Embed Size (px)
Citation preview

Paralelni programski modeli
pthreadsMPICilk/OpenMPIPP, TBB
1

IPPIPP = Integrated Performance Primitives
Visoko optimizovane primitive za paralelno programiranjeMogu se bezbedno pozivati iz TBB niti, OpenMP niti ili Cilk linija
Širok skup primitiva specifičnih za razne domeneObrada 1D signalaObrada 2D signala (slike)Rad sa matricama (vektorima)KriptografijaKompresija podataka... 2

TBB (Threading Building Blocks)Teme
Paralelni forRedukcija u paralelnoj petljiProtočna obradaMeđusobno isključivanjeAtomske operacijeDodela memorijeZadaciKontejneri
3

TBB (Threading Building Blocks)Podsetimo se iz C++-a:
1. Šta određuje poziv funkcije u Ce++-u? (Preklapanje funckija)
2. Generičko programiranje (šabloni, tj. templejti)3. Konstruktori4. Preklapanje operatora5. Funktori6. (Funktorski literali, tj. lambda funkcije)
4

C++ podsećanje: od konkretnom ka apstraktnom
5
int r1 = 3 * 3 + 4 * 4 * 4;
int a, b;
int r2 = a * a + b * b * b;

C++ podsećanje: od konkretnom ka apstraktnom
6
int r1 = 3 * 3 + 4 * 4 * 4;
int a, b;
int r2 = a * a + b * b * b;
int c, d;
int r3 = c * c + d * d * d;

C++ podsećanje: od konkretnom ka apstraktnom
7
int sumPow23(int x, int y) {
return x * x + y * y * y;
}
int r1 = sumPow23(3, 4);
int a, b;
int r2 = sumPow23(a, b);
int c, d;
int r3 = sumPow23(c, d);

C++ podsećanje: od konkretnom ka apstraktnom
8
int sumPow23(int x, int y) {
return x * x + y * y * y;
}
int r1 = sumPow23(3, 4);
int a, b;
int r2 = sumPow23(a, b);
double c, d;
double r3 = ?

C++ podsećanje: od konkretnom ka apstraktnom
9
int sumPow23(int x, int y) {
return x * x + y * y * y;
}
double sumPow23(double x, double y) {
return x * x + y * y * y;
}
int r1 = sumPow23(3, 4);
int a, b;
int r2 = sumPow23(a, b);
double c, d;
double r3 = sumPow23(c, d);

C++ podsećanje: od konkretnom ka apstraktnom
10
int sumPow23(int x, int y) {
return x * x + y * y * y;
}
mov eax, DWORD PTR [rbp-4]
imul eax, DWORD PTR [rbp-4]
mov edx, eax
mov eax, DWORD PTR [rbp-8]
imul eax, DWORD PTR [rbp-8]
imul eax, DWORD PTR [rbp-8]
add eax, edx
double sumPow23(double x, double y) {
return x * x + y * y * y;
}
movsd xmm0, QWORD PTR [rbp-8]
movapd xmm1, xmm0
mulsd xmm1, QWORD PTR [rbp-8]
movsd xmm0, QWORD PTR [rbp-16]
mulsd xmm0, QWORD PTR [rbp-16]
mulsd xmm0, QWORD PTR [rbp-16]
addsd xmm0, xmm1
Tip je vrlo važan, jer smisao i izvršavanje zavise od toga.Mašinski kod je vrlo različit za različite tipove!

C++ podsećanje: od konkretnom ka apstraktnom
11
template<typename T> Т sumPow23(T x, T y) {
return x * x + y * y * y;
}
int r1 = sumPow23<int>(3, 4);
int r1 = sumPow23(3, 4);
int a, b;
int r2 = sumPow23(a, b);
double c, d;
double r3 = sumPow23(c, d);

C++ podsećanje: od konkretnom ka apstraktnom
12
template<class T> Т sumPow23(T x, T y) {
return x * x + y * y * y;
}
// ali:
int x;
float y;
int z = sumPow23(x, y);
string e, f;
string r4 = sumPow23(e, f);

C++ podsećanje: Funkcijski objekti (Funktori)
13
Funkcijski objekti (funktori) su promenljive („objekti“) koji se sintaksno ponašaju kao funkcije, odnosno mogu tako da se upotrebljavaju.To se obezbeđuje preklapanjem operatora ()
struct FunctionObjectShowroom{
...
int operator()(int x);
float operator()(double x);
void operator()(int x, double y);
int* operator()(float x, int y, long z);
...
};
FunctionObjectShowroom foo;
a = foo(6);
b = foo(7.6);
foo(a, b);
c = foo(7.5f, a, 46L);

C++ podsećanje: Funkcijski objekti (Funktori)
14
Ova dva koda su suštinski ista. Razlikuju se samo sintaksno.
struct FunctionObjectShowroom{
...
int operator()(int x);
float operator()(double x);
...
};
FunctionObjectShowroom foo;
a = foo(6);
b = foo(7.6);
struct FOS{
...
int funjkcija(int x);
float funjkcija(double x);
...
};
FOS foo;
a = foo.funjkcija(6);
b = foo.funjkcija(7.6);

C++ podsećanje: Lambda funkcije
15
Lambda funkcije su forma funktorskog literala.
struct Foo{
int operator()(int x) {
return x * x;
}
};
Foo foo;
a = foo(6);
b = foo(7);
auto foo = [](int x) { return x * x; };
a = foo(6);
b = foo(7);

C++ podsećanje: Lambda funkcije
16
Lambda funkcije su forma funktorskog literala.Kao i funktori, mogu imati atribute.
class Foo{
int const m_y;
public:
Foo(int y) : m_y(y) {}
int operator()(int x) {
return x * x - y;
}
};
int p;
Foo foo(p);
a = foo(6);
b = foo(7);
int p;
auto foo = [=](int x) { return x * x - p; };
a = foo(6);
b = foo(7);

Jenostavne petlje: primerNeka je bezbedno paralelno primeniti funkciju Foo na sve elemente niza A
17
void SerialApplyFoo(float a[], size_t n) {
for (size_t i = 0; i != n; ++i)
Foo(a[i]);
}

Jenostavne petlje: primerDa bi paralelizovali sekvencijalno rešenje
Formiramo objekat telaTo je klasa čija metoda operator() radi nad delom iteracionog prostorablocked_range<T> opisuje jednodimenzioni prostor
18
#include "tbb/parallel_for.h"
void ParallelApplyFoo(float a[], size_t n) {
parallel_for(blocked_range<size_t>(0, n), ApplyFoo(a));
}
void SerialApplyFoo(float a[], size_t n) {
for (size_t i = 0; i != n; ++i)
Foo(a[i]);
}

Jenostavne petlje: primer#include "tbb/parallel_for.h"
using namespace tbb;
class ApplyFoo {
float* const m_a;
public:
ApplyFoo(float a[]) : my_a(a) {}
void operator()(const blocked_range<size_t>& r) const {
float* a = m_a;
for (size_t i = r.begin(); i != r.end(); ++i)
Foo(a[i]);
}
};
_______________________________________________
void ParallelApplyFoo(float a[], size_t n) {
parallel_for(blocked_range<size_t>(0, n), ApplyFoo(a));
}
19

Jenostavne petlje: primer#include "tbb/parallel_for.h"
using namespace tbb;
class ApplyFoo {
float* const m_a;
public:
ApplyFoo(float a[]) : my_a(a) {}
void operator()(const blocked_range<size_t>& r) const {
float* a = m_a;
for (size_t i = r.begin(); i != r.end(); ++i)
Foo(a[i]);
}
};
_______________________________________________
void ParallelApplyFoo(float a[], size_t n) {
parallel_for(blocked_range<size_t>(0, n), ApplyFoo(a));
}
20

Jenostavne petlje: primer#include "tbb/parallel_for.h"
using namespace tbb;
class ApplyFoo {
float* const m_a;
public:
ApplyFoo(float a[]) : my_a(a) {}
void operator()(const blocked_range<size_t>& r) const {
float* a = m_a;
for (size_t i = r.begin(); i != r.end(); ++i)
Foo(a[i]);
}
};
_______________________________________________
void ParallelApplyFoo(float a[], size_t n) {
parallel_for(blocked_range<size_t>(0, n), ApplyFoo(a));
}
21

Jenostavne petlje: primer#include "tbb/parallel_for.h"
using namespace tbb;
class ApplyFoo {
float* const m_a;
public:
ApplyFoo(float a[]) : my_a(a) {}
void operator()(const blocked_range<size_t>& r) const {
float* a = m_a;
for (size_t i = r.begin(); i != r.end(); ++i)
Foo(a[i]);
}
};
_______________________________________________
void ParallelApplyFoo(float a[], size_t n) {
parallel_for(blocked_range<size_t>(0, n), ApplyFoo(a));
}
22
for (size_t i = 0; i != n; ++i)
Foo(a[i]);

Jenostavne petlje: primerlambda funkcijevoid ParallelApplyFoo(float a[], size_t n) {
parallel_for(blocked_range<size_t>(0, n), ApplyFoo(a));
}
____________________________________________
void ParallelApplyFoo(float a[], size_t n) {
parallel_for(blocked_range<size_t>(0, n),
[=](const blocked_range<size_t>& r) {
for (size_t i = r.begin(); i != r.end(); ++i)
Foo(a[i]);
}
);
}
____________________________________________
// Specijalni slučaj
void ParallelApplyFoo(float a[], size_t n) {
parallel_for(size_t(0), n, [=](size_t i) {
Foo(a[i]);
});
} 23

Jednostavne petljeKontrolisana podela iteracionog prostora
Kontrola podele pomoću partitioner i grainsizeZadati simple_partitioner() unutar parallel_forPostoje još auto_partitioner (podrazumevani), affinity_partitioner i static_partitioner
blocked_range<T>(begin, end, grainsize)simple_partitioner garantuje ⎡G/2⎤ ≤ chunksize ≤ Gauto_partitioner garatuje samo ⎡G/2⎤ ≤ chunksize
24
#include "tbb/parallel_for.h"
void ParallelApplyFoo(float a[], size_t n) {
parallel_for(blocked_range<size_t>(0, n, G), ApplyFoo(a),
simple_partitioner());
}
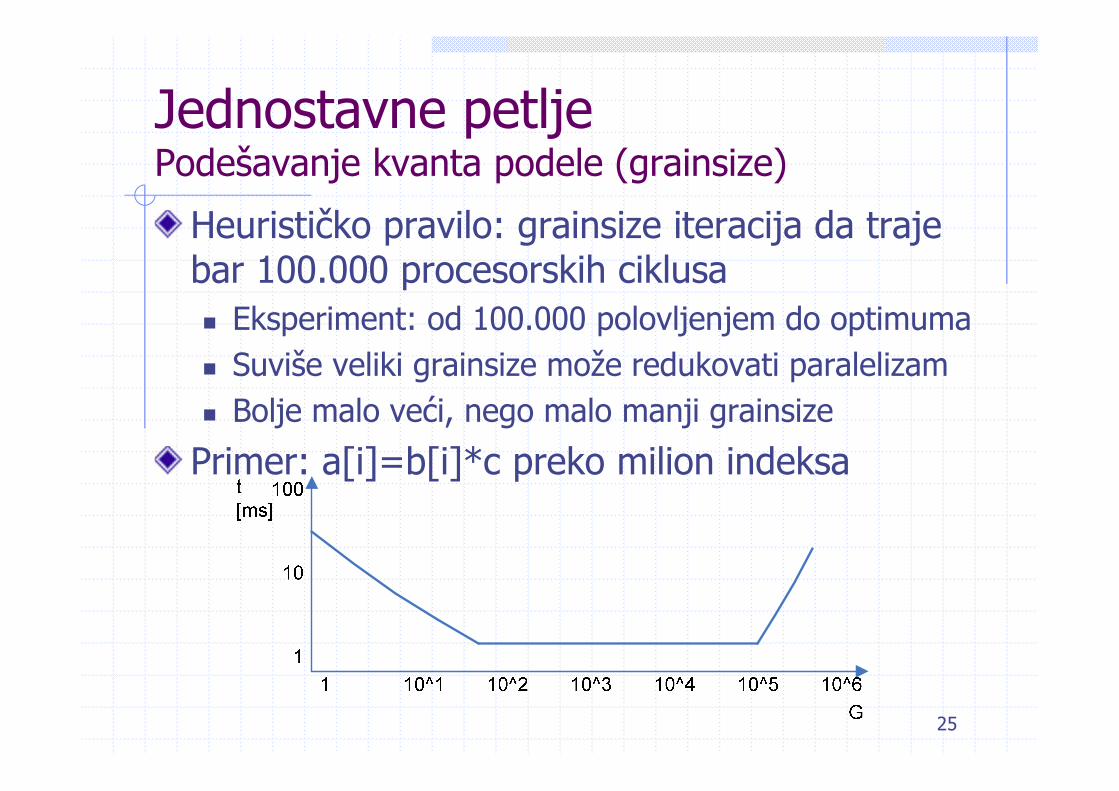
Jednostavne petljePodešavanje kvanta podele (grainsize)
Heurističko pravilo: grainsize iteracija da trajebar 100.000 procesorskih ciklusa
Eksperiment: od 100.000 polovljenjem do optimumaSuviše veliki grainsize može redukovati paralelizamBolje malo veći, nego malo manji grainsize
Primer: a[i]=b[i]*c preko milion indeksa
25

Jednostavne petljeŠirina propusnog opsega i bliskost pri keširanju
Malo ubrzanje zbog nedovoljnog propusnog opsega između procesora i memorije
Prestruktuirati radi boljeg iskorišćenja keš memorije
Ili, iskoristiti affinity_partitioner, kadaObradu čine par operacija po pristupu podatkuPodaci nad kojima petlja radi staju u kešuPetlja ili slična petlja se izvodi nad istim podacima
26

Jednostavne petljePrimer korišćenja affinity_partitioner (ap)
affinity_partitioner mora da živi preko iteracija petlje
To se postiže deklaracijom da je static (statičke trajnosti)affinity_partitioner dodeljuje iteraciju onoj niti koja ju je ranije izvršavala
27
void ParallelApplyFoo(float a[], size_t n) {
static affinity_partitioner ap;
parallel_for(blocked_range<size_t>(0,n), ApplyFoo(a), ap);
}
void TimeStepFoo(float a[], size_t n, int steps) {
for (int t = 0; t < steps; ++t)
ParallelApplyFoo(a, n);
}
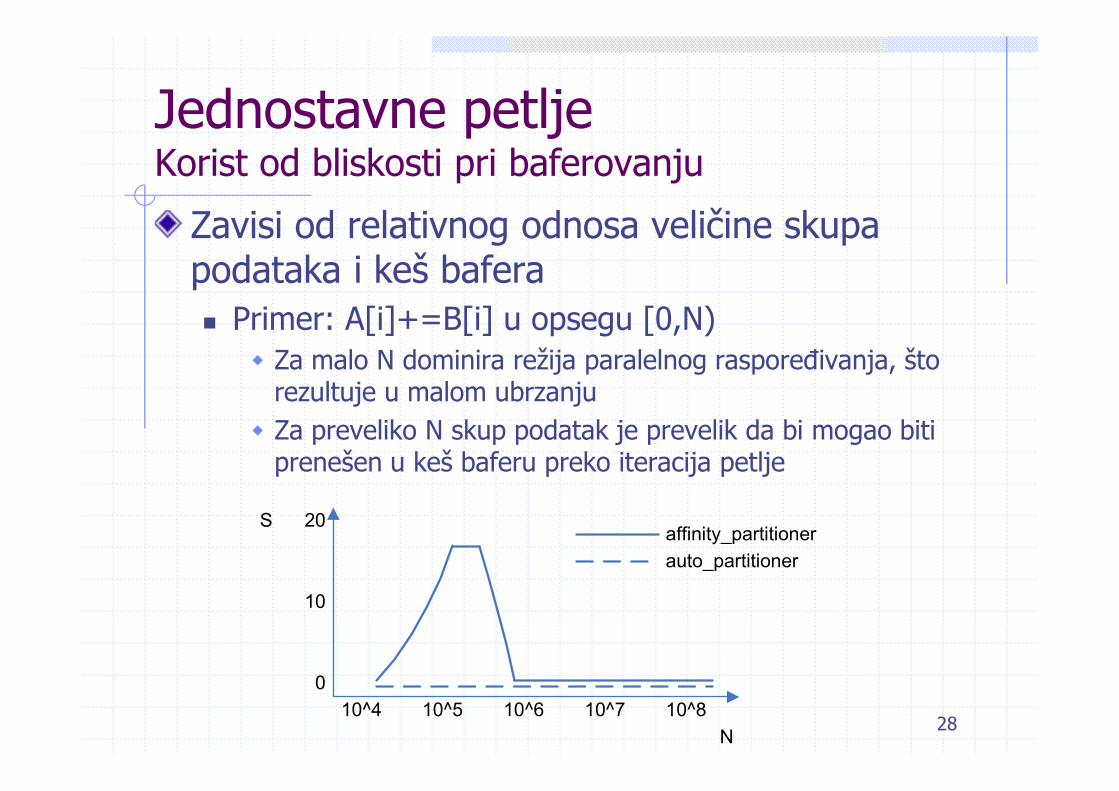
Jednostavne petljeKorist od bliskosti pri baferovanju
Zavisi od relativnog odnosa veličine skupa podataka i keš bafera
Primer: A[i]+=B[i] u opsegu [0,N)Za malo N dominira režija paralelnog raspoređivanja, što rezultuje u malom ubrzanjuZa preveliko N skup podatak je prevelik da bi mogao biti prenešen u keš baferu preko iteracija petlje
28
20
10
0
10^4 10^5 10^6 10^7 10^8
N
Saffinity_partitioner
auto_partitioner

Jednostavne petljeparallel_reduce
Ako su iteracije nezavisne, gornja petlja se može paralelizovati sa parallel_reduce
29
float SerialSumFoo(float a[], size_t n) {
float sum = 0;
for (size_t i = 0; i != n; ++i)
sum += Foo(a[i]);
return sum;
}
#include “tbb/parallel_reduce.h”
float ParallelSumFoo(const float a[], size_t n) {
SumFoo sf(a);
parallel_reduce(blocked_range<size_t>(0, n), sf);
return sf.m_sum;
}

Jednostavne petljeparallel_reduce
30
class SumFoo {
float* const m_a;
public:
float m_sum;
SumFoo(float a[]) : m_a(a), m_sum(0) {}
SumFoo(SumFoo& x, split y) : m_a(x.m_a), m_sum(0) {}
void join(const SumFoo& y) { m_sum += y.m_sum; }
void operator()(const blocked_range<size_t>& r) {
float* a = m_a;
float sum = m_sum;
for (size_t i = r.begin(); i != r.end(); ++i)
sum += Foo(a[i]);
m_sum = sum;
}
};

Jednostavne petljeparallel_reduce – razlike u odnosu na ApplyFoo
31
class SumFoo {
float* const m_a;
public:
float m_sum;
SumFoo(float a[]) : m_a(a), m_sum(0) {}
SumFoo(SumFoo& x, split y) : m_a(x.m_a), m_sum(0) {}
void join(const SumFoo& y) { m_sum += y.m_sum; }
void operator()(const blocked_range<size_t>& r) {
float* a = m_a;
float sum = m_sum;
for (size_t i = r.begin(); i != r.end(); ++i)
sum += Foo(a[i]);
m_sum = sum;
}
};
nema const

Jednostavne petljeIzvršenje parallel_reduce-a
Kada je nit radnik (worker) raspoloživaPoziva se konstruktor razdvajanja
Pravi se podzadatak za nit radnikaNakon završetka podzadatka poziva se join radi akumuliranja njegovog rezultata
32

Složene petljeprotočna obrada
TBB realizuje mustru protočne obradeApstrakcije: pipeline i filterPrimer: kvadriranje brojeva u datoteci
Stepeni protočne obrade: čitaj iz dat., kvadriraj, piši u dat.Blok podataka (4000 znakova) predstavljen klasom TextSlice
33
class TextSlice {
...
};

Složene petljeprotočna obrada
Kod za pravljenje i izvršenje protočne obradeTextSlice objekti se prosleđuju putem pokazivača
34
void RunPipeline(int ntoken, FILE* input_file, FILE* output_file) {
tbb::parallel_pipeline(
ntoken,
tbb::make_filter<void, TextSlice*>(
tbb::filter::serial_in_order, MyInputFunc(input_file))
&
tbb::make_filter<TextSlice*, TextSlice*>(
tbb::filter::parallel, MyTransformFunc())
&
tbb::make_filter<TextSlice*, void>(
tbb::filter::serial_in_order, MyOutputFunc(output_file))
);
}
funktori

Složene petljeprotočna obrada
Kod za pravljenje i izvršenje protočne obradeTextSlice objekti se prosleđuju putem pokazivača
35
void RunPipeline(int ntoken, FILE* input_file, FILE* output_file) {
tbb::parallel_pipeline(
ntoken,
tbb::make_filter<void, TextSlice*>(
tbb::filter::serial_in_order, MyInputFunc(input_file))
&
tbb::make_filter<TextSlice*, TextSlice*>(
tbb::filter::parallel, MyTransformFunc())
&
tbb::make_filter<TextSlice*, void>(
tbb::filter::serial_in_order, MyOutputFunc(output_file))
);
}
funktori
kog tipa?
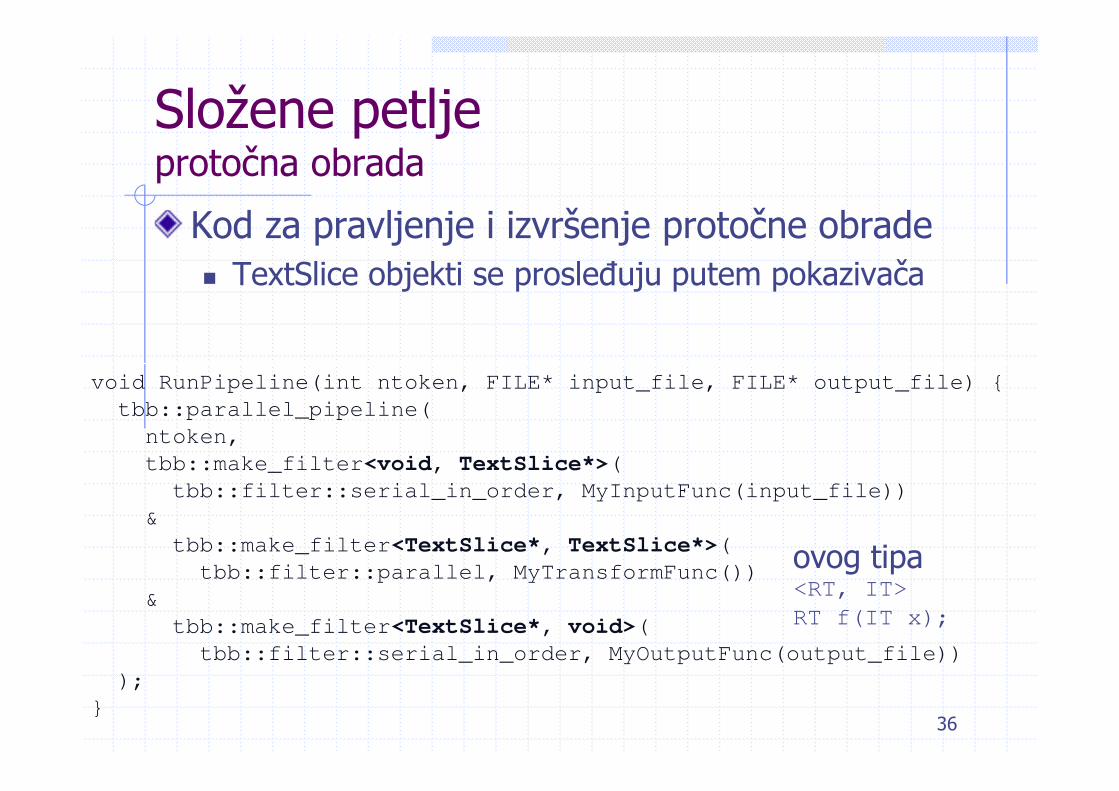
Složene petljeprotočna obrada
Kod za pravljenje i izvršenje protočne obradeTextSlice objekti se prosleđuju putem pokazivača
36
void RunPipeline(int ntoken, FILE* input_file, FILE* output_file) {
tbb::parallel_pipeline(
ntoken,
tbb::make_filter<void, TextSlice*>(
tbb::filter::serial_in_order, MyInputFunc(input_file))
&
tbb::make_filter<TextSlice*, TextSlice*>(
tbb::filter::parallel, MyTransformFunc())
&
tbb::make_filter<TextSlice*, void>(
tbb::filter::serial_in_order, MyOutputFunc(output_file))
);
}
ovog tipa<RT, IT>
RT f(IT x);

Složene petljeprotočna obrada
Parametar ntoken kotroliše nivo paralelizmaserial_in_order filter: serijska obradaparallel filter: paralelna obradaPotencijalan problem: gde čuvati znake u srednjem stepenuntoken specificira max br. znakova koji su u protočnoj obradi
Drugi parametar specificira niz filtaramake_filter<inputType, outputType>(mode, functor)Filtri se spajaju pomoću operatora &serial_out_of_order filter: ne održava originalni redosled
37

Međusobno isključivanje nitiRealizuje se pomoću mutex i locks
mutex je objekat koji nit može zaključati, prethodno dobijenim ključemSamo jedna nit može imati ključ, ostale moraju čekati
Najjednostavniji mutex je spin_mutexAdekvatan ako se ključ drži samo kratko vremePrimer: FreeListMutex štiti FreeListGrupisanje iskaza u blok može izgledati neobično –uloga je da se skrati vreme života ključa
38

Međusobno isključivanje nitiPrimer upotrebe spin_mutex-aNode* FreeList;
typedef spin_mutex FreeListMutexType;
FreeListMutexType FreeListMutex;
Node* AllocateNode() {
Node* n;
{
// konstruktor zaključava listu
FreeListMutexType::scoped_lock lock(FreeListMutex);
n = FreeList;
if (n)
FreeList = n->next;
} // destruktor otključava listu
if (!n)
n = new Node();
return n;
}
39

Međusobno isključivanje nitiAlternativan primer upotrebe spin_mutex-a
Metode acquire i releaseOO sprega – otključavanje u slučaju izuzetkaMutex tipa M ima ključ tipa M::scoped_lock
40
Node* AllocateNode() {
Node* n;
FreeListMutexType::scoped_lock lock;
lock.acquire(FreeListMutex);
n = FreeList;
if (n)
FreeList = n->next;
lock.release();
if (!n)
n = new Node();
return n;
}

Međusobno isključivanje nitiOsobine i vrste mutex-a
Osobine mutex-aScalable/Non-scalable, Fair/Unfair, Recursive/Non-recursive, Yield/Block (yield – upošljeno čekanje)
Vrste mutex-aspin_mutex
Non-scalable, unfair, non-recursive, yields
queuing_mutexScalable, fair, non-recursive, yields
spin_rw_mutex i queuing_rw_mutexKao prethodni + podrška za ključeve čitača (readers)
speculative_spin_mutex i speculative_spin_rw_mutexNa hardveru koji ima transakcionu memoriju
mutex i recursive_mutex su omotači oko OS primitiva
null_mutex and null_rw_mutex – ne rade ništa 41

Međusobno isključivanje nitiMutex-i čitača-pisača
Mutex-i su potrebni ako bar jedna nit piše u objekat
Više čitača mogu dobiti ulaz u zaštićeni deo koda
Mutex-i sa _rw_ u imenu razlikuju ključeve Ključevi za čitanje i upis
Ključ za čitanje se može podići na nivo za pisanjeMetoda upgrade_to_writer može privremeno osloboditi ključinače bi moglo doći do međusobnog blokiranja (deadlock)
42

Atomske operacijeDefinicija (1/2)
Druge niti vide atomske operacije kao trenutneBrže su od operacija sa zaključavanjimaPrednost: nema uobičajenih problema koji postoje kod muteksaNedostatak: rade ograničen skup operacijaKlasa atomic<T> implementira atomske operacije
Primer: brojanje referenci: akcija ako x==0Sekvencijalno: --x; if(x==0) action()U sl. više niti, x postaje deljena promenljivaSmanjenje x i provera da li je 0 mora se uraditi neprekidivox deklarisati kao atomic<int> i napisati if(--x==0) action()
43

Atomske operacijeDefinicija (2/2)
atomic<T>, T int, enum ili pokazivačPet osnovnih operacija nad x tipa atomic<T>
= x, pročitaj xx =, upiši vredost u x i vrati tu vrednostx.fetch_and_store(y), uradi x=y i vrati staru vrednost od xx.fetch_and_add(y), uradi x+=y i vrati staru vrednost od xx.compare_and_swap(y,z), ako je x==z, uradi x=y. Uvek vrati staru vrednost od x
44
atomic<unsigned> counter;
unsigned GetUniqueInteger() {
// return different int, until counter wraps around
return counter.fetch_and_add(1);
}

Dodela memorijescalable_allocator<T> rešava problem skalabilnosti
Konvencionalan allocator: ekskluzivan pristup mem. bazenuscalable_allocator<T>: više niti istovremeno dobija objekte tipa T
cache_aligned_allocator<T> rešava lažno deljenje linije keša
Nastaje kad dve niti pristupaju različitim rečima u liniji baferaKad jedno jezgro promeni liniju, pa je promeni drugo jezgro, linija se iz prvog prebacuje u drugo – nekoliko stotina taktovaRešenje: cache_aligned_allocator<T> - garantuje da objekti koje napravi neće deliti istu liniju bafera
Za potpuno razumevanje kako se ovo krosti, pogledati std::allocator. 45

Raspoređivač zadatakaRealizuje paralelne apstrakcije visokog niova
Nudi API koji se može direktno koristitiMoguće je relizovati svoje apstrakcije visokog nivoaTreba koristiti logičke zadatke; prednosti:
Poklapanje paralelizma sa resursima, brže dizanje i spuštanje sistema, efikasniji redosled evaluacije, bolje uravnoteženje opterećenja, i razmišljanje na višem nivou
Programske niti se preslikavaju na fizička jezgraKrajnosti pretplate: nedovoljna i prevelikaPrevelika pretplata: dovodi do pada performanse zbog deljenja vremena (time slicing)
Raspoređivač pokušava da ima jednu nit na jednom jezgru
46

Raspoređivač zadatakaTBB zadaci
Zadaci su puno “lakši” od niti (brže se pokreću)Na OS Linux 18 puta, a na Windows više od 100 putaZadatak (task) u TBB je mala rutina (nema kontekst)TBB zadaci jedan drugog ne istiskuju
TBB raspoređivač je efikasan zato što nije pravedanOn poseduje infoрmacije o zadacima, tako da može da žrtvuje pravednost za efikasnostZadatak se pokreće tek kad može da učini koristan napredakRaspoređivač uravnotežuje opterećenje
47

Raspoređivač zadatakaPrimer: n-ti element Fibonačijevog niza
Dat je serijski kod i paralelna verzija sa zadacima
48
int SerialFib(int n) {
if (n <= 1) return n;
x = SerialFib(n - 1);
y = SerialFib(n - 2);
return x + y;
}
#include “tbb/task_group.h”
int Fib(int n) {
int x, y;
task_group g;
g.run([&]{x = Fib(n - 1);});
g.run([&]{y = Fib(n - 2);});
g.wait();
return x + y;
}

Raspoređivač zadatakaPrimer: n-ti element Fibonačijevog niza
49
int SerialFib(int n) {
if (n <= 1) return n;
x = SerialFib(n - 1);
y = SerialFib(n - 2);
return x + y;
}
#include “tbb/task_group.h”
int Fib(int n) {
int x, y;
task_group g;
g.run(FibTask(x, n – 1));
g.run(FibTask(y, n – 2));
g.wait();
return x + y;
}
class FibTask {
int& m_res;
int const m_n;
public:
FibTask(int& res, int n)
: m_res(res), m_n(n) {}
int operator()() {
m_res = Fib(m_n);
}
};

Raspoređivač zadatakaPrimer: n-ti element Fibonačijevog niza
Može i sa potkresivanjem stabla
50
int Fib(int n) {
int x, y;
task_group g;
g.run([&]{ x = (n-1 < CutOff) ? SerialFib(n-1) : Fib(n-1); });
g.run([&]{ y = (n-2 < CutOff) ? SerialFib(n-2) : Fib(n-2); });
g.wait();
return x + y;
}

Raspoređivač zadatakaPrimer: n-ti element Fibonačijevog niza
Malo drugačiji način koji omogućava veću kontrolu, ali je malo složeniji.
51
int SerialFib(int n) {
if (n <= 1) return n;
x = SerialFib(n - 1);
y = SerialFib(n - 2);
return x + y;
}
int Fib(int n) {
long sum;
FibTask& a = *new(task::allocate_root()) FibTask(n, &sum);
task::spawn_root_and_wait(a);
return sum;
}

Raspoređivač zadatakaPrimer: n-ti element Fibonačijevog niza
Funkcija ParallelFib1. Dodeljuje prostor za zadatak root2. Konstruiše zadatak root3. Pokreće ga i čeka zadatak root
Stvarni posao obavlja klasa FibTask
52
class FibTask : public task {
int& m_res;
const int m_n;
public:
FibTask(int& res, int n) : m_res(res), m_n(n) {}
//nastavak na drugom slajdu
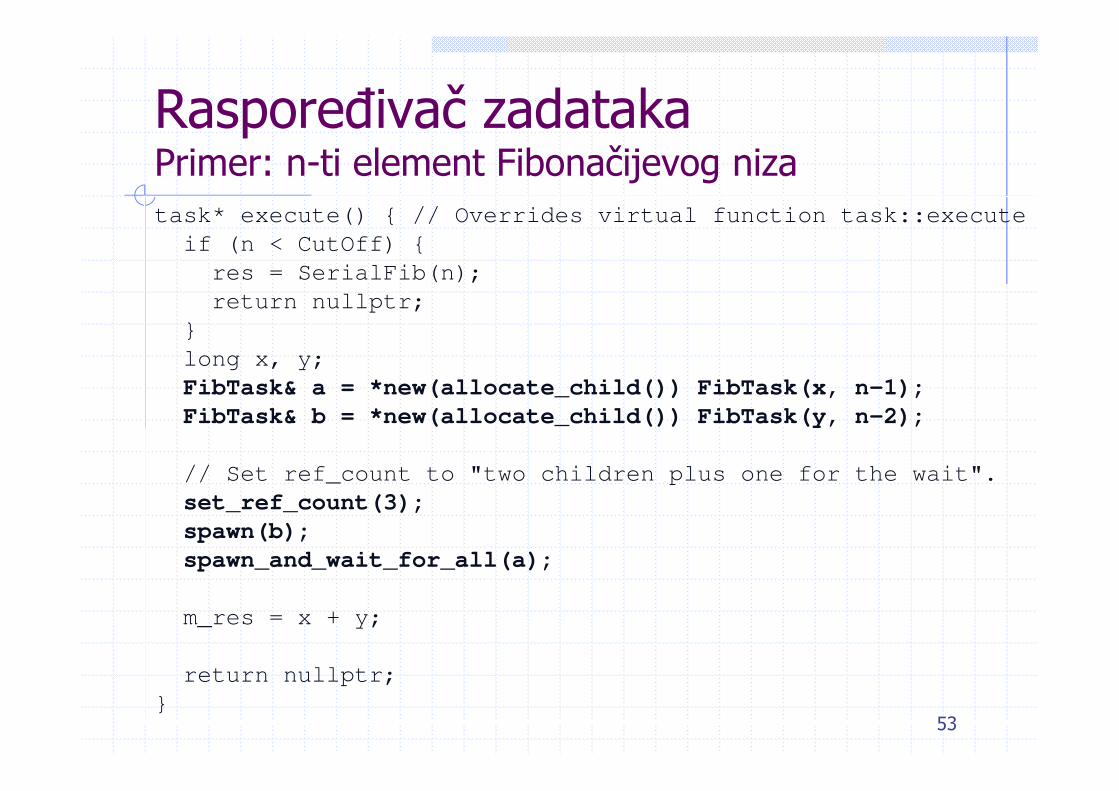
Raspoređivač zadatakaPrimer: n-ti element Fibonačijevog nizatask* execute() { // Overrides virtual function task::execute
if (n < CutOff) {
res = SerialFib(n);
return nullptr;
}
long x, y;
FibTask& a = *new(allocate_child()) FibTask(x, n-1);
FibTask& b = *new(allocate_child()) FibTask(y, n-2);
// Set ref_count to "two children plus one for the wait".
set_ref_count(3);
spawn(b);
spawn_and_wait_for_all(a);
m_res = x + y;
return nullptr;
}53

Raspoređivač zadatakaGraf zadataka
Raspoređivač obrađuje graf zadatakaUsmeren graf, svaki čvor je zadatakSvaki zadatak pokazuje na naslednika, koji ga čekaSvaki zadatak ima refcount: br. zadataka čiji je on naslednik, dodaje se 1 za eksplicitno čekanje (wait)
Pimer grafa zadataka iz primera Fibonačijev nizA, B i C su izmrestili svoje potomke i čekaju ihD se izvršava, još nije izmrestio potomkeE, F i G čekaju na izvršenje
54

Raspoređivač zadatakaAlgoritam raspoređivača (1/3)
Minimizira memorijske zahteve i komunikaciju nitiBalansira izvršenje u dubinu i u širinuIzvršenje u dubinu je najbolje za serijsko izvršenje
Radi dok je bafer vruć. D je najnoviji, zatim C, pa A i B.Minimizira prostor. U širinu, eksp. br. zadataka. U dubinu, linearan, jer se ostali smeštaju na stek (E, F i G iz primera).
Iako izvršenje u širinu ima problem sa potrošnjom memorije, ono maksimizira paralelizam
Koristiti dovoljno paralelizma, da jezgra budu upošljena
55

Raspoređivač zadatakaAlgoritam raspoređivača (2/3)
Hibrid izvršenja u dubinu i u širinuSvako jezgro ima svoj red sa dva kraja (deque)Npr. kad zadatak F izmresti E, gurne ga na dno reda
Jezgro bira sledeći zadatak za izvršenjeOnaj koji vrati metoda execute, ako nije NULLOnaj sa dna svog reda, ako nije prazanPreuzima zadatak sa vrha reda drugog, obično slučajno izabranog, jezgra
56

Raspoređivač zadatakaAlgoritam raspoređivača (3/3)
Tri uslova da jezgro gurne zadatak na dno redaEksplicitno izmrešćen zadatakZadatak označen za ponovno izvršenjeNakon izvršenja zadnjeg prethodnika, refcount naslednika postaje 0 i jezgro gura naslednika na dno svog reda
Strategija: “Radi u dubinu, preuzimaj u širinu”“breadth-first theft and depth-first work”Izvršenje u širinu ide samo do potrebnog paralelizmaIzvršenje u dubinu održava operativnu efikasnost, jednom kada ima dovoljno posla
57

KontejneriOmogućavaju istovremen pristup za više niti
Zaštita STL kontejnera objektima isključivog pristupa ograničava paralelizam, odnosno ubrzanjeTBB koristi dve metode
Fino zaključavanje (fine-grained locking) samo onih delova kontejnera koji se moraju zaključatiTehnike bez zaključavanja – niti uračunavaju i popravljaju efekte drugih niti koje ih ometaju
Primitive kontejnera za paralelni pristup su duže nego kod klasičnih STL kontejnera
Treba ih koristiti samo ako se isplati dodatni paralelizam koji one omogućavaju
58

Kontejnericoncurrent_hash_map
concurrent_hash_map<Key, T, HashCompare >HashCompare je tip koji određuje kako se računa ključ i kako se dva ključa porede
59
// Structure that defines hashing and comparison operations
struct MyHashCompare {
static size_t hash(const string& x) {
size_t h = 1;
for (const char* s = x.c_str(); *s; ++s)
h = (h * 17) ^ *s;
return h;
}
// ! True if strings are equal
static bool equal(const string& x, const string& y) {
return x == y;
}
};

Kontejnericoncurrent_hash_map
60
typedef concurrent_hash_map<string,int,MyHashCompare> StringTable;
// Function object for counting occurrences of strings.
struct Tally {
StringTable& table;
Tally(StringTable& table_) : table(table_) {}
void operator()(const blocked_range<string*> range) const {
for (string* p = range.begin(); p != range.end(); ++p) {
StringTable::accessor a;
table.insert(a, *p);
a->second += 1;
}
}
};
string Data[N];
StringTable table;
parallel_for(blocked_range<string*>(Data, Data+N, 1000), tally(table));

Kontejnericoncurrent_hash_map
61
typedef concurrent_hash_map<string,int,MyHashCompare> StringTable;
// Function object for counting occurrences of strings.
struct Tally {
StringTable& table;
Tally(StringTable& table_) : table(table_) {}
void operator()(const blocked_range<string*> range) const {
for (string* p = range.begin(); p != range.end(); ++p) {
StringTable::accessor a;
table.insert(a, *p);
a->second += 1;
// a.release();
}
}
};
string Data[N];
StringTable table;
parallel_for(blocked_range<string*>(Data, Data+N, 1000), tally(table));

Kontejnericoncurrent_vector
concurrent_vector<T>Metode: push_back, grow_by, grow_to_at_leastNužno je sinhronizovati konstruisanje i pristup elementimaOperacije nad concurrent_vector traju duže nego nad vector
Potrebno je sinhronizovati stvaranje elementa i pristup:
Čekanje elementa v[i] koji dodaje druga nitČekaj dok je i<v.size()Čekaj da v[i] bude konstruisan
62

Kontejnericoncurrent_queue
concurrent_queue<T,Alloc >, red vrednosti tipa TOsnove operacije: push i try_popU programu sa jednom niti red je FIFO strukturaZa više niti, red odražava redosled po redosledu ubacivanjaRed je neograničen i neblokirajući
concurrent_bounded_queue<T,Alloc >Ograničen red: varijanta sa blokiranjemOperacije: push, pop, try_push, sizeMetoda size vraća broje nepreuzetih elemenata redaVeličina se postavlja metodom set_capacity
63





























