Embed Size (px)
Citation preview

Otros temas del analisis deregresi6n
/ Esquema del capituw
14.1. Metodologia para la construccion de modelos Especificacion del modele Estimacion de los coeficientes Verificacion del modele Interpretacion del modele e inferencia
14.2. Variables ficticias y diseno experimental Modelos de diseno experimental
14.3. Val ores retardados de las variables dependientes como regresores 14.4. Sesgo de especificacion 14.5. Multicolinealidad 14.6. Heterocedasticidad 14.7. Errores autocorrelacionados
Estimacion de las regresiones con errores autocorrelacionados Errores autocorrelacionados en los modelos con variables dependientes retardadas
Introducci6n En los Capltulos 12 y 13 presentamos la regresion simple y la regresion multiple como instrumentos para estimar los coeficientes de modelos lineales para aplicaciones empresariales y economicas. Ahora comprendemos que el fin de ajustar una ecuacion de regresion es utilizar la informacion sobre las variables independientes para explicar la conducta de las variables dependientes y para hacer predicciones de la variable dependiente. Los coeficientes del modelo tambien pueden utilizarse para estimar la tasa de variacion de la variable dependiente como consecuencia de las variaciones de una variable independiente, siempre y cuando el conjunto especffico de otras variables independientes incluidas en el modelo se mantenga fijo. En este capitulo estudiamos un conjunto de especificaciones alternativas. Consideramos, ademas, situaciones en las que se violan los supuestos basicos del anal isis de regresion.
EI lector puede seleccionar los temas de este capitulo para complementar su estudio del anal isis de regresion. A casi todo el mundo Ie interesara el analisis de la construccion de modelos del apartado siguiente. EI proceso de construccion de modelos es fundamental para todas las aplicaciones del anal isis de regresion, por 10 que comenzamos con esas ideas. EI apartado sobre las variables ficticias y el disefio experimental contiene metodos para extender las aplicaciones de los modelos. Los apartados como el de la heterocedasticidad y las autocorrelaciones indican como se aborda la cuestion de las violaciones de los supuestos.

576 Estadfstica para administracion y economfa
Se desarrollan modelos de regresion en aplicaciones empresariales y econ6micas para aumentar la comprensi6n y servir de orientaci6n para tomar decisiones. Para desarrollar estos modelos, es necesario comprender bien el sistema y el proceso estudiados. La teorfa estadfstica sirve de nexo entre el proceso subyacente y los datos observados en ese proceso. Esta relacion entre el contexto del problema y un buen anal isis estadfstico normalmente requiere un equipo interdisciplinar que pueda aportar sus conocimientos sobre todos los aspectos del problema. Los auiores piensan por experiencia que estos equipos s610 tend ran exito cuando todos sus miembros aprendan unos de otros: los expertos en producci6n deben tener unos conocimientos basicos de los metodos estadfsticos y los estadfsticos deben comprender el proceso de producci6n.
14.1. Metodologfa ara la construccion de modeloS
Figura 14.1. Fases de la construcci6n de modelos estadfsticos.
Aquf desarrollamos una estrategia general para construir modelos de regresion. Vivimos en un mundo complejo y nadie cree que podamos recoger exactamente las complejidades de la conducta economica y empresarial en una 0 mas ecuaciones. Nuestro objetivo es utilizar un modele relativamente sencillo que refleje la compleja realidad con la suficiente precision como para que aporte utiles ideas. EJ arte de la construccion de modelos reconoce la imposibilidad de representar todos los facto res que influyen en una variable dependiente y trata de seleccionar las variables mas influyentes. A continuacion, es necesario formular un modele para representar las relaciones entre estosfactores. Queremos construir un sen cillo modele que sea facil de interpretar, pero no tan excesivamente simplificado que no tenga en cuenta las influencias importantes.
El proceso de construccion de modelos estadfsticos depende de cada problema. Nuestro enfoque depende de la informacion de que se dispone sobre la conducta de las cantidades estudiadas y de los datos existentes. En la Figura 14.1 presentamos las distintas fases de la construccion de modelos.
Especificacion del mOdel~ __ J
1 • Estimacion de los coeficientes 1 _________ ._. __ 1
1 I
Verificacion del modelo i ---~
1 Interpretacion e infer~ncia I

Capitulo 14. Otros temas del anal isis de regresion 577
Especificacion del modelo
El amilisis comienza con el desarrollo de la especificacion del modelo. Comprende la seleccion de la variable dependiente y de las variables independientes y la forma algebraica del modelo. Buscamos una especificacion que represente correctamente el sistema y el proceso estudiados. Los ejemplos de los Capftulos 12 y 13 que se refieren a las ventas al por menor, la rentabilidad de las asociaciones de ahorro y credito inmobiliario y la produccion de algodon postulaban todos ellos una relacion lineal entre la variable dependiente y las variables independientes. Los model os lineales a menudo reflejan bien el problema de interes. Pero no siempre es as!.
La especificacion del modelo comienza con la comprension de la teorfa que constituye el contexto para el modelo. Debemos estudiar detenidamente la literatura existente y enteramos de que se sabe sobre la situacion de la que tratamos de desarrollar un modelo. Este estudio debe incluir la realizacion de consultas a los que. conocen el contexto, a los que han hecho investigaciones sobre el tema y a los que han desarrollado model os parecidos. Cuando se trata de estudios aplicados, tambien debe entrarse en contacto con los profesionales con experiencia que conocen en la pnictica el sistema que se pretende estudiar.
La especificacion del modelo normal mente exige un profundo estudio del sistema y del proceso que subyace al problema. Cuando tenemos complejos problemas en los que intervienen varios factores, es importante que el equipo interdisciplinario analice minuciosamente todos los aspectos del problema. Puede ser necesario realizar mas investigaciones y quiza incluir a otros que tengan ideas importantes. La especificacion requiere un estudio y un anaIisis serios. Este tambien es el momenta en el que es necesario decidir los datos necesarios para el estudio. En muchos casos, eso puede significar decidir si los datos existentes -0 los que podrfan obtenerse- seran adecuados para estimar el modelo. Si no sabemos 10 que queremos hacer 0 no comprendemos el contexto del problema, hay sofisticados instrumentos analfticos y analistas competentes que nos daran la mejor respuesta po sible. Los analistas sin experiencia a menu do realizan calculos por computador antes de analizar minuciosamente el problema. Los analistas profesionales saben que con ese enfoque se obtienen resultados inferiores.
Estimacion de los coeficientes
Un modelo estadfstico, una vez especificado, normalmente tiene algunos coeficientes desconocidos, llamados parametros. EI paso siguiente del ejercicio de construccion de un modelo es emplear los datos de los que se dispone en la estimacion de estos coeficientes. Deben realizarse estimaciones puntuales y estimaciones de intervalos para el modelo de regresion multiple
Desde el punto de vista estadfstico, los objetivos del modelo de regresion pueden dividirse en la prediccion de la media de la variable dependiente, Y, 0 la estimacion de uno 0 mas de los coeficientes individuales, fJj" En muchos casos, los objetivos no son totalmente independientes, pero estas alternativas identifican importantes opciones.
Si el objetivo es la prediccion, queremos un modelo en el que el error tipico de la estimacion, Se' sea pequeno. No nos preocupa tanto que las variables independientes esten correlacionadas, porque sabemos que la precision de la prediccion sera la misma con una serie de diferentes combinaciones de variables correlacionadas. Sin embargo, necesitamos

578 Estadfstica para administracion y economfa
saber si las correlaciones entre las variables independientes continuanin cumpliendose en futuras poblaciones. Tambien necesitamos que las variables independientes tengan una amplia dispersion para que la varianza de la prediccion sea pequefia en el rango deseado de la aplicacion del modelo.
Si el objetivo es la estimacion, la estimacion de los coeficientes de la pendiente nos lleva a considerar una variedad mayor de cuestiones. En la desviacion tipica estimada, s", de los coeficientes de la pendiente influye directamente el error tipico del modelo e inve~samente la dispersion de las variables independientes y las correlaciones entre las variables independientes, como se observa en el apartado 13.4. La multicolinealidad -las correlaciones entre variables independientes- es una cuestion fundamental, como veremos en el apartado 14.5. Tambien veremos en el apartado 14.4 que cuando no se incluyen importantes variables de prediccion, el estimador de los coeficientes de las variables de prediccion incluidas en el modelo es un estimador sesgado. Estos dos resultados llevan a un problema estadistico clasico. (,Incluimos una variable de prediccion que esta estrechamente correlacionada con las demas para evitar una estimacion sesgada de los coeficientes pero aumentamos tambien considerablemente la varianza del estimador de los coeficientes? (,0 excluimos una variable de prediccion correlacionada para reducir la varianza del estimador de los coeficientes pero aumentamos el sesgo? La seleccion del equilibrio adecuado entre el sesgo del estimador y la varianza a menudo es un problema en la construccion de un modelo aplicado.
Verificaci6n del modelo
Cuando desarrollamos la especificacion del modelo, incorporamos ideas sobre la conducta del sistema y el proceso subyacentes. Cuando se trasladan estas ideas a formas algebraicas y cuando se seleccionan datos para estimar el modelo, se realizan algunas simplificaciones y se postulan algunos supuestos. Como algunos pueden resultar insostenibles, es importante comprobar la adecuacion del modelo.
Despues de estimar una ecuacion de regresion, podemos observar que las estimaciones no tienen sentido, dado 10 que sabemos del proceso. Supongamos, por ejemplo, que el modelo indica que la demanda de automoviles aumenta cuando suben los precios, 10 cual es contrario a la teoria economica basica. Ese resultado puede deberse a que los datos no son adecuados 0 a que existen algunas correlaciones estrechas entre el precio y otras variables de prediccion. Estas son las razones por las que el signo de los coeficientes puede ser incorrecto. Pero el problema tambien puede deberse a que el modelo no se ha especificado correctamente. Si no se incluye el conjunto adecuado de variables de prediccion, los coeficientes pueden estar sesgados y los signos ser incorrectos. Tambien es necesario verificar los supuestos postulados sobre las variables aleatorias del modelo. Por ejemplo, los supuestos basicos del analisis de regresion establecen que los terminos de error tienen todos ellos la misma varianza y no estan correlacionados entre sf. En los apartados 14.6 y 14.7 vemos como pueden comprobarse estos supuestos utilizando los datos existentes.
Si obtenemos resultados inverosimiles, tenemos que examinar nuestros supuestos, la especificacion del modelo y los datos. Eso puede llevarnos a considerar otra especificacion del modelo. Asi, en la Figura 14.1 10 indicamos con una flecha de retroalimentacion en el proceso de construccion de modelos. A medida que adquiramos experiencia en la construccion de modelos y en la resolucion de otros dificiles problemas, descubriremos que estos procesos tienden a repetirse y que se vuelve a fases anteriores hasta que se desarrolla un modelo satisfactorio y se soluciona el problema.

Capitulo 14. Otros temas del anal isis de regresi6n 579
Interpretacion del modelo e inferencia
Una vez que se ha construido un modelo, puede utilizarse para obtener alguna informaci6n sobre el sistema y el proceso estudiados. En el analisis de regresi6n, puede significar buscar intervalos de confianza para los parametros del modelo, contrastar hip6tesis de interes o predecir los futuros valores de la variable dependiente, dados los val ores supuestos de las variables independientes. Es importante reconocer que este tipo de inferencia se bas a en el supuesto de que el modelo esta especificado y estimado correctamente. Cuanto mas graves son los errores de especificaci6n 0 de estimaci6n, menos fiables son las inferencias realizadas a partir del modelo estimado.
Tambien deberiamos reconocer que algunos resultados de nuestro analisis bas ado en los datos existentes pueden no estar de acuerdo con 10 que se sabia hasta entonces. Cuando eso ocurre, es necesario comparar minuciosamente nuestros resultados con 10 que se sabia hasta entonces. Las diferencias pueden deberse a que la especificaci6n del modelo es diferente 0 incorrecta, a errores de los datos 0 alguna otra deficiencia. Pero tambien podriamos descubrir algunos importantes resultados nuevos debido a que la especificaci6n del modelo es mejor 0 a nuevos datos que representan un cambio del contexto estudiado. En cualquier caso, debemos estar dispuestos a hacer correcciones 0 a presentar nuestros nuevos resultados de una manera 16gica.
J4.2. Variables ficticias y disefio experimental
En el apartado 13.8 introdujimos las variables ficticias en aplicaciones en las que habia modelos de regresi6n aplicados ados subconjuntos diferentes de datos. Por ejemplo, vimos c6mo podrfan utilizarse para averiguar la existencia de discriminaci6n sexual en el ejemplo de los salarios.
En este apartado ampliamos las aplicaciones potenciales de las variables ficticias. En primer lugar, presentamos una aplicaci6n en la que se aplica un modelo de regresi6n a mas de dos subconjuntos de datos. A continuaci6n, mostramos c6mo pueden utilizarse las variables ficticias para estimar los efectos estacionales en un modelo de regresi6n aplicado a datos de series temporales. Por ultimo, mostramos c6mo pueden utilizarse las variables ficticias para analizar datos de situaciones experimentales, definidas por variables categ6ricas que contienen multiples niveles.
EJEMPLO 14.1. Demanda de productos de lana (analisis del modelo utilizando variables ficticias)
Un analista de marketing para la Asociaci6n de Fabricantes de Productos de Lana tiene interes en estimar la demanda de productos de lana en algunas ciudades en funci6n de la renta total disponible de la ciudad. Se han recogido datos de 30 areas metropolitanas seleccionadas aleatoriamente. En primer lugar, el analista especifica un modelo de regresi6n de la relaci6n entre las ventas y la renta disponible:
donde Xl es la renta disponible anual per capita de una ciudad e Y son las vent as per capita de productos de lana en la ciudad. Tras algunas conversaciones mas, el analista
580 Estadistica para administraci6n yeconomia
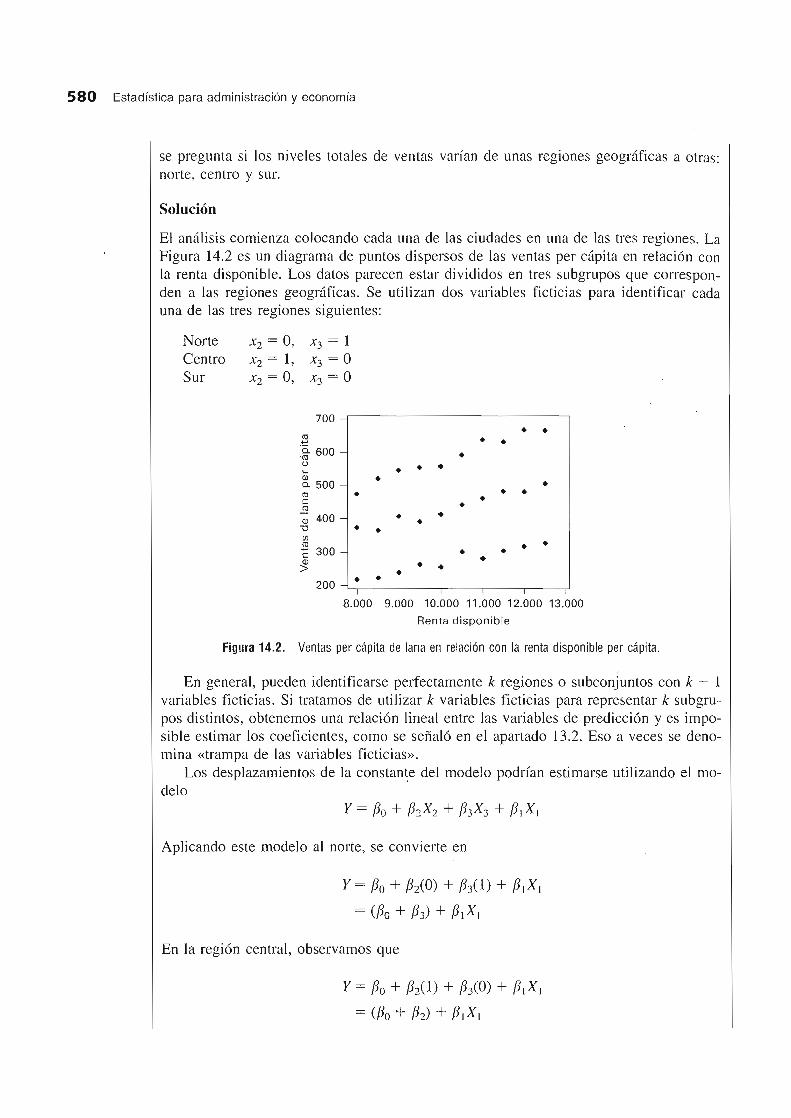
se pregunta si los niveles totales de ventas varian de unas regiones geogrMicas a otras: norte, centro y sur.
Solucion
El amllisis comienza colocando cada una de las ciudades en una de las tres regiones. La Figura 14.2 es un diagrama de puntos dispersos de las ventas per capita en relaci6n con la renta disponible. Los datos parecen estar divididos en tres subgrupos que cOlTesponden a las regiones geogrMicas. Se uti Ii zan dos variables ficticias para identificar cada una de las tres regiones siguientes:
Norte X2 = 0, X3 = 1 Centro X2 = 1, X3 = 0 Sur X2 = 0, X3 = 0
700 -• • 19 • • :g. 600 - •
t.l • • ~ • QJ • c. 500 - • C1l • • • c •
..':':! • • • QJ 400 - • "D • • I/)
• 19 300 - • • • c • ~ • • • 200 • •
8.000 9.000 10.000 11.000 12.000 13.000
Renta disponible
Figura 14.2. Ventas per capita de lana en relacion con la renta disponible per capita.
En general, pueden identificarse perfectamente k regiones 0 subconjuntos con k - 1 variables ficticias. Si tratamos de utilizar k variables ficticias para representar k subgrupos distintos, obtenemos una relaci6n lineal entre las variables de predicci6n y es imposible estimar los coeficientes, como se sefial6 en el apartado 13.2. Eso a veces se denomin a «trampa de las variables ficticias».
Los desplazamientos de la constan~e del modelo podrfan estimarse utilizando el modelo
Aplicando este modelo al norte, se convierte en
y = f30 + f32(0) + f33(l) + f3 ,X ,
= (f3o + f33) + f3,X,
En la regi6n central, observamos que
y = f30 + f32(l) + f33(0) + f3I X I
= (f3o + fJ2) + f3,X,

Capitulo 14. Otros temas del analisis de regresion 581
Por ultimo, en el caso de la region meridional el modelo es
Y = {30 + /32(0) + /J 3(0) + {31X1
= {30 + {3)X)
Resumiendo estos resultados, las constantes de las distintas regiones son:
Norte Centro Sur
Esta f()rmulacion define el sur como la con stante «base»; {33 y {32 definen el desplazamiento de la funcion de las ciudades del norte y el centro, respectivamente. Podrfan utilizarse contrastes de hipotesis, utilizando el estadfstico t de Student de los coeficientes, para averiguar si hay diferencias significativas entre las constantes de las diferentes regiones en comparacion, en este caso, con la constante de la region del sur. Podrfan obte-
. nerse constantes para mas regiones utilizando variables ficticias que continuen esta pautao Podrfamos especificar las variables ficticias de manera que cualquier nivel fuera el nivel base conel que se comparan los demas niveles. En este problema, la especificacion del sur como condicion base es natural , dados los objeti vos . del problema.
EI modelo en el que se incJuyen diferel1cias entre los coeficientes de la pendiente y las constantes es
Y = {30 + {32X2 + {33X3 + ({3) + /34X2 + {33 X3)Xj
= {30 + {32X2 + {33X3 + {3)X) + {34X2X ) + {3SX3X )
Aplicando este modelo a Ia region del nOlte, vemos que
Y = {30 + {32(0) + {33(1) + ({3) + {34(0) + {3s(1))X)
= ({30 + {33) + ({3) + {3s)X1
En el caso de ia region central, el modelo es
Y = {30 + {32(1) + {33(0) + ({31 + {3il) + {3s(O))X)
= ({30 ~ {32) + ({31 + {34)X I
Por ultimo, en el casQ de la region del sur
Y = {30 + {32(0) + {33(0) + ({31 + {34(0) + {3s(O))Xj
= {30 + {3I X j
EI coeficiente de la pendiente de Xl de las ciudades de diferentes regiones es:
Norte Centro Stir

582 Estadfstica para adrilinistracion y economfa
Una vez mas, el sur es la condici6n base que tiene la pendiente fJ /. Pueden utilizarse contrastes de hip6tesis para averiguar la significaci6n estadfstica de las diferencias entre los coeficientes de la pendiente y la condici6n base, que en este caso es la regi6n del sur. Utilizando este modelo de regresi6n que contiene variables ficticias , el analista puede estimar la relaci6n entre las ventas y la renta disponible por regiones.
Utilizando la muestra de 30 areas metropolitanas divididas por igual entre las tres regiones geogrMicas, se estim6 un modelo de regresi6n multiple con varfables ficticias utilizando Minitab. Los resultados se muestran en la Figura 14.3. A partir del modelo de regresion podemos averiguar las caracterfsticas de las pautas de compra de lana: Pueden utilizarse contrastes de hipotesis condicionados de la forma
Ho: fJj = ° I fJz i= 0, l = 1, .. . , K, l i= j
H I : fJj i= ° I fJz i= 0, l = 1, ... , K, l i= j
para averiguar los efectos condicionados de los distintos factores en la demand a de lana. El coeficiente de la variable ficticia X3, fJ3 = 138,46, indica que las personas del norte gastan una media de 138,46 $ mas que las del sur. Asimismo, las personas de la region central gas tan una media de 96,33 $ mas que las del sur. Estos coeficientes son significativos. El coeficiente de la renta disponible es 0,0252, 10 que indica que, en el caso de las personas del sur, cada dolar de aumento de la renta per capita incrementa la compra de productos de lana en 0,025, y este resultado es significativo. En el caso de las personas del norte, cada dolar de aumento de la renta incrementa el gasto en productos de lana en 0,042 (0,0252 + 0,0168) y la diferencia entre los aumentos de la pendiente es significativa. La tasa estimada de aumento de la compra por dolar de aumento de la renta tambien es mayor en el caso de las personas que viven en la region central que en el de las que viven en la region del sur. Sin embargo, esa diferencia no es significativa. Utilizando estos resultados, las ventas por regi6n pueden predecirse con mayor precision que con un modelo que combine todas las regiones y solo utilice la renta per capita.
The regression equation is Per Capita Wool Sales = 12.7 + 138 North X3 + 96 . 3 Central X2
+ 0 . 0252 Disposable Income + 0.0168 NorX3Inc + 0.00608 CentX2Inc
Predictor Coef StDev T P Constant 12.73 27.74 0 . 53 0.600 North X3 138.46 39 . 22 3.53 0 . 022 Central X2 96.33 39 . 22 2 . 46 0.002 Disposab 0 . 025231 0.002680 9.42 0 . 000 NorX3 Inc 0.016839 0.003790 4 . 44 0.000 CentX2 In 0.006085 0.003790 1. 61 0.121
S = 12 . 17 R-Sq = 99 . 4% R-Sq (adj) = 99.2%
Analysis of Variance
Source DF SS MS F P Regression 5 553704 110741 747.71 0.000 Residual Error . 24 3555 148 Total 29 557259
Figura 14.3. Modelo de regresion multiple utilizando variables ficticias par estimar el consumo de lana per capita (salida Minitab).

Capitulo 14. Otros temas del analisis de regresion 583
EJEMPLO 14.2. Predicci6n de las ventas de productos de lana (variables ficticias estacionales)
Tras acabar el amllisis de las ventas regionales, el analista decidio estudiar la relacion entre las ventas y la renta disponible utilizando datos de series temporales. Tras realizar algunos analisis, se dio cuenta de que las ventas varian de unos trimestres a otros. Por ejemplo, durante el cuarto trimestre son altas en prevision de los regalos de Navidad y de la bajada de la temperatura. Le ha pedido que 10 ayude a realizar el estudio.
Solucion
Tras analizar el problema, Ie recomienda que represente los cuatro trimestres de cada ano por medio de tres variables ficticias. De esta fonna, puede utilizarse el modelo de regresion multiple para estimar las diferencias entre las ventas de los diferentes trimestres. Concretamente, Ie propone una estructura similar a la del modelo de variables ficticias regionales:
Primer trimestre: Segundo trimestre: Tercer trimestre: Cuarto trimestre:
X2 = 0, X3 = 0, X4 = ° X2 = 1, X3 = 0, X4 = ° X2 = 0, X3 = 1, X4 = ° X2 = 0, X3 = 0, X4 = 1
Los coeficientes de las variables ficticias son estimaciones de los desplazamientos de la fundon de con sumo de lana entre los trimestres en el modelo de los datos
don de Y son las ventas totales de productos de lana y Xl es la renta disponible. Las constantes de los distintos trimestres son:
Primer trimestre: Segundo trimestre: Tercer trimestre: Cuarto trimestre:
Modelos de diseno experimental
Los metodos de diseno experimental han sido una importante area de investigacion y practica estadfsticas durante algunos anos. Los primeros estudios se referian a investigaciones agricolas. Los esfuerzos realizados por estadisticos como R. A. Fisher y O. L. Davies en Inglaterra durante la decaca de 1920 sentaron las bases de la metodologfa del diseno experimental y de la practica estadfstica en general. Los experimentos agrfcolas requieren una temporada entera de cultivo para obtener datos. Era, pues, importante desarrollar metodos que pudieran dar respuesta a una serie de cuestiones y conseguir una gran precision. Ademas, la mayorfa de los experimentos definfan la actividad utilizando variables con niveles discretos en lugar de continuos. Los metodos de diseno experimental tambien se han utilizado mucho para estudiar la conducta humana y para realizar algunos experimentos industriales. El enfasis reciente en la mejora de la cali dad y la productividad ha aumentado la actividad en esta area de la estadfstica con importantes aportaciones de grupos como el Center for Quality and Productivity de la Universidad de Wisconsin.

584 Estadfstica para administracion y economfa
Diseiio experimental
La regresion utilizando variables ficticias puede emplearse como instrumento en los estudios de disefio experimental. Los experimentos tienen una unica variable de resultado, que contiene todo el error aleatorio. Cada resultado experimental corresponde a una combinaci6n discreta de las variables experimentales (independientes), >So
Existe una importante diferencia de filosoffa entre los disefios experimentales y la mayorfa de los problemas que hemos examinado. EI disefio experimental intenta identificar las causas de las variaciones de la variable dependiente, especificando previamente combinaciones de variables independientes discretas cuyos valores se utilizan para medir la variable dependienteo Un importante objetivo es elegir puntos experimentales, definidos por variables independientes, que constituyan estimadores de las varianzas mfnimas. EI orden en el que se realizan los experimentos se elige aleatoriamente para evitar sesgos introducidos por variables no incluidas en el experimento.
Los resultados experimentales, Y, corresponden a combinaciones espedficas de niveles de las variables de tratamiento y de bloqueo. Una variable de tratamiento es una variable cuyo efecto tenemos interes en estimar con una varianza minima. Por ejemplo, podrfamos querer saber cwil de cuatro maquinas de producci6n es mas productiva por hora. En ese caso, el tratamiento son las maquinas de producci6n representadas por una variable categ6-rica de cuatro niveles, Zj" Una variable de bloqueo representa una variable que forma parte del entorno y, por 10 tanto, no puede preseleccionarse el nivel de la variable. Pero queremos incluir el nivel de la variable de bloqueo en nuestro modelo, con el fin de eliminar la variabilidad de la variable de resultado, Y, que esta relacionada con los diferentes niveles de las variables de bloqueo. Podemos representar una variable de tratamiento 0 de bloqueo de K niveles utilizando K - 1 variables ficticias . Consideremos un sen cillo ejemplo que tiene una variable de tratamiento de cuatro niveles, ZI ' Y una variable de bloqueo de tres niveles, Z2. Estas variables podrfan representarse por medio de variable& ficticias, como se muestra en la Tabla 14.1. A continuaci6n, utilizando estas variables ficticias, podrfa estimarse el modele de disefio experimental mediante el modelo de regresi6n multiple
Tabla 14.1. Ejemplo de especificaci6n de las variables ficticias para las variables de tratamiento y de bloqueo
Zl Xl Xz X3
1 0 0 0 2 1 0 0 3 0 1 0 4 0 0 1
Zz X4 Xs
1 0 0 2 1 0 3 0 1
En este modelo, por ejemplo, el coeficiente f33 es una estimaci6n de la cantidad en la que la productividad del nivel de tratamiento 4 es mayor que la del nivel de tratamiento 1, para la variable de tratamiento categ6rica, Z t. Naturalmente, si f33 es negativo, sabemos

Capitulo 14. Otros temas del analisis de regresi6n 585
que el nivel de tratamiento 1 tiene una productividad mayor que el 4. Siguiendo la 16gica de la regresi6n multiple, sabemos que las variables X4 y Xs explican parte de la variabilidad de Y y, por 10 tanto, el estimador de la varianza es menor. Este modelo puede expandirse facilmente para incluir varias variables de tratamiento simultaneamente con algunas otras variables de bloqueo. Ademas, S1 hay una variable continua -por ejemplo, la temperatura ambiente- que afecta a la productividad, esa variable tambien puede anadirse directamente al modelo de regresi6n. En much os casos, se replica varias veces el disefio basico para obtener suficientes grados de libertad para el error. Este proceso se muestra en el ejemplo 14.3.
EJEMPLO 14.3. Programa de formacion de los trabajadores (especificacion del modelo utilizando variables ficticias)
Marfa Cruz es la directora de producci6n de una gran fabrica de piezas de autom6vil. Tiene interes en saber c6mo afecta un nuevo program a de formaci6n a la productividad de los trabajadores. Existen muchas investigaciones que apoyan la conclusi6n de que en la productividad influyen el tipo de maquina y la cantidad de formaci6n que ha recibido el trabajador.
Soluci6n
Marfa define las siguientes variables para el experimento:
Y El numero de unidades producidas por turno de 8 horas Zl El tipo de formaci6n
1. Clase tradicional en un aula y presentaci6n de pelfculas 2. Ensefianza interactiva asistida por computador (CAl)
Z2 Tipo de maquina
1.' Maquina de tipo 1 2. Maquina de tipo 2 3. Maquina de tipo 3
Z3 Nivel de estudios de los trabajadores 1. Nivel de estudios secundarios 2. AI menos un ano de estudios postsecundarios
La variable ZI se llama variable de tratarniento pOl"que el principal objetivo del estudio es evaluar el programa de formaci6n. Las variables ~ y Z3 se lIaman variables de bloqueo porque se incluyen para' ayudar a reducir 0 bloquear parte de la variabilidad sin explicar. De esta forma se reduce la varianza y el contraste de los principales efectos del tratamiento tiene mayor potencia. La expresi6n variable de bloqueo proviene de los experimentos agricolas en los que las parcel as se dividfan en pequefios bloques, cuyo suelo tenIa unas condiciones que variaban de unos a otros. Tambien es posible estimar el efecto de estas variables de bloqueo. Por 10 tanto, no se pierde informaci6n llamando a ciertas variables «variables de bloqueo» en lugar de «variables de tratamiento».
Las observaciones del disefio experimental se definen previamente utilizando las variables independientes. La Tabla 14.2 contiene una lista de las observaciones, en la que cada observaci6n se designa utilizando los niveles de las variables Z. En este diseno, que se llama disefio factorial completo, hay 12 observaciones, una para cada combina-

586 Estadfstica para administracion y economfa
Tabla 14.2. Disefio experimental para el estudio de la productividad.
Produccion Y Formacion Zl Maquina Z2 Nivel de estudios Z3
Y1 1 1 Y2 1 2 Y3 2 1 Y4 2 2 Ys 3 Y6 3 2 Y7 2 Ys 2 2 Y9 2 2
YlO 2 2 2 Yll 2 3 1 Y12 2 3 2
cion de las variables de tratamiento y de bloqueo. Las Yi observaciones representan las respuestas medidas en cada una de las condiciones experimentales. En los datos, el modelo Yi contiene el efecto de las variables de tratamiento y de bloqueo mas un error aleatorio. En muchos disefios experimentales, esta pauta de 12 observaciones se replica (se repite) para obtener mas grados de libertad para el error y estimaciones mas bajas de las varianzas de los efectos de las variables de disefio. Este disefio tambien puede analizarse utilizando los metodos del analisis de la varianza. Sin embargo, aquf mostramos como puede realizarse el analisis recurriendo a la regresion basada en variables ficticias.
Los niveles de cada una de las tres variables de disefio -Z[, Z2 y Z3- pueden expresarse como un conjunto de variables ficticias. Defin(,lmos las siguientes variables ficticias:
Z[ = 1 -+X[ = 0 ZI = 2 -+X[ = 1 Z2 = 1 -+ X2 = 0 & X3 = 0 Z2 = 2 -+ Xz = 1 & X3 = 0 Z2 = 3 -+ Xz = 0 & X3 = 1 Z3 = 1 -+ X4 = 0 Z3 = 2 -+ X4 = 1
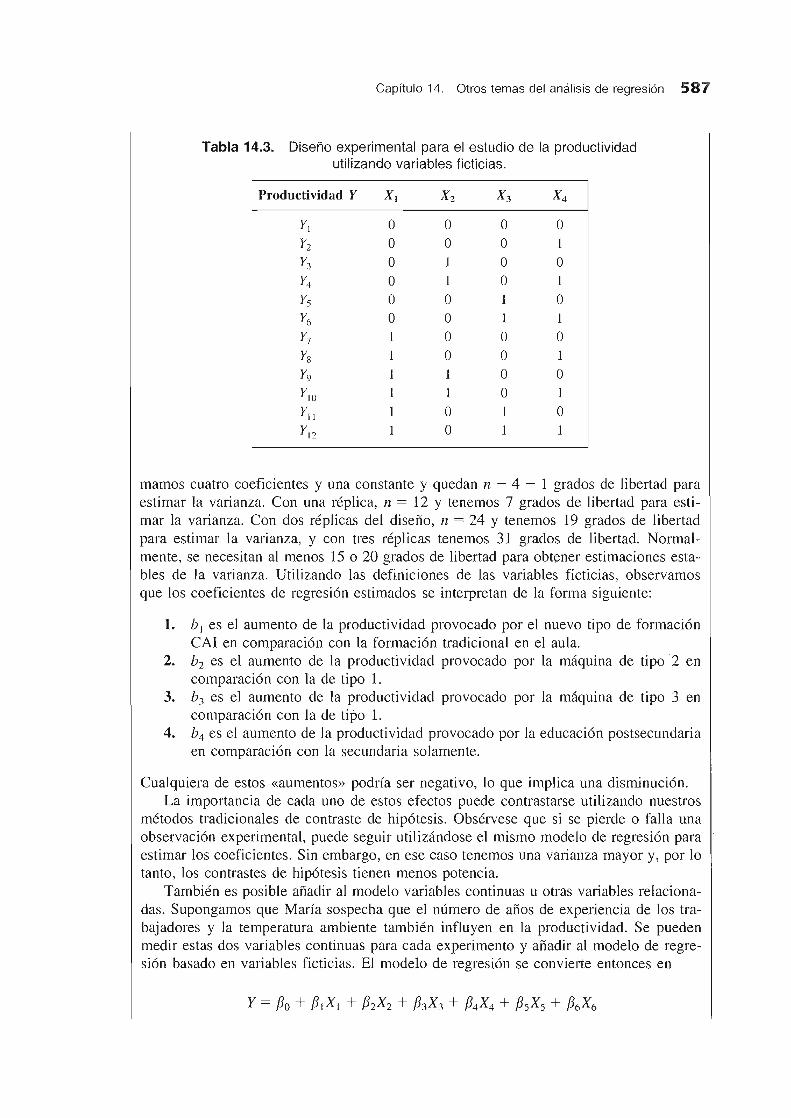
Utilizando estas relaciones, el modelo de disefio experimental de la Tabla 14.2, que utiliza las variables Z, puede representarse por medio de variables ficticias, como muestra la Tabla 14.3. Utilizando estas variables ficticias, podemos definir un modelo de regresion multiple:
Los coeficientes de regresion se estiinan utilizando las variables especificadas previamente. Los 12 experimentos u observaciones definidos en las Tablas 14.2 y 14.3 son una replica del disefio experimental. Una replica contiene todos los experimentos individuales que se incluyen en el disefio experimental. A menudo se realizan varias replicas del disefio para estimar con mayor precision los coeficientes y obtener suficientes grados de libertad para estimar la varianza. En el modelo basado en variables ficticias, esti-
Capitulo 14. Otros temas del anal isis de regresion 587
Tabla 14.3. Diseno experimental para el estudio de la productividad utilizando variables ficticias.
Productividad Y XI X 2 X3 X4
Y1 0 0 0 0 Y2 0 0 0 1
Y3 0 1 0 0 Y4 0 1 0 1
Y5 0 0 1 0 Y6 0 0 1 1
Y7 1 0 0 0 Y8 1 0 0 1
Y9 1 1 0 0
YIO 1 1 0 1
Y11 1 0 1 0 Y12 1 0 1 1
mamos cuatro coeficientes y una con stante y quedan n - 4 - 1 grados de libertad para estimar la varianza. Con una replica, n = 12 Y tenemos 7 grados de libertad para estimar la varianza. Con dos replicas del disefio, 11 = 24 Y tenemos 19 grados de libertad para estimar la varianza, y con tres replicas tenemos 31 grados de libertad. Normalmente, se necesitan al menos 15 0 20 grados de libertad para obtener estimaciones estables de la varianza. Utilizando las definiciones de las variables ficticias, observamos que los coeficientes de regresion estimados se interpretan de la forma siguiente:
1. b l es el aumento de la productividad provocado por el nuevo tipo de formacion CAl en comparacion con la formacion tradicional en el aula.
2. b2 es el aumento de la productividad provocado por la maquina de tipo2 en comparacion con la de tipo 1.
3. b3 es el aumento de la productividad provocado por la maquina de tipo 3 en comparacion con la de tipo 1.
4. b4 es el aumento de la productividad provocado por la educacion postsecundaria en comparacion con la secundaria solamente.
Cualquiera de estos «aumentos» podria ser negativo, 10 que implica una disminucion. La importancia de cada uno de estos efectos puede contrastarse utilizando nuestros
metodos tradicionales de contraste de hipotesis. Observese que si se pierde 0 falla una observacion experimental, puede seguir utilizandose el mismo modele de regresion para estimar los coeficientes. Sin embargo, en ese caso tenemos una varianza mayor y, pOI' 10 tanto, los contrastes de hipotesis tienen menos potencia.
Tambien es po sible afiadir al modelo variables continuas u otras variables relacionadas. Supongamos que Marfa sospecha que el mimero de afios de experiencia de los trabajadores y la temperatura ambiente tambien influyen en la productividad. Se pueden medir estas dos variables continuas para cada experimento y afiadir al modelo de regresion basado en variables ficticias. EI modele de regresion se convierte entonces en


Capitulo 14. Otros temas del analisis de regresion 589
EJERCICIOS
Ejercicios basicos
14.1. Farmule la especificaci6n de un model a y defina las variables de un modeJo de regresi6n multiple para predecir la calificaci6n media obtenida en la universidad en funci6n de la nota media obtenida en el bachillerato y del ano de estudios universitarios: primer ano, segundo ano, tercer ano, cuarto ano .
14.2. Formule la especificaci6n del modele y defina las variables de un modele de regresi6n multiple para predecir los salarios en d6Jares estadounidenses en funci6n de los anos de experiencia y del pais de empleo (Alemania, Gran Bretana, Japan, Estados Unidos y Turqufa).
14.3. Formule la especificaci6n del modele y defina las variables de un modelo de regresi6n multiple para predecir el coste por unidad producida en funci6n del tipo de fabrica (tecnologia clasica, maquinas controladas par computador y manipulaci6n del material control ada por computador) y en funci6n del pals (Colombia, SudMrica y Japan).
14.4. Un economista quiere estimar una ecuaci6n de regresi6n que relacione la demanda de un producto (Y) con su precio (X ,) y la renta (X2 ). Tiene que basarse en 12 an os de datos trimestrales. Sin embargo, se sabe que la demanda de este producto es estacional, es decir, es mayor en unos momentos del ano que en otros .
a) Una posibilidad para tener en cuenta la estacionalidad es estimar eJ modele
Yl = f30 + f3 , X'1 + f32 x 21 + f33x 3, + f34 X4,
+ f3SXSI + f36 x 6, + el
donde X31' X41' XS 1 Y X61 son val ores de las variables ficticias , siendo
X31 = 1 en el primer trimestre de cada ano, 0 en el resto
X41 = 1 en el segundo trimestre de cada ano, 0 en el resto
XS 1 = 1 en el tercer trimestre de cada ano, 0 en el resto
X61 = 1 en el cuarto trimestre, 0 en el resto
Explique par que este modele no puede estimarse por minimos cuadrados.
b) Un modele que puede estimarse es
y, = f30 + f3,xl! + f32X 21 + f33x 31 + f34 X41 + f3SXSl + e,
Interprete los coeficientes de las variables ficticias de este modelo.
Ejercicios aplicados
14.5. Sharon Parsons, presidente de Gourmet Box Mini Pizza, Ie ha pedido ayuda para desarrollar un modele que prediga la demanda de la nueva pizza llamada Pizzal. Este producto compite en el mercado con otras tres marcas que Ilamaremos B2, B3 y B4. Actualmente, los productos son vendidos por tres gran des cadenas de distribuci6n llamadas 1, 2 y 3 para identificarlas. Estas tres cadenas tienen diferentes cuotas de mercado y, por 10 tanto, es probable que las ventas de cada distribuidar sean diferentes. EI fichero de datos Market contiene datos semanales recogidos en las 52 ultimas semanas en las tres cadenas de distribucion. A continuaci6n, se definen las variables del fichero de datos .
Utilice la regresi6n multiple para desarrollar un modele que prediga la cantidad de PizzaJ vendida a la semana par cada distribuidor. El modele s610 debe contener variab les de predicci6n importantes.
Distribuidor Identificador numerico del distribuidor
Weeknum Numero secuencial de la semana en la que se recogieron los datos
Sales Pizzal Numero de unidades de Pizza I vendidas por el di stribuidor durante la semana
Price Pizzal Precio al pOl' menor de Pizza I cobrado por el distribuidor durante esa semana
Promotion Nivel de promoci6n de la semana: 0 significa Ninguna promoci6n; 1 significa Anuncios en televisi6n; 2 significa Exposici6n en las tiendas; 3 significa Anuncios en la televisi6n y Exposici6n en las tiendas
Sales B2 Numero de unidades de la marca 2 vendidas por el distribuidor durante la semana
Price B2 Precio al por men or de la marca 2 cobrado por el distribuidor dm'ante la semana
Sales B3 Numero de unidades de la marca 3 vendidas pOl' el clistribllidor durante la semana
Price B3 Precio al par menor de la marca 3 cobrado por el distribuidor durante la semana
Sales B4 Numero de unidades de la marca 4 vendidas pOI' el dist.ribuidor durante la semana
Price B4 Precio al. por menor de la marca 4 cobrado por el. distribllidor durante la semana
14.6. Le han pedido que desarrolle un modele de regresi6n multiple para predecir las ventas per capita de cereales de desayuno en las ciudades de mas de 100.000 habitantes. En primer lugar, celebra una reuni6n con los principales directivos de marketing que tienen experiencia en la venta de cereales. En esta reunion, descubre que se es-

590 Estadfstica para administraci6n y economfa
pera que en las ventas per capita influyan el precio de los cereales, el precio de los cereales rivales, la renta media per capita, el porcentaje de titulados universitarios, la temperatura anual media y la pluviosidad anual media. Tambien se entera de que la relaci6n lineal entre el precio y las ventas per capita se espera que tenga una pendiente diferente en las ciudades que se encuentran al este del rfo Misisipi. Se espera que las ventas per capita sean mayores en las ciudades que tienen una renta per capita alta y baja que en las ciudades que tienen una renta per capita intermedia. Tambien se espera que las ventas per capita sean diferentes en los cuatro sectores siguientes del pals: noroeste, sudoeste, noreste y sudeste.
Formule una especificaci6n del modelo cuyos coeficientes puedan estimarse por medio de la regresi6n multiple. Defina cada variable completamente e indique la forma matematica del modelo. Analice su especificaci6n, indique que variables espera que sean estadfsticamente significativas y explique las razones por las que 10 espera.
14.7. Maximo Marquez, presidente de Piezas Buenas, S.A., Ie ha pedido que desarrolle un modele que prediga e l n(imero de piezas defectuosas por turno de 8 horas de su fabrica. Cree que existen diferencias entre los tres turnos diarios y entre los cuatro proveedores de materias primas. Ademas, se piensa que cuanto mayor es la producci6n y mayor el numero de trabajadores, mayor es el numero de piezas defectuosas. Maximo visita la fabrica varias veces en los tres turnos para observar las operaciones y dar consejos. Le ha facilitado una lista de los turnos que ha visitado y quiere saber si el numero de piezas defectuosas aumenta 0 disminuye cuando visita la fabrica.
Describa por escrito como desarrollarfa un modele para estimar y contrastar los distintos factores que pueden influir en el numero de piezas defectuosas producidas por turno. Defina detenidamente cada coeficiente de su modele y el contraste que utilizarfa. Indique como recogerfa los datos y como definirfa cada variable utilizada en el modelo. Analice las interpretaciones que haria a partir de su especificacion del modelo.
14.8. Maderas de Calidad, S.A. , lleva 40 afios en el sector. Hace muebles de madera de encargo de alta calidad e interiores de armarios y trabajos de madera de interiores de muy buena calidad para viviendas y oficinas caras. La empresa ha tenido mucho exito debido en gran parte a la elevada cualificacion de los artesanos que disefian y
producen sus productos en consulta con sus clientes. Muchos de sus productos han recibido premios nacionales por la calidad de su disefio y el trabajo bien hecho. Cada producto hecho de encargo es producido por un equipo de dos artesanos 0 mas que primero se reunen con el cliente, realizan un primer disefio, 10 revisan con el cliente y despues fabrican el producto. Los clientes tam bien pueden reunirse con los artesanos varias veces durante la produccion.
Los artesanos tienen una buena formacion y han adquirido excelentes cualificaciones en el trabajo de la madera. La mayorfa tienen tftulo universitario y se han formado con artesanos cualificados. Los empleados se clasifican en tres niveles: I . Aprendiz, 2. Profesional y 3. Maestro. Los salarios de los niveles 2 y 3 son mas altos y los trabajadores normal mente ascienden con forme adquieren experiencia y cualificacion. Actualmente, la empresa tiene una plantilla diversa, en la que hay trabajadores blancos, negros y latinos y tanto hombres como mujeres. Cuando comenzo hace 40 afios, todos los trabajadores eran blancos. Hace unos 20 afios, comenzo a contratar artesanos negros y latinos, y hace unos 10 afios contrato artesanas. Los trabajadores blancos varones tienden a estar sobrerrepresentados en las clasificaciones de los puestos de trabajo mas altas debido en parte a que tienen mas experiencia. Actualmente, la plantilla tiene un 40 por ciento de hombres blancos, un 30 por ciento de hombres negros y latinos, un 15 por ciento de mujeres blancas y un 15 por ciento de mujeres negras y latinas.
Recientemente, algunos han expresado su preocupacion por la discriminacion salaria!. Concretamente, dicen que las mujeres y los que no son blancos no estan recibiendo una remuneracion acorde con su experiencia. La direccion de la empresa sostiene que todas las personas cobran en funcion de los afios de experiencia, del nivel de clasificacion del puesto de trabajo y de la capacidad personal. Sostiene que no existen diferencias salariales basadas en la raza 0 el sexo por 10 que se refiere al salario base 0 al incremento por cada afio de experiencia.
Explique como realizarfa un analisi s para averiguar si la afirmacion de la direccion es ciertao Muestre los detalles de su analisis y razonelos claramente. Indique los datos que deben recogerse y los nombres y las descripciones de las variables que utilizara en el anaLisis . Indique claramente los contrastes estadfsticos que utilizarfa

para averiguar cmil es la verdadera situacion e indique las reglas de decision basadas en los contrastes de hipotesis y los resultados de los datos.
14.9. Le han pedido que haga de consultor y de testigo experto en un juicio por discriminacion salaria!. Un grupo de mujeres latinas y negras ha demandado a su empresa, Distribuidores Reunidos, S.A. Las mujeres, que tienen entre 5 y 25 aiios de antigliedad en la empresa, alegan que su subida salarial anual media ha side significativamente menor que la de un grupo de hombres blancos y un grupo de mujeres blancas. Los puestos de trabajo de los tres grupos contienen diversos componentes administrativos, analiticos y directivos. Todos los empleados tenian titulacion universitaria de primer ciclo cuando empezaron a trabajar y los aiios de experiencia son un importante factor para predecir el rendimiento y la productividad de los trabajadores. Le han facilitado el salario mensual actual y el numero de aiios de experiencia de todos los trabajadores de los tres
Capftulo 14. Otros temas del analisis de regresion 591
grupos. Ademas, los datos indican los miembros de los tres grupos que tienen un master en administracion de empresas. Observe que en este problema no realiza ningun analisis de los datos.
a) Desarrolle un modele y un analisis estadfsticos que permitan analizar los datos . Indique los contrastes de hipotesis que pueden utilizarse para aportar pruebas contundentes de la existencia de discriminacion salarial si es que existe. La compaiifa tambien ha contratado a un estadfstico como consultor y testigo experto. Describa su analisis de una forma exhaustiva y clara.
b) Suponga que sus contrastes de hipotesis aportan pruebas contundentes que apoyan la tesis de sus clientes. Resuma brevemente las observaciones clave que hara en su comparecencia en el juicio. Es de esperar que el abogado de la empresa Ie contrainterrogue con la ayuda de su estadfstico, que enseiia estadfstica en una prestigiosa universidad.
14.3. Valores retardados de las variables dependientes como regresores
En este apartado examinamos las variables dependientes retardadas, un importante tema cuando se analizan datos de series temporales, es decir, cuando se realizan mediciones de las cantidades a 10 largo del tiempo. Por ejemplo, podemos tener observaciones mensuales, observaciones trimestrales u observaciones anuales. Los economistas normalmente utilizan variables de series temporales como los tipos de interes, medidas de la inflaci6n, la inversi6n agregada y el con sumo agregado para realizar anaIisis y desarrollar modelos. Especificamos las observaciones de series temporales utilizando el subfndice t para indicar el tiempo en lugar de la i que empleamos para indicar los datos de corte transversal. Por 10 tanto, un modelo de regresi6n multiple serfa
En muchas aplicaciones de series temporales, la variable dependiente en el periodo t a menudo tam bien est<'i relacionada con el valor que tom6 esta variable en el periodo anterior, es decir, con Yt- I' El valor de la variable dependiente en un periodo anterior se llama variable dependiente retardada.
Regresiones que contienen variables dependientes retardadas Consideremos el siguiente modele de regresi6n que relaciona una variable dependiente, Y, con K variables independientes:
(14.1 )

592 Estadfstica para administraci6n y economfa
don de fio' IJ1 , . .. , fi K , y son coeficientes fijos. Si se generan datos con este modelo:
a) Un aumento de la variable independiente X de 1 unidad en el periodo t, manteniendose fijas todas las demas variables independien'tes, provoca un aumento esperado de la variable dependiente de (i . en el periodo t, fJ ·y en el periodo (t + 1), fJ ·y2 en el periodo (t + 2), fJ
j/ en el period6 (t + 3), etc. EI aufnento total esperado en t6dos los periodos
actuales y futuros es
[3 . .I
(l - y)
b) Los coeficientes fJo' fi1, ... , 13K, y pueden estimarse por minimos cuadrados como siempre.
c) Pueden calcularse intervalos de confianza y contrastes de hip6tesis para los coeficientes de regresi6n exactamente igual que en el modele de regresi6n multiple ordinario (en rigor, cuando la ecuaci6n de regresi6n contiene variables dependientes retardadas, estos metodos s610 son aproximadamente validos. La calidad de la aproximaci6n mejora, manteniendose todo 10 demas constante, cuando aumenta el numero de observaciones muestrales) .
d) Cuando se utilizan intervalos de confianza y contrastes de hip6tesis con datos de series temporales, hay que tener cautela. Existe la posibilidad de que los errores de las ecuaciones, ei , ya no sean independientes entre sf. En el apartado 14.7 sobre las autocorrelaciones examinamos esta cuesti6n. En particular, cuando los errores estan correlacionados, las estimaciones de los coeficientes son insesgadas, pero no eficientes. Por 10 tanto, los intervalos de confianza y los contrastes de hip6tesis ya no son validos. Los econ6metras han desarrollado metodos para hacer estimaciones en estas condiciones, que se introducen en el apartado 14.7.
Para ilustrar el calculo de las estimaciones y de la inferencia basada en la ecuaci6n de regresi6n ajustada cuando el modelo contiene variables dependientes retardadas, examinamos el extenso ejemplo 14.4 (v ease la referencia bibliografica 1).
EJEMPLO 14.4. Los gastos publicitarios en funcion de las ventas al por menor (modelo de regresion con variables retardadas)
Un investigador tenia interes en predecir los gastos publicitarios en funci6n de las ventas al por menor, sabiendo que la publici dad del ano anterior tambien habia influido.
Solucion
Se crda que la publicidad local por hogar dependfa de las ventas al por men or por hogar. Ademas, como los publicistas pueden no querer 0 no poder ajustar sus planes a los cambios repentinos del nivel de ventas al por menor, se anadi6 al modelo el valor de los gastos publicitarios locales pOI' hogar del ano anterior. Por 10 tanto, los gastos publicitarios de este ano estan relacionados con las ventas al por menor (x,) de este ano y con los gastos publicitarios (Yt - I) del ano anterior. EI modelo que hay que ajustar es, pues,
don de
Yt = publicidad local por hogar en el ano t x, = ventas al pOI' menor por hogar en el ano t

>;
i
Advertising Retail
Capitulo 14. Otros temas del analisis de regresi6n 593
Los datos sobre la pubJicidad y las ventas al por menor se encuentran en un fichero de datos Minitab lIamado Advertising Retail. EI valor retardado Yt- I puede generarse en Minitab utilizando la funcion retardo (lag) en las rutinas de la calcuJadora y en todos los demas buenos paquetes estadisticos utilizando procedimientos similares. Despues de realizar la transformacion del retardo, el fichero de datos incluye la variable retardada. La observaci6n 1 de la variable retardada es inexistente, por 10 que el conjunto de datos solo tiene 21 observaciones. Siempre sera asf cuando se creen variables retardadas. Naturalmente, podrfamos tener acceso a datos del ano anterior -del ano ° en este ejemplo- y ese valor podrfa sustituir al valor que faltaba. Ahora ya estan listos los datos para realizar una regresion multiple utilizando los comandos convencionaJes de Minitab. La Figura 14.4 muestra la salida del analisis de regresion resultante.
The regression equation is Advertising y(t) = -43.8 + 0 . 01 88 Retail Sales X(t) + 0 . 479 lag advertising
21 cases used 1 cases contain missing values
Predictor Cons t ant Retai l S lag adve
Coef -43.766
0.018777 0.47906
SE Coef 9 . 843
0 . 002855 0 . 08732
T -4.45
6 . 58 5 . 49
P 0.000 0 . 000 0.000
S = 3 . 451 R- Sq = 96 . 3% R-Sq(adj) = 95.9%
Analysis of Variance
Source DF SS MS Regression 2 5559.1 2779.5 Residual Error 18 214 . 3 To t al 20 5773.4
Source DF Seq SS Retail S 1 5200.7 lag adve 1 358.4
Unusual observations obs Retail S Adv ertis
4 5507 119.220 20 6394 145 . 37 0
Fit 112 . 716 151.853
11. 9
F 233.43
P 0.000
SE Fit Residual 1.222 6 . 504 1.774 - 6 . 483
R denotes an observation with a large standardized residual
St Resid 2.02R
-2.19R
Figura 14.4. Gastos publicitarios en funci6n de las ventas al par menor y de los gastos publicitarios retardados (salida Minitab).
La regresion resultante de este problema (con la ausencia de la primera observacion) es
~
Yt = - 43,8 + 0,0188xt + 0,479Yt - I
(0,0029) (0,087)
Los numeros que figuran debajo de los coeficientes de regresion son las desviaciones tfpicas de los coeficientes. EI estadistico t de Student de cada coeficiente es bastante alto y los p-valores resultantes son 0,00, 10 que indica que podemos rechazar la hipotesis nula de que los coeficientes son 0. Con 18 grados de libertad para el error, el valor crftico del estadfstico t de Student de una hipotesis de dos colas suponiendo que (X = 0,05 es t = 2,101.

594 Estadfstica para administraci6n y ecanamfa
:~
INTERPRETACION
En los modelos de series temporales, el coeficiente de determinacion R2 puede ser algo enganoso. Por ejemplo, el elevado valor de R2 = 96,3 por ciento del presente problema no indica necesariamente que exista una estrecha relacion entre la publicidad local y las ventas al por menor. Es un hecho empfrico perfectamente conocido que los gnificos de much as series temporales empresariales y economicas muestran una pauta evolutiva bastante uniforme a 10 largo del tiempo. Este mero hecho es suficiente para que el coeficiente de determinacion tenga un valor alto cuando se incluye una variable dependiente retardada en el modelo de regresion. A efectos pnkticos, aconsejamos al lector que preste relativamente poca atencion al valor de R2 en esos modelos.
La regresion estimada para este problema puede interpretarse de la siguiente manera. Supongamos que las ventas al por menor por hogar aumentan 1 $ este ano. EI efecto esperado en la publici dad local por hogar es un aumento de 0,0188 este ano, otro aumento de
(0,479)(0,0188) = 0,0090 $
el proximo ano, otro aumento de
(0,479i (0,0188) = 0,0043 $
dentro de dos anos, y as! sucesivamente. El efecto total en los futuros gastos publicitarios totales por hogar es un aumento esperado de
00188 1 ~ 0,479 = 0,0361 $
Vemos, pues, que el efecto esperado de un aumento de las ventas es un aumento inmediato de los gastos publicitarios, un aumento menor durante el proximo ano, un aumento Min men or dentro de dos alios, etc. La Figura 14.5 ilustra este efecto geometricamente decreciente de un aumento de las ventas este ano en la publicidad de futuros anos.
~ "0 m "0
:~ .0 ::J
0,018
0. 0,012 ~
OJ "0 o "0 ~ OJ 0. ~ 0,006
.8 c OJ
E ::J « I I I I ° 234567
Numera de arias en el futuro
Figura 14.5. Aumentos futuros esperados de la publicidad local por hogar.

Capftulo 14. Otros temas del analisis de regresion 595
EJERCICIOS
Ejercicios basicos
14.10. Considere los siguientes modelos estimados utilizando un analisi s de regresi6n aplicado a datos de series temporales. i,Que efecto produce a largo plazo un aumento de x de 1 unidad en el periodo t?
a) Yt = 10 + 2x, + 0,34Yt _ 1 b) Yt = 10 + 2,5x, + 0,24Yt _ I c) Yt = 10 + 2xt + O,64Yt - 1 d) Yt = 10 + 4,3xt + 0,34Yt _ 1
14.11. Un analista de mercado tiene interes en saber cual es la cantidad media de dinero que gas tan al ano los estudiantes universitarios en ropa. Basandose en 25 anos de datos anuales, se ha obtenido la siguiente regresi6n estimada por mfnimos cuadrados:
Yt = 50,72 + 0,142x lt + 0,027x2t + 0,432Yt- I (0,047) (0,021) (0,136)
donde
Y = gasto por estudiante, en d61ares, en ropa XI = renta disponible por estudiante, en d6lares,
tras el pago de la matrfcula, las tasas y la manutenci6n
X2 = fndice de publicidad sobre ropa destinada al mercado estudiantil
Los numeros entre parentesis que se encuentran debajo de los coeficientes son los errores tfpicos de los coeficientes.
a) Contraste al nivel del 5 por ciento la hip6tesis nula de que, manteniendose todo 10 demas constante, la publici dad no afecta a los gastos en ropa en este mercado frente a la hip6tesis alternativa unilateral obvia.
b) Halle el intervalo de confianza aJ 95 por ciento del coeficiente de XI de la regresi6n poblacional.
c) Manteniendo fija la publicidad, i,cual serfa el efecto esperado con el paso del tiempo de un aumento de la renta disponible por estudiante de 1 $ en el gasto en ropa?
Ejercicios aplicados
14.12. f 11 Uti lice los datos del fichero Retail Sales para estimar el modele de regresi6n
Yt = f30 + f31X, + YY, - I + 8t
y contraste la hip6tesis nula de que Y = 0, donde
y, = ventas al por menor por hogar X t = renta disponible por hogar
14.13. f lI! Utilice el fichero de datos Money UK, que contiene observaciones del Reino Unido sobre la cantidad de dinero, en millones de libras (Y); la renta, en mill ones de libras (X I); y el tipo de interes de las autoridades locales (X2). Estime el modelo (vease la referencia bibliografica 5)
Yt = f30 + f31 XIt + f32 X2t + YYt - 1 + 8t
y realice un informe sobre sus resultados.
14.14. ~!I El fichero de datos Pension Funds contiene datos sobre el rendimiento de mercado (X) de las acciones y el porcentaje (Y) que representan las acciones ordinarias aJ valor de mercado a finales de ano en la cartera de los fondos privados de pensiones. Estime el modele
y, = f30 + f3 lx, + YYt - 1 + 8,
y escriba un informe sobre sus resultados.
14.15. ,. ~ El fichero de datos Income Canada muestra observaciones trimestrales sobre la renta (Y) y sobre la oferta monetaria (X) de Canada. Estime el modele (vease la referencia bibliogrMica 3)
y, = f30 + f3I Xt + YYt - 1 + 8t
y realice un informe sobre sus resultados.
14.16. € i!f El fichero de datos Births Australia muestra observaciones anuales sobre el primer parto de un nacido vivo del matrimonio actual (Y) y el mimero de primeros matrimonios (de mujeres) registrado en el ano anterior (X) en Australi a. Estime el modele (vease la referencia bibliografica 4)
Yt = f30 + f3I Xt + YYt - 1 + 8,
y real ice un informe sobre sus resultados.
14.17. t, El fichero de datos Pinkham Sales muestra observaciones anuales sobre las ventas unitarias (Y) y sobre los gastos publicitarios (X), ambos en miles de d61ares, de Lydia E. Pinkham. Estime el modele
log y, = f30 + f311ogx, + y lOgYt - l + 8t
y realice un informe sobre sus resultados (vease la referencia bibliografica 2).
14.18. , ~ El fichero de datos Thailand Consumption muestra 29 observaciones anuales sobre el consumo privado (Y) y la renta disponible (X) de Tailandia. Ajuste el modelo de regresi6n
log Yt = f30 + f3llogxlt + Y2 10g Y, - 1 + 6,
y realice un informe sobre sus resultados .

596 Estadfstica para administracion y economfa
La especificacion de un modele estadfstico que describa correctamente la conducta del mundo real es una tarea delicada y diffcil. Sabemos que ningun modele sencillo puede describir perfectamente la naturaleza de un proceso y los determinantes de sus resultados. El objetivo de la construccion de modelos es descubrir una formulacion sencilla que ref1eje correctamente el proceso subyacente para las cuestiones de interes. Sin embargo, tambien debemos sefialar que hay algunos casos en los que existe una divergencia considerable entre el modelo y la realidad que puede lIevar a extraer conclusiones seriamente erroneas.
Hemos visto anteriormente algunas tecnicas para especificar un modelo que refleje mejor el proceso. Nuestro uso de variables ficticias en los apartados 13.8 y 14.2 Y las transformaciones de model os no lineales en lineales en el 13.7 son importantes ejemplos. En este apartado examinamos las consecuencias de no incluir importantes variables de prediccion en nuestro modele de regresion.
Para formular un modelo de regresion, un investigador intenta relacionar la variable dependiente de interes con todos sus determinantes importantes. Por 10 tanto, si adoptamos un modelo lineal , queremos incluir como variables independientes todas las variables que podrfan influir considerable mente en la variable dependiente de interes. Para formular el modelo de regresion
suponemos implfcitamente que el conjunto de variables independientes, Xl' X2 , ... , XK , contiene todas las cantidades que afectan significativamente a la conducta de la variable dependiente, Y. Sabemos que en cualquier problema aplicado real hay otros factores que tambien afectan a la variable dependiente. La influencia conjunta de estos factores se absorbe dentro del termino de error, e;. Puede plantearse un grave problema si se omite una variable importante de la lista de variables independientes.
Sesgo provocado por la exclusion de variables de prediccion importantes Cuando se omiten en el modelo variables de predicci6n importantes, las estimaciones de coeficientes por minimos cuadrados incluidas en el modelo normalmente estan sesgadas y las afirmaciones inferenciales habituales basadas en los contrastes de hip6tesis 0 en los intervalos de confianza pueden ser seriamente engafiosas. Ademas, el error del modelo estimado incluye el efecto de las variables omitidas y, por 10 tanto, es mayor. En el raro caso en el que las variables omitidas no estan correlacionadas con las variables independientes incluidas en el modelo de regresi6n, no existe este sesgo en la estimaci6n de los coeficientes.
Examinemos un sencillo ejemplo sobre el mercado al por menor de gasolina. Supongamos que somos propietarios de la estacion de servicio A, que vende gasolina, y que la estacion de servicio B, que se encuentra a 100 metros de distancia, tambien vende gasolina. Creemos firmemente que si bajaramos el precio, las ventas unitarias aumentarfan y que si 10 subieramos, las ventas unitarias disminuirfan. Pero si la estacion B subiera y bajara su precio, este precio tambien influirfa en la variacion de nuestras ventas unitarias. Por 10 tanto, si no tenemos en cuenta el precio de la estacion B y solo consideramos nuestros pre-

Capftulo 14. Otros temas del analisis de regresi6n 597
cios cuando intentamos predecir las ventas unitarias, normalmente cometeremos graves elTores en nuestra estimacion de la relacion entre nuestro precio y nuestras ventas unitarias. A continuacion, mostramos este resultado matematicamente.
Mostramos como se produce el sesgo en la estimacion de los coeficientes de regresion mostrando el efecto de la omision de una variable en un modelo con dos variables independientes:
Supongamos que en esta situacion el analista excluye la variable X2 y estima, en su lugar, el modelo de regresion
Observese que hemos utilizado dos sfmbolos diferentes para hacer hincapie en el hecho de que los estimadores de los coeficientes senin diferentes. En el modelo de regresion simple, el estimador del coeficiente de x I es
II
~ i = j IX1=-n-- ---
'\' ( -)2 L. Xli - X
; = 1
Sustituyendo el modelo conecto con dos variables de prediccion y determinando el valor esperado, observamos que
1/ 1/
i= 1 n n =E
; = 1
i= 1 i = 1
Cuando calculamos el valor esperado, observamos que
n
L (Xl i - XI)X2i i=1
n
i=l
Vemos, pues, que el coeficiente de la variable Xl esta sesgado a menos que la conelacion entre XI y X2 sea O.
Los resultados matematicos anteriores muestran el sesgo de las estimaciones de los coeficientes que se produce cuando se omite una variable importante. En el Capitulo 13 mostramos matematicamente y de una forma intuitiva que en las estimaciones de los coeficientes de un modelo de regresion multiple influyen todas las variables independientes incluidas en el modelo. Por 10 tanto, si omitimos una variable independiente importante, los coeficientes estimados del resto de las variables seran diferentes. El ejemplo 14.5 muestra este resultado numericamente y debe estudiarse atentamente.

598 Estadfstica para administracion y economfa
Savings and Loan
~
INTERPRETACION
EJEMPLO 14.5. Modelo de regresion de las asociaciones de ahorro y credito inmobiliario con una variable omitida (error de especificacion del modelo)
Consideremos el ejemplo de las asociaciones de ahorro y credito inmobiliario uti lizado en el CapItulo 13. En ese ejemplo se hacfa una regresion del margen porcentual anual de beneficios (Y) de las asociaciones de ahorro y credito inmobiliario con respecto a sus ingresos porcentuales netos por dolar depositado (XI) y el numero de oficinas (X2).
En el ejemplo 13.3 estimamos los coeficientes de regresion y observamos que el mode-10 era
y = 1,565 + 0,237xl - 0,000249x2 R2 = 0,865 (0,0556) (0,0000321)
Una de las conclusiones de este am'ilisis es que, dado un numero fijo de oficinas, un aumento de los ingresos netos por dolar depositado de 1 unidad provoca un aumento esperado del margen de beneficios de 0,237 unidades. i,Que ocurrirfa si hicieramos una regresion del margen de beneficios unicamente con respecto a los ingresos netos por dolar depositado utilizando los datos almacenados en el fichero Savings and Loan?
Solucion
Utilizando los datos, hemos hecho una regresion del margen de beneficios (Y) con respecto a los ingresos netos por dolar depositado (Xl) Y hemos observado que el modelo era
y = 1,326 - 0,169x] (0,036)
R2 = 0,50
Comparando los dos modelos ajustados, observamos que una de las consecuencias de omitir X2 es que la variabilidad porcentual explicada, R2, disminuye considerablemente.
La omision produce, sin embargo, un efecto mas serio en el coeficiente de los ingresos netos. En el modelo de regresion multiple, un aumento de los ingresos netos de 1 unidad elevo los beneficios en 0,237, mientras que en el modelo de regresion simple el efecto fue una disminucion de 0,169. Este resultado va claramente en contra de la intuicion: no es de esperar que un aumento de los ingresos netos reduzca el margen de beneficios. En los dos modelos, rechazarfamos la hipotesis nula de que no existe una relacion. AquI vemos el resultado del estimador sesgado del coeficiente que se obtiene cuando no se incluye una variable importante, X2, en el modelo. Sin incluir el efecto condicionado del numero de oficinas, obtenemos un estimador sesgado.
Este ejemplo ilustra magnfficamente la cuestion. Si no se inclUye una variable explicativa importante en el modelo de regresion, cualquier conclusion que se extraiga sobre los efectos de otras variables independientes puede ser seriamente enganosa. En este caso, hemos visto que la introduccion de otra variable relevante mas podrfa muy bien alterar la conclusion de la existencia de una relacion negativa significativa y sustituirla por la conclusion de la existencia de una relacion positiva significativa. Observando los datos de la Tabla 13.1, es posible obtener mas informacion. En la segunda parte del periodo, al menos, el margen de beneficios disminuyo y los ingresos netos aumentaron, 10 que sugiere la existencia de una relacion negativa entre estas variables. Sin embargo, los datos revelan un aumento del numero de oficinas durante ese mismo periodo, 10 que sugiere la posibilidad

Capitulo 14. Otros temas del anal isis de regresi6n 599
de que este factor fuera la causa de la disminuci6n del margen de beneficios. La (mica forma legftima de distinguir los efectos de estas dos variables independientes en la variable dependiente es analizarlas conjuntamente en una ecuaci6n de regresi6n. Este ejemplo muestra la importancia de utilizar el modelo de regresi6n multiple en lugar de la ecuaci6n de regresi6n lineal simple cuando hay mas de una variable independiente relevante.
EJERCICIOS
Ejercicios basicos 14.19. Suponga que el verdadero modelo lineal de un
proceso era
y = f30 + f3I XI + f32 X2 + f33 X3
y que ha estimado incorrectamente el modelo
y = lXo + IX I X2
Interprete y contraste los coeficientes de X2 estimados en los dos modelos. Muestre el sesgo que se produce utilizando el segundo modelo.
14.20. Suponga que una relaci6n de regresi6n viene dada por
y= f30 + f3I X) + f32 X2 + I::
Si se estima la regresi6n lineal simple de Y con respecto a Xl a partir de una muestra de 11 observaciones, la estimaci6n resultante de la pendiente f31 generalmente esta sesgada. Sin embargo, en el caso especial en el que la correlaci6n muestral entre XI y X2 es 0, no ocurre asL De hecho, en ese caso la estimaci6n es la misma independientemente de que se incluya o no X2 en la ecuaci6n de regresi6n.
a) Explique verbal mente por que es cierta esta afirmaci6n.
b) Demuestre algebraicamente que esta afirmaci6n es cierta.
Ejercicios aplicados
14.21. ~; Transportation Research Inc. Ie ha pedido que formule algunas ecuaciones de regresi6n multiple para estimar el efecto de algunas variables en el ahorro de combustible. Los datos pa-
14.5. Multicolinealidad
ra realizar este estudio se encuentran en el fichero de datos Motors y la variable dependiente esta en millas por gal6n -milpgal- conforme a la certificaci6n del Departamento de Transporte.
a) Formule una ecuaci6n de regresi6n que utilice la potencia de los vehfculos -horsepower- y el peso de estos -weight- como variables independientes. Interprete los coeficientes.
b) Formule una segunda regresi6n sesgada que no incluya el peso de los vehfculos. i,Que conclusiones puede extraer sobre el coeficiente de la potencia?
14.22. f. Utilice los datos del fichero Citydat para estimar una ecuaci6n de regresi6n que perrnita averiguar el efecto marginal del porcentaje de locales comerciales en el valor de mercado por vivienda ocupada por su propietario (Hseval) . Incluya en su ecuaci6n de regresi6n multiple el porcentaje de viviendas ocupadas por sus propietarios (Homper), el porcentaje de locales industriales (Indper), el numero mediano de habitaciones por vivienda (sizehse) y la renta per capita (Incom72) como variables de predicci6n adicionales. Las variables estan incluidas en su disco de datos. Indique que variables son significativas. Su ecuaci6n final debe incluir solamente las variables significativas. Haga una segunda regresi6n excluyendo el numero mediano de habitaciones por vivienda. Interprete el nuevo coeficiente del porcentaje de locales comerciales que se obtiene en la segunda regresi6n. Compare los dos coeficientes.
Si se especifica correctamente un modelo de regresi6n y se satisfacen los supuestos, las estimaciones por minimos cuadrados son las mejores que pueden lograrse. No obstante, en algunas circunstancias j pueden no ser mu y buenas!

600 Estadfstica para administraci6n y economfa
Figura 14.6.
Para ilustrarlo supongamos que queremos desarrollar un modelo para predecir las ventas unitarias en funcion de nuestro precio y del precio del competidor. Imaginemos ahora que estamos en la afortunada posicion del cientifico de laboratorio, que somos capaces de disenar el experimento para estudiar este problema. El mejor enfoque para seleccionar las observaciones depende algo de los objetivos del amilisis, pero hay mejores estrategias.
Existen, sin embargo, opciones que no elegiriamos. Por ejemplo, no elegiriamos los mismos valores de las variables independientes para todas las observaciones. Tampoco seleccionarfamos variables independientes que esten muy correlacionadas. En el apartado 13.2 vimos que serfa imposible estimar los coeficientes si las variables independientes estuvieran perfectamente correlacionadas. Y en el 13.4 vimos que la varianza de los estimadores de los coeficientes aumenta a medida que la correlacion se aleja de O. En la Figura 14.6 vemos ejemplos de correlacion perfecta entre las variables Xl y X2• En estos graficos vemos que las variaciones de una variable estan relacionadas directamente con las variaciones de la otra. Supongamos ahora que estuvieramos intentando utilizar valores de las variables independientes como estos para estimar los coeficientes del modelo de regresion
La inutilidad de esa tare a es evidente. Si Xl varia al mismo tiempo que X2 , no podemos saber cual de las variables independientes esta relacionada realmente con la variacion de Y. Si queremos evaluar los efectos de cada variable independiente por separado, es esencial que no vaden exactamente al unisono en el experimento. Los supuestos habituales del ana!isis de regresion multiple excluyen los casos de correlacion perfecta entre variables independientes.
X2i
Dos disefios con correlaci6n perfecta. • •
• • 7.900 7 .900
• • 7.700 • 7.700 •
• • 7.500 • 7 .500 •
3,0 3,2 3,4 X1i 3,0 3,2 3,4 (a) (b)
El uso de las variables independientes en la Figura 14.6 seria una mala eleccion. La 14.7 muestra un caso algo menos extremo. Aqui los puntos del disefio no se encuentran en una unica lfnea recta, pero casi. En esta situacion, los resultados suministran alguna informacion sobre la influencia de cada variable independiente, pero no mucha. Es posible calcular estimaciones por minimos cuadrados de los coeficientes, pero estas estimaciones tendrian una elevada varianza. Como consecuencia, los coeficientes estimados no seran estadisticamente significativos, incluso aunque las relaciones sean muy estrechas. Este fenomeno se llama multicolinealidad. En el Capitulo 13 analizamos extensamente los efectos de las variables independientes correlacionadas.

Figura 14.7. Dos disenos con una elevada corre lac i6n.
Capitulo 14. Otros temas del anal isis de regresion 601
7.900 7.900
7.700 7.700
7 .500 7.500
3,0 3,2 3,4 3,0 3,2 3,4 (a ) (b )
En la inmensa mayorfa de los casos practicos relacionados con el mundo de la empresa y la economfa, no podemos controlar la elecci6n de las observaciones de las variables sino que nos vemos obligados a trabajar con el conjunto de datos que el destino nos ha dado. En este contexto, pues, la multicolinealidad es un problema que no se debe a que se hayan elegido mal los datos sino a los datos de que se dispone para hacer el amilisis . En el ejemplo de las asociaciones de ahorro y credito inmobiliario del Capftulo 13, habfa una elevada correlaci6n entre las variables independientes, pero esa era la realidad del contexto del problema. En terminos mas generales, en las ecuaciones de regresi6n en las que hay vadas variables independientes, el problema de multicolinealidad se debe a la existencia de pautas de estrechas intercorrelaciones entre las variables independientes. Quiza el aspecto mas frustrante del problema, que puede resumirse en la existencia de datos que no surninistran much a informaci6n sobre los parametros de interes, radique en que normal mente es poco 10 que se puede hacer para resolverlo. Sin embargo, aun asf es importante ser conscientes del problema y vigilar por si se plantea.
Hay algunos elementos que indican la posibilidad de que haya multicolinealidad. En primer lugar, siempre debe examinarse, por supuesto, una matriz de correlaciones simples de las variables independientes para averiguar si cualquiera de ell as esta correlacionada individualmente, como hicimos en el extenso ejemplo del apartado 13.9. Otra indicaci6n de la probable presencia de multicolinealidad es que parezca que un conjunto de variables independientes consideradas como un grupo ejerce una influencia considerable en la variable dependiente y que cuando se examinan por separado, por medio de contrastes de hip6tesis, parezca que todas son individualmente insignificantes. En este caso, podrfa utilizarse una funci6n lineal de las distintas variables para calcular una variable que sustituya a las distintas variables correlacionadas. Otra estrategia es hacer una regresi6n de las variables individuales independientes con respecto a todas las demas variables independientes del modelo. Eso puede mostrar complejas situaciones de multicolinealidad. Dada la presencia de multicolinealidad, en estas circunstancias serfa imprudente extraer la conclusi6n de que una determinada variable independiente no afecta a la variable dependiente. Es preferible reconocer que el grupo en su conjunto es claramente influyente, pero los datos no son 10 suficientemente informativos para poder distinguir con precisi6n los efectos de cada uno de sus miembros por separado.
Existe otro problema relacionado con este si se incluyen en un modelo variables de predicci6n redundantes 0 irrelevantes. Si estas variables innecesarias estan correlacionadas con las demas variables de predicci6n -y a menudo 10 estan-, la varianza de las estima-

602 Estadfstica para administraci6n y economfa
ciones de los coeficientes de las variables importantes aumentani, como se sefiala en el apartado 13.4. Como consecuencia, disminuini la eficiencia global de las estimaciones de los coeficientes. Debe tenerse cui dado de no incluir variables de prediccion inelevantes.
En las situaciones en las que la multicolinealidad es un problema, pueden utilizarse diversos enfoques. En todos ellos, es necesario analizar y valorar atentamente los objetivos del modelo y el entorno del problema que representa. En primer lugar, se puede eliminar una variable independiente que esta estrechamente correlacionada con una 0 mcis variables independientes. Eso reducira la varianza de la estimacion de los coeficientes, pero, como se muestra en el apartado 14.4, se podrfa introducir un sesgo en la estimacion de los coeficientes si la variable omitida es importante en el modelo. Se podria construir una nueva variable independiente que fuera una funcion de varias variables independientes estrechamente correlacionadas. Se podria sustituir por una nueva variable independiente que represente la misma influencia, pero no este conelacionada con otras variables independientes. Ninguno de estos enfoques es siempre la solucion perfecta. La multicolinealidad y las variables omitidas del apartado anterior son cuestiones que requieren una buena especificacion del modelo basada en una buena valoracion, en la experiencia y en la comprension del contexto del problema.
EJERCICIOS
Ejercicios aplicados 14.23. En el modele de regresi6n
Y = fJo + fJIXI + fJ2X2 + 8
es posible averiguar en que medida existe multicolinealidad hallando la correlaci6n entre XI Y X2 en la muestra. Explique por que es as!.
14.24. Un economista estima el modele de regresi6n
Y; = fJo + fJjX li + fJ2 X2; + 8;
Las estimaciones de los parametros fJ j Y fJ2 no son muy grandes en comparaci6n con sus errores tfpicos respectivos. Pero el tamano del coeficiente de determinaci6n indica la existencia de una relaci6n bastante estrecha entre la variable dependiente y el par de variables independientes. Una vez obtenidos estos resultados, el economista tiene firmes sospechas de la presencia de multicolinealidad. Como 10 que mas Ie interesa es saber c6mo influye XI en la variable dependiente, decide que evitara el problema de multi coline ali dad haciendo una regresi6n de Y
14.6. Heterocedasticidad
con respecto a XI solamente. Comente esta estrategia.
14.25. Basandose en los datos de 63 pafses, se estim6 el siguiente modelo por mfnimos cuadrados:
y = 0,58 - 0,052x I - 0,005X2 R2 = 0,17 (0,019) (0,042)
donde
y = tasa de crecimiento del producto interior bruto real
XI = renta real per capita X2 = tipo impositivo medio en porcentaje del
producto nacional bruto
Los numeros situados debajo de los coeficientes son los errores tfpicos de los coeficientes. Una vez eliminada en el modele la variable independiente XI' la renta real per capita, se estim6 la regresi6n de la tasa de crecimiento del producto interior bruto real con respecto a X2, el tipo impositivo medio, y se obtuvo el modele ajustado
y = 0,060 - 0,074x2 R2 = 0,072 (0,34)
Comente este resultado.
El metodo de estimacion por rninimos cuadrados y sus metodos inferenciales se basan en los supuestos tradicionales del amilisis de regresion . Cuando se cumplen estos supuestos, la regresion por mfnimos cuadrados proporciona un poderoso conjunto de instrumentos analf-

Capitulo 14. Otros temas del analisis de regresion 603
ticos. Sin embargo, cuando se viola uno 0 mas de estos supuestos, los coeficientes estimados pueden ser ineficientes y las inferencias realizadas pueden ser enganosas.
En este apartado y en el siguiente, consideramos los problemas que plantean los supuestos relacionados con la distribuci6n de los terminos de elTor Cj en el modelo
Concretamente, hemos supuesto que estos errores tienen una varianza uniforme y no estan cOlTelacionados entre sf. En el siguiente apartado, examinamos la posibilidad de que existan elTores correlacionados. Aqui analizamos el supuesto de la varianza uniforme.
Existen muchos ejemplos que sugieren la posibilidad de que la varianza no sea uniforme. Consideremos una situaci6n en la que nos interesa conocer los factores que afectan a la producci6n de una industria. Recogemos datos de varias empresas que contienen medidas de la producci6n y otras posibles variables de predicci6n. Si estas empresas son de diferente tamafio, la producci6n total varia. Es probable, ademas, que la varianza de la medida de la producci6n sea mayor en las gran des empresas que en las pequenas. Eso se debe a la observaci6n de que hay mas factores que afectan a los terminos de error en una empresa grande que en una pequefia. Por 10 tanto, los terminos de elTor seran mayores tanto en los terminos positivos como en los negativos.
Se dice que los modelos en los que los terminos de elTor no tienen todos la misma varianza muestran heterocedasticidad. Cuando este fen6meno esta presente, el metoda de minimos cuadrados no es el mas eficiente para estimar los coeficientes del modelo de regresi6n. Ademas, los metodos habituales para obtener intervalos de confianza y contrastes de hip6tesis de estos coeficientes ya no son validos. Necesitamos, pues, metodos para averiguar si existe heterocedasticidad. La mayoria de los metodos habituales comprueban el supuesto de la varianza constante de los elTores frente a alguna alternativa razonable. Podemos observar que la magnitud de la varianza de los elTores esta relacionada directamente con una de las variables de predicci6n independientes. Otra posibilidad es que la varianza aumente con el valor esperado de la variable dependiente.
En nuestro modelo de regresi6n estimado, podemos obtener estimaciones de los valores esperados de la variable dependiente utilizando
Y podemos estimar, a su vez, los terminos de error, ei' mediante los residuos
A menudo observamos que las tecnicas graficas son utiles para detectar la presencia de heterocedasticidad. En la practica, trazamos diagramas de puntos dispersos de los residuos en relaci6n con las variables independientes y los valores predichos, Yi' de la regresi6n. Consideremos, por ejemplo, la Figura 14.8, que muestra posibles graficos del residuo, ej, en relaci6n con la variable independiente X l i' En la parte (a) de la figura, vemos que la magnitud de los errores tiende a aumentar conforme mayores son los valores de Xl' 10 que indica que las varianzas de los errores no son constantes. En cambio, la parte (b) de la figura muestra que no existe una relaci6n sistematica entre los elTores y Xl' Por 10 tanto, en la parte (b) no existen pruebas de que la varianza no sea uniforme.
En el Capitulo 13 desarrollamos un modelo de regresi6n por minimos cuadrados para estimar la relaci6n entre el margen de beneficios de las asociaciones de aholTo y credito

604 Estadistica para administraci6n y economia
Figura 14.8. ei • ei
G raticos de los • • residuos en relaci6n • • • • can una variable independiente. • • • •
•
• • • • • •
U5 w 0:::
0.1 -
•• 0.0 -
• -0.1 -
3
• • • • • • • • • • • • • •
• • • X1i
• • •
• • X1i • • • • • • • • • •
• (a) Heterocedasticidad (b) Ninguna heterocedasticidad evidente
inmobiliario (Y) y los ingresos netos por d61ar depositado (X ,) y el numero de oficinas (X2 )
por medio del modelo
Consideremos el modelo de regresi6n estimado de la Figura 13.3. Calculamos los residuos de todas las observaciones utilizando el metodo expuesto en el extenso problema del apartado 13.9. En las Figuras 14.9 y 14.10 presentamos diagram as de puntos dispersos de los residuos en relaci6n con los ingresos por d61ar depositado y en relaci6n con el numero de oficinas. El examen de estos diagramas indica que no parece que exista ninguna relaci6n entre la magnitud de los residuos y cuaiquiera de las dos variables independientes. La Figura 14.11 presenta un diagrama de puntos dispersos de los residuos en relaci6n con el valor predicho de la variable dependiente. De nuevo, no parece que exista ninguna relaci6n entre el valor predicho de Y y la magnitud de los residuos. Basandonos en el examen de los graficos de los residuos, no encontramos pruebas de la existencia de heterocedasticidad.
A continuaci6n, examinamos un metodo mas formal para detectar la presencia de heterocedasticidad y para estimar los coeficientes de los modelos de regresi6n cuando se tienen firmes sospechas de que se viola el supuesto de las varianzas constantes de los en·ores. Hay muchos tipos de heterocedasticidad que pueden detectarse por medio de diversos metodos. Examinaremos uno de ellos que puede utilizarse para detectar la presencia de heterocedasticidad cuando la varianza del termino de error tiene una relaci6n lineal con el valor predicho de la variable dependiente .
• 0.1 - • • • • •
• •• • • •
• • • • •
• • , • U5
, • w 0.0 - • 0::: • • • • • • • • • • • • •• • • •
• • -0.1 -
4 5 6500 7500 8500 9500
X1 revenue X2 offices
Figura 14.9. Gratico de los residuos en relaci6n can los ingresos par d61ar depositado.
Figura 14.10. Gratico de los residuos en relaci6n con el numero de oficinas.

Figura 14.11. Dos diseiios con una elevada correlaci6n.
Capitu lo 14. Otros temas del analisis de regresion 60S
0.1 - • • • •
•• • • • • • • (j)
0.0 -w • 0::: • • • • • •
• • • • • •
-0 .1 -
0.4 0.5 0 .6 0.7 0.8
FITS1
Contraste de la presencia de heterocedasticidad Consideremos un modelo de regresion
Yi = f30 + f31Xli + f32X2i + ... + f3KXKi + ei
que relaciona una variable dependiente con K variables independientes y se bas a en n conjuntos de observaciones. Sean bo' b1, ... , bK la estimacion por mfnimos cuadrados de los coeficientes del modelo, con los valores predichos
Yi = b o + b1xli + b 2X 2i + ... + bKxKi
y sean los residuos del modelo ajustado
Para contrastar la hipotesis nula de que los terminos de error, ci ' tienen todos ellos la misma varianza frente a la alternativa de que sus varianzas dependen de los valores esperados
estimamos una regresion simple. En esta regresion, la variable dependiente es la rafz cuadrada de los residuos -es decir, Eif- y la variable independiente es el valor predicho, Yi ,
(14.2)
Sea R2 el coeficiente de determinacion de esta regresion auxiliar. En ese caso, en un contraste de nivel de significacion (J., la hipotesis nula se rechaza si nR2 es mayor que x~.~ , donde X~,a es el valor crftico de la variable aleatoria ji-cuadrado con 1 grado de libertad y una probabilidad de error (J..
Pondremos un ejemplo de este contraste utilizando el ejemplo de las asociaciones de ahorro y credito inmobiliario. La Figura 14.12 muestra un subconjunto de la salida Minitab del amilisis de regresi6n. Se emple6 el programa Minitab para calcular los cuadrados de los residuos y se realiz6 una regresi6n de los residuos con respecto al valor predicho.
A partir de la regresi6n de los cuadrados de los residuos con respecto a los valores predichos, obtenemos el modelo estimado
e2 = 0,00621 + 0,00550; (0,00433)
R2 = 0,066

606 Estadfstica para administracion y economfa
Figura 14.12. Reg resion de los cuad rados de los residuos con respecto al valor predicho (salida Minitab).
The regression equation is ResSquared 0.00621 - 0.00550 FITSI
Predictor Cons tant FITS1
Coef 0.006 211
-0.005503
SE Coef 0.002 970 0 . 004327
T 2.09
-1 .2 7
S = 0.002742 R-Sq = 6.6% R-Sq(adj) = 2.5%
Analysi s of variance
P 0 . 048 0.216
Source Regression Residual Error Total
DF SS MS F P 1 0.00 00 12158 0 . 000 01 2158 1.62 0.216
23 0.000172939 0.000007519 24 0 .000 185 09 7
La regresion contiene n = 25 observaciones y, por 10 tanto, el estadfstico del contraste es
nR2 = (25)(0,066) = 1,65
En la Tabla 7 del apendice observamos que para un contraste al nivel de significacion del 10 por ciento
Xf,O,lO = 2,71
Por 10 tanto, no podemos rechazar la hipotesis nula de que en el modelo de regresion los valores predichos tienen una varianza uniforme. Eso confirma nuestras conclusiones iniciales basadas en el examen de los diagramas de puntos dispersos de los residuos de las Figuras 14.9, 14.10 Y 14.11.
Supongamos ahora que hubieramos rechazado la hipotesis nul a de que la varianza era uniforme. En ese caso, el metoda ordinario de mfnimos cuadrados no serfa el me to do de estimacion adecuado para el modelo inicial. Existen varias estrategias de estimacion dependiendo de como sean de poco uniformes los errores. La mayorfa de los metodos implican la transformacion de las variables del modelo de manera que los terminos de error tengan una magnitud uniforme en el rango del modelo. Consideremos el ejemplo en el que la varianza de los terminos de error es directamente proporcional a] cuadrado del valor esperado de la variable dependiente. En este caso, podrfamos expresar aproximadamente el termino de error del modelo de la forma siguiente:
donde (ji es una variable aleatoria que tiene una varianza uniforme en el rango del modelo de regresion. Utilizando este termino de error, el modelo de regresion serfa
En esta aproximacion, el termino de error aumenta linealmente con el valor esperado, 10 cual implica que la varianza aumenta con el cuadrado del valor esperado. Aquf podemos obtener un termino de error cuya magnitud es uniforme en el modelo dividiendo cada termino de los dos miembros de la ecuacion por Yi' Cuando se parte de esta forma concreta,

Capitulo 14. Otros temas del amilisis de regresion 607
se utiliza un sencillo metodo de dos etapas para estimar los parametros del modelo de regresi6n. En la primera etapa, se estima el modelo por mfnimos cuadrados de la forma habitual y se registran los valores predichos, y;, de la variable dependiente. En la segunda etapa, se estima la ecuaci6n de regresi6n
con un termino de error que satisface los supuestos habituales del amilisis de regresi6n. En este modelo,hacemos una regresi6n de yJy; con respecto a las variables independientes 1!'y[, x li /Y1- x2;!Y!> ... , xK;!Y,. Este modelo no incluye una constante y la mayorfa de los paquetes estadfsticos tienen una opci6n que calcula estimaciones de los coeficientes excluyendo el terminG constante. Los coeficientes estimados son las estimaciones de los coeficientes del modelo original. Existen otros muchos metodos en cualquier buen libro de econometrfa en el apartado dedicado a los «minimos cuadrados ponderados».
Tambien pueden aparecer errores heterocedasticos si se estima un modelo de regresi6n lineal en circunstancias en las que es adecuado un modelo logarftmico-lineal. Cuando el proceso es tal que es adecuado un modelo logarftmico-lineal, debemos hacer las transformaciones y estimar un modelo logarftmico-lineal. Tomando logaritmos, disminuye la influencia de las gran des observaciones, sobre to do si estas se deben al crecimiento porcentual con respecto a momentos anteriores: una pauta de crecimiento exponencial. El modelo resultante a menu do parecera que esta libre de heterocedasticidad. Los modelos logarftmico-lineales a menudo son adecuados cuando los datos estudiados son series temporales de variables econ6micas, como el consumo, la renta y el dinero, que tienden a crecer exponencialmente con el paso del tiempo.
EJERCICIOS
Ejercicios aplicados
14.26. En el Capitulo 12, se estimo por minimos cuadrados la regresion de las ventas al por men or por hogar con respecto a la renta disponible por hogar. Los datos se encuentran en la Tabla 12.1 y la 12.2 muestra los residuos y los valores predichos de la variable dependiente.
a) A verigiie graficamente si existe heterocedasticidad en los errores de regresion.
b) Averigiie si existe heterocedasticidad utilizando un contraste formal.
14.27. Considere un modelo de regresion que utiliza 48 observaciones. Sea ei los residuos de la regresion ajustada e Yi los valores predichos de la variable dependiente dentro del rango de la muestra. La regresion por minimos cuadrados
de e; con respecto a Yi tiene un coeficiente de determinacion de 0,032. (,Que conclusiones puede extraer de este resultado?
14.28. '" El fichero de datos Household Income contiene datos de 50 estados de Estados Unidos. Las variables incluidas en el fichero son el porcentaje de mujeres que participan en la poblacion activa (y), la mediana de la renta personal de los hogares (Xl)' el numero medio de afios de estudios de las mujeres (X2) y la tasa de desempleo de las mujeres (X3).
a) Calcule la regresion multiple de Y con respecto a Xl> X2 Y X3 ·
b) Compruebe graficamente la presencia de heterocedasticidad en los errores de regresion.
c) Utilice un contraste formal para detectar la presencia de heterocedasticidad.

608 Estadfstica para adl11inistracion y econol11fa
14.7. Errores autocorrelacionados En este apartado, vemos que ocurre con el modele de regresi6n si los terminos de error estan correlacionados entre sf. Hasta ahora hemos supuesto que los errores aleatorios de nuestro modelo son independientes. Sin embargo, en muchos problemas empresariales y econ6micos utilizamos datos de series temporales. Cuando se analizan datos de series temporales, el termino de error representa el efecto de todos los factores, salvo las variables independientes, que influyen en la variable dependiente. En los datos de series temporales, la conducta de muchos de estos factores puede ser bastante parecida en varios periodos de tiempo y el resultado seria una correlaci6n entre los terminos de error que estan cerca en el tiempo.
Para hacer hincapie en el hecho de que las observaciones son observaciones de series temporales, colocamos el subindice t y formulamos el modelo de regresi6n de la siguiente manera:
En la regresi6n multiple, los contrastes de hip6tesis y los interval os de confianza suponen que los errores son independientes. Si no 10 son, los errores tfpicos estimados de los coeficientes estan sesgados. Por ejemplo, puede demostrarse que, si existe una correlaci6n positiva entre los terminos de error de observaciones de series temporales adyacentes, la estimaci6n del error tipico de los coeficientes por minimos cuadrados es demasiado pequena. Como consecuencia, el estadfstico t de Student calculado para el coeficiente es demasiado grande. Eso puede llevarnos a concluir que algunos coeficientes son significativamente diferentes de 0 -rechazando la hip6tesis nula Pj = 0- cuando, en realidad, no debe rechazarse. Ademas, los intervalos de confianza estimados serfan demasiado estrechos.
Es, pues, fundamental en las regresiones con datos de series temporales contrastar la hip6tesis de que los terminos de error no estan correlacionados entre sf. El hecho de que los errores de primer orden esten correlacionados a 10 largo del tiempo se conoce con el nombre de problema de errores autocorrelacionados. Cuando estudiamos este problema, es util tener presente alguna estructura de correlaci6n. Un modelo atractivo es que el error en el peliodo t, 8t , este estrechamente correlacionado con el error del periodo anterior, 81 _ I '
pero menos correlacionado con los errores de dos 0 mas periodos anteriores. Definimos
don de p es un coeficiente de correlaci6n y, por 10 tanto, su range es de - 1 a + 1, como vimos en el Capitulo 12. En la mayorfa de las aplicaciones, nos interesan sobre to do los valores positivos del coeficiente de correlaci6n. En el caso de los errores que estan separados por I periodos, la autocorrelaci6n puede definirse de la siguiente manera:
Corr(8p 81 - /) = /
Como consecuencia, la correlaci6n disminuye rapidamente a medida que aumenta el numero de periodos de separaci6n. Vemos, pues, que la correlaci6n entre los errores que estan separados en el tiempo es relativamente debil, mientras que la correlaci6n entre los errores que estan pr6ximos en el tiempo posiblemente sea bastante estrecha.
Ahora bien, si suponemos que los errores 8t tienen todos ellos la misma varianza, es po sible demostrar que la estructura de autocorrelaci6n corresponde al modele
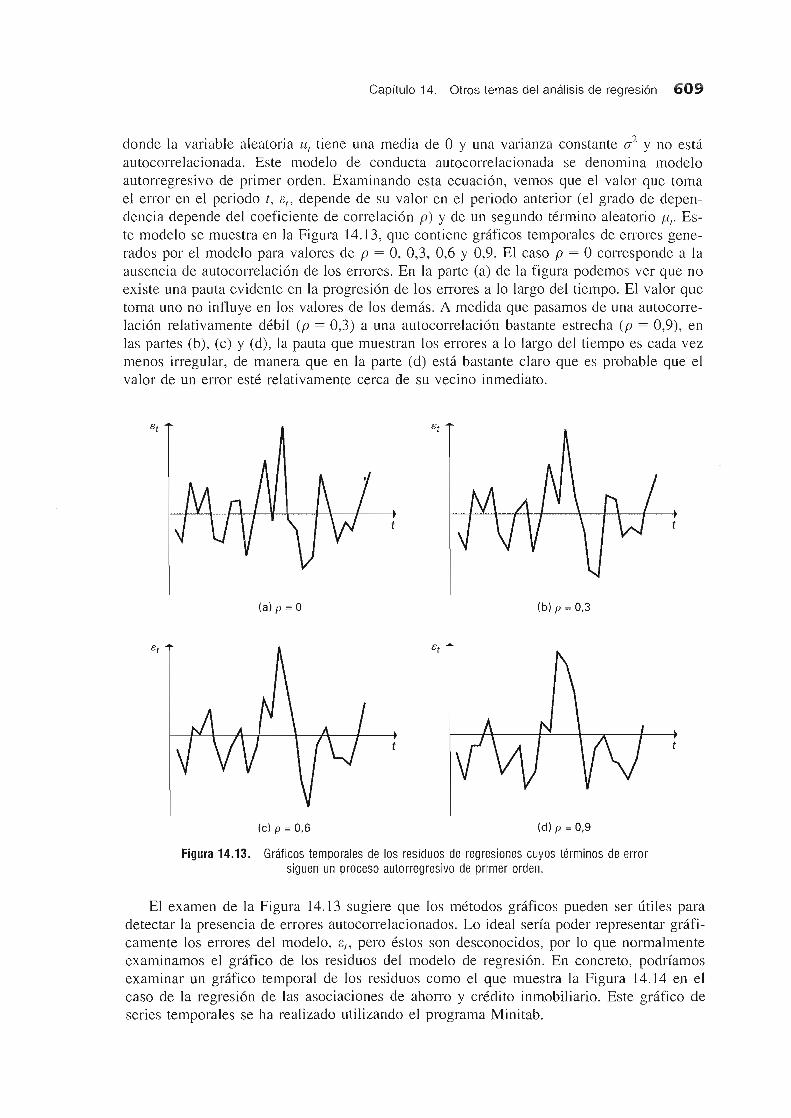
Capitulo 14. Otros temas del anal isis de regresion 609
donde la variable aleatoria U t tiene una media de ° y una varianza constante (J2 y no esta autocorrelacionada. Este modelo de conducta autocorrelacionada se denomina modelo autorregresivo de primer orden. Examinando esta ecuaci6n, vemos que el valor que toma el error en el periodo t, 8" depende de su valor en el periodo anterior (el grado de dependencia depende del coeficiente de correlaci6n p) y de un segundo termino aleatorio {it. Este modelo se muestra en la Figura 14.13, que contiene gnificos temporales de errores generados por el modelo para valores de p = 0, 0,3, 0,6 y 0,9. EI caso p = ° corresponde a la ausencia de autocorrelaci6n de los errores. En la parte (a) de la figura podemos ver que no existe una pauta evidente en la progresi6n de los errores a 10 largo del tiempo. El valor que toma uno no influye en los valores de los demas. A medida que pasamos de una autocorrelaci6n relativamente debil (p = 0,3) a una autocorrelaci6n bastante estrecha (p = 0,9), en las partes (b), (c) y (d), la pauta que muestran los errores a 10 largo del tiempo es cada vez menos irregular, de manera que en la parte (d) esta bastante claro que es probable que el valor de un error este relativamente cerca de su vecino inmediato.
(a) p = ° (b) p = 0,3
t
(c) p = 0,6 (d) p = 0,9
Figura 14.13. Graticos temporales de los residuos de regresiones cuyos terminos de error siguen un proceso autorregresivo de primer orden.
t
El examen de la Figura 14.13 sugiere que los metodos graficos pueden ser utiles para detectar la presencia de errores autocorrelacionados. Lo ideal serfa poder representar graficamente los errores del modelo, 8" pero estos son desconocidos, por 10 que normalmente examinamos el grafico de los residuos del modelo de regresi6n. En concreto, podrfamos examinar un grafico temporal de los residuos como el que muestra la Figura 14.14 en el caso de la regresi6n de las asociaciones de ahorro y credito inmobiliario. Este grafico de series temporales se ha realizado utilizando el programa Minitab.

610 Estadfstica para administraci6n y economfa
Figura 14.14. Grafico de series temporales de los residuos de la regresion de las asociaciones de ahorro y credito inmobiliario.
0.1
-0.1 '-__ ,--__ .---_-,-__ -,--__ ..-'
Index 5 10 15 20 25
Examinando el gnlfico de series temporales de la Figura 14.14, no vemos ninguna autocorrelacion de los residuos sino la pauta irregular de la Figura 14.13(a). Esta es una prueba en contra de la existencia de autocorrelacion. Sin embargo, como el problema es tan importante, es deseable tener un contraste mas formal de la hipotesis de que no existe ninguna autocorrelacion en los errores de un modelo de regresion.
EI contraste que m:ls se utiliza es el contraste de Durbin-Watson, basado en los residuos del modelo, et • El estadistico del contraste, d, se calcula de la siguiente manera:
n
L (e, - e,_ 1)2
d = _1=_2 ____ __ Il
y el metodo de contraste se describe a continuacion. Podemos demostrar que el estadistico de Durbin-Watson puede expresarse aproximada
mente de la forma siguiente:
d = 2(1 - r)
don de r es la estimacion muestral de la correlacion poblacional, p, entre los errores adyacentes. Si los errores no estan autocorrelacionados, entonces r es aproximadamente 0 y d es aproximadamente 2. En cambio, con una correlacion positiva los valores de d son bajos y 0 es el limite inferior y con una correlacion negativa, los valores de d son altos y 4 es el limite superior. Hay una dificultad teorica cuando se basan los contrastes de los errores autocorrelacionados en el estadistico de Durbin-Watson. EI problema estriba en que la distribucion muestral efectiva de d, incluso cuando la hipotesis de la ausencia de autocorrelacion es · verdadera, depende de los val ores de las variables independientes. Es evidentemente inviable calcular la distribucion con·espondiente a todos los conjuntos posibles de val ores de las variables independientes. Afortunadamente, se sabe que cualesquiera que sean las variables independientes, la distribucion de d se encuentra entre las distribuciones de otras dos variables aleatorias cuyos puntos porcentuales pueden calcularse. La Tabla 12 del apendice muestra los puntos de corte de estas variables aleatorias en el caso de los contrastes a niveles de significacion dell y el 5 por ciento. La tabla indica los valores de dL Y du correspondientes a divers as combinaciones de n y K. Se rechaza la hipotesis nula de que no existe ninguna autocorrelacion frente a la hipotesis alternativa de que existe una autocorrelacion positiva si el valor calculado de d es menor que el de dv Se acepta la hipotesis nul a si el valor de d es mayor que el de du y menor que 4 - du, mientras que el

Figura 14.15.
Capitulo 14. Otros lemas del anal isis de regresi6n 611
contraste no es concluyente si d se encuentra entre dL y duo Por ultimo, si el estadfstico d es mayor que 4 - dv concluirfamos que no existe ninguna autocorrelaci6n negativa. Esta compleja pauta se muestra en la Figura 14. 15.
p = o p<o Regia de decision para el contraste de Durbin-Watson. o
~ ________ ~A~ ________ _
o 4-
~ __ -,A~ __ --.,
d 4
Contraste no concluyente Contraste no concluyente
Contraste de Durbin-Watson Consideremos el modelo de regresion
basado en conjuntos de n observaciones. Nos interesa averiguar si los terminos de error estan autocorrelacionados y siguen un modelo autorregresivo de primer orden
donde ut no esta autocorrelacionado. EI contraste de la hipotesis nula de que no existe autocorrelacion
se basa en el estadistico de Durbin-Watson:
n
L (e t - et - 1)2
d = _t =_2 ________ _ n (14.3)
L e; t = 1
donde los et son los residuos cuando la ecuaci6n de regresion se estima por minimos cuadrados. Cuando la hip6tesis alternativa es que existe una autocorrelacion positiva de los errores, es decir,
H1 : p > 0
la regia de decision es la siguiente:
Rechazar Ho si d < dL Aceptar Ho sj d > du Contraste no concluyente Sl dL < d < du
don de dL
y du corresponden a los valores de n y K Y los niveles de signiticaci6n del 1 y el 5 por ciento que se encuentran en la Tabla 12 del apendice.
A veces queremos hacer un contraste trente a la hipotesis alternativa de que existe una autocorrelacion negativa, es decir,
HI:p <0

612 Estadfstica para administraci6n y economfa
En ese caso, la regia de decision es la siguiente:
Rechazar He si d > 4 - dL Aceptar He si d < 4 - du Contraste no concluyente si 4 - dL > d > 4 - du
La mayorfa de los program as informaticos calculan opcionalmente el estadfstico d de Durbin-Watson como parte de la estimacion de la regresion. La Figura 14.16 muestra la salida Minitab del ejemplo de las asociaciones de ahorro y credito inmobiliario con el estadfstico d de Durbin-Watson calculado. Este es igual a 1,95 y en el apendice vemos que cuando IX = 0,01, k = 2 y n = 25, los valores crfticos son dL = 0,98 Y du = 1,30. Por 10 tanto, Ho: P = ° no puede rechazarse, por 10 que concluimos que los terminos de error no estan autocorrelacionados.
Figura 14.16. Calcu lo del estadfstico de Durbin-Watson d (salida Minitab).
The regression equation is Y prof i t = l. 56 + 0.237 Xl rev enue -0.000249 X2 of fi ces
Predictor Coef StDev T p
Constant 1.56450 0.07940 19 . 70 0.000 Xl reven 0.2 3720 0.05556 4.27 0 .000 X2 offit -0.00024908 0.00003205 - 7.77 0 . 00 0
S = 0.05330 R- Sq = 86 .5 % R-Sq(adj) = 85 . 3%
nalysis of Variance
Source DF SS MS F Regression 2 0 .401 51 0 . 20076 70 . 66 Residua l Error 22 0 .0 6250 0 .00 284 To ta l 24 0.46402
Durbin-Watson statistic 1.95
0.000
Estimacion de las regresiones con errores autocorrelacionados
Cuando concluimos, basandonos en el contraste de Durbin-Watson, que tenemos en-ores autocorrelacionados, hay que modificar el metoda de regresion para eliminar el efecto de estos errores autocorrelacionados. Normalmente, se hace mediante una transformacion adecuada de las variables utilizadas en el metodo de estimacion de la regresi6n. Desarrollamos el metodo basi co en los pasos siguientes. En primer lugar, consideramos un modelo de regresi6n multiple con errores autocorrelacionados:
El mismo modele de regresi6n en el periodo t - 1:
Multiplicando los dos miembros de esta ecuaci6n por p, la correlaci6n entre los errores adyacentes nos da
PYt - l = {30 + {3IPXl,t - 1 + {32PX2,t - 1 + ... + {3k PXk,r - 1 + pCt- 1

Capitulo 14. Otros temas del analisis de regresi6n 613
A continuaci6n, restamos esta ecuaci6n de la primera para obtener
donde
Yt - PYt~ I = f3o(l - p) + f3I(Xt; - pxl.t~ I) + f32(X2t - PX2,t~ I)
+ ... + f3k(Xkt - Pxk.t ~ l) + Ilt
Ut = 8t - p8t ~ I
y la variable aleatoria ut tiene una varianza uniforme y no esta autocorrelacionada. Vemos que ahora tenemos un modelo de regresi6n que relaciona la variable dependiente (Yt - PYt~ I) Y las variables independientes (x lt - PXI.t ~ I), (X2t - PX2.t~ I), ... , (xkt - Xk.t~ 1)' Los parametros de este modelo son exactamente los mismos que los del modelo original, salvo que e\ termino constante es f3o(l - p) en lugar de 130' Mas importante es el hecho de que en este modelo los errores no estan autocorrelacionados y, por 10 tanto, puede utilizarse el metodo de regresi6n multiple por mfnimos cuadrados para estimar los coeficientes del modelo. Los metodos inferenciales por mfnimos cuadrados para hallar intervalos de confianza y realizar contrastes de hip6tesis son adecuados para este modelo transformado.
Basandonos en este analisis, vemos que el problema de los errores autocorrelacionados puede evitarse estimando la regresi6n por mfnimos cuadrados utilizando la variable dependiente (Yt - PYt~ I) Y las variables dependientes (Xli - PXI.t ~ I), (X2t - PX2.t~ I), ... , (Xkt - PXk. t ~ I)' Desgraciadamente, este enfoque plantea un problema en la practica porque no conocemos el valor de p. En diferentes program as informiiticos se utilizan distintos metodos para estimar p. Aquf, mostramos un sencillo metodo en el que utilizamos
r = 1
para estimar p.
d
2
Estimacion de modelos de regresion con errores autocorrelacionados Supongamos que queremos estimar los coeficientes del modele de regresi6n
cuando el termino de error 8 t esta autocorrelacionado. Podemos estimarlos en dos etapas de la forma siguiente:
1. Estimamos el modelo p~r minimos cuadrados, obteniendo el estadistico de DurbinWatson y, por 10 tanto, la estimaci6n
d r=l--
2 (14.4)
del parametro de autocorrelaci6n. 2. Estimamos por minimos cuadrados una segunda regresi6n en la que la variable de
pendiente es (Yt - ryt - 1 ) y las variables independientes son (Xlt - rXI.t ~ 1)'
(X21 - rX2.t ~ 1)' ... , (Xkt - rXk.t ~ I)·
Los parametros [31' [32' ... , [3k son los coeficientes de regresi6n estimados en este segundo mo-delo. Se obtiene una estimaci6n de [30 dividiendo la constante estimada en el segundo modelo por (1 - r). Los contrastes de hip6tesis y los intervalos de confianza de los coeficientes de regresi6n pueden realizarse utilizando los resultados de la segunda regresi6n.

614 Estadfstica para administracion y economfa
Macro2003
EJEMPLO 14.6. Modelo de regresion de series temporales (analisis de regresion con errores correlacionados)
En este ejemplo extenso, mostramos c6mo se realiza un amilisis de regresi6n, utilizando el program a Minitab, cuando los errores esUin autocorrelacionados. En este ejempl0, queremos desalTollar un modelo que prediga el con sumo agregado de bienes duraderos en funci6n de la renta disponible y del tipo de interes de los fondos federales.
Solucion
Los datos de este proyecto se encuentran en un fichero llamado Macro2003. Las variables de este fichero se describen en el apendice del capitulo. Utilizamos las variables
CDR YPDR FFED
Gastos person ales de consumo: bienes duraderos (d6lares reales de 1996) Renta personal disponible (d6lares reales de 1996) Tipo efectivo de los fondos federales
El fichero de datos contiene datos trimestrales desde el primer trimestre de 1946 hasta el segundo de 2003, pero queremos estimar el modelo utilizando datos del periodo comprendido entre el primer trimestre de 1980 y el segundo de 2003. Por 10 tanto, nuestra primera tarea es obtener un subconjunto de estos datos utilizando el programa Minitab.
A continuaci6n, hacemos la regresi6n multiple y mostramos la salida en la Figura 14.17.
Regression Analysis: CDH versus VPDH, FFED
The regression equation is CDH = - 654 + 0 . 224 YPDH + 6 . 71 FFED
Predictor Coef 8E Coef T P Constant -653.52 46.47 -14 . 06 0 . 000 YPDH 0.224220 0.006785 33 . 05 0.000 FFED 6 . 709 1. 893 3 . 54 0.001
8 = 41.4305 R-Sq = 96.3% R-8q(adj) = 96.2%
Analysis of Variance
Source DF 88 MS F P Regression 2 4139436 2069718 1205.7 9 0.000 Residual Error 92 157917 1716 Total 94 4297352
Durbin- Watson statistic = 0 . 284994
Figura 14.17. Regresion multiple para predecir el consumo de bienes duraderos: datos originales (salida Minitab).
EI estadlstico de Durbin-Watson de este modelo es 0,28, 10 que indica que existe una autocorrelaci6n positiva. Por 10 tanto, es necesario utilizar transformaciones para obtener variables apropiadas para realizar la regresi6n. Se calcula un valor estimado de la correlaci6n serial, r, utilizando la relaci6n de la ecuaci6n 14.4:
d 0,28 r = 1 - 2 = 1 - - 2- = 0,86

Capitulo 14. Otros temas del anal isis de regresi6n 615
A continuaci6n, se calculan las variables transformadas en el programa Minitab utilizando el valor estimado r = 0,86. Como la transformaci6n utiliza un valor retardado de cada variable, perdemos la primera observaci6n del conjunto de datos. Esa es la raz6n por la que incluimos el cuarto trimestre de 1979 en el conjunto de datos seleccionados. La Figura 14.18 presenta el modelo de regresi6n preparado utilizando las variables modificadas.
Regression Analysis: cdhadj versus ypdhadj, FFEDadj
The regression equation is cdhadj = -68.2 + 0.201 ypdhadj - 1.78 FFEDadj
94 cases used, 1 cases contain missing values
Predictor Coef SE Coef T P Constant -68.21 11.13 -6 . 13 0.000 Ypdhadj 0.20060 0.01318 15.22 0.000 FFEDadj - l. 777 1.886 -0.94 0.349
S = 19.5675 R-Sq = 74.3% R-Sq (adj) = 73 . 7%
Analysis of Variance
Source DF SS Regression 2 100696 Residual Error 91 34843 Total 93 135538
Durbin-Watson statistic = 2 .38 972
MS 50348
383
F
131.50 P
0 . 000
Figura 14.18. Regresion multiple para predecir el consumo de bienes duraderos: variables transformadas sin autocorrelacion (salida Minitab).
La comparaci6n de las salidas de las Figuras 14.17 y 14.18 indica claramente los problemas que plantean los modelos de regresi6n que tienen errores autocorrelacionados. EI primer analisis de regresi6n es
CDH = -654 + 0,224 YPDH + 6,71 FFED (0,006785) (1 ,893)
R2 = 0,963 d = 0,28
Observese que los numeros que figuran debajo de los coeficientes son los errores estadfsticos de los coeficientes.
La primera regresi6n tiene un estadfstico d de Durbin-Watson de 0,28, 10 que indica que existe una fuerte autocorrelaci6n positiva. Basandonos en los estadfsticos de los coeficientes estimados concluimos que tanto la renta disponible (b l = 0,224) como el tipo de interes de los fondos federales (b2 = 6,71) son predictores estadfsticamente significati vos de los gastos de con sumo en bienes duraderos.
Sin embargo, el segundo analisis de regresi6n -basado en datos del modelo sin errores autocorrelacionados- lleva a una conclusi6n diferente:
CDHadj = -68,2 + 0,201 YPDHadj - 1,78 FFEDadj (0,01318) (l,886)
R2 = 0,743 d = 2,39

616 Estadfstica para administraci6n y economfa
Observese que los nombres de las variables se han modificado para retlejar el hecho de que se han transformado en variables que produciran un modelo que no tendra autocorrelacion. Observese tambien que el estadistico d de Durbin-Watson es 2,39, 10 que indica que no existe autocorrelacion. Vemos que el coeficiente estimado de la renta disponible, b l = 0,201, es similar al de la primera regresion y que el error tfpico del coeficiente es 0,01318. El estadfstico t de Student resultante, 15,22, nos lleva a conduir que la renta disponible es un predictor importante del consumo de bienes duraderos. En cambio, el coeficiente del tipo de interes de los fondos federales es b2 = -1,78 con un estadfstico t de Student de - 0,94. Por 10 tanto, no podemos rechazar la hipotesis nula de que el coeficiente del tipo de los fondos federales es ° y de que debemos eliminar esa variable como predictor en el modelo de regresion.
En este ejemplo, hemos visto que la autocorrelacion lleva a extraer una conclusion incorrecta sobre la importancia del tipo de interes de los fondos federales. Sin ajustar los datos para eliminar la correlacion, habrfamos utilizado el estadfstico t de Student del modelo con los datos originales y ese estadfstico t de Student de la regresion sin ajustar sobreestima el estadfstico t de Student de la regresion ajustada. El estadfstico t de Student del coeficiente de la renta disponible de la primera regresion tambien esta sobreestimado. Sin embargo, tras realizar los ajustes pertinentes para obtener el estimador correcto, observamos que el coeficiente sigue siendo considerablemente diferente de 0.
Algunos paquetes estadfsticos como Eviews3 y SAS, que estan pensados para trabajar con datos de series temporales, tienen rutinas que estiman automaticamente el coeficiente de autocorrelacion y realizan los ajustes necesarios para tener en cuenta la autocorrelacion. Muchas de estas rutinas tienen rutinas de calculo iterativas, por 10 que generan estimaciones de los coeficientes y de las varianzas del modelo mejores que con la rutina mostrada aquf. Asi pues, si el lector tiene acceso a un program a de ese tipo, Ie resultara mas facil la estimacion que con el Minitab 0 el Excel. En general, esos otros programas informaticos obtienen estimaciones mas eficientes de los coeficientes.
Errores autocorrelacionados en los modelos con variables dependientes retardadas
Cuando tenemos un modelo de regresion con variables dependientes retardadas en el segundo miembro y tambien tenemos errores autocorrelacionados, los metodos habituales de mfnimos cuadrados pueden plantear problemas incluso mas graves. Ademas de los problemas habituales que plantea la estimacion de los errores de los coeficientes, tambien sabemos que los estimadores de los coeficientes estan sesgados y no son consistentes, debido a que existe una correlacion entre el error del modelo y una variable de prediccion y eso introduce un sesgo en la estimacion de los coeficientes. Desgraciadamente, en esta situacion en que hay variables dependientes retardadas, los metodos antes analizados para detectar la presencia de errores autocorrelacionados no son validos, por 10 que presentaremos brevemente un metodo adecuado.
Consideremos el modelo

Capitulo 14. Otros temas del analisis de regresi6n 617
Supongamos que se ajusta este modelo a n conjuntos de observaciones muestrales por mfnimos cuadrados. Sea d el estadfstico de Durbin-Watson habitual con
r = 1 d
2
y sea Sc la desviacion tfpica estimada del coeficiente estimado y de la variable dependiente retardada. Nuestra hipotesis nula es que el panimetro autorregresivo P es 0. Un contraste de esta hipotesis, aproximadamente valido en las gran des muestras, se basa en el estadfstico h de Durbin:
h = rJn/O - ns~)
En la hipotesis nula, este estadfstico tiene una distribucion de la que la distribucion normal estandar es una buena aproximacion cuando las muestras son grandes. Asf, por ejemplo, se rechaza la hipotesis nula de que no existe autocorrelacion frente a la hipotesis alternati va de que P es positivo al nivel de significacion del 5 por ciento si el estadfstico h es superior a 1,645.
Si el error autorregresivo es
entonces, utilizando una modificacion del metodo antes desarrollado para el ajuste para tener en cuenta la autocorrelacion, podemos desarrollar el siguiente modelo:
Y, = PY, - I = fJoO - p) + fJl(X 11 - PX1 ,(- I) + fJiX21 - PX2,I - I) + + fJk(Xkl - PXk,I- I) + Y(Yt - I - PY, - 2) + 6,
Uno de los enfoques posibles para estimar los parametros, que solo requiere un programa ordinario de estimacion por mfnimos cuadrados, es introducir, a su vez, en la ecuacion anterior los valores posibles de P, par ejemplo, 0,1, 0,3, 0,5, 0,7 Y 0,9. En ese caso, la regresion de la variable dependiente (Yt - PY, - I) Y las variables independientes (XII - PXI ,I- I), (X21 - PX2 (- I), ... , (Xkt - PXk (- I), (Yt - I - PYt - 2) se ajusta par minimos cuadrados para ca-" ' ,,'
da valor posible de p. El valor de P elegido es aquel con el que la suma resultante de los cuadrados de los en'ores es menor. La inferencia sobre fJj se basa entonces en la regresion ajustada correspondiente,
EJERCICIOS
Ejercicios basicos
14.29. Suponga que se realiza una regresi6n con tres variables independientes y 30 observaciones. EI estadfstico de Durbin-Watson es 0,50. Contraste la hip6tesis de que no hay autocolTelaci6n. Calcule una estimaci6n del coeficiente de autocorrelaci6n si los datos indican que hay autocon'elaci6n .
a) Repita con un estadfstico Durbin-Watson igual a 0,80.
b) Repita con un estadfstico Durbin-Watson igual a 1,10.
c) Repita con un estadfstico Durbin-Watson igual a 1,25.
d) Repita con un estadfstico Durbin-Watson igual a 1,70.
14.30. Suponga que se realiza una regresi6n con tres variables independientes y 28 observaciones. El estadfstico de Durbin-Watson es 0,50. Contraste la hip6tesis de que no hay autocorrela-

618 Estadfstica para administracion yeconomfa
cion. Calcule una estimacion del coeficiente de autocorrelacion si los datos indican que hay autocorrelacion.
a) Repita con un estadfstico Durbin-Watson igual a 0,80.
b) Repita con un estadfstico Durbi n -Watson igual a 1,10.
e) Repita con un estadfstico Durbin-Watson igual a 1,25.
d) Repita con un estadfstico Durbin-Watson igual a 1,70.
Ejercicios aplicados
14.31. En una regresion basada en 30 observaciones anuales, se relaciono la renta agricola de Estados Unidos con cuatro variables independientes: las exportaciones de cereales, las subvenciones federales , la poblacion y una variable ficticia de los alios de mal tiempo. EI modelo se aj usto por mfnimos cuadrados, 10 que dio como resultado un estadfstico de Durbin-Watson de 1,29. La regresion de et con respecto a Yi dio un coeficiente de determinacion de 0,043.
a) Realice un contraste de la heteroscedasticidad.
b) Realice un contraste de la existencia de errores autocorrelacionados.
14.32. Considere el modele de regresion
y, = Po + PIXI, + P2X2, + ... + PKXK, + s, Demuestre que si
Var(s) = Kx; (K > 0)
entonces
var(~) = K
Analice la posible relevancia de este resultado en el tratamiento de un tipo de heterocedasticidad.
14.33. Vuelva al ejercicio 14.13. Sea ei los residuos de la regresion ajustada e y, los valores predichos dentro del rango de la muestra. La regresion por mlnimos cuadrados de ef con respecto a Yi tiene un coeficiente de determinacion de 0,087. i,Que conclusion puede ex traer de este resultado?
14.34. (i ~ Vuelva al ejercicio 14.13 sobre la oferta monetaria del Reino Unido. i,Que conclusion puede ext:raer del estadfstico de Durbin-Watson de la regresion ajustada? (Fichero de datos, Money UK).
14.35. (, Vuelva al ejercicio 14.18 sobre el consumo en Tailandia. Contraste la hipotesis nula de que no existen errores autocorrelacionados frente a la aJternativa de que existe una autocorrelacion positiva (fichero de datos, Thailand Consumption).
14.36. Un empresario crefa que sus costes de produccion unitarios (y) dependfan del salario (XI), de los costes de otros factores (X2), de los costes generales (X3) y de los gastos publicitarios (X4)' Se obtuvo una serie de 24 observaciones mensuales y se realizo una estimacion por mfnimos cuadrados del modele que dio los siguientes resultados:
y, = 0,75 + 0,24xl' + 0,56x21 - 0,32x3' + 0,23x4' (0,07) (0, 12) (0,23) (0,05)
R2 = 0,79 d = 0,85
Las cifras entre parentesis situadas debajo de los coeficientes estimados son sus errores tfpicos estimados. i,Que conclusiones puede extraer de estos resultados?
14.37. ( J El fichero de datos Advertising Retail muestra 22 alios consecutivos de datos sobre las ventas (y) y la publicidad (x) de una empresa de bienes de consumo.
a) Estime la regresion
y, = Po + f3lx, + s, b) A verigiie si hay errores autocorrelacionados
en este modelo. e) Si es necesario, estime de nuevo el modelo,
teniendo en cuenta la posible existencia de errores autocorrelacionados.
14.38. La omision de una variable independiente importante en un modele de regresion de series temporales puede provocar la aparicion de errores autocorrelacionados. En el ejemplo 14.5, hemos estimado el modele
y, = f30 + PIXI, + s, que relaciona el margen de beneficios con los ingresos netos basandose en nuestros datos de las asociaciones de ahorro y credito inmobiliario. Realice un contraste de Durbin-Watson de los residuos de este modelo. i,Que puede inferir de los i'esultados?
14.39. Vuelva al ejercicio 14.11 sobre el dinero que gas tan los estudiantes en ropa. El estadfstico de Durbin-Watson del modelo de regresion ajustado es 1,82. Contraste la hipotesis nula de que no hay en'ores autocOiTelacionados frente a la alternativa de que hay una autocorrelacion positiva.

Capitulo 14. Otros temas del analisis de regresion 619
RESUMEN
En este capitulo hemos mostrado que la construccion de modelos de regresion consiste en algo mas que en los metodos basicos presentados en los Capftulos 12 y 13. En la practica, la construccion de un buen modele tiene mucho de arte y exige hacer un detenido analisis. En particular, no deben dejarse de lade importantes variables explicativas. Algunos problemas exigen la utilizacion de variables ficticias 0 de variables independientes retardadas. Recuerdese que en el CapItulo 13 mostramos que tambien pueden utili zarse modelos transformados que incluyan formas cuadraticas y formas logarltmico-lineales.
Como hemos visto, debemos comprobar tambien, en la medida de 10 posible, cualquier supuesto postula-
do sobre la conducta de los terminos de error. Pueden realizarse contrastes de heterocedasticidad y en'ores autocorrelacionados si se sospecha que existe alguno de los dos problemas. Y si ex isten, es necesario estimar de nuevo el modele utilizando metodos adecuados desarrollados en este capItulo y en textos avanzados .
Aquf hemos analizado algunas de las circunstancias posibles en las que es deseable desviarse del an<ili sis de regresion tradicional. Hay otros muchos metodos que se explican en los libros de texto de econometrfa. Si el lector tiene alguna incertidumbre sobre los supuestos de un metodo concreto, debe consultar un libro de texto avanzado 0 a un econometra familiari zado con esos metodos avanzados.
TERMINOS CLAVE
contraste de Durbin-Watson, 610 contraste de la presencia
estimacion de coeficientes, 577 estimacion de modelos
regresiones que contienen variables dependientes retardadas, 591 de heterocedasticidad, 605
disefio experimental, 584 errores autocorrelacionados, 608 errores autocorrelacionados con
de regresion con errores autocorrelacionados, 613
heterocedasticidad, 603 interpretacion del modelo
sesgo provocado por la exclusion de variables de prediccion importantes, 596
variables dependientes retardadas, 616 especificacion del modelo, 577
e inferencia, 578 variables ficticias, 579 verificacion del modelo, 578 multicolinealidad, 600
EJERCICIOS V APLICACIONES DEL CAPiTULO
14.40. Escriba breves informes con ejemplos explicando como se utilizan en la especificaciOri de los modelos de regresion de:
a) Las variables ficticias b) Las variables dependientes retardadas c) La transformacion logaritmica
14.41. Considere el ajuste del modele
y = f30 + f3I XI + f32 X2 + f33 X3 + 8
donde
Y = ingresos fiscales en porcentaje del producto nacional brute de un pafs
XI = exportaciones en porcentaje del producto nacional bruto del pais
X2 = renta per capita del pafs X3 = variable ficticia que toma el valor 1 si el
pais participa en algun tipo de integracion economica y 0 en caso contrario.
Esta es una forma de tener en cuenta los efectos que produce en los ingresos fiscales la partici-
pacion en aIgun tipo de integracion economica. Otra posibilidad serfa estimar la regresion
Y = f30 + f3I XI + f32X2 + 8
por separado para los palses que participan y no participan en algun tipo de integracion economica. Explique en que se diferencian estos enfoques del problema.
14.42. Analice la siguiente afirmaci6n: «En muchos problemas practicos de regresi6n, la multioolinealidad es tan grave que serfa mejor realizar regresiones lineales simples independientes de la variable dependiente con respecto a cada variable independiente».
14.43. Explique la naturaleza de cada uno de los siguientes problemas y las dificultades que plantean:
a) La heterocedasticidad b) Los errores autocorrelacionados

620 Estadfstica para administraci6n y economfa
14.44. Se ha ajustado eI siguiente modelo a los datos de 90 empresas qufmicas alemanas:
51 = 0,819 + 2,llxj + 0,96x2 - 0,059x3 + 5,87x4 ( 1,79) (1 ,94) (0, 144) (4,08)
+ 0,00226xs R 2 = 0,410 (0,00115)
donde los numeros entre parentesis son los errores tfpicos de los coeficientes estimados y
y = precio de la acci6n X I = beneficios por acci6n X2 = flujo de fondos por acci6n X3 = dividendos por acci6n X4 = valor con table por acci6n Xs = medida del crecimiento
a) Contraste al nivel del 10 por ciento la hip6-tesis nula de que el coeficiente de XI es 0 en la regresi6n poblacional frente a la hip6tesis alternativa de que el verdadero coeficiente es positivo.
b) Contraste al nivel del 10 por ciento la hip6-tesis nula de que el coeficiente de x2 es 0 en la regresi6n poblacional frente a la hip6tesis alternativa de que el verdadero coeficiente es positivo.
c) La variable X2 se ha eliminado del modelo original y se ha estimado la regresi6n de Y con respecto a (XI> X3 , X4 , Xs). El coeficiente estimado de XI es 2,95 con un error tfpico de 0,63. i,C6mo puede conciliarse este resultado con la conclusi6n del apartado (a)?
14.45. Se ha ajustado el siguiente modelo a los datos de 28 paises correspondientes a 1989 para explicar el valor de mercado de su deuda en ese momenta:
y = 77,2 - 9,6xl - 17,2x2 - 0,15x3 + 2,2x4 (8,0) (2,73) (0,056) (1,0)
R2 = 0,84 donde
y = precio en el mercado secundario, en d61ares, en 1989 de 100 $ de deuda del pais
XI = 1 si los reguladores bancarios de Estados Unidos han obligado a los bancos de Estados Unidos a amortizar los activos que tienen del pafs, 0 en caso contrario
X2 = 1 si el pafs suspendi6 el pago de los intereses de la deuda en 1989, 2 si suspendi6 el pago de los intereses de la deuda antes de 1989 y aun sigue suspendido y 0 en caso contrario
X3 = cociente entre la deuda y el producto nacional bruto
X4 = tasa de crecimiento del producto nacional bruto real, 1980-1985
Los numeros entre parentesis situados debajo de los coeficientes son los errores tfpicos de los coeficientes.
a) Interprete el coeficiente estimado de X I'
b) Contraste la hip6tesis nul a de que, manteniendose todo 10 demas constante, el cociente entre la deuda y el producto nacional bruto no influye linealmente en el valor de mercado de la deuda de un pafs frente a la alternativa de que cuanto mas alto es este cociente, menor es el valor de la deuda.
c) Interprete el coeficiente de determinaci6n. d) La especificaci6n de la variable fictici a x2
no es ortodoxa. Una alternativa seria sustituir X2 por el par de variables (xs, X6):
Xs = 1 si el pais suspendi6 el pago de los intereses de la deuda en 1989, 0 en caso contrario
X6 = 1 si el pais suspendi6 el pago de los intereses de la deuda antes de 1989 y aun sigue suspendido, 0 en caso contrario
Compare las implicaciones de estas dos especificaciones alternativas.
14.46. Se ha intentado construir un modele de regresi6n que explique las calificaciones obtenidas por los estudiantes en los cursos de economia intermedia (vease la referencia bibliografica 6). El modelo de regresi6n poblacional suponia que
Y = calificaci6n total de los estudiantes en los cursos de economfa intermedia
XI = calificaci6n en matematicas en el examen normalizado SAT
X2 = calificaci6n en lengua en el examen normalizado SAT
X3 = calificaci6n obtenida en algebra en la universidad (A = 4, B = 3, C = 2, D = 1)
X4 = calificaci6n obtenida en la asignatura de principios de economfa de la universidad
Xs = variable ficticia que toma el valor 1 si el estudiante es mujer y 0 si es hombre
X6 = variable ficticia que toma el valor 1 si el profesor es hombre y 0 si es mujer
X7 = variable ficticia que toma el valor 1 si el estudiante y el profesor son del mismo sexo y 0 en caso contrario
Este modelo se ajust6 con datos de 262 estudiantes. A continuaci6n, indicamos los estadisticos t; que son el cociente entre la estimaci6n de

f3i Y su error tfpico estimado correspondiente. Estos cocientes son
tl = 4,69
t5 = 0,13
t2 = 2,89 t3 = 0,46 t4 = 4,90
t6 = -1,08 t7 = 0,88
El objetivo de este estudio era evaluar la influencia del sexo del estudiante y del profesor en el rendimiento. Realice un breve informe esbozando la informacion que ha obtenido sobre esta cuestion.
14.47. Se ha ajustado la siguiente regresion por minimos cuadrados a 32 observaciones anuales sobre datos de series temporales:
log Yt = 4,52 - 0,62 log XII + 0,92 log X21 + 0,6110gx31 (0,28) (0,38) (0,21)
+ 0,1610gx41 (0,12)
iP = 0,683 d = 0,61
donde
Y, = cantidad de trigo exportada por Estados Unidos
XII = precio del trigo de Estados Unidos en el mercado mundial
X2t = cantidad cultivada de trigo en Estados Unidos
x31 = medida de la renta en los pafses que impartan trigo de Estados Unidos
X4t = precio de la cebada en el mercado mun-dial
Los numeros situ ados debajo de los coeficientes son los errores tipicos de los coeficientes.
a) Interprete el coeficiente estimado de 10gXII en el contexte del modelo supuesto.
b) Contraste al nivel del 5 por ciento la hipotesis nula de que, manteniendose to do 10 demas constante, la renta de los pafses que importan trigo no influye en las exportaciones de trigo de Estados Unidos frente a la hipotesis altemativa de que un aumento de la renta eleva las exportaciones esperadas (no tenga en cuenta de momenta el estadfstico d de Durbin-Watson).
c) i,Que hipotesis nula puede contrastarse por medio del estadfstico d? Realice este contraste en el presente problema, utilizando un nivel de significacion dell por ciento.
d) Dados los resultados obtenidos en el apartado (c), comente sus conclusiones del apartado (b). i,Como contrastaria la hipotesis nul a del apartado (b)?
Capitulo 14. Otros temas del anal isis de regresion 621
14.48. Se ha ajustado la siguiente regresion por mlnimos cuadrados a 30 observaciones anuales sobre datos de series temporales:
logy, = 4,31 + 0,2710gXII + 0,5310gx2t - 0,8210gx31 (0,17) (0,21) (0,30)
iP = 0,615 d = 0,49 donde
Y, = numero de quiebras de empresas XII = tasa de desempleo X21 = tipo de interes a corto plazo X31 = valor de los nuevos pedidos realizados
Los nlImeros situados debajo de los coeficientes son los errores tfpicos de los coeficientes.
a) Interprete el coeficiente estimado de log X31 en el contexto del modelo supuesto.
b) i,Que hipotesis nula puede contrastarse par medio del estadfstico d? Realice este contraste en el presente problema utilizando un nivel de significacion del 1 por ciento.
c) Dados los resultados del apartado (a), i,es posible contrastar con la informacion dada la hipotesis nula de que, manteniendose todo 10 demas constante, los tipos de interes a corto plazo no influyen en las quiebras de empresas?
d) Estime la correlacion entre los terminos de error adyacentes en el modele de regresion.
14.49. Un corredor de bolsa tiene interes en saber cuales son los factores que influyen en la tasa de rendimiento de las acciones ordinarias de los bancos. Se ha estimado por minimos cuadrados la siguiente regresion con una muestra de 30 bancos:
Y = 2,37 + 0,84xl + 0,15X2 - 0,13x3 + 1,67x4 (0,39) (0,12) (0,09) (1 ,97)
R2 = 0,317 donde
y = tasa porcentual de rendimiento de las acciones ordinarias del banco
XI = tasa porcentual de crecimiento de los beneficios del banco
X2 = tasa porcentual de crecimiento de los activos del banco
X3 = perdidas por prestamos en porcentaje de los activos del banco
X4 = 1 si la central del banco esta en Nueva York y ° en caso contrario
Los numeros situados debajo de los coeficientes son los errores tfpicos de los coeficientes.
a) Interprete el coeficiente estimado de X4' b) Interprete el coeficiente de determinacion y
utilfcelo para contrastar la hipotesis nula de

622 Estadfstica para administraci6n y economfa
que las cuatro variables independientes, consideradas en conjunto, no influyen linealmente en la variable dependiente.
c) Sea ei los residuos de la regresi6n ajustada e ? los valores predichos de la variable dependiente dentro del rango de la muestra. La regresi6n de minimos cuadrados de e~ con respecto a? gener6 un coeficiente de determinaci6n de 0,082. l,Que conclusiones pueden extraerse de este resultado?
14.50. Un analista de mere ado esta interesado en saber cua! es la cantidad media de dinero que gastan anualmente los estudiantes en ocio. Se ha estimade por minimos cuadrados la siguiente regresi6n con datos anuales de 30 afios:
Yt = 40,93 + 0,253xI + 0,546YI_I d = 1,86 (0,106) (0,134)
donde
YI = gasto por estudiante, en d6lares, en ocio XI = renta disponible por estudiante, en d6lares,
una vez pagada la matrfcula, las tasas y la manutenci6n
Los numeros situados debajo de los coeficientes son los errores tfpicos de los coeficientes.
a) Halle el intervalo de confianza al 95 por ciento del coeficiente de X, en la regresi6n poblacional.
b) l, Que efecto es de esperar que produzca a 10 largo del tiempo un aumento de la renta disponible por estudiante de 1 $ en el gasto en ocio?
c) Contraste la hip6tesis nula de que no existe ninguna autocorrelaci6n en los errores frente a la hip6tesis alternativa de que existe una autocon'elaci6n positiva.
14.51. A una empresa local de servicios publicos Ie gustarfa ser capaz de predecir la factura mensual media en electricidad de una vivienda. EI estadistico de la empresa ha estimado por minimos cuadrados el siguiente modelo de regresi6n:
donde
Y = factura mensual media en electricidad, en d6lares
Xl = factura bimestral media en gasol ina para autom6viles
X2 = numero de habitaciones de la vivienda
EI estadistico obtuvo la siguiente salida SAS basandose en una muest:ra de 25 viviendas:
STUDENT'S t STD.
FOR HO: ERROR OF
PARAMETER ESTIMATE PARAMETER = 0 ESTIMATE
INTERCEPT Xl
- 10 . 80 30 - 0. 0247 -0 . 956 0 . 0259
X2 10. 94 09 18 . 517 0. 5909
a) Interprete, en el contexte del problema, la estimaci6n por minimos cuadrados de f32'
b) Contraste la hip6tesis nula
Ho:f31 = 0
frente a la hip6tesis alternativa bilateral. c) El estadfstico esta preocupado por la posibi
lidad de que exista multicolinealidad. l,Que informaci6n se necesita para evaluar la posible gravedad de este problema?
d) Se sugiere que la renta de los hogares es un importante determinante de la cuantfa de la factura de electricidad. De ser eso cierto, l,que puede decirse sobre la regresi6n estimada por el estadfstico?
e) Dado el modele ajustado, el estadfstico obtiene las facturas predichas de electricidad, y, y los residuos, e. A continuaci6n, hace una regresi6n de e2 con respecto a y, y observa que la regresi6n tiene un coeficiente de determinaci6n de 0,0470. Interprete este resultado.
14.52. ~ V El fichero de datos Indonesia Revenue muestra 15 observaciones anuales de Indonesia sobre los ingresos fiscales totales, salvo los generados por el petr61eo (y), la renta nacional (Xl) y el valor afiadido por el petr6leo en porcentaje del producto interior bruto (X2)' Estime por minimos cuadrados la regresi6n
10gYI = fJo + fJllogXlt + fJ210gx2t + G,
Realice un informe que resuma sus resultados, incluido un contraste de la existencia de heterocedasticidad y otro de la existencia de errores autocorrelacionados.
14.53. f. .'ll EI fichero de datos German Income muestra 22 observaciones anuales de la Republica Federal de Alemania sobre la variaci6n porcentual de los sueldos y salarios (y), el crecimiento de la productividad (Xl) y la tasa de inflaci6n (X2) medida por medio del deflactor del producto nacional bruto. Estime por minimos cuadrados la regresi6n
Yt = fJo + fJIXI I + fJ2 X2t + GI
Escriba un informe que resuma sus resultados, incluido un contraste de la existencia de heterocedasticidad y un contraste de la existencia de errores autocorrelacionados.

14.54. ('i EI fichero de datos Japan ImpOits muestra 35 observaciones trimestrales de Japon sobre la cantidad de importaciones (y), el cociente entre los precios de las importaciones y los precios interiores (XI) y el producto nacional bruto real (X2)' Estime por minimos cuadrados la regresion
10gYt= f30 + f3l logx lt + f32 10g x2t + Y log Y, - I + Sf
Realice un informe que resuma sus resultados, incluido un contraste de la existencia de errores autocorrelacionados.
14.55. Se ha realizado un estudio sobre los costes por hora de trabajo de las auditorfas realizadas a los bancos por el banco central. Se han obtenido datos sobre 91 auditorfas. Algunas han sido realizadas directamente por el banco central y en otras han intervenido auditores externos. Los allditores han calificado la direccion de los bancos de buena, satisfactoria, correcta 0 insatisfactoria. EI modelo estimado es
logy = 2,41 +0,367410gxI + 0,221710gx2+ 0,080310gx3 (0,0477) (0,0628) (0,0287)
- 0,1755x4 + 0,2799xs + 0,5634x6 - 0,2572x7 (0,2905) (0,1044) (0,1657) (0,0787)
R2 = 0,766 donde
Y = horas de trabajo de los auditores del banco central
XI = total de activos del banco X2 = numero total de oficinas del banco X3 = cociente entre los prestamos clasificados
como dudosos y los prestamos totales del banco
X4 = 1 si la valoracion de la direccion es «buena» y 0 en caso contrario
Xs = 1 si la valoracion de la direccion es «correcta» y 0 en caso contrario
x6 = 1 si la valoracion de la direccion es «insatisfactoria» y 0 en caso contrario
X7 = 1 si la auditorfa se realizo conjuntamente con auditores extemos y 0 en caso contrario
Los numeros entre parentesis situados debajo de los coeficientes son los errores tfpicos de los coeficientes.
14.56. fliJ EI fic hero de datos Britain Sick Leave muestra datos de Gran Bretafia sobre el numero de dias de baja por enfermedad por persona (Y), la tasa de desempleo (Xl)' el cociente entre las prestaciones y los ingresos (X2) y el salario real (X3 ) . Estime el modelo
10gYt = f30 + f31 10gxI' + f3210gX2f + f3310gX3f + s,
y realice un informe sobre sus resultados. 1ncluya en su amllisis una comprobacion de la po-
Capftulo 14. Otros temas del anal isis de regresion 623
sibilidad de que haya errores autocorrelacionados y, si es necesario, una correccion para resolver este problema.
14.57. f..; EI Departamento de Comercio de Estados Unidos Ie ha pedido que desarrolle un modelo de regresion para predecir la inversion trimestral en prodllccion y eqllipo dllradero. Las valiables de prediccion sugeridas son el PIB, el tipo de interes preferencial, el fndice de precios de las mercancfas industriales y el gasto publico. Los datos de su amilisis se encuentran en el fichero de datos Macro2003, que esta aim acenado en su disco de datos y se describe en el diccionario de datos del apendice de este capftulo. Uti lice datos del periodo de tiempo comprendido entre el primer trimestre de 1976 y el segundo de 2003.
a) Estime un modelo de regresion utilizando solamente el tipo de interes para predecir la inversion. Utilice el estadfstico de DurbinWatson para contrastar la existencia de autocorrelacion.
b) Halle la mejor ecuacion de regresion multiple para predecir la inversi6n utilizando las variables de predicci6n indicadas anteriormente. Utilice el estadistico de Durbin-Watson para contrastar la existencia de autocorrelacion.
c) i,Que diferencias hay entre los model os de regresion de los apartados (a) y (b) desde el punto de vista de la bondad del ajuste, la capacidad de prediccion, la autocorrelacion y la contribucion a comprender el problema de inversion?
14.58. I ~ Un economista Ie ha pedido que desarrolle un modelo de regresion para predecir el consumo de servicios en funci6n del PNB y de otras variables importantes. Los datos para hacer el aniilisis se encuentran en el fichero de datos Macro2003, que estan almacenados en su disco de datos y se describen en el apendice del capitulo. Utilice datos del periodo comprendido entre el primer trimestre de 1003 Y el cuarto de 2000.
a) Estime un modelo de regresion utilizando solamente el PIB para predecir el consumo de servicios. Contraste la existencia de autocorrel aci6n utilizando el estadistico de Durbin-Watson.
b) Estime un modelo de regresion multiple utilizando el PNB, el consumo total retardado 1 periodo y el tipo de interes preferencial como predictores adicionales. Contraste la existencia de autocorrelaci6n. i,Reduce esta

624 Estadistica para administracion y economia
regresi6n multiple el problema de la autocorrelacion?
14.59. , ~ Jack Wong, inversor de Tokio, esta considerando la posibilidad de establecer una planta de acero primario en Japon. Tras revisar la propuesta inicial, Ie preocupa la combinacion propuesta de capital y trabajo. Le ha pedido que formule varias funciones de produccion utilizando algunos datos historicos de Estados Unidos. El fichero de datos Metals contiene 27 observaciones de la produccion, medida por el valor afiadido, de la cantidad de trabajo y del valor bruto de la planta y equipo de cada fablica.
a) Utilice una regresion mUltiple para estimar una funci6n de producci6n lineal haciendo una regresion del valor afiadido con respecto al trabajo y el capital.
b) Represente graficamente los residuos en relacion con el trabajo y el equipo. Sefiale las pautas excepcionales que pueda haber.
c) Utilice una regresion mUltiple con variables transformadas para estimar una funcion de produccion Cobb-Douglas de la forma
y = f3od 'KfJ2
donde y es el valor afiadido, L es la cantidad de trabajo y K es la cantidad de capital.
d) Utilice una regresion multiple con variables transformadas para estimar una funci6n de producci6n Cobb-Douglas con rendimientos constantes de escala. Observe que esta funci6n de produccion tiene la misma forma que la funcion estimada del apartado (c), pero tiene la restricci6n adicional de que f3 , + /32 = 1. Para desarrollar el modele de regresion transform ado, exprese /32 en funci6n de /31 y convierta la expresi6n a un formato de regresion.
e) Compare las tres funciones de producci6n utilizando graficos de los residuos y un error tipico de la estimacion expresado en la mis-
Apendice
rna escala. Tendra que convertir los valores predichos de los apartados (c) y (d) (que estan en logaritmos) en las unidades originales . A continuaci6n, puede restar los valores predichos de los valores originales de Y para obtener los residuos. Utilice los residuos para calcular errores tfpicos comparables de la estimacion.
14.60. f Ij Las autoridades de una pequefia ciudad Ie han pedido que identifique las variables que influyen en el valor medio de mercado de las viviendas de las ciudades pequefias del Medio Oeste. El fichero de datos Citydat contiene datos de algunas pequefias ciudades. Las variables de predicci6n candidatas son el tamafio medio de la vivienda (sizehse), el tipo del impuesto sobre bienes inmuebles (taxrate) (el impuesto dividido por el valor catastral total), los gastos totales en servicios municipales (totexp) y el porcentaje de locales comerciales (comper) .
a) Estime el modele de regresi6n multiple utilizando todas las variables de prediccion indicadas. Selecciones unicamente las variables estadisticamente significativas para formular su ecuacion final.
b) Segun un economista, como los datos proceden de ciudades que tienen diferente numero de habitantes, es probable que su modelo contenga heterocedasticidad. Sostiene que los precios medios de las viviendas de las ciudades mayores tendrfan una varianza menor, ya que el numero de viviendas utilizadas para calcular los precios medios de la vivienda serfa mayor. Realice un contraste de la existencia de heterocedasticidad.
c) Estime la ecuaci6n de regresi6n mUltiple utilizando minimos cuadrados ponderados con la poblacion como variable de ponderacion. Compare los coeficientes de los modelos de regresion multiple ponderado y no ponderado.
Diccionario de datos del fichero de datos Macro2003 El fichero de datos contiene datos trimestrales que van del primer trimestre de 1946 al segundo de 2003. Salvo que se indique 10 contrario, los datos estin expresados en d61ares de 1996 utilizando el nuevo indice de precios encadenado. Algunas series no comienzan en 1946, 10 cual se indica diciendo que tienen menos de 218 observaciones.

FM2
FFED
FBPR
CDH
CNH
CSH
CH
Chtot
FNH
FRH
VH
IH
IHTOT
XH
MH
GH
GDPH
Gdphtot
IGDP
YP
YPD
YPDH
YPSV
YPO
serie
serie
serie
serie
serie
serie
serie
serie
serie
serie
serie
serie
serie
serie
serie
serie
serie
serie
serie
serie
serie
M
M
M
Q
Q
Q
Q
Q
Q
Q
Q
Q
Q
Q
Q
Q
Q
Q Q
Q Q
Q
Q Q
Capitulo 14. Otros temas del anal isis de regresion 625
Cantidad de dinero: M2 (desestacionalizada, mm $)
Tipo [efectivo] de los fondos federal es (% anual)
Tipo preferencial de los prestamos bancarios (% anual)
Gastos personales de consumo: bienes duraderos (TAD -tasa anual desestacionalizada-, mm $ de 1996 encadenados)
Gastos personales de consumo: bienes no duraderos (TAD, mm $ de 1996 encadenados)
Gastos personales de consumo: servicios (TAD, mm $ de 1996 encadenados)
Gastos person ales de consumo (TAD, mm $ de 1996 encadenados)
CDH + CNH + CSH
Inversi6n no residencial fija privada (TAD, mm $ de 1996 encadenados)
Inversi6n privada fija en viviendas (TAD, mm $ de 1996 encadenados)
Variaci6n de las existencias de las empresas (TAD, mm $ de 1996 encadenados)
Inversi6n bruta interior privada (TAD, mm $ de 1996 encadenados)
FNH + FRH + VH
Exportaciones de bienes y servicios (TAD, mm $ de 1996 encadenados)
Importaciones de bienes y servicios (TAD, mm $ de 1996 encadenados)
Gasto publico de consumo/inversi6n bruta (TAD, mm $ de 1996 encadenados)
Producto interior bruto (TAD, mm $ de 1996 encadenados)
CHTOT + IHTOT + GH + XH - MH
Producto interior bruto: fndice de precios encadenado (desestacionalizado, 1996 = 100)
Renta personal (TAD, mm $ de 1996)
Renta personal disponible (TAD, mm $ de 1996)
Renta personal disponible (TAD, mm $ de 1996 encadenados)
Ahorro personal (TAD, mm $ de 1996)
Gasto personal (TAD, mm $ de 1996)

626 Estadfstica para administracion y economfa
Bibliografla
1. Dhalla, N. K., «Short-Term Forecasts of Advertising Expenditures», Journal of Advertising Research, 19, n.o I , 1979, pags. 7-14.
2. Erikson, G. M., «Using Ridge Regression to Estimate Directly Lagged Effects in Marketing», Journal of American Statistical Association, 76, 1981, pags. 766-773.
3. Hsiao, c., «Autoregressive Modeling of Canadian Money and Income Data», Journal of American Statistical Association, 74, 1979, pags. 553-560.
4. McDonald, J., «Modeling Demographic Relationships: An Analysis of Forecast Functions for Australian Births», Journal of the American Statistical Association, 76, 1981, pags. 782-792.
5. Mills, T. c., «The Functional Form of the UK Demand for Money», Applied Statistics, 27, 1978, pags. 52-57.
6. Waldauer, c., V. G. Duggal y M. L. Williams, «Gender Differences in Economic Knowledge: A Further Extension of the Analysis», Quarterly Review of Economics and Finance, 32, n.o 4, 1992, pags. 138-143.





























