Embed Size (px)
Citation preview

2015 OSIsoft TechCon
Optimizing SQL Queries
for Performance using
PI JDBC and PI ODBC

2015 TechCon Session
2 | P a g e
OSIsoft, LLC
777 Davis St., Suite 250
San Leandro, CA 94577 USA
Tel: (01) 510-297-5800
Web: http://www.osisoft.com
© 2015 by OSIsoft, LLC. All rights reserved.
No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or
by any means, mechanical, photocopying, recording, or otherwise, without the prior written permission
of OSIsoft, LLC.
OSIsoft, the OSIsoft logo and logotype, PI Analytics, PI ProcessBook, PI DataLink, ProcessPoint, PI Asset
Framework (PI AF), IT Monitor, MCN Health Monitor, PI System, PI ActiveView, PI ACE, PI AlarmView, PI
BatchView, PI Coresight, PI Data Services, PI Event Frames, PI Manual Logger, PI ProfileView, PI
WebParts, ProTRAQ, RLINK, RtAnalytics, RtBaseline, RtPortal, RtPM, RtReports and RtWebParts are all
trademarks of OSIsoft, LLC. All other trademarks or trade names used herein are the property of their
respective owners.
U.S. GOVERNMENT RIGHTS
Use, duplication or disclosure by the U.S. Government is subject to restrictions set forth in the OSIsoft,
LLC license agreement and as provided in DFARS 227.7202, DFARS 252.227-7013, FAR 12.212, FAR
52.227, as applicable. OSIsoft, LLC.
Published: May 6, 2015

Table of Contents
3 | P a g e
Table of Contents
Contents Table of Contents .......................................................................................................................................... 3
Optimizing SQL Queries for Performance using PI JDBC and PI ODBC ......................................................... 4
Overview ................................................................................................................................................... 4
Required Software .................................................................................................................................... 5
Part 1 Optimization walk through ............................................................................................................. 6
Tip........................................................................................................................................................ 13
Part 2 Microsoft Access........................................................................................................................... 14
OSIsoft Virtual Learning Environment ........................................................................................................ 22

2015 TechCon Session
4 | P a g e
Optimizing SQL Queries for Performance using PI JDBC and PI ODBC
Overview
In this lab, you will learn a few techniques for creating truly performing SQL using PI ODBC and PI JDBC.
This Lab will also point out what it takes to verify if queries that are automatically generated by 3rd
party tools have issues.
Part 1 Optimization walk through
Part 2 Investigating performance issues by a query generated by 3rd party Microsoft product
Not all of the features are completely explained in this tutorial. Please be sure to stay within the
workbook instructions for the best learning experience.

Optimizing SQL Queries for Performance using PI JDBC and PI ODBC
5 | P a g e
Required Software
• PI ODBC 2014 3.0.3.0260
• PI JDBC 2012 (including PI SQL DAS)
• DB Visualizer
• Microsoft Access
2015 TechCon Session
6 | P a g e
Part 1 Optimization walk through
This section will guide you through some PI ODBC/PI JDBC query engine details and demonstrate how to
write a query in a way it is executed optimally. We will use DBVisualizer for PI JDBC, PI SQL Commander
Lite for PI ODBC to run the queries and inspect the results and the execution times.
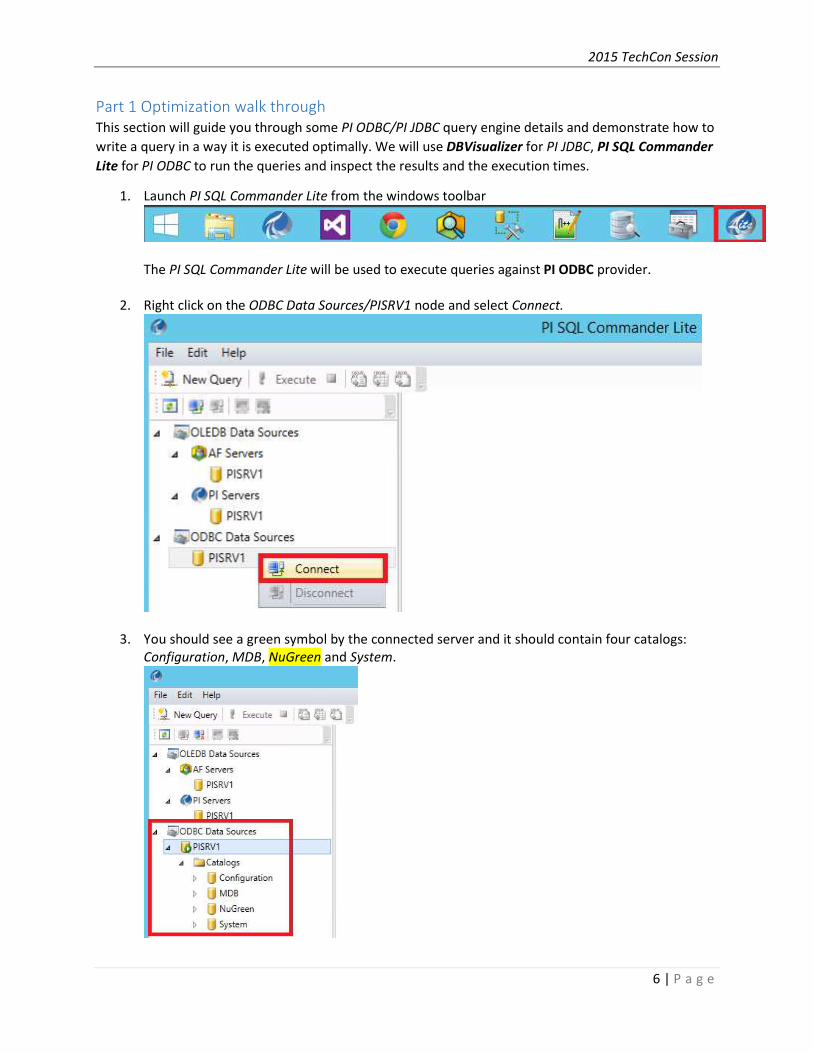
1. Launch PI SQL Commander Lite from the windows toolbar
The PI SQL Commander Lite will be used to execute queries against PI ODBC provider.
2. Right click on the ODBC Data Sources/PISRV1 node and select Connect.
3. You should see a green symbol by the connected server and it should contain four catalogs:
Configuration, MDB, NuGreen and System.
Optimizing SQL Queries for Performance using PI JDBC and PI ODBC
7 | P a g e
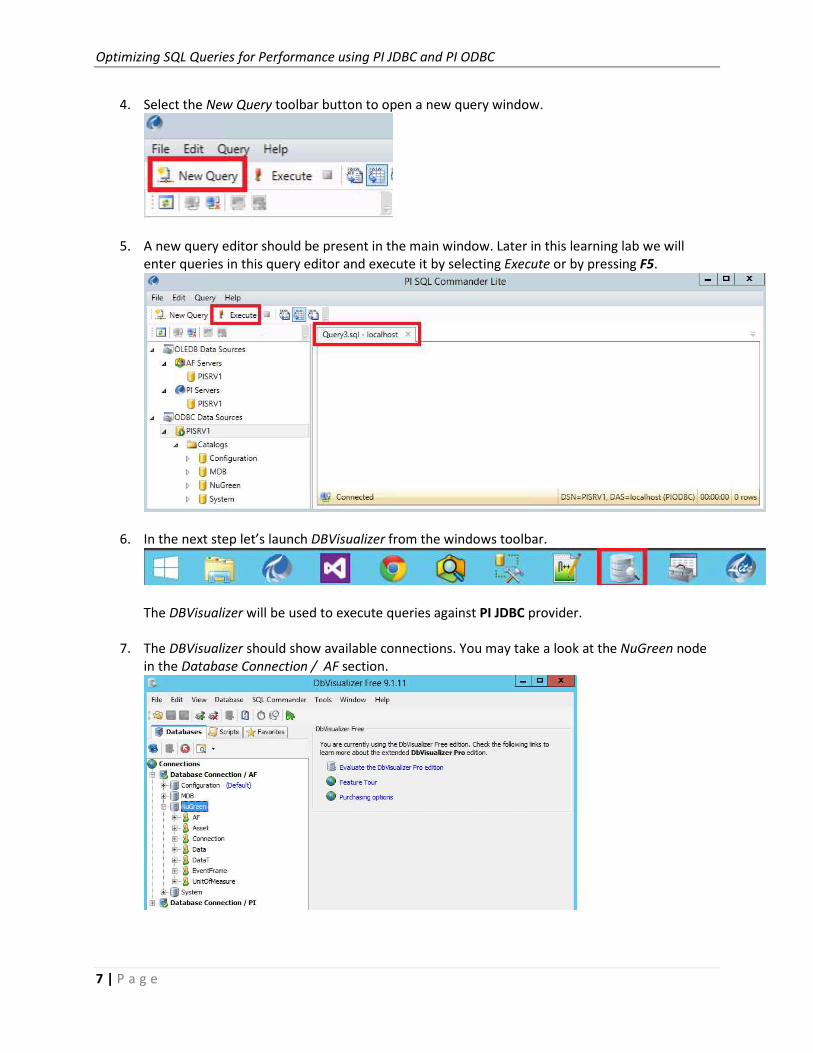
4. Select the New Query toolbar button to open a new query window.
5. A new query editor should be present in the main window. Later in this learning lab we will
enter queries in this query editor and execute it by selecting Execute or by pressing F5.
6. In the next step let’s launch DBVisualizer from the windows toolbar.
The DBVisualizer will be used to execute queries against PI JDBC provider.
7. The DBVisualizer should show available connections. You may take a look at the NuGreen node
in the Database Connection / AF section.
2015 TechCon Session
8 | P a g e
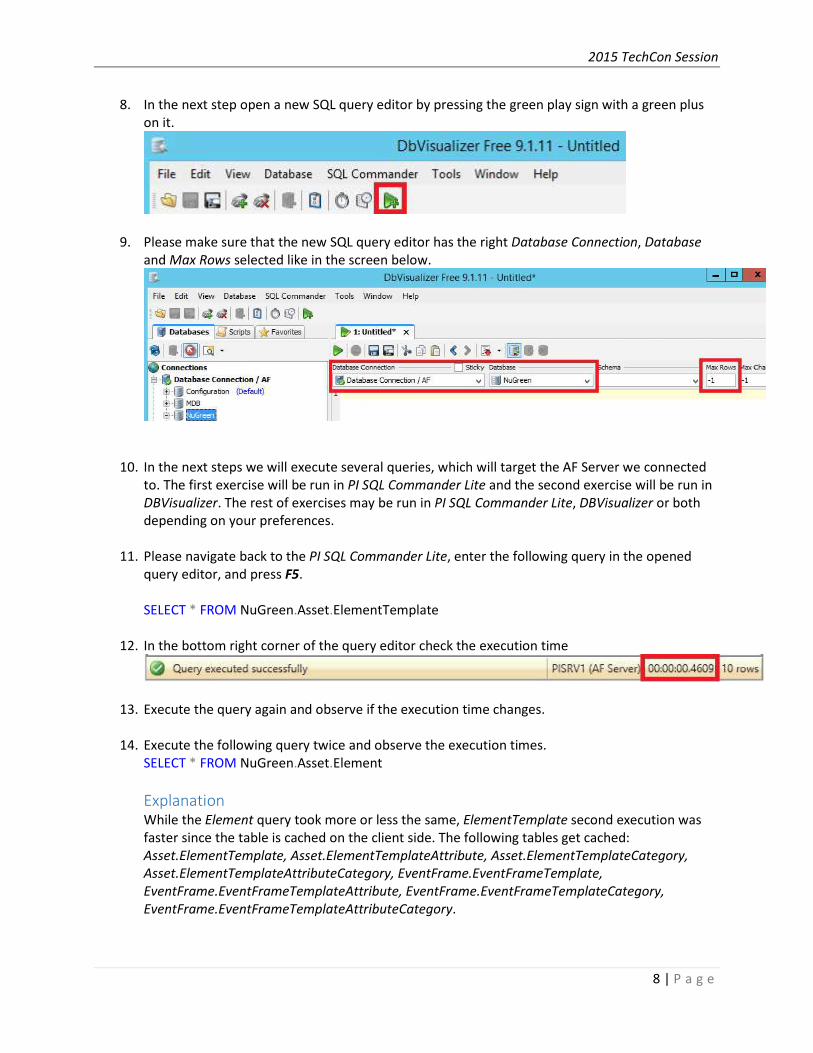
8. In the next step open a new SQL query editor by pressing the green play sign with a green plus
on it.
9. Please make sure that the new SQL query editor has the right Database Connection, Database
and Max Rows selected like in the screen below.
10. In the next steps we will execute several queries, which will target the AF Server we connected
to. The first exercise will be run in PI SQL Commander Lite and the second exercise will be run in
DBVisualizer. The rest of exercises may be run in PI SQL Commander Lite, DBVisualizer or both
depending on your preferences.
11. Please navigate back to the PI SQL Commander Lite, enter the following query in the opened
query editor, and press F5.
SELECT * FROM NuGreen.Asset.ElementTemplate
12. In the bottom right corner of the query editor check the execution time
13. Execute the query again and observe if the execution time changes.
14. Execute the following query twice and observe the execution times.
SELECT * FROM NuGreen.Asset.Element
Explanation
While the Element query took more or less the same, ElementTemplate second execution was
faster since the table is cached on the client side. The following tables get cached:
Asset.ElementTemplate, Asset.ElementTemplateAttribute, Asset.ElementTemplateCategory,
Asset.ElementTemplateAttributeCategory, EventFrame.EventFrameTemplate,
EventFrame.EventFrameTemplateAttribute, EventFrame.EventFrameTemplateCategory,
EventFrame.EventFrameTemplateAttributeCategory.
Optimizing SQL Queries for Performance using PI JDBC and PI ODBC
9 | P a g e
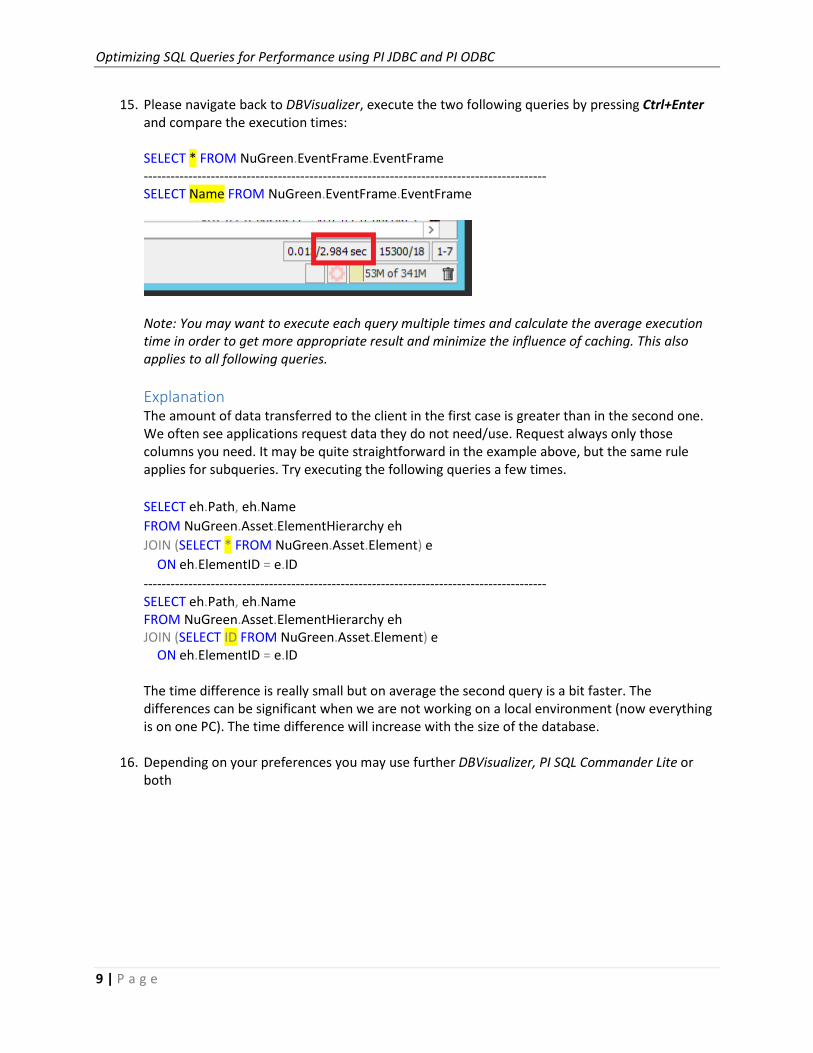
15. Please navigate back to DBVisualizer, execute the two following queries by pressing Ctrl+Enter
and compare the execution times:
SELECT * FROM NuGreen.EventFrame.EventFrame
------------------------------------------------------------------------------------------
SELECT Name FROM NuGreen.EventFrame.EventFrame
Note: You may want to execute each query multiple times and calculate the average execution
time in order to get more appropriate result and minimize the influence of caching. This also
applies to all following queries.
Explanation
The amount of data transferred to the client in the first case is greater than in the second one.
We often see applications request data they do not need/use. Request always only those
columns you need. It may be quite straightforward in the example above, but the same rule
applies for subqueries. Try executing the following queries a few times.
SELECT eh.Path, eh.Name
FROM NuGreen.Asset.ElementHierarchy eh
JOIN (SELECT * FROM NuGreen.Asset.Element) e
ON eh.ElementID = e.ID
------------------------------------------------------------------------------------------
SELECT eh.Path, eh.Name
FROM NuGreen.Asset.ElementHierarchy eh
JOIN (SELECT ID FROM NuGreen.Asset.Element) e
ON eh.ElementID = e.ID
The time difference is really small but on average the second query is a bit faster. The
differences can be significant when we are not working on a local environment (now everything
is on one PC). The time difference will increase with the size of the database.
16. Depending on your preferences you may use further DBVisualizer, PI SQL Commander Lite or
both

2015 TechCon Session
10 | P a g e
17. Execute the following two queries and compare the execution times.
SELECT Path, Name
FROM NuGreen.Asset.ElementHierarchy eh
WHERE EXISTS
(
SELECT 1
FROM NuGreen.Asset.ElementAttribute
WHERE ElementID = eh.ElementID
)
------------------------------------------------------------------------------------------
SELECT DISTINCT eh.Path, eh.Name
FROM NuGreen.Asset.ElementHierarchy eh
JOIN NuGreen.Asset.ElementAttribute ea
ON ea.ElementID = eh.ElementID
Explanation
The correlated subquery (SELECT 1…) in the first query is executed for every row from
Asset.ElementHierarchy table which makes it really slow. Try not to use correlated subqueries
(correlated queries are queries, which use values from the outer query).
18. Execute the following two queries and compare the execution times.
SELECT e.Name Element
FROM NuGreen.Asset.Element e
JOIN NuGreen.Asset.ElementTemplate et
ON et.ID = e.ElementTemplateID
JOIN NuGreen.Asset.ElementAttribute ea
ON ea.ElementID = e.ID
JOIN NuGreen.Data.Snapshot s
ON s.ElementAttributeID = ea.ID
WHERE et.Name = N'Boiler' AND ea.Name = N'Manufacturer' AND s.ValueStr = N'NATCOM'
------------------------------------------------------------------------------------------
SELECT e.Name Element
FROM NuGreen.Asset.ElementTemplate et
JOIN NuGreen.Asset.ElementTemplateAttribute eta
ON eta.ElementTemplateID = et.ID
JOIN NuGreen.Data.Snapshot s
ON s.ElementTemplateAttributeID = eta.ID
JOIN NuGreen.Asset.ElementAttribute ea
ON ea.ID = s.ElementAttributeID
JOIN NuGreen.Asset.Element e
ON e.ID = ea.ElementID
WHERE et.Name = N'Boiler' AND eta.Name = N'Manufacturer' AND s.ValueStr = N'NATCOM'
Explanation
Efficient "by value" searches for non-data reference based template attributes (static attributes

Optimizing SQL Queries for Performance using PI JDBC and PI ODBC
11 | P a g e
inherited from an element template) are supported. This applies to Data.Snapshot table, user-
created transpose functions, and function tables if access via Asset.ElementTemplateAttribute
table.
The first query uses access to snapshot data via Asset.ElementAttribute table which is not
optimized.
19. Execute the following two queries and compare the execution times.
SELECT ea.Name, a.Time, a.Value
FROM NuGreen.Asset.ElementTemplate et
JOIN NuGreen.Asset.ElementTemplateAttribute eta
ON eta.ElementTemplateID = et.ID
JOIN NuGreen.Asset.ElementAttribute ea
ON ea.ElementTemplateAttributeID = eta.ID
JOIN NuGreen.Data.Archive a
ON a.ElementAttributeID = ea.ID
WHERE et.Name = N'Heater' AND (a.Time > N'1-Feb-2015' AND a.Time < N'10-Feb-
2015' OR a.Time > N'12-Feb-2015' AND a.Time < N'22-Feb-2015')
------------------------------------------------------------------------------------------
SELECT ea.Name, a.Time, a.Value
FROM NuGreen.Asset.ElementTemplate et
JOIN NuGreen.Asset.ElementTemplateAttribute eta
ON eta.ElementTemplateID = et.ID
JOIN NuGreen.Asset.ElementAttribute ea
ON ea.ElementTemplateAttributeID = eta.ID
JOIN NuGreen.Data.Archive a
ON a.ElementAttributeID = ea.ID
WHERE et.Name = N'Heater' AND a.Time > N'1-Feb-2015' AND a.Time < N'10-Feb-2015'
UNION ALL
SELECT ea.Name, a.Time, a.Value
FROM NuGreen.Asset.ElementTemplate et
JOIN NuGreen.Asset.ElementTemplateAttribute eta
ON eta.ElementTemplateID = et.ID
JOIN NuGreen.Asset.ElementAttribute ea
ON ea.ElementTemplateAttributeID = eta.ID
JOIN NuGreen.Data.Archive a
ON a.ElementAttributeID = ea.ID
WHERE et.Name = N'Heater' AND a.Time > N'12-Feb-2015' AND a.Time < N'22-Feb-2015'
Explanation
The UNION and UNION ALL queries are executed in parallel. The WHERE condition can be split
into two where the first takes the first part of the OR clause and the second one the second one.
The queries are then executed in parallel and the results are concatenated at the end.

2015 TechCon Session
12 | P a g e
20. Execute the following two queries and compare the execution times.
SELECT e.Name, ea.Name, s.Value
FROM NuGreen.Asset.Element e
JOIN NuGreen.Asset.ElementAttribute ea
ON e.ID = ea.ElementID
JOIN NuGreen.Data.Snapshot s
ON ea.ID = s.ElementAttributeID
WHERE s.Value = N'NATCOM' and ea.Name LIKE N'Manu%' AND e.Name LIKE N'B%'
OPTION (ALLOW EXPENSIVE, IGNORE ERRORS)
------------------------------------------------------------------------------------------
SELECT e.Name, ea.Name, s.Value
FROM NuGreen.Asset.Element e
JOIN NuGreen.Asset.ElementAttribute ea
ON e.ID = ea.ElementID
JOIN NuGreen.Data.Snapshot s
ON ea.ID = s.ElementAttributeID
WHERE s.Value = N'NATCOM' and ea.Name LIKE N'Manu%' AND e.Name LIKE N'B%'
OPTION (FORCE ORDER, ALLOW EXPENSIVE, IGNORE ERRORS)
Explanation
Based on the restrictions defined by the WHERE clause the query engine makes a decision on
how to execute the join. It first requests the data from one table and then from the other one
using the data from the first table as an additional restriction. The query engine tries to estimate
which of the restriction is more restrictive (will lead to less rows in the result) and request the
data from such table first. It made here a wrong decision and requested data from Snapshot and
Element Attribute table first. You may help the query engine with the decision and use FORCE
ORDER option which forces the same order as the order of the tables in join.
The OPTION (FORCE ORDER) clause must be used with caution. If used inappropriately, the
execution plan might be less optimal when compared to the one that the query engine would
generate otherwise.
21. Execute the following two queries and compare the execution times.
SELECT Name, Path
FROM NuGreen.Asset.ElementHierarchy
WHERE Path LIKE N'%NuGreen\Houston\%'
------------------------------------------------------------------------------------------
SELECT Name, Path
FROM NuGreen.Asset.ElementHierarchy
WHERE Path LIKE N'\NuGreen\Houston\%'
Explanation
If % is used at the beginning of the search pattern, the query engine cannot index the values in
the search column and therefore needs to inspect all values. Try to avoid LIKE conditions with %
at the beginning.

Optimizing SQL Queries for Performance using PI JDBC and PI ODBC
13 | P a g e
Tip
PI OLEDB Enterprise optimization concepts are described in detail in PI OLEDB Enterprise SQL
Optimization white paper that can be downloaded from OSIsoft Tech Support web site
(https://techsupport.osisoft.com/). You can also download it using the direct link.
2015 TechCon Session
14 | P a g e
Part 2 Microsoft Access
In this part we will execute queries in Microsoft Access using PI ODBC as an external data source. The
principles may be extrapolated to any third party product such as Oracle or SAP as well as to PI JDBC. We
will investigate what queries have been actually executed and the impact on performance.
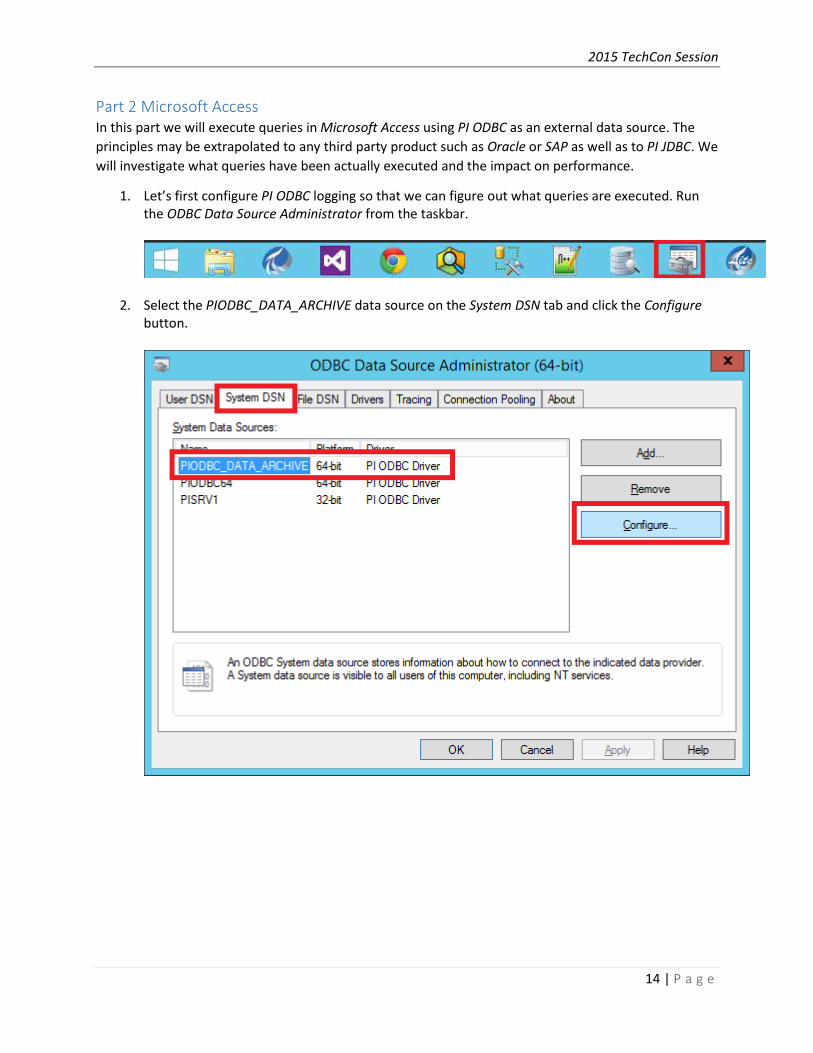
1. Let’s first configure PI ODBC logging so that we can figure out what queries are executed. Run
the ODBC Data Source Administrator from the taskbar.
2. Select the PIODBC_DATA_ARCHIVE data source on the System DSN tab and click the Configure
button.
Optimizing SQL Queries for Performance using PI JDBC and PI ODBC
15 | P a g e
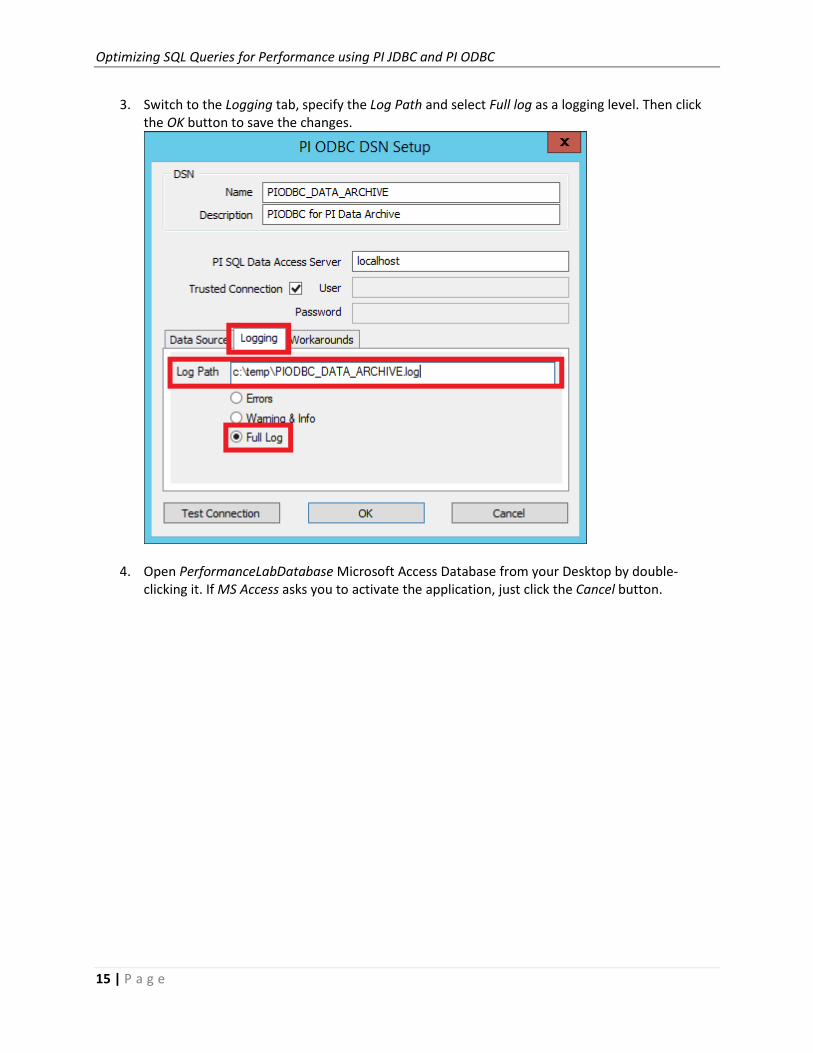
3. Switch to the Logging tab, specify the Log Path and select Full log as a logging level. Then click
the OK button to save the changes.
4. Open PerformanceLabDatabase Microsoft Access Database from your Desktop by double-
clicking it. If MS Access asks you to activate the application, just click the Cancel button.
2015 TechCon Session
16 | P a g e
5. On the left hand side you should see several objects, we will use throughout this part.
Optimizing SQL Queries for Performance using PI JDBC and PI ODBC
17 | P a g e
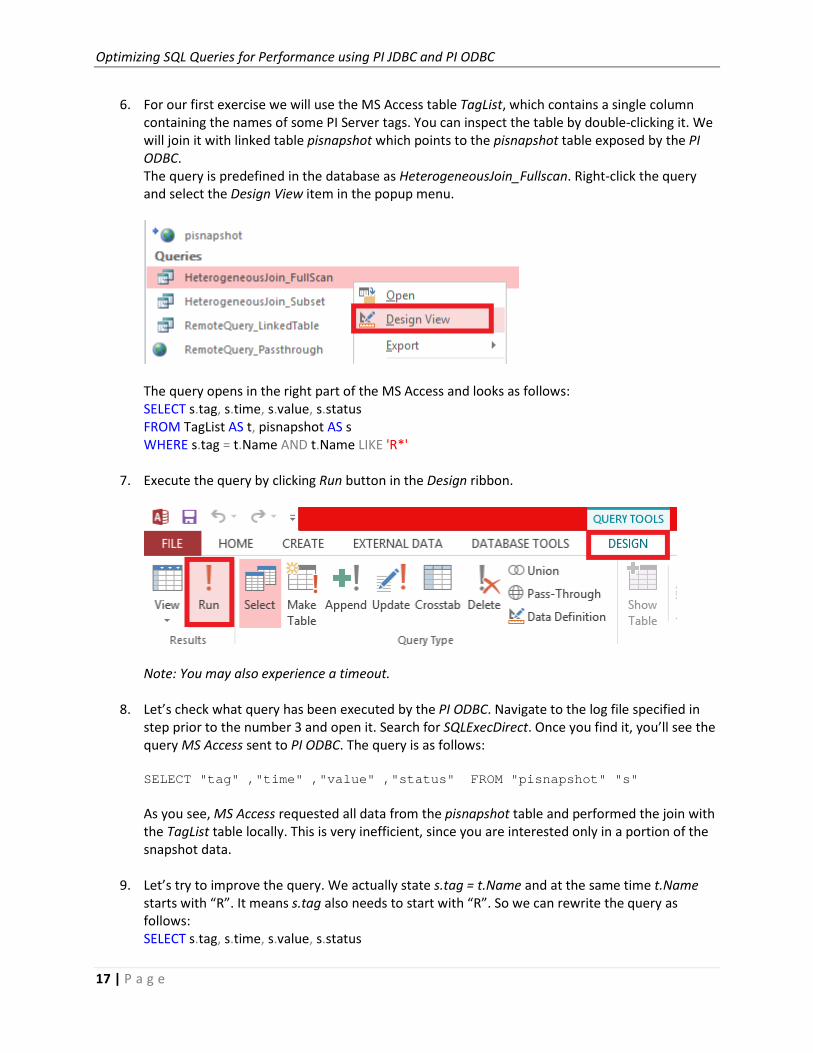
6. For our first exercise we will use the MS Access table TagList, which contains a single column
containing the names of some PI Server tags. You can inspect the table by double-clicking it. We
will join it with linked table pisnapshot which points to the pisnapshot table exposed by the PI
ODBC.
The query is predefined in the database as HeterogeneousJoin_Fullscan. Right-click the query
and select the Design View item in the popup menu.
The query opens in the right part of the MS Access and looks as follows:
SELECT s.tag, s.time, s.value, s.status
FROM TagList AS t, pisnapshot AS s
WHERE s.tag = t.Name AND t.Name LIKE 'R*'
7. Execute the query by clicking Run button in the Design ribbon.
Note: You may also experience a timeout.
8. Let’s check what query has been executed by the PI ODBC. Navigate to the log file specified in
step prior to the number 3 and open it. Search for SQLExecDirect. Once you find it, you’ll see the
query MS Access sent to PI ODBC. The query is as follows:
SELECT "tag" ,"time" ,"value" ,"status" FROM "pisn apshot" "s"
As you see, MS Access requested all data from the pisnapshot table and performed the join with
the TagList table locally. This is very inefficient, since you are interested only in a portion of the
snapshot data.
9. Let’s try to improve the query. We actually state s.tag = t.Name and at the same time t.Name
starts with “R”. It means s.tag also needs to start with “R”. So we can rewrite the query as
follows:
SELECT s.tag, s.time, s.value, s.status

2015 TechCon Session
18 | P a g e
FROM TagList AS t, pisnapshot AS s
WHERE s.tag=t.Name AND t.Name LIKE 'R*' AND s.tag LIKE 'R*'
The query is predefined in the database as HeterogeneousJoin_Subset. Right-click the query and
select the Design View item in the popup menu to check it and execute it by clicking the Run
button in the Design ribbon.
10. Let’s check the PI ODBC logfile again. The query is now as follows:
SELECT "tag" ,"time" ,"value" ,"status" FROM "pisn apshot" "s" WHERE ("tag" LIKE 'R%' )
As you can see, this is already much better, but in case the pisnapshot table contained more tags
than the TagList table, MS Access would still request more data than it really needs. In order to
request the minimum data from the pisnapshot table we need to request relevant data from the
TagList table and using this result to request data from the pisnapshot table.
Optimizing SQL Queries for Performance using PI JDBC and PI ODBC
19 | P a g e
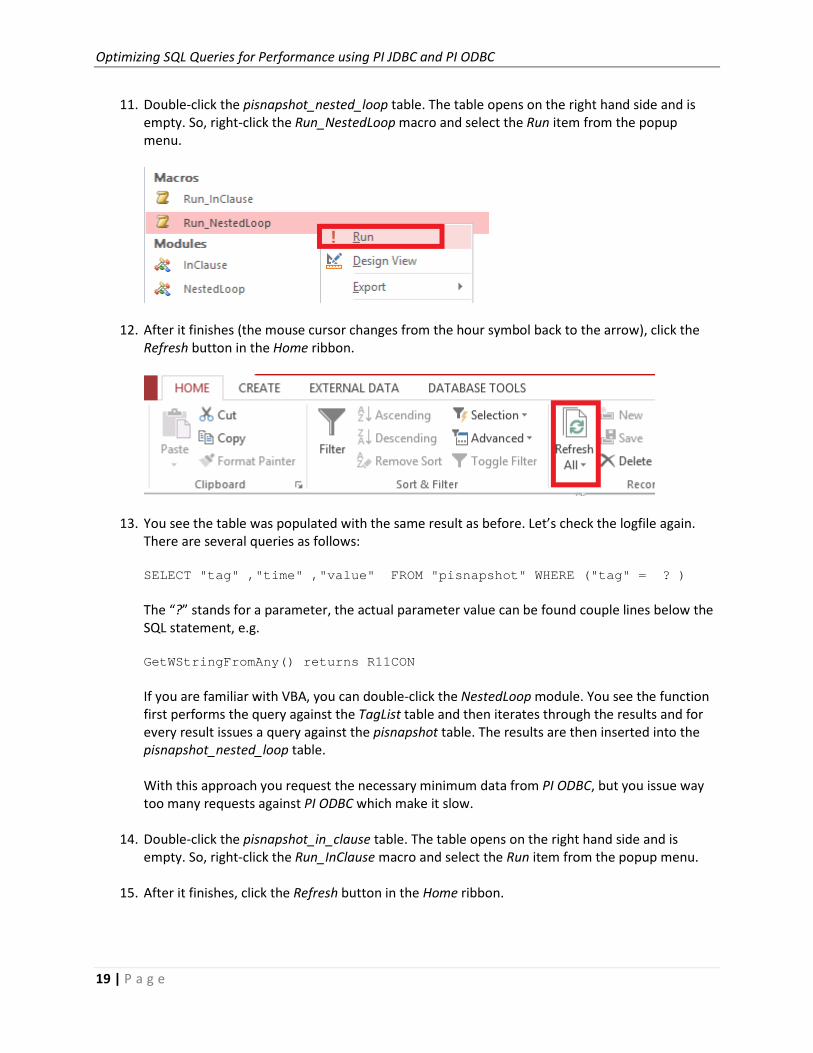
11. Double-click the pisnapshot_nested_loop table. The table opens on the right hand side and is
empty. So, right-click the Run_NestedLoop macro and select the Run item from the popup
menu.
12. After it finishes (the mouse cursor changes from the hour symbol back to the arrow), click the
Refresh button in the Home ribbon.
13. You see the table was populated with the same result as before. Let’s check the logfile again.
There are several queries as follows:
SELECT "tag" ,"time" ,"value" FROM "pisnapshot" WH ERE ("tag" = ? )
The “?” stands for a parameter, the actual parameter value can be found couple lines below the
SQL statement, e.g.
GetWStringFromAny() returns R11CON
If you are familiar with VBA, you can double-click the NestedLoop module. You see the function
first performs the query against the TagList table and then iterates through the results and for
every result issues a query against the pisnapshot table. The results are then inserted into the
pisnapshot_nested_loop table.
With this approach you request the necessary minimum data from PI ODBC, but you issue way
too many requests against PI ODBC which make it slow.
14. Double-click the pisnapshot_in_clause table. The table opens on the right hand side and is
empty. So, right-click the Run_InClause macro and select the Run item from the popup menu.
15. After it finishes, click the Refresh button in the Home ribbon.

2015 TechCon Session
20 | P a g e
16. You see the table was populated with the same result as before. Let’s check the logfile again.
There is only a single query now and it looks as follows:
SELECT "tag" ,"time" ,"value" ,"status" FROM "pisn apshot" WHERE ("tag" IN ( ? , ? , ? …
The actual parameters can be again found below.
If you are familiar with VBA, you can double-click the InClause module. You see the function first
performs the query against the TagList table as in the previous example and then iterates
through the results, but rather than issuing a query against the pisnapshot table, it generates an
IN clause. After all results are iterated, single query against the pisnapshot table is issued.
Note: If the result from TagList were larger, it would be wise to modify the script in a way it
issues the query multiple times with just a portion of the result. In some environment reading
these portions and executing them against PI ODBC/JDBC may even run in parallel.
17. Right-click the RemoteQuery_LinkedTable query and select the Design View item in the popup
menu. The query looks as follows:
SELECT tag, time, value, timestep
FROM piavg
WHERE tag = 'cdt158'
AND time BETWEEN 'y' AND 't'
AND timestep = '2h'
18. Run the query using the Run button in the Design ribbon. The query is successfully executed.
Right-click the result tab and select the SQL View item from the popup menu.
This image cannot currently be displayed.

Optimizing SQL Queries for Performance using PI JDBC and PI ODBC
21 | P a g e
19. Modify the query to use PI ODBC specific function DATE.
SELECT tag, time, value, timestep, DATE('y'), DATE('t')
FROM piavg
WHERE tag = 'cdt158'
AND time BETWEEN 'y' AND 't'
AND timestep = '2h'
Execute the query again. The query fails with the following error:
MS Access processes the query before passing it to PI ODBC. Since the DATE function is unknown
to MS Access specific, it fails.
20. Right-click the RemoteQuery_Passthrough query and select the Design View item in the popup
menu. The query looks as in the previous step. Notice the query is defined as Pass-Through in
the Design ribbon.
21. Click the Run button in the Design ribbon. Select Data Source dialog pops-up, select the
PIODBC_DATA_ARCHIVE data source on the Machine Data Source tab and click OK button.

2015 TechCon Session
22 | P a g e
The query is executed successfully. Pass-through queries are not processed by MS Access and
are passed directly to the data source (PI ODBC). You should get the best performance and use
data source specific constructions, such as PI ODBC specific functions or options, e.g. OPTION
(FORCE ORDER).
OSIsoft Virtual Learning Environment
The OSIsoft Virtual Environment provides you with virtual machines where you can complete the
exercises contained in this workbook. After you launch the Virtual Learning Environment, connect to
PISRV1 with the credentials: pischool\student01, student.
The environment contains the following machines:
PISRV1: a windows server that runs the PI System and that contains all the software and configuration
necessary to perform the exercises on this workbook. This is the machine you need to connect to. This
machine cannot be accessed from the outside except by rdp, however, from inside the machine, you can
access Coresight and other applications with the url: http://pisrv1/, (i.e. http://pisrv1/coresight).
PIDC: a domain controller that provides network and authentication functions.
The system will create these machines for you upon request and this process may take between 5 to 10
minutes. During that time you can start reading the workbook to understand what you will be doing in
the machine.
This image cannot currently be displayed.

OSIsoft Virtual Learning Environment
23 | P a g e
After you launch the virtual learning environment your session will run for up to 8 hours, after which
your session will be deleted. You can save your work by using a cloud storage solution like onedrive or
box. From the virtual learning environment you can access any of these cloud solutions and upload the
files you are interested in saving.
System requirements: the Virtual Learning Environment is composed of virtual machines hosted on
Microsoft Azure that you can access remotely. In order to access these virtual machines you need a
Remote Desktop Protocol (RDP) Client and you will also need to be able to access the domain
cloudapp.net where the machines are hosted. A typical connection string has the form
cloudservicename.cloudapp.net:xxxxx, where the cloud service name is specific to a group of virtual
machines and xxxxx is a port in the range 41952-65535. Therefore users connecting to Azure virtual
machines must be allowed to connect to the domain *.cloudapp.net throughout the port range 41952-
65535. If you cannot connect, check your company firewall policies and ensure that you can connect to
this domain on the required ports.