Embed Size (px)
Citation preview

PARALLEL COMPUTINGPetr Štětka
Jakub Vlášek
Department of Applied Electronics and Telecommunications, Faculty of electrical engineering, University of West Bohemia, Czech Republic

About the project• Laboratory of Information Technology of JINR• Project supervisor
• Sergey Mitsyn, Alexander Ayriyan
• Topics• Grids - gLite • MPI• NVIDIA CUDA
2

Grids – introduction
3

Grids II• Loose federation of shared resources
• More efficient usage• Security
• Grid provides• Computational resources (Computing Elements)• Storage resources (Storage Elements)• Resource broker (Workload Management System)
4

gLite framework• Middleware • EGEE (Enabling Grids for E-sciencE)• User Management (security)
• Users, Groups, Sites• Certificate based
• Data Management• Replication
• Workload Management• Matching requirements against resources
5

gLite – User management• Users
• Each user needs a certificate• Accepts AUP• Membership in a Virtual Organization
• Proxy certificates• Applications use it on user’s behalf• Proxy certificate initializationvoms-proxy-init –voms edu
6
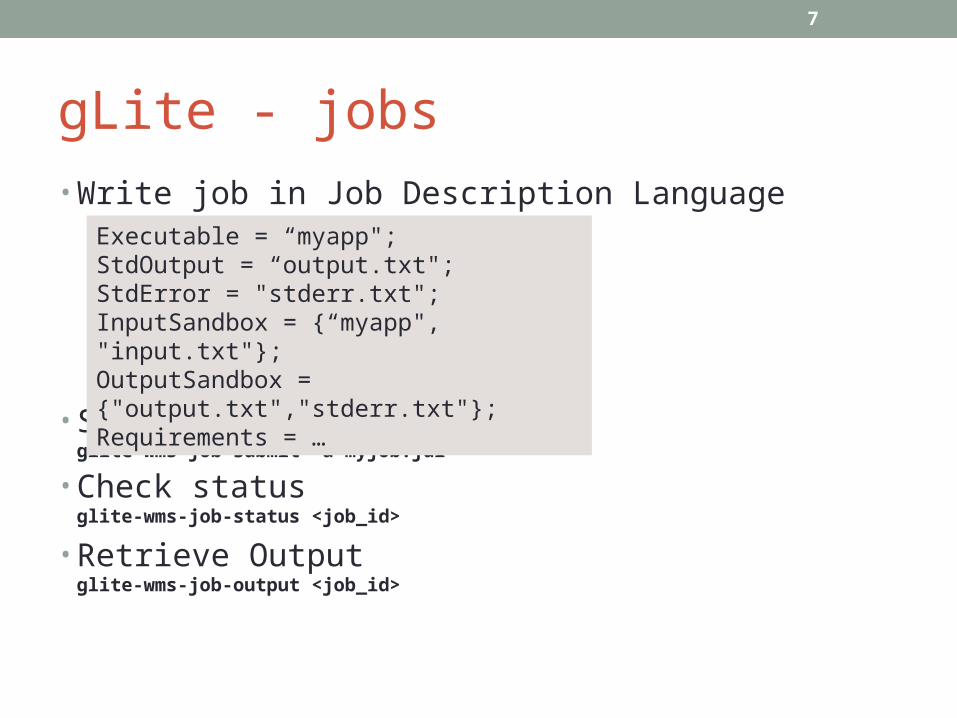
gLite - jobs• Write job in Job Description Language
• Submit jobglite-wms-job-submit –a myjob.jdl
• Check statusglite-wms-job-status <job_id>
• Retrieve Outputglite-wms-job-output <job_id>
7
Executable = “myapp";StdOutput = “output.txt";StdError = "stderr.txt";InputSandbox = {“myapp", "input.txt"};OutputSandbox = {"output.txt","stderr.txt"};Requirements = …

Algorithmic parallelization • Embarrassingly parallel
• Set of independent data
• Hard to parallelize • Interdependent data, performance depends on interconnect
• Amdahl's law - example• Program takes 100 hours • Particular portion of 5 hours cannot be parallelized• Remaining portion of 95 hours(%) can be parallelized• => Execution can not be shorter than 5 hours, no matter how many
resources we allocate.• Speedup is limited up to 20×
8

Message Passing Interface• API (Application Programming Interface)• De facto standard for parallel programming
• Multi processor systems• Clusters• Supercomputers
• Abstracts away the complexity of writing parallel programs• Available bindings
• C• C++• Fortran• Python• Java
9

Message Passing Interface II• Process communication
• Master slave model• Broadcast• Point to point• Blocking or non-blocking
• Process communication topology• Cartesian• Graph
• Requires specification of data type• Provides interface to shared file system
• Every process has a “view” of a file• Locking primitives
10
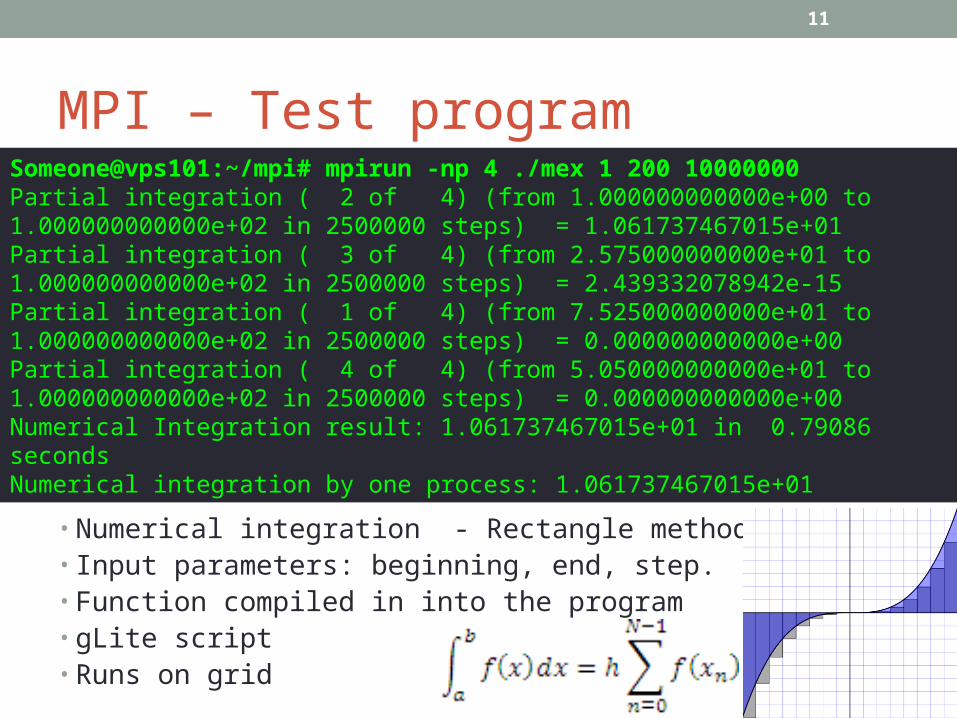
MPI – Test program
11
Someone@vps101:~/mpi# mpirun -np 4 ./mex 1 200 10000000Partial integration ( 2 of 4) (from 1.000000000000e+00 to 1.000000000000e+02 in 2500000 steps) = 1.061737467015e+01Partial integration ( 3 of 4) (from 2.575000000000e+01 to 1.000000000000e+02 in 2500000 steps) = 2.439332078942e-15Partial integration ( 1 of 4) (from 7.525000000000e+01 to 1.000000000000e+02 in 2500000 steps) = 0.000000000000e+00Partial integration ( 4 of 4) (from 5.050000000000e+01 to 1.000000000000e+02 in 2500000 steps) = 0.000000000000e+00Numerical Integration result: 1.061737467015e+01 in 0.79086 secondsNumerical integration by one process: 1.061737467015e+01
• Numerical integration - Rectangle method top-left• Input parameters: beginning, end, step.• Function compiled in into the program• gLite script • Runs on grid

Test program evaluation – 4 core CPU
12

CUDA• Programmed in C++
language• Gridable• GPGPU• Parallel architecture• Proprietary technology• GeForce 8000+• FP precision• PFLOPS range (Tesla)
13

CUDA II
• An enormous part of the GPU is dedicated to execution, unlike the CPU
• Blocks * threads representthe total number of threadsthat will be processed by the kernel
14

CUDA Test program
• Numerical integration - Rectangle method top-left• Ported version of MPI Test program• 23 times faster on a notebook NVIDIA NVS4200M than
one core of Sandy Bridge i5 [email protected]• 160 times faster on a desktop GeForce GTX 480 than one
core of AMD 1055T [email protected]
15
CUDA CLI OutputIntegration (CUDA) = 10.621515274048 in 1297.801025 ms (SINGLE)Integration (CUDA) = 10.617374518106 in 1679.833374 ms (DOUBLE)Integration (CUDA) = 10.617374518106 in 1501.769043 ms (DOUBLE, GLOBAL)Integration (CPU) = 10.564660072327 in 30408.316406 ms (SINGLE)Integration (CPU) = 10.617374670093 in 30827.710938 ms (DOUBLE)Press any key to continue . . .

Conclusion• Familiarized with parallel computing technologies
• Grid with gLite middleware• MPI API• CUDA technology
• Written program for numerical integration• Running on grid• With MPI support• Also ported to Graphic card using CUDA technology
• It works!
16
THANK YOU FOR YOUR ATTENTION
17

Distributed Computing• CPU scavenging• 1997 ditstributed.net – RC5 cipher cracking
• Proof of concept
• 1999 SETI • BOINC• Clusters• Cloud computing• Grids
• LHC
18

MPI - functions• Initialization
• Data type creation
• Data exchange – all process to all process
19
MPI_Init(&argc, &argv);MPI_Comm_rank(MPI_COMM_WORLD, &procnum);MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Type_contiguous(int count, MPI_Datatype oldtype, MPI_Datatype *newtype)MPI_Type_commit(MPI_Datatype *datatype)
MPI_Finalize();
MPI_Gather(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
…





























