Embed Size (px)
Citation preview

Computer Networks 76 (2015) 191–206
Contents lists available at ScienceDirect
Computer Networks
journal homepage: www.elsevier .com/ locate/comnet
On the tradeoff of availability and consistency for quorumsystems in data center networks
http://dx.doi.org/10.1016/j.comnet.2014.11.0061389-1286/� 2014 Elsevier B.V. All rights reserved.
⇑ Corresponding author. Tel.: +86 13811909091.E-mail addresses: [email protected] (X. Wang), sunhl@act.
buaa.edu.cn (H. Sun), [email protected] (T. Deng), [email protected] (J. Huai).
Xu Wang, Hailong Sun ⇑, Ting Deng, Jinpeng HuaiSchool of Computer Science and Engineering, Beihang University, Beijing 100191, China
a r t i c l e i n f o
Article history:Received 23 May 2014Received in revised form 15 September2014Accepted 10 November 2014Available online 15 November 2014
Keywords:Quorum systemsAvailabilityData center networks
a b s t r a c t
Large-scale distributed storage systems often replicate data across servers and even geo-graphically-distributed data centers for high availability, while existing theories like CAPand PACELC show that there is a tradeoff between availability and consistency. Thus even-tual consistency is proposed to provide highly available storage systems. However, currentpractice is mainly experience-based and lacks quantitative analysis for identifying a goodtradeoff between the two. In this work, we are concerned with providing a quantitativeanalysis on availability for widely-used quorum systems in data center networks. First, aprobabilistic model is proposed to quantify availability for typical data center networks:2-tier basic tree, 3-tier basic tree, fat tree and folded clos, and even geo-distributed datacenter networks. Second, we analyze replica placements on network topologies to obtainmaximal availability. Third, we build the availability-consistency table and propose a setof rules to quantitatively make tradeoff between availability and consistency. Finally, withMonte Carlo based simulations, we validate our presented quantitative results and showthat our approach to make tradeoff between availability and consistency is effective.
� 2014 Elsevier B.V. All rights reserved.
1. Introduction
Data centers as a mainstay for large-scale distributedstorage systems, often face the challenges of high availabil-ity and scalability [1,2]. They typically replicate data acrossmultiple servers and even geographically-distributed datacenters [3] to tolerate network partition and node crashes.However, the CAP [4] and PACELC [5] theorems show thatthere is a tradeoff between availability and consistency indata replication. High availability is regarded as an impor-tant property in service level agreements for cloud ser-vices. For example, Amazon EC2 claims the availability of99.95% [6]; Google Cloud Storage’s service level commit-ment provides 99.9% availability [7]; and the availability
of Microsoft Windows Azure is promised as 99.9% [8]. Inorder to provide extremely high availability, systems suchas Amazon Dynamo [9] and Apache Cassandra [10] ofteneschew strong consistent replicas and instead provideeventual consistency [11,12]. But eventual consistencymay lead to inconsistency such as read staleness [13] andwrite conflicts [9], since the newest value of a data itemis eventually returned and the same data item may beupdated on different, potentially disconnected replicas.Therefore it is necessary to understand how much avail-ability can be obtained in different consistency levels suchthat we can quantitatively make tradeoff between them.
Distributed quorums [14] are widely used for eventu-ally consistent storage systems in data centers[9,10,15,16]. With quorum replication, these storage sys-tems write a data item by sending it to a set of replicas(write quorums) and read from a possibly different set ofreplicas (read quorums). Strong consistency is provided

192 X. Wang et al. / Computer Networks 76 (2015) 191–206
by guaranteeing the intersection of write quorums andread quorums; otherwise, read requests may return stalevalues, thus resulting in inconsistency. In practical quorumsystems, any W replicas are defined as write quorums andany R replicas as read ones. With N replicas, if W þ R > N,strong consistency is achieved since the overlapping ofwrite and read quorums is always guaranteed; and ifW þ R 6 N, the overlapping condition may not be satisfied,therefore it can cause inconsistency. The former is a strictquorum system [17] and the latter is a probabilistic quo-rum system [18]. Almost all practical quorum systems likeDynamo and Cassandra provide the configuration capabil-ity on W and R. It is obvious that greater W and R will resultin stronger consistency, but will lower system availabilitysince greater W and R require more live replicas to beaccessed for available write and read requests during fail-ures. How to configure ðW;RÞ to get the best solution forboth consistency and availability? The current practice ismainly experience-based and lack quantitative analysisfor identifying a good tradeoff between them.
The quantitative consistency analysis for quorum sys-tems has been well studied [13,18]. However, availabilityis network topology-aware because network partition isthe main cause of system unavailability according to theCAP theorem [4], and data center networks are complex[19–21] such as basic tree, fat tree, folded clos networkand even geo-distributed data centers, therefore the quan-titative analysis on availability of quorum systems in datacenter networks is challenging. There are several bodiesof work [18,22–26] on quantifying the availability of quo-rum systems, but they have two limitations: (1) they usu-ally assume simple network topologies such as the fullyconnected network and ring topology; and (2) they definethe availability of quorum systems as the probability thatat least one quorum is alive, but in practice live quorumsmay be inaccessible due to failures of switches in networks.
In this work, we focus on evaluating the availability ofquorum systems in four typical data center networks: 2-tier basic tree, 3-tier basic tree, fat tree and folded clos net-work, and even geo-distributed data centers [19–21]. Atfirst, we propose a system model QSðDCN; PM;W=RÞ forquorum systems, where DCN represents the data centernetwork topologies containing core switches, aggregationswitches, ToR (Top of Rack) switches, servers and theirlinks, PM is a vector describing the placement of replicason servers, and W=R are the sizes of write/read quorums.Since write requests should reaches at least W live replicasand read requests must wait for responses from at least Rreplicas, they are equivalent to each other for our availabil-ity analysis and we only consider write requests. Based onQSðDCN; PM;WÞ, the write availability is defined as theprobability that a write can reach one live replica (i.e. thecoordinator) from live core switches and at least otherW � 1 live replicas from the coordinator. Although typicaldata center networks are complex especially for the fat treeand folded clos network, they are essentially tree-like.Therefore, after calculating the write availability for a sim-ple 2-tier basic tree, we use super nodes to represent sub-trees or groups of nodes for 3-tier basic tree, fat tree andfolded clos network which are logically equivalent to eachother and obtain simplified network topologies. Then the
write availability for the 3-tier basic tree, fat tree and foldedclos network is computed by conditional probability andreusing the result of 2-tier basic tree. In addition, we extendour quantitative write availability from one single data cen-ter to geo-distributed data centers. We also analyze theimpact of replica placement on maximizing write availabil-ity. Based on the quantitative results of availability, webuild an availability-consistency table filled with valuesof hAvailability;Consistencyi for quorum systems, and pro-pose a set of rules to choose the best ðW;RÞ to make tradeoffbetween availability and consistency. Finally, throughMonte Carlo based event driven simulations, we validateour quantitative results and show the effectiveness of ourmethod for balancing availability and consistency.
We make the following contributions:
� We propose a system model QSðDCN; PM;W=RÞ forquorum systems in typical data center networks.Unlike earlier work, our system model considerspractical complex data center network DCN whereswitches may fail, and the placement of replicason servers PM;
� On the basis of QSðDCN; PM;WÞ, we build a probabi-listic model for the write availability of quorum sys-tems in four typical data center networks: 2-tierbasic tree, 3-tier basic tree, fat tree and folded closnetwork. We also extend the write availability fromone single data center to geo-distributed datacenters;
� We analyze how to place replicas on network topol-ogies to maximize write availability and discussspecial cases when the network topology is a 2-tierbasic tree and the number of replicas is a popularvalue 3;
� We build an availability-consistency table filledwith hAvailability;Consistencyi, and then propose aset of rules to choose the best ðW;RÞ configurationfor a specific quorum system to balance availabilityand consistency;
� With Monte Carlo based event driven simulations,we validate our quantitative results and show theeffectiveness of our proposed approach to quantita-tively make tradeoffs between availability andconsistency.
The remainder of this paper is structured as follows.Section 2 introduces the background. Section 3 presentsour system model. Section 4 describes how to quantifythe write availability of quorum systems. Section 5 pro-pose the impact of replica placements on availability.How to make tradeoffs between availability and consis-tency is shown in Section 6. Section 7 provides our exper-imental results. Related work and discussion are presentedin Section 8 and Section 9, respectively. Finally, Section 10concludes the work.
2. Background
In this section, we present the background, includingthe preliminary knowledge of quorum systems and datacenter networks.

Clients
…
R responses
(READ Coordinator)
W responses
Newest data
Clients R responses
W responses
No overlapping,Stale data
Replica1
Replica2
ReplicaN
Replica3
(WRITE Coordinator) timeline
Fig. 1. An example of quorum system.
Servers
ToR SwitchEdge
Core SwitchCore
…
(a) 2-tier Basic Tree
Servers
ToR SwitchEdge
Core SwitchCore
Aggrega�on SwitchAggrega�on
…
(b) 3-tier Basic Tree
Edge
Aggrega�onSwitch
Aggrega�onK=4
ToR Switch
CoreSwitchCore
…
Pod1 Podk
Servers
(c) K-ary Fat Tree
Edge
Aggrega�on
ToRSwitch
CoreSwitchCore
…
Servers
Aggrega�onSwitch
(d) Folded Clos
Fig. 2. Typical data center networks.
X. Wang et al. / Computer Networks 76 (2015) 191–206 193
2.1. Quorum systems
Quorums have long been used in distributed storagesystems [27], which is actually a set system that is a setof subsets of all replicas U. In practical quorum systems,two parameters W and R are predefined for N replicas, thatis N ¼ jUj and 1 6W; R 6 N. Let the write quorum set beSw ¼ fQ jQ # U ^ jQ j ¼Wg and the read quorum set beSr ¼ fQ jQ # U ^ jQ j ¼ Rg. Obviously, if W þ R > N, two ele-ments from Sw and from Sr , respectively, must intersect,thus any read can return the newest write and guaranteesstrong consistency. On the contrary, if W þ R 6 N, the twoelements overlap with a probability Poverlap:
Poverlap ¼ 1�
N
W
� �N �W
R
� �N
W
� �N
R
� � ¼ 1�
N �W
R
� �N
R
� � ð1Þ
where e ¼ N �WR
� ��NR
� �can also be viewed as an
important measurement of inconsistency for quorumsystems [13].
Fig. 1 shows an example for the quorum system. For awrite request, firstly it is sent to a replica as thecoordinator, and then the coordinator propagates the writeto all other replicas. After getting at least W � 1 responses,the coordinator returns. A read request is processed in thesame way as the write request but the coordinator should
wait for at least R� 1 responses. If the read set ofreplicas overlaps with the write one, the read request canreturn the newest value; otherwise, it will return staledata.
According to [22,24,25], assuming that each replica failsindependently with probability p and replicas are fullyconnected, the availability of practical quorum systems(denoted by Avail) is the probability that at least one quo-rum survives:
Avail ¼ 1�XN
i¼N�Wþ1
N
i
� �pið1� pÞN�i ð2Þ
Since read requests perform in the same way as writerequests, we only consider writes in Eq. (2). This kind ofavailability has two limitations: (a) replicas are often fullyconnected or are in other simple topologies like a ring. Thisassumption does not consider switch failures in practicalcomplex networks; (b) it potentially assumes that thesurviving quorums are always accessible for writes.However, as analyzed in [28], the possibility that writescan reach a replica in the surviving quorums is also animportant factor for system availability. Both limitationsare unified in practical network topologies where serversand switches may fail, and only part of switches canreceive outward write requests. Thus it is necessary todiscuss the availability of quorum systems in practical datacenter networks.

194 X. Wang et al. / Computer Networks 76 (2015) 191–206
2.2. Data center networks
Data center networks can be classified to switch-centrictopologies [19–21] and server-centric topologies [29].Since the server-centric topologies are based on multiple-port servers, they are promising but not widely-used now-adays. Thus we only consider switch-centric topologies inthis work.
Switch-centric topologies of data center networks aretree-like but differ in the tiers, the links and the numberof switches. As shown in Fig. 2, they usually have three-tierswitches (or routers): core tier in the root of the tree, aggre-gation tier in the middle and edge tier at the leaves of thetree. The core switches (CS), the aggregation switches (AS)and the ToR (Top of Rack) switches are in different tiers.
Typical tree-based data center networks include 2-tierbasic tree, 3-tier basic tree, K-ary fat tree and folded closnetwork, and the details of these four network topologiesare as follows:
1. The 2-tier basic tree does not have the aggregationtier. It includes only one core switch which connectsto a number of ToR switches and underlying servers;
2. The 3-tier basic tree includes only one core switchwhich connects to a number of aggregationswitches, and each aggregation switch links someToR switches and corresponding servers;
3. The K-ary fat tree has K pods and ðK=2Þ2 K-port coreswitches. Every pod includes K=2 K-port aggrega-tion switches and K=2 K-port ToR switches, andeach aggregation switch connects to all ToRswitches in the same pod. In addition, the ith coreswitch connects to the ð½i=ðK=2Þ� þ 1Þth aggregationswitch in all pods; and
4. The folded clos network is built based on twoparameters: DA and DI , where DA denotes the doublenumber of core switches and DI denotes the numberof aggregation switches. Thus a folded clos networkhas DA=2 DI-port core switches and DI DA-portaggregation switches, and each core switch con-nects to all aggregation switches. Every DA=2 ToRswitches connect to two same aggregation switches.
3. System model
In this section, we will propose a quorum system modelthat is aware of the data center network topologies and theplacement of replicas.
Our system model for quorum systems (QSs) in datacenter networks is a triple QSðDCN; PM;W=RÞ, where
� DCN 2 {2-tier basic tree, 3-tier basic tree, K-ary fattree, folded clos}; that is, DCN is one of the four typ-ical data center networks as described above.
� PM is a 0/1 vector representing the placement ofreplicas on servers.
� W=R describe the sizes of write quorums and readquorums.
In the four data center networks, we assume there arethree kinds of switches: core switches (10-GigE switches)
with the crash probability Pc , aggregation switches (10-GigE switches) with the crash probability Pa and ToRswitches (1-GigE switches) with the crash probability Pt .We also assume that the links never crash, servers arehomogenous with the crash probability Ps, and the crashevents are independent.
When data replicas are placed on servers, they shouldbe put on different physical machines or virtual machinesacross different physical ones to improve availability. Thus‘‘servers’’ in this work refer to physical machines as well asvirtual machines on them, which are also the ones con-necting to ToR switches in data center networks. Withoutloss of generality, we assume there is an order for alldevices with the same type, and we use 1 and 0 torepresent a replica on and not on a server, respectively.So PM is a 0/1 vector whose length equals the number ofservers (denoted by nserver), and the number of 1 is thenumber of replicas (N). That is PM ¼ hrs
1; rs2; . . . ; rs
nserveri,
where rsi ¼ 0 or 1ð1 6 i 6 nserverÞ and
Pnserveri¼1 rs
i ¼ N. In addi-tion, we define PMtor ¼ hrt
1; rt2; . . . ; rt
ntori where ntor denotes
the number of ToR switches and element rti means the
number of replicas that the ith ToRS can access from down-links, thus we have
Pntori¼1rt
i ¼ N. Similarly, PMas for aggrega-tion switches can be defined. For example, there are 3replicas (i.e., N ¼ 3) for a 3-tier basic tree in Fig. 3, thenPM¼h0;1;1;0;0;1;0;0i; PMtor¼h1;1;1;0i and PMas¼h2;1i.
In practical quorum systems, W and R are the number ofreplicas for write and read, respectively. An available readperforms similarly with an available write, thus read avail-ability can be obtained by replacing W with R in the resultsof write availability, and we only consider write availabil-ity in the next section.
4. Quantitative analysis of availability
Given the replication placement vector PM and thevalue of W, the write availability of a quorum system inone data center network is defined as the probability thata write request reaches at least one live replica throughcore switches and the replica can arrive at least otherðW � 1Þ live replicas. In this section, we will compute thewrite availability for four typical data center networks:2-tier basic tree (bt2), 3-tier basic tree (bt3), k-ary fat tree(ft) and folded clos network (fc). In addition, the writeavailability is extended from one single data center togeo-distributed data centers.
4.1. Sketch of quantitative analysis
At first, although practical data center networks usuallyhave thousands of and even tens of thousands of nodes, ouranalysis focuses on the replicas of one data item and theinvolved sub-network since the number of replicas is usu-ally not big (e.g., Cassandra has a default configuration ofN ¼ 3; W ¼ R ¼ 1 [30]). As shown in Fig. 4, three replicas(i.e., N ¼ 3) of a data item are placed on a 3-tier basic treewhich may have thousands of nodes, but we only need toanalyze the sub-network marked by the dash line sincethe involved sub-network includes all possible routingpaths from the core switch to N replicas. The servers and
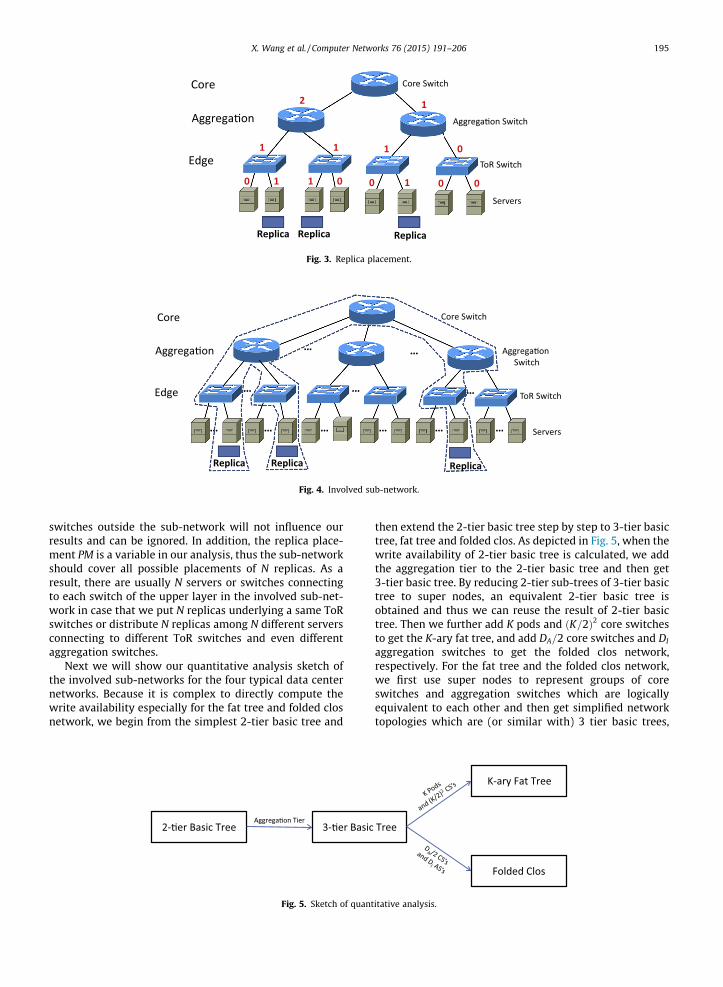
Servers
ToR SwitchEdge
Core SwitchCore
Aggrega�on SwitchAggrega�on
Replica ReplicaReplica
0 1 1 0 0 1 0 0
1 1 1 0
2 1
Fig. 3. Replica placement.
Servers
ToR SwitchEdge
Core SwitchCore
Aggrega�on Switch
Aggrega�on
Replica ReplicaReplica
… …
… … …
… … … … … …
Fig. 4. Involved sub-network.
X. Wang et al. / Computer Networks 76 (2015) 191–206 195
switches outside the sub-network will not influence ourresults and can be ignored. In addition, the replica place-ment PM is a variable in our analysis, thus the sub-networkshould cover all possible placements of N replicas. As aresult, there are usually N servers or switches connectingto each switch of the upper layer in the involved sub-net-work in case that we put N replicas underlying a same ToRswitches or distribute N replicas among N different serversconnecting to different ToR switches and even differentaggregation switches.
Next we will show our quantitative analysis sketch ofthe involved sub-networks for the four typical data centernetworks. Because it is complex to directly compute thewrite availability especially for the fat tree and folded closnetwork, we begin from the simplest 2-tier basic tree and
2-�er Basic Tree 3-�er BasicAggrega�on Tier
Fig. 5. Sketch of quant
then extend the 2-tier basic tree step by step to 3-tier basictree, fat tree and folded clos. As depicted in Fig. 5, when thewrite availability of 2-tier basic tree is calculated, we addthe aggregation tier to the 2-tier basic tree and then get3-tier basic tree. By reducing 2-tier sub-trees of 3-tier basictree to super nodes, an equivalent 2-tier basic tree isobtained and thus we can reuse the result of 2-tier basictree. Then we further add K pods and ðK=2Þ2 core switchesto get the K-ary fat tree, and add DA=2 core switches and DI
aggregation switches to get the folded clos network,respectively. For the fat tree and the folded clos network,we first use super nodes to represent groups of coreswitches and aggregation switches which are logicallyequivalent to each other and then get simplified networktopologies which are (or similar with) 3 tier basic trees,
Tree
K-ary Fat Tree
Folded Clos
itative analysis.

Server
ToRSEdge
CSCore
…
CoordinatorReplica Replica
ToRi
WRITE
… … …
Fig. 6. Available write for 2-tier basic tree.
196 X. Wang et al. / Computer Networks 76 (2015) 191–206
thus we can simplify the computation of the fat tree andthe folded clos network by reusing the result of 3-tier basictree.
4.2. 2-Tier basic tree
Typically, a two-tier basic tree network can support 5–8 K servers [20] in data centers. Since only the core switchcan receive write requests, we just consider the involvedsub-network which includes all possible routing pathsfrom the core switch to N replicas. The sub-network con-tains N ToRSs, and each ToRS connects to N servers, thusany placement of N replicas is possible. As shown inFig. 6, if a write request reaches the CS, it will be sent toone live replica as the coordinator via a live ToRS, and thenthe coordinator sends the write request to other replicasvia ToRSs and the CS. After getting ðW � 1Þ acknowledge-ment (ACK) messages, the coordinator will return the writeand thus the write is available. Otherwise, the write isunavailable.
It is obvious that if a write is available in a two-tierbasic tree network, the write can access at least W live rep-licas via the live CS; and inversely, if a write can access atleast W live replicas via the live CS, the write must be avail-able. Therefore the event that a write is available is equiv-alent to the event that a write can access at least W livereplicas via the live CS.
Let stochastic variable Ai be the number of accessiblelive replicas underlying the ith ToRS from the live CS,where 1 6 i 6 N. Given PM ¼ hrs
1; rs2; . . . ; rs
nserveriðnserver ¼
N2Þ, we can get PMtor ¼ hrt1; r
t2; . . . ; rt
Ni where rti ¼PiN
j¼ði�1ÞNþ1rsj . Then we calculate the probability density
function (pdf) of Ai as follows:
PrðAi¼miÞ¼Ptþð1�PtÞðPsÞr
ti rt
i Pmi¼0;
ð1�PtÞrt
i
mi
� �ð1�PsÞmi ðPsÞr
ti�mi rt
i Pmi>0:
8><>:
where mi ¼ 0 if the ith ToRS fails, or the ith ToRS is aliveand all rt
i servers with replicas fail; and mi > 0 if the ithToRS is alive and exact mi servers with replicas are alive.Recall that Pt and Ps are the crash probability of ToRS andservers, respectively, and have been defined in Section 3.
Let stochastic variable Xbt2�tor be the number of accessi-ble live replicas from the live CS in the two-tier basic treenetwork, and the probability of Xbt2�tor ¼ x is the sum of the
probability for all possible cases that A1 þ A2 þ � � � þ AN ¼ x.Since the CS is alive and PMtor is given, A1; . . . ;AN are inde-pendent. Thus we have:
PrðXbt2�tor ¼ xÞ ¼X
m1þm2þ���þmN¼x
YN
i¼1
PrðAi ¼ miÞ
where 0 6 mi 6 rti . Define a function Qbt2�torðxÞ ¼
PrðXbt2�tor ¼ xÞ for simplicity, then the probability that awrite can access at least W live replicas via the live CS isð1� PcÞ
PNx¼W Qbt2�torðxÞ. That is:
AvailðQSðbt2; PM;WÞÞ ¼ ð1� PcÞXN
x¼W
Qbt2�torðxÞ ð3Þ
where AvailðQSðbt2; PM;WÞÞ denotes the write availabilityof quorum systems in 2-tier basic tree where thereplica placement is PM and the size of write quorums isW. Similarly, AvailðQSðbt3; PM;WÞÞ for 3-tier basic tree,AvailðQSðft; PM;WÞÞ for fat tree and AvailðQSðfc; PM;WÞÞfor folded clos can be defined.
4.3. 3-Tier basic tree
In the three-tier basic tree, we also only consider thepossible involved sub-network. The sub-network has NASs, and each AS connects to N ToRSs. Any ToRS also con-nects to N servers. Fig. 7 shows an example. If a writerequest reaches the CS, it will be sent to one live replicawhich is the coordinator via a live AS and a live ToRS,and then the coordinator sends the write to other replicasthrough ToRSs, ASs and the CS. When the coordinatorreceives ðW � 1Þ ACK messages from other replicas, it willreturn the write result and then the write is available.Otherwise, the write is unavailable. Similarly, we can seethat, the event that a write is available is equivalent tothe event that a write can access at least W live replicasvia the live CS in the 3-tier basic tree.
Let stochastic variable Bj be the number of accessiblelive replicas under the jth AS from the live CS, where1 6 j 6 N. Given PM ¼ hrs
1; rs2; . . . ; rs
nN3i, we can get PMtor ¼
hrt1; r
t2; . . . ; rt
N2 i where rti ¼
PiNj¼ði�1ÞNþ1rs
j , and PMas ¼hra
1; ra2; . . . ; ra
Ni where rai ¼
PiNj¼ði�1ÞNþ1rt
j . As shown in Fig. 7,the sub-trees marked by dash lines can be seen as two-tierbasic trees when we replace ASs with CSs, thus we calcu-late the pdf of Bj by reusing the results of two-tier basictrees:
PrðBj ¼ m0jÞ ¼Pa þ ð1� PaÞQ bt2�torð0Þ ra
i P m0j ¼ 0;
ð1� PaÞQ bt2�torðm0jÞ rai P m0j > 0:
(
where m0j ¼ 0 if the jth AS fails, or the jth AS is alive and thesub-tree whose root is the jth AS can access 0 live replicas;and m0j > 0 if the jth AS is alive and there are exact m0j rep-licas which can be accessed in the sub-tree whose root isthe jth AS.
Let stochastic variable Xbt3�as be the number of accessi-ble live replicas from the live CS in the three-tier basic treenetwork, and the probability of Xbt3�as ¼ x0 is the sum of theprobability for all possible cases that B1 þ B2 þ � � � þ

Server
ToRS
CS
…
AS
CoordinatorReplica Replica
WRITE
… … … …
Fig. 7. Available write for 3-tier basic tree.
X. Wang et al. / Computer Networks 76 (2015) 191–206 197
BN ¼ x0. Since the CS is alive and PMas is given, B1; . . . ;BN areindependent. Thus:
PrðXbt3�as ¼ x0Þ ¼X
m01þm02þ���þm0N¼x0
YNj¼1
PrðBj ¼ m0jÞ
where 0 6 m0j 6 raj .
Because the write availability of three-tier basic treeequals the probability that a write can access at least Wlive replicas via the live CS, we have:
AvailðQSðbt3; PM;WÞÞ ¼ ð1� PcÞXN
x0¼W
PrðXbt3�as ¼ x0Þ ð4Þ
4.4. Fat tree
The K-ary fat tree has K pods and ðK=2Þ2 CSs. There areK=2 ASs and K=2 ToRSs in a pod where each AS connects toall ToRSs, and each ToRS connects to N servers. In addition,the ith CS connects to the ð½i=ðK=2Þ� þ 1Þth aggregationswitch in all pods. From Fig. 8 we can see that, if we putevery ðK=2Þ CSs into a group from left to right, we can haveðK=2Þ groups of CSs and the jth group of CSs are all con-necting to the jth AS in every pods. As shown in Fig. 8, awrite request can be sent to any live CS and reaches one
…
Pod1
WRITE
… … …
…
…
……
Coordinator Replica
Group1
Fig. 8. Available write f
live replica which is the coordinator via a live AS and a liveToRS in one pod, and then the coordinator sends the writeto other replicas through ToRSs, ASs and one CS. If ðW � 1ÞACK messages from other replicas are received by the coor-dinator, the write will be returned to clients and it isavailable.
To simplify the K-ary fat tree, we use a core switchgroup (GCS) to represent a group of CSs since they connectto the same ASs, and use a super aggregation switches(SAS) to represent all ASs in a pod because they connectto the same ToRSs. For a GCS, its crash probability Pgc isthe probability that all internal CSs crash, thusPgc ¼ ðPcÞK=2. If there are exact xð1 6 x 6 K=2Þ live GCSs,the crash probability Psa for a SAS is the probability thatall the internal x ASs which connect to the x live GCSscrash, thus Psa ¼ ðPaÞx. Fig. 9 shows GCSs and SASs in thesimplified fat tree.
Let stochastic variable Cj be the number of accessiblelive replicas underlying the jth SAS from the x live GCSs,where 1 6 j 6 K. Given PM ¼ hrs
1; rs2; . . . ; rs
nserveri, we can get
PMtor ¼hrt1;r
t2; . . . ;r
tK2=2i where rt
i ¼PiN
j¼ði�1ÞNþ1rsj , and PMsas¼
hrsa1 ;r
sa2 ; . . . ;r
saK i where rsa
i ¼PiK=2
j¼ði�1ÞK=2þ1rtj . As shown in
Fig. 9, pods can be seen as two-tier basic trees when wereplace SASs with CSs, thus we can compute the pdf ofCj when there are exact x live GCSs:
AS
ToRS
CS
Podk
Server…
…
…
…
Replica
Groupk/2
or K-ary fat tree.

AS
ToRS
CS
…
Pod1 Podk
Server
WRITE
… … … …
… …
…
Coordinator ReplicaReplica
GCS1 GCSx
SAS1 SASk
Fig. 9. GCSs and SASs in fat tree.
198 X. Wang et al. / Computer Networks 76 (2015) 191–206
PrðCj ¼ m0jÞ ¼Psa þ ð1� PsaÞQ bt2�torð0Þ rsa
i P m0j ¼ 0;
ð1� PsaÞQ bt2�torðm0jÞ rsai P m0j > 0:
(
where m0j ¼ 0 if the jth SAS fails, or the jth SAS is alive andthe sub-tree whose root is the jth SAS can access 0 live rep-licas; and m0j > 0 if the jth SAS is alive and there are exactm0j replicas which can be accessed in the sub-tree whoseroot is the jth SAS.
Let stochastic variable Xft�sas be the number of accessi-ble live replicas in the fat tree network and the numberof live GCSs is denoted by stochastic variable Xgcs. Whenthere are exact x live GCSs, the probability of Xft�sas ¼ x0 isthe sum of the probability for all possible cases thatC1 þ C2 þ � � � þ CK ¼ x0. Since every live GCS connects toall K SASs, C1; . . . ;CK are independent. Thus:
PrðXft�sas ¼ x0jXgcs ¼ xÞ ¼X
m01þm02þ���þm0K¼x0
YK
j¼1
PrðCj ¼ m0jÞ
where 0 6 m0j 6 rsaj . At the same time, we can have:
PrðXgcs ¼ xÞ ¼K=2x
� �ð1� PgcÞxðPgcÞK=2�x
Then we can get PrðXft�sas ¼ x0Þ by summing the condi-tional probability for each possible xð1 6 x 6 K=2Þ:
PrðXft�sas ¼ x0Þ ¼XK=2
x¼1
PrðXft�sas ¼ x0jXgcs ¼ xÞPrðXgcs ¼ xÞ
Finally the probability that a write can access at least Wlive replicas in the K-ary fat tree is
PNx0¼W PrðXft�sas ¼ x0Þ,
which can also be seen as the probability that a write isavailable. That is:
AvailðQSðft; PM;WÞÞ ¼XN
x0¼W
PrðXft�sas ¼ x0Þ ð5Þ
Note that, if a write is available, it must be able to accessat least W live replicas in the K-ary fat tree. However, whena write can access at least W live replicas in the fat treewhere the W live replicas can be accessed only by CSs indifferent groups, the write coordinator may not cross mul-tiple CSs to reach other replicas, but this possibility is very
small since partitioning two CSs in different groupsrequires cutting so many redundant paths between themin the fat tree. Therefore Eq. (5) is a conservative upperbound on write availability of K-ary fat tree but accurateenough for us.
4.5. Folded clos network
The folded clos network includes DA=2 CSs and DI ASs.Any CS and any AS are connected, and every DA=2 ToRSsconnect to two ASs. And each ToRS connects to N servers.As shown in Fig. 10, a write request can be sent to any liveCS and reaches one live replica as the coordinator via a liveAS and a live ToRS, and then the coordinator sends thewrite to other replicas through ToRSs, ASs and one CS. IfðW � 1Þ ACK messages from other replicas are receivedby the coordinator, the write will reply and makes itselfavailable. Similarly, the event that a write is available isequivalent to the event that a write can access at least Wlive replicas in the folded clos network since CSs and ASsare fully connected.
Like the K-ary fat tree, we use a GCS to represent all CSssince they connect to the same ASs, and use a SAS to rep-resent two ASs which connect to the same ToRSs. Fig. 11shows the GCS and SASs in the simplified folded clos. Forthe GCS, its crash probability P0gc is the probability thatall CSs crash, thus P0gc ¼ ðPcÞDA=2; For the SASs, the crashprobability P0sa for a SAS is the probability that both inter-nal ASs crash, thus P0sa ¼ ðPaÞ2.
Let stochastic variable Dj be the number of accessiblelive replicas underlying the jth SAS from the GCS,where 1 6 j 6 DI=2. Given PM ¼ hrs
1; rs2; . . . ; rs
nserveri, we have
PMtor ¼ hrt1; r
t2; . . . ; rt
DADI=4i where rti ¼
PiNj¼ði�1ÞNþ1rs
j , and
PMsas ¼ hrsa1 ; r
sa2 ; . . . ; rsa
DI=2i where rsai ¼
PiDA=2j¼ði�1ÞDA=2þ1 rt
j . As
shown in Fig. 11, the sub-trees marked by dash lines canbe seen as two-tier basic trees when we replace SASs withCSs, thus we calculate the pdf of Dj by reusing the results oftwo-tier basic trees:
PrðDj ¼ m0jÞ ¼P0sa þ ð1� P0saÞQ bt2�torð0Þ rsa
i P m0j ¼ 0;
ð1� P0saÞQbt2�torðm0jÞ rsai P m0j > 0:
(

Fig. 10. Available write for folded clos network.
ToRS
CS
…
Server
AS
WRITE
Coordinator ReplicaReplica
SAS1SASDI/2
GCS
Fig. 11. GCSs and SASs in folded clos.
X. Wang et al. / Computer Networks 76 (2015) 191–206 199
where m0j ¼ 0 if the jth SAS fails, or the jth SAS is alive andthe sub-tree whose root is the jth SAS can access 0 live rep-licas; and m0j > 0 if the jth SAS is alive and there are exactm0j replicas which can be accessed in the sub-tree whoseroot is the jth SAS.
Let stochastic variable Xfc�sas be the number of accessi-ble live replicas from the live GCS in the folded clos net-work, and the probability of Xfc�sas ¼ x0 is the sum of theprobability for all possible cases that D1 þ D2 þ � � � þDDI=2 ¼ x0. Since the GCS is alive, D1; . . . ;DDI=2 are indepen-dent. Thus:
PrðXfc�sas ¼ x0Þ ¼X
m01þm02þ���þm0DI=2¼x0
YDI=2
j¼1
PrðDj ¼ m0jÞ
where 0 6 m0j 6 rsaj . Finally we can have:
AvailðQSðfc; PM;WÞÞ ¼ ð1� P0gcÞXN
x0¼W
PrðXfc�sas ¼ x0Þ ð6Þ
4.6. Geo-distributed data centers
In above analysis, we propose the quantitative results ofwrite availability for four kinds of data center networks. Infact, replicas are usually deployed not on one single data
center but across multiple geo-distributed data centers[3] for further improving availability.
Assume that there are M geo-distributed data centersGDCS ¼ fDCN1;DCN2; . . . ;DCNMg, and we place N replicasacross them by PM ¼ fPM1; PM2; . . . ; PMMg. The numberof replicas in DCNi is denoted by jPMijð1 6 i 6 MÞ. Let sto-chastic variable Xgdcs be the number of accessible live rep-licas in the geo-distributed data centers, and Xdcni
be thenumber of accessible live replicas in the DCNið1 6 i 6 MÞ.Then the probability of Xgdcs ¼ x is the sum of the probabil-ity for all possible cases that Xdcn1 þ Xdcn2 þ � � � þ XdcnM ¼ x.By Eqs. (3)–(6), we have:
PrðXdcni¼ xiÞ ¼
ð1� PcÞQ bt2�torðxiÞ DCNi ¼ bt2;
ð1� PcÞPrðXbt3�as ¼ xiÞ DCNi ¼ bt3;
PrðXft�sas ¼ xiÞ DCNi ¼ ft;
ð1� P0gcÞPrðXfc�sas ¼ xiÞ DCNi ¼ fc:
8>>>>>><>>>>>>:
Since these data centers are usually in different geo-graphical locations, we assume that they are independent.Thus we have:
PrðXgdcs ¼ xÞ ¼X
x1þx2þ���þxM¼x
YMi¼1
PrðXdcni¼ xiÞ

200 X. Wang et al. / Computer Networks 76 (2015) 191–206
where 0 6 xi 6 jPMij. As a result, we have the probabilitythat a write can access at least W live replicas, which canalso be seen as the write availability of geo-distributeddata centers:
AvailðQSðGDCS; PM;WÞÞ ¼XN
x¼W
PrðXgdcs ¼ xÞ
Now the write availability of quorum systems for typi-cal data center networks can be obtained by Eqs. (3)–(6) aswell as the geo-distributed data centers. Compared withEq. (2) which is the result based on previous studies suchas [22,24,25], our results are more accurate to estimatesystem availability of practical quorum systems in datacenter networks since switches can fail and our systemmodel is more practical. In fact, when Pc ¼ 0; Pa ¼ 0 andPt ¼ 0, that is, all replicas are always connected and livequorums are always accessible, Eqs. (3)–(6) will bedegraded to Eq. (2). In this way, previous studies can beviewed as special cases of our work on quantifying avail-ability of practical quorum systems.
Note that since read requests are performed similarlywith write requests in quorum systems, thus the readavailability of quorum systems can be represented by AvailðQSðDCN; PM;RÞÞ and Avail ðQSðGDCS; PM;RÞÞ where wereplace W with R in the equations of write availability.
5. Replica placement
In this section, we will discuss the impact of replicaplacements on the write availability of quorum systems.
During the placements of replicas, what we want is tofind the best solution to distribute replicas in one data cen-ter network topology such that we can have the maximalwrite availability. In fact, given the data center networksDCN (including crash probabilities of devices) and the val-ues of N; W , the problem is how to find the best PM (PMtor)for maximizing the write availability of quorum systems. Itcan be represented as a combinatorial optimizationproblem:
Maximize AvailðQSðDCN; PMtor ¼< rt1; r
t2; . . . ; rt
ntor>;WÞÞ
subject to Pntori¼1rt
i ¼ N
0 6 rti ; r
ti 2 Zð1 6 i 6 ntorÞ
(
Solving this combinatorial optimization problem is verydifficult since Eqs. (3)–(6) are complicated. However, if Nis small (e.g., N < 10), we can use computers to calculatethe numerical values of Eqs. (3)–(6) and exhaustivelysearch all feasible solutions to find the maximal value of
Table 1Write availability for 2-tier basic tree when N ¼ 3.
Avail PMtor1 ¼ h1;1;1i PM
W = 1 ð3� 3 �Pt�Ps þ �Pt
2 �Ps2ÞF1 ð1
W = 2 �Ptð1þ 2Pt þ 2Ps�PtÞF2 ð1
W = 3 �Pt2F3
�Pt
the objective function within a few seconds. In addition,when the data center network is not very large (supportless than 8 K servers [20]) which can use a 2-tier basic treetopology and the number of replicas is the common valueof 3, more insightful conclusions can be provided.
For a data center network with the 2-tier basic treetopology, we have three different placements of replicaswhenN ¼ 3 : PMtor
1 ¼ h1;1;1i; PMtor2 ¼ h2;1;0i; PMtor
3 ¼ h3;0;0i.It is obvious that other replica placements are equivalentto one of the three placements. Table 1 indicates the writeavailability of these three different replica placements for2-tier basic tree when W ¼ 1;2;3, respectively, whereF1 ¼ ð1� PcÞð1� PtÞð1� PsÞ; F2 ¼ ð1� PcÞð1� PtÞð1� PsÞ2;F3 ¼ ð1� PcÞð1� PtÞð1� PsÞ3; �Pt ¼ 1� Pt and �Ps ¼ 1� Ps.
Since 0 < Pc; Pt ; Ps; �Pt ; F1; F2; F3 < 1, thus �Pt2F3 < �PtF3 <
F3 and we can have:
AvailðPMtor1 ;3Þ < AvailðPMtor
2 ;3Þ < AvailðPMtor3 ;3Þ
If W ¼ 2, it is obvious that AvailðPMtor2 ;2Þ <
AvailðPMtor3 ;2Þ. At the same time, we have:
AvailðPMtor1 ;2Þ�AvailðPMtor
2 ;2Þ¼ PtF2ð1�2Pt�2Psþ2PsPtÞ
so AvailðPMtor1 ;2Þ > AvailðPMtor
2 ;2Þ if 1� 2Pt � 2Psþ2PsPt > 0, otherwise AvailðPMtor
1 ;2Þ 6 AvailðPMtor2 ;2Þ. Simi-
larly, we can get:
AvailðPMtor1 ;2Þ�AvailðPMtor
3 ;2Þ¼ PtF2ð1�4Ps�2Ptþ2PsPtÞ
then if 1� 4Ps � 2Pt þ 2PsPt > 0 we have AvailðPMtor1 ;2Þ >
AvailðPMtor3 ;2Þ, otherwise AvailðPMtor
1 ;2Þ 6 AvailðPMtor3 ;2Þ.
When W ¼ 1, because 0 < Pc; Pt; Ps < 1 we have:
AvailðPMtor1 ;1Þ�AvailðPMtor
2 ;1Þ ¼ PtF1ðPsð1�PsÞþPtð1�PsÞ2Þ>0
and:
AvailðPMtor2 ;1Þ � AvailðPMtor
3 ;1Þ ¼ PtF1ð1� P2s Þ > 0
therefore we get:
AvailðPMtor1 ;1Þ > AvailðPMtor
2 ;1Þ > AvailðPMtor3 ;1Þ
In summary, we show our conclusions in Table 2. Wecan see that the placement PMtor
1 ¼ h1;1;1i which putsthree replicas in different racks has the maximal availabil-ity when W ¼ 1, while it obtains the minimal availabilitywhen W ¼ 3. And the placement PMtor
3 ¼ h3;0;0i whichputs three replicas in one same rack has the opposite effecton availability. When W ¼ 2, whether PMtor
3 or PMtor1 have
the maximal availability is determined by the values ofPt and Ps. In addition, we find that the placement
tor2 ¼ h2;1;0i PMtor
3 ¼ h3;0;0i
þ Ps þ Pt þ P2s
�PtÞF1 ð1þ Ps þ P2s ÞF1
þ 2Ps�PtÞF2 ð1þ 2PsÞF2
F3 F3

Table 2Availability comparison for 2-tier basic tree with different replica placements.
W Availability comparison
1 AvailðPMtor1 Þ > AvailðPMtor
2 Þ > AvailðPMtor3 Þ
2 AvailðPMtor1 Þ 6 AvailðPMtor
2 Þ < AvailðPMtor3 Þ 1þ 2PsPt 6 2Ps þ 2Pt
AvailðPMtor2 Þ < AvailðPMtor
1 Þ 6 AvailðPMtor3 Þ 2Ps þ 2Pt < 1þ 2PsPt 6 4Ps þ 2Pt
AvailðPMtor2 Þ < AvailðPMtor
3 Þ < AvailðPMtor1 Þ 1þ 2PsPt > 4Ps þ 2Pt
3 AvailðPMtor1 Þ < AvailðPMtor
2 Þ < AvailðPMtor3 Þ
X. Wang et al. / Computer Networks 76 (2015) 191–206 201
PMtor2 ¼ h2;1;0i which places two replicas in one rack and
the third in another (remote) rack never gets the maximalavailability, and may has the worst availability if W ¼ 2and 1þ 2PsPt > 2Ps þ 2Pt .
In practice, the common Hadoop configuration [31] isPMtor
2 (two replicas in one rack and the third inanother rack). Since network bandwidth between serversin the same rack is greater than network bandwidthbetween servers in different racks, designers say that thisconfiguration may have a better bandwidth than PMtor
1 aswell as a higher availability than PMtor
3 . However, accordingto Table 2, it is true only if W ¼ 1, and if W ¼ 2 or 3 weshow that PMtor
3 may be better than PMtor2 in both aspects
of network bandwidth and availability. Ref. [32] indicatesthat Apache Cassandra has two different replica strategies:one is to put replicas in different nodes withoutconsidering racks, and the other is to place replicas indistinct racks. That is, the former may be one ofPMtor
1 ; PMtor2 and PMtor
3 and its availability can be seen asthe average availability of PMtor
1 ; PMtor2 and PMtor
3 , whichis a moderate and conservative choice for availability;and the latter is our replica placement PMtor
1 , which isthe best configuration when W ¼ 1 or W ¼ 2 as wellas 1þ 2PsPt > 4Ps þ 2Pt but may be the worst suchas W ¼ 3.
6. Quantitative configuration for availability andconsistency
Theories like CAP and PACELC show that there is atradeoff between availability and consistency for replica-tion, and the current practice is more or less experience-based and lacks quantitative analysis for identifying a goodtradeoff between the two. In this section, we will discusshow to make tradeoff between them for quorum systemsin a quantitative way.
For a specific quorum system and all possible place-ments of replicas, we assume that the ratio of writerequests is að0 6 a � 1Þ, thus the ratio of read requests is1� a. In this way, the system availability with the config-uration ðW;RÞ is:
AvailðW;RÞ ¼maxPMðaAvailðQSðWÞÞ þ ð1� aÞAvailðQSðRÞÞÞ
In Section 2 we mention that e ¼ N �WR
� �=
NR
� �are
often viewed as an important measurement of inconsis-
tency for practical quorum systems [13]. In this work wealso use it to measure the inconsistency, that is:
ConsistencyðW;RÞ ¼ 1�
N �W
R
� �N
R
� �
where W þ R 6 N. When W þ R > N, quorum systems arestrongly consistent (Consistency ¼ 1). Note that failures ofswitches and servers also affect the consistency of quorumsystems, but this impact may be hidden in the probabilitytail and thus can be ignored [13].
In practical systems, system providers should promise abounded availability in their service agreement levels,which is usually described by the number of nines:
Nn ¼ � lgð1� AvailðW;RÞÞ
However, availability bounded by Nn (often one positiveinteger), it does not mean that greater Nn is better sinceit will cause weaker consistency of data replicas. In fact,we want to know a configuration ðW;RÞ for a specific quo-rum system whose availability is no lower than the prom-ised Nn, as well as the possible strongest consistency. SinceW;Rð1 6W;R 6 NÞ are positive integers and N is not verybig, we suggest an approach based on the availability-con-sistency table to look up the best configuration.
The availability-consistency table (ACT) consists of Nrows and N columns, where the row represents the valueof W and the column represents the value of R. ElementACTðW;RÞ in the table is filled with a tupleh½Nn�;Consistencyi. Note that Nn is rounded down to matchthe bounded availability. Since availability decreases andconsistency increases when W and R rise, the number ofnines will decline and consistency will increase fromACTð1;1Þ to ACT ðN;NÞ. An example of the availability-con-sistency table is shown in Table 4.
When the bounded availability is given as one positiveinteger Nn0 , we look up all feasible elements whose avail-ability is no lower than Nn0 in the availability-consistencytable. But how to choose the best one when there are morethan one feasible element? a set of rules is provided asfollows:
1. If we want to obtain a stronger consistency at thesame time, the one with smaller ½Nn� in two feasibleelements is better;
2. If two feasible elements have the same ½Nn�, the onewith stronger consistency is better; and
3. If two feasible elements have the same ½Nn� and thesame consistency, the one with smaller value ofaW þ ð1� aÞR is better since aW þ ð1� aÞR can be

202 X. Wang et al. / Computer Networks 76 (2015) 191–206
viewed as an estimation of system performance. Forexample, for a read-dominated quorum system,which means that a is near 0, we prefer that R beas small as possible if we have the same ½Nn� andthe same consistency.
In fact, above rules show that we prefer to configureðW;RÞ by an availability! consistency!performance prior-ity order. But this is just an example, system providers canadapt it based on the availability-consistency table by theirpersonalized preferences.
7. Experiments
According to Eqs. (3)–(6) as discussed in Section 4, thewrite availability of quorum systems depends on the typesof data center networks, the failure rates of servers, ToRSs,ASs and CSs, the placement of replicas on servers, and thevalue of W for write quorums. In this section, we focus onvalidating our presented results, and discussing the trendswhile choosing different experimental parameters.
7.1. Monte Carlo simulation
Considering the complexity of Eqs. (3)–(6) and verifi-ability for experimental results, we implementQSðDCN; PM;WÞ using Monte Carlo based event drivensimulations. The data center network topologies are simu-lated by extending CloudSim [33]. In the simulations, eachwrite request is randomly sent to one replica across datacenter networks. If any switch or server crashes, it thendoes not route write requests. For every ten million writes,we detect write availability by checking whether awrite is answered or lead to a timeout. The number ofavailable writes is recorded as Naw. Thus we estimateAvailðQSðDCN; PM;WÞÞ by Naw=10;000;000.
7.2. Validating write availability
In this experiment, we compare our prediction resultscalculated by Eqs. (3)–(6) with the observed experimentalvalues to validate them. We have tried to choose the morereasonable and practical parameters. According to the sta-tistics of [2,34], failure rate Ps is set to 2%, 3% and 4%; Pt is1%, 2%, 3%, 4% and 5%; Pa is one of 1%, 5% and 10%, and Pc is1%, 2%. The placement of replicas is represented by PMtor ,and some replica placements may be equivalent to eachother for our experiments thus we choose one of them.Obviously the number of possible placements is less thanN! for 2-tier basic tree and ðN!Þ2 for 3-tier basic tree, fat treeand folded clos network, which makes our simulations fea-sible when N is often small, e.g., Cassandra has a defaultconfiguration (N ¼ 3; W ¼ R ¼ 1 [30]).
While building a 2-tier basic tree, the number of ToRS inthe involved sub-network is set to N so that eachreplica can be connected to one ToRS, and one ToRSconnects to N servers so that all N replicas can be locatedon servers under one same ToRS, which ensures that anyplacements can be possible. We repeat experiments forN 2 ½3;9�; W 2 ½1;N� and all possible placements, and then
record the value of Naw to estimate AvailðQSðbt2; PM;WÞÞ.Comparing observed values with predicted ones of writeavailability in all cases, we have an average RMSE(rootmean square error) = 0.000472% and std.dev. (standarddeviation) = 0.000417%.
In the 3-tier basic tree, the respective sub-network hasN ASs, N2 ToRSs and N3 servers for all possible placements.And we repeat experiments for N 2 ½3;9� and W 2 ½1;N�. Bycomparing observed values with predicted write availabil-ity in all cases, we get an average RMSE = 0.000763% andstd.dev. = 0.000668%.
For the K-ary fat tree, K P 2N since every ToRS connectsto K=2 servers and we want to observe the case that all Nreplicas are connected to one same ToRS. Without loss ofgenerality, we set K ¼ 2N and repeat experiments forN 2 ½3;9� and W 2 ½1;N�, and the average RMSE = 0.00117%and std.dev. = 0.000934% between the observed values andpredicted values in all cases.
In the folded clos network, similarly DA P 2N andDI P 2N for all possible placements of replicas. Withoutloss of generality, we set DA ¼ DI ¼ 2N and make experi-ments for N 2 ½3;9� and W 2 ½1;N�, and we find our averageRMSE = 0.000845% and std. dev. = 0.000689% between theobserved values and predicted write availability for all pos-sible placements of replicas.
Table 3 shows all the experimental results of averageRMSE and std. dev. between the observed values and pre-dicted write availability for four typical data center net-works, which validate our predicted results. In addition,the accuracy of our prediction is high enough to at least4 nines of availability.
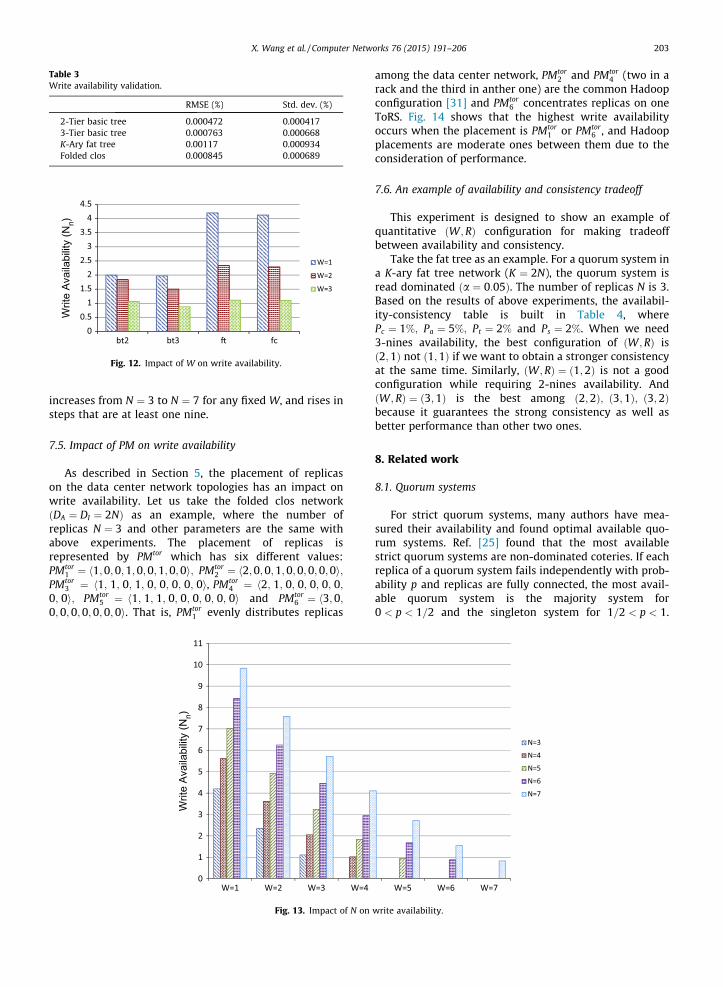
7.3. Impact of W on write availability
Eq. (3)–(6) reveals the relation of write availability andW. In this experiment, we want to show the change ofwrite availability with respect to W more intuitively. With-out loss of generality, we set Pc ¼ 1%; Pa ¼ 5%; Pt ¼ 2%
and Ps ¼ 2%. The number of replicas N is a common value3, and the placement of replicas is the one which maxi-mizes write availability. To highlight the variance of differ-ent write availability, we use the number of nines torepresent it. As shown in Fig. 12, we can see that the num-ber of nines decreases as W is increased for any data centernetworks. In addition, we can obtain different nines ofwrite availability by tuning the value of W for the fat treeand folded clos network but may not for the 2-tier and 3-tier basic tree.
7.4. Impact of N on write availability
This experiment is to show the trend of write availabil-ity with respect to N. Likewise, Pc ¼ 1%; Pa ¼ 5%; Pt ¼ 2%
and Ps ¼ 2%, and the replica placement chooses the onewhich maximizes write availability. Since the fat tree andfolded clos network are more widely used in practical dis-tributed systems, we take the fat tree as an example andour experiments show that other three topologies havethe same result. Fig. 13 indicates the impact of N on thenines of write availability in the K-ary fat tree (K ¼ 2N)from N ¼ 3 to N ¼ 7. It shows that the write availability
00.5
11.5
22.5
33.5
44.5
bt2 bt3 � fc
W=1
W=2
W=3
Fig. 12. Impact of W on write availability.
Table 3Write availability validation.
RMSE (%) Std. dev. (%)
2-Tier basic tree 0.000472 0.0004173-Tier basic tree 0.000763 0.000668K-Ary fat tree 0.00117 0.000934Folded clos 0.000845 0.000689
X. Wang et al. / Computer Networks 76 (2015) 191–206 203
increases from N ¼ 3 to N ¼ 7 for any fixed W, and rises insteps that are at least one nine.
7.5. Impact of PM on write availability
As described in Section 5, the placement of replicason the data center network topologies has an impact onwrite availability. Let us take the folded clos networkðDA ¼ DI ¼ 2NÞ as an example, where the number ofreplicas N ¼ 3 and other parameters are the same withabove experiments. The placement of replicas isrepresented by PMtor which has six different values:PMtor
1 ¼ h1;0;0;1;0;0;1;0;0i; PMtor2 ¼ h2;0;0;1;0;0;0;0;0i;
PMtor3 ¼ h1; 1; 0; 1; 0; 0; 0; 0; 0i, PMtor
4 ¼ h2; 1; 0; 0; 0; 0; 0;0; 0i; PMtor
5 ¼ h1; 1; 1; 0; 0; 0; 0; 0; 0i and PMtor6 ¼ h3;0;
0;0;0;0;0;0;0i. That is, PMtor1 evenly distributes replicas
0
1
2
3
4
5
6
7
8
9
10
11
W=1 W=2 W=3 W=4
Fig. 13. Impact of N on
among the data center network, PMtor2 and PMtor
4 (two in arack and the third in anther one) are the common Hadoopconfiguration [31] and PMtor
6 concentrates replicas on oneToRS. Fig. 14 shows that the highest write availabilityoccurs when the placement is PMtor
1 or PMtor6 , and Hadoop
placements are moderate ones between them due to theconsideration of performance.
7.6. An example of availability and consistency tradeoff
This experiment is designed to show an example ofquantitative ðW;RÞ configuration for making tradeoffbetween availability and consistency.
Take the fat tree as an example. For a quorum system ina K-ary fat tree network (K ¼ 2N), the quorum system isread dominated ða ¼ 0:05Þ. The number of replicas N is 3.Based on the results of above experiments, the availabil-ity-consistency table is built in Table 4, wherePc ¼ 1%; Pa ¼ 5%; Pt ¼ 2% and Ps ¼ 2%. When we need3-nines availability, the best configuration of ðW;RÞ isð2;1Þ not ð1;1Þ if we want to obtain a stronger consistencyat the same time. Similarly, ðW;RÞ ¼ ð1;2Þ is not a goodconfiguration while requiring 2-nines availability. AndðW;RÞ ¼ ð3;1Þ is the best among ð2;2Þ; ð3;1Þ; ð3;2Þbecause it guarantees the strong consistency as well asbetter performance than other two ones.
8. Related work
8.1. Quorum systems
For strict quorum systems, many authors have mea-sured their availability and found optimal available quo-rum systems. Ref. [25] found that the most availablestrict quorum systems are non-dominated coteries. If eachreplica of a quorum system fails independently with prob-ability p and replicas are fully connected, the most avail-able quorum system is the majority system for0 < p < 1=2 and the singleton system for 1=2 < p < 1.
W=5 W=6 W=7
N=3
N=4
N=5
N=6
N=7
write availability.
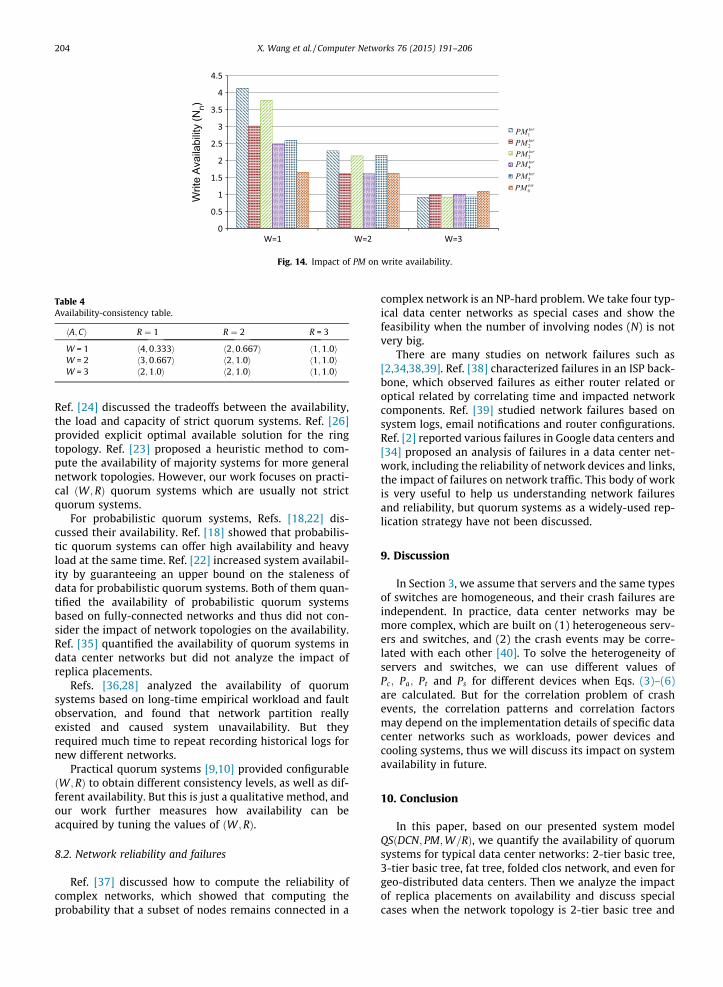
torPM1torPM 2torPM 3torPM 4torPM 5torPM
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
W=1 W=2 W=3
Fig. 14. Impact of PM on write availability.
Table 4Availability-consistency table.
hA;Ci R ¼ 1 R ¼ 2 R = 3
W = 1 h4;0:333i h2;0:667i h1;1:0iW = 2 h3;0:667i h2;1:0i h1;1:0iW = 3 h2;1:0i h2;1:0i h1;1:0i
204 X. Wang et al. / Computer Networks 76 (2015) 191–206
Ref. [24] discussed the tradeoffs between the availability,the load and capacity of strict quorum systems. Ref. [26]provided explicit optimal available solution for the ringtopology. Ref. [23] proposed a heuristic method to com-pute the availability of majority systems for more generalnetwork topologies. However, our work focuses on practi-cal ðW;RÞ quorum systems which are usually not strictquorum systems.
For probabilistic quorum systems, Refs. [18,22] dis-cussed their availability. Ref. [18] showed that probabilis-tic quorum systems can offer high availability and heavyload at the same time. Ref. [22] increased system availabil-ity by guaranteeing an upper bound on the staleness ofdata for probabilistic quorum systems. Both of them quan-tified the availability of probabilistic quorum systemsbased on fully-connected networks and thus did not con-sider the impact of network topologies on the availability.Ref. [35] quantified the availability of quorum systems indata center networks but did not analyze the impact ofreplica placements.
Refs. [36,28] analyzed the availability of quorumsystems based on long-time empirical workload and faultobservation, and found that network partition reallyexisted and caused system unavailability. But theyrequired much time to repeat recording historical logs fornew different networks.
Practical quorum systems [9,10] provided configurableðW;RÞ to obtain different consistency levels, as well as dif-ferent availability. But this is just a qualitative method, andour work further measures how availability can beacquired by tuning the values of ðW;RÞ.
8.2. Network reliability and failures
Ref. [37] discussed how to compute the reliability ofcomplex networks, which showed that computing theprobability that a subset of nodes remains connected in a
complex network is an NP-hard problem. We take four typ-ical data center networks as special cases and show thefeasibility when the number of involving nodes (N) is notvery big.
There are many studies on network failures such as[2,34,38,39]. Ref. [38] characterized failures in an ISP back-bone, which observed failures as either router related oroptical related by correlating time and impacted networkcomponents. Ref. [39] studied network failures based onsystem logs, email notifications and router configurations.Ref. [2] reported various failures in Google data centers and[34] proposed an analysis of failures in a data center net-work, including the reliability of network devices and links,the impact of failures on network traffic. This body of workis very useful to help us understanding network failuresand reliability, but quorum systems as a widely-used rep-lication strategy have not been discussed.
9. Discussion
In Section 3, we assume that servers and the same typesof switches are homogeneous, and their crash failures areindependent. In practice, data center networks may bemore complex, which are built on (1) heterogeneous serv-ers and switches, and (2) the crash events may be corre-lated with each other [40]. To solve the heterogeneity ofservers and switches, we can use different values ofPc; Pa; Pt and Ps for different devices when Eqs. (3)–(6)are calculated. But for the correlation problem of crashevents, the correlation patterns and correlation factorsmay depend on the implementation details of specific datacenter networks such as workloads, power devices andcooling systems, thus we will discuss its impact on systemavailability in future.
10. Conclusion
In this paper, based on our presented system modelQSðDCN; PM;W=RÞ, we quantify the availability of quorumsystems for typical data center networks: 2-tier basic tree,3-tier basic tree, fat tree, folded clos network, and even forgeo-distributed data centers. Then we analyze the impactof replica placements on availability and discuss specialcases when the network topology is 2-tier basic tree and

X. Wang et al. / Computer Networks 76 (2015) 191–206 205
the number of replicas is a popular value 3. With the quan-titative results of availability, we build the availability-consistency table and propose a set of rules to choose thebest ðW;RÞ configuration for quantitatively making trade-off between availability and consistency for quorum sys-tems. Through Monte Carlo simulations, we validate ourquantitative results and show the effectiveness of ourapproach to quantitatively balance availability andconsistency.
Acknowledgments
This work was supported by National Natural ScienceFoundation of China (No. 61370057), China 863 program(No. 2012AA011203), China 973 program (No.2014CB340300), A Foundation for the Author of NationalExcellent Doctoral Dissertation of PR China (No. 201159),and Beijing Nova Program (2011022).
Appendix A. Supplementary material
Supplementary data associated with this article can befound, in the online version, at http://dx.doi.org/10.1016/j.comnet.2014.11.006.
References
[1] Amazon.com, Summary of the Amazon EC2 and Amazon RDS ServiceDisruption in the US East Region, April 2014. <http://aws.amazon.com/cn/message/65648/>.
[2] J. Dean, Designs, lessons, and advice from building large distributedsystems, in: LADIS Keynote, 2009.
[3] Y. Sovran, R. Power, M.K. Aguilera, J. Li, Transactional storage for geo-replicated systems, in: SOSP, 2011.
[4] E.A. Brewer, Towards robust distributed systems, in: PODC, 2000, pp.7–7.
[5] D.J. Abadi, Consistency tradeoffs in modern distributed databasesystem design: CAP is only part of the story, IEEE Comput. 45 (2)(2012) 37–42.
[6] Amazon EC2, Amazon EC2 Service Level Agreement, April 2014.<http://aws.amazon.com/ec2-sla/>.
[7] Google, Google Cloud Storage SLA, December 2013. <https://developers.google.com/storage/sla>.
[8] Windows Azure, Windows Azure Service Level Agreement,December 2013. <http://www.windowsazure.com/en-us/support/legal/sla/>.
[9] G. DeCandia, D. Hastorun, M. Jampani, G. Kakulapati, A. Lakshman, A.Pilchin, S. Sivasubramanian, P. Vosshall, W. Vogels, Dynamo:amazons highly available key-value store, in: SOSP, 2007.
[10] The Apache Cassandra Project, April 2014. <http://cassandra.apache.org/>.
[11] Sebastian Burckhardt, Alexey Gotsman, Hongseok Yang,Understanding Eventual Consistency, Technical Report MSR-TR-2013-39,Microsoft Research.
[12] W. Vogels, Eventually consistent, Commun. ACM 52 (2009) 40–44.[13] P. Bailis, S. Venkataraman, M.J. Franklin, J.M. Hellerstein, I. Stoica,
Probabilistically bounded staleness for practical partial quorums, in:VLDB, 2012.
[14] M. Merideth, M. Reiter, Selected results from the latest decade ofquorum systems research, Replicat., Lect. Notes Comput. Sci. 5959(2010) 185–206.
[15] Basho riak, April 2014. <http://basho.com/products/riak-overview/>.[16] A. Feinberg, Project voldemort: reliable distributed storage, in: ICDE,
2011.[17] R. Jimenez-Peris, M. Patino Martinez, G. Alonso, K. Bettina, Are
quorums an alternative for data replication?, ACM Trans DatabaseSyst. 28 (2003) 257–294.
[18] D. Malkhi, M. Reiter, A. Wool, R. Wright, Probabilistic quorumsystems, Inf. Commun. 170 (2001) 184–206.
[19] A. Greenberg, J.R. Hamilton, N. Jain, S. Kandula, C. Kim, P. Lahiri, D.A.Maltz, P. Patel, S. Sengupta, VL2: a scalable and flexible data centernetwork, in: SIGCOMM, 2009.
[20] M. Al-Fares, A. Loukissas, A. Vahdat, A scalable, commodity datacenter network architecture, in: SIGCOMM, 2008.
[21] R. Niranjan Mysore, A. Pamboris, N. Farrington, N. Huang, P. Miri, S.Radhakrishnan, V. Subramanya, A. Vahdat, Portland: a scalable fault-tolerant layer 2 data center network fabric, in: SIGCOMM, 2009.
[22] A. Aiyer, L. Alvisi, R.A. Bazzi, On the availability of non-strict quorumsystems, in: DISC, 2005.
[23] D. Barbara, H. Garcia-Molina, The reliability of voting mechanisms,IEEE Trans. Comput. 100 (10) (1987) 1197–1208.
[24] Moni Naor, Avishai Wool, The load, capacity, and availability ofquorum systems, SIAM J. Comput. 27 (2) (1998) 423–447.
[25] D. Peleg, A. Wool, The availability of quorum systems, Inf. Comput.123 (2) (1995) 210–223.
[26] T. Ibaraki, H. Nagamochi, T. Kameda, Optimal coteries for rings andrelated networks, Distrib. Comput. 8 (1995) 191–201.
[27] D.K. Gifford, Weighted voting for replicated data, in: SOSP, 1979.[28] Yu Haifeng, Amin Vahdat, The costs and limits of availability for
replicated services, ACM Trans. Comput. Syst. 24 (1) (2006) 70–113.
[29] C. Guo, G. Lu, D. Li, H. Wu, X. Zhang, Y. Shi, C. Tian, Y. Zhang, S. Lu,BCube: a high performance, server-centric network architecture formodular data centers, ACM SIGCOMM Comput. Commun. Rev. 39 (4)(2009) 63–74.
[30] Apache Cassandra, Cassandra 1.0 Thrift Configuration, April 2014.<https://github.com/apache/cassandra/blob/cassandra-1.0/interface/cassandra.thrift>.
[31] Apache Hadoop, HDFS Architecture Guide, April 2014. <http://hadoop.apache.org/docs/r1.2.1/hdfs_design.html>.
[32] Apache Cassandra, Data Replication, December 2013. <http://www.datastax.com/documentation/cassandra/2.0/cassandra/architecture/architectureDataDistributeReplication_c.html>.
[33] R.N. Calheiros, R. Ranjan, A. Beloglazov, C.A. De Rose, R. Buyya,CloudSim: a toolkit for modeling and simulation of cloud computingenvironments and evaluation of resource provisioning algorithms,Softw.: Pract. Exper. 41 (1) (2011) 23–50.
[34] P. Gill, N. Jain, N. Nagappan, Understanding network failures in datacenters: measurement, analysis, and implications, ACM SIGCOMMComputer Communication Review, vol. 41, ACM, 2011, pp. 350–361.
[35] X. Wang, H. Sun, T. Deng, J. Huai, A quantitative analysis of quorumsystem availability in data centers, in: 2014 22nd IEEE/ACMInternational Symposium on Quality of Service (IWQoS), IEEE/ACM,2014.
[36] Y. Amir, A. Wool, Evaluating quorum systems over the internet, in:Proceedings of the Annual International Symposium on Fault-Tolerant Computing, 1996.
[37] A. Rosenthal, Computing the reliability of a complex network, SIAMJ. Appl. Math. 32 (1977) 384–393.
[38] A. Markopoulou, G. Iannaccone, S. Bhattacharyya, C.-N. Chuah, Y.Ganjali, C. Diot, Characterization of failures in an operational ipbackbone network, IEEE/ACM Trans. Netw. (TON) 16 (4) (2008) 749–762.
[39] D. Turner, K. Levchenko, A.C. Snoeren, S. Savage, California faultlines: understanding the causes and impact of network failures, ACMSIGCOMM Comput. Commun. Rev. 40 (4) (2010) 315–326.
[40] Y. Liu, J. Muppala, Fault-tolerance characteristics of data centernetwork topologies using fault regions, in: 43rd Annual IEEE/IFIPInternational Conference on Dependable Systems and Networks(DSN), IEEE, 2013, pp. 1–6.
Xu Wang received the BS degree from Bei-hang University, China, in 2008. Currently, heis working toward the PhD degree in theSchool of Computer Science and Engineering,Beihang University, Beijing, China. Hisresearch interests include the areas of dis-tributed systems, service computing, replica-tion, and availability.

206 X. Wang et al. / Computer Networks 76 (2015) 191–206
Hailong Sun received the BS degree in com-puter science from Beijing Jiaotong Universityin 2001. He received the PhD degree in com-puter software and theory from Beihang Uni-versity in 2008. He is an Associate Professor inthe School of Computer Science and Engi-neering, Beihang University, Beijing, China.His research interests include services com-puting, cloud computing and distributed sys-tems. He is a member of the IEEE and theACM.
Ting Deng received the PhD degree in Com-puter Science from the Beihang University,Beijing China, in 2011. Currently, she is anassistant professor at Beihang University. Herresearch interests include distributed system,Service oriented computing and recommen-dation systems.
Jinpeng Huai is a Professor and President ofBeihang University. He used to serve on theSteering Committee for Advanced ComputingTechnology Subject for the National High-Tech Program (863) as Chief Scientist. He is amember of the Consulting Committee of theCentral Government’s Information Office, andChairman of the Expert Committee in both theNational e-Government Engineering Task-force and the National e-Government Stan-dard office. His research interests includenetworked software, cloud computing and
trustworthiness & security.





























