Embed Size (px)
Citation preview

Designing Parallel Algorithms
Parallel Processing (CS526) Spring 2012(Week 5)

There are no rules, only intuition, experience and imagination!
We consider design techniques, particularly top-down approaches, in which we find the main structure first, using a set of useful conceptual paradigms.
We also look for useful primitives to compose in a bottom-up approach.
Designing Parallel Algorithms

A parallel algorithm emerges from a process in which a number of interlocked issues must be addressed:
Where do the basic units of computation (tasks) come from? ◦ This is sometimes called “partitioning" or
“decomposition". Sometimes it is natural to think in terms of
partitioning the input or output data (or both). On other occasions a functional decomposition
may be more appropriate (i.e. thinking in terms of a collection of distinct, interacting activities).
Designing Parallel Algorithms

How do the tasks interact? ◦ We have to consider the dependencies between tasks
(dependency, interaction graphs). Dependencies will be expressed in implementations as communication, synchronisation and sharing(depending upon the machine model).
Are the natural tasks of a suitable granularity? ◦ Depending upon the machine, too many small tasks
may incur high overheads in their interaction. Should they be agglomerated (collected together) into super-tasks? This is related to scaling-down.
Designing Parallel Algorithms

How should we assign tasks to processors? ◦ Again, in the presence of more tasks than
processors, this is related to scaling down. The owner computes rule is natural for some algorithms which have been devised with a data-oriented partitioning. We need to ensure that tasks which interact can do so as (quickly) as possible.
These issues are often in tension with each other
Designing Parallel Algorithms

Use recursive problem decomposition. Create sub-problems of the same kind,
which are solved recursively. Combine sub-solutions to solve the original
problem. Define a base case for direct solution of
simple instances. Well-known examples include quick-sort,
merge-sort, matrix multiply.
Divide & Conquer

©2010 Goodrich, Tamassia7
Merge-Sort
Merge-sort on an input sequence S with n elements consists of three steps:◦ Divide: partition S into
two sequences S1 and S2 of about n/2 elements each
◦ Recur: recursively sort S1 and S2
◦ Conquer: merge S1 and S2 into a unique sorted sequence
Algorithm mergeSort(S, C)Input sequence S with n
elements, comparator C
Output sequence S sortedaccording to Cif S.size() > 1
(S1, S2 ) partition)S, n/2( mergeSort(S1, C)
mergeSort(S2, C)
S merge(S1, S2)

©2010 Goodrich, Tamassia 8
Merging Two Sorted Sequences
The conquer step of merge-sort consists of merging two sorted sequences A and B into a sorted sequence S containing the union of the elements of A and B
Merging two sorted sequences, each with n/2 elements takes O(n) time
I.e Mergesort have a sequential complexity of
Ts=O(nlogn)
Algorithm merge(A, B)Input sequences A and B with n/2 elements each
Output sorted sequence of A B
S empty sequence
while A.isEmpty() B.isEmpty)(if A.first().element() < B.first().element)(
S.addLast(A.remove(A.first()))elseS.addLast(B.remove(B.first()))while A.isEmpty()S.addLast(A.remove(A.first()))while B.isEmpty()S.addLast(B.remove(B.first()))return S
©2010 Goodrich, Tamassia 9
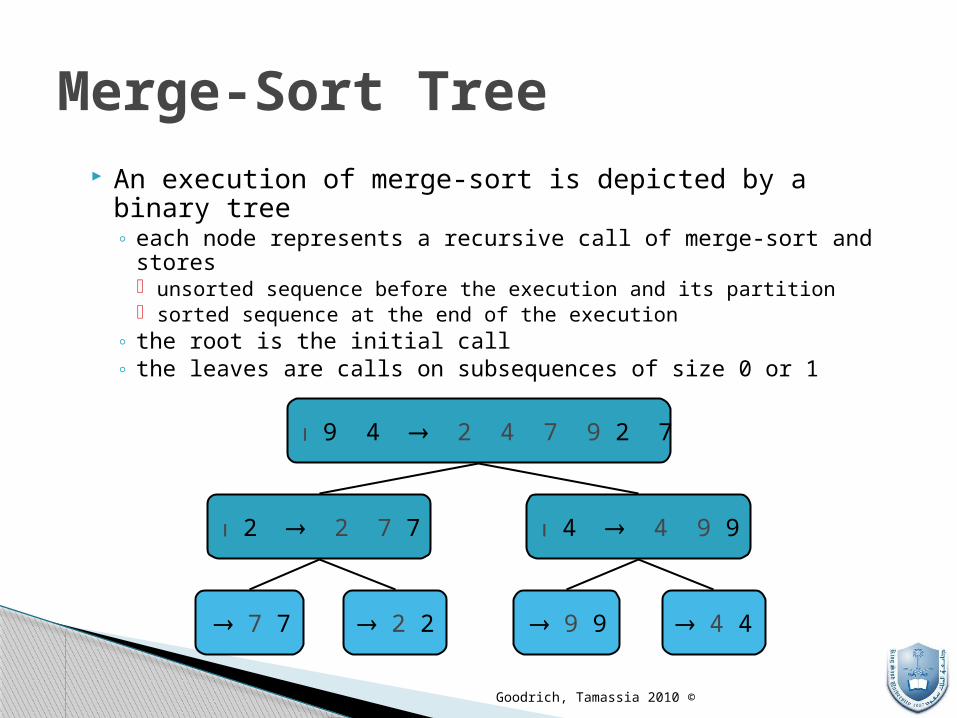
Merge-Sort Tree An execution of merge-sort is depicted by a binary tree
◦ each node represents a recursive call of merge-sort and stores unsorted sequence before the execution and its partition sorted sequence at the end of the execution
◦ the root is the initial call ◦ the leaves are calls on subsequences of size 0 or 1
7 2 9 4 2 4 7 9
7 2 2 7 9 4 4 9
7 7 2 2 9 9 4 4

There is an obvious tree of processes to be mapped to available processors.
There may be a sequential bottleneck at the root.
Producing an efficient algorithm may require us to parallelize it, producing nested parallelism.
Small problems may not be worth distributing trade on between distribution costs and re-
computation costs.
Parallelizing Divide & Conquer

Parallelizing Merge-Sort Algorithm Parallel_mergeSort(S, C)
Input sequence S with n elements, comparator C Output sequence S sorted
◦ according to Cif S.size() > 1
(S1, S2) partition(S, n/2)
initiate a process to invoke mergeSort(S1, C)
mergeSort(S2, C)============
Sync all invoked processes============
S merge(S1, S2)

Parallelizing Merge-Sort Analysis
The serial runtime for the Merge sort can be expressed as:◦ Ts(n)=nlogn+n
= O(nlogn)
Parallel runtime for Merge-sort on n processors:Tp(n)=logn+n
= O(n) Þ S= O(logn)Cost = n2 is it cost optimal??

We have a parallelism bottleneck (Merge) ◦ can we Parallelize it?
We have two sorted lists Searching in a sorted list is best done using
a divide an conquer (binary search) O(logn) If we partition the two lists on the middle
element and merge the two lists depending on a binary search technique we could reduce the merge operation to a O(logn2)
Parallelizing Merge-Sort Analysis

ListA Parallel_Merge(S1,S2){
if (length of any S1 or S2 ==1){add the element in the shortest list to the other list and return the resulting list.}
Else TS1 all elements from 0 to S1.length/2
TS2 all elements from S1.length/2 to S1.length-1TS3 all elements from 0 to S2.length/2
TS4 all elements from S2.length/2 to S2.length-1in parallel merge these list according to a comparison between the splitting elements calling recursively Parallel merge function for each process which will return the two partitions S1,S2 sorted as S1<S2
Sync A S1+S2}
Parallel Merge

Parallel Merge: Example
2 4 6 8 10 1 3 5 7 9
2 4 6 8 101 3 5 7 9
7 98 101 3 52 4 6
9 107 8
9 107 8
5 61 32 4
1 2 3 4
1 2 3 4 5 6
9 107 81 2 3 4 5 6

The serial runtime for the Merge sort can be expressed as:◦ Ts(n)=nlogn+n
= O(nlogn)
Parallel runtime for Merge-sort on n processors:Tp(n)=logn+logn
= O(logn) Þ S= O(n)Cost = nlogn is it cost optimal??
Read the Paper on the website for another parallel merge-sort algorithm
Parallel Merge: Example Analysis

We ignored a very important overhead cost which is communication cost.
Think of the implementation of this algorithm if it was on a message passing environment.
The analysis of an algorithm must take into account the underlying platform in which it will operate.
What about the merge sort what is the cost if it was on a message passing parallel archetecture?
Parallel Merge Sort: cost

Parallel Algorithems Design Patterns

In reality its some times difficult or inefficient to assign tasks to processing elements at the design time.
The Bag of Tasks pattern suggests an approach which may be able to reduce overhead, while still providing the flexibility to express such dynamic, unpredictable parallelism.
In bag of tasks, a fixed number of worker processes/threads maintain and process a dynamic collection of homogeneous “tasks". Execution of a particular task may lead to the creation of more task instances.
The Bag of Tasks Design Pattern

The Bag of Tasks Design Patternplace initial task(s) in bag;
co [w = 1 to P] {while (all tasks not done) {get a task;execute the task;possibly add new tasks to the bag;}
}
The pattern is naturally load-balanced: each worker will probably complete a different number of tasks, but will do roughly the same amount of work overall.

The Producers-Consumers pattern arises when a group of activities generate data which is consumed by another group of activities.
The key characteristic is that the conceptual data flow is all in one direction, from producer(s) to consumer(s).
In general, we want to allow production and consumption to be loosely synchronized, so we will need some buffering in the system.
The programming challenges are to ensure that no producer overwrites a buffer entry before a consumer has used it, and that no consumer tries to consume an entry which doesn't really exist (or re-use an already consumed entry).
Producers-Consumers

Depending upon the model, these challenges motivate the need for various facilities. For example, with a buffer in shared address space, we may need atomic actions and condition synchronization.
Similarly, in a distributed implementation we want to avoid tight synchronization between sends to the buffer and receives from it.
Producers-Consumers
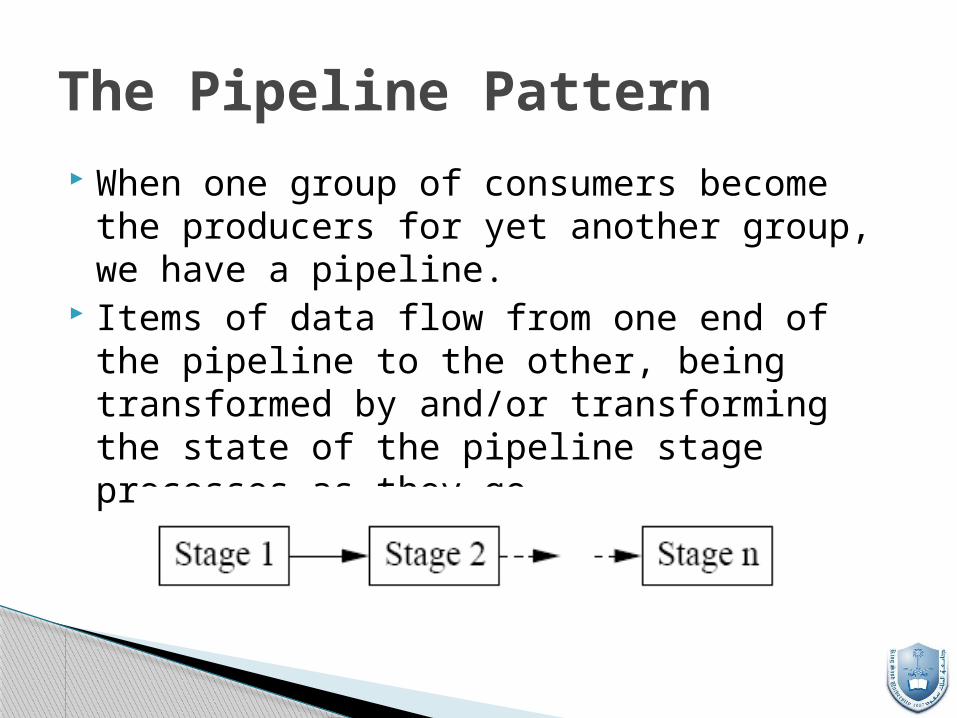
When one group of consumers become the producers for yet another group, we have a pipeline.
Items of data flow from one end of the pipeline to the other, being transformed by and/or transforming the state of the pipeline stage processes as they go.
The Pipeline Pattern

The Sieve of Eratosthenes provides a simple pipeline example, with the additional factor that we build the pipeline dynamically.
The object is to find all prime numbers in the range 2 to N. The gist of the original algorithm was to write down all integers in the range, then repeatedly remove all multiples of the smallest remaining number. After each removal phase, the new smallest remaining number is guaranteed to be prime
We will implement a message passing pipelined parallel version by creating a generator process and a sequence of sieve processes, each of which does the work of one removal phase. The pipeline grows dynamically, creating new sieves on demand, as unsieved numbers emerge from the pipeline.
The Pipeline Pattern
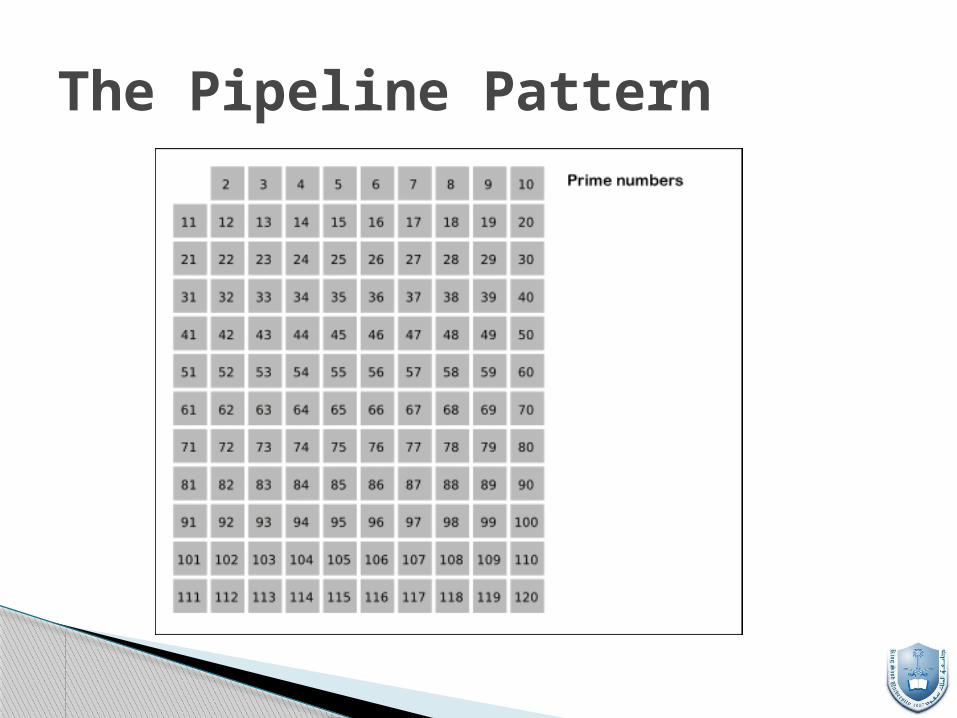
The Pipeline Pattern

The Pipeline Pattern: Example

The Pipeline Pattern: Example






![USING Intuition - Laura Silva Quesadalaurasilvaquesada.com/wp-content/uploads/2017/03/Intuition-in... · USING Intuition IN BUSINESS [2] Using INTUITION IN Business INTUITION AND](https://img.pdfslide.net/doc/110x75/5ab27fd57f8b9a7e1d8d5a95/using-intuition-laura-silva-ques-intuition-in-business-2-using-intuition-in.jpg)






















