Embed Size (px)
Citation preview

Computers in Industry xxx (2014) xxx–xxx
G Model
COMIND-2600; No. of Pages 14
Ontology-based approach for context modeling in enterpriseapplications
Drazen Nadoveza *, Dimitris Kiritsis
Ecole Polytechnique Federale de Lausanne, Laboratory for Computer-Aided Design and Production, STI-IGM-LICP, Station 9, CH-1015 Lausanne, Vaud,
Switzerland
A R T I C L E I N F O
Article history:
Received 17 December 2013
Received in revised form 17 June 2014
Accepted 11 July 2014
Available online xxx
Keywords:
Context modeling
User context
Business context
Ontology engineering
Software engineering
A B S T R A C T
Today, enterprise applications provide large amounts of data and finding the right information on time
for a given purpose is often a challenge. In these environments, users do not know what information is
important, why it is important and finally, how to find this important information. Therefore, an
enterprise application has to decide which information is relevant in certain a situation for certain a user.
In order to accomplish that, the context of the information must be taken to account. Moreover, this
application must be able to capture the context of the application user as well as the overall business
context which describes the situation in which information is relevant. In this paper we propose an
ontology-based context model which captures the general concepts about user and business context.
Also, we discuss the challenges for context reasoning and interpreting and we present a case study to
demonstrate the benefits of the developed concepts.
� 2014 Elsevier B.V. All rights reserved.
Contents lists available at ScienceDirect
Computers in Industry
jo ur n al ho m epag e: ww w.els evier . c om / lo cat e/co mp in d
1. Introduction
Over the past years, reliance on enterprise applications forproviding and storing information has grown rapidly. Theseapplications are becoming increasingly more complex and aregoing to be used eventually on any number of devices, from mobilesmart phones to industrial computer networks. Thus, to increasetheir efficiency and electiveness, applications will need to be madeaware of the context they are being used in, in order toautomatically adapt to it.
Sandkuhl [1] states that in today’s information society,information is considered as an important production factor inaddition to capital, human resources and material. Furthermore,the task of finding the right information to support a work task, abusiness decision, or a cooperation process is often very difficult.Some studies revealed that 39% of all business executives spendmore than 2 h per day in searching for the right information [2].This proves that the main challenge is no longer to guarantee theexistence of much needed information, but rather to find andprovide the right information [1,3].
* Corresponding author.
E-mail addresses: [email protected] (D. Nadoveza),
[email protected] (D. Kiritsis).
Please cite this article in press as: D. Nadoveza, D. Kiritsis, Ontology-Comput. Industry (2014), http://dx.doi.org/10.1016/j.compind.2014.
http://dx.doi.org/10.1016/j.compind.2014.07.007
0166-3615/� 2014 Elsevier B.V. All rights reserved.
The motivation for this work lays in the fact that in certainsituations not all information provided by an information system isimportant and relevant to the end user. Modern enterpriseinformation systems provide huge amounts of information andin these large volumes very often the user cannot identifyappropriate and important information at the right time.Moreover, in complex business environments users may not befully aware of the current situation which in turn can negativelyinfluence the decision making process. So, it is very important toprovide the appropriate information to the user considering therespective situation. However, even if the user is provided with thisinformation, the problem is not essentially solved. The user alsohas to understand why the provided information is importantwhich means that he/she has to comprehend the current situationor to be aware of the context in which this situation happened. Inthis way, the user is able to fully understand the real meaning ofthe information. Therefore, it has become crucial for enterpriseapplications to be aware of the context they are being used in.
Nowadays, enterprise applications collect and store variouskinds of data and information. This data describes users as well asthe various aspects of business. This means that if properlyinterpreted, this data could be used to describe the overall user andbusiness context. However this is no easy task as context data issubject to constant change and can be highly heterogeneous.
This paper proposes an approach to solve these problems byproviding an ontology-based context model and rules for its
based approach for context modeling in enterprise applications,07.007

D. Nadoveza, D. Kiritsis / Computers in Industry xxx (2014) xxx–xxx2
G Model
COMIND-2600; No. of Pages 14
interpretation. This model will classify with the help of OWL-builtontologies the context of the users (the employees of a businesswho are accessing the system) and the context of the business. Theuser and business context will allow for an enterprise applicationto anticipate which information is important and relevant in orderto serve it to the appropriate user. Since the solution utilizescontextual information and provides information and servicesaccording to it, the proposed approach could thus be characterizedas ‘‘context-aware’’.
This paper reviews the notion of context as well as variousmethods for context modeling and proposes an approach forcontext modeling in enterprise applications. After the introductionsection the formal definitions of context are discussed. Therequirements that any context model must meet are presentedin Section 2 as well as the review of the context modeling methodswith special focus on the ontology based modeling in Section 3.Section 4 gives an overview of the proposed approach for thecontext interpretation and the context ontology is introduced andpresented together with the outstanding features of the approach.Finally, a case study based on the industrial scenario is presented inSection 5.
2. Context definition
The meaning of the term context had an evolution toward alarger acceptance and now the meaning generally accepted is thatcontext is the set of circumstances that frames an event or anobject [4]. Context is increasingly being used in various disciplineslike psychology, especially since the emergence of situatedcognition theories [5], those theories considering cognition in itsnatural context [6]. However, it is difficult to find a relevantsatisfying definition for every discipline. Some approaches emergein Artificial Intelligence ([4,7]).
In his work on formalization of context, McCarthy [8] pointedout the difficulty in computer science of modeling context becausecontext possesses an infinite dimension. Furthermore, headdresses the difficulty in translating contextual assessment thathas been conducted in the psychological or philosophical realminto formal computational logic. Parker et al. [9] emphasize thenecessity when considering context to also consider the humanability to analyze the context of a situation and rank the differentstimuli of the outside environment. Bazire and Brezillon [4]analyzed a corpus of 166 definitions of context found in a numberof domains and came to the conclusion that context can be derivedfrom anything that is significant in a given moment including theenvironment, an item within that environment, a user, or even anobserver [9].
Even though context is a difficult concept to grasp and define, awidely accepted general definition is as follows:
Context is any information that can be used to characterize the
situation of an entity. An entity is a person, place, or object that is
considered relevant to the interaction between a user and an
application, including the user and applications themselves. [10]
Another widely accepted definition of context is given byBrezillon and Pomerol and it says that context is:
That which constrains something without intervening in it
explicitly. [11]
These definitions outline two different notions related tocontext: information about the relation of an entity vis-a-vis itssituation and using this information to help an applicationcomplete its task. However, Zimmerman [12] states that thisdefinition is too formal and universal and missing an importantoperational part. Indeed, the type of information needed to define
Please cite this article in press as: D. Nadoveza, D. Kiritsis, Ontology-Comput. Industry (2014), http://dx.doi.org/10.1016/j.compind.2014.
the entity-situation relation is not defined in the above definitionbut is required for any pragmatic approach to context modeling.The authors of [12] propose the following five categories ofcontext information: individuality, activity, location, time andrelations.
Considering the origin of the context information, it can beretrieved from internal and/or external sources. Internal context isrepresented by data and information that comes from the system,such as system state, events that happen etc. On the other hand,external context is represented with information coming fromoutside the system, such as device type, location etc. Some authorshave classified context depending on the way data is captured intothree groups: physical context, virtual context and logical context.Physical context is represented with data coming from physicalsensors such as GPS devices, light sensors etc. Virtual context isbased on information coming from software applications orservices. For example the position of the user can be determinedby browsing his electronic calendar, emails etc. Finally, logicalcontext is derived from information coming from variousinformation sources. It combines information both from physicaland virtual sensors [13].
Although most authors refer to abstract context sources, themainly used and tested sources currently are physical sensors.Virtual and logical sensors are capable of providing useful contextdata as well and this will be incorporated in this research [13].
3. Context modeling
As shown in the previous section, context information can beobtained in a wide range of forms. Thus, efficient and effectivemeans of modeling the information are needed. One of the biggestproblems in the existing solutions is the variety of the used contextmodels as well as the different ways to find and access the contextsources. Every system and framework uses its own format todescribe context and its own communications mechanisms toaccess it. Standardized formats in this domain however are crucialfor the enhancement of context-aware systems to shift the focusfrom the communication between context sources and users to thedevelopment of valuable context services.
Before moving on to the state of the art of context modelling,the requirements that these models must meet are given. A contextmodel must meet the following requirements as defined in [14]:
� Applicability. A context model should be able to be used formany different applications entered around a single task. Thisrequirement entails that context models must be flexible in theway they can complete a given task, due to the fact that contextdata is heterogeneous.� Information analysis. Context information, as already stated,
can be of many different types, since it is extracted from amultitude of sources. The model must be able to compare theinformation resulting from different measurements. Further-more, the model must be able to determine the source ofinformation and how it has previously been processed. Thisrequirement is known as traceability. Finally, acquired data frommultiple sources may be incomplete or contradict itself, resultingin the need for methods for resolving such issues.� History. Any context model must provide a means of storing and
accessing past information. Indeed past information can beuseful to make predictions that may be valuable for presentdecisions.� Inference. The information acquired from devices such as
sensors is only raw data, also known as low-order context. Acontext model is required to able to apply reasoning on low-order context data in order to obtain high-order context onwhich to base decisions.
based approach for context modeling in enterprise applications,07.007

D. Nadoveza, D. Kiritsis / Computers in Industry xxx (2014) xxx–xxx 3
G Model
COMIND-2600; No. of Pages 14
In the literature there exists a variety of context modelingtechniques. The main methods are first presented briefly. Theontology-based context modeling approach are separately pre-sented last and in more depth as it possesses key advantages.
� Key-value models. Simple and easy to manage, key-valuecontext models are based on a list of attributes that are assignedvalues describing the application’s environment ([15,16]).However this method clearly lacks efficient means of meetingthe aforementioned requirements such as quality control,analyzing relationships and inferring higher-order context [16].� Markup scheme models. This category of context models uses
markup languages such as XML and even RDF(S) to develophierarchical data structures [15]. These types of models can beseen as an enhancement of key-value models as they grouprelated key-value pairs under specific markup tags and providebasic reasoning methods [16]. However they still possess thesame limitations as key-value models.� Graphical models. Graphical modeling techniques use diagrams
with explicit symbols to help map out the relationships andinteractions between objects belonging to the domain beingmodeled [15]. The graphical aspect of these methods possessesthe advantage of being easier for humans to understand andimplement.� Logic-based models. Logic-based models use simple abstract
mathematical rules that give the ability to derive and concludenew facts after reasoning of a set of known facts [15].� Object oriented models. These types of models try to use object
oriented programming techniques to describe context. Suchtechniques used are encapsulation (hiding and grouping vari-ables inside classes) and inheritance (hierarchy of classes withproperty inheritance) [15].
3.1. Ontology-based models
Ontologies are, in the general sense of the term, a set ofconcepts and relationships used to describe a particular domainof knowledge. In other words they provide the vocabulary for adomain. The above modeling techniques possess distinctmethods of modeling context. Due to their varying approaches,they each meet different requirements as described earlier.However, none of them are able to meet all of the requirementsin a satisfactory manner. On the other hand ontology-basedmodels are particularly promising due the fact that they possessthe potential to meet most, if not all, of the previously describedrequirements. The main point exposed is that ontologicalmodels use simple description logic languages to build complexmodels.
Ontology models are known for the following advantages forcontext modeling:
� Due to the fact that they are based on simple yet flexibledescription languages, they have a high expressive power [17].This is important for context modeling, as context data canevolve and be heterogeneous.� They possess a high degree of formality, facilitating knowledge
sharing of heterogeneous context data [16]. Indeed they providepredefined classes, properties and rules that provide a formalbasis on which to create new classes and properties for specificcontext domains.� Reusability is also an important advantage of ontology models.
Indeed, [18] demonstrates the use of generic and reusable upperontologies such as CONON [18] or CoDAMoS [19] on top of whichone can create unique and domain-specific ontologies.
Please cite this article in press as: D. Nadoveza, D. Kiritsis, Ontology-Comput. Industry (2014), http://dx.doi.org/10.1016/j.compind.2014.
� Finally, the formal rules provided provide logical reasoningmechanisms. This allows, as already stated, for inference of newinformation based on lower-order raw data as well as to evaluatecontext by checking for consistency, compatibility, incomplete-ness and ambiguity ([14,18]).
Thus, we see that being based on description logics, ontologymodeling is well-suited for describing context. However they dopossess notable disadvantages:
� Ontology based models are computationally expensive forcomplex context domains [16]. Indeed these domains demandextensive computational effort to maintain decidability, so muchso that languages such as OWL-DL (a widely used subset of OWL)have reduced the number of provided classes and properties,thus favoring ensured decidability over expressive power.� They are not well adapted for modeling temporal descriptions of
context as little support is provided in this respect [16].
Despite these problems, ontology-based context models remainthe current best hope for developing context-aware applications.
Considerable research is being made into developing ontologiesspecifically designed for context descriptions, generally byextending existing basic ontology languages such as OWL [20].Such ontologies include CONON [18], CoDAMoS [19] and SOUPA[21] ontologies that define new classes related to applications thatinteract with humans. There are many more of these newontologies being developed, but most of them rely on a commonvocabulary base, in order for them to remain interoperable [14].This last point is very important as there will probably never be asingle solution due to the large number of requirements. Instead,integrated ontologies working together may be needed dependingon the type of tasks an application will be used for [16].
However, most of the current available context models areapplied in pervasive and ubiquitous computing and are meant tocapture only the low level physical context. Context models forcomplex enterprise applications which are able to describe thecontext in which an enterprise application has to provide itsservices are not being addressed in the research community so far.Also, since a significant amount of information that can beconsidered as context is already available in the various industrialsystems, the utilization of virtual and logical context could greatlyimprove the usability of the enterprise applications withoutinvesting a lot of resources in a new information infrastructure.
4. Proposed approach for context-aware systems
4.1. Concept overview
In order to have context-aware services, the most importantaspect of the application is to be able to acquire contextinformation and then to model it in a way that can be properlyinterpreted and managed.
As mentioned previously, context information has to satisfydifferent requirements such as: applicability, history, inference,analysis. But beside these functional requirements, one of the mostimportant properties of context is that it is dynamic and thuscontext information is dynamic too. This corresponds to the factthat the context information volume is always increasing, which isespecially highlighted in dynamic enterprise environments.
In order to correctly model context information, variousapplication domains in which a model could be applied shouldbe taken into account. This basically means that it is necessary toprovide a generic model which can be used in various applicationdomains and use-cases. Having a generic model provides the
based approach for context modeling in enterprise applications,07.007

D. Nadoveza, D. Kiritsis / Computers in Industry xxx (2014) xxx–xxx4
G Model
COMIND-2600; No. of Pages 14
distinct advantages of easy context information exchange as well asreusability of the model. On the other hand, it significantly reducesthe expressiveness of the model and requires more computing tointerpret it. Therefore, this approach proposes the upper model(ontology) which specifies only the common and generic concepts ofcontext and supports context information exchange.
However, it is not possible to model different domains onlywith the upper model, which means that for each case, a domainspecific model should be specified. This domain specific modelshould extend the generic upper model and describe the specificdomain in more detail. One of the advantages of the proposedsolution is that it supports the reuse of already existing modelsusing them as domain specific ontology and linking them with theupper ontology. The use of this approach encompasses theinteroperability benefits from the upper ontology and theexpressiveness from the domain specific ontology.
But what exactly could be considered as context information inan enterprise application? Since, according to Dey, context couldbe any information which can characterize the situation of anentity [10], it is necessary to identify what kind of contextinformation is available to describe the situation of an entity,where an entity is the information which is of relevance to the enduser. Furthermore, Brezillon’s and Pomerol’s definition [11]implies that context should help determine (constrain) theinformation relevance but not change the information’s meaning.
Therefore, since the information is to be provided to the user,logically it depends on the user which consumes that information,in a way that it has to satisfy his needs taking into account both hispersonal and business situation. However, this is not enough sincethe application also has to be aware of the current state of thebusiness which means that the final information depends on whatis going on in the enterprise or so to say, to be aware of the overallbusiness situation. Finally, the information which has to be servedto the user also depends on itself, which means that it depends onits content. It is important to note that the most of this informationalready exists in the modern enterprise applications, such as ERP,MES, etc. Today, these systems cover different aspects of theenterprise and integrate various tools and applications whichgenerate a large volume of information which can certainly beconsidered as context.
But how could this context information can be used? Theproposed approach is based on the three major steps illustrated inFig. 1, which are necessary to execute/pass in order to deliver therelevant information to the end user. The first step is actually tocapture and pick the information which is considered as contextmodel with an ontology. This context could be considered as loworder context and it is usually information which is alreadyavailable in the system or coming from physical sensors (e.g.location). This information (sometimes even the location of theuser) is usually gathered by the so called virtual sensors. This stepallows for further context information interpretation as well asexchange of context information between different applications.
Since the low order context could come in large volumes andcan change very quickly, sometimes it can be very difficult to
Fig. 1. Steps for context interpretation.
Please cite this article in press as: D. Nadoveza, D. Kiritsis, Ontology-Comput. Industry (2014), http://dx.doi.org/10.1016/j.compind.2014.
interpret it and use it directly. Therefore the intermediate step isadded in which the low order context is interpreted as user andbusiness states. Basically in this step the context information isdiscretized and made more convenient (and less dynamical) forfurther usage. The low order context is transformed into the socalled higher order context which is more suitable for further rule-based interpretation. This transformation, or state assessment, isdone using predefined rules. Also, it is important to note that someuser and business states could be directly imported from differentexternal or internal sources (e.g. some web agents).
Finally, states are used in the last step to define the currentsituation and according to it, provide the appropriate information tothe end user. Situation is considered to be a set of currently activebusiness and/or user states. Again rules are used to interpret thesituation and select appropriate information which should satisfythe end.
4.2. Proposed context model
This section gives an overview or the proposed context ontologyfor modeling context in enterprise applications. As previouslystated, formalization and generalization of all context informationwould be an impossible task, but some general concepts arefundamental for describing the situation in which an application isexecuted. These general concepts are modeled as an upperontology and provide the basis for further domain-specific contextmodel extensions.
The upper ontology describes general concepts like space,matter, object, event and action while domain ontologies specifythe vocabulary and properties related to a generic domain or ageneric task by specializing the terms introduced in the upperontology. Different enterprise applications and different use-casespresume different context models which could be described withdomain-specific extensions of the upper-level context ontology.
The core of the proposed concept is the upper context ontologywhich should be able to describe any situation, in which context,certain information provided by the information system is relevant.Due to the nature of enterprise applications and the informationwhich they provide, the upper ontology has been separated in threeparts (sub-models). As illustrated in Fig. 2 the upper contextontology’ three interconnected sub-models are: (a) user context, (b)business context and (c) information feature model [13].
The user context model captures all the information concerningthe end user which is accessing the system. That information variesfrom the simple user’s name and role, or the device which he used toaccess the system, to the business activities he is currently involvedin. The business context model captures the current state of thebusiness and must be able to define the overall business situation. Itcaptures various ongoing, past and future business activities as wellas the relevant events which have occurred during some businessactivity or by using some business resources. And lastly, information
Fig. 2. Conceptual context model.
based approach for context modeling in enterprise applications,07.007

Fig. 4. UserContext class and subclasses.
D. Nadoveza, D. Kiritsis / Computers in Industry xxx (2014) xxx–xxx 5
G Model
COMIND-2600; No. of Pages 14
features can be considered as basic information providers in theinformation systems; they can be GUI widgets as well as simple dataqueries. Therefore, the Information feature model has to be able todefine the nature of the application feature as well as theinformation which it provides.
Most of the existing context ontologies generically modeldifferent context variables. These models lacks of expressivity andthe significant efforts should be made for the interpretation of it.Furthermore, mostly they focus on the user context, while businesscontext, as a concept described in this work, doesn’t exist. Lastly,most of the systems utilizes only the physical context (comingfrom physical sensors) while virtual context, coming from theexisting data, is neglected.
4.3. Upper ontology
One of the key requirements an ontology-based context modelmust respect is applicability [16]. Thus we define what is called anupper ontology infrastructure, as a generic set of classes andproperty relations which can be used in different applications anddomains.
The model of the upper ontology is composed of multipleclasses and subclasses and is based on the conceptual model foundin [13]. Fig. 3 shows the basic concepts of this ontology whichmodel the context as well as the information features to bepresented to the end user. The main class is the ContextEntity classwhich abstracts all information which could be considered ascontext. ContextEntity is specialized by two subclasses, theUserContext and BusinessContext classes.
The InformationFeature class represents all business informa-tion that users would wish to access. It doesn’t represent specificinformation but rather it specifies the type of information, theentities to which it refers as well as the way to retrieve it.Moreover, it could be said that Information Features represent thebasic information providers of an information system. Typicallythese are GUI components such as widgets, data tables, UI formsetc., but this approach also considers other information providerssuch as data queries, information aggregators such as KPIs, datacalculators etc. It is assumed that each information system has apredefined number of information features which can be describedwith our model during design-time. We differentiate between twobasic types of information features [13]:
� Non-parameterized information features: Very simple infor-mation providers which always serve the same information. Atypical example is gauge, which shows to the user thetemperature of the shop floor.� Parameterized information features: Information providers
which serve information depending on the parameters which arepassed to it. For example, this can be a widget which shows to theuser information about a specific business activity, where theactivity ID is a parameter.
4.4. User context ontology
User context represents the various entities and concepts whichare considered as relevant for describing the current user situationand its interaction with the system. It captures the information
Fig. 3. Upper ontology.
Please cite this article in press as: D. Nadoveza, D. Kiritsis, Ontology-Comput. Industry (2014), http://dx.doi.org/10.1016/j.compind.2014.
about the user identity, his physical location as well as hisinteraction with the other users. Furthermore, the user’s positionin the business, his/her involvement in the business activities aswell as his/her responsibilities and preferences could be consid-ered as user context. Of course, this information depends on thetype of application, domain and business organization of theenterprise. Regarding the origin of this information, it usuallyalready exists in the systems with the exception of the physicallocation and accessing device. In the user context ontology, everyinformation which describes user’s context is represented with thesuper class UserContext and it is directly inherited from theContextEntity class. Figs. 4 and 5 illustrate the class hierarchy of theUser context ontology and the following text briefly specifies themost important concepts, relations and properties.
� User. This class contains the individuals that are accessing thesystem in order to obtain information features. It is the core ofthe UserContext class, since all the other classes are related to itthrough object property relations shown in Fig. 5. Indeed allother subclasses of ContextEntity exist in order to describe thecontext of a given user.� User status. This class groups the information regarding a user’s
work statusand consists of two subclasses: UserWorking andUserNotWorking.� Location. The location of the user is also an important part of his
context. A user’s location can be absolute (spatial coordinates) orrelative (conference room, production floor, etc.) and thus twosubclasses are defined: AbsoluteLocation and RelativeLocation.� Role. A user’s role represents his position in a business’
hierarchyand determines which Information Features he/shehas access to. This is done through the Permission class and thehas Permission object property.� Access device. The access device is the device (PC, Machine
terminal, tablet, phone, etc.) the user is using to access the system.� Area of responsibility or AOR represents a set of different
business activities and resources for which a user is responsible for.� Area of interests or AOI class represents user preferences for
specific Information Features. AOI’s are updated manually by theuser.
4.5. Business context ontology
Business context represents the various entities and conceptswhich are considered as relevant for describing the current
based approach for context modeling in enterprise applications,07.007

Fig. 5. User class and its object property relationships.
D. Nadoveza, D. Kiritsis / Computers in Industry xxx (2014) xxx–xxx6
G Model
COMIND-2600; No. of Pages 14
business situation. It captures all the information which arenecessary to describe what is currently going on in the business.Basically the business context could be defined with three basicinformation: information about current, past and future businessactivities; information about the resources used/consumed/produced during these activities and; information about expectedor unexpected events which occurred. Depending on the enterpriseapplication, this information might be directly retrieved from thesystem or imported from external sources or even specified by auser. Furthermore, business context is very domain dependent,which means that different business domains require furtherspecialization of the concepts from the upper ontology. Thebusiness context ontology is represented with the super classBusinessContext which is directly inherited from the ContextEntity
class. The class hierarchy of the BusinessContext as well as the mostimportant concepts, relations and properties are shown in Figs. 6and 7 and described in the following text.
� Business activity. This class describes the past, current, andfuture activities of a business. Like the user class describedbefore, the BusinessActivity class is at the core of the Business-
Context class. Indeed as shown in Fig. 7 the other subclasses arerelated to it via object properties.� Activity status. This class describes the status (ongoing,
cancelled, etc.) of any given business activity.� Activity result. It defines the final result of a business activity.� Business resource. In general, a business activity requires a
given resource (e.g. a machine or a person) in order to becompleted.� Business event. The above classes of the business context model
are simple and general concepts that will not always be ofparticular interest to any user. However the BusinessEvent classdescribes events that are more user-orientated, as they describe
Fig. 6. BusinessContext class and subclasses.
Please cite this article in press as: D. Nadoveza, D. Kiritsis, Ontology-Comput. Industry (2014), http://dx.doi.org/10.1016/j.compind.2014.
sudden changes in the system that can be of direct interest tousers.
4.6. From low-order context to higher-order context: Inferring the
business and user states
Up to this point, the described UserContext and BusinessContext
provide a means of classifying and relating through properties datathat is either provided by the application itself or manuallyupdated by the user. This data can be viewed as being low-ordercontext data. However, in any real implementation of these modelsthis would not suffice due to the dynamic nature of context and thespecificity of different domains. Indeed one must remember thatthese business and context models are just a general upperontology and that they will be completed during implementationwith specific domain ontology. The simple concepts describedbefore could be specialized with multiple classes, sometimescontaining a hundred or even a thousand individuals. Therefore,even with the provided context data, getting the right informationto the right user at the right time might be still too difficult.
Due to these problems, a further concept is required: thebusiness and user states. The purpose of these two concepts is todiscretize the low order context data and to provide the veryessence of business and user context information in a more simpleand accessible manner. Thus two new concepts are defined namedUserState and BusinessState, which specify the predefined states (ordescriptions). In order to assess these states, SWRL [22] rules haveto be specified by an appropriate expert. When certain individualsof the low-order context models have certain properties, then theappropriate state will be activated through an SWRL rule. Henceboth the BusinessState and UserState classes specify statesdepending on the situation of the user context and businesscontext. The final step would be to implement rules stating that ifcertain business states and user states are currently activated, thenthe particular user would be interested in specific informationfeatures. One can thus see that the concept of states allows filteringthe complex and dynamic low-order context information in orderto obtain short and easily usable descriptions of what is currentlygoing on inside a business. Fig. 8 gives an overview of this process.Furthermore, these descriptions can also be used as valuableinformation to describe the actual situation to the end user.
4.7. Putting the information in the context—Explaining the situation
to a user
Up to now, this paper has mostly addressed the problems ofmodeling the context and providing the appropriate information tothe end user. However, in order to efficiently consume theprovided information, it is essential that the user also understandsit. More specifically, it means that he/she has to know why certaininformation is important for him/her. Isolated information out of
based approach for context modeling in enterprise applications,07.007
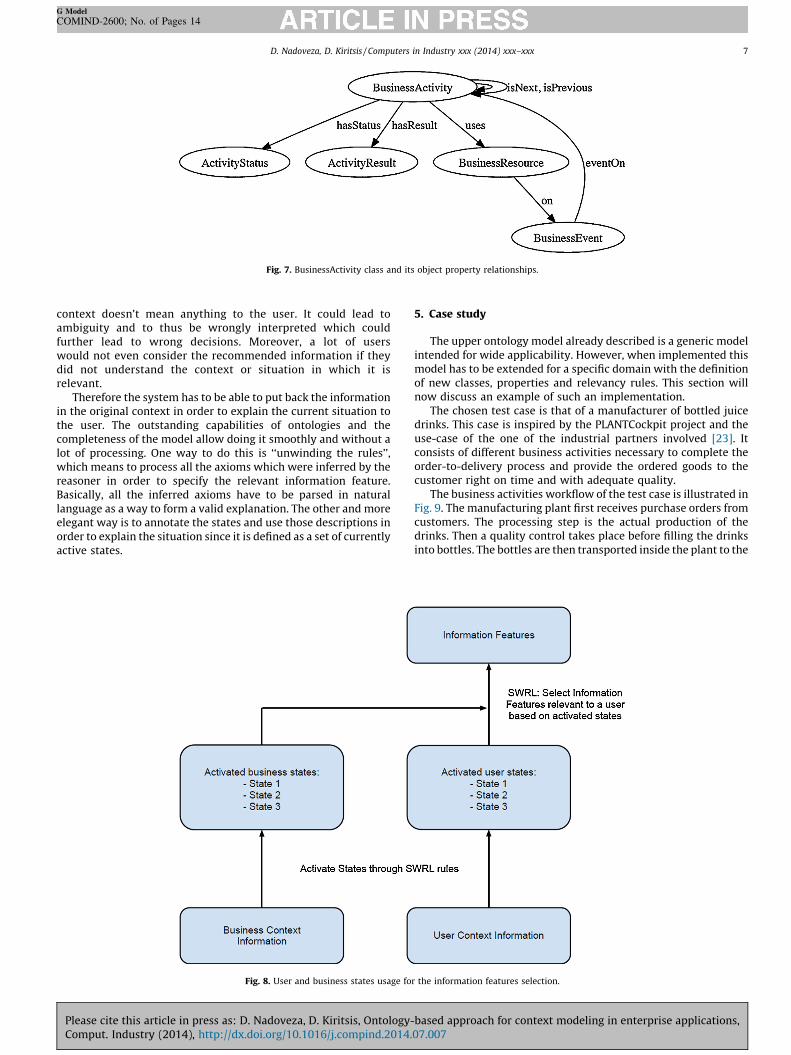
Fig. 7. BusinessActivity class and its object property relationships.
D. Nadoveza, D. Kiritsis / Computers in Industry xxx (2014) xxx–xxx 7
G Model
COMIND-2600; No. of Pages 14
context doesn’t mean anything to the user. It could lead toambiguity and to thus be wrongly interpreted which couldfurther lead to wrong decisions. Moreover, a lot of userswould not even consider the recommended information if theydid not understand the context or situation in which it isrelevant.
Therefore the system has to be able to put back the informationin the original context in order to explain the current situation tothe user. The outstanding capabilities of ontologies and thecompleteness of the model allow doing it smoothly and without alot of processing. One way to do this is ‘‘unwinding the rules’’,which means to process all the axioms which were inferred by thereasoner in order to specify the relevant information feature.Basically, all the inferred axioms have to be parsed in naturallanguage as a way to form a valid explanation. The other and moreelegant way is to annotate the states and use those descriptions inorder to explain the situation since it is defined as a set of currentlyactive states.
Fig. 8. User and business states usage fo
Please cite this article in press as: D. Nadoveza, D. Kiritsis, Ontology-Comput. Industry (2014), http://dx.doi.org/10.1016/j.compind.2014.
5. Case study
The upper ontology model already described is a generic modelintended for wide applicability. However, when implemented thismodel has to be extended for a specific domain with the definitionof new classes, properties and relevancy rules. This section willnow discuss an example of such an implementation.
The chosen test case is that of a manufacturer of bottled juicedrinks. This case is inspired by the PLANTCockpit project and theuse-case of the one of the industrial partners involved [23]. Itconsists of different business activities necessary to complete theorder-to-delivery process and provide the ordered goods to thecustomer right on time and with adequate quality.
The business activities workflow of the test case is illustrated inFig. 9. The manufacturing plant first receives purchase orders fromcustomers. The processing step is the actual production of thedrinks. Then a quality control takes place before filling the drinksinto bottles. The bottles are then transported inside the plant to the
r the information features selection.
based approach for context modeling in enterprise applications,07.007

Fig. 9. Business activities workflow of a manufacturer of bottled juice drinks.
D. Nadoveza, D. Kiritsis / Computers in Industry xxx (2014) xxx–xxx8
G Model
COMIND-2600; No. of Pages 14
loading docks where they await external transport to their finaldestination for delivery.
Each of these steps is described by information features in theform of orders (e.g. Process order, Filling order, etc.). These orderscontain very vital information such as start and end times,resources to be used for task completion, etc. The problems arisewhen the manufacturer receives up to a 100 customer orders a day.For each customer order received, subsequent orders fromprocessing to delivery have to be created by the employees ofthe production planning department. It is inevitable in anymanufacturing business that deviations will arise, resulting inthe need for active searches toward finding a solution.
This requires today an active search in different data sourcesand linking disparate data; a process which is very time consumingand mostly performed when delays have already occurred and isthus too late to find a solution. For example, such deviations canoccur when raw materials or semi-final products are not providedat the right time to the production line. The reasons for theseissuescan vary: problems/delays in production orders, problems inthe logistical chain inside the plant, delays on transports fromexternal suppliers, productions in time but with insufficientquality, etc. The Information concerning the delays in theprocurement and transport of these raw materials and semi-finalproducts today is not automatically redirected to the appropriateperson and as a result, valuable time is lost in order to findalternative raw materials and/or reschedule production and fillingprocess orders.
In the current situation of the manufacturer in question, theproduction planners have to manually sort through the variousorders in a process that is highly time consuming and may result in
Fig. 10. BusinessResource subclasses and ind
Please cite this article in press as: D. Nadoveza, D. Kiritsis, Ontology-Comput. Industry (2014), http://dx.doi.org/10.1016/j.compind.2014.
solutions that are usually discovered too late. Thus, the objective isto apply the upper ontology described in Section 4 and extend it forthe manufacturer in question in order for the system to provide theappropriate information features to the right employees automat-ically when production deviations arise.
5.1. Extending the upper ontology
In order to illustrate the practical usage of the proposedconcepts, the upper ontology is extended with the domainontology which corresponds with the chosen test case. It isimportant to note that some of the concepts are simplified andadapted in order to perform faster prototyping and at the sametime demonstrate the proposed concepts. The case study iscompletely implemented in the Protege [24] ontology editor andERP data from the manufacturer is simulated.
In the following text the domain specific extensions for theupper ontology will be presented as well as the usage examplesbased on two test scenarios.
5.1.1. Business resources
In this test case, it is the manufacturing resources that are ofmain interest. However, it must be noted that a company will haveof course other resources such as financial, material and researchresources. As shown in Fig. 10, the BusinessResource class of theupper ontology has been specialized with multiple classes. Theproduction resources of interest were considered to be part of theSwiss manufacturing plant of the company. The SwissPlant classcontains a ProductionLine subclass containing four individuals: twofilling lines and two processing lines.
ividuals implemented for this scenario.
based approach for context modeling in enterprise applications,07.007

Fig. 11. BusinessActivity subclasses and individuals implemented for this scenario.
D. Nadoveza, D. Kiritsis / Computers in Industry xxx (2014) xxx–xxx 9
G Model
COMIND-2600; No. of Pages 14
5.1.2. Business activities
The BusinessActivities class of the upper ontology was special-ized with four activity subclasses for processing, quality control,filling and transportation. For each subclass one individual (e.g.Filling1) was created (Fig. 11). In order to identify that all theseindividuals are in fact the different activity stages for one singlecustomer order, they were all given one same Product ID attributethrough a newly defined hasProductID object property. The conceptof the product ID was implemented to facilitate the writing ofSWRL rules concerning the status of the different activities.However, one must understand that this concept is only aworkaround to the fact that in the current version of Protege,there exists no means of inferring new individuals, meaning thatall individuals must be created manually. Nevertheless, in a realimplementation of the model, this drawback would not exist as thecontext model would be created with a more complete means thana ontology editor like Protege. Thus when an activity for a certaincustomer ends, the next activity corresponding to that customerorder would automatically be created.
5.1.3. Business events
The BusinessEvents class was also specified with various types ofevents and alarms for the various stages of production. Therefore,
Fig. 12. BusinessEvents subclasses and indi
Please cite this article in press as: D. Nadoveza, D. Kiritsis, Ontology-Comput. Industry (2014), http://dx.doi.org/10.1016/j.compind.2014.
there are events and alarms which describe different situationsconcerning the processing, filling, transporting, etc (Fig. 12).
5.1.4. Activity status
Various simple activity statuses like Completed and Ongoing
were implemented as shown in Fig. 13.
5.1.5. Information features
The information features implemented for this businessscenario are business objects of the manufacturer’s ERP thatdescribe the various stages of production:
� Purchase order: Incoming message from a customer in variousforms (email, phone call, fax etc.) which is a starting point toenter a customer order in the system.� Customer order: It describes all information from the purchase
order into the ERP system and carries the ‘‘demand’’ from thecustomer.� Process order: Description of all information concerning produc-
tion process.� Filling order: Description of all information concerning the filling.� Inspection lot: Collection of all reference information for the bulk,
after the quality inspection.
viduals implemented for this scenario.
based approach for context modeling in enterprise applications,07.007

Fig. 13. ActivityStatus subclasses and individuals implemented for this scenario.
D. Nadoveza, D. Kiritsis / Computers in Industry xxx (2014) xxx–xxx10
G Model
COMIND-2600; No. of Pages 14
� Internal transportation order: It describes all information con-cerning transportation within the plant (conveyor belt, forklifts).� Transportation order: It describes all actual outgoing transporta-
tion info from the external transportation company. Includes alldelivery information (what, when, where, to whom, etc.).� Delivery: Description enclosing all outgoing delivery info: what
(+ quantity) to deliver, to whom (customer), where (address) andwhen (delivery date) etc.
The resulting class hierarchy is shown in Fig. 14. An order wascreated for each stage of production (e.g. ProcessOrder1). Theseorders describe the production activities for the same product,illustrated in Fig. 11, and thus also have the same Product ID.
5.1.6. User roles
For this test case seven users are created with different roles inthe company:
� A plant manager: Responsible for the whole plant and interestedin the overall performance.� A processing line manager: Responsible for the two processing
lines A and B of the plant. He is interested only in the deviationsof the planned processing.� A filling line manager: Responsible for the two filling lines A and B
of the plant. He is interested only in the deviations of the plannedfilling.� Two processing line operators: Each operator responsible for his
processing line and is interested in all ongoing activitiesconcerning his line.
Fig. 14. InformationFeatures subclasses and in
Please cite this article in press as: D. Nadoveza, D. Kiritsis, Ontology-Comput. Industry (2014), http://dx.doi.org/10.1016/j.compind.2014.
� Two filling line managers: Each operator is responsible for hisfilling line and is interested in all ongoing activities concerninghis line.
These users were implemented as individuals of the User classand each given a role through the performs object property,illustrated in the diagram of Fig. 15.
For the purpose of demonstration, some basic logic rules werewritten concerning the Plant employee hierarchy. Indeed witheach role, one can automatically infer a user’s superiors, peers andsubordinates using SWRL statements combined with isSuperiorOf,isPeerTo, isSubordinateOf object properties provided by the upperontology. Later, it will be shown how this information could beused in the test case. An example of such a rule statement is thefollowing:
Performs ð?u1; ?rÞ; performs ð?u2; ?rÞ ! isPeerTo ð?u1; ?u2Þ
Stating that if two users u1 and u2 have the same role r thenthey are peers. Similar rules were written for the isSuperiorOf andisSubordinateOf properties. An example of the inferred informationfor the plant manager is shown in Fig. 16, taken from Protege.
5.1.7. User locations and access devices
The Location class was extended with some simple subclassesand individuals reflecting various locations of the production plant(Fig. 17). Only the RelativeLocation subclass was extended as theAbsoluteLocation subclass would have been too complicated and
dividuals implemented for this scenario.
based approach for context modeling in enterprise applications,07.007

Fig. 15. User class populated with the different individuals, each performing a role.
Fig. 16. From the simple statement that the user performs the PlantManager role, his
situation in the plant employee hierarchy is inferred (yellow property assertions).
(For interpretation of the references to color in this figure legend, the reader is
referred to the web version of this article.)
D. Nadoveza, D. Kiritsis / Computers in Industry xxx (2014) xxx–xxx 11
G Model
COMIND-2600; No. of Pages 14
not very interesting to implement (it would have required somesort of positioning device like GPS).
Some simple SWRL rules were again implemented giving theability to infer the relative location of a user based on which accessdevice is being used. An example of such a rule statement is thefollowing:
accessedWithð?u; ProcessingLineBTerminalÞ1 isLocatedInð?u; ProcessingFloorÞ
Stating that if the user u accessed the system from theProcessingLineBTerminal then the user u is located in theProcessingFloor.
The various access devices implemented are shown in Fig. 18. Ofcourse other means of determining the position exist such asemployees using access cards to enter various zones of the plant.
Fig. 17. Location subclasses and individ
Please cite this article in press as: D. Nadoveza, D. Kiritsis, Ontology-Comput. Industry (2014), http://dx.doi.org/10.1016/j.compind.2014.
5.1.8. User status
The upper ontology also provided the UserStatus class fordetermining whether or not the user is working. Various statuseswere implemented such as UserOnVacation and UserOnBreak
(Fig. 19).
5.1.9. Assessing business and user states to select relevant information
features
The previous section focused on describing the variousextensions brought to the upper ontology. As shown, the upperontology grew into a more complex model with a number of newsubclasses and individuals. One must remember that the businessscenario in question has been simplified and that in any realimplementation the domain context model would be far greater. Abusiness might have over a hundred customer orders per day,resulting in as many production orders. The number of businessactivities, resources and users would also be very high. Thus we seethe need to use business and user states to help describe in a moresuccinct manner what is happening at any given moment in thebusiness.
This section focuses on demonstrating through several testshow predefined business and user states can be activated and howthese states can be used to select the relevant Information Featuresfor various users. Some simple examples of business states thatwere defined as individuals of the BusinessState class are as follows:
� ProcessingOngoingAsPlanned.� ProcessingOngoingBehindSchedule.� AbnormalFillingState.
uals implemented for this scenario.
based approach for context modeling in enterprise applications,07.007

Fig. 18. AccessDevice subclasses and individuals implemented for this scenario.
Fig. 19. UserStatus subclasses and individuals implemented for this scenario.
D. Nadoveza, D. Kiritsis / Computers in Industry xxx (2014) xxx–xxx12
G Model
COMIND-2600; No. of Pages 14
� BadQualityState.
Also the following states are some examples of user statesimplemented:
� UserWorking.� UserNotWorking.
5.1.10. Test 1: Processing behind schedule
In this test, the status processing activity Processing1 was set toOngoingBehindSchedule, as shown in Fig. 20.
With the following rule the corresponding business state wasactivated:
ProcessingActivityð?pÞ;hasStatusð?p; OngoingBehindScheduleÞ; describedByð?p;?oÞ! activateBusinessStateðProcessingOngoingBehindSchedule;
trueÞ; isRelevantð?o; ProcessingOngoingBehindScheduleÞ
Fig. 20. Protege property assertions and inferred information (in yellow) about
Processing1 activity. (For interpretation of the references to color in this figure
legend, the reader is referred to the web version of this article.)
Please cite this article in press as: D. Nadoveza, D. Kiritsis, Ontology-Comput. Industry (2014), http://dx.doi.org/10.1016/j.compind.2014.
This rule states that if any processing activity p has a currentstatus set to OngoingBehindSchedule and is described by anInformation Feature order o, then the corresponding businessstate is activated (set to boolean value true) through the objectproperty activateBusinessState. Furthermore this rule will make thesystem infer that the Information Feature order o is relevant to thisactivated business state. The result is shown in Fig. 21. As we cansee in yellow, the state is inferred to be activated.
Finally, we want the processing line manager to be informed ofthe fact that there is a processing activity which is behind schedule.This is done through the following relevancy rule:
activateBusinessState ðProcessingOngoingBehindSchedule;trueÞ; describedByðProcessingOngoingBehindSchedule;?oÞ;
BusinessActivityð?aÞ; usesð?a;?rÞ;describedByð?a;?oÞ; hasStateð?u; UserWorkingÞ;
isResponsibleForð?u;?rÞ; performsð?u; LineManagerÞ! isInterestedInð?u;?oÞ
This rule basically states that if the business state Processin-
gOngoingBehindSchedule is activated and described by a certainbusiness order o, then the user whose state is UserWorking and whois responsible for the resource being used for the activity that is
Fig. 21. Inferred information (in yellow) about business state
ProcessingOngoingBehindSchedule. (For interpretation of the references to color in
this figure legend, the reader is referred to the web version of this article.)
based approach for context modeling in enterprise applications,07.007

Fig. 22. Inferred information (in yellow) about the Processing Line Manager. (For
interpretation of the references to color in this figure legend, the reader is referred
to the web version of this article.)
Fig. 24. Inferred information (in yellow) about the Processing line manager. (For
interpretation of the references to color in this figure legend, the reader is referred
to the web version of this article.)
D. Nadoveza, D. Kiritsis / Computers in Industry xxx (2014) xxx–xxx 13
G Model
COMIND-2600; No. of Pages 14
behind schedule is interested in the order o. In this case, the user inquestion is the processing line manager. As we can see from Fig. 22, heis indeed inferred to be interested in such order (ProcessingOrder1).
Furthermore, we can ask the system why it deems theprocessing line manager interested in ProcessOrder1. The resultof this query in Protege is shown in Fig. 23. The figure shows all thesteps the system took in order to infer the final result. Theexplanation as we can see is complicated as it shows all the stepsundertaken, some of which are not very interesting. However, in areal implementation of the model, a user friendly interface wouldbe developed. For example, one could imagine that the processingline manager would receive on his desktop computer or businesssmartphone a notification. He would then open it and be shown therelevant information feature along with succinct and easy tounderstand explanation as to why the system deemed it necessaryfor him to be notified.
5.1.11. Test 2: Filling alarm and line manager on vacation
In this test a FillingAlarm event arises on the ongoing businessactivity Filling1. However, the filling line manager is currently onvacation. The goal is to see if the system is able to understand thiscontext and alert the filling line manager’s peer. Since the first test wasdescribed in detail, the current test description will be more succinct.
The main relevancy rule that is used to accomplish the desiredresult is as follows:
activateBusinessStateðFillingAlarm; trueÞ;describedByðFillingAlarm;?oÞ; BusinessActivityð?aÞ;describedByð?a;?oÞ; usesð?a;?rÞ;hasStateð?u1; UserNotWorkingÞ;performsð?u1; LineManagerÞ; isResponsibleForð?u1; ?rÞ;hasStateð?u2; UserWorkingÞ; isPeerToð?u1; ?u2Þ! isInterestedInð?u2; ?oÞ
Fig. 23. Explanation given by Protege as to why the pro
Please cite this article in press as: D. Nadoveza, D. Kiritsis, Ontology-Comput. Industry (2014), http://dx.doi.org/10.1016/j.compind.2014.
The rule basically states that when a FillingAlarm is activatedbut the person in charge of the activity on which the alarm event ishappening is not working, then the system should search for thatperson’s peer and notify him of the information feature describingthe activity that is the source of the alarm. Please note that thecriteria for the peer selection in this simple example are the sameuser role. However, in more complex scenarios and examples, thepeer selection and the corresponding rules could be much morecomplex.
The result of this rule in the case of this test should be to notifythe processing line manager, as he is the peer of the production linemanager. This is indeed the case as is shown in Fig. 24.
As in the first test, the processing line manager would benotified through a user interface. He would receive the filling orderin question. Since he is not responsible for the filling process, hecould for example click on a button Explain and receive anexplanation stating that since his colleague is on vacation he is theone to be notified of the alarm.
5.1.12. Final remarks on the tests
As we can see, the above model provides a means for notifyingwith the correct information features the appropriate person basedon low-order context information. Of course the tests and domainmodel are far from complete, but the purpose was to give thereader a sense of what this type of model is capable of achieving.Furthermore, the number and complexity of business and userstates would be far greater and more specific. However, we can seethat the purpose of such states is to describe in a more succinctmanner the business and user contexts. In this way, the writing ofrelevancy rules is greatly facilitated.
cessing line manager is interested in ProcessOrder1.
based approach for context modeling in enterprise applications,07.007

D. Nadoveza, D. Kiritsis / Computers in Industry xxx (2014) xxx–xxx14
G Model
COMIND-2600; No. of Pages 14
6. Conclusions
This work proposed an ontology-based context model as asolution to the problem of getting the right information to the rightperson in a business environment. The first part of the modelpresented was the upper ontology model, consisting of aninfrastructure of generic classes and properties intended forwidespread application in the manufacturing industry. The modelwas mainly divided into two parts: the description of the user’scontext through classes such as his Status, Location and Role, andthe description of the business context through such classes asBusinessActivity, ActivityStatus and BusinessResource. The Informa-
tionFeatures class was also defined containing the variousdocuments and data a user might be interested in. Furthermoretwo concepts were added to the model called the UserState andBusinessState classes. These classes provide a means of filtering thecontext information in order to obtain a simpler and more succinctdescription of both context entities. Finally it was shown howbased on a user’s state and the current state of the business, onecould write SWRL relevancy rules in order to determine whichinformation feature is deemed relevant to the user. In this manner,the user no longer has to actively search through large sets of dataat the cost of wasting valuable time. Instead, the systemrecommends and notifies the user automatically of relevantinformation as well as explains why the provided information isrelevant.
The second part of this work focused on implementing adomain specific extension of the upper ontology model using theontology editor Protege. The simplified business scenario was thatof a manufacturer of bottled juice drinks. Once the extendedcontext model was described, two tests were performed in whichalarms arose during production. The reader was able to see, usingSWRL relevancy rules based on the user and business states, howthe system could automatically notify the appropriate user.Furthermore the user in question would have the possibility toask the system for an explanation as to why he/she is beingnotified. This is a key advantage of using an ontology-basedcontext model. Indeed, by asking for such an explanation, the userwill be presented with the various steps the system took whenassessing the business and user states and selecting the appropri-ate information feature. Thus, this new set of information will beadded to that of the information feature notification, therebyincreasing the user’s understanding of what is currently going inthe business. Therefore the user will be able to make betterdecisions in less time.
References
[1] K. Sandkuhl, Information logistics in networked organizations: selected conceptsand applications, in: W. Aalst, J. Mylopoulos, N.M. Sadeh, M.J. Shaw, C. Szyperski,J. Filipe, J. Cardoso (Eds.), Enterp. Inf. Syst., 12, 2009, pp. 43–54, Retrieved fromhhttp://dx.doi.org/10.1007/978-3-540-88710-2_4i.
[2] Delphi Group, Perspectives on Information Retrieval, Delphi Group, Boston, MA,2002.
[3] R. Skjong, O. Johnsen, J. Weitzenbock, S. Brynestad, T. Mestl, Technology Outlook,Det Norske Veritas, Norway, 2004p. 109.
[4] M. Bazire, P. Brezillon, Understanding context before using it, in: A.K. Dey, BoichoKokinov, D. Leake, R. Turner (Eds.), International Conference on Contexts, 2005,pp. 29–40, Retrieved from hhttp://link.springer.com/chapter/10.1007/11508373_3i.
[5] W.J. Clancey, No title, in: Situated Cognition: How Representations are Createdand Given Meaning, 1998 hRetrieved from http://cogprints.org/661/1/133.htmi.
[6] C. Seifert, Situated Cognition and Learning. The MIT Encyclopedia of the CognitiveSciences, The MIT Press, Cambridge, 1999.
Please cite this article in press as: D. Nadoveza, D. Kiritsis, Ontology-Comput. Industry (2014), http://dx.doi.org/10.1016/j.compind.2014.
[7] Patrick Brezillon, Representation of procedures and practices in contextualgraphs, Knowl. Eng. Rev. 18 (2) (2003) 147–174.
[8] J. McCarthy, Notes on Formalizing Context, 1993.[9] J.E. Parker, D.L. Hollister, A.J. Gonzalez, P. Brezillon, S.T. Parker, Looking for a
Synergy between Human and Artificial Cognition, in: Modeling and Using Con-text, Springer, Berlin, Heidelberg, 2013, pp. 45–58.
[10] A. Dey, Understanding and using context, in: Personal and Ubiquitous Computing,2001 Retrieved from hhttp://dl.acm.org/citation.cfm?id=593572i.
[11] P. Brezillon, J. Pomerol, Contextual knowledge sharing and cooperation in intelli-gent assistant systems, in: Le Travail Humain, 1999, pp. 1–33 Retrieved fromhhttp://www.jstor.org/stable/10.2307/40660305i.
[12] A. Zimmermann, A. Lorenz, R. Oppermann, An operational definition of context,in: Modeling and Using Context, Springer, Berlin, Heidelberg, 2007, pp. 558–571.
[13] D. Nadoveza, D. Kiritsis, Concept for context-aware manufacturing dashboardapplications, Manufacturing Modelling, Management, and Control, vol. 7, 2013.
[14] R. Krummenacher, T. Strang, Ontology-based context modeling, in: ProceedingsThird Workshop on Context, 2007, hRetrieved from http://elib.dlr.de/47459/01/CAPS07CameraReadyVersion.pdfi.
[15] T. Strang, C. Linnhoff-Popien, A context modeling survey, in: Workshop Proceed-ings, 2004, Retrieved from hhttp://elib.dlr.de/7444/i.
[16] C. Bettini, O. Brdiczka, K. Henricksen, J. Indulska, D. Nicklas, A. Ranganathan, D.Riboni, A survey of context modelling and reasoning techniques, Pervasive Mob.Comput. 6 (2) (2010) 161–180, doi: 10.1016/j.pmcj.2009.06.002.
[17] D. Ejigu, M. Scuturici, L. Brunie, An ontology-based approach to context modelingand reasoning in pervasive computing, in: Fifth Annual IEEE International Con-ference on Pervasive Computing and Communications Workshops (Per-ComW’07), 2007, pp. 14–19, doi: 10.1109/PERCOMW.2007.22.
[18] X.H. Wang, T. Gu, D.Q. Zhang, H.K. Pung, Ontology based context modeling andreasoning using OWL, in: IEEE Annual Conference on Pervasive Computing andCommunications Workshops, 2004. Proceedings of the Second, 2004, pp. 18–22,doi: 10.1109/PERCOMW.2004.1276898.
[19] D. Preuveneers, J. Van Den. Bergh, Towards an extensible context ontology forambient intelligence, in: Ambient Intelligence, 2004, pp. 148–159 Retrieved fromhhttp://link.springer.com/chapter/10.1007/978-3-540-30473-9_15i.
[20] D.L. McGuinness, F. Van Harmelen, OWL web ontology language overview, W3CRecommendation 10 (10) (2004), 2004.
[21] H. Chen, F. Perich, T. Finin, a. Joshi, SOUPA: standard ontology for ubiquitous andpervasive applications, in: The First Annual International Conference on Mobileand Ubiquitous Systems: Networking and Services, MOBIQUITOUS 2004, 2004,pp. 258–267, doi: 10.1109/MOBIQ.2004.1331732.
[22] I. Horrocks, P. Patel-Schneider, SWRL: a semantic web rule language combiningOWL and RuleML, in: W3C Member . . ., (May), 2004.
[23] PLANTCockpit, PLANTCockpit Consortium, PLANTCockpit, 2013.[24] H. Knublauch, R.W. Fergerson, N.F. Noy, M.A. Musen, The Protege OWL plugin: an
open development environment for semantic web applications, in: The SemanticWeb—ISWC 2004, Springer, Berlin, 2004, pp. 229–243.
Drazen Nadoveza has received his master degree inApplied Computer Science in 2009 from the Universityof Novi Sad, Serbia. Since 2010 he is working on hisPh.D. thesis in the Laboratory for Computer-AidedDesign and Production (LICP) of the Swiss FederalInstitute of Technology in Lausanne (EPFL). His majorresearch interests include: context-aware systems,software architectures, Semantic Web, business intelli-gence, Life-cycle Assesment and Product LifecycleManagement.
Dimitris Kiritsis is a faculty member at the School ofEngineering of EPFL. He has more than eighteen years ofresearch and teaching experience with the LICPLaboratory of EPFL, including initiating and leadinginternational research projects in the domain of closed-loop PLM with applications of product embeddedinformation devices, product lifecycle modelling andsimulation, ontology based engineering, predictivemaintenance and engineering asset management andsustainable manufacturing. Dr. Kiritsis is the initiatorand scientific responsible of the FP6 IP 507100PROMISE. He is currently involved in the FP7 FoFprojectLinkedDesign as well as in the FP7 ICT project e-SAVE and the FP7 NMP project SuPLight. Dr. Kiritsis wasalso involved in the FP7 FoF CSA ActionPlanT contrib-uting to the produced roadmap and responsible for theactivities on Industrial Learning.
based approach for context modeling in enterprise applications,07.007





























