Embed Size (px)
Citation preview

OpenCL – OpenACC & Exascale
F. Bodin

• Exascale architectures may be o Massively parallel o Heterogeneous compute units o Hierarchical memory systems o Unreliable o Asynchronous o Very energy saving oriented o …
• Exascale roadmap needs to be build on programming standards o Nobody can afford re-writing applications again and again o Exascale roadmap, HPC, mass market many-core and embedded systems are sharing
many common issues o Exascale is not about an heroic technology development o Exascale project must provide technology for a large industry base/uses
• OpenACC and OpenCL may be candidates o Dealing with inside the node o Part of a standardization initiative o OpenACC complementary to OpenCL
• This presentation try to forecast OpenACC and OpenCL in the light of Exascale challenges o Challenges as identified by the ETP4HPC (http://www.etp4hpc.eu)
Introduction
WSTOOLS 2012 2 www.caps-entreprise.com

www.caps-entreprise.com 3 WSTOOLS 2012
http://www.etp4hpc.eu

1. Standardization initiative o Software developments need visibility
2. Intellectual property issues o Impact on tools development and interactions o Fundamental for creating an ecosystem o Everything open source is not the answer
3. Software engineering, applications and users expectations o Minimizing maintenance effort, one code for all targets
4. Tools development strategy o How to create coherent ecosystem?
Programming Environments Context
WSTOOLS 2012 4 www.caps-entreprise.com

• A very short overview of OpenCL
• A very short overview of OpenACC
• OpenACC-OpenCL versus Exascale challenges
www.caps-entreprise.com 5 WSTOOLS 2012
Outline of the presentation

• Open Computing Language o C-based cross-platform programming interface o Subset of ISO C99 with language extensions o Data- and task- parallel compute model
• Host-Compute Devices (GPUs) model
• Platform layer API and runtime API o Hardware abstraction layer, … o Manage resources
• Portable syntax
www.caps-entreprise.com 6 WSTOOLS 2012
OpenCL Overview

• Four distinct memory regions o Global Memory o Local Memory o Constant Memory o Private Memory
• Global and Constant memories are common to all WI o May be cached depending on the hardware capabilities
• Local memory is shared by all WI of a WG
• Private memory is private to each WI
www.caps-entreprise.com 7
Memory Model
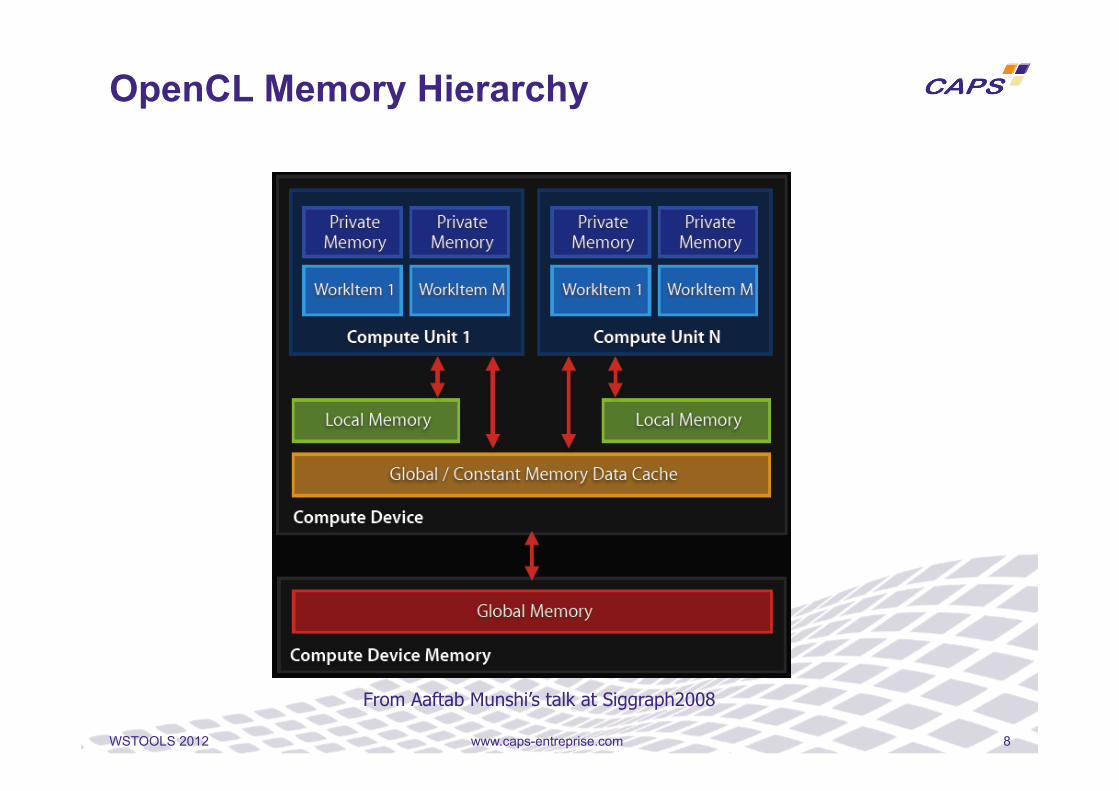
www.caps-entreprise.com 8 WSTOOLS 2012
OpenCL Memory Hierarchy
From Aaftab Munshi’s talk at Siggraph2008
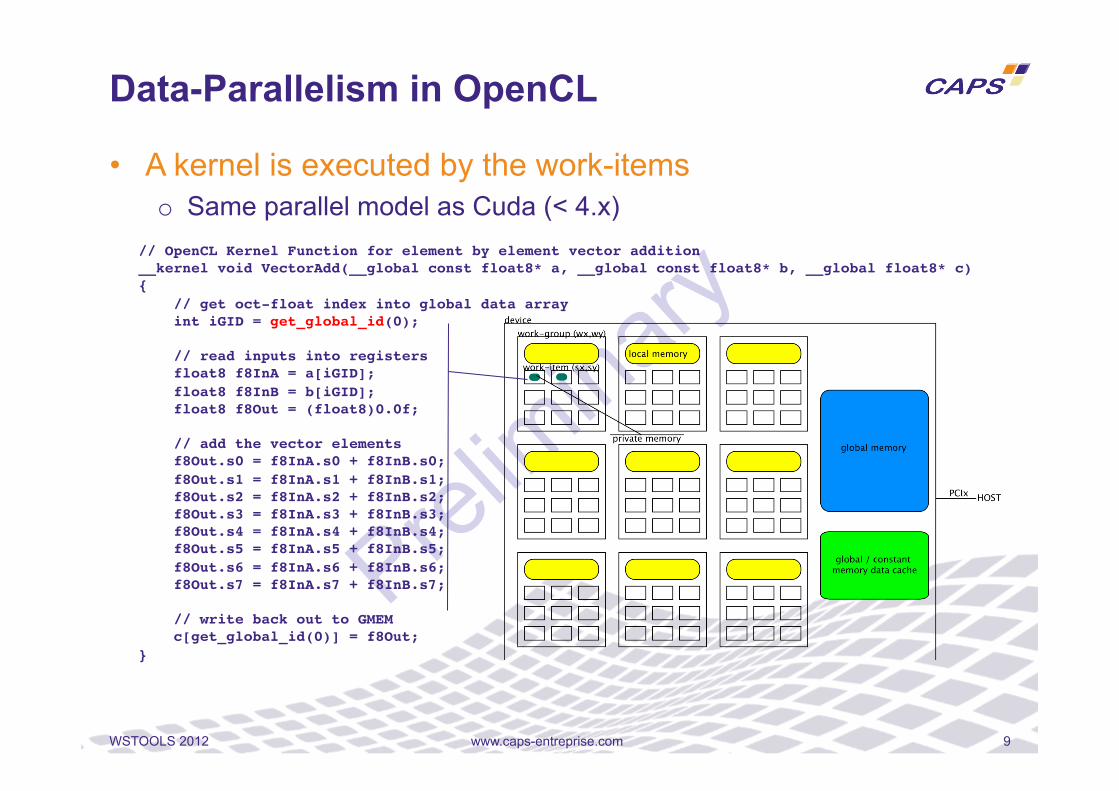
• A kernel is executed by the work-items o Same parallel model as Cuda (< 4.x)
www.caps-entreprise.com 9 WSTOOLS 2012
Data-Parallelism in OpenCL
// OpenCL Kernel Function for element by element vector addition!__kernel void VectorAdd(__global const float8* a, __global const float8* b, __global float8* c)!{! // get oct-float index into global data array! int iGID = get_global_id(0);!
// read inputs into registers! float8 f8InA = a[iGID];! float8 f8InB = b[iGID];! float8 f8Out = (float8)0.0f;!
// add the vector elements! f8Out.s0 = f8InA.s0 + f8InB.s0;! f8Out.s1 = f8InA.s1 + f8InB.s1;! f8Out.s2 = f8InA.s2 + f8InB.s2;! f8Out.s3 = f8InA.s3 + f8InB.s3;! f8Out.s4 = f8InA.s4 + f8InB.s4;! f8Out.s5 = f8InA.s5 + f8InB.s5;! f8Out.s6 = f8InA.s6 + f8InB.s6;! f8Out.s7 = f8InA.s7 + f8InB.s7;!
// write back out to GMEM! c[get_global_id(0)] = f8Out;!}!

OpenCL vs CUDA
• OpenCL and CUDA share the same parallel programming model
• Runtime API is different o OpenCL is lower level than CUDA
• OpenCL and CUDA may use different implementations that could lead to different execution times for a similar kernel on the same hardware
www.caps-entreprise.com 10
OPENCL CUDA
kernel kernel host pgm host pgm NDrange grid work item thread work group block Global mem global mem cst mem cst mem local mem shared mem private mem local mem
November 2011

• Create a command-queue
• Then queue up OpenCL events o Data transfers o Kernel launches
• Allocate the accelerator’s memory o Before transferring data
• Free the memory
• Manage errors
www.caps-entreprise.com 11
Basic OpenCL Runtime Operations

• Command-queue can be used to queue a set of operations
• Having multiple command-queues allows applications to queue multiple independent commands without requiring synchronization
• Create an OpenCL command-queue
www.caps-entreprise.com 12
The Command Queue (1)
cl_command_queue clCreateCommandQueue( cl_context context, cl_device_id device, cl_command_queue_properties properties, cl_int *errcode_ret)

• Example o Allocation of a queue for the device 0
• Flush a command queue o All commands have started
• Finish a command queue (synchronization) o All commands have terminated
www.caps-entreprise.com 13
The Command Queue (2)
cl_int clFlush(cl_command_queue command_queue)
cl_command_queue my_cmd_queue; my_cmd_queue = clCreateCommandQueue(my_context, devices[0], 0, NULL);
cl_int clFinish(cl_command_queue command_queue)

• Possible to have multiple command queues on a device o Command queues are Asynchronous o The programmer must synchronize when needed
www.caps-entreprise.com 14
The Command Queue (3)

• Memory objects are categorized into two types o Buffer Objects : 1D memory o Image Objects : 2D-3D memory
• It can be o A scalar data type o A vector data type o A user defined structure
• Memory objects are described by a cl_mem object
• Kernels take cl_mem objects as input or output
www.caps-entreprise.com 15
How to Allocate Memory on a device ?

• Create a buffer
• Example o Allocate a single precision float matrix as input
o And as output
www.caps-entreprise.com 16
Allocate 1D Memory
size_t memsize = nb_elements * sizeof(float); cl_mem mat_a_gpu = clCreateBuffer(my_context, CL_MEM_READ_ONLY, memsize, NULL, &err);
cl_mem mat_res_gpu = clCreateBuffer(my_context, CL_MEM_WRITE_ONLY, memsize, NULL, &err);
cl_mem clCreateBuffer( cl_context context, cl_mem_flags flags, size_t size_in_bytes, void *host_ptr, cl_int *errcode_ret)

• Any data transfer to/from the device implies o A host pointer o A device memory object o The size of data (in bytes) o The command queue o If it is a blocking transfer or not o …
• In case of non-blocking transfer o Link a cl_event to the transfer o Check the transfer finish with :
www.caps-entreprise.com 17
Transfer data to Device (1)
cl_int clWaitForEvents (cl_uint num_events, const cl_event *event_list)

• Write in a buffer
• Example o Transferring synchronously mat_a!
www.caps-entreprise.com 18
Transfer data to Device (2)
err = clEnqueueWriteBuffer(cmd_queue, mat_a_gpu, CL_TRUE, 0, memsize, (void*) mat_a, 0,NULL,&evt);
cl_int clEnqueueWriteBuffer ( cl_command_queue command_queue,
cl_mem buffer, cl_bool blocking_write, size_t offset, size_t size_in_bytes, const void *ptr, cl_uint num_events_in_wait_list, const cl_event *event_wait_list, cl_event *event)

• A kernel needs arguments o So we must set these arguments o Arguments can be scalar, vector or user-defined data types
• Set the kernel arguments
• Example o Set a argument o Set res argument o Set size argument
www.caps-entreprise.com 19
Kernel Arguments
err = clSetKernelArg(my_kernel, 0, sizeof(cl_mem), (void*) &mat_a_gpu); err = clSetKernelArg(my_kernel, 1, sizeof(cl_mem), (void*) &mat_res_gpu); err = clSetKernelArg(my_kernel, 2, sizeof(int), (void*) & nb_elements);
cl_int clSetKernelArg( cl_kernel kernel,
cl_uint arg_index, size_t arg_size, const void *arg_value)

• Set the NDRange (grid) geometry
• Task parallel model is used for CPU o General task : complex, independent, …
• Data-parallel is used for GPU o Need to set a grid, NDRange in OpenCL
www.caps-entreprise.com 20
Settings for Kernel Launching
int global_work_size[2] = {nb_elements_x, nb_elements_y}; int local_work_size[2] = {16, 16};

• If task kernel o Use the queued task command
• If data-parallel kernel o Use the queued NDRange kernel command
www.caps-entreprise.com 21
Kernel Launch (1)
cl_int clEnqueueNDRangeKernel( cl_command_queue command_queue,
cl_kernel kernel, cl_uint work_dim,
const size_t *global_work_offset, const size_t *global_work_size, const size_t *local_work_size, cl_uint num_events_in_wait_list, const cl_event *event_wait_list, cl_event *event)
cl_int clEnqueueTask(cl_command_queue command_queue, cl_kernel kernel, cl_uint num_events_in_wait_list, const cl_event *event_wait_list, cl_event *event)

• The launch of the kernel is asynchronous by default
www.caps-entreprise.com 22
Kernel Launch (2)
err = clEnqueueNDRangeKernel( cmd_queue, kernel[0], 2, NULL, &global_work_size[0], &local_work_size[0], 0, NULL, &evt);
clFinish(cmd_queue);

• About the same as the copy in o From device to host
• Example
www.caps-entreprise.com 23
Copy Back the Results
cl_int clEnqueueReadBuffer( cl_command_queue command_queue,
cl_mem buffer, cl_bool blocking_read, size_t offset, size_t sizeinbytes, void *ptr,
cl_uint num_events_in_wait_list, const cl_event *event_wait_list, cl_event *event)
err = clEnqueueReadBuffer(cmd_queue, res_mem, CL_TRUE, 0, size, (void*) mat_res, 0, NULL, NULL); clFinish(cmd_queue);

• At the end you need to release the allocated memory
• Releasing the memory
• Example o Release matrix a on GPU o Release matrix res on GPU
www.caps-entreprise.com 24
Free Device’s Memory
cl_int clReleaseMemObject(cl_mem memobj)
clReleaseMemObject(mat_a_gpu); clReleaseMemObject(mat_res_gpu);

• At the end, you must release o The programs o The kernels o The command queues o And the context
www.caps-entreprise.com 25
Release Objects
cl_int clReleaseKernel (cl_kernel kernel)
cl_int clReleaseProgram (cl_program program)
cl_int clReleaseCommandQueue (cl_command_queue command_queue)
cl_int clReleaseContext (cl_context context)

• Do not forget to manage errors o Example with the copy back
www.caps-entreprise.com 26
Error Management
// read output image err = clEnqueueReadBuffer(cmd_queue, memobjs[2], CL_TRUE, 0, n * sizeof(cl_float), dst, 0, NULL, NULL);
if (err != CL_SUCCESS) { delete_memobjs(memobjs, 3); clReleaseKernel(kernel); clReleaseProgram(program); clReleaseCommandQueue(cmd_queue); clReleaseContext(context);return -1; }

• Parallel programming model o Simple and massively parallel (for node programming) o Helps to exploit memory bandwidth via vector accesses o Performance is kind of "predictable" (i.e. similar to MPI that have
explicit communication)
• Fine grain control over resources o Details API, JIT Compilation
• Available on most platforms o Nvidia/AMD/ARM GPUs o Intel/AMD/… CPU o Intel MIC
www.caps-entreprise.com 27 WSTOOLS 2012
OpenCL Interesting Characteristics
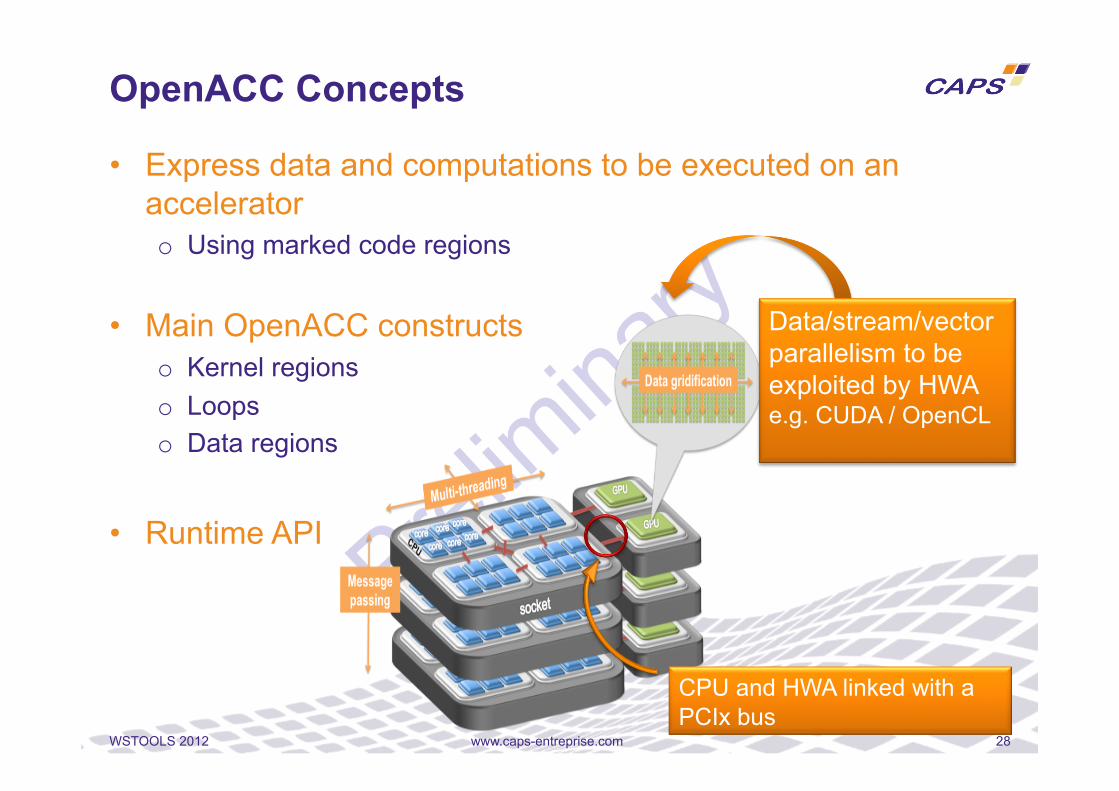
• Express data and computations to be executed on an accelerator o Using marked code regions
• Main OpenACC constructs o Kernel regions o Loops o Data regions
• Runtime API
www.caps-entreprise.com 28 WSTOOLS 2012
OpenACC Concepts
Data/stream/vector parallelism to be exploited by HWA e.g. CUDA / OpenCL
CPU and HWA linked with a PCIx bus

• Identifies sections of code to be executed on the accelerator • Parallel loops inside a kernel region are turned into
accelerator kernels o Such as CUDA or OpenCL kernels o Different loop nests may have different gridifications
www.caps-entreprise.com 29 WSTOOLS 2012
OpenACC Kernels Regions
#pragma acc kernels { for (int i = 0; i < n; ++i){ for (int j = 0; j < n; ++j){ for (int k = 0; k < n; ++k){ B[i][j*k%n] = A[i][j*k%n]; } } } ... for (int i = 0; i < n; ++i){ for (int j = 0; j < m; ++j){ B[i][j] = i * j * A[i][j]; } } ... }

• Based on three parallelism levels o Gangs – coarse-grain o Workers – fine-grain o Vectors – Finest grain
• Mapping on physical architecture compiler dependent
www.caps-entreprise.com 30 WSTOOLS 2012
OpenACC Kernel Execution Model
Gang Worker
Vectors
Device
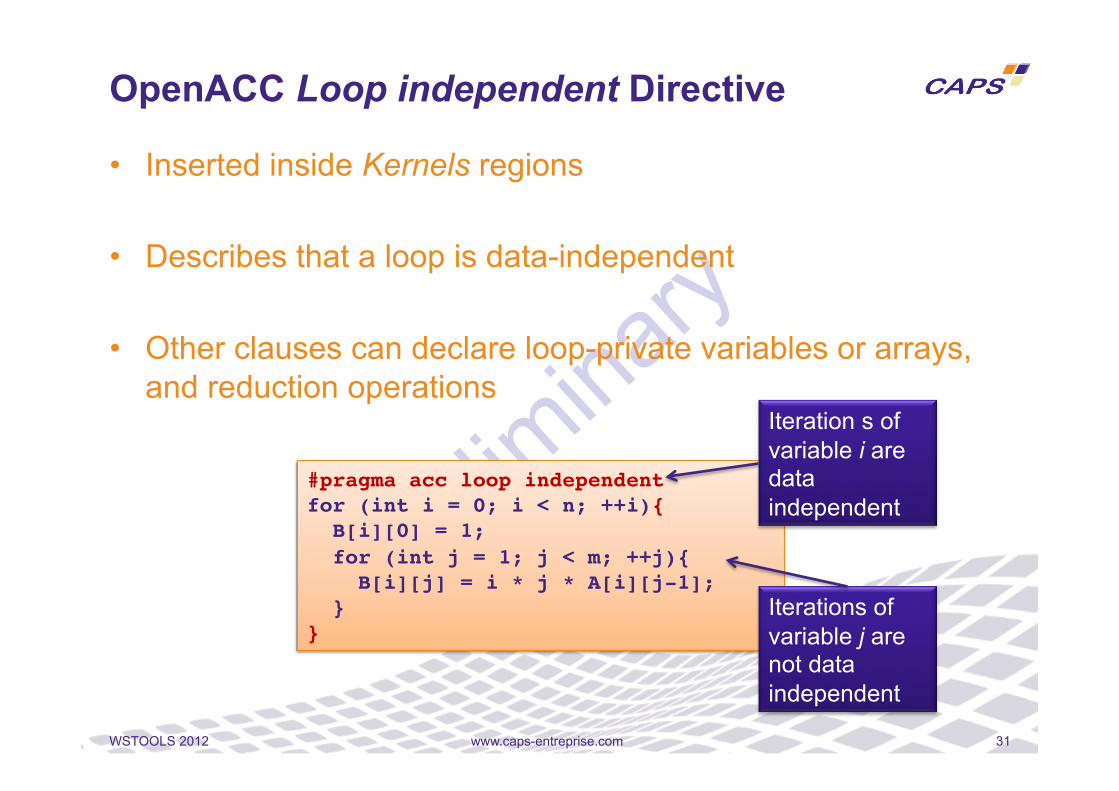
• Inserted inside Kernels regions
• Describes that a loop is data-independent
• Other clauses can declare loop-private variables or arrays, and reduction operations
www.caps-entreprise.com 31 WSTOOLS 2012
OpenACC Loop independent Directive
#pragma acc loop independent!for (int i = 0; i < n; ++i){! B[i][0] = 1;! for (int j = 1; j < m; ++j){ ! B[i][j] = i * j * A[i][j-1];! }!}!
Iteration s of variable i are data independent
Iterations of variable j are not data independent

• Data regions define scalars, arrays and sub-arrays o To be allocated in the device memory for the duration of the region o To be explicitly managed using transfer clauses or directives
• Optimizing transfers consists in: o Transferring data
• From CPU to GPU when entering a data region • From GPU to CPU when exiting a data region
o Launching several kernels • That can reuse the data inside this data region
• Kernels regions implicitly define data regions
www.caps-entreprise.com 32 WSTOOLS 2012
OpenACC Data Regions

www.caps-entreprise.com 33 WSTOOLS 2012
Data Management Directives Example
#pragma acc data copyin(A[1:N-2]), copyout(B[N])!{! #pragma acc kernels! {! #pragma acc loop independant! for (int i = 0; i < N; ++i){! A[i][0] = ...;! A[i][M - 1] = 0.0f;! }! ...! }! #pragma acc update host(A)! ...! #pragma acc kernels! for (int i = 0; i < n; ++i){! B[i] = ...;! }!}!
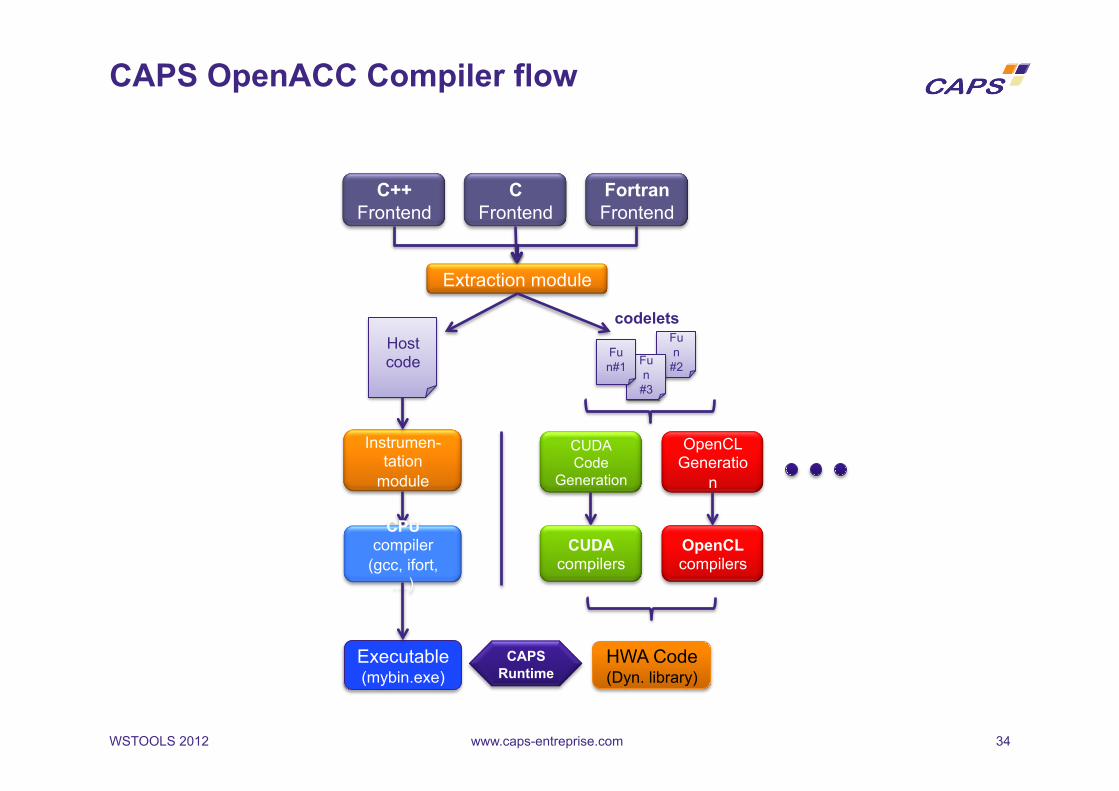
www.caps-entreprise.com 34
CAPS OpenACC Compiler flow
C++ Frontend
C Frontend
Fortran Frontend
CUDA Code
Generation
Executable (mybin.exe)
Instrumen-tation
module
CPU compiler
(gcc, ifort, …)
CUDA compilers
HWA Code (Dyn. library)
WSTOOLS 2012
OpenCL Generatio
n
OpenCL compilers
Extraction module
Fun
#2 Fun
#3
Fun#1
Host code
codelets
CAPS Runtime

• Talk about data structures and multiple address spaces o Does not assume a coherent unique shared address space
• Simple parallel model o Parallel nested loops
• Easy to extend o Directives or clauses can be goal specific, does not modify base
language
• Available on many platforms o Via the use of OpenCL as a compiler target
• Many open source projects o Many of them based on LLVM
• Should be very closed to OpenMP Accelerator Extension o Worst case, easy to move OpenACC to OpenMP accelerator
extension
www.caps-entreprise.com 35 WSTOOLS 2012
OpenACC Interesting Characteristics
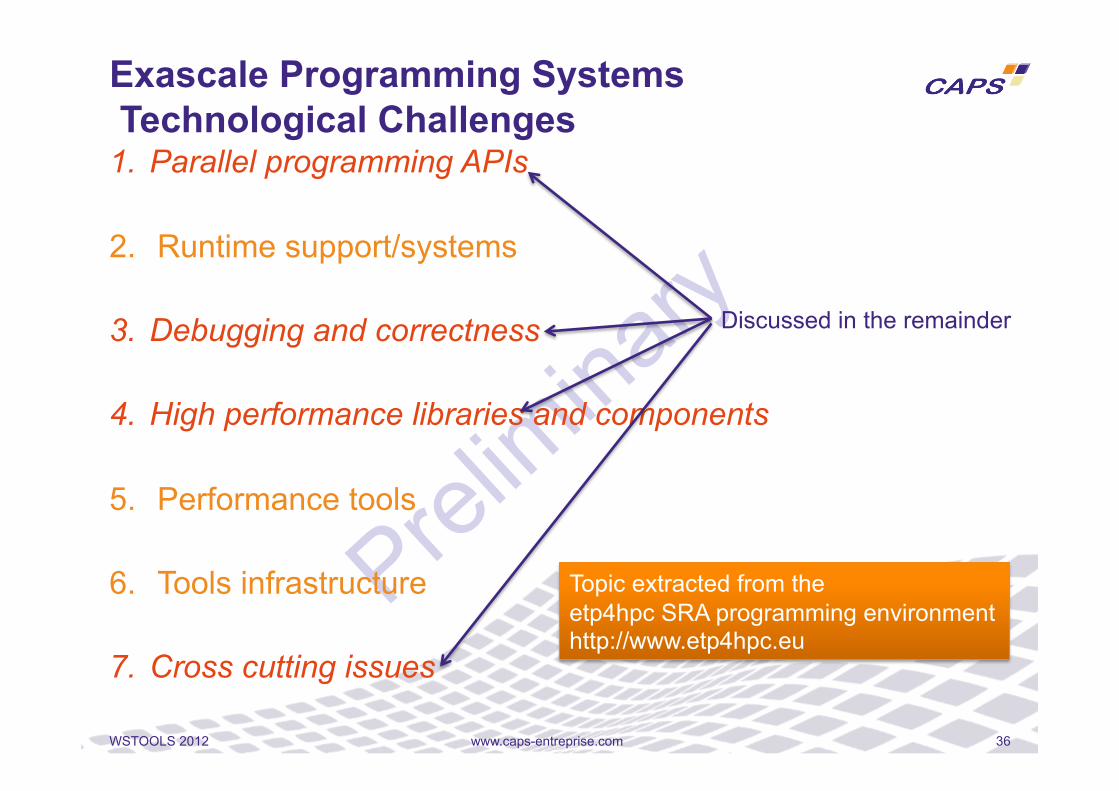
1. Parallel programming APIs
2. Runtime support/systems
3. Debugging and correctness
4. High performance libraries and components
5. Performance tools
6. Tools infrastructure
7. Cross cutting issues
Exascale Programming Systems Technological Challenges
WSTOOLS 2012 36 www.caps-entreprise.com
Discussed in the remainder
Topic extracted from the etp4hpc SRA programming environment http://www.etp4hpc.eu

• Domain specific languages • API for legacy codes • MPI + X approaches • Partitioned Global Address Space (PGAS) languages and
APIs • Dealing with hardware heterogeneity • Data oriented approaches and languages • Auto-tuning API • Asynchronous programming models and languages
Parallel Programming APIs Research Topics
WSTOOLS 2012 37 www.caps-entreprise.com

• OpenACC o Directive based approaches particularly suited to legacy codes o Focused on heterogeneous node o Not C only targets also Fortran and C++
• OpenCL o Not that convenient for legacy codes o Complex to mix with OpenMP o Can be used to unify multithreading
www.caps-entreprise.com 38 WSTOOLS 2012
API for legacy codes

• OpenACC o Complementary to MPI o Complex to mix with OpenMP, i.e. balancing the load over the CPUs
and accelerators o OpenACC to deal with threads and accelerator parallelism but
parallelism expression not for all applications
• OpenCL o idem
www.caps-entreprise.com 39 WSTOOLS 2012
MPI + X approaches

• OpenACC o Designed for this o May simplify code tuning o No automatic load balancing over the heterogeneous units, need to be
extended o Better understanding of the code by the compiler (e.g. exposed data
management, parallel nested loops) • Provide restructuring capabilities
o May be extended to consider non volatile memories (NVM) o Does not consider multiple accelerators
• Extension to come
• OpenCL o Designed for this o Code tuning exposes many low level details o Detailed API for resources management
• Gives many control to users • Programming may be complex
o Interesting parallel model to help vectorization
www.caps-entreprise.com 40 WSTOOLS 2012
Dealing with hardware heterogeneity

• Targeting performance portability issues • What would provide a auto-tuning API?
o Decision point description • e.g. callsite
o Variants description • Abstract syntax trees • Execution constraints (e.g. specialized codelets)
o Execution context • Parameter values • Hardware target description and allocation
o Runtime control to select variants or drive runtime code generation • OpenACC
o OpenACC gives more opportunity to compilers/automatic tools o Can be extended to provide a standard API o Many tuning techniques over parallel loops o Orthogonal to programming
• OpenCL o Can integrate auto-tuning but may be limited in scope o OpenCL is low level, guessing high level properties difficult
www.caps-entreprise.com 41 WSTOOLS 2012
Auto-tuning API

• OpenACC o Limited asynchronous capabilities, constraints by the host-accelerator
model o Not suited for data flow approaches, need to be extended
(OpenHMPP codelet concept more suitable for this)
• OpenCL o idem
www.caps-entreprise.com 42 WSTOOLS 2012
Asynchronous programming models and languages

1. Debugging heterogeneous/hybrid code 2. Static debugging 3. Dynamic debugging 4. Debugging highly asynchronous parallel code at full
(Peta-,Exa-)scale 5. Runtime and debugger integration 6. Model aware debugging 7. Automatic techniques
Debugging and Correctness Research Topics
WSTOOLS 2012 43 www.caps-entreprise.com

• OpenACC o Preserve most of the serial semantic, helps a lot to design debugging
tools o Helps to distinguish serial bugs from parallel ones o Programming can be very incremental, simplifying debugging
• OpenCL o Complex debugging due to many low level details and parallel /
memory model
www.caps-entreprise.com 44 WSTOOLS 2012
Debugging heterogeneous/hybrid code

1. Application componentization 2. Templates/skeleton/component based approaches and
languages 3. Components / library interoperability 4. Self- / auto-tuning libraries and components 5. New parallel algorithms / parallelization paradigms; e.g.
resilient algorithms
High performance libraries and components Research Topics
WSTOOLS 2012 45 www.caps-entreprise.com

• OpenACC o Can be used to write libraries, can exploit already allocated data/HW
(pcopy clause) o If extended with tuning directives such as hmppcg (e.g. loop
transformations) can be used to express templates: • Templates to express static code transformations • Use runtime technique to tune dynamic parameters such as the number
of gangs, workers and vector sizes
• OpenCL o Used a lot to write libraries o Fits well with C++ components development
www.caps-entreprise.com 46 WSTOOLS 2012
Templates/skeleton/component based approaches and languages

• Library calls can usually only be partially replaced o Want a unique source code even when using accelerated libraries, CPU
version is the reference point o No one-to-one mapping between libraries (e.g.BLAS Cublas, FFTW CuFFT) o No access to all application codes (i.e. need to keep the CPU library)
• Deal with multiple address spaces / multi-HWA o Data location may not be unique (copies, mirrors) o Usual library calls assume shared memory o Library efficiency depends on updated data location (long term effect)
• OpenACC o Needs to interact with users codes, currently limited to sharing the device data ptr o Missing automatic data management allocation (e.g. StarPU) to deal with
computation migrations (needed to adapt to hardware resources and compute load)
• OpenCL o OpenACC and OpenCL have to interact efficiently o API can easily be normalized thanks to standardization initiative
www.caps-entreprise.com 47 WSTOOLS 2012
Components / library interoperability
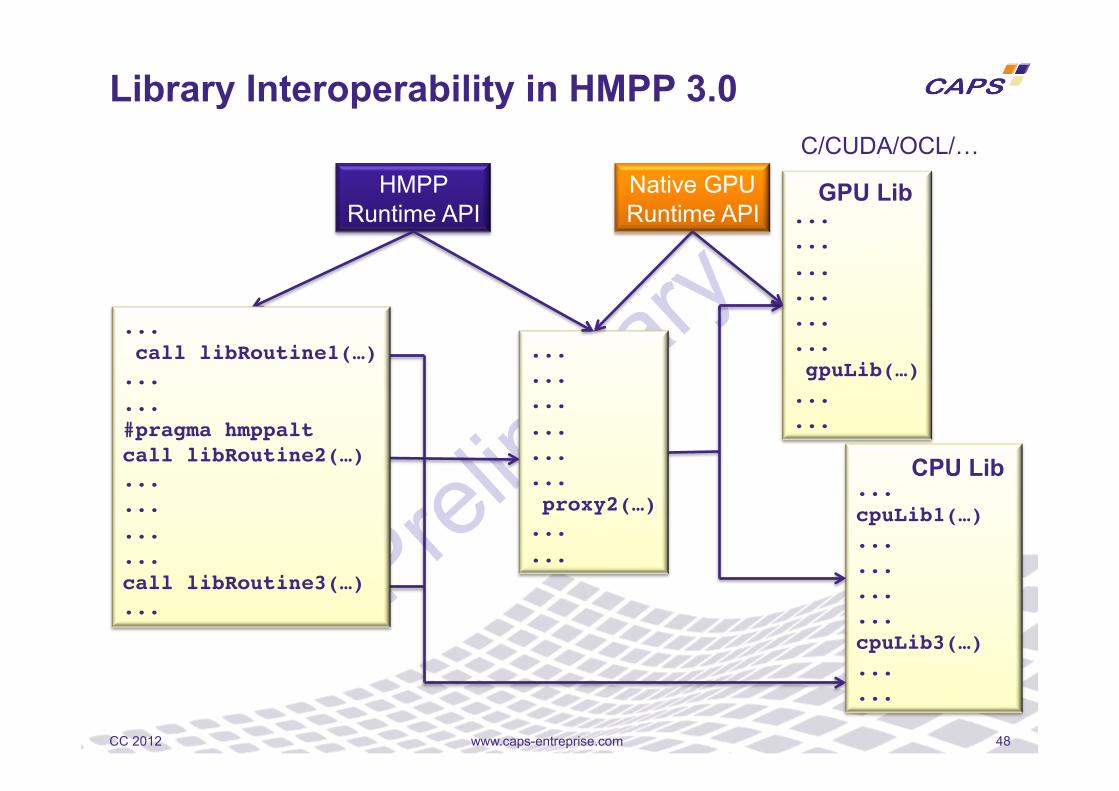
Library Interoperability in HMPP 3.0
www.caps-entreprise.com 48 CC 2012
...!
...!
...!
...!
...!
...! proxy2(…)!...!...!
...!
...!
...!
...!
...!
...! gpuLib(…)!...!...!
...!cpuLib1(…)!...!...!...!...!cpuLib3(…)!...!...!
GPU Lib
CPU Lib
HMPP Runtime API
Native GPU Runtime API
C/CUDA/OCL/…
...! call libRoutine1(…)!...!...!#pragma hmppalt!call libRoutine2(…)!...!...!...!...!call libRoutine3(…)!...!
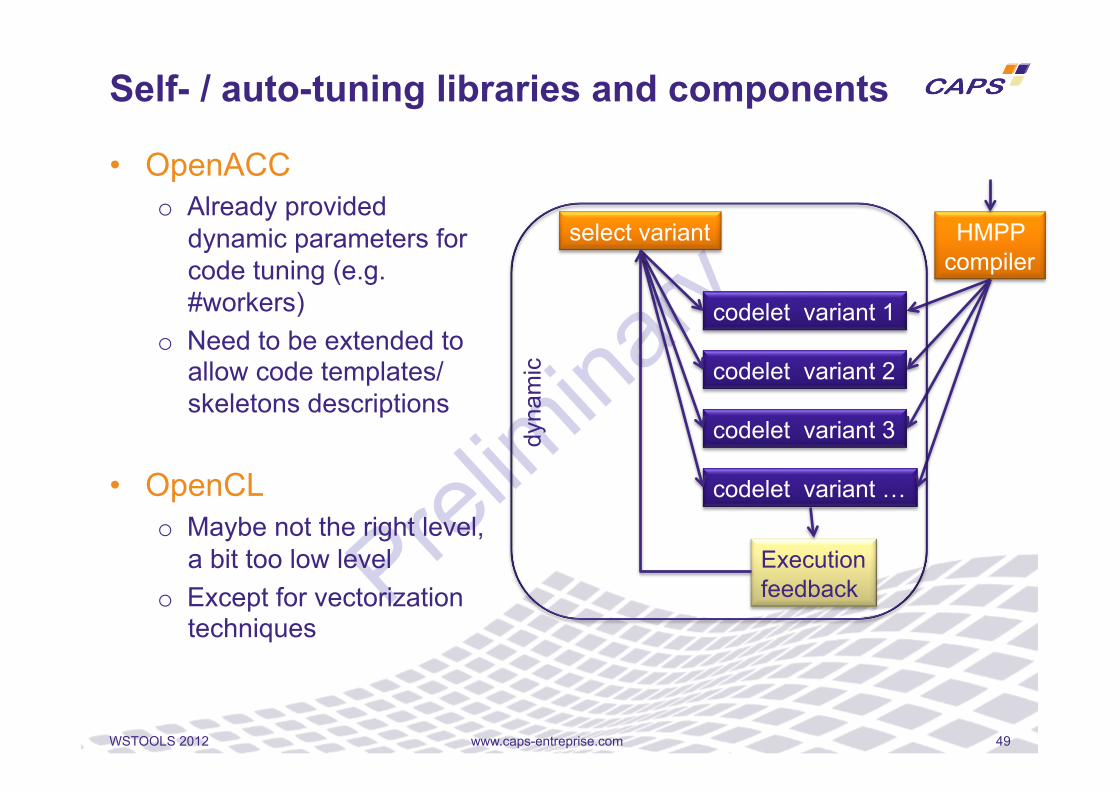
• OpenACC o Already provided
dynamic parameters for code tuning (e.g. #workers)
o Need to be extended to allow code templates/skeletons descriptions
• OpenCL o Maybe not the right level,
a bit too low level o Except for vectorization
techniques
www.caps-entreprise.com 49 WSTOOLS 2012
Self- / auto-tuning libraries and components
select variant
codelet variant 1
Execution feedback
codelet variant 2
codelet variant 3
codelet variant …
HMPP compiler
dyna
mic

1. Standardization initiative 2. Fault tolerance at programming level 3. Programming energy consumption control 4. Tools interfaces and public APIs 5. Intellectual property issues 6. Performance portability issues 7. Software engineering, applications and users expectations 8. Tools development strategy 9. Validation: Benchmarks and other mini-apps 10. Co-design (hardware - software; applications -programming
environment)
[Cross cutting issues]
WSTOOLS 2012 50 www.caps-entreprise.com

• OpenACC o OpenACC data region can be extended to mark structures for specific
fault tolerance management o Extension of the memory model for NVM, etc.
• OpenCL o Data management via the API makes it difficult for static tools (e.g.
compiler, analyzer)
www.caps-entreprise.com 51 WSTOOLS 2012
Fault Tolerance at Programming Level

• OpenACC o Extremely important to have exascale potential good measurements o Kernels are not enough o Tools are usually designed to match benchmark requirement
• Very influential of the output o Mini-apps (e.g. Hydro/Prace, Mantevo) pragmatic and efficient
approach • But extremely expensive to design • Must be production quality • Need to exhibit extremely scalable algorithms
o On the critical path for the foundation of an ecosystem • OpenCL
o Idem o Limited to C
www.caps-entreprise.com 52 WSTOOLS 2012
Validation: Benchmarks and other mini-apps

• OpenACC provides an interesting framework for designing an Exascale, non revolutionary, programming environment o Leverage existing academic and industrial initiative o May be used as a basic infrastructure for higher level approach o Mixable with MPI, PGAS, … o Available on many hardware targets
• OpenCL very complementary as a device basic programming layer
• Need to mix in a consistent manner high-level and low-level approaches o Inside nodes, OpenACC/OpenMP-AE U OpenCL at list worth a try as
a basis for studying an exascale programming environments o Complementary with more revolutionary approaches
www.caps-entreprise.com 53 WSTOOLS 2012
Conclusion
Accelerator Programming Model Parallelization
Directive-based programming GPGPU Manycore programming
Hybrid Manycore Programming HPC community OpenACC
Petaflops Parallel computing HPC open standard Multicore programming Exaflops NVIDIA Cuda
Code speedup Hardware accelerators programming High Performance Computing OpenHMPP
Parallel programming interface Massively parallel
Open CL
http://www.caps-entreprise.com http://twitter.com/CAPSentreprise http://www.openacc-standard.org/
http://www.openhmpp.org





























