Embed Size (px)
Citation preview

Paired t-test & Friedman test
Journal Club: Statistical Methodology in Nutrition
Education and Behavior Research
Barbara Lohse, PhD, RD, LDN
April 20, 2015
www.needscenter.org

t-test for paired samples
Also called t-test for dependent means or t-test for correlated samples.
Determines if the means of two groups of related pairs are statistically different from each other.
Matched pairs (e.g., parent & child, husband & wife or pre/post test) is one form of experimental control since it removes the matching factor as a cause for observed differences. However, the degrees of freedom are halved (n refers to numbers of pairs, not numbers of individuals) so matching must be done carefully.
With independent samples the covariance is zero. In matched samples the covariance is positive, thus the variance between means is less for matched than unmatched groups.

Assumptions for paired t-test
Assume that the dispersion or variance of the two
samples is equal. For paired t-test this is a problem only
with very unequal variances.
Assumption of normally distributed data is important, but
not as important as the assumption of homogeneous
variances, especially with a moderate sample size (e.g.,
40 cases).
When samples are quite large the assumptions of
normality and homogenous variances are relatively
unimportant--the test is said to be robust.

Computing t for paired samples
t = Sum of differences between groups/ SE of difference, i.e., square root of the sum of the differences squared between groups divided by number of pairs of observations -1.
t = ΣD
nΣD 2 - (ΣD) 2
(n-1)
Tests the H0 that the means of the two groups are equal. df = n (of pairs) - 1
Signal to Noise Ratio

Trochim WMK. The Research Methods Knowledge Base. Mason, OH: Thomson; 2007
Signal to Noise Ratio Mean: Variability
Signal
Noise

Use of nonparametric methods
Assumptions are violated
e.g., distribution not normal
Distribution-free
Not dependent on means, SD, variances
Ordinal or nominal data are analyzed Likert Scales or categories
e.g., rate restaurant preference on 1 -5 (1=Strongly dislike); 1 is not considered to be 5 times worse than a 5; 1 to 2 is not the same difference in preference as 2 to 3.
Small samples
If data are not normally distributed but the sample size is ≥ 30 then a parametric test CAN be used.
Harris et al., J Amer Diet Assoc. 2008;1008:1488-1496.

More on nonparametric methods
They don’t use some data characteristics, e.g. means.
Instead use ranks, directions, etc….
Results are more conservative, with less power. Less likely
to correctly reject a false null hypothesis.
As noted last week, the nonparametric equivalent of the
paired t-test is the Wilcoxon Signed-Rank Test, which compares ranks and their directions.
Harris et al., J Amer Diet Assoc. 2008;1008:1488-1496.

Friedman’s Test
Used when analyzing matched data for more than 2
values when data are nonparametric. Used instead of
repeated measures ANOVA when data are
nonparametric.
The Chi distribution is used; the test statistic is Χ2.
Ranks are assigned to each data point and the sum of
ranks compared to Χ2 distribution. The degrees of
freedom is the number of treatment/measures – 1.

Sample Friedman’s test calculation
Child Preference Brand 1 Preference Brand 2 Preference Brand 3
1 5 4 3
2 4 4 1
3 2 3 5
4 2 4 5
5 4 4 3
6 2 5 3
7 1 2 5
8 3 2 4
9 4 5 5
10 5 2 3
10 children rate from 1 – 5 their preference for 3 brands of crackers

Sample Friedman’s test calculation
Child Preference Brand 1 Preference Brand 2 Preference Brand 3
1 5 [3] 4 [2] 3 [1]
2 4 [2.5] 4 [2.5] 1 [1]
3 2 [1] 3 [2] 5 [3]
4 2 [1] 4 [2] 5 [3]
5 4 [2.5] 4 [2.5] 3 [1]
6 2 [1] 5 [3] 3 [2]
7 1 [1] 2 [2] 5 [3]
8 3 [2] 2 [1] 4 [3]
9 4 [1] 5 [2.5] 5 [2.5]
10 5 [3] 2 [1] 3 [2]
Total 18 20.5 21.5
10 children rate from 1 – 5 their preference for 3 brands of crackers

Friedman test statistic calculation
Χ2 = 12 ΣR j2 - 3n(k + 1)
nk(k + 1)
k = number of columns; tx
n= number of rows (cases)
Rj=sum of ranks in column j
Brand 1 2 3
Sum of Ranks 18 20.1 21.5
(Sum of Ranks)2 324 404.01 462.25
No. Columns, k 3
(324 + 404.01 + 462.25)
12/(10 * 3 *4)
3 * 10 * 4
(0.1 * 1190.26) - 120
No. Rows, n 10
ΣR2 1190.26
12/nk (k+1) 0.1
3n (k+1) 120
Test Statistic - .97

Application of t-test
Test – retest reliability of 3 scales administered to 4th graders
Self-efficacy
8 items. Scored from 1 – 5 (1 is most positive)
Possible range 8 - 40
Attitude
6 items. Scored from 1 – 5 (1 is most positive)
Possible range 6 – 30
Fruit & Vegetable Preference
16 items (5 fruits/11 vegetables; Scored from 1-5 with 1 most positive.
Possible range 16 - 80

Attitude toward F & V
Paired t-test
T1 9.0 ± 3.4
T2 8.8 ± 3.3
Mean difference .17 (2.0)
t= 1.34 df 259
P=0.18
Correlation 0.82 P< 0.001

Skewness is a measure of
asymmetry.
Normal
Distribution
skewness = 0;
+ means tail to
right; depends
on sample size
Kurtosis is a measure of
distribution
flatness. Normal
distribution
kurtosis = 3; but
correction
factor so can =
0; depends on
sample size.
≤ 2 * SE






Fruit & Vegetable Preference
Paired t-test
T1 35.9 ± 9.0
T2 35.2 ± 9.8
Mean difference .70 (4.7)
t= 2.33 df 244
P=0.021
Correlation 0.88 P< 0.001
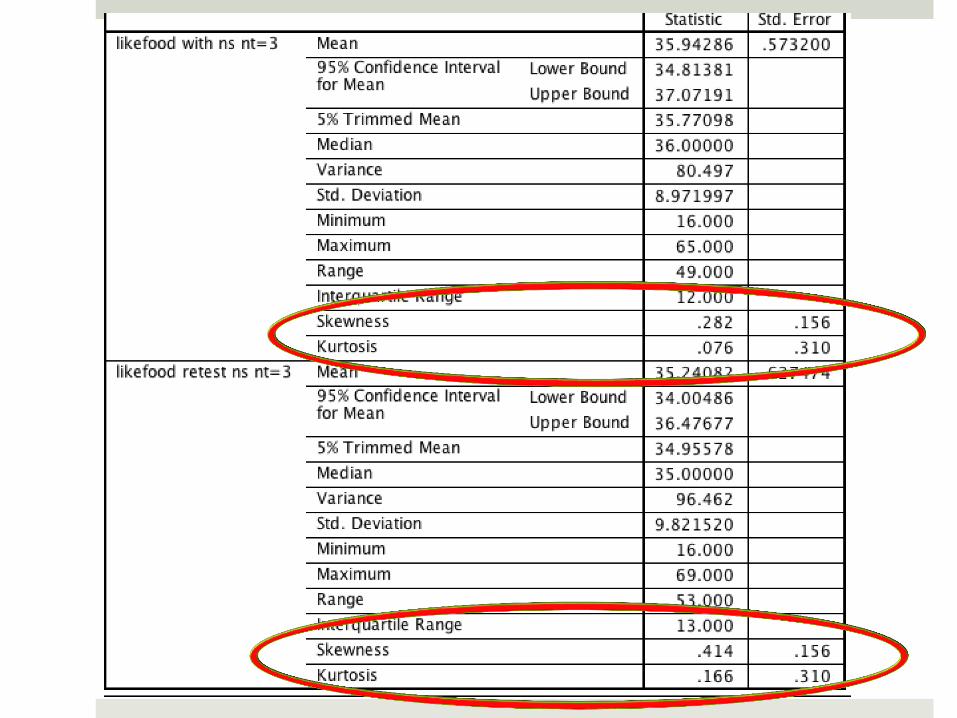






Interpretation Considerations
T1 and T2 internal consistency similar (.74; .79)
Scores significantly correlated (0.88).
Results did not differ among subgroups (e.g. Hispanic, grade level).
Clinical meaning of absolute difference ( 0.70 on a
possible range of 16 – 80).
Paired t-test not significant for boys, only for girls and total
sample.

Self-efficacy Cooking Skills
Paired t-test
T1 12.6 ± 4.5
T2 11.9 ± 4.4
Mean difference .71 (2.9)
t= 3.95 df 251
P < 0.001
Correlation 0.80 P< 0.001







Interpretation Considerations
(Note: Also identified for Attitude scale)
T1 and T2 scores significantly correlated (r=0.80).
Similar T1 and T2 internal consistencies (0.75, 0.78).
Similar T1 and T2 subgroup relationships (e.g., ethnicity, sex)
Clinical meaning of absolute difference ( 0.71 on a possible range of 8 – 40).
Assuming an ordinal (rather than a continuous) variable revealed similar distributions for 5 of the 8 scale items; means of 5-item scale remained significantly different.
Factor analysis revealed content validity between T1 and T2 items, i.e., at each time, the 8 items loaded similarly onto 2 meaningful factors accounting for nearly the same amount of variance.

?
?
?
?
?
?

Homework
Dataset with, weight, BMI,
waist circumference, and
systolic blood pressure at 2
time points (pre and post
intervention).
BMI at 3 time points
Did the measures change
significantly after the
intervention?
Is a nonparametric statistic
indicated? Why or why
not?
Weight was measured
again one year later and
BMI calculated. Was any
effect retained?



















