Embed Size (px)
Citation preview

ON RANK AGGREGATION FOR FACE RECOGNITION FROM VIDEOS
Himanshu S. Bhatt, Richa Singh and Mayank Vatsa
IIIT-Delhi, India
ABSTRACT
Face recognition from still face images suffers due to intra-personal variations caused by pose, illumination, and expres-sion that degrade the performance. On the other hand, videosprovide abundant information that can be leveraged to com-pensate the limitations of still face images and enhance facerecognition performance. This paper presents a video basedface recognition algorithm that computes a discriminativevideo signature as an ordered list of still face images. Thevideo signature embeds diverse intra-personal and temporalvariations across multiple frames, thus facilitates matchingtwo videos with large variations. Two videos are matched bycomparing their discriminative signatures using the Kendalltau similarity distance measure. Performance comparisonwith the benchmark results and a commercial face recogni-tion system on the publicly available YouTube faces databaseshow the efficacy of the proposed video based face recogni-tion algorithm.
Index Terms— Video based face recognition, Rank ag-gregation, Dictionary based face recognition
1. INTRODUCTION
Face recognition from still images is a well-studied problemand several algorithms have been proposed to address differ-ent covariates such as pose, illumination, expression, aging,and disguise [1]. However, the performance of face recogni-tion algorithms is affected by large intra-personal variationsin unconstrained scenario. Though significant amount ofresearch has been done in matching still face images underdifferent conditions, use of videos for face recognition isrelatively less explored. The challenges and limitations ofstill face recognition drive the research in video based facerecognition. Moreover, widespread use of video camerasfor surveillance and security applications, improvementsinquality, and reduction in price of sensors (video cameras)have stirred extensive research interest in video based facerecognition. Videos cover wide intra-personal variationswithmultiple frames capturing different pose, illumination, andexpression variations. This diverse information can be ag-gregated together for efficient face recognition across largevariations.
Survey on video based face recognition by Barret al. [2]
categorizes different approaches as set-based and sequence-based approaches. Set-based approaches [3, 4] utilize abun-dance and variety of information in a video to achieve re-silience to sub-optimal capture conditions. Approaches thatmodel image sets as distributions use between-distributionsimilarity to match two image sets [5, 6]. However, the per-formance of such approaches is dependent on the parameterestimation of the underlying distribution. Image sets are oftenmodeled as linear sub-spaces [7, 8] and manifolds [5, 9, 10]where matching is performed by measuring the similarity be-tween the input and reference subspaces/manifolds. The per-formance of a subspace/manifold based approach is depen-dent on maintaining the image set correspondences. To ad-dress this limitation, Cuiet al. [11] propose to align two im-age sets using a common reference set before matching. Onthe other hand, sequence-based approaches explicitly utilizethe temporal information, such as modeling it with HiddenMarkov Models (HMM) [12], for improved face recognitionperformance.
This research proposes a video based face recognition al-gorithm where the discriminative signature of a video is gen-erated as an ordered list of still face images from a dictionary.A dictionary is a large collection of face images where ev-ery individual has multiple images captured under differentpose, illumination, and expression variations. Further, twovideos are matched by comparing their video signatures us-ing Kendall tau similarity distance [13].
2. PROPOSED ALGORITHM
Recent studies in face recognition [14, 15] show that generat-ing image signature based on a dictionary is more robust formatching images across large variations than directly com-paring two images or its features. Patelet al. [14] proposeda sparse approximation based approach where test images areprojected onto a span of elements in learned dictionaries andresulting residual vectors are used for classification. Primar-ily, dictionary based face recognition approaches are limitedto still face images except for a video based face recogni-tion technique proposed by Chenet al. [16] using video-dictionaries. Moreover, existing approaches discard the char-acteristics embedded in ranked lists and only consider theoverlap between two ranked lists as final similarity. As shownin Fig. 1, the proposed algorithm starts by extracting multi-

Fig. 1. Illustrates the block diagram of the proposed approach formatching two videos.
ple frames from a video. A ranked list of images from thedictionary is computed for each frame. A ranked list is an or-dered list of still face images where each image is positionedbased on its similarity to the input frame with the most sim-ilar image positioned at the top of list. Since each video hasseveral frames, the algorithm computes multiple ranked listsacross all video frames. These ranked lists are then combinedinto a single list using Markov chain based rank aggregationtechnique [13]. The aggregated ranked list forms the discrim-inative video signature. Finally for matching two videos, theiraggregated ranked lists are compared using Kendall tau sim-ilarity distance that incorporates the rankings as well as thesimilarity among images to compute the final similarity be-tween two lists. The proposed algorithm draws its motivationfrom rank aggregation techniques in information retrieval. Inbiometrics, rank aggregation techniques such as Borda count[17] have been explored for rank-level fusion; however to thebest of our knowledge, it is the first approach that proposesrank aggregation for combining multiple ranked lists to char-acterize an individual in a video.
2.1. Dictionary
Dictionary is a large collection of still face images whereeach individual has multiple images capturing a wide rangeof intra-personal variations. In our research, the dictionarycomprises38, 488 images pertaining to337 individuals fromthe CMU Multi-PIE [18] database captured in four sessions.
2.2. Computing the Ranked List
Let U be the set of all images in the dictionary andV be avideo of an individual comprisingn frames. Face region fromeach frame is detected1 and represented as{F1, F2, ..., Fn}.To generate the ranked lists, face region from each frame is
1OpenCV’s boosted cascade of haar-like features is used for face detec-tion and detected faces are resized to 192× 224 pixels.
compared with all images in the dictionary using uniform cir-cular local binary patterns (UCLBP) [19, 20]. In this research,UCLBP is used because of its robustness to gray-level inten-sity changes and high computational efficiency. For comput-ing UCLBP descriptor, the face image is first tessellated intonon-overlapping local patches of size32× 32. For each localpatch, the UCLBP descriptor is computed based on8 neigh-boring pixels uniformly sampled on a circle of radius size2.The concatenation of descriptors from each local patch consti-tutes the UCLBP descriptor of an image and two UCLBP de-scriptors are matched usingχ2 distance. To generate a rankedlist Ri corresponding to the input frameFi, the retrieved dic-tionary images are positioned based on their distance toFi
with the least distinct image positioned at the top of the list.For a videoV , the proposed algorithm computes a set ofranked lists{R1, R2, ..., Rn} corresponding ton frames ofthe video. Multiple ranked lists across different video framesfacilitate to capture large temporal and intra-personal varia-tions of an individual.
2.3. Aggregating Ranked List using Markov Chains
Multiple ranked lists computed acrossn frames of a videohave significant amount of overlap. It is computationally ex-pensive and inefficient to compare multiple ranked lists acrosstwo videos because of the redundant information. Therefore,multiple ranked lists of a video are aggregated into a singleoptimized ranked list, denoted asOR, to form the video sig-nature. Rank aggregation is aimed at computing an aggregateranking that minimizes the distance from each of the inputranked lists. To compute the video signature, multiple rankedlists are mapped onto a Markov chain. A Markov chain isrepresented by a set of states (nodes)S={1, ..., s}. The pro-cess starts in one of these states and moves successively fromone state to another with a probability denoted bypi,j . Theprobability depends only upon the current state and not onany previous states. The probabilitiespi,j are called transi-

tion probabilities and are represented by a transition probabil-ity matrix P of dimensions × s. The transition probabilitiesare defined by relative rankings of images in the ranked listsacross multiple frames of the video.
2.3.1. Mapping Ranked Lists onto a Markov Chain
Dwork et al. [21] proposed different schemes to map multipleranked lists onto a Markov chain. According to the MCS4mapping scheme, a transition from the stateSk = I to Sk+1
is performed by choosing a stateJ randomly fromU . I andJare the images retrieved from dictionary that form states inthemarkov chain. Ifr(J) < r(I), wherer(·) represents the rank,for a majority of ranked lists that ranked bothI andJ , thenSk+1 = J , otherwise similarity transition with a probabilityγ (γ = 1) is executed. A similarity transition is defined basedon the similarity among the nodes. A similarity transitionfrom Sk = I is executed by selectingJ from U randomlyfrom the weighted distribution,
Pr(I → J) =Sim(I, J)
∑l∈U Sim(I, l)
(1)
where,Sim(I, J) is the similarity between two imagesI andJ computed using UCLBP. It facilitates to utilize the similar-ity among the images along with their rankings across multi-ple ranked lists of a video. If no similarity transition is exe-cuted, then an epsilon transition with a probabilityǫ (ǫ = 0.1)is executed. Epsilon transition is executed atSk by choos-ing an itemJ randomly fromU and settingSk+1 = J . Ep-silon transitions eliminate the possibility of sink nodes in theMarkov chain and ensure a smooth ranking of all items inU . If no epsilon transition is executed, thenSk+1 = I. Us-ing these mapping rules, multiple ranked lists for a video aretransformed into a Markov chain.
2.3.2. Ordering Nodes using Stationary Distribution
The stationary distribution represents the proportion of timethat a Markov chain is in any particular state. A row vectorπ is called stationary distribution over a set of statesS if π
is a probability distribution such thatπ = πP , whereP isthe transition probability matrix. It represents the equilibriumstate of a Markov chain and can be approximated using powermethod on the transition probability matrix to find the domi-nant eigenvector of the matrix. Dworket al [21] observed thatstationary distribution implies an ordering on states whenthetransition probabilities in a Markov chain are representedbyrelative rankings. In this research, it is utilized for combin-ing ranked lists across multiple frames of a video to generatea combined ranked list as the video signature. The states ina Markov chain are ranked based on the stationary distribu-tion where the state with the highest value inπ is positionedat the top of the ranked list. It is observed that the similar-ity between a video frame and images in the dictionary drops
after a particular rank (say rankq) and the order of imagesis less discriminative beyond that point. Therefore, in thefi-nal aggregated ranked list, images till rankq (q = 100 in ourcase) are considered as the video signature. The algorithm tocompute the discriminative video signature based on still faceimages from the dictionary is described in Algorithm 1.
Algorithm 1 Algorithm for computing the video signatureInput: A set of dictionary imagesU and a videoV .Process:Decompose videoV into n frames and detect fa-cial regions asF1, F2, ...., Fn for all frames.Compute Ranked ListsIterate: i= 1 to n (number of frames)ComputeRi fromU using UCLBP andχ2 distance.end iterate.Rank AggregationStep-1: Map ranked listsR1, R2, ...., Rn onto a MarkovchainM : states inM ∈ U .Step-2: Compute the stationary distributionπ onM .Step-3: Sort states inM with decreasing values inπ.Output: Aggregated ranked listOR as the video signature.
2.4. Matching the Ranked Lists
Rank aggregation across multiple ranked lists yields similarrankings to similar items. Therefore, the distance measureto compare two ranked lists should penalize the score if twosimilar items are not placed nearby in the aggregated rankedlists. The standard Kendall tau distance does not account forsimilarity among items in the list. Therefore, to incorporatethe similarity among the dictionary images while computingthe number of pairwise disagreements in the ranked lists, theKendall tau similarity distance proposed by Sculley [13] isused. It incorporates the similarity among dictionary imagesby formulating an aggregate similarity position function (g)and an aggregate similarity list (Rg). The aggregate similarityposition of an image,I, for a listRi with similarity functionSim(·, ·) is defined as:
g(I,Ri, Sim(·, ·)) =
∑J∈Ri
Sim(I, J)Ri(J)∑
J∈RiSim(I, J)
(2)
whereJ is an image in the ranked listRi andSim(·, ·) isthe similarity computed using UCLBP. Aggregate similaritylist, Rg, is composed from listsOR1 andOR2 such that forevery imageI ∈ OR1, Rg(I) = g(I,OR2, Sim(·, ·)). TheKendall tau similarity distance between two ranked listsOR1
andOR2 is given as:
Ksim(OR1, OR2, Sim(·, ·)) =
1
2{K(OR1, Rg(OR1, OR2, Sim(·, ·))) +
K(OR2, Rg(OR2, OR1, Sim(·, ·)))} (3)
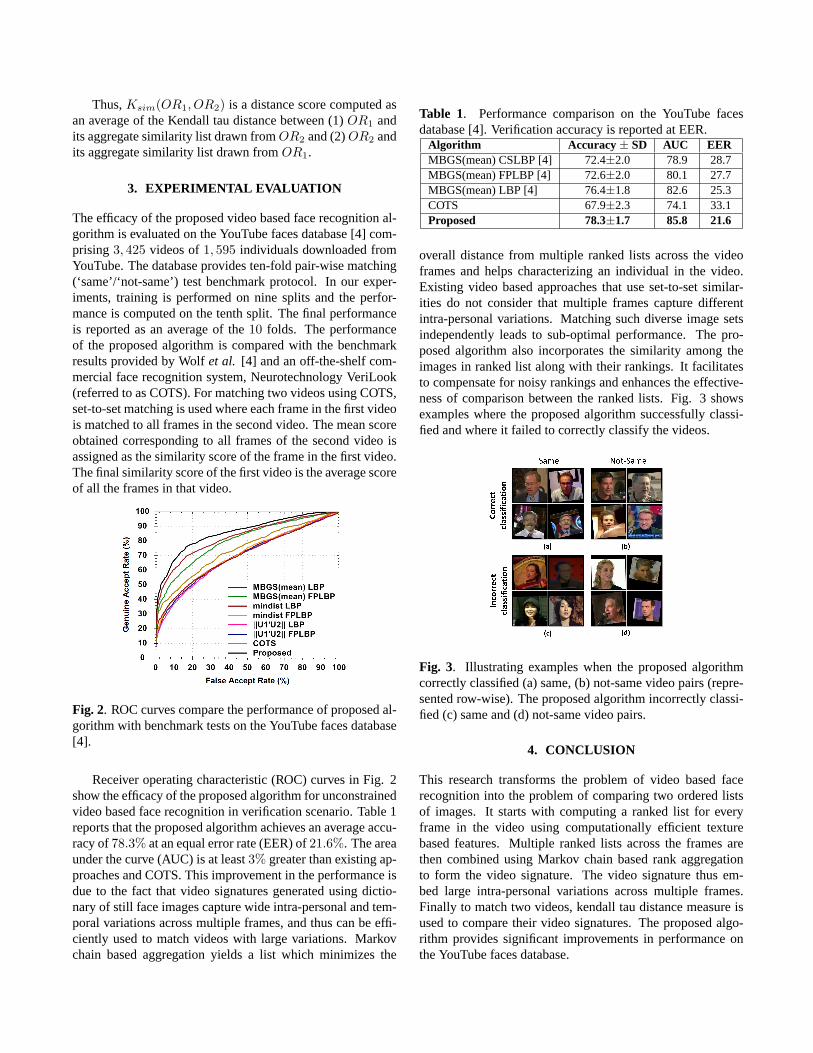
Thus,Ksim(OR1, OR2) is a distance score computed asan average of the Kendall tau distance between (1)OR1 andits aggregate similarity list drawn fromOR2 and (2)OR2 andits aggregate similarity list drawn fromOR1.
3. EXPERIMENTAL EVALUATION
The efficacy of the proposed video based face recognition al-gorithm is evaluated on the YouTube faces database [4] com-prising3, 425 videos of1, 595 individuals downloaded fromYouTube. The database provides ten-fold pair-wise matching(‘same’/‘not-same’) test benchmark protocol. In our exper-iments, training is performed on nine splits and the perfor-mance is computed on the tenth split. The final performanceis reported as an average of the10 folds. The performanceof the proposed algorithm is compared with the benchmarkresults provided by Wolfet al. [4] and an off-the-shelf com-mercial face recognition system, Neurotechnology VeriLook(referred to as COTS). For matching two videos using COTS,set-to-set matching is used where each frame in the first videois matched to all frames in the second video. The mean scoreobtained corresponding to all frames of the second video isassigned as the similarity score of the frame in the first video.The final similarity score of the first video is the average scoreof all the frames in that video.
Fig. 2. ROC curves compare the performance of proposed al-gorithm with benchmark tests on the YouTube faces database[4].
Receiver operating characteristic (ROC) curves in Fig. 2show the efficacy of the proposed algorithm for unconstrainedvideo based face recognition in verification scenario. Table 1reports that the proposed algorithm achieves an average accu-racy of78.3% at an equal error rate (EER) of21.6%. The areaunder the curve (AUC) is at least3% greater than existing ap-proaches and COTS. This improvement in the performance isdue to the fact that video signatures generated using dictio-nary of still face images capture wide intra-personal and tem-poral variations across multiple frames, and thus can be effi-ciently used to match videos with large variations. Markovchain based aggregation yields a list which minimizes the
Table 1. Performance comparison on the YouTube facesdatabase [4]. Verification accuracy is reported at EER.
Algorithm Accuracy± SD AUC EERMBGS(mean) CSLBP [4] 72.4±2.0 78.9 28.7MBGS(mean) FPLBP [4] 72.6±2.0 80.1 27.7MBGS(mean) LBP [4] 76.4±1.8 82.6 25.3COTS 67.9±2.3 74.1 33.1Proposed 78.3±1.7 85.8 21.6
overall distance from multiple ranked lists across the videoframes and helps characterizing an individual in the video.Existing video based approaches that use set-to-set similar-ities do not consider that multiple frames capture differentintra-personal variations. Matching such diverse image setsindependently leads to sub-optimal performance. The pro-posed algorithm also incorporates the similarity among theimages in ranked list along with their rankings. It facilitatesto compensate for noisy rankings and enhances the effective-ness of comparison between the ranked lists. Fig. 3 showsexamples where the proposed algorithm successfully classi-fied and where it failed to correctly classify the videos.
Fig. 3. Illustrating examples when the proposed algorithmcorrectly classified (a) same, (b) not-same video pairs (repre-sented row-wise). The proposed algorithm incorrectly classi-fied (c) same and (d) not-same video pairs.
4. CONCLUSION
This research transforms the problem of video based facerecognition into the problem of comparing two ordered listsof images. It starts with computing a ranked list for everyframe in the video using computationally efficient texturebased features. Multiple ranked lists across the frames arethen combined using Markov chain based rank aggregationto form the video signature. The video signature thus em-bed large intra-personal variations across multiple frames.Finally to match two videos, kendall tau distance measure isused to compare their video signatures. The proposed algo-rithm provides significant improvements in performance onthe YouTube faces database.

5. REFERENCES
[1] S. Z. Li and A. K. Jain,Handbook of Face Recognition,2nd Edition, Springer, 2011.
[2] J. R. Barr, K. W. Bowyer, P. J. Flynn, and S. Biswas,“Face recognition from video : A review,”Journal ofPattern Recognition and Artificial Intelligence, vol. 26,no. 5, 2012.
[3] J. Stallkamp, H. K. Ekenel, and R. Stiefelhagen, “Video-based face recognition on real-world data,” inProceed-ings of International Conference on Computer Vision,2007, pp. 1–8.
[4] L. Wolf, T. Hassner, and I. Maoz, “Face recognitionin unconstrained videos with matched background simi-larity,” in Proceedings of International Conference onComputer Vision and Pattern Recognition, 2011, pp.529–534.
[5] O. Arandjelovic, G. Shakhnarovich, J. Fisher,R. Cipolla, and T. Darrell, “Face recognition withimage sets using manifold density divergence,” inProceedings of International Conference on ComputerVision and Pattern Recognition, 2005, pp. 581–588.
[6] G. Shakhnarovich, J. W. Fisher, III, and T. Darrell,“Face recognition from long-term observations,” inPro-ceedings of European Conference on Computer Vision,2002, pp. 851–868.
[7] G. Aggarwal, A. K. R. Chowdhury, and R. Chellappa,“A system identification approach for video-based facerecognition,” inProceedings of International Confer-ence on Pattern Recognition, 2004, pp. 175–178.
[8] M. Nishiyama, M. Yuasa, T. Shibata, T. Wakasugi,T. Kawahara, and O. Yamaguchi, “Recognizing faces ofmoving people by hierarchical image-set matching,” inProceedings of International Conference on ComputerVision and Pattern Recognition, 2007, pp. 1–8.
[9] M. T. Harandi, C. Sanderson, S. Shirazi, and B. C.Lovell, “Graph embedding discriminant analysis ongrassmannian manifolds for improved image set match-ing,” in Proceedings of International Conference onComputer Vision and Pattern Recognition, 2011, pp.2705–2712.
[10] R. Wang, S. Shan, X. Chen, Q. Dai, and W. Gao,“Manifold-manifold distance and its application to facerecognition with image sets,”IEEE Transactions on Im-age Processing, vol. 21, no. 10, pp. 4466–4479, 2012.
[11] Z. Cui, S. Shan, H. Zhang, S. Lao, and X. Chen, “Im-age sets alignment for video-based face recognition,” inProceedings of International Conference on ComputerVision and Pattern Recognition, 2012, pp. 2626–2633.
[12] M. Kim, S. Kumar, V. Pavlovic, and H. Rowley, “Facetracking and recognition with visual constraints in real-world videos,” in Proceedings of International Con-ference on Computer Vision and Pattern Recognition,2008, pp. 1–8.
[13] D. Sculley, “Rank aggregation for similar items,” inProceedings of the International Conference on DataMining, 2007, pp. 587–592.
[14] V. M. Patel, T. Wu, S. Biswas, P. J. Phillips, and R. Chel-lappa, “Dictionary-based face recognition under vari-able lighting and pose.,”IEEE Transactions on Informa-tion Forensics and Security, vol. 7, no. 3, pp. 954–965,2012.
[15] F. Schroff, T. Treibitz, D. Kriegman, and S. Belongie,“Pose, illumination and expression invariant pairwiseface-similarity measure via doppelganger list compar-ison,” in Proceedings of International Conference onComputer Vision, 2011, pp. 2494–2501.
[16] Y. C. Chen, V. M. Patel, P. J. Phillips, and R. Chellappa,“Dictionary-based face recognition from video,” inPro-ceedings of European Conference on Computer Vision,2012, pp. 766–779.
[17] A. Abaza and A. Ross, “Quality based rank-level fusionin multibiometric systems,” inProceedings of Interna-tional Conference on Biometrics: Theory, Applications,and Systems, 2009, pp. 1–6.
[18] R. Gross, I. Matthews, J. Cohn, T. Kanade, and S. Baker,“Multi-pie,” Image and Vision Computing, vol. 28, no.5, pp. 807–813, 2010.
[19] T. Ojala, M. Pietikainen, and T. Maenpaa, “Multiresolu-tion gray-scale and rotation invariant texture classifica-tion with local binary patterns,”IEEE Transactions onPattern Analysis and Machine Intelligence, vol. 24, no.7, pp. 971–987, 2002.
[20] T. Ahonen, A. Hadid, and M. Pietikainen, “Face de-scription with local binary patterns: Application to facerecognition,” IEEE Transactions on Pattern Analysisand Machine Intelligence, vol. 28, no. 12, pp. 2037–2041, 2006.
[21] C. Dwork, R. Kumar, M. Naor, and D. Sivakumar,“Rank aggregation methods for the web,” inProceed-ings of International Conference on World Wide Web,2001, pp. 613–622.













