Embed Size (px)
Citation preview

NationalBioinformaticsNetwork
Oleg Reva
Network
Oleg Reva
Oligonucleotide signatures of pathogenic microorganisms for pathogenic microorganisms for diagnostic genetic chips and
t imetagenomics
Dep. of Biochemistry, Bioinformatics and Computational Biology Unit, University of Pretoria, Lynnwood road, Hillcrest, Pretoria, 0002, South Africa

Bioinformatics – the most democratic field of researchresearch
• C titi f th lt d ’t d d• Competitiveness of the results doesn’t depend extremely on the level of investments;
• The area where researches of developingThe area where researches of developing countries have a real opportunities to lead the fashion of science rather then follow 1st Word
hresearches.• The shortest way from achievement of the
results to deploymentresults to deployment.
• It’s not easy to prove relevance of the• It s not easy to prove relevance of the bioinformatic research to every day needs and pressing challenges of a country with straggling economics;
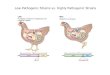
Challenges of the current sequencing technologies
0.07 MbSanger
20 MbRoche 454
10000 MbSolexa
0 1 2 0
Throughput per run1000 bpSanger
250 bpRoche 454
25 bp
0 1 2 0 0
Solexa
Maximal length of DNA reads

DNA sequenceTGGTGGGTCGTGTAGGATTCGAACCTACGACCAATTGGTTAAAAGACAATTGGCCTAGGTCTCTCTAGGAAGGGTTTTAAAGCCCCGTACCGATTTAGCTGAGCAGCCTCTAATGACCCCATTAGAGGCTATCTCAATGAAAGCGACTTCGGTTGTATCCACCAAGGGTGGTGTAGGGAAGTCCACCACCGCCGCCAACCTCGGTGCATTTTGCGAAGGGTGGTGTAGGGAAGTCCACCACCGCCGCCAACCTCGGTGCATTTTGCGCCGATGCTGGCCTGAAGACCCTCCTCATCGACCTGGACCCCGTCCAGCCCTCCCTATCTTCGTACTACGAGCTTCCTGAAGTCGCCCAGGGCGGCATCTACGACCTGCTCGCCGCCAACATAACTGACCCAGCGAGGATCATCTCCAGGACGATTATCCCCCTCGCCGCCAACATAACTGACCCAGCGAGGATCATCTCCAGGACGATTATCCCCAACCTGGACGTCGTGATTTCCAACGACCAGAACAACCAGCTCAACAACCTACTGCTCCAGGCGCCCGATGGCCGGCTCCGGCTGGCAAACCTCATGCCGTCCCTGAAACAGGGCTACGACCTGGTGCTGATCGACACCCAAGGTGCGCGCTCCGCTTTAAACAGGGCTACGACCTGGTGCTGATCGACACCCAAGGTGCGCGCTCCGCTTTACTAGAAATGGTCGTGCTCGCATCGGATCTGGTTGTTTCCCCCCTGCAGCCCAACATGCTCACTGCTTCTGTGCTCGAAACGACTGTCCCGGATGCCGTCGTGTTTCGCAACGCAGCATCGCGCGGGCTACCAGCGCACCGCCTCGAAACGCGGCAACCGCAACGCAGCATCGCGCGGGCTACCAGCGCACCGCCTCGAAACGCGGCAACCCTCCAATCGCACATCAGCGCCCGCGCTGGAAATCATCCGTAACCTGGCCATCGAGGTCTTTCCCGAGTGGACTGACCGCTTCCTCGCGCTGACGCCGGAGGCGGTAGCAGCACTGGTCAAGGGAGGGCGCTGACATGGCGAAGCCTCCTATCACCCATAGCAGCACTGGTCAAGGGAGGGCGCTGACATGGCGAAGCCTCCTATCACCCAAGCCCGCGACGTCGACGCGGAACTTGTGCTGCAACTGAACAAGTTCGGCAGCGCCGCCGACCTTCGGAGCCAACAGGCCAAGTTGACCGGCGCTGCGCGAGAAATACGCAAGCTGACTGGTGGCGGTACCGACCTGTTCGGGAAGCTGGGTTGCTACTTGAGCTTCGAGCAAAAGCAGCTCCTACAAGACGCTGCGCGCTCTGGAAATCCTGCAGATCGCGTTGATCTACAACCGGGCCAAGGTGTTCGATCG

DNA sequence
CAACATAACTGACCCAGCGAG
TCCTGAAGTCGCCCAGGGCG
CAACATAACTGACCCAGCGAG
GTCGTGATTTCCAACGACCAGCCTACTGCTCCAGGCGCCCG
CGCCCGATGGCCGGCTCCGGCTAGGAAGGGTTTTAAAG
CGCCCGATGGCCGGCTCCGGTCCCTGAAACAGGGCTACGAC
TGGTGGGTCGTGTAGGATTCG
AGCTGACTGGTGGCGGTACCTAGGGAAGTCCACCACCGCC CGCCCGATGGCCGGCTCCGG
TCAGCGCCCGCGCTGGAAAT
TAGGGAAGTCCACCACCGCCCGCCCGATGGCCGGCTCCGG
TCCCTGAAACAGGGCTACGAC
CGCCCGATGGCCGGCTCCGGCTAGGAAGGGTTTTAAAG
CCTACTGCTCCAGGCGCCCG
TCCCTGAAACAGGGCTACGAC
TAGGGAAGTCCACCACCGCCGCCCAACATGCTCACTGCTTCCCTACTGCTCCAGGCGCCCG
TCAGCGCCCGCGCTGGAAATCTAGGAAGGGTTTTAAAG
AAATGGTCGTGCTCGCATCGG
AGCTGACTGGTGGCGGTACCTCCCTGAAACAGGGCTACGACCTCGAAACGACTGTCCCGGAT
GCCCAACATGCTCACTGCTTC
TCCCTGAAACAGGGCTACGACCTCGAAACGACTGTCCCGGAT
TCAGCGCCCGCGCTGGAAATCTAGGAAGGGTTTTAAAG
TCCCTGAAACAGGGCTACGAC
TAGGGAAGTCCACCACCGCC
TCAGCGCCCGCGCTGGAAATCCTACTGCTCCAGGCGCCCGTAGGGAAGTCCACCACCGCCCTCGAAACGACTGTCCCGGAT
GCCCAACATGCTCACTGCTTCCCTACTGCTCCAGGCGCCCG
AAATGGTCGTGCTCGCATCGGCTAGGAAGGGTTTTAAAGCCTACTGCTCCAGGCGCCCGGCCCAACATGCTCACTGCTTCCTCGAAACGACTGTCCCGGAT
GCCCAACATGCTCACTGCTTCCTCGAAACGACTGTCCCGGAT
TCAGCGCCCGCGCTGGAAATCTAGGAAGGGTTTTAAAG
CGCCCGATGGCCGGCTCCGG
Environmental sequencing
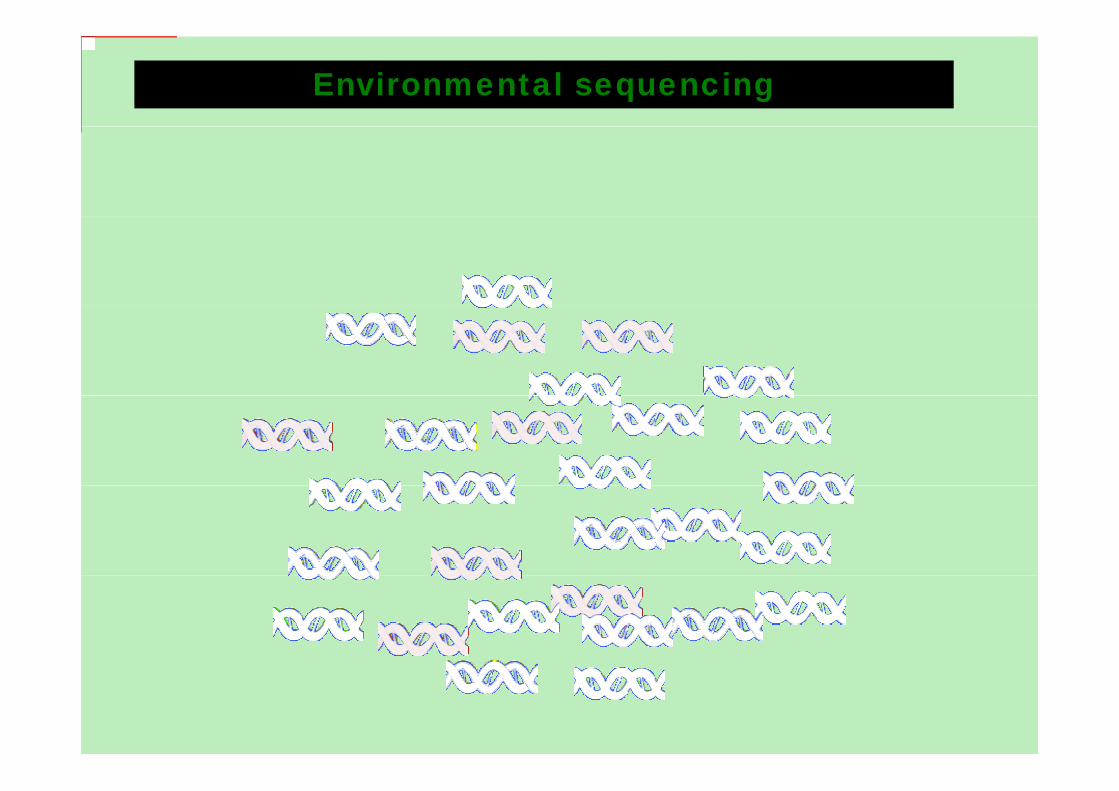
Teranucleotide (n1_4mer) usage patterns
Escherichia coli K-12 Pseudomonas putida KT2440 Bacillus subtilis 168
A A A A A A A G A A G A A A G G A G A A A G A G A G G A A G G G G A A A G A A G G A G A G A G G G G A A G G A G G G G A G G G G
A A A C A A A T A A G C A A G T A G A C A G A T A G G C A G G T G A A C G A A T G A G C G A G T G G A C G G A T G G G C G G G T
256 possible tetranucleotides:
A A C A A A C G A A T A A A T G A G C A A G C G A G T A A G T G G A C A G A C G G A T A G A T G G G C A G G C G G G T A G G T G
A A C C A A C T A A T C A A T T A G C C A G C T A G T C A G T T G A C C G A C T G A T C G A T T G G C C G G C T G G T C G G T T
A C A A A C A G A C G A A C G G A T A A A T A G A T G A A T G G G C A A G C A G G C G A G C G G G T A A G T A G G T G A G T G G
A C A C A C A T A C G C A C G T A T A C A T A T A T G C A T G T G C A C G C A T G C G C G C G T G T A C G T A T G T G C G T G T
A C C A A C C G A C T A A C T G A T C A A T C G A T T A A T T G G C C A G C C G G C T A G C T G G T C A G T C G G T T A G T T G
A C C C A C C T A C T C A C T T A T C C A T C T A T T C A T T T G C C C G C C T G C T C G C T T G T C C G T C T G T T C G T T T
C A A A C A A G C A G A C A G G C G A A C G A G C G G A C G G G T A A A T A A G T A G A T A G G T G A A T G A G T G G A T G G G
C A A C C A A T C A G C C A G T C G A C C G A T C G G C C G G T T A A C T A A T T A G C T A G T T G A C T G A T T G G C T G G T
C A C A C A C G C A T A C A T G C G C A C G C G C G T A C G T G T A C A T A C G T A T A T A T G T G C A T G C G T G T A T G T G
C A C C C A C T C A T C C A T T C G C C C G C T C G T C C G T T T A C C T A C T T A T C T A T T T G C C T G C T T G T C T G T T
C C A A C C A G C C G A C C G G C T A A C T A G C T G A C T G G T C A A T C A G T C G A T C G G T T A A T T A G T T G A T T G G
C C A C C C A T C C G C C C G T C T A C C T A T C T G C C T G T T C A C T C A T T C G C T C G T T T A C T T A T T T G C T T G T
C C C A C C C G C C T A C C T G C T C A C T C G C T T A C T T G T C C A T C C G T C T A T C T G T T C A T T C G T T T A T T T G
C C C C C C C T C C T C C C T T C T C C C T C T C T T C C T T T T C C C T C C T T C T C T C T T T T C C T T C T T T T C T T T T
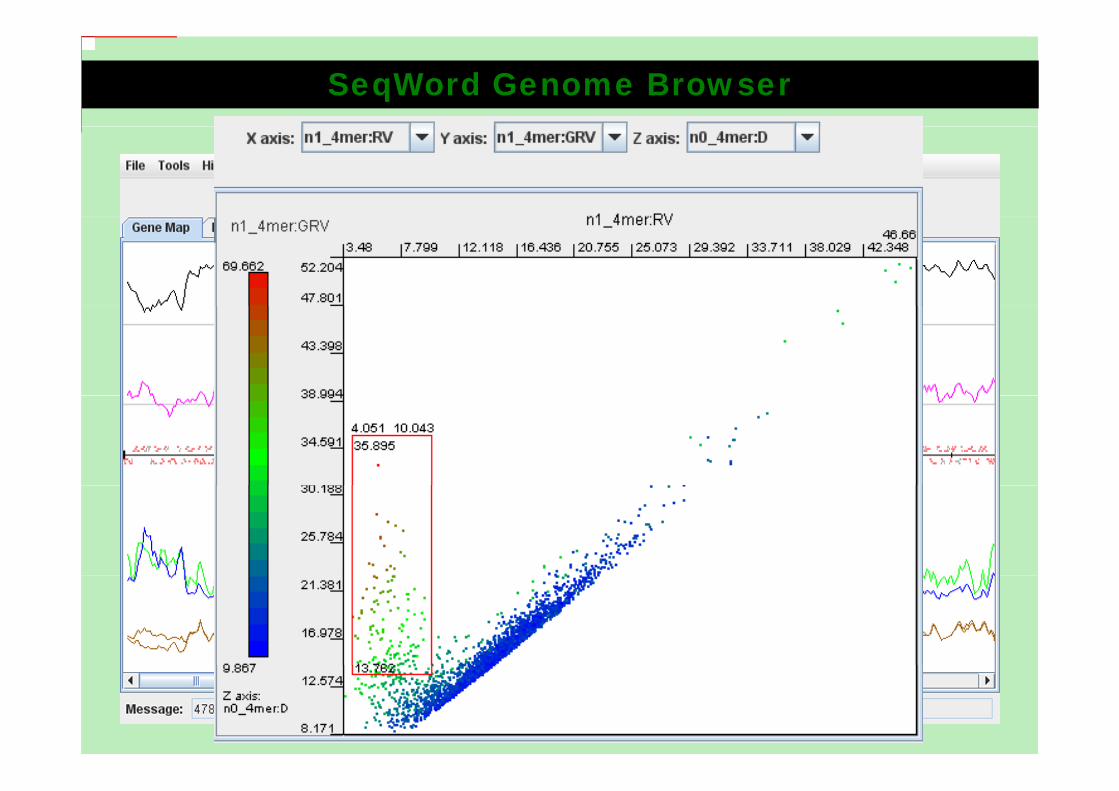
SeqWord Genome Browser
http://www.bi.up.ac.za/IntCalc/ (South Africa)http://genomics1.mh-hannover.de/seqword/ (Germany)http://seqword bx psu edu/ (USA)http://seqword.bx.psu.edu/ (USA)
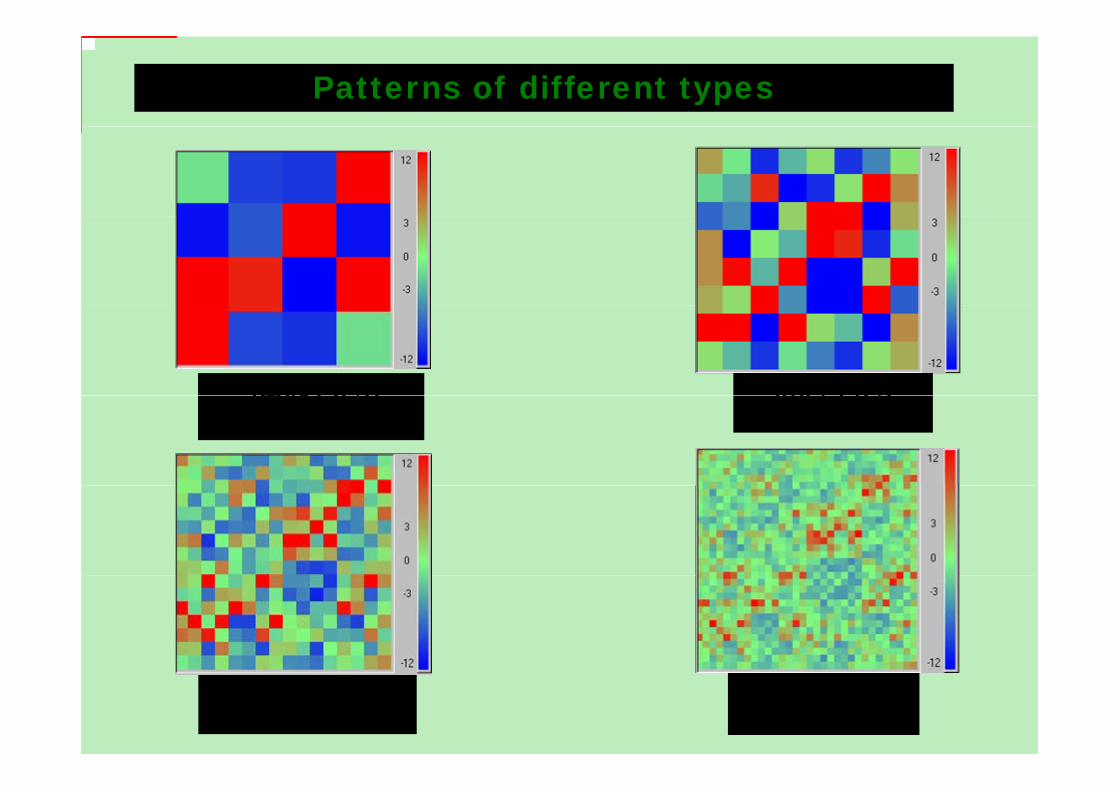
Patterns of different types
2mer OUP 3mer OUP2mer OUPMinimal window - 300 bp
3mer OUPMinimal window - 1.5 kbp
5mer OUPMinimal window - 20 kbp
4mer OUPMinimal window - 5 kbp

Self-organizing hierarchical grouping algorithmThe algorithm comprises 3 major procedures:assignment, splitting and joining of clusters
50% 30% 15% 7%
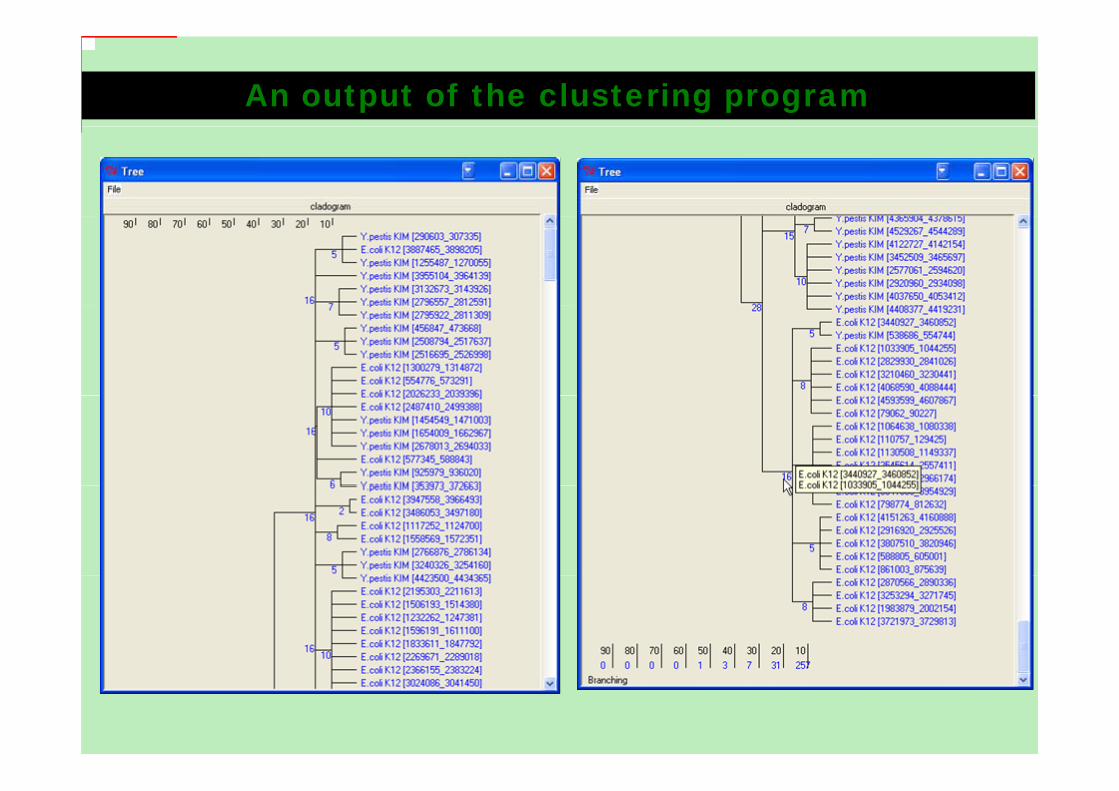
An output of the clustering program
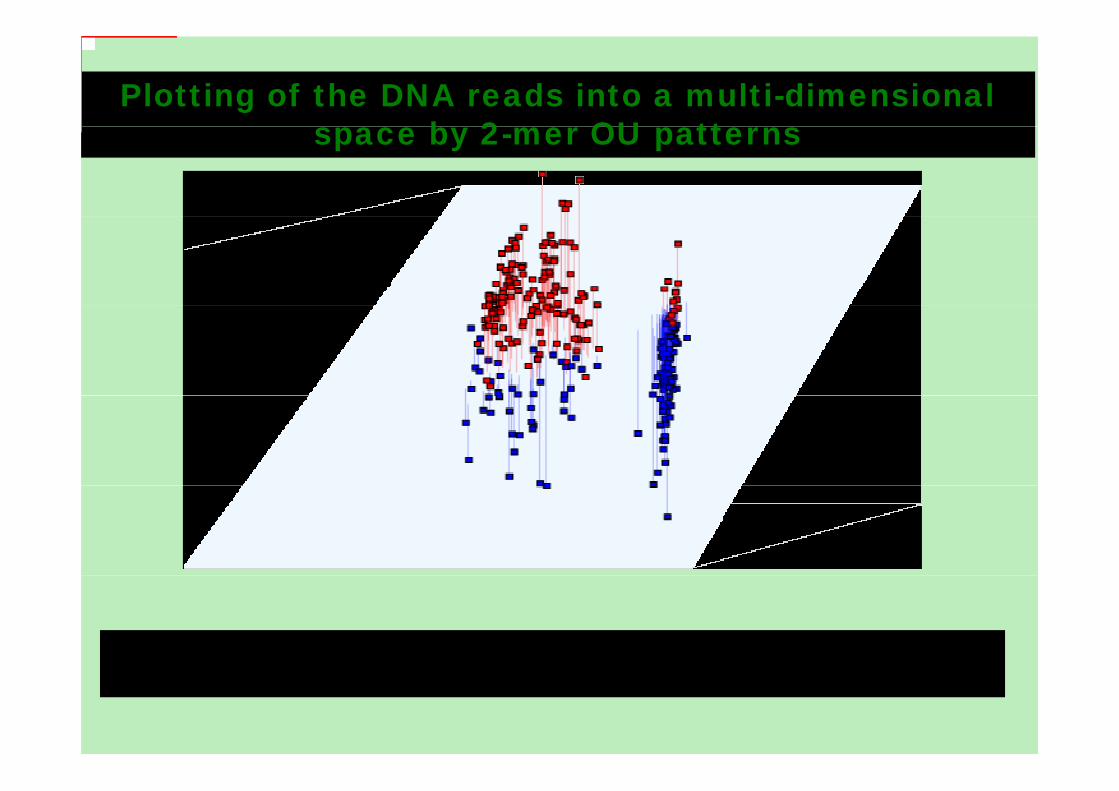
Plotting of the DNA reads into a multi-dimensional b 2 OU tt space by 2-mer OU patterns
In a total 300 DNA reads of length from 800 to 1500 bp were randomly selected from B.subtilis, B.anthracis, M.tuberculosis and P.aeruginosa genomes


H.pylori J99: n1 4mer, 0-1643831
Identification of 4mer OU patternspy o J99 _ e , 0 6 383
M.capsulatus: n1_4mer, 0-3304554 bp.B.bronchiseptica RB50: n1_4mer, 0-5339179 bp.B.pertussis: n1_4mer, 0-4086189 bp.B.parapertussis: n1_4mer, 0-4773551 bp.B.mallei ATCC23344 I: n1 4mer, 0-3510148 bp.B.mallei ATCC23344_I: n1_4mer, 0 3510148 bp.B.cenocepacia AU 1054 ch 1: n1_4mer, 0-329456Burkholderia sp. 383 ch 1: n1_4mer, 0-3694126 bpS.coelicolor: n1_4mer, 0-8667507 bp.S.avermitilis: n1_4mer, 0-9025608 bp.M leprae: n1 4mer 0 3268203 bpM.leprae: n1_4mer, 0-3268203 bp.M.bovis: n1_4mer, 0-4345492 bp.M.tuberculosis H37Rv: n1_4mer, 0-2846214 bp.M.avium K10: n1_4mer, 0-4829781 bp.S.typhi LT2: n1_4mer, 0-3367785 bp.S b i 1 4 0 4460105 bS.bongori: n1_4mer, 0-4460105 bp.E.carotovora SCRI1043: n1_4mer, 0-5064019 bp.S.flexneri 2457T: n1_4mer, 0-4599354 bp.E.coli K12: n1_4mer, 0-4639221 bp.B.thuringiensis konkukian: n1_4mer, 0-5237682 bpB.anthracis 0581: n1_4mer, 0-5227419 bp.B.cereus ATCC14579: n1_4mer, 0-5411809 bp.B.subtilis168: n1_4mer, 0-4214814 bp.B.licheniformis ATCC14580: n1_4mer, 0-4222336 H.influenzae: n1 4mer, 0-1830138 bp.H.influenzae: n1_4mer, 0 1830138 bp.H.ducreyi 3500HP: n1_4mer, 0-1698955 bp.E.faecalis V583: n1_4mer, 0-3218031 bp.Y.pestis KIM: n1_4mer, 0-4600755 bp.P.luminescens TT01: n1_4mer, 0-5688987 bp.Y enterocolitica 8081: n1 4mer 0-4615899 bpY.enterocolitica 8081: n1_4mer, 0-4615899 bp.A.borkumensis: n1_4mer, 0-3120143 bp.C.perfringens: n1_4mer, 0-3031430 bp.C.tetani: n1_4mer, 0-2044514 bp.C.acetobutylicum: n1_4mer, 0-3940880 bp.
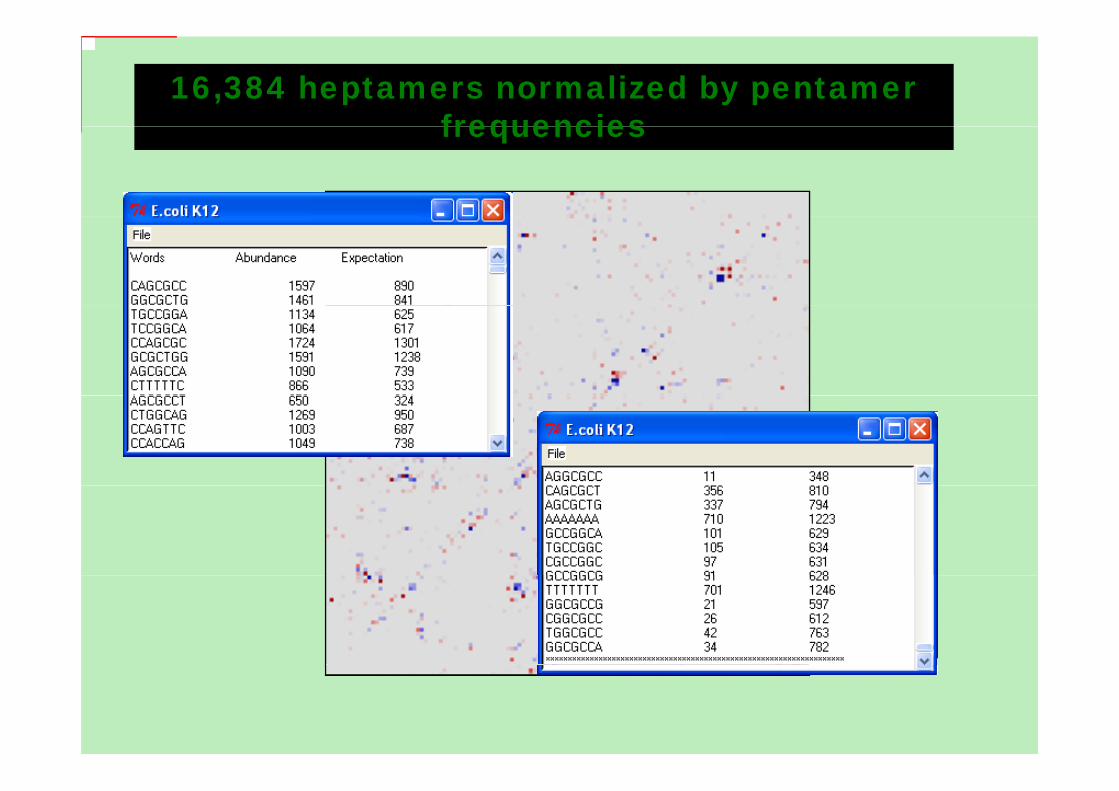
16,384 heptamers normalized by pentamer frequenciesfrequencies

Genome signature words for microarrays
1 : NC_008596.1: Mycobacterium smegmatis str. MC2 1552 : NC 002755 2: Mycobacterium tuberculosis CDC15512 : NC_002755.2: Mycobacterium tuberculosis CDC15513 : NC_002944.2: Mycobacterium avium subsp. paratuberculosis K-104 : NC_008726.1: Mycobacterium vanbaalenii PYR-15 : NC_008611.1: Mycobacterium ulcerans Agy996 : NC_002677.1: Mycobacterium leprae TN
1 2 3 4 5 6CTCGGCGAGCGC 63 9 36 50 9 0CTCGGCGAGCGC 63 9 36 50 9 0CGGCGAGCACCGC 49 6 16 27 7 0CCGGCGGCAACGG 10 7 118 9 84 0CGCCGGCCCCGCCG 6 255 9 3 145 0AGTGCATCGATGA 0 1 0 1 0 20GCCTGCCGGATCAC 1 0 0 1 204 0CGTCACGCCAGCGT 0 0 45 0 6 0GACGATGCAGAGCG 0 48 18 0 6 12GACGATGCAGAGCG 0 48 18 0 6 12

Genome signature words for metagenomics
1 : NC_008596.1: Mycobacterium smegmatis str. MC2 1552 : NC_002755.2: Mycobacterium tuberculosis CDC15513 : NC 002944.2: Mycobacterium avium subsp. paratuberculosis K-10_ y p p4 : NC_008726.1: Mycobacterium vanbaalenii PYR-15 : NC_008611.1: Mycobacterium ulcerans Agy996 : NC_002677.1: Mycobacterium leprae TN
1 2 3 4 5 6CTCGGCGAGCGC 0.582 0.164 0.61 0.498 0.151 0CGGCGAGCACCGC 0 442 0 141 0 287 0 298 0 123 0CGGCGAGCACCGC 0.442 0.141 0.287 0.298 0.123 0CCGGCGGCAACGG 0.102 0.127 1.097 0.113 0.101 0CGCCGGCCCCGCCG 0.077 1.707 0.18 0.05 1.179 0AGTGCATCGATGA 0 0.042 0 0.024 0 0.531GCCTGCCGGATCAC 0.021 0 0 0.024 2.519 0CGTCACGCCAGCGT 0 0 0.61 0 0.096 0GACGATGCAGAGCG 0 0.52 0.245 0 0.091 0.313

The final step – looking for the practical use
• Lack of grants to establish links betweenLack of grants to establish links between developers of bioinformatics tools and potential users.potential users.
• Logistic problems of communication between researchers.between researchers.
• There is still a big gap between fundamental science and commercialfundamental science and commercial application.