Embed Size (px)
Citation preview

Object Contour Detection with a Fully Convolutional Encoder-Decoder Network
Jimei YangAdobe Research
Brian PriceAdobe [email protected]
Scott CohenAdobe [email protected]
Honglak LeeUniversity of Michigan, Ann Arbor
Ming-Hsuan YangUC Merced
Abstract
We develop a deep learning algorithm for contour de-tection with a fully convolutional encoder-decoder network.Different from previous low-level edge detection, our al-gorithm focuses on detecting higher-level object contours.Our network is trained end-to-end on PASCAL VOC withrefined ground truth from inaccurate polygon annotations,yielding much higher precision in object contour detectionthan previous methods. We find that the learned model gen-eralizes well to unseen object classes from the same super-categories on MS COCO and can match state-of-the-artedge detection on BSDS500 with fine-tuning. By combiningwith the multiscale combinatorial grouping algorithm, ourmethod can generate high-quality segmented object propos-als, which significantly advance the state-of-the-art on PAS-CAL VOC (improving average recall from 0.62 to 0.67) witha relatively small amount of candidates (∼1660 per image).
1. Introduction
Object contour detection is fundamental for numerousvision tasks. For example, it can be used for image segmen-tation [44, 3], for object detection [16, 19], and for occlu-sion and depth reasoning [22, 2]. Given its axiomatic im-portance, however, we find that object contour detection isrelatively under-explored in the literature [49]. At the sametime, many works have been devoted to edge detection thatresponds to both foreground objects and background bound-aries (Figure 1 (b)). In this paper, we address “object-only”contour detection that is expected to suppress backgroundboundaries (Figure 1(c)).
Edge detection has a long history. Early research fo-cused on designing simple filters to detect pixels with high-est gradients in their local neighborhood, e.g. Sobel [17]and Canny [9]. The main problem with filter based methods
(a) Image (b) [13] Ours
Figure 1. Object contour detection. Given input images (a), ourmodel can effectively learn to detect contours of foreground ob-jects (c) in contrast to traditional edge detection (b).
is that they only look at the color or brightness differencesbetween adjacent pixels but cannot tell the texture differ-ences in a larger receptive field. With the advance of texturedescriptors [37], Martin et al. [39] combined color, bright-ness and texture gradients in their probabilistic boundarydetector. Arbelaez et al. [3] further improved upon thisby computing local cues from multiscale and spectral clus-tering, known as gPb, which yields state-of-the-art accu-racy. However, the globalization step of gPb significantlyincreases the computational load. Lim and Dollar [32, 13]analyzed the clustering structure of local contour maps anddeveloped efficient supervised learning algorithms for fastedge detection [13]. These efforts lift edge detection to ahigher abstract level, but still fall below human perceptiondue to their lack of object-level knowledge.
Recently deep convolutional networks [31] have demon-strated remarkable ability of learning high-level represen-tations for object recognition [19, 11]. These learned fea-tures have been adopted to detect natural image edges [27,6, 46, 51] and yield a new state-of-the-art performance [51].All these methods require training on ground truth contourannotations. However, since it is very challenging to col-lect high-quality contour annotations, the available datasets
1

for training contour detectors are actually very limited andin small scale. For example, the standard benchmarks,Berkeley segmentation (BSDS500) [38] and NYU depth v2(NYUDv2) [47] datasets only include 200 and 381 trainingimages, respectively. Therefore, the representation powerof deep convolutional networks has not been entirely har-nessed for contour detection. In this paper, we scale upthe training set of deep learning based contour detection tomore than 10k images on PASCAL VOC [15]. To addressthe quality issue of ground truth contour annotations, wedevelop a method based on dense CRF [28] to refine theobject segmentation masks from polygons.
Given image-contour pairs, we formulate object contourdetection as an image labeling problem. Inspired by thesuccess of fully convolutional networks [36] and deconvolu-tional networks [40] on semantic segmentation, we developa fully convolutional encoder-decoder network (CEDN).Being fully convolutional, our CEDN network can operateon arbitrary image size and the encoder-decoder networkemphasizes its asymmetric structure that differs from de-convolutional network [40]. We initialize our encoder withVGG-16 net [48] (up to the “fc6” layer) and to achievedense prediction of image size our decoder is constructedby alternating unpooling and convolution layers where un-pooling layers re-use the switches from max-pooling layersof encoder to upscale the feature maps. During training,we fix the encoder parameters (VGG-16) and only optimizedecoder parameters. This allows the encoder to maintain itsgeneralization ability so that the learned decoder networkcan be easily combined with other tasks, such as boundingbox regression or semantic segmentation.
We evaluate the trained network on unseen object cat-egories from BSDS500 and MS COCO datasets [33], andfind the network generalizes well to objects in similar“super-categories” to those in the training set, e.g. it gener-alizes to objects like “bear” in the “animal” super-categorysince “dog” and “cat” are in the training set. We also showthe trained network can be easily adapted to detect natu-ral image edges through a few iterations of fine-tuning andyields comparable results with the state-of-the-art [51].
An immediate application of contour detection is gener-ating object proposals. Previous literature has investigatedvarious methods of generating bounding box or segmentedobject proposals by scoring edge features [53, 12] and com-binatorial grouping [50, 10, 4] and etc. In this paper, we usea multiscale combinatorial grouping (MCG) algorithm [4]to generate segmented object proposals from our detectedcontour maps. As a result, our method significantly im-proves the quality of segmented object proposals on thePASCAL VOC 2012 validation set, achieving 0.67 aver-age recall from overlap 0.5 to 1.0 with only about 1660candidates per image, compared to the 0.62 average re-call by original MCG algorithm with near 5140 candidates
per image. We also evaluate object proposals on the MSCOCO dataset with 80 object classes and analyze the av-erage recalls from different object classes and their super-categories. Our key contributions are summarized below:
• We develop a simple yet effective fully convolutionalencoder-decoder network for object contour detectionand the trained model generalizes well to unseen ob-ject classes from the same super-categories, yieldingsignificantly higher precision than previous methods.
• We show we can fine tune our network for edge detec-tion and match the state-of-the-art in terms of precisionand recall.
• We develop a method to generate accurate object con-tours from imperfect polygon based segmentation an-notations, which makes training easier.
• Our method significantly improves the state-of-the-artresults on segmented object proposals by integratingwith combinatorial grouping [4].
2. Related WorkSemantic contour detection. Hariharan et al. [20] studythe problem of detecting semantic boundaries betweendifferent object classes without considering the occlusionboundaries of two adjacent object instances from the sameclass, e.g. a mom hugging her daughter. Although theirmethod can be extended to detect object instance contours,it might encounter challenges of generalizing to unseen ob-ject classes due to the use of object detector output. Berta-sius et al. [7] improve semantic contour detection with con-volutional features and shows its application to semanticsegmentation. Our object contour detector can be poten-tially used to improve a more challenging and practicalproblem of instance-level semantic segmentation [21].
Occlusion boundary detection. Hoiem et al. [22] studythe problem of recovering occlusion boundaries from a sin-gle image. It is a very challenging ill-posed problem dueto the partial observability while projecting 3D scenes onto2D image planes. They formulate a CRF model to inte-grate various cues: color, position, edges, surface orienta-tion and depth estimates. We believe our instance-level ob-ject contours will provide another strong cue for addressingthis problem that is worth investigating in the future.
Object proposal generation. There is a large body ofworks on generating bounding box or segmented object pro-posals. Hosang et al. [23] and Pont-Tuset et al. [42] presentnice overviews and analyses about the state-of-the-art algo-rithms. Bounding box proposal generation [50, 53, 12, 1] is

Max poolingMax pooling
Max poolingMax pooling
Max poolingUnpooling
UnpoolingUnpooling
UnpoolingUnpooling
Convolutional EncoderConv1Conv2
Conv3Conv4
Conv6Conv5
Deconv1Deconv2
Deconv3Deconv4
Deconv5Deconv6
Convolutional Decoder Pred
Figure 2. Architecture of the proposed fully convolutional encoder-decoder network.
motivated by efficient object detection. One of their draw-backs is that bounding boxes usually cannot provide accu-rate object localization. More related to our work is gener-ating segmented object proposals [4, 10, 14, 24, 26, 29, 43].At the core of segmented object proposal algorithms is con-tour detection and superpixel segmentation. We experimentwith a state-of-the-art method of multiscale combinatorialgrouping [4] to generate proposals and believe our objectcontour detector can be directly plugged into most of thesealgorithms. In addition, Pinheiro et al. [41] propose a net-work that learns to generate proposals directly from the testimage without the grouping stage.
3. Object Contour DetectionIn this section, we introduce the proposed fully convo-
lutional encoder-decoder network for object contour detec-tion.
3.1. Fully Convolutional Encoder-Decoder Network
We formulate contour detection as a binary image la-beling problem where “1” and “0” indicates “contour” and“non-contour”, respectively. Image labeling is a task that re-quires both high-level knowledge and low-level cues. Giventhe success of deep convolutional networks [31] for learn-ing rich feature hierarchies, image labeling has been greatlyadvanced, especially on the task of semantic segmenta-tion [11, 36, 34, 52, 40, 35]. Among those end-to-endmethods, fully convolutional networks [36] scale well upto the image size but cannot produce very accurate label-ing boundaries; unpooling layers help deconvolutional net-works [40] to generate better label localization but theirsymmetric structure introduces a heavy decoder networkwhich is difficult to train with limited samples.
We borrow the ideas of full convolution and unpoolingfrom above two works and develop a fully convolutionalencoder-decoder network for object contour detection. Thenetwork architecture is demonstrated in Figure 2. We usethe layers up to “fc6” from VGG-16 net [48] as our encoder.Since we convert the “fc6” to be convolutional, so we nameit “conv6” in our decoder. Due to the asymmetric nature ofimage labeling problems (image input and mask output), webreak the symmetric structure of deconvolutional networks
and introduce a light-weighted decoder. The first layer ofdecoder “deconv6” is designed for dimension reduction thatprojects 4096-d “conv6” to 512-d with 1×1 kernel so thatwe can re-use the pooling switches from “conv5” to upscalethe feature maps by twice in the following “deconv5” layer.The number of channels of every decoder layer is properlydesigned to allow unpooling from its corresponding max-pooling layer. All the decoder convolution layers except“deconv6” use 5×5 kernels. All the decoder convolutionlayers except the one next to the output label are followedby relu activation function. We also add a dropout layerafter each relu layer in the decoder. A complete decodernetwork setup is listed in Table 1 and the loss function issimply the pixel-wise logistic loss.
Table 1. Decoder network setup.name deconv6 deconv5 deconv4setup conv unpool-conv unpool-convkernel 1×1×512 5×5×512 5×5×256
acti relu relu reluname deconv3 deconv2 deconv1 predsetup unpool-conv unpool-conv unpool-conv convkernel 5×5×128 5×5×64 5×5×32 5×5×1
activation relu relu relu sigmoid
3.2. Contour Ground Truth Refinement
Drawing detailed and accurate contours of objects is achallenging task for human beings. This is why many largescale segmentation datasets [45, 15, 33] provide contour an-notations with polygons as they are less expensive to col-lect at scale. However, because of unpredictable behaviorsof human annotators and limitations of polygon representa-tion, the annotated contours usually do not align well withthe true image boundaries and thus cannot be directly usedas ground truth for training. Among all, the PASCAL VOCdataset is a widely-accepted benchmark with high-qualityannotation for object segmentation. VOC 2012 release in-cludes 11540 images from 20 classes covering a majority ofcommon objects from categories such as “person”, “vehi-cle”, “animal” and “household”, where 1464 and 1449 im-ages are annotated with object instance contours for train-ing and validation. Hariharan et al. [20] further contribute

(a) Image (b) Annotation
(c) GraphCut refinement (d) DenseCRF refinement
Figure 3. Contour refinement. The polygon based annotations (a)cannot be directly used for training due to its inaccurate boundaries(thin white area reflects unlabeled pixels between objects). Wealign them to image boundaries by re-labeling the uncertain areaswith dense CRF (d), compared to Graph Cut (c).
more than 10000 high-quality annotations to the remainingimages. Together there are 10582 images for training and1449 images for validation (the exact 2012 validation set).We choose this dataset for training our object contour detec-tor with the proposed fully convolutional encoder-decodernetwork.
The original PASCAL VOC annotations leave a thin un-labeled (or uncertain) area between occluded objects (Fig-ure 3(b)). To find the high-fidelity contour ground truth fortraining, we need to align the annotated contours with thetrue image boundaries. We consider contour alignment asa multi-class labeling problem and introduce a dense CRFmodel [28] where every instance (or background) is as-signed with one unique label. The dense CRF optimizationthen fills the uncertain area with neighboring instance labelsso that we obtain refined contours at the labeling boundaries(Figure 3(d)). We also experimented with the Graph Cutmethod [8] but find it usually produces jaggy contours dueto its shortcutting bias (Figure 3(c)).
3.3. Training
We train the network using Caffe [25]. For each trainingimage, we randomly crop four 224×224×3 patches and to-gether with their mirrored ones compose a 224×224×3×8minibatch. The ground truth contour mask is processed inthe same way. We initialize the encoder with pre-trainedVGG-16 net and the decoder with random values. Dur-ing training, we fix the encoder parameters and only op-timize the decoder parameters. This allows our model tobe easily integrated with bounding box regression [18] andother decoders such as semantic segmentation [40] for jointtraining. As the “contour” and “non-contour” pixels are ex-tremely imbalanced in each minibatch, the penalty for being
“contour” is set to be 10 times the penalty for being “non-contour”. We use the Adam method [5] to optimize the net-work parameters and find it is more efficient than standardstochastic gradient descent. We set the learning rate to 10−4
and train the network with 30 epochs with all the trainingimages being processed each epoch. Note that we fix thetraining patch to 224×224 for memory efficiency and thelearned parameters can be used on images of arbitrary sizebecause of its fully convolutional nature. Our CEDN net-work can be trained easily and efficiently in a single stagewithout batch-normalization due to the much smaller “de-conv6” layer, which only contains 4096×1×1×512 param-eters in comparison with 4096×7×7×512 parameters of“deconv-fc6” layer of DeconvNet [40].
4. Results
In this section, we evaluate our method on contour detec-tion and proposal generation using three datasets: PASCALVOC 2012, BSDS500 and MS COCO. We will explain thedetails of generating object proposals using our method af-ter the contour detection evaluation. More evaluation resultsare in the supplementary materials.
4.1. Contour Detection
Given trained models, all the test images are fed-forwardthrough our CEDN network in their original sizes to pro-duce contour detection maps. The detection accuraciesare evaluated by precision-recall curves and F-measure (F).Note that a standard non-maximum suppression is used toclean up the predicted contour maps (thinning the contours)before evaluation.
PASCAL val2012. We present quantitative results onthe PASCAL VOC 2012 validation set, shortly “PAS-CAL val2012”, with comparisons to three baselines, struc-tured edge detection (SE) [13], singlescale combinatorialgrouping (SCG) and multiscale combinatorial grouping(MCG) [4]. We also compare with the latest holistically-nested edge detection (HED) algorithm [51]. Note thatthe HED model was originally trained on the BSDSdataset [38]. We refer the results of applying the pretrainedHED model to PASCAL val2012 as “HED-pretrain”. Tohave a fair comparison, we further re-trained the HEDmodel on PASCAL VOC using the same training data asour model with 30000 iterations. The contour predictionprecision-recall curves from our CEDN model, baselines,HED-pretrain and HED are illustrated in Figure 5. It canbe seen that the F-score of HED is improved (from 0.42 to0.44) by training on PASCAL VOC but still significantlylower than CEDN (0.57). Note that we use the originallyannotated contours instead of our refined ones as groundtruth for unbiased evaluation. Accordingly we consider the
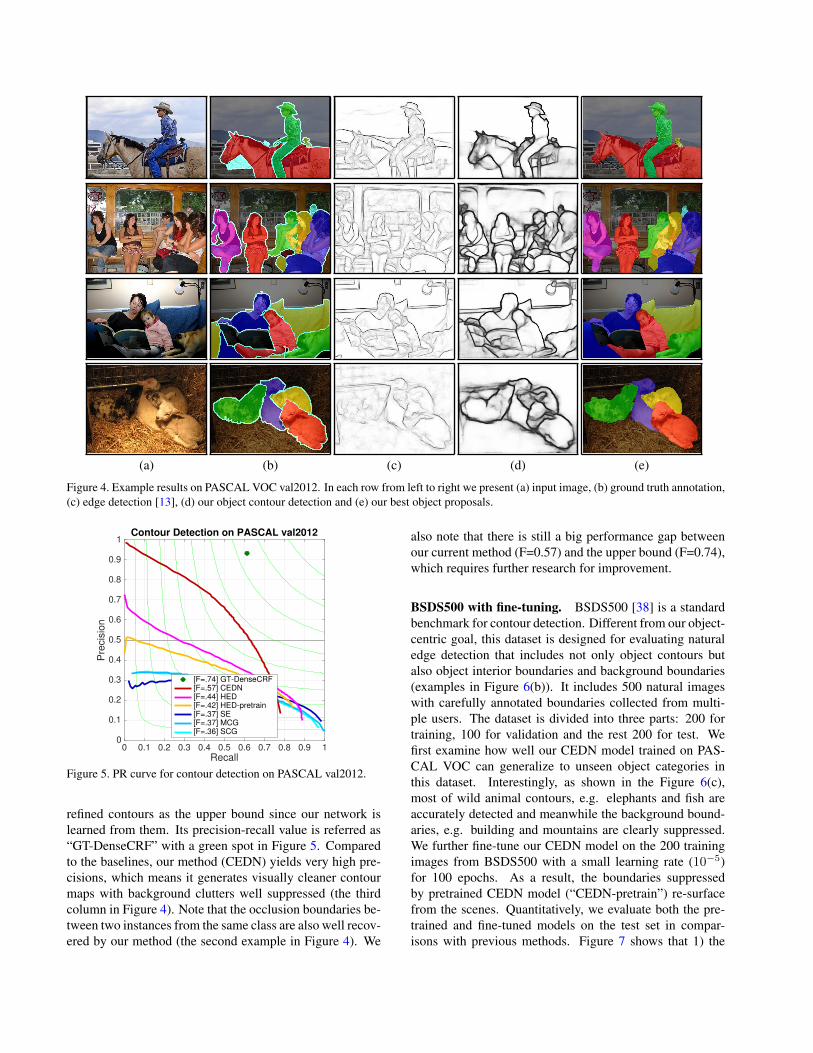
(a) (b) (c) (d) (e)
Figure 4. Example results on PASCAL VOC val2012. In each row from left to right we present (a) input image, (b) ground truth annotation,(c) edge detection [13], (d) our object contour detection and (e) our best object proposals.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1Recall
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Pre
cis
ion
Contour Detection on PASCAL val2012
[F=.74] GT-DenseCRF[F=.57] CEDN[F=.44] HED[F=.42] HED-pretrain[F=.37] SE[F=.37] MCG[F=.36] SCG
Figure 5. PR curve for contour detection on PASCAL val2012.
refined contours as the upper bound since our network islearned from them. Its precision-recall value is referred as“GT-DenseCRF” with a green spot in Figure 5. Comparedto the baselines, our method (CEDN) yields very high pre-cisions, which means it generates visually cleaner contourmaps with background clutters well suppressed (the thirdcolumn in Figure 4). Note that the occlusion boundaries be-tween two instances from the same class are also well recov-ered by our method (the second example in Figure 4). We
also note that there is still a big performance gap betweenour current method (F=0.57) and the upper bound (F=0.74),which requires further research for improvement.
BSDS500 with fine-tuning. BSDS500 [38] is a standardbenchmark for contour detection. Different from our object-centric goal, this dataset is designed for evaluating naturaledge detection that includes not only object contours butalso object interior boundaries and background boundaries(examples in Figure 6(b)). It includes 500 natural imageswith carefully annotated boundaries collected from multi-ple users. The dataset is divided into three parts: 200 fortraining, 100 for validation and the rest 200 for test. Wefirst examine how well our CEDN model trained on PAS-CAL VOC can generalize to unseen object categories inthis dataset. Interestingly, as shown in the Figure 6(c),most of wild animal contours, e.g. elephants and fish areaccurately detected and meanwhile the background bound-aries, e.g. building and mountains are clearly suppressed.We further fine-tune our CEDN model on the 200 trainingimages from BSDS500 with a small learning rate (10−5)for 100 epochs. As a result, the boundaries suppressedby pretrained CEDN model (“CEDN-pretrain”) re-surfacefrom the scenes. Quantitatively, we evaluate both the pre-trained and fine-tuned models on the test set in compar-isons with previous methods. Figure 7 shows that 1) the
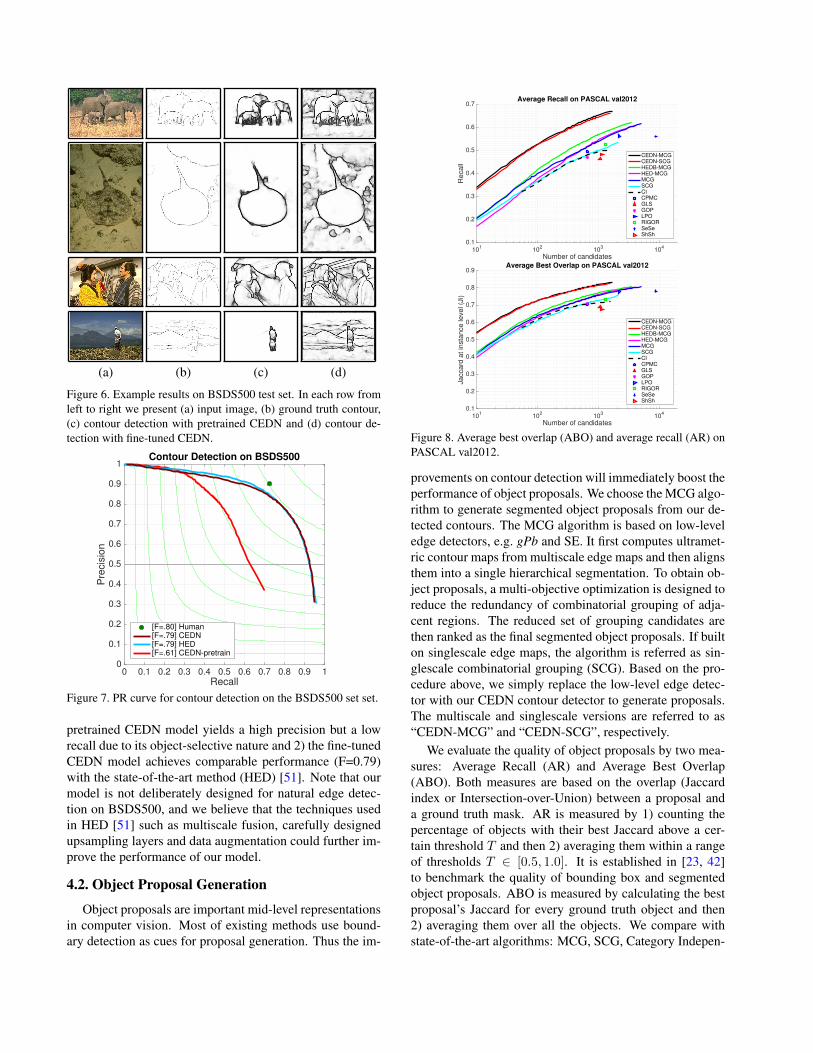
(a) (b) (c) (d)
Figure 6. Example results on BSDS500 test set. In each row fromleft to right we present (a) input image, (b) ground truth contour,(c) contour detection with pretrained CEDN and (d) contour de-tection with fine-tuned CEDN.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1Recall
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Pre
cis
ion
Contour Detection on BSDS500
[F=.80] Human[F=.79] CEDN[F=.79] HED[F=.61] CEDN-pretrain
Figure 7. PR curve for contour detection on the BSDS500 set set.
pretrained CEDN model yields a high precision but a lowrecall due to its object-selective nature and 2) the fine-tunedCEDN model achieves comparable performance (F=0.79)with the state-of-the-art method (HED) [51]. Note that ourmodel is not deliberately designed for natural edge detec-tion on BSDS500, and we believe that the techniques usedin HED [51] such as multiscale fusion, carefully designedupsampling layers and data augmentation could further im-prove the performance of our model.
4.2. Object Proposal Generation
Object proposals are important mid-level representationsin computer vision. Most of existing methods use bound-ary detection as cues for proposal generation. Thus the im-
101
102
103
104
Number of candidates
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Re
ca
ll
Average Recall on PASCAL val2012
CEDN-MCG
CEDN-SCG
HEDB-MCG
HED-MCG
MCG
SCG
CI
CPMC
GLS
GOP
LPO
RIGOR
SeSe
ShSh
101
102
103
104
Number of candidates
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Ja
cca
rd a
t in
sta
nce
le
ve
l (J
i)
Average Best Overlap on PASCAL val2012
CEDN-MCGCEDN-SCGHEDB-MCGHED-MCGMCGSCGCICPMCGLSGOPLPORIGORSeSeShSh
Figure 8. Average best overlap (ABO) and average recall (AR) onPASCAL val2012.
provements on contour detection will immediately boost theperformance of object proposals. We choose the MCG algo-rithm to generate segmented object proposals from our de-tected contours. The MCG algorithm is based on low-leveledge detectors, e.g. gPb and SE. It first computes ultramet-ric contour maps from multiscale edge maps and then alignsthem into a single hierarchical segmentation. To obtain ob-ject proposals, a multi-objective optimization is designed toreduce the redundancy of combinatorial grouping of adja-cent regions. The reduced set of grouping candidates arethen ranked as the final segmented object proposals. If builton singlescale edge maps, the algorithm is referred as sin-glescale combinatorial grouping (SCG). Based on the pro-cedure above, we simply replace the low-level edge detec-tor with our CEDN contour detector to generate proposals.The multiscale and singlescale versions are referred to as“CEDN-MCG” and “CEDN-SCG”, respectively.
We evaluate the quality of object proposals by two mea-sures: Average Recall (AR) and Average Best Overlap(ABO). Both measures are based on the overlap (Jaccardindex or Intersection-over-Union) between a proposal anda ground truth mask. AR is measured by 1) counting thepercentage of objects with their best Jaccard above a cer-tain threshold T and then 2) averaging them within a rangeof thresholds T ∈ [0.5, 1.0]. It is established in [23, 42]to benchmark the quality of bounding box and segmentedobject proposals. ABO is measured by calculating the bestproposal’s Jaccard for every ground truth object and then2) averaging them over all the objects. We compare withstate-of-the-art algorithms: MCG, SCG, Category Indepen-
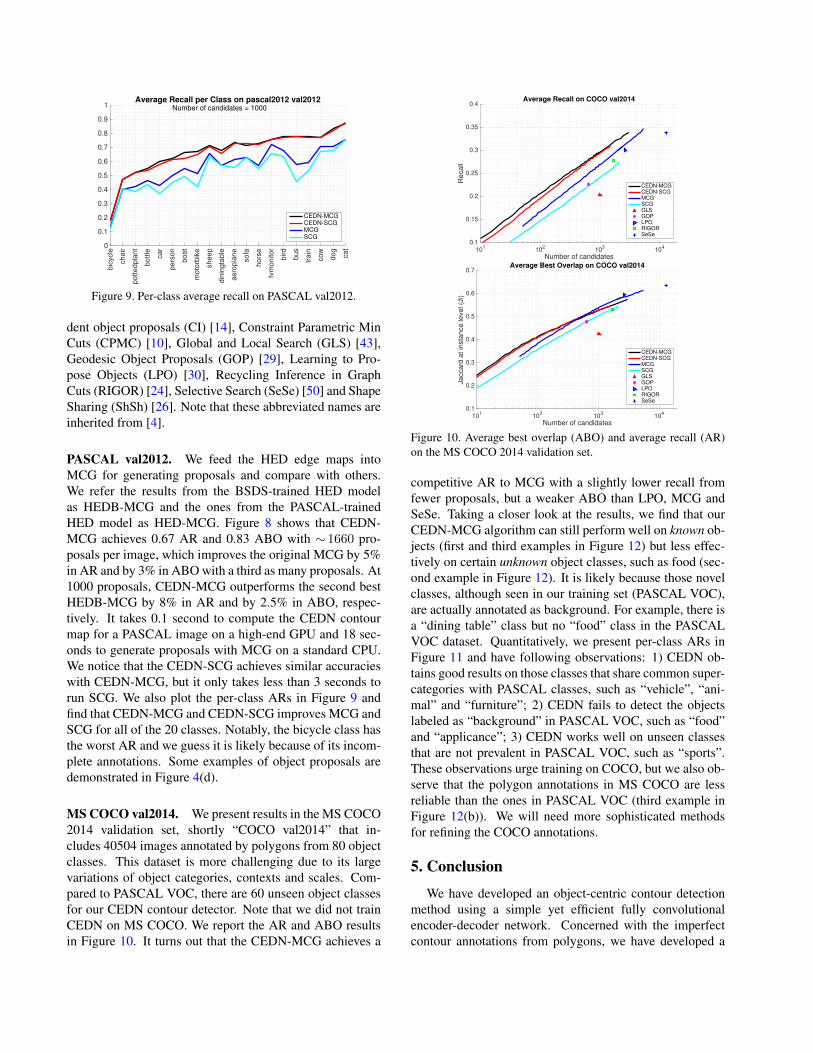
bic
ycle
ch
air
po
tte
dp
lan
t
bo
ttle
ca
r
pe
rso
n
bo
at
mo
torb
ike
sh
ee
p
din
ing
tab
le
ae
rop
lan
e
so
fa
ho
rse
tvm
on
ito
r
bird
bu
s
tra
in
co
w
do
g
ca
t0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Average Recall per Class on pascal2012 val2012
Number of candidates = 1000
CEDN-MCGCEDN-SCGMCGSCG
Figure 9. Per-class average recall on PASCAL val2012.
dent object proposals (CI) [14], Constraint Parametric MinCuts (CPMC) [10], Global and Local Search (GLS) [43],Geodesic Object Proposals (GOP) [29], Learning to Pro-pose Objects (LPO) [30], Recycling Inference in GraphCuts (RIGOR) [24], Selective Search (SeSe) [50] and ShapeSharing (ShSh) [26]. Note that these abbreviated names areinherited from [4].
PASCAL val2012. We feed the HED edge maps intoMCG for generating proposals and compare with others.We refer the results from the BSDS-trained HED modelas HEDB-MCG and the ones from the PASCAL-trainedHED model as HED-MCG. Figure 8 shows that CEDN-MCG achieves 0.67 AR and 0.83 ABO with ∼1660 pro-posals per image, which improves the original MCG by 5%in AR and by 3% in ABO with a third as many proposals. At1000 proposals, CEDN-MCG outperforms the second bestHEDB-MCG by 8% in AR and by 2.5% in ABO, respec-tively. It takes 0.1 second to compute the CEDN contourmap for a PASCAL image on a high-end GPU and 18 sec-onds to generate proposals with MCG on a standard CPU.We notice that the CEDN-SCG achieves similar accuracieswith CEDN-MCG, but it only takes less than 3 seconds torun SCG. We also plot the per-class ARs in Figure 9 andfind that CEDN-MCG and CEDN-SCG improves MCG andSCG for all of the 20 classes. Notably, the bicycle class hasthe worst AR and we guess it is likely because of its incom-plete annotations. Some examples of object proposals aredemonstrated in Figure 4(d).
MS COCO val2014. We present results in the MS COCO2014 validation set, shortly “COCO val2014” that in-cludes 40504 images annotated by polygons from 80 objectclasses. This dataset is more challenging due to its largevariations of object categories, contexts and scales. Com-pared to PASCAL VOC, there are 60 unseen object classesfor our CEDN contour detector. Note that we did not trainCEDN on MS COCO. We report the AR and ABO resultsin Figure 10. It turns out that the CEDN-MCG achieves a
101
102
103
104
Number of candidates
0.1
0.15
0.2
0.25
0.3
0.35
0.4
Re
ca
ll
Average Recall on COCO val2014
CEDN-MCG
CEDN-SCG
MCG
SCG
GLS
GOP
LPO
RIGOR
SeSe
101
102
103
104
Number of candidates
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Ja
cca
rd a
t in
sta
nce
le
ve
l (J
i)
Average Best Overlap on COCO val2014
CEDN-MCGCEDN-SCGMCGSCGGLSGOPLPORIGORSeSe
Figure 10. Average best overlap (ABO) and average recall (AR)on the MS COCO 2014 validation set.
competitive AR to MCG with a slightly lower recall fromfewer proposals, but a weaker ABO than LPO, MCG andSeSe. Taking a closer look at the results, we find that ourCEDN-MCG algorithm can still perform well on known ob-jects (first and third examples in Figure 12) but less effec-tively on certain unknown object classes, such as food (sec-ond example in Figure 12). It is likely because those novelclasses, although seen in our training set (PASCAL VOC),are actually annotated as background. For example, there isa “dining table” class but no “food” class in the PASCALVOC dataset. Quantitatively, we present per-class ARs inFigure 11 and have following observations: 1) CEDN ob-tains good results on those classes that share common super-categories with PASCAL classes, such as “vehicle”, “ani-mal” and “furniture”; 2) CEDN fails to detect the objectslabeled as “background” in PASCAL VOC, such as “food”and “applicance”; 3) CEDN works well on unseen classesthat are not prevalent in PASCAL VOC, such as “sports”.These observations urge training on COCO, but we also ob-serve that the polygon annotations in MS COCO are lessreliable than the ones in PASCAL VOC (third example inFigure 12(b)). We will need more sophisticated methodsfor refining the COCO annotations.
5. Conclusion
We have developed an object-centric contour detectionmethod using a simple yet efficient fully convolutionalencoder-decoder network. Concerned with the imperfectcontour annotations from polygons, we have developed a
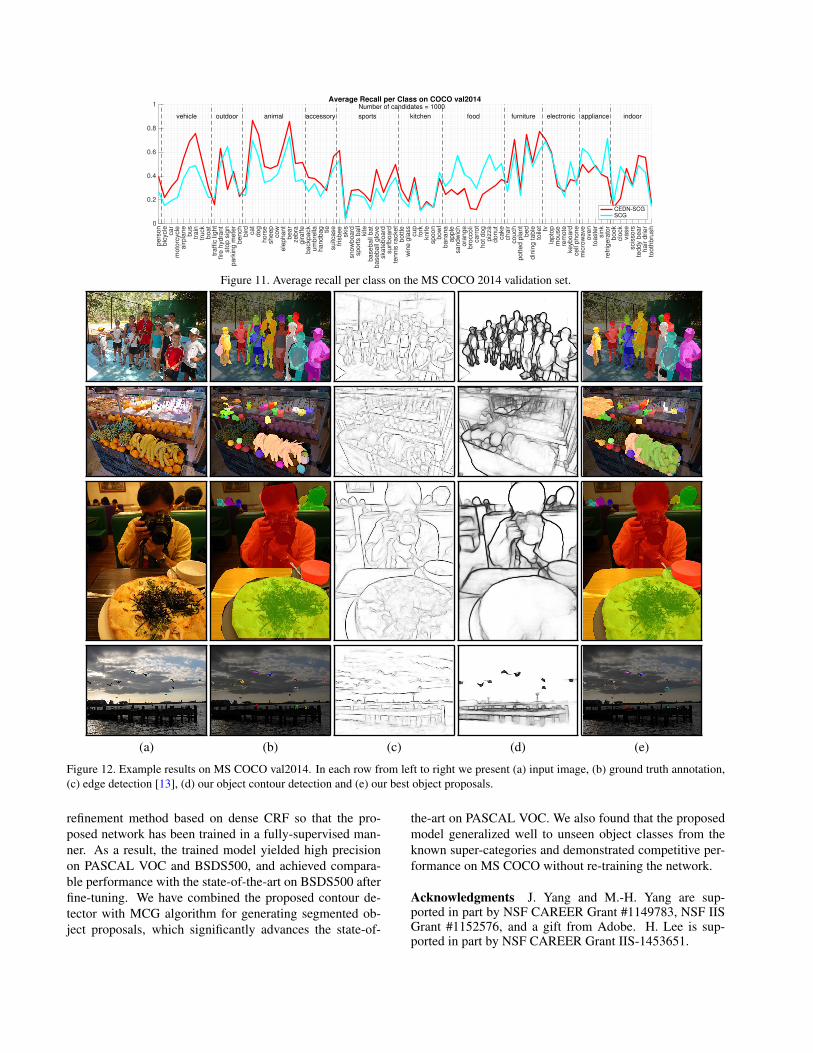
pers
on
bic
ycle
car
moto
rcycle
airpla
ne
bus
train
truck
boat
traffic
lig
ht
fire
hydra
nt
sto
p s
ign
park
ing m
ete
rbench
bird
cat
dog
hors
esheep
cow
ele
phant
bear
zebra
giraffe
backpack
um
bre
llahandbag tie
suitcase
fris
bee
skis
snow
board
sport
s b
all
kite
baseball
bat
baseball
glo
ve
skate
board
surf
board
tennis
racket
bottle
win
e g
lass
cup
fork
knife
spoon
bow
lbanana
apple
sandw
ich
ora
nge
bro
ccoli
carr
ot
hot dog
piz
za
donut
cake
chair
couch
potted p
lant
bed
din
ing table
toile
ttv
lapto
pm
ouse
rem
ote
keyboard
cell
phone
mic
row
ave
oven
toaste
rsin
kre
frig
era
tor
book
clo
ck
vase
scis
sors
teddy b
ear
hair d
rier
tooth
bru
sh
0
0.2
0.4
0.6
0.8
1Average Recall per Class on COCO val2014
Number of candidates = 1000
vehicle outdoor animal accessory sports kitchen food furniture electronic appliance indoor
CEDN-SCGSCG
Figure 11. Average recall per class on the MS COCO 2014 validation set.
(a) (b) (c) (d) (e)
Figure 12. Example results on MS COCO val2014. In each row from left to right we present (a) input image, (b) ground truth annotation,(c) edge detection [13], (d) our object contour detection and (e) our best object proposals.
refinement method based on dense CRF so that the pro-posed network has been trained in a fully-supervised man-ner. As a result, the trained model yielded high precisionon PASCAL VOC and BSDS500, and achieved compara-ble performance with the state-of-the-art on BSDS500 afterfine-tuning. We have combined the proposed contour de-tector with MCG algorithm for generating segmented ob-ject proposals, which significantly advances the state-of-
the-art on PASCAL VOC. We also found that the proposedmodel generalized well to unseen object classes from theknown super-categories and demonstrated competitive per-formance on MS COCO without re-training the network.
Acknowledgments J. Yang and M.-H. Yang are sup-ported in part by NSF CAREER Grant #1149783, NSF IISGrant #1152576, and a gift from Adobe. H. Lee is sup-ported in part by NSF CAREER Grant IIS-1453651.

References[1] B. Alexe, T. Deselaers, and V. Ferrari. Measuring the object-
ness of image windows. PAMI, 34:2189–2202, 2012.[2] M. R. Amer, S. Yousefi, R. Raich, and S. Todorovic. Monoc-
ular extraction of 2.1 D sketch using constrained convex op-timization. IJCV, 112(1):23–42, 2015.
[3] P. Arbelaez, M. Maire, C. Fowlkes, and J. Malik. Con-tour detection and hierarchical image segmentation. PAMI,33(5):898–916, 2011.
[4] P. Arbelaez, J. Pont-Tuset, J. Barron, F. Marques, and J. Ma-lik. Multiscale combinatorial grouping. In CVPR, 2014.
[5] J. Ba and D. Kingma. Adam: A method for stochastic opti-mization. In ICLR, 2015.
[6] G. Bertasius, J. Shi, and L. Torresani. Deepedge: A multi-scale bifurcated deep network for top-down contour detec-tion. In CVPR, 2015.
[7] G. Bertasius, J. Shi, and L. Torresani. High-for-low and low-for-high: Efficient boundary detection from deep object fea-tures and its applications to high-level vision. In ICCV, 2015.
[8] Y. Y. Boykov and M.-P. Jolly. Interactive graph cuts for op-timal boundary & region segmentation of objects in n-d im-ages. In ICCV, 2001.
[9] J. Canny. A computational approach to edge detection.PAMI, (6):679–698, 1986.
[10] J. Carreira and C. Sminchisescu. Constrained parametricmin-cuts for automatic object segmentation. In CVPR, 2010.
[11] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, andA. L. Yuille. Semantic image segmentation with deep con-volutional nets and fully connected crfs. arXiv preprintarXiv:1412.7062, 2014.
[12] M.-M. Cheng, Z. Zhang, W.-Y. Lin, and P. Torr. BING: Bina-rized normed gradients for objectness estimation at 300fps.In CVPR, 2014.
[13] P. Dollar and C. Zitnick. Structured forests for fast edge de-tection. In ICCV, 2013.
[14] I. Endres and D. Hoiem. Category independent object pro-posals. In ECCV, 2010.
[15] M. Everingham, L. J. V. Gool, C. K. I. Williams, J. M. Winn,and A. Zisserman. The Pascal visual object classes (VOC)challenge. IJCV, 88(2):303–338, 2010.
[16] V. Ferrari, L. Fevrier, F. Jurie, and C. Schmid. Groupsof adjacent contour segments for object detection. PAMI,30(1):36–51, 2008.
[17] D. A. Forsyth and J. Ponce. Computer Vision: A ModernApproach. Pearson Education, 2003.
[18] R. Girshick. Fast R-CNN. In ICCV, 2015.[19] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich fea-
ture hierarchies for accurate object detection and semanticsegmentation. In CVPR, 2014.
[20] B. Hariharan, P. Arbelaez, L. Bourdev, S. Maji, and J. Malik.Semantic contours from inverse detectors. In ICCV, 2011.
[21] B. Hariharan, P. Arbelaez, R. Girshick, and J. Malik. Simul-taneous detection and segmentation. In ECCV, 2014.
[22] D. Hoiem, A. N. Stein, A. Efros, and M. Hebert. Recoveringocclusion boundaries from a single image. In ICCV, 2007.
[23] J. Hosang, R. Benenson, P. Dollar, and B. Schiele. Whatmakes for effective detection proposals? PAMI, 2015.
[24] A. Humayun, F. Li, and J. M. Rehg. RIGOR: Reusing infer-ence in graph cuts for generating object regions. In CVPR,2014.
[25] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Gir-shick, S. Guadarrama, and T. Darrell. Caffe: Convolu-tional architecture for fast feature embedding. arXiv preprintarXiv:1408.5093, 2014.
[26] J. Kim and K. Grauman. Shape sharing for object segmenta-tion. In ECCV, 2012.
[27] J. J. Kivinen, C. K. Williams, and N. Heess. Visual bound-ary prediction: A deep neural prediction network and qualitydissection. In AISTATS, 2014.
[28] P. Krahenbuhl and V. Koltun. Efficient inference in fully con-nected CRFs with gaussian edge potentials. In NIPS, 2011.
[29] P. Krahenbuhl and V. Koltun. Geodesic object proposals. InECCV, 2014.
[30] P. Krahenbuhl and V. Koltun. Learning to propose objects.In CVPR, 2015.
[31] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenetclassification with deep convolutional neural networks. InNIPS, 2012.
[32] J. J. Lim, C. L. Zitnick, and P. Dollar. Sketch tokens: Alearned mid-level representation for contour and object de-tection. In CVPR, 2013.
[33] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ra-manan, P. Dollar, and C. L. Zitnick. Microsoft COCO: Com-mon objects in context. In ECCV, 2014.
[34] S. Liu, J. Yang, C. Huang, and M.-H. Yang. Multi-objectiveconvolutional learning for face labeling. In CVPR, 2015.
[35] Z. Liu, X. Li, P. Luo, C. C. Loy, and X. Tang. Semantic im-age segmentation via deep parsing network. In ICCV, 2015.
[36] J. Long, E. Shelhamer, and T. Darrell. Fully convolutionalnetworks for semantic segmentation. In CVPR, 2015.
[37] J. Malik, S. Belongie, T. Leung, and J. Shi. Contour andtexture analysis for image segmentation. IJCV, 2001.
[38] D. Martin, C. Fowlkes, D. Tal, and J. Malik. A databaseof human segmented natural images and its application toevaluating segmentation algorithms and measuring ecologi-cal statistics. In ICCV, 2001.
[39] D. R. Martin, C. C. Fowlkes, and J. Malik. Learning to detectnatural image boundaries using local brightness, color, andtexture cues. PAMI, 26(5):530–549, 2004.
[40] H. Noh, S. Hong, and B. Han. Learning deconvolution net-work for semantic segmentation. In ICCV, 2015.
[41] P. O. Pinheiro, R. Collobert, and P. Dollar. Learning to seg-ment object candidates. In NIPS, 2015.
[42] J. Pont-Tuset and L. J. V. Gool. Boosting object proposals:From Pascal to COCO. In ICCV, 2015.
[43] P. Rantalankila, J. Kannala, and E. Rahtu. Generating ob-ject segmentation proposals using global and local search. InCVPR, 2014.
[44] C. Rother, V. Kolmogorov, and A. Blake. Grabcut -interactive foreground extraction using iterated graph cuts.ACM Transactions on Graphics (SIGGRAPH), 2004.

[45] B. C. Russell, A. Torralba, K. P. Murphy, and W. T. Free-man. LabelMe: a database and web-based tool for imageannotation. IJCV, 2008.
[46] W. Shen, X. Wang, Y. Wang, X. Bai, and Z. Zhang. Deep-contour: A deep convolutional feature learned by positive-sharing loss for contour detection. In CVPR, 2015.
[47] N. Silberman, P. Kohli, D. Hoiem, and R. Fergus. Indoorsegmentation and support inference from rgbd images. InECCV, 2012.
[48] K. Simonyan and A. Zisserman. Very deep convolutionalnetworks for large-scale image recognition. In ICLR, 2015.
[49] J. Uijlings and V. Ferrar. Situational object boundary detec-tion. In CVPR, 2015.
[50] K. E. A. van de Sande, J. R. R. Uijlingsy, T. Gevers, andA. W. M. Smeulders. Segmentation as selective search forobject recognition. In ICCV, 2011.
[51] S. Xie and Z. Tu. Holistically-nested edge detection. InICCV, 2015.
[52] S. Zheng, S. Jayasumana, B. Romera-Paredes, V. Vineet,Z. Su, D. Du, C. Huang, and P. Torr. Conditional randomfields as recurrent neural networks. In ICCV, 2015.
[53] C. L. Zitnick and P. Dollar. Edge boxes: Locating objectproposals from edge. In ECCV, 2014.











![Fully Convolutional Networks for Semantic Segmentation [1] › ~yjlee › teaching › ecs289g... · Fully Convolutional Networks for Semantic Segmentation [1] Jonathan Long, Evan](https://img.pdfslide.net/doc/110x75/5f1e3b914f511927f07843d5/fully-convolutional-networks-for-semantic-segmentation-1-a-yjlee-a-teaching.jpg)
















