if abs(b-a) < 1.0E-12 then
return m;
else
print( "Nach 100 Iterationen keine
Nullstelle von g gefunden." );
end if;
end proc;
Die Eingabewerte A und B fur die Intervallgrenzen mussen in der Prozedur in lokale Varia-
blen umgespeichert werden, damit sie im Lauf des Bisektionsverfahrens uberschrieben wer-
den konnen. Dabei wird vorausgesetzt, dass die Funktion g im aufrufenden Maple-Worksheet
definiert ist und dass geeignete Werte von A und B an die Prozedur ubergeben werden.

38 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
Die maximale Anzahl von 100 Iterationen stellt sicher, dass
die Prozedur auch bei fehlerhaften Eingabewerten beendet
wird. Mit Hilfe der while-Bedingung wird die Iteration abge-
brochen, wenn die gesuchte Nullstelle mit der gewunschten
Genauigkeit (hier: 10−12) bestimmt ist.
Bei einer Variante des Bisektionsverfahrens, der regula fal-
si, wird mk nicht durch Halbierung, sondern durch linea-
re Interpolation der Randwerte von Ik−1 bestimmt. Ebenso
wie das Bisektionsverfahren ist die regula falsi fur eine ste-
tige Funktion g linear konvergent.
a0
m1
b0
g
Abb. 2.11: regula falsi
2.6 Vektor- und Matrixnormen
Definition 2.16 Sei V ein reeller Vektorraum. Eine Abbildung ‖.‖ : V → R+0 heißt Norm, falls
sie die folgenden Eigenschaften erfullt:
(i) ‖x‖ ≥ 0 fur alle x ∈ V .
‖x‖ = 0 ⇔ x = 0 (Nullvektor) (Definitheit)
(ii) ‖αx‖ = |α| ‖x‖ fur alle x ∈ V , α ∈ R. (Homogenitat)
(iii) ‖x + y‖ ≤ ‖x‖ + ‖y‖ fur alle x, y ∈ V . (Dreiecks-Ungleichung)
Eine Norm auf Rn heißt Vektornorm, eine Norm auf Rn×n Matrixnorm.
Beispiel 2.17 Der Nachweis der Normeigenschaften ist bei den folgenden Normen jeweils als
Ubungsaufgabe gestellt.
1. V = Rn, p ≥ 1: ‖x‖p := p
√√√√n∑
i=1
|xi|p p-Norm
speziell p = 1: ‖x‖1 :=n∑
i=1
|xi|
p = 2: ‖x‖2 :=
√√√√n∑
i=1
x2i Euklid-Norm
2. V = Rn: ‖x‖∞ :=n
maxi=1
|xi| Maximumnorm
3. V = Rn×n: ‖A‖F :=
√√√√n∑
i,j=1
a2ij Frobenius-Norm
Bemerkung 2.18 Jede Norm erfullt die umgekehrte Dreiecks-Ungleichung
(iii)’ |‖x‖ − ‖y‖| ≤ ‖x − y‖ fur alle x, y ∈ V.
(iii)’ ist eine verkleidete Stetigkeitsaussage. Jede Norm ist stetig, denn aus y → x folgt nach
(iii)’ auch ‖y‖ → ‖x‖.
Fur Fehlerabschatzungen benotigt man in der Numerik Matrixnormen mit zusatzlichen Eigen-
schaften.

Numerische Mathematik fur das Lehramt · SS 2009 39
Definition 2.19
1. Eine Matrixnorm ‖.‖ heißt submultiplikativ, wenn
‖A · B‖ ≤ ‖A‖ · ‖B‖ fur alle A, B ∈ Rn×n
gilt.
2. Eine Matrixnorm ‖.‖M heißt mit einer Vektornorm ‖.‖V vertraglich, wenn
‖Ax‖V ≤ ‖A‖M · ‖x‖V fur alle A ∈ Rn×n, x ∈ Rn
gilt.
3. Sei ‖.‖V eine Vektornorm. Dann heißt
‖A‖V := supx 6=0
‖Ax‖V
‖x‖V
= max‖x‖V =1
‖Ax‖V (2.16)
die von ‖.‖V induzierte Matrixnorm.
Bemerkung 2.20
1. Das Gleichheitszeichen in (2.16) begrundet sich durch
(i) die Homogenitat der Norm,
(ii) die Stetigkeit der Norm,
(iii) die Kompaktheit der Einheitskugel im Rn.
2. Wegen
‖A‖V ≥ ‖Ax‖V
‖x‖V
fur alle x ∈ Rn
ist jede induzierte Matrixnorm mit ihrer induzierenden Vektornorm vertraglich.
3. Die Normeigenschaften der induzierten Matrixnorm sind leicht nachprufbar. Weiter gilt:
(a) Eine induzierte Matrixnorm ist submultiplikativ, denn aus der Vertraglichkeit mit der
induzierenden Vektornorm folgt
‖A · B‖V = supx 6=0
‖ABx‖V
‖x‖V
= supx 6=0
‖A(Bx)‖V
‖x‖V
≤ supx 6=0
‖A‖V ‖Bx‖V
‖x‖V
= ‖A‖V · ‖B‖V .
(b) In einer induzierten Matrixnorm besitzt die Einheitsmatrix I die Norm 1:
‖I‖V = max‖x‖V =1
‖Ix‖V = max‖x‖V =1
‖x‖V = 1.
Aus dieser Eigenschaft kann man z.B. schließen, dass die Frobenius-Norm von
keiner Vektornorm induziert wird. Fur I ∈ Rn×n, n > 1, gilt namlich
‖I‖F =√
n > 1.

40 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
4. Im Rn (und ebenso im Rn×n) sind alle Normen aquivalent. Fur je zwei Normen ‖.‖I , ‖.‖II
gibt es c1, c2 > 0, so dass
c1 ‖x‖I ≤ ‖x‖II ≤ c2 ‖x‖I fur alle x ∈ Rn
gilt.
Die Konvergenz einer Vektorfolge hangt also nicht von der Norm ab. Fur die Gute nume-
rischer Abschatzungen kann die richtige Wahl der Norm aber entscheidend sein.
Satz 2.21 Sei A ∈ Rn×n. Dann gilt fur die induzierten p-Normen von A:
a) ‖A‖1 =n
maxj=1
n∑
i=1
|aij | Spaltensummennorm,
b) ‖A‖2 =(ρ(AT A)
) 1
2 Spektralnorm,
c) ‖A‖∞ =n
maxi=1
n∑
j=1
|aij | Zeilensummennorm.
Dabei bezeichnet ρ(AT A) den betragsgroßten Eigenwert von AT A.
Beweis:
von c): Sei v ∈ Rn mit ‖v‖∞ = 1. Dann gilt
‖Av‖∞ =n
maxi=1
∣∣∣∣∣∣
n∑
j=1
aijvj
∣∣∣∣∣∣≤ n
maxi=1
n∑
j=1
|aij | |vj | ≤n
maxi=1
n∑
j=1
|aij | . (2.17)
Sei nun k ein Index, fur den die Zeilensumme der Betrage von A maximal wird. Fur v = (vj)mit
vj =
+1, falls akj ≥ 0
−1, falls akj < 0
gilt in (2.17) jeweils Gleichheit. Hieraus folgt die Behauptung.
von a): Ahnlich (Ubungsaufgabe).
von b): Mit Hilfe einer Orthonormalbasis aus Eigenvektoren von AT A (Spektralsatz).
2

Numerische Mathematik fur das Lehramt · SS 2009 41
2.7 Iterationsverfahren im Rn
Die eingefuhrten Normen ermoglichen es, fur Abbildungen f : Rn → Rn einen zum Fixpunkt-
satz 2.5 aquivalenten Fixpunktsatz zu formulieren. Im Beweis dieses Satzes ist lediglich jeder
reelle Betrag durch eine Vektornorm zu ersetzen. Ebenso lasst sich die lokal quadratische
Konvergenz des Newton-Verfahrens fur Funktionen von Rn nach Rn aus der Fixpunktiteration
ableiten.
Falls in diesem Kapitel bei einem Vektor rechts unten ein Index auftritt, so bezeichnet er eine
Komponente des Vektors, z.B.
x =
(x1
x2
)∈ R2.
Einen Iterationsindex bringen wir rechts oben an und versehen ihn mit Klammern: x(k) be-
zeichnet die k-te Iterierte eines Iterationsverfahrens.
Definition 2.22 Es sei ‖.‖ eine beliebige Vektornorm. Eine Abbildung f : D ⊆ Rn → Rn heißt
kontrahierend, wenn ein 0 ≤ L < 1 existiert mit
‖f(x) − f(y)‖ ≤ L ‖x − y‖ fur alle x, y ∈ D.
Fur kontrahierende Selbstabbildungen gilt der Banach’sche Fixpunktsatz im Rn sinngemaß
wie fur reellwertige Funktionen (Satz 2.5). Im Wesentlichen wird nur der reelle Betrag durch
eine Vektornorm ersetzt.
Satz 2.23 (Banach’scher Fixpunktsatz im Rn) Vor.: D ⊆ Rn sei nichtleer und abgeschlos-
sen. f : D → D sei eine kontrahierende Selbstabbildung auf D mit Kontraktionskonstante
L < 1.
Beh.: Dann gilt:
1. f besitzt in D genau einen Fixpunkt ξ.
2. Das Iterationsverfahren
(IV)
{x(0) ∈ D,
x(k+1) = f(x(k)), k = 0, 1, . . .
konvergiert fur jeden Startwert x(0) ∈ D gegen ξ.
3. Fur k ∈ N gilt die a priori-Abschatzung
∥∥∥x(k) − ξ∥∥∥ ≤ Lk
1 − L
∥∥∥x(1) − x(0)∥∥∥ .
4. Fur k ∈ N gilt die a posteriori-Abschatzung
∥∥∥x(k) − ξ∥∥∥ ≤ L
1 − L
∥∥∥x(k) − x(k−1)∥∥∥ .
Beweis: Wie von Satz 2.5. 2

42 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
Bevor wir weitere Satze uber reellwertige Funktionen auf Funktionen f : Rn → Rn ubertra-
gen, wollen wir klaren, wie man fur eine Funktion f : Rn → Rn Kontraktion nachweist. Wir
betrachten
f : D ⊆ Rn → Rn; f =
f1
...
fn
, x =
x1
...
xn
, y =
y1
...
yn
.
Im Folgenden setzen wir voraus, dass f in D differenzierbar ist. Dann definieren wir fur i =1, . . . , n die reellwertigen, differenzierbaren Funktionen
ϕi(t) := fi(ty + (1 − t)x) = fi(x + t(y − x)), t ∈ [0, 1].
Zunachst ist
ϕi(0) = fi(x), ϕi(1) = fi(y).
Nach dem Mittelwertsatz existiert ein ηi ∈ (0, 1) mit
|fi(x) − fi(y)| = |ϕi(1) − ϕi(0)| =∣∣ϕ′
i(ηi)∣∣ =
∣∣(gradfi
(x + ηi(y − x)
))· (y − x)
∣∣
=
∣∣∣∣∣∣
n∑
j=1
∂fi
∂xj(x + ηi(y − x)) · (yj − xj)
∣∣∣∣∣∣≤
n∑
j=1
maxz∈D
∣∣∣∣∂fi
∂xj(z)
∣∣∣∣ · |yj − xj |
≤ nmaxj=1
|yj − xj | ·n∑
j=1
maxz∈D
∣∣∣∣∂fi
∂xj(z)
∣∣∣∣ ≤ ‖y − x‖∞ · nmaxi=1
n∑
j=1
maxz∈D
∣∣∣∣∂fi
∂xj(z)
∣∣∣∣
= ‖Jmax‖∞ · ‖y − x‖∞
mit
(Jmax)ij = maxz∈D
∣∣∣∣∂fi
∂xj(z)
∣∣∣∣ . (2.18)
Durch Maximumbildung uber alle i folgt die Abschatzung
‖f(y) − f(x)‖∞ ≤ ‖Jmax‖∞ · ‖y − x‖∞ .
Im Fall ‖Jmax‖∞ < 1 ist f kontrahierend und aus Satz 2.23 erhalten wir
Korollar 2.24 Vor.: D ⊆ Rn sei abgeschlossen. f : D → D sei eine stetig differenzierbare
Selbstabbildung und es sei Jmax wie in (2.18) definiert.
Beh.: Falls ‖Jmax‖∞ < 1 gilt, ist f auf D kontrahierend (in der Maximumnorm) und die Fixpunkt-
iteration {x(0) ∈ D,
x(k+1) = f(x(k)), k = 0, 1, . . .
konvergiert fur jedes x(0) ∈ D gegen den eindeutig bestimmten Fixpunkt ξ von f .
Beispiel 2.25 Gesucht ist ein Schnittpunkt der Kurven

Numerische Mathematik fur das Lehramt · SS 2009 43
K1
K2
Abb. 2.12: Fixpunktiteration im R2
K1 : x − 1
5y2 = 0, K2 : x2 + (y − 3)2 = 8.
Dieser soll im Intervall I := [−1, 1]× [−1, 1] durch Fixpunkt-
iteration berechnet werden. Dazu formen wir die Gleichun-
gen der Kurven zuerst geeignet um:
x − 1
5y2 = 0 ⇔ 4
5x =
1
5y2 − 1
5x ⇔ x =
1
4(y2 − x),
x2 + (y − 3)2 = 8 ⇔ 6y = x2 + y2 + 1
⇔ y =1
6(x2 + y2 + 1).
Um die Notation einfach zu halten, bezeichnen wir im Folgenden die Vektorkomponenten mit
x und y statt x1 und x2. Indizes an x und y bezeichnen wie in Kapitel 2.1 Iterierte.
Die Funktionen
f1(x, y) =1
4(y2 − x),
f2(x, y) =1
6(x2 + y2 + 1).
erfullen fur x, y ∈ [−1, 1] die Abschatzungen
−1
4=
1
4(0 − 1) ≤ f1(x, y) ≤ 1
4(1 + 1) =
1
2,
1
6=
1
6(0 + 0 + 1) ≤ f2(x, y) ≤ 1
6(1 + 1 + 1) =
1
2,
so dass f = (f1(x, y), f2(x, y))T das Intervall I in sich abbildet.
Weiter gilt fur die Jacobi-Matrix
Jf (x, y) =
−1
4
1
2y
1
3x
1
3y
auf I die Abschatzung
‖Jf (x, y)‖∞ ≤
∥∥∥∥∥∥∥∥
1
4+
1
2
1
3+
1
3
∥∥∥∥∥∥∥∥∞
=3
4.
Also ist f auf I eine kontrahierende Selbstabbildung und die Fixpunktiteration
(x0
y0
)∈ I,
(xk+1
yk+1
)=
(f1(xk, yk)f2(xk, yk)
), k = 0, 1, . . .

44 Markus Neher, Universitat Karlsruhe (TH) · 14. Mai 2009
konvergiert fur jeden Startwert (x0, y0)T ∈ I gegen den in I eindeutigen Schnittpunkt ξ von K1
und K2.
Fur (x0, y0)T = (0, 0)T erhalt man die folgenden Iterierten:
(x1, y1)T = (0.000000, 0.166667)T ,
(x2, y2)T = (0.006944, 0.171296)T ,
(x3, y3)T = (0.005599, 0.171565)T ,
(x4, y4)T = (0.005959, 0.171578)T ,
(x5, y5)T = (0.005870, 0.171579)T ,
(x6, y6)T = (0.005892, 0.171579)T ,
die wie erwartet gegen
ξ = (0.005888 . . . , 0.171579 . . . )T
konvergieren.
Wie fur reellwertige Funktionen beweist man den folgenden lokalen Fixpunktsatz:
Satz 2.26 Vor.: f : D ⊆ Rn → Rn besitze einen Fixpunkt ξ ∈ D und sei in einer Umgebung
von ξ stetig differenzierbar. Außerdem gelte fur die Jacobi-Matrix Jf (ξ)
‖Jf (ξ)‖∞ < 1.
Beh.: Dann existiert eine abgeschlossene Kugel Bε(ξ) := {x ∈ Rn : ‖x − ξ‖∞ ≤ ε}, so dass fBε in sich abbildet und auf Bε kontrahierend ist. Die Fixpunktiteration
{x(0) ∈ Bε,
x(k+1) = f(x(k)), k = 0, 1, . . .
konvergiert fur jedes x(0) ∈ Bε gegen ξ.
Auch das Newton-Verfahren lasst sich fast wortlich auf Funktionen g : Rn → Rn ubertragen.
Dazu muss nur die in (2.12) auftretende Division durch f ′ als Multilikation mit der Inversen der
Ableitung interpretiert werden.
Satz 2.27 Vor.: Sei D ⊆ Rn offen. g : D → Rn besitze eine Nullstelle ξ ∈ D und sei in einer
offenen Umgebung von ξ zweimal stetig differenzierbar. Die Jacobi-Matrix Jg(x) sei an der
Stelle ξ regular:
det (Jg(ξ)) 6= 0.
Beh.: Dann konvergiert das Newton-Verfahren
{x(0) ∈ D,
x(k+1) = x(k) −(Jg(x
(k)))−1
g(x(k)), k = 0, 1, . . .
lokal quadratisch gegen ξ.
Bemerkung 2.28 Bei der praktischen Durchfuhrung des Newton-Verfahrens wird die Inverse
der Jacobi-Matrix nicht berechnet. Stattdessen lost man in jedem Iterationsschritt das lineare
Gleichungssystem
Jg(x(k)) · (x(k+1) − x(k)) = −g(x(k)).

Numerische Mathematik fur das Lehramt · SS 2009 45
Beispiel 2.29 Wir bestimmen den Schnittpunkt der Kurven
K1 : x − 1
5y2 = 0, K2 : x2 + (y − 3)2 = 8
mit dem Newton-Verfahren. Wie in Beispiel 2.25 bezeichnen wir die Vektorkomponenten mit xund y.
Fur die Funktionen
g1(x, y) = x − 1
5y2,
g2(x, y) = x2 + (y − 3)2 − 8,
erhalt man die Jacobi-Matrix
Jg(x, y) =
∂g1
∂x(x, y)
∂g1
∂y(x, y)
∂g2
∂x(x, y)
∂g2
∂y(x, y)
=
1 −2
5y
2x 2y − 6
.
An der Stelle (x0, y0)T = (0, 0)T gilt also
Jg(0, 0) =
1 0
0 −6
.
Im ersten Iterationsschritt ist das lineare Gleichungssystem
1 0
0 −6
·((
x1
y1
)−
(0
0
))= −
(g1(0, 0)
g2(0, 0)
)=
(0
−1
)
zu losen. Dies ergibt(
x1
y1
)=
0
1
6
.
Im zweiten Iterationsschritt lautet die Jacobi-Matrix
Jg(0,1
6) =
1 − 1
15
0 −17
3
.
Das lineare Gleichungssystem
1 − 1
15
0 −17
3
·
(
x2
y2
)−
0
1
6
= −
g1(0,
1
6)
g2(0,1
6)
=
1
180
− 1
36
besitzt die Losung
x2
y2
=
0
1
6
+
1
180+
1
15 · 204
1
204
=
0.005882
0.171568
,
womit man bereits nach zwei Iterationsschritten eine gute Naherung fur
ξ = (0.005888 . . . , 0.171579 . . . )T
erhalt.





























