Embed Size (px)
Citation preview

© SOAS | 3740
Centre for Development, Environment and Policy
P101
Applied Econometrics
Prepared by Francesca Di Nuzzo
This module is partially based on the earlier module ‘Applied
Econometrics for the Agricultural and Food Sector’ prepared for the
University of London’s External Programme by Alison Burrell.

Applied Econometrics Module Introduction
© SOAS CeDEP 2
ABOUT THIS MODULE
This module is about econometric methods and how they are applied to estimate and
test the unknown parameters of economic relationships. Priority is given to both the
statistical reasoning underlying the methodology and the practical considerations
involved in using this methodology with a variety of models and real data.
The focus of the module is on the classical linear regression model. This is the basis
for much econometric methodology and it provides the framework for organising the
module.
The module covers
the principles of regression analysis and its statistical foundations
the simple linear regression model
the multiple linear regression model
violations of the assumptions of classical linear regression
There is a limit to the distance that can be covered in the study time available. In an
econometrics module, the trade-off between breadth and depth is low since, without
good groundwork and sufficient information at each stage, ideas may be
misunderstood and techniques misapplied. This module follows the standard itinerary
of most econometrics textbooks.
The practical exercises designed to be done with the help of the free computer
software package R are an important element of the module.

Applied Econometrics Module Introduction
© SOAS CeDEP 3
STRUCTURE OF THE MODULE
Each unit in the study guide follows the same format.
Each unit will always start with a section on ideas or issues, whose purpose is to
explain, in simple words and with a minimum of technical notation, the basic
substance of the unit. The aim is to give you an intuitive feel for the subject matter
before going into technical detail. If you feel that mathematics and statistics is not
your strongest suit, this regular section will give you a few ‘analytical handles’ to
hold on to when studying relevant techniques. But even if you are confident with
mathematics and statistics, it is important not to skip this section.
Technical expertise is not just a question of one’s ability to work out the steps in a
technical procedure or to understand a mathematical derivation. It also involves
understanding the type of questions a technique tries to address and the
assumptions on which it is based as well as judging the appropriateness of particular
technical procedures in specific conditions.
Next, the module units contain a Key Concepts section, which guides your study in
further detail. The purpose of this section is to highlight the main concepts as well as
to structure your reading of the textbook.
Following on from this, you will find a section containing an example (except Units 6
and 10). The purpose of this section is twofold.
First, the example highlights a specific aspect of the topic under study in a
particular unit of the module.
Second, the example also gives you a glimpse of econometrics in action.
The examples aim to highlight the links between economic theory and empirical
investigation, and to illustrate the problems that can arise when we work with real
data.
Often, you will find a set of self-assessment questions at the end of each section.
It is important that you work through all of these. Their purpose is threefold:
to check your understanding of basic concepts and ideas
to verify your ability to execute technical procedures in practice
to develop your skills in interpreting the results of empirical analysis.
Also, you will find additional exercises at the end of each unit, which aim to give you
hands-on examples of how to carry out empirical analysis; in many cases, you will be
asked to work with actual data and to interpret results. Answers to the self-
assessment questions are provided.
For each unit (except in Units 6 and 10) you will find a guide that explains how to
use R – the software package you will use to carry out econometric exercises. This
guide will help you to master this particular econometrics software package. You may
find it more convenient to study each R guide individually at the end of each unit
(before the section ‘Unit Self-Assessment Questions’).

Applied Econometrics Module Introduction
© SOAS CeDEP 4
When studying each unit, we suggest that you study the text at your own pace and
then work through the questions which are always designed to test your
understanding of the unit material. If these questions reveal some weak spots,
refresh them first before going on to the applied, data-based questions which you
will need to answer in conjunction with the R guide. The Summary at the end of
each unit briefly describes the topics covered, and the table of Key Terms and
Concepts lists all the important concepts you should have learned through your
study.
Applied statistics and econometrics are subjects with a great deal of specialised
jargon. It can be disconcerting to be faced with a number of unfamiliar new terms,
many of them quite long and often rather similar to each other. We recommend very
strongly that, right from the beginning of the module, you keep a glossary in which
you list each new term as you encounter it, together with an explanation of the
term in your own words. You should read through this glossary every few weeks,
updating your definitions if you find that, as the module progresses, your
understanding of the term develops along with your familiarity with the concept.

Applied Econometrics Module Introduction
© SOAS CeDEP 5
WHAT YOU WILL LEARN
Module Aims
The specific aims of the module are:
To explain the principles of econometric estimation and its statistical
foundations.
To present the theory of the classical linear regression model and explain why
the conditions in such a model provide an ideal environment for ordinary least
squares regression.
To develop practical skills of data analysis, use of regression techniques and
interpretation of regression results.
To explain the procedures of interval estimation and hypothesis testing in the
classical normal linear regression model.
To show how econometric models can be made more realistic through the use
of dummy variables.
To explain how linear restrictions can be imposed on parameters during
estimation and how these restrictions can be tested.
To investigate the consequences of heteroscedasticity of the disturbances and
endogeneity of the regressors.
To encourage an appreciation of what constitutes a ‘good’ econometric model,
and how to test that a model is well specified.
Module Learning Outcomes
By the end of this module students should be able to:
understand and selectively and critically apply the basic principles of regression
analysis and statistical inference in the context of a single-equation regression
model
formulate a single-equation regression model, estimate its parameters, carry
out a variety of tests relating to model specification and critically interpret all
results
test hypotheses about economic behaviour and critically interpret the results of
these tests
specify and interpret models using dummy variables, different types of
dynamic specification and incorporate and test linear restrictions
test for heteroscedasticity and endogeneity, and take appropriate action when
these conditions are found to be present.

Applied Econometrics Module Introduction
© SOAS CeDEP 6
ASSESSMENT
This module is assessed by:
• an examined assignment (EA) worth 40%
• a written examination worth 60%.
Since the EA is an element of the formal examination process, please note the
following:
(a) The EA questions and submission date will be available on the Virtual Learning
Environment (VLE).
(b) The EA is submitted by uploading it to the VLE.
(c) The EA is marked by the module tutor and students will receive a percentage
mark and feedback.
(d) Answers submitted must be entirely the student’s own work and not a product
of collaboration.
(e) Plagiarism is a breach of regulations. To ensure compliance with the specific
University of London regulations, all students are advised to read the
guidelines on referencing the work of other people. For more detailed
information, see the FAQ on the VLE.

Applied Econometrics Module Introduction
© SOAS CeDEP 7
STUDY MATERIALS
Except for Unit 9, for which separate material will be provided, the single textbook
for the module is:
Gujarati, D. & Porter, D. (2010) Essentials of Econometrics. 4th edition.
International Edition. McGraw-Hill.
This book has been chosen for this self-study module because of its attention to full
explanations of concepts and procedures, its long introductory section presenting the
basic statistical concepts used in regression modelling, and its avoidance of
unnecessary algebra and difficult notation.
You are also encouraged to read those parts that are not specifically identified in the
module texts, since all the material here should be within your grasp and will
reinforce your understanding of the subject. By the end of the module, you will know
this textbook well and will be ready for other more advanced readings.
The following are not compulsory; however, they are more advanced in terms of
notation and explanations, should you wish to go into more depth about specific
concepts. Please note that these texts are recommendations and are not provided.
Intermediate
Greene, W. (2000) Econometric Analysis. 4th edition. New Jersey, Prentice Hall.
Gujarati, D. (1979) Basic Econometrics. Singapore, McGraw-Hill.
Gujarati, D. (2011) Econometrics by Example. Palgrave Macmillan.
Advanced
Maddala, G.S. & Lahiri, K. (2009) Introduction to Econometrics. 4th edition.
Chichester, John Wiley & Sons.
Other
Hallam, D. (1990) Econometric Modelling of Agricultural Commodity Markets.
London, Routledge.
Discussion of econometric modelling in agricultural economics.

Applied Econometrics Module Introduction
© SOAS CeDEP 8
For each of the module units, the following are provided.
Key Readings
These are drawn mainly from the textbook and relevant academic journals and
internationally respected reports. Key Readings are provided to add breadth and
depth to the unit materials, as appropriate, and are required reading as they contain
material on which students may be examined. The notes under each reading indicate
the scope and relevance of the reading.
Further Readings
These texts are not provided in hard copy, but weblinks have been included. Further
Readings are NOT examinable and are provided to enable students to pursue their
own areas of interest.
Multimedia
The e-version of the study guide includes a number of interviews with rural
development managers in which they discuss particular aspects of their management
experience. These interviews can be treated rather like audio case studies to
illustrate concepts and arguments presented in the module text.
References
Each unit contains a full list of all material cited in the text. All references cited in the
unit text are listed in the relevant units. However, this is primarily a matter of good
academic practice: to show where points made in the text can be substantiated.
Students are not expected to consult these references as part of their study of this
module.
Self-Assessment Questions
Often, you will find a set of Self-Assessment Questions at the end of each section
within a unit. It is important that you work through all of these. Their purpose is
threefold:
to check your understanding of basic concepts and ideas
to verify your ability to execute technical procedures in practice
to develop your skills in interpreting the results of empirical analysis.
Also, you will find additional Unit Self-Assessment Questions at the end of each
unit, which aim to help you assess your broader understanding of the unit material.
Answers to the Self-Assessment Questions are provided in the Answer Booklet.

Applied Econometrics Module Introduction
© SOAS CeDEP 9
In-text Questions
This icon invites you to answer a question for which an answer is
provided. Try not to look at the answer immediately; first write down
what you think is a reasonable answer to the question before reading
on. This is equivalent to lecturers asking a question of their class and
using the answers as a springboard for further explanation.
In-text Activities
This symbol invites you to halt and consider an issue or engage in a
practical activity.
Key Terms and Concepts
At the end of each unit you are provided with a list of Key Terms and Concepts which
have been introduced in the unit. The first time these appear in the text guide they
are Bold Italicised. Some key terms are very likely to be used in examination
questions, and an explanation of the meaning of relevant key terms will nearly
always gain you credit in your answers.
Acronyms and Abbreviations
As you progress through the module you may need to check unfamiliar acronyms
that are used. A full list of these is provided for you at the end of the Introduction.

Applied Econometrics Module Introduction
© SOAS CeDEP 10
TUTORIAL SUPPORT
There are two opportunities for receiving support from tutors during your study, and
you are strongly advised to take advantage of both. These opportunities involve:
(a) participating in the Virtual Learning Environment (VLE)
(b) completing the examined assignment (EA).
Virtual Learning Environment (VLE)
The Virtual Learning Environment provides an opportunity for you to interact with
both other students and tutors. A discussion forum is provided through which you
can post questions regarding any study topic that you have difficulty with, or for
which you require further clarification. You can also discuss more general issues on
the News forum within the CeDEP Programme Area.
Applied Econometrics Module Introduction
© SOAS CeDEP 11
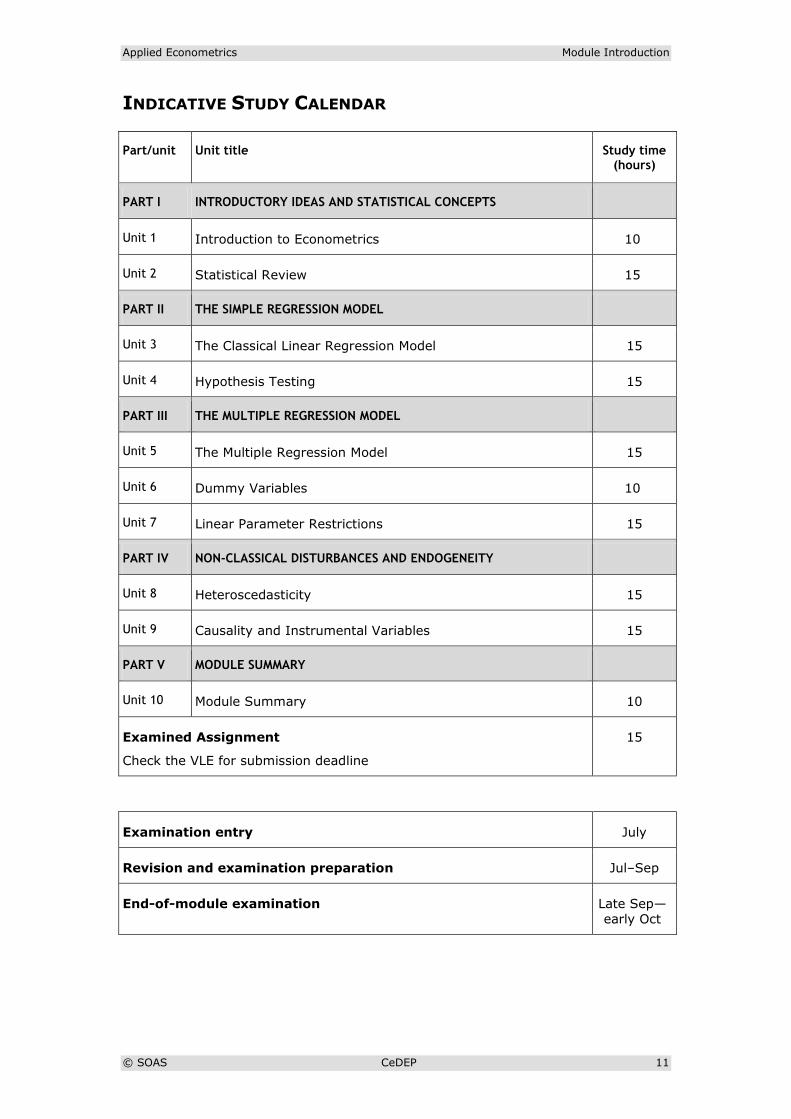
INDICATIVE STUDY CALENDAR
Part/unit Unit title Study time (hours)
PART I INTRODUCTORY IDEAS AND STATISTICAL CONCEPTS
Unit 1 Introduction to Econometrics 10
Unit 2 Statistical Review 15
PART II THE SIMPLE REGRESSION MODEL
Unit 3 The Classical Linear Regression Model 15
Unit 4 Hypothesis Testing 15
PART III THE MULTIPLE REGRESSION MODEL
Unit 5 The Multiple Regression Model 15
Unit 6 Dummy Variables 10
Unit 7 Linear Parameter Restrictions 15
PART IV NON-CLASSICAL DISTURBANCES AND ENDOGENEITY
Unit 8 Heteroscedasticity 15
Unit 9 Causality and Instrumental Variables 15
PART V MODULE SUMMARY
Unit 10 Module Summary 10
Examined Assignment
Check the VLE for submission deadline
15
Examination entry July
Revision and examination preparation Jul–Sep
End-of-module examination Late Sep—
early Oct

Applied Econometrics Module Introduction
© SOAS CeDEP 12
ACRONYMS AND ABBREVIATIONS
BLUE best linear unbiased estimator
CLRM classical linear regression model
CLT central limit theorem
CNLRM classical normal linear regression model
CPI consumer price index
d.f. degrees of freedom
ESS explained sum of squares
FAO Food and Agriculture Organization
FDI foreign direct investment
GDP gross domestic product
GNP gross national product
LM Lagrange multiplier
MBA Masters of Business Administration
ML maximum likelihood
MPC marginal propensity to consume
MSE mean square error
MT Metical; the currency of Mozambique
OLS ordinary least squares
PDF probability density function
PRF objective of regression
PRL population regression line
RLS restricted least squares
RSS residual sum of squares
SRF sample regression function
SUR seemingly unrelated regression
TSS total sum of squares
VIF variance inflation factor
WLS weighted least squares

Unit One: Introduction to Econometrics
Unit Information 2
Unit Overview 2 Unit Aims 2
Unit Learning Outcomes 2 Unit Interdependencies 3
Key Readings 4
References 5
1.0 Ideas and issues 6
Section Overview 6 Section Learning Outcomes 6
1.1 What is econometrics? 6 1.2 Econometrics in theory and in practice 9
2.0 Key concepts: the concept of regression 11
Section Overview 11
Section Learning Outcomes 11 2.1 What is regression? 11
2.2 Linearity and log-linearity 15 2.3 Correlation versus regression analysis 16
2.4 Data and regression 16 2.5 A word of caution on notation 17
Section 2 Self-Assessment Question 18
3.0 Example: The Keynesian consumption function 19
Unit Summary 22
Unit Self-Assessment Questions 23
Key Terms and Concepts 26

Applied Econometrics Unit 1
© SOAS CeDEP 2
UNIT INFORMATION
Unit Overview
This unit introduces you to the study of econometrics. It begins by defining
econometrics and then explains how econometrics relates to and differs from other
branches of economics. The important roles of economic theory and data in
econometric work are emphasised. Regression analysis is identified as the basis of
econometric procedure. The aims and purpose of regression analysis are explained.
The main steps of a typical econometric investigation are described and illustrated
with an example.
Unit Aims
To define the nature and scope of econometrics.
To identify the special characteristics of econometrics as a tool of applied
economics.
To describe and illustrate the main steps of an econometric investigation.
To identify some characteristics of economic data.
To practise some basic techniques of data investigation.
Unit Learning Outcomes
By the end of this unit, students should:
have an appreciation of econometrics as a method of empirical investigation
have an understanding of major differences between econometric models and
economic models
have an understanding of the main steps of an econometric investigation
have a knowledge of essential terminology relating to regression analysis
know how to perform basic data analysis in R.

Applied Econometrics Unit 1
© SOAS CeDEP 3
Unit Interdependencies
Unit 3
In Unit 3, you will take the first steps into linear regression analysis, which is one
technique to deal with non-experimental data.
Unit 4
In this unit, we discuss the methodology of econometrics, which involves testing our
maintained hypothesis; this is what you will be introduced to in Unit 4.
Unit 5
In Unit 5, we expand linear regression to multivariate regression, which is commonly
used to perform empirical analysis. Also, we will make use of correlation analysis in
dealing with the issue of multicollinearity.
Unit 8
In this Unit, you will learn that we can use a variety of functional forms to specify our
model. In Unit 8 you will review the logarithmic transformation and employ it to
mitigate the effect of non-constant variance in the residuals, ie heteroscedasticity.
Unit 9
In this unit we introduce the concept of regression analysis. This kind of analysis
implies that a causal nexus is identified between two or more variables. In Unit 9 the
issues of causality are discussed more extensively.

Applied Econometrics Unit 1
© SOAS CeDEP 4
KEY READINGS
Gujarati, D. & Porter, D. (2010) The nature and scope of econometrics. In: Essentials
of Econometrics. 4th edition. International Edition, McGraw-Hill. pp. 1–13.
Gujarati and Porter (2010) is the main textbook for the study of this module. This introductory
chapter will give you an overview of the course and it will define the field of econometrics, its
methodologies and types of data. The chapter is straightforward and can be read fairly quickly.
Gujarati, D. & Porter, D. (2010) Basic ideas of linear regression: the two-variable
model. In: Essentials of Econometrics. 4th edition. International Edition, McGraw-
Hill. Sections 2.1–2.6, pp. 21–32.
Sections 2.1 to 2.6 provide a brief, clear explanation of the key introductory concepts of
linear regression. Make sure that you refer to these definitions also as you go through the
following units.

Applied Econometrics Unit 1
© SOAS CeDEP 5
REFERENCES
Maddala, G.S. (2009) Introduction to Econometrics. 4th edition. Chichester, John
Wiley & Sons.
ONS. (1991) Economic Trends Annual Supplement 1991. Unipub.
Tsai, P.L. (1991) Determinants of foreign direct investment in Taiwan: an alternative
approach with time series data. World Development, 19 (2–3), 275–285.

Applied Econometrics Unit 1
© SOAS CeDEP 6
1.0 IDEAS AND ISSUES
Section Overview
In this section, we begin to explore the subject of econometrics, what it does and
how it is used in applied research.
Section Learning Outcomes
By the end of this section, students should be able to:
understand what econometrics does and how it is employed in empirical
research
understand the nature of the data and methods used in econometrics.
1.1 What is econometrics?
Welcome to this module. Its aim is to give you an introduction to econometric
methods or, more specifically, to linear regression which is the main statistical
foundation for econometric work. Throughout the module you will be working with
data; we hope you will find this interesting.
Economic theory is concerned with relationships between variables. You might have
already met some of these, such as demand and supply functions for agricultural
products, production functions, labour supply and demand functions, and so on.
Economic theory aims to explain economic behaviour; this involves studying the
relationship between economic variables and the factors that influence them.
The purpose of econometrics is to quantify economic relationships. Econometrics
can provide numerical estimates of the parameters of these relationships and a
framework for testing hypotheses about them. Broadly defined, econometrics is
‘ … the application of statistical and mathematical methods to the
analysis of economic data, with the purpose of giving empirical content to
economic theories and verifying them or refuting them …’
Source: Maddala (2009) p. 3.
Other definitions are possible: you will come across a number of definitions that each
has a slightly different emphasis. Common to all definitions, however, is the stress
on the empirical nature of econometric work.
The process of econometrics involves the confrontation between economic
theory and economic data in quantifying economic relat ionships.
Econometrics is not just a branch of mathematical economics. Mathematical
economics need not have any empirical content at all whereas in econometrics the
emphasis is on empirical analysis. At the same time, econometrics is not just a
‘box of tools’ to work with data. It requires, undoubtedly, a good training in statistical
techniques but these techniques need to be deployed in an interactive process
between theory and the data.

Applied Econometrics Unit 1
© SOAS CeDEP 7
This module can be studied in its own right, but normally we would expect you to
take it as part of the MSc programme where, in Part I, you will have studied various
economic theories and models. You should therefore be familiar with a range of
questions raised in theoretical discussions and with the results of some applied
empirical studies. These are good foundations on which to build the study of
econometrics. If up to now you have approached empirical studies from the point of
view of theory or the consequences for policy making, we now invite you to look at
them from the point of view of an econometrician. What is the difference?
To give empirical content to economic theories, the econometrician is confronted with
four problems that hardly concern the economic theorist. These four problems are
explained below.
(a) Non-experimental data
Economic theory develops models using a priori reasoning applied to relatively simple
assumptions. This procedure involves abstracting from secondary complications by
assuming that ‘other things remain equal’ (or ceteris paribus), in order to
investigate the links between a few key economic variables.
For example, in demand theory we say that the quantity demanded of a commodity
(that is not a Giffen good) will fall if its price rises, other things being equal. These
‘other things’ which we assume are held constant include consumers’ incomes and
income distribution, and the prices of substitutes and complementary goods.
This method is fruitful in economic theory but, unfortunately, it is rarely possible to
carry out controlled experiments to test such statements. Therefore, in empirical
economics the scope for observing such behaviour is severely limited. A researcher
cannot alter a commodity’s price, holding other things constant, in order to see what
happens to its demand.
In general, economic data are not the outcome of experiments but rather are
observed and recorded in a non-experimental world where other things are
never equal. Therefore, econometrics involves untangling the effects of different
factors that act simultaneously rather than analysing the results of a laboratory
experiment.
(b) Stochastic relationships
Economic theory usually involves deterministic relationships between economic
variables. This can be explained with a simple example: the Keynesian consumption
function. In economic theory we assume that, if we know the level of aggregate real
income, consumption will be uniquely determined. That is, for each value of
aggregate real income there corresponds a given level of aggregate consumption.
In reality, however, we do not expect theoretical relationships to hold exactly. Even
when all the main factors that systematically affect the behaviour of an economic
variable are taken into account, there will still be some random variation due to non-
systematic, ‘one-off’ factors and human variability.
Hence, in econometric work we deal with relationships between variables that
contain a random or stochastic element, and that are therefore not deterministic in
nature. We investigate functions between variables which we believe to be reasonably
stable on average, but there is always a degree of uncertainty about them.

Applied Econometrics Unit 1
© SOAS CeDEP 8
In econometrics we make explicit assumptions about these random components,
called disturbances. This is why econometrics draws heavily on probability theory
and statistical inference.
(c) Observed variables
In economic theory we work with theoretical variables. Econometrics, in contrast,
deals with observed data.
Obviously, there is a certain correspondence between them: data collection is
inspired by some theoretical framework. For example, the framework for measuring
national income account data derives from Keynesian economics, which is centred on
the analysis of theoretical aggregates such as output, demand, employment and the
price level.
However, observed variables do not fully correspond to their theoretical counterparts
because of differences in definition and coverage, and errors in measurement. For
example, the ‘price level’ is an abstract concept that is usually represented
empirically by some aggregate price index; however, the values it takes depend on
the goods whose prices are covered by the index and the method of calculating the
index.
Another example concerns modelling technology. In agricultural supply functions, the
‘state of technology’ is an important variable: changes in supply over time are driven
both by price changes and by the pace of technological change. But how can
technological development be measured? Many researchers resort to a simple time
trend to represent this important variable.
Finally, ‘management’ is a key input in the theoretical specification of an agricultural
production function but one that is always difficult to measure empirically .
Econometricians sometimes resort to proxy variables for management like the
number of years of education the farmer has received.
In econometrics we need to be aware of the discrepancy between theoretical
concepts and observed data, and its implications when quantifying theoretical
propositions.
(d) The treatment of time
The econometrician must make explicit assumptions about the role of time in his
model. When economic theory postulates that consumption depends on disposable
income, ceteris paribus, it implies that when income takes different values so does
consumption. Econometrics can quantify this dependency by using information about
how consumption changes as income takes different values. However, this
dependency could be observed empirically in two alternative ways:
(i) by recording how consumption and income move together over time, or
(ii) by recording the consumption of households at different income levels during
the same time period.
In the first case, we have a time-series model, requiring time-series data
(measured at different intervals over time).
In the second case, we have a cross-section model, requiring cross-section data
(measured for different individuals or micro-units at the same point or during the

Applied Econometrics Unit 1
© SOAS CeDEP 9
same period in time). The choice between a time-series and a cross-section model
often depends on data availability, although this choice is less straightforward than
it may seem.
First, we may need to modify our theory for explaining consumption changes over
time before it can be applied to cross-sectional consumption analysis.
Second, there may be data considerations; for example, a time-series approach is
hardly appropriate for studying how consumption varies with income during periods
in which there has been virtually zero income growth.
1.2 Econometrics in theory and in practice
The four elements above give econometric work its distinctive flavour:
the fact that we cannot hold other things constant in empirical analysis
the random (or stochastic) nature of relationships between variables
the discrepancies between theoretical variables and observed data
the need to make explicit assumptions about time.
We cannot move straight from an economic model as formulated by economic theory
to parameter estimation without dealing with these issues. In empirical analysis, our
data never behave exactly as our theoretical models would lead us to believe. Simple
theoretical models are useful abstractions.
But in empirical work the relationships we wish to disentangle from the data may
involve a number of variables, and may be subject to uncertainties that our theories
could not possibly aim to explain. ‘Econometric methodology’ therefore includes
approaches for dealing with these issues, as well as the statistical techniques of
parameter estimation.
Regression analysis provides us with an analytical framework for handling
relationships involving a number of causal factors, including random elements. It
seeks to establish statistical regularities among observed variables. To do this we
need to deal with the randomness inherent in the behaviour of our variables. This
requires the help of statistical theory, which allows us to model randomness as an
integral part of the relationship between variables. How this is done, and how we
should interpret the results, is the subject of this module.
The following are the main points to remember.
In econometrics we confront theory with economic data so as to quantify
economic relationships and to test hypotheses about them.
In practice, we deal with stochastic relationships between variables which we
can only observe in a non-experimental context.
Econometric methodology has been developed in order to deal with this
situation, and differs significantly from the way regression analysis is applied to
experimental data. There are many outstanding issues and unresolved
methodological problems in the practice of econometrics.

Applied Econometrics Unit 1
© SOAS CeDEP 10
Moreover, the conclusions we draw in a particular context will always involve a
considerable degree of uncertainty, even if our model is correctly specified.
For this reason, we rely on probability theory and statistical inference to deal
with uncertainty in assessing the results of empirical analysis.
Econometrics is concerned primarily with quantifying and testing relationships
between variables, and regression analysis is its main tool of statistical
analysis.

Applied Econometrics Unit 1
© SOAS CeDEP 11
2.0 KEY CONCEPTS: THE CONCEPT OF REGRESSION
Section Overview
Linear regression is one important tool of econometrics. In this section, we discuss
the general nature of regression analysis and provide a background that will be used
to interpret real examples in the rest of the module.
Section Learning Outcomes
By the end of this section, students should be able to:
understand the concept of linear regression
identify the components of regression analysis.
Teaching and learning econometrics involves a preoccupation with tec hnical details,
definitions of technical terms, mathematical derivations, step by step descriptions of
statistical procedures etc, all expressed in technical notation.
This is normal and, indeed, necessary. But this preoccupation with technical detail
often implies that students lose a perspective on ‘What is it all about?’ and ‘Why are
we doing this?’ That is, there is a need to keep a grip on the kinds of basic questions,
which give substance to the subsequent technical exercises, uncluttered by notation
and technical detail. We need to get an overview of a problem before we attack it
aided by our technical armoury. We need to know the simple questions and intuitive
insights which have prompted elaborate technical enquiries.
Let us first start with the concept of regression analysis.
2.1 What is regression?
An intuitive explanation
Regression is the main statistical tool of econometrics. But what is it exactly?
Regression can best be explained by an example. Consider a famous empirical law of
consumer behaviour, formulated by German economist and statistician Engel. This
was based on a household budget survey of Belgian working class families collected
in 1855. Engel observed that the share of expenditure on food in total household
expenditure (= the -variable) was a declining function of household income (= the
-variable).
This is indeed what one would expect: on average, poorer families spend a higher
proportion of their income on food in comparison with better-off families. Note that
we refer to the proportion of total household expenditures spent on food and not
total food consumption of the family (one would expect better-off families to spend
more money on food even though these expenditures are generally a smaller
proportion of their total expenditure).
Hence, we expect that, on average, the share of food in household expenditures is
inversely related to household income. But we do not expect this relationship to be
exact. That is, if we were to sample 10 families with identical income (ie equal -

Applied Econometrics Unit 1
© SOAS CeDEP 12
values), we would not expect to get 10 identical shares of food consumption in total
household expenditures (the -values).
Differences in the demographic composition of families, in consumption habits and in
tastes will account for differences in food expenditures. In fact, many budget studies,
in the past and in the present, reveal that there is considerable variation within
each income class with respect to the proportion of household expenditures spent on
food. But, nevertheless, it is still valid to say that, on average, the proportion of
household expenditures spent on food declines as the level of income increases.
This leads us to the concept of regression. Regression methods bring out this
average relationship between a dependent variable (the -variable) on the one
hand and one or more independent variables (the -variables, also called the
explanatory variables) on the other.
In our example, the average relationship between the share of food in household
expenditure and the level of household income is the regression of the former
variable on the latter.
Hence, in regression analysis we seek to model the chance variation around the
average as well as the average itself.
In summary, we hope that our model captures the basic structure of
interaction between economic variables. We expect that the behavioural
relationships are reasonably stable but we know that they do not hold exactly
because of the random component (the disturbance term). At most, we expect these
relations to hold ‘on average’.
Trying to determine this average relationship amidst the random variation in the data
is like trying to separate sound from noise when listening to a badly tuned radio.
Thus, a regression model has two components.
(a) A regression line, which models the average relationship between the
dependent variable and its explanatory variable(s). This requires us to make an
explicit assumption about the shape of the regression line: the function that
expresses it may be linear, quadratic, exponential, etc.
(b) Disturbances; we acknowledge the existence of chance fluctuations due to a
multitude of factors not explicitly recognised in the model. We model this
element of uncertainty (the noise) in the form of a disturbance term which
constitutes an integral part of our model. This disturbance term is a ‘catchall
for all the variables considered as irrelevant for the purpose of this model as
well as all unforeseen events’ (Maddala, 2009: p. 5). It is a random variable
that we cannot observe or measure in practice.
We are not interested in the disturbance term as a variable per se, but we are keen
to remove its blurred messages that hamper our attempts to investigate the
behavioural relationship between the variables of our model. To do this, we need to
model the stochastic (probabilistic) nature of the disturbance term. This is no easy
task and we always need to think carefully about whether the assumptions we
make about the behaviour of the disturbance term are indeed appropriate for the
relationship under study. Not surprisingly, a great deal of econometric theory and
practice revolves around these assumptions.

Applied Econometrics Unit 1
© SOAS CeDEP 13
A formal explanation
It is useful to express these important ideas more formally. We start with the
population regression function. This function is a theoretical construct
representing a hypothesis about how the data are generated. For the simple, two-
variable linear regression model we have
(1.1)
where is the dependent variable (sometimes called the ‘regressand’)
is the explanatory variable or independent variable (or ‘regressor’)
is the disturbance term
and are the regression parameters: 1 is the intercept, or constant,
and is the slope coefficient.
The subscript indicates the -th observation, ie the -th person or object sampled.
Typically, the variables and are observable for each observation , the
disturbance takes different values for each but is not observable, whereas the
parameters and are unknown but constant for all observations.
The presence of the random disturbance in equation (1.1) means that is stochastic.
The population regression function may be viewed as comprising two components:
a systematic element represented by a straight line showing the statistical
dependence of on ;
a random, or stochastic, element represented by the disturbance term u.
The systematic element can be expressed as
( | ) (1.2)
that is, the average, or expected, value of conditional on a given value of X is a
linear function of . Therefore, the population regression function joins the
conditional means of .
The disturbance term, , accounts for the variation in Y around the population
regression line. In later units, you will learn about the assumptions made concerning .
Regression enables us to quantify the unknown parameters and , and the
unknown disturbances * +, for , ... , , in equation (1.1).
Using a sample of data on and , we obtain estimates and , of the unknown
population parameters ( is read as ‘hat’, hence is ‘beta 1 hat’). We have the
sample regression function
(1.3)
in which and are random variables (the particular estimates obtained depend
on the particular sample of data on and used) that differ from the population
parameters and .

Applied Econometrics Unit 1
© SOAS CeDEP 14
Consequently, the sample residuals, , differ from the unknown population
disturbances, .
Whereas the disturbance term accounts for the variation in around the population
regression line, the residuals give us the deviations of the observed -values from
the estimated regression line.
2.1.1 Difference between disturbances and residuals
Name Notation Refers to
Disturbances Population regression line (computed on the entire population)
Residuals Estimated regression line (computed on the sample)
Source: unit author
The residuals, therefore, are not identical with the disturbances, but clearly they may
contain some information that can help us understand the behaviour of the
disturbances. How to analyse the information contained in the residuals is addressed
in later units.
Please note that different textbooks use different definitions for disturbances
and residuals; for example, some use the term ‘error’ instead of residuals. In
this module, we try to be as flexible as possible with terminology.
The predicted (or fitted) value of the dependent variable, , is given by the sample
regression line
(1.4)
in which is the fitted value of the dependent variable, the estimator of ( | ),
that is the estimator of the population conditional mean (cf. equation (1.2)).
The sample linear regression line is an estimator of the population
regression line.

Applied Econometrics Unit 1
© SOAS CeDEP 15
2.2 Linearity and log-linearity
Equation (1.1) is an example of a linear regression model. That is, is linear in
and in the parameters and . With the linear regression line
the interpretation given to relies on the fact that
(1.5)
In case you are not familiar with derivatives, this means that an increase of one unit
in (measured in units of ) results in an increase of units in (measured in
units of ).
On the intercept – in theory, is the predicted value of (in units of ) if . In
practice, this interpretation of is not recommended unless zero values of could
reasonably occur.
Now consider the model
(1.6)
which, after taking natural logarithms of both sides of the equation, can be written as
(1.7)
where If you are not familiar with this transformation, please make sure
that you revise the algebra in a basic textbook; this kind of topics is usually in the
appendix.
This model is also linear in the parameters and . We may view the model as
(1.8)
where and
.
This model is known by various names – logarithmic, double log, log-log, log-linear
and constant elasticity – and is frequently used in applied work to characterise the
form of the functional relationship between the variables. It has the property that the
slope coefficient measures the elasticity of with respect to because
⁄ (1.9)
Again, if you do not feel comfortable with this formulation, please make sure that
you refresh the basic mathematical tools.

Applied Econometrics Unit 1
© SOAS CeDEP 16
2.3 Correlation versus regression analysis
Although regression analysis is related to correlation analysis, conceptually these two
types of analysis are very different.
The main aim of correlation analysis is to measure the degree of linear association
between two variables and this is summarised by a value, the correlation
coefficient.
The two variables are treated symmetrically:
both are considered random
there is no distinction between dependent and explanatory variables
there is no implication of causality in a particular direction from one variable to
the other.
Regression analysis, on the other hand, can deal with relationships between two or
more variables and the variables are not treated symmetrically:
the dependent and explanatory variables are carefully distinguished
the former is random whereas the latter are often assumed to take the same
values in different samples – often referred to as ‘fixed in repeated samples’
the underlying economic theory implies that , an explanatory variable,
‘causes’ or ‘determines’ , the dependent variable
moreover, with more than one explanatory variable, regression analysis
quantifies the influence of each explanatory variable on the dependent
variable.
It is important to note that the regression of on does not give the same
sample regression line as the regression of on .
The appropriate direction of causality is determined by the modeller according to a
priori reasoning, based on theory or common sense.
2.4 Data and regression
Regression methods allow us to investigate associations between variables, but the
justification for these relationships comes from theory. Relationships have to be
meaningful and whether they are or not depends on theoretical argument s.
This does not mean, however, that data play only a passive role in economic
analysis. Empirical investigation is an active part of theoretical analysis inasmuch as
it involves testing theoretical hypotheses against the data as well as, in many
instances, providing clues and hints towards new avenues of theoretical enquiry.
Theoretical insights have to be translated into empirically testable hypotheses that
we can investigate with observed data. Hence, theory and data are interactive:
theoretical propositions should be continually tested empirically and theoretical
insights can be improved with the aid of signals from the data.

Applied Econometrics Unit 1
© SOAS CeDEP 17
Most of the data we use in applied economic analysis are not obtained from
experiments but are the result of surveys and observational programmes.
For example: national income accounts, agricultural and industrial surveys,
financial accounts, employment surveys, population census data, household
budget surveys, and price and income data, that are collected by various
statistical offices.
They are records of unplanned events; they are not the outcome of experiments. The
nature of economic data makes an econometrician’s work quite different from that of
a psychologist or an agricultural scientist.
In the latter cases, experiments play a central role in empirical research, and much
emphasis is put on the careful design of experiments in order to single out the
‘stimulus-response’ relationship between two variables whilst controlling for the
influence of other variables (that is, by holding them constant ).
In economics, the scope for experimentation is very limited. We cannot change the
price of a commodity, holding incomes and all other prices constant, just to see what
would happen to the demand for it. In economic theory, we assume that ‘other
things are equal’ (ceteris paribus) and focus on cause and effect between the
remaining variables. But in empirical analysis other things are never equal, and we
have to observe the behaviour of economic agents from survey data. Multiple
regression techniques allow us to ‘account’ for the influence of other variables whilst
investigating the interaction between two key variables, but this is not the same as
‘holding other variables constant’.
A careful observer uses data not just to confirm his or her theories, but also to get
clues from empirical analysis to advance his/her theoretical grasp of a problem. It is
primarily this aspect that enables data to contribute to the process of analysis.
2.5 A word of caution on notation
You will notice that terminology and notation may be different from the textbook in
some instances. Although these differences are inconvenient, it is an unfortunate fact
that terminology and notation are not wholly standardised amongst econometricians.
For example, we maintain the ‘hat’ to denote estimators, eg – instead of .
You should not be alarmed by these discrepancies; we invite you to focus on the
concepts and ideas rather than on the technicalities. This material is specifically
designed to keep technical contents to a minimum, and our aim is for everyone to
enjoy the course independently of their mathematical knowledge.

Applied Econometrics Unit 1
© SOAS CeDEP 18
Section 2 Self-Assessment Question
uestion 1
What are the links between econometrics and both economic theory and
mathematical economics?
Q

Applied Econometrics Unit 1
© SOAS CeDEP 19
3.0 EXAMPLE: THE KEYNESIAN CONSUMPTION FUNCTION
We shall now illustrate several phases in the methodology of econometrics with an
example, the Keynesian consumption function.
Statement of the theory
The Keynesian theory of consumption is the basis of our model of consumption
expenditure. This theory states that real consumption expenditure depends on real
disposable income, other things held constant. When income rises, consumption
expenditure rises, but changes in consumption expenditure are less than the change
in income. Also, as income rises, the average propensity to consume, that is,
consumption per unit of income, falls.
Mathematical model of the theory
Suppose we represent the Keynesian consumption function as a linear relationship
(1.10)
where is real consumption expenditure, is real disposable income, is a
constant and is the slope of the consumption function, ie the marginal propensity
to consume out of disposable income. Because of our a priori expectations
concerning the average and marginal propensities to consume, we expect and
. (Note that the average propensity to consume is ⁄ ( )⁄ . For
this to fall as income rises, we need .)
Econometric model of the theory
The econometric model is stochastic. It includes a random disturbance, , which
captures the influence of all the other variables that may influence consumption
expenditure.
(1.11)

Applied Econometrics Unit 1
© SOAS CeDEP 20
Collection of data
The data to be used are annual time-series data for the UK covering the period
19551991. They are aggregate consumption expenditure and personal disposable
income both measured in £(1985) million. The source of the data is the Economic
Trends Annual Supplement 1991 (ONS, 1991). Thus, our model represents a theory
about the behaviour of aggregate consumption over time. A scatter plot of these
data is given in the figure in 3.1.1.
It is obvious from this scatter plot that the relationship is upward sloping and it
seems to be reasonably linear.
3.1.1 Scatter plot of aggregate consumption expenditure ( ) and personal disposable
income ( )
Source: unit author using data from Economic Trends Annual Supplement (ONS, 1991)
Parameter estimation
Using these data the parameters and can be estimated to obtain the average
relationship between and . Just how the coefficients of the population regression
function are estimated will be explained in detail in later units. The consumption
function estimated with our data is
(1.12)
and this represents the average relationship between consumption expenditure and
personal disposable income.
The estimated value of is 3952 and of is 0.889.
Consequently if personal disposable income increases by £1 million, consumption
expenditure increases on average by £0.889 million.

Applied Econometrics Unit 1
© SOAS CeDEP 21
In this case, the interpretation of the intercept is not so meaningful. Mechanical
interpretation of the estimate tells us that consumption expenditure is £3952 million
if aggregate personal disposable income is zero. However, this is not particularly
helpful because if aggregate personal disposable income is zero then the economy
would be in chaos and the Keynesian theory of consumption expenditure would not
be appropriate. The fact is that, in our sample, the -values are a long way from
zero, and we really have no idea what the consumption function might look like at
low levels of income.
Alternatively, some explain the value of the intercept as the average of all the
variables omitted from the model.
Tests of the hypothesis
Do the results conform to the theory of the consumption function?
With our theory we expect and .
Is each of these hypotheses supported by the results? Clearly, our estimates are
consistent with what we expected to obtain. For a discussion of formal hypothesis
tests, we must wait until the corresponding units.
Prediction
We can use the estimated model to predict what consumption expenditure would be
if personal disposable income were a particular amount. Suppose personal disposable
income was £250 000 million. The predicted amount of consumption expenditure is
= 3952 + 0.889(250 000)
∴ =226 202
That is, consumption expenditure is predicted to be £226 202 million if disposable
income is £250 000 million.

Applied Econometrics Unit 1
© SOAS CeDEP 22
UNIT SUMMARY
In this unit we have introduced some basic ideas on econometrics and regression
analysis. The most important points to remember are the following.
Econometrics is the application of statistical and mathematical methods to the
analysis of economic data, with the purpose of giving empirical content to
economic theories and testing them against ‘reality’.
The econometrician’s approach differs from that of the economic theorist
because:
- we cannot ‘hold other things constant’ in empirical analysis
- the random nature of relationships between variables means that the
results and conclusions of empirical analysis always contain an element of
uncertainty
- there is a discrepancy between theoretical variables and observed data in
terms of coverage and precision of measurement
- econometricians cannot avoid explicit assumptions about the time frame of
their model, since the data they use have been generated in a ‘real-time’
context.
Regression analysis is the statistical basis of econometric theory and practice.
Its aim is to quantify relationships between variables, especially between
variables whose relationship is subject to chance variation.
Regression involves finding an average line that summarises the relationship
whereby depends on in the midst of random variation and uncertainty of
outcome.
The randomness inherent in conclusions and outcomes based on regression
analysis is formally modelled by introducing a disturbance term into our
behavioural equations. This is a stochastic variable which is not observable.
However, the residuals of a sample regression function may provide us with an
indication as to the behaviour of these unknown disturbances.
Regression allows us to investigate the association between variables, but it
cannot ‘discover’ causality between them. To establish causality we need to
resort to economic theory.
Empirical work in economics cannot rely on experimentation. Econometric
analysis is therefore based on careful observation of data drawn from within a
context which we do not control.
In terms of practical skills, this unit requires that:
you are familiar with the scatter plot as a practical tool of empirical analysis
you know how to load data into R software from a pre-existing data file
you know the R software commands to obtain a summary of descriptive
statistics of a variable, make a scatter plot and create logarithms of variables.

Applied Econometrics Unit 1
© SOAS CeDEP 23
UNIT SELF-ASSESSMENT QUESTIONS
To answer the Unit Self-assessment Questions, you will need to use R software.
Please refer to the R Guide for Unit 1 (available on your e-study guide) and follow
the instructions given.
uestion 1
The data file u1q2.txt contains annual time-series data for the United States over the
period 19591991 on aggregate consumption expenditure, , and disposable income,
, both measured per head of population and in billions of constant 1987$. (Source:
Economic Report of the President, 1992: table B-5, p. 305).
(a) Use R software to produce a scatter plot of on the vertical axis and on the
horizontal axis. Comment on the scatter plot: would a linear regression seem
appropriate?
(b) Use R software to obtain time-series plots of and . Describe the way
consumption and income have moved over the period 19581991.
uestion 2
The hypothesis that foreign direct investment is determined by demand suggests
that foreign direct investment and gross domestic product are positively related,
other variables remaining constant. The data file u1q3.txt contains annual time-
series data for the period 19581985 on foreign direct investment, FDI, and gross
domestic product, GDP, for Taiwan. (Source: Tsai 1991: Table A-1, p. 285).
Use R software to obtain scatter plots of FDI on GDP and of the logarithm of FDI on
the logarithm of GDP, both for the period 19581985. Comment on the two scatter
plots. Remember that a log transformation is used in empirical research to reduce
the ‘noise’ (stored in the disturbances) associated with higher values of relative to
that associated with lower -values.
Which of the following would you expect to be the more appropriate linear regression
model:
(a)
or
(b) ?
Q
Q

Applied Econometrics Unit 1
© SOAS CeDEP 24
uestion 3
The data file u1q4.txt contains cross-section data from a sample of 100 rural
households on the value of their consumption and income during a given month.
Income ( ) includes cash income from all sources during the month concerned, plus
the (imputed) market value of own production consumed by the household.
Consumption ( ) includes the value of all purchased items, plus the value of own
production consumed by the household. The units are measured in the local currency
rounded to the nearest whole number.
(a) Obtain the scatter plot of on . What is the main difference between this
scatter plot and the one constructed in Question 1?
(b) Use R software to obtain the histograms of and . Income has the usual
positively skewed distribution that we would expect, whereas the distribution of
consumption is less skewed. Can you suggest a reason for this?
(c) Use R software
(i) to obtain the average propensity to consume at the sample means
(ii) to compare the degree of skewness of the two variables
(iii)to obtain their correlation coefficient.
You may remember that the correlation coefficient (or Pearson’s coefficient)
is defined as:
( ) ( )
It measures the degree of linear dependence between the two variables, it varies
between −1 and 1 and it is invariant to the units of measurement (eg $, thousands $
etc). A positive (negative) coefficient indicates that the variables are positively
(negatively) correlated, with a zero-value coefficient indicating that they are
uncorrelated random variables.
Q

Applied Econometrics Unit 1
© SOAS CeDEP 25
uestion 4
Weekly earnings can vary considerably in the case of casual dock labourers recruited
on a day-to-day basis. There are differences between workers as well as across
weeks. Weekly earnings will vary from week to week depending on the activity of the
harbour which determines the demand for labour. Daily recruitment will be high if
demand is high, and vice versa. Earnings also vary between workers in any given
week. These depend on the numbers of days a worker manages to get recruited for
in a particular week, on whether he or she is recruited for the day shift or the night
shift, and on the number of hours of overtime he or she works in that week.
In this exercise you will look at data on the weekly earnings of casual workers, ECAS,
and the recruitment of casual workers, CASREC. The data file u1q5.txt contains
paired observations on the two variables ECAS and CASREC. The data were taken
from a field study carried out in 1980/1981 by the Centre of African Studies in
Mozambique (Eduardo Mondlane University, Maputo) on casual labour on the docks
of Maputo harbour. The earnings data are in units of 100 MT, the local currency
being the Metical.
(a) Using R software, calculate the means, standard deviations, and minimum and
maximum values for both variables.
(b) A particular worker is randomly chosen from the labour force in a particular
week in 1980/1981 that is also randomly chosen. Using the information in your
answer to part (a), what is your best estimate of the weekly earnings of this
randomly selected worker?
(c) With R software, obtain the scatter plot of ECAS against CASREC. Write down
what you observe.
Q

Applied Econometrics Unit 1
© SOAS CeDEP 26
KEY TERMS AND CONCEPTS
cross-section data Type of data collected by observing a number of individuals,
countries, firms etc at the same point in time.
disturbances The unobserved random component that explains the
difference between observed and predicted values of .
econometrics The discipline that investigates economic data and
relationships using statistical techniques.
linear regression The statistical methodology that models the relationship
between a dependent variable and one or more explanatory
variables. In linear regression, this relationship (or function) is
assumed to be linear. Other methodologies can deal with
other functional forms, eg exponential, quadratic.
non-experimental data
Type of data that are not compiled as a result of experiments.
Other factors in the model are assumed to be fixed, although
the researcher cannot actually hold them fixed as he could do
in an experimental context.
time-series data Type of data collected by observing the same individual,
country, firm etc over a period of time.





























