Embed Size (px)
Citation preview

Overview
Decision Tree
Director of TEAMLABSungchul Choi

머신러닝의 학습 방법들
- Gradient descent based learning
- Probability theory based learning
- Information theory based learning
- Distance similarity based learning

Overview- Akinator – 스무고개로 유명인, 캐릭터를 맞추는 게임

Overview

Decision Tree Classifier- Data를 가장 잘 구분할 수 있는 Tree를 구성함

Guess who남자 긴 머리 안경 이름
예 아니오 예 브라이언
예 아니오 아니오 존
아니오 예 아니오 에이프라
아니오 아니오 아니오 아이오페

Guess who안경을
쓰고 있는가?
남자인가
머리가 긴가
브라이언
존
에이프라 아오이페
안경을쓰고 있는가?
남자인가
머리가 긴가
브라이언존 에이프라 아오이페



Decision Tree 만들기
- 어떤 질문이 가장 많은 해답을 줄 것인가?
- 결국 어떤 질문은 답의 모호성을 줄여줄 것인가?
- 문제를 통해서 splitting point을 설정è 남은 정보로 splitting point를 설정하는 식

Guess who안경을
쓰고 있는가?
남자인가
머리가 긴가
브라이언
존
에이프라 아오이페
남자 긴 머리 안경 이름
예 아니오 예 브라이언
예 아니오 아니오 존
아니오 예 아니오 에이프라
아니오 아니오 아니오 아이오페

Human knowledge belongs to the world.

Information theory - Entropy
Decision Tree
Director of TEAMLABSungchul Choi

Entropy
- Entropy는 목적 달성을 위한 경우의 수를 정량적으로표현하는 수치 è 작을 수록 경우의 수가 적음
- Higher Entropy à Higher uncertainty
- Lower Entropy à Lower uncertainty
Entropy가 작으면 얻을 수 있는 정보가 많다.

Entropy
p(i) p(i)
log2 p(i) � log2 p(i)
h(D) = �mPi=1
pilog2(pi) where
(D Data set
pi Probability of label i

Entropy
p(i)
� log2 p(i)
h(D) = �mPi=1
pilog2(pi) where
(D Data set
pi Probability of label i
- 확률이 1이면 Entropy 0
- 확률이 작을수록 커짐

Entropy -Example

h(D) = �mX
i=1
pi log2(pi)
h(D) = � 9
14
log29
14
+� 5
14
log25
14
= 0.940bits

Human knowledge belongs to the world.

Algorithms of Decision Tree
Decision Tree
Director of TEAMLABSungchul Choi

Growing a Decision Tree
- Decision Tree를 성장(만드는) 시키는 알고리즘이 필요
- 어떻게 하면 가장 잘 분기(branch)를 만들수 있는가?
- Data의 attribute를 기준으로 분기를 생성
- 어떤 attribute를 기준이면 가장 entropy가 작은가?
- 하나를 자른 후에 그 다음은 어떻게 할 것인가?
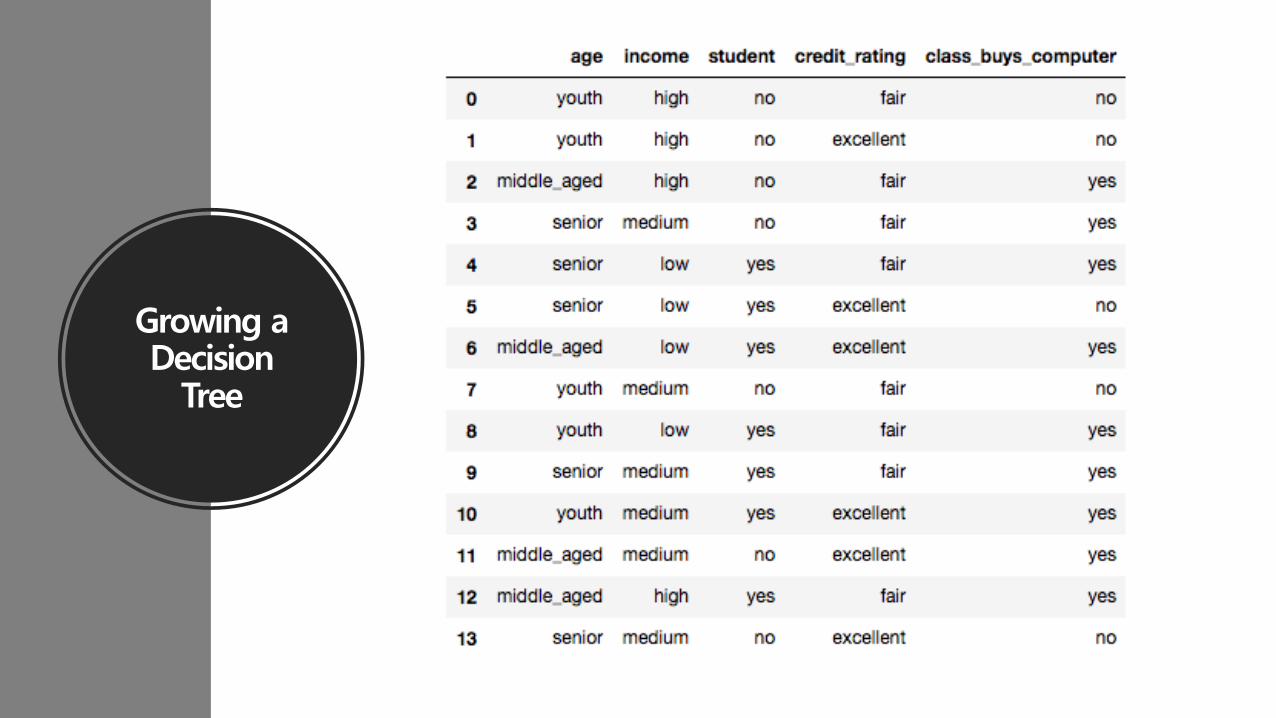
Growing a Decision
Tree

Growing a Decision TreeAge
youth
Middle_aged
senior

Growing a Decision TreeAge
youth
Middle_aged
senior
buyStudent
yes no

Growing a Decision TreeAge
youth
Middle_aged
senior
buyStudent
yes no
NOTbuy
Credit
fair excellent

Growing a Decision TreeAge
youth
Middle_aged
senior
buyStudent
yes no
NOTbuy
Credit
fair excellent
NOTbuy

Growing a Decision Tree
- Decision Tree는 재귀적으로 생김
- 대상 라벨에 대해 어떤 Attribute가 더 확실한 정보를제공하고 있는가? 로 branch attribute를 선택
- 확실한 정보의 선택 기준은 알고리즘 별로 차이가 남
- Tree 생성후 pruning을 통해 Tree generalization 시행
- 일반적으로 효율을 위해 Binary Tree를 사용

Decision Tree의 특징
- 비교적 간단하고 직관적으로 결과를 표현
- 훈련시간이 길고, 메모리 공간을 많이 사용함
- Top-down, Recursive, Divide and Conquer 기법
- Greedy 알고리즘 -> 부분 최적화

Decision Tree의 장점
- 트리의 상단 부분 attribute들이 가장 중요한 예측변수è attribute 선택 기법으로도 활용할 수 있음
- Attribute의 scaling이 필요없음
- 관측치의 절대값이 아닌 순서가 중요 à Outlier에 이점
- 자동적 변수 부분선택 ç Tree pruning

Algorithms of Decision Tree
- 크게 두 가지 형태의 decision tree 알고리즘 존재
- 알고리즘 별 attribute branch 방법이 다름
- ID3 à C4.5(Ross Quinlan), CART
- 연속형 변수를 위한 regression tree도 존재

Human knowledge belongs to the world.

ID3 & Information Gain
Decision Tree
Director of TEAMLABSungchul Choi

Information Gain
- Entropy 함수를 도입하여 branch splitting
- Information Gain: Entropy를 사용하여 속성별 분류시Impurity를 측정하는 지표
- (전체 Entropy – 속성별 Entropy )로속성별 Information Gain을 계산함

Information GainInfo(D) = �
nX
i=1
pi log2(pi)
InfoA(D) = �vX
j=1
|Dj |D
⇤ Info(Dj)
Gain(A) = Info(D)� InfoA(D)
전체 데이터 D의 정보량
속성 A로 분류시 정보량
A 속성의 정보 소득

ID3 Process

Growing a Decision
Tree

Growing a Decision TreeAge
Credit
Income
Student
Gain(age) = Info(D)� Infoage(D)
Gain(credit) = Info(D)� Infocredit(D)
Gain(Income) = Info(D)� Info
Income
(D)
Gain(Studnet) = Info(D)� InfoStudent(D)

Growing a Decision TreeAge Gain(age) = Info(D)� Infoage(D)
Infoage(D) = �vX
j=1
|Dj |D
⇤ Info(Dj)
j 3 {youth, moddle age, senior}

Growing a Decision TreeAge Gain(age) = Info(D)� Infoage(D)
Infoage(D) = �vX
j=1
|Dj |D
⇤ Info(Dj)
Infoage(D) =
5
14
⇥✓�2
5
log22
5
� 3
5
log23
5
◆
+
4
14
⇥✓�4
4
log24
4
◆
+
5
14
⇥✓�3
5
log23
5
� 2
5
log22
5
◆

Growing a Decision TreeAge Gain(age) = Info(D)� Infoage(D)
Info(D) = � 9
14
✓log2
9
14
◆� 5
14
✓log2
5
14
◆
Gain(age) = Info(D)� Infoage(D)

Growing a Decision TreeAge Gain(age) = Info(D)� Infoage(D)
Info(D) = � 9
14
✓log2
9
14
◆� 5
14
✓log2
5
14
◆

Growing a Decision TreeAge Gain(age) = Info(D)� Infoage(D)
Infoage(D) = �vX
j=1
|Dj |D
⇤ Info(Dj)
j 3 {youth, moddle age, senior}

Growing a Decision TreeAge Gain(age) = Info(D)� Infoage(D)

Growing a Decision TreeAge
Credit
Income
Student
Gain(age) = Info(D)� Infoage(D)
Gain(credit) = Info(D)� Infocredit(D)
Gain(Income) = Info(D)� Info
Income
(D)
Gain(Studnet) = Info(D)� InfoStudent(D)
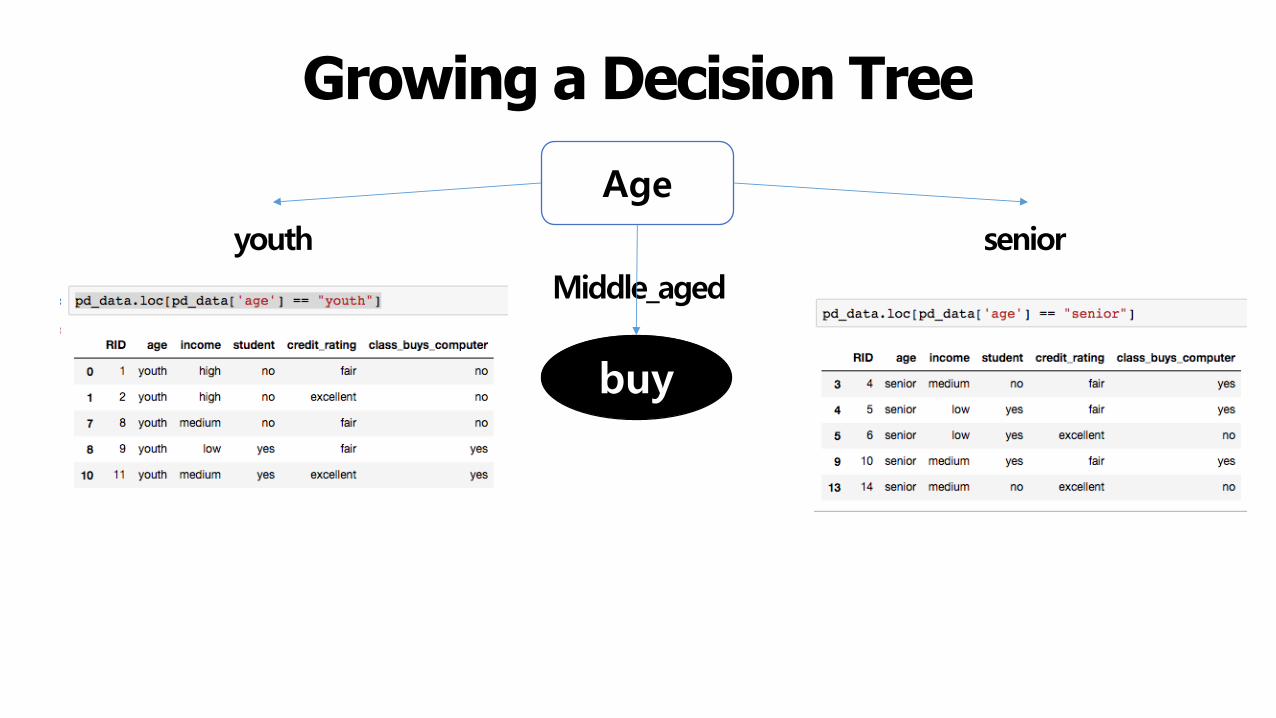
Growing a Decision TreeAge
youth
Middle_aged
senior
buy

Growing a Decision Tree
Gain(credit) = Info(Dyouth
)� Info
credit
(Dyouth
)
Gain(Income) = Info(Dyouth
)� Info
Income
(Dyouth
)
Gain(Student) = Info(Dyouth
)� Info
Student
(Dyouth
)
Credit
Income
Student

Growing a Decision TreeAge
youth
Middle_aged
senior
buyStudent
yes no
NOTbuy
Credit
fair excellent

Human knowledge belongs to the world.

C4.5 & Gini Index
Decision Tree
Director of TEAMLABSungchul Choi

Information Gain의 문제점
- Attribute에 포함된 값이 다양할 수록 선택하고자 함
- 한 Attribute 가 모두 다른 값을 가질 때?
Info(D) = �nX
i=1
pi log2(pi)
Gain(A) = Info(D)� InfoA(D)
InfoA(D) =vX
j=1
|Dj ||D| ⇤ Info(Dj)
보완을 해 줄 다른 Measure가 필요

Gain Ratio
- ID3의 발전형인 C4.5 알고리즘에서 사용되는 measurehttp://dl.acm.org/citation.cfm?id=152181
- Info(D)의 값을 평준화 시켜 분할 정보 값을 대신 사용
SplitInfoA(D) = �vX
j=1
|Dj ||D| ⇤
✓log2
|Dj ||D|
◆
GainRatio(A) =Gain(A)
SplitInfoA(D)=
Info(D)� Infoa(D)
SplitInfoA(D)
p(i)
� log2 p(i)

Gini Index
- CART 알고리즘의 split measure
- 훈련 튜플 세트를 파티션으로 나누었 때 불순한 정도 측정
https://www.amazon.com/dp/0412048418?tag=inspiredalgor-20
Gini(D) = 1�mX
i=1
p2i = 1�mX
i=1
|Ci,D||D| where Ci is a class
- 데이터의 대상 속성을 얼마나 잘못 분류할지를 계산

Gini Index
Gini(D) =mX
i=1
pi(1� pi) = 1�mX
i=1
p2i
- 실제 Gini Index는 Entropy와 비슷한 그래프가 그려짐
- 0.5일 때 Impurity의 최대화, 약 극점에서 0
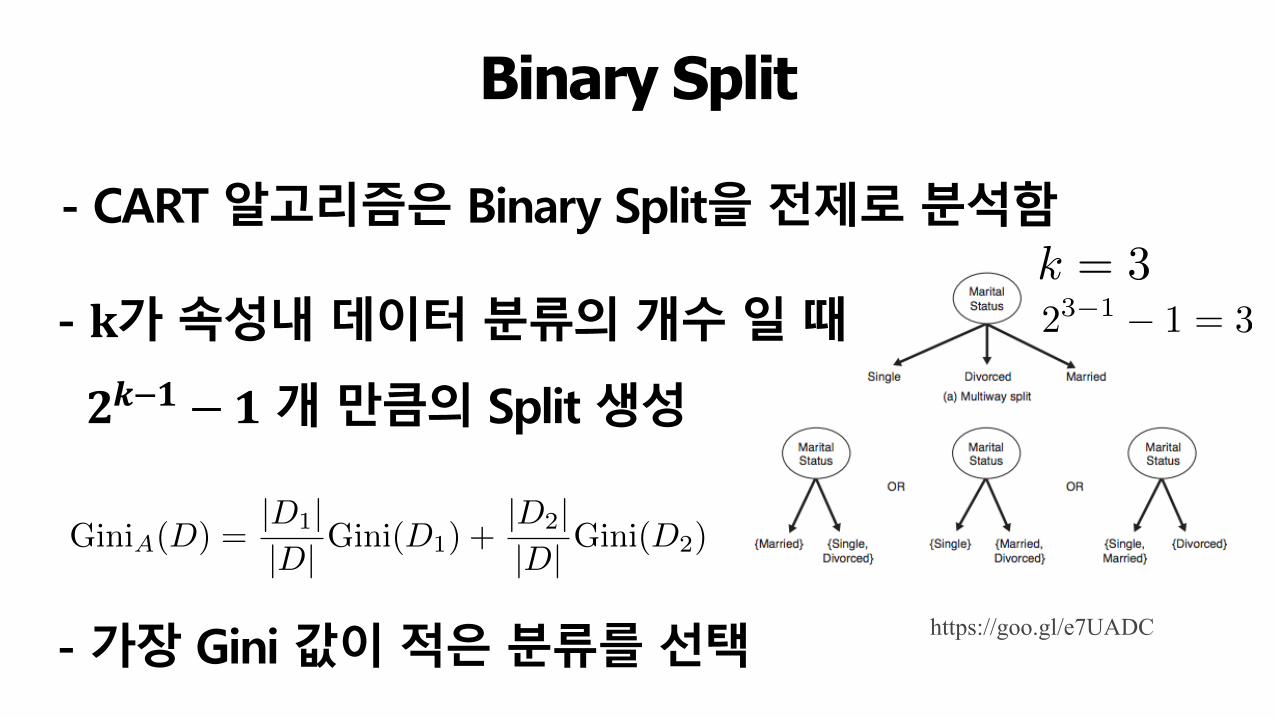
Binary Split
- CART 알고리즘은 Binary Split을 전제로 분석함
https://goo.gl/e7UADC
- 𝐤가 속성내 데이터 분류의 개수 일 때
𝟐𝒌$𝟏 −𝟏 개 만큼의 Split 생성
k = 323�1 � 1 = 3
GiniA(D) =|D1||D| Gini(D1) +
|D2||D| Gini(D2)
- 가장 Gini 값이 적은 분류를 선택

Growing a Decision
Tree

Growing a CART Decision TreeAge
Credit
Income
Student
Giniage
(D)
Ginicredit
(D)
Giniincome
(D)
Ginistudent
(D)

Growing a CART Decision TreeAge Giniage(D)
age 2 {youth,middle age, senior}
age1 2 {youth} = {middle age, senior}age2 2 {middle age} = {youth, senior}age3 2 {senior} = {youth,middle age}
세 가지 경우의 모든 Gini Index 산출

Growing a CART Decision TreeAge Giniage(D)
age 2 {youth,middle age, senior}
GiniA(D) =|D1||D| Gini(D1) +
|D2||D| Gini(D2)
Giniage1(D) =5
14Gini(D1) +
9
14Gini(D2)
Gini(D1) = 1�✓3
5
◆2
�✓2
5
◆2
Gini(D2) = 1�✓7
9
◆2
�✓2
9
◆2

Growing a CART Decision TreeAge Giniage(D)
age 2 {youth,middle age, senior}
age1 2 {youth} = {middle age, senior}age2 2 {middle age} = {youth, senior}age3 2 {senior} = {youth,middle age}
Min(Giniagei) = 0.357

Growing a CART Decision Tree
Min(Giniagei) = 0.357
Min(Giniincomei) = 0.443
Min(Ginicredit
) = 0.429
Min(Ginistudent
) = 0.367

CODE
Gini(D) = 1�mX
i=1
p2i = 1�mX
i=1
|Ci,D||D| where Ci is a class

CODE

CODE
GiniA(D) =|D1||D| Gini(D1) +
|D2||D| Gini(D2)

Human knowledge belongs to the world.

Tree prunning
Decision Tree
Director of TEAMLABSungchul Choi

Decision Tree를 만들다 생기는 문제점
- class의 leaf node의 결정
- 너무 많을 경우 à Overfitting
- impurity 또는 variance는 낮은데, 노드에 데이터가 1개
- 어떤 시점에서 트리 가지치기 해야할 지 결정이 중요

Pre-pruning
- Tree를 생성할 때, 일정 기준 이하면 노드 생성 X
è 하위 노드 개수, 하위노드의 label 비율(한쪽이 95?)
- Threshold를 잡아줘야 하는 어려움, CHAID등 사용
- 계산 효율이 좋고, 작은 데이터셋에서 잘 작동
- 속성을 놓칠 수 있음, underfitting 가능성이 높음

Post-pruning
- Tree를 생성한 후, 트리의 오차율 최소화를 위해 실행
- 오분류율 최소화, cost complexity 최소화 등을 사용
- 검증을 위한 validation set을 따로 생성함

오분류율 최소화
- 아래와 같은 검증 데이터가 있을 경우

오분류율 최소화

오분류율 최소화

Human knowledge belongs to the world.













